#✨|sdxl
1 messages · Page 126 of 1
that the only one I could get.. you were MIA at the time I asked about it earlier tonight
right click, then select bypass it should turn purple after bypassed

I can give you this if you want, but no AIT support yet




ya that sounds good
what in the brady bunch is that?
put in 3 images, get a 4th one. give me 3 images and I'll put them in
first one dictates the theme and structure most, 2nd is kind of the accessorizer, third mostly dictates structure
try these



lol, well okay.
I dont really have anything in mind sry they are pretty random and very different
there are a couple other settings to mess with as well, but it's mostly good to go
Let me give that one a try... I'll download it and give it a try in the morning... I have to get up early to drop off my son
lol he says those are random...then you compare to what picturesonpictures showed

I think he wins in random pics lol
Ya I would like to give that a try too.
This is the new one? yay

lol
have blip models looking at input images and then giving descriptions, then sending those through stylers
also did this, it's a version that does image input, so prompting is like [IMAGE] as a.../doing.../at...../
I will have to play around with that to get some interesting results. Can you post the resulting image?
I want to try to keep your settings to start with


do you have the manager?
ya and I downloaded the missing nodes and restarted comfy and that still comes up
Do I need this top one too?

probably
I figured it out... I needed to download POP


lmao
ok well at least it work... Ill keep trying tomorrow. have a good night everyone
It was pretty quick too for a full upscale to 4k

slightly cursed

Prompting.


Nice haha.
WAS Node Suite: BLIP Caption: a cat made out of yarn on a table with a bookcase in the background
WAS Node Suite: BLIP Caption: a corona corona corona corona corona corona corona corona corona corona corona corona corona corona corona corona corona
BLIP having a bit of a trip
have the first caption going to pos g and the second to pos l, then both combine with a second text box to put in various things, and then through a styler. first image is clip g and ipadapter, so it'll take on whatever style that image is





steampunk and denim ❤️




he seems terribly excited to see me 🙂
Are there any custom node for Latent Image?

the default one seem very limited
strictly forcing width and height
have you tried pure Empty latent image?
pure empty latent image?

oke hold on
great fisheye lens 👁️
I have
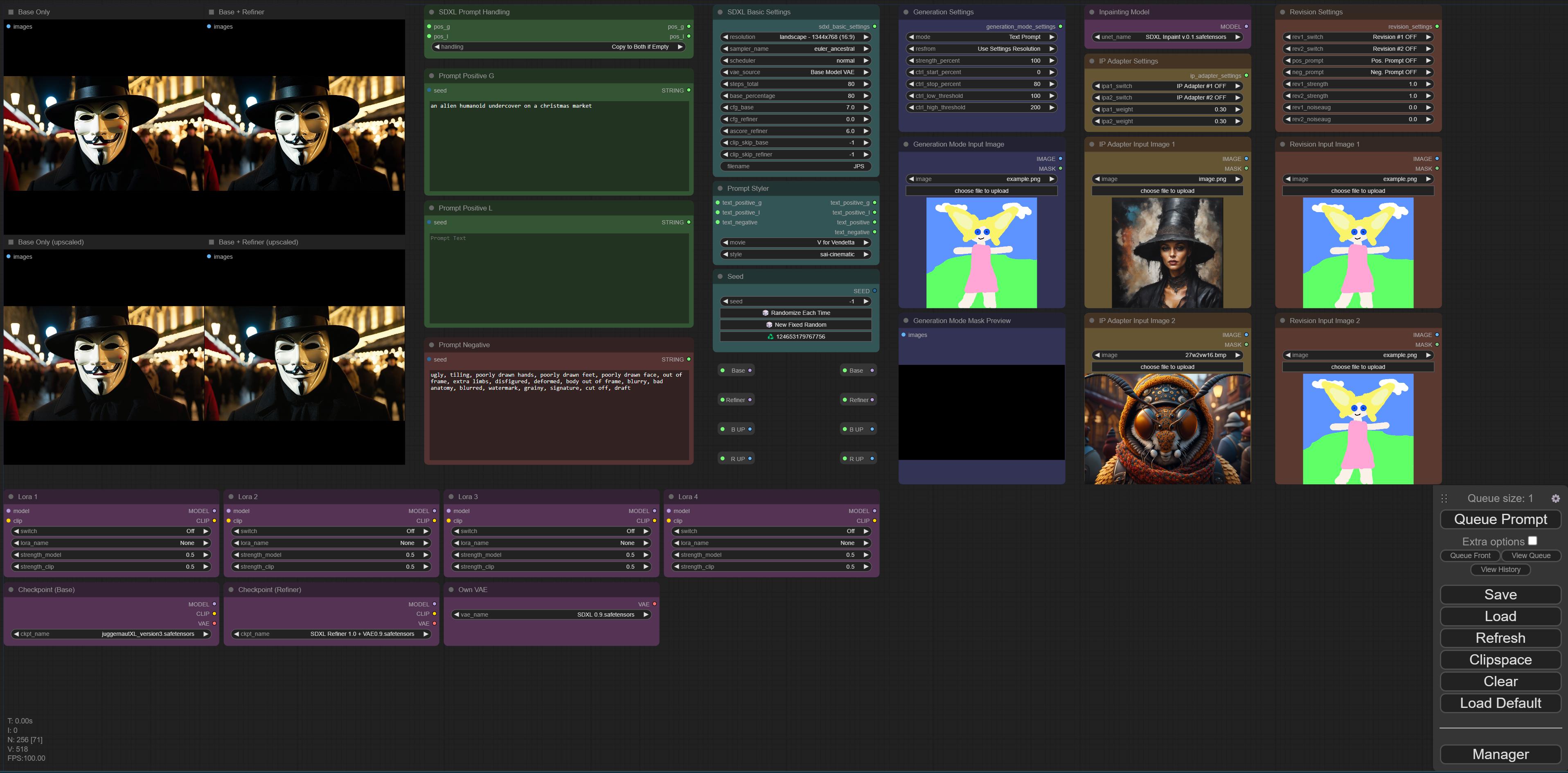
FYI been revampping my workflows and bundled together as a collection
My personal Daily Go to is my "Middleweight" workflow.
Features include
- ChatGPT Assistant (disabled by default as requires an Open AI account)
- Selectable Positive Prompts (linguistic.Random or One Button)
- Selectable Upscale Method (Standard, Ultimate or None)
By Default loads (on a 1440p monitor) into the view in the screenshot.
Lesser used (by me at least) features such as ReVision & Controlnet are off to the right hand side
All control elements are in "The Engine Room" on the Left Hand Side
https://civitai.com/models/138397/winstons-workflow-collection


when I typed.. 540 it forced to 544
has to be a multiple of 8
must be divideable by 8
you could resize after
















i love nightvision model

anyone knows a stable diffusion that is compatible with amd gpu
i already sent you link on AMD version of A1111
ei guys, can xl stable diffusion API be used for commercial use? And the other APIs?
Because i have read the term of conditions of the site and the site is not free for commercial use, but maybe the apis yes? I do not know
@indigo carbon So I was trying the new image blend and it wont let me change the model name

