#✨|sdxl
1 messages · Page 102 of 1

i only put on the show so you can see me

the color transfer takes 7.53 seconds on a 3060Ti. as far as GroundedSAM or OSX I don't know yet.

Okay I done with my soliloquy




when... when it dus that good good

Problem is we just never know that
The Lora needs to be loaded in the negative prompt or positive?

true
anyone getting big differences in results when running in comfyUI in web ui vs running with websocket script?
or know reasons?


















trying to create beauty

@ me when you get something you want to show. I want to see it in the morning. I gotta go to bed. Night.
indeed. goodnight, sir

lol, wat?

LOL

yeah, but sort of looks like a bomb going horizontal
Oh you dont get it
That is a steampunk bomb bot
it flies to a destination then nukes the entire area
yes, exactly
OH? Like FO but steampunk style?

Yeah.


man, I broke fallout new vegas. slaughtered an entire settlement for the baddies, while inadvertently clearing it entirely of oversized bees or something. so I was able to be good with both factions at the same time.
thought you guys would want to know about that
ok, ive clearly done something wrong.....anyone know when I run "Revision" my input pics have no impact and i get just random pictures
Only one, besides 76, I never played


looks more like an issue specifically wth Ksampler Advanced.
I see this same issue (shown in Console) with Ksampler advanced configured as shown, if I changes to 200 steps starting at 194 then corrrectly does x/6 rather than x/40
If I trasnsfer the setings to an efficiency NodesKsampler Advanced than at 300 Steps starting at 294 it correctly shows 6/6
@visual glade @ionic gulch (as I justsaw summat else)


Me?
damn, are those guns shooting into each other?
looked like it

heres are some bullets colliding
https://www.youtube.com/watch?v=KBdvY_4dAfk

We made history today. The first success in a much larger project coming soon!
deflection
there is an even more incredible video where bullets completely stop mid air
didn't they find bullets that hit after some war battle? or maybe that was a bs story I read
from the Slo MO Guys? I thinks thats the ones I meant to search for but im onlyjust out of bed lol
there was an incident allegedly duringthe US civil war
man, being able to make slowmo videos like that and make all kinds of money from it would be a pretty sweet gig

Get a Ridge Wallet! 👉👉 https://ridge.com/smarter 👈👈
Sign up for the SED Email List: https://www.smartereveryday.com/email-list
Click here if you're interested in subscribing: http://bit.ly/Subscribe2SED
⇊ Click below for more links! ⇊
GET SMARTER SECTION
https://www.civilwar.si.edu/weapons_minieball.html
http...this one
Destyn!!
that was brutal war
they got perfect transfer of energy
think of the odds of tha thappening
the bullet stops dead in the middle
its one of the most incredible things I have ever seen
it looks soooo fake haha
dude, yeah
all of the others deflected, but that one stopped dead
very satisfying to watch tht one

assless chaps lmao
haha
getting ready to ship the beta feedback version of my new high res fix workflow to some peers
I didn't even prompt that
one on the right needs to do some squats I think
man, this combo is just making black dudes. no trump or z'dar influence at all. even turned snoop down to 60 percent
Seriously, I am unsure how to really give my lora a work out.

have an llm write you a long crazy prompt

alright, now it's starting to turn a bit

has anyone else noticed when you double click on a value in comfy to type in a number it doesn't automatically have the text box or whatever you'd call it activated?

Why does SD refuse to generate scuba tanks? I mean.. just saying.

1.5 nor XL will lol
yeah that looks more like an AC compression tank tbh with the insulators and
I mean and scuba tanks are standardized world wide, they are very easily recognized lol, it literally WILL not except in very rare and alternate media types (not photographic) might make one that looks okay...
I have 1000 images today with so many prompts just trying to get one photograph of haha, I've become obsessed.
hmm, well seems like it's doable somehow
and this? I asked for A scuba tank... it gave me nine NOT scuba tanks lol it is playing with me now 😦


I've tried different tank names, styles, naming, different tank types / o2 oxygen acetylene and so on .

