#📝|prompting-help
1 messages · Page 26 of 1
That's a very odd reason that prevents you from generating art.
I just want to create a promo for this character.
Hello, i am completely new to AI and i wanted to know how Stable Diffusion learns
If i make a prompt with some specificities to make my model learn a specific type of picture
Will it apply this type for future pictures ?
Because he learned this way
Or do i need to go back to a simple description of my picture type ?
I am probably not very clear, so i'm sorry for this xD
Try ratatoskrAnimalCreature model. No special prompts needed for this kind of thing! ( 1woman, anthro dragon )
if im understanding correctly, you are under the impression that your text to image model will change based on the prompts you give? It is not the case. You can finetune your base model (oversimply put and ignoring the entire complex process, it would do what you just described), create embeddings, loras, etc that can be used to create similar images
if you want to create the same image, but with slight variations, make sure to use the same seed as the output had. modify prompt slightly, or cfg, or steps, or use different models, add controlnets, extensions, etc.
Is there the way how to create full digital stickerpack with 1 anime-realism character using SD?
If I need to generate a graph that can be seamlessly connected from beginning to end. What prompt should I use? (Sorry, my English is very poor)
could use some help with Stable Audio. I'm trying out SA. Probably using it wrong. I thought I'd have fun screwing around with a minimalist time-signature phase piece... like the 60s and 70s Steve Reich and friends. But apparently, you can't do accelerandos & decelerandos? I tried using "slow down" and "speed up" as well. I think I can cut and paste in a sound editor to do what I want. But it seems a doable thing? Here's part of the percussion stem I tried to execute.... "Solo symphonic percussion anvil only, no change in pitch, just a simple beat with gradual accelerandos, decelerandos as indicated. Anvil sets heavy 4/4 beat strong downbeat, diminishing echoes on beats 2, 3, 4. Start at 106 BPM, anvil only, 8 measures. Then 8 more measures Accelerando to 112 BPM, anvil only. 114 measures 112 BPM, anvil only. Then decelerando to 100 BPM over 8 measures, finally 100 BPM [ast 4 measures. 1. 8 measures, - solo Anvil sets a heavy 4/4 beat 106 BPM, strong downbeat, diminishing echoes on beats 2, 3, 4. 2. 8 measures 106 BPM gradual accelerando to 112 BPM, solo anvil. 3. 14 measures 112 BPM, solo anvil. 4. 8 measures 112 BPM decelerando to 100 BPM, solo anvil. 5. 4 measures 100 BPM, Solo anvil continues then ends. "
In Img2img I've gotten it to make a very long list of keywords for interrogating deepbooru, but I cant remember how to do it; anyone possibly be able to remind me ~ ❤️
Hi Everyone. Not sure if this is the right channel for this. I'm looking for a stable diffusion / MidJourney professional who can assist with a project on digitally altering images of socks. I have PNG images and 3D files of the socks. The goal is to take these images, keep the socks unchanged, and completely transform the model and background to a design of my choice. I would also love to learn this process. If anyone is skilled in these techniques and is open to collaboration and teaching, please DM me. I've attached an example of the final result we want. Thanks!

In img2img you can interrogate deepbooru by clicking the Cardbox icon under the generate button
Hi guys, I really like a particular artstyle and found an image/artstyle I want to replicate, I installed everything but when generating I'm getting a "LoRA not found" message when I look into the img info

I really like this art style and I want to replicate it, downloaded both but am I doing something wrong?
Since the LoRA has a "SDXL" tag, does that mean I need to have base SDXL for it too? 🤔
for it to work?
isn't the local installation of A1111 automatically pulling all the trigger words a LoRA has into the prompt? 
you need an SDXL checkpoint for that to work as well. but you also need an SDXL VAE in order to even change the checkpoint to an SDXL one. do you run on A1111's stable?
i found this shit and it looks amazing ngl
need help with this, i just installed SD today using Auto1111

maybe my problem is trying to make the icon with text
instead of just something abstract
Hey, 1.5 models are trained on a 512x512 resolution.
And sdxl models are trained on 1024x1024
So don't go lower than that for the model versions.
You find models on Civitai.com

So once again I am getting some results I really like on Bing, but I am wanting to try to replicate them on Stable Diffusion.
The close-up image of the bunny (left) is the one I made on Bing, and the wider shot in a more 2D style (right) is what I've come up with so far in Stable Diffusion using Peakifurry checkpoint and just chat commands, no LorA's.
Any suggestions of how I can replicate more closely to the Bing image would be GREATLY appreciated, ty ❤️


/help
yeah but isnt there a way to make the list longer- the string code it gives you?
I swear ive like, turned the GFC or something up before and the list was longer; it wasn't THAT but it was something simple >_<
With what? Not gonna give big papa details?
hello does someone know a good model that allows me to make a Image similar to this atleast the color of skind and hair

hi yall! I was wondering if anyone's used turboXL in deforum before? for somereason, when i use an init image of a person, and prompt the camera to move towards the left, the person's face is squished in a really weird way 
how do you stop junk from forming? like there's only supposed to be food on the plate but it seems to want to add details where there shouldn't?

can I just tell it to shut
What prompt should i use to create exact image?

You do not need to prompt to create this exact image - That would be difficult and time consuming also probably would not result anywhere close.
You can utilize controlnet openpose and depth; anyone add more if I am missing anything or better model
#🏞|general-with-images action hero Thor playing play station 4 on television at home
The prompt would be something like:
Woman standing in front of a yellow wall, brown hair, straight hair, long hair, arms behind back, wearing a shirt with leave pattern, portrait, red lips, earring,

which model?
also what are you trying to get? The same Pose?, the exact same image? the same style?
Stable Diffusion XL 1.0
yes
Yes what? Everything or only the pose? Or the style?
Because if you want to get the exact same image composition then you need to use Controlnet
@bitter briar erm erm uh please please generate image!
Image composition still wont get you the 'exact' image you need other controlnet models
@frigid kernel One thing when I started out was to use the interrogation button on SD it will create the prompt for whatever image then you can clean it up. There are a bunch of alternatives as well so whatever one you fine to be the best or works for you.
Where is the interrogation button ?
Open image in img2img

Anyone know any Loras and/or prompts I can use to make the hair produce this effect?

Any ideas what prompts / checkpoints / whatevers (very new to SD) I could use to consistently produce images in this style? Not only the overall aesthetic but how it's on the floor near a bend in the wall - I essentially just want to be able to replace the flower / cage with other objects. I created this on bing but have moved to SD for more precise control.


How to create consistant lora of style and charater to use as a maskot from this picture? (Created in Dall-E 3)

Hey
Anyone up? 🙂
I have a prompt and happy with it..
I wanna do 50 of these images and wanna try to use Img2Img .. because I usally do Text2Img and use Hires fix.
But what do I set in img2img to generate better pictures and higher res?

Or should I sue Hirex. fix instead?
In img2img use the SD upscale script
Set the denois below 0.3 and set the resolution to a sqaure
The one in settings right?
At the bottom of img2img
I enabled this

and with the SD upscaler I get weird images :/
I don't know whyt
Show me the settings


Please show the denois strength and the resolution too
I use reszie by to 1.5 or 2.0 from 512x512 and Denosing strength 1 .. and I wanna use 1 to get "random images" and not the same looking
You can't generate + upscale at the same time in img2img
Bump
hello guys, what should i type in prompt to get a half face image please ? i tried (half face) (left side) (partial face)... none worked. is there a way to do that ? Thanks!
Try CosXL
I'm a prompter ... not good in editing pictures ...
You probably just want to photoshop, yea, there isn't much for AI, maybe just to fix some issues after moving them, cover up editing, but that's about it
I thought inpainting would work
my bad sorry
Everything OK. There are many different pretty specific ways to use AI. Hard to be good in all of them 🙂
CosXL
Thanks, Any tutorial available for cosXL ?

Reddit
Explore this post and more from the StableDiffusion community
how to generate image from text
download software or go to a website
thanks
Hey guys! How would you form a prompt for random hair and eye colors? I am generating anime women for games and I am so sick of having to manually exchange green eyes for red eyes, yellow eyes, etc., and things like blonde, brunette, red hair, etc. Ideally, I'd like to set a batch of 30-40 and get a plethora of hair colors and eye colors.
https://github.com/adieyal/sd-dynamic-prompts
Welp this just solves literally everything
hello! can anyone here help me with making a prompt for designing ball-jointed dolls?
Also check out the wildcard extension
hey guys how are you, i need help please!! I need to create an image for a cover, is it possible to create only specific body parts? I need to create an image of a woman diving but only part of her butt is out of the water... can anyone help me with the prompt?
Can I send an example image here?
Hey. I generated this image with DALL-E. Is there any checkpoint/prompt in SD that I can use to replicate the style? I've tried a bunch but never really found one that has both pretty high detail in clothing and such, but still retaining that anime style.