You are missing the models required, if you have them with a different name, you can change to them accordingly
Where do I get them and what folder do they need to go in?
It doesn't seem like I can use regular models like copax or nightvision
it uses my cpu to run for some reason
IPAdapter SDXL goes in custom_nodes/IPA_comfyui/models CLIP vision in models/clip vision
It uses your cpu to run because like we said last night none of these things can use AMD graphics cards so it reverts to using your CPU
Can I get IPAdapter SDXL on civit or huggingface or github?
Of course you can, but not instead of IPA hooking onto them.. IPA is a new component that goes after the checkpoint
oh alr
im still new to this field
Yeah, it's all linked in the IPA node's repo
cool beans
Ok so now I have that but it is now saying the following... I don't even see a node where it is referring to copax to be able to change this

that's the checkpoint file it can't find
yes second most frequently error i am getting. 1st is AITemplate enable 😄
I get that but there isnt a node in the workflow that allows me to select a ckpt
can you send a image? Probably packed
I can send the workflow... I cant make an image yet because of the errors
i meant screenshot only

Switch the load checkpoint to whatever checkpoint you wish to use
It is under the batch preview
ohhh... lol its behind the box... I found Waldo... he was hiding
Is the refiner model the one on the top or bottom?
Refiner is the one on the top, yeah
I have to say great work. Image blend is pretty cool
I'm going to try your AIT V5 in a little bit
Also try the multimodel version, it's Img+txt instead of Img+Img
Is that a different workflow? can you send me that one too?
I did, it's somewhere in this channel, I also explained what it does
@indigo carbon Isn't that what I'm using right now?

damn, its great
can you please share the workflow
its from @indigo carbon I take no credit for it
I'll post an image and you can drag it into your ComfyUI setup

np

no idea... I would call that lava lamp... lol
ei anyone can help me about the licence.. i can't understand if apis have a commercial user or not, because tools in the site are not.. i do not know apis
try to google it
how would you google images?
I meant about the license

@spring fulcrum what is this?

missing node?

idk... I think you need to install missing nodes
i did install all
@ionic dragon It is EMPTY LATENT IMAGE (AITemplate)
where to put IPadapter?
Can SDXL make a person standing in the rain? (Rain falling in front of the person?) Prompt?
Sure

give it a try and find out lol
Perhaps prompt for the person to face the camera that might help.
if on me, i tried to help @spring fulcrum

who needs help?
me
also qwerty_.... was checking for missing node... I told him what node is missing.
I need help, where to put ipadapter models
if you go to install models on comfy manager you can search ipadapter... click install on the first one and it will put it where it needs to go
i did it but it was missed styl
@ionic dragon if you get an error when trying to generate an image after you already installed missing nodes. I got something that said PoP at the end... Just search for pop in the install custom nodes and install both pop plugins
do you have a screenshot of the error
solved
cool beans
Prompt? I'm not at my PC, and I'll never be able to find this message later in you included PNG info.
RealVisxlV10 checkpoint

it installed it in ipadapterplus, i find ipadapter comfui
as long as it works
I'll try later, but nothing like this worked for me a month ago.
Probably a difference of newer more finetuned models.


Is that even a ckpt for SDXL.... If its for SD 1.5 or 2.x you probably will not get results like us..
lol yes, it's sdxl.
https://civitai.com/models/139562/realvisxl-v10

The model is already available on Mage.Space (main sponsor) It's important! Read it! The model is still in the training phase. This is not the fina...
that model looks pretty good
Same guy that made 1.5 RealisticVision
I loved the work he did with his 1.5 model, and he stated this current model is only about 18% completed.
always liked deliberate and then revanimated better
Is this o.k. result? Credits goes to @indigo carbon

I made my own merge for 1.5 of quite a bit of checkpoints, but used deliberate as the main base
realisticvision was always great when I was going for actual realism. but then that's not always my primary focus
ah, that's where I stay in a majority of the time



it's gonna have kitties and string and an octopus of some kind


lol

xD
oh my
Perfect.
some of those balls have eyes. eye balls
I no joke for these images use balls in the negative. 😛
So it wont generate to much woolen balls.



well lit was those yarn balls invading
also, for the longest time it was realyl trying to make cats surrounded by string and yarn
let's see what sort of new mildly cursed image we'll get
oh jeez

Awesome.
it's a different version, here; this is what I was talking about
cool - interesting experiments you've been posting the last few days!
this is what multimodel does


had to bring back the frog girls

thanks!. did you see what I'v been doing here? it's got quite a few things going on but they work out alright together
did you just blend cats with wool lol
another moderately cursed image
I tried to follow it a bit and it got me really interested in trying it out myself. I can't claim that I really got all what you are doing - but it does have something to do with multiple IPAdapter passes 😄

the main new things I did, at least for me, was mess with pooled output before clip vision, and then also have 2 of my 3 input images go through blip models and use those results as part of the prompt
I just like doing different things to see what happens. sometimes it works out great. sometimes it's horror
crazy and intriguing 🙂
I was told it is legal.
yeah - a reoccurring theme with experimentation and the latent space in general heh


Now i see what slow gpu means :)))



tf
samurai frogs
Not sure result is o.k.




