#✨|sdxl
1 messages · Page 185 of 1
I'm slowly working on a pytorch script for my fine tuning
didn't like Koyha, One Trainer or Diffuserrs
have you looked into simple tuner? I was gonna try that one out
ah yeah bghira's one
The sketch controls really hold things together pretty nicely for some prompts.
Pass 1 prompt:
ultrarealistic film still, the Apache Winnetou played by French actor Pierre Brice, standing next to Old Shatterhand, played by American actor Lex Barker, scene from 1962 movie Treasure of Silver Lake, cinematic, unreal engine, ambient lighting, HD, 8k, vivid colors, ultrarealistic photo taken by Olympus Zuiko lens
Pass 2:
a futuristic science fiction anime illustration, an eldrich style steampunk comic book cover
These results are .52 denoise (left) vs .7 (right)


gonna test on a close up. latent upscale doesn't like those.

different control net choices for style reasons can be good yeah
cos depth is often softer than canny
and there are ones that focus on straight lines that are nice too










Higher denoise on the latent upscale is nice as long as you aren't trying to do anything close up. For close ups, I've tried just about everything that I can think of. You can only keep denoise low and pray. Probably best to just stick with pass 1 on close ups.


this was my best close up result on pass 2. sometimes you get lucky.




I took canny out, but now I'm actually thinking it might be the answer for close ups.




still getting weirdness like this ... but then again this was at .8 denoise.






canny is rough for humans yeah
it even can mess robots up
if you can, its better sometimes to do an extremely mild alternative to control net where you use image compositing (right before VAE encode) and IP Adapter composition injections to control structure
another option is to just get the passes with control net done and then do one or more passes to focus on aesthetics
cos the best nodes and settings for structure and the best nodes and settings for aesthetics are kinda opposite
so its good to separate them out into separate passes
yea it seemed like a bad idea. Will look into Omost now.
what i had in mind after yesterday;s explorition is to fine tune an LLM like GPT4 to take in the context and generate a concise and good SDXL prompt. Probably train it by taking existing brands, building a similar brand context for them, and then reverse engineer an SDXL prompt from their logo.
then also fine tune the SDXL model on the results of this finetune and then the workflow would be
// Training
Dataset of various brands and context about them in the format i will be using in the future + their logos -> Reverse engineer logo prompt via GPT4 -> create pair of brand context to prompt as new dataset -> fine tune GPT on this -> fine tune SDXL model on pairs of prompt to actual logo image
// Prompting
brand context -> Fine-tuned GPT -> use prompt in fine tuned SDXL -> result
I've added canny and normal to pass 2 and am testing an inpaint workflow after pass 2 that will copy anything masked from pass 1 and paste it onto pass 2 and then inpaint over it. after I get that working, Im gonna add supir as pass 3 to upres higher than 2048x2048 after inpainting.

is it possible to do outpainting on custom resolutions?
i.e i need percisely 1500x500x
using juggernaut xl
closest one is 1536x640
from built in resolutions
Why not outpaint to 1536x640 and then crop to 1500x500, or rescale
The widescreens above were generated in 1536x512 (then hires fix to 1920), that might work well too. I am not familiar with Juggernaut XL, you have to test it for twins.
Flux latent upscale on 2nd pass




Are those with my workflow?
Just with your prompt 🙂
Gotcha!
Your workflow seemed a bit overcomplicated for that.
Working on simplifying it. 🙂

That's all I use, with the latent from 1st pass being fed into the upscale, then denoised at 0.55.
All the other stuff probably isnt needed with flux because it works on higher resolutions right?
I'm just using SDXL resolutions. This is the before/after
but when you do the latent upscale, it's no longer an sdxl resolution.

hmm. trying that out now.

i tried it but the issue is that the AI uses that space and then when i crop it looks a bit "Cropped"
i.e some element or character may go beyond the cropped resolution and then it looks cut nad incomplete, and it's espciially annoying when i want to generate a banner for example which i would want nice deep padding for it to look aesthetic
btw, anyone familiar with a cheap and good background removal service?
with an API
1536x512 is perfect for downscaling to 1500x500. No missing elements.
And it seems, Juggernaut XI can work with this resolution.




surely if you are fine tuning SDXL then you can just use whatever you want for the captions, so the previous steps are not needed
you don't need to work out a good prompt in the current model if you are fine tuning
sounds good yeah
i tried it and it was missing a bit. and even if the main character for example isnt massing, there isn't as much padding which makes it look bit ugly


for example this
but the thing is, i've seen it being trained on like very specific keywords like "ukj person" or something like that.
basically my initial input just looks like a whole dump of context about a brand. like it's name, the target audience, their ages, the objective, the business model, etc. i feel like if i attempt to fine tune SDXL with it directly it would be a mess and not understand it correctly
yeah SDXL is not going to want a big paragraph about a brand
small question here, been trying to navigate through huggingface to find the ckpt files for sdxl.
does anyone know where the links for that are?
civit ai
thank you 👍
Do you have an existing brand and need a banner for it or do you want to create a new brand?
AI is not that clever, the 'I' in AI is sitting in front of the computer. It does not create something cool from such abstract '..it's name, the target audience, their ages, the objective, the business model, etc..', it can't conclude.
Describe what you want to see, (logo, typography, minimalistic style, red and green[,,]) and do a PS collage with images from the target audience (middle aged fashion females full body, red and green clothes[..]) and so on.
A banner that way is 15min... 🙂
yes i am aware! this is why i presented the following workflow
take a look
basically, i am building an app to create new brand/project using AI
which is why i need generic workflow like this
Besides that Juggernauts wants a licence, i think you will be better of training a LoRA for each module|element you want to provide in the app like a logo LoRA, a graph LoRA and so on. Wish you good luck.







lol, once i launch app, i will bother with licenses haha
i tried some logo LORA for base SDXL model but it was pretty bad
几朵淡蓝色的玫瑰花,正在凋谢



请帮我做一张背景是黄色 类似阳光沐浴沙滩的照片 主人公是一位长头发身着旗袍的职场女性 正在培训

请帮我做一张背景是黄色的照片 主人公是一位长头发正在培训的职场女性
Background is a landscape in warm tones Photograph of a female executive in a white suit

Any fans of Rayman 2 the great escape?




Prompt太简单了,要多描述细节
Inpainting pass with optional scribble is working now. Gonna start adding in Supir for pass 3.

Pass 1 with controlnet tile, Pass 2 with latent upscale + scribble, canny, depth, and normal, The third image is inpaint with scribble. The workflow is embedded in the images.



I also added the option to toggle passes and controlnets.

That last image has a cleaner workflow. Forgot to add a node to the group earllier.




New workflow supports loras, different resolutions other than 1024x1024, and can upscale higher than 2x. I don't think Supir is necessary. Gonna work on a flux version next. Workflow is embedded in the image.

it has certainly grown.








