#✨|sdxl
1 messages · Page 73 of 1
AMD still have this mountain to climb. theyre so far behind


Im must say cats in XL are really high detail
probably one of the easiest to get instant results
unfortunately they have drug addict

he's chillin with that smoke though
he hates the filter

AMD works in Linux
mmh i like the quality cuz i use other "one install and go " tool but dont get such quality images

i used this https://github.com/nod-ai/SHARK
GitHub
SHARK - High Performance Machine Learning Distribution - GitHub - nod-ai/SHARK: SHARK - High Performance Machine Learning Distribution
That's graphics. Let's not even get started with how far behind they are with AI
try comfyui easy instal too
yep, plus software integration
Nvidia beats the sht out of AMD as of now
yes im trying im at tech-support channel will check out later maybe it will work
If they really want to be relevant to AI they should make ROCm closed source and start developing it like Nvidia does. Because in terms of hardware, they aren't that far behind. Actually, I'm pretty sure AMD has more VRAM than Nvidia
It's just their software and compatibility that's eating Nvidia's sht
Hi all. When using ComfyUI in Windows11, are there any generative speed related optimizations that are recommended for users to add via command line when using a RTX 4090? For example "xformers", or is that redundant once the Standalone Portable Windows Build is installed?
AIT support is coming soon. @visual glade said they are working on it. AIT is capable of tripling performance without losing precision.
--gpu-only
Yes, I've seen AIT support mentioned a few times. Not sure how that gets implemented though. Is it as simple as updating the ComfyUI via git, or do you think it will be more involved?
More involved. Comfy is working on it, I think they want to implement it as a CMD flag or a node. I tested the old AIT custom node that only works on 1.5 models- I have a 4070ti, and with pure pytorch I get ~19it/s and with AIT I get more than 55it/s
full size gui without visible lines:
https://i.imgur.com/gUQ4vdz.jpg
Jensen cooking up the next gen GPU

let him cook 🔥
where do they have more vram? in their basement? vram depends on the single product of course. for consumer cards both max out at 24gb. for professional cards nvidia goes up to 48gb afaik, while amd stops at 32gb
Hey, anyone know if there's any controlnet for automatic1111 sdxl available yet?
ControlNet is not out yet for SDXL
Yeah I've been using one for like a week now
Look on huggingface
which one is that?
I think I used https://huggingface.co/SargeZT/controlnet-v1e-sdxl-depth/tree/main but there's probably better ones by now

ah yeah true, that has been around. corrected 🙂
Thanks, I found that one earlier but had no clue how to install it, didnt work via the extension link, what is the correct way if you dont mind me asking
it should work in ComfyUI
Bro, spotify will not drop Peter Gabriel from my recommended
I listened to 3 of his songs for the challenge, did not like any of it, and now I get alerted at every new release of his. I do not care lmao
ive listened to him so much.. my dad loves him and always listens to it lmao
I have gone as far as to block him on my spotify, yet he is STILL IN MY NEW RELEASES
I don't want him there lol
I listen to my new releases and he always manages to find himself in my playlists
I did fully bar his music from my spotify, so now it just pops up an error message when it tries to play one of his songs
but like... why is it still coming up, its very annoying lol
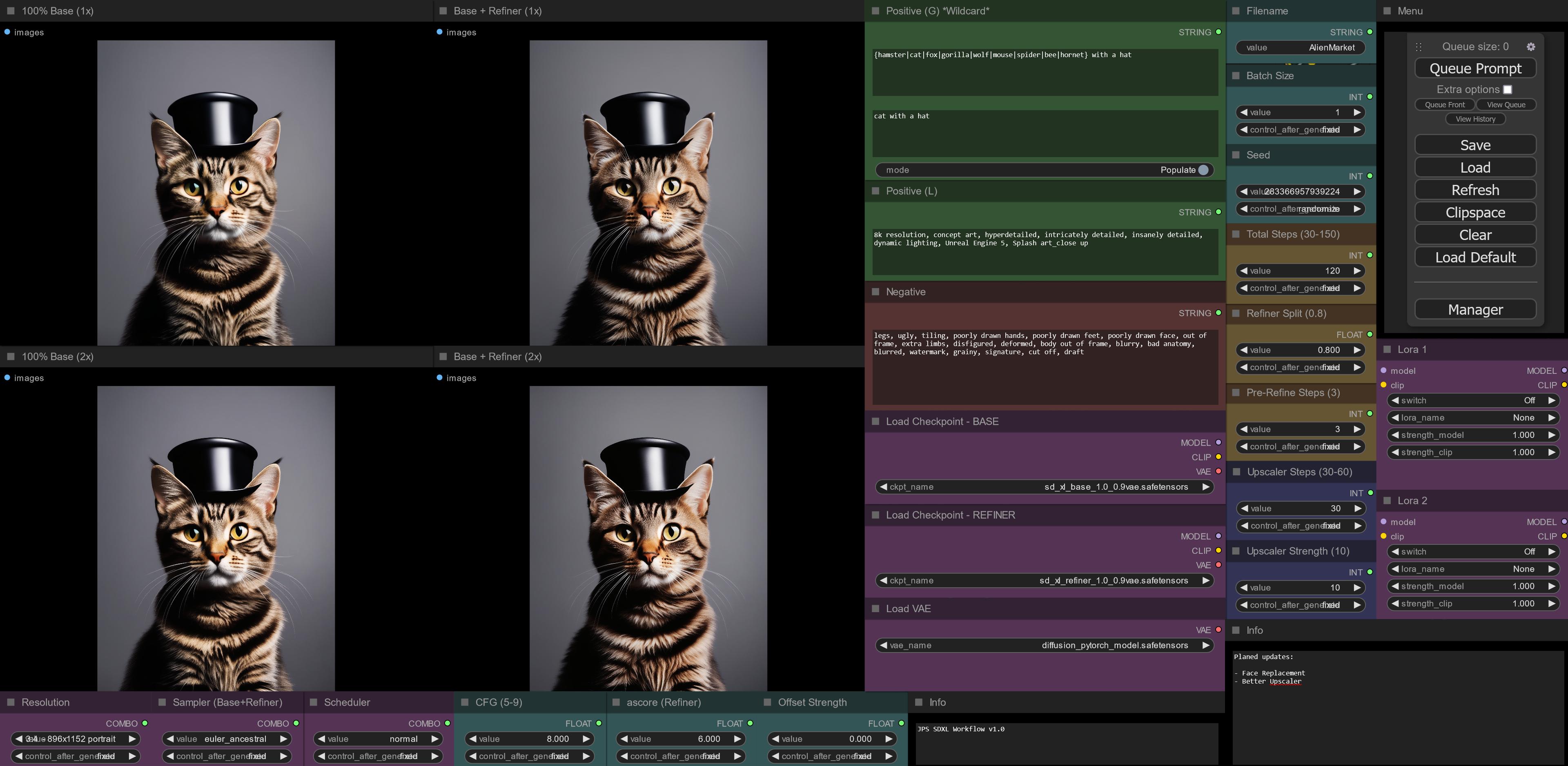
I recently spent a few days exploring and experimenting with my modification of Sytan's excellent workflow. I wanted to make sure it worked as best as I could get it, I must admit there could still be some issues with my mess lol. I setup a Google Drive folder containing 3 sets of 3 images. These images illustrate the base+refiner, face-fixing process, and final result with the metadata embedded. You'll also find a JSON file and links to the models I used in this directory. https://drive.google.com/drive/folders/10eED4sDSL37g_BfsvElNkcmIx43ZMpvI?usp=sharing
Since all of this is still very new to me, I tried mixing and matching samplers and upscalers for most of the time. The settings I ended up going with result in some high-quality images and stay pretty true to the original image, at least to my eye. However, one issue I have noticed is with faces that are extremely close to the "camera." You get strange distortions during the face-fixing stage if they're too close. I suspect this might be related to the crop factor settings, but I'm unsure what to modify to correct it as changing the settings here either blurred or overly sharpened the image. Frankly, I don't really want a face that close in the images anyway.