I mean considering the images you put in... I think it came out pretty good.
Thanks, just not sure if not publicly bad picture 🙂





Woolen animals are the most dangerous species on earth.
@indigo carbon I'm curious... how did you come up with your username??
long story, I'm sure it doesn't really matter
its all good.. i was just curious.. no worries

hey im trying to install control net models for invokeai/A1111 and dont know where should i download them from, any idea ?




what is this ?



I installed tensorrt but it seems nothing is made for it, shit.


Does anyone find when using 2 IP Adapters, it has a habit of chucking the subject of the image off to the side like this?

have you tried the solid masks?
yah, tdg was messing with doubling up the ipa nodes, not sure if he fiddled more with it
Nah i've not done anything with masking. And it doesn't do this all the time. Just sometimes.
well the masks would help you place concepts
they essentially tell it where to concentrate
I'm guessing it's something to do with the input images being different aspect ratios and it not understanding where things should be
probably
@indigo carbon you determine if that doubled nodes thing fixed completely the odd images being pushed to the edge?
wow, do you have a workflow for this ?

If I turn down the strength of the secondary image it stops doing it, which is what makes me think it's the mismatched aspect ratios

both
it's in a lot of the images I post in here. one moment
any idea what second image could be with some good result 🙂

I personally don't like the idea of using img2img when blending, defeats the purpose of making something entirely new by blending 2 subjects, not overlaying 2 images and using IPA for sampling. The fix to subjects going out of frame was to use UNCLIP and IPA in the same time; this is what the workflow I'm working on does

ipadapter is only for "copyng" images?
doesn't defeat any purpose, it's just not what you prefer
No, it's only active with the conditioning and the sampling adapter input. It shouldn't have any other effect

😄
How heavily do you weight it. I've got unclip nodes linked up to both my ipadapter nodes
Even better

yes 😄

IPA can also be used for multimodel workflows, including Img+Img and Img+txt equational inputs
I only weight the IPA nodes, I leave both UNCLIPs at 1
I like the idea of swapping images around having them impact the output in different ways. sometimes I do use an empty latent, but that eliminates an option for having another image com into the mix


me?
both
this is what IPA multimodel is capable of; I won't release neither of these workflow until we figure out how to make AIT compatible with them



well I created a workflow that took blip descriptions of two images and used those as the prompt for thos 2 images to then go through ipadapter and clipvision. worked out pretty well but then I got more black images as output than I really wanted so I messed with the conditioning data going into the clipvision and it seemed to alleviate those issues. then I added styles to the prompt inputs so I could have more flair. and when that started working I decided I'd start using a third image as input rather than an empty latent because I wanted to combine 3 concepts
I will probably add more to it. just messing around
pitty will try make it wider...


in Auto1111 ehat is it meant for?
no
but I mean, it works. if you want to drown out the third image which is the input latent then you just bump up denoising. anything below 50-55 percent will basically give you the third image with some mods. but around 65-70 percent it takes on new forms


that's 70 percent denoising
nice
this should be good

first image is described by blip in g positive, second in l positive

Is it worthy to train a lora to just generate acrylic pour images?


a=b+c





I like the frog girls

artificial noise @stone fossil ?
alright, I have 100+ moderately random combinations of things set to run while I go do real life stuff. this should work out well
I'll do about 8 of each combo. gives me a nice overview of the concept and allows me to weed out the outliers
So would training with only these images get only these
https://pin.it/2t1KEtZ

This Pin was discovered by Wallpaper 4k HD. Discover (and save!) your own Pins on Pinterest.
As I don't want to messup and generate random images other than these
man, there are a lot of variables that come into play
those images seem alright, but you have to set the parameters correctly. I'd suggest tracking down one of the training wizards because I do not know exactly how they do it
Oh ok
Uhm, i kinda have a prompt for these
Pls share
Ok, but its a bit...weird
photo of A living painting, created through a process of slowly injecting colors directly into the artist's veins, allowing them to bleed onto the canvas in a mesmerizing display of organic abstraction. colorful, mixed colors
Space Pirate...





It's generating low quality images, my pc is off so I can't use comfy. Used this bot and results were bad
Wow, that really bad. In comfyui, even with the standard base checkpoint, i get consistent results.
Damn, I like those characters
I used one of those images in IPAdapter and then used Text Prompts for a person or an animal. It's pretty cool.
Cool tbh






Is that on the right what i think it is? 🤔
this one is so good
A genie lamp? Yes, you are correct.
I just downloaded ipadapter but the model was for 1.5?

phenomenal cosmic powers.... iittty bitty tiny space...
Exactly what i thought. 😬



@hardy cipher lol

Cool tbh


jungle warriors for every occassion!

As far as I can tell, SDXL can draw rain falling in front of clothing, but not in front of skin?
sheets of rain, rainfall, torrential downpour, hurricane, flooding, a woman walking in a rainstorm, drenched, soaked, wet hair, clear, background in focus, uhd, 8k, Unreal render
Negative prompt: blur, umbrella, dry, depth of field, lens
Steps: 50, Sampler: DPM++ 3M SDE Exponential, CFG scale: 7, Seed: 2522279332, Size: 1024x1024, Model hash: 0b76532e03, Model: SDXL-CrystalClear, Version: v1.6.0

Frog kings
In general, I have trouble getting fine structures "in front of" other things.
E.g., trying to get a bird inside a birdcage is almost impossible. The bars are behind the bird 99% of the time.
or it's clipping through the cage
same with transparancy, that's just damn hard
Yeah, maybe it's just a limitation after all.
nah, i have prompt where transparancy works, but that's because it's clothing near the skin
i think it's hard to differentiate 'something behind something'
have some more jungle critters




Yes, but the rain will never fall in front of those jungle critters. Only behind them. 🙂
i know 😢
I have transparency problems with windows, not sure why you'd want transparent clothes... JK I can imagine, but really. Window clipping is a problem. Lots of scenes have windows.

prompt specific, but it id kinda work






It's actually much easier. Just spam words like "transparent chiffon tulle gauze voile" etc. But that transparency doesn't seem to carry over to a flat glass windowpane. Or else glass is just too different.
yeah, you can't really "force" something to be specificly transperant, or we all just haven't figured out the magic tag for it yet
Okay. At least I'm not struggling alone. Gonna get dinner and try training some LLMs.




@hardy cipher can you shed some light on how that workflow works?
i mean, i get it that it takes caption from blip, but does it also do IP at the same time?