Hi can anyone tell me the difference between control net inpainting and general inpainting?
No, but wait until you find out about differential diffusion.
Hi can anyone tell me the difference between control net inpainting, differential diffusion and general inpainting?
Does anyone have tips for ensuring text is correct in SD3?
Breh, I put the prompt to put an eyepatch on the left eye, but it keeps putting it on the right
Nevermind, fixed it
For prompts, is there also a pin or something detailing the usage of characters like () as well as adding values like 0.8?
I need some help I am trying to convert Images taken from Second Life to make them look real. I know a little about img2img Im just stuck
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#prompt-editing, this means decreasing a factor (attention to the object) or higher than 1 means increasing attention, brackets have the same fucntion, the more you use higher the attention

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
what's really interesting though with that stuff is unsampling
or using IPadapter instead of controlnet
Yeah, control net inpainting, differential diffusion, general inpainting, unsampling and IPadapter is a great way of doing that.
and clownscheduling
you should also look into noise injection
and attention masking, and regional prompting
Nobody has time for that. But we can add COSXL Edit to the list.
also don't forget about soft inpainting... some ppl get it mixed up as being the same as differential diffusion but really they're completely different
Good call. Control net inpainting, differential diffusion, general inpainting, unsampling, IPadapter, noise injection, attention masking, regional prompting, COSXL Edit and soft inpainting.
with regional prompting, you can't afford to forget about timestepping the conditioning, and locking the bounds to the masked region in early steps then shifting to the more relaxed default mode
or you could even use regional lora, or even TwoSamplersForMask, using an entirely different unet, sampler, scheduler, and denoise value for each masked area
another possibility is chaining ksampleradvanced nodes, but the problem there is you lose momentum
but that at least allows you to timestep models and attention masks along the temporal domain
Totally forgot about this method. Just switching the complete unet. Well, now we only need somebody that writes a comprehensive explanation on the differences of those methods.
pretty sure we already went into sufficient depth here
I have this problem. It usually works in A111 but not in ComfyUI with a plugin rgthree. It seems that it's completely ignored, resulting in poor quality.

Am I missing any node here? I use the basic setup and it is correctly written.
where can I generate a video?I can't find dreambot
#1047610792226340935 they’re down
can SDXL write symbols like ≠?
I'm getting trolled by my AI, I write that I want cyan eyes, but it also colors the hair with some cyan too
How do I get it to stop coloring the hair blue and only focus on coloring the eyes blue?
You can move blue eyes behind the hair tag
Or you can install the Cutoff extension
Cutoff extension? 
I tried that, but doesn't work
it works better on non realistic models
I'm trying to do this on cetusmix_whalefall
it should work with that
Whats best model for inpainting
Where's the download button for it?
you have to install it via the extensions tab
with install by url
Hm, do I need to specify the branch name or local directory?
\stable-diffusion-webui\extension
nope, you just copy the url in here then click install

Oh uh, I used a different link
Looks like it got the job done though
so it works now?
I'm applying it and restarting my UI
there is a fork of cutoff but i would suggest using the normal one
Fork?
an other version of it
Tried using the cut off extension but can't seem to get it to do anything
@silver valley How do I use this exactly? The instructions are kinda vague
Perhaps the BREAK syntax in A1111 or the conditioning concat in Comfyui can solve this problem.
How does BREAK work?
The main prompts, BREAK, the prompts that bring color pollution. I have not really used it, I have only used Comfyui's conditioning concat. But they should have the same effect.
Do I just write BREAK in between two tags?
The prompt words that will not cause pollution can be written together, just separate the words that cause pollution.


You can see the impact it brings.
Still not working
You type in the colors in the cutoff text field like:
black, blue, yellow, red,
then you use them in the prompt like
Blue eyes, yellow pants, red shoes, black hair,
important is that the colored object needs to be directly after the color.
"Blue short pants" won't work cause it would apply "blue" to "short"
Yeah, I have the prompt set to Cyan Eyes and Black Hair. In the CutOff field I have Cyan, Black. But still not working
When I don't type cyan eyes like ((cyan eyes)) or just with single parenthesis then the eyes are colored a purple hue
I want red highlights in the hair, but if I type that in, then the eyes are colored red too
I can test and show you later
Okay
Some models and clip model understand such a syntax: cyan_eyes and pink_hair
They don't understand?
i tested it and for anime models it mostly colors their hair too xD

Bruh, idk why this is happening with cyan eyes and black hair specifically
I did green eyes and orange hair, no problem
Even gold eyes and purple hair with no problems
true its only with cyan and even aqua
Sounds like something that needs to be looked into at a developer level
I tried blue eyes and it came out somewhere between blue and purple
Anyone know how I could replicate a similar image? Specifically the head being human like but being blended with a skull? I can't remember for the life of me what prompts I used to make this and wondered if anyone had any ideas

if you have the original image you can drop it into the PNG-Info tab of auto1111 to see the meta data which includes Prompt and settings
@silver valley Hey, so I have an image of a process I stopped, but it came out a little blurry because it was mid generation before the image would turn into a completely differnet style than what I wanted. Anyway I can get it to replicate it very close?
What would be the best Controlnet option to ensure that each generation has roughly the same framing? I want the pose to be able to be slightly different. But I want all characters to be the same size and framing.
With img2img or if you have the output file then drop it into png-info and then to txt2img
Hello everyone, can anyone suggest if there is a tool which recognizes errors in the prompt and the reason for it. It is for Amazon bedrock specific
What type of errors are you referring to?
filter words
?
r rated words
Oh. Don't think there's such a tool. Because if you don't want it in your prompt, you simply don't put it in your prompt. But I suppose you can just throw it in like ChatGPT and ask it to filter that out.
where can I find a good tutorial how to construct promts for SD3?
Hey guys,
I wanted to generate a foreground overlay of a forest akin to this image from The Legend of Zelda - Minish Cap, though I wanted the leaves and branches to be more exaggerated. I am having trouble figuring out how to prompt this as the middle area that I want empty gets filled and the perspective of the forest generates far perspective rather than an a perpective inside the forest.

guys, using AUTO1111 it seems i can't get any model on any sampler to draw 2 faces with opened eyes. when 1 face in the image the eyes are great, but with 2+ faces all the eyes are closed or deformed. how can i fix this please ?
Hey, you can use the Adetailer Extension for this
i believe something is wrong with my settings. this is only happened when i restored my PC and re-installed automatic1111. maybe it is something to do with memory or something ? because 2 days ago this issue does not exist.
Can you show an example? Also Also what's your GPU?




i'm using 3060 12GB vram
when a single person in the image.. the result is great



it doesn't matter what model i'm using. they all the same result when multiple persons in the image.
Its caused by your prompt
Hi, i am completely new to ai image generation. I have this bit of abstract art and i want to create another piece of abstract art using the same color scheme. Is that possible? If so, how do i do that?

While possible, it would take some intermediate/advanced workflow to do that. Seeing that you're new to AI image creation, you've got a larger road in front of you to understand how to do that than is likely worth embarking on if that's your only goal. Ultimately, the more specific your goals, the more likely AI could only play a small part. You will be much happier either trying to set less-specific goals or skipping the use of AI for something like that. (It's not impossible, it's just a hefty investment unless you water down your expectations.)
Okay what's the deal with "trigger alternation"?? I see different commands at different sites, some show [white|black|red] table cloth, while others show {white|black|red} table cloth. And I'm getting NONE of them to work 🤣
If it were to work, wouldn't my prompt alternate between the words and give different outcomes if I increase the batch count?
can you please help me fix the prompt ? what is the wrong part of my prompt that causes this issue ? thanks!
i dont know which word, but the the sentences are really vague, and not describing anything other then a overall composition
i would restructure it like: a couple is sitting in ...., lovely atmosphere, .. fantasy style.. etc
i see
this is a chatGPT prompt generator. i guess it's useless then
i'll try constructing my own prompts i believe. Thank you!
np, yea try out for yourself, you will get better results 🙂
How do I make SD generate an austronaut suit covered with flowers like on this image:

This is the best result I could get

I'm a noob at this, but does anyone know how i could maybe get more consistent eyes? I'm using ComfyUI and yionked someones workflow and added my own Lora for this woman. Is there like an eye Lora i could use? ty in advance

I'm a noob at this, but does anyone know how i could maybe get more consistent eyes? I'm using ComfyUI and yionked someones workflow and added my own Lora for this woman. Is there like an eye Lora i could use? ty in advance
Hi! Were do I generate my AI images?
this is the result of "man wearing a kilt" it seems that models (1.5) do know the concept of the scottish skirt for males.

@blissful breach
is this you
what if i type same words in prompt?
will it strenghten the focus on that word or not?
pls explain someone
Hii, i recently swaped to comfyui (im went from a1111) and im using the same lora, same checkpoint, same prompt etc.... and im getting very bad result, can you help me guys pls?

my images on a1111 look like this one

and now on comfyui idk what happend, thanks for read! also if someone was on the journey of AI models im here to exchange knowledge 😉
and this is the actual output with comfyui

I am not sure if you are supposed to plug the clip of the lora into the negative clip text encode. Just connect the negative clip to the model loader.
yes, put the image into the img2img tab and press the clip icon or the box icon
tysm
Speaking of CLIP interrogating
Are they still really, really bad, or are there any good [local] CLIP models out there?
im waiting for over 7 mins now to create my prompt
from the image
hope itll be very detailed
how long does it usually take? @silver valley
check the cmd, it first needs to download a clip model
then it can take like 10 mins
Do the CLIP models interrogate based on the model you have loaded (like if you're using an SDXL checkpoint) or just their own data?
"a woman with a bunch of heads on her head and a lot of other heads on her head, all in a headdress<error>"
this is the prompt
from this pic

this shit kinda ass ngl
also why tf it says error in the rendered prompt
they are their own model
So, basically, they're useless at their claimed purpose? which is, to help reverse engineer a prompt for an image?
What we need is the ability to CLIP interrogate the model that's actually designing our images
clip interrogate a model?
what should that output look like?
It should look like the exact prompt that would design that image, using the model you intend to use to generate images
Like, my understanding is that CLIP exists to help reverse engineer an image's prompt
But as it stands, the current CLIP models a) suck at it and b) don't give any relevant outputs if they have zero relation to the models we're actually using to generate images, see?
(full disclosure, I'm not a coder: I'm just a stupid end user)
yes, the clip thing is a barebone ai which scans the image for stuff it recognises
its like asking chatgpt what it sees in the image
We need something more concrete than that
It's a great idea but it's impossible to use it for anything, well,useful
in its current form
true
you should try the Box clip version
(the box icon)
its better
I really don't understand a single fucking thing
You've just said

