#✨|sdxl
1 messages · Page 18 of 1

@upbeat summit

ooOoOoOooo



it is like a frog monkey superhero
ooh
lmao

a stunning portrait of the cookie monster

Theres so many people where it's really close, but just off
like there was a 3way between the hulk, lesser monkey, and a frog
hey does anyone know the hour/s of the day that most of the significant 'announcements'/releases occurred?
by Stability
SD 2.0 came out about now in November
I want to see what they'll say for 'recommended' workflow
like how to use the models and how to do the styles, etc

• 😱
The workflow I started using for SDXL is not recognized as the "correct" way to do it by staff, so I will be hoping they suggest mine haha

well I think it is great that we can do whatever the hell we [all] want, but I also would rather start at some place that is pretty good based off of the bazillions of votes and data they gather from here haha
have u tried your workflow with load image and vae encode nodes,i mean img2img,i just tested.it can't work well
and then move from there especially when I see more rigorous comparisons
I'm also collecting SDXL prompts, currently collected like ~15000 over the last week
woah

I'm guessing that has/will have a SDXL 1.0 section/tag/filter soon?
I hope so
I'm getting like 2000 new prompts per day, since I only collect Showdown prompts
The regular bot-X prompts are super nsfw
Showdown is like 7% NSFW by my calculations
soon to be like 50% 😛 hahaha
I hope not
well j/k not sure they would do that here anyways. but NSFW makes the world go around AFAIK. but I can appreciate NSFW and SFW.
I have not at the moment, however I do have some ideas as to how I could potentially get it working p
can't wait for you sharing
How long after SDXL drops can we start asking about SD 3.0?
When SD 3.0?
So u know what works for sdxl nsfw 

Yeah I do
Soon(tm)
SDXL 1.0 Soon®
I can tell you that just adding 1girl increases the image's NSFW score quite a bit
In the prompt I mean

And also women outnumber men 4:1 in the showdown images
It's not difficult at all to get nsfw on SDXL
People still crying about it because their "gape" tag doesn't work
So danbooru tags?
yeah
that tag alone can strongly skew the image
So please, don't make images with that
Cuz I want clean images in the showdown for my dataset
people are gwoss.
gape might not, but leg spread sure does, I've got hand crafted filters now
And people asking for "anatomy"
As in literally, anatomy
gn8 all and have fun! ttyl - today's gonna be the day!

When I tested. It would do upper but not lower.
yea it introduced changes to the top
i found a way to fix the eyes!

wow so realistic, please teach us
Alright, I am here specifically talking for now
mom and i are out to dinner and I can't use comfy without a flat surface haha
pumpkin grimlen

Any advice for killing the text that likes to pop up in various places? It's present in almost all generations seemingly regardless of sampler.
I've tried heavily biasing the negatives with things like
"symbols, watermark, text, writing, signature, artist signature, "
but it seems to be an almost ever present part of certain prompts, seemingly regardless of seed




sounds like something old people do lol
Hi Helen, how ru?
I will old people your face >:C
lol


damnnnn, this restaurant only has one waitress right now

I wonder what happened to the others, they are super overwokred right now
come on man, don't be as bad as the mods lmao
I almost said something a little problematic, so I changed my message before sending
also ew, I do not recognize you
Your PFP looks like a botched Bea Arthur lmao
its betty white
stunning portrait of an overworked waitress at a restaurant, cinematic, epic

helen mirren
Really? It looks so much more like Bea Arthur lmfao
well it sure as hell doesn't look like betty white lmao
i'm pretty bad with celeb names, but that's what came to my mind
or Bea

Thats not what Bea Arthur looks like




i'd totally eat cookies out of that


@high skiff 

chapples



Talking Shid Taking Shit 
@high skiff bear cat 😁

What time is SDXL dropping?
What is the deal with the pruned fp16 model I keep seeing? What are its advantages, and is it publicly available?
it's already out! we've already been using it
Link?
bear cats

He's doing a little bit of trolling 
pruning and converting to fp16 are ways to make a model easier to load, and you can do em yourself with just a lil bit of technical experience and/or any updated UI that supports it (eg auto webui's checkpoint merger can do it).
If other people are reuploading models like that, uh, I don't think that's currently permitted for the research release due to the temporary strict licensing so probably avoid those for now
Good to hear confirmation that that's temporary lol
Ah ok, thanks! For doing that myself, will the old version of a1111 work for that, or is there an updated version I would need to use?

This is fantastic!
mcmonkey is typing
hindustani ghostbusters

Wait to be clear, would I be permitted to do that for myself and not upload it?
If it's strictly for research purposes I'm sure
Yeah
Its already 5h late in london time
They didnt say 12AM

THEY SAID THE 18TH and LIED
its still the 17th here lol
so meanwhile, i'm using this pheonix optimizer on 0.9 loras and wowwweeeee it works good with 10 images
I also think people should note that its not guaranteed to launch today lol
oh? Whats this you are speaking of?
set your clock forward to get access to 1.0
I am gonna go home and mess with some SDXL LoRA's
newest kohya has a new optimizer thats a derivative of dadapt
grated, 1.0 should be releasing very soon lol
It's July 18th 6:15pm in Kiritimati Island
as long as you're not uploading it you can do anything you want lol
0.9 loras should be able to merge with 1.0 loras so not bad to mess with
does anyone have a good sdxl workflow?
wink wink
yes
I am away from my PC at the moment tho
ok nw
I am gonna go home and write up expanded documentation on how to prompt
we're on the cusp of a release event. what happened if they had dropped it at midnight. not very prepared
Do you plan on adding a text l field to your custom node? I'm loving the styles you created btw
Wtf 40 gb?
Imagine that MegaModel guy on Civitai right now 🤣
I will nuke you lol
I am at an akward middle ground where I have no idea if the final release will have a refiner