@high skiff good to see your layout being proliferated. /u/inagy ported it to comfybox https://www.reddit.com/r/StableDiffusion/comments/15j12sk/converted_sytan_sdxl_workflow_for_comfybox/

reddit
19 votes and 2 comments so far on Reddit
i think i found a new easy install for amd users
GitHub
Stable Diffusion web UI. Contribute to lshqqytiger/stable-diffusion-webui-directml development by creating an account on GitHub.
to use sdxl
:O
Love
❤️
@visual glade Hello, just curious if you'd be able to provide some insight on how to get a Primitive Node with INT output to connect to the INT input of another node? In this case it's an INT to TEXT node but the noodles won't connect. Any pointers would be appreciated

i like how the gpu makes different sound when generating with sdxl compared to other lol xD different coil whining on my card
the primitive nodes need improvement, connecting only works if the min, max are the same
I've had some of them connect in peculiar ways. or they'll connect but then not really be compatible or something
That explains a problem I was having with using one node for all width/height connections.
It would connect to all CLIP nodes or to the latent node but not both.
but it's more experimentation than anything else on my end
Thank you, how would one see the min/max values of the node, look at the underlying JSON after saving the draft workflow?

really nice sdxl is dope

looks like it could be touched
I could probably refine them a bit better

these images getting better and better created by <350 usd gpus ....
I'm becoming a perfectionist with xl. previously it was just nice to get them close to what I wanted

Do you know where I could find a good preset for img2img in sdxl comfyui?
left a decent sized queue to render while I was gone
use the example SDXL workflow and give it a VAEEncoded image instead of an empty one
ty
idk, it looks like a poor generation
to lower denoise adjust the start step of the first sampler
cheers, hope i'll like a node based ui, will be interesting
thanks for the constructive criticism
sorry I didnt mean it like that, I dont know enough about sdxl to give advice
are those with refiner?
like i said above, I would like to work on refining them more
haven't quite figured out the optimal approach
but these aren't intended to be realistic images per se, so kind of hard for me to really gauge it here
I made one that adjusts most of the settings for you based on the denoise value you select
https://civitai.com/models/123048

This SDXL focused Image2Image process utilizes your desired SDXL base model with the SDXL Refiner. To ease the process, all steps are automatically...
I don't know if more refiner would help, but seems to zap the detail if I up it much beyond 20-25 percent of the total steps
oh nice, ill try that out right now, thank you
I'll be seeing later tonight about auto adjusting the image scale, will look at some options for that. Currently you either just connect input image to the vae encode, or use the image upscale to tell it the initial size you want. Say you gave it an upscaled image that's already massive, you can pare that down so you don't end with a monstrous size
do any of you guys know much about the scheduler setting? what do you normally use?
I mostly use normal and karras. you can find a bit more info here: https://github.com/comfyanonymous/ComfyUI/discussions/227
thanks
how do i make pipe.enable_model_cpu_offload work?
got the issue that idont have enough vram for 1024 1024 images
@foggy notch in webui-user.bat add in commandline_args -lowvram or medvram. Start with medvram, and if it doesnt help change it for lowvram.
There are more settings suggested to AMD
for me karras feels sometimes more creative. but I'm very used to it because I ran it exclusively in a1111 with SD 2.1 + DPM+++SDE Karras
any idea why these fail to load?

missing node packs?
oh ok ill figure it out, new to comfyui
you are missing these for sure:
https://github.com/RockOfFire/ComfyUI_Comfyroll_CustomNodes
there are a bunch of 3rd part node packs that you cna install from the manager inside of the UI
or you can do it manually if you choose
gotcha, like extensions in 1111
grab this to better manage custom nodes https://github.com/ltdrdata/ComfyUI-Manager
GitHub
Contribute to ltdrdata/ComfyUI-Manager development by creating an account on GitHub.
ill install those
yeah better use the comfyui-manager
okay cool
this stable ui is already using xformers
just use discretion and don't just start installing everything like I did
I've integrated shrink/grow mask and separate masks. It works well when the masks are hand painted.

soooo many different libraries and things that need to interact
But it's not the best at detecting a lot of faces when trying to mask by text. anyone know how to do this a little better?

I've uninstalled quite a few that seem to be abandoned projects or something
"I just need that one node - here take the full package with all the dependencies first" 😄
yes, and I had a couple with unresolvable dependency issues
one needed a version of a library that the other wasn't compatible with
The bane of my existence too
yeah I try to keep it light as well. I mostly use utility nodes. I have two separate installs running - one for testing that I reset to a clean install anytime I'm done.
I think it might be possible to use some trickery with venv and possibly run the incompatible node packs, but didn't seem like a worthwhile endeavor to me
I had to fix a couple by installing the requirements manually
I've done a bunch of that
the --medvram command is working using 9 out of 12 gb vram
but I guess it's time to build some nodes of my own, because sometimes I just need one feature from a package. all packages should be modular 😉
ran a command to install all the requirements txt files in all the node folder
btw are all nodes safe or is there something you have to check for before installing them
but hey now I can pin and unpin all nodes twice in my right-click menu 
just install everything in a virtual environment. but I don't think they're unsafe exactly. just outdated
well - you are downloading dozens of open source software packages. so there are no guarantees really. just hoping the community will identify a threat pretty quickly
I would strongly suggest the virtual environment. that way if it all blows up you just delete that and everyting else is intact
skip steps
this reminds me i figured out why my auto1111 was operating at half the speed i'm used to. because i tried using --medvram to see if it worked as optimized as it does with comfy. it did not
well shit too late, ill keep it in mind
no. but your other settings have a big impact on how it comes out

I wonder if sdxl knows about daddy long neck
dude the coil whine is annoying af never hear the shiet card whining so hard
not even on 1000fps test scenes lol
one of my fans stopped working at one point. pulled it out and messed with it a bit. squeezed it a bit to push everything back tight again. strangely enough it works fine again
holy shiet this image takes 6 minutes now lets see what we get
its like a suprise these images...
let me tell you, getting to the gpu fans in this laptop was not a simple task. had to remove like 30 screws. had no idea what I was doing, lol
its kinad weird that its working at 2 images at the same time refinery but ok
its working, thanks a lot everyone
comfui-manager is great too
appreciate the help