English please
I don't talk Mongolian
lol
im not the admin, and we dont need offers
Your rank is above developers
Means you're important here
And i have a proposition
Hello, I’m coming here to get some help to achieve the looks I’m going for.
I specifically want to generate images with a similar style to vtuber, but I’m not quite sure how to go about that (the one tutorial I found didn’t help much tbh)
Vtuber is basically a 2d (or 3D, but I’m making 2D) character people use to make videos on YouTube. That’s not my intention, I’m just “doing”the drawings for fun tbh, but I still wish t achieve similar results
its faster, but it generated like 5 words XD
Qeustion: maybe someone can help me. When I tell SDXL in a prompt I want the left arm... left eye... left whatever to be something. Does it assume it's left from the viewer's point of view or left from the subject in the image facing the viewer.
which one looks good? what should i look for in the pics to say that one is better than other? i mean each pic looks different , i cant figure out which one is better




How I can refer to an unknown object in my prompt?
I have an ebay store where I am uploading images of products, masking them, and then changing the background using SD.
The product is always different, it can be a stapler, a car tire, a skincare product, etc..
I want to automate the changing of the background without having to specify every time what the object is.
Ideally, let's say the object is a stapler, I can just prompt: "object on a desk, in an office, etc.."
Essentially, I need a way to refer to the masked object as some arbitrary word so the prompt understands I am referring to the masked object.
Hey Guys any help on how can I recreate this kind of style? It's like digital painting or oil painting? I'm trying with different models but I cannot get even close to it

Take a look at something magical called IPAdapter


I will thanks, those looks awesome
hey which ip-adapter model was that?
IPAdapter Plus with style transfer & UNetTemporalAttention Multiply
for me the style transfer doesnt work :/
In A1111 or ComfyUi?
in a1111
Oh, sorry. I can't help with that. Styletransfer is pretty neat with the IPA in comfyui
See, stole the style from an image above.

yea but which settings for ip adapter? also style transfer or style transfer strong? and which weight?
Uhm, i actually dont have this settings in my workflow. I just use the "IPAdapter plus sdxl vit h" with the weight_type "style transfer (SDXL)" and the embeds_scaling "K+mean(V) w/ C penalty". 0.8 Weight on the regular SDXL checkpoint. Actually pretty hard to describe a workflow with text 😅
ohh now you said sdxl xD
Yes. SDXL. But i think styletransfer is also implemented for 1.5 models
yes, but i asked what ip-adapetr model before and you just said ip-adapter plus not sdxl ^^
Ohhhh, ok. Now i understand. I mostly use SDXL. The time of its infancy is over and i think its way more versatile
true, since zluda works so good on amd im also mostly using SDXL
anyone know what kinda prompt i need to type to get a character from a game
ive looked around for Lora of it but there isnt anything
Is there any way to make sure an image isn’t cropped? I’ve added cropped on the negative prompts but still it comes cropped
I want to convert my photo in to anime photo pleas help it don't work in image to image face are not generate correctly
Hey, that can be done via img2img and Controlnet
Hello, does anyone know any good models and prompts for scary horror results? Like what you'd see in analog horror for example.

wo okay
Realistic photo of a rustic wooden table in a kitchen with sunny morning light taken from eye level. On the table is one bowl of strawberry ice cream, next to a jar of strawberry jam, next to one plate of waffles topped with strawberries and whipped cream, next to one glass of strawberry shake, next to one bowl of spinach salad mixed with small chopped walnuts and tiny bits of strawberries mixed in
Indeed. But y'all gotta accept the models are heavily Biased.
Como puedo usar los comandos para crear imágenes y videos
Here is the image you requested.

How can I generate gown designs based on any input photo as an inspiration? I’ve used ip adapter but it fails to make the output a full body image
Any other good ways to transfer the “context” of an image to another ?
In comfyui
Does anyone have a good list of women's hairstyles they use to get specific cuts? I'm trying to find some on google but I'm not really satisfied.
Reduce the controlnet weight to get a full body pose
Hello can anyone suggest same feature that Runway uses for Erase and replace (ai-tools/erase-and-replace) in Stable Diffusion sdxl? I have used inpainting but i cannot replicate the same through prompt which runway does.
Open random online shop of underwear and try to figure out how exactly this thing called
According to my research, it's called "high waisted french knickers"
How do you control for breast size? What prompts do you guys like to use? I usually try small, medium, large, but I'd like something more precise.
Ah i forgot about control net… now i fixed it, thanks
small upper chest
Bottom left looks the best. Top left also looks good
Is there any way to create a promt that actually generates scars or burns properly? I think this is likely less prompting and more about the model but I have tried so many models and prompts and I am beginning to think its just not possible.
Thanks. I'm finding (petite breasts) is working a little better. Lots of these models seem to be weighted toward much larger busts than average.
hi guys, i wondering if someone know a way to generate a multiple view of an object , like from Z axis , Y axis , -Y axis and an isometric view, in a single image , i tried some thing without any good result...
or maybe if i have a good one view of an item i like , to create other view without changing the model...
hi all. not sure if this is the right place to ask. I'm using the following api endpoint to create images https://api.stability.ai/v1/generation/stable-diffusion-xl-1024-v1-0/text-to-image
var prompt = new
{
cfg_scale = 7,
clip_guidance_preset = "FAST_BLUE",
height = model.Height,
width = model.Width,
sampler = "K_DPM_2_ANCESTRAL",
samples = 1,
steps = 30,
text_prompts = new[]
{
new { text = promptText, weight = 1 },
new { text = "labels text diagram words" , weight = -1 },
}
};
I am passing in a description in for promptText and I get results like the images attached. But I'm wanting to ensure that all the images are of the illustration type like images 1, 3 and 4 in the example.
I'm not sure how to change settings or the prompt to get this style rather than the 2nd image in the example.
Any help/suggestions would be hugely appreciated.

Hi guys, bit of a basic question not sure where to post it, if i create an image and want to re do the eyes via inpainting with the same checkpoint rather than an in painting model, do i just leave the promp as is and run it through with the mask? or do i change the prompt to be nothing but green eyes detailed eyes brown eyes or whatever?
i change my prompt to what I want to see inside the masked area
Any ways to add stuff to a generated image in comfyui except inpainting ?
It's ComfyUI, you can literally do whatever you want to it. If you want to add something, add something.
For instance, pipe the output to something that defines a masking area, then grab a workflow that outputs something with transparency, generate that with whatever you want, then take that item and combine it with the other image in the masked area.
ComfyUI is a "sky's the limit" sort of thing. You do what you want with it since you're in control of the workflow.
How can I get my IMG2IMG results to come out more clear?

I cant resize any larger than 1.8
These are my settings

I tried to add "clear image, Masterpiece, best quality," to the main code
and "unfocused" to the bottom negitive code but it made it worse
🤡
use sd upscale script instead of resize by
How do you do that?
OH
I see it!
That much better!
Not perfect but!
major improvments
It just took and made liek 10 images and combind them 😮

I've never seen it do something like this!
Thank you for helping me improve my image CS1o
😭 your advice broke it
lmfao

You need to set the denois below 0.3
Then set the resolution (resize to) to a square (it won't be the output res)
What's the denois ?
Try 0.2 or 0.3 but you can also remove every person specific word from the prompt.
Then it won't happen
🤔
wdym every person specific word
i wouldnt have a code 😂
and yeah dropping denise its just making the image input, but bad quality
like, making the same original image i put in
could be my CFG scale being 11?
Remove everything from the prompt and just add, masterpiece, beste quality, highres,
ill try it
Negative prompt should be kept
Also make sure to select an anime upscaler at the bottom
Also use 30 steps
what does tile overlap do?
SD upscale script tiles the image into multiple tiles. The overlap is the spot where they get melted together at the last step
Leave it default
oooooooooh ok
heh
and could you remind me of CFG scale?
are high or low numbers going to make it "make up its own art"
Cfg is how much it should follow the prompt or using its fantasy
The lower the more it stays to the prompt
Cfg 7 is mostly the right spot
Cooli cuz I want it to use its own fantasy to make stuff
Then use 7 but it won't do much at upscaling
Its more effective in txt2img or when using img2img
No problem, did the upscale worked now?
eh
Its just recreating the image I put in
It's not making anything new, and the quality is good, just as good as the original image I put in
its like its just copying it to the output
Your main question was how to get it more clear and how to upscale it higher
Not how to get more stuff in it 😮
this is true
I should have added more detail to my original information question; my bad~
It DID upscale the image I put in tho! So now I know how to do that
😂
Do you know how to make it take the original image, make its own original art, and have it be good quality?
So it shouldn't be the same output?
With more details
Like getting other variants ?
Ahh okay

