#🔧|finetune
1 messages · Page 19 of 1
maybe kai can give some tips on dreambooth on sdxl
and if you have larger datasets all is alot of effoert
one thing tho. i have learned that if you use random crop you can train 5 models close to overfit and if you merge them later into one model the results get really neat
so for me the key to sucess was merging multiple models into one final
the difference was so big to the single models you wont believe
also if you advance your model i like to add the new resuling model on top of the old or vice versa
especially for faces that make alot of difference
this way you can also add new stuff to your old models
oooooh. this is a cool Idea. 👍
trust me it works great
i recommend to start merging based on a very low learning rate model
if will give a very flexible result
the model you start your merge with makes huge difference
xDD
its a pain isnt it?
i started with one
then 2
and now 4
and i wish i had that a100 cluster you refered to
but if you have a progessive model that you advanced over time
try to merge it
the results are much better sometimes as long as you weight in the newer with enough weight
but this might be a good time to ask... does it actually double your generating speed? also can you actually run them in multi gpu mode, or do you just run 2 instances of your training XD
no, I only train lora
but you can merge loras, too
in principal there is nothing you can't do with lora you could do with Dreambooth
so you loose about 20% speed with multiple gpus because of the syncronization
but it still much faster
if you run a script to randomly crop them pre-training, and pentuple your dataset - wonder if that would help too
it would. but if you run 200 or 300 epochs with 2-10x repetion just imagine how many variants you will get
which is fine.... might try it x_x then I can finally run vit-big-g without relying on hacks
for me random crop together witn not downscaling buckets really did alot to the quality
also flip augmentation
with those the models tend to overfit much later
and the resulting model was way less producing closeups
its like 3x slower tho
hm, I don't like flip augmentation.
regarding cropping: this problem does not exist anymore in adxl
flip augmentation acually does not "flip". it only flips by a few percent
maybe i need to try that
if the subject has certain facial features on the left side I don't want to flip them
i do have my issues with the faces
maybe removing the flip augmentation improoves that
need to try
@stiff dust so you have not tried dreambooth on sdxl yet?
wait. so it isnt just a 100% horizontal flip?
no
never questioned that one due to the wording x_x
actually yea
but from my experiance its just a vertial clip
very see any artifcats from horizontal flip
welp this is also why I can usually get nowhere in finding optimal parameters
everyone has their own opinion on what to do, what not to do
just when I thought I found the perfect params, someone tells me why I shouldnt use them
guess it all boils down to trial and error in the end. There just never is a consensus on most things around here.
settings work along context.
• dataset size matters
• how your lora is intended to be used. what is your target success rate? (like out of 10 images generated, how many out of those need to be good enough to share with others, for you to consider it a success)
• what you're training (style/face of a person/clothing/a pose/general composition/etc...)
• how much vram you have (since above 16, under 16gb, under 12, under 10 you need entireley different workflows to make it work on your system)
• how you do your tagging
• how small are the details that you need to capture/making sure your dataset doesn't have noise, since you dont want to train fine details and accidentally make a "youtube compression noise" lora by accident
• does your training include concepts that aren't known by sdxl (like nudity, facial accessories, new clothing articles, proprietary or new subjects that dont exist in public datasets)
• are you training eyes? (yeah. training eyes messes up more than you'd think. its a long conversation)
yes its alot like that
only tip I can give, is don't go over rank 32, unless you know what happens at higher ranks, since your mistakes get more hidden at higher ranks, but dont actually dissappear, and will lead you down endless rabbitholes that feel like you're just one setting away from fixing them
how can i make it so adetailer doesnt entirely change my render? i only want the eyes to be better but i dont know what setting makes it so different

left is adetailer, right is how i want it to be
dont use adetailer
its way hyped up
nothing beats good ol cnet and inpainting
can i make the eyes render better that way?
no the eyes shape depends on the model
only way to change eye shape is either use another model or use an artist style lora
its less about the shape but rather about the clearness (i guess?), i want it to look this like render

it depends on the resolution and model some models add a lot of details but theres also models that are very flat and clean without much details
have you tried inpainting?
you could also use a lora style for that
like the inpainting under adetailer? ive seen it but dont know how to use it
that be nice, do you by chance know any lora's of that kind?
oh, i just saw inpainting under adetailer assumed it was that one
or atleast, when i open the tab inpainting appears

on civitai search for style and filter by lora/lycoris to see all of them theres a lot for 1.5 (more than 1k)
okay, thanks i'll give it a go
What does your rig look like to be able to fit 4x 4090s? I'm thinking about getting a rig at work.
I've looked at specs at vast.ai for 4x 4090s. But interested in your setup.
I guess you would need a large PSU or even multiple.
How exactly does kohya decide how many reg images to use per subject image? Is it the total subject images*repetitions divided by total reg images*repetitions? Im getting an issue with my images becoming a little too toasty during training and I'm ready to blame my reg images but can't narrow down what exactly kohya is doing with my regs.
This is a problem that I've had since the dawn of time and I remember it being able to solve it by simply adding more reg images per subject image. Otherwise, I have to lower the CFG of my gens all the way down to 2 to avoid them looking overcooked af.
This wasn't a problem in A1111 dreambooth because you can explicitly say how many regs*subject you want but I cant go back to that since it has too many bugs. Halp plz.
How does the reg dataset work in fine tuning?
the reg images will influence the output images of the whole model
as well as your class images ofc
when it's only a small influence, it's perfect for when you have super-detailed images on your reg images so they blend with your class images, thus your output images are super highly detailed
but if the influence is too much, the outputs are overfitted to the reg images and everyone starts looking like wrinkly grandmas. Finding the sweetspot is hard and I'm finally convinced it's impossible with current technology to train a model with more than 10 subjects that is decent.
1:1 by default.
1:n where n is repetitions. its basically the only good reason to use repetitions in your datasets
any additional reg images in the folder just stay unused
in case of not enough reg images, it starts to repeat them until that equation checks out
you don't use the technique of matching datasets when training multiple subjects who have different class images?

So if I'm training 4 subjects, one has 400 class images, the other 200, the other 50, 25. Would'nt you train them as 1_A person, 2_B person, 8_C person and 16_D person?
in 1.5, absolutely. in sdxl, it gets so much more complicated x_x
yeah I aint touching xl in a year or two
but would that mean that one person gets 1 reggie, the other 2 reggies, the other 8 reggies etc. so they all get an uneven number of reggies?
I just want a solid 20 per subject goddangit. Why does kohya make things hard.
rule of thumb is treat everything with a tenfold amount of images. so when you go for sdxl, just remember to up your dataset by 10, to achieve a 1.5 equivalent result. (but obviously at the higher 1024px)
and once you get into 4k image territory, then standard rules of finetuning change. for the better even, but its a mess, since it depends on so many factors
oh. I see what you mean. I do manual tagging for my reg images, so I dont have that issue. it just literally increases the quality of the resulting model
1 word/folder class type of reg images always had their own issues, so I stopped doing that :/
it basically messed up the text encoder, and only changed how the model was overfit, instead of protecting it from overfitting
not an issue if you're doing like a pose for women, or a face expression for men - since you're not gonna generate cats/dogs/cars etc., but it does matter if you're trying to do more general type of lora/full finetune without damaging the core sd model
wait, manual tagging?
you mean the reg image filename? or you use captions for the reggie?
I have 11,000 reg images in my folder so that GPT autotagger better come out soon 💀
Thankfully this is only an issue when training multi-subject models, so I'll have to bite the bullet and train a lot of small models and just buy a new ssd I guess. Really curious to see if tagging all those reggies would work 🤔
it is already T.T but you're still limited by the normal gpt limits. unless you go api, which will probably run you dry
yep. I'
I'm currently at 6k manually edited images + manual tags 🤣
The manually edited images I believe, the tags for reggies I do not
And I thought I was no-lifing this shit 💀
I mean honestly, a generic reggie dreambooth with a tagged lora is already an insanely accurate combo
here's my woman subset 🤣

do you use boorudatasettagmanager or do you recommend something else?
assuming you're mad enough, then hydrus network is not only the best option, but also the only. Which makes me sad. Cause hydrus is terrible. But sorta required T.T
I'm decided that the optimal path is untagged dreambooth + tagged lora. Anything else would only be good for huge multi-subject training but I sure as hell am not gonna test that theory just to have it blow up in my face with all that time tagging reggs
For manual tagging?
yep. though its also the no. app for scraping boorus
in fact I think that's how it came to be
the manual tagging was an afterthought XD
there's always the option of just using them as proper training images, instead of reg images.
but at that point, might as well full finetune
Do you by any chance have a model that was trained with tagged reggies vs. untagged reggies and all other parameters the same that you can share on civitai? Even if it's weeb stuff I really only want to see what kind of effect tagging has on the reggies which up until today I have never heard of
only for sdxl - which is way way way overkill for 1.5
not negatively - but also not needed
like by far
you can get away with so much more in 1.5
my plan is to master all my subjects in 1.5 training, then if I wanna move them to XL, just use the best gens from 1.5 directly upscaled to 1024 and train those
I'd recommend you to use vit-big-g to autotag all your reg images with captions only
so that's also why I plan on waiting out XL
that way you get essentially the same result - but its 100% automated
Ty for the tip. I never really used anything besides boorutag
in webui, install Interrogator extension
then use the batch option with Vit-bigG enabled and set to caption to autotag all your reg images

it will give you natural language prompts that are about 80~90% accurate for all your images
warning, Vit-bigG requires a 3090/4090. not sure how much lower you can go
If you are low on resources, you can use Vit-H to caption them instead
not nearly as good - but good enough since its just for the reg images
I dont speak the language of people with short vram. 
seriously, thank you so much for the tip. I'm excited at the prospect of this leveling up my model game.
feel free to @ me if you ever have questions ^^
I am taking a dress (on a mannequin) and creating an image of a model wearing it. I highlighted the details in this post https://www.reddit.com/r/StableDiffusion/comments/17x13pf/update_1_clothing_on_model/
Progress so far: https://imgur.com/a/ilZdU2D
Does anyone have ideas what I can do to improve image generation?
Reddit
Explore this post and more from the StableDiffusion community

Hi, I'm not sure where is best to ask this, so I will try here.
My grandparents passed away this year and I would like to create a special gift for my mother. I have scanned old photos of them and I would like to try and upscale / restore them- but I'm unsure on what the best way to do it is. I tried using upscale with codeformer however it seemed to change the look of them too much that I could tell it wasn't my grandma. I also don't know how to remove the artifacts from the scanning, such as speckles and white dots.
If anyone could help point me in the right direction for me that would be very helpful. I'm hoping I can get it all done for Christmas
Hey, if the amount of photos isn't too much, I own a copy of https://www.topazlabs.com/topaz-photo-ai
I can offer to restore them for you, free of cost.