well I mean it may not be so common that someone took the time to train one, it's just weird it has no idea what it even is...at all
aqualung?
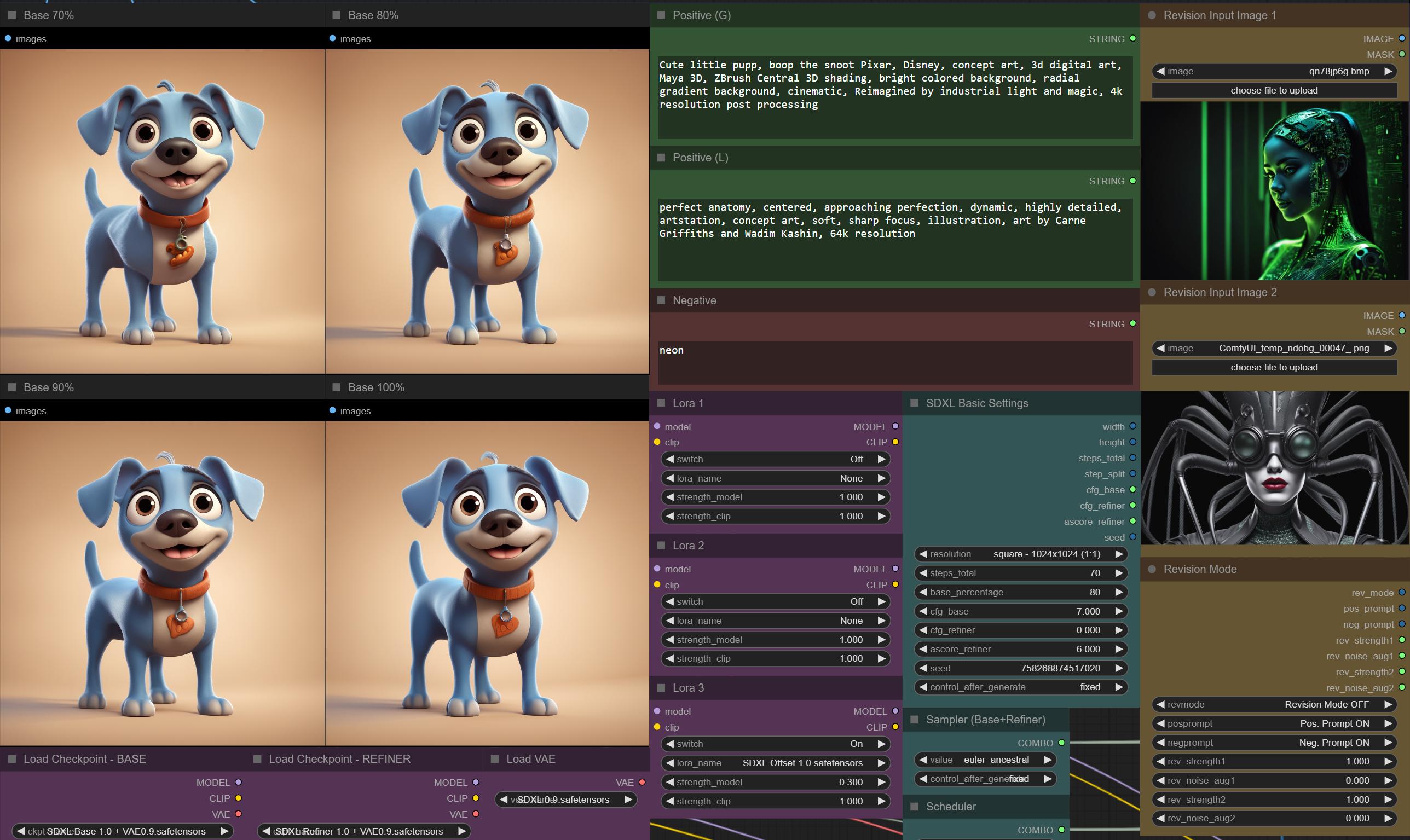
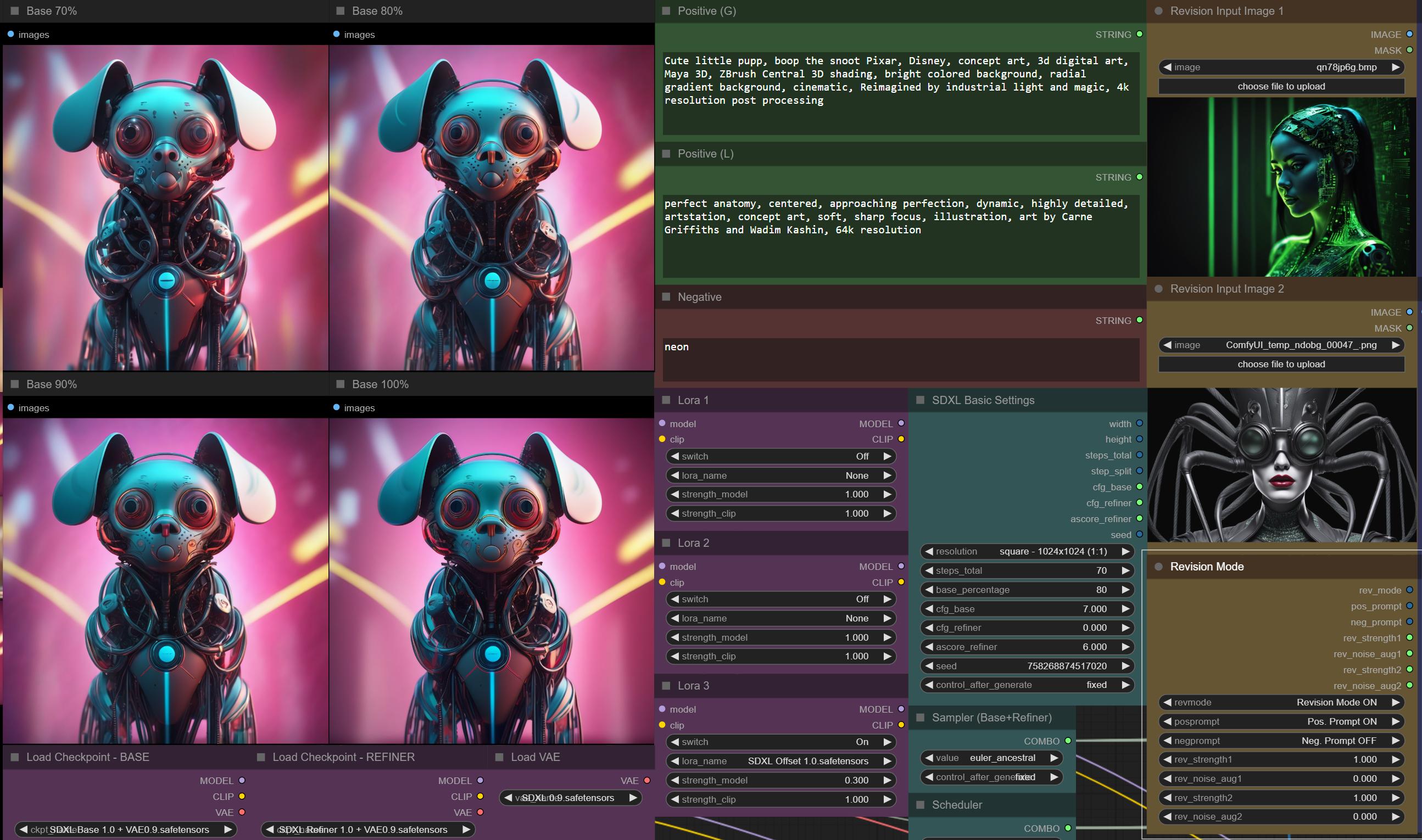
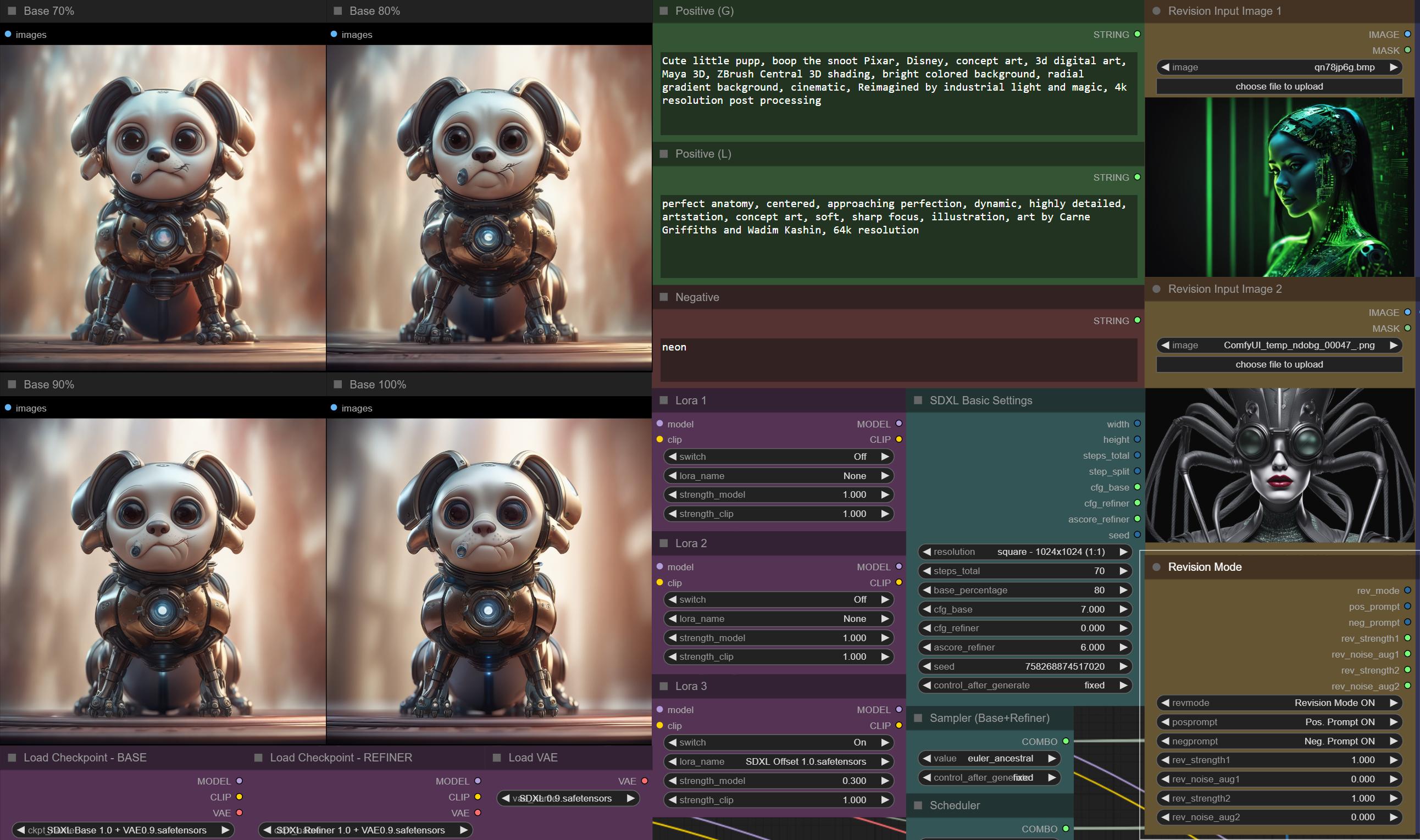
Workflow 4in1 + Rev v3.0 beta - improved Revision mode with two input images
Example 1 - Revision Mode OFF - dog like prompted
Example 2 - Revision Mode ON - no TXT prompt (just mixing the two images)
Example 3 - Revision Mode ON - positive TXT prompt (turning the image to a dog picture)
Example 4 - Revision Mode ON - positive + negative TXT prompt (removing the neon color)
https://i.imgur.com/NzM6cDt.jpg
https://i.imgur.com/28VWm1i.jpg
https://i.imgur.com/3Ce7hG6.jpg
https://i.imgur.com/ycztf5Q.jpg

