#🔧|finetune
1 messages · Page 10 of 1
Had a thought earlier bout what would happen if i make a model in DB then added a trained hypernetwork ontop of that 🤔 er atleast train a DB-model, then perhaps use hypernetworks for postures.
Hell yeah! 😁 👍
Just tried my checkpoint model on step 42000. Hella way to strong still though, but actually starting to look really good 😁
I’ve done this a fair bit with hypernetwork a and got some good results - moving to different models other than what was originally trained the hypernetwork on. Moving between the models, for example one specifically trained towards sketching, or anime models etc. as long as the cfg isn’t too high it can be a good way to explore the subject creatively.
I trained a network on the hatbox ghost from haunted mansion @ Disney and then experimented with some different models. This is an example of comics diffusion (Charlie Bo artstyle) and into the spiderverse models, after training the ghost HN with the sd 1.5 pruned model. The spiderverse model is totally a unique interpretation that’s kinda fun.


I quite like the technique for “exploration”, which is necessary sometimes when the client doesn’t know specifically what they want and you can output 1000 different variations.
Sweet! 😁 haha, yeah looking forward to learn more about that kind of techniques also . Right now i made a controlled random code-generator for my DB modells, that tries a few hundred variations of the best prompts i managed to create, all giving the model a different style, different traits, different settings, and then giving the client a the best of the batch to look if they find any particularly style thats more to their liking, and then keep working from that viewpoint 😌 not totalt completed though, due to the AI branch keeps evolving like a motherfucking mutant spider every day it feels like 😂 #loveit
Oooh yeah right. If it’s a colab you could edit the code cell to pull a specific version away from the head. That way you don’t have to worry about updates if you don’t want them
Or a batch file etc. I don’t use invoke but I’ve seen some that have a batch file that pull the latest each time the user runs it
https://www.youtube.com/watch?v=DK3xg8QLh_U - you find everything here
Made a video for it
Dreambooth + pix2pix
Textual inversion training works too
Nice one! 💪 😁 just watched it all. Im going to try it out tomorrow! Dont know if i dare open another Google Colab process (not used to GC) if that could lead to that my current training can be canceled 😅
Yeah, if you're on the same google account, you can't run 2 sessions at the same time
hmm.. but can one log in with two different accounts perhaps? 🤔
Hmm.. will check! .. really dont feel like compromising the current training now after 12 h, at 27% 😂 ..but as always, to curious to be able to wait

Jeex.. now i can actually train two models at the same time, and still produce content locally 😅 this is not good for the thing called social-life.
Right now a model of my girlfriend. Trying to get a as accurate model as possible, all the way into the bone marrow 🙂 then i have a couple of other projects to try. Going to make a painting/photo of all my parents pets they have had since i was a kid, and put them all in one photo, standing infront of the house we all lived in. Yeah, and of course some dirty shit tentacle porn. Got many female friends who's into that also and want themself portraited in different kind of tantaclisch-situations 😂
But firstly, trying to find the perfect formula in how to make the best of the best model possible. What kind of photos needed, what pre-editing that is the best, what training settings and amount of images needed, etc.
:))))))))))
Do the woman really want that?
:)))
I'm at the step of finding the best formula
Haha some actually do, yeah 😂
It's bad that the people who really know how to make good models do not tell others
about the settings, data images etc.
Really? 🙂 Interesting! I would love to share information about that. Coz, as you say. Nobody shares that info, atleast not what i have found from scavenging the interwebs thoroughly for the last months 😂 ..more then the basics on how to get a avarat though
Yea, watched many youtube videos
But they all failed
they are "average" only with face photos
but they don't work with styles or with full body shots
Yeah, feels the same way. Would be more productive for the community if people share more of their information 😄 but then again, I guess plenty of people is aiming to try to ern some money in this hype and dont want to let others onto the same path. Personally im just amazed on the tech and what in can do, and want to learn more about it 😌 ..and to create amazing art of course! 😂
It's very risky to sell ai generated art nowadays.
Have you experimented with the captions also, and perhaps got some knowledge on how its best to produce them to get the best result? ..that is probably my next step in model-processing right now. My first atempt is the model i produce now, but with almost 3000 images the editing was.. quite simple. Is it woth it to edit every caption to describe exactly the image content, of is BLIP interogation with adjustments for faulty information enough?
guys what is the path to finetune this : https://huggingface.co/Cryonicus/Gemini_Anime


BLIP is decent
It should work without manually captioning
It's easier to complete the CKPT_Link tab
And yea, the path to huggingface is Cryonicus/Gemini_Anime
i got errors D:
I Make ckpts , not safetensors
will it make me a finetuned ckpt if i put this in the text space
its broken

No
Don't put the link at the huggingface path
put it at the "CKPT_Link"
this
and leave the path to huggingface blank
Did it work?
oh my god..... r.i.p drive space
it has 5.98 GB
that model
you can do the following trick
Runtime -> Disconnect and delete runtime
And reopen the notebook inserting the good link
where I said
This way, it will download only the gemini model
nah
a ckpt is almost the same
but you can use the dreambooth extension directly in webui
I found out how to do it
i dont undetstand

i have a old version
I made dreambooth to work inside webui
I made a google colab notebook
Like the one you use right now
You use google colab to train it now
can i have the link
also can i have the link to the gemini CKPT. it had a horrible conversion error
Wait a little. Gonna personalize the notebook to include exactly your model
Gemini
done

GitHub
Contribute to Bullseye-StableDiffusion/stable_diffusion_webui_allinone_dreambooth development by creating an account on GitHub.
Right click on Raw and Save link as...
Then you open that .ipynb file in google colab
ok how do i load it to the lastben
You wish to train right now or to use the gemini model?

On what I gave you, you can either train or use the gemini model as it is
i already did it
but i want to upload this link into the last ben
bc idk how to finetune in any other places
i want to train it in the last ben
dreambooth


Yea, seems like it can't be converted into diffusers
:C model must be broken
yea
Did you try to write Cryonicus/Gemini_Anime in the huggingface path leaving everything else blank?
yes i got errors
Does anyone know what are the best settings for a person training in dreambooth?
Because the settings found on youtube keep failing
@fast epoch can you tell us more about what you are running now and what is failing?
Yea, I'll give you examples
When I try training an older pt backup I get stuck at this task.
"Applying cross attention optimization (Doggettx)."
I can always train a new hypernetwork and back ups don't always freeze here but they do more times than not.
putting max steps higher than the step the tp file finished on fixed it.. does someone have a better understanding why? I mean it made enough sense for me to try and it worked but why? does it keep track of it's total steps and sees its self done if the steps are lower??????
How do you know if the pt file in your embedding is actually being called? Even if there isn't an associated pt file in your embedding, having anything extra added to the prompt despite keeping seed the same will have a change on the result. Sometimes I get an error at boot up saying my pt files have failed to load too.
Hey, are any stable diffusion experts out there that could you lend me a hand with something? I hope that this is the correct chat for this.
I have made a custom model of a face using the Google colab resources rather than my own since my laptop does not have enough VRAM for training but it handles generation just fine. However, I would love it if I could have that model as an embedding to use in other models like analog-diffusion or open-journey, rather than just the base 1.5 that I trained it on. I do not have the VRAM for training an embedding sadly. Checkpoint merging doesn't work so well and it degenerates the likeness of the custom model, or I may not have the sliders or values correct. Any tips on this? I would appreciate it so much! 🥹 .
Merging custom dreambooth models are usually, New Model (A) + DreamBooth Model (B) - Model DreamBooth was trained on (C) with Add Difference = 1 (There are a couple other numbers you could try here). If the New Model is close to the DreamBooth data you added, then it should work well.
Here's a good video on it:
https://www.youtube.com/watch?v=xLQcWKI5OLk&t=2s

Merging Models in Automatic 1111 is the BEST way to refine and improve your Models. Checkpoint Merging in Automatic 1111 explained in a very easy away. Weighted sum and Add difference for Checkpoint Merger explaint in Automatic 1111 for Stable Diffusion. Merge any Stable Diffusion Model to mix different styles and models together. Improve the lo...
This is what I get when I start Stable Diffusion with a hypernetwork trained pt file in the embedding directory. How do I actually use my results?
Error loading embedding cammyTrainedModel012823.pt:
Traceback (most recent call last):
File "C:\StableDiffusion\stable-diffusion-webui\modules\textual_inversion\textual_inversion.py", line 205, in load_from_dir
self.load_from_file(fullfn, fn)
File "C:\StableDiffusion\stable-diffusion-webui\modules\textual_inversion\textual_inversion.py", line 177, in load_from_file
raise Exception(f"Couldn't identify {filename} as neither textual inversion embedding nor diffuser concept.")
Exception: Couldn't identify cammyTrainedModel012823.pt as neither textual inversion embedding nor diffuser concept.
Thank you Alicat! I will test that out. I think the sliders and values that I am using are off as I already tried that merge formula. I will check out that video and see if I can see where I am going wrong  .
.
Hypernetworks go in the "hypernetworks" folder
I'm not sure what Auto did in the recent updates
I think you can now?
and i can call it in prompt?
darn missed that, i was looking through the dummies guide thanks! ill see if it works
it works! 😁 thanks! ive gone over that page you linked me so many times, hypernetworks section was so brief!
Yeah, was recently updated
Has anyone tried finetuning with 15,000 or more training images & text pairs? How long did training take?
has anyone ever tried throwing desired results from training into the database with the originals to push it more in the desired direction?
yep
works well 
is how I turned a 1 image dataset into an 8 image dataset for better variety, by cherrypicking and editing the results and then feeding them back in
Biggest imageset so far is my current model in training. ~3000 images, and the traning time in Google Colab was aprox 45 h.
Idk, but the dreambooth doesn't work anymore
they updated something today or yesterday
in the webui
Damn 🫤 just woke up and was planning to try that DB out 😂
Nice! 😁 then i will try that one in a bit. The current model worked out.. well.. not good at all 🫤 became way to strong, and some elements lingered on into every render, like a painting she was working on and a bed she lay on. And those also makes it almost impossible to put other preferences into the image despite the setting from the original image.. hmm..
Might be a good model to merge though, if it turned out that strong 🤔
Gonna refix this

Textual inversion training
I don't really get the results on which I wish
still training
trying to make a model for Margot Robbie just to see what are the best settings
Bad that the "textual inversion masters" don't show us some settings
And how do I know if the model is flexible enough?
This server has around 21000 people online
And no one answers :))))
Nah, the dreambooth is still not working
What GPU?
Does anyone remember M.U.S.C.L.E men? I want to fine tune a model that can imagine new variations. Is there a notebook that would be particularly suited to this?




