#🔧|finetune
1 messages · Page 3 of 1
hey, I'm following Arki's Dreambooth guide (https://stablediffusionguides.carrd.co/#training-p) and managed to train the model on runpod.io, but now I have to download it and the download speeds are abismal, like 200kbps. Does anyone know perhaps of a solution to that?

is here any option to make small specialized SD for img2img who will be like 100 times faster and use less vram, and like hardcoded only one prompt ?
not sure thats immediately possible but you can reduce steps and/or denoising strength
Using a v1.2 model or earlier might be lighter
they're all the same model, just more or less training
minimal steps what give at last something is still too slow for me
i'm more about another model i can create and train
just like "cat into dog" dataset, or single style
not sure if smaller Unet or something still be able to give good images
Guys I'm trying to train it with a logitech G935 headphone, but even after 20k steps it still not able to really catch it, any tips?


it has around 40 photos for learning and BLIP captions, so I'm training the embedded with subject_filewords too
screenshot of training images?

some of the training images look a bit too close up and may confuse it
did you think selecting images that are more "clean" would help? or those with texts around it, etc aren't such a problem?
ideally you want your training images to be very well cropped, I would remove the images where the entire headset is not visible
like, a small portion close up might be ok, but.. I see quite a few there that are cropped weidly
🤔 hmm I will try to use just good ones then and see if I get better results, I thought closeup ones would help to improve details
it can, but they probably need to be a much smaller % of the total training set
you can see from your outputs you get heavily cropped images, too
that's true I haven't paid attention to it
I would say keep the extreme close ups like 5% max of the total set, just as a rough idea
so maybe 1-2 images out of 40, or maybe try once with none of them cropped, only full photos
I will take pics of my real one so I can get it more controlled, the main problem is that I proably will be holding it with my hands so not quite sure if that's a good idea lol
maybe get a string or coat hanger or something to hang them from
take some photos outside, too
or on your own head
then caption "a man wearing logitech headset" or whatever
good idea, Thanks for the advice, lets see if I can get this thing good
do you think the filewords are relevant at all?
for embedding?
what sort of training are you doing? TI? dreambooth?
I'm doing with TI, I've also tried with HN
well yeah for faces TI didn't do very well like HN, maybe my images aren't helping it so I will try to take more consistent photos and see which one can catch it better
no real idea on HN but I got the impression it is something more useful for styles than objects/subjects?
for faces it does a great job
not sure if I'm right but I think faces are mainly a subject type?
I'm going to try with something else, took photos of a thermometer once I manage to get it being replicated then I get back to the headset, my headset is too dusty for pictures 😅
if i train an embedding with a hypernetwork selected in settings will it use the hypernetwork while training
@viral jay talking about product objects did you see this by the way? https://mobile.twitter.com/StrangeNative/status/1579848925993136128
Products with simple forms and organic lines reproduce exceptionally well. We took this trainer on adventures across unfamiliar terrain. 👟🏔 [2/10]
Likes
105




that looks damn cool
I got it from huggingface. Google search reddit and huggingface
What kind of time averages are people getting for training an embedding? It takes like a half a second per step, and not sure how many steps are recommended.
Should I just reduce the max step field? Or is that going to significantly hurt the model?
And also, trying to track an embeddings "progress". It generates an image every 500 steps? But what even is that image represeting? just an amalgome of all the images so far?
Or it is just a random test file created?
it tries to generate an image of the last class or caption trained I believe
ok cool thanks, I did a google search first but nothing came up. but ill go and dig at huggingface 👍
I can find in an hour or so. Gotta feed the kids first.
ripped out regularization from dreambooth as I reform code to just do full fine tuning and seeing quite a drop in vram use, good sign

also seems existing codebases (xavier, etc) are using lightning 1.5.9 and may be improvements moving to 1.60+
Did an interesting comparison between mixing model files
https://www.reddit.com/r/StableDiffusion/comments/yaiyw6/comparing_results_from_model_mixing_checkpoint/


reddit
0 votes and 1 comment so far on Reddit

Do people know good resources for custom models? I need to generate 2d dashboards, web ui, app UI and logos. The current 1.5 model is focusing on art and photography. There might be models out there that has been trained specially for 2d designers
Btw, the legendary works of Neville Brody, the Designers Republic and Alex Trochut are completely seem to be missing from the datasets. All from the 2000's, so internet era.
Wondering this myself
How do they deal with not owning the image?
up to batch size 6 now on local fine tuning

I don't have anywhere near the resources required, but I kind of want to leave this link here in case anyone wants to pick it up: https://github.com/hukenovs/hagrid

GitHub
HAnd Gesture Recognition Image Dataset. Contribute to hukenovs/hagrid development by creating an account on GitHub.
It's a dataset of 500k images of people with their hands making different gestures, like so: https://github.com/hukenovs/hagrid/blob/master/images/example.jpeg?raw=true
Hello colleagues, could somebody point out the information on how to fine-tune SD to introduce new category to the model? Not a dreambooth way
I mean vanilla SD, that does text 2 image
/r/StableDiffusion had an app-icon-generating model posted. Generally you can use Dreambooth to finetune, so gather up and describe samples of icons, UIs, logos, etc. and feed 'em to the machine.
hey guys, so I'm following Nerdy Rodent tut on dreambooth, but when I run the last command (./my_training.sh), I get this error, how should I fix it, any idea?
train_dreambooth.py: error: the following arguments are required: --pretrained_model_name_or_path, --instance_data_dir Traceback (most recent call last):
maybe it means you do not add this commands to command line while starting this script
just python script do not get it
thanks for the help, looks like it was due to extra space during copy/past. but I'm stuck again with this new error : /
accelerator.py", line 286, in _init_ raise ValueError(err.format(mode="fp16", requirement="a GPU"))
I own gtx 1070 so i tried with and without deepspeed, but the same error even when I chose CPU.
"Unable to proceed, no GPU resources available", not sure why.
i just run the command torch.cuda.is_available() and the result was false : (
edit: nvm, probbaly need to update my windows to allow cuda pass through.
dumb question, what's an epoch? some models say they were trained by X number of steps and others talk about epochs
"An epoch means training the neural network with all the training data for one cycle."
generally means one look at every training sample, but a lot of the code people are running has repeats so its actually a lot more than 1 look per sample
on what resolution was novel ai trained on??
god im so lost
all i want is to make my midjourney images cleaner and nicer and enlarge
I dont know what Im doing. I managed to figure out how to run the notebooks though lol
I tried to research but now i know 100 new things that have nothing to do with what im trying to actually do 🤣
do yourself a favor, just buy topaz gigapixel or something
the current model is completely capable of generating all those things. i was able to gen game icons and logos with 1.4









reddit
896 votes and 100 comments so far on Reddit
should be able to use a dataset like that to train the recent stabilityai released improved kl-f8 autoencoder, and then bolt it over any model you have to reap the benefits
unfortunately there is no guide out there as far as I know on how to further finetune the autoencoder.. if anyone know of one let me know, I am willing to use some of my cloud gpu credits to try and finetune
I only know how to use it with the popular gui, it was recently updated to import the weights from the vae file into the model you are running.
How am i supposed to make a mask for the mask upload feature in some guis? (using automatic)
If i paint in the area i want to redo in black, its treated as a negative mask when generating, i have to select "Inpaint not masked" for it to work
So then it surely makes sense that white would be positive. But a white area does nothing at all, it just generates the whole image
Hey what workflow or colab with SD 1.5 are you using to fine-tune with only one to a few base images?
Same as 1.4
finally managed to create a custom model.ckpt with dreambooth colab. The difference is astonishing. See the default SD 1.5 model image vs the newly trained model. I trained the model on about 10 images of Hide the Pain Harold. https://huggingface.co/bencser/harold




Do you guys know if its possible to train/dreambooth ckpt file instead of diffuser? localy? if so which guide I should follow?
thanks that explained it
the webui has a very simple interface which I assume "just works" as long as you have enough VRAM
can you share for me a link to the one you are referring? does it train ckpt file directly?
it looks fairly featured

Thanks, but that's different, dreambooth is way more different and better result.
oh I didn't know, so dreambooth is not textual inversion?
this colab has a "convert weights to ckpt" option https://colab.research.google.com/github/ShivamShrirao/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb

nope.
thanks, but I wonder if there is one that train ckpt file directly.
"This code repository is based on that of Textual Inversion. Note that Textual Inversion only optimizes word ebedding, while dreambooth fine-tunes the whole diffusion model. "
I think I found it.
https://github.com/XavierXiao/Dreambooth-Stable-Diffusion

GitHub
Implementation of Dreambooth (https://arxiv.org/abs/2208.12242) with Stable Diffusion - GitHub - XavierXiao/Dreambooth-Stable-Diffusion: Implementation of Dreambooth (https://arxiv.org/abs/2208.122...
nice
tut https://www.youtube.com/watch?v=xSkyLuRnt4g&list=PLaOL9kx0jIPDZTr8AG5HzMleK-JOwWdpp&index=12&t=1s