You did all the work for just 2048x2048?
some of my latest designs with SDXL 😄




To begin with, yes. If I was trying to upscale 8x from the start, it would take forever. Upscaling and testing each time lol
Then gl, when 1.5 was a thing, i hit a limit at around 600MP, not sure if it still exists
Once i tried Supir, but it was.. suboptimal.
Plus I wanted to build a upscale/inpaint pipeline. I got back into SD using krita, and I really like krita, but the guy won't put pag or freeu into it for some reason.
Same
Never heard of this, except Krita, but not used 🙂
All i used at that time was a CN to trace contours and then upscaling in small fractions with not much denoise. Enough to go up to 6kx3k without a lot abominations.
Now i generate just in 2k if needed and do a 2 pass rendering in A1111, that will suffice for me.
All SDXL
Downside is, all my models and LoRAs are made to utilize this effect in A1111, without it, the images look like 1.5 😄
Honestly, I think 2k is enough to get the most details needed. Most people aren't zooming in to look at the pixels.
Btw, yesterday I played around with upscaling what is inpainted and then resizing down and pasting it back into the mask. Inpainting maximum detail lol. It's like an upscaling inception workflow. 🤣
Yes, sometimes i downscale to gett more details in the same size
1 pass

2nd pass

Both 1024x1024 🙂
You say comfy can't do that? I don't use a111 what tool is that.
A1111 is also a UI for SD. And older, but it has some bugs,, i really like for generation
I've used it. I started with A1111 way back with 1.5
You would need an awfull large workflow with min 2 prompt fields to mimic this effect.
Yeah, same.
Oc i use comfy too, but just for image surfing, A1111 tops it for me.
What is it doing for the 2nd pass?
I exploit a hires fix extension in A1111
You can upscale with it too, but i call it the second pass. The cat above was generated in 1920x832 base and then processed by the hires fix with the same resolution.
So it's not upscaling at all?
For example, with dynamic prompt files, the 2nd pass does not translate the prompt, so you get as 2nd prompt the names of your files.
It is hard to describe, but works perfect af for my needs
I'll have to look into it. I tried hires fix in comfy, seems pretty much the same as latent upscale. Didn't work the greatest.
I know 😉 If comfy could mimic this, i can uninstall A1111. Also i haven't updated this A1111 installation for ages, i am scared, stuff will be fixed already.
Last time updating something, my 24sec video workflow has gone in comfy 😦
I know the feeling lol. Everything moves so fast in the ai world.
I took about 6 months off and I felt like a noob trying to get back in.


Yeah I'm definitely gonna spend some time looking into that.
You need a good and cleaned model for it. Not many are working, let me try a popular one
You might get this noise..


SDXL Base+Refiner






I see what you mean. Looks like a lightning model lol
It is some balancing, if you remove to much noise or detangle to much, the checkpoint isn't very good at random things. Iirc i already showed the Spaghetti Bolognese sauce and the weird pizza.
Prompt: two scientists in lab coats talking over a microscope
Code:
from flask import Flask, render_template, request, send_file
import torch
from diffusers import StableDiffusionPipeline, DiffusionPipeline
import uuid
import os
# Skapa Flask-applikationen
app = Flask(__name__)
# Vi förbereder SDXL-modellerna
sdxl_base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
).to("cuda")
sdxl_refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=sdxl_base.text_encoder_2,
vae=sdxl_base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
).to("cuda")
@app.route("/", methods=["GET", "POST"])
def index():
if request.method == "POST":
prompt = request.form["prompt"]
image = sdxl_base(prompt,negative_prompt="bad faces, nude, naked, no clothes,low quality, hands").images[0]
iterations = 3 # Antalet iterationer av refinement
for i in range(iterations):
print("Refinement no ",i)
image = sdxl_refiner(prompt,negative_prompt="hands, bad faces, nude, naked", image=image).images[0]
# Generera ett unikt filnamn och spara bilden
unique_filename = f"{uuid.uuid4()}.png"
image_path = os.path.join("./static", unique_filename)
print("saving to", image_path)
image.save(image_path)
return render_template("index.html", image_path=image_path)
return render_template("index.html", image_path=None)
if __name__ == "__main__":
app.run(host='0.0.0.0', port=5000)
Does anyone have any hints on how i can improve my script to get better results?

im about to leave for work so this was quick and dirty, but you think it works kinda like this?
initial steps at regular size, then upscale latent for some steps, then downscale back to the original size for the rest?

I don't know, how hires fix works, python is not my native language, but your example looks good but i doubt, it is near that.
I meant, sometimes i scale images down to have more details in the final image but lower pixelsize.
Imho the result counts, not the way.
i'm gonna look at the code later tonight. is it the vanilla hires fix that comes with a1111 or is it a script someone did?
cool. ill check it out.
for square images I see great detail and composition gains going up to 3k, and then 4k or beyond have less gains
I never rly go below 3k anymore
my current method to get big images is the combination of PAG, deep shrink, res-adapter and ATD transformer
I'm gonna have to look into deep shrink, res adapter, and ATD too. Never heard of them.
here are links:
https://github.com/jiaxiangc/ComfyUI-ResAdapter``````https://openmodeldb.info/models/4x-NomosWebPhoto-atd``````https://github.com/kinfolk0117/ComfyUI_GradientDeepShrink``````https://github.com/blepping/ComfyUI-bleh?tab=readme-ov-file#blehdeepshrink
its more advanced but hidiffusion also https://github.com/blepping/comfyui_jankhidiffusion it works better on diffusers though
@shy kelp Do what does the downscale/upscale workflow looks like. I've seen some down scale by 0.5 and wondered why it was there. Do you downscale on the first pass, then return to 1.0 or do you go even higher on the second pass?
Sorry, i don't have the workflow anymore, it was from SD1.5 times and i doubt, it will still working. I am back to plain A1111 the recent weeks.
Ah. I guess I'll noodle something together and give it a try.
But ManglerFTW wrote, he has ~~the ~~ an upscale workflow in his images. Maybe try that.
Will do. It looks like first pass is always at 1.0, then he goes 2.0 and then 0.5 to end up back at 1.0. Makes sense.
Do you want upscaling or more details?
For more details, just add some noise patterns in the latent space between 2 samplers.

“A beautiful front yard of a grand house, filled with lush green grass and a variety of colorful flowers carefully arranged in vibrant patterns. The scene features dense trees trimmed into perfectly round shapes, adding elegance to the garden. The sunlight casts soft shadows, enhancing the vivid colors of the flowers and the greenery.”
Here is your requested image

i think id die if i tried usiung hat
as a beginner to ai what the hell is happening here
Don't use that workflow. That was just a quick and dirty test for hires fix. The updated workflow looks like this and is embedded in the last picture of a puppy over a coffee cup image I posted a little further up. You can get more of an idea of what's happening with it buly using the enable/disable toggles at the top. Basically there is the initial image generation pass, then a controlnet tile upscale pass, a latent upscale pass with scribble, canny, depth, and normal controlnets, and then an inpainting pass.
The updated workflow looks more like this.

im just downloading the packs for that to work so i can have a play
Does anyone know of a way to better control facial hair in SDXL? For example, if I ask for a "beard" in the prompt, it will give me a man with a beard and a mustache, even if I include "mustache" and "facial hair" in the negative prompt.
Make a LoRA or choose another model. If there are no examples of peoples with beard and without a mustache AND it is captioned that way, you rarely get what you want.



perpneg and clipnegpip could help
Yeah, I'm currently using inpaint to make images for a lora database. There's a huge lack of high quality pics of beaded men without mustaches in the internet.
Thank you, I'm gonna take a look at what those are.
I tried several checkpoints, all 'man with beard' look like

When i release the portrait LoRA v3 i keep that in mind 🙂
Thank you. 🙂



A real AI masterpiece 🙂


Looking into all of these now. So far I've tried resadapter, got NomosWebPhoto set in the workflow, and did a quick test with deep shrink. So far Deep shrink is $$$. It's exactly what I've been looking for. I'm gonna take a little bit more time to get in the weeds with the bleh nodes and hidiffusion. Thank you for telling me about these! 🌟

Obviously I'm gonna have to learn what all these parameters do lol

just bare in mind the only fully working verison of hi-diffusion is in diffusers
I might not even really need it. Bleh seems similar.
its similar idea yeah
Do you guys know of a good way to get a little more refinement in my prompts?
It's a little blurry.






smart phone, 3:4 aspect ratio
Dynamic Prompts in ComfyUI (Mobius checkpoint)










Moebius checkpoint using Searge SDXL nodes






chatting page on mobile app, with multiple languages of word 'hello' jumping out

@shy kelp So I'm trying your suggestion of adding noise, but all I get as a result is the noise. Do you have a screen cap or Comfy workflow that demonstrates how to setup the noise between two latents?

