#✨|sdxl
1 messages · Page 114 of 1
Or will ComfyUI just use AIT on UNET?
accelerated upscale_models? yes please
it's going to be AIT only on unet
damoniano being a spicy boi. wow
I'm not planning to do ESRGAN so feel free to do that
it's not a priority because it's probably never going to break if you make an accelerated ESRGAN node
because I never touch that code
I might, because that's the part that takes the most time in the AIT workflow I made. Also, will the official implementation support IPA and CNET?
could anyone explain why I randomally get all black output images when using ipadaptor?
probably not IPAdapter but controlnet should work
or it's seemingly random. ran the same setup with different seed numbers and some were all black

it's going to "work" with ipadapter by switching to the pytorch implementation
Who defines what the IImportant Nodes are.
What makes one Node more Improtant than another?
How do you prioritise Nodes?
There's an argument that Child Nodes should follow the PArent Node rather than the PArent follow the child.
Thi is the joys of opensource & git hub
This is the way 🙂

I am not sure what do you mean by IImportant Nodes, but that wasn't an argument. Me and Comfy discussed about moving forward
I was generalising not being specific
you used the phrase "Important nodes" originally 🙂

its a general issue with anything opensource/github not specific to CXOmfy or A1111 etc


relatable



Here is another 1960's LoRA

FWIW I am impressed by Ideogram.ai - perhaps the best response for AI text yet! https://ideogram.ai/u/Torcello
Ideogram: Helping people become more creative.
Ideogram: Helping people become more creative.

ideogram?

today is the first day of school in China,the first grade primary school students have to learn English and mandarin meanwhile,it's a big step forward,a couple of years ago,english teaching begin at only junior high school



If I check the Google Drive checkbox, will it download to my Google storage? does it mean i don't have to redownloading models every time I open Colab?

well it doesn't exactly download your storage. but it'll have access to it
checkbox in colab is only an running procedure option, downloading model or not it depends on the code,most of time it will download to your current working folder,if you want to reuse the model,you should download the model and mount on google driver
comfyUI github python code supports not only mount on google drive but also comfy updates option
what's your favorite upscaling method for sdxl at the moment?
ESRGAN
ultrasharp 4X is good for me ,anyway actually SAI's API upscaling only have two options:RealESRGANUpscale and LatentUpscalerUpscale
i've changed to ultrasharp 4X since sdxl can be run on comfyUI
Ultrasharp_4x was made 3 years ago. there is an upscaler in the upscale DB that was released about a month ago, it's actually incredible
Just d/loaded! 🙂
Topaz GigaPixel
what upscaler is that... the one that was released a month ago? What is the link for that database?
I am very interesting on GigaGan upscale but I don't know how to utilize it.
this upscaler is CRAZY
easily my personal favorite
database: https://openmodeldb.info/

OpenModelDB
OpenModelDB is a community driven database of AI Upscaling models. We aim to provide a better way to find and compare models than existing sources.
do you use a special workflow for the upscaling? or just basic upscaling with the upscale image node?
yep,upscale nodes requires more VRAM it's a trade-off
I made two workflows I use all the time. one is the normal AIT workflow, the second is the image+image version I made 12 hours ago
too bad there isnt something we can use to turn these images into vectors then upscaling isnt that important.
i've tested,any pre-training model out there? GAN and diffusion are two mainstream vision computing generative AI technics
controlnet is another big issue,huggingface released some small models already,optimized on RESNET and unet
Can you post an image with your two latest workflows? I'd like to check them out.
SD run slower than GAN main reason is noise and denoise iteration.GAN speed up with different routine,generator and discriminator,but sometimes model collapse issue
both are on my civitAI. the normal AIT one is actually the official one for AIT atm.
https://civitai.com/user/tdg8uu/models
GAN and SD both requires huge training datasets and too many parameters already
Do we have ControlNet yet for SDXL in A1111?
I'm a bit out of the loop. I know it's working in Comfy
i've run diffusers controlnet model on google colab,have to pay attention to canny algorithm thr opencv library of python and others,such as depth or whatever,and GPU vram run highly
when i run on any webUI or GUI,it takes much more time,so i give up when you have not enough computing power
I keep getting this when generating an image?




How is called that black glass in helmet? Visor?





Try welding mask.

@stone fossil she actualy was welding 🙂 Thank you!
well, I actually got a dreambooth to work on XL
would you guess it is only 768x768?






reminds China house because roof
LoRA style?
model, not a lora. A bit strange
oh alright, trained on the style or just zombie woman ?
all the before are the same model
that's an issue with newer version of ComfyUI, the first commit from august 28th is the last one that works with AIT
my segal lora with my style model

@spring fulcrum merge that commit with the one you currently have and replace all conflicts; that's the current fix
I'm preparing a data set to train a style LoRA, do you think training on SDXL is better now then 1.5?
yes
well, it is dang harder for sure
lora is lora but making a full model is a pita
can you even train a full scale model on a 4090?
I just did
harder on what aspect? hardware or settings?
How do you do that? I have a 4090 and wanna make a model
It is a style model like this

I do believe I seen Jesus! Praise the Lort! (in my best southern baptist accent)
LOL
I need prompts to see what this has done cause, so far, I like the style but that is not any style I used for my training images
speaking of that lmao where do you guys go to get good prompts, used to use lexica but the generations there are not as good as they used to be
I still use it but lexica is a bit suck now 😦

i only have 4gb vram, how can i optimize comfy ui?
I use prompts from civitai images I like then change them to suit my liking.. I also use ChatGPT to help me get creative sometimes
gpt4? and any plugins?
or just gpt3.5
use --lowvram as a command line arguement in your .bat file

I just have 2 sections when I use ComfyUI, first; I generate some cool images, second; I blend the ones I like best, it's an endless cycle
I dont use plugins for that directly in ComfyUI... I just go to the civitai site and look at pictures I like and with chatgpt I just explain to it the format of the promt I am looking for and then ask it to produce image ideas in that format for Ideas I feed it... Or i even ask it for suggestions
I see ! thanks for sharing 
@vital ermine I think this much better then lexica atm xd
It works well for me





I tried to get the DB extension for auto1111 to work, but no dice


I submitted the ticket as the file he creates his own program thinks it is pickled and to use --disable-safe-unpickle YET it is already being used.

d8hazard went nuts once on his users for reporting bugs then he came back so not sure if it will be answered or not.
His is different than Kohya
how to solve this i keep getting 'pause' and while render, and when continue it disconnect


Hmm looks like a dupe ive seen before. 😉
Meow.

