#✨|sdxl
1 messages · Page 86 of 1
no, thats why he's laughing
nobody knows how this works anymore !
still the same result for:
https://i.imgur.com/WMWVgOD.png
I've changed input_types to cls, and did the int(largest)
imo this is some bug, if you only have one output value - because it changes behavior if you add a second one
I always avoid the youtube links. maybe I shouldn't. I turned off the video link search results in google. and then it just showed me more youtube videos
no hate on the youtubers trying to make a buck, but it's so tiresome
2x speed on those videos
you know, I was doing that for a while and then forgot about it, lol
but thanks for reminding me
so if you add the same value twice, it doesn't create those 3 wrong outputs:
https://i.imgur.com/2T7gv5a.png
that's why i think this is a bug in comfyui

This is great info jps
I just want to know if it somehow split INT up into 3 outputs, or if it's something else entirely
the output still doesn't work for some other reason. i always get 1024 instead of the larger one of the two inputs.
class JPS_Math_LargestInt:
def init(self):
pass
@classmethod
def INPUT_TYPES(cls):
return {
"required": {
"value_a": ("INT", {"default": 1,}),
"value_b": ("INT", {"default": 1,}),
}
}
RETURN_TYPES = ("INT", )
RETURN_NAMES = ("largest", )
FUNCTION = "get_lrg"
CATEGORY="JPS Nodes/Math"
def get_lrg(self,value_a,value_b):
largest = int(1024)
if value_a >= value_b:
largest = value_a
if value_b < value_a:
largest = value_b
return(int(largest), )

@vast galleon what did you change? does it work for you if you input two int values? does it give you the larger one as output?
trying to test it. what's the best node to hook it up to and see?
@vast galleon still outputs 1024 all the time (but display is fine now - only one output) - i use it for height and width values and want to get the higher one of those two values, but get 1024 instead - so i guess the if part is wrong too
also had if / else before, with the same result
my brain is slow and has no idea what you're trying to do, lol
try
def get_lrg(self,value_a,value_b):
largest = int(1024)
largest = value_b
if value_a >= value_b:
largest = value_a
return(int(largest), )
I should put together some of the math nodes so you can put in any value for height or width and it'll output what the other one should be
sometimes the refiner makes me mad
I'm experimenting with running the same lora settings on refiner as I am base
also, I've just been sending both my G and L prompts to it. combining them
because I have no idea what I'm actually supposed to do


@wet nacelle thanks for the prompt!

Wicked
very nice! I'm actually going for a moderately similar look with what I'm putting together
haven't got there yet. messing with a new setup
I don't understand these people that dislike the noodles. it's like playing with ai legos
It's even odder when you realize that a lot of these people either have autism or extreme ADHD.
How the fuck do you not find this easier?
thanks. this one seems to work. can you explain me why the commas are needed? i did some other nodes without any problems even without the commas
for example, this one works:
https://i.imgur.com/sW9X2oh.png
lol. yeah. plus all the quick image adjustments. it's basically what I would do in photoshop endlessly. not as in depth obviously. but being able to just put all those blends and stuff into a workflow and have them execute in a half second
so satisfying
Totally!
The last commas aren't needed if you have more than 1 output. As to why, that's a question either for comfy, or the guy who created litegraph.
@vast galleon oh, so this is not a general python syntax thing, but some "special" thing about comfy or litegraph?
I've been doing weird things. get the difference between two similar outputs, then take the result and use that on one of the images. maybe a bit of burn or dodge depending on the situation
brings out a lot of detail
Yes, it's how they defined node classes
and the if part had a problem with executing everything after the if only if the condition was met i guess?
Or the node doesn't even show up as available
@hardy cipher @ionic gulch @vast galleon alright. Otter time guys. https://youtu.be/kNQxjjOjF9A

Ui is surprisingly kind to small creatures.
Please show that kindness to Aty…
Day 1 Wood Design Park, Shiso City, Hyogo Prefecture
Day 2 Iwakuni, Yamaguchi Kintai Bridge
Day 3 Karato Market, Shimonoseki, Yamaguchi
Day 4 Kannon Waterfall, Umakomon Market, Mikaeri Waterfall, Saga Prefecture
Day 5 Todoroki ravine, Ayugaeri waterfall, Mizuhoiwato S...
otterly wonderful

have you ever tried to switch the lora loader name widget to input?
lol, it did not seem to like it when I did that
I just pushed a commit that should let you customize the time format, so you should be able to do that now!


very excellent

all ideas from my prompt gen
there was a guy in here that was like, guys i want to do a local LLM for prompts , what would you ask it?
and i was like, sounds like a weekend project

ooh, did you finetune one? create a lora?
I'm really curious how that worls. what data do you use?
not that you have to tell me specifically

but in general, I don't know what I'd use for training, or how much is required
i used this, and its a helpful reference for anyone
i also have 4 or 5 custom txt files with prompt work scraped off the ol web
I've wanted to finetune a small LLM for prompting for quite a while, but don't know where I'd start. seems yours is working out well
nice img2img result:
https://i.imgur.com/zf58ZOL.jpg https://i.imgur.com/7BImqCP.jpg


no code chat bots are an easy place to start

Voiceflow is the collaborative AI agent building platform for teams to design, develop, and launch chat and voice assistants.
neat. didn't know that was a thing
and this one makes it pretty easy, sign up, start the tutorial for gettings started, upload data documents to knowlege base, and run a test
I'll check it out. I've tried with oobabooga. but it's like a111 if it was way buggier and had almost no documentation
or maybe there's documentation, but everything is so fragmented and incomplete
that styles website is great
yeah, textgen webui is fun and all but its not production ready lol
I rage quit and deleted it at least 3 times before I finally got it to work
i also pulled from this website for styles/idea generation

Prompt & settings guide for the SDXL image generation model. Copy these SDXL prompt templates for many photographic & artistic styles.
I was just looking at that a few minutes ago
good. there's about 20 ads on that page for every prompt. at least when I looked at it on my phone

the online LLMs are terrible at prompting in my experience. I can finesse them to give me some cool descriptions, but when I try to explain the how the prompts work they still use normal conversational english

that is verbatim, copy and paste, stick it into the blender
on another note, have you ever observed that when parameters get pushed too far in weird directions that the resulting image tends to take on a circular shape? like it starts to kaleidoscope essentially? maybe I'm just imagining things, but it used to happen when I'd push cfg too high with a long prompt in 1.5, and just had the same issue with xl
hmm, I'll post a couple of the images. they're trash, lol. but they can't all be winners




then i used the style cheat sheet to pick a random artist, this is in the style of Emily Balivet:1.5

