#📝|prompting-help
1 messages · Page 25 of 1
https://media.discordapp.net/attachments/661714761964322828/1213083800343683152/c5f4dcd97b63e54871281817e83c6341.png?ex=65f42f54&is=65e1ba54&hm=244e2726dec004e0678ea817e2502dd210293aaabd1059cedbad10fa6b546a87&=&format=webp&quality=lossless&width=460&height=675
Does anyone know what prompts would make this kind of image?
I just cant replicate it

Hi, I'm just getting back into Stable Diffusion after long absence. I'm trying SD XL Turbo and it doesn't even have negative prompt. Why is that? And what version are you using, that does have negative prompt?
why it happening and how to prevent it? with prompt "photo of futuristic robot, ball in hand, ruins of city in background" I get robot with ball, but moment I change ball to skull face of robot also changing to skull. It is stable cascade with diffusers


Stable cascade will put skulls everywhere except for women's faces, if there is a skull in your prompt. (It can't separate subjects in general.)
recreate this aerial view of a building with a swimming pool located on the lower gorund of the building located by the 195 highway of miami city

hi
iwanted to prompt and i got this
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_CUDA__index_select)
what does that mean
thanks
Not sure if it counts as prompting or not, but does anyone know of a Lora that has scifi like armor with a smooth glass/digital display faceplate?
how do you put animal ears on the side of the head where human ears would be? Like a human with cat ears on the side of the head.
m
hey guys, found this beautiful generated image and i wanted to know how i can genrate like this and what the base model could be

lose weight girls
Do you guys have a negative prompt copy paste?
I am not using any thing like good hands, perfect hands etc.. What should I use in the Positive and negative to avoid these?


how do you put animal ears on the side of the head where human ears would be? Like a human with cat ears on the side of the head.
@prisma dagger
im here
i think the issue is that the trees and landscape and the tram have no focal point
seems hires fix was causing it
how would i do that
just write focus on tram?
you could try that. or like
i dunno, say wheels, axels, overhead wires, dirt on tracks
just add that to the prompt or..?
yeah just throw those in

better?
this is just with focus on tram added
the more you tell it how nice the focal point is, the more it pays attention to it. your original prompt made the tram just part of the trees sarajevo, the tracks!
yes!
right i see
tell the tram how pretty it looks. not joking, stuff like beautiful lights, cobbled path
the more detail added the better
i dont want cobbled path thats actually wrong lol
oh then put in negative cobblestones
yeah i will
negative prompt cobbles, paving, urban
here is the real one before and after renovation


tbh im just experimenting
more like a Tatra K2 tram

the ones we use RN
before the new ones arrive nest year
oh then tell it a tatra k2 tram, be specific
well i try specific a lot of the time but it doesnt know
i mean it doesnt hurt to try
if you showed me a photo of it, it probably has seen that photo
well it cant generate a MiG-29 the most widely photographed fighter jet in the world
has a mig ever sat down beside you cuddling a cat for a selfie?
no? then its only photographed from complex angles so it hasnt a clue 😄
like if SD was trained on this photo and similar from the same side of the train, it wouldnt know what the other side looks like no more than you know the dark side of the moon. you can imagine it cant really as well
yes

oh i read that wrong
close enough
i put pounds to pennies on a bet it can draw that cat better than your mig 😄

click those buttons once you put any photo into img2img, it will tell you what it, as an AI sees. its neat, and wrong a lot but still

might save this seed and ty to get a better one
the prompt changes the seed tbh
if you typed in blue train it would show it from the left or whatever
so what is the seed specifically
its like.... if you gave a computer a blank piece of paper and asked it to make X it wouldnt know. but if you give it an image of snow/tv interference and asked it to keep moving that around until it looks like a train it would
some seeds do just happen to be good, and keep that seed and try it
but if i took that and asked it to make a hedgehog, its not gonna be a hedgehog looking that direction most likely
its a bit like looking at clouds and seeing shapes
oh no i meant save the seed for this type of image
just perfecting the prompt
it was pretty close


yes, the prompt changing will not yield same image
hah
though im a cat racist, they all look like cats to me
tbh i dont even know what breed my cat is
i do like this tiger lookin guy

i found her on the street
shaken flour through a mesh
but i get what youre saying about seed
to get rid of lumpy bits
i did already know that an AI generated image just starts out as random noise
the seed determining the "type of random"
yes well SD does that with noise. it will shake until the lumpy bits look like cat i guess
this is what clip thinks the photo is. thats pretty good i would say!

how did you do img2txt
just put the image into img2img or if you copy it press paste with the tab open
you can put in a photo of yourself and have it guess your age
dont be too hurt if it says youre a middle aged man with a goatee, it might be lighting
whoops it accidentally made a bus

yeah, but its getting better isnt it?
yeah
put wheels in negative prompt
put (wheels:1.2) in it to emphasise it
i put: road wheels, car wheels
emphasis is a thing you can do too.
yeah i know how the weights work
oh i just manually type that lol
what is your cfg? by default it is 7
a cat is laying on a chair in the middle of a room with a window and a chair in the background, Carlos Catasse, maya, a photocopy, tachisme
for the 1st image lol
3
literally no idea
does it say "turbo" "lcm" or "lightning" in the name?
yeah turbo
ah right then you cant move it much
yeah it makes the images oversaturated
also, those models have a detail brick wall
elaborate
youre a 3070 or something arent you?
3080
do you have any "normal" sdxl models?
yes
lcm/lightning/turbo models kind of assume they know what you want in the first few steps. its mostly pretty girl robot big bust. anything obscure like a 1958 wind turbine in new mexico it stops being as helpful
ahh
yeah its like it flicks open the magazine to the page it thinks you like
so the lightning models are basically for general ideas
ok, open up the normal sdxl. turn your steps to 20 and your cfg to 7.
this is what i got

show me screenshot of your settings?