Make good photos great. Sharpen, denoise, and upscale your images with tomorrow’s technology.
yeah. agreed. topaz ai is your best bet for automatic, photoshop + photoshop knowledge ist your best bet for manual.
Stable Diffusion, while powerful, is random. You won't be able to get the face details right by doing only SD upscaling
hello! Im new to SD and im having trouble getting the juggernautXL model to work. I just get images like this, does anyone know a fix?

heres the image details beautiful lady, (freckles), big smile, green eyes, long hair, dark makeup, hyperdetailed photography, soft light, head and shoulders portrait, cover, random hair color, supermodel face lora:add_detail:1
Negative prompt: badhandv4, (worst quality, low quality, normal quality, lowres, low details, oversaturated, undersaturated, overexposed, underexposed, grayscale, bw, bad photo, bad photography, bad art:1.4), (watermark, signature, text font, username, error, logo, words, letters, digits, autograph, trademark, name:1.2), (blur, blurry, grainy), morbid, ugly, asymmetrical, mutated malformed, mutilated, poorly lit, bad shadow, draft, cropped, out of frame, cut off, censored, jpeg artifacts, out of focus, glitch, duplicate, (airbrushed, cartoon, anime, semi-realistic, cgi, render, blender, digital art, manga, amateur:1.3), (3D ,3D Game, 3D Game Scene, 3D Character:1.1), (bad hands, bad anatomy, bad body, bad face, bad teeth, bad arms, bad legs, deformities:1.3)
Steps: 40, Sampler: DPM++ 3M SDE Exponential, CFG scale: 5, Seed: 3685031502, Size: 512x512, Model hash: 1fe6c7ec54, Model: juggernautXL_version6Rundiffusion, VAE hash: c6a580b13a, VAE: vae-ft-mse-840000-ema-pruned.ckpt, Denoising strength: 0.7, Token merging ratio: 0.2, Token merging ratio hr: 0.2, Hires upscale: 2, Hires steps: 15, Hires upscaler: Latent, Lora hashes: "add_detail: 7c6bad76eb54", Version: v1.6.0-2-g4afaaf8a
don't use 1.5 vae on sdxl model
i dont understand lol
explain to me like im a small child
i think i understand now
Also, you might use 1024x1024 to get better result rather than 512x512
Sdxl didnt use the same vae which is used in sd1.5. It is why your image get weird effect. sdxl is designed to generate image on 1024x1024 without high res fix.

kohya got a bunch of updates and is using a newer bitsandbytes now. so full bf16 training? whats that about?
yo caith
I tried ur autotagger and for some reason it tagged all my women as either "araf, araffed or arafed" and as far as I can search that isn't a real word
did it do that to yours? Should I replace that word?
I was watching my picture generating, i had that first timage: i was like wow what a nice city it'll be perfect ... i'll take a screenshot of that, but two second later i see this, a less quality image with not what i prompted in the background and so my question i noticed several times, why sometimes my pictures are better when they are not finish ?


hiresfix? if so it's probably the denoise strength
standard is 0.7 i think but i usually use 0.35
Idk i never really changed it
if its at 0.7 it changes the look a lot
anyone know of a tool to edit safetensor metadata?
i found mention of one coming soon in the kohya-ss gui github page, but no sign of it
#🔧|finetune just want to train the local sd to get this kind of result in img2img, can anyone guide me /??


use an animated model + lora
or if u got the vram cojones for it, train a dreambooth on it instead
is it possible to train a lora on top of SDXL that
- trains on a high quality dataset of captioned images
- that have a mix of new terms, like more than one distinct character
- and correctly generalizes on new captions that contain those characters
let's say my dataset contains pictures of two kinds of pokemon that CLIP has never seen before, Pokemon_X and Pokemon_Y. let's say they are never pictured together in this dataset. in order to correctly generate imagery for a photo of Pokemon_X and Pokemon_Y together which requires generalization, is it sufficient to (1) properly tokenize the captions to use an uninitialized pre-existing token / a new token (2) train the text encoder simultaneously with the unet? i am a sophisticated user.
i have placed the model and tried to get result but not working, can you tell me how to set lora?
I would say, yes, but I haven't tried it myself. However, SDXL tends to mix up concepts if you prompt for more than one subject. So quite often it's still better to use regional loras and regional prompts
actually, I tried it with two separate Loras and it works. So if you have a Lora on subject A and a lora on subject B and you use both of them together you can show them in one image (e.g. shaking hands).
However, it did not worked for all my loras equally well. For some Loras it starts mixing up concepts, for others it could well separate the subjects
but if it works with separated loras, it should work even better within a single lora
Anyone got a python script for using GPT Vision API for captioning?
That takes all images in input folder, creates txt for them and puts generated description in correct txt
GitHub
This Python project is designed to prepare training data for Stable Diffusion models by generating detailed descriptions of images using OpenAI's GPT Vision API. - GitHub - psdwizzard/GPTVi...
Didn't try it out yet, but saved it for later
thank you. Ill test it today
Hello sd users , i am getting this error while generating images


It gives very good captions
nice, great to hear
you used it as it is?
you might want to ask that in #🤝|tech-support
changed prompt slightly
"can you give me a description of this image content. Separate each sentence with commas and dont use dots"
Only issue with the script is that it will not handle rate limiting or any other error for that matter. But it can be improved.
why. are. my. fucking. prodigy. loras. so. fucking. random
kohya can suck a phat dick I aint even bullshittin
sometimes theyre overtrained at 200 steps, sometimes it takes 5000 steps, sometimes they won't train properly at all
do yall recommend shuffling tags and turning on weighted captions?
nvm I figured it out. I had some extreme closeups in the dataset that were tripping the lora up despite me tagging them with double weights that these are extreme closeups.
what does appear to be random is how many reps to do in the folder. Some train beautifully with 01, some only with 20+ despite being the same number of steps. I can't find any rhyme or reason to this other than trial and error
hey guys, do you recommend windows or linux for kohyass and Finetuning?
im setting up a new device and im wondering what is the advantages of either or
dont tor un weighted captions unless you actually hav weighted captions
also i recommend random crop as well as adding a noise offset of at least 0.03-0.05
regarding repete i recommend to balance out the model with no more than 15 reps. i usually do no less than 3 and no more than 10 to 15
epochs really do the trick for me
also note that some concepts are much harder to learn than others.this depends alot on the base model you train on. if the base model allready know the concept and you are fintuning it it takes way les steps than if it is something that the base model has never seen or heared
oh shit that's a good observation
do you weigh your captions using (()) or :x.x?
my autotagger uses escape slashes before the parentheses and I'm wondering if that's affecting anything
i think the format need to be correct
anyone know if for finetuning sdxl i in kohya ss i need to use the sdxl brance still or can i use the master branch by now?
it's been merged into master yes
That has been my experience as well. We are having some success with one Lora multiple characters so far too
if you want to have multiple characters in one lora you probably have to train it as one lora and not as 2
anyone using kohyass with multiple gpus on windows?
yes, in order to increase the batch size
however i do not use the scripts directly, i use the code as a package and operate it directly from a proper python package
we authored types and documented all the args
however it apparently hasn't be uploaded yet
anyone using kohya ss gui with windows and multiple gpus? for some reason windows only uses the first gpu
however on linux it uses them all
Hello! Anyone offers freelance services to help train models?
I've been trying to train an embedding recently, with textual inversion, both with a1111 and kohya. In both case it failed. No idea why. I get an embedding at the end, but it doesn't look like the subject, especially after I switch from sd-v1-5 model to a custom model.
anyone can help me? (actual good links that explain it properly, for example)
mememememe
as long as it fits in a single 3090
try a lora. TIs are outdated
i solved the issue with multi gpu on windows, however i had to change the backend from nccl to glue - anyone knows if there is any drawbacks from that
anyone get OOM trying to extract Lora from an XL Dreambooth? seems others are doing it fine but I cant even with 48gb ram and 24gb vram
Are there any completely free online ways to train models? Google colab is now paid 😦
Alternatively, how can I train custom models with a 30 to 100 img dataset on comfyui?
You don't train on comfyui
6gb is pushing it too much
Im gonna say no
You dont train on comfy, you train on either kohya or old school A1111
You can train a lora though, should be good enough for most purposes.
If you do want a dreambooth though, I can train one for you, no charge. This is one of the rare cases where I'm intentionally backing off of training just because I've been experimenting so much it's making my head spin.
How would i train a lora in a1111? If it helps, I'm trying to train it on unrealistic cartoony images. I can send an example if you want.
lora is only for kohya
I would recommend training that on an animated model of your choice
this is the current training file I use and it's pretty neato mosquitarooni so far
just replace the folders with the ones with ur images and I suggest anywhere from 10-60 repetitions on the subject folder
Hi, my Lora train process stopped at epoch 10/10 98% because the Google Collab runtime stopped, what do I need to do with this existing epoch so that it becomes final Lora?
just use the last saved one as the lora
ahh ok ok
Why did the lora that I trained on a portrait generate rotated portraits at interference