I didn't put anything in my prompt anywhere that would imply it should crate something like that
the cartographer is poking through
I could track down some of my 1.5 images that would do the same thing
but I just took out the weirdness from my prompt so it's a bit better now
high CFG on dpmpp_2m karras does WEIRD stuff
GitHub
Dynamic Thresholding (CFG Scale Fix) for SD Auto WebUI - GitHub - mcmonkeyprojects/sd-dynamic-thresholding: Dynamic Thresholding (CFG Scale Fix) for SD Auto WebUI
I'd use that to push cfg well above 20 in a1111
i think thats prob most common sampler cause its consistent, fast, and converges
well man, that extension is great. but no idea how to emulate it in comfy
it'd really make sharp details and everything would pop. and then I'd schedule the mimic cfg and cfg to work together in unison so nothing would break
I'd couple it with the noise offset extension
I'll see if I can find an example
the readme for that github is very incomplete. it has way more to it than it says
that's a high cfg there

not sure exactly what. probably between 17-22
oh, oh my thats intoxicating
did you prompt this one for circular/kaleidoscoping?
thats nutso

Does anyone know if there are other refiner models for SDXL 1.0 other than the sd_xl_refiner_1.0.safetensors ?



as well as the noise offput, loras. I had quite a little setup going for a while
tried to do it there

Not that I've seen, but not really a need for a separate model since the refiner should only be making extremely minor detail changes. Nothing really a different model would change in that regard
anyway, I could post hundreds of examples, but just curious about what's going on and haven't really found any info
yeah those are some sick photos, curious to know whats going on behind the scenes
a bit of it going on there

these are all super high cfg as well. never had that happen without it
not gonna lie, some of these images have me missing that old workflow I had






ahh. that sort of makes sense to me. it just sort of breaks down to a degree? it just felt like I was trying to push it too hard and it didn't really know how to respond
I'd really love to figure out how that extension works and how to get the same functionality in comfy
I know how the settings work in application, but not really behind the scenes
sounds like latent stacking , pretty sure you would need a custom node
yeah. and I'm not even sure how it would really work. if I'd have to modify a sampler, or if it could be done externally
damn this guy has some cool math going on in his plugin
this is the gist

so its defining the limits for every step and then using the math to stack them togther
with those ones above I was using repeating cosine modulation, or however you'd say it, so the cfg would go high to low, high to low, several times over the course of the render
the concept of mimic cfg still eludes me. I've read about it a bit, but it's kind of hard to wrap my head around. lots of new concepts

😆
the creator of that plugin actually got hired on by SAI for this and mabey some other ones
thats mcmonkey
are you F* kidding hahahahahahhaha
cool! good for him

you know, i'm somewhat of a mather myself
my brain is quite satisfied by mathy things. but I really need to catch up on the programming side of it
I used it for some time in a1111. I could control the effects a bit, but I didn't get 95% of the math or logic behind it
well since the creator is a regular on this server I think I might try to ask him how the mimic scale works if I see him
I simulated noise offset effects with it. got really dark images out of it. it could also enhance image fidelity or details. but most of the time you would make images that were burned and overcooked
sometimes overcooked, but I'd mess with noise offset to fix that
prompt, sampler settings and CFG scheduling had all to be balanced each time
oh yeah, it was like trying to juggle 10 things at once
some SD2 + cfg scheduling experiments




so you could get more brighter and darker perceived images than SD2 was capable of before noise offset was a thing. but of course the cfg scheduling has other side effects
why cartoon ?

why not?
wasnt like this before
I don't know what your workflow is from the screenshot. is it the same model and prompt...
are you doing img2img etc
everything comes out low quality cartoon picture
yesterday it was working fine
bug ?
cannot diagnose with what little information you provided
let me queue once more
it looks like all your style tokens from the prompt are missing or it's a total different model
sdxl 1.0
right on. it really does amp up the saturation and contrast. yours are a lot more cohesive than a lot of the things I made, lol
thank you! yeah, it took days to find the right settings and prompt combination
are you using any kind of node that inserts styles into your prompt?
if you haven't updated your setup and load an old image, it should make the same image if you are not using wildcard files
new workspace

your old workspace probably had a node that inserted styles for you into the prompt. at least that is my best guess
styles ?
tried adding cartoon in negative
I can't say how your old workflow looked like and what nodes it used. from the image you've posted the styles are totally different. so I guess the image in anime style had a different prompt
man, I spent so much time messing with that stuff. after a whle it almost became intuitive
like I'd see something undesirable and know exactly which settings to adjust
yeah. I was pushing the CFG as high as I could. like CFG 30 and than mimic 6-8. it worked with some prompts

Cheers for the shout out on social mdeia platform formerly known as twitter
@high skiff

the readme said use half cosine up I believe. but I was a rebel and I'd use cosine down for cfg
well not always, but it worked well for me. just had to adjust values differently than most people would
hehe yeah I played a lot with those settings. I really liked this combo... 3D anime, created that style with many TI embeds and cfg scheduling (SD2)



that makes sense
here's some naturish images I made with it










a refiner would make that a masterpiece
those are beautiful! also very interesting to look at and there's lot to explore.
a perfect use case for the effects of mimicing imo. CFG scheduling does have a strong impact on structures and details. the backgrounds are probably very much enhanced here because of it
thanks! yeah, those ones came out pretty well. I have soooo many more too. once I got the settings properly tuned it was pretty much plug and play
I was trying to make them look like paintings but translated into real-life if that makes any sense
it does 🙂 they could be HDR nature photography but they are paintings
and I just couldn't bring out those colors without the extensions I was using. not sure it'd even be possible
yeah probably not
well at least not with the way things were structured
I have not tried it yet, but comfy made this script that is very similar to CFG scheduling: https://github.com/comfyanonymous/ComfyUI_experiments#sampler_tonemappy
I've messed with a bit. doesn't offer quite the same functionality but it does help
I see
if you have collection i can upload them in my youtube photobook channel
5 subscriber 😂
lol








cool. yeah, I could upload them and give you a link. you could put whatever you wanted on there