Commands
18:02 git clone https://github.com/XavierXiao/Dreambooth-Stable-Diffusion.git
18:18 cd Dreambooth-Stable-Diffusion
18:34 conda env create -f environment.yaml
19:08 wget --http-user=USERNAME --http-password=PASSWORD https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4-full-ema.ckpt
20:43 import zipfile as...
What to do if we only have one picture?
Hello I wanna do some dreambooth trainig
what is the best repo for doing that as of today? I have a GPU with 23GB VRAM
tried to do it with a repo about 1 or 2 weeks ago but I was getting errors because of lack of VRAM
You can try augmentation, but with little/bad raw data you can only ever go so far… see here for example http://d2l.ai/chapter_computer-vision/image-augmentation.html
But consider that for Image Generation you are much less flexible in augmentations e.g. of colors vs for the usual classification that most augmentation guides will probably aim at
Hmm right.
Have anyone tried to use Stable Diffusion fine-tuning with WebAssembly (with Rust bindings or just Python) so that the client run the training part?
greetings, does anyone know about this error when training HN?
AssertionError: no gradient found for the trained weight after backward() for 10 steps in a row; this is a bug; training cannot continue
yes this is the original dreambooth repo, several forks out there now but this unfreezes the unet and vae and requires 24gb
original for SD at least, there are also diffusers versions, some* diffusers don't unfreeze everything though, there's a trade off on VRAM use and how much of the model is unfrozen, and results are different if they don't unfreeze everything
so diffuser gives a better result? or it's not related?
some of the early diffusers ones were only unfreezing unet I think, and it doesn't work as well, but I haven't messed with diffusers myself so take that with a grain of salt
if diffusers unfreezes the same parts of the model I imagine they're close either way, but all the 8gb/10gb/16gb stuff I believe is simply not unfreezing the entire model and that probably leads to worse results, but there's also the concept of "enough" to get your project done
there are differences in optimizers in diffusers and such, too
people get either to "work" but most people are also doing fairly small scale projects, like 10-50 images of their dog, or their own face, etc
my take is if you have higher ambitions, unfreezing the entire (latent diffusion*)model, caption training, etc is far more capable and moves you away from TI/dreambooth towards more general fine tuning, depends on your goals, your hardware capabilities or what you want to rent, etc
I see, thanks for the info.
we got alot of stuff out there in a very short time, I can't keep up with all.
I want to do a test similar to the pokemon model outs there but instead of generating pokemon, I would like to use naruto anime, so I figured I train the model with a bunch of naruto pictures, you think this can do that?
its the last ben repo of dream booth.
don't know, I think most people have to work on their projects a bit to get them to work and gain experience, try different things
anime might be harder than more photo real type characters from what I've seen of other people's experiences, but I don't do anime stuff myself, nor do I use diffusers
I'm trying to update the lightning trainer (local/xaiver/compvis based) to see what can be done about getting it more up to speed, its still running on some old libraries
Hypernetworks dont work with 1.5 yet?
I try to train a Hypernetwork with 1.5 model but i get a error messagfe.
could summarize what are the clear symptoms of overfitting please? also how CFG would be affected (eg it'd have to be lower and lower etc)
at least sometimes, faces look sunburnt or high contrast at standard cfg
for instance i trained 36 images 3600 steps with 1500 regs, then another 900 steps to make it 4500. i'm pretty sure at 4500 the results are starting to look both less like the subject (a bad thing), but also just look less like the training images (eg more variety in the outputs so a good thing). i'd expected if i overfitted then it would all look like my training images with not much variety? i need to compare exact sampler parameters between the 2 models though
what are we calling standard CFG? 7?
yeah close enough
7.5 was default on compvis launch, auto defaults to 7 i think, either way close enough
what would you say is a good sampler/steps for just a basic unstyled output eg (photo of jmp909 man) as a baseline test?
normal steps should be fine
you mean 20 Eular A?
euler a is the default selected in a1111, that's why i was wondering what sampler is a good baseline default for unstyled output
you can make it render more than 1 sampler
sure i know you can do that in extras, i was just wondering opinion on sampler/steps for outputting a baseline unstyled result to compare 2 sets of training on a photo likeness
i know there are a so many variables to it all it makes it tricky to generalize
like at 3600 steps i could get a good likeness with DPM adaptive, 20 steps, cfg 8..... now at 4500 steps if i don't lower the CFG to about 3.5 there, i get somebody else's face that has similar features but does not look like the subject
with photo of (jmp909 man) wearing yellow hat .. obviously the emphasis has some effect there on both tho
actually i think with 4500 i can take the emphasis out and get a better result. what i cant work out is how far to take the training to actually improve things
being able to take the emphasis out for the same CFG suggests the model is doing better?
not necessarily ? try other steps
yeah doing an X/Y on CFG vs steps now thanks
Hi guys, I want to train DreamBooth for a style. I did it a few time for faces no problem.
Is it the same process for styles?
Setting it up with prior preseveration, what is the class of a style.
For example if I want to train for watercolor images, the class would be what kind of images do I have to supply? just random other styles for comparison?
The regularization images would be whatever images the model would generate previously with the class keyword:
Prompt: artstyle -> your regularization images
oops sorry, sent wrong place
ok thanks I think I was to general, I though my class is "style" but I guess that is stupid
I tried "style" for a specific artist, results did not come out well. But, maybe I configured it wrong, it was on v1.4 too, v1.5 might like "style" better. When I switched to "painting", I got better (but not amazing) results. Seems like DreamBooth is not the best for style. Might want to also try image embedding for style as well, those are supposed to work well for style.
I imagine it should work if you use captioned training and describe the art such as "a wolf standing in a forest by Biff Artistman" or whatever for each image, haven't messed too much with outright styles though
oh interesting, most of the images I used are captioned, how do I do captioned training? Haven't seen the option in the dreambooth colab I am using
mrwho added it to joepenna repo
there's some setup to name the files and organize them into subfolders
works in kanewallman's repo just based on filename but the notebook is probably not maintained
hey now
Works fine for other people: https://old.reddit.com/r/StableDiffusion/comments/yaquby/2d_illustration_styles_are_scarce_on_stable/
reddit
561 votes and 190 comments so far on Reddit
Yo, looking for advice. If I wanted to train this shit on different species of cavemen, what would be the best option for that? I assume I'd have to do one at a time, yes?
Well, more importantly, would it have to be a particular individual, or would different ones of the same category work well together?
Ok, it's time to step up.
I know dreambooth can be used to train one particular style or subject in, but how would I train the model in general -- as in pick up training of SD 1.5 with my own dataset of various different things?
you can caption all your images and train as much stuff as you want
you'd have to check the diffusers stuff though on 16GB, the lightning/xavier repos take 24gb because they unfreeze the entire model, or rent runpod/vast or colab pro I guess
I'm already renting on vast
How do I train multiple things with JoePenna's repo, or should I check another one?
there's some stuff with how you put things in subfolders, unfortunately they hadn't put any documentation on it last I checked
there are other options local or if you dont might doing everything from the CLI but I gues everyone doing remote runtimes are likely using notebook
technically all you need is a terminal on the runtime even on a runpod or vast but you need to be kinda familiar with linux command prompt instead of just clicking the play button on a notebook...
im working on a general fine tuning trainer, ill see if I can make a notebook for it at some point...
I don't mind the CLI. I use Arch btw.
do you know how to push your own files into the rte and move them around in folders? i.e. your training files
https://github.com/victorchall/everydream-trainer you can try mine, haven't run it on a remote rte but should work just fine, or you can use kane's https://github.com/kanewallmann/Dreambooth-Stable-Diffusion they're fairly similar at this point
readme on both should explain how to organize files, mine doesn't use regularization per-se, but you can put reguliarization images in the training folder if you want anyway
how big is your training set?
tbh these work better with larger sets, I used kanes with 600, 900, and 1400 and then forked mine last one I did with 1600
I have around 400 images (half of which I'm still tagging)
I'm gonna make a tool to help me tag stuff
both mine and kane wallmann's use the same naming convention of "your caption goes here_n.ext"
"Show image, input tags in text box, click next"
yeah you can do it in automatic but its not batch, you can probably script calling interrogate.py but I want to build something in myself
tbh, for datasets less than 1000, I think fully manual tagging is king
getting it exactly right seems really important when you have fewer images to train on
you can batch name them with clip then just replace "a man" with "john cena" or whatever
yeah my results have improved greatly, first 4 character one I did was just all "name of character_n.ext" then I ran them through clip to get the surrounding context and it helped quite a bit
slowing building training set with a mix of other ground truth data...

thanks, probably something wrong with my setup. I do see they used "artstyle" instead of "style", I'll have to try that one
Class word was artsyle. Token was holliemengert. Prompt for instance would be holliemengert artstyle
Any opinions on which DreamBooth implementation works the best?
- JoePenna - https://github.com/JoePenna/Dreambooth-Stable-Diffusion
- XavierXiao - https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
- ShivamShrirao - https://github.com/ShivamShrirao/diffusers
Shivam is good as well
What makes the ckpt 2GB? I mean if we remove the full float and unnecessary data?
How can we make sure to add to the ckpt instead of overwriting it?
Or the answer to these questions are still not out there?
Only just reading up on Aesthetics Gradients. Good explanation: https://metaphysic.ai/custom-styles-in-stable-diffusion-without-retraining-or-high-computing-resources/

A researcher from Spain has developed a new method for users to generate their own styles in Stable Diffusion (or any other latent diffusion model that is publicly accessible) without fine-tuning the trained model or needing to gain access to exorbitant computing resources, as is currently the case with Google's DreamBooth and with Textual Inver...
Definitely gonna be the new way
That's a really good read!
Mmm, makes me wanna make an embedding for Attack on Titan scenery
where can I find thousands of regularization images of woman
using custom models = a new era for humanity,
man dreambooth is so much better compared to TI and HN, shame I'm not able to run it locally
dreambooth with 1200 steps, it's a fiat uno, the damn thing has learn it quite well

this is TI after 5k steps

what I'm finding cool about it is that I still able to edit the results, for example the first image of car on snow, there's no pictures that have been trained on snow, on bottom its also on snow but from 10 images I've generated only one had something leaning to snow and wasn't correct at all
any tips on how to achieve the same with TI or HN?
Would be interested to know if anyone's figured out how to get this to consistently work. I had a play with it last night and I can't figure out the relationship between the training images and the results.
You also get wildly different results from just changing the gradient steps by 1, or even changing the learning rate by 0.0001
Yeah it sounds tricky for sure. A lot of it probably comes down to consistency in the training images at a guess
I can sometimes see hints of the images I've put in, but other times it just does completely unrelated things.
I think thats sort of the idea though? From what im reading it's more of a method of nudging art style in the right direction, rather than adding specific elements
Or you get the opposite. I trained one on vapourwave style images and all it took from them was the colours and it turned everything into a purple/yellow blob
Yeah it sometimes does stuff that looks kinda related to the images. But it's no different to what you'd get by just using prompts.
I think it needs to work with prompt engineering. So you get something close to what you want and then that can maybe just push it over the edge to exactly what you want.
Yeah that sounds about right. Time shall tell more i suppose
hey guys , I am using this repo of optimised dreambooth https://github.com/gammagec/Dreambooth-SD-optimized
the problem is my training always stop after around 19 minutes , like there is a timer or something .. how do I edit the code to make it work till it finish certain amount of steps

GitHub
Implementation of Dreambooth (https://arxiv.org/abs/2208.12242) with Stable Diffusion - GitHub - gammagec/Dreambooth-SD-optimized: Implementation of Dreambooth (https://arxiv.org/abs/2208.12242) wi...
Has anyone merged with the inpainting model? I'm wondering if it works and retains its inpainting abilities with the trained elements of a secondary model
Are you changing the maximum steps setting?
Don't believe you can. It has extra layers compared with normal models.
where can I find that variable
Not at my computer so can't 100% remember but I believe it's in the bottom of this file
configs/stable-diffusion/v1-finetune_unfrozen.yaml
this ?

does the algorithme choose how many steps it needs ?
like did the algorithme did choose 2264 steps , or there is a variable
Ignore that. It's based on the amount of training data.
It will stop at whatever step count you set.
And yes, the max steps
I made 8000
I found the best for speed / decent accuracy was between 4-6k but your mileage may vary.
8k should be fine too
You don't usually start overtraining until a decent bit over
Keep an eye on the renders it makes to track how well it's doing.
so it will go beyound 2k since I set the max 8k
can I traing model then put generate 2k pictures and then choose 200 pictures from the generated pictures as regularisation
Yeah it will move to the next epoch
When you resume training like that it's almost like merging models. For best results you need to do it all in 1 go.
can you please explain , what do you mean by doing it all in 1 go
You made it sound like you were planning on stopping changing the data and resuming.
You can't do that and have good results in my experience. You need all your training and regularisation data set from the beginning. And then set your steps and let it complete the whole process.
ahh , cant I do something to pick good pictures for ai
Well you need to pick your own training images for what to train. For regularisation images what I did was used stable diffusion and created a few hundred images using my chosen class name as the prompt.
that exacty what i did
where do people download image datasets that are great for training? For example I need open source images of everyday women and men, same folks, with different settings, emotions, clothes etc. There are a lot to be found by celebrities, but not from open sourced people.
LAION, or have the model generate them
The latter is mostly acceptable, since the point of the images is to make sure the model can still generate the same stuff it could before finetuning
If I want to train text encoders with Dreambooth, do I need to change any .json files before running the training script? I'm using gallery-dl to get my images and I have the metadata, I just don't know if or where I should be putting the file
Training images are best generated by your model. If you’re training on an anime-based model but have regularization images with real people, you’re training the AI on both your reg images and the instance prompt. Just use your model “a picture of xxx” and make a bunch of images
Update: now using ShivamShirao's repo locally; even faster than JoePenna's repo on the cloud GPU
keep in mind there may be several flags strewn about that limit training, might be settings in the yaml and another setting on the CLI args, make sure to double check, tbh hard to keep track of all the repos args but some have multiple limits
might be useful to just delete or set the default on cli args to 99999 and just use the yaml to keep it all in one place if you find other limits so you're not chasing your tail constantly
where does the speed increase come from? I updated but didnt see a difference yet
from my understanding some of the diffusers stuff isn't unfreezing the entire latent diffusion model like the xavierxiao based repos (joe/kane/gamma) do, so be wary of comparisons because it may not be apples to apples
fwiw my last model only used laion data and turned out well, better rthan previous model that used SD-generated regularization images IMO, but I'm also training much larger/longer than others
I would propose not to use dreambooth in your case but use approach of finetuning done with pokemon directly. caption your naruto images with BLIP then train on this text-image pairs
correct me if I'm wrong, so finetune uses ckpt but dreambooth will ask for diffuser right?
And when it would be a better choice to finetune and when it would be the best to train using dreambooth?
fine tuning and dreambooth are similar. dreambooth keeps the text to image portion frozen. where as fine tuning will train all of them together.
I see, thanks!
@hybrid pilot If I want to train the model with a new art style, what would be the best choice?
depends really on how you want to use it. I'm still sort of figuring things out, but I wills say that dreambooth does great at adding a single specific thing or a very apparent art style, fine tuning is the "best" way, but has the draw back that you really need to know what your doing to not mess up weights.
I would say textual inversion actually. the downside being it will take up some context space, but for a quick style, it does the job really well
or the new aesthetic diffusion thing I've seen mentioned. that looks like it has room to really set a style
hypernetworks are too heavy for just a single style
disclaimer: I have no idea what I'm doing and this is purely just things I've read/observed, I could be 100% wrong
I've used all 3 -- dreambooth gives the best results
for styles, TI is pretty good most of the time
Hypernetworks are hit and miss
that's not quite true anymore; for example, ShivamShirao's version allows you to train the text encoder at the same time
we can do TI using auto out of the box? how much vram it would need?
automatic1111's web UI includes it in the "Train" tab. I think it works with 8 GB VRAM there.
If this was around when I was a kid, I'd be a data scientist instead of a sysadmin lol
I just finished training and testing my first Dreambooth using TheLastBen, with only 800 steps and 24 pictures, I feel like the source images I feed the model leaked all over the ckpt, or am I hallucinating?
that can happen when not using regularization images and the prior preservation loss flag
"With_Prior_Preservation" is checked and the Dreambooth says it will auto generate 200 picture for the class.
that's strange then, since that should prevent just that.
can you see the 200 created images in the folder structure of the colab?
yes.
Hey guys, can someone please tell me what's the best way to Fine Tune Stable diffusion for Set of Characters from Anime?
I'm lost then, sorry
It's not happening with the other repos like that and I dont know if its missing a configuration or if it doesn't do it correctly
Has anyone converted this into a ckpt yet?
https://huggingface.co/sd-dreambooth-library/homelander
I'm not sure, but it's simple to do it yourself if you have python and pytorch installed
if you want a set of characters all in one model you'll need a caption-enabled repo so you can name or otherwise somehow mark your individual training images for each character
uh.... How much Vram? 😅
Converting models doesn't require any VRAM. It occurs on the CPU.
I don't think ckpt convertors touch the gpu at all?
ckpt files are just tar files (like a zip file) you can even open them in 7zip and look around
Surprisingly fast!
Or maybe I just didn't do research about the conversion process
great! 👍

actually, maybe not that great, but I did only make a 2 GB model
It's not doing so well when it comes to placing the said person in different locations, probably because it was trained in colab???
Hmmmm 👀 I’ll look
but what about SD upscale 
Oh my god
lol I saw that homelander model, didn't like it, made my own