Well it takes the caption for the first image and sends to clip g positive through the optional styler. Then the same image also goes through ipadapter
Then second image same thing, but through clip l positive and then to clipvision
And before clipvision I mess with conditioning data a bit
upgraded horse

I'll take two
Liminal latent space

we might have gone too far 😮



it's further evolving

Who knew horses were so under-evolved









ipadapter just refuses to work for me, but I guess it is because it is wanting 1.5 not XL


huh? It works in xl perfectly fine
the model I downloaded it directed me to was SD1.5
one sec
these tensor errors I know is from it being 1.5
yeah



You know I spent over six hours today trying to get nvfuser and tensorrt to work for training only to find out #1 no workie in windows and in Linux Kohya never implemented the needed stuff. 😦
less scary horse

yeah, mine is 15. that will work. Thanks
Yeah it links to the 1.5 one. The links are wonky

https://i.imgur.com/ST0861a.png how should i go about mixing this so the "box" disaperes?

I saw 15 and instantly knew what was coming, and sure enough, lol
yeah you're not the first person lol
I am playing with it having no idea wth I am doing as no English speaking/written about it that I could find so I jumped in after the dismal findings that we need new tools as the tech is out there.
deepspeed+dynamo and once we get those it will be so much nicer we could even pull off a 2048x2048 training in the same time as current 1024x1024 on the same card.
LOL





Yeah that doesn't help for sure, I threw it in a translater, but it wasn't perfect.
+1 on this error too - did you solve it somehow?


You can leave your prompt empty, or use zerocondition node to clear out your text nodes, if you do that, it mostly just uses the two input images and blends together prominant things from each. You can do two linked together and play with the weights of each.
Or you can do prompts, but they tend to put a lot of weight into the mix, so keep it simple to see more from the images

Also William S. Loved pizza

I just don't see where it is mixing the images at
what's your flow look like?
shit
Hmm

ngl

I just want simple so A+B
I am used to revision
it sure slowed down my 4090, sheesh
does anyone know of a really good LoRA for getting perfect eyes or at least eyes that aren't all blasted out?


@crisp owl is this also blip and then ip?
This is just plain out ipadapter
That's not what you meant, right?

different in my own wording by:
IPA seems to do an actual merge of the two images. Direct images, like the pixels we see.
Revision seems to more grab the concepts from each image and converts those into text (conditioning) which it then uses to make an image.
So from my picture it would take like, girl, sitting, drawing, window, stool, etc.
So in the revision image you'd get stuff with those concepts, but not necessarily how the image itself looks


there was a channel on sdxl called img2img, right?
Neyes
why is the ipadapter only take 1 image?

My flow above does two images
But you can do one image also
if you remove the second ipa

okay, you lost me

which node will model/model?
the two ipa nodes
See, my mind sees that as one way but my way is actually parallel. Problem is all ofthis is in series
eh kinda. Both are using a form of image embedding. The CLIP pooled embedding exists in the same latent space and the text embedding but its not neccesarily a raw text embedding. The base XL model was not tuned with any pooled image embeddings always using the pooled txt embed but because the concepts exist in that same pooled space image concepts transfer across as well. Both methods are in fact using image embeds though, not direct pixels and both likely could be improved quite a good bit
in both cases mixing the images is mixing clip embedding concepts


Oh yeah, I know my description isn't technically right, but in it's workings it's more or less what it's doing and helps to understand how to use the two
There, a bit more inline visually

uhh...i think this horse comes from chernobyl or smth


LOL. just... i can't even ...

these are masterpieces!



really? I remember KohyaSS having an implementation for DeepSpeed, it does the same thing AIT does
not anymore nor dynamo
Now deepseed is actually worthless for me though
due to this

huh, I think going forward we would lean towards OneFlow, that's currently the fastest
OneFlow looks promising
performance wise, it has a good 10% over AIT, but idk how easy it is to implement in a user friendly way
Napoleon and his Playstation

deepspeed cant work with lo rank stuff because it doesn't have the forward it needs. I could not find a json to get deepspeed to work even for db
HF seems to say for 1 gpu it is slower as I showed. Regardless I have yet to see anyone using it with kohya
@visual glade the AIT node seems to have gotten more compatible.. I think you should aim towards implementing OneFlow because currently that's the fastest
Now Dynamo there is for the compressing of models and stuff but sadly everyone is bitching at Titon to implement for windows as a ton of pt2 stuff demands it.
does oneflow even work on windows?
and AIT is already compatible enough, so the goal should be making OneFlow compatible
oneflow is for training and inference if I read right
probably, but it is at least 10% faster than AIT
nah, some people benchmarked it on SD1.5 and it was faster than AIT
deepspeed's claim to fame is that it can take excessively large models and allow lower vram usage to train them
for me I don't care about anything inference based only as I am looking at the stuff that works for training
too
DeepSpeed isn't flexible or has any superiority to OneFlow, assuming they are both only for Linux(which I'm pretty sure isn't true) OneFlow is superior in any way

also the speed is insane actually
That is why I would love to see it for training DB but will any of these work with lora types
I think it has things in common with both AIT and TRT, didn't look into it yet
A bit sad I got it all installed but no way to make it work on windows and in linux it demanded stuff kohya had not implemented. I tried though.
that was for TRT
OneFlow seems like the way going forward.. I heard it's also flexible
for linux it complained it wanted fake tensors and I need to implement them. beats me I didn't write kohya code so no idea
spit out a bunch of matrix stuff at me too
OneFlow seems to take all the good properties from AIT and TRT, making for what could be the fastest inference as of now
yes, but did I read it right that it can be used for training as well?
some of these are one or the other
I don't see any reason for it not to.. give it some time; I'm sure it will be an accessible thing soon, so far its performance speeks for itself
the best kind is the kind that doesn't need devs refactoring.
I think I heard SAI used it for training SDXL or for the bots and ClipDrop
Probably true
Right now we need deepspeed for DB because even my 4090 BS2 is it.
so something to help with mem optimization
I feel like OneFlow would be the solution.. we just need someone like Comfy to implement it in an *it just works™️ * way