A conversational AI system that listens, learns, and challenges
imagine

ask away.. the community is helpful you will probably get your answer when the nerds are back
AIT implementation in the works, maybe?! https://github.com/facebookincubator/AITemplate/issues/867

GitHub
The original stable diffusion implementation for SD1.x only supports latent sizes that are multiples of 8 however there is a trick (here it is implemented in diffusers) to upsample the latent in th...
this workflow is so advance it crash my gpu

weird happenings in lego world






I do hope your tongue was firmly in your cheek when you wrote that ;o)
there are some nice structures in there 🙂 love the bottom mid one with the green hair
Is there any information that indicates whether the same dataset and data was used to train both CLIP ViT-L and OpenCLIP ViT-bigG in SDXL? I think I've heard somewhere that same data was used on both but not sure where.
I like this one


Lego(ish) using my favourote swedish girl in a bar prompt (very very loosley lol)










definitely unique
hans memling meets legos and drugs, lol
or it might be negative for the style
that might be true. hard to say I guess. I'd like to explore those prompts again, but didn't have as much luck with the workflow I had going in comfy
Guys has anyone here tried to get the outline of an image with img2img?
@soft zealot I sent a PM to you
how do you maintain a sort of similar character in different pictures?
Can't you do this with controlnet?
I'm asking because I didn't try yet
I was thinking of building a comfyui flow for this
Includes controlnet: https://civitai.com/models/119257/gtm-comfyui-workflows-including-sdxl-and-sd15
The SDXL workflow includes wildcards, base+refiner stages, Ultimate SD Upscaler (using a 1.5 refined model) and a switchable face detailer. Now wit...
I'm a check that thanks

i just need help with the craSHING part
maybe need to update
well given all you've said is that your GPU is crashing thats a bit like going to the GP and saying "I dont feel well"
Bare miinimum need before any opinions etc can be formed
- What GPU do you have?
- What error messages (if any)are you getting in the condole when it "crashes" ?
GTX 1660 6gb ram
no console.. just closed
if you're trying torun an SDXL model thats probably most of the problem
some days it runs fine
may AI doesnt like monday
aye but its probably teetering on the edge and one more chrome tab or YT video opening is enough to push it over
hmmm seems like it
try to restart your computer, start NO other programs at all, and see if it then runs
came to post this and you just did! important notice, this openpose controlnet for sdxl does not work with Auto1111, just Comfy for now.
Hey all,
does anyone know how to get realistic hands? I'm using SDXL in comfyUI and Searge's nodes, which is great. But I cannot believe that Midjourney is doing a better Job at creating hands.
Any idea?
https://imagen.research.google/video/paper.pdf diffusion video coming soo
Any tutorial to make my own node ?

Love!





Midjourney 5.1 was specifically trained for hands, I suggest to find a sdxl model with similar features












a while ago since i fired it up, but as far as i remember, there is an option in the settings where you can configure the samplers to show
then i dont know sry
I am here
What did i miss?
Awesome, I’ll check it out!





this is realistic af

Guys I know there's been a heatwave for the last week. Just come to work guys. Pwease?


"Elon. Please. We don't want to be in the factory today."
can i ask about AIT loader in ComfUI?
It makes it/s twice faster, but on VAE box it stay loooong about 10sec. So what i gain with AIT i lost with VAE decoder. Any solution to this?


100% real image, nice try
are you sure? 


the one with the close-up is 100% ai generated the last one probably too.

My sweat fetish helps with the realism prompting a lot.
I can totes see the imperfections though.
sweat fetish
yuppers
might be the first time I've seen those two words combined like that
And it will likely be the last.
I mean, I think there are much worse things in the world, lol. whatever floats your boat
Totes.
Here is the upscale. The smaller nose is the upscaled one.
I think it destroyed the overall texture and facial structure of her face.
It's as if the image was ran through topaz labs.


so I never did figure out that controlnet thing. but I did figure out how to make a node
her skin looks a bit distressed 
I watched his other video on setting up controlnet with comfyui.
It seems that I need the windows portable install for it to work at all.
I don't want to go through moving everything into another folder yet.
hmm, I wonder what that's about



this workflow hurts me 
did you use workping.py to embed a workflow that generated a different image in here?
I have DLd the same Model & Lora you used plus used same seed/sampler/scheduler/prompt and got a different image from yours.
Now maybe it's me.....................

I don't know that humbo jumbo honestly. workping.py? huh?
I know what in the embeded Json thats how I went looking fo rthe model & LORA
as I said, it may well be me doing something different (in fact theres every chandce it is as I use a Pre conditioning step)
Simply oibserving I got a different genrate dimage 🙂
I really don't know more than just prompting knowledge really.
Right. odd.
my nodes are now available in comfy manager:
https://i.imgur.com/E4AVGTX.png

even got a nice id (111) :)

GitHub
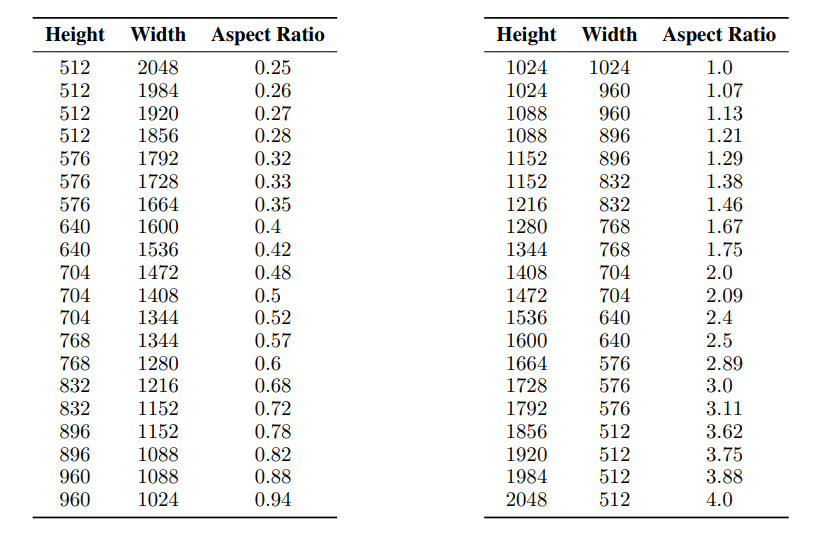
input aspect ratio, output dimensions. Contribute to picturesonpictures/comfy_PoP development by creating an account on GitHub.
calculates any aspect ratio for any resolution square up to 4096. not sure how useful that is, but you know
so basically 1024x1024, put in any 2 numbers for AR, and it'll output values that correspond to the same pixel count
or 512x512, 1742x1742
lots of downloads as you can see
well done
is it just the pixel count or do you consider other factors as well?
such as? are there other things I should consider?
dont dash his hopes and dreams man!
I mean, I can change it if it needs to be changed