if not, then my workflow is useless now and diffusers changed their code for nothing
half expecting them to merge sdxl into sd 1.5
Cause I would put out my workflow later tonight, but I have 0 idea how compatible it will be with 1.0
it'll blow people's computers up. they're all gonna laugh at you
Thats not even possible 😅
Teasing us 
Emad mentioned a new refiner on Twitter, so trust that as you want.
The way it works now is it concatenates the prompt from the styles.json file with the user prompt and feeds that into the clip_l
He said its done, which means it could be done as in done training, or done as in this is the end of the road for it
just average the weights, bro. just add them all up and divide by two. new model is torch.tensor([3.1253])
They are based in london. So they are late but not that late lol
they'll release the beta refiner renamed as 1.0 lol joking, but it still works if that's the case
Yes, but the latent scaling would be very different
ahhhh i see
SD 1.5 is a square 512x model, SDXL is a 1024^2 equivalwnt multi crop model
Chances are the 0.9's refiner should work 1.0's latent images, so even if 1.0 refiner won't be a thing, we still can use it to add a little bit of details.
But that might not be mandatory
That is true
yeah, I am in an awkward middle ground
cause on one end, I want the refiner otherwise my contributions to comfy and diffusers are kinda pointless, but at the same time, training LoRA's and such would be so much easier with no second model to worry about
will people train loras for the refiner you figure?
I'll be in the same awkward middle ground until tomorrow lol
Thats the biggest concern
The idea that eveyr LoRA would need to be trained for the base and the refiner
The license tho
embeddings as in TEs?
yeah
*TIs?
I can't read this as anything but done training.

oh, thats very nice to hear, how have they been working in comfy?
kohya has support to train sdxl TIs
pretty well! i could tell it had effect but my training params i know sucked
alright, in that case I would likely agree, tho Emad is about as reliable as a house of cards in amn earthquake
"you're finished! DONE! you hear me? You'll never refine in this town again!" -emad prbably
I would not be surprised
We made a new type of refiner not compatible with Sytans workflow, we just finished it
also, flowwolf, what happened to you? Why are you new here now?
The refiner has been sacrificed to this thing and is now finished.

lose your account/leave?
Well, I am not using it commercially now anyway, and it's unlikely that the model police breaks into my house to remove my fp16 pruned safetensors copy, in case SAI won't release the updated version xD
left. i was wasting a lot of time here and got fed up. but now i'm excited again
Ok, you don't have to come for my throat with such hot guy gens, SMH
fair enough haha
alright, so when I get home I will be writing better documentation on what I have learned for SDXL in general related to my workflow
including info on why I made the choices I did, and some ways to better suite other styles than just realism
That's good.
I've heard someone claiming 1.5's TIs work, but my testing shows they are extremely erratic, since they only affect Clip_L. Some of them are erratic, others are just... Goofy?
So even though they do work, they aren't useful with SDXL 0.9
I would be interested in trying out TI's if they end up working as good as some people are theorizing
well, like, one of the text encoders is the same clip used in 1.5 right?
legitimately asking, i dont know if thats right
Nah. Even in theory, they'd only work for style embeddings.
And even those don't work properly for some reason
Oh also, I would like to mention that I will be releasing a more complex workflow, and a much more simple workflow with only 1 text encoder for those who seem to think my workflow is terrible cause it can't work well with single word prompts 😅
yeah
I believe its Clip L
IIRC, clip L is the same from 1.5, and clip G is the new natural language TE
I have quite a collection of TIs to test. There might be some random lucky one that does work, but that's pure luck. Most of them either don't work at all, or they reduce the output quality.
textual inversions on clip L i could see being some kind of effective. maybe there is a translator that couldd be made to affect the dual encoder with old embeddings
which is how they are split and addressed in my workflow, and I will be adding more documentation towards that as well
errr
if you have TIs to test, are those from SDXL?
or are they 1.5 TIs? because those will not work, you have.. ya know, nvm. i'm too lazy
i've heard the murmurings that people have old embeddings working too, but thats one of those i'll believe it when i see it things
No, I am talking about 1.5 TIs claimed to be working.
Technically that claim is correct, to a point. But it's not really useful.
prompt: snoop dogg, style: padam


It would make sense i they work for CLIP-L I guess

color pencil, it's a fantastic style. I wanna thank you again for making your workflow available
How do I update it btw? Can I just git clone it again? @west breach
open a terminal in the folder and run git pull
ignore the horrifying faces in the background

I will say, if you manage to get a photorealistic style that preserves a deep depth of field, you will have solved a ton of peoples' problems. I've seen a ton of people trying to get it working @west breach
do you mean without the background blurred?
yeah
i doubt sdxl has a violation on celeb generation
From what I've noticed, the prompt "shot on iPhone" OCCASIONALLY works
or at least helps
ok interesting. I'll give it a go! 🙂
Thank you!
already at 709 words in my documentation for SDXL, and I have a ton more to share


thought id share some of the images i made tonight


icky!
Would be interested in this as well!
i am half day through and still didnt get 1.0 😭
@hearty ginkgo@fair crowhttps://github.com/SytanSD/Sytan-SDXL-ComfyUI
Here you gusy go. Please stay tuned as I work on new information, and a couple new workflows to upload as well, including one that plays with my fractional offset diffusion for better tonal contrast, and also a simplified workflow that utilizes just one positive text encoder for those who do not want to mess with dual text encoders
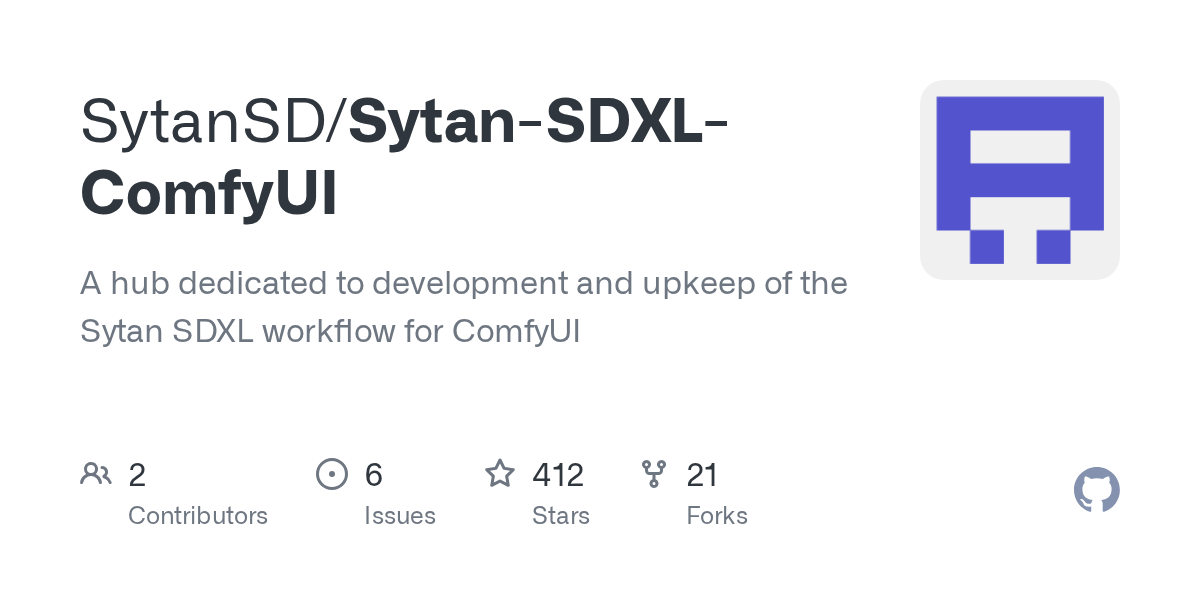
GitHub
A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI - GitHub - SytanSD/Sytan-SDXL-ComfyUI: A hub dedicated to development and upkeep of the Sytan SDXL workflow for ComfyUI
Thanks man, truly appreciated!
just reached 1000 words on my new documentation I am writing up
No problem! Hope it serves you well!
They are in London right? So probably still a few hours until they release it
It’s like 6:30 am over there
hopefully
is there suposed to be something new on your github?
not at this moment
just sharing for other people who don't have it yet
I am working on new stuff tho
oh im dumb yeah i see that now lmao