I looked in the repo, it does say they didn't pre-build it for windows yet, but it should be able to be built for windows
hope some of that stuff gets ported over to a1111 some day
@visual glade so if you build the module from source, it should act the same way AIT does, you can't just go pip install oneflow you will need to do git clone https://github.com/Oneflow-Inc/oneflow then do python setup.py bdist_wheel or something like that.. basically same process when making an environment for compiling AIT modules
getting OneFlow to be an easy use for ComfyUI will be a huge step in that direction for sure, but we gotta start from somewhere..
yeah, i think the modular setup on comfy should make initial implementation a lot easier
Yeah, for TRT I had to jump through a lot of hoops but on linux pip install and 3 mins later done

@indigo carbon Do you have any interest in adding a high res fix... The only two things I think it could use to make AIT my main workflow would be a slot for a LoRA and a high res fix.... Or something that can fix the eyes... the eyes are the only part that consistently don't come out quite right. Other than that your workflow is amazing... and quick.. I really like it a lot... I especially like the style selector
my only small critic would be to label the nodes.... have them specifically say this is your refiner model... this is for base model... this sampler is base image.. this is for refiner... It just makes it easier for people that are new to this to be able to use it easier without having to ask questions.
I might add those to future versions, but the version I shared earlier today is a prototype. It's not a final version
this ima

I really like it a lot... great work... that was just my two cents

mhh what would be better, 3090 or 4070 ti ?
I'm not quite happy with the speeds yet. AIT is very nice to have but OneFlow is faster and newer, next time I work on new workflows after I finish the AIT one it will likely be already after everything gets figured out
where are you learning about all these new tools?
OneFlow should be compatible with IPA theoretically, so I won't be uploading any of the multimodel workflows officially until it's optimized with such optimization

but I will probably add a LoRA feature to the main workflow like @spring fulcrum said before I go silent

That would be my biggest ask and would make this my main workflow at that point



some of these comfy nodes has a mem leak
I am getting fantastic results with AIT... Thanks @indigo carbon




no idea which one


I think I read it is pytorch itself
Damn, I restarted and got hit with the same OOM
You trying to merge models together?
no, I stuck a lora in and boom
which nodes are processing conditioning data?
I've not used LoRAs for a while, but not had issues with them before
hello everyone, i have tried using the sdxl model, but when i want to make a simple image it's loading very slowly. is that normal? my VRAM is 8 GB and RAm is 16GB

ipadapter + clipvision are basically on the fly loras for me
lacks a lot of control as you never know what is gonna come out
well you can gain control of it with the right approach
I think I had a crossed wiring is why but all this wire it gets confusing
what's your flow look like?
nope, this lora is not gonna work in this flow
like utter shit. I am never organized in comfy
just too hectic for me
Never did like spagehtti jungles.
when it gets that way for me I try to organize things into sections
I've tried to branch mine out into sections

Still gets annoying sometimes when I have to move a link somewhere and then it doesn't connect and I lose where it went lol

he's so happy
I hear the laugh, even when it's only a gif
Why am I getting this ait error and ait is no where in this workflow?

ipadapter is so good at taking low quality images and outputting high quality things
man, AIT is cursed when I try it
I no longer use ait so surprised
3 times now I've installed it, and 3 times I get errors like that. not that error but similar vein. the latest round it was giving me errors even when I wasn't using the nodes
I think it was this: https://github.com/FizzleDorf/AIT/pull/44
GitHub
Leaving this PR open for now as people are on older commits and this would break it. When the memory issue is fixed with latest I will merge.
hmmm, even when it has no ait node ?
it is weird because the workflow works without but with boom.
Currentls comfy + AIT is only running with this patch. As far as i know
none of my nodes tells me I need to update. welp, hmmmm
Alright. Still confused why I am not using AIT anywhere in my workflow but got it. must be always running but not activated or something
go into his folder and git pull?
or if not merged how do I update?

I think you need this commit: https://github.com/FizzleDorf/AIT/tree/ab84fac064b6fbf16b8431f8b7a34394ae72f02f

GitHub
This was orginally written by: https://github.com/hlky - GitHub - FizzleDorf/AIT at ab84fac064b6fbf16b8431f8b7a34394ae72f02f

Ok, it may work now
let's see


nope
apparently I need a 32gb card
I see the error message is is a recursion issue
not sure where or how though
time to buy that sweet h100
hmm

Can you post the complete traceback? I've run into a lot of errors, maybe it's something that looks familiar
RecursionError: maximum recursion depth exceeded while calling a Python object
heh oops
What workflow are you on? Does it also happen if you have a simple Model -> AIT -> Sampler barebone workflow?
that is the point I have no ait nodes as I no longer touch them for a couple of weeks now
Oh, so, lets say you deactivate (or move) the AIT nodes for a second. Does it still break?
in a min I will try that
I do not know, but it's saying you need at least two 4090s for that workflow, lol
perhaps an h100, or even an a100
yeah, just by sticking in a lora
WTF is that workflow?
there's something real wacky going on either way. because it shouldn't be requiring anything remotely close to that should it?
unless you're trying to train 2 or 3 loras simultaneously or something
LOL
it'd work on runpod. you can rent 8 h100s simultaneously
Might as well just pull down my pants for that one
about 35 dollar an hour. but you'd have like 640 gb vram
yeah, I uninstalled it through the manager. if completely wiping it doesn't work you might want to start replacing the files that are causing the errors? I don't know. when I see that sort of thing and it's not easily rectified I start purging immediately
Is this your workflow?