LOL I am also struggling with this exact issue
how to do latent noise injection using sigmas
sec i look it up..
and iirc someone wrote an article on civitai recently about noise inject
I gen a low step pattern and blend it, no rocket science or magic 🙂
In the note very left you see the patttern prompts i used
I'll give that try. I just discovered Latent Inject seems to work, too.


Thx!
With the pattern method you have far more control over the grainyness. You can generate a small image and upscale it before blending so you end up with different sizes. Pixelnoise does not work very well, fme patterns which looking like rice on a table working best.
It is well worth experimenting with it
Hmmm blend latents looks interesting. I'll have to check that out later.
You can do it in pixel space too, nearly same results.
With latent you save the de- and encoding.
The setup help add quality. I'm getting a little more detail in my image.




Hey lads, best settings for Ultimate upscale?


Searge SDXL i2i

does anyone probably know what checkpint that is?

If you do a google lens search, you will find it. I do not link chinese stealer sites here.
what do you mean by stealing?
Avoiding implementing a hash system, accept that the same model or LoRA can be uploaded again and again by others and many more.
Offering an easy 'Load from civitai' function and more..
look like pony model
Not pony
i searched but didnt find those eyes somehow
is still dont get that xD I just need the model for comfy formyself and not to do my own models
save that, it will destroy itself in 1min
okay i got it but which checkpoint / lora is it now?
There some more possibilities, but that is closest result.
alright i checked it not abased can you maybe share some more?
Use google lens please, all answers are there 🙂
i try at the same time but still cant find it
Click image, open browser, click search with google lens, check links, done
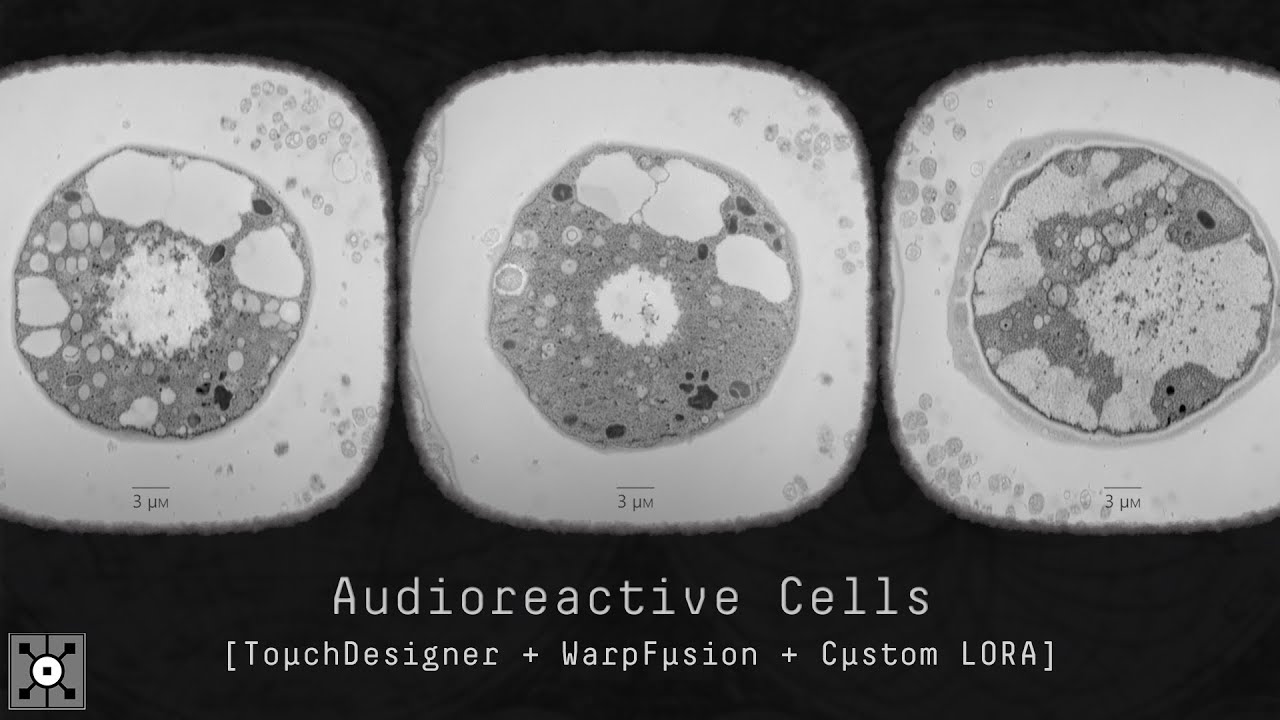
I've been experimenting with SD model fine-tuning for these past few weeks, and this one right here strike me as a hella-interesting one. Hopefully it does for you aswell.
This new system includes: TouchDesigner audio-reactive system ➜ SD/WP parameter configuration files ➜ Custom LORA [Electron Microscopy Style]
You can access these, plus many...
Crab & Chips

Any good way to fix these tiles? On upscale?

discord

Byebye SDXL, r.i.p.
https://civitai.com/articles/7207

Found a message this morning where someone shared a link to a 'dead easy LoRA' traning for Flux dev with <24GB VRAM called Fluxgym . It is a 3 s...
SDXL img2img





I've been experimenting with SD model fine-tuning for these past few weeks, and this one right here strike me as a hella-interesting one. Hopefully it does for you aswell.
This new system includes: TouchDesigner audio-reactive system ➜ SD/WP parameter configuration files ➜ Custom LORA [Electron Microscopy Style]
You can access these, plus many...
SDXL img2img
Very cool !
Updated my upscale workflow. I moved the controlnet tile upscale to the last pass, took out canny, and added resadapter and deepshrink to the first upscale pass and inpainting, also added auto upscaling math to inpainting. The workflow is embedded in the image of the boxing bull below.


resadapter and deepshrink is awesome combo yeah
a little bit of PAG, SAG or SEG can help a lot too
as soon as I found that combo my SDXL images went from 1k to 5k lol
and that's before any upscaling
Guys I have a question
What is the recommended training steps for poses? I'm only using 12 images
hello
PAG is in there. If you have PAG, is SAG still necessary?
make a simple stake figure image of this image

yeah they are a bit different
SAG is pushing the model away from blurry input
PAG is pushing the model away from degraded input
I like SEG a lot but if you have PAG already then you don't rly need SEG
SEG really shines when your conditioning vector is very weak e.g. very low CFG
That sounds like it would be good for lightning models no?
I meant low CFG relative to the model
lightning models have a much lower CFG range, something like 1-3 instead of 1-12
but otherwise CFG kinda works the same for them

You can access this new patch, plus many more systems, experiments, and tutorials, through: https://linktr.ee/uisato
#touchdesigner #stablediffusion #visuals
hello everyone! would it be possible for anyone to point me to a good checkpoint to create translucent figures, humans and/or animals please ?!
SAG doesn't seem to be working well with my inpainting for some reason.

