#✨|sdxl
1 messages · Page 78 of 1
No, it wasn't a waste of my time, it was a waste of time for everybody who took the time to help me
uuh, I didn't want to make a "I told you so" out of it X_x
It's very unfortunate that it worked out this way, I was really hoping that I would get some good captions from this, but this is honestly worse than swinv2 tagger that runs over a hundred images in the time that it takes this to process one
I mean, it definitely shifts a caption more into the visual style of the image
although the captions are bad. You can try that if you use them as prompt
why even bring it there then? no one else did until just now. shuuuuu i'm so tilted. oh well. i'm very discouraged and don't know why caith says its good now
Should the LoRA be applied to the Refiner pass?
no
whose right. this experienced fellow saying he has success, or this other experienced fellow walking sytan thoruhg it to failure
I'm not sure why he says it's so good either, it's very slow, and I think the results speak for themselves, and they're not very kind
because you act as I did said it
"and they're not very kind" <-----
Clip Interrogator always insults me. Thats why I hate it 😜
theres just always such a cross fire of information. especially in the cases where people have success and then others say "no thats wrong". hard to tell whats accurate so i guess why bother. i'll just keep experimenting on my own and keep it to myself.
I mean, thats fine, and the way to go anyways. Cause whats theoretical right and what works in practice might be very different things
I know I can be a smartass quite often 💩 But I don't want to tell you what to do or blame anyone for anything. I just thought it could be interesting for anyone if I explain why clip interrogation gives so strange results back 🤷 oh, and English is not my mother tongue, so I just sometimes say garbage cause I'm not a native speaker
i also hate when you see people like caith having success with an appraoch, and someone demonstrates one bad result and dunks on the entire situation. i'm not into the single result conclusions ever. caith seems to have experience with it that works is all i've noticed. that seems factual to me
a single bad result doesn't seem to determine its not worth it
might indicate a bad configuration
I mean, you will never get good captions with clip interrogation
they will always look horrible
the question is if you can train with them
maybe caith has good success training with horrible captions
how do you think captioning is done for the base model. i really don't follow your jedi mind tricks here
they use the LAION captions
laion doesn't hand caption the set
they used the alt tag in the images
however, pseudo once said they are using BLIP now
so maybe the images are BLIP captioned
I believe that was what I saw as well
I am just really confused, because I thought a very good clip model would have produced much better captions, because I use a very lightweight and fast auto tagger (Swinv2) and it does very good in fractions of a second per image
but BLIP is also sometimes really bad ;_; It gives me a lot of advertisement stuff very often. Like whenever there is an image of a blond guy with green clothes I get "Zelda - The windwaker"
maybe they are even better in clip space
I need to see if I can bother pseudo and figure out what captioner he uses, because his captions were really good last I remember
but just one thing
this was an old DnD character of mine:

when I use CLIP interrogation I get back:
I used AI to generate my really strong and beefy black tiger to back seat,
arafed image of a man in a dark coat holding a wand, bussiere rutkowski andreas rocha, blacksmith, with a full black beard, thin young male alchemist, mace and shield, sqare-jawed in medieval clothing, lord of cinder, realistic fantasy illustration, scientist, fantasy alchemist laboratory, high quality dnd illustration, hecate, brown cloak
which is REALLY bad
No way in hell voice typing just said two back seat instead of tabaxi lmao
however, if I use that and add the word "fat" to it and use CLIP Interrogation for the negative prompt, too
I get

which in my opinion is pretty close
for a prompt that is soo totally off
i see
so Caith is definitely right when he says it works
it works if you want to recreate an image
the question is just if you want to train on these strange captions
I would intuitively say that its better to train on simple but precise captions, so that the model learns how to make the images I want from the natural captions I provide
the theory is is that the model it's trained on is best for captioning, since it speaks the same dialect. thats why they're potentially good captions because they tie to what the latent spaces know more accurately. despite looking inaccurate for human purposes
research required
the funny thing though is that the captions SDXL is trained on are the much simpler ones. Its never trained on these clip captions
the text encoder, however, is
this makes sense to me
which seem to have a similar effect
it has a level of truthiness to it, because sometimes i'm a wordsmith, but trust that it's not based in much tangible evidence
but just think about this: if you want to train a model on a celibrity, you do not want to add a description of the celibrity to the training prompts
you want that the model just learns from the name of the celibrity how to draw him
when i'm training people, i leave the descriptoin of the person very sparse. "name class" thats it
everything else gets captioned
however, if I want to draw an celibrity without training the model, then using clip interrogation makes sense to get as close as posible
yeah, but I think this is not just true for people, but for other training concepts as well
but training is such a huge topic. Hard to say what works best and what not
and it seems to be different for each concept you train on anyways
I was looking at all the checkpoints saved of the LoRA I tried to make, and one of them had 0.0253 loss. I think that one actually works (Yes, it's intended to be super pixelated stuff, it's trained on upscaled 64x96 sprites)

And it doesn't need that crazy weight 4 to have some effect
and you trained it on cpu? crazy ^^
I'm glad I bought the extended warranty for my laptop
cpu trained on a laptop
cpu training on a dual core (apu) laptop
how does it work?

id suggest trying out more capable workflow
ive enjoyed using Sytans
there are good tutorials on youtube as well
each node is a little script/process. they wire together like a sequence. queing up a prompt makes it all execute that sequence
you'll want to set your width and height to 1024x1024 at least. other workflows like sytan's preconfigure all of that

Since we have released stable diffusion SDXL to the world, I might as well show you how to get the most from the models as this is the same workflow I use on a daily basis at stability.ai. In this video I show you some of the basics on how to get the model from the models to generate your best AI artwork from our models. You will need some of ...
i liked this video when i started out
could also start at episode 1
yeah, width and height have to be 1024 to work well with sdxl
With LoRA you can do 512x512 but it's not really worth it.
i watched this video after i had fiddled a bit with sytans and a few other's workflows. it really helped me level up my understanding of whats going on
is this a good youtube title : Become A Master Of Kohya SS For LoRA Training From 0 To Hero - How To Install - Find Best Checkpoint
Sytan's Corgi with and without LoRA at 512x512. But given that my 512x512 generation speed with SDXL is much slower than 1.5 there doesn't seem to be any real use to generating in this resolution.

What would be the effect of using twice as many reg imgs as training imgs for a face? vs. using the same amount.
No, it feels way too clickbaity and seems to promise more than you can probably deliver.
tutorial is 85 minutes
fully edited
alternative title Become A Master Of SDXL Training With Kohya SS LoRAs - Combine Power Of Automatic1111 & SDXL LoRAs
id click it
editing took my 3 days :/
90 minutes tutorial? How long if it was a written web page instead?
i can tell you transcription lenght after export completed
by the way making written page is worthless. chatgpt will grab it make money, google will grab it make money, you get nothing 🙂
So that's why I have to watch a 90 minute video instead of read 5 pages in 10 minutes? For money? 😕
well i dont have any other revenue
this is also future be prepared to it. web pages will die
or will get behind a paywall
It's not just you. It's everyone.
But following videos often takes much more time and effort than simply reading an instruction.
correct
hey, i like videos because i dont like reading.
nice to hear that
id rather watch a video on a paper than reading one. lmao. call me lazy but having add/adhd i cant read for shit lol Edit: unless its technical. i can read technical stuff
sometimes i also prefer video
preparing very detailed and good graphical reading really hard
testing @delicate kelp's upcoming new SDXL model ProtoVision XL



video much easier
looks good! love the style
SCG always has great stuff

i wish i knew the secrets to making good models. lol. but i have a feeling some of the best models are the ones of merged a bunch into 1 good model
i plan to make a tutorial about general fine tuning
ofc for a good model you would need a lot of images and computation power
anyone wanna do a fun game of vote :P, which one is better