Nice can I ask how you’re training please? Mind you.. he’d be in the model already
Also what % of generations are actually decent?
If I wanted to train a bunch of caveman species, what should I do?
Dataset protip: Install gallery-dl, and scrape dozens of images at a time
e.g. gallery-dl -D mydataset --range 1-25 <danbooru search results link>
This was the first person I trained, did over 20 models using colab and they were all bad, like 10% success rate on prompting
cooolll
but the colab notebooks have improved since then
No advice?
thanks
has anybody got a technical explanation why if i train photo of jmp90 man then photo of jmp91 man man will also give close results.... is it just converting jmp90 to a number internally that jmp91 is also close to and will crossover essentially ... not sure how far the difference is eg jmp9, jmp etc
Some fine-tune mention "This version uses the new train-text-encoder", anyone can explain this to us? and how can we use it to train/ finetune our model?
probably has to do with how the prompt is tokenized
if it's split as ('jmp', '9', '0', 'man') then ('jmp', '9', '1', 'man') will be similar
use 🏃♂️
what do you mean Caption-enabled repo?
and which type of training???
FYI: allegedly runpod.io machines running dreambooth create better ckpt, nicer images: https://www.youtube.com/watch?v=mVOfSuUTbSg

Dreambooth, Google's new AI, allows you to train a stable diffusion model with your own images, producing better results than textual inversion. Dreambooth was built on the Imagen text-to-image model, which allows you to insert any character (yourself, friends, family), object, or animal you want into a stable diffusion model with just a few ima...
Dreambooth training for Stable Diffusion is extremely powerful. You can train a new token to the "person" class to create very convincing looking images of them. I've posted some examples in the past days.
But it's not the coolest thing you can do...
I was unlucky with google colab today. I even paid $9.00 to get an undisturbed training. 1 out of 6 training processes went through, others just stalled, stopped, "something went wrong" after an hour wait. I think it's a bad quality product from google, the ux is also terrible. Now trying runpod
I think the issue was the diffusers repos were not unfreezing the entire model, it made it work on less VRAM but doesn't produce as good results
fine tuners or dreambooth repos that let you have a caption on each training image instead of just a "token" or "classword"
You could've gotten an instance on vast.ai for $0.40/hr. It'd be more reliable than colab
yes. runpod is unstable - it's a joke. I want a reliable training server, not a shared machine
who has a web service where I can upload images and I get a ckpt file back. Without the painful interruptions, errors and 100s of log files?
runpod works pretty well
Not for me. Training stop every time
hmm..
(jmp person:1.0) and jmp person are not the same it seems... if you have Use old emphasis implementation ticked in a1111
(jmp person:1.1) and (jmp person) are also not the same in that scenario
I had assumed each bracket was 1.1, with ie 2 brackets being 1.21
Hi, does anyone know how can I implement stable diffusion on my own macbook?
When it comes to improving the quality of the faces around a specific model for 1.4, what comes to mind?
We are not happy with the results
Should we try training the model longer?
What do you mean by”entire”?
Not just the Unet but also the ClipEmbedder and the Autoencoder?
Aren’t they supposed to be generic and good enough in their pre-trained variant or you think there would be benefit if my data is kind-of more specialized than laion?
clip remains frozen
unet and autoencoder for the local repos, and I think you can unfreeze them both in diffusers with the right setup if you choose but I'm a bit behind on that
at least the how part
but I believe it is an option
Hey, I've noticed after training an embedding of a character with Auto1111's textual inversion interface, that after a certain point, using the embedding tends to make duplicates of the character. Can it be because of too many steps of training? Is there a way to prevent that? Have any of you had the same thing happen?
I’m using the SD repo if that’s what you mean. Thanks, you are giving me options to explore further
if you have the vram I think unfreezing the whole model is worth it from what I've seen
maybe for some projects its not terribly important
I’ll add that to the list of experiments, thanks
yeah the backlog problem is real 😆
how do i remove colors with inpainting? I'm making an image of a wasteland, and it has lots of glowy red spots on the ground that i don't want, i'm trying to just replace them with boring, cracked black dirt. But it keeps maintaining the colors and just painting in red cracks. I've even got black in the prompt, and red in the negative prompt
Example: I selected all the red bits that aren't on the pillar, used prompt cracked black ashen ground and negative prompt red pink color
Still red everywhere 😐
using automatic ui
i only want red on the pillar not the ground, any thoughts?
What about something like (red_pillar:1.2) in prompt and (red_ground:2) in negative ?
Keep the underscores see if it works
Play with CFG level
Dunno
i dont need to do anything with the pillar, i'm happy with this overall composition, just want to finetune details, hence using this channel 😛
Inpaint after?
I read maybe a few weeks ago that someone had made a SD version that was trained STRICTLY for HANDS (and maybe feet too), but I can't find it anymore... Anyone knows which one it is and it's any good?
Please ping me if you find out, i desire this too
I think I saw @north ledge mention it but I don't know if he made it. Might know where it is though
If there’s multiple people in a photo and you just want to train one of them what’s the best way to exclude the rest? Just mask them out with noise?
You could crop the image or mask it
But don't use noise. I think white or black works best
Hey, can somebody help me with Dreambooth?
I'm trying to train a Person Face, should I leave these two values as they are?

For making it easy, yes
You could also change them if you know what you are doing.
What reg images are you using?
thanks
reg images???
Or is this the new Lastben repo without them? Sometimes called class images?

GitHub
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - diffusers/examples/dreambooth at main · ShivamShrirao/diffusers
Shivam's Repo.
Ah yeah, that's the one I'm using.
I don't understand too much about AI and all these stuff, so yeah, please don't ask too complex questions. I would prefer normal english.😅
I still didn't understood what you meant by class images.
I just added face images on training folder...
Tutorial I was following said that Class images will be generated automatically. I guess...
To make it as easy as possible I'd leave the settings as is and try it without any modifications.
If that test runs well and gives you good results you could come back to that ☺️
btw, what's your rig specs?
3090, Ryzen 9, 32GB RAM and a normal HDD
Anyone have any suggestions for working with different ckpt / weights quickly? I'm using A111111 SD Webui. For me it takes up to a minute or so.
faster hard drive will help, its fast to load on an NVMe drive
loading a 4gb file from spinning rust will be slow, but it only takes 2-3 seconds on a fast NVMe drive
Ok so those YT vids I've seen where folks are switching 'instantly' are time snipped I guess
1-2GB/sec read on NVMe drive means 4gb is just a couple seconds
Oh really OK, 2-3 seconds, wow then I'm doing it wrong, thanks
I initially started using SD off my NAS, it's reasonably fast NAS but it would still take 20 seconds or so to load, on NVMe drive its just a few seconds
SATA SSD is like 6-10 seconds, etc
I simlinked my models from my nvme drive - some of them anyway. I seem to remember it didn't help initial checkpoint weights loading, so never pursued it
I very superficially looked at how to point the SD webui at an external location for the models
Yeah on my M.2 SSD it's a few seconds. It's also worth trying out embeddings if you haven't. Much lighter than checkpoints and ideal for styles.
Anyone got a good tutorial link on how to fine tune the model? with 10k+ images. lambdalab's pokemon demo looks horrendous...
Have you asked him?
on shivam's, for a person what do you currently recommend steps wise for 12 images @ 1e6 with 300 regs? i'm goin up in steps of 800, up to 4800. .. i'm not sure 100 per image does it.. or maybe 800 was to low and 1600 too much.. but the face isnt settling
2e-6 converged (well a bit) a lot quicker
it was defaulted at 5e-6 at one point wasnt? i've seen someone here training 20 images for 4040 steps so dunno
there's some unnatural data in these photos tho this time, eg i've moved a person from the edge of a photo to the middle, cropped anybody else off and filled with black.. it's probably problematic
Out of all the 28 or 29 activation functions of the hypernetwork on Automatic1111, and the Layer weights initialization. What is the best/recommended options i should choose? I AM SO CONFUSED as to which i should go with.
i used to do linear, but
Linear is not there anymore, and they added layer weights initialization
Also this Select Layer weights initialization. relu-like - Kaiming, sigmoid-like - Xavier is recommended
is very vague
what does that mean? i should mix Relu with Kaiming Normal and always use Sigmoid with Xavier?
That is so vague and confusing
I made a bunch of interesting photos to say the lease
it's so new maybe people don't know yet
Guess i'll have to find out myself.
try training with the same stuff and just change the init setting and compare after I guess, it's pretty experimental stuff
this is a bunch of images I generated
i tried earlier and im still a bit confused, either way i'l keep experimenting with it.
but what a common theme between all of them is that there is something inherently wrong with their limbs and faces
does anyone know how to fix that?
Potentially Dangerous file That's not good....
Yhea but Disocrd do be like that
Those faces look....weird, i see
Have you tried using mutated, disfigured in the negative prompt?
or any other limb correcting phrase?
Well that certainly can help
this was just an initial test of mine where I put in a series of photos with the prompt "anime girl"
Negative prompt basically is what you don't want in the image
the webui?
like where did you download it from?
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
Then Automatic1111
well there's LOTS of things to do on it so i cant name all of them, i suggest taking a look at this.
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
the features mainly
but tips specifically
well:
- You can use Loopback on img2img to make the image sort of better over time
- in order to upscale an image you can use a 512x512 image and pass it to img2img with denoise strength at 0.50-60 or use ESRGAN
- 20-50 steps is more than enough, unless you are doing img2img or oupainting or inpainting.
- The recommended sampling methods are usually, Euler_a, Euler or DDIM, you can use the others but i mainly and other people use those.
- using [] or () with a specific word inside like:
[dark alley] with a (red light) on the ceiling.
[] = Doesn't pay much attention to what's inside but its still there
() = Pays more attention
the more (()) the more attention as well as [[]] for less attention
- The more complex your prompt, sometimes is better but sometimes cutting back helps, so don't go crazy with the prompt.
- Things like "an anime girl is running down the road" is much better like this "1girl, anime, running, street"
But most of these you can find as well on the Automatic1111 GitHub, just read around and you'll see it.
tysm
No problem
any tips for drastic inpainting? it works fine when I mask an object and try to replace it with something similar, but if (for example) I mask a wall and prompt "hole in the wall" often very little to nothing will change, irrespective of cfg/steps/sampler/etc
My dune SD fine-tune https://huggingface.co/nagolinc/sd-dune

The slow speed in loading weights seems to have to do with Python's relatively slow pickle deserialization (I should try to profile it). I'm stuck waiting for 10-20 seconds even with an NVMe SSD and 32 GB of RAM.
Found a nice guide for the Hypernetwork thing (activation function of hypernetwork)

Neural network activation functions are a crucial component of deep learning. Activation functions determine the output of a deep learning
basically explains what they look like
Hrm I don't think it takes more than a few seconds to switch model for me, running off a Samsung 980 pro and loading onto an rtx 3060, with the i5 12400 maybe doing some decompressing. It could be something else
You can always load them into ram using Checkpoints to cache in RAM
under stable diffusion in settings

Activation functions are functions that we apply in neural networks after (typically) applying an affine transformation combining weights and input features. They are typically non-linear functions. The rectified linear unit, or ReLU, has been the most popular in the past decade, although the choice is architecture dependent and many alternative...
as far as i can see (currently training) elu is good
The best seem to be, relu, rrelu, swish, sigmoid (hard to say), leakyrelu, tanh.
you can add selu to the list, it's also good.
Hrm.... I'm playing with textural inversion, and I'm getting results that appear to be over fitting? ie. If you put * in as a prompt, it tries to literally regenerate one of the sample photos. Such things as 'a * themed lunchbox' just don't work at all.
I've been reading all the issues on the original textural inversion github... but, there's just heaps of people trying to random stuff as far as I can tell.
eg. 'set num_vectors_per_token to 60'
Even though the original work didn't do anything remotely like that.
Does anyone know of a good guide for the right settings to use?
number of vectors is roughly the equivalent of number of words if you were trying to type out a prompt to do it, and SD only takes up to 75 vectors, so a high number will overwhelm anything else
Yes, so I fail to see how that’s useful despite the advice in various places to do so, and simply set the inference number to some arbitrary lower value like 8
…but practically the number of vectors of 6 (used in the original repo) seems to give results that don’t do anything remotely like what they describe.
“Banksy art of *” gives gives me a photo of *
Is there a trick to making it do something meaningful, instead of just spitting out the training images?
(I’m reading, for example, https://github.com/rinongal/textual_inversion/issues/35 but people just seem to be posting pictures and not actually bothering to say how they got them)

GitHub
Hey @rinongal thank you so much for this amazing repo. I trained with over 10K steps I believe, and around 7 images. (Trained on my face) Using this colab I then used those pt files in running the ...
Eh. https://github.com/rinongal/textual_inversion/issues/92 I have the same results as this guy trying to repeat the original results in the paper.