3090
yea gonna cancel my sub soon I think, this quality is way better then midjourney..
the thing that I still like about midjourney is that I can put reference images but I guess someone will find a way to do that in SDXL soon
never needed to use mid journey. i've always been after the full journey
i spend 7 minutes for this 😦 feelsbadman

maybe try decoding the image on multiple passes, that way u can cancel when the preview images are bad
I do multiple passes with multiple settings in my workflow 3 base then 3 refiner then upscale 2 base and 2 refiner
Links are in the notes on the graph. Close that warning and you'll find those notes in brown nodes
fixed, works great man thank you
mine takes quite a while too, 104 seconds on 3090
wuts sampling method?
anyone create a Blender addon yet for Comfy? using the webhook right now, but a nice addon would be dope
euler A good enough to take?
I use dpmpp_2m and karras scheduler

vaporwave kitty
oh sick
my oobabooga install is dead
I love when I do literally nothing and a program breaks lol
man, that program is a big buggy anyway
yeah, its hard to recommend with how frequently and severely it breaks itself
it can't do anything now
have you ever tried to train any loras with it? I've looked into but it's not very clear how to prep data and what not
everything is just errors, for nor eason
No, i haven't
well time to nuke it, lol
I think I installed it 2 or 3 times before I even got it working properly
error doesn't even make any sense

I don't wanna have to go through all the installation BS again
hmm
shame it doesn't just work for more than a few days at a time
I wonder what's going on there
Anyone having any luck getting control over framing - specifically just trying to get images without centered subjects? Seems like with SDXL it's very rigid about centering subjects. No luck at all with trying to prompt it (rule of thirds, specifying crops/framing, off-center, etc.). Also tried using the crop width/height but while it can be inconsistently helpful, it also seems to degrade quality a good bit
has something to do with history
welp, here goes reinstalling all of ooba again just to have it break in a couple more days
if you look at those errors in chat.py they all have something to do with "history"
and now the installers don't work
ooba gets an automatic1111/10 on the incompetence scale lol
nah, it was trying to be as good as a1111
like, how do you ship a one click installer than doesn't have its own dependencies
I think it even says that
A1111 is a sad target to aim for TBH
lol
all I have heard is that they are even worse than this
kobold is pretty bad, but maybe it works better than ooba not even being able to install
oh, I have no doubt about that
I don't understand how a one click install fucks itself this hard
outdated dependencies? who knows. are you trying to install on windows or linux?
I had more luck using WSL than trying directly in windows
I think that's how I installed mine a while ago, but tbh I don't recall anymore. But usually what I do
so it nuked itself
I've had to learn so many new things to play with AI stuff
I go to reinstall it, it says it can't build miniconda cause the folder has spaces
it had spaces before and worked fine
well this time miniconda ain't about those spaces
not sure how that suddenly is an issue, its the same folder
I've been so exasperated with that install
Hey @high skiff , what's the "latent sizes" node do in your workflow? Should I leave it be when changing resolution? The workflow is yielding some awesome results btw, thanks for making it available to us ❤️
I am doing active research into that, I'll share my findings when I can
Spaces can be finicky with programs
I am super burned out on SDXL right now
why's that?
just a lot of work
It gets repetative, especially when there is no incentive to keep doing it over and over
Fair enough, I'll stay tuned. And yeah, I just took a week-long break from it myself. I imagine the burnout is even worse when you are actively developing a workflow. I just tinker
I still haven't optimized my approach, but still interesting to me. but haven't had it that long myself
I still haven't figured it out, been off and on trying to optimize workflows. It's just so tedious trying to figure out exactly what is doing what. Especially considering I am running with 6gb of VRAM lol
ah yeah, thats a squeeze haha
The 1+ minute image gen times 
lol, that's what I have too. used to think it was a decent amount
I made a new profile for my GPU to save a ton of power, and its been great
I guess it is for normie thigns
remind me, which GPU did you end up getting?
EVGA FTW3 Ultra 3090
spicy
just came in a couple days ago
my new profile maintains 80% performance of stock clocks at just 48% stock power
AKA, what took my 3080 380 watts to do before, this 3090 can do a little faster at just 200 watts
The it/s must be lovely
with a cranked OC, I can hit about 4.6it/s at 1024x in SDXL
this image gen just legit took me over 6 minutes
and about 28it/s at 512x in 1.5
Damn
dang. well mine was pretty high actually
in ooba, when it works, i can hit about 50t/s in a 13b model
which is mental to see in real time
I get 1.52 it/s for 1024x1024 on my 2060 max q
a 20 step 1024x image in comfy takes my 3090 about 5.2 seconds with VAE decode
eventually im gonna have to suck it up and stop using my gaming laptop from college. But i'm damn sure going to push it as far as it can go lol
when doing batch processing, I can get that down to about 4.2 seconds an image at BS 16
gpu use 129-149 watts
thats like the speed i can get when generating a 512x512 sd1.5 image lol
I'm honestly debating subbing to colab
I would recommend some other services
I have seen some people renting out their PC's with like 4x3090's for a couple bucks an hour
oh damn
4 A100s??? Who the hell needs 4 A100s lol
to train base model
me
and that guy
my research partner is looking into an 8xA100 setup lol
i can play crysis in 16k resolution then?
hes trying to finetune all of SDXL into v-param
and its showing some cool results so far
I am going to fucking explode lmao
reinstalled ooba from scratch
identical issue
where are you installing it?
what do you mean?

tell it you want a thicc neck
What are you tryna do with ooba?
continue my work on a character for prompt processing
talk to waifu
man, how are you going about trying to do that? it's something I've thought about, but no idea how I'd start
awww i think its generating smth good now
mission completed now i can stop wasting electricity
learning hwo to use instruction templates
oh
I did something
its working now
ok...
so its just instruct thats fucked
well thats great, cause I need instruct to be un fucked lol
I feel like with those sorts of programs you always have to mess with something to get them working right
I fixed it
what did you do?
it decided to force unload all of its instruct templates
do you think that's the same issue as before?
yes, likely
I'm curious about that history thing
I am not sure why it suddenly did that
its not consistent, cause I deleted all of the previous files before the install
the problem was, without the template, it wasn't marking my messages as "user"
I'd normally just paste my errors into bing and see what it said
bard can't help with anything
bard sucks left ass cheek lol
it would literally ride the short bus if it were a human
I've asked it if it could help me with something so it'd get acclimated. it'd say yes. then I'd paste the issue and "as an AI language model I am unable to assist you with that"
then I'd berate it and it'd apologize profusely and I'd feel bad, lol
oh, i can't send its response lmao
apparently there is something in this response that is against the servers filter lol
vicuna 13b in 15 seconds on my 3090

damn
thats in assistant character, let me try instruct
before I figured out how to configre deepspeed I was getting a token every few seconds at 7b
lol
instruct mode in 12 seconds