Oh LOL sorry, I just loaded my workflow and the seed was the same



reminds me this

that reminds me of pictures I've seen of an inland sea in Russia I think it is (somewhere along the route of the Road of Bones) thats dried up and left a load of ships landbound
The Aral Sea

yes in south afrika there is something similar. Cemetery of ships. <- for sure i misspelled something.
the only misspelling I see (no pun intended ) probably isn't the one you're thinking of (and I cant really comment with my typing!!
(afrika rather than africa)
and that depends on your mother tongue
o.k. now i see it. 🙂
what do you think about consistency. His wearing isnt very detailed described i think it can be used somehow in animation.
Yes we say Afrika, Germany maybe as well. But yes for sure in English Africa.




some minor differences but nothing I would call major
yes i know. 2nd and 3rd got not that spike in armor, as well knee protection. And last got more vivid colors 🙂
Love the volume and the background on that one.
You find yourself adrift in the vast expanse of the ocean, surrounded by nothing but endless waves. A radiant sunset paints the skies in hues of orange and purple, casting a warm glow over the tranquil waters. In the distance, a school of playful dolphins leaps from the water, their graceful bodies glistening under the sunlight. As you navigate the choppy waters, a lone seagull swoops down, guiding you towards a distant island silhouette on the horizon. The image captures the serenity and hope amidst the challenge of being lost at sea.

nope I see no dolphins lol
they are underwater
btw i am experimenting with IP-sadapter and get this erro: missing clip vision: ['vision_model.embeddings.position_ids']
the thing seems to work though.
am i mising something or it is OK?
I was red walling originally with something similar and then I switched to the Dev branch
GitHub
experimental. Contribute to laksjdjf/IPAdapter-ComfyUI development by creating an account on GitHub.
dev branch always!



IP Adaptor?
Nope, that is my model I just retrained.
Civit prompts have too many loras and stuff in them



I think this one came out very well

not exactly what i was thinking but pretty funny
Oh, man

what kills me is when it blips out 100% and realism strikes. I trained on artstyles so ugh



Same 2 input images + the word "dragon" through my ipadaptor loop


1+2+"huge fire dragon" = 3



this IP thing really works

has somebody did some short focused only on this workflow?




because I'm perverse. I've used image senders/receivers to send the output back to the input (after the first gen) and then started a fresh gen withthe "auto queue prompt" option enabled
Going down the rabbit hole lol

(temp setup ., just playing)
Looking complicated enough 😄
its a self perpatuating loop lol
He looks realy odd 😄

I released this if anyone missed it

going for it!
the next generation
Wonder where it will end up if I leave it for some time lol

will it just converge?






clip vision encoder i will find in manager, models?

4 levels deep & counting lol







I was doing this yesterday and created a nice clipspace loop
this has no info in it

now 6 levels deep from the original 2 images 🙂
think I'll stop there





@indigo carbon i cant use it getting some recursive error and as well mentioned AIT...

maybe not enough memory.



it's on CivitAI



i know where was problem... 4 batches, now i need it consume less memory. Where to put in Comfui, medvram or lowvram please?