its more a matter of how complex you want it to get
i'm not sure, but afair the resolutions should also be devidable by some number like 16 or 64. not sure where i got that info.
well I could have restricted it to only 512, 768, 1024 or something
but didn't see a reason
here is some info i found:
https://stablediffusionxl.com/sdxl-resolutions-and-aspect-ratios/#:~:text=For the best results%2C it,x 896 (9%3A7)
that's where i got the resolutions for my resolution node
Compared to previous models, Stable Diffusion XL offers significantly improved image generation capabilities regarding image and composition details. Mostly
and you might be right as far as it being divisible by those numbers. but that's not a hard fix
i believe thats right, official docs maybe?
i believe those are the best practice resolutions
had something to do with how it was trained
meh, well I'm curious to see what difference it makes
let me see if i can find it
could also just make another one that adheres to that, it'd be pretty easy
yeah, that's what I was thinking
guess it reduces the risk of double objects, but other resolutions should work too, if you try often enough.
I actually don't really know python. so it took me a little while to figure out wtf I was doing. but it does work as it's supposed to
thats a W
A lot of my generations have a very slight layer of blurriness, prior to any upscaling attempts using. Does anyone else run into this?
I've tried 1024x1024 or 832x1216 for example.
base model: sdxl_base_1.0
refiner: sdxl_refiner_1.0
vae: sdxl_vae
@hardy cipher great. after you've got that first one, additional nodes will be much easier. and it's great to have a way to adjust everything to your own needs.
even got it to show up in it's own folder in the node menue rather than one of the random default node menus
wasn't sure what category to put it in. but it works so all good
it could be lots of different things
Thanks for sharing it!
Look at this assclown for example

those are my 4 main ones, that reduced the needed space in my gui a lot:
https://i.imgur.com/p1UatDd.png
CONFIRMED, divisible by 16 for best results

for sure. I figured I'd post it and be informed I didn't do something correctly, but all good. I'll probably implement the option to adhere to the proper multiples of 16 or 64 or whatever

Since we have released stable diffusion SDXL to the world, I might as well show you how to get the most from the models as this is the same workflow I use on a daily basis at stability.ai. In this video I show you some of the basics on how to get the model from the models to generate your best AI artwork from our models. You will need some of ...
video timestamp if anyone cares
but also, would be kind of nice to veer from that and see what difference it makes
or interesting
that is a nice node
the top right
what sampler, scheduler, and step count (base/refiner/total)
I do like the efficient nodes. and the pipes. although running sdxl through the basic pip gives me all kinds of errors about tensor sizes
not sure if it impacts the results or what
but stopped using them
sampler: euler
scheduler: normal
steps: 30
cfg: 7
most of them should be very universal, only the additional settings are especially for my own workflow.
im guessing the refiner is smashing things in its particle colider
I'm trying to trace it... it's based on Searge SDXL.
can you send a screenshot of the main settings?
oh sure, sorry. I thought it was in the pic I sent of the joker.

lol maybe i just didnt drag and rop
output is named input but it is output right ?
this might help, i suspect the step count is too low
for your chosen sampler/scheduler combo
try 45 and see if you see an improvement
would try euler a and 60+ steps to be sure that sampler and steps are not the problem. 30 is not much for base + refiner
(or increase the CFG but thats a bit more delicate lol)
Ah okay, very well. I'll move back to eulerA and bump up the steps.
Ah yes, thank you for the reminder on my seed.
np
scheduler, normal or karras?
i like karras personally
let's test some dpmpp_3m

hello friends, while waiting on SDXL training methods, check out post on SDXL 'implementation' in ComfyUI from scratch.
I also try to discuss different aspects of the model architechture along with basics of the tool so maybe you'll find it interesting.
It will get much deeper starting from part 2
https://followfoxai.substack.com/p/part-1-sdxl-in-comfyui-from-scratch

Series to master ComfyUI with SDXL

yes
a crimmminall minddd is alll i have!
is it open access?

ooo depth controlnet is out finally. i can stop bracing

thanks for sharing it! I will definitely take look.

stop the party

3m SDE tho 👀


https://huggingface.co/thibaud/controlnet-openpose-sdxl-1.0 thibaud coming in hot too!
sarge updated his depth model today too
what a time to be alive!
thibaud dropped it all!! scribble, hev, all of it!
wait no mb. just openpose.
Yeah other stuff is 2.1
oh good catch, you mean on the nodes?
he updated it all today to trix me
Anybody here found success trying to get uncentered images yet? Still struggling to get any remotely consistent control of framing at the prompt level
It seems like an improvement having just bumped it up to 45 steps.
I kept the same seed from the previous image, but it generated a different result anyway. I guess because of the sampler change...

My effects lora seems to work but seems dependant on subject a bit

controlnet openpose is out now apparantly. that'll be a success
Yeah been messing with them, unfortunately they tend to fall apart fairly quickly if your prompt isn't fairly strongly correlated to the controlnet model's input. Like for architecture for instance. Works ok if all you want to do is basic human posing, but if you stray from that the prompt coherence goes out the window (this is including canny, depth, and pose)

looks much better
definitely sampler will change how noise is handled
@rovo excellent write up here if you are interested in understanding more: https://stable-diffusion-art.com/samplers/#So8230_which_one_is_the_best

Many sampling methods are available in AUTOMATIC1111. Euler a, Heun, DDIM... What are samplers? How do they work? What is the difference between them? Which

nice - that looks cool 🙂
Thanks, it is like a lofi
scan lines and all
I can't use it in comfy since he doesn't work with ia3 lora
sepia and scanlines seem like an odd mixture to me
@rovo heres another great one, less reading, more doing, pick your poison

Or how I learned to make weird cats
yeah effects loras are very interesting - and glitches are great anyway.
ah cool, really nicely put together. Thank you.
yep, that is the effect I was going after
glitch effect.
Yeah, this needs a bit more time in an oven
I see I see. also a person with well organized resources. very good. 
crash when using refiner

is it so much a strain on gpu ? using two loader
strain implies it could break the gpu. it's not being strained
it eats vram, that's it
and heat, it does heat
explains the crash


and eats dust 
my lora as a neg

the sun was beaming thorugh my window directly onto my pc case for about an hour yesterday. it crashed on me then haha. the one hour of the day during the one week in august that it could happen

That's Time for ya! Always indicating just where the sun is going to strike the surface of our planet. 😄
really digging the asthetic on these
Top one was with my lora as a neg
60 from 45 steps;
I'm seeing the light now.


thats base?

more steps more fun ?