That’s 6

llms can't count
vicuna can do math tho, which surprised me lol
... also why no stablebeluga-13b
it can only do logic if it writes it down in the response
one time I asked bard how it could have forgotten our wedding anniversary and it planned a whole date for us
cause its horrifically slow
a walk on the beach, our favorite restaurant
slow? huh?
like 0.7t/s on a 3090 levels slow
cause it uses 29GB VRAM
it... uses 10 GiB running through exllama
must be using a quantized version then
well yeah, naturally
the one SAI posted themselves is 16 bit, and it runs at ass speeds
well... yeah fp16 is silly to use for inference
useful for training quality still tho
if you join the discord for ooba https://discord.gg/u27RhJECcW you can test stablebeluga-13b via the bot
I have used a stable beluga 4bit quantized version tho
it wasn't as good as vicuna 13b
stable beluga
I could test them head to head again
open source llms are named like week strains
yeah lol
beluga is a horrible name
but oh well
@wicked frigategot a link to a specific version of beluga you recommend?
purple wizard vicuna raptor tiger
did you remove some of the layers or whatever?
still managed to run faster than 16 bit beluga 
1 token every 30 seconds, lol
no
shockingly 1.2t/s
36GB VRAM
it was a 3bit version
my bot's running https://huggingface.co/TheBloke/StableBeluga-13B-GPTQ this'n
well 36gb vram, god damn
yeah, thats the one I used, wasn't as good as wizard vicuna 13b I use
But I can give it another try
with my system RAM, my GPU has access to a total pool of 56GB
if I could raise that, it could be closer to 70GB
I have 64gb of semi-useless ram, lol. seems like it doesn't help with anything AI related
I have 64GB of fast DDR5 now, which helps a lot over DDR4 for pooling
I bought the best ddr4 my laptop would allow
@wicked frigateI have it installed now, any recommendations of things to do to give it the best shot against wizcuna?
I will use the stable beluga V2 instruction template to give it the best shot


which do you prefer @wicked frigate ?
one is Wizcuna, the other is beluga


@wicked frigate Jumping over to #1098025024541167646 for more comparisons
trying to make neanderthals over here.
and how is it going?

but you are close 🙂


perfection 😄
well that's before I remembered to change the latent to 1024x1024
SDXL512 art - its own category
The web UIs should have a warning (that can be turned off) when using wrong resolutions. So many questions about that.
got it working ... kinda. need to figure out how to color correct.

evolution!
there are soooo many different nodes for color correction. I get a bit lost in them sometimes
have to wrangle myself back in
know any specific good ones?
https://github.com/WASasquatch/was-node-suite-comfyui offers a lot of nodes including image processing
I use imageeffectsadjustment and image blending mode most
but then, I forget which packs they're from
WAS 🙂
one is for adjusting an individual image. the second is for blending two as you may have guessed
and this probably: https://github.com/Nourepide/ComfyUI-Allor
I've used the image blending mode node a couple of times from WAS - adding film grain etc or mixing two passes together
it seems like they all let you adjust the image, but by hand. I wonder if there is anything that will look at the colors of the original and adjust automatically.
I don't know what that means exactly
it corrects the colors to match the original. so say you inpaint a face and the result happens to be a little tanner than the original, it will correct the colors to blend it better, but without losing the details of the result
ahh. haven't done much iinpainting with it so can't say :/
hmm I'm pretty sure that there are scripts and apps out there that may do it, like the face detection script from facedetailer, but not sure if there's a node already for it
Couldn't find anything. but I did find how it's done in auto which will help.
Problem installing The Bloke's Beluga ... ?

Set up a separate venv.
playing around with base model as an upscaler with level_detail





free the mipple
gotta say, for anime, 1.5 to Ultimate upscale to sdxl base = amazing
yeah, I've seen a couple of 1.5 upscale examples - not only anime. it works quite well
before and after


everyone that ive done it basically almost makes all the text legible which is cool.
The Grizzled Granddads of Groanabbey Beach! 😄




What workflow are you guys using for sdxl?
can i merge sdxl checkpoints in auto1111?
for sdxl i used a modified version of sytans workflow to suit my needs
Sytan, Scott Detweiler's Triple RBR Process ...
anyone successfully get either of these scripts to run inside blender yet?https://github.com/comfyanonymous/ComfyUI/tree/master/script_examples
there are so many. many are posting theirs with their image and many are starting out with this one: https://github.com/SytanSD/Sytan-SDXL-ComfyUI
Thank you
it's well organized so it's a good workflow to learn a bit
my workflows tend to be a mess haha

Been on vacation for a week and a half haven't had to chance to keep up with all the new info and other stuff
(That guy's got a third hand holding his umbrella for him!!! 😄 )
but it has robots! so...
crazy how just a week and it seems like you can be out of date with ai. crazy times we live in
it feels like 1 day is enough to be out of the loop right now 😉
this one has a lot of features and customizability. I'm working with the creator to add in more features like level-detail for basemodel upscaling. https://civitai.com/models/119528?modelVersionId=134007
SDXL 1.0 ComfyUI ULTIMATE Workflow Everything you need to generate amazing images! Packed full of useful features that you can enable and disable o...

very true, if i miss a day ill feel like im missing out on new stuff lmao.
ooo i like that one. but what if i just want to do t2i? do i just unlink evberything else?
exactly
yeah there some controls to turn off all upscaling
i see that now. i just read it lmao
lol comfyui is the best advertisement of midjourney. all non-tech users will end up with moving to midjourney if they begin with comfyui.
But if they begin with a1111, perhaps at least half of them will keep using SD
but ppl who want to generate girls will stay
People just use whatever they want. Don't worry about that
that workflow got my computer runnin good haha
After SDXL, I rarely open A1111 for only one or two functions. Mostly working on my comfy workflow and I feel great.
implying online services for custom sdxl checkpoints wont be a much better option than midjourney soon
depends on your work too,if u do videos u gotta keep using a1111
i use it for interrogatting images lmao
I use another approach to do caption for sdxl
Yes comfyui is pretty cool when people move from a1111 to comfyui.
But when some newbie begins with comfyui, without your previous experiences in a1111, chances of moving to midjourney is more than 90%
this is why I say comfyui is the best advertisement of midjourney lol
not when midjourney is censored
when i saw comfyui for the first time my eyes glowed in excitement. there are two people, ones that just wanna type and get an image. and ones that want to have full control and understand how things work. nothing wrong with either.
well nice
keep getting RuntimeError: CUDA error: the launch timed out and was terminated on Comfy
after 30 min of generation
like for 1 picture only

something like this
https://github.com/jbmiller10/CaptionFusionator This project used 3 caption tools and summarize by llm. It provides great enough caption which beat my handemade caption in loha training. But it requires many ram and vram to run it.