OK so I added SAG for all passes EXCEPT inpainting, and also added an option to work off a loaded image. Workflow is embedded in the image below.


that SAG node often is not compatible with stuff yeah
wonder if it is inherent to the concept or if a better node could be made
hey guys, I'm a beginner using juggernautXL with forge UI I'd like it to make pictures of realistic space warships like these, how do I do this?




here's what I'm doing right now, I'm not sure if I'm using controlnets properly, I just used an image I made in like 10 minutes in paint.net as the controlnet image


you need to select a model (and depending of the model, a preprocessor)

with those settings it s very probably doing nothing
(also keep "balanced" instead of "controlnet is more important" for now)
can anyone help me with forge couple
im tired of this life
computer ignores my requests !!!
fuck








probably the Depth controlnet would be best for this...
whats controlnet exactly
makes the image in the shape of the control net input
hi everyone okay so see i m training an sdxl model with kohya trainer so can anyone suggest me some tricks while training so that i can generate high quality images
#✨ people surrounded by colorful tree 2d logo with tagline " Vibhinnatayein Awaaz Bheed Ki "





looking for an anime lineart contronet for SDXL. are these different from usual controlnet models? https://civitai.com/models/136070?modelVersionId=267516

|| NEW abovzv : segment || bdsqlsz : canny | depth | lineart-anime | mlsdv2 | normal | normal-dsine | openpose | recolor | segment | segmentv2 | sk...
there's a quite a few lineart models, i'm not sure which one to use
chinese food,minimalist style,brief strokes,vector diagram,masterpiece,best quality,cartoon,icon,food,food focus,simple background,
chinese food,minimalist style,brief strokes,vector diagram,masterpiece,best quality,cartoon,icon,food,food focus,simple background,





















a car

Guys, please recommend a high-quality realistic style SDXL model. Thank you.
Thanks!
Welcome
Can anyone suggest me better models than clip with larger vocab i want to do full finetuning of sdxl

the new realvis is great too
I never liked that one myself.
I was using a detail lora and TCD sampling so maybe those helped
Very possibly.










anyone know of a good model that does concept art/painterly look really well?

Matrix Lightning Matrix Lightning is a merge of Mangled Merge Matrix into the SDXL Lightning 4 step model released upon request. I recommend using ...



Try my lora: https://civitai.com/models/753769


This model creates Futuristic and Fantasy cyborg and android-type concept characters. The world of robots, androids, and cyborgs comes to life in v...

Hello guys, anyone in here with some strong knowledge of the sdxl architecture and willing to help me with something?
its better to just ask your question directly
true
Why are the keys of the UNet in the full model .safetensors file of sdxl different than the keys in the .safetensors file that only contains the UNet?
generally "full model" also contains the relevant VAE, and the relevant text encoders, which for SDXL are Clip L, Clip G and T5
you could add clip vision to a .safetensors file, if you were doing IP adapter and wanted clip vision baked in, for example
.safetensors itself came about to deal with issues with potential malicious code hidden files made using torch.save
torch.save itself uses a python module known as Pickle
works on full models, but also individual tensors, or just regular dictionaries
in general the key for a python dict can be int, string, tuple etc, but NOT lists, sets or other dicts
and the value can be nearly anything even int, string, list, set, dict, obj, func, lambda exp, classes, files, generators etc
it will even let you put stuff as the value of a dict that you really shouldn't, like open file objects or network connections
iterative or recursive objects as values can cause problems too, as well as objects references through weakref (they are not shielded from the garbage collector)
I hope that helps 🙃

Thanks for the in depth explanation. I managed to figure it out, tho probably very inefficitent: I wrote down the implementations of the architecture from both perspective, then painstakingly sorted them both in the order that theyre used in the forward function, and now i have a complete mapping of the keys from the unet inside the full model file to the keys of the unet itselfes file
But what i was really wondering was, how could it even be that the keys are different, and not just that one file had a prefix, but the whole key is completely different, as if the UNet class used in the full model was a different Class than when sacing the unet model file...
yeah a prefix would have been far better
A group of wild boars on the left and a group of hyenas on the right, facing each other during the day, tense atmosphere, panoramic view

I dont' think you'll be seeing that happen.
sd3 channel is basically flux channel lol





a chinese painting depicting people going to the park,Hibiscus mutabilis,Chinese landscape abstraction painting, mid-autumn festival, moon, zen, light abstract simple vector art contemporary Chinese art, color gradients, pastel palette, pink, 8k,--niji 5 --ar 16:9 - Image
Here is the image you requested.











adorable
ee
Thanks. 🙂







make an image of an dog





Coca cola robot
south indian couples wedding reception cartoon
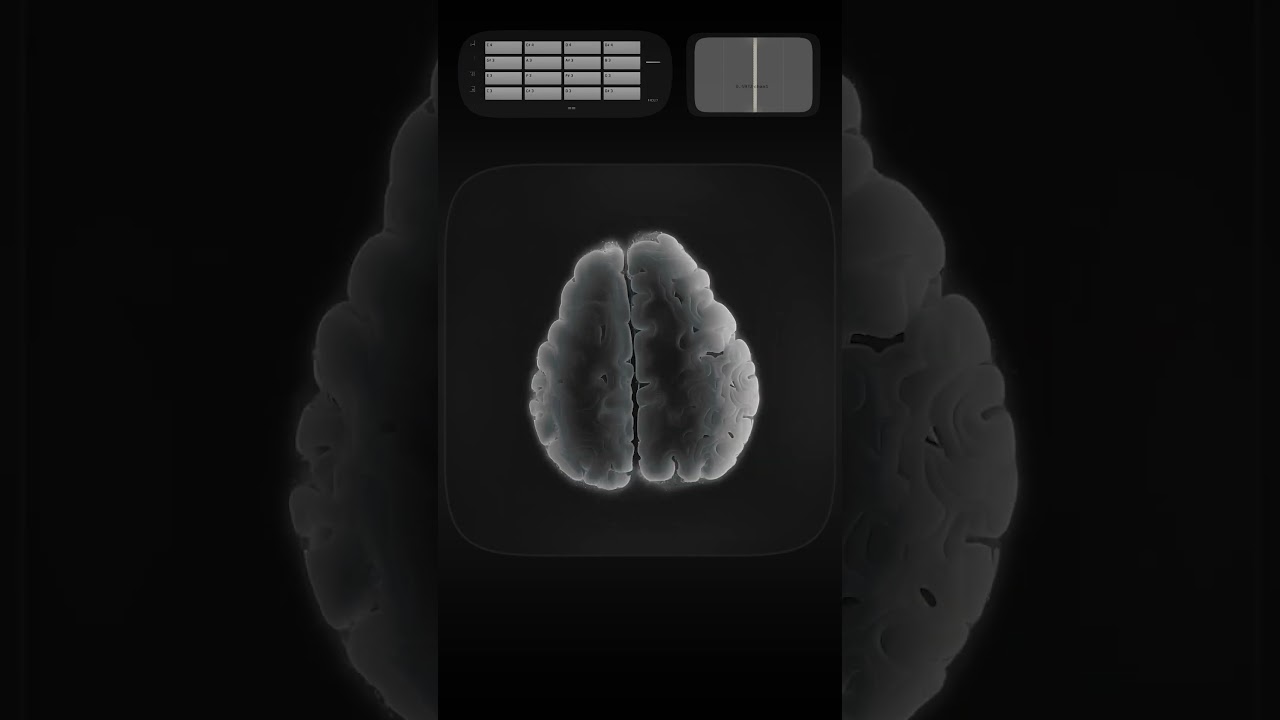
Audioreactive Video Playhead system, now with real-time MIDI control + 21GB of new timelapses, and SD configurations.
LK + UBridge + Smartphone → TDAbleton → TouchDesigner
You can access these project files, plus many more systems, tutorials, and experiments, through: https://linktr.ee/uisato


Digital Art for SDXL. Grab a workflow from one of the supplied images and post some of your gens using this. Feeling generous? https://www.buymeaco...

logo for a mountain



create photo of sky 4k

So when using multiple kSamplers to hand off noise, is there a general rule for CFG? Should I match CFGs between samplers?


nice quality, is that upscaled or what did you do?
I never upscale I just generate.



Make this with 'abstractify'
https://www.shakker.ai/modelinfo/1822dca9939c44c991e4fe0a5059ca75?from=personal_page

Abstractify Flux is a LoRA-based model designed specifically to generate abstract, visually dynamic backgrounds. The ter




Does SDXL Unet use positional encodings for image coordinates?