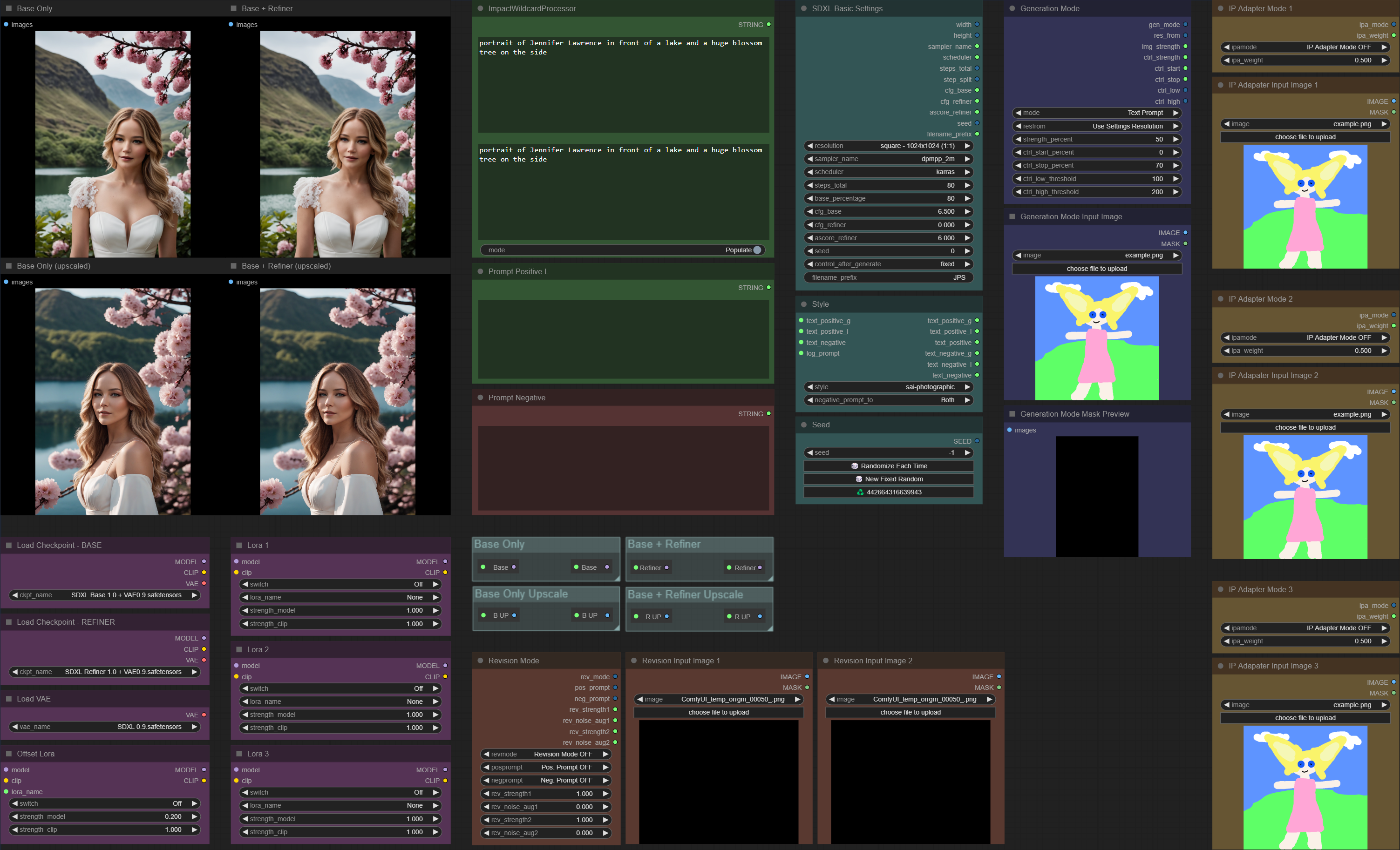
new "2x Upscale - v1.0" workflow with upscaler (basic solution based on @high skiff - will be improved in the future) and option to turn off parts of the workflow (for example the upscaler) by cutting wires in the menu section - also has improved seed option and only generates two non-upscaled versions instead of four.
https://imgur.com/tltvAth.jpg
https://github.com/JPS-GER/JPS-ComfyUI-Workflows

GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.

I have a new gen high res fix 2.0 workflow for my 1.1 release of my SDXL workflow, but I am just kinda burned out. I can't seem to get it reliable, and it shows promise of being way better than anything I have seen from anybody else, and its fast, but the fuckery I use to get it to work introduces some severe issues I cannot figure out how to fix 
Dunno what that is, just used controlnet in ComfyUI
yes, i've seen you talking about it and was wondering when you will release the new version. but already guessed there are some problems as it didn't happen. hope you can solve the issues somehow.
if I could just figure out how to fix the latent issue I have with my current 2nd gen high res fix workflow, I am confident it would be one of the single highest quality, most reliable, easiest to use, and most effecient ways to do high res upscaling
like here
base image vs old high res fix vs new high res fix
As you can see, the detail and texture/realism on the face in the V2 version is incredible, but it murders all of the background information, and I am not sure why.



and I have spent hours and hours trying to engineer some fancy work around, and I just can't
I mean, its obvious that the core concept works exceptionally good

from my own tests i think we will need different upscalers for different art styles and realism. i've tried to build an own solution for a while, but evertime i have something working well, it won't work for different styles.
so i went for your 1.0 upscaler for now, as it at least improves some of the images and doesn't take too long.
I think you might try to seperate the main character and the background to get the job done?
FWIW this would still be useful af. Can always do a composite in photoshop etc
the V2 is kinda faster, and improves texture monumentally in a lot of images, but sadly, it also adds texture where its not wanted
no easy/reliable/fast weay to do that, especially with stock only nodes unfortunately
stock only nodes is the limitation. It should able to done with Groundingdino by prompt
can i have a link?
i would die if i only had the stock nodes. especially the menu would look so much worse without my own nodes
if they want stock nodes, they have to provide more options imo.
All of the stuff I have done so far has been with stocky only, as thats the requirement to be on the offical wiki
and I have been able to still produce some very high quality results, but I am hitting a wall that I am not even sure custom nodes can fix
a basic workflow may be possible, but if you want to do ip adpater, revision, switching between txt2img and img2img, etc. you will also hit a wall soon - not only because of the special nodes needed for those things, but also for the math and logical elements, like switches, to make those features optional.
tons of people adapt my baseline work for stuff like that. My core workflow is made fo rthe masses that want high quality images with no extra work, and then people adapt it for higher tier use
FWIW Ive switched to using a very simple upscale that I'm happy with (not with that model though lol)



DW Pose is much better than Open Pose Full. Especially the Hand Tracking works really well with DW Pose. This is a full review. Full Install Guide for DW Pose in A1111 for Stable Diffusion
links from the Video
DW Pose: https://github.com/IDEA-Research/DWPose
A1111 1.6 Guide https://youtu.be/1Ldc5kZKKFw?si=Hgb0rtVEhLxEQkkL
IMPORTANT: F...
Hey guys. I don't know if it's only my problem or not. Latest version of ComfyUI showing this error message, when I'm using controlnet models. Few weeks ago everything worked nice. Do anyone have same errors?