For that you could use img2img with a higher denois. But you can't upscale at the same time.
Low cfg scale 7 sry I was confused before
For denois its higher = less input image affected
Click two times on interrupt
To instant cancel it
🥲 nope LMFAO its being stubborn gonna have to reboot it or something idfk LMFAO
Thank you for everything n_n
ill keep tinkering ❤️
Sure np 🙂
Its so late xD I'm sry, but I don't want to give wrong info.
So to be clear now the higher the cfg scale the more random the output gets. But also the quality suffers the higher the value is.
So 7-12 is the common used value to play around with.
Turbo and LCM models need a very low cfg as they also need less steps.
Gn
Thank you! Sleep well!
what are the best quality tags?
currently I'm using
best quality, ultra high res, 8K, HDR, (blurry background:1.3), (blurry foreground:1.3)
Blurry fore and background should be in the negative prompt field
For 1.5 anime models masterpiece and highres are good too
Good day everyone. This is my first time posting here (i am not very familiar with discord at all).
I am trying to replicate the work of an user on civitai that makes these beautiful images, with beautiful colors (saturated? warm? i don't even know how to describe them).
I tried everything: both on comfyui and with forge, i changed the prompt, the loras, the Vae, and applyying refienrs, but nothing come even close to that.
Do you have any tips for me?
Thx


this is the generation data i am using
score_9, score_8_up, score_7_up, san, 1girl, full body, squatting, solo, short hair, brown hair, gray eyes, headband, face paint, earrings, white sleeveless top, navy under dress, arm cuffs, fur headdress, fur cape, light-skinned female, female focus, looking at viewer, smiling, forest, (blush:1.1) <lora:Concept Art Twilight Style SDXL_LoRA_Pony Diffusion V6 XL:0.8> concept art, realistic, lora:Expressive_H-000001:0.8 expressiveh, <lora:Kenva - artist:0.7> knva, lora:_XL_san_pony_v4
lora:_XL_sinfully_stylish_SDXL
Negative prompt: score_6, score_5, score_4
Steps: 25, Sampler: Euler a, CFG scale: 7, Seed: 3269595310, Size: 896x1152, Model hash: 67ab2fd8ec, Model: ponyDiffusionV6XL_v6StartWithThisOne, VAE hash: 74bd301605, VAE: sdxl_vae.safetensors, Denoising strength: 0.5, ENSD: 31337, Hires upscale: 1.5, Hires upscaler: 4x-AnimeSharp, Lora hashes: "Concept Art Twilight Style SDXL_LoRA_Pony Diffusion V6 XL: e5fe96cd307b, Expressive_H-000001: 5671f20a9a6b, Kenva - artist: cfa45d23d34c, _XL_san_pony_v4: b813362e3eb8, _XL_sinfully_stylish_SDXL: 076fa4d920a9", Discard penultimate sigma: True, Schedule type: karras, Version: f0.0.17v1.8.0rc-latest-276-g29be1da7
Hey, thats mostly a VAE issue. You need to use the sdxl VAE
That image is generated witht the sdxl vae. I tried every vae on civitai
Oh I see you used it
They are not even close
Is the right output yours?
Yes
I made the xy plot
The thing that come the closest is using the refiner
But it changes the details
Do you have a link to the original image, so I can check its metadata
The creator used comfyui and your using forge webui. Thats a big difference.
i tried also comfy, but copying the workflow the result isn't the same
this thing is making me crazy
Does the comfyui workflow comes out with normal colors?
Or the same grey like in forge?
with comfy

Hmm strange
i don't know if theres a way to censor the generation data, so that it appears differently for other users
because i believe that the pictures are upscaled and "adetailed" but there is no sign of that from the generation data
or maybe i am just too noob to understand comfy
You can modify everything before uploading it. But if the workflow .json file is available then I doubt that
the only way is to reverse engineer the data
looking at what is able to make these colors
Do you get normal colors with pony when making your own images?
I would say that my image looks normal, but none "pops out" like that one.
I found this conversation between the author and another user in another picture. As i suspected there is both upscaling and adetailing in play.

Any tips on making compelling batch prompts? I believe they are also referred to as "traveling prompts."
yes

no actually, lol, it adds a depth to it
with vs without


i didnt add a background but having a background it still blurs it
Hi, I have to integrate tripo SR image to 3D API in node JS. Is there anyone who can answer some of my general questions here?
Another question
Yo guys here's a 140 page document with styles, artists and tags. Enjoy https://docs.google.com/document/d/e/2PACX-1vQMMTGP3gpYSACITKiZUE24oyqcZD-2ZcvFC92eXbxJcgHGGitde1CK0qgty6CvDxvAwHY9v44yWn36/pub
belle femme génie sou forme de silhouette lumineuse , qui tient la lune devant elle, la tête incliner vers le bas, rendu tableau penture
Hey, I'm a bit curious on what kind of different angles you guys use .. It's there a list that I can use of?
I use these as standard
- Pov from behind
- View from behind
- View from the side
- Cowboy shot ( not 100% sure what it does)
Do you guys use others that are better?? I would love to hear more and get some tips 🙂
Je me demande si prompt en français est vraiment efficace 
Give "worm's-eye view" a go. That sometimes creates amazing perspectives. There's also aerial view, Dutch angle, distal view, lateral, anterior, and posterior.
An image of an eagle flying in the ocean
problem with that one and for example "cowboy shot" is that the concept "worm" "cowboy", etc, will bleed into the generation. I prefer using photography more neutral terms as "low angle" "high angle", panoramic, etc
That's what negative is for. "worm's-eye view" with "worm" in negative if it starts creeping in.
yes I've done something that with other terms, but 1) it might as well bleed 2) putting things in the negatives may change the style or alter things in unexpecting ways. It might work well, but there is that.
It's just how that stuff works. There are plenty of times where that happens with other words and you just have to cautiously craft your prompt. Sometimes it's going to come down to seed hunting, too.
Thanks, I'll test them out 🙂
Hi everyone, I'm new to this group. I wonder if anyone has experience using the "structure" API? I'm trying to generate animation sprite sheets using a reference example:

but I keep getting results of inconsistant clothing or colors like this:

Here is my prompt: 2D anime style, masterpiece, pixel perfect, character animation sheet: cute a girl, pink hair, yellow jacket.
Negative Prompt: malformed arms, malformed legs, malformed hands, bad hands, hidden, extra legs, extra arms, missing arms, unnatrual pose, mismatching clothing
I tried different control strength, but when it is to low the poses will be different, and even at 0.99 strength it is still not consistent.
this is cool, but what would you do with it? Does it apply to one particular checkpoint?
Oh my bad, missed the explaining part 😅 It's routine for me by now so I didn't think of it.
Anyway, there is an extension which everyone should have cause its awesome. Its called Stylez https://github.com/javsezlol1/Stylez and it introduces you to:
- A new UI with a library with styles and things to customize.
- The style bar! Here, you can create your own styles, or add other people's styles. Click on the paintbrush to go into the style bar menu. To create a style you just type in a fitting name for it, a positive prompt and negative. You can play around with this a bit, for example you can only add negative prompts and/or negative embeddings, so that you have your most used ones ready to go at anytime. To load a style, simply click on the bar next to the paintbrush, click or type in the name of your style(s) you want to use, and you're done. When you are generating your next image, you can see below the image preview that it has included your style(s) in the prompts. Hope this makes sense!






Any tips on making compelling batch prompts? I believe they are also referred to as "traveling prompts."
Never heard of it I'm afraid
As GIF/mp4 animation ?
Btw @silver valley, are you familiar with the Dynamic Prompts extension? Been trying to get it to work for maybe 10 hours, I'm about to go crazy
What's the issue?
So I've been playing around with the {A|B|C} synthax, supposedly you can set this up to generate things in specific orders/ways. For example, a prompt could be "t-shirt design, green background, {Insect|Wolf|Cat|Dragon|Guitar}" and it can be set up so that it will cycle through all the options before ending the generation, but I cannot make it do that, no matter what I try
Someone said to just increase the batch count/size, but they get totally ignored in the generation when I have dynamic prompts enabled
The only thing I could get to work as of now is to TURN OFF the freaking extension, write prompt+{Insect|Wolf|Cat|Dragon|Guitar} and increase batch count to 50 or whatever to get enough variations. Then it actually works (somewhat) lol
I could also send you some pictures with png info in them if that helps
Okay, I would say checkout this video. Maybe it helps:
https://youtu.be/bQK5diN59NA

Dynamic Prompt Extension for Automatic 1111. Generate 1000 Prompts in 1 Click. This Extension allows you to use Wildcard Lists and also create Prompt Words in your Prompt that are randomly selected. You can also use the Prompt Magic to have the Dynamic Prompt Extension create more Prompt Details for you, based on the Prompt you have already wri...
I've been avoiding using wildcards, there's lots of people that seems to run into issues when using them, but I'll give it a go at least
I haven't used dynamic prompts but I used wildcards, and they work pretty good. But with wildcards its always random.
In the video he combines both
So maybe You'll see a setting you missed
Yeah I really fucking hope that 😄 if this doesn't work I'm just over it lol
what am I doing wrong? maybe missing vae?

clip skip -2
also scheduler and sampler matter a lot
dpmpp_sde and karras are pretty standard with pony
or euler_a
Where do i put the clip skip -2? In advanced ksampler?
between clip encode and lora
load lora -> setCLIPLastLayer -> conditionings
also ive found that the lora:xy:z style tags can hurt the output a lot in some cases, if the lora has a trigger word use that instead
you have quite a bit of negative condition too, you may want to ease up on it if you keep getting garbage output

shot in profile, medium shot, close-up, extreme close up, cowboy shot, high angle shot, low angle shot
reverse angle, over-the-shoulder
What prompts should I use to remove the divide of trees? Make the forest more dense without a clear defined path.

Hello everyone. Can anyone suggest how can I shift the floral motif near the chest to the centre of the t shirt. I am using inpainting and through controlnet, but not getting perfect results. 2nd pic is what i am expecting.


hi can I get some help? I am trying to achieve something on the lines of this:
but I am failing I only get abominations can you guys please help me?