I heard some people saying that instead of training models on subjects/styles it's better to train a lora and then merge the lora with a model
Any truth to this?
hi guys need some help with training embeddings ? i have 2 pcs, 1 works fine and the second with better hardware doesn't seem to pickup any of the images i do, even if they are the same input
chai from hi-fi rush


Haven't tried that yet, but it sounds as an interesting idea though! If you find out more I'm interested to know more!
Yeah, feels like this channel aint overflowing with active users 😂
Oh, holding my thumbs for ya!
Im running some tests on the model in training. Step 104 000 to step 124 000 in evaluation now 🥳
Updated and tested
working as of now
it has dreambooth, lora training and pix2pix
I've had really good results with 6-12 images and using the default training scripts available in the lora repo
Quality of images have a very big impact in my experience
Yeah, LoRAs are faster, more flexible, smaller, and can produce good results. Since it's just training the specific weights instead of the whole model. I would recommend 
Kohya's repo for LoRA training is the best ATM, imo
Here's the GUI version

GitHub
Contribute to bmaltais/kohya_ss development by creating an account on GitHub.
I need some help with TI. I've trained a really good one on some ghosty things before, it was fantastic, worked great. Today, I have been trying to train another one, but when using all the same settings, it just doesn't work! I have preprocessed all of the images, all are the same size, have captions, etc. But after looking at the training files and testing out some of the produced .pt files on a sparate device, it actually isn't training anything. DIfferent embeddings produce pixel-prefect copies, and it doesn't actually look like anything in the training data. It just look like a normal generation. Has anyone else faced anything like this before? Any help would be greatly appreciated.
Here are the settings from the embedding training
I've tried training three times today and this has happened all three times
I'm trying restarting sd and deleting venv, I doubt this will work
But we will see
In your txt2img tab, did you select a model?
I did notice a weird "x/800000 steps" in the command line that would increase with every step of an image
Yep,sd1.5 as seen in the settings
that's what can trip me up from time to time, just making sure it wasn't something like that
I haven't had any issues where nothing is training though
It is a very weird issue
i really need a colab of this repo, it can also extract a lora file from an already trained dreambooth model
https://www.reddit.com/r/StableDiffusion/comments/10kuzmh/how_to_extract_small_lora_file_from_custom/
i love how the people in civitai are slowly transitioning to LoRAs instead of textual inversions and dreambooth models
I don't understand really what lora is, I tried it once but it wasn't working because i kept running out of memory (I can do it now since I figured out the mem issue) but I don't know how to use it. Is it like a dreambooth model? Or something else fancy?
alright, I'm retrying the training, I will probably know within the first two training images if it's working ot not
Ok, based on the first training image I think it's working? The outfit is more similar to one of the input images than what I was getting previously.
I'll make sure to look at the second and third to really make sure
weird, I am still getting this line
I do not have it set to 80000 steos
it only goes up with the images generated during training, but then it also went up with images generated normally. I think that's the issue maybe? Or could be a side effect of whatever the issue is?
well that line is gone now
Must be a weird bug
But it might be working now
I guess the only way I will know for sure is if I test the embedding for differences in an image
Oh I think it's working!
Not really what I am going for, but this is only at 200 steps

Nevermind, training is still broken :(((
Why
It just doesn't actually train anything
This is my issue
Fuck
there's a colab version, one sec
I still think that second line has something to do with my issue and I have no clue why it's there

I'm curious if having "overwrite old embedding" checked in the create embedding tab is the issue, htough I just did a clean install of the webui so I guess I will never know
not the solution I guess, either things. I guess I have to revert to an old version.
wait
It might be working?!
Hoenslty idk at this point, the training images are very different between 50 and 100 steps
ill wait a few hundred more steps then go to bed
nah I don't think it's working, that 100 step training image was probably coincidence?
Heya I'm complete noob in coding, could you help me how to install this ?,
any steps would be appreciated
thanks in advance
Yo
Download that file
Search "google colab" on google
click on "upload", then upload the downloaded file there (on google colab) and then run all the cell codes
but not all at the same time
Step by step
https://www.youtube.com/watch?v=DK3xg8QLh_U&t=13s - made this video tutorial

Thanks for watching!
I created a Discord server for discussions/help about Stable Diffusion on Google Colab: discord.gg/rH9YXMYfpT
You can download the notebook file for Google Colab from: github.com/Bullseye-StableDiffusion/stable_diffusion_webui_allinone_dreambooth/blob/main/SD_All_in_One_with_dreambooth_and_with_everything_workingv1.ipynb
Jus...
If you still have issues, let me to know
Working on a method to launch the notebook from google drive and to save all the progress there
atm
to make google drive as a "HDD/SSD" for launching webui
Made it to run on google drive memory
so you don't have to redownload everything all the time
@fast epoch my virus-guard jumped up and down for some trojans when i installed that colab into my drive btw. could it be because of the civitai extension perhaps?
Yea
for one of the extensions or for the newest xformers
or even the model can be
if it's ckpt
the safetensors are the safest
cool, im gonna try and see what happen
thank youu
Huge thanks for explaining everything, I will try it out and reach you out if I have any problems
@fast epoch I will try to load a different model with it later on and see, looked like it wored though! 😁 👍
Yea, it works
Even if the progress will stop at a certain point in webui (it will show like "1 hour left" and nothing changes), if you check the code from google colab it is doing the job
training epochs...
Anybody has a good way of telling when a model is overtranied, and when to train it further, but with smaller steps etc? 🤔 rignt now i've trained a model with aprox 3000 images, 200 000 steps. Now I have to evaluate which save of the model that is the best, and were it started to get overtranined. Right now I've mostly been guessing and gone by feeling,. But perhaps someone here has more experience of Dreambooth models?
When you'll see "model saved" or something like this, it is really finished and you can reload the webui page
There's a couple ways. For example, visual distortions (there's a certain look overfitted models get) and you can do overfitting tests.
for the overfitting tests, basically make prompts that require like the character changing outfits or changing styles
or a prompt that doesn't fit the base data
if the result always puts on a certain outfit that you trained on and doesn't do anything else, then it means it's overfit
If you still have issues, you can ask for help on my server.
If you need to have a low CFG in order to get good results, it's probably overfit 
I will try to sett a trial prompt, working trough all of the step-savings that has been produced and see. I have never tried to train such a big model eralier, so its a first trial and error now i suppose. But the feeling I had when i run a few testruns from step 2000 up to 122 000 steps, it felt like it was very hard to make the AI to use the model in almost any kind of "nre situation", it kinda clinged on to the original images and settings all the time. So far its been no visual distortions though. Im about to run the last batch from 122 000 steps - 202 000 steps now and see what the result will be.
I have a feeling that when working with one single model and such a big number of images, perhaps i need to work more with the captions too. Describe more if expressions and postures and such.
I dont know though, in the end thats just a feeling that I perhaps need to try, but hopefullt has somebody already tried that and knows some about it 😂
Added
At the end of the day, it just comes down to what your goal is
If the model does what your goal is, then you're golden
even if it's overfit
Mmhm true that. Im actually not sure if i have a specific "goal". Im trying to see what it takes to make a as perfect model as possible. To be able to catch a human persons all looks, personal physical traits and quirks into one model. If it is possible and how good of a model it is possible to produce, and perhaps find out a formula for being able to do that 😌
Test the boundaries of the AI modelwise so to say
To be able to catch a human persons all looks, personal physical traits and quirks into one model.
Then you can test for that, and if it can do that, then you're golden
Yeah. Thats why i have a feeling i need to specify that in the captions. What is going on in the pictures. How else should the AI know what is what. I dont know though how "strong"/important the captions is for the result during Dreambooth training.
If the captions are vital for the result, i would not have any problem sitting down a week and write the captions manually. But when i dont know if it would be a waste of time or not i'm really not there to invest that time yet 😂 ..probably though, even if nobody knows of i cant find out how vital it is, i will probably try anyway some day. But hopefully there are people who knows more about this than i do and can guide me on the right path 😁
The captions are a huge contributor to quality. For large datasets, people batch caption. Tho, inaccurate tags do hurt the quality but it's just a matter of the cost of time vs quality
Also if you're doing large datasets, are you caption training (finetuning)? DreamBooth is good for like a few concepts but finetuning is better for many
Thats what i did this time. i BLIPet the captions, then searched all the files for errors it usually does, like describing the female model as a hi, and misinterpreting tattoos for bracelets and stuff.
I have done like 50-60 different models using dreambooth out of friends and family mostly, trying different settings for getting the best result. So for "avatars-training" i have a formula. But when truing to get body language, natural poses etc into the mix, and also needing to up the image quantity im back to being a newbie it feels like. A long way to go and the variables are far greater when working with larger image sets, and trying to get it more detailed.
Caption training? Hmm.. i do train the text_encoder in dreambooth if that is what you mean.
I'll post my settings. brb.
This is my current setting (first tryout) for the large imageset with 2948 images.

are you using an instance token?
On that i must say no.
You're probably finetuning then if you're learning off the captions and aren't using an instance token / instance prompt
Yeah, no im not using any instance tokens. Then perhaps its even More important that the captions are describin the main images correctly and as accurate as possible 🤔
My next wounder about captions is, how detailed should they be. Is a few lines alright.
Like this is pretty much the standard format of the caption (just took one out of the batch on random)
"a woman with a necklace on her neck smiling at the camera with a smile on her face and a necklace on her neck"
If you want a model that's good at making women, necklaces, smiling at the camera, then yep!
But if you want it to "catch a human persons all looks, personal physical traits and quirks into one model" then you need to include those captions on those images
Or at least, including those captions will allow you to get them when you prompt for them
if they're missing it won't happen unless it's overfit (and that will only mean some things are possible)
Now when actually discussing it with someone it suddenly feels so obvious that is the way to go 😂
Well.. i'll see what this model is capable of doing at least, and then start working for more detailed information in the captions in the next one.
Now i saw that dreabooth actually renamed the captions-folder from "captions" to "captionsoff" also 🤔 perhaps me adding the captions.zip and captions in the ../model/cations/ folder manually perhaps didnt work at all.
Dreambooth refused to let me add the captions during the image-upload phase and started to abort due to that "model(1845).txt" is not a supported imageformat. So i had to add them to the drive manually before I started the training.
😮💨


Mmhm.. im going to try @fast epoch webUI version now instead of lastbens fast-dreambooth. Hopefully it will work better. Atleast until i've upgraded my computer so i can run all this locally instead 😅
@split acorn do you know how extensive you should write the captions also?
If your goal is to ""catch a human persons all looks, personal physical traits and quirks into one model"
So make sure to include "looks, personal physical traits and quirks, body language, and poses" for example
I'm not sure what the limit is or how to go about that in the most optimal way, but that's the general jist of it
You could try small datasets first with various captioning methods
to figure out which one works best for what your goal is and then scale it up from there
Good idea there. Perhaps its better to acctually go through each different set of images, containing different kind of expressions and traits, to get that set to work in a model first, then when all different "sets" are working, add them up into one model containing them all 🤔
mm mm, is an idea
For more complicated models or for training that includes "sets", I would recommend Kohya, personally
but that's just me what you're doing could work perfectly fine
Lets you rebalance the sets easier
(or at least it's one that im familair with that allows easy balancing)
There's a colab for it too, but I can't speak to how good it is or if it's better vs what you're using
Everydream is nice too 
Ooh.. i haven't tried Kohya yet. Found it somewhere yesterday and actually has an open window with a colab running kohya open, thinking of checking it out. I think someone mentioned that Dreambooth is better for smaller amount of images, and kohya could be better for, as you said, more complex models. Everydream was also mentioned in the same sentence as Kohya so i have a window with that one too. But hasnt found a cloab of it yet 😂
If I have any thoughts when trying it, perhaps i can check with you for some pointers?
Yep, sure. I haven't done any large scale models yet though, so someone else might provide better feedback
There's a server for DreamBooth and EveryDream and many people for Kohya hang out on a couple servers (no official one, that I'm aware of)
they might be able to help more than I can
Sweet tx ^_^