nah, I was being sarcastic there. but you are right. I wonder if there's another term it'd prefer?
seems you know more about it than I do
yeah uh... no... god no aqualung:


it happened today when I was trying to just whip up a face replace with the kid in a scuba set, but... no tank, ever. then I tried on adults. nope. nothing. and now I''m here... wondering wtf cos it isn't as if it is that uncommon, it is well known activity






yeah so, aqualung, is... I have no idea what the heck is going on here how that is "aqualung" related in any sense...

lol. wtf

lol

Jethro Tull would even do a wtf with that.
yeah and this is another "aqualung"

how is z,dar, trump, kim jong un a black man?
Damn, that is close to one of his album covers from the album with Aqualung.

find yourself a korean wife and find out



only the pool boy knows :)









I need some community feedback
would you guys rather have a smooth and a high detail high res fix that are fast
Or three options: Smooth, high detail, and a slower texture enhance high res fix? So 3 options in one workflow
If the quality's better, worth the wait
Assuming it can just be bypassed if you're not looking for final quality
Depends if the 3 options are easy enough to figure out even for more basic users or not.
May be better to have a single streamline, but, options are better.
I like options personally
its just as simple as connecting one node or the other
I am beta testing the workflow across some peers
I only have some screenshots
options are always better in my world
Node connecting is simple enough, just as long as it's obvious for those users.
The annoying thing comes when people constantly inquire "how does X work" when it's right in their face
base 1024x, old (soft) high res fix, fast (detailed) high res fix, textured (slow) upscale

you can really decide the level of texture improvement
Here, let me send a full res comparison
ICAt to the rescue

base 1024x, high res fix 1.0, high res fix 2.0 (fast), high res fix 2.0 (slow)
slow looks worth it but I also dunno how slow you're talking
nice work
there is an unfortunate trade off that I am trying to balance
see, scuba tank is meaningless to all things CLIP
the 2 on the right side greatly enhance details and textures, but they also often leave noise/grit in smooth areas
Not always, but sometimes
Literally... red ball blue box
I am trying to find a way to fix it
add extra steps to the end stage
its not something that can be tweaked unfortunately. I am leveraging a really broken and messy process, which works pretty well with how I am doing it, but I need to figure out how to eliminate those small issues
it has to be a specific sampler, scheduler, step count, crossover, everything
change one value and it explodes
thats why the fact I got 2 different ones working is interesting
I have some ideas to fix it
increase the total steps on the second sampler to smooth out residual noise
I had to test like 300 different sampler/scheduler pairings to get ones that worked haha
Earlier i queried with a1111's clip interrogator with this image and it said "a blue propanent on a white background with a clipping for a clipping for a clipping for a clipping for a clipping for a clipping, Aquirax Uno, blue, a stock photo, plasticien" I mean what is wrong with scuba tanks and AI images?

wasn't much better than your's response
I guess I could do that, tho its not likely to fix anything based off of how this words
technically, only the context makes it a suba tank
its just an air/gas tank
the text repetition is like a bad setting in an inference llm...
its just the old clip interigator isnt that great. Sounds like early blip that tended to repeat itself. This took all of 3 seconds to inference the response here

not true, it has different connections, colors and such.
extra step added to total steps on the second sampler

yeah still shows that scuba tank is not realized, And @high skiff I understand that, but even on a diver's back, it does not properly recognize
I know what you mean, but its not something I can just do here
nor can you get it to generate an image with scube tanks lol, except norman rockwell looking illustrations for some reason
I have to used a very specific pre-determined split for this to work, which means every step I add is just adding more to a really low resolution area
want an even harder challenge. Try making a crowbar
harder? hrmm, mmaybe equal... also aqualung? Lol


clip interrogator is using blip first then using clip to figure out what matches best right?
Now I get to try and learn this ait



14/15 on stage 1, then 15 to 32 on stage 2
early 2000s Anime feel.
they're also around 8k reso
I wonder if AIT is worth it? I downloaded it in the manager
what is that
closest I got to a tank. But that was 1 out of 5 gens


yeah I got things like that occasionally, it looks more like an air compressor you'd find in a gas station lol
And It WILL not put it on a person's back
it does this strange tank a lot, that looks like a gas stank, that would be on the botton of a car.