GitHub
Contribute to jbmiller10/CaptionFusionator development by creating an account on GitHub.
good news. i got 24gb vram lmao
You might try it.
Well I mean if you do not know those SD knowledges, the first feeling on comfyui is similar to what blender feels like.
I still have not started using blender because I am just afraid of it. Though I planed to learn blender since 2 years ago.
Is it really necessary to make things this scary?
you can literally use somebody else's node
In blender I can also use others’ projects, but it still looks so scary and seems that I need to quit a full time job to master it.
i dont think its scary, its fun to learn new things, when i saw blender for the first time yeah i was scared but also intrigued and motivated. seeing others use it with ease makes me feel like i can do it to.
StableSwarmui, StableStudio, Sd.Next, A1111 webui. It is no wrong to use another ui to run SDXL
u can also just wait someone will probably optimize the other UI's so they run sdxl better
some of the node still can be straightfoward as it seem
it is not like you need to know a thing with an entire thesis
question: when the file extension is b2cap can kohya read that or is it necessary to change it to .txt?
Yes some nodes are simple when you already know SD.
Everyone who know blender very well also say those nodes are simple.
But they are just scary to newbies.
If u only want to use b2cap result, U might change the caption ext in kohya training setting.
they are not that scary

thanks for sharing this workflow. it may become my main workflow. i love its ease of use.

you trying to build a picture of the earth or sum? jeez lmao
The llm result would be .txt which summarize 3 captions result
ignore those line, can you set those?

hmm okay. ill try it out! thanks for showing me. are the results better than vit-h?
sure the node i am using are for advance usage
I am not sure how about vit-h result. You might make a comparison and show me the difference.
haha after seeing this I plan to input my credit card number in midjourney - see you next time in another discord channel
ill try it out tomorrow its 2:18am here lmao
good bye. Feel free to use another tool to achieve your target
actually there is this bot @copper marsh
work similar as Midjourney lol and for free
post the videos u created with midjourney here
Haha just kidding. But this is just to let you know that if you recommended A1111 rather than comfyui, the story will be different. SD will get another user.
I get into SD with a1111 several months ago and I am pretty sure that I will not be here if my entry point is to try comfyui
1 click, 32 images with varied compositions in the same theme
well lets hope the maker of a1111 can get his ducks in a row and make it work well with sdxl
and also make up better memory optimization
but I guess it is kinda like the difference between Linux and Windows
you can have same functionality with both while Linux is more open source and you can almost edit any code in it
and Windows being first-user friendly

please dont tell me those are all save image nodes...
This is fun
I was just talking about making something like this to a bud
Lol this is different from Linux vs windows. I already said that
comfyui is pretty cool when people move from a1111 to comfyui.
But when some newbie begins with comfyui, without your previous experiences in a1111, chances of moving to midjourney is more than 90%
this is why I say comfyui is the best advertisement of midjourney lol
half are
Just use whatever you want to use. If u dont like comfyui, just dont use it.
bruh.
tbh I don't really need the preview nodes anymore
are they all different image processors or something whats going on why so many
I split them up at specific stages in their generation to maximize composition variability without using anything but ksamplers
Cool then just let us work together to help midjourney by recommending comfyui to all new people
you could do whatever you want.
that mp4 of a farmers market up above is 1 click worth of generations
You mean Bluewillow?  /hj
/hj
your crazy man.. i like it lmao
lol

I honestly think that MJ should hire a group of people to promote comfyui to new users of Stable Diffusion. This will make all new users to voluntarily choose MJ
this makes me sooo want to make a video on comfyui. like a simple this is what you do kinda video.
There's already some
whats your gpu?
yeah i know but some of them kinda ramble.lol id be the type to be like "use this node, it does this, next"
not yet
Some community controlnet are out but not official one
Controlnet is a modification of base model. SAI want to improve the structure of it.
from what ive seen so far. there new controlnet type thing is impressive and i have high hopes for it. just hope it comes soon lol.
I released update v3.2 for my SDXL ComfyUI workflow on https://civitai.com/models/111463 - this should solve the issue with the large search box size, has added more prompting modes, and is compatible with Python 3.9 again for anyone who doesn't already use Python 3.10
The documentation in the description of the Github repository for it has also been updated to show some examples for the different prompting modes and it explains how to switch between txt2img, img2img, and inpainting.


Searge SDXL v3.x - "Truly Reborn" Version 3 is here and it's the biggest update so far. The workflow has been completely overhauled and the custom ...


is it still running?
no no, it paused
is it bcuz of the sample prompts?
did you put a sample prompt at the bottom of the parameters page?
yeah
should I share the sample prompts?
does anyone know what I'm supposed to do to get the models in my comfy folder on google drive to be seen when I run it on colab? I only see the basic default models but nothing else. it's a bit frustrating
I'm connected to the drive. it loads all the nodes, but none of the models showing up
the data in your config file is indeed not encoded as UTF-8; everything is ASCII except for that single 0x92 byte,you should check your json configuratin out
is the error bcuz of the config or sample prompts?
bcuz it said generating sample images
and then it gave that unicode error
6 GB ram gpu can run sdxl ? automatic1111
no, use comfy
well anyway, more than a little bit frustrating, lol. but whatever, I guess I'll just deal with it
if you command with wget,the model will not download,another option u should download base and refine models first then upload u your drive under comfy/models folder,than u can see all of'em
why comfy and not automatic1111 .. just the whys
use automatic1111 if you'd like. it's just not as good for sdxl, and not even sure it'll run it on 6gb vram
so comfy runs 6 gb ram
ok then
yes
a1111 doesnt run on 6gb vram
comfy is efficient
but anyway, is there a file or something that lists models? why isn't it seeing my models? boo hiss
@primal vault


always update the custom node extension as well and restart Comfy, then the new workflow will load
Anybody interested in The Bloke's Beluga text workflow?
did that
Something went wrong then, those nodes are definitely in the latest version. Are you using v3.2 of both the workflow json file and the extension?
got it

i am using 3.2 reborn, and got this, i dont want to input a model
i want to use t2i
To me it looks like you are trying to load an older version of the workflow
no, i just downloaded the new ver
from civitai
@primal vault
Let me double check
PSY ANIMATED XL 5000 image model finetune ive been working on


Beachy Scenes 😄 Sytan's W/flow




Are you sure it's this one? I just downloaded it from Civit to check the zip


the link you sent above

Check the file searge_sdxl_sampler_node.py in the extension folder and see if class SeargeCheckpointLoader: is in there, should be line 722
Otherwise the extension is not up to date
Do you use the official notebook? There is plenty of models there (sdxl base and refiner too btw) for a bigger list I recommend Comfy-Manager
done installation where can i get the model files
yeah, I have the official notebook and I copied the models and loras from my computer into the corresponding folders on my drive.

checkpoints and loras
https://huggingface.co/stabilityai
get base_1.0 and refiner_1.0
If you used A111 you can use the extra_models to point to the models you used there: https://github.com/comfyanonymous/ComfyUI/blob/master/extra_model_paths.yaml.example