nice, thanks for your efforts! they will not go to waste.
Thanks very much I have been using this one since last night added the ultimate upscaler node also I sent you a dm so u have it if you don't mind when you finish the other workshops and don't mind sharing please give me a dm or @ me

WIll do. I will have another workflow with ultimate upscale baked directly in at some point, though I need to figure out some strange issues with it before opening that to the public

Does SDXL understand natural language? I was using 1.5 & 2 mostly with comma separated keywords but no setence.

Great, Comfy bugged out and refuses to work for my workflow now
It won't load any workflow for me
I love this art style you've achieved
Probably going to have to throw away 30 minutes of tedious work because of the buggy primitives
And I dont even know if I can add all the features I want now
It's almost impossible to add inputs to existing nodes
i know this feel 😦
Thanks!
I wish it would give an error instead of the queue prompt button just not clicking

yes
I can get it to run now thankfully even though its not an elegant solution
yes, one of the text encoders is made for natural language
Maybe someday I will clean up this massive animation workflow and put it online
Go through your outputs from 1.5 lol
preferably nothing too extreme that will really stress SDXL lol
When will it be publicly released ?
so cool
they are all hot guys and realism gens lmao
July 18th, likely the date where you are
Oh so today
I'm new to this and not sure how it works but, once released, can I use the checkpoint or safetensors in Automatic 1111 ?
@west breach @boreal bough You two fella's got any ideas for test prompts?
Linguistic: A thrilling photograph capturing the fierce battle as a pirate ship sails through stormy seas, cannons ablaze and crew members engaging in a dramatic fight against rival vessels.
Supporting: maritime adventure, historical reenactment, naval warfare, dramatic lighting, crashing waves, billowing sails, intense action, immersive storytelling, high energy.
Fundamental Negative: Blurry motion, lack of dynamic composition, unconvincing battle scene, dull colors, poor detail, lackluster atmosphere, uninteresting framing.
oh wow, you got it all formatted as I need and everything haha
a man doing a cartwheel on a bicycle 😄
Idk about those negatives bro
I will have to trim this down as it is pretty intense, but I can work with it!
try them
Maybe I'll give them a shot but they seem sus
i was lazy lol i just inputing systan prompt guiding and the orginal postivitve supporting and netigtive terms into chatgpt
anyone else having issues with the refiner adding text to seemingly everything? 

@slender coral You excited for SDXL?
@deft quiver Yes, when CFG is high I've noticed it.
i just did those it was ass ngl
Even at cfg around 3-4 it seems to crop up alot, you can see the patterning crop up in many places as well. Really unsure how to fix
try using an unprompted unguided refiner pass but that actually made things worse


I am redoing the prompt susbstantially, but you have me the inspiration haha
lol
trying to turn it into a wood carving mural lol
I wanna give prompts that have very different styles for people to poke at
I am pretty happy with this haha

this is the best i got with midjournery that your competition @high skiff



yeah no idea, it's almost like the prompt is inherently too noisy



I love this
I don't try to compete with midjourney. These are supposed to be prompts just to show people how to use SDXL
wow that a lot of text everywhre
midjournery is a pain in the ass to compete with
yeah I have no idea how to fix it
What CFG is this?

would someone sanity check that this isin't just my generation setup
"Cosmic Shark Octopus Warrior, volcanic explosions in the background, cinematic masterpiece, massive scene, best quality 4k, 8k, cinematic art by Tom Bagshaw"
its likely the 4k and 8k tags
running but my pc is slow so give me like 3 mins
call me crazy but try "background volcanic explosions" rather than "volcanic explosions in the background"
I would recommend "With a volcano exploding in the distance"
over processed but still cute... any suggestions on how to get it to be less smoothed out?


Maybe it's Tom 🙂
like my corgi :>
oh, maybe get rid of background entirely? -could be hitting wallpaper instead
Wow now I get the MJ hype 😅

well the only reason i actaully use mj is because my dad pays for it for his businness instead of paying like 500 a month to istock for images
yeah even like permutations of prompts and artists


does not seem to do much
lol
chronic text

hmm I wonder if it's my generation setup

Nice carving!
trying to diversify my 5 sample prompts

This is a fantastic style
Sytan what upscale model are you using? Is the 4x ultrasharp good?
if it's a markdown/rich text format 100% create a summary with refs to all the categories
my PC crashed lmao
how
I got too intense on my OC lol
3090 or 3080
how is it
amazing
now that I can run both models cached in VRAM, and also benefit from the new nightly torch VAE that is basically instant, I can run images more than 2x as fast as on the 3080 while using the same power
nightly torch vae?
from 11.6 seconds to 5.2 seconds
2 more weeks, i guess
nice argument why dont you back it up with a source
there is a nightly torch build that allows for a BF16 VAE, and it can do even like BS 32 near instant
for me, BS 8 is less than 1 second to decode
@winter raptor how are these? any prompts to try?