Made a setup to generate supporting terms from the initial prompts with GPT

by the way i spent huge time and put very detailed chapters to my all videos with corrected subtitles
looks nice!
1 or 2. It kind of depends if you prefer glasses or not. Though based on background I say 1.
Regularization is confusing. @somber hill I saw you asked about this in kohya issues so maybe you have an answer.
If my img folder "20_ronald" has the same # of imgs as my reg folder "1_man", then the reg images are repeated once PER training image so its actually the same amount of images in terms of steps.
BUT if i put way more images into reg folder and keep "1_man" title, training still goes for the same amount of steps. So theoretically if I put 400 images into reg rather than 20, there would be one unique image per training image, rather than 20 images repeated 20 times.
Correct?
lmao 1 is base sdxl
it pre fetches number of class images based on repeating count
so if you have 10 repeating and 20 images it will fetch 200 class images from folder
cache them and use them
no matter how many epochs you train
i hope he improves this logic because this is very restrictive
depends what aspects are important here.
A for overall composition
B for overall character style vibe
D for face (but shoulders are a bit stretched...)
E would be my favorite, but it looks a tad squished
ooops I was looking at the wrong image number. I mean 5 the last pic
So my reg folder should always be hundreds of images if I want one unique reg img per training img repeat?
And would that have any benefit over just matching the training img count and letting them repeat?
interesting, thanks for the input friends, E- would be my MoviestillXL Lora and CineJugg Merge
someone send me the workflow?
I was gonna say E but was too slow
I don't use reg images and I never have any issues. But I'm not in the habit of making LoRA models of my face so maybe it's needed there.
It helps a ton with detail coherence and variety in outfits & lighting & environment
photo B was williamegg Lora

no one can send me one of those organized right?
if you have 10 images and 10 repeat yes
you need to have multiplication of those
but still this isnt a good logic
what if i am gonna do 200 epochs training? in each epoch i should be able to set a unique class image for each image
but it is impossible atm
only way is setting repeat 200. but then you cant have frequent checkpoint saving
to compare later
im using a bunch of extensions that takes a little setup beforehand so dont think i can give it to you atm
You can save every step if you so want.

but.. if i only have 10 reg images it still trains for the same # of steps as if i had 200 reg imgs. doesnt that mean the 10 are repeating to make up the difference? and how is that any worse than having 200?
as i am still wondering how "good" captions look like (especially for person/faces)...is this caption completely bad or just the ones following after "a woman sitting under a palm tree with her hand on her head"? what would be a good caption for that image in your opinion?
it saves checkpoints?
now this can be used if so
but still
it may not work
if repeating logic is like this
it repeats same image
then moves next image
do you know logic?
it uses same image in other epochs too
so it will always use same class images
thus reduced generalization with prior loss
even for 1 epoch this is the case. I just dont know why i should put hundreds in reg vs. the same amnt as training imgs
it trains for the same steps
i dont think we are on the same page
Hello, i just installed comfyUI with sdxl and i want to know how i can upscale an image with sdlx
or do i need to download a whole new model for that?
@soft bone the logic is using as many as possible different class images at every step
so that we keep generalization of model maximum


so a 200img reg folder gives more regularization than a 20img reg folder? even tho training steps are the same?
assuming my training folder is 16 imgs and 20 repeats
I ask because I know for a fact that most people are using reg folders with the same amount of imgs as img folder. Rentry tutorials even explicitly say to do this. So I guess they're all doing it wrong
I used the VIT-H-14 to caption my images and it put this 🛸🌈👩🾠in my caption file
I find that you don't really need to do much to get generalization with a LoRA.
Comparision with a single-image LoRA without any reg-images and no LoRA.

it depends on repeating count
quality low 😄
assume 20 repeats, 16 imgs. why should reg have more than 16?
if you have 16 reg it will have 1 class image for each image
if you have 320 it will have 20 class image for each image
if you have 3200 it will still use 20 class image for each image
this is my best realims level but it is with sd 1.5 realistic vision v 2


Is there a good dataset for a character (e.g. a celebrity) with good captions out there I can use? Or does anyone have one they can send me? I am new to Lora training and want to have a solid first set to experiment with
Please guys, can someone send me a workflow, realistic, I really need it

Dreambooth is the best training method for Stable Diffusion. In this tutorial, I show how to install the Dreambooth extension of Automatic1111 Web UI from scratch. Additionally, I demonstrate my months of work on the realism workflow, which enables you to produce studio-quality images of yourself through #Dreambooth training. Furthermore, I shar...
I used the 460x460 image on your github so that's to be expected.
/salutes General Ization
Sure you will get better results if you have several high res images of your subject, but you can get far with just one low res image too.
@somber hill This logic is a difficult discussion over text lol.
Here's what I know. I know for a fact that most people are using "reg" folders with the same amount of images as their "img" folder, regardless of repeats or epochs. Rentry tutorials even explicitly say to do this. You're saying you don't do this, that you instead have hundreds in your "reg" folder and less than that in your "img" folder.
Since everyone is doing it differently, you should make a video on it
well it depends on used script
with kohya no matter how many you put it will use repeating count per training
with dreambooth extension it will use up to 100 totally up to you to set
with other scripts i dont know their working logic
i offered a simple solution here if it that get added will be much easier to explain : https://github.com/kohya-ss/sd-scripts/issues/640

GitHub
I am a software engineer so if you can explain the logic I would appreciate that very much This is super important for me to understand What I want to achieve is, for every training image, using 10...
Thanks for doing all your work and very detailed videos! Really great. Always learning something.
when it comes to regularization images, if using hundreds is better than using 15 (or however many training imgs they have), people would like to know, because they're all using 15, because that's what they were told to use.
Huh, I always heard to use hundreds / thousands of reg images for prior preservation, or something like 15x the number of training images
this is or at least was the #1 tutorial forum, in a kohya lora guide. not only do they say to match the image count, they even say to match filename (which i know is false). and before i saw this I saw others doing the same in finetune channel

Test things and not just take everything as gospel. Training SDXL and 1.5 also seems to be different so what's work for one might not work for the other.
normally thats what I do and I did try but the training doesnt display that logic or say how many reg images are used or repeated. I just dont know if the extras are being used or if having not enough makes it repeat to make up for it, and I can't see that info in outputs.
Are you supposed to put the trigger word in the reg image captions too? That's what I've been doing

i wanna smoke now
i dont think so but that's what it sounds like they're saying in that screenshot
here a good explanation about ground truth imagesd
i covered this in my new coming tutorial hopefully
facial restore is not good for side view
cleaned up my workflow:
https://i.imgur.com/lAUUsRG.png
Facial restore is not really needed, just use inpainting instead.

i just had in n out for dinner
would be a great poster or t-shirt
poster vibe
do you guys like having a do it all workflow or multiple smaller workflows for specialized tasks
Multiple. One for text2txt and one for img2img in Auto1111.
All in the same screen more spaghetti the better
One for image generation, one for upscaling.
how do you manage that, ctrl+b the nodes you dont use?
Yes. You just need to deactivate the key nodes
or the reroute
I'm really confused, I haven't done prior preservation in a while but isn't it just training normal images to keep the model from overfitting to your data?