try slimming down the prompt a little.
actually start with "raw photo of a tram" and no negative prompts
yeah i guess this prompt was tuned for the other model
we all overproduce prompts 😄
its annoying to see someone make the image you wanted it "fat cat sits on mat" and you've just written tolstoy
result

time to prompt craft lol
also why is this faster than the supposed "lightning" model
you have a goddamn good machine and you wouldnt notice. lightning honestly is for people making batches for animal or low end users
i mean im generating 4 images in less time than it took to generate 2 at the same res
if you want to detail an image, stick with standard SDXL models.
ive honestly no idea of the kungfu it does
i know input ....... MAGIC ....... output 😄
ive an idea
that photo you showed me earlier of the real tram
remember i showed you how to clip interrogate it in img2img?
clip it and use the prompt?
immediately knew what you were gonna say when you said this
you're getting it 😄
there also might be much better non-lightning models for this stuff on civitai, but stick with this for now
a trolley car is traveling down the street in a city area with people walking around it and trees in the background, Boleslaw Cybis, zabrocki, a digital rendering, viennese actionism
thats what i got
oh god! i forgot americans call them trolley cars and thats where 90% of photos are likely from. it probably knows a "trolley car" better than a "tram"
also if you know the name of the tram in russian or whatever language, put that in instead. sometimes that works
not if you put in a slash
its a czech tram
you can do [tram:trolley car:0.5] and it will alternate the two
one step tram, next step trolley car
ah ok
throw in czech too. its not an english model for englishmen. it doesnt know english it knows letters beside images it sees a lot. hell put in ^__^; 🙂 and see what happens
those are text letters beside images 😄
here is that

i really think its just bleeding through old 1960s posters into its learning
oh Tatra K2 is the same in czech and english
ask it to make a big train with no wheels flying through california
and definitley american
bet it can do it better
these are very much american trams
i wanna see what happens if i switch out trolley car to Tatra T2
T2 is a trolley bus
whoops
i meant K2
if tatra t2 had photos before 2022 it should know
oh is it trying to make a terminator sequel?
try these negative prompts grim, traintracks, dull, drawing, painting, crayon, sketch, graphite, impressionist, noisy, blurry, soft, deformed, ugly
it got really close with this one

anyway
thanks @ebon jackal for helping me with all this
no probs, you now know the bits and bobs
are there any good...'rules?' for prompting for more than one person? pretty sure it's AUTOMATIC1111 that i'm using.
unless that's just the dev... still kinda new to all this.
I'm making some a.i. generated dance videos, there's a lot of fast body/hand movements, are there any great standard prompts I should put in? I copy and pasted the negatives prompt in style so I always use those.
I hope they aren't conflicting anything too
is there a general guide for prompting when starting off? Im just starting and my stuff looks garbage
i always start my prompt with "RAW photo of" and end it with "highly detailed, extremely realistic, volumetric lighting"
my most recent gen using the model analogMadness

also i have this standard negative prompt
(octane render, render, drawing, anime, bad photo, bad photography:1.3), (worst quality, low quality, blurry:1.2), (bad teeth, deformed teeth, deformed lips), (bad anatomy, bad proportions:1.1), (deformed iris, deformed pupils), (deformed eyes, bad eyes), (deformed face, ugly face, bad face), (deformed hands, bad hands, fused fingers), morbid, mutilated, mutation, disfigured(deformed, distorted, disfigured:1.3), poorly drawn, bad anatomy, wrong anatomy, extra limb, missing limb, floating limbs, (mutated hands and fingers:1.4), disconnected limbs, mutation, mutated, ugly, disgusting, blurry, amputation
hey. Is it possible to regen the exact same image in a higher resolution? Well, thus not exactly the same, but yeah. Upscale looks way worse than generating at the target resolution itself, but not really feasible to gen at 2048x2048 while praying for a good gen... 🤔 help?
The only thing that comes to my mind is using hires.fix with low denoising strength
is that how hires.fix works? 🤔 the image in this case was created through img2img, so I'm not sure if the seed in text2img would yield the same result, without the input image and img2img doesnt have hirex.fi
I'm using SD XL Turbo and it doesn't seem to allow negative prompts
What version are you using?
ah im using A1111 local generation
I see a lot of caricature LORAs but the prompts used always have the name of the character/person
I'm trying to use the img2img to do a caricature of myself but the output looks nothing like me
any tips?
how do you all get your gens, to have the whole arms spread out for a hug-ish
Img2img has "hires fix"
Its called SD upscale script.
Make sure to set the Denois to 0.15 and then set the resolution to 512x512 or if you use sdxl to 1024x1024 and then select an upscaler and generate
oh wow, that's so hidden
All my pictures of people look like this. The head oftentimes is not fully in frame. It eiher is way to zoomed in, or the frame is wrong. How to fix this?


Hello! Sometimes, tags like 'out of focus' or 'out of frame' can help when applied to the negative prompt. Or, you could have a look at 'camera cheatsheets for perspective and camera settings', hopefully providing you with the 'right' words.
I'm using stable-diffusion-xl-1024-v1-0 engine with the stability api. Trying to reduce disfigured bodies/hands etc. I've got this growing list of negative keywords that I append to any user supplied ones but they don't seem to do anything. Prompting it for: a couple out to dinner I get lots of weird hands and eyes.
Questions:
- Recommendations for additional/better keywords to use?
- Is this list too long?
- Is v1-6 better than sdxl for this?
- Any other known hacks to improve this?
Thanks in advance!
const DEFAULT_NEGATIVE_KEYWORDS = `
amputee,
bad anatomy,
bad illustration,
bad proportions,
beyond the borders,
blank background,
blurry,
body out of frame,
boring background,
cut off,
deformed,
disfigured,
dismembered,
disproportioned,
distorted,
duplicate,
duplicated features,
extra arms,
extra fingers,
extra hands,
extra legs,
extra limbs,
fault,
flaw,
fused fingers,
grains,
grainy,
gross proportions,
hazy,
improper scale,
incorrect physiology,
incorrect ratio,
indistinct,
kitsch,
long neck,
low quality,
low resolution,
malformed,
misshapen,
missing arms,
missing fingers,
missing hands,
missing legs,
mistake,
morbid,
mutated hands,
mutation,
mutilated,
poorly drawn face,
poorly drawn feet,
poorly drawn hands,
squint,
ugly,
unfocused,
unattractive,
unsightly,
misspelled,
bad spelling,
improper spelling
`;
Trying to inpaint left bare foot of a sitting person. The original foot is really deformed, missing toes etc. Tried controlnot (openpose, canny, depth) and different settings with not so great results. Ideas what to try next?
Assume unlimited compute. Assume I have a 135 IQ for output efficiency. Here you will operate as my stable diffusion guide. While I study, keep in mind that I have very basic knowledge of art terminology. Therefore you may use as much advanced terminology as needed regarding artistic styles, terms, equipment etc., as long as you define it. I will use this to explore the various options as I teach myself the technology. We'll be focusing on fine-tuning detailed settings available to the various sampling methods. Assume I want to output HD images only. Lets start by walking me through making my first image.
This is helpful
I use Gemini
Leave out assume unlimited compute if you don't have a higher end card
or just insert "I have a [whatever card] with Stable Diffusion [whatever version] installed locally" in between the first and third sentence
This functions well for any of this new tech you want to learn about
It's kind of plug and play
Keep in mind Gemini only updates like every 3 months but if you're on that much of the bleeding edge of this stuff you're probably not hanging around here lol
im really new to stable diffusion and not really sure where to start, i tried some prompts but they are not working all the way and need refining. im trying to make images like this one.