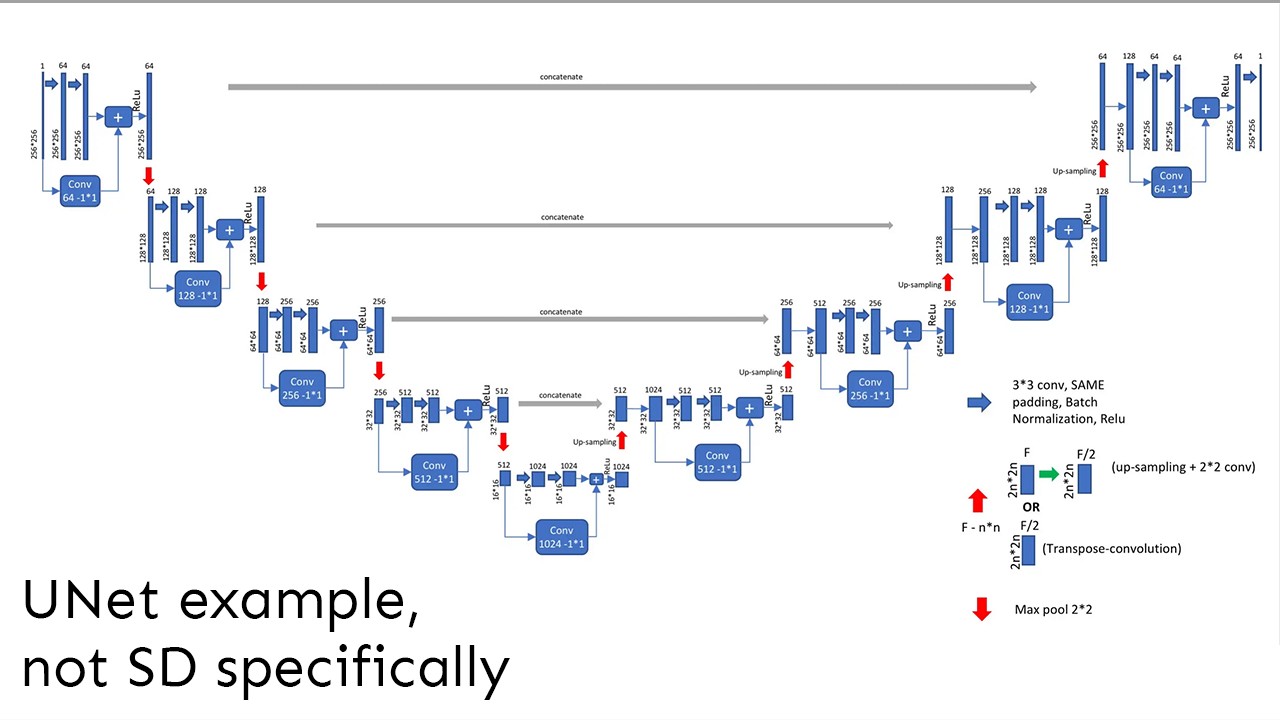
There are 5 methods for teaching specific concepts, objects of styles to your Stable Diffusion: Textual Inversion, Dreambooth, Hypernetworks, LoRA and Aesthetic Gradients. The question is: which one should you use?
In this video we review 3 key research papers, look at the underlying mathematical mechanics behind each method, analyze data from...
is a good video, as well
That was a interesting one informationwise 😂 thanks for sharing!
Anyone have this issue?
Renders look most like subject during training preview - then turn into a completely different person
I have noticed that the live previews look amazing, albeit a bit blurry, during the beginning of the render process. Then, after about half way through, they start morphing into some unrecognizable subject, which usually ends up looking like a weird relative of the subject, or they just turn into a senior citizen.
I have created 4 models so far based on different subjects, all with the same settings/amount of training. Two of them produce some pretty amazing results, while the other two behave in the way I just described.
Why does this happen and are there any tips on how to prevent this?
I have had that issue also, dont know why or how to solve it though.
is this for Dreambooth or TI embeds?
ahh yeah i have that issue before too. i am assuming you using later version of Dreambooth
i actually switched back to early december build
cause i was struggling to learn while they kept changing the code
and i had same exact issue .... never resolved.... but i also haven't gone back to new code
december builds were much simpler
but they didn't work with SD2.x
anyone know any servers or locations that work with embeddings/TI? i'm having issues getting mine to look like my subject. i did tutorials.... SECourses had a good tutorial with sample iimages... i followed along... got great results... then when i put my images in... horrible
so i'm guessing it's my source images. but i have no idea why. they are clear and i even changed all the backgrounds
@inner meteor what do you mean by "version of dreambooth" do you mean their train_dreambooth.py?
yeah you can go to old versions of the code
let me get url
so ... like here - https://github.com/d8ahazard/sd_dreambooth_extension
GitHub
Contribute to d8ahazard/sd_dreambooth_extension development by creating an account on GitHub.
if you click on COMMITS
on the right hand side...

see under <>code
then you can download the build from any point in time
so what i did was uninstalled the extension
and used an old code base from mid december
i know they slowed down and are now focusing on stabilizing what's there
but i'm not sure if it's "polished" yet
i'd look at tutorials you following, and look at the date they posted... then get a build from around then
Anyone now of a way to solve the saturate image output in Stable Diffusion (Automatik 1111). I feel most images are over-saturated by at least 30%, giving the images a kind of childish comic look.
Is it just me or is pix2pix super inconsistent af?
Like it seems only once in a blue moon it actually does something without making the image look like bullshit
Hi everyone,
I am looking for available options to fine-tune stable diffusion inpainting for a custom dataset and need some help. I found two open-source models- one by runaway ml https://github.com/runwayml/stable-diffusion, the checkpoint is provided but the training code seems to be missing there, and the other one in the StabilityAI stable diffusion repo https://github.com/Stability-AI/stablediffusion for which I am currently trying to run the existing model, Not sure whether training scripts are available or not.
Is the training or fine-tuning code available on GitHub or hugging face for stable diffusion inpainting? or is anyone able to fine-tune the text2img stable-diffusion or inpainting model?
Also, the major thing is what are the minimum hardware requirements to fine-tune the model? I do see some stats posted for the model trained from scratch. Can't find any info related to hardware specs for fine-tuning?
Apology for any redundant questions. I started exploring stable diffusion last week only and recently joined this discord channel.

GitHub
High-Resolution Image Synthesis with Latent Diffusion Models - GitHub - Stability-AI/stablediffusion: High-Resolution Image Synthesis with Latent Diffusion Models
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/7264 I FOUND MY ISSUE

GitHub
Is there an existing issue for this? I have searched the existing issues and checked the recent builds/commits What happened? When you Train Embedding on RTX 4080 or 4090 (after last Torch and xfor...
(I'm not on 40 series but it's the same issue I am having)

You could try reinstalling python. Make sure to install for all users and click the "Add to PATH" box.
already tried a couple of times, with python the paths are registered, the command line recognizes the command. Python version according to documentation
oh.. looks like it looks like I slightly mixed up the channel in dc (
Hi guys! Is there anyone succeed in using dreambooth to fine-tune stable diffusion inpainting? Neither https://github.com/huggingface/diffusers/tree/main/examples/research_projects/dreambooth_inpaint nor https://github.com/ShivamShrirao/diffusers/blob/main/examples/dreambooth/train_inpainting_dreambooth.py works
GitHub
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - diffusers/examples/research_projects/dreambooth_inpaint at main · huggingface/diffusers
GitHub
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - diffusers/train_inpainting_dreambooth.py at main · ShivamShrirao/diffusers
i have read that you can train a normal dreambooth model and then merge it with the inpainting model with a certain config, it will give you a good custom inpainting model:
https://www.reddit.com/r/sdforall/comments/zyieht/how_to_turn_any_model_into_an_inpainting_model/
reddit
188 votes and 41 comments so far on Reddit
Something similar happened to me and the problem was that i deleted the background (to a solid color) to isolate my subject in my training images, and it gave me very inconsistent results. I tried again but with the original images and it turned out great
Hi! I would like to share my finetuned model:
v2-base and v2-1 fine-tuned with NovelAI-like aspect-ratio-bucketing https://huggingface.co/ttj/flex-diffusion-2-1

200 epochs. Does this mean my learning rate was a little too low, since it still seems to be learning, or should I keep going with the epochs?

Anyone know? 
I honestly don't know what loss means for training stuff, could you explain?
Basically it's the penalty score for how bad the model's prediction is. The higher the number the less predictable the model will be = bad results
A "perfect" theoretical model would have a loss of 0 for example
But that would take forever to train?
I'm currently at 407 epochs in my currently training embedding
A perfect 0 will always be impossible I believe
Ah yeah I'm doing about 6800 images 😭
Yeah of course
I'm trying to see if I can do huge data properly and seems to be working well, but it's all photography stuff
Ah
I just released an embedding today and I plan to release another one in a few hours
Is your model on anything specific?
I'm just getting really lucky with mine I think 😆
It's specific to modern art photography I would say
Anything from portraits, animals, and weird art stuff
I photographed some friends pets to use for the animals so they always come out 😂
Aw that's cute
I've been wanting to train something on my cat. I have like 300 photos of her on my phone anyway
Yeah do it up!
The biggest thing I learned was, make sure they are all in different backgrounds and settings
That makes the biggest difference
Well she is an indoor cat, so the backgrounds are very similar
Bathroom, bedroom, by the window, kitchen, in fridge, in bathtub, etc etc
why would my cat be in the fridge
And ofc in a box

very cute
what would be good LORA settings for characters , Using Kohya_ss variant ?
is it possible to fine tune the instruct-pix2pix models with textual embeddings / LoRA? has anyone tried this?
I'm wondering if it's possible to teach instruct-pix2pix to do geometric transformations, like "rotate the cube"
Anyone have a guide of how to utilize textual inversion files in Automatic's client?
so .pt files
anyone able to help a fine-tuning noob? i'm stuck on getting the process beyond initialization because of my column naming. Various TypeErrors. Using the ImageFolder method
Traceback (most recent call last):
File "/notebooks/training/diffusers/examples/text_to_image/train_text_to_image.py", line 730, in <module>
main()
File "/notebooks/training/diffusers/examples/text_to_image/train_text_to_image.py", line 474, in main
if image_column not in column_names:
TypeError: argument of type 'JpegImageFile' is not iterable
Is this gist of it.
Put your pt files in sd-webui/embeddings/. Under the "generate" button on the top right, the third button is called "additional networks" - it will open a menu with embeds, hypernetworks, loRA, the whole shaaabang
Question for those using DreamBooth: For training faces what has been your best settings? I'm getting inconsistent results. My settings have been 1e-6 training, 2-4k steps, with and without class images, with and without instance prompts. Wondering if you have found a config that has worked well for you
R they enabled by default
Yea when you load the ui from a terminal window, you should see an output with all the names of your embeddings

So I understand that having different backgrounds is pretty important for textual inversion. Does anyone have experience with masking their image and adding plain colored backgrounds? Or would that defeat the purpose of textual inversion?
Im getting blurry images after training a model, does it mean its over training? only used 69 epochs, learning rate of 0.000001, 16 input images and 10X for reg. images
I think I used these same settings another time and got good results
yeah, doing that can work fine. Just make sure to describe the background. And keep in mind if all your pictures have it, then it can start sticking with your generations
This graph means that I should continue with my training, as the loss is still going down, correct? My sanity sample prompt still holds the original artist's style.

Can anymore kindly explain to me or refer to some resources on how to finetune the inpainting checkpoint of the stable diffusion model on my custom dataset?
Yo guys me and my mate are very new to this, how would we take a hyper realistic image of a person that was generated and feed it back into stable diffusion to finetune or fix certain elements of the photo?
Any reference point of where we can start to research or look into?
When training a woman's face with textual inversion, should avoid pictures the woman whose head is turned sideways, like when she is lying down?
hi guys, i am trying to train SDv2.1 with Dreambooth but i'm having some problems with the results. The context right now is people in wheelchairs but the idea is to extend it to others disabilities. I'm using 10 instance images of persons in wheelchair and 200 class images generated by the model before training. But the resulting images are too plain compared with the original model and there is often "extra fingers, extra limbs, deformed face, deformed wheelchair, etc". All of these words are in my negative prompt but it seems that is not enough. I know that "person in wheel chair" is recognized by the model but it has the same problems with deformities even with negative prompts. I am using diffusers repository btw. Do you know if i the approach that im following is right or should i change it? or if it exists some repo that do something similar... any kind of advice is welcome, thx
you can do it with inpainting(manual masking parts to be replaced), and also there is pix2pix option now which I havent tried but it works by instructing AI to make changes on given image
Hi guys, what is the current best colab notebook for training a dream booth model? Im trying to have it train on garden blueprints
Do you know if there's a google colab notebook made for textual inversion training except this one https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb ?