posable fingers!
anyone here has a basic comfy workflow with controlnet that supports regional prompting? Like controlnet for entire image, but part follows prompt a, the rest prompt b, and there is an overarching background prompt. i just can't get that to work.
i'm basically using @high skiff solution. it looks quite similar. will have to check for the details, if i can improve it with your solution and settings:
https://i.imgur.com/8uxWGmU.png
theres a reason its similar lol
the current solution I have found for my high res fix V2, which monumentally improves textures and detail retention, also seems to be the cause of its one biggest downfall, which will likely make most people hate it, so I am considering releasing it as an advanced branch. But for now I am just kinda depressed about all the workflow stuff. I was hoping things would go a little bit better with it all, but that does not seem to be the case so far
You using AIT? that or outdated custom nodes
@ionic gulch essentially all I've done is simplify it by using a sstandard rather than an advanced sampler do I can just select a denoise value insread of doing match and dropped the contrast fix
does the problem boil down to getting unwanted texture everywhere, not only with subject?
basically, yes
What about setting a latent noise mask prior to the sample portion to keep texture only where you want it
sometimes its good, sometimes its not
Manual mask for testing, but if you want convenience i think you'd have to do custom node with SAM detector, or SEGS
that will never be reliable enough to put out for the masses in any meaningful way unfortunately
I am sure I could get it working by manually masking and doing 2 gens then compositing, but almost nobody will ever wanna do that, and its also not likely to look very good
maybe you can do some kind of automatic background recognition and compose them automatically.
this right here is the real solution, but not with stock nodes 😛
i already have 3 or 4 ideas for how to do it but not with stock lol
That would be good, but again, it will never be reliable with our current technology/tools
It is unfortunate, because the method does show huge promise, especially in images that have high levels of texture all over, they really do bring out detail to another level compared to everything else I have seen.
I just wish I knew how to properly manipulate what I'm doing to get it to work better
I thought about maybe using depth map blending, but that's horrifically unreliable, and yielded terrible results
A friend proposed an idea using the cany filter and then fill tooling in the silhouettes of things, but that also doesn't sound like it would work very well, and it would be a bitch and a half to get working
I've tried it with standard ComfyUI nodes too, without AIT. The same error. Both 1.5 & XL
This looks like an AIT specific error.
Not in a reliable or consistent way, not really.
I have done hundreds, if not thousands of variations on it, and I never got to a result that was consistently good enough to ship, therefore I have tons of different values that all work in quite drastically different ways, so I couldn't really explain it in a way that would allow for proper consideration across all of the potential outcomes
Once you do find the good values, it's a set and forget sort of thing, you never have to worry about it again, but the results will only be as good as the values that you choose permanently, and I've been trying to search through hundred/thousands of variations of these settings in different setups to try and tweak ever so slightly to get it closer to what I'm looking for, but I can never really get it there
basically image > upscale> downscale > resample > combine images?
The current settings I have right now work phenomenal for things like watercolor painting, oil painting, and high frequency realism, where there's a lot of background detail
But it really starts to fall apart on more simple subjects, where it can introduce some beautiful textures to finer details, but also tends to chew up smooth/softer shapes and details

If I really were to kind of explain the general idea of what's happening it's, image, upscale, downscale, first sample, pass, second noise pass, one step fractional offset diffusion, into a second sampler, combining two separate latents together with a form of mixed math, then running it through a third sampler, to then output it into a VAE encoder, and then multiplying the image by itself to make up for the lost contrast and fidelity
But again, there's still a lot of variations in that process that I have tried, and that one is not the best or the worst
i was also trying to do the upscaling at 80%, so the last 20% would already use the higher resolution, with the guide of the first 80% (so less double objects). it worked great for some images, but after changing style it broke.
In the end, even with all of those steps, it's the same speed or faster than my 1.0 upscale, which means you can get a 2048x2048 image on a 3090 in like 15 seconds?
You might introduce multiple workflow for different type of generation.
It's very fast, and it goes even faster if you use AIT, however that's not exactly reliable in any capacity right now, especially not for lower dedication general usage
Unfortunately, if I were to do that, then it would really only be available for a small range of styles, effectively being styles that have a ton of detail in them and absolutely no smooth surfaces, because there's no combination of settings that makes it Good for anything outside of highly textured and detailed images
The one example where this new upscale blows any other that I've seen out of the water is specifically watercolor paintings, it does an incredibly good job of upscaling and properly texturing watercolor paintings
you could include different upscalers and make them switchable by reconnecting a single wire. that should be possible with stock nodes.
That's kind of already what I'm doing, but again, you would be choosing between V1 for 95% of images, and V2 for a very narrow select few images that would benefit from it, and the average end user does not like that sort of thing
And the problem is, while V1 does look good on its own, compared to what V2 can do in some cases, it just makes V1 look terrible, which really sucks because you're forced to use V1 most of the time
In isolation, V1 looks fine, because you don't have the context of how incredible V2 can look at times
But the second you see V2 and realize how much better the potential is, V1 looks horrible
I know it sounds like I'm talking it up a lot, but I genuinely do mean it when I say it makes V1 look like dog shit when it works properly lol
left is original base image, middle is V2, right is V2

as you can see, the amount of texture and fine contrast it can bring out in water color is truly incredible
and even in photo realistic images such as this one