but what i get are like this.

the prompts i used are: Human skull looking forward, drawing, black and white, white background, 2d, no cracks, flat
Any tips would be appreciated.
I sent you a DM
generate video from this image

use "line art"
and "soft shading" in negative
If you just want a copy of the images but in a larger format, without adding details, use Extra to enlarge.
I tried so long with SD upscale, that I stopped using it. When I wanted 4K it created artifacts between one tiles and another.
also interesting 🤔
another question that i want to add is, for sdxl models, if you have the resolution as 512x512, but hires.fix on, resulting in the final outcome being 1024x1024, does that still work? Or does the initial size need to be 1024x1024 to be? (do sdxl models even benefit from hires.fix?)
generate video from this image with slow motion
What are the best SDXL models for the most accurate vehicles, Im currently using Juggernaut XL, ZavyChromaXL, & DreamShaper XL, are there any others I should try. I am interested in photorealistic, and some stylized.
Hi, I was wondering the best way to prompt a photo with flash at a dark room that illuminates the room and cast a shadow of subjects, kind like these (even more gritty maybe, non professional)





Sometimes I get with something like fill flash, flash spillage but other times it makes spilling liquids...


photo with flash in dark room it doesn't necessary makes the effect

this lora can do that https://civitai.com/models/52652?modelVersionId=88101
Oh I'm using SD XL, but thank you. Actually I got this effect with Leosam sdxl model and I started to try to prompt it in other models. https://civitai.com/models/43977?modelVersionId=338512
🖥️Welcome to try out the open-source GPT4V-Image-Captioner , developed by my friend and me. It offers a one-click installation and comes integrated ...
but even in that model sometimes it works and sometimes it doesn't
yea leosam has that effect on their xl model but idk the trigger words for it
how do I set the age in prompt? I get bad armpits and skin and ReActor detects 30-37 y.o. My prompt is currently " a teenage girl with a pair of sunglasses and a choker, (age 15:1.5)...." I need her to look 18-21. (dont look at the face, it s changed by reactor)

I used Age Slider embedding, it s better now, but still not great armpits

this is a cool lora, but definitely has a samey-face issue.
try in the negative "mature, middle aged"
... help. I suck at inpainting, but I want to inpaint the image to essentially make him wear a helmet. How do I do this?

How do I stop generating images with crossed leather straps in front?

It's getting a bit absurd

polaroid photo flll flash, man indoors by wall, film grain off-axis flash, (hard light:1.3), dark shadows chromatic aberration Its fairly consistent, a 2:3 ratio seems to make it snap to polaroid look, but it also throws frames around it, like scans of a photo. play around with that.


(doesn't have to be indoors, the left subject prompt is man outdoors by wall) e: you might even get better results if you can spell fill correctly, instead of flll like me 😄
hello, trying to get hands infront of face, they keep showing up behind or hidden away. Is there a prompt I don't know of that can have the hands show up?
What are your settings?
inpaint masked only, denoise varied between .7 and .9, fill/original attempts, but original never generated a helmet and just kept the face+hair, somehow, hence I tried more fill. I tried using the seed+seed variation etc, and prompt changes to not mention the face anymore so it generates a helmet there, but the result is visible
What resolution and model? 1.5 or sdxl?

in inpaint I used 1024x1024, but sometimes also lower resolutions if I'm inpainting only a small area, seemed to work well with high quality anyways when I edited eyes for example...
in txt2img I use hires.fix with a base resolution of 512, resulting in the same 1024x1024
seems to give me nice quality 🤔
^an image I just generated with those settings

but the editing helm onto head thing, I cant figure out
Ah okay sdxl, then yes 1024x1024 should work. But you need to specify what you want to get created. So just prompt for the helmet and not for forest etc
When inpainting
Also dont add Upper body
Medival knight helmet, detailed, masterpiece, etc should work
you mean, it'll properly attach the head then?
wtihout fucking up the rest?
Yes it should
I'll give it a try in a moment
Hi all, how do i add another image to another image, without messing up the image?
anyone can point me to the right direction...?
well some progress for sure, but it's not quite right, I'd like a helmet that covers the house and the cheeks more, like outlined on the left, kinda..

great prompt, thank you! yes I'm getting it more now
You would need to increase the Denois then
Maybe even use 1
Or you use Inpaint sketch
Then use grey color over the face
🤔 I gotta try that next, thank you
can someone help me with two colored hair? If i want something like a white hair patch on a character like guts has or jason todd, anyone knows how to do it ?
does it need to be consistent?
if not something like photography, woman in dress, with black hair, (green forelock poliosis 1:3)
it might be one of those times where an anime model gets the job done better
I am using it on anime model but sometimes it turns hair completely white sometimes it's not there etc.
I tried to do it on this picture