10 instance images is too little
I usually run 100+ for good results
I also recommend using ur own reggies and not self-generated
source: master dreamboother
Can anyone point me to a place that can give me good examples of under and over training and when to decide to stop training or change rates?
ive recently tried 1e-5 for 2000 steps and then going to 1e-6 but I still don't really know what to look for... some stuff I guess with smaller databases start getting rainbow edges and details a lot sooner, what can I do?
i use a really smooth image upscaler for small images.
I have a question about training with LoRA. What should my dataset look like for a person who isn't already in the SD dataset? About how many pictures and what should their minimum or ideal resolution be? I've seen some AMAZING LoRAs but mine are coming out garbage. I think it's my dataset.
10 can work just fine (people generally recommend 10-100 for most things), and the whole purpose of regularization is to basically tell the program "these images are normal". There'd be no point if the reguarization images weren't created by the model you're training on. Any good results would just be placebo if you're not.
Hey, can you give me a tip on what to look for when starting on a dataset and choosing when to chance to a finer rate? Should there ever be a point where my results look exactly like my source or should I always be trying to keep it a little ahead so it looks a little like my source but not exactly? Are rainbowing edges a sign of a blown hypernetwork?
You're hypernetwork training?
Mmm one sec
i kinda like it but I hear it takes I while, im having issues recognizing what good and bad training looks like early on though :S
I've trained all this last week on a few things with a wide variety of result
overfitting can look like rainbowing edges yeah, like the quality of the generations loses overall quality
Honestly, it just depends on what your goal is
If you're doing a character hypernetwork, what you could do is test if you're able to switch details of the subject
if you're not able to, then it's a sign of overfitting
If general prompts (non-super specific ones) are looking quite similar to your source images, then that's also overfitting
backgrounds can give it away
From my experience, with smaller datasets, it's pretty easy to figure that out 
will the size of the dataset effect how many steps you can go before it starts falling apart? If there are these rainbow artifacts presents or will using other ai generated photos to learn on also increase this effect?
oh ok
I'd personally recommend LoRA over hypernetworks though, because with hypernetworks your modifying the layers indirectly, where LoRA is directly. But I honestly have no idea what one is better or not, I just prefer the direct control.
Yep! size of dataset and number of steps until it breaks are related
with larger ones you can typically get away with more steps, and with smaller ones, it tends to break sooner
I don't understand the second question though
ok, excelent, about the second question. Ive used some ai generated photos within some of my hypernet datasets and I would find those details showing up sooner, It was a small set though too.
What about tags? Does it help if I go ahead and load them up with a bunch from deepbooru? I've had some sets that had most prompts the same and I found it go down hill faster but then again it was a set of around 20 images. My problems might all be related to my dataset quantity. I understand better now.
just a last question, is there any broad chart or recommendation that cross-references number of images by most effective steps???
like if im training 20 img, should I start with a higher rate and change before 1000 steps?
ive been going twice beyond that
mmmm
These are some good sources of information on hypernetworks
Number of images vs most effective steps changes depending on the model, settings, dataset and goal so BUT these links have some good general recommendations for settings
I just trained a lora model for the first time, does anyone know why I would be getting this error when trying to use it?

Thank you for your help! The possibilities with this tool seem almost unlimited, can be quite overwhelming lol
I should probably try asking in #🤝|tech-support
You could try the extension instead (ironic given the error but )

GitHub
Contribute to kohya-ss/sd-webui-additional-networks development by creating an account on GitHub.
Ah, is that a replacement for the button thing?
this was the original
and yeah, an alternative
I prefer this, also gives you fancy sliders
I mean, a different lora I have seemed to work
This extension should work for all of them (?)
(well, assuming they were trained on Kohya, I suppose, or recent db extension)
I used the dreambooth extension for training
Ooohh that might be the cause
older dreambooth extension training might not be compatible
I think the only way to use that is to merge your lora into a model
Oh :(
yeahhhh was dark times back then
Well the only reason I did it was because I had a large dataset with 200 images, would textual inversion respond well to that?
I personally have no idea. LoRA responds well to large datasets like that though
one sec, I'll check
Thanks :)
Yep! TI can do larger datasets like that, as well.
I haven't made any TI that large though, so I can't help with that
I only have an 8gb gpu, and have been successfully training some things with around 25 images, so I wonder if my settings should change. Should I use gradient accumulation? I feel like it makes training slower but I would be running this one over night.
I also should probably have a pretty high vector count
high vector count isn't always a good thing. Kindly like higher DIM count with LoRAs
Honestly I don't know what DIM is (I never followed a guide when making my lora earlier)
GA can work if you want higher batch size but don't mind sacrificing time, since you're limited on VRAM
I don't understand why higher batch size is better to be honest
I get good results on a batch size of 5, which trains pretty fast. I also have GA to 1.
How it was explained to me is DIM can be seen as how many points on a curve there are. The more points, the more information it absorbs, but some of that information can be "noise" from the image, stuff that you don't want it learning on
higher batch can improve the training but like everything, there are limits
So a batch size of 5 and a gradient accumulation size of 5 would get me 25 images at a time, but take like 5 times longer.
especially with smaller datasets
Ah
So if I have a large one it's not really necessary?
And do you think more steps would be better with a large dataset? I would assume so
I'd just defer you to the link 
Good idea 😆
My settings

Theoretically should work
I guess I will see in the morning
Thank you for all your help @split acorn :)
Tis on its way, if I have time before school tomorrow I might share results. Depends.

Yosh, good luck
Well shoot, forgot I had a faulty power supply and everything just shut off really loudly so the training failed
Dunno if I want to get up and retry
Maybe tomorrow
Maybe I should install those new batteries into my power supply that I have
Anyway imma go back to sleep
Dream Studio is trolling me

I'm trying to generate a yellow surfboard, but I get a weird blurry blob instead 😭
Worked long time with dreambooth from last year probably November commit, updated to the newest one, and the training process is going, but the model learns nothing, just receive the random images. What could it be?
I think it has to do with xformers and the latest versions of cuda and torch. The same thing happens with textual inversion. Basically you gotta revert to an older version of the webui and delete venv to redownload all the python packages.
Well, my computer didn't shut off while I was at school, and it made it to about 7000 steps in about 9.5 hours.
I am tesating it all now
Welp, I hath released the embedding. https://discord.com/channels/1002292111942635562/1071271601699553320
Seems there's a bug in many popular models where the first word in the prompt is ignored, which might explain strange training behaviour with them, as well as a potential way to fix it
https://www.reddit.com/r/StableDiffusion/comments/10baavg/bug_warning_with_some_models_other_than_sd14_like/
https://github.com/arenatemp/stable-diffusion-webui-model-toolkit
Ooooo nice job
Somehow fast-dreambooth wont accept me uploading captions with my images in google colab anymore.
I always get a error message that 'modelname (xxxx).txt is not a recognised image file', and the training stops..
So I have to add the captions to the session manually afterwards. But when training, dreambooth renames the 'captions' folder to 'captionsoff' despite me checking the external captions box. So i supposes that it's not using my captions 🤔 Perhaps someone here can confirm if that might be the case, and even better.. tell me how to be able to force fast-dreambooth to use the manually added captions in the model-training 😂
Anyone had this issue and knows if my feeling is true?
And if so, how to fix it?
Did anyone have any luck with training LORAs on objects, in particular weapons? I am struggling with what ratio to maintain between the pics of weapons themselves and people wielding them.
Hello, a brief question, I tried using batch generation with masks and I could not find the results anywhere in the output folders and only a grid layout of the results in the designated output directory.
Finished another embedding :) https://discord.com/channels/1002292111942635562/1071827026991915049
Here is a thing people might find interesting. You can finetune the model a lot with something as simple as Ben's fast dreambooth without touching UNET or Textencoder. Just train concept with good images and the model improves accordingly on that concept.
Since it basically just finetuned the text encoder more.
So if you are struggling with something, just concept train in DB and you can improve it. This allows you to keep the model otherwise intact.
Is it a problem if I wish to train a person who has the same background in almost all the photos?
Could be. If the pictures are from pretty much the same angle the background often seems to "stick" and can be really hard to change to whatever setting you'd like. Sometimes it works better and sometimes its hopeless to remove it.
If you caption the background, and add that background to the negatives, you can kinda get around that
It's best to not have them all the same though, yosh
But even that doesn't really fix it sometimes
I have some image-sets that seems to stick no matter how much i train the images. Thinking about trying to remove/replace the background manually on those to try to get them to work.
Yep, honest the best way to salvage the dataset
Imo
I've done all gray backgrounds, and then captioned it, and it worked quite well. Though, when it started to overfit, you could see the gray leaking in the background
Then what's the best approach? Selecting the person and leaving with a transparent background or to swap the background's color in every single photo?
White is popular
to make the background white in every photo?
Yep
Just make sure to caption it
I'm not sure what other people are doing though for transparent backgrounds. From what I've seen/heard, that's the most popular option
Nah, I don't use tags/captions
I only did gray because my subject had white hair
The best method without captions
Oh yeah, I don't think that'd work
It's looking for similarities between the images, after all
Oooh yeah with different backgrounds yeah, that's fine, that'd work
But if they're all the same, I think it'll leak in super easy
At least from my experience with that method
so to add different colors to the background leaving only the person the same
You'll get your person and the backgrounds will be of varying solid colors
I think
Not sure if they would be solid or a mess of different colors, would be interesting to know
Im planning to try different methods for that. Blurred background, solid colours and change the background to mixed backgrounds. Future project though. Glad to hear this worked out for you though 😁 👍 makes me hopeful for all of my "useless image-sets"
Absolutely! 😄 👍 Kind of curious of what makes the best result for this issue.
So hey, I've just started trying to experiment with textual inversion to train some embeddings in automatic1111, and uhhhh... Yeah this kinda thing is what I'm getting. I've left the learning rate on the default 0.005, but watching it go, it's generating utter garbage without any discernable difference all the way from step 50 to 5000. I wouldn't be surprised if it was just not matching the training concept well, but I don't know why it's mangling everything so badly like this or where to start on fixing it. (Not every image is this bad, but all the rest are still super grainy junk.)