here is an aircompressor on someone's back lol

is there an on and off button for loras in comfyui?

now if you try to make some norman rockwell illustrations - it WILL totally make a scuba diver

even though it kind of looks like a baby bottle more than an air tank
another doing similarly, same kind of norma rockwell style affect, with watercolor

from another guy i was discussing this earler
be careful when using that. ive made the mistake of turning it off and leaving the strength at weird numbers and it does actually change the image with it off,
I hardly ever use any lora's for styles or characters
But, saying that, I do use the offset noise 100% of the time


scuba tank does this too sometimes lol
quality 100%
XL makes the best things

Yeah, it is weird
Dorito Puffs OD. Sad
yeah, wasn't quite what I had in mind, but, close, still it kinda turned out, different



trying to use control net in comfyui, so I load it, click queue prompt and an actual crash error !!! Exception during processing !!!
i got just now from nowhere "ZeroDivisionError: float division by zero"
ugh
make sure your controlnet is compatible with the model you are using
well, this loaded my screen but the first one is "ComfyUI\execution.py", line 151, in recursive_execute
output_data, output_ui = get_output_data(obj, input_data_all)"
I only have the base model
and those 700mb one from HF
Oh, darn thing it reverted me to 2.1 model
I just spotted it
Thanks @visual glade
does anyone here know how to modify .json files? I finished compiling AIT XL and XLR modules for all gen params (including batch sizes), can't figure out how to get modules.json to see them.
Oh, lordie I grabbed the download for ait but I know zip about it
total steps: 30/31/32. Sometimes extra noise works well, other times it doesn't. Let the user decide


Hi comfy, restarted and getting it still. Some mentioning of AIT, but i am absolutely noob. Will try for curiosity changing prompt.

yah revision
that is like the MJ tool
ish
aye
if anyone here can, DM me. much appreciated
oh yeah, diving suits. But no scuba tank, also... whatever this is ]

this is the only thing holding batch size AIT support back.
JSON files are plain text. You can just edit them with notepad, if that was the question.


not as simple. it needs clarifications specified I can't figure out how to do. I had to write a new AIT compile script to get it to do BS, it compiled after a few hours.. can't get the node to see it..


Ok, then I am out, sorry. Did you asked chatgpt or bing chat by providing the original file? Maybe you find your answer there 🤔
did try, they basically said "skill issue", they didn't give me any explanation except typical "ReStArT Pc" bullsh!t
useless LM models
That's a bit harsh of them. If you already edited a json file, you can run it through an online json check (or whatever that's called). You might miss a curly bracket or a comma somewhere.
use a proper editor, gvim or something, so you don't leave hanging opens
really? they've never said that to me. They usually will give me an outline of how to fix it, and then I'll say show me how to fix it, then they do
that step of them giving you instructions or outlines, is normal, but they'll complete what you ask, if they say 3. modify json to be correct
say "could you complete 3 for me"
done done
they've always done that.
sounds like AIT is not yet, really, ready for prime time only for the ones in the know and ultra power users.
Yeah, I also never had a problem with bing myself. It even figured out how to write complete comfyui nodes.
I already sent the compile BS solution to FizzleDorf, it's a matter of time until it's added to the node
it was able to do BS using test script, and it has a way wide enough range
I downloaded that through the manager but if you are going through hell with it then I am going to stay away
I'm going through hell with it because I'm helping improve it. BS1 works flawlessly right away
that worked well...

...
Ohhhhh, I was the whole time under the impression that he was cursing 😅. "BS solution" "get it to do BS". Now that makes more sense now.
also whatever asshat decided backspace should delete nodes needs to be flogged.. .
That has bitten me more than once and no undo
yeah it is REALLY stupid.
delete exists, why map to bkspc
especially when there is a lot of text entry in the system
at least in davinci resolve I can undo deleteing a node and it reattaches all the node points too
I should join the comfy discord and complain about backspace for an hour and a half
Love its node based system which all programs should strive to become.
I use olive oil because it likes the lotion
Olive is an open source node based video editor
it's not, polished well but it works not bad
I don't like black magic at all but the devil his due resolve is fantastic
i know, I can tell you enjoy it,
I just use img2img + ffmpeg command line
cos...ease of use
What I love is that I can just use the damn thing like an auto1111 or if I need the power I can get into it and use its nodes for a comfyui approach not one or the other but both
and I'm a nerd who knows every command line -switch I will ever need
get in, do the deed, get out or get your hands dirty your choice.
I like fairlight as well but the other one that starts with an F (in its own package) no, it was slow and crashed a lot
and maybe people will like that I added a midi player to it, not for the editing itslef, but just to play one of ten midis I added from the sound track of Quest for Glory 1 and 2, from Sierra online in the mid 90s. So they can be enjoyed while editing nodes
everyone complained about it
can't do that with resolve, unfortunately
Did you see the new cameras from them? WOW, they have AI in them and will remove the background, etc... on the fly in real time
I bet they are hellishly expensive because they are made for pros. 10k + cameras
I just use a filter app made by some guy in romania that does something like that, you just have to watch an ad for something called wifebeater simulator by popcap games, twice and it'll work for about 20m before another set of ads. Same kind of thing,
what is a wife beater simmulator
I dunno, I'm'' kidding about the app, but there is annoying phone ad where it''s like some thing and shows decisions you can make, and she says something to the guy and he throws her out in the cold rain, and she becomes homeless. it's some game it kept advertising to me when I let my premium youtube run out on accident
a phone app I think
oh yea i know those weird edgy phone game ads,theres also one where a guy kicks a pregnant woman in the stomach,
I want to know who came up with that ad format
and why it's used for games that have nothing to do with the ads
prob to fool ppl into downloading the game,even if they only open it for like 10mins they get money for the ads
comes home, another woman there, gotta go,


kinda wtf... there's another where it had soimething like this, and then it was like "do you choose, take revenge?" ad chose that, and she was in the house with the man and was looking kinda ded in a lazy boy while she was cooking eggs or some such, I was like uhhh wtf
ai generated ads
I think they're mostly made in china or something. and some of the stuff doesn't translate very well



made some changes to the AIT workflow, which is better? right is new and left is old.



maybe put black in the negative
yeah. it's honestly made a black man every single time. different combos of people. I don't get it









I was trying to use the zero out conditioning and only base the results off the input images. but I guess that's not going to work for Kim Jong Trump Z'dar
try with only zdar and trump 
whoa

real
its only been a year with sd release, imagine the kinda finetunes we gonna have in a year with sdxl lol
well I originally had snoop dogg in there instead of kim jong un. I'll do turmp z'dar now
turmp
he has double teeth on the bottom. this is a future human

lol

that doesn't even make any sense
I guess I have to use that negative still. so weird
this revision is not acting like I thought it would
I've attempted 12 different combinations of people now, and every result has been a black man
woke af, heh
and just using run diffusion with noise offset and photorealistic loras. maybe they're contributing to it, but still
what's it even doing? I'm not upset, just doesn't make sense to me
what do you get when two white men marry? A black man. :/
it really doesn't make sense how
put [[[black man]]] in the negative and

that's not what a trump-z'dar love child would look like
maybe in 90 years
extra white
put old ma,old person in neg