GitHub
Hi, I'm trying to reproduce the paper results, especially the 'cat_statue' concept below in Figure 1, but it seems like extra information is needed to do that. Inversion and...
TLDR; he can’t.
Meh, I think this may actually just be broken with LD.
hello, how to add a new style in SD ? i precise that i have not it running on my pc, i use it online
to increase negative emphasis in te negative prompt (ie I want it even less like the word) do I use (word) or [word]?
like instead of red in the negative prompt, i want to say I really really dont want red.. is that ((red)) or [[red]] ?
not sure because it's negative
it depends on the repo, it's a hack added on top of base SD and each one does it differently. I'm guessing you should use (word)
I've had some success with TI but am too busy to go through it all in detail right now. I'm pretty sure Automatic's implementation is broken though, if that's what you're using
Wasn't always broken, at least
Yeah I've had some success with it, but can't get anything good out of it now. I have some very minor modifications, but they're the same as I have in other repos (reading prompts directly from filenames)
They are bringing Linear back to Hypernetworks... nice

GitHub
In hypernetwork, the linear activation_func that the old implementation used is missing from ui.
Add the linear activation in hypernetwork back to ui.
just uploaded my cyberpunk dreambooth model to huggingface (its overtrained and I LOVE it) https://huggingface.co/Phantasion/phaninc

Has anyone had any luck determining a more optimal prompt for multiple subjects without distortions or merging taking place?
is that a fine tuning question or a prompting question?
because putting group photos in your training set helps
that's a render of a trained model that includes group photos

getting outfits on specific characters in group photos is still elusive
oh my bad yeah prompting question i missed the channel for that xD
What is the best way to train an art style in dreambooth? I picked 150 samples and trained with 2000 steps, the results are impressive but seems the model can't understand some concepts that appeared in the dataset
Maybe bcs there are few references to those concepts
I’m a newb hoping to make a Transformers model, and I have two questions:
-
If I want to teach the AI to recognize details like a ‘red helm’ (specifically the blocky face-framing element some Transformers have) or a pair of ‘blue pedes’ (the nonhuman feet of a Transformer, trying to avoid toes), is it better to say “red helm/blue pedes”, “red-helm/blue-pedes”, or “redhelm/bluepedes” when teaching? Or something else entirely?
-
Is it possible to teach the AI multiple tags at the same time? I found SD through NovelAI, which made a model that recognizes most danbooru tags, and I would really like to be able to do something similar. Eg) “whirl-idw1, blue-long-empuratee-helm, yellow-long-empuratee-optic, neck-up, from-side, suspicious” to describe a picture in the dataset, and “swindle-g1-cartoon, black-helm, gray-face, purple-optics, black-neck, yellow-pauldrons, yellow-chest, glass-windshield, purple-torso, waist-up, from-front, fake-happy” to describe another. Is there a way to do this efficiently?
I apologize if these are ridiculous questions with obvious answers. I’m new to this.
I have spent...hours trying to determine which Hypernetwork activation function to use. I have determined......SCREW IT!
It's Math, it's all different ways to plot a graph and based on that graph your training will go different. My advice...... There's no better method, they just all produce different things. There saved you the trouble, just stay on Linear, relu, selu, elu and leakyrelu. Those seem to be stable......for the love of god....don't change the Layer weights initialization from Normal. Jus leave it there, DON'T touch it. Also....DON'T use SIGMOID, it's just a mess......if anyone wants to keep trying, go for it. But for me? im good with Linear.
as for Dropout....well be careful with that. i could do some perfect stuff without it before, but it will drastically change your outputs as well.
Maybe for the good or bad.
Here is some examples of what the graphs look like.


Do with that what you will.

@hot breach what ratio have you been using between training images and reg images?
1:100 ?
i have 400 training images for a model im trying to make, kinda lame to generate 40000 reg images
I installed dreambooth locally for local training, but getting a cuda memory error. RTX3060 6GB VRAM Anyone successfully trained locally?
at some point I read you needed 24GB VRAM to train, maybe that changed
6GBs? No, it can't be done.
maybe in a few months...
the model is simply too big to be loaded in 6GBs of VRAM
last model didn't have reg images, it was trained on 1:1 training images and laion image scrape, no difference in repeats
guys I've installed dreambooth on WSL, but when I convert to ckpt and load it on automatic webui I'm getting this error, if I copy the whole folder and execute same command but on windows directly it works, any idea?

auto has a safety checker on the ckpt that rejects if it there are unexpected things in it so people don't end up getting malware
it may be the converter being used on the repo you have from diffusers->ckpt is doing something unexpected in the ckpt pickle file
his safety checker is probably far from perfect, but better than nothing
yeah disabling the checker make it work, the weird thing is that same script on windows creates a working ckpt but on debian produces that message
that's certainly an interesting data point
hello everyone. I was thinking a way to produce datasets of generated characters for fine tuning and today I founded a simple way to do it.
I did just a few tests using img2img, the idea is cropping every image in each angle and use it in dreambooth


Probably has to do with python/pytorch version
added micro model training to my trainer since people seem interested in that, will damage the model if you do too much but worked ok for training Ted from the Seth McFarland of the same name https://github.com/victorchall/EveryDream-trainer/blob/main/MICROMODELS.MD sorry no notebooks yet, just local on 24GB gpus

not bad for 13 minutes of training

I've got to say I'm struggling to see what really changed other than the config in https://github.com/kanewallmann/Dreambooth-Stable-Diffusion/compare/main...victorchall:EveryDream-trainer:main

GitHub
Implementation of Dreambooth (https://arxiv.org/abs/2208.12242) with Stable Diffusion (tweaks focused on training faces) - Comparing kanewallmann:main...victorchall:main · kanewallmann/Dreambooth-S...
Drops the reg as part of the loss in the unfrozen finetuning?
Prompt is simply "ted bennett" <-- why no complex prompt?
I have a dataset that I created by parsing one site, image tags are inserted in the file names, and I want to finetune SD so that it understands the tags of this site. What is the best way to do this?
Yo quick question, if im training a hypernetwork on a specific anime character. Is it better if i do this for the textual inversion template?
Ichigo, [filewords] ? or [filewords] since im thinking adding ichigo will make it more pronounce to know that the anime character im training it on is called Ichigo and every time i say 1boy, orange hair it wont just generate a random dude with orange hair instead. So that's why im thinking if i do Ichigo, 1boy, orange hair it will consistently make it like the guy i trained it on. What do yo guys think?
there's not much need for it, the text encoding is quite smart from what I can tell and it's too painful at inference to remember magic prompts and magic tokens, I don't think the magic tokens really has legs, no one is going to want to have to read a giant prompt guide especially as mega models start flowing in place of having a drive full of a hundred 2GB dreambooth trainings
regularization pairing is removed, kane is off doing his phd so I forked it to keep moving forward, I'm up to batch size size 6, which is like running the other xavier forks with batch size 3 with the train/reg pairing and wasn't possible for one thing, they max out at 2 (or equivalent of 4 on my fork)
the data management to change the ratio of preservation to training data is obtuse if you use kane's, it was sort of fixed at 1:1 without a complex explanation of moving data between "reg" and train folders
kane's was essentially just passing pairs of train/reg and training them equally, which actually worked very well for preservation using laion data in place of "regularization" in dreambooth paper terms, captioning already removed token/class so at this point it back to a more general case fine tuner and there's nothing left of the dreambooth paper in there really, and I wanted to be able to more easily manage the ratios of new and preservation data
I'm actually fairly pessimistic about "fast" "dreambooth" (no regularization) long term because but people seemed hyped about it so I did a POC for it above and it only took me like 30 minutes of actual work to run a test and write up the readme for ted bennett to show it works
getting super off results when training hypernetwork with automatic1111, running 2000 steps and the outputs are nothing that matches the prompt... any suggestions on how to direct the model closer to the prompt?
What are your settings? and are you trying to train a person, object or a style?
by settings i mean, activation method, layer structure, learning rate, etc.
linear, (1, 2, 1) and 0.00005
i'm training purple boots / shoes
so moreso object
By getting super off results do you mean the images degrade (deep-fry) over time or do they just not look as what you are training?
both, they start to fry around 1700 steps, but all images prior to that are just super off , for example a random car showed up and then what seemed like a japanese zen garden ... so totally all over the place
i recommend first using this method: but also make sure your images are of your subject and nothing else just to be safe, "Quality over quantity" as the guide says.
yeah, i only have 10 images, all just of the target, very clean/focused on the target too
Enter hypernetwork layer structure: 1, 1 (linear)
Select Layer weights initialization Normal
Use Dropout: Enabled
make sure they are 512x512 or resize them.
Hypernetwork Learning rate: 5e-5:100, 1e-5:1000, 5e-6
also make a custom prompt template with something like
Shoes.txt inside> a picture of purple shoes or Purple shoes
if that doesn't work try using:
Select activation function of hypernetwork: relu, rrelu, elu, swish, leakyrelu
usually depending on what i am training i get good results at 2k
also make sure you have in settings Move VAE and CLIP to RAM when training hypernetwork. Saves VRAM. Enabled
ok awesome will try this now
and
Stop At last layers of CLIP model: 1
your results will also depend on what model you are using, SD 1.4~5 is mostly real stuff and Waifu diffusion for anime training
and also
make sure while training a hypernetwork you don't accidentally have another hypernetwork enabled
That's all i can say, it should be pretty straightforward. if even after everything, it still fails. Well....idk
its worked well with me for textual inversion training with diffusers a few weeks back so i hope to get this one working to but sometimes it's just 🤦♀️ 🥲
Yhea they changed a few stuff and i was mad because i had to re-learn hypernetworks again.
to help you a bit...

These are the activation functions
basically they are the weight of the learning
something like sigmoid has a high starting point therefore you might get weird noise and stuff. Linear is straight forward and it gets better overtime, however it has a negative slope too, relu is basically linear without that negative slope.
Hope that helps in visualizing how your hypernetwork might change overtime
yeah, that's great, thank you
No prob, dont be afraid to change the learning rate btw just dont go over 0.00005 (5e-5) or your network will die quickly at 1000 or more
so in short
1e-4 = no
5e-5, 1e-5, 5e-6, 1e-6, 5e-7, etc. = good
and, for the sizing, keep it at 512 x 512 ? would for example 768 x 512 inject extra time/error ?
well, from what i understand it's better to play it safe at 512x512 but you can do 768x768 but not uneven numbers, they have to have a 1:1 ratio.
or else you might get weird stuff
ok great, implementing now the updates 🤞
Good luck! Make sure to experiment.
any luck with anything except linear? if I use sigmoid or anything else I just get noise
Anyone trained 30 images or so of a person on shiv’s? And if so what was your LR and steps? Thanks
Yhea sigmoid is for me a hard skip, i just use relu, swish, elu, selu, linear or rrelu. Swish is slow to learn but its safer from what ive heard. Sometimes selu gives good stuff. I've done A LOT of experimenting and im still not on a solid activation method, but i do use Linear more often.
Im training Elastigirl right now using selu
step 50

step 900

im not using Linear right now so i can't give an example but as you can see selu gives good stuff, obviously this is still training so it's bad rn
step 1150

where is selu?
Hi all, is there any relations between the layer structure and learning rate? Should I use learning rate smaller than 5e-7 when layer is more than [1, 2, 1] ?
https://github.com/victorchall/EveryDream updated Laion scraper for better capture rate, fixed quite a few issues with junk in TEXT/caption fields
anyone running into an issue where the ai understands who some characters are, but not others?
might need to be more specific on what you're training, posting examples would help
im not training it
Then the model likely wasn't fed many examples of that particular character in it's training data
Can anyone link a decent tutorial on how to navigate the embedding/textual inversion procedure? Thanks and I am sorry if not the correct place to ask.
someone just linked some guides: #💬|general-chat message
there are some basics on automatic1111's wiki on his github too
this is the right place
Ty. I appreciate the help
How many steps should a dreambooth model be trained on? E.g how many steps should you use relative to the amount of sample images
Currently, I'm using a 1:100 ratio. I used 40 images previously, so that's 4000 steps. However, it seemed to have overfitted the model. Thoughts?
to avoid overfitting, you could use this repo, you'll need to caption your images https://github.com/kanewallmann/Dreambooth-Stable-Diffusion/
depending on the investment you want to put in, you could then use this one : https://github.com/victorchall/EveryDream-trainer
https://huggingface.co/hlky/xynthii-diffusion
dreambooth model of Xynthii (cyclops monster girls)
1000 steps, will be testing different amounts, results from num_train_epochs=24 (1920 steps) are good
the same images (and prompt) were used for both instance and class

by using the technique used in the repos above, the model is able to understand the concepts much better
for example you can train painting styles, and get results like this :

here the subject was already known by the model and not in the training images, but it "understood" what it meant to represent subject in the style i was training
playing with dreambooth, any ideas on how to avoid text on the images? the images used for training have no text, but I've used microsphere worlds as prompt so I think its the root of text on the image, maybe using a random word would help?