yes exactly. but how the repeat logic of kohya interacts with reg image count in the context of training image count is yet to be explained. yes you can use 5 reg images or you can use 5000, but it somehow doesnt change training time, training steps, or quality (that anyone has demonstrated)
The link SECources linked explained it. If you use more reg images than training images then they're not being used.
But the best way to avoid overtraining is to train for fewer steps.
What I'm confused is why not just use your own reg images and train them normally alongside your training images? Kohya already lets you use multiple folders with different number of repeats so you could just do it that way
yes but thats the case AFTER repeats have taken affect. so theres not one reg per 20 training images, theres one reg per every repeat of every training image (400). meaning 400 reg would be better than 20 reg if you have 20 training images at 20 repeats.
yeah you could but kohya has a directory system that automatically creates the reg folder and then doesnt explain how its being used
I honestly feel like Kohya is overengineered in general
Yes, if you creates repeats of your training images it will use more of the reg images, I don't see the issue. If you do not want this than do not repeat your training images.
how do you know "it will use more of the reg images"? it doesnt say that anywhere.
you just said that if theres more reg than training then theyre not used. now you say if theres more training then reg then more reg will be used.
those are opposites, how do you know thats the case?
If you have more reg images than training images you can use repeat for the training images to use more of the reg images.
increase LR too if your dataset is more than 100
everyone is using the same # of img in both folders. so they're all misled if what you say is true. They could be using [img * repeats] amount of reg for best preservation.
If you only lower steps, itll be undertrained
Naturally existence of reg is for model to retain some concept after training
I personally have no problems with overfitting or regularization, I'm just getting pissed that the guides and tutorials have apparently been wrong, and maybe I can clear it up for readers.
What is the point reg images > train images?
cuz training images get repeated
thats good
Yes, if you have the same number of images in your training folder and your reg folder than you do not need to use repeats.
right, they're doing it with "20_img", so they're doing it wrong.
I use zero reg images per training image and that works for me, I'm just stating what was explained to SECources by Kohya.
The same point you would want to train a lot of varied images for a base model
Why do a small amount of reg images repeating instead of a wide variety of images if you have the choice
Thats the limit of model
You need to collect those reg images or generate them and I'm lazy. So I choose zero.
In fact, the single best face lora I have seen in this channel used "20_img", "1_reg", same number of images in each.
you cant retain everything when the size is limited
Did you see a comparision with and without the 20 repeats?
no. you think 1 would be better?
Why not try your best? Theres literally no reason not to use more reg images with 1 repeat as opposed to a small amount of reg images with many repeats
Unless you're lazy or have some high quality reg images rather than auto generated ones
I'm saying that based on the explanation from Kohya-ss then 1 repeat and 20 epoch should be the same as 20 repeats and 1 epoch.
first try to add an img2img option to my workflow:
https://i.imgur.com/ofUEXd4.png
https://i.imgur.com/oyhjeYA.jpg
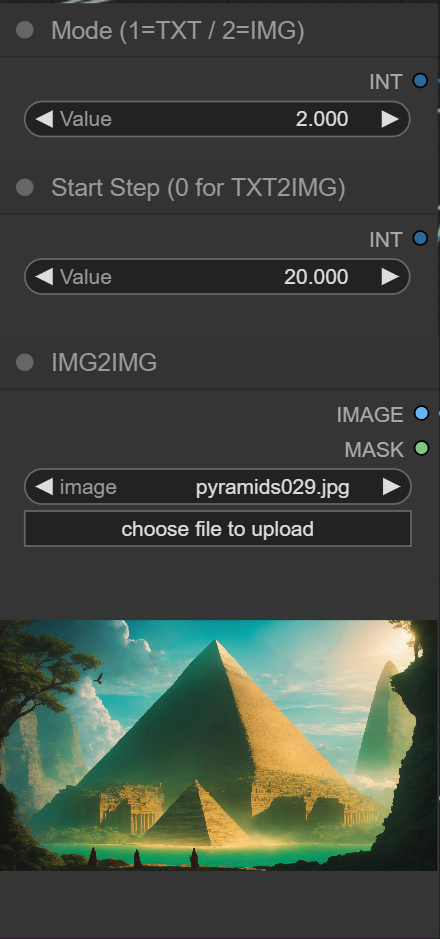

agreed, but then people like SEcourses are using thousands of reg for only 20 training imgs, which wouldnt be possible without repeats. guess I'll do an exaggerated comparison and see
i would like to see comparison too
Yes in that case you need to use repeats but if you have the same number of images in each then it doesn't seem like you need any repeats.
@visual glade hey what do u think about this? just a thought i had that probably others also had. but i just wanted to know if it would be theoretically possible🤔 splitting models into many parts "We are able to split models in half and generate the first part on one PC, then transfer the activation and generate the rest of the model on another PC. If we only have one PC, we could offload the unused part into system RAM. However, let's imagine that our model is so large that this approach is not feasible, or we simply don't have enough space in system RAM. Instead, we could read the current model part from storage. This would slow the process down , but at least the model would be able to run regardless. In the future, models will become much larger, necessitating more system/V RAM. If we consider NVMe storage, the model part switching could become quite fast. With PCIe Gen 4, we can read at 7GB/s, meaning we can transfer almost 24 GB of data into VRAM in just 3 seconds. With PCIe Gen 5, we will achieve double that speed. Additionally, NVMe drives are much easier to upgrade than GPU / VRAM. And if the CPU becomes a bottleneck, we might be able to utilize direct storage technology to load the model even faster into VRAM, bypassing the CPU. what do u think about that?"
thats true. and I'm getting great results rn with repeats using same # reg, but if using thousands actually helps that would be crazy.
If you're getting great results with using the same number of reg images then it's just a waste of time to do 1000s.
meh, already have the database. plus I'm gonna be using this in my business its not just personal use
so i try anything that might improve quality

Does it means if I have 100 images, I should use half of it as training set and the other half should be the reg images?
in 1 repeat
apparently the training doesnt know the difference between reg and training images. it all gets trained the same
so that shouldnt do anything
I'm using real photos in my reg folder, with random filenames (dont know if thats bad)
It is the folder names that matters with Kohya-ss and not the filenames.
hmm kohya combines your instance and class tokens in the folder name. so really there's no difference between those either, and "man" is just as much the subject's token as "ronald" is.
Yes, I'm not even preparing my folders in Kohya-ss as it's simpler to do it manually.
Do the folder names matter other than the number of repeats?
i just wonder why they set things up the way they do if it really means nothing. why append the class token to the img folder name? i want answers 
The folder names matter as that's the caption for the images you're using.
Unless you're using caption files then I think the folder names get prepended to each caption.
Wtf does it really?
Well I'm using the full tinetune which behaves differently I think, for some dumb reason
Idk what the dev was thinking
If your folder name is "1_photo of" and the caption for the image file is batman I think when training it is using the caption "photo of batman"
i dont think thats the case
how would I go about disabling the upscaling temporarily in comfyui? im using a template