Yes, that is Base. Slightly upscaled.

Love the 'scan lines' reminds me of my old 625 line TV 🤩
that is excellent for base

The man on fire is back
initial 3m SDE GPU speed tests: no change to 2m, lol
quality up next
doens't have the GPU ones that I can tell, but you can take a look at this chart for sampler rendering time

Have they used upscaled images to train SDXL ?
grrrr mutter mutter
OOM when trying SDXL ControlNet
(Yellow are debug only to confirm ControlNet Input Image aint mahoosive)


how do you hide links ?
Do you guys notice SDXL produces the same lips in every photo for women?
it was possible before with failfast QoL package but since ComfyUI now has native support for Link Render modes in the settings, failfast removed it from the package - so was the Link Render mode option: none.
it was removed
ah I still have it instal;led, dont think I updated
will uncomment uit if OOTB now
Im not disputing 🙂
yeah, that wasn't my intention 😄 just a src
Any reason he removed those that has been discussed?
because comfy added the option OOTB so not needed ?
Ah gotcha
minus the "show none links at all" option
fair enough lol
ah so the OOTB option doesnt have the HIDE Option?
correct
Didn't realize it was also a native option as I still have the failfa option I've been using. But yeah no hide option in the native menu I see
leaves his failfast in place and makes note to not upgradeit
just so much cleaner with everything hidden
question about lora and model training sdxl. 24gb absolute or can you squeeze by on 16?

obligatory thx

is it back in or did you get the previous commit?
did you prompt different lips?
3m SDE GPU looks like its still there
the only thing I heard was - the CFG is much hotter now

CFG is next!
is this a1111?
negative, comfy
yeah still need to try efficiency plots. installed a1111 just to do plots 😄
anyone getting a message "Killed" after a bunch of rendering on ComfyUI? running -lowvram on a 3080 10GB

theres the workflow, try it 😛
ah awesome! thank you for doing the tests and the workflow!

yesterday it was recommended to only run it with the exponential scheduler
really? hmmmm why is that?
pulled exp in to test, removed normal and ddim
it seems to be updated now according to the last commits. I couldn'T find any info about 3m
only that there's a pull request for a1111 as well

how did you get grid in comfy/
yeah exp does look best here
GitHub
A collection of ComfyUI custom nodes. Contribute to LucianoCirino/efficiency-nodes-comfyui development by creating an account on GitHub.
which node?
XY plotters
your gonna love this next test
sneak peak

teaser!
thank you
did you use AIT on this?
yes, all ait
be advised, starting tests with SD1.5 for comparison later

cfg 6.5, steps 55 could be the start of overcooking
steps 55 all look on the verge
but maybe it's the seed
I will do tests tonight as well
all run with exponential?
the steps 53 lane has some interesting details
running tests higher to push boundary
sure. but it's SDE - so
53 was my fav
yeah - looks most coherent
SDXL will come next lol, but makes sense to eliminate options before running in sdxl
I mean I ran a couple of sessions with dpmpp_sde_gpu at 55 steps the last few days
sde gpu at 50 for me, testing
but this changes it for sure
at one point you will have reached final convergence 😄

dpmpp_sde can look great from 15-55 - depends on the rest of the settings and prompt

cfg 12 come on


i see you have the documentation on your side


17 is the limit lol
but man im suprised by 15/53
There it is again, 53....
I may have read that but I knew it from testing before - because I made over 100k images with SD2
it were probably 150k - but who counts (beside my electricity bill)
tooo true
SDXL is a beast holy shit

Thanks for testing high cfg

my pleasure

going to run the sdxl plots now
and it doesn't look as burned as I would have expected





not at all im super surpised, looks like 3m improved quality SUBSTANTIALLY
karras and exp are my fav
initial tests to figure boundaries

its insane that there is actually intelligibility at CFG:20
SDXL is flexing tho

with cfg scheduling I ran cfg 30 / mimic 5 😄
i havent messed with mimic, hows it look
I used it in a1111 with SD2 7 months ago. interesting effects, but not easy to dial in. you mostly get overcooked images. everything can look like wax.
once I had dialed it in with the correct settings and a fitting prompt, it changed contrast, increased details in the whole scene and you could emulate a way darker lighting environment compared to what SD2 was capable of before noise offset was a thing.
I used it for some time making SD2 images.


15 is definitely too hot here
oh for sure, 12.75 look sjust on the verge
but still looks great, it has a great aesthetic if thats what you are going for
consistency is impeccable too
25 steps not enough for high cfg
yeah you can see how the coherence isn't there

46 does have it's charm. 60 has more details

I'm running plots right now :/ so thanks for doing some testing
send pics or it didnt happen!
lol send your favs, im interested in what you come up wiht
Are y’all using like Fibonacci numbers or something?😂
ok last one for a bit
I wanna see this - than I'll be back in a bit and see what I can find out

I guess 60 it is 😉
WOW
this is some ish
2m performs remarkably well here, but 3m is clearly king of the details/aesthetic/vibe
compositon is better, DR is better
I'd like to know what sort of psychopaths are rendering 5 and 10 step images
you totally can, but I won't