I'm just crossing my fingers ai or something figures out how to stop aging before I hit that point. or at least do some altered carbon sort of thing
i dont think revision is really meant for merging, just variations based off input images.
well should I use unclip models then? I thought it was for merging
maybe a transfer of our collectiveness into a new ai entity. I could go that
i just wanna have like 10 years where i'm like actually alive cx
that's what they were saying? or maybe I misunderstood
we go to sleep then wake up with a new android body yet we feel no difference
look in the mirror and do a wtf?
well it can merge. im not saying it cant. but it probably would have a hard time merging the likeness of 3 different people lmao
eternal robot pain noises cx
as for the black man thing. idek lmao
No pain which is why I would go for it
well not saying it'd be on point. but doesn't it take the attributes of each image?
yes. this is what we need
wake up as this guy

Oh, hell no
look at his double teeth on the bottom
live forever as them, but you get to keep the glasses cx
heavy eyeliner on this one
Its also no good for those of us on older cards (and no the answer is not "buy a newer gen card", its should be "we the devs will ensure backwards compatability" with NON AIT workflows)
it took twice as long per iteration for me with that ait thing. maybe it's not meant for me
Yep. My 1060 is retired now and I am suffering as my bill for this card gets paid on 6th. Wish, I didn't have to do it but it was time and the 1060 was limping about to die. I turn on my system and it would make clack clack clack really fast sound each time. Was a fan near death and third set of fans already in 6 years.

That merge seemed to work...sort of
why so strong?

I would prefer Hardware failure than (semi) planned obsolscence due to lack of support ;o)

1 str for both

last night i had something similiar, likt was stuck at certian neighberhood in the model and didnt want to go out... @hardy cipher
Planned is how Nvidia, or AMD work. Maxwell is now dead for any updates, Kepler before it, and rsn Pascal will get axed.
i got these, even though i was using a lora trained on someone who looks entirely different



it's all black men unless I put that in the negative, then it's outlandishly pale white men
literally my uncle

indeed
Aye and hopefully the devs of the various UIs used in this field we're currently camping in don't bring that date further forwards then Nvidia/AMD do
this is the guy from the original Lora though

"I just hate hair and six-pack on titties!!!" 😄
I had the same problem. I really had to fiddle with stuff like 'dark olive tan skin' to get the right complexion
Even then, it's still hit or miss sometimes
well I'm just disappointed it can't be zeroed out conditioning going into the images
looks to be of some sort of indian ethnicity to me
whoever he is
I fear they may. Already 24GB is barely enough to train on so go buy a 48GB card or pay for the cloud.
we almost all are in a way 🙂
either way, not making a Trump Z'dar I guess
i had the same thing with a few other sdxl loras
I'm going to go with that

Just FWIW, you can use 'South Asian' to refer to India/Pakistan/Sri Lanka/Bangladesh/Tibet

@ivory blaze mixed yours with my cockpit



that's gonna be my new pickup line
nice cockpit
Ok so there are 2 sorts of users of SD.
There are "power users" who like to develop and there are "Joe Public" users who want to simply generate pretty pictures.
Currently the latter can certainly comfortably go back as far as a 1080ti even with SDXL (and I understand that there are others out there using slightly older succesfully).
It's the "Joe Public" audience I want to ensure doesn't get alienated.
Sorry Power Users but I cry for you haveing to struggle to train on 24Gb!!

whilst you can I'm sure you also missed several companies out there.
To me the larger gentleman (see I didnt say fat) from the Lora looks of some sort of indian (with a small i not a large I) origin.
Without the power users training you would be stuck with just base. You might like just base but most love the models the power user train for them to use.
I will concede to that request 🙂
plus u can make money if u make pretty/beautiful/unique models,just sell them
he's a local kids star from Israel.
(he's a very cool cat with jack black kind of energy)
he's Jewish north African descendent, guessing Iraq or similar - but like i said lately i had a lot of generations being made very "south Asia"...
mostly with nightvision model i believe
I wish I could but I suck at such things when money is involved. I always have.
wdym "sell models" never heard of any site selling finetunes
SDXL "does not know what six-pack is!!!" LOL
lol
it was a joke
was suggesting that telling it you hate it, would make it spit it out
it also has no idea what a scuba tank is
and if I saw one I would steer away from it. Same as these people "selling" prompts
some paid sites have their own private models,they hire ppl who make good models to train a specific style model
If models are being breed together that'd be a copy right trial waiting to happen
SIGH
I dunno Astra
you have no power here
Copyright is kinda... ephemeral with AI and training data
thats a load of bollocks as the core licence allows sharing and deriratives
i'm just gonna post this and sip my tea siip

the byte for byte model may have copyright. but it isn't' a plant
I'm going to post this and see if the guy will sell me his Mogwai

mentions a point
chat disliked that cx
the models themselves cannot (I believe) be copyrighted. Where thedebate opens up wider is wthere generativtive works made using AI Models can be copyrighted and thats far from a simple answer
lets talk about cute girls instead

well you could aat least have posted a cute girl ;o)
😔
True, but possible to edit it in a few ways to make it "'your own" under the current copyright laws, as we see with videos of copyrighted material which is discussing it or changing it in some way

I want to bonk the heads of the weirdo artists who think that it is "their" work that made the model anything, no, it's everyting and all of it, remove your little yellow splattrs and two red lines abstract art, and the model will not even change a bit
But it is ASSUREDLY modified to such a degree that their copyright cannot be retained within the model
TBF unless you're in a business selling shed loads of generated works etc then on the whole for most "Joe Public" ussers copyright isnt an issue

in reality artists /celebs etc would have to make an individual copyright claim for each instance where their copyroght has allegedly been breached so that each case can be determined on its individual merits
||controlnet works||