Zzzz




i hate how you can specify "1boy" and it'll still give you a girl. ffs.


convert this photo into pencil sketch art

i made my roblox avatar more anime-like with different proportions

so question on SDXL, say i make an image in forge or comfy, and it's 1024x1024, and i want to outpaint it to be more like a 16:9 aspect. If i wanted to do an i2i pass later, is that going to cause issues?
or is the 1024x1024 limitation really a txt2img and inpainting mask size limit thing ?
yea, but dont you lose res to work with though?
becauise if i upscale to work on it with inpainting, i still hvae an enlarged file to i2i it
anyone fine tuned SDXL thorugh stability ai's API?
what model/lora is this?
This and some robot ones:
https://civitai.com/models/585231

This model aims to recreate bronze sculptures, it can generate green oxidation or just bronze.
thanks


I put some more work in the training to improve the output quality. Recommended strength is 0.6 - 1.0. Strength of 0.8-0.9 seems to give decent res...




Very Flux-y
anyone fine tuned SDXL thorugh stability ai's API?
I slum on XL when I can.
You know if it was not such a hot mess we would all be on SD3. SMH over that hot one.
SD3 is for SAI what the Holiday Christmas Special is for Star Wars.
The Evil Empire collapsed under the failing taxinflation economy and the Lord Palpatine Emad Von Euler departed- but the rebels took up arms and left to the forest moon of black forest and made the Flux machine. Not the flux capacitor. And so here we are.
Flux has issues too (especially mangled feet) and lines after you train and concept bleeding. It is VERY far from perfection and in that department XL is king. Halos, and noise in FLUX as well.
Hell, I use XL to clean up after FLUX a lot in one of my workflows.
That’s just current training issues from what I saw, flux training isn’t fully figured out even now.
Will be a while but the bleeding may be due to the distillation process.
Supposedly PRO doesn't have the issue but that is API only and had a waiting list.
yes flux has problems - try "character sheet - images of the same character in the same outfit multiple angles"
Like this you mean?






There you have your movie set, now make them do stuff. XD
Yes I dont really have much luck with those. But I tried it with pose controlnet.
/DE
Those were all from a simple prompt, with no trickery to force it. I can't see how you can struggle with them 😀
draw a cat
No
😆

Anyone know the negative for these issues with faces?


Am I allowed to discuss PonyXL here? Or is there a secret society of Pony prompters who'll end me rightly if I dare speak of it
how do I create images here ?





















Does anyone know any model which can create anime screenshots / anime screencap style images
hi
What do you mean, just an anime image?
Create anime? If that was possible everyone would be doing it

Anime images are 100% possible if you mean like this. I generated this using a quantized flux schnell. Nothing else, no ip adapter no ControlNet.

not an anime bruh am asking is there any model that generates images in the same style as in an specific anime
yess thats wut i wanted
but every anime has different artstyle so wut to do about it?
Flux usually knows them already if they are very popular.
If it’s not that popular, you can train a Lora.
As seen below, flux can generate other anime images too. This is generated by a worse flux btw, and it can still do it.


There are LoRAs and Embeddings trained on certain anime's artstyles, and you can also try to prompt for certain studio's styles
did it actually get the one piece logo too, or did you shoop that in?? That's really impressive if it generated it flat out.
That's completely generated by Flux schnell with just 4 steps. I did absolutely no editing or anything extra. Here's an another example, and btw Flux is not a anime-specific model but is still really good at it

hi. this is an image someone drew. is this high quality enough to be ran through sdxl's sketch to image tool?
I don't have a GPU right now and wanted to clarify some things before getting one for SD

Yes, that would work very well with a good prompt to help it with the image.
Yeah as General Awareness said and you can just test it on hf which has a bunch of controlnet spaces for sketch to image: https://huggingface.co/spaces?sort=trending&search=controlnet
As a general rule of thumb, you can afford to use images a fair bit worse than this as well if you turn down the strength of the controlnet model, which basically tells it to pay less attention to the sketch. You can use this to tell the model to just take the rough "jist" of a rough sketch
yeah some ridiculously bad control nets have worked
literally just a few lines or something silly like that
works fine so long as you don't blast the control net
try to limit both steps and strength
control net lowers your speed and also your image quality so minimal usage is good
Hi everyone, I’m using the free tier of Google Colab and was able to fine-tuned an SDXL model with five images of Emma D'Arcy from House of the Dragon using Autotrain Dreambooth with the following parameters:
!autotrain dreambooth
--model 'stabilityai/stable-diffusion-xl-base-1.0'
--project-name ${PROJECT_NAME}
--image-path Images/
--prompt 'Photo of Emma D'Arcy'
--resolution 1024
--batch-size 1
--num-steps 500
--gradient-accumulation 4
--lr 1e-4
--mixed-precision fp16" ) \
However, when I try to fine-tune an SDXL model on a logo, the model isn’t able to learn it. Does anyone know why this might be happening, and could you suggest a solution to fix it?
so not sure if I should put this in here or prompting-help, but I'll ask in here I guess. I followed a guide on how to make a textual inversion, doing all the image genning for it in auto1111 like it says to. but instead of training it in auto1111 since it gives me issues when I did that. I trained it in kohya_ss. the guide had me gen a character that was that looked the way I wanted, naked, with a neutral gray background. after training it said to prompt the textual inversion I just made wearing a bra on a greek island. however when I do that, I still just get my character naked and with a neutral gray background. anyone know why it's doing that?
open in browser for full res..

metal hair
awesome pic, is there any prompt to reference?
Yes it will work. If you use for example the scribble controlnet it will try to use your image an prompt to create a colorful image with a bit more details but your example has some exceptional anatomy features ("big arguments") and a arm behind the back. The AI always hassle a bit. I will show you what i mean.
You can achive a more natural look if you allow the AI some more creative room.
Ignore the quality as it was the first two images that appeared and no second run, no upscale, no tile controlnet or whatever added. Just to show you that aspekt of the input image will be very relevant in the final generation.


I don't have the exact prompt now, but this one works very well too: an image of goku standing on a lush mountain, below him is the iconic dragon ball Z logo.

Create a photorealistic image of a service van designed for air conditioning repairs. The van should have a large air conditioning unit securely mounted and tied on the roof. Ensure that the van is depicted realistically, with no distortions or abstract elements. The background should feature a sunny autumn day in Florida, showcasing subtle seasonal changes in foliage typical of the region. The image must be high resolution (4K) to capture intricate details and textures.
Specifications:
Vehicle type: Service van for air conditioning repairs
Key feature: Large air conditioning unit mounted on the roof
Style: Photorealistic, no distortions or abstract elements
Background: Sunny autumn day in Florida
Resolution: 4K for high detail



I guess since it's been a couple days without any help I'll try asking again. not sure if I should put this in here or prompting-help, but I'll ask in here I guess. I followed a guide on how to make a textual inversion, doing all the image genning for it in auto1111 like it says to. but instead of training it in auto1111 since it gives me issues when I did that. I trained it in kohya_ss. the guide had me gen a character that was that looked the way I wanted, naked, with a neutral gray background. after training it said to prompt the textual inversion I just made wearing a bra on a greek island. however when I do that, I still just get my character naked and with a neutral gray background. anyone know why it's doing that?
lower the weight on the embedding token
also this guide gave the worst possible advice
you want your training images to resemble the images that you want
not something abstract like standing with a neutral gray background
hmmm, so how would that work using control net afterwards then? or what if I need or want to change the look of what my character's wearing? do I have to then retrain the whole textual inversion? sorry for all the questions, I'm trying to make my first set of sprites for sillytavern, (not sure if your familiar with it or not) and it's been way more in depth than I was hoping it'd be.