Hey everyone I am new to stable diffusion and would like to create a sort of comic strip maintaining the same character throught. Is this possible? For example if the initial prompt was 2 dogs walking on the street could I make those exact same 2 dogs in a different setting and pose like eating inside?
thanks for the help
I'm using both forge and comfyUI at the moment.
It's a bit odd, but I'm trying to get a character to sniff things and I'm not sure how to prompt it. With Pony, the character always seems to assume it's supposed to smell underwear.
I've tried to get the face to be pressed against things first but I can't make that happen either.
Any advice?
Hey! I am new to this discord (and sd), what would be a good channel or person (if someone is willing to chat) to ask some noob questions in regard to how to start building their own model?
It is possible, it's a bit involved if you're just getting started though. You either need to make a lora for those dogs (this is probably the better option in the long run). A lora is something that consistently creates something specific. For example a pose, a concept, an action, a person, etc.
Or you need to use something like face adapter in comfyUI to replace the dogs with the proper dogs in the images over and over. This isn't any easier to get started with honestly.
Lora would probably be what you want. There are fairly good tutorials on youtube. I don't want to overwhelm you with information.
Just set your expectations a bit low in the beginning, and work up. From experience it can be a bit disappointing how much work is actually required to get consistency if you expect it to come easier than drawing on your own. Once you have things set up, things are much quicker though.
If I'm composing an image with 3 people, but I don't want any clones. Whats the promt for that?
There isn't a good one. You're better off using inpainting or a regional prompter.
Does inpainter in Img2img, allow you to replace a character with an unused, but specified character?
Yeah, you could do that.
The most important thing to know when getting started with inpainting is the denoise slider.
The denoise slider decides how much of the original image should influence the new one. If it is really low, nothing will happen, if it is max it might create a new image entirely inside the mask.
Generally it should be on the higher side, but turn it up or down depending on how much you want it to remember what was there before
In the prompt, remember to only write the things you are actually inpainting. If you have masked out the face, write "face" and whatever features you want.
If you have a lora for the character or style, you want it in there as well.
output image has this blurry look to it, what do I do?

I'm an extreme beginner so IDK what my options are here
maybe it's just me or smth
here it doesn't look as blurry
hmm
Can I get some help turning this Blender image into an AI image? It mangles the hands, and I have tried multiple YouTube tutorials about fixing hands - to no avail


you can do a depth map in Blender and use a ControlNet Depth model

something like this, but for SD the depth map have to be inverted or something https://youtu.be/wqCUi13rgBE?si=xNJU5UlOm5gKUjd9
check our r/depthmaps on reddit
let me know if should clarify anything
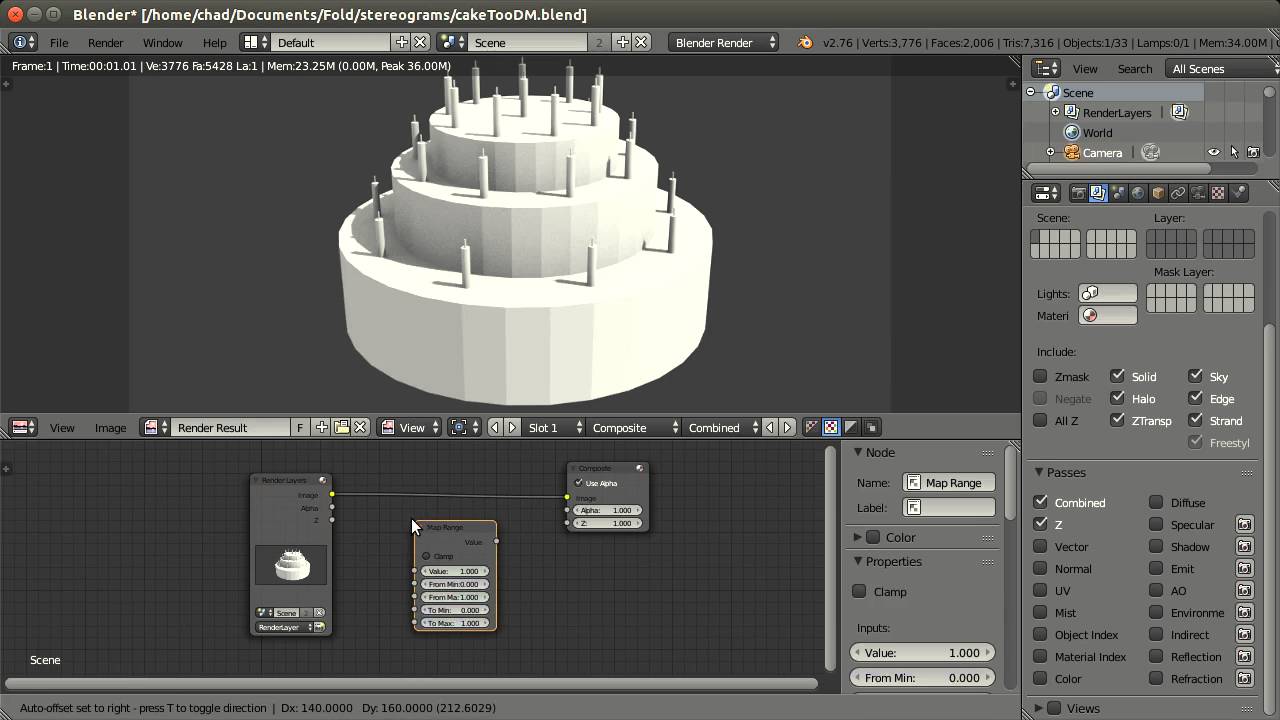
We look at two ways of making a depth map in Blender. We first use nodes to create a new composite. Secondly, we use a linear mist with shadeless objects.
Ah that's amazing, but the image is from a friend - I'll have to see if they're up for sending me a depth map
Ah, it was kind of complex for me at the time to set it up, but it is worth as when you have a perfect depth map, SD can really follow
If I have to set it up I should look it up again, I save that screen because I think is the correct set-up, but I don't remember well
You don't need preprocessor, and you should play with the CN strength
If you want to fix the hands, well it is a lot of tries with inpainting, different zoom levels and denoising strengh for each step
yeah the best I've got so far is to just keep clicking generate with random noise :/ it's a LOT of misses
yes it is like that, I've learn so tricks to get it done without much frustration, in Automatic1111
I try to first inpaint both hands in "large" zoom, so SD can see the body, trying different denoising, and then when the hands make sense I start to inpaint with higher "zoom", because that is sometimes the problem, at generation size the hands are too little for SD to make them correctly, so I work details of the hands with low denoisee
guys i need help, i have generated a very good emoji and i want to make more then 1 of it but with different face and so on can someone tell how?
Any ways to detect lips ONLY and apply lip makeup in comfyui? Media pipe face mesh doesn’t work for me
What promt would i use, to make sure the head is actually being generated?
These are my promts, 1 girl, solo, focus, medium hair, black hair, choker, looking at viewer, medium breasts, head in focus,

prompt for the eyes too
Right... Make it taller is one i can try. sec
Yep. Height and eyes did it. Fanks :3
Didn't turn out badly tbh

nice
First gen, no img2img as well ;3
Hello guys... I'm new here.. Anyone can share to me video show combine image using Ai?.. using photoshop take many works and time 😅
Is it possible to transfer a person’s makeup to another via face id v2 ?
Why am i seeing all those tutorial videos being able to transfer even the makeup to the resultant image ? But i can’t for some reason
I use face id plus v2
ok what do you mean by large zoom?
I just ran the inpaint mask through 57 models to see if the issue was my model choice. The issue is not my model choice.
Is there a promt available to do random poses?
Like cycling through random poses, each gen, if you do a large batchgen
wildcards can do this
I looked at one earlier... I have forgotten its name
UmiAI i think it was called
HMm no. Not that
Lemme dig around for it, and come back with an additional ping, cause it mentions wildcards yes, but no location etc
Aight, installing that then. How does it work?
you need text files with words in it, then add a trigger word in the prompt and the extension will use a random word from the text file
with pose words in them? Such as "kneeling, sitting, lying," etc?
exactly
works with anyhting
like colors
.excel, or notepad file, and which folder?
txt
So a text file named "wildcard.txt", i don't see a wildcard folder though

No wildcard directory fren

extensions\stable-diffusion-webui-wildcards\wildcards

Fair nuff.
OOOOH I SEE. So name is replaced with "Poses.txt", and then __ poses __ draws promts that that.
THen you can add in another file called "hairstyles.txt", and so on?
Those coding cookies r smart
exactly
Those r sum clever cookies.
when you inpaint on Automatic1111 you can do "Whole picture", which creates an image with the same dimensions and generate in the masked area. If the areaa is small, the resolution is small, the zoom is 100 %. If you do "only masked", the area of the inpaint will be a square (or rectangle) around the area of the inpaint, so more zoom, more resolution. But less context for SD. So for creating hands you need to give it enough context; for improving the hands and give it more detail, it helps more zoom and low denoising. Something like that might help to make the process less painful, changing the zoom and denoising in each step
Is there a promt i can add, to discourage the ai in doing pure white eyes, with no pupil?
A negative promt*

just specify pupil in your positive prompt
Like just "pupil"?
what's your current prompt?
2 sec. Just noticed i missed a promt i usually put in
using the expressive faces lora,
but what's your prompt?
Not quite sfw material,
okay, so as an example, let's say your prompt was something like "a cute girl with large dark eyes, 2d line drawing, cell shaded" - i would change it to "a cute girl with large dark blue eyes, small black pupils, 2d line drawing, cell shaded"
specfying the eye color and the fact that there's a pupil and how large
2d line drawing..?
i'm just giving you an example of what to do about specfying eyes.
i don't know what your prompt is
OOoh, i c. 2d line is a promt
I thought it was similiar to BREAK xD
Is 3 am. 1Has not had much slep
the second line is me explaining to you what i'm doing. i'm "specfying the eye color and the fact that there's a pupil and how large"
the original example prompt and how i would change it are the first line
I found the one i wanted to install prior to this conversation 😄 https://civitai.com/models/45448/full-feature-fantasy-prompts-characters?modelVersionId=243705 That one
100+ detailed dynamic prompts with fantasy, sci-fi, video game, mythological and historical themes. Each prompt includes setting, background, pose ...
Anyone knows how the execution order works in comfyui? How can I decide if i want to use bot or top preview first?