Pure AI work is treatable as Public Domain/CC0 Copyright. Anyone can use pure AI Generative Art - irrespective of who has generated it! Derivatives of AI Generated Art is more difficult - how far have you added value by modifying the original AI? Modified AI is a minefield when it comes to ownership - but pure AI is free-for-all!
SDXL is trained on LAION, which isn't copyrightable. idk why people think they can copywrite AI models
@peak dove it is not a minefield, it assuredly becomes copyrighted with signifigant change to differ it from the original
@indigo carbon it needs no (c) to sell it though
as Isaid, average Joe Public user doesnt give a toss
@indigo carbon as well, see if a big company won't fire a legal letter off to joe christmas who is passing around their uncopyrightable AI model
and see how no one cares and even a suit he'd win hands down, he proabbly won't want to pay an attorney and deal, basically a SLAPP but for distribution of open public domain material
I bet we see some of that in the coming years
e.g. I make a graphic novel. The narrative, typefont, layout of this publication © me - of that there is no doubt! But! The pure AI Generated photos are not copyrightable - and so may be lifted from "my publication" by anybody - and freely used, as I can claim no copyright over those AI Generated pictures!
if only the AI photos are
however, if you adjust them, in a manner which is different from the base you started with,
cos see here's where the thing gets... funny
normally it is the copyright owner who forces the person used their IP in some manner, to prove it is fair use
Yes, modification brings them closer to being copyrightable - but test that in a court of law - you may be surprised as to what degree of modification is necessary before © you!
however, in this case, it would be the faire use user, going after another party, and there''s no real...case law for reverse defense of fairuse ownership of this sort of thing, so
because it isn't per say fair use
but the same qualifiers to is this "signifigant" enough of a change, but without the need to prove so much as one would need in court against an owner, as none exists here

i think the defendants in such suits will be smmall people, not companies, so the legal system will probablyh not bow to the end user, but the corps
See Kris Kashtanova and the award of copyright on her Zelda Graphic Novel - which copyright was revoked by the USA Copyright Office - three months after it was awarded!!!
he who has the most money always wins

yea doesnt matter if its fair use,if u are a poor person against a big corporation u already lost
MidJourney paid for her lawyers to bring her copyright to copyright court!
unless i punch them in the eye
Sleepy time for me.
But here's a woman and her Raven for my departure


safe travels









this is how I feel about copyright law..
Sharkbucks!!!
yes

I do not know why I made these.
i forgot, I did the wrong thiing and searched for png in my output... apparently I have over 102,000 images :\
Oh, SB is about to update their logo and one was AI made and the other by a human. The AI one was so much cleaner





but do we "own" the depth map cx


who needs euclidian space...


in any case, based shark memes


I like it when looks Ai

© me later! 🙂

Summer's day in London 😄
will send royalties @peak dove



I also came across this earlier today if anyone else wants it

it sd xl ratios/resolutions

Some ComfyUI this a.m.





that sounds like my last week
my loopback kick is making dump lots of images
image hoarders anonymous ...
has anyone gotten facebook's text to music up and running?
Ends up with such awful things as this
i figure there's an audio clean up model somewhere too and the two could be used in tandum
"Is that all?!" 😄

If public broadcast and community shows were still a thing, I'd get my 30m and play nothing but these awful things I've made and some public domain swing music the entire time.
10\10 would watch this (on drugs)
that was 100% a story

Glittergyno!!! 😄
I totally would if they still had such, I think they have public broadcast still of course, but not the old tv channel where you could just go and be like, I wanna do a show., and then you do
It seems Kappa_neuro's false loras have been removed by Civitai
what was a story? the video? lol



So the way this worked is using loopback img2img, generate, using prompt, send image back repeat, with lower noise levels. each cycle is 12, every 2-4 cycles II modify the prompt a wee bit, or with big changes. So you have control over it. now, doing 12 frames and then making over4000, it does take a minute

cos each run is a 12 batched feedback look
Look at what is on his right shoulder
but, So here is MY question about this. At the end, when it goes all hyper contrast colors and mayan / egyptian looking artsy, WHERE did that come from, cos... 100% the prompt was "A field of golden sunflowers" noothing more. and it went down that strange road.
here's another for when you find enough drugs @vital ermine
its a bit of a longer one.
yeah
The entire input over several hours or days "stays in the background" and can erupt sporadically and in a random fashion?
@peak dove I press generate, for each set of 12... cos I would decide if that set of 12 would be good for the half second of video i was going ot use, if not , delete and retry, or move on, then adjust prompt a littel ever 1-2 seconds
took about 16 hours for all the frames

it was manually interacted with the entire time. So its random output seemed. really strange to me. I could not get it to do anyting BUT that.

@tepid surge this one has more "story" like elements to it, in a way, it is "somehwat" more cohesive with one prompt shift to the next having somme relevance, if but in a David Lynch kind of manner
I suspect the software owners allow certain "complementing functions" (unwanted I know!) to grace and 'promote' their software!?

What software do you mean?


What software are you using at all?
ah, i just pick up and put stuff togther in story type elements regardless of intention p naturally, i read tarot and stuff and it p much the same vibe
automatic1111 and some customized loopback script edits, and some other little tweaks I did


@tepid surge I mean it had... a purpose of sorts. like the staring skeletons and the monster, which then exploded, and left the land peaceful. It's not really so much story, I guess, just linear cohesion, weak as it may be

There's ComfiUI logic x.x https://github.com/theUpsider/ComfyUI-Logic

GitHub
Logic nodes to perform conditional renders based on an input or comparision - GitHub - theUpsider/ComfyUI-Logic: Logic nodes to perform conditional renders based on an input or comparision
A1111 has an incredible memory, if someone uses one of my prompts on another machine entirely, it looks nothing like my own output. A1111 seems to retain a memory of past input over a long period, which informs and colours future output, and is unique from machine to machine.
deforum?
?

I think something gets kinked up in its wonky to this day color correction in img2img for sure.
the animation
what about it, I dunno what deforum is :p
I meant to ask, what is deforum, ?

webui + loopback+ auto img2img move for last output + repeat + a lot of time and goofing with it
some of that, like img2img on last output was just a quickhack I shoved into loopback to push it's final image to img2img so on repeat it would not use the prior and so on

I kept noise down aroound .3-.35 on img to img it kept it from losing pixel cohesian but was slow enough to reduce flicker signifigantly
when it loses cohesiion it becomes ugly af
that's from lizard to bird at .01 noise. until the end when I kicked up to .035

it amuses me to see it barf into CMYK
I wonder if that is because of training images being CMYK or if the noise initialization is CMYK

This is what electric cars are preventing!!! (_8^(|) d'oh!!!
uh oh, clip text encode should be the same resolution as the latent right?
when it first starts breaking down it looks a bit like blown out latents. Likely you are pushing the latent values too high and then its ofc trying to recover but it goes into that color spectrum typically seen with it. just crank up cfg to like 30 and you will likely see similar colors
@sour obsidian it's cfg 7 and noise 0.01 for like 1000 frames
I think 0.01 noise decoheres from the resolution of the image
and it breaks down

cos the noise is mid pixel values probably I dunno
the noise it adds is just pure random gaussian, basically rgb static but in latent space
it is not RGB though THAT is what makes it interesting to me
the decoherence here is CMYK
yea that CMYK color is what you will see often when latent values trend too high going through the VAE
I wondering if it is NOT as it appears but is it trying to actually do its job, and using training data, that's output is indeed, decoherent, and the training data is more CMYK
ha ok
whoa