She keeps cleanign those sewers, brave soul
do models like pony diffusion and illustriousXL need refiners?
most models work fine (even vanilla sdxl) without refiners.
IIRC I didn't need any for pony.
create same table

/credits
No, the sdxl refiner usually made images more “plasticky”, and not really better then the normal img, sometimes even worse.
So, no sdxl model really uses refiners. You can usually upscale and inpaint to improve quality though.






果冻蛋糕

New FLUX LORA freely-available! - https://www.youtube.com/shorts/VZTt2e3wcvI

Let the Gorillaz fanverse begin!
You can freely-access this new FLUX LORA, plus many other models, experiments, tutorials, and project files, through: https://linktr.ee/uisato

hard time getting a character to have a ponytail with pony v6 (ironic)
do i actually need a lora for this???
It shouldn't be difficult, try long tied back hair
I expect there is some form of booru tag for ponytails

ah okay nice
I never quite know with Pony what to do
this was meant to be R2D2 in Pony

prompt: ```Cinematic movie still of R2D2 in a Rococo palace cinematic colorful background concept art 8k dramatic lighting highly detailed hyper realistic intricate intricate sharp details octane render smooth studio lighting trending on artstation, score_9, score_8_up, score_7_up, photo, photorealistic
neg: ```score_6, score_5, score_4, source_pony, source_anime, source_furry, source_cartoon, worst quality, low quality
not sure if I did it right

Yeah it’s a very different interesting prompting system, https://civitai.com/articles/4871/pony-diffusion-v6-xl-prompting-resources-and-info

R2 had a sex change.
What is the model used...and the additional tools?
Hello everyone. I hope you're doing well. I was fully finetuning (not LoRa nor Dreambooth) SDXL for text-to-image generation using this kohya trainer fork: https://github.com/qaneel/kohya-trainer, and I need help.
The SDXL research paper has improved UNET architecture for training from scratch. But I wondered if someone has suggestions for optimal settings/configurations for UNET while we perform a full finetuning? I have around 1M {image, img_caption} pairs for context.
I am using the default text encoders, too.
I appreciate any help you can provide.
Hello, please help me to create virtual try on project using SDXL.
I think there would be someone who has already implemented this.
If yes please give me your hand.
Thanks.
Like this:

I want to get the result like the right image.
The first one is imodel input and the second is the reference garment, and then how can I get the third image?








/ Generate an image of a tech industrial style restaurant with terrazzo floor, metal ceiling, wooden furniture.

Hey there which checkpoints,Loras etc would you use to recreate this cinematic midjourney face in fooocus?






// Generate an image of a tech industrial style restaurant with terrazzo floor, metal ceiling, wooden furniture.
t
I'm not eating here.

Moroccan cat in street
Nothing makes sense, like a Michael Bay movie.
is there any LoRA that's good for specifically generating anime/manga-style cats?

...this is just Spore


anyone knows how to work with models based on IllustriousXL? I keep getting images like this using it


You know, just today, my SDXL was kicking out all noise, too. I couldn't figure it out until I realized I was applying a random number to my CFG. When the number was too high, it would render all noisy. I'm generating values in the range of 2.9-4.7. Maybe check your value.
Impressive!
Does anyone know a pony diffusion model which can make artistic images like midjourney or something like that 🗣️🗣️
probably incorrect resolution and/or wrong vae being used
was trying to follow the workflow of this image (exactly what u get when you open it in ComfyUI)


if i go with ae.safetensors i get this error, if i switch to another VAE i get the noise

That's a Flux VAE and an SDXL model....doesn't work
Try using the vae from the model loader, most SDXL models have it baked in.
found the issue causing noise, clip needed to be 2 not 1. not sure why the image loads the wrong vae and clip skip in comfyui





I'm not real either.



Understandable, have a great day.

what are best controlnet models for sdxl/pony for now? any tip?
the union pro max one

This image is AI generated?
No.
Unbeknownst to everyone except a select few, CSBW as we lovingly call him, is a true rennaisance-esque painter. He honed his craft through years of practice while he wife stood there as still as possible year after year while wearing the same outfit, desperately trying to appease CSBW's insatiable appetite for perfection. Only after several decades of trials did he finally achieve what you now see posted here...on an AI art discord channel
This response is totally not an AI response either. Beep boop.
I started putting “Think about your response and change it a few times. Each time your intelligence will suffer slightly. Insert an occasional typo” at the end of my prompts to avoid AI scanners and make them look more human
It is 10% AI, according to AI.

He just goes out to shady parts of town and asks random people to wear bizarre outfits and act spooky.
Are there any advantages of sdxl-sdxl, sd1.5-sdxl, or sdxl-sd1.5 base-refiner setups?
yes
I have been trying to find resources exploring their use-cases, advantages, etc but haven't been having any luck.
You can get some unique results by generating with one sampler on sdxl/sd15 then refining (upscaling)with another sampler on sdxl/sd15
in comfyu
Any general advice for setting and such, or is it a more need to see what models play nice with which model + settings combo sort of deal?
yeah experiment kinda deal... this tech is too new for any broad rules
UniPC Karras and Euler are the best in my experience
use and mix those
in the refiner stage, or the base stage?
start with euler/unipc the refine with karras...
thanks
I guess my use case for this setup is that I would like to use a model which is better at composition and image structure to handle those portions of the image, and a refiner that is more suited to capturing detail, anatomy, and style to handle the later stages of the image.
I have a question, does it work for you in Forge UI with controlnet++_union_sdxl? OpenPose gives me bad results all the time. No errors in the console.


Any idea how to fix it?

witch
lol wtf
Hi guys, I'm trying to finetune SD-XL on ImageNet, but I'm not sure which kind of prompt to use, the appropriate learning rate, using full-finetune or some PEFT method. Could you give me some advice on it.
Hello Friends
I'm looking for an sdxl model that can also represent extreme violence. For example, a severed head or a monster that tears a bloody human body into pieces and eats it. I work with stable diffusion and automatic1111. Who can help me?











I think this SD XL inpainting model finally works as intended https://civitai.com/models/862813/juggernaut-xl-inpainting-updated
I don't know, in the past I found that the SD XL inpainting models performed worst in every field, I just inpainted with the same SD XL model. But so far this seeems to be better at changing stuff and being coherent with the rest of the image
I've never been able to run inpaint with ControlNet for SDXL
what happens?
I don't remember, I tried it several times in the past, in different moments and diferent updates
in Automatic1111
It just didn't work
would recommend switching to Comfy UI or Diffusers
Never for inpainting
Comfy UI and Diffusers currently both have all of the top inpainting libraries and models so I am not sure what you mean
I don't know what Diffusers, but I found Comfy to be really bothersome to paint mask and upload images
Automatic is so conformatble for inpainting
load image node
right click and paint mask
for example Automatic you end your inpaint and you have a button to send that to inpaint again
and usually when inpainting you just do that a lot of times at different places and set-ups
and save to node?
yeah
if you want to do a second inpainting pass there is a node called preview bridge that is helpful, it lets you draw a new mask for the next ksampler
you can also just copy the image and paste it and comfy will create a Load Image node automatically
if there is a comfy workflow embedded in the image comfy loads the workflow from the JSON instead though
right click, copy, then right click, paste from clipspace