Did Shivam’s dreambooth update break training for anyone? I’m having issues after updating it recently. My training setup is:
3080TI
Windows using Ubuntu
Shivam’s DB
CUDA v 11.6
Python 3.9
Everything else basically set up with nerdy rodent’s 10GB dreambooth video
I’m using 300 reg images with 20 training images. I’ve tried 800 steps at 5e-6 and 2000 at 1e-6 but the ckpt ends up giving either all black images or the colored images. What’s frustrating is that the loss rate is really inconsistent: sometimes it says at 0.18 and other times it goes to nan by 50%
I’m trying to do the training locally, not on collab
How knowledgeable are you lot with Textual Inversion embeddings. I can't seem to get anything but guesses about the actual parameters. What I'm struggling with is that the embedding is too dominant, as it overtakes everything. Even with token range of two. However this seems to be the case regardless of the learning rate. I have understood that adjusting the learning rate can be used to influence the scale dominance. Should I try drastically lower rates? Since noise loss doesn't seem to be tied to learning rate.
Also does the initialisation term(s) act as if they were prompts. Should I give it a term or broader range of terms. As in "Underwear" or "Underwear, briefs, pants" with or without the comma. There sodesn't seem to be much of useful information and which there is seem to conflict. I even read the original paper on the topic.
However I think all current implementations are different and advanced compared to the original paper.
What is the primary stuggle really is to ensure editability of the embedding in use. Currently they seem to work fine even if dominant to make generic basic SD outputs, but if you try to force style it refuses to.
Update from epoch48
a classical preraphaelite painting of a beautiful cyberpunk vaporwave xynthii by john william waterhouse and William-Adolphe Bouguereau
k_euler_a 69 steps cfg scale 7.5

Hallo all, I want to train a model on a subject but I've only got 20 good images, if I train a baby model, output 100s of pics until I get a new one that looks very very decent - can I do that until I've got 10 new ones and retrain with the new decent fake 10 to get a better 30 model?  Sounds feasible to me but very new to this so not sure if there's some hidden pitfall
Sounds feasible to me but very new to this so not sure if there's some hidden pitfall
sounds like a good idea to me. as long as those outputs are the style youre looking for. no harm in trying it!
Nice, I will try it and see then 
Will have to be extremely selective and mind hands of the warp
I've also done some others - I trained 2 60 image models on 6000 steps earlier, and the 6000 ckpt seemed a bit wonkier/worse than the 4500ish one Is that something anyone else has found, that there are sweetspots with image numbers/steps?
I’ve seen n*80 suggested as a figure, but it’s anecdotal obviously
Since it depends on your data, I think you just have to hone in on it
@vocal pawn which trainer?
Using the colab fast db atm
i think the reason that 30 images /3000 steps is suggested is cuz any higher than that can have diminishing returns on the training. but thats case by case
Which sampler should I use if I want very photorealistic results, like this sample?

this is dall-e but I am trying to get as close as possible with SD
and any other settings recommendations to get this?
the prompt is A photo portrait of a female supermodel, soft neutral expression, long blonde hair, symmetrical face, front facing, looking at camera, studio lighting, 8k. Dramatic, professional photography. UHD.
👍 I see, lots to test
Ty for that :>
here are some photo-realistics i've done with SD. i always use euler_a, but the results are more up to your prompts than sampler. try adding things like "award winning photo, 50mm, highly detailed". i dont like using things like "uhd, 8k, hyper realistic" because those terms are rarely associated with real photos which is what we want SD to draw from.
OMG those look amazing! Mind sharing the prompts for the last two?
sure. i'll have to dig for them, gimme a minute
are these trained subjects? If so could you tell us what you trained please? Steps, subject count rate etc thanks
nope these are just random people that SD created
Ah right yeah I can get great results from the core model for sure. Thanks for prompts tho
getting closer by putting those KW's in!


for the sweater one: stunningly beautiful fit woman with shorter hair, wearing knit sweater and denim pants, skinny, full body portrait, award winning photo, sharp focus, detailed, photography, 50mm
Steps: 35, Sampler: Euler a, CFG scale: 8.5, Seed: 4293303383, Face restoration: GFPGAN, Size: 960x1344, Denoising strength: 0.32 and for the blonde one: stunningly beautiful young woman with shorter wavy blond hair, thin, wide shot, award winning photo, sharp focus, detailed, photography, 50mm
Steps: 35, Sampler: Euler a, CFG scale: 9.5, Seed: 4192447683, Face restoration: GFPGAN, Size: 896x1408, Denoising strength: 0.32
TY
yes, because its real
I get particularly confused about this style of prompting. Does SD really know what "stunningly beautiful" as opposed to "stunning, beautiful"
Mostly i just wonder what it does with the "ly" i guess
https://github.com/victorchall/EveryDream/blob/main/doc/AUTO_CAPTION.md auto captioning added to my tools repo those using caption training, should work with kanewallmann or my fork, or using MrWho's schema of "00001@my caption.jpg" for use with joepenna fork

GitHub
Advanced fine tuning tools for vision models. Contribute to victorchall/EveryDream development by creating an account on GitHub.
Added a colab notebook for above, any scuffed nvidia GPU should work, just need maybe 4GB?
Made a script for making 512x512 dreambooth images, crops to a 1:1 image first and then resizes to 512x512to preserve as much of the image as possible; for use with TheLastBen's fast-dreambooth
You can use birme and it lets you move the cropping window so you dont cut people's heads off: https://www.birme.net/?target_width=512&target_height=512&auto_focal=false&image_format=webp&quality_jpeg=95&quality_webp=99

Nice tool!
yeah its just js in the browser
sometimes chokes if you put too many huge images in but works 98%
Could've made something like that myself but I don't need to reinvent the wheel 😄
Dreambooth
prior-preservation loss
train text encoder
105 images
same images used for both instance and class
prompt of "taylor swift" for both instance and class
69 epochs/7245 steps lr 2e-6
prompt: taylor swift k_euler_a 69 steps
works quite well, another test of my idea to use the same images/prompt for instance and class

Birme completely destroys image quality, you should use other tools
Has anyone content to recommend on regularization images ?
Some sort of theory guide ?
I know they're supposed to match what you are going for during inference, but there's probably more to it
I have few dozens pictures of art style I am trying to replicate, but what reg images should I use to train a style in Dreambooth, please?
can I use the person dataset?
I tried generate 200 images with prompt "graphic style" and I will see how it goes 🙂
how do I save the values used for training textual inversion?
Hello channel, anything reference code to recommend please if I'd like to finetune SD-1-4 on a customer image-text dataset?
Am i supposed to resume from SD-1-4 or SD-1-4-ema?
Thanks!
what samplers you guys use after training your model with dream booth?
I usually use lms but after training my model with dream booth, the only good sampler that gives a good image is euler a, not sure why.
my lms gives a really bad result.
in my experience EMA is better at keeping the model's "world knowledge" and mixing it with your style, e.g. the fine-tuning dataset
Do you mean the original Stable Diffusion project? If so I found most helpful an example by LambdaLabs / Justin Pinkney:
https://github.com/LambdaLabsML/examples/tree/main/stable-diffusion-finetuning
GitHub
Deep Learning Examples. Contribute to LambdaLabsML/examples development by creating an account on GitHub.
I see! thanks a lot for the pointer.
Got it! I see the CompVis ema ckpt available here (https://huggingface.co/CompVis/stable-diffusion-v-1-4-original), but I don't see it in the HF diffuser format. Need to convert manually if want to use hf diffuser?
I think you should use the non-original ckpt with Diffusers:
https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main

(original is for the CompVis repository and their scripts that don't use huggingface.diffusers)
I checked this before and it seems no ema weights are included. I might miss sth tho.
ah, sorry then, I haven't used the Diffusers library yet so I'm not familiar with what's available for it
btw is finetuning/training even possible with diffusers (the library)?
No worries! I got this (https://github.com/huggingface/diffusers/blob/main/examples/text_to_image/train_text_to_image.py) from their repo. But seems experimental atm.

GitHub
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - diffusers/train_text_to_image.py at main · huggingface/diffusers
Don't think they have a full training pipeline supported otherwise.
Yeah, last time I checked I couldn't find anything.
Thanks for sharing! It does seem fresh 🙂
if you set quality to 99 it does not, thus the link
Ok guess I'm a retard
I guess png support would be nice but I think at 99 you're losing very little
dreambooth is pretty crazy, did a model to do emojis

is there a dummy guide to dreambooth for Collab?
I am asking, as I am having a hard time getting to understand some of the notebooks, and the performance is not as good as I expected.
hi, how to train the style of sam yang https://www.instagram.com/samdoesarts/ in the dataset? 🙂
Hello everyone! newbie here.
I followed Arki's guide to install InvokeAI. I am now looking for how to train it with custom faces. Is there a guide somewhere by any chance?
Or do I have to use another version than InvokeAi?
nerdy rodent does good guides https://youtu.be/VgKDZqAii1I

Want to add things to your AI art but don't have a powerful Nvidia GPU at home? No worries - got you covered with this diffusers version of Dreambooth which can be run for FREE on Google Colab! Works GREAT on a T4 with just 15GB VRAM. No need to install anything - just run straight from your web browser. Even runs on a potato computer ;)
As a b...
might be slightly different, as it was a month ago
which in AI time, is about a year
Hoy Manu imgs was your training set? What class did You use?
24 images, 1000 steps, I didn't used a class at all, I've generated my own images for class
a bunch of different images with modelling clay look
it produces good results

What class name did you used?, Local GPU?, I'm training a toy car, it looks aceptable but Will need to train wheels separately
Anyone tried doing (something like) Dreambooth on JUST the text encoder, while freezing the main part of the model?
I'm experimenting with this now but I'm not sure what to expect
would you mind sharing a pointer to these images you use? Thanks a lot.
Following up on this: it worked reasonably well on pictures of my own face, although it didn't replicate my likeness quite as much as normal Dreambooth. I haven't tried textual inversion, but I'd expect that the results are roughly comparable given the similarity between the methods. Possible that the results would be better if I used a lower learning rate than 5e-6, always used 1e-6 or lower for normal Dreambooth.
I'm using a paid set of emojis, but I got the ones with visual style I was looking for, then I created 50 class images on webui using different variations, like 5 images of emoticons with modelling clay looking, then another 5 images of cars with modelling clay looking, so I could add different types of classes to apply the style
I've now created a new model, but instead of 1000 steps 1e-6 I'm with 6000 steps 1e-7, it's a bit more free to create different stuff now, still looking for the right spot
with second model I can create logos and other stuff applying the same look which is very nice


You can try the invokeai discord, but the tldr is, it only does textual inversion, not real fine tuning. You’ll have to use a different version.
(Difference; it’s quicker to do but the results are significantly worse)
Thank you 😍 I will start with textual inversion and work from there
thanks a lot for the information. absolutely amazing to see these.
I just found that using TI + my emoji model I can then create emojis based on real people, my wife and me for example


Amazing! What do you mean by TI?
It'a the Textual Inversion, but I said it wrong I'm actually using Hypernetwork + model, I think TI can also help to direct the image but HN for me on photos has give some better results, we can use a custom model like disney or this emoji one with HN or TI that has been trained on another model even if it's not suggested to as results may vary
if anyone is interested, i made this script for automatic webui to generate regularization images for a set of training images, to then use with kanewallman's repo
it's pretty ugly but seems to work
for each training image, it first creates a caption using BLIP, then generates X reg images out of it


can be used with txt2img or img2img, haven't really tested training yet so I can't tell what yields better results

i should probably expand it to automatize the captioning and renaming of training images as well, now that i think about it
I am going to attempt to do some hypernetwork training. Do I need to use the bigger 1.5 checkpoint? And once I've done the training, can I use the hypernetwork .pt I create with the smaller 1.5 (emaonly, whatever that means) checkpoint file?
does anyone have examples or a better explanation of what the prior preservation does on dreambooth?
its there to keep knowledge in the model, beyond that you probably want to read the dreambooth paper and it gets math heavy fast
if you train without any effort to keep the model in tack you'll cause "damage" to the model, things will start to look messed up. You will with dreambooth too but the regularization/prior presevation is there to try to slow that down







Further development on this. Retrained using a larger more refined dataset (235 images total), still experimenting with the idea of using the same images/prompt for instance and class however this time some images were excluded from the instance set (205 remaining out of 235 total).
These results are 19 steps k_euler_a, 512x704, 7.5 cfg scale, gfpgan1.4 + RealESRGAN_x4plus, they are not cherry picked either, 8/10 results at 19 steps are good
prompt: a photograph of taylor swift, outdoors, shot on iphone 14 instagram 2022
Personally I haven't seen anyone else's results with dreambooth produce such an accurate likeness to the person trained.
Just to note: this is purely for research purposes, I have no intention of releasing these models. I do want to write up my findings along with my thoughts on the implications of models like this which can accurately reproduce a person.
Also if you're wondering about the choice of subject, I chose Taylor Swift for two reasons, mainly because she is a celebrity so everyone knows what she looks like, if I tested this method on myself I couldn't really ask people "does this look like me", then the deciding factor was just that I like the new album and I've been listening to it a lot.

hey guys, Python noob here and i'm trying to fine-tune my first custom ckpt model, Kinda like that robo diffusion model, would love it if you can provide me with any links to tutorials or resources to help me get started?