like this
None of my training data is rotated
looks like a bug, lol
in SD they always specify images in (height, width) while in basically any graphics tool it is (width, height)
thus it might happen that scripts accidentally swap both values
I am just wondering. If I want to train say, an urban techwear style hoodie, but the patterns and designs aren't very varied in the images of it I have with it being worn, is it possible to include photos of different jackets or ones that aren't being worn to get it to take some of those pattern / design variations without it ruining the concept?
what did you use to train it kohya?
some trainers might rotate the data for more variety though its usually something you need to turn on yourself kohya shouldnt do that automatically though another trainer might
I did in kohya
what settings did you use
is anyone familiar with an approach for LORA training with a text encoder training that
- adds a new token to CLIP, thereby changing its shape, initializing the embedding for that token appropriately
- correctly accounts for the change in CLIP's shape, and correctly does NOT change the interaction between clip and the conditional UNET, since that shape should NOT change
- "somehow" freezes the weights in pretrained clip, and only "trains" the new vocab token as it appears in the dataset as part of the broader LORA training approach
- achieves this training with the same complexity as LORA training, because such a vocab increase "only" increases the rank of CLIP weights "by 1" in "a few places"
the goal is to not rely on community-discovered "rare token" since nobody has done this in a scientifically rigorous way, and i plan to train a lot of new distinct characters / concepts
OR is someone aware of a scientifically rigorous discovery of "rare tokens" (meaning in the context of SDXL, "low impact" on the conditional unet when used)
what you say is basically "textual inversion"
however, I assume you want something different, like training the complete text encoder on a new token without changing it for other tokens
your training software is not respecting exif orientation, this is common if you are using photos off your phone. Phones commonly record images in the same orientation to the CCD on the camera itself, then just put a tag in the EXIF info to tell the applications that open it to rotate it on load (based on your phone's inertial sensor, i.e. gravity), by default PIL package won't fix this on loading and you have to add my_image.exif_transpose() somewhere in the code to fix it
have you tried simply using the actual names for things? Like first+last name for people or characters. I agree, finding more rare tokens, then having some cheat sheet or lookup table to relate actual names to some rare token is a completely garbage workflow, and also its never been needed at least for fine tuning where you can and should be using natural language and real words/names for things
@stiff dust i am indeed describing textual inversion 🤦♂️
my colleague and i are right now doing a scientifically reasonable, rigorous search for rare tokens, for a variety of definitions of rare
even if you find a bunch of rare tokens, constantly having a reference sheet for them or having to code around that is just a pain
yeah but we'd program the pipeline
give the text encoder some credit, it's not a 1:1 translation engine of tokens to embedding outputs
like it would be transparent
that's true, but it has been our experience that even the community's rare tokens, which were not rigorously discovered, work a lot better for loras with text encoder training enabled
i'm excited to share more on the work.
I've never been convinced it is worth seeking rare tokens vs using natural language and letting the text encoder do its job
i want the low computational complexity of a LORA, and also the ability to train CLIP together with the conditional unets, instead of "just" CLIP.
though I focus a lot more on fine tuning
most opinions i've seen online is "the lora is your token"
but that approach does not tackle character X is holding hands with character Y
@swift loom
what you say is basically "textual inversion"
why are there so few community textual inversion models for SDXL?
are you familiar with textual inversion where i choose which tokens to adapt? it looks like it may make random choices
is it as simple as, i use the rare token in the image's caption, just like i would with a LORA?
Anyone know the ideal parameters for Lora training at 12gb vram?
is triton good for anything?
in textual inversion you only train a single token which is newly introduced into the tokenizer (and, thus, is maximal rare ;)). So you don't need rare tokens when you use textual inversion. However, it has several disadvantages (which is why it is not used so often anymore):
- training is much slower than Lora. Computationally, you don't save that much time training only an embedding instead of a lora. So time per step is similar. But you need much more steps to train a textual inversion. In Lora you train many matrices at once, so each step makes bigger changes to the model, while in textual inversion you only change ~2k parameters.
- results are similar or worse than TE lora
- most the downsides of TE loras are also happening in textual inversion
You could think that textual inversion is less destructive, as it only changes a single token and not the rest of the caption. But that's not really the case: even if you don't train CLIP, it will propagate your token to the complete caption. During training textual inversion, the embedding is learnt such that it seems to get as much attention as possible. Textual inversions often tend to dominate the caption, such that you lose prompt understanding.
In SD 2.1 I used textual inversion a lot. In SDXL it never worked so well for me and I found TE loras always better (and even try are very tricky). Quite often, only training unet is the better option :/
changing setting sd_model_checkpoint to ohwxBusB_step_2000.ckpt [136f107cjn]: AttributeError
Traceback (most recent call last):
File "D:\SD\stable-diffusion-webui\modules\options.py", line 140, in set
option.onchange()
File "D:\SD\stable-diffusion-webui\modules\call_queue.py", line 13, in f
res = func(*args, **kwargs)
File "D:\SD\stable-diffusion-webui\modules\initialize_util.py", line 170, in <lambda>
shared.opts.onchange("sd_model_checkpoint", wrap_queued_call(lambda: sd_models.reload_model_weights()), call=False)
File "D:\SD\stable-diffusion-webui\modules\sd_models.py", line 741, in reload_model_weights
state_dict = get_checkpoint_state_dict(checkpoint_info, timer)
File "D:\SD\stable-diffusion-webui\modules\sd_models.py", line 315, in get_checkpoint_state_dict
res = read_state_dict(checkpoint_info.filename)
File "D:\SD\stable-diffusion-webui\modules\sd_models.py", line 301, in read_state_dict
sd = get_state_dict_from_checkpoint(pl_sd)
File "D:\SD\stable-diffusion-webui\modules\sd_models.py", line 245, in get_state_dict_from_checkpoint
pl_sd = pl_sd.pop("state_dict", pl_sd)
AttributeError: 'NoneType' object has no attribute 'pop' I've trained 4 different models with fast-dreambooth colab repo but when it comes to select it from A1111 this error occurs. Whats wrong?
that pop error is hella ancient it feels like I havent seen it in years lol
I'm trying to train a model for a face on my own machine(16 GB VRAM). Would anyone recommend a model I can train relatively quickly? Also, what mechanism are people using to train SD models locally these days? Automatic1111?
I’m training Loras on sdxl of animals, and in general it’s working great. But for some animals, it randomly ignores their color with many prompts. Even simple prompts. Anyone have any idea how you might address this?
thanks for the detailed explanation. i'll follow up with a comparison of LoRA on very rare token versus textual inversion for various challenges.
we're polishing an ETL pipeline to make this reproducible. dagster & dask are pretty great with preprocessing, and our packagized kohya scripts are also really handy
kohyas sd-scripts is the most common way of training Loras for SDXL. There are also some forks with UIs
nice, I'm looking forward to hear more about this.
I compared myself TI+UNet, TI+TE, TI+TE+Unet and TE+Unet and found TE+Unet works best. TI often overfitted on style for me. However, I also found that these things depend heavily on your captions and your images, so results might be very different on other data
Is it a bad idea to train a LoRA on ~1000 images?
no, why?
we are trying a lot of different captioning approaches from the literature. imo, the biggest problem with the community approaches is that people do not design the splits, they make random splits, and for so few images, often a concept does not appear in all three splits
that and all the default LR settings in kohya are trash 👀
what do you mean with splits?
if you want to learn about character X, a distinct example of it should be in the training, validation and test sets
clearly for a lora only on that one character, no problem
but if you depict the character in different wardrobe for example, and you bothered to caption it, tough cookie, you have to design the training, validation and test sets
I never use test and validation sets... 😅
the loss is not a good metric anyways
I always use validation prompts and compare the results visually
i'll be honest i'm not sure yet how impactful all this stuff is. i will report soon
I needed to improve my workflow for captioning datasets, so I made this GUI: https://github.com/MakingMadness/caption-fletcher/tree/main
I hope someone finds it useful.
Only tested on linux, so would appreciate feedback from windows users.
GitHub
A simple caption editor for image datasets. Automatically create captions, and hone them to be right on target! - GitHub - MakingMadness/caption-fletcher: A simple caption editor for image dataset...
Here's a screenshot 🙂


300 is a good number. Above it is overkill. I see many loras with 1000-1500 images with really bad or poor results. And many good loras with 100-200. What i mean is: pick the best cherries (images). Good quality, low noise, focus, different poses, different distance, light, etc... study the training parameters repeating the process. There is not a bullet proof recipe cuz each dataset need parameters adjustments. Try with a small data set first for faster training time.
Is it published? If so I'd like to check it out 🙂
Uploaded to git but haven't write the readme yet. It is still in development. https://github.com/lrzjason/DatasetManagement
GitHub
DatasetManagement is builded for easily manage image and captions. - GitHub - lrzjason/DatasetManagement: DatasetManagement is builded for easily manage image and captions.
Cool, thanks, I took a look! Good luck with it 😄
quality > quantity
but assuming they are all good + well captioned, then yeah. more is definitely better - but its a question of if you can keep up quality that long?
basically, the less images, the more you rely on overfitting. the more images you have, the more flexible your lora becomes.
its a complex topic since it changes depending on what you're training.
One important tip is to fail fast. I'd suggest to a get a 'barely working' lora with 50 images, so that you can run different settings/variations fast. See what parts overfit faster than others. Then fix those as best you can.
then double the dataset each time.
you dont need to do this each time you train a lora - because the lessons learned stay the same. the next time you can start with a more complex setup right out of the box.
fyi: my biggest lora is currently at 6k (manually tagged) images. so I say this from experience
Anyone know what the most likely cause would be for a lora that doesn't like negative prompts? Just finished my 5th training on SDXL and everything seems to work quite well for most of the testing but if I add any token to the negative prompt it completely overbakes, like more than bumping the CFG to 10+
I noticed the lora epochs themselves seem to burn easier the longer it trained, cfg 11 for epoch 2 versus cfg 6 for epoch 10 as an example, but even epoch 1 burns if I use a negative prompt at all
Just ran another training with 10 repeats instead of 20 and lowered learning rate from 0.0003 to 0.0001 and it did move the "finished" epoch from ~4 to 9 but the burning is still happening 😒
Makes me wonder if it's the model(s) i'm testing on
or I'm missing something else
After a bit of checking the models I have it seems like there's a common problem with negative prompt causing the quality to tank, and one of them even requires clip skip -2. That's really annoying
do you train text encoder?
I've tried both at this point
one video said not to, that lora is basically useless on most models
I think I may have finally figured it out. My lora training wasn't actually the problem, it was the models I was testing with (trained on base). Specifically, the AlbedoBaseXL model says "Leaving the negative prompt blank is the way to achieve the nice quality". It should say you can't use the negative prompt over CFG ~3 with a lora or it fries everything completely. At least the ones I've tried, not just my own. Multiple other models I was testing are based, likely heavily, on AlbedoBaseXL so the problem was widespread in my collection
probably albedobasexl was then training the text encocer, too
I agree that training unet only is not always an option. Training text encoder improves results often, but might also often have undesired side effects
I ran a massive x/y with 3 epochs (5, 7, 10) from each of the 7 loras I trained, against every XL model I have. Found all but 2 were burning when there was a negative prompt
did that for CFG 5,7,9
Then I tested all the same loras on a 'good' model with CFG scales 2-15 and found the model only burned on a couple of the loras
Most of them were the "finished" epoch 10 versions, multiple epoch 5-7 were fine
Turns out the best training I have was actually epoch 5 of the first lora I trained, but the eyes 'glow' if I specify an eye color, which is what started all this.. some negative prompting can clean that up though I guess
oh, yes, I know that problem. Specifying eye color is not possible in base model
to be fair: CFG is a hack. If you specify any CFG value over 1 the model is not doing what it was trained on
hello guys, I'm new to finetuning sd and ran into a small problem
I get this error when trying to train with dreambooth: died with <Signals.SIGKILL: 9>.
is this a memory error? My dataset has 4k images, and my cpu ram is around 13 gbs
I can share my collab if needed, I'm using V100 rn, but can go for A100 if needed
If I am merging pruned models into my unpruned model, will it still be decent for lora training in the future? Or should I really only be merging unpruned if my goal is to use it for training?
Does anybody know if finetunes using perturbed noise or min snr gamma produce noisy outputs? I think one of the two is causing issues, but I'm not sure which (think it might be the former, but I want to know if anybody knows for sure)
example

Which option do I have to adjust for training if the face comes out well in the aDetailer with the prompt "photo of ohwx woman" and not without?
so basically a prompt with "photo of ohwx woman" yields very good resemblance with the training data
but "portrait of (ohwx woman) as a viking, ...." has no resemblance without aDetailer, only if I heavily weight (ohwx woman:1.7)
I assume the training of TE 1+2 are out of balance? As I train unet + te1 + te2
this sounds rather like a RAM problem, not vram. Guess the process was killed because it took too much ram
Thanks for response
Yeah I upgraded and it worked
I prefer to train on sd1.5 base model.
There is no benefit to training on a tune or merge? Even if I want to use that lora with said merge pretty much primarily?
Many discord friends too. To avoid any unexpected effect.
On tuned or merged a lora will inherit some characteristics, good (ex: style) or bad but is not possible to predict what will happens exactly.
On base 1.5 will have a "healthy" lora.
Will not get any plus but wont get any flaws too.
That does make sense. I will actually try both to compare. 🙂 But I guess I still am wondering if merging pruned and unpruned models has any issues. For training on em afterwards. Logic says it shouldn't
It is good because it will be easier to correlate parameters adjustments and results. The point is: there is something strange on my lora, it is because my parameters or the checkpoint is guilty?
No problem merge pruned with full. With some checkpoints it won't works, dont merge, don't know why. So you will have to prune all. But most times works perfectly.
Awesome. Thank you for your advice.
I had only 3 cases where was unable to merge. Rare.
I did a lot of MBW on my merges. It took forever to figure out what worked properly. I was worried I would have problems training on it lol.
Yeah. MBW is very time consuming but is the best way if you will merge many models
Maybe someday I will delve into Elemental merges. But I am not that crazy right now. 🙂
For up to 3 merges with "health" checkpoints normal merge is ok.
Hehehe.
I just notice normal merging just sorta smears everything together. Especially if I wanna mix realism and anime together.
That is why things look like plastic all the time.
Many merges sometimes destroy the text encoder.
True.
That is something I wanted to know. Is there a way to fix the text encoder?
Would I BASE merge a good one?
Man... i still don't found a good way to fix a damaged TE. Dont import base TE into your merge. It will make it more dumb. What i do with some success is: make a prompts set and create the images (all same parameters) with some checkpoints and your damaged model. Next analyze what checkpoint match closer your model. Export the TE from it and import on yours.
That makes a lot of sense.
AFAIK I never touch base.
Set 0 or 1.
The problem seems to stem when you touch models that have a lot of loras merged in, or furry models since they don't use danbooru tags.
It seems to be what I notice fractures the TE.
Checkpoints is a zoo right now. XL is still healty. But almost all 1.5 are "contaminated".
Very true. But I know some crazy person will release a tool or paper to fix all the contamination.
It's more of a when than an if.
Example: realistic model with anime perfect eyes injected. It is very common problem
Yes. 100%.
But that is because people just do too many alpha merges.
I really do think Elemental Merges might be able to fix that. But with 600 paramaters or whatever it is per layer. Its too hard to do by hand.
Im polishing a model for 9 months. Trying to remove many problems.
Famous models mix made some problems spread quickly.
Eyes, warped face, non symmetric body, long arms or fingers, old face but having young body, etc etc etc
But is fun and we learn alot trying to figure out and fix things
Throw it all in the trash and go back to 1.5 base. Lol
More some months and migrate to XL makes more sense.
But im still in love with 1.5
Same.
This model im working for long time can generate cool images with cfg 2 and steps 6 in 1sec. While there is alot of buzz about turbo xl.
And i prefer the non perfect (non crystal clear) mood of 1.5
I agree.
LCM is pretty magical.
can you give me some more info on this?
i am using the image metadata and Adobe Bridge / similar applications
It is still in development. It contains a vue front end and a python api. You need to run npm run dev in vue front end folder and python api.py in python folder. After starting both program, you could get the interface in localhost running.
Hello everyone,
I'm having a real hard time understanding Lora training. I followed a tutorial to the letter, but I always get the same error.
Can someone please help ?
I'm using kohya_ss 22.2.2
Nevermind... Just found the solution, it seems
Anyone has any idea how I could use CLIP models with the embedding size (77, 512) instead of (77, 768) for guidance in stable diffusion? Is it possible to do it?
what would the purpose be? there's no deterministic way to do that, you'd have to find a function to translate the embeddings, its own scientific problem
does anyone know which tokenizer concretely was used by Stability in training SDXL's CLIPs? the vocabulary 2,496/34,483 of the vocab terms have word terminators, which are never produced by e.g. comfyui
of course they are
the word terminators are implicitly there whenever you have a word ending with a blank or nonalphabetic character
Hey folks! I've just fine tuned my first model following this tutorial. Model is saved on my Google Drive but now I'm wondering how can I run the inference on it? I don't have Colab Pro, so can't use AUTOMATIC1111 Stable Diffusion WebUI
I found some pretrained CLIP models that I wanted to experiment with, and they have the embedding shape of 512 instead of 768, hence I asked. Also, does the 77 in (77, 768) matter more or can SDs be conditioned with a shape of say (x, 768)?
if you change the text encoder, you basically have to train SD from scratch
regarding token count: in theory you can change the token count from 77 to something else, but results can be unpredictable
i guess i have found other bugs. you can pass exact matches to the vocab in the clip tokenizer, and it will still break it apart
i have a feeling there are more
the large amount of mojibake in vocab.json is not reassuring
Hello, I am developing dreambooth model using 1 training image.
And I am not sure what is the proper hyperparameters to train lora model
I am currently using realistic_vision_5.1_no_vae as based model.
And lora rank is 4.
Please help me.
🙏
anyone knows what's currently the best vae for sdxl?
is it just this one? https://huggingface.co/madebyollin/sdxl-vae-fp16-fix