Not quite sure. In your example the order should not matter. In other words scenarios where the order of the nodes matter you would chain up the nodes in the order. My actual observations would say comfyui works from the last nodes (preview image, save image etc. ) toward the first note like load checkpoint
I've got an Image Comparer node where I want to check between last image I generated with the new image. Maybe there's another workaround, but I can't think of one yet

Since the node "LoadLastImage" only saves the first image in the the directory added it doesn't work with just adding that node, and in the example above the node LoadLastImage goes before "save" or "preview image", so I don't know how to make sure that the LoadLastImage node goes first after decode node to fix the image comparer
Guess I found a fix, just add a couple of upscale x1 and it will go for the LoadLastImage first. Tried to add a couple of reroute, but they don't seem to have any weights to them

whats the wildcard thingy ? I see iit in mage.space but dk what it iws
Is there some kind of node that can help if you have model A and model B and you want different input values in Lora's weights, instead of making copies of the Lora nodes?
YAY. FInally have a SFW image, i need help with! 😄
Ok, so I'm using https://civitai.com/models/148333/xl-and-pony-weapon-scythe-by-hailoknight with the PonyXL checkpoint. They are compatible.
HOWEVER; when i enter the promt, and no matter how tall i make the image (To make room for an obviously tall weapon), this happens.
Promts be: lora:Wakfu_CartoonV02:1 breasts, collarbone, medium breasts, <lora:Perfect Hands:1> perfect, hand, hands, lora:princess_xl_v2:1 woman, princess, girl, hair, cartoon, long, standing, lora:Expressive_H:1 lora:Kim_Possible:1 Kim Possible, long hair, orange hair, green eyes, choker, medium breasts, slim waist, lora:V2_Pony_Fantasy_Knights_-_By_HailoKnight:1 hkstyle,dress, black dress, white sleeves, bare shoulders, silver trim, Black and silver shield, sword in hand, holding sword, lora:Pony_Weapon_Scythe_-_By_HailoKnight:1 scythe, (holding a golden scythe:1.2)




XL & Pony Weapon Scythe - By HailoKnight Hello! This is a LoRA for SDXL and Pony to make cool scythe weapons. Things To know: You should use th...
Might have found my issue. Genning to see
nop. No fix found 😦
 whats this amount of loras and perfect hand in prompt
whats this amount of loras and perfect hand in prompt
I'd recommend delete all that xD
and not use as insane many amounts of torso prompts
they don't need to exist, just prompt for full body or cowboy shot, full body would probably be better if you want more view
pony is already good at hands
Don't worry about the loras
I have had gens, where i saw 19 fingers... from 1 hand.
okay but thats not a reason to type perfect hand in a prompt
its not a thing
pony goes by tags most of the time, you just do them and you'll be fine
I can't tell what those bunch of loras are doing, so I can only say to simplify that prompt to find whats wrong
Is how i put in my Lora's . Add the tags so they get plopped down, as i deploy them

Might not be the best method, but is how i understand amt
Nop. No real reason
Is there a way to prompt multiple characters without using regional prompter?
you could inpaint them
like do 2 random characters and then inpaint to get the distinct features
but other than that and not using extensions that make it easier its pretty much a shot in the dark
If I want to use multiple adjectives to describe the same thing, should I just string them together or list them out separately? For instance, if I want a simple long sleeve floor length green dress, is it better to say that or to say: simple dress, long sleeve dress, floor length dress, green dress?
I would avoid repeating the same word multiple times if possible. @desert shard
I got a character to have this haircut once in an SD1.5 model.
The issue is that I've moved on over to PonyXL. Pony seems completely incapable of tucking hair out of the way behind the ears.


Anyone have any advice on this? I would like to recreate the hair from the picture again.
To make it more clear, pony seems to constantly put hair before the ears. I'm having a real hard time tucking it behind the ear.


anyone know how to get different aspect ratios while using SD3 within the Poe platform?
I'm attempting to create something like this, but after 30 min of typing promts, and genning, I simply cannot get any of my promts to really work, Ignoring the sword and shield for now, could anyone help me pin in a bit on what i should be using?

Not exactly the same post but i used:
The image features a fierce and determined warrior woman, likely a Viking, in mid-action. She has long blonde hair styled in braids and wears chainmail, a sword for combat, she holds a round shield, The background is a stormy, overcast sky, contributing to the dramatic and intense atmosphere. Her stance, with one knee bent and the other leg forward, suggests readiness for battle, conveying strength and resolve.
Pretty sure a viking shield etc. could get closer to the original image.

"Wooden shield with iron brim"; perhaps would fix the shield, but thanks @sour beacon 🙂
Iron edge, etc.
Phrasing**
If you need the excat pose you could go with open pose
Still haven't learned how to use the controlnet for anything, especially poses xD

Shame I'm using Auto1111 xD
Simple Workflow, used the image you provided, let the node determine the pose (colorful sketch person) then conect it with apply controlnet load the model for pose. Then add it beween the prompt and the sampler. And you see the result is a woman in the same pose.
And yes shame on you 🙂
You miss an easy to use, comprehensive and very structural user interface 😄
Thats the downside of using google to begin your journey into this. You find the prettiest UI,
Also, that looks very complex to me, so will need a few hrs with someone literally hand holding me, over text, in discord xD
ignoring the sword, the wooden shield with iron edge promt worked.
she holds a round wooden shield with an iron edge,

With a "[[wooden_shield]] " as well, amongst the promps.
Yep. 3/4 images had it. 🙂

Hello everyone, I just stopped by to ask if any of you know or recognize which model, Lora, or tool was used to generate this AI image. Can anyone recognize the face of this woman? If anyone knows, please let me know, I would really appreciate it

what prompt's can i use to make 2 different characters fight?
Newbie here and learning the various models, prompts, etc. Focused on fantasy creature artwork and currently trying to make phoenixes...sort of like my avatar image but better. Making some progress...but also this female fire elemental/harpy keeps showing up.



Maybe she's a shapeshifter...anyway, any suggestions on models or prompts?
Has anyone noticed that sometimes negative prompt seems to be treated as positive. There are times where certain elements appear in iterations from time to time, but when I specify them in negative prompt, they start appearing in every single generation. Even cranking up the modifier doesn't help it.
Your best bet is to research and use regional prompter. It allows you to separate picture into different parts and write prompts for every part separately. That ensures your characters will not be randomly assigned features from each other.
What's a regional prompter?
Do you have any idea of how to remove the edges of the following gravel texture to create a tilemap akin to the following image using ComfyuUI/Forge?


Pony... Hehe.
Does anyone maybe know what model / prompt I could use to create such an image?

I still dont fully understand this. I believe you’re right, its just counter intuitive for me.
This might be a good place to start from: https://civitai.com/images/12124281

Any idea how to get similar style? Models, loras, prompts?

Hi! Can anyone link me the newest state-of-the-art for object positioning / prompt adherence? I want... viking funeral pyre longship ON the water, not next to it, and I want the thing having the viking funeral to be an AK47...
Can someone help me with the prompts?

new here how do i prompt and where ?
There is no bot on the server, at least no free one. You can register / create a account and get some free credits to use the artisan bots here in discord or to use the api. If you have decent enough GPU you can find install howto in the tech-support channel (pinned messages).
any tips of generating designs that are not Insitu wall art, posters, etc. Basically I want the flat graphics without the frames, chairs, preview photography.
I've tried various models and loras but maybe my text prompts could be better. My negative prompt is "NSFW, character, robot, portrait, framed, background, paper, wall, small text"
about 60% are unusable
Also how would you recommend upscaling these in Auto1111

so what is the image you want to get, some red lines, flat patterns etc?
just random billboard posters for cyberpunk theme
example of a good result

just tried two prompts:
"futuristic headphone advertising" and "futuristic flat simplified headphone advertising" and same with car instead of headphone



I think when you start adding text etc that's when it starts messing with fullscreen
Yeah so add the text later, and even text and AI are not great friends for the time beeing
Hey, this is my first try on a Lora, need some advice  Its a concept lora made for split/forked tongues. The first picture is from my lora, and it shows
Its a concept lora made for split/forked tongues. The first picture is from my lora, and it shows "ss_tag_frequency": { "img": {,
which makes me think that it did not catch up any trigger names? The second picture shows a lora that's made from someone else, and they have the trigger
"ss_tag_frequency": { "holding blank sign":.
Clearly I missed something important, but I don't know what. If it's of any help, I made the lora via civitai


Pony is the bane of my existence, please help! Every non-pony based model works amazingly well, but then I get to Pony and it's all terrible. I'm on comfy btw, if that's relevant at all.
Pony works a bit different from SDXL/1.5 as I've understood it. What seems to be the problem?
Everything! When it works well, the fingers look horrid, when it doesn't work well it's just mush. I've even tried other people's prompts, and workflows from civitae etc....
I create NSFW furry stuff, and I'm used to BB95, etc. (in case you've heard of that one).
Huh.. I seldom have any problem with hands in pony. Are you new to SD in general? Just to get a perspective on what could be the problem
I used SD via Magespace for about a year, then local install for only 2 months.
But, but, most other models produce amazing results!!!!
Are you mixing anything pony related with SD1.5/SDXL? Like loras, checkpoints, embeddings
I haven't tried mixing them
Can you give me an example on a picture and what resources you used for it?
I'll go put some shorts on my output people, brb 😄
Like, I don't care, but I'm not sure about there rules on the server
you can just dm it to me I guess
I'm glad I had to go make a SFW one, since I think my prompts were to long for Pony!
It came out decently with a very short prompt. I somehow doubt Pony has trouble with NSFW, I've seen the images lololol
The type of stuff I usualy get (cropped bc of discord)

I'm mostly making nsfw with pony, I get it 😄
but today, I actually got some that didn't suck (with my shorter prompt

That looks a bit oversaturated. Whats the prompt?