Having a hard time making a D&D-style Kenku. Any suggestions for artists or any other prompts to add?

This is fantastic. Bravo! I've been trying to do this exact thing. And for your emoji model, you say you used a variety of class images made from "modeling clay"? That's interesting. How did you decide on that? It seems to worked amazingly well
How do you use captions in this case?
does it add captions to reg images as well as training images?
Can KaneWallmans repo be used on colab / runpod?
Wanted to know about captioning but dont understand yet how it works or why is it useful.
LastBen is the easiest to use colab, maybe you can start there.
So you just use the first imageSet as template, add a prompt according to what you need, can you provide any template to try img2img?
thanks buddy, this repo worked like magic, I want to look at ways to improve the quality of generation of these images, any suggestions? more varied data I guess right?
good lightning conditions with many facial expressions etc.
how much do you think this (same tokens/images for instance and class) comes from the model already knowing about taylor swift as opposed to training it on e.g. yourself or someone the model doesn't yet know (some "sks person/face").
I'll need to do more testing however the same method worked very well for https://huggingface.co/hlky/xynthii-diffusion that's where I first got the idea because the design of the character is so unique that no class prompt would generate images anywhere close to the subject
Thanks for clarifying! ^^
What is a good tool for finetuning with Dreambooth locally? I have a 3090, I've been using n00mkrad's text2image-gui. I am comfortable with the cli.
Maybe this https://github.com/smy20011/dreambooth-gui
GitHub
Contribute to smy20011/dreambooth-gui development by creating an account on GitHub.
GitHub
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - diffusers/examples/dreambooth at main · ShivamShrirao/diffusers
how do you guys measure model "corruption" when fine tuning, to tell if you are overfitting or not ?
for now it doens't deal with training images as i already had them captioned, but yeah i think my script target should be : give me a folder of training images and i will make a dataset to be used with kane's repo
https://miro.com/app/board/uXjVPI19lP8=/
made v3 with the dataset created using my script
Hi guys, I wonder if any of you guys know the procedure for finetuning stable diffusion for inpainting task only (the one that they described in v1.5). There seems to be a config file for inpainting inference, I am not sure about training and how to run the script for inpainting. Hope that someone can help me out! Thank you in advanced!
Yup, I've generated around 50 class images, but with several different types around 5 images per generation the idea was to try to not bias the style to something exactly, but I'm also playing more with it and I found that using no class images also brings good results, I'm kinda lost right now because I did so many tests lol but I will try to get something more "scientific" with proper results later so I can study and share better info about it.
guys what the dreambooth train_batch_size does exactly? its a bit confusing because I thought it would train 2 images per interaction, but it seems to take almost same time as using batch_size 1? or speed keeps the same but it can do more? like 1 batch_size = 500 it and 2 batch_size = 1000 it?
yes, just that simple. I get the templetes googling "3d heads" or "face in multiple angles". This for example https://us.v-cdn.net/5021068/uploads/editor/49/c4hsv0sqapit.png

Haha. Okay, glad to hear you're as lost as I am. I keep doing the same thing, running my own detailed experiments, thinking that I'm on to something, and then finding it all to be wrong and having to start all over. Either way, great work on your emojis. I'm currently trying to replicate your method
one thing that I found important to get proper images with white background, use img2img 😄
img2img with a full white image produces a image with white background, use 1.0 for denoise strength
Ooo, good tip. Thank you. Do you mean for your training images or reg images? Or both?
I mean for actually generating the emoji
Oh, gotcha. Gotcha. Roger that
or use an image like this

Interesting. That makes sense. Great tips! Thank you
it can get some good results, using 0.95 denoise strength, and we can easily change the background color that way, I've used a purple background with noise circle, so it generates the emoji on top of that


So here's probably the best results I achieved for emoji, 50 class images, 22 (I have selected less images from what I had, reduce count of faces itself) emoji images with style I wanted to replicate, 1000 steps LR=1e-6


dreambooth instace prompt was "dreamfoil emoji" and this is the result of "dreamfoil emoji, head girl with colorful hair"

here's more examples of results



shut ... the front ... door. these are awesome! holy crap
This is kind of vague because I don't have time right now to write more about my experiences with this, but I tried running dreambooth but only optimizing the weights of the attention modules, i.e. 'CrossAttention', 'SpatialTransformer', 'SpatialSelfAttention', and 'LinearAttention', and my first impressions are that it seems to work BETTER than optimizing the entire model (with or without optimizing the cond stage). Better generalizability during inference and harder to overfit.
If anyone is interested, I've uploaded a large selection of regularization image datasets for DreamBooth training. Currently available datasets include "artwork style", "illustration style", "fighter jet", "person", "woman", "train", "supermodel", & "erotic photography": https://huggingface.co/datasets/ProGamerGov/StableDiffusion-v1-5-Regularization-Images

Has anybody dreambooth'd it with the best midjourney images yet? You'd think so.
Fakebook and copper? Oh I use those!
sphere worlds, 12 images, 1000 steps and no class images, loving dreambooth

dude. what the heck. you're killing it! that's amazing
Did you use lastBen when training?
Those were your training imgs?
finetuned on 24 pieces by Yves Tanguy, 2400 steps




prob my fav result so far

kay sage is next on the list
Woah so good! Will you make the model available somewhere?
Do people recommend using female / woman as a training class vs person? what are the best practices?
lastBen? not sure what you mean? the training images used are from a Brazillian artist
GitHub
fast-stable-diffusion, +25-50% speed increase + memory efficient + DreamBooth - GitHub - TheLastBen/fast-stable-diffusion: fast-stable-diffusion, +25-50% speed increase + memory efficient + DreamBooth
This is what he meant
Amazing. Can I trouble you elaborating a bit more details how these images are genearated?
I'm trying to inpaint and something very odd is happening
https://i.imgur.com/3vnh2em.png

Some of the black inpainting mask is appearing in the output
that dark part is there in all of them, its what i painted and not a generated result
why/how can this be happening?
does anyone have a guide on how to train or further train a model hosting on paperspace
For each class / prompt, I used Automatic's "Generate Forever" feature to create 2-4 thousand images. Every image in a particular dataset uses the exact same settings, with only the seed value being different
You can use my regularization / class image datatsets with https://github.com/ShivamShrirao/diffusers, https://github.com/JoePenna/Dreambooth-Stable-Diffusion, https://github.com/TheLastBen/fast-stable-diffusion, and any other DreamBooth repo with support for prior preservation loss. Normally generating the reg images for prior preservation loss is one of the most time consuming part of DreamBooth model training, so using my datatsets help speed things up significantly!
With an Nvidia A100 40GB graphic card, I was able to produce 50 images every 1 minute and 22 seconds. The speed could potentially be improved if I could get xformers setup properly
a little research on the effect of small variations of prompt : https://openart.ai/@owl-deafening-97/study-small-change-of-prompt-a-duck-da-vinci-greg-rutkowsky-beeple

OpenArt
Search 10M+ of AI art and prompts generated by DALL·E 2, Midjourney, Stable Diffusion
has anyone tested the effect of including the updated stabilityai vaes into dreambooth training vs adding them after training?
Can you use an embedding in the initialisation text for a new embedding?
Can You add vae after training?
yeah
Just replace the model with your dreambooth result

Wellllll?
Anyone with a good config to train Dreambooth on a 3090 on Runpod?
I get CUDA out of memory with lots of configs and it seems a bit weird
Ok, on another topic, I hear that ---medvram is crap for textual inversion, but if I disable it I get out of memory errors. I heard from the interwebs that I could edit "v1-finetune_lowmemory.yaml" to make num_workers = 4 (instead of 8), but I don't see that file in a1111. Please help?
Which type of machine are you using? ([0] No distributed training, [1] multi-CPU, [2] multi-GPU, [3] TPU [4] MPS): 0
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:
Do you want to use DeepSpeed? [yes/NO]:
Do you wish to use FP16 or BF16 (mixed precision)? [NO/fp16/bf16]: fp16
or
In which compute environment are you running? ([0] This machine, [1] AWS (Amazon SageMaker)): 0
Which type of machine are you using? ([0] No distributed training, [1] multi-CPU, [2] multi-GPU, [3] TPU [4] MPS): 2
How many different machines will you use (use more than 1 for multi-node training)? [1]:
Do you want to use DeepSpeed? [yes/NO]:
Do you want to use FullyShardedDataParallel? [yes/NO]:
How many GPU(s) should be used for distributed training? [1]:2
Do you wish to use FP16 or BF16 (mixed precision)? [NO/fp16/bf16]: fp16
got variable aspect ratio training working, need a touch more work on the code before release but works surprisingly well, posted some tests in #1010579244188958901
the real gain is never having to crop or resize images again
That’s a nice thought 😁 looking forward to see how you made it work
Anyone know how the hell to run TI properly on a 3060 using a1111?

I don't think you can (it needs 8gb of vram)
there's a 12gb 3060 version, but i have not tried TI yet
With 12gb it should work just fine
I guess i just need to not use the a1111 version. Shame.
awesome, using Joe's or Diffusers?
let me know if you need a tester
its my own fork
based on who?
I forked from kanewallmann, it's one of the xavier forks using lightning trainer, at this point the code is mostly xavier's original DB implementation and my changes
kane was the first to put in the ability to fully caption images so I started from his
I did my first couple of experiments training images with dreambooth. I copied the ckpt files into the models/stable-doffusion directory, and have been able to utilize them, with decent results so far. Probably need to do some retraining with better photos. But my question is this: Do I need to merge the ckpt file into the 1.5 ckpt file for best results?
there's been a LOT of hacking on the code, I think djbielejeski put in some meaningful changes as well
in my experience 1.4 is a bit easier for dreambooth than 1.5. for 1.5 you probably want to work with lower learning rates and fewer training steps (like 1e-6 and 2000 vs 2e-6 and 7000), but that also depends on the number of your training examples.
i have not merged dreambooth ckpts into original ckpts yet but i assume you get best results by proper training and just using the dreambooth ckpt
Thank you for that. I only did 25 images, and the only setting I adjusted was steps from 800 to 1000. Sounds like I could/should try much higher number of steps?
my first tests were 4/5 images, sd 1.4 and 800 steps and those were pretty decent (photo realistic character). now scaling up from there with much more nuanced expectations...
If I'm testing different checkpoints of my embeddings (.pt) in the embeddings folder of automatic's gui, do I have to restart the server to pick up the changes?
cool cool, can I have a link to your repo?
idk if this is the right server to ask my question but my 1050ti went from generating 1 iteration every 1.5seconds to 1 iteration every 6.5seconds and i changed nothing.
https://github.com/victorchall/EveryDream-trainer I need a bit more work on the multi-aspect stuff before pushing but should be ready soon(tm)
nice thx
automatic bulk image captioning script and laion data scraper in my tools repo here: https://github.com/victorchall/EveryDream
I'm trying to train a massive dataset (About 100k images or so) using this notebook https://colab.research.google.com/drive/1vrh_MUSaAMaC5tsLWDxkFILKJ790Z4Bl?usp=sharing&authuser=4#scrollTo=Um6kJUmIlDaC (It's the only one I know that allows image names as prompts) but whenever it tried to generate a sample, I get the error "KeyError: 'sample'". I tried changing stuff on my own based on errors I saw on github but it never worked. Is there a better colab for finetuning a network on longer prompt images?
dreambooth'd every king's quest 6 bg, 5000 steps. chef's kiss