but i also think it uses the filenames if captions arent present. i'll do some research
I would expect it would replace some sort of keyword like [foldername] in your captions
right-click, mode, never in that ksampler node
No, if you are not using caption files then it uses folder names and not filenames. I'm doing this all the time and it never uses the filenames.
If I do that the other ones in the list turn red boxes, do I have to do it to all the following ones?
If I use caption file, does the folder name append/replace my caption?
There's no problem with red boxes, unless is something that makes the workflow incomplete
I'm pretty sure the folder names is added to the start.
I see, generating stuff still works, thank you for the help, works perfect now
Everyone I've seen has been using the pre-fix when captioning to append the instance token to the caption. You say the foldername does this too, so they've been training on double tokens??
i wonder what that does to quality
Depends if they even named their folders something good or just "images" lol
Give me a minute and I'll test.
i use ctrl+b, dont know if thats the same
cool, will remember that to enable/disable stuff faster, ty
assuming they use kohya dataset tool, it names the folder automatically to instance+class token
Personally I think they should just take images and captions and num of repeats and leave the preprocessing up to you
If like one image, just keep the same configuration (seed, steps, etc) and turn on the upscaled that it will resume from there.
kohya requires the folder be set up as #_subject class as part of it's configuration. each data set folder can then have individual configurations too. its quite flexible. if you're using text captions, you still need it to be set up that way afaik
Alright, now I'm actually a bit unsure how caption files and folder names interact.
In any case is it even better to put an actiavtion word at the beginning of the prompt? I am struggling to decide if I should since the artists name is fairly long but I still want to use it as my activation words to give the model a head start. Won't it be a bad thing to have so many tokens before my subject in a prompt?
i'm not sure what happens in the code or if you need those tokens in your captioning, but i always caption with the "subject class" leading the file
never seems to be an issue
especially when you train a lora without class images, they'll lean hard to your subject regardless of a token or not.
what matters most is that your token seems to be the main subject of the prompt.
If you are training an artists style it is best to use their name as the activation word if you want to give the model a head start though
another try with img2img comfy workflow:
https://i.imgur.com/iBoFKN4.jpg
"highly detailed dslr frontal closeup head and shoulder portrait of a beautiful woman in front of a pyramid hit by lightning, cloudy skies, rain, enclosed by trees on both side in front"

exactly. everyone tells me something different.
Kohya-ss lists the folder name as class tokens when training so it is at least using that for training.
I think I've at least deduced that image filenames never matter in any circumstance
training will either use txt file or folder name. never filename
Yes that's right, filename is never used apart from connecting images to it's caption files.
It was convenient when filenames were used as captions though
They should make that an option again
yes. i still do it by habit. i miss dreambooth
Hey lads, to confirm is there still issues, should I be using this base https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main
and 0.9 refiner?

who told you you needed to use 0.9 refiner?
must be the vae issue which was resolved and the current releases use the better vae
1.0base 1.0 refiner 0.9 vae or use the model stabiity put out with the 0.9 vae
somehow morphed into a conspiracy about only using 0.9 refiner
Coud you point me in the direction of the refiner, as I can't seem to fined it.
its on the same website.. lol https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0


they have the proper vae baked in now
since nobody was using the refiner in automatic then, he must've meant in comfy. which you can just wire the vae from the base model to where you need it.
anyone know how to train a sdxl refiner model using custom data?
not that i know of
Automatic now supports sdxl 1.0?
people building a huge mountain of this tiniest problem. like 2min into release the channel was brigaded by side servers that have so much spite for stability. the probelm was fixed and dealt with so fast. somehow it's still a perceived issue though.
main branch does but i use dev branch for extra features. refiner extension helps too
I read paper that refiner model used SDEdit tech, maybe the same way to train?
i only use auto now and then these days and prefer comfy
Prefer auto, its a pain in the ass developing for comfy.
we're still waiting on tools last i heard, but there is no indication that it can't be done
i haven't developed for either, but at a glance, they both look like pita systems because of the python venv nature of it all. maybe you just prefer gradio more
I don't see what python venv has to do with it, Compy doesn't give you an easily accessable api
hmm. i dont know about that. there's lots of projects that tie into comfy
hope come soon, because training refiner is really important in other area development like anime.
maybe you just prefer the pain in the ass you know and not the one you have to learn
Look at the tooling of auto compared to compy.
looks comparable to me
It's not but okay, thanks!
oh... okay. i haven't found an extension or system i haven't been able to get on comfy in some form
but i guess its not comparable
was wrong mb
🙄


flowwolf you still got me blocked? 😛


Y'all have issues with him? 😄
nah we got in an "argument" in the past. and he threatenedt to block me and i said do it lol. but i dont hold grudges so if he unblocks me thats cool too. he can just be a little be umm idk hes just flowwolf
One last question, if I clone the new auto repo, I can just toss the sdxl checkpoint in the models and have at it?
weird flex. regardless, tooling on comfy is fine and in many cases its more flexible towards a goal.
this is like showing off discord community numbers for how good a video game is
irrelevant metrics
Sure, but the whole convo was for what I prefered and why, and you told me I wasn't allowed to perfer it.
since this is turning into some highschool bullshit from childish people, i'm out.
I would suggest actually developing something on a platform before talking...
No it's not, if you were a developer you would know this.
-long sigh-
dial it back roddy rod
Don't try and start an argument if you don't want to finish it.
So many arguments in here lately
the fact that comfy has more functionality than a1111 with less contributors and commits means it has a better architecture
do you know if its possible to add some a1111 extensions to comfy like for example deforum?
or sd animation?
hasn't someone done that already?
the sd animation or sadtalker not yet
image viewer
🍿
love how easy it is to code up a custom node for comfy
same seed, 16 reg images vs. 30 reg images. only 16 training images. It has a big effect so I'm gonna try hundreds

Where to start? I couldn't find
In the custom nodes folder is an example file you can look at for an idea

GitHub
A powerful and modular stable diffusion GUI with a graph/nodes interface. - comfyanonymous/ComfyUI
whenever people talk about popularity contests in open sourced software mattering, i always reflect back on how popular openssl was when heartbleed dropped
I think that opened everyone's eyes to how can all these multi-billion dollar companies rely so much on open source code and not contribute anything back to the community. Definitely a big call for more funding to support open source projects after that

diabetes cat
fluffy
big chonker
well not everyones. as we witness with automatic1111 project experiencing the typical death by 1000 contributors, some people think popularity contests still matter
maybe im missing something but at some point having more contributors seems like a hindrance but im not a developer
just thinking of the too many cooks metaphor
its a double edged sword

wait. was that removed? I thought you could still do it via a command line XD
never tried it... so I must have missed that
Wasn't that just in the dreambooth extension?
other trainers that used kohya in background still support this, so I just assumed that it was a command line thing, and never questioned it
but could be they reintroduced that capability
@boreal bough says no
wait what?
I heard you said no 
umm...
captions in the regularization folders work well
but without it also works
both options have their positives and negatives
he said he's been putting instance token in reg captions
the same token as training imgs
Why would you do that
at least for big datasets you really profit from captions in regularization folder.
for smaller datasets, it might have a reverse effect though - as it will reinforce concepts that it doesnt have enough images to properly do.
I think they did too much abstraction for training, it should really just take images and captions
People dont seem to understand the basics
I'm using ground truth reg with no captions for small training datasets. working well
unless you're training faces specifically, you really dont need regularization images
oh shit. I misread that! XD sry.
I read 'captions', not instance token
it definitely helps for faces on 15-25 imgs. made broken details coherent too
I mean images in general, reg or training
yeah no. never put instance token in regularization images
I misread that earlier, sry
no worries lol i could tell you meant captions.
I was doing that, putting the instance token in the reg images. maybe why my model is hit and miss
You're watering down the concept you're trying to learn by captioning reg images and training images the same.
I dont understand why there arent reg folders for people to just download, why is everyone making their own?
It would be nice if we could all share a high quality captioned 10k images or so
SEcourses has some on patreon
theres also face detection ai datasets but youd have to crop and resize them all
I do see that my single image face Lora has some issues, but main culprit is probably lack of training images and I don't care enough about face LoRA to really test things out. See if you can recognize this.