bf16 vaes have worked for me for a while. < 1 second on 1024 but > 1 minute on 2048
i have no source because it's the most obvious route
Those are really nice! Try generating a man standing in a cyberpunk city street, that has given me a ton of trouble
why? lmao
they pushed it back, no way it's coming anytime soon
and where did you see that?
i don't think im allowed to share it here, will send you a DM

if you can't share information, then don't message me lmao
finally

oh shoot rocm 5.6 was marked as ready for merge in torch an hour ago. New nightly tomorrow hopefully 🤞
D-ID ban for celeb uploading image,damn
i can't but i must not, but i will
LMAO cap send me the info
bro is just flat out lying lol
i believe it
what he lyin about?
let's see it
Has 1.0 dropped yet?!
it's getting delayed apparently
huh
In the UK it is 18th already! 🙂
you asked for it and i'll blame you if this gets me in trouble
https://www.reddit.com/r/StableDiffusion/comments/152oey2/comment/jsf2oih/?context=3
reddit
0 votes and 6 comments so far on Reddit
no timezones matter but hte USA

It's the 18th in flroida USA but it dosnt even matter the model won't drop till atleast work hours start if not later during the day ingeneral
sad truth
even then, it was just a goal, not a promise lol
expect dissapointing official news in the morning
Thats unfortunate
florida, texas, EST, CST is already 18th but not PST
and where is this from?
4chan, which got it from reddit.
cries
i mean joe commented in the reddit thread
4chan and reddit? I couldn't imagine two more credibles sources of information
don't expect much

why are u acting tone-deaf joe is literally in that screenshot.
Wow!!! This is awesome
the man is literally there

tone deaf is not the right term, and my bad, I forgot that people haven't faked screenshots about SD before
screenshots of text. usually fake
where is this post?
https://www.reddit.com/r/StableDiffusion/comments/152oey2/hi_guys_is_sdxl_10_released_today/jsf7p64/
reddit
0 votes and 6 comments so far on Reddit
its litreally above u scroll up 2 times
blud
the reddit thread is real, someone from the staff commented on it.
Vlad AUTOMATIC1111 SDXL 0.9




idk what would someone even gain from faking smth like that lool
giggles
alright, that's a little more concrete in that case
Hey guys is 1.0 out yet.

bro, people in this community have faked shit before lol
if more time = better model, sweet
unfortunate though
I was just messing around. 😄 my bad.
i've some datasets ready to be trained
Well the last version of the refiner to model to ever release is out so like 50%
finme by me if they are finding a model thats better than the current base 1.0, cause I am still not too happy with base 1.0
screenshots of text are always faked. woven bullshit usually. wonder what joe talking about but screenshots of text are just dumb
tho it does seem to be that they confirmed that the second pass is staying, which is good to see
I think you really nailed it
guess I just play more skyrim for a while
I am going to sleep lol

What exactly is 1.0 releasing that 0.9 doesn't have? Just more training data?
an indefinite delay is an indefinite delay, a better model might come but it also may not
the chance is there
havnt decided to delete refiner or keep it yet
yeah, tho it seems that now we would be able to see what its like
I expect they will release it today anyways but I still need a little bit more time to work on my workflow so I wouldn't mind
welp, oh well, gives me more time to write my docs
we can't ignore the possibility of cacellation
its not gonna get cancelled lmfao
Yeah we can lol
if you git pull, there is a new style called deep-field. it's still hit or miss. had to put landscape and panoramic keywords to stop the blur, so it does affect the composition away from portrait photos a lot
bruh there is absolutely 0 shot it gets cancelled
then you are just being a fool
I doubt it. we can pretty much finetune 0.9 to improve quality. they're just making a better base with good parent data so finetuning is easier
like, sure, delayed, I'll give you that
Cancelled? Thats just stupid lmao
i have doubts if they really think they came upon a breakthrugh then they will wait, they are scared of 2.x reaction lol, but also pls train more nsfw
I mean never say never but dumping hella money into a model that's been performing well just to cancel it is kinda wild
Its clearly delayed but it will not be canceled lol
if that's what you want to believe, so be it.
oh snap, the text problem was being caused by xformers memory efficient attention
nah i belive it
What would the motive be for them to release research weights and then cancel, trying to get people to use their paid API while the weights are wrapped up in a restrictive license?
sure. look at base 1.5 its dogshit. finetuning can literally do wonders
text is more memory efficient than pixels obvs
you said it, i didn't
how does that not cross your mind lool
pog, it's not ruined anymore


I can sleep tonight
lets ignore the text on her shirt
oh well RIP joe. nothing like a leaked info to make your workday easier, for a decision you dont make yourself ^^'
person who makes images of lovecraftian sea horrors
Anyone know what teh diff between 0.9 and 1.0 may be?
at least 0.1
and be stuck in a model finetuning hell until the cycle repeats? sure beats being stuck on 1.5
No refiner for 1.0
😄

It's built into the prompt?
0.9 exists
Only base model
I like the refiner though.
Surely additional training for NSFW should come from the Community rather than SAI ?
I'll give it a try, it's not a huge deal if it prevents close ups because typically the background will matter less there. If I come up with anything I'll let you know, I really appreciate all of the help and work you have done!
nothing wrong with finetuning a model to improve. finetuning in repeats are good. (it just crossed my mind that you're pretty but clueless abt finetuning. are u new or just never has finetuned anything before)

and so begins the delves into #conspiracy for the next week
it would be better if it came from SAI built into model, it would make it easierfor community/finetuners to train it,
thought we couldn't do gifs
they added it like 2 days ago
easy to train a concept it already knows vs training froms scratch
I am about to test that theory
still a SFW official work server - wrong server for this type of conversation
I wouldn't mind a push back, like Ive been mentioning I would like to see SAI finetunes like Anime, Photography, and Traditional Art
i remember when that wans't an option
now that we have some more time before 1.0 launches, I'm gonna make a LoRA
but remeber what may be klegal in one poart of the world may not be legal in anaother. Why should SAI expose themselves (no pun intended) to excessive risk of complaint?
Is it delayed?
have fun, god knows it's the only thing we can have nowadays
finetuning has always been an option. Optimizations come as soon as they could. shelling 100 bucks on a few A100s to tune doesn't make u poor.
yes
or skill issue ig
seems to be
Source?
i dont think that's the problem. they're in the UK and tey're safe there for ML
SAI is not gonna hand hold you. they're made as base model to be tuned
this argument makes no sense