Damn that could be an incredible tool for retro adventure game creation with far bigger maps than was previously possible. You could also put say all the King's Quest or Quest for Glory games in the same style, e.g. QFG2 which never got a higher quality remake like the first game did
I did a set today with 5000 steps and it seems like it produced lesser quality results than when I used 800 steps. It seems like with the set I did 5000 steps on, the images it produces are too similar to the original images, and nothing else in the prompt has the effect I'd normally expect it to.
But I'm very new to dreambooth, so I haven't figured out much yet.
When convertng the weights to ckpt, what's the purpose of converting to fp16? Does that 50% reduction in size also reduce quality?
@crimson wasp I think you gotta be careful, spread across too many games and you start to lose the style for sure

best option in my opinion would be either picking a single game's style for each gen just based on the intended scene (ie kq6 only), training together very similar artists (ie kq5, kq6, sq5 or so), or training only within a particular genre (ie "fantasy" with kq5, kq6, conquest of the longbow)
depending on what youre using to train, there is usually a way to produce sample images at an interval you set. so you can do a long training, and see it changing every whatever steps eg 250
I'm using Dreambooth on Colab
merged can comprehend certain things better that are in the other games that arent in just kq6, though it tends to smooth out finer details and has more perspective (when the flatter scenes are likely more preferable for a 90s style graphic adventure game)











hmm, after trying kq6+laurabow2 training, I gotta say that similar detail doesn't work quite as well, worse than similar genres (the fantasy merged one above).
I think composition and nostalgiawise, the best approach is a per-game 5000 step model
Could someone point me in the right direction to understand how to train dreambooth with a 'style' rather than a 'model'?
anything trained on faces? Especially diverse faces (not all good looking. maybe some ugly. different ages)
from my understanding to train a style you need different objects sharing a similar feature?
Guys, has anyone tried to train normal map images to see if we can get it as a style?
Dumb question but do I have to use the full-ema model to generate images if I have trained an embedding on it or can use the same model's pruned version and get the same results?
if you're just training an embedding I don't know if it will matter much
if you're unfreezing the model the "right" thing to do is train on the full file with both ema and nonema weights in it, and only prune to a 2GB ema only file when you're "done"
the lightning trainer will use nonema weights to train when present and fall back to ema weights if it can'tfind the nonema weights
again if you're just doing an embedding/TI I don't think it will matter a whole lot
Alright, I'm just creating embeddings, I don't have enough VRAM for the rest, thanks!
Another question: what's the difference between those VAE?
stabilityai/sd-vae-ft-mse
stabilityai/sd-vae-ft-ema
stabilityai/sd-vae-ft-ema-original
I can see the diff on the pictures here https://huggingface.co/stabilityai/sd-vae-ft-ema-original#visual but I don't understand how I should choose one above the others.

Does anyone have a publicly-accessible trained model I can use as a test? Nothing sinister, I promise 🙂
I‘d say the difference is close to negligible. I‘ve played a lot with the -mse which supposedly gives smoother output. But depending on what you try to achieve, this can be very low on your priorities. I mostly go with the default original at the moment and don’t bother. I might look at the -mse when it’s just about a last bit of polish.
What is best dreambooth repo for my rtx 3080 10gb?
I see many of the top repo ask me to give them like 24GB or more
So I'm trying to do fine-tuning on SD 1.5 with a large dataset (900k image). I have the training running on a 5-GPU A100 box with 90 cpus and 470 GB Ram.
For some reason anytime I run training with multiple GPUs it runs slower than just a single GPU. I've been trying to figure this out for hours now but can't explain that yet.
Does anyone have a guess as to what I'm missing? Or an example of training on mult-GPU computers?
Thank you, I'll use original for now, I didn't want to spend time comparing them right now.
This video has the info you are looking for. Also @dapper prism put together some regulaization images, including a "style" that you can use for your training.

Want to run Dreambooth for Stable Diffusion locally so you can train multiple concepts at once really quickly? Not a problem! Runs on Google Colab as well, so you don't actually need a modern computer to train.
Works on Microsoft Windows (partly), but for the lowest VRAM usage you'll need to use Linux (as with most AI stuff). Also remember to c...
Thanks!
I'd go with the MSE one as its been trained the longest, and seems to perform the best according the general consensus
Then if that doesn't work, I'd start looking at the other options
best jojo results so far, 900 step training on part 4 character portrait renders, cropped at the top square

are there any other image up scaling models? I tried to use ESRGAN to upscale the images generated by SD, the results are good, was easily able to get 4x resolution bump, but I am seeing more artifacts in the images compared to the original outputs from SD. Any Suggestions?
SwinIR
Sorry to ping but I have been trying to use embeddings for a week now with no success.
I have downloaded them from huggingface but I don't feel they do anything and if I up the importance above 1.6 the generated image is chaos.
the files are about 40kb. Super small.
training on any aspect ratio/image size now available on 24GB here: https://github.com/victorchall/everydream-trainer

GitHub
General fine tuning for Stable Diffusion. Contribute to victorchall/EveryDream-trainer development by creating an account on GitHub.
no cropping or resizing required at all
going to work on updating some stuff so I can bring vram requirements down, then probably work on notebooks

example training set directly fed into trainer

I have a few questions about Dreambooth
So, I wanna give it a try training a model, but I have a question: do you train the model to the style that you want your outputs to follow (let’s say for example anime style), or do you train it using a subject that you want your outputs to be like (let’s say for example an actor)? Or you can do both? And if so, how do you train your model for each purpose?
Both. You can do styles with Dreambooth, but its strength is definitely in subjects. I've heard hypernetworks are best for styles but maybe someone with more experience can add their input on that. If you're training an anime-ish subject then use a NAI/WaifuDiffusion model.
UPDATED MY HUGGINGFACE PAGE WITH NEW INFO, DESCRIPTIONS, INVITE LINKS, FASTER INTERNET, BETTER FUEL ECONOMY, HIGH FPS, AND BIGGER TITS/COCKS/APPENDAGES:
https://huggingface.co/ShinCore/MMDv1-18

you should take a break you seem exhausted
Great script ! do you mind if I integrate it in the colab ?
Are you using the original CompVis repo?
FYI I did some experiments with it with 2-4x A100 and noticed a proper speed-up.
I also drew some inspiration from https://github.com/LambdaLabsML/examples/tree/main/stable-diffusion-finetuning but I noticed they modified the source code... which I didn't for my experiments. I just compared my .yml config with their pokemon.yaml
do you have an example at hand that gives more details about non-ema vs ema in general? Is EMA "simply" the optimizer's parameters? If so, what's the reason to choose the variant without by default?
ema and nonema are standard ML terminology, lots of info on the web, but short version is EMA is intended for inference and is a way to keep the model from being biased to the most recent training samples it was trained on
for fine tuning, it is generally preferred to use non-ema weights because the ema is going to bias the starting point of your fine tuning
I guess in practice with SD using EMA weights for fine tuning doesn't seem like some huge critical failure, but it's the general suggested practice
but isn't ema supposed to keep more of the model's original "knowledge"? In that case it's actually good to "keep the model from being biased to the most recent training samples"
(I'm trying to understand it and make up my mind what's best in my case)
I'm not sure what you mean by "bias the starting point of your fine tuning". Maybe I should read more indeed 🙂
biases the start of fine tuning because when you fine tune it is creating nonema weights anyway, ema weights are a byproduct
the trainers will (or should) use nonema weights if present in the ckpt
if nonema weights are not present, it will copy paste the ema weights to nonema weights, then start training and be training on nonema weights, only producing ema weights as a byproduct
it will probably make more sense if you do a bit of reading on ema
Definitely! I'd do that and thank you for the effort
again, in practice, I'm not seeing that using normal 4gb/2gb files as a starting point screws stuff up a bunch, maybe its not a big deal for stable diffusion, but its just a best practice type thing
btw my assumptions were based on the Catastrophic forgetting? section in this article. (Since I used it for ideas for most of my experiments)
https://www.justinpinkney.com/pokemon-generator/

Fine tuning Stable Diffusion to generate Pokemon
there are a lot of weird things people are doing that fall out of best practice, so just be careful of what the masses parrot around, I imagine SD is most people's first foray into training machine learning stuff and they usually are sort of "going through the motions" after watching a couple youtube videos, and the popular creators are often just as ignorant
I agree, I'm trying to filter those out as well
I've had a lot of "wtf" moments watching what people do or tell others to do, or when they state opinions on what is best, etc
and back to ema/nonema I'd like to A/B test that and compare just an issue of time to do it, but since I did most of my early stuff just off the 4gb ema-only 1.4 and it wasn't a disaster its just been low priority
SD may be more resilient to ema vs nonema due to its architecture vs other ML models? just guessing, or the LR people are using for fine tuning is low enough the recency bias is not that large
btw I had the chance to try non-ema before switching to with-ema and it seemed like the model was quicker to "forget" it's general knowledge and start producing stuff similar to my training data (a very small dataset)
with EMA it takes noticeably more epochs before it shifts that way (without changing other hyperparameters)
so it's like striking a balance between what you need - more original model or more "your" model. And I believe there's multiple ways strike this balance, considering other hyperparameters like learning rate
Yeah I forked Justin Pinkney's repo. I suspect my issue is actually that I thought the progress bar was an aggregate of all GPUs but it might just be for a single GPU. How did you measure the speedup?
there's a progress bar (tqdm?) for each epoch and it reports the time for that epoch.. I just noticed those times are shorter when on 4 gpus. Today I also noticed there's an "Average epoch time" in the logs as well so you could pay attention to it as well, I guess
makes sense. I haven't got to one epoch yet since that would take a long time with 900k images and I want to solve the performance issue before I do
why not make a subset of 900 images and play with it to streamline the process first? 🙂
ha yeah, good obvious idea that I hadn't thought of. to be fair, I didn't expect the metrics to be like this
I'm also planning to add some better multi-gpu metrics
what kind of metrics do you mean?
samples per second, # iterations per second, # batches per second.
its my suspicion that the progress bar stats, other than epoch, are only coming from the first GPU
actually, you may be right - I remember something like the # of steps in an epoch being less when I switched from 1 gpu to multiple
I'm new to Dreambooth but so far I've trained 5 or 6 models with photos of myself and family members. I've noticed that with some of the models, SD struggles to produce images that are significantly different from the input images. I am sure I've made some missteps in the training process, but I'm not sure where to start in terms of correcting those mistakes. For each set, I used 30 images, cropped to 512x512, with training steps of 3000, and 3e-6 learning rate (also did some with 1e-6). I used generic "man" and "woman" class names. I am able to get outputs that look like the people I trained in the models, but can't seem to get it to change their appearance much, such as with a prompt like "XYZ man as superman". Any advice on what I can adjust to correct this?
SwinIR and SD upscale is my preferred way to upscale while also adding in additional details. It takes a lot of experimentation to find the right combination of settings to produce the best results, but once you hone in on htose settings, it can produce awesome results.
So, it seems like with a model I trained with Dreambooth and converted into a ckpt file for use with Automatic111, I need to use much lower CFG scale than I normally use in order for it to honor the prompt and not just give me recycled versions of the images I trained on. Is that related to the number of images I trained on, the number of epochs, and/or the learning rate?
struggling to generate something other than training images and having to lower cfg scale is a sign of overtraining
adding more images to train and/or decreasing steps might help
ideally, you are getting multiple checkpoints when you train at different step intervals and you can test several out and pick the best one, if you only get one ckpt then you're kinda stuck starting over to try fewer steps
Is 30 images not enough? Is 3000 steps too many for 30 images? I'm using the Dreambooth colab notebook, I don't know if I'm getting multiple checkpoints. My save interval was 4000 when I ran 3000 steps. Does that have anything to do with it?
your save interval should be lower than your steps. when you have 3000 and a save interval of 500 it creates a checkpoint every 500 steps. You would end up with 6 checkpoints (500,1000,1500,2000.2500 an 3000)
Ok, that makes sense. And is that a recommended save interval for 3000 steps?
is there a comparison doing embedding vs hypernetwork in automatic1111? i understand the differences, but i don't think i've seen any comparisons online
i'm trying to train an embedding right now and so far I'm getting much better results than hypernetwork
that's up to you how many check points you want. if you want 10 check points you go for 300 interval steps, if the end result is overtrained you can always fall back on an earlier check point.
I see. So the purpose of the checkpoints is to give me the option of choosing which checkpoint produces the best results?
yes, since overtraining is a common problem
yes there's a chronic problem because of how dreambooth has been popularized
people just try to guess how many steps they need and only generate one ckpt file, if you overtrained you're screwed and have to start over
if you use an online service you'll need more volume storage to store the files as you train, but its well worth the small extra cost for the volume storage so you don't have to keep renting the instance again to start over
My understanding is that hypernetworks are better for style, but I haven't experimented enough to know for sure