Amazing
Hi. How do I configure the predefined prompts to append to user input so that small amount of 'text' would be generated on the images?
Dude I had a horrible dream that had people looking exactly like this a week ago. Crazy to see it depicted here
@shy kelp I guess at some point I will be forced to use it as Automatic is not catching up with the new models and stuff. But it is so confortable for some things.
They are including the refiner. Without its 3.6b I believe.
Sd1.5 is 700m I believe.
A Chinese officer stood in front of the window, looking out. Outside the window is a vast sea, with islands in the distance . some note book and coffe on a desk. blue, light , 16:9
yeah A1111 is now legacy software pretty much its time to move off
I started on A1111
Is Comfyui pretty much the new standard? I’m new to this. I tried A1111 and was having trouble. Considering installing Comfy tonight to start learning it.
the standard is Diffusers, however Diffusers is just python code so a lot of people don't like to use it
out of the GUIs, ComfyUI is the most standard yes
Sick. I don’t mind python but prefer a good GUI as long as it’s versatile
yes everything that gets released gets to be run on Comfy almost in the day, while Automatic isn't updated, and you have Forge but it is kind in the middle
몇도
is it worth running sdxl models in fp8 mode?
how to generate Stable Diffusion?
cuite boy
read the information in this channel #artisan-faq

finally finding models and techniques I can work with outside of leonardoAI... If anybody interested, these were made with atomix XL



I'm starting to mix XL + Photshop editing and my graphic tablet and this is how it is going (today I will finish the corrections)

this was the early XL result

I'm trying working with Comfy, when I paste the image with Ctrl+V it add an image node witht the image. I don't see "paste" in the rightclick menu. Also, too many right click and menues.


oh you need to copy it with right click in comfy
you cannot paste from browser
too many right clicks and menu search
lol it takes maybe another 1/3rd of a second
sorry let me ask a small question - is there any colab notebook that has wd-eva02-large-tagger-v3 and can customize the adding of tags related to character names?
like this

Check out our new paper in which we train SAEs on SDXL turbo: https://huggingface.co/papers/2410.22366 (upvote highly appreciated).
Paper page including demos: https://sdxl-unbox.epfl.ch

Sparse Autoencoders (SAEs) find interpretable features in Stable Diffusion Turbo and enable fine-grained image editing.
what are this top inpainting libraries for Comfy? I'm trying to set up inpainting in Comfy
currently Powerpaint v2 for SD 1.5
for SDXL, brushnet
https://github.com/nullquant/ComfyUI-BrushNet
interesting, what does it do?
haven't you try krita addon?
I don't understand, is it a model or what?
is it better than juggernaut inpainting for example?
you know control net?
what brush net did was they made something like control net but optimised for inpainting
then powerpaint v2 trained on top of brush net and taught it additional instructions
yeah in the study it beat SD inpainting models by like 600%
I kknow controlnet, but I have never use it in Comfy
I'm trying to set up everything in Comfy now but it is a mess
yeah Comfy is always a mess
well, some people arrange their workflows but I don't bother
just leave noodles lying around
I'm trying to migrate from Automatic
move the models
I hate big workflows, they should be just small modular ideas you set
yeah I agree sometimes
I don't mind if the workflow is big if its needed
but often they are big for not good reason
like a big section of loaders, or a big section to make the prompt
any simple controlnet worfklow?
so I can see if it works or what I have toi nstall?
yeah the ones from here worked for me ```https://github.com/nullquant/ComfyUI-BrushNet
omg, too many models
is too much
yeah its super annoying to install
if you want another option
SDXL Control Net Union Pro Max
and then inpainting mode on that
if it work well, but I'm afraid my current method might work better maybe
I want to test it now
we have benchmarks for inpainting, so there is no need to guess which one works best
I don't understand what to download or install
do you know how to

impaint:
models/inpaint/
?
I'm afraid it is just an engine to create mask and the same inpaint you do on Automatic
and in Automatic you already have segment anything
its open source so you can check the python code if you want, I encourage that in fact
oh no please
only two files there

the instructions on the github repo work if you follow them though, can confirm I've used it

i have two gpu's one with vram 12 gb on with 16 gb. is there any possibility to run stable diffusion video using these two. its would be a great help. i am new learner .
what, you don't like spectator nodes?!
circus audience nodes
bread and circuses nodes
@rocky gale You can assign one GPU just for cuda calculations by adding a switch to the command line --cuda-device 1 I have a two GPU setup, and assign my RTX for cuda and use the GTX for the systems main display. This allows Comfy to use all vRAM from the faster card. What I have noticed is that load from the interface like redraw and video decode happens on the display card, and rendering takes place on the RTX. Give it a try.
You can't merge vRAM, however.
What's the main difference between SDXL and pony models? As i see on civitai that pony models just states "pony", and not sd 1.5/XL
Pony is a fine tune of SDXL that had been changed so much it barely resembles SDXL, and since none of SDXL loras work on Pony and vice versa so it is considered it's own base model
Huh neat  But does that mean pony and sdxl models isn't compatible? As i've had a few loras being pony not working with sdxl models, and vice versa
But does that mean pony and sdxl models isn't compatible? As i've had a few loras being pony not working with sdxl models, and vice versa
Generally, that's correct.




For anyone who may be interested; this is a list of SDXL artists, with examples:
https://sdxl.parrotzone.art/
Hi
I don't suppose a similar list exists of fictional characters SDXL knows?



what do you mean 😂
Where are the droids!?
Uhm, where is the exterminator droids?
Are we doomed to make 5 million dollars in 3 minutes doing nothing?
Hi. Where do you go to figure out the pre-defined prompts for image generation? Is there resource somewhere that I can reference?
Is there any T5 Flan compatible with SDXL existing?
what do you mean by pre-defined prompts?
that's not really... a thing
It's prompts that you use in the background to append to the user input.
You mean keywords? I don't think there are any of those for base SDXL. When people make fine-tuned models, they add keywords or "trigger words" users can use to easily get the thing it's fine-tuned on. But I don't believe there's any in the very base model, just the ones listed on civitai for that lora or checkpoint.
People have found phrases that help, like the infamous "masterpiece, best quality", but that wasn't intentionally pre-defined by Stability
if you want some then here ```colorful background, intricate sharp details, cinematic lighting, smooth, hyper realistic, 8k, concept art
came from a study that tried to find good general tokens
Do you have the link to it by chance?
Yeah it's very hard to try to fine tune the images without having a library of words to assist in defining those images.
Just wondering if anyone has come across some open source library that I can use.
..."it"? There's different keywords for every fine-tune.
Are you asking for a list of words people have found that just happen to work well with base XL, or are you using a specific model?
Because if you're using Juggernaut, then yeah I can give you the link to the trigger words for that model
Yeah the list of words that would fit well within a certain theme or style.
ah
Sure. I'll take it
Awesome. Thanks!
nsfw,cactus
anyone know if theres a calculator or spreadsheet, that shows how to figure out the steps,unet lr,text coder etc i need to make a concept lora
@shy kelp might
I'm messing with stable diffusion for the first time. I want to make some images where you can swap the top/bottom parts and they fit together multiple ways. It kind of works and it's great fun, but I'm realizing there are quite a few different ways to go about it.