That's 1000 times better than what I've gotten previously with Pony or Autism!!!
Lol u don't even need me
xd
Making the prompts shorter is gonna help you get more stable images
for example in that picture you can get even shorter by writing it "anthro male, tshirt, jeans"
THIS is what Pony gives me when I prompt furries! (another person's prompt, and their image was amazing)

Taking other's prompts blindly can be deceiving
More often than not, people are editing their images with post edits
like inpaint
I'll find my usual non-pony prompt that produces the most amazing non-pony images
For example, I made this with the prompt "Pony_PDXL_Embeddings, 8k,UHD,ultra-detailed, (saliva,drool,saliva string:1.5), xenomorph,open mouth,sharp teeth, (smile:1.2), source_cartoon, xenomorph lora:Pony_xenomorph_pdxl:0.8" according to the metadata. But this is one of many steps of the inpainting I did, so its missing a ton of metadata
This was one of my earlier prompts for the same image
Pony_PDXL_Embeddings,<lora:xenomorph_pdxl:1>,8k,UHD,ultra-detailed,low-angle view,wide shot,(solo:1.3),xenomorph,lying,on side,grass field,detailed forest background,thick forest,looking at viewer,saliva,sharp teeth,drool,saliva string,holding blank sign,Hold up a sign saying Follow me,(thumbs up:1.3),(blush lines:0.8),happy mood,source_cartoon,faceless,eyeless,<lora:holding blank sign_P_XL:0.8>,
they are very different
HOLY HELL DISCORD!!!!
Something wrong
I took out all the naughty bits of the prompt, but still lol
You lost me xd
It keeps blocking my posts



I borrowed your beautiful image, loaded it to see...
Used Autism since I don't have the model you used. I also used a Pony specific lora.
This is what I got lol @naive bluff

As long as graphic futa prompts don't give you nightmares 😄
Yeah but that is exactly my point, I edited that image several times via inpainting, therefore just copying peoples prompts can be deceiving
I suggest you build up your prompts
Start with very low token count
like "person" "background"
Then you just add stuff
Then its much easier to see when it breaks
I used to use MJ (the shorter the prompt the bettter with them), I"ll try some of those as well!
Cool  Tell me how it goes
Tell me how it goes
I grabbed your entire workflow within that image though!
Sharing is caring
I'll post shoulders up versions 😄
You are 100% right, the shorter the prompt the better with Pony 🙂 2nd image
Though, the same short prompts suck for 1.5 or 2.0 furry models! (for me at least). 1st image
I got distracted and threw a checkpoint I made (it sucks usually lol) into your workflow 😄 3rd image



Hi! What is the current best way to do like a face adapter using a reference image in inpainting?
is it ip-adapter-face or somethign?
I think Face-ID is very good for inpainting, and its workflow requires a reference image to pose the face, so it's perfect
It doesn't take the style of the original like ip-adapterface, it uses insight face
Hi Folks, Is it possible to generate multiple images through a single prompt?
I am using sdxl model through aws bedrock
I only know comfy, but I hit the wrong button before going out to do errands, and came home to 140 images 😄
You can set it to create however many you like, but your GPU will limit you to a certain amount at a time without things crashing.
So 140 image variations right?
what if i have ten recipe names and i want to generate images for each of them, can i pas all of them into one single prompt and get 10 images?
can someone give me ideas and examples what should i do with this ? these are real pictures that have been scaned and than scans have been copyed , printed and soo on - how do i restore them or fix the quality ?








Without seeing what they should look like, and how bad the changes are, it's hard to restore them. I ran the first one through my upscaler, and this is what I got.

Can you maybe tell me how did you do that so i can replicate on my end?
I got rtx 4060 ti 16gb, ryzen 5 5600x, and 4x16 GB RAM
It's an upscaler from here: https://www.patreon.com/user/posts?u=90661954
I converted it to use SDXL, plus a few other changes, instead of SD1.5
A ComfyUI workflow

I got comfyUI
If Not here can you maybe message me with some instructions on how you did it?
I would like to learn
You'd need to download the upscaler from that link I gave you.
Does anybody know the style of this image. I am look for checkpoints/Lora for this illustration

Looks like "Mandala"
search for it
how do i fix the program to not keep doing out of frame shots?

Does anyone have a handy little guide, in regards to PonyXL's ratings, score? Not what they do, but what their actual prompts are.
maybe I am wrong, but I think your dimensions should be 512x512 or 512x768? Also sometimes using full body in prompt can help
Hey, I am wondering if there is a way to get rid of these stuff ?

They don't always come in every picture xD

Guys, how do we make appear different people, wearing different things, different hairstyles, or different positions ? I cant seems to get more than 1 person most of the time
Hi, I was wondering how to prompt for a dream vision like these



excuse me guys, just starting at different models on CivitAI to get inspired, discovering Loras and whatnote, perhaps even learning some prompts. And ive discovered some terms I dont know, like what's a ohwx woman ?
Also, perhaps not related, but does actually putting smileys in prompts gives the face we want to obtain for the character ? If yes I find it very cool lol
Ohwx Is a trigger word used by lora model trainers to give the character or concept or style a unique word for trigging the lora that has no meaning in English so when prompted it won't invoque unwanted concepts in the main model. Some say it is not necessary to use that trick.
In civit.ai in the lora page you have the triggers associated with the lora, for each lora and creator
I have never prompted like that, it is easier to describe the gesture with words, I think.
Which word/s do I need to remove?

if allowed, can someone help me with nsfw prompt?
in general, i am having trouble with producing widescreen images with a single subject. they are off frame, or leaning over very close to the camera in some awkward pose.
what are some prompts i can use to get a single subject in frame on a widescreen resolution?
The way I understand this issue is: the more details you add about the subject, SD will try to make it closer to the camera, as it don't have other ways of drawing the details if it is far away
panoramic, long shot, a woman with an umbrella at an open field



A simple prompt will help SD make the composition and not be forced to zoom into the subject. Then with inpaint you can give the subject the desired characteristics.
Or another method would be to create a background and then photobash the subject from another generation or reference, or create it from zero via inpainting, but it takes more judging and work
im having trouble with generating a decent quality 1080p photo. my workflow creates a 960x540 photo and then upscales it by 2.
in your opinion, should i work on the upscaler, or would it be best to try to generate a larger base image?
SD 1.5 works best with 1/4 megapixel (512x512 or derivatives) and SDXL works best with 1 megapixel (1024x1024 or derivatives). There are steps you can take to generate them at a larger starting resolution, and sometimes those other sizes work without an issue, but you're best off working from one of those starting points. You're working at just under 1/2 megapixel (0.4944), which would likely see odd things happen from either common model version more frequently.
makes sense. thank you
panoramic photo of New York City
#image A man is leaving a luxury brand store with many shopping bags in his hands.
I'm new so excuse me but
SD force feminizes this character 50% of the time, which is based tbh but how do I control when it does it? neg prompting things like "girl, woman, breasts," etc. doesn't really work
also is this a problem with the models I'm using or am I really just prompting wrong


hello everyone, can anyone suggest me a model from civit.ai where i can drape garments on models.
it's animagine from civit
you didnt provide a prompt yet
but there is also a male finetunes for animagine
okay I'll look into that, thanks
no problem idk whats the name for them finetunes
you could also put "feminime, androgynous" on negative prompt and see if that works
I searched for the male fine tunes but wasn't able to find them, do you have any leads?
(I'm using 3.1 XL)
using autisimmix for ponyxl, and all the images being prompted have those smaller squinty rectangular eyes. How do i get round ones without using a lora?

you can try using adetailer extension
i am, but can't really figure out the prompt for it
i tried "round_eyes", "large_eyes", doesn't seem to work
"Cute round eyes", "cute", "pixar eyes". Or describe an expression that will force the eyes to change shape. Joy, surprised or happiness for example.
In inpainting the expected behavior if you don't put a prompt is to delete the selected object? Can somebody confirm?
Nope. It won't delete the masked object
Oh Thank you!!, so it will do something based on the rest of the image, but not necessarily delete 100%. Ex Modify it?
I am using SD2 Inpaiting https://huggingface.co/stabilityai/stable-diffusion-2-inpainting and by the paper they use I understood that yes

@teal leafIllustrate a photorealistic cinematic shot featuring Sheikh Mujib, a mid-aged man radiating confidence and sophistication, standing beside a vintage expensive car. Clad in a dark grey suit that exudes refinement, Sheikh Mujib epitomizes intelligence and style, further emphasized by his bold-framed eyeglasses and back-brushed hair. With cinematic lighting setting the scene aglow, Sheikh Mujib leans against the car with an air of assurance, projecting an unwavering confidence. His gaze is directed forward, reflecting his steadfast determination and vision. In the background, a picturesque mountain looms majestically, enhancing the timeless elegance of the setting. This composition captures the essence of a distinguished individual in a photorealistic manner, inviting viewers to appreciate his poise and charisma in this cinematic shot.

Is there a way to create a prompt that specifies the details of what I want, for example, to generate an image of a guy wearing a T-shirt, but I want the algorithm to randomly choose one color from the options I provide?
https://github.com/adieyal/sd-dynamic-prompts/
if you are using A1111 pretty sure custom wildcards nodes for comfyui exist too

GitHub
A custom script for AUTOMATIC1111/stable-diffusion-webui to implement a tiny template language for random prompt generation - adieyal/sd-dynamic-prompts
how would I create a prompt that can output this?