Wait has dpmpp_2m been overtaken as the best sampler??
when I used DPM++ SDE Karras with 15 steps on SD2 I was told that 10 would be enough. So I pumped it to 20 and ended up at 30. good sweetspot - great quality
for me yeah, its up to personal tastes.....but im not saying i didnt just render like 300 comparisons showing that yeah dpmpp_2m_sde_gpu with exponential scheduler outperforms
i came up learning that anything over 25 is A LOT so when i see these 50 and 70 step workflows i'm like surprisedpikachu.gif
not saying i know anything at all. just saying im surprised
The pathway to exponential is considered unnatural
yeah - if I can see details emerging, why would I not want that? speed? okay... is it always necessary? no
Ah okay lol, I’ll have to try it out for my taste then.
huh?
if you know how to compose what you want then its much less about generating qty, and you can focus on quality
yeah - I always trade speed for quality with this
i posted all my work in here so you can see some comparisons if you go up
Yeah I’m lookin at em!
is that by choice or necessity? lol

choice. I can always choose different settings, but my main thing with this here is pushing the fidelity - see how far it can go
i think i misread, you prefer quality right?
same
well I totally get rendering at lower steps for some things, or if you're trying to find the right setup. but then I see people so flabbergasted when they see someone else used more steps. like the goal is to mass produce as many images as possible
and I do a pretty good job of that with my little insufficient video card
yeah, that's exactly the reason AIT exists, crazy speed without precision loss
if it's a super nominal decrease in quality for significant increase in speed, that makes sense, but people are just silly about it
i dont want 1000 potato heads
I produce a lot of images. in the early days of SD1 and than SD2 my way of getting interesting images was pure brute force. render 500 images - get 20-25 good ones that I found acceptable. like a photographer that shoots 500 photos and gets 3 - 5 really good ones.
with SDXL it has changed quite a bit. the ratio of interesting images is much higher now - which is really satisfying and cool 🙂
we already proved that, more consistent than Xformers- while being incredibly fast.
yeah, much higher win frequency
I believe it. not doubting you. I wasn't attempting to call you out or anything. I'm all about it
4k in
4k image?
yes
bro, that doesn't fit within the size parameter restrictions
upscale a la mode
I've set scale_by by accident to 2.0 using 4x Ultrasharp - ended up with a 13000x7000 image - took 29 seconds. of course it's way to blurry for so many pixels but it was very fast
yeah, I've made some HUGE images. well not really bigger than that actually
but they're what, 100 mb or something?
60mb png
that's the reason the AIT workflow I made has upscale by to 0.6, this makes ~4k consistently, without loosing any speed
my 4k images are 30 I believe
I blew an image up to 8k in 1.5 so I could go wild with inpainting
then realized there was hardly any way to send it to people online. or host it even. almost every service will either shrink it or not allow you to send it
i give it about a month before hosting services are like "okay hold on wtf is going on here"

it's not so much the file sizes of individual generations. it's the constant deluge of uploads
if they don't actually shrink it resolution wise they still gut it
my goto fix is to just make sure it's saved as a jpg
rather than png
yeah you could compress it, but that costs compute
tile it. split it up into 1/9ths

at some point, we may just start swapping parameters and people will generate the entire image on client side with perfect reproduction
this is the way
a lot of protocols will need to be developed but i think the compression benefits of offloading it to the client is something data centers are going to be like "yup"
discord with its own sample decode haha, that sounds incredible, excellent data transmission with transcode process
could even imagine a way of storing a low dimensional latent version of a photo from a camera, and reproducing that in higher fidelity with diffusion. as part of a fileformat
someone just needs to come up with an efficient way of doing that
it just seems like something someone might just pop up out of nowhere and release in 3 months
Any idea how to make these kind of artifects tidy in A1111?:

now we are talking
i'm just high level spitballing and have really no idea if this is actually possible, but from the papers and research i've glanced at it really seems like this is the direction
discord's image data storage is probably an equivalent to what youtube is for video (minus a couple of exabyte)
lets dream
intel probably. hyped like "MMX TECHNOLOGY"

TV commercial aired in 1997 in Australia for the new Pentium MMX. Features the disco hit "Play That Funky Music" by Wild Cherry.
oh god
I remember there being an image format that only works with certain software that no matter how much you zoom it, it's never low res and files are ~2mb, it only worked on images created with that specific format though
real media?
I don't remember names, but there was something like that somewhere.. I'm sure if you look for it you will end up finding it
Guys im trying to make a Logo on SDXL, any tips on what to put in to make it proffesional looking?
theres been so many failed iamge formats. i like the old interlacing ones that tried to encode higher fidelities into tricks that crt could provide. it was the way konami made oldschool cool pixel art
depends on the style you want to do
Like generate json data filtering prompts
start with a plan and rough sketches then use diffusion to realize that plan. That's how professionals should be doing it
Any idea what model would be best?
if you haven't done at least 2 dozen thumbnail sketches for this logo yet, you haven't even considered designing a logo. imo.
I'm sure it might be possible to make something like PNG that does something similar though. it's definitely a possibility
here's one from at&t that required hardware

well thats why im using SD because it will come up with a million possibilities that i wouldnt think of lol
done

feels cheaty but in a Kobayashi maru kinda way
yeah, AI needs some format like that to store gens. I'm sure it will show up eventually
this was so good and impressive at the time, like the final fantasy 7 characters looking HD on a potato
almost certainly. we're at gen 2 of diffusion (imo) and it's making 80mb files lol
sometimes Load button doesn't do anything in Chrome, there a fix for that?
hey - hacking is allowed in space (or at the academy)
yeah LOL, like, it's probably taking so much of my storage

yeah hahaha. i remember loading it in an emulator for the first time and thinking "this looked way better before" always gas lighting myself thinking i was just blinded by nostalgia. but yeah, it actually do look WAY better on a CRT
"professional logo design, minimalist, sleek, modern, award-winning" - add creative idea here
i had this exact reaction too!
i mean. barret's hands were cubes. there was a little bit of nostalgia
good old barret's hands
is that a gun or a hand, its a gun and a hand, ok im cool with it - young me prob
now we have more fingers than we need

I think it would've looked better to do plasma
Because plasma can exist under water
it obvioulsy would have looked better to do plastic bottles and oil!
Bruh
was diffusion used to create that "zygote monster" episode in oats studios?