That's the only one i'm aware of that works properly, there are a couple others on civitai but they aren't fp16 so they take a lot more memory to use
regarding text encoders in sdxl:
was sdxl trained with both encoders getting the same prompt?
is their any official statement on how they really relate to each other?
there are some tests what might be the best way to use them, but I never found anything official
regarding training unet only vs textencoder:
if you feed the unet with image / captions pairs the unet will have some knowlegde about the captions?
the textencoder has it's somehow limited vocabulary file, but also can concat single letters to build unknown words?
-> then u only have to provide enough samples to learn a new concept?
why do you ever want to train the text encoder then? (maybe to faster associate an image with a caption)?
yes, both text encoders always get the same prompt
to be honest: I assume that the CLIP-L is just there because the images look better with it during the experiments
but was this also the case for the initial sdxl training?
there were always complains about CLIP-G being less effective for certain artists and styles
so they just used both
aaaah i see 😄 thanks!
i did some tests with seperate captions for each decoder during finetuning, and it turns out pretty well
using different prompts for CLIP-L and CLIP-G is very problematic. I wrote about that multiple times
so i was wondering
it works and sometimes might make the results better, but in most cases it will make things worse
https://github.com/kohya-ss/sd-scripts/issues/781
can you have a look at this 🙏 ?

GitHub
From what I have read about the 2 text encoders that SDXL uses, the G CLIP encoder is better at understanding natural human language/full sentences, whereas the L CLIP encoder isn't as advanced...
i have the assumption that CLIP L works very well for a style tag and G for the rest
people assume that since the beginning, because it fits this idea of clip-g being better in understanding and clip-l is better at styles
but there is not a single study that proofs that
but if sdxl was trained on both at the same time ... i think than it doesn't matter seperating them..
whenever somebody really made a big case study with dozens of prompts and compared them it was always better to use both with same caption
but you can always make examples where some strategy works and the other not
i see, you have point there
the reason why I don't like separate captions is the following:
the way clip+unet works is that your sentence consists of tokens (in most simple case these are words) and each token is connected with parts of your image (like each latent pixel in the image gets a probability to belong to a certain token)
this way, a face in your image might be connected to the token "trump" and during diffusion process the pixels are changed in a way to look more like trump
when you have two clip encoders, the embeddings of the tokens are just concatenated
so say you have a caption "trump as pope" and a second caption "hyperrealistic photography"
then what sdxl becomes as input is the token ["trump"+"hyperrealistic"], the second token is ["as"+photography"] and the third token is ["pope"+""]
this doesn't make any sense
i think "when you have two clip encoders, the embeddings of the tokens are just concatenated" is the crucial point.
is this internally in sdxl? because in comfy for example you can feed the captions seperate
doesn't matter. They are concatenated as soon as they enter the unet
concatenated means: the first token in CLIP-L is combined with the first token in CLIP-G
yeah I understand that, but it's somehow a little bit sad xD
hmm thanks for all your thougths
don't get me wrong: there are many weird things that surprisingly work even though they don't make sense
is there any paper or something like that how sdxl works under the hood?
I don't say that it's forbidden to use different captions
yeah, there are so many different parameters whcih influence the whole training process
but I would never ever encourage people to do that without evaluating theirself what works better
that's one reason why I don't like the concept of shuffling captions, because it even adds more randomness to a random thing xD
unfortunately, the claim that using linguistic prompts for CLIP-G and style prompts for CLIP-L is distributed and repeated very often without people ever questio that or evaluate that. Whenever such discussions pops up, somebody comes with a single example where it makes things so much better and acts as this would be a proof
shuffling captions makes sense if you train many many epochs
you don't want the model start relying on the exact order of the content in the prompt
hmm that makes sense
in general: if you train many epochs you might want to add some randomization to the training process to avoid that the model starts memorizing things
this can be random cropping, flipping (dangerous), caption shuffling or dropout
the text encoder can do single letters. That is knows whole words is mostly a performance trick. Each token costs you a lot of time and memory, so you want to keep the number of tokens as low as possible
ahhh 🤩
so if you give the text encoder a word that is tokenized into single letters, it will still learn that the combination of these letters make up this word
yes
which is then also bad for SD, because the unet also has to use all these tokens
(which doesn't matter that much as the unet is using a fixed length of 77 tokens anyways)
after some weeks of debugging koyhas scripts I wondering at every line: "why is this like this xD what happens if i change this to that xD"
i also don't understand why we need this super complex multi layer text encoder when the model was trainined on alt tags
because of that
if you have a french word it will not be contained in the dictionary
so the text encoder has to learn that this combination of tokens belong to a single word
i made some tests with using the different layers als input (clip skip) but I'm no smarter than before
which will take many layers
i see 🤔
but yes, alt tags are horrible. But this is the reason why CLIP is used, as CLIP is very robust to shitty captions
but it's also the reason why the text encoder is so extremely stupid in many cases. The alt tags are just too bad to learn something really useful
i imagine something like this: "i have a really high creafted vector embedding by clip which should be compared to a alt tag vector embedding"
how can they even be close to each other xD?=
CLIP-L has only 11 layers. That's actually a very small transformer given the amount of data it is trained on
G has 32 ot something like that i thing
yes. I'm sceptical about that xD
like it definitely has a better text understanding
but it's probably wasted on alt tags
jap xD
i don't udnerstand why not instead of using alt text clip or blib was used to caption the images befor?
I mean, CLIP is older than BLIP
also BLIP makes a lot of errors
even newer models like llava or coglvm make a lot of errors
maybe as a adition to the alt text
llava is sometimes not even able to distinguish a monochrome photo from a colorful photo
hmmm
but I agree that this is the way to go
Dall-E 3 and Pixart Alpha did that
they made automatic captions and trained on them
Pixart Alpha is almost as good as SDXL, but was trained on 1/100 of the data
i have my eyes on pixart too xD
but currently so deep into sdxl so i want to learn everything about it first xD
can i ask another question xD? you have some seroius knowledge
have you tried training with zsnr fix?
i read sdxl already implemented it
and koyha supports it
but my results are not getting really better with it
haha, you should ask Pseudoterminalx about that
I think zsnr fix in kohya is something different than zsnr
at least koyha uses the little script which is used in the offical paper
fix beta: zero terminal SNR
print(f"fix noise scheduler betas: https://arxiv.org/abs/2305.08891")
...
it's absurd that a view beta values can change the result that much 😅
as I understand zsnr you cannot use it for epsilon prediction
with v-pred I alwys get grey images
during training and even in comfy
don't know how to get this to work
you cannot easily change the prediction type
in koyha you can enable it with v_parameterization but he also writes to not use it with sdxl
if a model is trained on epsilon, you cannot let it predict v
ahhhhhhhhh
you have to completely retrain the model for hundred thousands or even million of steps
😭 again xD
pseudoterminalx is training an SDXL variant with v-pred
woah cool xD looking forward to the results
thanks so much for your knowledge :D!!

Im planning on trying to train my first lora on a comic book artist's style, are there things I should avoid for the training dataset, such as text?
fwiw, i've found lots of big surprises with tokenization in transformers being really unoptimal
and it's almost certainly not what stability uses for its training
like the tokenization is... let's say weak oftentimes
it's just not using the vocabulary correctly
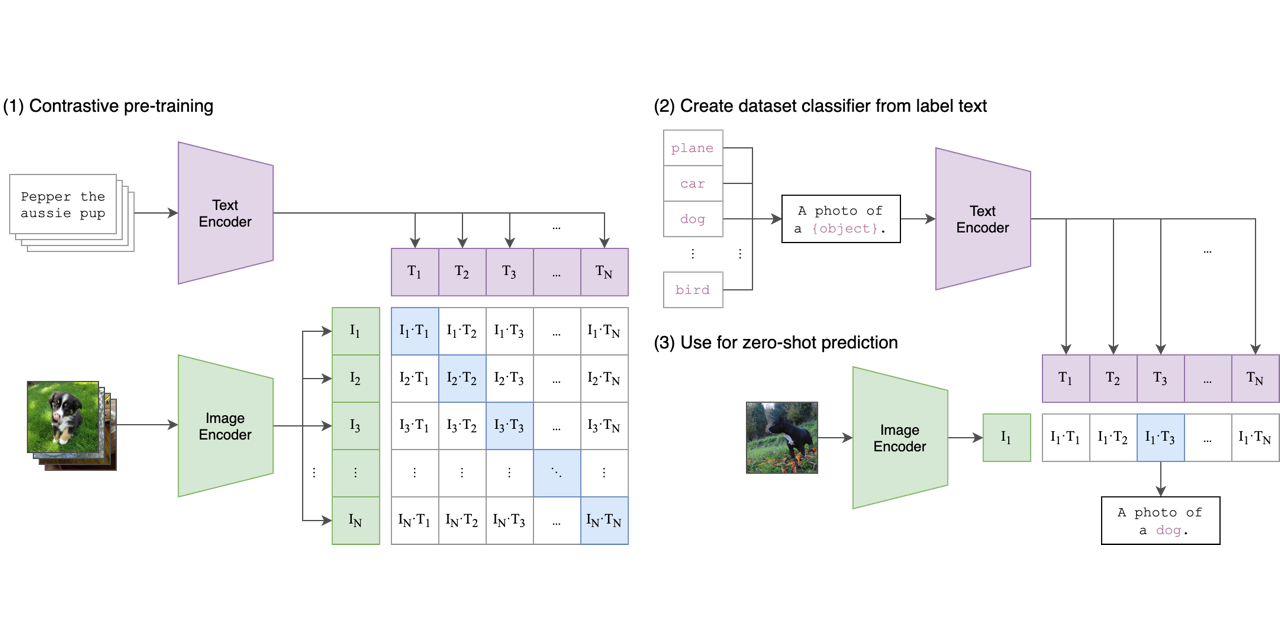
huggingface and comfyui both played telephone with https://github.com/openai/CLIP/blob/main/clip/simple_tokenizer.py and got something different
GitHub
CLIP (Contrastive Language-Image Pretraining), Predict the most relevant text snippet given an image - openai/CLIP
which, obviously, this implementation isnt' the one OpenAI used to train CLIP, and openclip... they also played telephone - https://github.com/mlfoundations/open_clip/blob/main/src/open_clip/tokenizer.py