Omg not surprised at all...
oh well, if anything, I should feel much better by the time it does release, as I am sick right now
I feel like a lot of people are misremembering how base 1.5 handled nsfw because 90% of finetunes enhance it in some way
the whole point of the base model is exactly to hand hold you
Its still a rosk regardless of where based,
expect dissapointment and lockdown tomorrow
they use or used to use loian database, they dont get in trouble the db would
thats not a source really
we'll see in a few hours
the chance is there and it's the most likely scenario
So what's the point of the bot voting if they just say nevermind we have another candidate?
anyways elsewhere, because I;m a pervert I switchd base to point at he refiner model and refiner to point at the base model

it's just such a weird thing people do posting screenshots of text in an html inspector world
whose a gooboy

they should just release all 3 candidates as SDXL 0.97, SDXL 0.98, SDXL 0.99
ah yes, using html inspector on discord mobile
that is because of the bot, u dont read, that is what post said, the bot u are voting on had very well liked photos, and those photos correspond to other models they have, so in essence the bots or "you" voted for this
how didn't i thought about that
they'll never do that
I know
yeah, just wishful thinking 🥲
like i bet we almost didn't got 0.9 out there
it was a miracle someone got it out there
It wasn't. The guys knew the leak was coming. LMAO
the alternative is to just say screw it, and release everything I have for 0.9 and start posting the training guides XD
I think its fair to say that SAI only released an official SAI in order to make it easier to stamp on the leaked versions
joe literally annoucned the leak
mcmonkey was right the the moment it got leaked in the SAIL discord
finetune levels of training can be achieved with lora now - so not like it would be a hindrence...
asked him and he wasn't suprised 
Since I don't read but you do, where in the screenshot was the bot mentioned?
"they're cancelling it" still has me laughing
same lmao

not because its whimsical and cute, but because someone said it with conviction
yeah...

Bombastic side eye
Where's that screenshot from? It's not in this server
I think that's the future tbh. A strong enough base then just a bunch of experts in the form of loras.
is gigapixel still the best option to upscale those creations ?
hope u understand arrows

no. its an ancient gan by today's standards
gigapixel as always been shit. find yourself a good upscaler from the upscale wiki
it must be an internal message or maybe a group, the message says that he will @ everyone tomorrow
topaz has been out of date fora long while

its a bit of effort to get the datasets properly set up - but the training is easy. just takes a while (20~40 hours on rtx4090)
Thanks you saved my day
already have 2 finished as a proof of concept :/

@boreal boughHey caithhhh
I have my 3090 nowwww, and I wanna dick around with some LoRA'ssssss
also, good day to you
okay this time I'm definitely actually sure, the source of text was in fact the refiner


I am gonna try kohya
Oh no I don't train I just download a hundred of them from civit and mix them together after performing a ritual to the old gods
I'll get the guides ready tonight - and give you access to my google docs.
Please try a full finetune
trained a few sdxl loras with it, works great
If you play with the lora strengths you can mix like 8 together in one inference without too much destructive interference
Mcmonkey said it should be easily doable
you want the training configs sy?
That is for later when Pseudo and I break in his A100
for now just use kohya (either directly, or via derrian)
kohya ui works... but... did odd things when I ran it - so I'm back to using kohya directly for now (due to the hourly updates)
that may have been a little passive agressive, it was all in good spirits, hope it is worth it if they do delay...
Same, I can open my stuff to you as well
Sdxl releases today right?
To when
no rumors. we dont know yet
indefinite
I will get a 3090 if full finetune actually works
wait for an anouncement
^^ a good upscaler to use on my own gui ? Curretnyl i havent figured the ui for my own pc
needs (multiple) A100 - also, not needed if you just want 1.5 levels of 'finetune'
No problem, I really didn't read carefully...
reddit
0 votes and 7 comments so far on Reddit
this guy is trolling
it does but it's extremely slow
every 5 mins another blud asks for sdxl 😭 check the announcement post

Have you done it
esrgan and a tune of it called real-esrgan are the two most popular
its not announced in this server
for gui use ChaiNNer and for upscalers get it from the upscale wiki
I got 2000 steps in and gave up, it's too slow on batch size 1 for me personally
but it does work
they'll announce it if they release later duh
on what GPU?
3090ti
hmm
this is stability's server. why woudln't it be?
for full finetuning?
but full fine tune it's reallllly slow
what is a "tune of it" ? like some extra model ?
excited to see how SDXL works with hyperdreambooths
watch them announcing a mid august release, then a mid september, then mid october, then mid novemeber, then mid december, then mid 2024
hyperdreambooth if google ever releases code
yea just an alternate version
Thanks, Ill buy the 3090 then
❤️ apreciate it will try
it does - but not how you think it does
basically, the bigger the batch size - the better the fine tune
with 24gb vram, you can do batch 1.
@west breach I got this out of it which is pretty cool