Here as well (tho you can start to see the issues with the over texturing in the background blur)

as well as these two


and in all of these cases, its no slower than the normal V1 version
@ionic gulch@vale eagle@strong field
Just so you guys can see what it is capable of in a vew different cases
Yeah. You were right. I've disabled AIT nodes in manager and it start working. Thx!
the watercolor is my fav use case
yeah, it really just works incredible for water color
the more texture something has/is supposed to have, the better it works
Lots of work going on behind the scenes with AIT, there is a plan to get it into Comfy main branch, but its a "soon" type of thing
I wonder if negative prompt could reduce the damage on background.
interesting
I have tested that, and it has helped basically none
in fact, the damage seems to be less without a prompt at all sometimes
big asterisk after sometimes
I am testing it with a realism finetune right now to see if maybe a finetune helps it
Actually
with this finetune... 1.0 seems to look much better than with base
If you would able to use controlnet, depth map might help
Already tried, it makes things way worse cause depth map is extreemly unreliable
has a huge propensity to make eyes super sunk in
in which case, if I used it as a mix mask, they would lose detail
how about after the current output, use depth map, invert the depth map and resample the background? I don't know if it would work or not. Just throw some idea.
interesting
so this finetune works amazing on animals (tigers is what I tested)
and it works like dogshit on humans
tho, this finetune with my realism LoRA looks incredible, I really must say
like, damn

too bad when you upscale it it looks like a wet fart lol

solved



@ionic gulch comfymanager couldng find these in your latest from civit...

oh.. having WAS problems i guess


hlo
yo
you know that ufospotted outside sandiego calif?
it was a transparentsphere, with a solid dark metalcube inside
try to make that in sdxl
icouldn't :/
neither could the others here


Some Underwater LoRA/1960's LoRA mix, ComfyUI






I have a question about lora training, it seems like the general consensus is to NOT train the text encoder for sdxl, but I've not seen anything describing what the consequences of not training TE are. does this mean that sdxl loras can't be trained on new concepts and that you shouldn't caption images?




where did you hear that?
here and on many parts of the internet
kohya_ss even says it in their webui


ahh. well just curious. not really an expert. I've just never heard that before. maybe that's a recent development or I misunderstood people or something.
I trained quite a few things in 1.5 and rarely captioned, but that's because I was lazy
ah no problem, yeah it seems like it bashes some of the text portions of the generation, and in my testing it does seem to make a difference not training the text encoder
I need to learn up on that stuff
I just want to know the why, being told "just don't do it" is not enough haha
I would imagine captions would still be used in the unet training I just don't know what I'm losing from 1.x-2.x models by not training the text encoder
yeah. I've been diving deeper into a lot of things. but it's like pandora's box
I found a post here about it but it's still not clear to me
it's too much fun
Not train the text encoder is true when you are try to train something the text encoder already know. If you are training something completely new to the text encoder, you still set the training rate of text encoder and train it.
yeah, realize it's not exactly the same thing. but yeah, not sure how not training the text encoder would even work? I played with it a little bit in 1.5, but not sure what method you guys are using now
interesting so how would the images be captioned in that case? do you still include captions for concepts it may know?
No captions also work in that type of training. Like some style training.
You might ask in #🔧|finetune channel to get more information.
one thing I have seen people say here is that you should name your concepts differently with xl. which doesn't fully make sense to me yet
I certainly confirm there are people tried freeze text encoder and get great result.
like if you trained on a specific person in 1.5 you'd name it something the model didn't recognize. but apparently with xl you shouldn't do that? I'd like to find a guide that lays it all out and explains it







There is a training method to find the closest celebrity which already learned by text encoder and provide images and caption to train the unet close to your image using celebrity token
This method works exceptionally well
taylor z'dar swift to steven z'dar seagal. the evolution everyone was waiting to see
I tried something similar in 1.5 and whatever I did really didn't work out well for me. but I realize xl is a differnt game
It is becuase xl already learned a lot of concept
and provide decent output
yeah. it's very interesting stuff. after the evolution of the tech in the last year, I'm very curious to see where it goes in the next 1-2 years
sdxl was released at the mid/end of july, its a baby
incredible to think about that



1.5 is a baby, lol. barely a year old
thats an eternity in AIT time
I have a dream. 😄



yeah. it's crazy though. I don't know how much I buy into the technologicla singularity concept in the way the media and openai hyped it, but seems like we're heading towards something. and it's going to get weird

100% weird, something we couldnt calculate, something different. AGI, SGAI, its going to get weird. ChatGPT 4 is Einstein level of aptitude, thats just not something any of us understand yet
What it means ill leave to the dogmatics and the simps

love these, fantatic work as always
gpt-4 is ridiculous. it's just unfortunate it's being ran by openai. I very quickly soured to their way of doing things
At your service. 🙂
live long enough to see yourself become the villain.
it's getting better now. but the overarching guardrails the put on it, and the memory limitations

well sam altman seems like a scumbag with a good PR team
definitely my opinion of the guy, there's a recent interview, hes on stage, big crowd, someone asks, we want to do what OpenAi does, how do we do it?
His response is basically, "dont try, nobody can compete with us now"
argued for the dire need for regulations on ai in the US. then went to the EU and argued the opposite a couple days later. because those regulations wouldn't benefit him
eh, ill just link, oopshttps://www.youtube.com/shorts/xHVsk7d1L-0

I'm not going to discount their contributions to the progress of AI
certainly not, but doesnt exclude them from valid criticisms
just their name is a PsyOp
Type all your emotions into SD and make a image instead.
like i said, ill leave that to the people that care, im just along for the ride now
I wonder what they have in the works. because seems to me the huge monolithic beast models might get passed up in a sense
they'll serve a purpose

but all these streamlined open source models that work much more efficiently. just seems like an ecosystem will evolve with different specialized models working in unison. I mean, we're already doing that now
theres a reason Meta and Microsoft on both sides of the fence
Now thats a start.