GitHub
A powerful and modular stable diffusion GUI with a graph/nodes interface. - comfyanonymous/ComfyUI
I already changed that file to point to the models folder they're all in
@primal vault all the nodes have loaded, but when executing I am getting this error
I'm out of ideas, it's all there and should work
Not talking to you
lol
Anyway, report it on Github if you can't figure it out, we should stop doing tech support here
And they don’t appear inside comfy?
no. I'll try running it again. nodes show up
Most reports are not done properly either on GitHub 🥲
but I just changed that file so who knows. maybe that will work
yeah, I guess I have to agree with Searge. but ugh
I went to the tech support channel and pretty much dead
ig, this can help
these arent running

should I dm?
yes, but I can close the ticket as invalid if I don't get a proper report 😉
Comfy has a matrix board… but for your issue it should en fairly simple to solve don’t give up 😊
Hehe agreed!
I'll just suffer ln silence with this stuff like I normally do
@heady vale My video card has been purchased (credit card willing), and this stung ALOT.
unable to do 720p
oooh exciting. which card?
DAMN! good choice
no, as I said, report it on the projects Github page
what does that do? does it get a prompt from oobabooga?
I'll undervolt it for sure. I almost bought the 7900XTX and was right about to then said no.
I made a mistake - I thought it would allow me to put text into images - but it wants to do ChatGPT as if it was AUTOMATIC1111
I deleted it from my cart and changed to the AIRO
Traceback (most recent call last):
File "E:\ComfyUI\main.py", line 66, in <module>
import comfy.utils
File "E:\ComfyUI\comfy\utils.py", line 5, in <module>
import safetensors.torch
ModuleNotFoundError: No module named 'safetensors'```yep AMD is a huge gamble. NV is guaranteed
i dont find github issues reliable
Then I can't help. And please stop pinging me now, I offered you a way to get help.
Yes, so many gonna, will have, should have, rumors of no new RDNA4 consumer high end cards (focusing on MI I think) plus I played around with Linux and read a lot, while in Linux, on ROCm, and too much smoke to save 600. This does hurt $$$$$ NGL
I'd love a node that got a response from oobabooga, I created a lora for the new beluga model that responds with prompts
just make sure to get some jobs done and make some money with it
Cool thing is it will be bottlenecked on my system so I can grow into the card since I plan on having it for a very very long time. 6 years was my norm now at least 6 if not 10.
I am no good at that.
I generate prompts at ChatGPT using a rolling prompt scheme developed by Johnny Asher https://youtu.be/VpTEdsspxbw

Johnny Archer's idea, all credit to him!

XL and ComfyUI killing my enjoyment 100% with this card and screwed up faces I have been getting with XL. Tried all kinds of workflows and gave up on faces if in a crowd.
faster gens will help for sure instead of 1+ minutes for failures at 20 steps
try runpod
did, no thanks
runpod Comfy? is it free?
fair, I get 70hrs of renders for 25 bucks on there
Nah its cheap af though
I use it for my model training, just let it cook in the background while I play video games sometimes I mess around with SD locally but I usually just use my 4090 for renders while I sleep
no comfyui I use auto1111
oh right
Tencent is an excellent place to "cure bad faces" https://arc.tencent.com/en/ai-demos/faceRestoration
that's where I got my prompts from originally to build the lora for the beluga model
ChatGPT (and not Johnny Asher?) 🙂
ChatGPT4. I have a chat session that you can just put a word and it will respond with 10 prompts
finally running
That rolling prompt scheme - you can swap-out "automobiles" - and replace with fashion/real-estate/castles/aeroplanes ... etc etc
... and its for a photographic look, but could be tailored for art
this is what my chat session looks like. I can just say something and it will respond with prompts. I use them to build wildcard files

SHould we really need to, though? XL is a horrible failure, for me, over any before it in this respect.
I've just used ComfyUI Manager/Update ComfyUI - and it has stalled at "Install: pip packages"
If you accept that AI Art/Generative AI will never be perfect - TenCent is a good, free alternative
You did not really listen to what I said, but alright.
alright, I give up. no where to ask for an answer and no way to figure this out
You mean that SDXL is not cutting the business for you in a personal manner? Which to say there's very little which can save you 😄
May I mirror/copy/borrow your scheme?
no
Let me break it down for you. As tech grows it should be getting better not worse. Not going to argue with you but same prompt 1.4, 1.5, 2.0, 2.1, XL XL rips the faces to hell and back YET should be the best one oout of those. Are we regressing?
Let me see if I can figure out how to get a chat to this stage from scratch since this has been going on for a while and neede a bit of coercing to get it to this stage
A lot of people are having this issue so that was a rhetorical question.
No, what we're really doing is blindly feeling our way out into the light ...
@west breach do you know any good workflows with lora?
why ?

probably a wacky lora or something
Try DDIM as Scheduler?
:\Users\Hi\AppData\Local\Programs\Python\Python310\lib\site-packages\torchsde_brownian\brownian_interval.py:585: UserWarning: Should have ta>=t0 but got ta=0.0291675366461277 and t0=0.029168.
warnings.warn(f"Should have ta>=t0 but got ta={ta} and t
lol
I get this, but someone said leave it alone ... ?>
question, when using SDXL 1.0, should I keep the refiner activated at all times, or should I refine images later?
no one really knows

What works for you? I've seen Bse then Refiner; Refiner, then Base, then Refiner again - but if you're saying Refiner all the time - when does the Base kick in?
what I mean is should I keep second pass enabled or not
gai, why wouldn't you show the model you're using?
it automatically does refiner if you have second pass

OK, increase 1) Steps to 50; if that doesn't work,2) increase cfg to 16; if that doesn't work, 3) change sde gpu to euler a ... ?
I think it's fairly simple to use the load lora node in an existing workflow. I made a custom node that supports the lora:lora_name syntax. There might be other nodes that also supports that
thank you
even found winston woof's workflow too
gai, do you have the sdxl vae?
no
maybe you should download it and try it out. see if it changes anything
where do i put the vae
you see where oyu have the red line going from "vae?"
you'd run it from the vae instead of there
because I don't think that model has it in there?
restarting

I mean, it's impossible to tell what's going on from what you just sent
this is what I've been waiting for
Cool - I might try similar ... 🙂
try it with the truck lora
Lol SDXL won't generate anything good at lower resolutions. You need to use at least 1024x1024
Which software is this?
good call
toally missed that
ComfyUI, but beware, it uses nodes which are EXTREMELY DANGEROUS
comfy
yes, many memes will tell you how terrifying they are
Dangerous how?
It's not I'm joking there's just a lot of memes lately about people who don't like the node based stuff
Is there a way to reuse the same prompt that I used immediately before without having to copy and paste it back into the discord channel? Want to edit it slightly.
I'd imagine you could try it and see what happens
To edit u must copy+paste
If you press Re-do - it just sets off without adjustment
is there a node, that gets all important meta data like prompts, samplers, resolution from an input image, so i could split upsampling to a separate workflow without any drawbacks?
When I was doing anime at The Bot - it let me do as many as I liked. When I started doing bath tubs etc, it kept telling me to "go and vote!" Seems the Bots are looking for a specific kind of input!!!
jps, just drag and drop the image into comfy
@hardy cipher i want to create a separate upscaler, that just takes an image as input and does upsampling with the prompts from the original image without copying those prompts manually. so the image loader has to fetch the meta data and provide it for further processing. would be very helpful for any kind of img2img, not just upsampling. even for txt2img it would be great, as you could import an image from another user and test their prompts in your own workflow without manual copy&pasting.
try 1024 x 1024 for sdxl
I don't know. might be a node or nodes that could help. but you'd have to dig for them
if you add lora nodes and img2img with refine model,it will load with more VRAM after i test with comfy workflow,anyway ,diffusers just updated their sdxl lora gradient checkpoints,maybe now we can run with 16G VRAM
i am using winston's
"yeah controlnet is not really a model modification, it's an extra model" - quoting comfy. also, I think in the SDXL 1.0 stage they stated that controlnet is kinda ready, but the model files are so large that it isn't really an option to any regular user
but first I am using a1111, to compare my different lora files
to check which is better
I'm running base with a lora on my laptop and it's using 3.4GB of VRAM
reddit
0 votes and 0 comments so far on Reddit
Stuck again making a Windows Symlink - anybody care to refresh my memory? 🙂
i installed https://github.com/ltdrdata/ComfyUI-Impact-Pack but i dont have the FaceDetailer node. how do i get that one?
GitHub
Contribute to ltdrdata/ComfyUI-Impact-Pack development by creating an account on GitHub.
you probably need the models. so click the button that says models. and download the models

lolwat?