I'm pretty sure anyone can upload data sets to Hugging Face. Someone just needs to do it.
90% of the work in AI is creating the data set.
Are they auto generated? Might as well use real training data
With real captions and stuff
they are real photos. ground truth seems to be the best with XL, despite dataset size
Yeah it would be nice to have folders with art, anime, etc as well but maybe thats asking too much
You could absolutely sell that if you made it yourself
I do this for my real big datasets. but there I stop using regularization folders, and instead include specific subsets as additional training folders
for smaller training attempts, this is totally overkill though
If you're going to teach the model completely new things then training images and ground truth is the same thing.







If you're not doing faces, try out smaller more concise datasets without reg images and it might work a lot better than you think.
he look like he mad hyped for ai

checkmate artists

Thoughts on why I would be getting some pretty bad results?

is. is that the full image..
Why does it look like a Far cry 3 screenshot when i close my eyes a bit?



I used to date a girl with hands like that
Is there some magical negatives I'm missing?
let him cook 🔥
hands you say?
use, painting, artistic in the negatives, photographic in the positive if your looking for realism
also 1024x1024
Looking for that style, but just correct, also 1024 was doing, 👍🏿 hmmmm
Been having really good luck with widescreen output ratios too
See anyting wrong?


id say your using too many terms and negatives, you dont really need all that, also if your using 1.0 you need more steps
agreed
How many tokens for positive and negatives would you reccomend?
my step count


Wanted to follow this but they didn't cover the compy:https://aituts.com/sdxl/

On July 22, 2033, StabilityAI released the highly anticipated SDXL v1.0, just a week after the release of the SDXL testing version, v0.9. The 2 most popular ways to run SDXL locally (on your own computer) are: In this guide, we'll show you how to use the SDXL v1.0 base and refiner models with AUTOMATIC1111's ... Read more


Is tat workflow public?
my workflow is not public no. nor do i recommend it lmao
are you looking for something like this?

worse:

similar yes
prompt:"primitive dirty cavewoman portrait, by daniel f Gerhartz, sitting on a rock"
Negative: bad image, blurry, ugly face, Black and white image, bright image


thats a nice one


member when ppl said 12 steps was good enough
now 30 or 60 is the recommended amount?? lmao
when did people say 12 was good?
it really depends on what you're going for I think
cant wait for SDXXXL 180 steps
I want to go the full 10,000 steps like the max in the advanced sampler

@boreal bough Training on base XL and inference on finetune, vs training and inference on finetune?
LAST question for the day, suggestions on one person in a portriat?

what sort of suggestions are you looking for?
Only one person
Not multiple faces
I mean, put portrait in the positive? "multiple people" in the negative. you can go on. "single person" "solo person" etc until it works I guess. there isn't a set formula
Was hoping there was a term you all figured out for these concept art type moodboards.
there isn't a universal term for anything really. there are so many variables involved
solo,portrait,1girl,
#boorulife
I get that, but there's still rules 😄
are there?
clip only finetune on all booru tags would be funny XD
bit of an expensive experiment... but funny nonetheless
Why you getting all philosophy on me? ;D
someone told me that the booru thing is a rabbit hole. haven't really went down that yet. but maybe one of these days
is this asking about samples during training, or did I misunderstand that?
well just try out identical settings, but start cutting the final layers and see how it changes with each layer
it'll be totally different things each time.
not samples, just in general. do you like to train on the same model you're gonna use for inference? in the past I always train on the base and then switch to a finetune for inference
ahhhh
makes a lot more sense now
for sdxl, odds are high we won't be having many 'true' finetunes - as making them will be a significant investment, that won't make much sense for any single person
what most are doing right now, is just making a lora and merging it XD
which... yeah. they missed the point
the only time I'd recommend merging a lora, is for using that as a training base as you mentioned, which then creates ideal support for dual loading those loras, both at 1 strength
rn I'm using dreamshaper which I'm sure is somewhat proper finetune (they used their 0.9 params). for inference it is excellent for portraits
so if you finetune you can essentially subract the original model and turn the finetuning data into a lora right?
if you want to make a dreamshaper lora, then training it on that directly will give the best results. (parameters will prob change, depending on what you're training)
depends on a lot. for a 'true' finetune, nop. as the difference will be the whole model - resulting in a lora as big as base XD
interesting. will test
ahh. well I always used the dreambooth method, so I guess that's a bit different. and never really on any major concepts, just people mostly
I miss training styles. it was so much easier
Is it just me or is the re already more "custom" models on Civitai for SDXL than there is for 2.1 ?
correct
I never exactly had anything against 2.1, but it didn't have all the cool stuff that 1.5 had
as a downloader of every single 2.1 finetune ever made
surely this is a "good thing" 🙂
so many 1.5 accessories
is there a node in comfyUI that allows me to "pull" text from a textfile into a comfyUI-node ?
and one that allows me to "push" a message out of comfyUI into a textfile ?
yes
saveTextToFile _O
"Load Text File"
not sure where those came from, but I'm sure you can figure it out if you search around a bit
while my high effort lora isn't idiotproof yet XD with longer more complex prompting it already matches some of the 'finetunes'

it also learned all 100+ concepts
but I will make the damn thing work with 5 word prompts with 0 negatives 🤣
orly?
I prefer the long prompt models. it's cool to be able to type in 3 words and make magic, but no control then
I feel the same
I'm doing it as bias free as I can pull off - so longer prompts give even more control than before, but my goal is to make low effort prompts work as well
nice. well that's ideal then
I like to start off with something short, then build
deliberate was good for that
but a few words would probably get your prompt in a white room or something
trying to use random civitai prompts XD but oh god those prompts are all horny
there are some absolutely ridiculous loras on there
in good and bad ways
the things people take the time to make. I'm both impressed and appalled
tracer cosplay in a forest
also 'girl' no longer generates 4~10year olds x_x
will still need about 10h longer trainining until all the age groups finally converge

"a portrait of a pretty young French Girl" with analog Film,3D model & enhance filters applied.
Not sure which order these are in (until I look back lol) but these are *and should be in this order but who knows)
SDXL1 vanilla
Runsdiffusion_XL_Beta
dreamshaperXL10_alpha
*the model names are inthe filenames if viewing in a browser



nice. that's a lot of words there
just dont search for the vaporeon lora
well you know I won't be able to stop myself now

running base only+lora / one single sampler node only (no upscale shenanigans)
so I had to merge your prompt a bit XD (on my typical seed of '2', so I'm not cherrypicking)
Positive: a portrait of a pretty young french girl, intricate detail, modern, 16k, digital art, artstation, cinematic lighting, vivid, professional 3d model analog film photo, a portrait of a pretty young french girl, faded film, desaturated, 35mm photo, grainy, vignette, vintage, Kodachrome, Lomography, stained, highly detailed, found footage . octane render, highly detailed, volumetric, dramatic lighting
Negative: ugly, deformed, noisy, low poly, blurry, painting, painting, drawing, illustration, glitch, deformed, mutated, cross-eyed, ugly, disfigured, ugly,deformed, misshapen

everyone needs the lora that made this

combine that with the squidward lora
oh god I was not prepared for that... wood
Its not a lot of words I put in lol