I've had very good results training a custom character.
But is there a best practices to inculding certain poses and angles among the images used for training?
for Dreambooth?
in any case, with Dreambooth at least, I've noticed that when I added 4 images that have the character sitting to the dataset of 16, so 4/20, that I started getting more results of the character in that position. If you want a certain pose, have more of it in the data set. If you want more diversity include more poses/angles.
With embeddings/hypernetworks, I imagine you could just note the pose in the template [textfiles]
yes!
Yeah I'm getting the hang of it i think. The comparison you posted is also very useful.
So embedding is just like training a word to become like a very specific prompt. So for example if you're using a model trained on real people only, you wouldn't be able to train an embed to fit an anime character
Hypernetwork is seems more like a continuation of the checkpoint where the image data is stored onto the network given the prompts you use which is closer (or is the same?) as how real training is done
how did you do the prompts for the hypernetwork in this case? did you write something like "an anime girl with grey hair and cat ears" or did you just write "an anime girl" ? or maybe the name of the character or something
upscaled results



normal 512 dimensioned stuff


Does anyone have any good tutorials for getting textual inversion/hypernetworks working? I tried myself with some that I downloaded off the Hugging face repository and I cannot seem to get them working. They always throw an error about things not being in the right memory space or something whenever I hit the train button.
I am wanting to train for my wife, step daughter, and pets so I can produce some art of them, but I can't seem to figure out what is going on.
Seems like a pytorch issue.
if you're doing anything anime related, you're going to want to use an anime model. No matter the training/tuning you do, the other data in the model will still effect the results. As for what you would do for prompts for a hypernetwork, I'm no expert. I'd just use the hypernetwork.txt file under the textual_inversion_templates folder from web ui. Yes embeddings effect the results of a given prompt, while a hypernetwork can be loaded and have its effects increased/decreased. They're both detached from the actual model file, unlike dreambooth which will create a new checkpoint file
I wish we could've seen a comparison using an original character (not in NAI)
You should be able to do textual inversion on an anime character. Then you could combine it with a hypernetwork of a style. I don't know about dreambooth. One important thing is you can generate an image with multiple textual inversion embeddings, so you can say [person1] and [person2] in X, where as the hypernetwork is 1 thing right now.
I've been running tests of [person1] and [person2] in [style] with and without using a hypernetwork in addition to that. I don't have any conclusions yet other than its probably worth training the same thing as textual inversion (do this first), then hypernetwork. Also I think hypernetworks should have more training samples where as textual inversion embeddings you may get better results on a low number.
The AUTOMATIC1111 webui should work out of the box. I was expecting it to be really complicated and it ran with zero problems on a Windows machine with a 3090ti. Running on google collab I had lots of problems. If you are getting memory errors your video card may not have enough vRAM. Textual inversion follow this https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Textual-Inversion (simplest, only 4-5 images should be enough) For hypernetworks follow this for settings - https://rentry.org/hypernetwork4dumdums
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
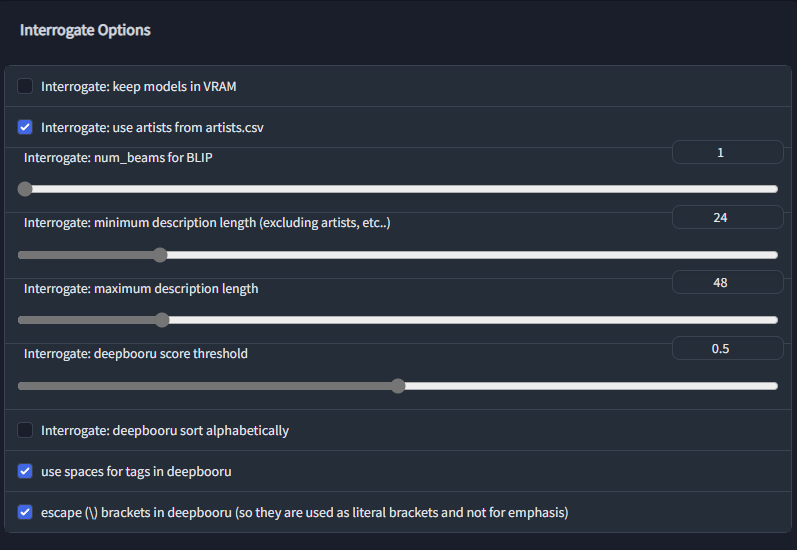
Based on my knowledge on 10/31/2022, by ixynetworkanon
I'll comment on anything with parenthesis in italics for things I don't know and need confirmation on.
This guide assumes you have decent knowledge of webui and stablediffusion, RTFM.
PREWORD
What is a hypernetwork????
Hell if I know, ask an...
not sure I understand, the character is right there on the bottom left. Or do you mean literally an Original Character that doesn't exist in the default model? I've had success training a character prompt that would only result in really bad results that barely resemble the character and characters that don't seem to be in the model at all.
yes that's what I meant, a brand new character. like a one-eyed horned man with red hair or something
ah, I don't see any charts for comparison but it should be doable. Especially with Dreambooth, I've seen some complicated and unorthodox characters finetuned/trained on it. For example https://huggingface.co/hlky/xynthii-diffusion

Trying to run hypernetwork training locally, getting a ValueError: the following 'model_kwargs' are not used by the model: ['encoder_hidden_states' , 'encoder_attention_mask']. Any idea what is causing this error? Can't find too much info about it online right now
this is during the preprocess step, seems to be an issue with BLIP as some extra info, PP runs fine if i turn off blip captioning
Can i just use an external clip interrogator and copy the prompts over for each image instead? Clip interrogator seems broken with the same error as well
blip/clip-interrogator seem to depend on transformers==4.15.0 while auto1111 will bump transformers to something more recent (4.24.0 is current)
So in ubuntu, would i just remove the current transformers package and reinstall the older one?
pip install transformers==4.15.0
then run clip-interrogator
when done run pip install -U transformers
I will try this out in a few minutes and report back if i have any more issues, thank you very much 🙂
I ran the hypernetwork training with no captions just to see what would happen while i waited so imma give it the last 10 minutes it needs to finish, this will atleast be a good test aswell of seeing what no captions does.
also just as a side questions, does it need to have the same name on the photos after the captions as the hypernetwork name? like if i named my hypernetwork CBReal should all the photos have CBReal1..2...3 etc before i preprocess?
never worked with hypernetworks, sorry
No worries! i appreciate your help at any rate, im starting with hypernetworks cuz the local dreambooth training is a bit above my head at the current moment
blip works up to 4.21.3 afaik
ah nice, tanks
👌 Noted,
well fuck me, its still erroring out, clip interrogate is showing TypeError: Unsupported operand types for += 'nonetype' and 'str'
Blip is still the same error as above
Yeah no luck with downgrading transformers, anyone got any other ideas, clip interrogate was working like a week ago idk what would make it stop
found the requirements file from blip seems a bunch of stuff was different version, gunna correct the versions it needs and see what happems
also fuck me i cant spell today
sadge, still not working
okay, noob/dumb question time. Using d8ahazard's extension would I use my folder with the regularization images for the Classification dataset directory?
and for "instance prompt" if I'm training a character on NAI would "masterpiece, best quality, artwork of 'X'" be ideal? In any case how does it know 'X' is the prompt I want? or would I be stuck with using "artwork of 'X'" for the prompt?
Is it possible to feed images of a 3D created city block and have SD train on that location? Anyone tried it yet?
Has anyone updated https://rentry.org/hypernetwork4dumdums or something similar to show the workflow with the new plugin for AUTOMATIC111's repo?
Based on my knowledge on 11/8/2022, by ixynetworkanon
I'll comment on anything with parenthesis in italics for things I don't know and need confirmation on.
This guide assumes you have decent knowledge of webui and stablediffusion, RTFM.
PREWORD
What is a hypernetwork????
Hell if I know, ask an a...
nm I just found this: https://www.reddit.com/r/StableDiffusion/comments/yqm9xv/how_to_use_dreambooth_in_automatic1111_in_10/

reddit
0 votes and 8 comments so far on Reddit
Ok, so I took your advice, and I retrained my model with 30 images up to 3000 steps with checkpoints every 500 steps. I'm finding that even on the 500 step and 1000 step checkpoints, my model is overtrained. Testing it with a 7.5 GS produces images that look too much like the original images and don't really honor the prompt, which as I understand it, means it's overtrained. Do any of these other settings look off to you?

Sp, what if you you use like 200 images of a subject? is there a rule for training steps? or is it a overkill?
dreamboothing of coarse
I read in a Dreambooth guide that you should use 200x the class images as you have training images, and another that said they generally just use 1000 class images generated by the script. So I tried changing the num_class_images parameter to 1000, but as I am watching it run, it is only attempting to generate 238 class images. Any ideas?
okey, pretty close to the art style of sleepy gimp. now I have to train trench coats I see 🤣 (trained on 13 images with out class data and 2400 training steps)

okey, needs some fine tuning. lets lower the learning rate
What's a good low learning rate? 1e-6?
Dunno, guess it's a good starting point. the above samples are 1e-6 i believe. I'm doing 5e-7 run now.
well there is a little bit of michille Michelle Pfeiffer in her... okey lets do 1e-7 and reduce the steps

I've been trying to train embeddings or hypernetwork (only 8gb of VRAM so no dreambooth 😭) and on a certain set of training images I ONLY get results like these: I've tried trimming down the image set (from like 50+ down to 20ish) with different lighting, clothing, a couple full body shots, a couple torso shots. I cropped and resized all the images myself. Went through and edited the pre-processed prompts blip spit out. I've tried both hypernetwork and embeddings (using auto1111). I've tried adjusting the learning rate up and down. I've tried various checkpoints from 1000 steps up to 5000 steps. I've tried changing up the keyword juuust in case its colliding with something else in the dataset. What gives? These should be photos of a person btw and I've successfully done this with other people.




rubber ducky your the one. I think I figured it out, the vectors per token was set to 1 with this embedding and not the others. Raising it seems to have fixed this issue.
so im using a dreambooth model of myselve
last night it worked okay
but then Sd updated and the layout is weird like this but not only that I get the same photo on every generation even with diffrent seeds

Did you reload the page, try ctrl + f5

{kind=link}
{kind=link}
{kind=link}
{kind=link}
The last update to AUTOMATIC1111 was on the 8th at 7AM UTC
too many steps or too high learning rate
yo
I tried to install dreambooth locally
but it keeps giving me errors
can't import some stuff
maybe there is a way to unistal it and reinstall it?
how many learning steps should I do for the dreambooth model with 14 images?
Depends on other variables like training text-encoder or not, prior preservation and if yes number of class images. Generally speaking 1000 steps are a good start and for sd-1.4 as base model I’d recommend lr 2e-6. with 1.5 I prefer 1e-6
Is there a way to label images with certain words, for the model fine tuning?
For example, let's say I am making magic staffs.
I would train this on images of staffs, and let's say 1 of the staffs is called a "staff of power".
I would want my model to be able to generate a "staff of power" but I don't want to make models for EACH of these descriptors.
I want to have 1 model, that is "staff" model, but I also want to instill into it the concept of a staff "of power"
Should i use larger batch size when training the model with dreambooth? I am able to set batch size of 4-6 on my rtx3060, and it runs significantly faster, if multiply iteration time times the number of batches.
I‘d probably first remove low vram limitations like fp16, training without text encoder etc, before increasing batch size. But for efficiency you want to use your vram as much as possible. I usually train with full features and bs 2 (on 24 gb vram)
larger batch size is probably better, computes gradient across the whole batch
how do I set the Ir steps? I dont see that option (I am using this notebook by the way: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb#scrollTo=1-9QbkfAVYYU)
also I took 3 more photos
The notebook seems to have a field for training steps (3000) but the learning rate is fixed in the code to 2e-6. you would need to modify that manually. I don’t train with notebooks, so can’t help much
For anyone running Dreambooth on colab, if you want to have all of your checkpoint weights to be converted to .ckpt files, you can modify the conversion cell to the following:
import subprocess
import os
half_arg = ""
#@markdown Whether to convert to fp16, takes half the space (2GB).
fp16 = True #@param {type: "boolean"}
if fp16:
half_arg = "--half"
print("Converting all weights located within " + WEIGHTS_DIR)
for dirname in os.scandir(WEIGHTS_DIR):
if os.path.isdir(dirname):
try:
print(dirname.path)
modelpath = dirname.path + "/model.ckpt"
print(modelpath)
val = subprocess.run(["python", "convert_diffusers_to_original_stable_diffusion.py", "--model_path", dirname.path, "--checkpoint_path", modelpath, half_arg])
except RuntimeError:
print(RuntimeError)
continue
I think this is a case for creating multiple models, then merging them together.