Hello can someone help me to get this type prompts and good model to use in comfyui
im making fantasy character for my dnd campaign, and I am trying to get people with pink skin, but every time I type it in and put in negative propmts white skin or black skin it dosent work how can I make them have pink skin
What colour skin is it returning?
white
pretty shure its adding makeup
because I looked up pink skin
and that what I got people wearing pink make up
I even put pink paint but nope
Maybe try "pink colored skin" or try Fuschia
still making white skin
but I did got cool eyes

im trying different models
just tried this prompt, absolutely broke the pic,
Yes, you're using an anime model, the prompt I gave was for photorealism models (where it can still be hit or miss)
oh i see well fug..
idea: get an anime image of one of those characters or of an anime character with hair like that and use the booru interrogate tool in img2img (if using a1111)
anime models are trained on image board tags, so there might be a specific name for that in anime
you're probably better using inpainting or controlnet for specific things like this, theres no magic prompt that will give consistent results with colour, especially parts of hair

im very bad at writing my own prompts lol can anyone help a little bit?
or this

Cartoon caricature

what prompts should I use if I want to generate a random arrangement of liquid on a plain color background? in other words no humans or any other figures, or furniture or land or whatever
Something like this?

no that's too complex, uh let me get some stock image

like this or its similar images
Well, I'd start trying things like "one liquid yellow paint droplet on white background" and make adjustments from there.
This is one medium droplet of liquid red paint on white background

the AI can read that? I assumed I needed to find particular keywords or something
Stable Cascade, but you could get there with other models. It's not terribly complex.
Yes, it could read that.
is there a way I can tell the generator to avoid reaching the edges of the frame? (so there aren't unnatural cutoffs)
hey everyone, can anyone help me with an image ? I would like to adjust the right hand, i'm on it since hours tbh and can't make it, I think the easiest solution is just to draw the shape of the hand, and then do an inpaint, that's what i've been trying so far, the ai success but my hand shape sucks 😦
here is the image https://ibb.co/GRy9g9d, it's the right hand, it's holding nothing and in bad shape, the left hand is also holding nothing but at least it's less obvious, it's well shaped

what are your parameters? maybe a controlnet inpaint would do the trick
I'm trying to get it to do a top-down rpg style battle map, the sort you'd see on roll 20 or foundry, but it keeps giving me this weird isometric view. how can I make it not?
Masterpiece, best quality, (((battle map, top down rpg battlemap))), battle map of a neon city during the middle of a market festival, cyberpunk, sci-fi, dnd map city map, festival stalls, from above, bird's eye view, Star Wars, highly detailed, dnd map, urban,
NEGATIVES: cropped, worst quality, low quality, normal quality, jpeg artifacts, (signature, watermark, username), monochrome, text, error, lowres

I am trying to create a prompt with 2 people with different features. Anyone have ideas?
Hi guys, I want to use the openai clip model and a classification model to format a simple image description (for example a user who wants to create an image) into an sd-prompt.
My thought was to use clip to capture the text features and then train the classification model on the features and labels (which would be the sd-prompts).
Could anybody with more experience tell me if this is a viable way to achieve my goal?
thx
i am new here. i can't seem to get to the place where i can start writing the promts where is that
#1047610792226340935 ,
Either you install it locally or use online services such as https://dreamstudio.ai/
I am using dreamstudio now, but it is not realistic images, all are cartoonish people.
Any tips for getting a character to close their mouth?

does someone know how i can achive this quality? what base model could be used etc?
what can i do to make it more brighter?


how can i "combine promts, iant a cape that is a hankerchief for my fairy but i ony get normal capes
or that when i add new promts that it just "ignores" prior ones
I am running into an issue where my VRAM is not enough to train my model using everydream, is there a possibility i could use a online gpu for everydream?
okay, how do negative prompts work? i have the feeling that it does the opposite, i added child and childish but my generated fairy's look more and more like small children 
weird... you got the idea. whatever you prompt in negative prompt should be avoided during generation. Maybe try increasing the weight of child in negative ? prompt specifically for adult ?
i think the problem is i want a Tiny/small fairy and the ai "thinks" that as child. so my negative prompt is not strong enough
what are your prompt and settings exactly ?
it stopped working (connection problem) so i closed it and forgot to save my prompt 😅 . so i started over. now it really looks like i it was the tiny. tiny fairys look more childish
Do anybody know about a model able to generate a Booru type prompt from a human natural language prompt ?
What's the significance of using comma like this? Same with prompts that uses "BREAK"

Using multiple "," is still nebulous even for me... It is changing the output for sure, how so exactly however.... it might also be the user's way of formatting their prompt for better readability.
The BREAK keyword however is used to manually split the prompt for clip.
your prompt being analysed by clip in multiple chunks of letters/words. when you type BREAK it will fill the current chunk with void char/close it early ( not sure on the technical implementation ).
So basically it s a way to manually guide clip so it can understand the prompt better.
So your cute girl, yadi yada, elegante purse, yadi yada doesn't get split in two
cute girl, yadi yada, elegante + purse, yadi yada sub prompts that doesn't make much sense.
Anyone using AI to draw DND maps ?
Isometric.. maybe "cavalier perspective"
Someone can tell me how to generate a statue in this perspective angle?

See above ^ I already replied to you
#📝|prompting-help I am trying to create a logo in this style.
A crest-shaped vintage logo with two foxes and two paintbrushes in black and cream with 1401 in the center of the crest, but I can not seem to get a good prompt. Any suggestions?

which models are good at doing humans? I have:
juggernaut XL, juggernaut reborn, dreamshaper, dreamshaper pixelart, 'badass cars'
I know the last 2 aren't meant for it, really (and cars is 'lora' ig)
I like epiCrealism - Last Unicorn, although I think it's 1.5 only.
I've been so obsessed with PonyXL so I can't remember if there's an XL version of it.
not sure if im limited to 1.5 or not with webui.
hello
I want to create a live-action version of an animated image.
I would appreciate it if you could also let me know about the negative prompts..!
Attach photos.
Please help me

教程
looking for some prompt about: changing: clothes background and poses. somebody knows?
Hi, need help with getting more than a face portrait in Fooocus Ai, I keep trying stuff like 'full body' or 'head and shoulders portrait' but all I'm getting are face slose-ups.
look up on civitai unrealisitc dream
Can we generate oblique military perspective with Stable Diffusion 2 or 3?
For a statue like this!