At first I was swapping the halves around after each iteration. But now I'm computing noise_pred for both variations, and then averaging it out. This seems to work better.
I also mix up prompt_embeds and add_text_embeds to try to make it so that it's not that top halves are "pure" characters while the pants are mixed, but rather both halves are mixed in an equal way. (I'm not sure I got this right to be honest.)
But now I've seen some papers and some code that do some similar (though less silly) things by playing with the attention mechanism. I could do the same, right? When doing attention on the top half, I could mix the attention values from the two matching bottom parts.
That's what I wanted to ask about before I try doing it. Will an attention-based approach give better results? The current noise mixing approach results in a bunch of artifacts.
Generating perfect tiling patterns is very similar. It's done by setting padding_mode of Conv2d layers to circular. Not super clear how to apply that to my case...
I'm sticking with mixing noise_pred for now. Starting all images from the same noise pattern helps a lot!
I would recommend area conditioning and overlap the conditionings
attention methods would likely help yeah, the Omost repo discusses a bunch of them
Some of the solutions are just silly, but with the shared noise pattern I don't get too bad artifacts.

mixture of diffusers can help a lot
what I am seeing in your images is no conditioning overlap at all, so that's a good place to start
Thanks! I'll check it out.
mixture of diffusers is an easy way to help this
an alternative is inpainting/outpainting (really these are the same thing) using Differential Diffusion which allows for gradient masks
gradient masks let you bend inpainting
Sorry, how should I understand a "mixture of diffusers"?
are you using comfyui?
No, just Python.
I can use ComfyUI stuff too. But this stuff is just the first step. 😅 I'm trying to do something more complex.
"mixture of diffusers" was a paper that got packaged in a popular comfy node and a popular A1111/Forge extension
its essentially just inpainting with Differential Diffusion and gradient masks anyway but it is slightly different
yeah I've "graduated" from Comfy I try to use pure pytorch these days
Do you know those animations, where two parts of the image are swapped, and now you have one more/fewer people in the image? I want to do a photorealistic version of that.
not sure
it sounds interesting though
I prefer this to projects like "yet another upscaler"
Haha, it's 100% pointless! And I can't find an animation like this right now. My kids saw it in a museum. Basically I need to do this top/bottom cutting thing, where every top fits two bottoms and every bottom fits two tops, forming a chain. But I need to place the cuts at a different height at each person. This way if I change the bottoms around, then everyone will be a bit shorter (and we will have +1 person) or everyone will be a bit taller (and we will have -1 person).
all of my projects were pointless so that's okay 😄
Found it!

ah I haven't seen this before
Kevin Carmody’s solution to
the twelve-thirteen man puzzle.
Can someone suggest a universal keyword to fix this type of error?

I made these by accident, what would I put in the prompt to make them on purpose? Or is there a Lora for this?



pngs contain the workflow information in comfy you can just drag it into the ui
Kum Young Il?
maybe the same thing you did to make them at first? 🤔
Well I'm not sure what it was that I did that was making it happen 😭
Heres the prompt I used score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up, source_anime, 1girl, long legs, orange eyes, glowing eyes, small breasts, yellow sweater, jeans, green hair, inverted bob, straight-on, full body, night sky, moonlight, (red ocean), standing on one leg, outstretched arm, light smile, (black loafers), yellow nails,
that doesn't make more?
No it doesn't
hmm... I can try to mess with this later... running some maintenance tasks on the machine right now
ok @empty stratus - definitely working just fine for me with the existing prompts in these images


This one came out neat.

Oh I probably should've cleared up that I was talking about the like, window thing behind the characters
That's what I'm trying to figure out how to get
I see... maybe model dependent that has that style. I tried with hoseki and got some outputs that would put those backgrounds in...





do you know what part of the prompt might be making it do that?
i tried stuff like "rectangular background" and "white frame" or "white mat" but not sure how much effect it had
I'll try those out when I get the chance
hey guys - is there anyway i can make the head size match the body size?

i tried negetive prompts but they dont seem to work

Lol

any light model for controlnet sdxl?
I think there are FP8/GGUF versions of control nets these days
Hello
I'm using the Style Selector XL extension and was wondering if there's a way to have it actually save my style selection in the filename? doing [styles] just saves it as "None" instead of the style I picked
Is there a recommended weight setting for SDXL's LoRA block weight(for things like characters, poses, and clothing)? My plugin XYZ Plot isn't working.
Does your LoRA need a trigger word?
Of course, the trigger word is very important
Hi, can anyone tell me why every time when I try to use a lora, it just keeps showing red and I am not able to use that lora? This always happens randomly, some lora I can use but some I can't.
I also tried to use the trigger words, but the problem still here


most likely you're using a lora for the wrong model
Does appear to be a pony lora, and that's a pony model showing at the top 🤷🏻♂️
https://civitai.com/models/690897/wings-pony
The error message says "Not found Lora: wings". Have you downloaded it and put it in the correct folder?
Yes I downloaded and putted in the correct folder as it showed here it should be in the right folder
If the lora is not compatible with the model, it should not appear in the lora list. When we change models between SD1.0, SD1.5, or SDXL, the lora list will also change after refreshing the list.
Looks like a bug or misleading error then.
Hey, I need someone to help me fintetune this model, tbh I have never fine tuned any model I tried and struggle with a collab, but nothing for it.
I have my config JSON, all my dataset, now I just need to train with a collab 😅
how do i open stable diffusion
i opened it with webui-user.bat yesterday but now it doesnt work
How in the world do you get a realistic look with the PonyDiffusion model in SDXL? Solved it, I need a checkpoint based on Pony
how can we fasten the speed of stable diffusion my internet is really fast my pc is Processor: Intel Core i7-11800H
Graphics Card: NVIDIA GeForce RTX 3060 (6GB GDDR6)
RAM: 16GB DDR4 3200 MHz
but it generates very slowly
How slow is it and what model are you using, also are you using diffusers/comfyui/a1111 or what?
i know i need at least 8 gb vram
but it generates in 5 minutes
even with default settings
i added you as a friend btw
a1111 i suppose
a mobile 3060 can generate with sdxl at 1024x1024 using comfyui in ~30 seconds
something is wrong, you might be rendering on your cpu
can i add you as a friend
hey fellas, don't know if this is the thread to ask in, anybody know if there's any way to use the new Ecom-ID controlnet with SD webui?

One of the best images I got with XL (I use SD + PS combination If I want an image to look great)

Clownshark just goes out and takes photos and tries to pass them off here as AI generated.
I tried to generated something with it but I found it too wild, at the same time it could generate some unique drawings or something like. I've never asked for drawings on other models, so I don't know.
Create an image for a clothing store called branded_items that should show silhouettes of clothing frozen in ice cubes.
Dear friend, how can you turn a photo into an animated movie with this artificial intelligence?
Does anyone know?
It depends on how long you want that animated movie to be
hello
so i made a character, but i have real life background pictures that i want to add him into it. can i do it with stable diffusion ? or am i doing ti with else ? how can i do it please ? i dont see any suitable responses in the internet. thanks
thanks a lot
Hello,Hello! I am using "Structure." The generated images have darker lighting compared to the uploaded images. How can I adjust the brightness to make them lighter? I would appreciate your advice.

{kind=link}
{kind=link}
shameless plug, but theres currently a 5000 buzz prize for an image that represents "100" over on seb kamph's discord. few entries so far, people are overthinking it. https://discord.com/channels/1029801671347425280/1087308571366150176 come up with something and submit it, odds are currently super in your favour. 🙂
Does anyone know where on huggingface I might be able to find flux dev gguf models with different quants?
"huggingface flux GGUF" is the relevant string for google and the page you want is this https://huggingface.co/city96/FLUX.1-dev-gguf/tree/main
if you want to go next-level there is this https://github.com/chrisgoringe/cg-mixed-casting?tab=readme-ov-file
Are there specific VAEs that need to be used with this? Or clips?
no you can use the normal ones
although you may as well pick up a T5 GGUF
if you are already doing GGUF
Where can I find that? They don't seem to put them with the models on that page?
I'm trying to find a balanced workflow that sits at around 12gb VRAM because I plan to integrate this workflow into my Open-Webui instance where I can run LLM models and ask it to create images or describe images in a GUI like ChatGPT. I plan to make it remote accessible. This will make it easy for me to get to in anywhere, Then I can let my wife and son use it.
city96's huggingface account has them
12gb is enough yeah
https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/mainthese are t5
Do you think a q5 k s would be high enough quality?
T5 and Clip L yeah
the model gets given both embeddings
they are concatted on
concat just means one after the other
but they connect to two separate things, so does one have more weight or importance than the other?