I am 100% on board with the coming ai apocalypse – “things are about to get weird” but GPT4 is nowhere near that level of intelligence
I have to give it to meta for their approach. I know they always have ulterior motives. but they have been releasing an insane number of open source models on huggingface

If they were ahead of open AI they would not be open sourcing though
it is but it isn't in my experience. it's like an extreme savant
It is very good and it is good at things I would not expect it to be good at. Like, it has an inkling of a theory of mind. Can do basic spatial reasoning?
But I do not think that if you removed all concepts of general relativity from it’s training set it would independently be capable of inferring GR
it can do some spatial reasoning stuff. but it's very bad at some things. and it has no idea that it's bad at them
Nor could it explain the ultraviolet catastrophe, contribute to quantum mechanics, etc
I don't think it can infer many independent things outside of what's it's specifically trained on
I've really tried to get it to

So like “it’s Einstein and the singularity is 2-4 years away” is just a big [citation needed] for me
It can’t even tell me what I should get for lunch grrrr
openai pushed a lot of that "tech singularity! be terrified!" stuff
because brings them attention and helps with potential regulations
that'd lock out competition
Yeah the incumbent always loves the idea of a frozen status quo heh
literally trying to snuff out open source models
the one that perplexes me the most is bard
ok
it's literally gotten way worse over the last few months
it just lies about anything and everything.

or "hallucinates"
not sure what google is doing there
and they seemed to zap it's personality or whatever you'd call that. used to come up with interesting creative things at least. but now it's so over restricted

bruh, did i tell you you are one of my fav creators yet? creativity abounds
it trips me out how real this one looks


yeah, thaevil coming out of nowhere
Lolz thanks mate I just have a keyboard and a mouse and 2 cats. 🙂
or somewhere
Thanks lol it means a lot to me.

I am not a social media person I just keep things private and giggle al them.

samsies
I have facebook but I ignore it other than talking to a couple people
dont even care to argue anymore, 1+1 = 5? Ok, you right
same
Would you be more happy if I did not strip meta data? xD
realized a couple years ago just how futile it was. I got nothing good from it and it was aggravating me. so disengaged
tsk tsk
if my images don't have metadata it's because I made them on dreambooth due to not being at my pc
ay, i respect it either way, with IPA and Revision im not sure the text encoder matters as much
or dreamstudio?
Hey but if you want to DM me some prompts i wont be mad

this funny AF








no love, no hope. no dreams, just beans
no need to sleep, don't need to eat, but the kids ravenously eat the beans because there's nothing else. but they never feel full
trying to fill an unfillable void







what model do you guys use?





this ipadaptor just decides to output black images for identical configurations of nodes and parameters. I'm going to assume no one knows what causes this, but it's disappointing

are you using clip vision with it?
or just the model inputs/output
what does ipadapter do?
what workflow you use there?
420
the right time

This is what it does, taking top LHS as input and then it will ReImagine it using clipspace, conditioning, whatever you choose.
I use a custom workflow that I am not willing to share
BUT your saving grace is, i made this other workflow to show the TLDR of it


as for what my custom workflow looks like, well,

i dont know why but this one is funny to me
😛
wow some of these were atrocious, but the bottom LHS is ok

does the sd15 indicates that it's a 1.5 model? and to do SDXL gonna need to get a different one?

that is correct, the models are downloadable from comfy manager
15 hours to train a Lora with my face.........
for sdxl it takes 30 mins....
btw results are great!







Hey now...





kohya?
holy... this vibe was sick


this my girl

Shes all urs.
@strong field I'm using the CLIPVision model. Is that incorrect?
can you show me a screenshot?
you will need clip vision model to run it, but you dont have to connect conditioning.
If you do, then yuou need to adjust your conditioning weights as well as your IPA weights

with @strong field tldr workflow and some lora



nice!


when ever you're feel like sharing the moe elaborate one, or some bits from it...
🙂
I can tell you what its using, Revision + IPA, IPA + Clip Vision Conditioning, Revision Only, IPA Clip Vision Only, IPA only, in no specific order, all hooked up to their own sampler, and then i just vary the settings according to how much influence i want



I built it for experimenting and comparing all the revision/ipa methods and fell in love with the reinterpretation machine

i love it as well
i do wish to learn how to bring even more details to the pics though.
i think latenet upscales is what i'm looking for?

you want them to add detail? or just be higher res?
add details
You can add some details via prompt, or lora

running wowifier and prompting for more details usually
p.s. let me know if you want any of these in higher res
im literally just messing around

I can upscale them trough the roof if needed.
The pics shared here are already degraded and meta deta stripped.
well i mean more than a screenshot of the gens im getting from your inputs, but i gues syou can screenshot, and resample lol

Not on my computer right now. But I'll take a screenshot when I'm able to








inpainting dropped?
I mean ComfyUI added support for it... so...
left(inpainted)


I am trying to use the ip-adapter in comfy with inpainting. It works fine in normal text-to-image but for inpainting I am getting very weird results. Is there anything different when using it for inpainting? For instance, I want to change the face of an image conditioning with a specific face in the ip-adapter, what would be the best way to achieve this?

Set latent noise mask, I paint with a separate prompt and conditioning from ipa
Thanks for the answer @strong field I'll take a look! Would you have an example?

bro thinks he batman 😭
Oh I found this https://github.com/comfyanonymous/ComfyUI/discussions/639 @strong field
GitHub
I'm an Automatic1111 user but was attracted to ComfyUI because of it's node based approach. I have about a decade of blender node experience, so I figured that this would be a perfect match...





Sour chips are nasty good.
Not at desk at the moment but I can ping you when I get back
Thanks! I highly appreciated
I see you getting that detail



Listen to more from Shaggy: https://Shaggy.lnk.to/Essentials
Discover more about Mr Boombastic here: http://www.udiscovermusic.com/artists/shaggy
Follow Shaggy
https://www.facebook.com/Shaggy/
https://twitter.com/DiRealShaggy
https://www.instagram.com/direalshaggy/
#Shaggy #Boombastic #Vevo #Pop #OfficialMusicVideo



5 Fingers and see through. Now i am exhausted.

nice work!
Thanks 😅

moar!
how should one go for trying to create real life versions of cartoons?
canny? I2t? img2img?
hey, I'm getting this weird error: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! what does this mean?