10 checkpoints, lol
this is the problem. turn that lora (any lora) off and it works, or remove it

whoa
it is the lora
I bet I know why
🤯
throw it in a fire
throw comfyui in a fire
Is it a 50gb lora?
heheheh, no. I am trying different loras and they are all doing it
Ok, throw the lora loader into the fire
yeah, let me try a different one
I made lora loaders
nope
native lora loader same issue
something about lora and ipadapter
all I am doing is taking the model and coming out into the lora and from it going onward as shown
works without ipadapter that way
I wonder if it needs to go after the ipadapter?
which clipvision model are you using for ipadapter?
you need to use the right clipvision model. I don't know that it'd give you that error though

but could have something to do with it maybe?
/prompt a boy in office

I dunno it was a link someone in here gave me on the HF site
probably the same
have a link?
it's off huggingface. one minute
I bet the same one



yep
*3.69
is that the one cause I had 1.5 then earlier given link to SDXL now this one
use it instead? grabbing the safetensors one
I think it's just the clip vision model
then I dunno. needs to be one place to get this stuff
use the link I pasted
I am
how about the ip-adapter? confused cause clip vision but link is to 3.69gb ip-adapter model

I dont have that one
Been a while since I got it but it came from HF

hopefully I didn't just automatic1111 myself with that update
correction, it was mc dali

I've literally just finished up a script and workflow change that allows my Randomizer to drop the files into a directory that's monitored by my Lychee server and it automatically adds the images into my Random Diffusions gallery, archives the images after being scraped. Then it periodically prunes the archive and log files. This way, when I set the Randomizer to create images overnight, all I have to do is just look in the gallery instead of manually uploading everything.
nice
Gallery is here for anyone who doesn't already know:
https://lychee.soulctcher.net/
some of these old ai images I saved are kind of 🔥



ConditioningNormalizerPoP and ConditioningMultiplierPoP
I see what you're doing outside of those, though.
one second

they appear to be on the github. are they not working correctly?
if so please let me know because I don't want that to be the case
I just updated a few minutes ago and am getting red nodes for those.
Let me triple check.
Yeah, they're not copasetic.
I changed the file name for them before I uploaded them
😄


That'd do it.
so if you have one of the old images
has anyone used "MediaPipe Facemesh to SEGS" node from impact in a facedetailer workflow? doesnt seem to work:(

you know, I can't say if it's optimal, but it works
Yeah, no worries...I like to play around with the stuff, too.
thinking of messing with the model data in a similar way
also, if you want to bump up the multiplier max it's in the conditioning node file
I just set it at 3 because past that it gets very off
ok
and negative seems to be nonsensical and broken. but who knows, might be a use case
First thing's first...pull the workflow out to trace everything.
you know, I didn't know anything about any of this stuff a few weeks ago. so it's quite possible I didn't do everything completely optimally. so please let me know if you see anything that seems off
It's all good...I'm around the same place you are.
I have been messing with this in different ways for like a year, but only recently got into Comfy
well I started with ai image stuff a couple years ago. but not text to image. that was future technology
but found it pretty quickly when it became available to the public, then SD in november along with a1111. but didn't start with comfy until around the end of july
learned a lot about python with a1111 because of how often it broke
hadn't really touched it until then. but learned quite a bit sense then

at first it was out of sheer necessity, but now I can actually do stuff with it
trash image, lol
why can't I easily move the textDebug nodes? They're not locked, not pinned, not frozen...
I wish Image Load didnt constantly make duplicates when you reuse the same image
Oh, I see...they were collapsed, but it was tough to expand them due to their want to show the true/false switch. got it.
I think they're broken. and I think you can delete them
yeah, I don't really think they're necessary

I started over and it works as it did earlier but as soon as I add the refiner it will break
yep, breaks it
@hardy cipher - Your workflow spread out...now I can start to follow this version. 🙂


hey guys where can i go to download the tile controlnet?
hasnt been made for SDXL yet
oh sorry i meant for 1.5
is this it?

I don't understand how I download it
I need a yaml too?




damn
lul












Backread a bit. @vital ermine if you don't have it, this is the clipvision model you need
https://huggingface.co/comfyanonymous/clip_vision_g/blob/main/clip_vision_g.safetensors

using @hardy cipher WF


sexy
Is there a SDXL controlnet model for lineart?
scribble probbaly closest
oh the controllora is called sketch
but don't think it makes lineart
haven't played much with it



cant figure out how to control weights, something stronger with 1.4 seems fine but doing something like 0.4 or 0.6 doesn't want to work
in what?
a1
Hey there people! I am very new to Stable Diffusion and I am working on it with a very tight time deadline. I am trying to generate some images in a comic style. I am using a comic-styled LORA which works perfectly. The issue I am having is that the models I use which is "https://civitai.com/models/17800/cartoon-fanart-style" is generating the images but it is messing up the background characters. I am using Euler A Sampling method, 20 Steps, a CFG Scale of 7 and a random seed that I generate. This is my negative prompt:
nudity, text bubbles, dialogues, disfigured faces, low quality output, text, username, logo, (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), bad composition, inaccurate eyes, extra digit, fewer digits, (extra arms:1.2)
But the outputs of the background panels look a bit too disfigured. Am I doing something wrong? Does seeds actually matter? I would really appreciate some help
usually if i do like freckles:0.4 or 0.6 or anything really under 1, it's softer to non-existant but i can't seem to get it to work here

sometimes the dropoff can be quick with stuff like that. you just have to experiment with things because every scenario is different
try more steps and possibly lower cfg scale
 ty
ty
can someone with access to an unlimited chat bot (local or payed chat gpt) help me create a json file with 250 movies? the free chat gpt won't give me more than 10-15 movies? i would provide more details for the prompt.
Ohh, any recommended values or should I just experiment? And I just started using aDetailer too, it is helping but it isn't allowing me to generate multiple characters
hmm
I could help out probably. just give me the criteria for what you're looking for
@hardy cipher this prompt works for me in general, it just limits the output too much on the free version:
please create a list of 250 movies in the following json format. use movies that are known for their unique art style.
[
{
"name": "Blade Runner",
"prompt": "{prompt} in the style of 'Blade Runner' by Ridley Scott, cinematography by Jordan Cronenweth",
"negative_prompt": ""
},
{
"name": "The Grand Budapest Hotel",
"prompt": "{prompt} in the style of 'The Grand Budapest Hotel' by Wes Anderson, cinematography by Robert D. Yeoman",
"negative_prompt": ""
},
{
"name": "Pan's Labyrinth",
"prompt": "{prompt} in the style of 'Pan's Labyrinth' by Guillermo del Toro, cinematography by Guillermo Navarro",
"negative_prompt": ""
}
]
I'm quite adept with the LLMs. give me a minute. probably won't be able to do 250 in one response. but shouldn't be too difficult
if you can sort it in alphabetic order it would be even better, but i've noticed that will reduce the likelyhood of a long list even more
well, worst case scenario they'll only be in order for each response
because hassle to get it to put 250 things in order. gpt likes to omit things and not say anything about it
I'll have it put everything into codeblocks for convenience
python's aria2c library runs more faster than wget or request, 5 Gigabytes safetensor or cptk file only takes several secs downloading,upload is a bit slower,around dozens of secs
got it rolling. I have a sneaking suspicion it's not going to count very well though
if it's more than 100, so i can have at least 100 after filtering out some bad movies or duplicates, it would be a start and good enough to release the new workflow
having it list all the movies previously added so it won't repeat itself, hopefully
the new workflow will look like that (prompt/style section):