I got previews that looked like jumbled messes when I clicked the "preview via txt2img" button and not having a prompt in the txt2img tab, but I'm not sure personally
This is my new wallpaper now 🙂
Couldn't launch python
exit code: 9009
help pls guys
Did you notice that the last dreambooth update made the extension to produce worse results (trainings)?
did you follow the github installation guide? Did you install python3 and did you add it to your PATH environment variable? Are you using anaconda, miniconda or anything similar?
Kinda felt so also, but trained such a large model without captions so took for granted it was due to that 🤔
I've heard people say it was because of something related to pytorch though not sure
them nips
Pretty hot right
hello people, over the weekend we've released a service to let people train SD 1.5 using Dreambooth as a fast and easy service: https://dreamlook.ai/create-models
i would be really interested in LoRAs, are you planning to add it?
Yep that’s definitely something we want to add
The newest webui is so bad. Made a model with dreambooth, tested it on the newest version of the automatic1111's webui and it generated some bad-decent images. Then I used the same model, with the same prompt on an older version and it generated way better images.
It might be worth it to just use one of the standalones, since then you can avoid all the potential dependency nightmares, especially considering that auto1111 updates so often
Hello, anybody know how to find the commit number of this video? for both Stable diffusion and dreambooth? https://www.youtube.com/watch?v=9Nu5tUl2zQw&t=194s

DreamBooth for Automatic 1111 is very easy to install with this guide. With DreamBooth for Automatic 1111 you can train yourself or any other subject. Use your own trained Model to create images in your styles or of yourself. The DreamBooth training in for Automatic 1111 takes only around 30-40 minutes with a good GPU.
LINKS From Video ##...
Hello
I have a question about what Ben wrote in his notebook
Image
Does it mean that we can train even with 1080p or 2160p images?
The maximum resolution there is 1024
But it also wrotes "or larger"

Not recommended, training will take too much times and probably colab will crash.
We're just not there yet, at least for 1024 x 1024.
For apsect ratio bucketing, you can get 256 x 1024 however! For 512x512 model training so if you have a 1:4 image, it would get resized accordingly.
I don't recall last ben having aspect ratio bucketing, however
#1047197565365538826 is now under the Stable Diffusion category
Try using an older version of bitsandbytes, for me that fixed things a bit

reddit
0 votes and 0 comments so far on Reddit
can you still train loras using dreambooth?
You can use Kohy's scripts to to so. not sure about the a1111 extension
The dreambooth extension is so bad
You can't even compare the extension's results with the dreambooth's script results
Same for LoRA
https://discord.com/channels/1002292111942635562/1073240057038782514 Just finished a new embedding!
hi! I trained two textual inverison embeddings, one with my girlfriends face and other with mine. The problem is, when I use both of them in the same prompt, somehow it only transforms the faces of the characters in the face of the first prompt word (i.e. myFace). What I am doing wrong? is there some configuration in training that i missed? or is it just a finetuning problem. THank you in advice!
Typically, if you want multiple faces with multiple embeddings, they would need to be generated seperately
so, for example, through inpainting
There are some repos that allow for multiple prompts for one generation which could you let you do both (I think Comfy UI could do this) but by default, I don't believe repos like Auto1111 or InvokeAI support it natively
quick question, probably has been answered plenty of times - can I merge two checkpoints but the base is the depth map one from SD?
problem is I believe there is a tensor size difference as the depth map model seems to have one more value compared to other models
Is normal that the upscaler fixes the bad eyes of my model?
I mean when I generate 512x512 images without upscaling, the eyes are pretty bad. When I use the upscaler, the eyes are very good.
does anyone know why im getting this errorwhen merging with pix2pix

if thisis not the right channel im sorry
Is there a lightweight dataset tool that simply displays the caption and image, and lets you edit the caption? I have a dataset that I need to refine the captions for
what format is the dataset in?
you will probably need a ryo solution, but I know how to open most formats in python
Hey guys. So I'm trying to train a embedding to use on a ckpt that is already heavily stylized . Call it ckpt 1.
When I train using images generated with "ckpt 1"
And then ran on ckpt 1 they seem super oversaturated. Clown faces and high contrast colors.
If I use trained embedding on stock SD 1.5, they perform much greater. But this is reverse of my desired result.
So I think what I need to do is use normal unstylized images to then train on ckpt 1, so then my embedding will not be overstyled when I use it on ckpt 1.
Would love some feedback or insight!
Its just image files and text files, where each text & image pair shares the same filename but obviously use a different extension
Basically the standard format
I just want a quick and easy way to double check all the captions visually
I haven't found anything ready made
Looks like this powershell script does the trick

GitHub
Streamlines AI image training sets for AI tools like Stable Diffusion - GitHub - Jukari2003/Caption-King: Streamlines AI image training sets for AI tools like Stable Diffusion
Thanks! I've been looking myself
I have a Breadboard fork that is designed for captions as well
GitHub
SD Captioning VIA Breadboard. Contribute to theovercomer8/breadboard development by creating an account on GitHub.
Say i want to train Dwarf fortress style SD. This is a game that generates long text descriptions of every crafted item by every creature in the game. Something like a "Jagged twisted metal sword, crafted of the highest quality, menacing with bones and spikes of granite" would be an simplified example. Obviously i would want a huge data set with tons of great tagging to do this training. Photos of metal ore, polished metals, different quality of materials, seperate photos of various metals that are twisted, jagged, smooth, bent, hooked, stones crafted into different shapes, photos of stuff adorned with bones and spiky stuff, leather, straps made of various quality, the list goes on an on. I could write 100s of different goal images for this set i want to develop no doubt.
What i'm wondering is, could I use SD to generate this set, curate the hell out of the results, and expect a healthy model from that? would the minor imperfections of SD like, train in harder and lead to inbred models?
Thanks for the suggestion! Currently, I find the powershell script's simplicity is really useful. It requires no installs and works on whatever windows device I run it on (its portable). I also don't need to do any autocaptioning right now (your tool seems to be more geared towards that), just manual fixes from stuff that was autocaptioned (and captioned by others).
yea, the editing of captions part is in the works. i've just been focusing on making an autocaptioner first
I don't know if I'm in the right place, but is there some documentation available regarding Block Weighted merging of diffusion models? Maybe someone documented their experiments and findings? Or are we all still stabbing in the dark seeing what sticks?
I get good results (very similar to my face) in first part of processing, then it's getting different af. Why?
we can see the process in webui
it happens in every lora model i created

Sources:
- picture
- doc
*Direction should be changed to influence.
Merge Block Weight Magic Codex 1.0Beta
- Introduction
- Getting Started Tutorial
2.1. Installation
2.2. Feature Introduction - MBW Fusion Introduction
3.1. Style Change
3.2. Improving the overall quality of the model (Composit...
Please send me feedback
This guide is still work in progress. Any and all feedback is highly appreciated, it doesn't have to be suggestions, even questions regarding things you didn't understand can help me figuring out what to refine. For the moment I can be found in /sdg/-threads, but I might m...
hot darn, thank you!
Yep, no problem
When I merge Models sometimes it works fine. And sometimes the resulting images get weird colours. I dont see the weird colours in the preview-images while rendering, but in the end they are there. Can anyone explain how this happens and how to avoid that?

GitHub
Extension for AUTOMATIC1111/stable-diffusion-webui for smoothing generated images by skipping a few very last steps and averaging together some images before them. - GitHub - klimaleksus/stable-dif...
This extension helps you avoid that
@livid axle
Thank you!
No problem
hmm, lastben fast-dreambooth are behaving strangely in Colab again 🤔

Been failing to train an Asian lady's face well on LoRA. I used 18 images. Should I use more pictures? Most images I used were close-up. Should I provide different poses? The file is only 9 MB btw
Your images should be different from one another, including background, clothing, poses
super duper thanks for that 🙂 I was looking for something better than mass tag editor extension.
Anybody has any knowledge about if it is possible to "over explain" a caption when preparing an imageset for training? Or is it "the more information the better" when coming to captions?
yeah, sometimes its nice to just have a simple tool for cleaning up the manual and autotagging outputs
any other small useful tools worth to mention ?
having a simple script for converting webp to png would be one
Like this one I made recently with ChatGPT: https://gist.github.com/ProGamerGov/c49d872b86fffd37be9f1fd118d89f97

Gist
Convert all '.webp' images in a dataset to '.png'. GitHub Gist: instantly share code, notes, and snippets.
Some of the dataset tools don't play nice with webp images, so its handy to convert them to a more well supported format
lucky for me and everybody, xnview (free) allow batch conversion without issues 🙂 but good to know (not everybody wants to instal whole image viewer for that small thing)
Found that as well (not useful as I not use tags for image descriptions) BooruDatasetTagManager
https://github.com/starik222/BooruDatasetTagManager
GitHub
Contribute to starik222/BooruDatasetTagManager development by creating an account on GitHub.
So a question about training: when I train a lora for SD1.5 on a specific face, and in some photos of that face, the person is wearing lipstick, do I add "wearing [color] lipstick" to the caption if I want to avoid the training paying attention to the lipstick? Do I understand that correctly?
Just remembered this spell checker tool that I find really useful for helping fix grammatical and spelling issues with my captions: https://github.com/tbroadley/spellchecker-cli

GitHub
A command-line tool for spellchecking files. Contribute to tbroadley/spellchecker-cli development by creating an account on GitHub.
Are there any extra good captioners besides BLIP for regular photos? 🤔 BLIP kinda sucks sometimes in so obvious images. (havnt googled even yet, just crossed my mind)
hey guys im trying to train an embedding for a girl useing the Babes 1.1 ckpt from civitai, i can create the look i want through prompting but i would rather create an embedding so i can just call up "sally" and get a close enough version.
Can i train useing images generated from Babes 1.1? use those images and then do i train useing stock 1.5 cpkt or on the babes 1.1 again?
it would seem that when i train on the babes 1.1 the embeddings are right fucked, hyper contrast over saturated looks.
id really appreciate if anyone with some experience in embedding training could DM me please. thank you!
Depends on how willing you are to use colab or a python script: this tool has BLIP 2, GIT, Coca, and CLIP
Hi, I'm using theLastBen for training 2.1-512 model on a dataset can anyone explain me about the concept training used by him. Also, how is it different from other methods
Ooh.. well thanks! Ill check that out during the day! 😄 👍
Ok I don't get it, one LoRA guide says "use at least 100 repeats and 1 epoch" other guides say "use 5-10 repeats and 10+ epochs" I've seen LoRA trained for 35~42 epochs... seriously what gives? I've tried to Train 10 images * 10 repeats * 10 epochs VS 10 img * 100 rep * 1 epoch, both result in very similar models. the single epoch LoRA might be ever so slightly more accurate... Is there one right answer?
Anyone else experimenting with 'Diffusion With Offset Noise'? It seems to solve the issue with training on really dark and really bright images, and lets you move the render output average away from the default half way between black and white: https://www.crosslabs.org/blog/diffusion-with-offset-noise

Fine-tuning against a modified noise, enables Stable Diffusion to generate very dark or light images easily.
@stuck parrot
Anyone have experience with aspect ratio bucketing? Are there issues I need to look out for?
How many epochs are people finetuning SD 2.x models for these days?
https://discord.com/channels/1002292111942635562/1075546510986596432 Made yet another embedding, I think this one came out really well
Anyone else having problems when training embedding? This error: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try using --no-half commandline argument to fix this.
repeats and epochs are fundamentally the same thing
Yea I gathered as much by now, I guess it's more adventageous to use epochs if you're going to save them and are worried about overtraining the model
hopefully whatever you're using is letting you save ckpts along the way regardless of using epochs or repeats, matter of using the right tool and using it properly
Hi All! Question. If I wanted to fine tune SD2.1 with my face, and a friends face. Can I do this in one finetune, or do I need two different models? What would be the process of labelling?
hey all, i am looking for some help training an embedding. if anyone has some experience i would love to chat. please DM me. i am trying to replicate/embed a character similar to this:

You should be able to do that in the same model. Just my renaming the imagesets to different keywords. For exampel "therealmiscanalysis-(1).png.. therealmiscanalysis-(2).png.. etc and you friends to miscanalysisfriend-(1).png.. etc.." i haven't tried training multiple subjects in the same model since i first started though. Heard it sometimes can mix up the data, or that one model gets "weaker" than the other. But worth a try!
Is it possible to train LORA with multiple concepts together instead of just one concept?
yes
Are there any guides for large scale model fine-tuning? Like how to make similar models to what's on huggingface or civitai? I've found tons of guides to textual inversions, dreambooth, lora, etc. But very little for large model fine-tuning. Found the pokemon model guide, and training parameters for waifu. But I'm having trouble figuring out how to design a good data set of ~1000 pictures. How many pictures to have of each body position, head shots, locations, characters, etc. Basically the ratios used in designing the data set.
https://github.com/victorchall/EveryDream2trainer/blob/main/doc/DATA.md that might be a good start, but I think in general there are no stepwise guides for this type of stuff
a few mores hints buried in here perhaps: https://github.com/victorchall/EveryDream2trainer/blob/main/doc/BALANCING.md#do-my-concepts-or-subjects-really-need-to-be-equalized
get friendly with tensorboard, start paying attention to what is going on with your training
this is a bit old from old version of the trainer, but some more ideas there from training a sorta large set of 1600: https://github.com/victorchall/EveryDream-trainer/blob/main/doc/README-FF7R.MD
the link over to huggingface from the above ff7r readme has more info as well
This is why I keep reverting back to Dec 31 2022 on my computer. Nothing new is working for Automatic 1111.
Thanks. I've already read all of those and I review them occasionally to see if they've been updated. Unfortunately you're right, there are no stepwise guides for large scale models. But I'm slowly working my way through it. Right now comparing EveryDream2Trainer Vs WebUI Dreambooth extension on how their different bucketing types affect model training. Maybe I'll write a guide if I ever manage to create a good model.
fundamentally its just training image:label pairs, so most of your effort should be tuning how you caption and tuning hyperparameters
ed2 takes care of aspect/size stuff on its own, I'm pretty confident in the code that handles that
there's a video on crop jitter on my youtube channel that explains most of that process but its not something you need to lose sleep over as its automated
Hey guys, new here
I was wondering if it was possible for my AI to improve its artstyle when re-creating my character's model (from digital drawings) with LORA but I don't know what parameters to be increasing or adjusting for it to grasp the details. The only thing I have done is change the Learning Rate and Unet Learning Rate by adding an extra 0 after the decimal place per training run and using the latest .safetensor model as the LoRA network weights. (I now have 4 safetensors files for each stage of its learning).
When using txt2img I notice that when it is generating an image, it can look amazing when it's still blurry and then the final image comes out distorted, over saturated or the good shading downgrades and I was wondering if im missing a setting or prompt to fix this?
Any links, resources or advice would be very appreciated

and also, should i use regularization images?
Pausing my ctpk tranings for a while and was thinking of trying out som LORA-traning instead. For how many steps would be recommended for a batch of 100 images? Anyone got some hints? Right now i put it on 670 repeats, but when looking around it seems unclear of what would be the best number of epoch that would be ideal 😂
Im using Kohya locally this time. Would prefer if the was a good colab-version though so one can keep on the content-creations meanwhile.
So hint for good lora-colabs har also very much welcome 😌
Some guide I watched said you should have 1500 training steps.... whatever that means. So for 100 images that would be 1 epoch of 15 repeats
It's also something I'm trying to figure out atm
Went down to 100 repeats though. Now im struggling with Kohya google colab, which wont work. Or well.. ir works, but the samt lora i trained earlier today which tock me 1,5 h now takes 15,8 h 😂
Finally getting started on LORA training
Impressed at the time it takes, but I think I need to work on.... something lol
My first guess would be captions in general.... I think
Not sure if I need to be more or less specific atm though
Yeah, I've noticed that image:labels pairs are extremely important, possibly the most important aspect of training. There is also the way training handles captions: how many tokens it accepts and shuffling. Now if only I could figure out how to use multiple gpus for training so I can train faster. Thanks for all the help.
any fine tuning stuff is ultimately doing image:label pairs, but "dreambooth" is only using a simpler token/class label for the caption effectively
if you use per-image captions you can increase the value of training by providing more information via a longer or varied caption per image
Generally, with a batch size of 1 --> 100 epochs. Your training image set also affects this: If you have images that are very similar, this can cause over training. I just did some tests on a training set of 137 images, and 100-150 epochs seemed best.
a few repos let you do that, I think kohya, and joepenna as well
you can label an image not just "cloud strife" but "cloud strife holding his buster sword" or "cloud strife standing in the midgar city slums district"
or "close up of cloud strife with a serious look on his face" or "cloud strife, full shot, facing to the side" etc
you get more value from the training that just labeling everything "cloud strife man" as traditional "dreambooth" would have you do it
I don't use dreambooth, only fine-tuning. And I manually caption each image using a sentence to describe the image, followed by a series of of tags mentioning details, specific body positions, environment, frame, etc .
this is the way
seems to work well, hoping it will work well with shuffling so I can test everydream trainer more.
I'm not sold on using shuffling unless it is a booru tagged dataset
thanks for all the help
I've been kicking around some better ways to do data augmentation on captions, its a more complex problem
there's a yaml driven captioning method, but its more complex and theres no good tool to make the yamls for you
I use the booru style, but not the specific tags. captions have over 75 tokens, so I got to do something to get all tha tinfor in.
ED2 supports a .yaml just like a .txt, but the yaml format is sort of complicated and again no real tool for it
never tried yaml
at some point I will build some sort of parquet/pandas DB-driven caption and meta data format for everything, and have something fancier to drive data augmentation on captions
looking forward to see what you come up with
yeah myself and a few other contributors have been kicking around ideas on what to do here, it would be nice to have like, say, subject, verb, direct object, then preposition phrases [] that can be randomly picked every epoch
its a secondary NLP problem, and creating the data is also very labor intensive so it needs to be automated
blip and other captioning programs.. sorta help at least, someone has been messing with training BLIP to learn specific character names, too
Once I learn how all this works, it might be worthwhile for me to learn some programming to help develop. I'm using this for my business, so if I can make it more profitable, it'll be worth the investment.
Any general advice for LORA training, particularly for portraits/faces?
From the little reading I've done so far, DreamBooth might be better for faces
Wondering if I can get anything similar with LORA since it takes so much less time IIUC
Where can I learn about the parameters of the stable diffusion model? I've heard: DALL-E 2 has around 3.5 Billion parameters, Imagen has 4.6 Billion, the first Stable Diffusion model has 890 million parameters. And talk about "extended parameter models" and "having to split data set into two models because the resulting models would have too many parameters." But I can't find any specific info on what the parameters are. I'm guessing it refers too stable diffusions CLIP or Imagen's T5 model, but I can't find more than that.
hello, is there a way to colorize a monochrome image? for example, i want to colorize a sepia image. by the way, im using auto1111
Try deoldify. It's a neural net speficifally trained to do that
thanks, will try that!
Waifu(sp?) Diffusion 5 released their source code, and they did a massive overhaul model. Techniques they used seem to include 10% caption dropout, which the SD 1.5 release notes also mentioned as helping somehow, and also randomizing the prompt order and occasionally dropping some parts of it (since they use an image tag list as the prompt) https://github.com/waifu-diffusion/network-trainer
They also used varied aspect ratios, rather than a set square resolution
Thanks, I'll check it out.
Anyone have a blank safetensor file
Like for the merge checkpoints it's possible to merge loras into models if we have a blank safetensor file right?
anyone here knows how i can add more layers to the output of SD? i'm trying to fine tune the model to get more channels as output. so like stability has done here: https://huggingface.co/stabilityai/stable-diffusion-2-depth which outputs 4 channels (i'd like to make it output more than that)

Im training CTPK-models mostly, but are thinking of "boosting" them with a lora on top of the base-model. Has anybody tried that. Im thinking of what will be the best. Use the base-model for the face, and then the lora for body and postures, or the opposite around.
Feel like they collide when the images-sets are a bit to similar. (faces and bodys etc in both)
how i can use bot pls ?
So, I just noticed I've been training loras wrong all the time (or so it seems). I used cosine with restarts as scheduler but never adjusted the number of cycles. Didn't have any luck finding sources talking about the correct way of defining the correct amount either. You guys have any advice?
I have a huge database of images, all treated and 1024x1024 mostly with the same style, pose, concept, what would be the best way to finetune that style? Ive heard that most anime models are already overtrained, would that be a problem? Thanks
no idea. but if you do find out, let me know. I'll look around too.
have you tried doing any training? embeddings are a pretty easy place to start. you don't need a huge amount of images though, and it's better to have fewer with better quality and better prompts than just more images
I tried all of them, with different steps also, got some interesting results but never what I was looking for, I see those huge models on Civitai like anything/grape/etc and I wonder how they did it, I've heard that dreambooth gets overkilled by 100+ images so I dont think that is the answer, I also tried lora, and that was probably the best results I got so far, I do want to retrain a improved version, and I would prefer it too be a checkpoint, so that I could freely use other loras, sorry if I didn't explain the situation clearly, and thanks for the reply
did you write custom prompts for the embeddings, or did you use auto generated ones
the first training I did was on embeddings and it was a long time ago so I dont remember clearly, but I dont think so, also the last checkpoints I did were with auto danbooru caption and cleaned to remove undesired stuff, embendings work well with over 100+ images?
Basically you adjust your resets if it doesn't train properly and feels like it's getting "stuck". There's no one size fits all answer so it's a lot of just testing and finding out.
Honestly, for getting practice or getting a better idea, I'd recommend starting with a small dataset first and then adjusting until you're getting good results and then start scaling up.
You really don't need that many pictures to have pretty good results. And after awhile, doing bigger datasets becomes easier since you'll have a good idea of good datasets vs bad ones and what captions work and what don't.
And it's waaaayyy less work to adjust with small datasets
Thanks, any more advice? or it is just test what works until it works?
probably a good idea to create like 4 different sets with different caption methods, or different groups of input images and run them all for the same time so you can compare
Hello, anyone have
advice on training a model for medical illustration? My initial plan is to first train it to mimic my style using DreamBooth, and then train it on anatomical concepts using LORAS.
hey guys! does anyone have any experience with using BLIP/deepbooru for captioning?
I have a very large dataset (30k+ images) and im not sure if im wasting my time generating captions. deepbooru gives me a shit ton of tags that seem generic (ie, bokeh, out of focus, girl, etc) and BLIP gives me somewhat more accurate tags but still generic (man standing with a light behind him, etc).
Do i need to be using captions? Do they help really with anything?
blip seems so bad lmao
how the hell did the pokemon dataset use blip???
yeah those pokemon descriptions are atrocious
i was told smaller more accurate datasets are better than bigger ones, so I'd try doing a set of like 100 with hand-written captions and see if you get better results
though I'd be interested to know if doing 30k images with autogenerated captions still works
In general, which of the 2 options is better for a finetuning a Text to Image model: A dataset of 1000 carefully labeled images (with low quality images manually filtered out) or a million images with auto generated captions and auto generated aesthetic scoring? Basically is quantity better than quality?
What docs are folks using to learn how to fine tune an inpainting model? These are the only docs I've found so far on the topic: https://github.com/huggingface/diffusers/tree/main/examples/research_projects/dreambooth_inpaint
GitHub
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - diffusers/examples/research_projects/dreambooth_inpaint at main · huggingface/diffusers
would 50k blip captioned images work better for style training an embedding over 100 hand captioned ones?
what about a hypernetwork?
im interested in this answer as well
i just finished captioning my 30k dataset
ill see what happens
Can somebody trow me some numbers for training a dreambooth model.
Approx. 100 images on a person. Try to train for photorealistic.
I feel i have stuck in a loop and need to try some new ways.
And would love some shared knowledge.
Base model,
Unet-steps,
Unet learning rate,
Text-steps,
Text-step learning rate.
Would really appreciate it 😅
For a style embedding I would say the hand captioned works better. Blip often gets things very wrong and repeated and doesn't caption things in a way a person would often enter a prompt.
i know, the blip captions are garbage, but does it actually make a difference in the results?
what are concept images for? are they usefull to train a particular style?
also, is it usefull to ''reflect'' the images used to fine tune a model?
lets say i have 5000 steps done in my embedding
i have 1000 images and 1000 blip captioned txt files
do i need to make a second embedding in order to test the results without captions?
and what would i do--simply remove the txt files from the dataset directory?
yeah that should do it i think. though I'd copy the folder first so you have a folder of images for each embedding
i made a new folder, copied the images, deleted the txt files, and got this error
\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\amp\grad_scaler.py", line 336, in step
assert len(optimizer_state["found_inf_per_device"]) > 0, "No inf checks were recorded for this optimizer."
AssertionError: No inf checks were recorded for this optimizer.
then went back and re-booted the prior (captioned) embedding training, and it started normally
makes me think that maybe it failed because there were no txt files
in which case ill need to have txt files but have them blank perhaps
heres a sample of the directory:

heres what it spat out after 5000 steps

definitely not there yet, the art looks literally like what DallE did 6 months ago
going to dinner while this runs another few thousand steps then will try to do a noncaptioned version
good idea, spell icons. How was it captionned for the training you showed here ? all using the same token or... ?
lots of possibilities in the captioning approach here
you could use the main "wowicon" token, plus the class, the type of spell, the main color, or so many other ways to describe an icon here. Never thought of that one before, good find
Base: I use my own model but Hassanblend 1.4 is good too.
Unet steps: 65 per image. I use 30 img.
Unet Lr: 1e-5 with lr scheduler polynomial.
Text steps: 350
Text Lr: 1e-6
Thanks! 😄 will give that a try next model!
I did that on LastBen colab, idk if that will have the same results on local/different colab.
I usually also go with lastben, coz im used to it. But will try Kohya's dreambooth lateron and see if there's any difference between them 🙂
heres an example of the blip captions





the danbooru captions are horrendous
 📎 00134-0-Ability_BossFelOrcs_Necromancer_Purple-realesrgan-x4plus.txt
📎 00134-0-Ability_BossFelOrcs_Necromancer_Purple-realesrgan-x4plus.txt
 📎 15841-0-INV_MISC_Ring_mop12-realesrgan-x4plus.txt
📎 15841-0-INV_MISC_Ring_mop12-realesrgan-x4plus.txt
 📎 23002-0-Spell_Shadow_ShadeTrueSight-realesrgan-x4plus.txt
📎 23002-0-Spell_Shadow_ShadeTrueSight-realesrgan-x4plus.txt
 📎 23013-0-Spell_Shadow_ShadowWordDominate-realesrgan-x4plus.txt
📎 23013-0-Spell_Shadow_ShadowWordDominate-realesrgan-x4plus.txt
 📎 23015-0-Spell_Shadow_SiphonMana-realesrgan-x4plus.txt
📎 23015-0-Spell_Shadow_SiphonMana-realesrgan-x4plus.txt
would it have been manual caption, I would have gone with something like one of those templates ;
- Mage WoWicon ice : Iceball
- Hunter WowIcon beast : Recall
... (I haven't played wow in a while)
this way, it would make a model able to spit out think on that same format easily
ill try it
you don't need all the icons to try
are there any other tokens you think it should know?
do a test on 50, it should start to lend results, given this is a style
I don't this so, I would stick to "wowicon' as main token, and specify the class and specialisation (mage, ice) on each, as secondary keywords. the last part, the real spell name, is more here for regularisation : by having lots of small tokens used only once, you make it so that overtraining will take longer before happening, letting you more room in terms of trainng steps
not sure how many class there is in WoW now, but I would use a total of 100 icons, evenly spread on the classes, and split each class "budget" between each of the 3 specialization, taking the most interesting icons
if that makes sense
can you give me an example for 1 image?
wowicon, warlock, drain life, shadow, green

like that?
👋 hi friends!
Sorry if this is too self-promote-y, but I figured folks in this channel might appreciate this blog post I wrote today, where I walk through using LoRA fine-tuning with Stable Diffusion on replicate.com
https://www.shruggingface.com/blog/self-portraits-with-stable-diffusion-and-lora

In this post, we walk through making self portraits with Stable Diffusion and LoRA
Hi. I'm trying to train a LoRA for proper figure skates. What kind of training photos do I need? Close-ups of one of them not worn, close-ups of one them worn, close-ups of both of them worn, or wide angle of them worn?
Yeah, If you tried all of the options you mentioned, I believe you would get some decent results!
Hi everyone, hope this is the right place to ask: I am about to train/tune for the first time(I have some cool 3d models I can render out). Could anyone here point me to good resources to pick a model(Dreambooth/LoRA/Textual Inversion) and maybe a step by step? That'd be amazing. Thanks!
(I am using Auto1111 on RunDiffusion, btw)
Embeddings are easiest so start there. This tutorial helped me: https://www.reddit.com/r/promptcraft/comments/zyc5eh/stable_diffusion_detailed_tutorial_on_embeddings/

reddit
10 votes and 1 comment so far on Reddit
Start with a small group of images with accurate prompts. You can do the blip thing to get your started, but you'll want to go in and fix them.
Awesome! Thank you, that's super useful materials! 🙏
I was wondering do I want to ask, or I need to search carefully, and I found your links! Thanks!
Btw if there a way to understand - do I need to train LoRa for stylistic or it's just an Text inversion, how I decide? I know it's matter of many trials, but ...
YASS, thank you so much!
is there a good guide anywhere for training a style in dreambooth that's up to date? I tried a training last night and i just get errors when i attempt to use it. Just having no luck at all with training whatsoever on dreambooth, lora, or textual inversion, so i'm definitely doing something wrong.
File "C:\AI\stable-diffusion-webui\modules\devices.py", line 152, in test_for_nans
raise NansException(message)
modules.devices.NansException: A tensor with all NaNs was produced in Unet. Use --disable-nan-check commandline argument to disable this check.
My first successful attempt of a v2 of an embedding, out now! I think it came out great! https://civitai.com/models/11642/digital-diffusion-21

Create amazing art in a "digital art" style with this 2.1 embedding! v1 or v2? You may notice that there are two versions available. Which should you use? While v1 can respond better to more complex prompts, v2 works with simpler prompts and just adds detail and color to them. v2 had a larger dataset than v1 so it is more diverse as well. I ...
I've had my first attempt at doing a TI training today. I'm running it on a 12GB 2060 and could only set the batch size to 2, but I've read elsewhere that others are getting much larger batch sizes on their 12GB GPUs. Any pointers to what I might have different which is causing me to run out of VRAM for the training?
I am able to do batch sizes of around 5 fairly quickly on an 8gb 3070. Make sure you have "use cross attention optimizations while training" checked! Though I think this might still be broken on newer versions of the webui, I have been training on one from early january with older versions of xformers and cuda instaleed since that is what breaks it. By broken, I mean it just doesn't train anything into the file.

Ah yes, I don't have that checked because I saw a lot of reports about it being broken. My first attempt finally finished (about 7 hours on 16 images) and I feel like I'm already pretty close to working workflow but also like I have done something fundamentally wrong. Doing a Prompt XY, some epochs generate extremely odd results, like it will change from a very good replication of the face to very strange things, like the image attached or what looks like patchwork dolls, before becoming accurate again.

would taking my least favorite outputs from my embedding, then training a second embedding on them, then putting that into the negative prompt, help me get better results?
that's a convoluted way of thinking but... maybe ? it could, but it could also have big problems. Like if you liked any part of your failed output, and that a similar part was in another failed output ? it could be learned, and then when used in negative, it would try to repulse something you like .
Also, there will be lots of weights opposing themselves between the two embeds, I worry that the negative would cancel a lot of what the positive brings
yeah i could see how that would be a problem, especially for something as simple as embeddings
even like the general style
if it's a cartoon
both embed will for sure learn that
even the fails will be cartoons I mean
could i use the first embedding in the prompt templates? doesn't that help negate info you dont want to be trained on?
hum... can you though ? I mean, will the embeds be triggered during training on the caption ?
I'm not sure those activate during training at all, but I could be wrong
maybe i can do some tests to figure it out
if you do, please hit me up with the results, I'm always interested in things like that
I’m trying to train an art style on dreambooth. It’s abstract silhouettes of things and the details play a huge part. It seems when training on 512 images I lose some of that detail. Is there a way to train on a higher resolution? I’ve heard it’s useless because it automatically resizes images anyway. Is that true?
So I’ve been training a LoRA without much success. I used 20 images. Been wondering if I should load up my training folder with a lot more (50-100) images that isn’t as good as the original images. Will more images dilute the effect from the original pool of images, or will it be constructive?
how many network rank u using, what is the size of the lora file u produced
What's a network rank? It's 9 MB in size
U probably use the default network rank which produce 9 mb file,try train it with 128 network rank and network alpha, I comes a long way to realize this, too.
On the training parameter, finds network rank and network alpha, set it to 128
Oh! Forgot to mention that I used Kohya ss to train my lora, so...
Me too using kohya ss
Why are all the tutorials telling me to use the main image directory which contains the folders of my training images for different loras, rather than the specific folder of the training images for my intended lora?

And it refuses to train if I choose my specific folder for my intended lora. Huh...
I think kohya ss like to expect there is only one folder on your img
Like 100_name
I haven't try to train multiple folder tho
Yup that's what I came to suspect as well. Thanks for confirming
Does this page look right for training white figure skates? I don't even know if the parameters on this page is used for the training lol

How many repeats should I pick? I have 28 images
What should my destination training directory be?
I did not use the tools tab
U define the output on the folders tab
I did not use the tools tab at all 🤣

The Easy Starter Guide to Installing LORA on Automatic 1111 for Stable Diffusion. Follow my super easy Lora setup guide and learn how to train your Lora files for super-high quality portraits. Use Realistic Vision V1.3 as the base model for extremely detailed and realistic results. Get better portraits with Lora, the super fast training tool tha...
I use this tutorial
Yeah that's what I used. It's awesome, but it's not enough for my use case
those seem like al right parameters to me.
Repeats don't depend on the image count : they are multipled by the image count. It's how many time each picture is trained on. Using the default or recommanded values on that seems the best. I haven't trained LORA but I did a lot of dreambooth, so the measures on this aren't the same. I would train on 100 to 200 repeats usually on subjects training like here.
about the destination folder, any empty folder on your disk will do. it's temporary data for the training
But the main difficulty that leads to good or bad quality results is usually the dataset. It's easy to not see some repetitions, some lower quality photos, to remove all texts, ... Numerous error and biases can happen, but to know what to change, the main way is to try to understand what problem your previously trained model had, and fix the dataset accordingly. That can be adding pictures for poses you want but didn't have, a close up or two to help on fine details learning, or removing pictures that repeat something that got trained by error the last time.
Or it could also be under/over training.
So if I have 100 training images, how many repeats should I have?
like I said, it doesn't matter in that way. You'll have the same number of repeats.
100 repeats on 50 pics = 5000 steps
100 repeats on 100 pics = 10000 steps
it multiplies.
Repeats are "how much" you need to train the model on the new concept. It mostly depends on if your concept is easy or not to get for the AI, from your dataset.
Last important parameter that isn't there is Learning Rate, it's "how fast" the model trains, it's how much each step is allowed to train the model at once. You don't need to change it here, I just wanted to be more complete
Network Alpha = 1 ok?
those I don't know, there aren't any networks to set in dreambooth
Is the logging folder only for debugging?
and outputs sometimes. it depends on the tool. mine puts everything in it, models, image, tensorflow, ...
since I never use Lora, I can't tell
Does anyone have an idea for converting the custom trained text2img model to inpainting model , rather than Automatic 111 Ui, any script to do the conversion
well, I don't think there is anything about this because :
- "txt2img models" can also do inpainting. badly but they can, we had only that for quite some time
- inpainting models are trained in a different way, they don't learn the same weights, and don't look for, or retain the same information, so there is no conversion possible from what I got from the dreambooth trainings I used and read
so you would need to retrain on the same dataset. Also possibly needing to use an inpainting model as base
(they have a different inner structure/yaml than classic models)
I have seen a script which can do the work, https://github.com/huggingface/diffusers/issues/1619
Hope you'll look but i still get an error while doing so

GitHub
Have scoured the docs for an answer to this, to no avail. Is it possible to add additional input channels to a model after initializing it using .from_pretrained. For example (taken from your Dream...
The error which I'm getting is Image and Mask must have the same batch size,
I trained my standard dreambooth text2img with a batch size of 4 and I'm thinking that this might be an issue to do so.
Can you @unique cloak look into it
thanks a lot, I had no knowledge of this !
right now, sad Guizmus has lots of things to do because he is sad following a hack. so not for a little while, I don't even have my training tools ready for now. sorry
Yeah ok no problem, if anyone in the server can solve the issue it's happy to look at it
Am i really training on 1 epoch by default?