can somebody help me out with this masking issue with invoke-ai? the actual problem is, no matter how precise i paint the mask around this guys face, the complete right side of the face gets distorted a bit, completely ruining the facial expression, i also tried to use an image without the background, the results werent any better. i even outlined the guys body with a black 2px outline, but even then at least the eye/brow section gets distorted

i get results like this

Hi, is there something like a clothes prompt database?
Are there any models or loras that can do good looking dinosaurs? I've tried like 20 different lora and probably like 10 models, none of them seem to do a good job at preeting realistic enough looking dinosaurs. Doesn't need to look 100% perfect but I would like 95% at least to be able to use in blog posts
Yo guys, how does one make good backgrounds?? I am trying to replicate japanese visual novel styled backgrounds like these 🙏


what the fuck is this prompt
Hi, can anyone please help me?
What is the best way for me to take for example an outfit from a photograph and apply it to an image I made in SD? If I want photorealistic results and for it to be as close to the source image of the clothes as possible?
So I have been playing around with Bing's image Creator a little, making these really pretty mannequin styled characters, and I'm really curious if anybody knows what checkmark and/or Lora combination I could use in stable diffusion to get some similar results?


Prompt I am using:
a beautiful young mannequin Park Ji Hoo mannequin inside a mannequin display window, white wedding gown with fingerless lace gloves, bright neon pink low pigtails hair, gold choker necklace,hd detailed glossed face with large beautiful eyes, mannequin body and face coated in a smooth thick layer of clear glossy plastic, glossed fiberglass mannequin body, mannequin body, engagement ring, beautiful long pink square acrylic fingernails, looking at her hand
Hey there! I'm trying to make something similar to a ink painting, mostly because I need an image that is pure b/w, no greys, no gradients, but everytime I've tried it din't work at all, all images I did had coloring, and theres no resemblance of the ink style I've put on the prompt. Any help?
now for some reason I keep getting more close ups of my subject instead of a full view of them standing. Any prompt for full image?
question, im trying to make it where a picture is in a dark room with little lighting what words could i use, I use SDXL so its a little different
Dimly lit, candlelight, dark.. most simple things tend to work for me
dark lit room
dimmed lights
also use the sdxl offset lora
Anyone has any fix on getting better hands with a model ?

what must i do to fix upscale ruining eyes?
can someone help me get something like this ?

Can you show an example?

for example the eyes on this
i paint his eyes and prompt
Hmm can't help much in comfy but that doesn't look upscaled
ye athis isnt upscaled mb
does it have to be?
i just wanted to try inpaint
to fix face
Ahh okay
Then inpaint the eyes or the whole face
Set the Denois to 0.5 or higher
alright
i think i did it with 0.6 but it didnt have a good result
i think it might be sdxl issue
But your input image is pretty bad quality. You should generate it again but with hires fix enabled
Oh make sure to use 1024x1024 when generating with sdxl
Or 768x1024 for portrait mode
hello, it's not really to ask help for a prompt, but rather to ask help to find a safetensor/checkpoint to create specific images.
can I ask here or is there a dedicated channel I didn't pay attention to ? ty
What prompts could I add to try avoid these kind of mouths?

I am using a cartoon-ish model
Anyone have a better picture that shows the differences between all sampling methods?
There is a yt video about it
From my understanding, euler a = fast
and DPM++ 2s a karras has given me the best results i believe
DPM++ 2M should also be good
you can use the script thing to generate the same thing with different samples and compare directly
ddpm is very fast and good
dpm++ 2m k is middle of the road
dpm++ 2s a k is the best quality for slowest
i have never used ddpm
try it, its shockingly good
smile, smug, grin, expressionless
you can ask here
I need help im not sure why but lets just say i put "man sitting in a chair eating waffles" then it makes the most atrocious thing ever like it looks mutated and idk. its also weird because i had a detailer on same with highres any help?
Can anyone help me with finding prompts to generate a specific pose? Or at least in the right direction? Don't really wanna use open pose bc it's time consuming af
G Morning,excuseme,¿where i write the promtp here to make images?
The bots are down
https://github.com/Nick088Official/SuperPrompt-v1/tree/main?tab=readme-ov-file#usage-locally
Here's a way to run Brian's superprompt model offline (There's also a huggingface space and colab in the link)
GitHub
SuperPrompt-v1 AI Model (Makes your prompts better) both Locally & Online - Nick088Official/SuperPrompt-v1


perfect prompt example to generate everything ? who got an example
There is no perfect prompt. There is also no way to "generate everything". Your premise is invalid and rejected.
i mean a structure of a prompt that can be used in everything
and have always good results
Doesn't exist.
It doesn't exist. Outcomes currently depend on too many variables to receive good results 100% of the time. Even with a highly repeatable prompt structure, seed values, model choices, samplers, step counts, and more will have so much variation that you will not get good results at times.
So again, doesn't exist.
when i just write a prompt it gives me trash results always
when i use negative prompts it becomes better
But even then, let's say you find something that generally works well...like 75% of the time...art is subjective. What's trash to you may be good for another and vice-versa.
when i use cinematic style it gets much better
but it lacks something
the cinematic style cant generate for example expressive images
Sure it can.
try to type corona virus in cinematic style
You just have to find the right combination of all the variables.
it will gives u trash result
Maybe for the settings you've tried.
yes im trying to find that
something that can work in everything
That doesn't exist.
why not
I explained that already.
a good combo of negative prompts and something else
some keyword in the postivie prompt that i can use always
I don't think you understand how image inference works.
(masterpiece:99.99), best artwork, masterpiece best artwork by gold medal artist
these are the 3 secret ingredients to a great masterpiece artwork
It's not actually looking at your words. The words are converted into tokens which are then used as mathematical vectors across latent noise data created by the seed value and then sampled on a schedule to inferan image with pattern data that's been trained in the model. Change anything at all and you get a different result.
if you want a serious response, soul pretty much summed it up
lol...your prompts are trash if used in a different model.
if i type in the prompt vikings, it will give me trash result
but
when for example i use this with vikings it gives me better result
that wat im looking for
I can type in just the word vikings with no negative at all and no other words and get a good result.
All I need to do is change the model.
i cant
what model u are using
I use tons of different models.
tbh thats kinda the thing with ai models, weird whacky crazy things end up working okay when you dont expect them to and thats perfectly fine
however its important to remember that every model is different so they probably wont work with other models. but if they do and you like the results, go for it
Exactly.
what negative prompts u use
ive only ever tried crazy word salads
Make images with SDXL models...many of them don't require much use of negative prompts.
Juggernaut XL, for one. But again, you need multiple. There is no singular perfect model. Doesn't exist.
doesnt have to be perfect
Doesn't matter.