I mean if I just bring noise up, it'll just turn into a bird, it's just the really low noise value, nothing else adjusted, over about 150frames at 0.01 it does this
could be in the long string of things. Seems across different vae's the same color pattern emerges with blown out latents. I actually do wonder why, since those ranges are outside the training data range
So here. IF you lower noise and loopback the image (output becomes input) over about 150 frames, at 0.01 you see this, it is not a single interation
this is 150 full img2img generations
each fed into the next generation

hmm yea. Could see it being a mismatch between the noise scheduler and the ammount of noise it thinks is actually being added. Then it might be trying to "remove" more noise than its adding at those real low values. That would be my totally naive guess
if you move the noise to 0.03 wavy patterns begin to emerge.

and it has a more fluid movement, even though it rarely will reach prompt

that gets more terrifying the long I look
at 28 I move from .01 to .03 and the clouds of cyan and darker blue, coalesce into wave patterns
yup makes me uncomfortable as well - I love it 😉
does she talk like one of those people with the voice things held to her neck
lady gaga new fashion style

im loving this xwx

yeah, I've been using your ferrofluid thing. but with that one I did "ferrofluid, hyperfluid, ferrosmoke, hypersmoke"
kick it up the max
the words don't have to make real sense as long as the ai finds a correlation in it's training
yeah. a sleek nice looking prompt is cool, but in the end the result is important and if I need nonsensical tokens or a very long prompt for that so be it
people have weird ideas about a lot of these things. at least to me. I've read so many tutorials and I guess opinions on prompts and so many people say short is good, long is bad, etc. but maybe they're going for something different from me.
with this tech - everything goes
there are a couple of good practices for quality and fidelity, but there are no rules
I think that's the thing that irks me a bit




sure, there are definitely things that are usually a bad idea, like turning cfg to 50, or 1 step renders, or things that will in general produce illegible results. but beyond that, people should really step outside of their own views and understand that it's all a matter of your preferences and goals
yeah it can be overwhelming. so it's best to never stop learning and find your own workflows
I have this weird built in fear that a second space after a comma, or a trailing comma, will cause my generation to be bad lol
yeees these logic nodes are amazing
I am sure it is just superstition but
I'm working on some new nodes
I don't know, cos it does change the token, which could shift the weight
we'll see how they work out
sdxl controlnet lora What is the difference between rank128 and rank256 ?
bigger number on the second one
size/resolution
what ?

it's the architecture of it but yee it used diffrently
256 is bigger, takes more v memory
woah
I was literally just figuring out Controlnet with comfi today cx

I tried to make controlnet figures in blender so I could animate, tween, and make the frames the blender controlnet "stickmen" what I wanted to generate in terms of placement
it worked... okay
i dunno how controlnet openpose really works, on the geneeration side, I understand it's modeling but not the way it utilizes it in the actual use

is this image o.k. i mean technical aspect -> contrast and such.

@tepid surge can you post your workflow for CN?
the one guy in the middle there, looks like he smells like 1980s bath toys
the weird chemical this miight not be healthy odor


of rubbery floaties
oddly specific
nah, it is specific, very much so.
😄
Should be plasticine
hahah
it looks like mid 80s flesh colored whatever they used for rubber ducks that had that smell
probably cancerous
cos they painted them, and when their eyes came off, in the water, it got that fleshy color like his
they were 't actually yellow..
maybe I am still here, so
hope not

yeah that flesh faded rubber of his eyes triggered a weird bit of memories from my child hood lol


How does it affect results?




id assume resolution, idk how it works technically
ok thank u

she has an abdominal arm
deformation is a siin xwx

Some more ComfyUI SDXL







did u use controlnet ?
No
okey
@feral glade oh that was you he responded to in the discussion lol
okay, makes sense now


@feral glade I suggest, setting up two control net nodes, two samplers, and just run the same prompt / seed/ all through both , except one have 128 and other have 256 and see how the output differs
Both give almost the same result and the processing time is the same bro
im trying to use the ReVision Feature in ComfyUI but i get some strange results in which the combined image is completly unrelated to the input images - does someone now what could cause this? Im using the clip vision g and sdxl base model

then maybe it is not a big deal, have you tested with heavy handed movements in img2img, eg, making someone looking left, look right, and such, typically that sees huge difference in testing with mutiple models ime
This is a hybrid photo - the wall pictures are made using ComfyUI SDXL - and the Pool-Table was Generative-Fill in PS, on a Public Domain photo of a room.

okey bro thank u


what's the clippy output?
those lumpy low poly lookiing putty things, might not be recognized as what they are and the combinatioin of what it thinks it sees, is, that cool race car
or it may think they're scuba tanks...
Anybody knows what is benefit of using -> [Upscale latent by] i have same performance with or without it as well as same output.
ookay....


im always getting completly unrelated results here a test with just two portraits - this is the complete node setup im using

ah
what even cx faces = vehicle
Hey so
it says G,
your outputs are all running G right, not combine
or L
hold on
I dunno how it worksl ol

oh it may be encoded already

yes im using g i tried this one sugested here: https://www.youtube.com/watch?v=1SwDCqgXZ-M&t=110s

If you caught the stability.ai discord livestream yesterday, you got the chance to see Comfy introduce this workflow to Amli and myself. The idea here is that you can take multiple images and have the CLIP model reverse engineer them, and then we use those to create something new! You can do this with photos, MidJourney images, DreamStudio, or...
why are you doing the conditioning combine?
id remove that and bump both strengths to 1.0
thank you will try that!


revision as it stands is a funny one, does some suprising things. I am not suprised it produces some odd results sometimes. Its very visually removed atm working on a conceptual basis mostly
geck

it's cool. just trying to understand it. literally only made black males no matter what combination of people I used. and then when I put that in the negative it made ghostly old white men
ok thats pretty interesting haha. No clue why its doing that but alright
I mean, didn't investigate it that much. I realize models and stuff have an impact. but it was run diffusion with the noise offset and photorealism loras. so nothing seemed like it'd really push things in any one direction





I have tried to add image as neg condition using revision.You could use anime image as neg to produce more realistic image. Will do more test on it.
yep this works nicely 🙂 good catch
I wonder if you put multiple people would it stop making more than one people lol
probably negate the core, but I suspect if you used grouping like three men, and you wanted one woman, it may work
xwx






what do you guys recommend for sampler
dpmpp_2s_ancestral fs fs if you want a swap up from euler_ancestral
i generate several with the diff samplers each run


this has been working well for me

wow you really have powerful device to generate all of that
that reminds me i still need to figure out what the scheduler does
try conditioning average
just a 3060, it's one after another




makes sure i get to explore a prompt kinda stuff
i still need to figure out how AITemplate worrks 😭
appreantly it speeds up generation a bunch xwx
what is that