That's fine, as long as it works. Not trying to make the next NAI lol
I mean you'll get worse results than with lora training
That's fine
in that case go for it. 24gb vram is enough
I have a 3090TI. I think its quite good for AI due to the large vram and still much less expensive than 4090
however, you don't need all the vram for training SDXL. Just train Lora. Its better than finetuning anyways
I need another PC build anyways
My animation workflow is gonna involve a lot of rendering and SD and waiting around if I try to do it on one computer locally
I use a 1080ti that cost <£200 with an ek waterblock fitted, sure uits slower than a 3090 but its also a lot cheaper.
Tortoise & Hare 🙂
but its cool anyways to be not so limited on vram. Like when you want to use BLIP2 or llms you will need large vram again
if all you do is prompt 1080ti is plenty
when did they release the 1090ti lol
Thanks for reminding me! I can run Vicuna 30b now!
its typo duh
I don't think thats a big thing
I know hence the lol
they released a similar paper months ago and nobody was talking about it afterwards
I imagine it's one of those shitty re-releases
Like the 12GB 2060
They slapped 22GB of 64bit bus VRAM on a 1080ti, called it a 1090ti and raised the price by 2.5x lol
Where is the LOG file located in Vlad AUTOMATIC1111?
dreambooth is just shit. tag your images and finetune. relying on 1 tag is pretty stupid
in theory, the same could be achieved with a bit longer training, an additional regularization set of faces + a 2/1 lora. right?
You can use tags with dreambooth tho? You always could
HyperDreambooth has nothing to do with Dreambooth
the big thing with hyperdreambooth is the tiny size you get in the end
but I don't know how many people really care about small size
yes you can set 1 token to recall training data
It is but isn’t. Gens take forever on higher scales
the difference is that they train faster than lora, because the initialize the lora using some hypernetwork
Wdym you can use full prompts with your dataset
I was being nice 😭
ofc 1080ti is dogshit in current standards
its cool if you have some cloud service or online game or something like that where your users can create images based on a photo. Because here it would be a huge difference if training times take 10 seconds or 10 minutes
no dum dum. when you're training u dont actually get to describe each images to train the text encoder you use a singular token to recall the training data
ofc you can prompt
finetune exists dreambooth is just if you're really lazy
for us its nonesense. We can just train 10 minutes. We can even train 4 hours and then get results that are 100 times better than Hyperdreambooth
No? Lol
Awesome 👍
Not sure what you're talking about tbh
I think he is talking about Dreambooth as it is described in the original paper
we nowadways call every finetuning "Dreambooth"
It isn’t dogshit either. That’s what’s on my pc and i can do like 3k res on it it’s just slow as a pig. It’s a powerhouse but is old. It could do 1.5 models just tine no complaints but SDXL is a whole nother beast.
then what you're talking about isn't dreambooth. dreambooth uses a token to recall data. u can still prompt. finetune is much better since u can tag all images
but actually, it was a technique how to train on your face by using a special token ("sks") to describe your face
according to who?
Is that the proper meaning of Dreambooth? I never heard it used so restrictively
Im just not willing to wait the time. i had a 3070 before i had my 3090 and it was dead slow on gens
Bruh
so the guy doesn't know what dreambooth is
its complicated - but in sdxl, you can train over 100 concepts - fully intact, with a 43mb lora, using 24gb vram, with around 20 hours

"fully tagged"
you're talking abot LoRA

@void loom Joe a.k.a Mystery Guitar man, part of the stability Ai staff
https://www.reddit.com/r/StableDiffusion/comments/152oey2/hi_guys_is_sdxl_10_released_today/

reddit
0 votes and 7 comments so far on Reddit
Dreambooth as it existed when it was first ported over to A111 at the very least could take full prompt tags, that is the colloquial meaning of the term
Dreambooth is just a fancy name of a technique from google. Its referring to this strict workflow of tagging your images with "photo of sks person" an then finetune it. We later used this term repeatedly for describing full finetuning in contrast to, for example, Loras
If SAI is delaying 1.0 because there is not enough info from the bots to choose a candidate, it is at least suspicious, the bot works pretty simple, it makes you 2 images, you choose 1, that is the better image, and not only that, there is a lawsuit currently and the plaintiff's lawyers said Emad that if the plaintiff does not get everything he wants he will "burn down" SAI, just saying.
and I quote Emad: "Furthermore, if Cyrus is unable to profit from this situation, he seems intent on harming the company. His counsel has communicated that he would "burn it down" if he ultimately recovers nothing."
https://twitter.com/EMostaque/status/1680774535342358528?t=qHQed3zpXby_FXEiG-glxw&s=33
In the interest of transparency and to set the record straight, I must address the unfounded lawsuit filed by my former colleague, Cyrus Hodes, against Stability AI and I on Thursday.
He alleges that he was deceived into selling his shares to me when he voluntarily left the…
Likes
665



in training it cant. you use an instence prompt to describe your training data, you can still prompt like normal.
thats why dreambooth sucks
Wrong
you do you g
I see, thanks
Yeah that sks crap originated from textual embeddings first yeah?
no
I guess it could mean that not enough people are voting for their images
I mean thats the point
I remember that exact tag mentioned for embeddings
textual embedding + finetuning would make much more sense
Yeah but they tested it very early and said it was unnecessary
It was the working theory
oh, that I totally don't believe ;D
Well somebody tested it, i dont remember who but I remember it was early on
the limitation of dreambooth is that they only train the unet and so, they have to use some special token like "sks" that is not associated in the unet with anything to train the unet on your face
if you train the unet + the textencoder, it wouldn't matter. You could just use your real name as prompt and the text encoder would learn to embed it properly
Dreambooth is that you have all your training data and you would use 1 tag called an "instance prompt" to describe that since captioning .txt images were not a thing in Dreambooth. you can still prompt as normal but u would have to still use that instance prompt to recall that concept it learned.
then the dreambooth guy implemented finetune later on which allowed you to caption describe your images individually which is better overall.
idk what @civic sigil is confused abt
@civic sigil but are you just arguing for the sake of arguing about the definition of a word and its lack of past ability?
Cause if you want progress, we have it
If you want to complain about new technologies having bad names - a legit argument, but not a long one.