sorry innly just seen this,(operation reasons) did you manage to sort in the end?
great to see you back. hope everything went well?
aye not even needed any pain killers , the joys of going private rather than NHS lol
oh yeah?
have you downloaded the truck lora?
it's trained on trucks
not trains though, unfortunately
is there a train one?
I wish, just trucks for now
Latest surrealist batch from Torcello Towers 😄




i want a deepsea diving lora
I want a fatman-in-a-bath-LoRA 😄
there's an underwater lora that looks like it's for people that want to see someone drowning
wth
xd
I mean, you tell me https://civitai.com/models/122740/underwater

Only for SDXL
This looks cool - bubblesome reflective watery art coming up! 😄
be careful on civitai, well for multiple reasons. but I have it set to only show things from sdxl right now. but then they introduce this new homepage thing that shows downloads I might like . didn't even realize and download some cool looking loras. everything looked like trash. so turns out they were 1.5 loras
dirty trick, I tell you what
So, where does a LoRA fit in the ComfyUI chain?
right after the checkpoint
connect lora loader after checkpoint
OK, checkpoint and LoRA together?
that's standard operation
Thank you

Have you checked this? It has all you need to get started: https://comfyanonymous.github.io/ComfyUI_examples/
She made from Lego? 😄
pixel art lora
Thank you - some light reading for later on 🙂
I've seen a voxel one for SDXL I believe yesterday!
drop this image to copy my workflow
its not that good
i tested it
idk maybe its me
i tried few batches and it was hard to get something good out of it
The examples on the page did not look bad but good to know, I'll try it out
I don't get any jokes
sadly I do as I am both
a) a brit
b) older
Lol


@inland vessel Hehe the pixelart lora tend to make grids for me, but nice example of using the nearest upscaler with it!

On 10 gens I had it twice, maybe just bad luck!


Now do zuck 😅
Your worklofw untouched just using the Voxel Lora... not bad!

whaat
i couldn't get that
i even used more advanced workflow
to test the voxel
epic
("replaced chick hot thick ass" with "black muscular man")
ima try it on this one then
LMAO
ima try voxel again
his toes
It needs a keyword maybe you missed that? voxel style must be in the prompt



Strange the only difference with yours is that I use easynegative
Zuck when fighting Elon Musk in Las Vegas
Lol not working well, but interesting base:

Strange now I have the same issue too.. Maybe interesting in img2img though
i just realize one thing
Do you able to use easynegative with SDXL?
somehow my generation in A1111 is faster than SDXL
you cannot, you need another textual inversion trained specifically for SDXL
there are some actually, people are pretty fast
I do think so
you can try
This is based on easyneg I believe yep: https://civitai.com/models/118418/negativexl
https://huggingface.co/gsdf/CounterfeitXL Negative Embeddings D…fixed
I use the A one
They just updated the D

アニメイラストにする力が強いらしいです。 手もきれいになりそうです。 It seems to have a high ability to fix hand. They say that the power to make animated illustrations is strong. 好...
they are also called "embedding" in SDXL now
instead of Textual Inversion
I think comfy always refered to them as embeddings
Is this specific to anime?
seem like it
when you make sure that your dataset has a high diversity of ethnicities
❤️
SDXL > LoRA v1 > LoRA v2
Same seed, same prompt
a boy --neg worst quality




What is lora v1 and v2?
No Lora used

This is SDXL?
Yeah XL

wait
why the hell textual inversion show nothing when my folder are full of them
bruh
The Lora seems to have an high tendency to make orthographic far away scenes, so I think it doesn't contribute much to the ones I posted
Showing where?

Ah sorry haven't used a1111 in a while
there is only the negativeXL embedding in the folder
in the same time I loaded SDXL in the webui
They are trained LoRAs for a style.
Each LoRA was trained on generated images of previous versions.
The images show
Original SDXL > our LoRA v1 > our LoRA v2
v2 was trained on such images (all generated by v1 of our LoRA)

wish i could get the skin less soft and photoshopped:

https://huggingface.co/SargeZT controlnet models for SDXL. Has anyone tried them?

depth and seg are already uploaded
@hardy cipher where would i find those models ?
whats the comfyUI manager ? how do i start it ?
wow, first img2img attempt with sdxl. "a woman in blue dress"/"a black woman in blue dress"/"a blonde woman in blue dress". 0.35 denoise.



the way the model understands the image and changes only that you ask it to change respecting the rest is amazing. no mask and inpainting is going to be necesary anymore. LOL
i installed the comfyuiManager but when i click on "manager" in the browser ui, nothing happens
did you restart comfy?
did you restart the browser too?

yes
i didnt have the point "manager" there before
so something did change, but now when i press it nothign happens
all i want is the faceDetailer faceRestore nodes 🙂

have you tried a different browser?
Looks like we did something right:
This generated image (of me) is untraceable by AI-detectors (using the-hive here)
https://thehive.ai/demos?hash=tGGqaDHktgQpR5hceJyCUm2ftrR0Q2eOqgzmNJ6+e+9+409UdPa2l8mJC9FZHvQRLievOuEpzydKCZwTTNQ71kDWeFvNUHzDYUs/lPjJXZHMrCeay4SB53g1QbWlF1lgE/UyZ8tcK1qN67X8yXWvBk0Z4JdGdn9eGIkuTWWsxmJMakBoThv1lb3souxLC9jOtWIY9sXDnaIrRx53CkuZglfhUjNlC1dsLwIWCwJjFYoCv35xuAZW+hNGP9qwWaZe2orVf0F2lmvjVxCe8bvI+ulKzrfbtp7+PDfDKDAl9FvJaAjhkaQtWW3zWVZyf58MjdCSzvjCrK+1AwvuMhGoGrzv2lHJeSOQomlxVzb23aMRu1Ssfl7O2BJBYnuWd8D/jm0YZ62XSKYubVYGM/SV9dlaJPso//54ZfwcSa+lr5ecvRvBxfDqZQYbDeCbdx/aBDUEcjhcJkSmUZip2Ha4tU/Zpq1DwDi51kwA96F/b4L0GZ4V0cLD62tvFbRPyMXF


you see this

how can i fix this
This Underwater LoRA's looking good ... images to follow
tried updating comfy?
will try, sec




update comfyui fixed the problem
now what must i do to get faceDetailer faceRestore ?
Not so much Under water - as water itself!
open manager and search
interestingly it thinks sdxl is midjourney