GitHub
AITemplate is a Python framework which renders neural network into high performance CUDA/HIP C++ code. Specialized for FP16 TensorCore (NVIDIA GPU) and MatrixCore (AMD GPU) inference. - GitHub - fa...
||there's nodes for it too, i just need to spend the time:|| https://github.com/FizzleDorf/AIT
GitHub
This was orginally written by: https://github.com/hlky - GitHub - FizzleDorf/AIT: This was orginally written by: https://github.com/hlky
just put it between your checkpoint loader and sampler

do comfy ui have like --midvram kinda stuff?
it has various options like that but for the most part you don't need to touch em, it will automatically select the best for your graphics card
sd xl runs on my 3gb 1060 with comfi xUx
ohh
What does it do exactly? 
aitemplate makes generation faster?
Did it need to got in a new folder in Models?
nup
dunno, it just works

Where is the node from and how to set it up? Its new to me 
astra linked it just above

Im blind 

its only for xl ? or both
XL only I think



what graphics card do you have?
3050 laptop
are you using preview?
nope
guys, help pls

I dont have to download anything else besides the node?
zoooom
don't think so
thank you @west breach ! didnt know all that was needed was linking it up
the error says it thinks the model is a lora. is it a lora??
Gives me weird artifacts in my setup
and takes triple the time

Can you tell me what I need to do, I'm just a beginner and I don't understand at all

Quick demo showing how easy it is to create beautiful and inspiring AI concepts in Easy Diffusion.
Easy Diffusion: https://github.com/cmdr2/stable-diffusion-ui
almighty yt
Try asking for help in #🤝|tech-support
i hope i can use it too
yeee ate up my v ram though

whilst it may be an interesting exercise your card isnt supported
(I have a 1080ti that is also not supported and even tried compling but she say no)

i have 3050 but laptop 



Works on my 3060 laptop


between 1344x768 and 1920x1080 therei s huge difference in quality
i wanst expecting it
I don't see any bugs
i was expecting same generation in scaling but nope
one of these days i need to get myself one of those data center gpu xwx
I just use my 3060 btw
yes just 1080 will generate most probably wrong thing, try if native generation 1088


results are completely different Ithink scaling is not just scaling
it is generation by itself
and it takes double the time
If you generate at a different resolution you get a different result
I use Ultrasharp but no upscaler is perfect
so none of them keeps the detail
not all of it usually
I like lollypop
i was thinking A series but apparently the 4090 beats it out cx
I am just using latent nearest
yeah that revision model doesn't seem to work well

Im doing upscale with model for the first pass and then with ultimate sd upscale
hmm
but my workflow only really is made for the 4090, cause it takes 80s for a 2048² image
cant go higher than 1344x768 thats the most stable one
tried alot of res
and it gives 1080 almost 1920x1099
those are the best res for sdxl i think

yep finetuned ones are these
did you tested this ultimate upscale with scheduler ?
does it work stable ?
For me it does, but takes some time and tweaking for good results
definitely not working right...

As i said I do pixel upscale by 4x with ultrasharp, then downscale into refiner and then ultimate upscale
too long for me 😄
generating hunderds of image same time at the moment.
with agent scheduler
You can try my simpler workflow if you want
it is simple I write prompt send to Que thats it 😄
what you never wasted 6 hours of your life for an 8k image? that's like 1.33k per hour!

such bootiful noodles 🥹
I will look at ultime upscaler later noted

damn 😄
tried generating 4k ones and I was like
helllll nooo
😄
open in browser... and zoom way in on the little house on the bottom right
lol
math checks out cx


I think 1080 is must if you want to share online
was going to make all 1344 but nope
too low res for people to use

that is one gorgeous woman ❤️🔥
is there a way to see what data is getting pushed on a line in comfy?
specifically from clipvision's out

I don't think this model is working right at all I think nothing is coming from those tubes...
I think the weird gens from the earlier guy who could not get it to work were just cfg
on empty
try searching for "print" or "debug" there might be node depending on what you're trying to look at
i need a help. I am trying dynamic prompt, but i dont know, where to connect it, it doesnt work with any box. Anybody can help?
what node is this
seems to work okay

ComfyRoll Aspect Ratio
also try with just one image and a prompt


it is not passing anything.
same seed = same output if I unhook image to clipvision
so clearly something bork
maybe need some updates somehwere
what's the different weight & height vs aspect ratio, are they related

which mmodel y9ou using
So you can set it to 768 and use it on 2.1 for example
night vision xl
aspect ratio uses your set width and height to calculate
so the output will be the size of aspect ratio?
I meant the clip model
with some finetuning you can make revision and positive text prompt work, like in this example. but it's not very useful. i get better results only using negative prompts in combination with revision:
https://i.imgur.com/3Ce7hG6.jpg
yep
clip_vision_g

oh it's a whole different model
lemme grab that one hold


My image is all garbled when using dpmpp_3m_sde sampler in comfyui. What can be the problem?

well that chokes
the shape in current model is torch.Size([1280]).
size mismatch for visual_projection.weight: copying a param with shape torch.Size([1280, 1664]) from checkpoint, the shape in current model is torch.Size([1024, 1280]).
i've had weird stuff with the 3m stuff too previous @fierce compass
dpmpp_2m is fine
I use 2s ancestral mostly
i only use ddim

never anything else.
use exponential scheduler with dpmpp_3m

ah! TIL. I was wondering where the karras samplers were (coming from a1111)
ahhh it was all my tabs open that was casuing my vram to spill over with the AIT
worked and then didnt worked then didnt cx





cuts a whole 10 sec from my generations
time to hook it into my animation graph cx
how do you get an idea what to prompt 


I just association when i'm searching for something specifc, or i use:

for when i'm just wanting random stuffs
like i'll start with "forest" then go "Forest, day time" then "forest daytime, lightshafts, dynamic lighting, vibrent" etc
willy yoda

where does it linked?

insert your ui prompt wild cards
Gone to watch BECK on TV - check out these ComfyUI beauties!







so Clipvision model, something was off with it, I grabbed it from another source, and it works fine. before I never saw the encoder nodes activate, but now they are . Weird. no errors or anything just did not work
well still doesn't work lol
whats the use of adding this clip?
something about extracting concepts from the image provided and using it as input

or at least the one I downloaded had a bunch of torch vomit and size issues, I just used manager to grab it, and it works bettere
so need for txt2img?

I think it still helps to provide a text prompt


does it improve the output, if I just generate images using text?

you need to provide an input image

then what is wrong with mine?


dynamic prompt, just got some question, if somebody using it, let me know please.


oh ok, then i dont need it


those are just photographs, bud


{kind=link}
{kind=link}
{kind=link}
{kind=link}
very nice
canny

are you on windows?
yep


Does anyone know any way that I can train a face on SDXL with colab?
these are amazing!
I'm just hungryl...