I am trying to learn the terminology you all are using, stop acting so childish
🤷♂️
If you dreamboothed a bunch of red cups labelled as "cup" and then prompted for a cup with the resulting model would that cup not be red?
@gentle mirage I don't think that "you cannot caption the image" is dreambooth. i mean, this are just implementation questions
Why would they wait until the last moment to announce it them?
sigh.
Hi! This is the day we get to run SDXL at home, right?
yes, but then all your cups would be red. The idea is that you can teach it a special kind of cups by calling them "sks cup"
Yeah, and that's not how you have to use it. Calling it bad overall because of how the people who wrote the paper forsaw it would be used is plain dumb in this field
Idk, i guess they were expecting more votes by the last moment but i guess they weren't enough? Idk it is quite suspicious
It’s the opposite some of their images are getting really good and received. Nd those images are from later models after their 1.0 contenders. U also no read.
We need a reading comprehension class.
I agree partly if its about this "you are not allowed to make a caption for your training data". They never claimed that in the paper
If you want to dreambooth an art style for instance I dont see why you cant have frozen TE? It works fine for me
but the point is that dreambooth refers to the idea of using a special token like "sks" to describe your concept
if you don't do this, its not dreambooth but regular finetuning
Alright fine, I concede the argument
Nobody uses the term that way anymore though lol
Bro is just trying to show off his history knowledge
• 'Dreambooth' is a word reused multiple times - often it refers to completely different (newer) techniques - some website even call all training 'dreambooth style training' - when all they're doing is LoRA in the background
• LoRA - a newer method of training, that works by applying a lot of theories all at once - and many of them work well. (however many features or lora remain unused, since they make as good as no difference)
• Lycoris - derivative of LoRA -> basically many versions of LoRA on drugs. Some good drugs/some bad drugs. Your mileage may vary - but useful if you know what you're doing
• Finetune - a full training of everything at once, hence why batch size is so important, since you dont want one picture to affect the outcome of thousands
• Merging/Extraction - its own topic, too long for one sentence
I checked the paper. They evaluated dreambooth against textual inversion. So they only checked if dreambooth works better than textual inversion alone. This is stupid of course. You cannot compare "training a token" versus "training the unet". They didn't checked if textual inversion + training the unet works better (and I'm VERY sure it works much better than dreambooth)
that's true, though
My understanding at the time was that they tested training a textual embedding as well as finetuning the model so that they wouldn't have to overfit the model as much. Maybe my interpretation was wrong since I was still new to SD back then
Probably cause Textual Embedding and Text Encoder have the same acronym lol
Could you please let me know if the WebUI already supports SDXL?
I remember they later tested training text encoder as well and found that it works much better
git switch sdxl
Yes but you need a lot of vram
If you have less than 8Gb of vram, you can still use comfyUI
But I have 4090.
How much vram?
4090 master race ❤️ (24gb vram)
but yeah. Thinks are complicated as everybody is using the terms differently. Just take caiths " LoRA - a newer method of training, that works by applying a lot of theories all at onc". Acutally, the term LoRA is very well defined, but there are so many new techniques and variations and sometimes they call themselve LoRA, sometimes they come up with a new fancy name
24
24gb
Nice i wish I had one of those, i only have 6Gb, love my little PC
I want the a100 ngl lol
emperor race be like
Training an SDXL LoRA!
Also, looks like I can use much bigger BS than I assumed
BS 4 is using 17.8GB VRAM
Does Kohyass support it?
Yeah
yes, its crazy. BS 12 is using not that much more vram than batchsize 1 oO
Kohy-ass lmfao
8 should be the max if you wanna keep using the pc without noticing the training
10~12 is the true max limit
Dope, thanks
I am just doing a low effort 20 step 1 epoch training to test the waters right now
See if it's grabbing onto anything, as I am messing with settings out of the box
So, do they have to release SDXL after work?
stay clear of faces/anatomy/words that describe the body like "legs" - for your first lora. everything else works easy ^^
I found that lora training on SDXL is as crazy as in previous versions. Sometimes it works, sometimes not. Sometimes you change a few training images and immediately everything gets much better. But overall, results with SDXL are just much better than with 2.1 or 1.5
I have done 50+ 1.5 LoRA's, so I hope my knowledge carries over haha
one thing I found strange is that when you train textual inversion then the anatomy really quickly can really go wrong
like if it doesn't like to get its tokens pushed out of the comfort zone
same. its why I'm still doing unet only
is 8GB of VRAM enough to run SDXL?
Yeah
I need to train some Lora to redraw scenes in product images, specifically areas other than the product. Is there anyone who can teach me some methods?
I then trained textual inversion on a initializer token (instead of random initialization) and with very low learning rate and epoch and then switched to text encoder training and unet training. That solved the anatomy issues for me. But maybe it also just good or bad luck. I would have to train more to understand that better
I've pretty much got anatomy training down now - but was hoping to test 1.0 if it changes anything T.T
yeah... the reason I stopped training was because I thought we would get 1.0 soon -_-
🫂
Would a k80 24gb be any good?
but given that Emad is usually writing hyping twitter messages every day before a release and we hear nothing is telling me we won't get SDXL so soon... ;_;
I'm still struggling to collect training datasets.
yeah, thats always the most difficult and most important task
It grows...

I tried using Midjourney, but when I made some changes to the subject, the image changed too much. It's completely unusable in the same training dataset.
Use mj to bot your prompts, then use those to train.
today's the day? maybe?
am I the anomaly here with 300k images saved? xD
The same prompt can also generate images with different decoration styles.
I have over 5 million so far.
i heard that sdxl1.0 will open source today,is that true?
noice!
(Cannot locate LOG file in vladmandic/automatic1111?) 🙂
Why
Who was your seller so I can avoid them lol
see ya'll later today

It just blue screened for the second time
With the same error
I'm going to hope it's just a bad driver, but I'm not sure
Video TDR Failure nvlddmkm.sys
You got CUDA problems?
No, I have video engine problems
brand new card?
Brand new to me, used from somebody else

reddit
0 votes and 22 comments so far on Reddit
I've also encountered an issue where after generating 100-200 images, it starts outputting solid-colored images. I was wondering what might be causing this.
check for any overclocks before anything else - disable all and see if it goes away/ then turn them back on over the days, one by one
(stock OC is still OC, and can be set to normal in bios)
"Whether of not 0.9 Loras will work" is so funny
We know
I hope its fake just for that
This TDR fault is when GPU switches from one power state to another ...
oh no
What's your psu wattage? I heard 3090 takes a lot

850, it should be just fine for it
Idk then but I will be spending $700 on my card just in case lol
what do you guys want made from the community most when 1.0 drops
I was running my 3080 on it for the last 2 days, and it uses more power
bios update if there is one
Good idea, it's a brand new motherboard and I forgot to check
Every time the PC turns on, I immediately get prompted to download some form of gigabyte bloatware for bios updates
Might as well just bite the bullet
TDR Power Management Issue ...
I'll inspect the cables on the GPU to ensure that they are plugged in properly
Although I will say, neither blue screen occurred while the GPU was doing anything above idle
The first time it blue screened while I was just scrolling on Amazon, and the second time was while I was going through my file explorer with just music in the background
What powersupply u have?
Cooler Master 850 watt gold plus MWE I believe
The first time I had a very severe overclock and I figured that was the issue, but now it was running completely stock, not even achieving its full boost clocks
But on top of that, it's not crashing when it's under load, it's only crashing at idle
Power Management - two competing clocks