GitHub
An open source implementation of CLIP. Contribute to mlfoundations/open_clip development by creating an account on GitHub.
@stiff dust i think one of the reasons lora training with text encoding is going so poorly on sdxl is because the tokenization is broken. what people think are rare tokens are not really. stability, laion, whoever, almost certainly precomputed tokenization for openclip on its corpus, which to do so performantly means authoring BPE in something like the polars DSL. they probably didn't use any of the ordinary unoptimized python code at all.
I saw somewhere they do only one pass through part (picked randomly) of laion db.
Image captioning for LoRa
Hi there,
I find image captioning a bit confusing as tutorials often have different approaches. My main problem is that they usually explain them on the example of subjects or styles. What I want to train is more of a concept. I want to train a LoRa that focuses on everything balloon related such as inflation and manipulation/handling by characters. I found that most models can’t produce any good results for this except for characters holding floating helium balloons.
So my questions are:
- How should I caption the images, what to describe, what not to describe? Sentences or single terms or both?
- Should I use a prefix? And if so should it be a term that the model is familiar with?
- Should I use a unique identifier?
- what Settings should I use for a concept like this? (Using Kohya SS)
- should I use as many images as possible (I have about 300 rn) or only use a few?
Any other tips and hints are welcome.
I’m new to this so I hope I don’t ask stupid questions.
Thank you guys
Hey man, I don't know how to answer some questions for your case (looks more complex than usually i have experience). On my loras i caption terms not related to my object of interest. Dont need be detailed: a table with fruits is ok. a table with orange, grapes and bananas is not necessary. Use a trigger not familiar to model. You can test before to see what is generated. I rather use something with consonants and numbers together like: h4th4w4y or short h4w4y. I like to train on sd1.5 base model. Minimal influence of model is better (my opinion). Settings is hard, there is no bulletproof recipe. Start with few images (20-30 best quality images) for faster training to adjust your parameters. When satisfied goes adding 30, adjust again, add 30, etc... For your case i think more is better (300-500). Simple loras 30-50 is enough with a good dataset. Sometimes 20 best image already does the magic.
Hi! Thanks for your advice. It is definitely helpful and I will try some of these steps. I’m not even sure if a Lora is the right choice or if other training methods would be more fitting. What makes it difficult is that I don’t really teach a single object but make an existing object more defined, in this case balloons. So I’m afraid if I only describe everything else the model can’t distinguish enough. One idea I had was to make balloon related terms for captions. Like „small balloon“, „uninflated balloon“, „fully inflated balloon“. Also actions like „inflating balloon“ „holding balloon“ etc. I’m not sure if this is the right approach, especially if I use pictures with multiple balloons in them, how should the model know what specific balloon I am describing.
Yeah. Your situation is really new to me. I think you should focus on balloon object condition. Actions most models should figure out it. If some action/pose is hard my intuition says to train it on separate lora and use it with balloon lora.
Assuming that I have a Lora that I already trained with dreambooth and saved on HF, how do I continue training this lora from where I left off?
Any clear guides on that? Maybe use the HF link as the checkpoint path or smth?
so in a nutshell, there are multiple approaches to this, that will all work, but have different downsides/side-effects
learning the different methods is obviously trial and error.
The easiest way to get it working, imho, would be to take the 50 best images of your set, and start with those. Basically get a lora working 'well enough' with only those images. (the full 300+ will be used later)
make sure that signatures are removed. You can crop to 1:1 to avoid certain pitfalls, but this is entirely optional. Ideally you want bucketing to work, since that also makes your lora better in the long run -but that's not the focus of this question.
once you have them, caption them using only caption style words.
"<trigger word>, <subject>, <action>, <location>" <- really depends on your dataset, but keep it simple, and be careful when captioning to not miss any/apply when not relevant. Add anything specific, that you want to be able to prompt for.
"balloon_style, woman, sitting, indoor" <- one potential image caption
(why not natural language style captions? <- is a long conversation. but with such small datasets, using captions will almost always get you better results)
trigger word always first. shuffle turned on. keep n tokens set to 1 (so that trigger word stays front)
min snr set to 5. (read up on min-snr if you're brave enough. but leave it on, as it helps train new subjects a lot faster) -> https://arxiv.org/abs/2303.09556
settings REALLY depend on your hardware. I could help you on a 3090/4090 setup, since that's what I have.
stuff that stays same:
• Leave offset noise at 0 <- can and usually will cause issues
• LR between 0.001 ~ 0.0005 + constant scheduler + adamw8bit <- for your first tests run at 0.001. While not ideal, it will still show you very very fast if you have issues somewhere else in your lora, that you need to fix first
• Network dim set to 32 <- 8 or 16 also work, and will make the final model more flexible, but will be harder to get right if you're not used to making loras. Do not go above 64 unless you know what that means, as 64~256 will cause significant damage to base sdxl, unless you know how to fix that.
• use all the performance gains you need to make it work (depends on hardware -> stuff like xformers, bitsandbytes, full bf16, etc... - there are other guides on performance gains)
• you can either try a lower LR, and get it working just right, or a higher LR and then use the final lora at like 0.5 strength. (getting it right means more flexibility - but takes like 7 hours to train VS training for 10~25 minutes, but working with getting results via overfitting to some extent)
• enable text encoder training <- while definitely not always recommended, for this specific scenario, if you roughly follow my captioning example, will work really well. Just don't use any words that pertain to anatomy (mostly nsfw stuff), cause that will break your entire training very very quickly
when you're done, run an "infinity grid" to compare results from without vs with lora, and to test different epochs, and to test different cfg + step values + different prompts
(infinity grid can be found in A1111 extensions, or stableswarmui has native support for it)
when you're happy with your lora, remake it with all images you have available, keep all settings the same except learning rate, which you should tone down to around 0.0005, and then generate your truly final final™ LoRA (expect this to run between 5~15 hours on 24gb vram)
@hollow spruce Good point about text encoder. ✨
hey guys, I'm fairly new to finetuning sdxl (tho I have some experience finetuning LLMs), can someone guide me to where I should look at to get up to speed with everyone?
I'm trying to train sdxl with a dalle 3 style captions (have around 5k images), but I feel like I'm missing a lot of knowledge that messes up my attempts
I'm not sure how dalle 3 captions are, but you want your captions to work on the model you're training (unless it's a completely new context) and depending on what you're training, 5k images is way too many to start with
dalle captions are highly descriptive natural language captions
In most cases you're better off with maybe 50 images, I train faces with 10-20 usually
but training SD, especially SDXL, is a lot of trial and error. Start with a small set and see if it works at all and then adjust from there
but like I'm trying to make it learn complex composition and who is where in the image, would a small dataset really give it that understanding?
stuff like this guy is in the right and this guy is in the left
SDXL in particular is good with natural language prompts, but you don't want you captions to be too long or overly descriptive
I'm not sure training a lora is the best option for things like composition
so full finetuning?
It is quite complicated. I think some model on civitai already used dalle3 like descriptive training.
controlnet would be way easier and likely more successful
oh really
any link please?
would love to talk to the guy and see what he learned
I am not sure which. I think pixelwave might be one of them.
The author of pixelwave is in this server. You might ask him in sdxl or here
huh, interesting

ah can I ping?
@ruby pond Hey man, I'm fairly new to sdxl finetuning and would really love to learn. I tried to finetune sdxl with a dataset captioned by cogvlm (similar to chatgpt4vision), and I had to hack into the dreambooth lora code quite a bit to make it able to accept long prompt (bigger than the native 77). Would love to learn how you did it
@dire orchid
Try to make a text encoder only LoRA as a proof of concept. I can guarantee that that works up to a certain degree.
Assuming you wanna go all the way with your plan, you'll need around 30~50k images with descriptions. Keep in mind they need to about under 77 tokens, since SDXL is not dalle 3 and cant keep up with such long captions.
Ifyou pull off such a dataset, then your next step is either a cheap finetune, where you finetune on a A6000 or A100 with however big of a batch size you can get into it + keep accumulation high.
If you have money to spare or a company behind you, then get a 8stack of A100s or even more, and do either a full finetune or multi step finetune (first TE -> freeze TE -> then UNET)
in either case, you'll need a good dataset with prompts that arent biased towards any specific subject, since you'll be hardcoding that bias into the TE
ah, okay, that helps a lot actually
Im not sure of my hack and Im sure it fucks up a lot of things
any easy way to train the text encoder?
yes
what gpu do you have?
ah neat
then you're more than good to go.
use kohya-ss -> enable TE training -> disable unet training
do a few test runs to see how high you can push your batch size. the bigger the better (cause it adds context to how the prompts relate/differ from one another)
then let it run for 5 epochs. (save each epoch) for LR feel free to stay around 0.0008 <- way too high, but this is just for testing it
on an a100 this should be damn fast. far less than a hour.
download your safetensor files. run locally and compare to base. you should see significant changes around epoch 5.
run a few tests like that to eliminate any possible errors in your settings.
when you're happy, run it with LR of 0.0001 to get your first final version.
as your dataset grows, you can slowly incread the network dim, and decrease the LR even further <-- will require a lot of testing to get it just right
okay, right now I have a super biased dataset that always starts with "This image is", quirk of cogvlm
I can easily change it with a simple LLM script
for starting, network dim 32 ~ 64 will probably be ideal
yeah cogvlm be like that XD
I usually limit its space, which gets rid of it. Probably not ideal though, so 🤷♂️


does starting with just 5k help or do I need to reach the 50k mark before it has any effect?
3k is roughly the minimum to make a proper impact. so you're more than ready
amazing
do I need kohya or does dreambooth allow for training just the text encoder?
also looking into the dreambooth code, I'm not sure where it saves the trained encoder
unless I missed something, kohya was the only one to do have proper sdxl LoRA support
(with exception of diffusers - if you wanna go that route)
ah gotcha
then kohya it is
since I no longer need to do some random compel stuff to extend the max length, this should be easy
ah, you gonna try to extent token limit and average it?
did it work? xD cause it shouldn't... but I really wanted to try it anyway...
ehh, it did train
Im not sure if it trained well
I can share the code and you take a look at it
I mean the resulting file?
(kohya has native support for that - you can extend up to 225 tokens)
so its a not a question of if you can, just if you should 🤣

all llm generated captions have hallucination. You might filter or fix your dataset before.
true, I should look through it manually
yo do you have a simple kohya implementation on colab?
the ones I see are big for no reason
I run stuff locally, so sadly not ^^'
ah rip
do you use this gui?