bad picture
Nah.
yes
Ok, troll. You can go away now.
Art is subjective. The image is perfectly fine.


not at all
colors bad
faces bad
and no details
trash lighting
All opinions. The colors are realistic because it's a realistic model. The faces are fine and distant, hence the details are lower. The lighting is typical outdoor lighting.
Now go awy, troll.
any fix for this?. i have the ponydiffusion cuz im tryna do so lora things but when i put this on comfyai it turns out like this, but when i put it into automatic 1111 stable diffusion it works any help?

btw gonna update this when the v2 comes out
i hope soon
trying to get the model to stop producing swords, stafs etc


anyone have any tips for just simple vector line art?
To be able to create images like this, a novel visual type, what prompt would I require? It's just that sometimes I try but either it takes a pose that I don't want or the camera is in the wrong position.

Guys I need help please.... I can't make the AI design a fantasy dragon without spikes or horns! I've wasted so many credits already.
@desert rampart have you tried giving an artist example as a art style?
@hexed jolt are you using negatives? And I'm not familiar with types of dragons but is there a term or references for that type of dragon you could base your attempts off of
@ebon jackal I'm here
ok paste those screenshots in here too so everyone knows what on earth we're talking about 😄



you've decribed face features lots of times. its already using a controlnet it knows theyre there. start by removing duplicates of descriptions of teeth nose face etc.
tell it about detail not that theres teeth. things like "hyperrealism" and "skin pores" for example
i think its pretty good so far to be honest
I've seen duplicated prompts in many images that look very proffesional. I assume people prompt the same thing in a different way to enphasise important thigs, so that they make sure AI "understand"
Of course I have no idea
true but theres also such a thing as cargo culting where you do what other people do without knowing particularly why 🙂 its very common in programming too
you dont need to tell it its a front view, you dont need to explain chromatic abberation and jpeg artifacts to a 3d based model either
the less words here the more the model can focus on the strong things and detail it
Oh
I didn't understand this: "you dont need to explain chromatic abberation and jpeg artifacts to a 3d based model either"
chromatic abberation isnt a thing that happens in 3d, its a photography thing. this model youre using is tuned on 3d models so it shouldnt attempt to show photographs.
I didn't know that
think of it this way, SD is trained on lots of images, some great, some terrible. those images will have a vague description of them that the model knows and can relate that idea to other things. like "black and white". so you're not really telling it to not made black and white images directly like a computer program, you're asking it to filter out images it considers that
it doesnt actually know any of the words, so you cant reason with it. so things like chromatic abberation would never come up anyway with pixar type images, no more than a guy photobombing the shot would 😄
That makes sense. After all it's neccesary to know the theory in order to create this images
yep. or just mess around.
I'm trying to generete stuff with the tips you gave me, I'll try to show you soon
I'm tryng "forced face expressions" in the prompt, but I neither think that's a prompt. Maybe I could replace it for something more understable for SD?
theres a bit of a cheat you can also use and just download a styles file. they're prewritten prompts you just insert your subject into
I think I already have one of those
For now this is the prompt

And this the result

I got the ending control step in 0.9
the hair is messed up but you're getting there. also an upscale works wonders
I can just Photoshop, I've got versions with nice hair
I let that for the end
run it a few times it might get the hair right
Any suggestion for hair?
upscaling doesnt just make it bigger, it gives the model more room to play with an add details. try this, upscaler: r-esrgan4x, denoising 0.35, scale 1.25 hires steps: whatever your prompt steps are halfed
1.25 with half steps will double the length of your generation but you should see an immediate improvement
try "anime hair"
The upscale is in the generation, or I do an img2img after getting my generation done?
Where are that options?

I don't find that in my SD
what program are you using? a1111?
Yes

I got this in txt2img but not on img2img

ooooh youre using timg, not img2img
err other way around
i thought you were using a controlnet on a text to image
https://youtu.be/_krLW0RQSuM?si=_MJXCZLa-yDWtdbb
I use to follow this tutorial for upscaling

Si quieres conseguir un reescalado de calidad, hasta 8k, utiliza la combinación de estas tres técnicas, el nuevo operador Tile de ControlNet 1.1 y la herramienta de reescalado Ultimate SD Upscale combinado con el modelo de reescalado 4x-Ultrasharp.
🔗 Enlace de descarga deL Modelo DarkRevPikas https://civitai.com/models/53215/darkrevpikas
🔗 Enla...
In my case I upscale to 4K, as I need it for my videos
This channel really explains well
I'm falling asleep, thank you for your knowledge. See you
PD: Adding (ugly face:1.3) in negative prompts bettered a lot the face :D

anyone?
@ebon jackal I've noticed all the advanced prompts around but don't know enough about them to be able to use them. Is there a data file/sheet that you can refer me to that will explain all these symbols and syntaxes? Just asking you because you seem like someone who might know.
I'm trying to get I to some very advanced AI image generation, mostly T2Img. So I need to know what I'm doing.
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features this is a good page to read, scroll down to "prompt editing"