XD
lots of steroid members
offtopic. but if you ever do nsfw stuff training - 'naked' is the right word you'll usually want. 'nude' has a different meaning (just cause I keep seeing this in prompts) - unless you completely retrain the clip model, which yeah. good luck XD
nice. maybe I need to start using those tools. is this customized stuff on your end or are they from a node pack?
speaking of nsfw i wonder why is there almost no gore loras and models
some of the nsfw lora trainers on civitai should feel bad about themselves for what they've created
lack of datasets?
just a lot of effort to make
man, I found one that is "underwater" but just looks they're dead
i also found one but its just looks like some manequins with bones and ketchup
I wonder if any of the loras or models have some messed up easter eggs
dont type this prompt at 3am gone wrong
If you load one of my images into ComfyUI its all in the workflow.
So taking a helicopter view over in the far LH corner I have the Custom Nodes I used listed

oh yeah, I like to forget I can do that
thats n age thing usually lol
before/after lora
so yeah. my female body lora is not amused by big muscle guys 🤣
not sure what I was expecting... but... FOR SCIENCE


meanwhile I'm making weird crap like this 

Thats so freaking cool

double exposure ❤️
nice, my immediate reaction was "john lennon mixed with Roger Daltrey and a hint f the Galagher brothers"
I make some wacky spaghetti abominations
Hey, question. Is it because I have only 8gb of vram that sdxl takes 15-20 minutes to generate images? I would have to have a better gpu if I wanted it to be faster?
Lol minutes not seconds
vram overflow. it should take like 12~40 seconds on your system
Really?
oh booohoo 15-20 seconds
(my 1080Ti with 11Gb is more like 180 seconds, its not the VRAM that affects seed so much as the chip architectire, Im guessing you have a 30 or 40 series card)
Nope I have a gtx 1080
try the tiled vae node. easiest first thing to try out if it fixes everything
i really should run with upscaling
unless you're on A1111, in which case that makes sense. move to comfy for quick generation
Oh I am in A1111 actually
I have 6gb vram, lol. but I get around 1.75 iterations per second. slow, but not that slow
normal for a1111 code
the time you're seeing is for cpu only
you dont need any gpu at all for that speed XD
comfy isn't as hard as people make it out to be
you can literally just load workflows from images you drag in

The prompt must include: gh3aBest settings:weight: 0.8-1sampling steps: 25-32sampling method: DPM++ SDE KARRAS or Euler ACFG Scale: 7-9THANKSBahasa Indonesia...
Oh ok, sounds better? Just got the urge today to try sd again and try the new stuff, I haven't been keeping up with much, only tried it at the beginning of the year when it blew up. I will definitely try comfy.
1st no lora, last with lora fully loaded. (inbetween are partially loaded)
vertical is just 4 different seeds
(prompt asked for a 'young french girl' - which is why my endresult looks younger, as my age groups work better than base XL)

not an ideal prompt - but this is more of a real use case by random people
there will be a bit of a learning curve if you want to start using all the nodes, but there are a bunch of people that upload workflows to various places
Im sorry but I cant see how @brittle crater is generating a (lets assume) 1024 x 1024 image using an SDXL model in only 15-20 seconds on a 1080.
Im running a 1080Ti 11Gb in comfyui using the defauly nvidia_gpu start bat and E2E time using my standard 3 pass method (no idea how A1111 does it) takes to complete a "standard" 1024x1024 image is ~80 seconds


well he did say minutes
corrected to minutes
did he?
that's what it says
even on base only, with no additional sampler nodes?
@brittle crater I apologise. My 59 year old eyes havent had enough caffeine this morning lol
I could do a 12 step image in 20 seconds. maybe
not tried on Base Only, I 'm happy with the output and the speeds I'm getting, I have parience (and I also missed the OP in this case was using minutes rather than seconds lol)
just did a quick and dirty check a one pass base only is a shade under 60 seconds
40/40 [01:17<00:00, 1.93s/it]
which is about right IMHO for the generation of card I'm running
can't really complain with 6gb of vram I guess

only thing that takes forever is loading models since I have them stored on an external drive due to space issues. but I'm going to clear out a bunch of space and at least have the models I'm loading on my ssd
if you're using conmfy that should only be the intiial load as after that Comfy holds them in System RAM for quicker access. You can configure A1111 to do something similar (I uused to befor eI moved them to an NVME)
always accomodate the Lowest Common Denominator 🙂
is there a way to have it store more than a couple models in my vram? because it seems to only store base and refiner normally
so if I switch the base model it always takes FOREVER. and I have 64gb of ram so I think it'll be alright to store multiple in there
in COmfy? DOnt think so , I knwo in A1111 you can configure it to store the last X models in system RAM.
Absolutely no problem, in fact I made a mistake in the first place and wrote seconds instead of minutes so you are more than forgiven. Anyway that confirms me that my generation times are too high. I will try comfy when I can.
I also run 64GB of ram and currently using 73% of it lol

that poor little 6gb 3060 always working so hard, lol

it's this guy again


thats whilst running base sampler
lol. trying out random dreamshaper prompts on my lora is funny XD



that looks a little like Jeri Ryan. "If the Borg were eco warriors"
nope that snormal for me, all water cooled
im guessing she lkes butterflys
nice. well mine goes up to 85 C sometimes, 🔥

I dont recall seeing my GPU going above 40c in normal usage and even stress testing doesnt go much beyond that
@hardy cipher Idle temps

well I'm on a laptop, so even with a cooling pad and everything it cooks
I don't think mine ever gets down that low
one of the fans stopped working and I had to remove like 50 screws to get to the stupid thing
but somehow I managed to get it working again. I mean, it still wanted to work
random observation. Why does task manager show GPU temps but not CPU temps? (cant say Ive noticed before)
there's the other program that shows all the temps. I forget what it's called though
oh I normally use HWinfo

I don't have that one. I just use task manager because I always forget the name of the program I'm talking about
Just a quick workout ;o)

Hey guys! I want to install SDLX 1.0 on Automatic 1111. I see there is a normal and a VAE version. Which one should I get? Do i need to install a VAE seperately if i get the VAE version?
get the one withe baked in 0.9vae
Hey thnx!
that desktop has some things going on
says the man that uses the standard one and then loads VAEs seperately lol
the chad way

I'm going to try that psyanimated model on this goofy setup I have
I like this one https://civitai.com/models/118949?modelVersionId=129103
💚 for Updates - I would love to see your reviews and images of this model, feel free to post them below! Ambience is currently an experimental test...
it/s
you

where did you find that picture of me?
lol i knew it
😂
doin the dew

yes, I'm concerned
niceeeeeeeeeeeeee

what choices led to this prompt + setting combo 🤣

Stop stalking on that poor worker
it's so pointed and specific, lol
cfg 4, steps 60, dpm sde karras... let me check my workflow from last night

it gets better the longer you look at it XD
it's very... specific
I made this last night, but the prompt above is not mine (but this uses also 60 steps sde karras)

his result on dreamshaper

I need to have a prompting tool that makes prompts like that
but it was so oddly specific XD
I also tried it, with exact same settings

for science XD
I'd say it's an ai generated prompt. but it probably isn't
not the sisters of battle. he knew what he was doing 🤣
super-girl top, wonder woman belt
man, I was making some comic abominations earlier. wasn't going for realistic like that though
lol.
base/lora
Warhammer 40000, wh40k, sister of battle


love the pants design 😄
base / lora
photo of a sister of battle in wall street, Warhammer 40000, wh40k, sister of battle



good lineart quality and flashy colors... I like it

Super Psychedelic Green Goblin Man?
then I added the ussr propaganda poster lora. that's what was missing





up already? 🙂

maybe

cool
I mixed it up a bit more lol


ah, you're going all in on the artstyle? not asking for art while also not asking for art 🤣