or do u just code it up in python
I've done both. but lately only the gui since I've gotten lazy xD
use the LoRA tab though
I'm looking at the Lora tab and there is so much stuff
not sure what to click/change
For anyone that's interested, it WAS perturbation noise. Not my model, but the person finetuning saw the problem lessen once perturbed noise was reduced.
If you have a noisy model and are training with perturbed noise, then consider reducing it.
here's a good link for what all the settings do
I'm seeing this and considering just dropping the learning rate to 0 for unet, but that seems extra stupid

nice, thank you!
I will go through all of it later
while it would work, it will still use up resources as if it were training x_x
@stiff dust do you know the param argument to disable unet training? (so it can be used for Text encoder only)

I cry everytime I want to find a specific kohya setting 🤣
--network_train_text_encoder_only
dear god that took way too long to find
and yep, it goes into that box
@dire orchid found it
also you should hide that link again ^^
Thanks for telling me lol
Thank you man!
Did you get that from parse args?
I should have done that work sorry
I train LoRAs with the number of tokens set to 225 in kohya 🙂
Yeah
hmm, I wanted to ask a question about that, can you pass kohey an hf dataset that it can parse on its own?
rather than download the images and the captions and send the local folder
this is the dataset in question: https://huggingface.co/datasets/Yorth/dalleTestDataFiltered2

I haven't tried that, only done training on local data
ah gotcha
so, how do you make sure that the images and caption pairs don't get randomly scrambled?
That's kinda what Im afraid of here
Scrambled?
Each image has a txt file with a matching name in the same folder
ah
so that's how the link is done, gotcha
imma just use id then for the name
and do you just specify the image folder here and thats it?

or is there like a caption thing somewhere else where I need to pass the same folder
sorry for asking too much btw
That folder should have a folder or multiple folders that are named starting with a number which is the number of repeats per epoch, e.g. 1_photo
The name isn't used unless you don't provide captions for each image
so, something like 1_1.jpeg and 1_1.txt could work?
for like the first image for example
this way I keep the names unique
The filenames don't need the number at the start, just the folder the files are in. E.g. I usually have a train_img folder with multiple folders like 1_photo 1_painting
Then select the train_img folder
so these subfolders are for classes?
or something like that?
or do they just hold image text pairs?
I'm not sure what's their use
It uses the folder name if the images aren't captioned. Otherwise just for organising or to balance how many times the images are seen because the number is how many repeats per epoch
did you do many repeats per epoch?
I'm thinking no repeat 5 epochs, unet plus text encoder training
over 5k images currently
Depends. If it's more of a general training on lots of photos, then 1 repeat 30 epochs. If training on a handful of images for a specific thing then I might do 10 repeats for 10 epochs
I usually just run overnight while I'm sleeping 🙂
yeah that make sense lol
also, wanted to ask, did you train text encoder too?
seems like it would help with model understanding too
I did, but then ended up putting the original sdxl clip model back into PixelWave as it started to behave weirdly. So I'd probably only train it if absolutely necessary, otherwise don't train it
ah gotcha
I trained my text encoder and it seemed to help
at least compositionwise
@ruby pond it messed up right from left half the time as base and no text encoder run from my evaluation
sample size was 20 images
but then again, I trained it using dreambooth and I hacked into that code a lot
so not sure if that was better or worse than the kohey implementation at least for this case
lots of trial and error with training 🙂 even when you have something that works well with the data and captions, it will not work well on a different set of data, and could be the captions at fault, could be the images, could be the settings
can you give some examples of captions you would like to render?
a textual inversion may be easier and simpler to train
where is the source code for this approach?
what's the best auto-captioner out now? any progress on that lately?
Blip has been quite good for me.
Now training 4500/1000 steps with around 170 images. Using Adafactor with linear LR scheduler, using 3e-5 as the LR. Is the quality supposed to get better? I thought linear is going down from that initial value?

I'm running Kohya-trainer-XL script, not sure if this is the latest, found via direct Google link. On the Github of Linargruf this is not linked.
Relative_step has to be False but doesn't this break the Adafactor LR adjustment. With true the script contains that warmup must be 0, but even if I set it there, training does not run. Adafactor scheduler never works, I'm getting the same error. I thought Adafactor scheduler would be the best with Adafactor optimiser?
Speaking of the linear scheduler, where does it head for the LR? Absolute zero?
Planned to train a lora with Pick a pic v2 dataset. 1k image pairs proof of concept testing. Next step is to train with 10k image pairs.
Original, 200 steps lora with 1k image pairs




Greetings, fellow creators. I want to ask you if any of you know how to mantain consistency in a face without using ReActor or any other faceswappers out there. Should I just train a checkpoint for my model, try specific prompts (I'd rather not), any other ideas? I appreciate your help.
cat
I would say, if the image is destroyed like this it can just get worse. What is your base model? Some custom models like juggernaut use really weird noise settings and can be difficult to finetune.
BLIP is really bad in my opinion. LLava is much better, you have to use quantization, though, if you want to use the biggest model. Then there is CogVLM, which is I think the best autocaptioning model (except for ChatGPT4 maybe)
everyone says to use constant, but it seems more logical to me to use linear... wouldn't it prevent over training by doing smaller steps near the end?
I also don't really understand what 'loss' means
During training an AI is asked to produce something and that is compared against what the AI is being trained to produce, and the difference is the loss. During training, the model is slowly tweaked to minimize the loss.
Hi what s the best way to train sdxl model?
I am trying to figure out lora training and I have 10 epochs that I am running through, about half of them seem to ignore the character I trained the lora on and fulfil everything else in the prompt, I get the same image from 5 epochs that has nothing to do with the lora I want. Does that mean those epochs were overtrained or is there something in the way I am testing it?
I am a newbie to all this, but three ways I am aware of: 1) downloading and using Koyha SS, 2) using a Google Colab of Koyha SS, 3) using the Civitai system. The first two didn't work for me, so I am using the third, but you have to pay for it.
what are the captions of your training data?
CogVLM just released something new yesterday


hey everyone, I'm working on fine-tuning a stable diffusion 1.5 model. was curious if anyone has a good way of seeing if the model is improving?
the problem I have is that because the noise + train timesteps are random the loss is very "jumpy" and doesn't give much sigal. does anyone have experience with metrics that help indicate it is learning? or does the fact that it is jumpy mean the network is not learning?
A/B testing is the way most do. Stability seems to have taken it a bit further with ELO scores.
thanks for the reply, for more context I'm trying to replicate animate anyone completely from scratch. the images generated are 99% still noise so I'm trying to debug if something is wrong with my code / architecture. I don't think I'm anywhere near being able to a/b test effectively and was curious if there is something that can be done much closer to the start of the training process
It was the base SDXL 1.0. The problem was the linear scheduler, and maybe a bad LR. I have to use constant with warmup and a constant rate, which kind of defeats the purpose of a dynamic optimiser, but the results are OK at least.
It's weird how almost none of the optimiser/scheduler settings even run in the original Kohya Colab script, and also Prodigy is missing :/ The GUI version is much better in this sense.


you might try constant lr to see does the loss go down.
does anyone have experience resumining training on a LoRA that was distributed on civitai? aka no gradients or related data, just weights. i understand that kohya supports resuming training, but on its own little data bundle. my expectation is that this has to be recreated with undefined data for the training snapshot, but with trained weights
you have to use a rare token for character names, not the character names themselves, in a caption
Does anyone know how to make the transitions between batches smoother in comfyui? I’m doing 150 batches and you can see the cut between them at 150,300,450 frames and so on. Is there a node that saves the last 5 frames from the previous batch so it will use that map for the new batch? If so what is the name and where does it go? Thanks! 🙏 (unless that node increases render time, then does anyone know how to make it smooth with davinci resolve?)
rare tokens are not necessary in all cases. In particular, if the character already has a unique name
you always can resume training. The first steps might be a bit destructive without the gradient statistics, but you could use learning rate warmup for the first epoch
I've been creating SDXL LORAs of cartoon characters which for the most part work great at replicating the characters and style - However I'd like them to be more flexible so that I can change the overall style to something that it wasn't trained on as currently they're following the training images a bit too closely. Should I add some sort of captioning for the style?
bob belcher, wearing a white shirt, mouth open, sat in a bank
I'm trying to train a LoRA of a specific building. I'm testing the LoRA now and it can consistently generate the general shapes of the building. However, very often the proportions are off and/or some parts of the building go on the wrong place or are just missing. And the building repeats everywhere. The building is a bit complicated, but I wonder if there is a way to make it more consistent
Am I wrong or more you give description in your .txt when you train your lora, then you get better freedom to change elements ?
For example I couldn't get a desert background until I described all my backgrounds in my databae

It seems like if you don't describe it in your database, your lora will generate it automatically. But if you do, it will give you the choice to modify it or not.
This is true, you describe anything you want to be about to change later. If you describe their hair, you can prompt for other colors. If your describe their clothing, you can prompt for other outfits. There's also an element of how overtrained... To some degree you can get away with not describing things, until you train a certain number of steps
Oh ok thank you. I try to describe clothing now. In order to see if I can change them easily.
Also, the gender is easier to change when you say it is a man. Instead of nothing.
And, I'm not sure but it seems a lower learning rate and repetition may change the way of changing things.
For example with a higher learning rate of 0.0004 + repetition of 10, the lora becomes overtrained quickly. Like around 20-25 epoch.
When at 0.0001 or 0.00005 and repetition of 2. After 100 epochs, lora stays flexible.
But sdxl lora are impressive and catch easier what you want. For example the spear the jaffa is holding. I put more Ma'tok staff images in my database and described it like a spear.
And it starts to look more like the thing from the show than a regular spear:

Same for the tissue strips attached to the helmet. They started to be generated when I described them in my .txt.
Hi all! Where do you put / find your finetuned SD models? I'm looking for a good existing anime-centric finetune of 1.5 . I figure there must be a dozen options for this, but can't seem to find any.
Hello, I need help with Inpaint and hands.. How can I solve this issue?

How do I set it up to fix the hands? :/
I am new with intune
Even in describing the clothes, it is really hard to change them. Like I cannot get my jaffa in a suit with a tie...



But the Matok shaft is awesome now...
and I can control the eye color....

oh yeah....

start understanding how to train my lora...
If you describe what its wearing in the training you’ll probably be able to control it
For example if you put desert background in the training image it will know that the background is a desert so it’ll be able to keep it out if you want to, otherwise it will just train it in and assume it should be there by default
I put green bodysuit + green and purple loincloth + antique belt
But it doesn't seem to change it...
I train with armor. Not easy to modify the clothes but I start getting something

I remove the head and use that in my data base



Hey all, pretty new to the space so sorry if this is a stupid question. I just made a dreambooth finetune using epicphotogasm, but all the images coming out of it are a bit fried. I used 15 images to train it. Also I've run this same prompt like 10x, and just about every single one has the same pose, facial expression, angle, etc. Does this mean it's overfitted? Any pointers on what I'm likely doing wrong here, or where I should look to get my answers? I've been googling for a while and haven't quite found anything clear yet.

It works !!!!!!




not perfect but much better than my last tries
they look intimidating now...

god bless sdxl lora...
And I keep flexibility for gender and background....

ok I will try few last things and start the ultimate lora about stargate !!!

damn... it really works....



lol i am reading this post on reddit now. good job

A new ai god is born
Also, Im not sure yet but I think it is important to remove th background when we can... SDXL Lora is really powerful and if you have a desert background, it will learn it at 100% and change the random desert background from sdxl model by the one of sdxl lora.
they should call SDXL Lora, CTRL + C, CTRL + V...
weird because previous Loras from 1.5 and 2.1 needed a background. Otherwise, you got only empty background everywhere....
I think I have the perfect parameters now...