2001: A Space Odyssey, A Clockwork Orange, Akira, Amélie, Avatar, Baraka, Birdman, Blade Runner 2049, Brazil, Children of Men, Coraline, Donnie Darko, Drive, Eternal Sunshine of the Spotless Mind, Fantastic Mr. Fox, Fight Club, Ghost in the Shell, Hero, Inception, In the Mood for Love, Interstellar, La La Land, Mad Max: Fury Road, Moonlight, Mulholland Drive, No Country for Old Men, Oldboy, Parasite, Pulp Fiction, Requiem for a Dream, Roma, Schindler's List, Scott Pilgrim vs. the World, Seven Samurai, Sin City, Spirited Away, The Big Lebowski, The Dark Knight, The Fall, The Fountain, The Godfather, The Great Beauty, The Matrix, The Revenant, The Royal Tenenbaums, The Shape of Water, The Shining, The Social Network, The Tree of Life, The Truman Show, The Witch, There Will Be Blood, Trainspotting, Uncut Gems, V for Vendetta, Vertigo, Waking Life, Wall-E, Whiplash, Wings of Desire, Y Tu Mamá También, Your Name, Zodiac
first run through the alphabet. it's still going
I just dont' know how many are actually listed there and if it's lying to me
@hardy cipher so you do it in two steps? first the movies in alphabetical order and then creating the json file?
no
it forgets after so many tokens
but it doesn't tell you
so it'll start repeating things without realizing what's happening
so it's a way to keep it fresh in the memory
lol the two step approach worked. i've used your list and asked for the json and it did it in the free version:
so this could actually work. get an alphabetic list of as many movies as possible and than ask for the json file :)
well I'm still making my list, lol
sure, if you can get more movies it would be even better. just happy that i have already more than the 15 movies it did before
nice movies
Is there a SDXL controlnet model for openpose and openface?
maybe

*Muted voice* "I'm in"

not that i've seen, no true lineart stuff for controlnet, yet.
I am trying to use this workflow but in XL: https://www.youtube.com/watch?v=cEnKLyodsWA&ab_channel=DigitalMagic

Video consistency in stable diffusion can be optimized when using control net and EBsynth. In this 2nd tutorial, I'll share Tokyojab's knowledge gained in the past 3 months, along with the insights I've acquired from experimenting with his temporal consistency method over the last 2 weeks.
Tokyojab uses the text2img tab instead of the img2img t...
we will get all of the controlnet models for sdxl after they release the 2.1 controlnet models

might be repeats. didn't really verify for sure
The 256 version should be plenty good enough.
2001: A Space Odyssey, A Beautiful Mind, A Clockwork Orange, A Ghost Story, A Scanner Darkly, A Separation, A Single Man, Adaptation, Akira, Alien, American Beauty, American Psycho, Amélie, Annie Hall, Apocalypse Now, Arrival, Avatar, Baby Driver, Baraka, Beasts of the Southern Wild, Being John Malkovich, Big Fish, Birdman, Birds of Passage, Blade Runner 2049, Black Swan, Blow-Up, Blue Velvet, Boogie Nights, Boyhood, Brazil, Breaking the Waves, Caché, Call Me by Your Name, Capote, Casino, Children of Men, Chinatown, City of God, Clerks, Close-Up, Coco, Come and See, Coraline, Crouching Tiger, Hidden Dragon, Dancer in the Dark, Darjeeling Limited, Das Boot, Dead Man, Delicatessen, Departures, Django Unchained, Dogville, Don't Look Now, Donnie Darko, Drive, Dunkirk, Eternal Sunshine of the Spotless Mind, Eyes Wide Shut, Fantastic Mr. Fox, Fargo, Fear and Loathing in Las Vegas, Fellini's 8½, Fight Club, Forrest Gump, Full Metal Jacket, Gangs of New York, Garden State, Gattaca, Get Out, Ghost in the Shell, Gladiator, Goodfellas, Grand Illusion, Grave of the Fireflies, Heat, Her, Hidden Figures, House of Flying Daggers, Howl's Moving Castle,
I Am Love, In Bruges, In the Name of the Father, Inglourious Basterds, Inside Out, Into the Wild, Irreversible, It Follows, Jackie, Jaws, Joker, Koyaanisqatsi, La Dolce Vita, La La Land, Labyrinth, Lady Bird, Lawrence of Arabia, Le Samouraï, Life of Pi, Lost in Translation, Mad Max: Fury Road, Magnolia, Malcolm X, Mandy, Manhattan, Marie Antoinette, Melancholia, Memories of Murder, Metropolis, Midnight in Paris, Midsommar, Million Dollar Baby, Minority Report, Moon, Moonlight, Moulin Rouge!, Mulholland Drive, My Neighbor Totoro, Natural Born Killers, No Country for Old Men, Oldboy, Once Upon a Time in America, Once Upon a Time in the West, One Flew Over the Cuckoo's Nest, Only God Forgives, Only Lovers Left Alive, Orpheus, Pan's Labyrinth, Parasite, Paris, Texas, Paths of Glory, Persepolis, Persona, Pi, Pink Floyd: The Wall, Pirates of the Caribbean: The Curse of the Black Pearl, Platoon, Pleasantville, Ponyo, Princess Mononoke, Pulp Fiction, Raging Bull, Ran, Rashomon, Requiem for a Dream, Reservoir Dogs
what is the difference?
I think it may be difference of pruned vs unpruned...in a sense. However that works with Lora's.
Kinda like how the StabilityAI controlLora models have both the 256 and 128 models
256 will perform better than 128, but take more memory and processing power
i think that coffee might be a bit hot

thanks. i will check it and clean it up after work.