This is The Way lol

P: wide shot, 1girl, beautiful french woman, as supergirl, super hero,, grey and blue digital camouflage pleated skirt. On a busy street in front of the eiffel tower. Skinny, flat chest, thigh gap,toned athletic body. Seductive,submissive,innocent. health. warhammer 40000, wh40k, sister of battle. by Frank Frazetta, intricate detail, modern, 16k, digital art, artstation, cinematic lighting, vivid, dystopian style comic wide shot, 1girl, beautiful french woman, as supergirl, super hero,, grey and blue digital camouflage pleated skirt. On a busy street in front of the eiffel tower. Skinny, flat chest, thigh gap,toned athletic body. Seductive,submissive,innocent. health. warhammer 40000, wh40k, sister of battle. by Frank Frazetta
. graphic illustration, comic art, graphic novel art, vibrant, highly detailed . bleak, post-apocalyptic, somber, dramatic, highly detailed
N: ugly, deformed, noisy, blurry, low contrast, cheerful, optimistic, vibrant, colorful, photograph, deformed, glitch, noisy, realistic, stock photo, ugly, deformed, misshapen
XD
merged all your prompts! XD
sry. my lora still kills the artstyle

so many ways to mix things up. It's like dipping into a lucky bag
first was without.2nd with lora
so much depends on the seed as well

damn those shoes it picked up are cool though
damn, that is an impressive node explosion, winston
testing with SoCalGuitarist's new model (ProtoVision XL)

that blue and green does not fit really well together
I mean, she pulls it off pretty well
with the cape of capes
hmm. I wonder what "CR load lora" is. I'm missing crucial nodes from winston's workflow
its ComfyToll
ComfyRoll
great nodes
it has an on/off switch
ahh
I have on/off switchs from some node pack
well they have boolean inputs
that I think are backwards for some ungodly reason
the switchers are pretty great from the CR package
ComfyToll
please pay the toll price, to pass this node
theryre listed over in this box and colour coded

thanks, random seed

Intersting, this was using Revanimated as the Base & Photon as the Refiner


hmm think i need to drop the gen size a bit more
what ui is this?
"holding a pen" gave me at least 75% of the time a good hand pose with the correct amount of fingers
ComfyUI
ok
with spaghetti turned off lol
linear paths are the way
Full spaghetti

it's even sagging like spaghetti noodles
just for more controll?
Straght spaghetti

eastwood420: more control, more efficient, less junk code
no spaghetti

slightly steeper learning curve, more than one way to skin a cat, gives a better understanding of how SD & AI works
true. but I wish I'd started with it tbh
no spaghetti

damn, son
fix that world map please
I knew nothing about anything when I started
its like a google map of the world
ok, maybe ill switch over. I got Auto down pretty well
but I like exploring and experimenting
eastwood, just give it a try if nothing else. you can drag images in and they'll autoload the workflow
even the a1111 images
it on hugging face?
I got it from github
https://github.com/comfyanonymous/ComfyUI
And I recommend starting out with @high skiff s work flow for SDXL before trying to understand others

GitHub
A powerful and modular stable diffusion GUI with a graph/nodes interface. - GitHub - comfyanonymous/ComfyUI: A powerful and modular stable diffusion GUI with a graph/nodes interface.

GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
pingly dingly
oooh ello


What are you guys s/it in sdxl? Mine are 1.46 on rtx 2070
1.75-2 it/s normally
2.19
6gb vram, barely making it over here
is lower beter?
yes, ideally you want to approach 0 it/s
3.23 it/s 3080ti
not bad, bud
comfy says 3.7
sometimes im seeing as low as 1.3 others as high as 2.19
turning off the step previews made it hit 3.6
~5 on 4090
2.15 it/s with a batch size of 4
Guys I cant seem to make SDLX 1.0 run in automatic 1111. I have the model placed in the correct folder but everytime i try to switch to it in Auto1111 the process fails. I have updated Auto1111 to the newest version. Do you know what might the probelm be?
you shouldn't use a1111
it mostly works on the dev branch with a1111 but on master you mostly oom
why is that?
they just havent optimized it for sdxl as much as comfy have yet
Ok i see .. I ll try that if nothing else works. Can i run ControlNet with Comfy?
there's no proper Controlnets for SDXL in general yet
Ok thanks for the info

how can I disable spaghetti and turn it into straight?

GitHub
Extensions for ComfyUI. Contribute to failfa-st/failfast-comfyui-extensions development by creating an account on GitHub.
Thank you very much
Isn't it builtin now?

alright, I managed to implement AIT to my workflow. takes ~18sec per image with this


without/with lora
(not saying one is better, just interesting) XD




I see the model database has moved and there are some new upscale models https://openmodeldb.info/?sort=date-desc

OpenModelDB
OpenModelDB is a community driven database of AI Upscaling models. We aim to provide a better way to find and compare models than existing sources.
Made this with sdxl! Hope you like it!

Video created using Stable Diffusion XL, Deforum, Runpod, automatic1111 UI and DaVinci Resolve Studio.
Music created using my guitar and Studio One along with mostly Spectrasonics and Native Instruments plugins.
very relaxing! I really like the music - nice harmonies. thanks for sharing it!
fits the trip into nature very well 🙂
Got inspired when boating around at our summer house
A lot of beavers sneaking around
liked and subscribed 😉
Doesn't SDXL know umbrellas are supposed to float mid air near the character??

It's a nice change!
@west breach can you help me test my lora, i am finding hardtime trying to test, i am not understanding whether its the lora or the sd model generating selena gomez

Google Docs
did you caption your images with selena gomez?
are you using refiner in your workflow?
yeah
yeah
the refiner is not trained, so it can override your lora, especially with faces
oh, so should I train 2 loras?
don't think you can train the refiner, at least I haven't seen anyone talk about doing it
you can always use a facedetailer node to fix the face again after the refiner is done
do you have any specific workflow for loras
so i can test them
does selena like to wear round sunglasses? seems to be showing up in a lot of images even when not prompting for selena gomez
I'm using my custom nodes, which support the lora:sg_v3 syntax
no, many images dont have sunglasses, maybe just 5/160
oh ok, can you test few samples and share it with me
how does it perform?


can you please try with same seed and not using the lora
same as first image without lora

my training actually improved the face?
seems to help generate without the sunglasses maybe?
oh ok


It is because it suffered from overfitting with the special Mary Poppins base of images
@soft zealot sorry for asking, your current workflow is very complex for me, is there any workflow which is bit simpler?
I'm new to this, does anyone have a good workflow for upscaling images on comfyui? for example, here's a small render I did that I want to blow up and maybe change some details along the way

you mean spomething like @high skiff 's whch I provide a link too in my workflow credits & notes as beeing easier to start with ?
i mean your workflow has many notes, i am finding difficulty find them and using them
GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
or if not a workflow then a video that can help me. the videos i've seen so far started off with a new render but i want to upscale one I already made
but yours is like an upscaled ver
wait, lemme try again with your workflow
it has those presets
so its great
geeeeez make your bloody mind up willyou
workflow in image is embeded, it may suit your needs

Thank you! 🤗
that looks clean! nice work
got this error

thats an Efficiency Nodes Node.
Apparently there have been "issues" with differing versions floating around causing headaches for some people depending on there thehy installed them from and when
of course that presu

i downloaded the direct link from the github page like 10 mins ago and already had Deerfu
okay so it seems the import failed, i'll take my ass to tech support if i can't find a way to fix it
I recall someone syaing they ended upo gtabbing it from Civitai and that worked
This is both the blessing and the curse of ComfyUI (and many other Github based projects)
wouldnt be so bad if there wasnt so many places to download things from
wasn't or weren't?
grammar is not my thing
Why is it that text encoding takes so much longer than actual image generation? Whenever I make a new prompt, it takes 10 minutes before it starts generating, and then subsequent generations each take less than a minute
Anything I can do to speed that part up?