Just d/load two or three and see which works better for you
its all models ? is a model a node ?
i m not really sure what i m doing here right now 🙂
Click on Install all three face_restore items ...
Then go thru each of them one at a time and see if they are of any use?
@zealous horizon with how many steps did your train your lora?
(Gee whizz!!! I'm a "Symlink Maven" now ... !!!)
It uses certain analysis, (probably looking for artifacts)
Since MJ uses SD it will make false asumptions.
Also if your gen does not contain such artifacts. it just fails
This one is detected at >50% not generated

this is generated on SD-1.5
also note: 0.0003 likely to be SD
See what this Underwater LoRA can achieve (when its not actually UNDER water?)




is it possible now to train textual embeddings with sdxl and a1111 ?
still no controlnet?
Comfy said to me that embeddings are not yet implemented in CUI - altho u can use .pt files already trained in A1111
This German YouTube tut (with subtitles) tells you how to use .pt files (embeddings) in CUI https://www.youtube.com/watch?v=TnBNTom_n88

In diesem Video tauche ich in die Welt der Textual Inversion ein und zeige dir, wie sie deine KI-generierten Bildergebnisse deutlich verbessern können! Textual Inversions sind clever zusammengestellte Begriffssammlungen, die deine Prompts optimieren und das Beste aus deinen KI-Modellen herausholen können. Begleite mich, während ich demonstriere,...
It does not tell you how to train embeddings in CUI
I was wondering the same thing. Anyone know the status of Controlnet?
10 epochs at 20 repeats on 10 highres images
Used epoch 7 at 0.9 weight
i wanted to use a1111 actually, for textual embeddings, not comfy
like back in 2.1
because i want to output each sample, one every turn
and that doesnt really work with comfy
just 10 images?
so its around 2000 steps
and you achieved superb quality
I made embeddings with one every 50 turns (with 15,000 max turns) - my computer is overloaded with .pt files!!!
Even 50 turns makes usable embeddings
Yes, 2.1, 1.4, 1.5, 768 ...
yes and no. here's a zoom of the "untraceable" image
I think the tool (the hive) is crap. But yes. the quality of images is quite good.
Using diverse poses, backgrounds and clothes (minor touchup with photoshop on the dataset)



did you train an embedding or a lora @peak dove ?
can someone tell me where i find a "bbox_detector" node ? and what that even is ?
did you do it wiht a1111 or comfy ?
You cannot make textual inversions in CUI - all my embeddings/ti's are with A1111

But you can use textual inversions/embedding in CUI after u have made them in A1111
Can't read red-on-black!!!


i got this now:

but it doesnt have the SAM thing

it cannot find the path
which makes sense, since its in comfyui\models\sams not comfyui\models\sam
maybe some error in the autoinstallerthing?
its like broken twice ...

its going d:\ai\comfyui\comfyui\sam instead of d:\ai\comfui\models\sams ... but where could i configure this ?
Something to do with face detection? https://github.com/ltdrdata/ComfyUI-extension-tutorials/blob/Main/ComfyUI-Impact-Pack/tutorial/advanced.md

GitHub
Contribute to ltdrdata/ComfyUI-extension-tutorials development by creating an account on GitHub.
it does have to do with facedetection, yes
current error is:
Error occurred when executing FaceDetailer:
Could not run 'torchvision::nms' with arguments from the 'CUDA' backend. This could be because the operator doesn't exist for this backend, or was omitted during the selective/custom build process (if using custom build). If you are a Facebook employee using PyTorch on mobile, please visit https://fburl.com/ptmfixes for possible resolutions. 'torchvision::nms' is only available for these backends: [CPU, QuantizedCPU, BackendSelect, Python, FuncTorchDynamicLayerBackMode, Functionalize, Named, Conjugate, Negative, ZeroTensor, ADInplaceOrView, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradMPS, AutogradXPU, AutogradHPU, AutogradLazy, AutogradMeta, Tracer, AutocastCPU, AutocastCUDA, FuncTorchBatched, FuncTorchVmapMode, Batched, VmapMode, FuncTorchGradWrapper, PythonTLSSnapshot, FuncTorchDynamicLayerFrontMode, PythonDispatcher].
you don't need the sam model
what does it do, why dont i need it, and whats with the torchvision problem ?
@peak dove could you check private msg ?
you only need the bbox node for that detailer node, the sam model from what I think is happening takes the mask from bbox and creates a new mask based on what it thinks the bbox is pointing at
OK - what's it say?
so its pretty easy to train celeb faces?
all the images on the web of celebs are edited profssionally
"can you help me with how to setup a1111 for sdxl and making embeddings ?" 🙂
@west breach i have that "could not run torchvision:nms problem still, even with out the SAM node
Is anyone getting the hang of sdxl prompting? Seems almost impossible to get someone to slam into a desk or do a karatekick in the air. Need to wait for pose controlnet i guess?
not sure, never seen that error
I think if you train on perfect images and do several highres fixes + upscaler (I used Skin_Diff) any tools attempting to detect AI will have a hard time.
The example I showed doesn't even have metadata/exif stripped. It came right out of ComfyUI.
Prompt_g: Man sitting at a desk, slamming his hand on the desk as hard as he can
Prompt_l: man, sitting at desk, slams the table, angry
If i understand sdxl prompting it should be something like this? vision table on the main, and short tags on the other?
Does anyone get this error with comyui/Searge ? "SyntaxError: Unexpected non-whitespace character after JSON at position 4"

{kind=link}
Hello! Is there a better Vae for SDXL than the original VAE that was released with the model?
put it in chatgpt
Tried to make him slam the desk, but he seems to be preparing the slam. Warning the table. Do I need more steps maybe? 🙃

How to make embeddings at A1111 https://youtu.be/7Lxdk89W2K0

Want to add your face to your stable diffusion art with maximum ease? Well, there's a new tab in the Automatic1111 WebUI for Textual Inversion! According to the documentation it needs 12+ GB VRAM, but it seemed to work in about 8 GB for me. Probably worth giving it a go and seeing what you can add to your stable diffusion art. Do let me know if ...
such embeddings can be used in ComfyUI - but are not trained at 1024x1024 - so the results could be interesting!
might need to install torchaudio, torchvision or reinstall pytorch with the correct cuda version? not sure.. just guessing base on a google search
I believe there's a Vae fixing the watermark on civitai. I've never noticed it, but here's the link anyway:
https://civitai.com/models/117188/sdxlfixedvaefp16remove-watermark

This is merge model for: 1. 100% stable-diffusion-xl-base-1.0 and 100% stable-diffusion-xl-refine-1.0 https://huggingface.co/stabilityai/stable-dif...
some abstract face

Some more Underwater LoRA results using Sytan's w/flow




accidentally got it lineart