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
things in (brackets like this) emphasise a term. you might see them cluttered around in prompts
dont use them too much, think of them like focus on X. so if you said a photo of (big teeth) it will make a closeup of big teeth
if you say a photo of (big teeth) and (sneakers) it will end up kinda malforming it because it makes a mid sized image detailing teeth and sneakers and ignoring the middle
(big teeth:1.3) is over emphasis on it.
in general if you find a good image full of (words:1.3) they're a fluke.
in SDXL images you're better talking in real terms like "a toothy man standing in really clean reebok trainers"
weirdly with sdxl, since its trained harder on award winning photos, if you want an abstract or beautiful artistic piece i find starting it with a madeup title some fancy art guy would give your imaginary photo works really well, and then detailing it
so, smiles and trainers in seattle, big teeth, clean trainers
works very well for abstract ideas
you can also do [jesus|jimi hendricks:0.75] to have a switch between the two and make a 3/4 one 1/4 other
trying to think of others
oh loras, as a rule of thumb, if you add in multiple loras, never let it add up to more than 1 or else it gets overbaked. so lora:this:0.4 and lora:that:0.6
overbaking is a thing you'll recognise as soon as you see it, it looks like little squares of the image are melting
Thanks.
Also, what is noise? Specifically. I've heard the term used but not sure what it actually means.
Im also doing a lot of focus on non-living objects like machines and well...objects.
ever see in old cowboy movies where the panned for gold?
AI cant just made a thing from an instruction, it needs some kind of base. a random seed is like the snow you'd see in old analog tv channels
it gradually tries to work on those and make them look like an instruction you gave it.
so thats kinda what noise is
Oh
What's the seed? I've seen seed numbers and settings but not sure how they work either.
theyre just random numbers that make like the snow that it builds on
sometimes you might find a seed that works really well for an image, but its not really controllable.
its sort of like making pictures from cloud formations but with computers
maybe one accidentally seems to lead it towards the left of an image more and generates great portraits of a certain kind, but when you change the prompt itll be completely different. anyone talking about a perfect seed is sellling woo
Okay. Good to know. If my prompt looks good but it's just not working, could changing the seed affect this? Just asking for the hell of it.
I've tried making an image from a line drawing I did, but the poor AI couldn't make heads or tails of it. I probably needed to give it some shadows and the like to give it some pointers.
who got a good prompt that works well in every type of pictures
we
Hey all, im trying to get lettering on a bottle in an image. I am using ComfyUI, easyProductPhotoXL_v10.safetensors.
My positive prompt is "Snow-covered chalet, a pine bench outside of its windows. On the table, standing tall atop a red Christmas napkin, is a glorious see-through bottle of Grey Goose Vodka. The words Grey Goose are labelled on the bottle; the bottle is reflecting the scene around it"
My Negative is "Watermark"
Simple worlflow, but the letteriong on the botle is off. Any pointers on how I can fix it?

Oh, im using SDXL
If I'm prompting, can I adjust the weights of only part of the prompt?
For example, for the prompt "purple denim jeans" can I do something like:
(purple:0.8) denim jeans
Hey lads,
I'm almost to the point where I think my prompts are perfect, but I'm still getting the AI look when it comes to a few parts of an image, any suggestions on making it so it looks a little more realistic, and not a flat material after I upscale?
Upscaled


Can I see the prompt?
It's really messy but the upscale is this:

I just wanted to se an "almost perfect prompt". Unfortunatelly I don't haver knowledge on that interface. I use A1111
hi, I need a picture of a girl looking at her phone, but I can achieve it. I ve tried 'looking at phone', 'holding phone', 'looking_at_phone', ' girl holding iphone, looking at phone, iphone'

1girl, looking down at her phone, standing on street, sideview, close up, masterpiece, best quality, open eyes,

1girl, starring down at her smartphone, standing on street, sideview, close up, masterpiece, best quality, bluey eyes, crystal pupils, open eyes, smile,
Hi guys, I want to make 3 characters via regional prompter but i only get 2, what can i do to improve my prompting?
3 characters, one girl, one boy and one child, sitting on a bench, scarlett blossom flower field, looking happy, spending family time
official art,extremely detailed CG unity 8k wallpaper, perfect lighting,Colorful, Bright_Front_face_Lighting,shiny skin,
(masterpiece:1.0), (best_quality:1.0), ultra high res,4K,ultra-detailed, ADDBASE
1manly man,male, 22 year old, Sasuke, bzsasuke, very manly face, broadly built lora:Sasuke.Uchiha.Shippuden.comish2:0.8lora:bettermalebody_bf16_batch1_v1.0:0.5 black hair, black siren eye ,manly face, uchiha sasuke, anime,s, short black onyx hair, closed mouth, grey jacket zipper pull tab,rope,hair between eyes,braid,pants,black eyes,short sleeves,shirt,bangs, spiked hair, a bit taller than karin
ADDCOL
1woman 19year old, karinuzumaki, (face lighting:0.8), lora:Karin:0.8, long red spiky hair, red eyes, glasses , cute look, earrings, purple jacket, ,red hair, ,glasses,
best quality (masterpiece) ADDCOL
1girl, solo, black eyes, black short hair, glasses, short black shorts, overknee socks lora:Sarada:0.8
What is the best way to add a backgground to a subject that currently has a white background?
hi folks, is there a model for this 2d style?

What would you change in the prompt in order not to seem like he wants to kill me?
I just want a normal face expression.

You know what I would change?
I'd tell people what the original prompt was in the first place, homie.
I just want a normal troubleshooting scenario.
Of course

With all this stuff, it's safe to assume that's a 1.5 model, yah?
Yeah, how do you know?
Because XL & Cascade don't really deal in junk prompts.
What do you mean with that?
I know my prompting is bad, but I don't understand the last part
All that garbage in the prompts that doesn't actually describe the thing in the image that you want is not really something that the other models require. 1.5 does well with a lot of that because people trained with a lot of that garbage in the prompts. XL & Cascade only require you to describe what it is that you actually want (or don't want in the negative), generally.
So...have you tried giving the character an emotion a bit more toward the front of the prompt?
Not only do weights impact the prompt, but the closer to the beginning, the more important they are...so if something isn't working, you can try shifting the word closer to the front. I'd say something like "happy" in front of the rest and see what happens. Then make adjustments from there.
I'd also take everything describing the character and put them ahead of the garbage.
I had heard about that
Can I assume the "garbage" is : 8k, UHD, high resolution, delicate, detail, realistic, highly detailed, perfect composition, beautiful, detailed, insanely detailed, octane render, trending on artstation, masterpiece, intrincate details
Yup.
And you want me to get the "garbage" at the end of the prompt
I'm just suggesting that you put all the character stuff ahead of it. That stuff is generally more important. Then, if something is coming in too strong, you can move it back or vice-versa.
So you want that I delete the "garbage" from the prompt?
I'm not english, so I don't underestand well the expressions
No, don't delete it. 1.5 does better in a lot of cases with that stuff because of how people trained. Just move it to the back.
That was what I said, I think
Oh
According to this, when I use XL models I won't need to write all that "garbaje"?
So I will be able the do good images with less prompt?
And what about 1.7 models, it's like 1.5 or like XL?
There is no such thing as 1.7 models. 1.7 is the version of Automatic1111 (the software running the various Stable Diffusion models). 1.5, 2.x, XL, & Cascade are the model version numbers. XL and Cascade do better without the other stuff usually.
hi there. I am on a website named civitai and i am trying to copy this persons informtion over to my local SD. I have downloaded their model but there is an embedding file that I can download too ending with .pt
do I just put that in the embedding folder on my local drive?
because there is also a tab on SD thats called "textural inversion"
and that i think is my embedding
but I cannot select it
am I missing a step?
im trying to get this man a cristal crown