Could you solve your problem? (I guess you mean github - my workflow i not on civit)
i'll admit i gave up later and didnt persue it 🙂
This means your workflow was using different device. Restart comfyui and try again?
have you used my workflows in the past? there shouldn't be a change for WAS nodes with the latest one.
i would love to reduce the needed third party nodes, but WAS is the only one if found, that provides image history and that many save options
really wish the core nodes had more of those basic features.
iirc you helped me run it on my other pc, but i had to remove all other custom nodes for it...

is that only a problem for me or for everyone? why doesn't it get fixed?



happens to me too.
zoom out fix it.

my WAS says ineed to update llvmlite...
how do i do that?




Can't you just change it in the requirements.txt and run "......\python_embeded\python.exe -s -m pip install -r requirements.txt" in the was folder?
no idea 🙂 but i'm going to try it

well, llvm is not here, should i just add it as a line?

or perhpas comment numba out

Give it a try. llvmlite==14.0.0. Commenting will probably have no effect since its already installed


no idea. never had to manually update anything in comfy until now. auto update through the manager did everything for me since i've moved to the standard - not standalone - version and installing python in user space, so it could update without admin rights.
changing the requirements.txt to your version may help if the new version isn't really needed, but that's just a "hotfix". would be better to really update that component or find which of your other nodes messes with the versions, if that is the case.
Control net still not working on auto1111? 😦
there are no other nodes, it's a clean and updated version.
just your workflow and what ever the required nodes were.
the hotfix did not work
and you installed everything through comfy manager? or manually?
did the same. the only thing i've installed manually is the manager.
yea, you got to start with manually adding the manger i guess 🙂
try to remove WAS nodes and add them again maybe. so it will install the requirements again. look at the console when you do the reinstall and check if it gives you any errors that could help to solve the problem
on it
was nodes is a very common addon. so more people should have that problem.


so good
no luck with that...
Is there any downside to using a 4x upscaler when you only need 2x upscaling? (I've been downscaling by hand but 16 times is too much for what I need)
seems most upscalers are 4x so just wondering
I love that he is watching a cucumber TV show 🤣

By hand? Just use a "Upscale Image By" Node after the 4x Upscale and set it to scale_by = 0.5
Well by hand yeah but it's not the downscaling I'm worried about 😆
using the Ultimate SD Upscale node on ComfyUI I can set "upscale_by" to 2 with ESRGAN_4x , but the result is a bit odd looking, with weird horizontal lines and stuff
it's not outright terrible, but with the added noise I can't say that's it's really better than just a bicubic upscale
There are 2x Models on https://openmodeldb.info .
OpenModelDB
OpenModelDB is a community driven database of AI Upscaling models. We aim to provide a better way to find and compare models than existing sources.
I would upscale by the factor the model was intended to upscale by
Fair enough, I've looked at the 2x models, there just isn't nearly as many as 4x which is why I'm wondering
My settings might very well just be fucked tbh, you guys use the base model as an input, right?

In this case i am out. i use sytan's method of upscaling.
Hmm I think it's the ESRGAN model that doesn't behave, some NMKD model actually upscales properly (even though at 2x I should probably reduce denoise)
Hey Guys! I'm new to stable diffusion. Is there any way that I can generate images of different camera angles but with the same background?

If I provide a specific background in the prompt every time I change the angle, will it work then?
i think it wont work, in best case you will have very similar results, but not identical. Maybe there can be way with controlnet, but i think not.
You're looking to keep the same background (looking down the river) but have the model face another direction?
Yes
Oh
If you want a coherent output, that's gonna be a lot of work
How should I start then? I'm relatively new, I don't even know which models are good to start with
I've only tried SDXL
I think futzing about with the prompt and see if you can get something that looks vaguely similar is your best bet, if you REALLY wanted to do that I don't think anything short of rendering the background alone, and then rendering a 3D model with matching perspective on a depthmap for a controlnet would work
truth is from my experience anything that doesn't involve a complete regeneration of an image just doesn't work aswell as you'd hope (inpainting/outpainting and such) but I'm sure a controlnet wizard could sort something out
I'll try that out, thanks!
good luck 
best resize algorithm










sexy 



Now I know I need to see a remake of fatboy slim, weapon of choice remade with seagal








Hey if Austin Powers can destroy the fembots with his dancing, it is a completely viable weapon

I already had these images on hand just in case someone wanted to see Steven Seagal dancing
as soon as AI movies are a thing, you know what to do

fifty shades of grey with steven seagal as main girl

whatever floats your boat, buddy 😄




thicc hands 



the messiah
looks like a recast of the righteous gemstones


Looks a bit like david Carradine

David Carradine eating a large pile of raw meat in 1978 classic movie RAW MEAT EATER



game of the year (all the years)


he grumpy






bro has the vegeta hairline
lmao











green screen revealed


this is the perfect male body
definitely




ranes the goat
















he kinda sus


massive chungus


Haha well that message gave me a chuckle
hehehe, I am taking prompts from civit
not sure why XL decided to slap me with the nake fat chick, but alright
have you taken any from the degenerate section?
no, I have a NSFW filter on
ahh, smart











Hellraiser remake
or a Hellboy














Here is a quick example of how this would work.



how strong is my magic? fuhghetaboutit



Really like the colors here

Did comfy add this pop up when you type in the nodes with embedding choices? I disabled my extensions so not sure how to disable that?

@strong field




hlo
anyone knows how to install gradio
i am having error in infinite zoom extension regarding that
I think pip install gradio should work?