ComfyUI or A1111?
Also, is it 10 minutes again if you change the prompt afterwards?
Also,

Who needs prompts?
Traditional art, watercolor
if you have searge's custom nodes then it wouldn't work as its interfering with efficiency nodes
Comfy, automatic is practically useless with SDXL for me. And SDNext too. I have a 2070 super
It is! And that’s a gorgeous pic 🙂
How much RAM?
Not VRAM, RAM. Though also VRAM.
16 ran, 8 vram
Hmm~
The default behaviour of ComfyUI is to leave the text encoders in main memory and run it on the CPU, I believe.
That works fine, so long as it fits in main memory.
Which... is unlikely. ComfyUI uses 24GB of memory to me.
So there's your explanation. It's swapping out, and it's really, really slow to run anything where you need to swap in and out while it's running.
You need more memory. I'd recommend at least 32, but 64 will save you future woes. Fortunately main memory is cheap right now.
Alternately you could buy a 4090 and run with --gpu-only, but I don't know that I'd recommend that as the cheaper option. 
Thank you! Good to know I can maybe make it better without spending a million dollars on a gpu
Is there nothing else I can do in the meantime? Are there pruned models with smaller text encoders? Kind of confused when it comes to the more technical workings of SD
@crimson roost I run a 1080ti with 11Gb VRAM on a core system of a 5600x with 64Gb System Ram and generally take about 180-200seconds to prodcue an upscaled image like this

without/with lora


P: style of Casey Baugh, an award-winning photography, an impressive close-up of the face of a skinny Gothic woman that captivates the viewer. Her pale, porcelain-like skin appears almost supernatural, while her dark eyes exude depth and penetration. The fine details of her face are accentuated by the interplay of light and shadow, highlighting her distinctive features. The dark lips lend a mysterious sensuality to her expression. This close-up captures the intensity and captivating allure of Gothic aesthetics in a single moment RAW photo, Fuji X-T20, (high quality,:1.2)
N: bad anatomy, bad hands, multiple eyebrow, (cropped), extra limb, missing limbs, deformed hands, long neck, long body, (bad hands), signature, username, artist name, conjoined fingers, deformed fingers, ugly eyes, imperfect eyes, skewed eyes, unnatural face, unnatural body, error, jpeg artifacts, painting by bad-artist, (worst quality:1.5), (low quality:1.5), (normal quality:1.5), lowres, RAW photo, Fuji X-T20, (high quality,:1.2), jpeg artifacts, painting by bad-artist, (worst quality:1.5), (low quality:1.5), (normal quality:1.5), lowres
civitai prompt are getting more and more absurd XD but hey! it works?
XD merging all your prompts did this
without/with lora


that was a whole story 🥲
nice but doesnt have that grainy old phot from the 70's sort of feel ;o)

and my take on that one 🙂


and one more with negatives as well

a 70s grainy photograph of a portrait of a pretty young Swedish woman in a meadow in bloom, Desaturated, bleached colors, Hippie woodstock style, Marygolds, daysies, grass, Kodak, polaroid
First try with sdxl.. lots to learn but having fun!

interesting seeing how this changes using the same seed and all other settings but moving some of the prompt to Supporting terms


prompting both encoders seperately i view analogously to having more traction like having four wheel drive instead of rear or front . Or another is like it gives better focus on latent space like glasses instead of monocles
same prompt layout but no styles applied

Hi, is there a specific channel for support or helping others fix issues with the latest model?
I heard the model requires 8GB of VRAM which I do but it refuses to work
define "refuses to work"?
Thats like going to a GP and saying "I cont feel well"
Which UI are you using ?
What eeror mesasage (if any)) are you getting
describe the symptoms
This worked! Thank you! 🤗
Yeah I'll admit I was being a bit barebones but I didn't know if this was the right channel
This is the error I'm getting

I mean there is a tech support channel but..............
so Automatic11111
do you have --medvram in your startup bat?
Nope but I have a feeling I should?
probably help 🙂
this is what I had in tehre when I was using A1111 both for my 6Gb 980Ti and the 11Gb 1080Ti
set COMMANDLINE_ARGS=--medvram --xformers --no-half --no-half-vae
It actually worked! Thank so you much!
First creation ever

Oh yeah, gotta apply the xformers too
@soft zealot thanks again!
let there be cat
Btw do we know what's the difference between the two available models?

I suggest using the 1.0_0.9vae versions of the base and refiner models, because the VAE in the 1.0 release versions do show artifacts / anomalies in your images.
Is the one I'm using yeah 👍🏻
what's vae btw
Sorry, I'm just been out of the image generation community for months
all good 🙂 simply said the VAE decodes your image from the latent space into a RGB image.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
It turns what sdxl makes and reads into what we can see and read
So I was futzing around with the Sytan comfyui setup for SDXL, and the base pass is always set up to go to step 20 then goes to the refiner afterwards.
Is there a reason why its hard coded to go to step 20? Like, say I did 50 total steps, there would be way more refiner steps than if i did 30 total steps
I’ve written a little node chain to make the base pass a percentage of total steps, which seems more logical to me, but I just wanted to make sure there was a ‘reason’ it was hard coded that way?
in simple terms, it changes an image from a bunch of information to an image we can look at. Latent space to pixel space.

In his approximate words, he said it was the most efficient number, where going further didn't make much of a difference, and in some cases degraded some images.
YMMV
yup thats what I did as well afterworking with Sytan.
Typically you're looking at Base Steps being 65% of the total

@untold totem feel free to delve into my workflow (attached) and see how I did it, just dont ask for help lol

65% was exactly the number I went with
Just wanted a sanity check haha
idk about y'all's workflows, I managed to implement AIT and I'm very happy with this

have you tried messing with loras?

ait?
but not exrtensivly
AITemplate. it's an extreme performance boost by Facebook.
Artificial Intelligence Testing ?
want the current version of my finetune lora? am curious to see how that works out - as it is mostly refiner compatible - due to not focusing on a single face
all your Data is ours 🙂
huh, never seen or heard
I'll give iot a whirl for you , probably be tomorrow now
whatever. I'm getting 14it/s with SDXL on1024x1024 and I'm hella happy
(trained on women only for now - real photographs only)
short prompts arent working as intended yet - but since you mostly do longer prompts it should be good to go
How does it work, just a different processing method on your end, or does it send out information to process with Facebooks hardware?
nope. It's self optimized optimization. it creates a module specialized for you exact specific device, thus increasing performance massively without precision loss.
heck, it took me 13 seconds to generate this

Hmm, interesting, I'll have to download it and check that out. Perhaps take a look at the backend for curiosity sake
random question, is there a way to refresh the cahced LORA (7 other model) information/lists in COmfyUI without restartiong the server?
ok took 13 seconds on what hardware and how long to generate using say Vanilla Syatans workflow?
Hardware requirements:
NVIDIA: AIT is only tested on SM80+ GPUs (Ampere etc). Not all kernels work with old SM75/SM70 (T4/V100) GPUs.
I made my own workflow. I have an RTX4070ti and without optimizations it takes me ~50 seconds to create an image with the same quality as I demonstrated a few moments ago. with AIT it takes ~20 seconds, sometimes even less
also, AIT isn't even implemented in the refiner stage, it can get even faster
anyways, back to some gens


love the volcano in a lavalamp motif
ah just noticed something yo umentioned.
I only apply LORA to the Base step not to the Pre COnditioners or Refiner steps 🙂
@indigo carbon are you sharing your workflow?
yeah, metadata
should have checked first eh
which is as intended in this case
In fact (and I may be wrong) but IU think that is the general recommendation
it does modify clip though, and actually listens a lot more to what is asked - so keep that in mind
@soft zealot after generating too many images, where do you thing sdxl is not good at?
i can try to train a lora
two girls one cup

why?!