What is fine tuning?
subtle art of creating lora, embedding, hypernetwork , etc...
And I find a guide to create captionning. the guy uses almost everything I use but in more detailed. I didn't know if I was making a mistake in using danbooru tags. But it seems good.
https://www.reddit.com/r/StableDiffusion/comments/118spz6/captioning_datasets_for_training_purposes/

Reddit
Explore this post and more from the StableDiffusion community
What do any of those mean?
huuh
Browse from thousands of free Stable Diffusion models, spanning unique anime art styles, immersive 3D renders, stunning photorealism, and more
checkpoints are general models
lora are some kind of style or you could call that flavor to the general model
for example, if you think the base Sdxl model is not able to generate a correct baby yoda. You will train it with a data base to have the one you want:

But most of Lora trained on civitai are useless. People are just bad at prompt engineering. Therefore, they create a lora. Since you can get a good baby yoda from the base model without training if you use the correct prompt.
But in my case, I try to create a stargate universe lora. And sdxl do not know that. Because sdxl dev probably do not know what stargate is or copyrights issue. Therefore, I have to create a data base and train a lora in order to get that:

Shortly, you just try to make your model learn something it doesn't know. And that is a lora, embedding, hypernetwork, fine tuning...
I am finding this trouble too with warhammer, are there any guides or tutorials to make your own lora?
/img 3d
So many. You really need 2-3 tutorials. One that focuses on proper captioning - Google for a reddit post named "captioning datasets for training purposes". Another that will explain the settings of your chosen trainer, kohya scripts or kohya_ss wrapper, everydream 2, etc. and optionally one to show to use cloud compute, unless you happen to have a top of the line card with lots of VRAM. Here's one that combines some of those https://aituts.com/sdxl-lora/

This guide will cover training an SDXL LoRA. It's meant to get you to a high-quality LoRA that you can use with SDXL models as fast as possible. "Fast" is relative of course. Gathering a high quality training dataset will take quite a bit of time. The actual model training will also take time, but ... Read more
There is guides on reddit. Type sdxl lora reddit. Or on youtube.
And you can train your lora locally or on colab

Unless you want crappy Lora, and piss off Google at the same time
Colab free works great for me. I opened 10 accounts and switch from one to another.
Only problem is my training must last less than 4h or I get kick out...
But it is ok. Instead of creating one big lora of 400 images. I just split it in 20 images
Not enough resources to do it correctly
Yep sdxl requires a lot of GPU ram... But Im not here to sell anything or create the ultimate sdxl lora. It is just to experiment and see some sexy jaffa

there are so many tutorials and each claims to be the ultimate guide. Don't take them too serious. If you have enough vram (12 gb are good) you should rather experiment yourself
what is frustrating is I need a lora around 40 epoch to get good details and flexibility. Also, I need to keep batch size at 3-4 and repetition around 5. If I reduce my database I lose control too. So I need at least 20 images.
So to train my lora it is something between 3h and 4h...
I got disconnected after 2h30 for 2 days....
last one stopped at 35 epoch, I was so close to get something really good...



when I think about all these guys with their 4090 just making nudes... Give me the same thing and I flood the world with real ai art !





I want to fix the collar and name tag in this picture.

I'm trying to use inpaint sketch, but it's changing everything for the worse.


What am I doing wrong here?
you can try better prompt. Add "detailed, collar" into negative prompt
I can't get the spots on the nose to work with my current prompt
I was able to add those with inpaint sketch
I'm just not getting consistent results with inpaint sketch probably because I don't understand it very well
inpaint Sketch is identical to juat changing the image with any graphics program before doing inpainting
I'm not sure what you mean
with inpainting you can just change the neck
inpaint sketch is the same as normal inpainting. But if you draw a red dot on the image and inpaint it it is more likely it gets something red
Thanks for the input
With ControlNet Inpainting, how is the behavior different with and without an input image in the ControlNet panel?
Is it okay if I only install SDXL through civitAI as a checkpoint?
Or do I have to do anything else
I am soft in the head
install sdxl turbo
faster and same quality

In this ComfyUI tutorial I show how to install ComfyUI and use it to generate amazing AI generated images with SDXL! ComfyUI is especially useful for SDXL as poor old Automatic1111 can have a hard time using it - especially if you try to use the refiner! Also works great for Stable Diffusion 1.5!
It's really easy to install - especially with th...
Me Im blocked on SDXL + Controlnet...

I try to use my Lora with controlnet but it doesn't seem to work in Comfyui...
i can give you access to more resources
I am trying to train dreambooth lora sdxl with diffusers
But doesn't work well for me.
I am using this code.
When I change the image directory, it does work
Could it be possible to merge a specific prompt and seed into another model?
Im wondering the same, it could be really sick to do a bot that has all custom models and then asks which is the best image and merges the best prompt+seed combo into the base model
you are general asking for a Reinforcement Learning from Human Feedback. The recent released paper DPO makde use of pickapicv2 dataset for such a thing.
Merging with layers doesn't directly effect specific concept. You might try the slider repo prompt training to extract that. https://sliders.baulab.info/
Precise and continuous control over concepts through low-rank model parameter directions
in general, the first and last layers encode fine details and the middle layer encodes composition
there is no general formula. Use validation images and train until the images look good. Often it's better to slightly overtrain the lora.
I asked that almost a year ago 😭
lol, sry, my discord is really buggy at the moment 😂
I think some people need to have handicap. Because they are so talented, the world is not ready. If with 8GB I can create that, I will probably destroy the competition with something more powerful. And merry christmas !










i'm experimenting with some effects like adding and removing shadows. is there a way i can query clip for captions whose embedding is -shadow? or is there a way to train with negative conditioning in the text encoder?
hey guys, can anyone help? I keep getting ValueError: '/data/DuaLipa/DL 3.jpg' is not in list when I'm trying to train model in dreambooth, anyone know why?
when training dreambooth or lora, is there any mechanism to try to steer the model towards only modifying the relevant parts?
for example, when I have a dataset that consists of images of "lamborghini super car driving on a mountain road", is there any mechanism that helps the training algorithm to only modify the neurons responsible for "lamborghini","super car","driving" and "mountain road"?
Wanna train a model for JAV-style images (SDXL finetuned on movies snapshots and posters), too bad there is no suitable dataset for that. 😢
text encoders will learn contrastive examples best. so you'd need images of
a ford pinto car driving on a mountain road (lambourghini contrast)
a Lamborghini motorcycle driving on a mountain road (car contrast)
a lamborghini super car parked on a mountain road (driving contrast. observe this may be indistinguishable from driving, which should illuminate for you why driving is hard to depict: it is not something you can see)
...
- you can interpolate embeddings, e.g. take the two captions "a tree near a house" and "a tree near a house with shadow" and then for each token compute the difference between both captions. You can then add the difference multiplied with some scaling to increase or decrease the shadow
- there are lora sliders that train the unet to increase or decrease a certain term, see https://github.com/rohitgandikota/sliders/tree/main
GitHub
Concept Sliders for Precise Control of Diffusion Models - GitHub - rohitgandikota/sliders: Concept Sliders for Precise Control of Diffusion Models
i guess shadows are complex because there's "shadow" in the sense of an explicit image of a shadow, and shadow in the sense of the intrinsic rules of lighting. i am trying to express that the image is missing the intrinsic rule of lighting that causes shadow, and that we want it back. slider lora sounds promising - to me this sounds like colorizing a black and white photograph, like something that needs a distinct approach to fix.
is there any community with deepfloyd loras?
I am fairly new to training stable diffusion , i had trained couple of lora model for specific use case, now i want to implement it on large scale with big dataset ,
i used kohya ss gui to train lora , now i am using a dtaset with 260000 images to train lora , but i unable to start it
I am using runpod with rtx 4090 gpu, using batch-size :1
Any idea how to do training or finetunning on large dataset

what's your dim and optimizer?
optimizer :- Adam W
no idea about dim
AdamW should be fine...
dim/rank is one of the most important parameters, you should check that. With so many images you can probably use high rank, but should be still below 64
You might try ShareGpt4v https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V instead of llava. It is closer to gpt4v in captioning.
GitHub
Contribute to InternLM/InternLM-XComposer development by creating an account on GitHub.
Why not just start a GitHub project vs polling a discord channel for interest, seems inefficient
Plus most people would prefer that link vs DM for more information
I released my filtered 4k image pairs human preference dataset, a subset of pickapicv2. https://mega.nz/file/fgsxhbIa#QSNcjVxm4vY2f68PyOzmlIMHQCQOe93EyyFK1rmRkEc
More information: https://civitai.com/articles/3620

Pickapicv2 dataset https://huggingface.co/datasets/yuvalkirstain/pickapic_v2 Collected 10k subset from pickapicv2 training split with hpsv2 score f...

Hey Guys,
I want to do some training and not sure if should use LoRa, Dreambooth, Textual Inversion or something completely different. Let’s do it on the example of big feet. So most models do know what feet are but can’t really distinguish between sizes. My approach would be to gather many images of people with big feet, use the WaifuDiffusion Tags to describe them, i.e. 1girl, sitting, …., feet, big feet. Then I would train a LoRa with those images and the descriptions. I’m not sure if this is the best approach since I don’t want to train every aspect of the pictures but just have the training focus on the „big feet“ aspect. Any advice? Thx
To control specific conecpt, you might try concept slider to train a lora
Hello, can anyone help me?
I am trying to create sdxl lora model based on 6 product images
Every image has white background
I wanna keep the original color but after I finish training, it struggles with color
It sometimes generate random color product even if it capture the exact shape of the product
does anyone can help me?
Are you using captions? If so provide an example
These are captions I am using.
{"file_name": "9535401033758.jpg", "prompt": "a photo of TOK, chanel quilted flap bag"}
{"file_name": "14590ch_chanel_classic_double_flap_medium_front_strap.jpg", "prompt": "a photo of TOK, chanel classic flap bag in black"}
{"file_name": "9536196280350.jpg", "prompt": "a photo of TOK, chanel black classic flap bag"}
{"file_name": "9535399264286.jpg", "prompt": "a photo of TOK, chanel black quilted flap bag"}
{"file_name": "9535401164830.jpg", "prompt": "a photo of TOK, chanel classic flap bag in black quilted leather"}
{"file_name": "9535397691422.jpg", "prompt": "a photo of TOK, chanel quilted flap bag with gold chain"}
{"file_name": "9535401099294.jpg", "prompt": "a photo of TOK, chanel black quilted flap bag with gold chain"}
These are the product images







remove black in catpion which would learn black with the bag
you will simply need a better training set and better captions. is this for a commercial project?
Yeah.
How can I improve captions?
can you show an example image where the color went wrong?
I tried that but it didn't work

This is the example image
wow, that's weird 😅
colors should be easy to learn...
do you use noise offset and if so how much?
Just use default
maybe the word "gold" is somewhat bleeding over the image. What happens if you generate the image with very low CFG (e.g. cfg 2-3)?