I'm fairly certain fire can exist under water
does the AIT custom nodes from the Manager install work on Linux now? or do we know?
You posted this image so many times !! 😂
yes, it was fixed a few days ago
Tdg8uU has his bangers and he's not shy about sharing them more than once
I just generated this.. I just really liked that prompt
no. after you share, it's done forever. keep it in the folder until bit rot. as is tradition.


did you use CPU ARG? it should look slightly better
probably not, that changable in a conf file somewhere?
also might be new record, 4090?
yeah, very first render on this new card (installed about 30 minutes ago after amazon shipping debacle)
it's enabled by default in \ComfyUI\nodes.py
you should change it to GPU ARG, it makes it work better with AIT for some reason

change line 1154 to noise = torch.zeros(latent_image.size(), dtype=latent_image.dtype, layout=latent_image.layout, device="device")
also do this while ComfyUI is not active, it might cause issues


all this spam safe to ignore?

hello
of course, you didn't get this before? this is how it should look like before loading models in general, not just with AIT
yeah it came up on first launch before AIT
@hoary saddle try to gen now, speed should be the same ~12 seconds but quality should be somewhat better

do you guys have any tips for generating consistent characters? im using comfyui and tried to to the celebrity name matching think but also read there's no alternate prompt editing, any suggestions for the prompt or the workflow? im new
You should look into generating LoRAs
also since someone asked me to do plasma, here it is..

Search YouTube for Koyha @shy kelp
i'm using base too instead of whatever checkpoint you have, could be it, but yeah 12 sec
using ultra long prompts, is giving great results
but also read there's no alternate prompt editing
this is incorrect, by default there's the usual prompt editing syntax from a1 here https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#prompt-editing
and also the dynamic prompt syntax of randomizing prompts {random1|random2|random3}
alright but is there anything i can do with the prompt?
i use those in my usual a1 prompts so that was pretty big in making the jump to comfy
yes thats where i read about it, and issues in comfy says they're not adding it i think
unsure about that, it works fine for me
you should try that model, it's my personal favorite XL finetune. same reason why it's there by default when using the AIT workflow I made
not saying it doesnt work for those users and mabey even you down the line but its not a hard fact that comfy doesnt support it is all im saying
the random is assigned at prompt evaluation time in comfy as far as i read and a1 allows for going back and forth between the option each step right
ahh so you suggest using a1?
no im just saying it should work, give it a try
the random prompt is assigned at the start for a1 as well, you can tell which one it uses with the metadata

looking it up now
Does anyone know if the only thing holding us back from using these new xl control nets in a1111 is just the lack of provided YAMLs?
confirming this works, i use it all the time, using it right now
assigned at gen is correct
i learned this form detweiler who works with comfy, so....supported unsuported? he said she said, but it works

this is sick
Any recommended comprehensive documentation of ComfyUI Nodes? Like as a table or list?
This is the closest I've found:
https://blenderneko.github.io/ComfyUI-docs/Core Nodes/
idk about A1111 anymore, the best modern alternative for people that hate nodes is probably ComfyBox, it's just a frontend that uses your ComfyUI install as a backend
i think thats the best ive found



i forgot that this existed
now i have another thing on the list to test with sdxl zzzzzzzz so much to do



can i train text embeddings with comfyui or do i need another tool did anyone do that?









not aware that comfy can train embeddings.
I think I got it working . all those ratios are on the stable diffusion list of proper aspect ratios. I realize it's probably basic stuff to a lot of you guys, but had to learn myself some new things figure this one out



for every lora i need a node ?
and there's still the option to do really dumb things, lol. just have the default values as they should be
everybody gotta start somewhere, at least you are taking initiative
there's that efficiency node that loads several, but then if I remember correctly the only output by default is to another one of the efficiency nodes
this, or chain the loras with a node per lora
now thats a good design
take off the training wheels and roll down the hill
I just chain the LoRAs normally. it's pretty quick
this, also you can CTRL+SHIFT+V to paste with same connections, speeds up the layout
well I thought about having it only load the listed ratios, but then what if I want to experiment with something off the wall to see why it won't work and is a waste of time?
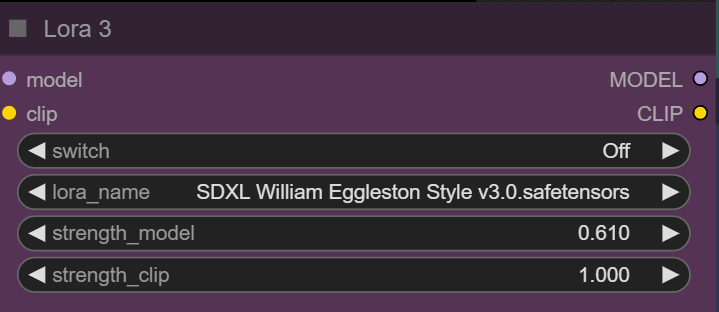
i like this lora loader with on/off switch. so you can wire 3-6 loaders permanetly and just turn them on/off as needed
I don't know if it's just my limited resources or what, but if I copy paste too many times in a short time span the user interface basically breaks and I have to refresh. not a huge deal, but it's like everything disappears
i like this approach
I think you should check the YouTube channel with the last event recording
Comfyroll ftw
doesn't happen with cloning, but cloning doesn't copy connections
usually i just turned down the strength lol
ctrl+shift+v
ctrlshift v wow okay
comfyui really needs more optional nodes. like turning on/off face-fix, upsaler, etc. without changing the wires
yes please
since we're giving paste protips, y'all know that win11 has a start+v little clipboard history feature?
i copy 8 different things then pull them all out of that
Is there a channel/forum/discord for ComfyUI?
Looks like this lora is trained for skin and hands (not tested) https://civitai.com/models/109043?modelVersionId=117467
*Publishing Notes: Version 1.0 is a merge of four different custom LoRAs: one for female skin, one for female hands, one for male skin and - surpri...
as I said, when I control V too many times in a short time span, my user interface glitches and I have to refresh the webpage
oh
but doesn't happen with cloning
is that model on Civi? i see one for 1.5 with similar name
is there a good upscaler for sdxl that doesn't remove the facial details the refiner added (like the one from Sytan does by using the base model for upscaling)?
nm, found it
Yes, it is called Crystal clear XL(CCXL)
scrolled right past it
all those ultimate upscale things make my computer mad. it'll be zooming along, then come to a screeching halt toward the end. I end up having to use tiled vae everything
yeah sytan's refiner pass kind of seems to not do anything outside of the default settings it comes wiht
can i use refiner over SD 1.5 model
yes
nice
i see no reason why not
asking the right question
everything i have used removes details at upscale, like a smoothing feature
there is a workflow with a face detailer after upscale

these are so badass
i'd prefer using the refiner after the hires pass if i am going to use it at all. haven't gotten there yet though. i'm relying on sytan's a lot
i'm using face detailer and upscaler at the moment - face detailer sometimes helps (but also smoothes the image a little but), but upscaler is only good for comic style. for realistic image it removes the details and makes everything look photoshopped
did someone want different lips earlier??