It's a very weird phenomena, it crashed about a minute after I was done with my LoRA training
Do you have any recommendations on how to fix this sort of thing?
Ill answer on behalfof everyone:
Realism model
Anime model
More detail lora
Nsfw lora
This should cover everyone. Ill add a selfish one, a web design lora
I'm currently heating up my food right now, but I will be taking a look at All of my power connectors to ensure that there are no problems there
That TDR picture I posted - the original poster says it was fixed after gBIOS file update from his GPU card manufacturer
All right, that makes sense
Although the bios on the GPU should be up-to-date, as I got it from somebody else who is using it just a couple days ago
But, some people in a different community pointed out that it might be a motherboard BIOS issue, as I did not check to update the BIOS on my motherboard
I guess if the gBIOS update is not the answer - then suspect "secondary stock"
Bad hardware
Who fking knows. Its like 8h late at this point, im starting to lose hope
Check if you 3080 has that bios switch

Good idea!
ik i have it on my 3070 not sure about the 3080 ik some do but it could also vary depning on brand
SDXL 1.0 is not releasing today?
just saying that gigabytes garbage software is highly insecure
same goes for asus
SDXL 0.9 Prompt - lowpoly 8k matte painting grand guignol venice carnival jazz dance streamline moderne tamara lempicka mads berg peregrine heathcoate catrin welz-stein georgy kurasov alenka sottler arief putra itzchak tarkay rené magritte victo ngai henri rousseau vladimir kush remedios varo - 20 steps, Euler A, 1024x1024, cfg 6






the GPU is Zotac

ZOTAC
This article covers the Dual Bios feature available on select 40 series GPU models. We’ll talk about what it is, what it does, and how to use it. Let’s get started.
It's a button
For the zotac gpu's
seems to be
disappointed but not surprised if true
oh so, their finetuned models are better than 1.0?
and figuring out which one to release?
thats for 4000 series
let me check mine
Have you googled the blue screen error b4?
GeForce experience?
I stay away from geforce experience
Best drivers are DIRECT from manufacturer's site
Of course it’s delayed
NVIDIA drivers? I don't think thats how that works-
Although GeForce has always been good to me - I use the Studio version of their drivers
I get my driver's either from GeForce experience or from the nvidiea site itself https://www.nvidia.com/download/index.aspx

Download the latest official NVIDIA drivers
I used to use studio drivers, until i found out they cut out some very key features
same here
Only use game drivers lol
Game Drivers kept crashing my Photoshop - so Studio Drivers was a godsend!
I used to use studio drives cause I did a ton of rendering before, so it kept it nice and stable
1000's of hours of rendering, and it never crashed once
Wait your driver's are the newest ones?
ok, maybe not PLURAL thousands, but at least 1000
Studio Drivers also allow a quieter fan noise 🙂
yes
just installed the GPU like... 7 hours ago lmao
Maybe it could be blue screening because the newest drivers is Cuda 12.2 and torch is only up to 12.1 I think
Because I got atleast 3 bluescreens and thousands of errors until I found a working version of torch that worked with my Cuda version bc I have the newest drivers


weird, all I know is SD likes 11.8
idk mine seems to work fine atm the version of torch im using is 2.0.1+cu118 also
only one that worked with cuda 12.2 for some reason took me like 10 trys unistaling and reinstalling torch
I thought sd likes the newest cuda
@visual glade any statement on this?
I have no issues with SD and using CUDA 12.1

Idk I got a bunch of errors that pytorch didn't support my Cuda or sum shit and then just found a torch version that worked
hmm
Does anyone know what time sdxl 1.0 will be released? I remember it was meant to release sometime today.
Sad…
I dont think they would wait till last minute to delay it
did they say anything about that? where?
Officially?
meanwhile before I forget :
@visual glade well impressed with the update I grabbed yesterday. A basic 1024x1024 using @high skiff workflow has gone from 80-90 seconds to around 50 seconds.
Plus I can actually run batchs of 8 without any issue 🙂
1080ti


reddit
0 votes and 32 comments so far on Reddit
thats one of the posts
reddit
3 votes and 12 comments so far on Reddit
this one too
So rumers?


but, they are saying its being delayed cause they have a few new tuned versions of it that are "blowing them away"
and they want them to cook fully
Why would they delay it on the day? Seems like pretty bad timing.
You answered that actually, lol.

He isnt even saying it's delayed in this post lol
I am fine with a delay but why wait to announce it
Milk or cream how about some sugar
now that I am not sure about

I agree
I would rather wait longer for a better product
don't want a cyberpunk 2077 of the AI world lol
ohhh
Wait


okay since that's leaked can i just say
the new models mentioned there?
hhhhhhhhhhhhhhhhhhhhhhhh
AAAAAAAAAAA
That is all
better live up to hype :p
that's not me trying to hype it that's just genuinely my own personal reaction
idk what others will think but those codenames are hiding some things i've been waiting to see happen
@sour obsidian just waltzed into my dms the other day like guess what i did and AA im happy
Kinda sad, really wanted to see 1.0 today. but i hope its worth the wait
Same here
Hope its just a rumor tho
the 1.0 tests in the bot's were... not looking so hot lol
McMonkey is a dev for SDXL
@wicked frigatewith that said, the model is currently delayed?
I hope the delay won't be too long because the people who thought "I won't finetune on 0.9 because 1.0 is only weeks away" might reconsider, most people have been holding off on releasing any 0.9 finetunes, but if we're going have to wait more than a few weeks for 1.0, that might change.
Stability really needs to get their shit together PR wise. They do a great job hyping things up but their messaging around delays, leaks, errors, and controversies (like when they took that user's discord and subreddit) leave a LOT to be desired. If they're really about to announce the day of that there's a delay it's the worst possible move. They should have announced at least a weak before about a possible delay of there was even a chance. And all of those problems are actually exacerbated by how good they are at hype. Do they have a PR team? If so I'm sorry but you guys need to either step up your game, reorganize, or hire some more people on that front.
as joe said, more info coming tomorrow (or, well, today technically now that it's 2am)

when will then be now?
(sorry that was re Sytan's question)
😭
I'm just a dev I'm not in charge of PR stuff, schedules, etc. so I defer to the higher ups on that
You'll get your model guys.
but when?
im sed
details tomorrowtoday
Tuesday
the current day but like give it somewhere between 1 and 24 hours idk how many
Yeah, Stability has time and again made a PR mess from things that really shouldn't even be a mild speed bump - a delay is fine and reasonable but announcing it (or rather, not even announcing it but just telling a select few people in discord) the day of the release is just terrible.
Gotta break out ol' reliable for this one...

why is it delayed
I guess SAI had to uphold their reputation
Apparently there are three models and they might be too good or some shit? Super vague messaging.