What does it take to train a flexible model? Like if i wanted it to be able to respond to any prompt? Would i need all the possible subjects covered in the data set or can it extrapolate once it's seen enough variety?
And what kind of dataset are we talking about for a model with reliable results. Hundreds, thousands, millions of pictures?
Does any one have a good tutorial about making embedding? I want to learn a bit more about setting number of images step and idk I feel kinda lost
I read from a YouTube comment that on LoRA training, if I increase the batch size, I should also adjust the learning rate. Can somebody confirm this, and how do I adjust it? Proportionally, or inverse proportionally?
is this typical for starting DB training? I'm training 30 images, probably more than I needed but I will let it run if it looks good so far

the training doesn't seem to have started yet in that capture. it's preparing the class images, and should take some time since you went with 9k pictures. This is a step you won't have to do twice anyway, those are class pictures you can use in other trainings too.
so all good for now
Using kohya to train a lora, I have managed to train a face of a person and she looks 70% accurate. I've been wondering where my stopping point should be - it should be at a point right before it's considered 'overtrained', right? If so, then what are some definite indicators that my subject is being overtrained? Would the subjects have deformities of the same kind as when their LoRA strength there is too high?
this is not for realistic style, but Nitrosocke made a guide that had a comparison as answer to this :

Has anyone tried to merge loras
from which check point would you finetune the model? 14 or 15? I think i could have used a few epochs more. There are 2 lora files used trained by me. One for the trench coat and one for the comic art style of Joëlle Jones. It's about the art style, the trench coat i'll fine tune another time.

okey, this might be stupid to use a 2nd lora file to check out which check point I should use. And i'll go for another training run with double the amount of repeats.
okey maybe I should use a second Lora to have some more highres resources instead of just the 512 base model which produces crap images with a slightly altered prompt
okey, can go even a step further i guess... lets double the repeats and also the epochs this time

I did a second install of A1111's webui and set it up to use xformers and Cross attention optimisation and it's happily running along at batch size 16 with VRAM usage switching between 7.1GB and 10.2GB. I didn't need to do any additional steps to get xformers to work.
Interesting, I guess it works now. I saw that it was working with the 0.17 dev build I think, I guess that was finally moved into a1111.
Thanks for letting me know, I have been missing some of the new features of later versions
anyone know how to make the small lora files from dreambooth? Its making these massive 4GB files, i thought they were supposed to be like 100MB or so
Adjust the network alpha and the other one to a lower value. Keep under 256 for dimm.
It's wise to keep them the same value. At the moment I use 255 for both.
And for better results in the lower end of the noise spectrum, I set the offset noise to 0.1
hey guys
when im training a model/lora, i notice its been saving extra checkpoints as its been moving along
now i want to run the model more iterations, but its finished
how do i "continue" training?
add more steps?
add more images to the directory?
@stone garden what is this cross-section/how are you getting this in training?
I guess you use automatic1111? Not been using automatic1111 now for a while, but there's a save checkpoint every certain steps or something. If you have 1200 total steps and 200 at save after certain steps the you get 6 checkpoints in total. Place them from your trading folder into your models/Lora or models/stable diffusion folder. If you want to continue select the checkpoint you want instead of the base model and raise the total amount of steps.
Select x/y/z plot at scripts choose prompt s/r at x and y.
So you added a Lora file like this lora:whayevername-00001:0.6 at x you type 00001,00002,00003,etc...
At y you type 0.6,0.7,0.8,etc..
The first value is the string/integer you want to replace in the prompt followed by the values you want to replace it with, separated with a comma
I'm training a lora model right now, but I see that you have to use a regular model along with it when you generate images? Or could I load the lora safetensor both as the main model and in the extension?
Or would I be better off just using dreambooth if I want to maintain the style of the lora model?
LORA models go "on top" of a model, and kind of merge with it during use, they apply their weights change inside it. It's why you need a base model.
You can merge for true a LORA inside a model, an make a ckpt where the LORA is inside, close to as if you had trained it without using LORA, as if directly in dreambooth
(I'm checking what I said on merging, I have a doubt)
I've never done training before so not sure what that meant lol
So how would I do that in the webui?
I don't need a good GPU if I were using dreambooth right
dreambooth is quite high on VRAM yeah, higher than LORA
need a better GPU for dreambooth than LORA usually
dreambooth is training a model. Input is a ckpt, output is a ckpt trained with what you wanted. When using that new ckpt in AUTOMATIC, it knows the new stuff and you can prompt on it.
LORA is kind of the same, but instead of being a big 2GB file output, it's a lot smaller file to share. It's a little lower quality than dreambooth usually.
When I was talking about merging, I meant, LORA training gives you a LORA file, that you can already use in your automatic. But you could also take that LORA file, a ckpt, and merge them into a single ckpt. This would make it close to if you had trained on dreambooth
But if merged a lora with an existing ckpt I'd be getting "style" from that merged ckpt
What I really want is the style of the lora
Meaning I don't want any other influences
Does this really mean dreambooth would be better in this case?
that means that you want to merge LORA with the model it was trained on. During training, LORA starts from a base model too, and those are its "default" weights
in almost any case where you have the sufficient hardware and time, dreambooth feels better to me yes
So would I just create two safetensor files and merge them somehow?
I really don't have the GPU power to do dreambooth 😅
Only like 6 GB
1/ train LORA with your pictures and any model as base model
2/ get a LORA file back from that training
3/ use that LORA in your automatic, no need to merge, it already works
or
3/ merge that LORA with the model you used in 1, and yes, get a new model, almost equivalent to as if you had just done a dreambooth on 1
(lots of those chans 😉 )
Oh yeah, just seeing the few posts that are here lets me know I'm in the right space. Thanks for the recommendations and the tips.
no problemo, I love this stuff
Here's the full output from my first attempt at training. I'm using 10 images with 10 captions (imagename.png and imagename.txt) and it was set to 120 epochs, batch size 10, fp16, gradient accumulation steps = 1

The results from testing the prompt aren't bad, but there's some anatomy that's a bit off and I think it could be much better. I'm trying to train a specific facial expression
ok so that's about 120 repeats
so yeah my thoughts, but keep in mind I mainly do dreambooth, not LORA
it's going down at a normal speed, so it could still be trained without problem to me
if you have some specifics that are not good, like face, maybe the dataset doesn't have clear shots, easily understandable by the AI, to train on
looking for those details specificaly in the dataset, and adding/changing a pic for a close shot of it can help on that side
but first of all I would add more steps
go up to 150 repeats
Yeah, that's a great idea, IMO. The parts that are messed up aren't entirely present across the dataset
oops, I replied to the wrong sentence.
about the dreambooth vs. Lora statement.. I'm using this notebook:
I'm not sure what the differences are in just using the dreambooth extension on A1111 vs. this type of notebook approach
that statement was mostly to say, the repeats/loss value I'm used to expect may not be the same and I could also say some wrong things in there
ah okay
LORA is trying to mimic how dreambooth works
but it changes one thing major
it saves the differences it's making in the model, and makes a file with all those differences (small file) where dreambooth makes a new model with all the changes (larger file)
the reality of it is that there is still a loss of quality, it's why you can add more "layers" in your lora, to keep track of more changes that would happen in the model and have a higher quality
so LORA calls itself dreambooth too, because it's effectively what it mimics
the dreambooth extension does dreambooth the classic way, making a ckpt
there is also a LORA extension to do it in automatic too
I didn't know this.. I'll have to try that with the next dataset I put together. ty
You're a wealth of knowledge and I appreciate you taking the time to reply to these questions. I'll make a few adjustments in the direction we've discussed here and post results a bit later. 🙏 
Actually one last question before I start the notebook and play the waiting game.. if you don't mind...
In testing the previous training attempt, I had 1 of the 4 test images for a prompt come out 99% perfect and the other 3 were quite poor.
What do you make of that situation when it occurs?
Is this another sign of under-trained but trending in the right direction?
this always occurs, and is a way for you to check for bleeding. in my tool I have 3 of each
Bleeding is when your concept starts to appear in other things, unprompted.
The good one is a picture made using one of your captions
The bad ones are the same but with CFGS to 0, meaning it will ignore the prompt
if you start to see things in there that come close to what you are training, this means you are bleeding all over
it's kind of another way to "overtrain"
this means you need more/better class pictures (can also be called regularisation pictures, depending on the tool)
They're called regularization images in this notebook and I assumed them to mean "images that contain similar concepts to what you are training but are not specifically the concept you're training" if that makes sense. Did I have that right?
One thing I should add, regarding the loss value : it's not always very relevant... Depending on the concept, the loss can just mean nothing at all even. it's based on a flawed function, you can't really rate if the model is close or not as simple as that, it has a hard time evaluating what you want it to really train
yes, it's usually that. Like training Steeve Jobs as main concept (instance data) and "a man" as class concept (regularisation data)
depending what you do, it can be very generic
it's a way for the model to not forget what it knew before
to "keep it grounded"
cool, I can likely improve on what I provided it then
yes, what you provide it will be trained on too in the end
by doing targeted training on your topic and generic training on regularisation, the model can keep more things in for longer. training is always a learn-forget relationship, end models still has the same size
So either one works, but merging that base model would mean introducing things from it right?
I'm currently using A1111 on my home PC with a 10GB RTX 3080 card. I am interested in fine tuning and training to be able to more readily reproduce certain character types or models. For example, training it to be able to generate images of D&D races like Dragonborn more effectively. I don't want to pay for a cloud computer so I know options are limited in that regard but things with SD and AI in general are progressing so quickly that it's easy to lose track of what options are available and are best recommended. Is Textual Inversion the best way to go here still? And if so, is there a guide for getting the best results? As an example, should I be looking to create an image set with close up of the face, full body, side view, back view, etc.. to get the most coverage and cover as many bases for various prompts as possible? What is a good target number of images? Should I be using things like file naming to help guide the AI as to what a prompt for the provided image might be to help it train better and identify the subject of the image better (as opposed to background elements or the like)? Any other information on the various settings and how they might impact the resulting embedding?
im a bit new to training--ive trained a LoRA using dreambooth and it finished. iwant to continue trianing. what do I do?
do I re-use that same model and just add more steps/epochs?
what is the file path to find the full loss chart over the entire trainig session?
i can only see the loss-per-epoch currently. in the model>dreambooth>[model name]>logging folder
I'm not sure about dreambooth specifically. I was doing the training in a Lora/Dreambooth notebook. It had a log file that I could use inside of the notebook directly into Tensorsensors or whatever the name of that package is
this is the notebook
Oddly enough, it's actually the broken 0.0.16rc425 that is installed, but it seems to work. Perhaps there is another variable at play and it is a combination of factors which cause it not to work?
I'm not sure if this is the right channel, but I'm right at the very beginning of trying to figure out how to generate images of a homebrew fantasy race. I have a few pieces of art with them depicted, and I have text descriptions, but I'm not how to use those or whether they will be enough?
like if the model had never heard of warcraft orcs before, how would I tell it?
There's lots of models out there that know what that is
I'm no expert, very much learning the ropes, but the first step will be to curate 10 to 20 (10 is usually plenty) good examples of your custom race or things that are really really close to their likeness.
Then pick a pre-existing model to serve as the base model
for example:

Here is the result of the first generation for "orc" as the positive prompt with "text" being the negative prompt
I used abyssorangemix3 model for this, though that model is probably WAY hornier than what you're after, but it does know what an orc is
Has anyone tried to train a model with a 12 GB VRAM? If so, how was it... is there any chance to do models with small samples on a GPU like that?
thanks for the reply! I'm not totally sure I understand when you say to pick a pre-existing model as the base model? Do you mean that I should get 10 or 20 images and use them to fine tune an existing model?
Can you walk me through how it would work a little more? Like suppose I had 20 images of my homebrew Octopus people called "Foobars" -- what do I do to train the model? How do I get the txt2img output?