has a sweet AR visor inside it
perfection

for refiner clip text , empty or clone the first prompt
that when I add it, seems to work better although in fairness to SDXL mostly facedetailing is superflous .
yeah, it's so incredible we can generate stuff like this in a few seconds at this point

i'm not talking about a facedetailing pass. i use those with lora portraits
I was looking at stuff I was makign pre-stable diffusion about a year ago
it was amazing to me at the time
not so much now
haha same. dall-e mini, now craiyon, had me enamoured
node ?
first text to image I found was wombo dream. it actually frustrated me even then because it was just styles. but better than nothing
i use 5 lora prompt in SD, how to do that in comfy ?
then deepdreamgenerator text to image was vastly better
bro, you just chain 5 loras together
eww
you stack them on top of each other
waiting for runway gen3 - gen5
take one photo and make it follow my script
T2V?
so if you're using lora in sdxl do you need to use two one for the base and another for refiner model?

in comfy ?
I don't know, I don't think it looks that terrible


chain them, stack em, collapse them
yup
yeah, I only collapse the stuff I'm probably not going to need to use again
it often seems bitter sweet to me, that the censorers are coming chicken little reveres, hold runway ml up as the hero of nsfw opensource ml, but never admit that gen2 isn't released to the public.
refiner steps = 80% of base steps
spoonfeed me
we will be fighting this fight till we pass the torch to the next gen

the main issue is that videos have sound, how would that work? it can't be a diffusion process, that's for sure..
comfy has that new feature where you can ctrl+b a node and it just bypasses inputs to outputs
eh, generate the frames, ill add the sound
so 5 loras chained doesn't feel so unreasonable
thx, was using ctrl+m but had to reroute
same. it was an update in the pst couple weeks he put it in, and it's not documented

that's so easy with stable diffusion already.. the issue is that it makes frame by frame, a true video model should iterate videos somehow, this also includes sounds
eh. nothing wrong with a many experts approach. apply another model ot the video post frames to get audio into it
https://sdxl.replicate.dev/
skip to refiner section
Or how I learned to make weird cats
then why not use SDXL for videos?..

there should be an entirely different architecture of models capable of iterating actual videos. I remember Google being able to achieve this, but it was sooo bad
i think it lacks temperal knowledge but i might be wrong.
i think there will be, they are being designed and built as we speak
after adding loras

your weights are insane in the membrane
yeah, I wonder if there will be a point where something like "VDXL" would exist, probably a year or two from now =p
the first motion pictures didn't have audio. it was added in after. nothing about a video inherently requires audio along to it and it can always be stitched in. none of this true video stuff.
hoping less 🙂
so the weights is not in the prompt
correct it is on the lora node "strength", set them all to .5 and see what you get
I can’t imagine the stack will look anything like a “video diffusion”. So much easier to have a pipeline that looks more like:
- AI generates script
- AI generates storyboards and concept art per scene
- AI generates a blender scene
- AI controls the rigging…
Etc, etc, at each step. Rather than doing the LLM model of “just train on a million hours of video”
yes, lots of specialized models doing one thing
Image and text generation are much more atomic problems than video generation. It makes more sense to break video down
kinda like ONE NODE PER FUNCTION

Sure, I just think it’s going to look a lot different than SD. I wouldn’t expect a “feed a prompt, get a video” setup in the next 2-3 years. The training alone requires 24x the data. So “are there going to be generative video AI tools” in 2-3 years, yes. Will it follow the training/prompt model of SD/DalleE/GPT… yeah I just don’t see it in that time frame
how long until text to feature-length film models?
I'm guessing the only real barrier will be resource usage
If you’re talking about adding AI to existing workflows?
given where we were at a year ago, I'd say give it another year. lol
I think 2-3 years we’ll see something crappy
doubt it'll be the sort of thing that can be done on a PC any time soon, but there will surely be subscription services for it
I just think the trick is training blender to build a scene to spec more than it is teaching a generative model to “make video”
Given what adobe has on deck in photoshop, etc, I don’t think “Create a scene with the following parameters and animate it in a cinematic style” is far off, and IMO could be done on a desktop.
Other than the rendering which would still require a farm
now we are all artist
Yeah I’ll move myself over to #philosophy for that one heh


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

valuable information https://www.libhunt.com/compare-ComfyUI-vs-LoRA
14 seconds at 1024x1024 with that model and square resolution

nice progress
did you use my latest AIT workflow? it should work with any AR
yeah, i just dropped in your image and changed res
does drag and drop with comfyui images not work anymore.. I cant get it to work from discord anymore
@trim orbit can I dm you
the image should contain the metadata
anyone uses linux?
@indigo carbon can you send me the link for the model you use?
yeah, that should do it. it calculates what resolution it should downscale to after upscaling 4x. this way all you need to set is empty latent image to the desired AR (both x and y values should add up to about 1 megapixel)
lol, added in a image2image node to your workflow at .9 denoise, 4 seconds


it's not meant for I2I, its built for T2I, but it seems you inferred it properly

honestly dont know what i'm doing but seems to work lol
denoise .75, back up to 12 sec

life with SD in general 😎
which is weird, i thought it was the other way around, less noise for i2i = faster render right?
that's one way to do it. if you guys want I can make an I2I version. but yeah, you used it correctly here
go for it, i like your workflow decisions
denoise strength is different from more/less noise
i had fun playing with this setting with controlnet tile and bumping the denoise str up on some samplers

didnt make too much of a difference either way tho
i like that model so far, much clearer than base
same, tbh my favorite XL model yet


which xl model?
crystalclear
What do you guys think is the current best inpainting model for SDXL especially related to photorealism?
1.5 model (obviously) 🙂
Can't SDXL itself do inpainting? if it can, why would you use 1.5 when SDXL is a waaay better model?
SDXL can be used for inpainting though I do see some artifacts around the subject after running img2img.