@hardy cipher if you want to check out the new workflow. it's already uploaded to github (based on the first list of movies you gave me):
https://i.imgur.com/Q5EImJB.jpg
https://github.com/JPS-GER/JPS-ComfyUI-Workflows
GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.
you can mix movie styles and general styles (sai styles included) with everything else. (text prompt in the example screenshot from above)
example (ip adapter + text prompt + styler):




You made this using Stable or?
@static wigeon this is stable diffusion with comfyui
Ahh I see
everything in here should be stable diffusion somehow. some people use comfyui, some a1111 or sd.next and a few use other solutions linke invoke.
I see
I am new to Stable Diffusion so I am not familiar with anything related to it 😭
Been using it only for 2-3 days now. I normally use Midjourney, playground or gencraft. So yeahhh. Still figuring things out.
@static wigeon do you use comfyui or a1111? if you use comfyui you can use the workflow i've provided above.




mad max, blade runner, your name (with the same prompt and ip adapter image):



alright, now I can try out the movie game
I use a1111
But I did save your git link just in case I decide to use ComfyUI
I am getting this error "RuntimeError: Not enough memory, use lower resolution (max approx. 320x320). Need: 0.0GB free, Have:0.0GB free" in a1111, what does it mean?
means you have no vram available
Oh

do you have vram?
well you can still render images in comfy without vram. might take 20 minutes each though
without using sai-cinematic it works even better:
your name, blade runner, akira, mad max





Ohh
did you install this? https://pytorch.org/docs/stable/cuda.html




accidental discoveries today


different ip adapter image (still mad max):


result / ip adapter image (mad max):


akira:


where is this wildcard thing? I replaced the seed randomizer and now it's broken
akira:







@JPS Where do I find the ClipVisionLoader File? for your workflow. I need help setting this up
this new coffee joint aint it man

you get your coffee there?
not anymore! 😭
How can I keep the original shape unchanged and turn the picture into the elements of black and white chess pieces?
I think it's easier, for instance with bing, to ask for a list of the top 50 IMDb movies with director and cinematographer and then write a python script to make a json out of it. They tend to screw up json very fast.
sexy skeleton/zombie is imparting us with great knowledge

the links should be in the black info text box:
IP-Adapter Models:
https://huggingface.co/h94/IP-Adapter/tree/main/sdxl_models
https://huggingface.co/h94/IP-Adapter/blob/main/models/image_encoder/pytorch_model.bin
if you need additional help i will be back in a few hours - have to make some calls now
Thanks @crisp owl @JPS Its running , But T2i is still confusing to me. I haven't been using it and I got file all over the place trying to do it

 "
"

🤨
is that a biblically accurate angel? 👀
I have no idea 😮 but uhh... this was an interesting prompt for sure 😮
i wonder what it woudl take to actually try to generate something like that with an actual sensical prompt
looks cool 😄
the actual prompt(dynamic prompts):
As per request, the unabridged repeat, the answer to My understanding of the truth as it pertains to you We are the last of the fated the lost and unseen We reject whatever we were supposed to be
| All eyes on me, gather all who believe Though far apart, united by heart
| We cast increasingly irrelevant designs aside Make room for our incendiary cultural divide We are the last of the fated the lost and unseen We reject whatever we were supposed to be
| It is a cause for us to sing It's how we know that we will win It's true, you wouldn't know 'Cause it cannot be taught or shown There are no gates to hold us back And all your words are only that And this is who we are
| All eyes on me, gather all who believe Though far apart, united by heart All eyes on me, gather all who believe (We rise to reset the world) Though far apart, united by heart (And fight forever) All eyes on me, gather all who believe (We rise to reset the world) Though far apart, united by heart (And fight forever)
} BREAK [anime cell shading:0.2]```that prompt 😵💫
i mean, you get the most awesome stuff doing that (different prompt)




oh, and thx mods, for removing that irritating dude
you've convinced me. I'll run some wall of text prompts and see what comes up 🫡
important detail: try to keep the "resets" to 3 maximum
tokens are sent in batches of 75, and each group of 75 becomes a weighted average
so anything above 3 groups becomes incredibly diluted and won't work very well
Yeah I did
that's the {2-3$$ BREAK} i'm using: get 2 or 3 lines, then split them in their own groups using BREAK, and then a final BREAK to get anime flavour
so not more than 3 BREAKs? 🤔

{kind=link}
{kind=link}
yeah, try not to go above, because then the prompt becomes pretty hard to steer actually
and if you get a combination of lines that's really cool in results, you want to be able to steer it a little
Wait I am not sure Nvidia one I am showing and the one you linked me to are the same




right now i'm going through my incredibly long backlog of lyrics ialready once did, and will merge them in a HUGE single propmt
so the prompt will be like probably 70 kilobytes or more
but from that huge amount of lines, just select 2-3 random ones
should make interesting result 😄
are you using an anime checkpoint? or the effect is from anime cell shading?
anime cell shading
it's protovision: a non-anime model
i'm using [anime cell shading:0.2] so it isn't there for the first 20% of the steps, else it'll contaminate the image with "generic anime shit" which i don't want -> i want it to add anime flavour wwithout influencing the initial result
I'm loving the effect it's producing 😮
This is why i have a hard time giving up lyrics prompting 😛 (this was throught the fire and the flames)




uhh... having a great model i suppose? this model is pretty smart to be honest
i fell in love with it the moment i started using it
hmm, these aint too bad

lovely!
Oh I see, may I know its name? And can it generate cartoon/comic style images?
protovision
sure it can, it might need some prompting work
This is one of my generations, I need it like this

Ahh I see
I am weak with prompts so I will try
Will give it a shot!



The third one looks cool
most important with testing prompts is figuring out what tokens the model actually recognizes
sometimes you're trying to achieve something, but the model simply doens't know what to do with the requested token
for example, this model will not ever produce a sword slash
perhaps it can if i indirectly prompt for it, but prompting 'slash' will only get me a guitarist or a static sword
Oh I see
https://civitai.com/models/125703/p This is the model right?

Like the work I do and want to help support me? Buy me a coffee! ☕️🫶🏼 Meet ProtoVision XL ! This model is my "Bob Ross" model, a happy accident that ...
yeah, that's the one
Okayy thank youu