An artstyle I trained that can go various ways. The name is unique. You can use this without the activation word, but for the best results use it a...
You shouldn't move a model when it is dispatched on multiple devices.
You shouldn't move a model when it is dispatched on multiple devices.
You shouldn't move a model when it is dispatched on multiple devices.
You shouldn't move a model when it is dispatched on multiple devices.
You shouldn't move a model when it is dispatched on multiple devices.
You shouldn't move a model when it is dispatched on multiple devices.
oh, okay, thanks for that
You shouldn't move a model when it is dispatched on multiple devices though
sound advice
I mean, I'm not though. but something surely thinks I am
or maybe these are more cautionary warnings. and it's just really adamant about me knowing

little donnie



cursed
we heard you liked hands





these lads are causing a ruckus
that wheelchair has a pretty unconventional wheel there
Sport version




hlo

how should i update this
i tried pip install --upgrade pip but it shows it is upto date
I wouldn' worry too much about that warning
A1111 uses it's own python environment
yep, done the proper way.
I was surprised at comfyui not using a virtual environment.

@willow bane solution python.exe -m pip install upgrade pip
When in folder script, didnt work?
Also i think as well it isnt important
why it is saying it is not able to find cuda cores i have rtx 3060
i can fix it by writing but will it limit something?
I think you will end deleting venv and then let it recreate it again.
For this is better to ask in #🤝|tech-support





inpainting fully implemented in my workflow:


/xena




SDXL Impaiting models coming? https://github.com/comfyanonymous/ComfyUI/commit/7931ff0fd95c1842b0c8e7f5cc3a2ce5d3b88b3b
difusers team released one
Ah, 17 hours ago. 👍
yeah its fresh



is there a simple workflow for it?













Version 3.0 of my workflow is available on Github now.
Features:
- TXT2IMG
- IMG2IMG
- Control Net Canny
- Control Net Depth
- Inpainting
- IP Adapter
- Revision
- Optional Upscaler

GitHub
Contribute to JPS-GER/JPS-ComfyUI-Workflows development by creating an account on GitHub.

i'm getting OOM with a 4090 on your workflow 😦
Hell, I just had a crash then another crash of a plugin due to a mem leak I guess. Not his workflow but python does have a leak I was told.
Hello everyone,
where can I find a SDXL controlnet tile Preprocessor safetensor?
Is it not out yet ? I only have the SD15
i'm not blaiming JPS of course, just venting my frustration bcz i can't wait to use his workflow 🙂
Oh, no worries as this is a mem leak while my 4090 hasn't had that happen today. :/
having to settle for my own mess 😛

try cutting the upscalers. they need the most vram. working fine on my 4090
big dawg 4090
if you both have a 4090 then why would there be OOM for one and not the other?
btw, @icy brook your Lora rocks on warp 🙂
maybe different nvidia drivers (i'm using the old ones) or too much other open applications.
no idea

maybe you don't use the fp16 versions of the models?

no the sdxl models
wait, is there a fp16 version of base and refiner or is the 6.4GB THE fp16 version?

I think it's the pruned....?
might be fp16 though
i'm using:

I can't remember as I had them from the first day

UNET:

painterly output from sdxl... possible? everything looks so instragrammy for me
Clip Vision:

also; It MIGHT be possible to stack TRT and AIT on each other. if that gets figured out, its safe to say that instant image generation is VERY close
VAE:

even getting the main subject to be off-center would be awesome
Fun stuff!
See, I want faster training speeds myself as gen speeds are alright.
Imao


your ip adapter looks twice the size as mine


I just used the manager to download it, but can i have a link to yours?



oh, i think we compared different files. you need two files for ip adapter. one is actually your size.
which one is the 2nd one?

one is in ComfyUI\models\clip_vision the other one is in a subfolder of the ip adapter custom node

{kind=link}
{kind=link}
0.7 gb

running only discord and chrome for these tries
my workflow doesn't go above 16gb for me with the example.jpg - even with upscaler, but i've seen 21-22gb before with larger images.

i wonder why lvmin zhang hasnt made official sdxl controlnets yet.. the community ones are kinda bad
He swore off SAI in an open letter due to the shit, his words, TE/Clip 2.x used. I am glad we had what we finally had for 2.1.
wait what
but hes still forcing on fooocus with sdxl
@zinc cargo maybe try "python.exe ComfyUI\main.py --disable-smart-memory" when launching comfy. the new smart memory management of comfy gave me problems before.
yep, was an open letter about it and he called them out heavily.
That is why it took forever for someone to make some of them for 2.1
That was a long while back so I have no idea. Check his Twitter feed.
He did say if they stuck with the same TE (clip) he wouldn't do it so that may be why. Community only with official only for 1.5
cant find anything of the sort, but he works on a webui for sdxl
new error

so i dont see why he wouldnt work on a controlnet
No idea but he was fucking pissed at SAI over it. Maybe 6 months ago now so things change.
We who did 2.1 was sad then we got a community few of them but the really good ones we never got
@ionic gulch you mind if i'll messege you instead of using public channel for support?
just realized what i'm doing here
sure. i've just tried with the new smart memory management. it uses up to 22gb of vram, but no oom for me.
lol. man, I need to get me one of those
just didn't have this stuff in mind when I got my computer
lol. the cat turned green:

Anyone know how to get XL to do a cyclops?
hmm. challenge accepted
second one was better - but still some artefacts on the mask border:

Yeah, I can't even get an interrogator to work
just like in paint an eye
it should know how to do it tbh
Probably
Can't get it to do that and even 1.5-SDXL interrogators mess it up

you could spend a few hours fiddling with prompts to avoid having two eyes or you could just in paint the eye after the initial gen
LOL, I would have to fight the damn thing each time I gen that way.