maybe the color is "too easy" such that it does not learn it. I don't think it's a problem with the caption. You can try using a higher noise offset and/or training with min-snr-gamma
I train the model with following parameter set.
accelerate launch train_dreambooth_lora_sdxl_advanced.py
--pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0"
--pretrained_vae_model_name_or_path="madebyollin/sdxl-vae-fp16-fix"
--dataset_name="./in"
--instance_prompt="a photo of a TOK"
--validation_prompt="a photo of a TOK, a beautiful young woman holding black chanel bag"
--output_dir="out"
--caption_column="prompt"
--mixed_precision="bf16"
--resolution=1024
--train_batch_size=1
--repeats=1
--optimizer="prodigy"
--learning_rate=1.0
--text_encoder_lr=1.0
--max_train_steps=720
--gradient_accumulation_steps=1
--gradient_checkpointing
--train_text_encoder_ti
--lr_scheduler="constant"
--lr_warmup_steps=0
--rank=32
--checkpointing_steps=2000
--seed="0" \
And also tried with this set.
accelerate launch train_dreambooth_lora_sdxl_advanced.py
--pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0"
--pretrained_vae_model_name_or_path="madebyollin/sdxl-vae-fp16-fix"
--dataset_name="./in"
--instance_prompt="a photo of a TOK"
--validation_prompt="a photo of a TOK, a beautiful young woman holding chanel bag"
--output_dir="out"
--caption_column="prompt"
--mixed_precision="bf16"
--resolution=1024
--train_batch_size=3
--repeats=1
--gradient_accumulation_steps=1
--gradient_checkpointing
--learning_rate=1.0
--text_encoder_lr=1.0
--adam_beta2=0.99
--optimizer="prodigy"
--train_text_encoder_ti
--train_text_encoder_ti_frac=0.5
--snr_gamma=5.0
--lr_scheduler="constant"
--lr_warmup_steps=0
--rank=32
--max_train_steps=1000
--checkpointing_steps=2000
--seed="0"
But both doesn't work well.
They (huggingface) combine some new stuff in that training method along with existing like prodigy optimizer. They are trying to find something that doesn't require as much adjustments of the hyperparameters.
Not had much luck with adaptive optimizers myself.
I’ve seen suggestions that it would be better to stick with fp16 instead of bf16 too.

his advice was good, if you caption the color of your subject, in this case a purse, you will get other colors in the inference. Only caption the things you dont want the training to learn. You can caption distance, some of your images are "close-up", some are "full shot", some are "medium shot". You can caption orientation, some of yours are "profile", some are "frontal". Doing that should allow you to ideally try to pull those out later. In general, just provide a token to be able to reference it later, "xyzpdq" ...or pick something else less cryptic, maybe include a designer "xyzdesigner" and a class "purse". In your training shuffle captions put your special token first, your class "purse" 2nd, and then for the rest just caption what you dont want..like maybe the white background? unless you want that in your results. Use "keep tokens" of 2, assuming you're using kohya, which keeps those special tokens prioritized
one thing I'll say here about having all images against a white background, unless that's desired, even with captions that will be hard. you're honestly better off doing some hack jobs to put the purse in some diverse backgrounds...or maybe you can do some creative things with controlnet. like generate a lora with the images you have, but then use that lora, in addition to controlnet to create a new image dataset as a source for your next generation of lora that's far more diverse.
you can do all black background vs all white, then in controlnet generate some depth images, canny, etc, and with those you'll have more power and flexibility to put the products in any kind of background you want
you aren't going to make progress with the assets you have. it will not generalize to coloring the bag differently. you will have to modify the bag in photoshop to generate more data; or, the best option is they mail you the variety of bags they want you incorporate, and you photograph it and caption it yourself. otherwise, most of your choices for the arguments look flawed to me.
is the expectation that it looks flawlessly like the chanel purse? i think the media managers for this kind of thing are pixel peepers
let's say I want to train a lora A against SDXL + another Lora B (lora B is frozen) aka instead of my weights looking like
SDXL (frozen) . LoRA A (backpropagation changes it in training)
i want SDXL . Lora B = SDXL'
and now i want to train
SDXL' (frozen) . LoRA A (backpropagation changes it in training)
is this possible?
I tried to augment background.
But it seems like during the training model also learn the background.
GitHub
Contribute to camenduru/background-replacement-hf development by creating an account on GitHub.
I used this code to replace the background.
But this code not working well and also, the final result was not good
One question in captioning is, if I use the color prompt in caption, is it possible to capture the exact color of the original product after training?
For example, the exact color of the product is black brown.
But I use black in captions.
After I train the model, I simply use the prompt like this.
"a black chanel handbag on the table"
The question is, does that color prompt black can capture the exact color of original bag - black brown? Or it will generate black bag?
you're telling it that the bag is black, so it will ignore the color entirely...I wouldnt describe the bag at all, if you want it to learn it as it was presented in your images, then let it learn it without trying to tell it what it sees
having just done what you are trying to do, i think you should maybe go back to to the folks you are working with and ask for more images like i said
i am not sure if this is true
uncertainty noted
for example, what is "it"? what does "ignore" mean?
well there is subject training and style training, "it" refers to the subject
there are guides online that say things like subject and style training
I thought it was pretty obvious the bag was the subject in the conversation
but all of that stuff is folksy wisdom
i mean some of it can be useful, but it isn't robust or generalizable. it's usually 1 person's experience doing like 10 things and reading 100 reddit posts. and maybe the 1 thing of the 10 that guy does works, and he writes about it
writing a caption "black chanel bag" in my opinion doesn't make the text encoder in CLIP ignore, or focus on, anything, in a generalized sense. but looking at the dataset, it would be more accurate to say that without an example of a white bag, a text encoder LoRA isn't going to separate associating blackness with the shape of the bag and the color of the bag
you casting shade over all the guides out there isnt really constructive in this case, I guess take what I said at face value, or dismiss it with all the other folklore then
yeah yeah, i mean the problem is the poor user way overpromised what can be done
@wind garden so you better break out photoshop or get more images
so you are right that the user should remove "black" from the caption, but only because there are no examples of white bags. with the current dataset, black would become associated with every aspect of the image, which is undesirable. it's the Contrastive in CLIP that is missing.
if he had a white bag, and he captioned white bag, I'm saying that would be a bad idea if he wanted it to be white, because by captioning it thus, you essentially turn the subjects color into a variable
i think the user also misunderstands the purpose of LoRA. it isn't a general subject or style learning approach that works with small datasets, it's computational trickery to make diffusion model fine tuning require way less resources
hmm, if he had images of both a black and a white bag, and he wanted to eventually generate a green bag, he should definitely include the color in the caption.
you can certainly still prompt for a white bag, but as you just pointed out, prompts can be flawed and using a color like that in a prompt may and almost certainly will bleed into other items in the image
it's dumb luck that it works well with styles and subjects undertrained with small datasets
i'm sure tencent is working on the exact application the user needs right now.
so all I am suggesting is to let the training discern the color, dont try and force it with captioning
this is somethnig I know to be true, if you have 10 images of someone with blonde hair, you'll always get blonde hair in your inference, unless you caption the hair
does there exist an idea of pretraining for loras? i.e., i would always resume lora training from a pretrained lora checkpoint, with its gradients and everythinglg?
what benefit does it have? train faster or better result?
i would assume better results. a pretraining for example might take SDXL's pre-existing dataset, and train a lora against it, which ought to produce no visible difference in the results. but such an "initialized" lora will have good gradients and weights for the unet & text encoder, even a learning rate, that may result in improvements when you resume that lora with your training set
You might do an experiment and share the results. I think if you are gonna to train several similar lora which has same style but different character, it might be helpful. But in general, everyone train with different dataset and push the lora close to the dataset. A general pretain might have contradict direction.
Hi every body, i try to make a lora but after many tries the result isn t good. My caracther is always malformed. I have read and listen many tutorial but it seems that any tuto was made by perso who understand clearly the concept. Somebody would answer my questions ? About caption, images... I have missed something but what ?
Your could use a save, but what makes more sense is to merge the lora back into the base and just use that checkpoint
Or just generate a full checkpoint in the first place
Checkpoints are big so you'll want to keep it in hugginface or gdrive
I wanna generate background of product image.
What is the best way to generate background of object?
if you replace too many backgrounds during fine-tune, wouldn't the model become worse at making the subject look realistically in the room/environment they're in? Because of lighting / color mismatches?
I had a question about photo quality, i need to resize photo to 512*512 for SD training. I download high quality of my character on the internet, but when i resize them (even if i crop them before to have only the portrait) i loose information (it's logic cause i pass from 1024 to 512 for example, and there are twice less information). There is a way to keep an extrem high quality when i zoom on the 512 picture ?
you don't need to crop the images at all. In kohya simply choose max-size 512x512 and it'll auto-crop everything.
ok, so i can crop image to get part that i want to train, no matter the size (10241024, 20482048, ...) kohya resize to 512. With good quality ? cause i have used a soft to crop all my image but result is less quality that when i use gimp and do it by hand
Hey guys, I need help with how to add certain objects or specific body parts to an image. Lets say I have a portrait of a man, and I want to add a military hat and badges to him. So I impaint the forehead and heair area for the hat, and the chestarea for the badges, but the results are poor. The color and style doesnt match well and it looks bad. The badges arent even thw type I wanted.
So my question is, is there any way to use own resources (google images) to add it and keep the consistency? I've read that lora works well for characters, but not sure if it works well with objects and faces
Not sure if new model, lora or embedding would do the best job for that
Lora's should work well enough yea as it limits the training data a bit more to what the lora is trained on instead of the whole model
So i just need to train lora with the object i want and should be fine?
what is the purpose of the art? is it a commercial or video game art or... helps us understand what quality you need
Its hobby haha
I just like sharp and high res stuff, but at least that looks realistic or in the context
for instance, this image from the user kuromi, how would you add a militar hat to the main subject?

generally, it is extremely hard to add a specific, coherent element to a pre-existing image. you must use inpainting, which means you must create a mask, which means you must use a real art tool
in this particular instance, there's no chance a diffusion model will correctly add a hat that is cropped by the top of the frame. you would need to outpaint some margin at the top of the image, then inpaint a hat, then crop it again.
there are some instruct2pix style solutions but none that are really easy to use by the community nor robust enough for whatever problem you throw at it
okay i get it
So better to generate similar image directly, instead of adding stuff right?
yes. for open source work, deepfloyd is the best model in terms of text comprehension, and then you can use its outputs for later workflows in stable diffusion for aesthetics and control
you can always add the hat yourself with a graphics program (e.g. cut the hat from one of the soldiers, increase its size and copy it to the guy) and then do inpainting afterwards to make the poor copy-pasted hat into a hat that fits to the image
DF is not an open license. Research only restricted licensing

Hello, Can anyone help me fix this?, when i use roop, or Reactor, this happen to the face, i tried to change Restore Face Visibility, CodeFormer Weight (Fidelity), same thing happen, and when i use ip adapter to change the face, it not recoganize the face,



it really depends on yoru goals because like kaibioinfo and i are saying, if you can use a tool that you work with by hand, like photoshop or something, to draw masks and to copy and paste items, this is achievable. if you want to do this without any human intervention, it is impracticable
you can draw masks directly in a few UI's . FOoooocus, invokaAI, automatic1111, vladmantic
i'm not sure if comfy or swarmui have anything setup for live masking
there's also great extensions like segment anything or inpaint anything, for automatic1111, which make creating masks a breeze
my point was not so much about drawing the mask (yes, thats possible in comfyui and any other ui I know), but about making a rough sketch what you want
if you want to inpaint a sword into the hand of a character, it's often easier to just copy&paste a sword into the hands and then inpaint on that
that technique is used tons in the past. before diffusion. its tried and true. good call. i've heard it called photobashing a lot
Hi guys, new to here. 🙂
I've created couple images of ppl posing in different locations. The images look otherwise quite nice but they lack detail and are somewhat soft. I've tried numerous ways to enhance the images with several upscalers, img2img to get more detail, ADetailer, LoRAs, ControlNet, combination of these, different noising strenght and sampling stemps and methods, tweaked promts etc. Still the results are far from good. - Ideas what to try next?
I'm on a Mac Studio Max M1, A1111
are you using a fine tune or lora you're developing yourself?
Everything I’m using is downloaded from hugging or civitai
maybe try the #1072238304042438758
has anyone tried a batch size of 2 when training XL with dreambooth? SEcourses config is batch 1 but I can fit another one on 24gb. cant really tell what it's doing to quality since I havent tested both on the same person yet.