I want to change some aspects of it with ai and generate it in different styles
for Automatic1111 https://github.com/adieyal/sd-dynamic-prompts

GitHub
A custom script for AUTOMATIC1111/stable-diffusion-webui to implement a tiny template language for random prompt generation - adieyal/sd-dynamic-prompts
Anyone know how to fix large eyebrows or to change the color?

I have added these prompts but doees not help black eyebrows, small eyebrows
Most of the time applying a color to the prompt helps. But when it doesn't you can change the environment or details to pick up the color. For example "teal spotlight" or "candy apple red scene". That's assuming "teal Tshirt, T-shirt, T Shirt" didn't work.
Example

Most colorist software, like Davinci Resolve, has a scope or means to yank any color from anywhere on the internet. So you can exact color match. Image to image can do the rest. If it doesn't you can resort to the below samples.



In these 3 examples (using image to image with your prompt) you will have a lime green:
- Surrounding environment
- White background with a man wearing a lime green shirt on the left side
3 Black background with a man wearing a lime green shirt on the right side
The larger you make that box the larger the AI will make the T shirt. Thus forcing camera distance and angle.
my gens keep doing this werid shit

It's been doing it no matter what model I use

the code strings VERY simple I took all amplifiers off and whatnot

lul...wtf is "volumatic"
its on so many images on CivitAi
do you mean "volumetric"
haha probs
i copy pasted it from someone else image
💀
🤷♂️ Help with my issue instead of critiquing grammar would be awesome and appreciated
THO I do appreciate you pointing that out~
well- I'll have to fuck with it some more then I guess Cant see why itd be making weird people blobs either
What happens when you don't use upscaling/hires fix?
TBH I Yeeted the whole code 💀 I just put in more more simple;

atleast she isnt a blob
Much
Ive still yet to make a 'perfect' image I see so many people who do I dont understand it
💀
A lot of the images you find on something like Civit are going to have other things that were done to them that aren't disclosed. Don't trust what you see.
huh interesting
However, straight Euler as the sampler isn't really the best choice most of the time.
Depends on the model. Go to the model page and see if they provide the suggestion for that particular model.
2sa Karras or something
Karras is a scheduler, not a sampler, but they are tied together.
oh huh interesting
Common ones you'd see would be something like DPM 2++ SDE Karras
But there are a lot of variations.
You should just try a bunch of them. Set the seed to not change, then go run a bunch of different combinations to see what works best if the model doesn't define it.
💯

Thicc.
Any ideas how to avoid the cameras I keep getting included in my images?
Put the word camera in your negative?
Already there, in parathesis for emphasis. So is tripod.
Maybe don't put camera in your positive?
Haha. I've considered that photorealistic or photo might be the problem and eliminated them.

I think the paparrazi just can't stay away.
IM working on a photo I would like the person to have Plugs in his ears does anyone know how I would do this?
"earplugs" or "wearing earplugs" didn't work?
That has happened to me many times as well. Try "hyper-realistic" instead. Or try "by a professional photographer" using a a very specific lens "using Sigma fp and Sigma 45mm f-2.8 DG DN". That excludes the "camera" in the prompt, but very rarely you'll still get a physical lens to show up in the scene. It's unavoidable. Just spin some more and you'll get your shot eventually.
How to get natural realistic background?
i scroll gallery of some realistic models and if character is very realistic, that background is almost always too artifical
My above tip should work for your project as well. Add mist or fog to bring more focus to your subject matter in the foreground. Also consider "natural shadows" or "natural light".
I think you can also mess with focus. "Very deep focus". Most of what I'm doing I'm fine with the background being slightly out of focus. Can also set the focus on a particular object.
喔
I usually use "whatever prompt this or that. shot on Canon EOS 5D 80mm f/2.8"
I have a question regarding upscaling.. I use the Extra tab and using Upscale .. should I use something else or is that enough?

Hires fix and img2img SD upscale script give better results than Extras tab
I use Hirex Fix first so it scale it 2x and then go to extra to get a higher rex. The Img2Img is only 1 image. I have a folder with multiple images
Ah okay, img2img also has Batch mode
Best setting then?
Im gonna test but I think about this?

I could not use Scale 4 .. have to use 2.. But with these settings it's just the same as Extra tab. At least for me
Use the SD upscale script at the bottom, set the resize mode to Latent.
Then set the resolution to 512x512 (it won't be the output res)
Then set denois below 0.3
And select an upscaler
Then upscale by 2
I will try later :3 But the images I often put in the extra tab I have already gone over and removed all images with weird stuff like extra finger or less fingers, bad hands and so on. So I just wanna upscale those images to higher and maybe better quality.
So the denois I may just put very low as I will not put any prompts or negatives..
Sure you can remove the prompt And just use quality tags to not get artefacts
And 0.1-0.3 denois
I have tried multiple variations of the following prompts, but the seats consistently come out wonky (and sometimes the rear spoiler as well). This image is about the best I can get... Can anyone recommend how to improve the consistency of the images seats (ie, 2 seats, equal height, in right position, etc). Or, potentially how best to fix them with img2img, because when I played around with it, the quality just came out considerably worse...
stylized illustration of a red 1988 BMW e30 m3 coupe,from front,white_background,full_shot,rear spoiler,tinted windows,poster,car advertisement stylized,<lora:add-detail-xl:0.9>
low quality,border,watermark

hello, can someone kindly help me. I don't understand why this comes out like this


I used the tutorial and this is the outcome

How to Generate Multiple Different Characters, Mix Characters, and/or Minimize Color Contamination | Regional Prompt, Adetailer, and Inpaint | My W...
is there a way to instruct Auto1111 to generate the same pic with the same seed, but 1 of each sampling method ?
Yea at the bottom of txt2img tab select the X/Y/Z script.
There select Sampler as X or Y and add the ones you like
Hi, I'm trying to get portrait of an angel-like being with three, separate sets of wings (ex. like seraphs or cherubims) - tried different models but didn't get even close to two sets of wings, could someone help how can i try to achive this? (tried dreamshape, juggernaut, playground, revanimated)
outside of Bing AI or Gemini, has there be any prompting to have a proper driver in a vehicle with feet on pedals and hands on the steering wheel? There are no LORAs that does this well in normal vehicles
Do you guys know prompting to generate set of 3 models? i can do it easily with midjourney, but using SD3 I cannot understand which promt is a trigger to make it draw sets of 3d models, like on my image.

prompting is really bad in SD3, ive tried many prompts to achieve what you are trying but had no luck.
even if the prompt or a character prompt is perfectly written SD3 tends to generate random faces .
What are the best settings for ControlNet?
I can't quite remember- Someone had helped me with it before
I went though them all and found I like using canny the most
I have an image not generate from stable diffusion, but I want to use it to make some changes. how can I generate seed number from the image?
It depends on the use case mostly
Anyone have any idea how to do regional prompting in stableswarm?
If I wanted a subject sitting at a computer with a mirrored "live-stream" of that character on the monitor how might that look prompt wise? Or should that be strictly an in-painting kind of thing?
im using irl pics of stuff and canny is doing great just would love to know how to fine tune it
ive been kinda jackin it up
I uninstalled stable diffusion, and upgraded to Stable Diffusion XL (i had a reason I did this)
But before I was using my IMVU avatar with ControlNet (Canny) to make my images...
it was working great before-
But now it seems I cant figure out what I need to do to get it to do what it was doing before 🥲
Anyone have experience using Canny to take (any image really) and use it as a guide for ControlNet?
Are the two images what you want or what you're currently getting?
Those two images, the left is my IMVU avatar, the RIGHT is what I genned with Stable Diffusion USING the left photo in ControlNet yesterday before I reinstalled everything.
i mean the left isnt even perfect but nothing a lil photoshop cant fix 🥲
What control weight were you using?
un well with the previous photos I posted I believe it was 1.5
Thats what I have it at currently
Im using Canny
What are you currently getting as an output?
Anyone got any good methods to color specific areas in SD. For example. I want gray boxing gloves. But it keeps giving me red. Help! 😅
If it's not generated by SD to begin with, it can't have a seed...?
Inpainting of the specific region works well for that sort of thing
gotcha how does that work? 🤔
Im tryina use controlnet (and figure my previously mentioned thing) out 🤔 still.
I feel like ControlNet's not doing anything cuz the image output doesn't change wether I enable it or not
if theres anyone who can help me tinker though this ❤️ id appreciate it
left image is without it enabled
right is with it enabled.


I have it set up with Canny which I had working perfect yesteray
ill send ss rn
its all random cuz ive been boopin' stuff around trying different stuff lol

where it says model none, select canny

uh I didnt have to to use it before, atleast I don't believe I did...
I did uninstall and reinstall stable diffusion so who knows what I lost in the process
i dont remember if the a1 controlnet plugin autodownloads or not.
in order for it to do anything, you'll need to download the model and place it in the correct folder
huh do you know where to find the model and what folder it goes in 🤔
yeah the controlnet GitHub in your extensions tab should link it in its description
should be on huggingface i believe

that should be the one

{kind=link}
i forget which folder youre supposed to place it in, the controlnet github should have that info though
I appreciate your help alot 🙂
np
Do you think that bit in the last screenshot is what Im seeking?
once you put it in the folder and hit the refresh button, you should be able to see and select the canny model and it should work (it was not doing anything before)
that extension is one that lets you edit openposes
its pretty handy, i use it myself
oh wait a second
are you using sdxl
that canny model (and others there) were specifically for 1.5
youll have to find the sdxl canny model. im unfamiliar with controlnets with sdxl since i never bothered to use it