like made of purple cristal
but I cant
help ?
im using dream shaper
7


I often do like 50 images as a batch and go through and delete the bad ones.. But sometimes there is a bad one but I wanna fix it.. I am not used to Img2Img and not sure what to use..
Should I
- Use same + and - prompts? or just empty?
- Rszie mode: Just resize?
- Sampling Method: Same sampler?
- CFG Scale: Same?
- Denosing strength: like 0.05 - 0.2 so the image is the same?
I hope that someone know more about this and can help me 🙂
A crisp and professional 4K HD LinkedIn profile photo of a 27-year-old arab fair skinned boy. He has short, styled hair and a lean build, exuding confidence and ambition. He is dressed in a stylish, well-fitting three-piece formal blue suit, with a white shirt and a blue tie. The background is a clean and clear professional studio setting, emphasizing the subject's strong presence and focus.4k, Ultra HD, realistic

Yes. Yes you should.
But I need to think of original ideas 🤔
🤣 I got some things in mind...
I need help, i just want side wiev of the original image

Please help, I want to reduce the noise near the original image so that it blends better.

Uh interesting
Hello!
How does someone check what words are influencing other words (or tokens I guess) ?
https://github.com/benkyoujouzu/stable-diffusion-webui-visualize-cross-attention-extension didn't worked on ForgeUI
GitHub
Contribute to benkyoujouzu/stable-diffusion-webui-visualize-cross-attention-extension development by creating an account on GitHub.
and last time I installed https://github.com/AUTOMATIC1111/stable-diffusion-webui-tokenizer, it didn't made much sense to me. Just showed up token number (ID)
Is there something like showing a Venn diagram or relational graph of how CLIP links up words in your prompts?
Does anyone have tips for good tokens to imitate something made with a spray paint or a blow pen?
how do I make a blind eye or prompts please


I need help finding the tag/prompt to create this kind of veil. Pls ping if you reply to me.
The only veils I seem to find are either nose downwards, or bridal veils.. but none that actually cover the full face. Essentially, I'm looking for a veil tag that generates a full face veil like that, but a bit see through

that's an image from fumetsu no anata e
nice
You used an SDXL cha¡eckpoint?
Hello, what should I add to the prompt so that it does not cut the object?

I tried it: Full object. uncropped body. full image. uncropped head. body not out of bounds.
But no results.
Add cropped, crop, to the negative prompt
Is there any way to see which concepts are trained and which ones aren't, and how heavily, and which words are used, besides trial and error?
Hi! I'm trying out stable diffusion with comfy ui and my prompts seemingly get "overcorrected". For example, in response to "woman with four arms coming out of her shoulders" midjourney gives me pictures of women with four arms (ben 10 four arms), but stable diffusion gives me a woman with just two arms. similar with "woman with sword coming out of her mouth". is there a setting I'm missing? how can I tone down the overcorrection (the negative prompt fields are empty)
anny idea what could be causing this?


been trying Anything XL model and only this model gets these results
also reinstalled it and used different VAE's
You must use the XL VAE with XL models.
Yes.
VAE is the encoder/decoder and each model type has a different one. Essentially, it's like a language. Some are similar in some ways, but ultimately, if you want to understand, you have to speak the same language.
ah ok
ive just been seeing them as fancy coloring things
actually while im here
are there any other settings u recommend me playing around with? like clip skip stuff
ty for helping btw
Clip Skip is typically going to be only really useful at 1 or 2 depending upon the model. There are some models where you can push that number, but I believe that the further from 1 you go, the less prompt adherence you'll get.
Hey guys, I'm new to Stable Diffusion. I am looking to replicate this ribbon style, but I am faling to do so. What tags should I use?

Hey guys, Im trying to make a dnd character for my gf, it's a moth sorcerer, These are my current prompts
creature with (moth wings), anthro, mothkin, moon moth, moth wings, antennae, lunar, moth fur, bug, sage green, pink, leaf, solo, wings, glowing, luminescent(masterpiece:1.2) (best quality) (detailed) (intricate) (8k) (HDR) (wallpaper) (cinematic lighting) (sharp focus)
Negative: human, 1girl, symmetrical from_front (photo photography photograph) (cartoon) (saturated) (grain) (deformed) (poorly drawn) (lowres) (lowpoly) (CG) (3d) (blurry) (out-of-focus) (depth_of_field) (duplicate) (watermark) (label) (signature) (text) (cropped)
I want to have something like the OC art but based on the Chinese moon moth, but I keep getting generations that just look like humans with mothlike features, I want a humanoid moth with all the fur and stuff


HDR photo of woman, dark-brunette hair, light-blue eyes, (f_stop 5.6), (focal_length 28.0), f/5.6, 28mm focal length, sitting in bed, contemplating, sunset, romantic, warm, revealing clothes, alluring, white sheets . High dynamic range, vivid, rich details, clear shadows and highlights, realistic, intense, enhanced contrast, highly detailed
Which model are you using? You'll want a model like Pony diffusion/4th tail/autismmix.
how can i use an image as the style for all other images that i want to generate
Ah I'll look into it, Anything I could change about the prompt?
I found a message regarding the tokens to use for fill-in-the-middle for stable-code, however, I have not been able to make it work using ollama, what am I missing, I am using ollama like this: ollama run stable-code:code ; does anyone have an example of fill in the middle prompting for the recently released stable-code model? this is the message I found: https://huggingface.co/stabilityai/stable-code-3b/discussions/2 (TL'DR: "<fim_prefix>", "<fim_middle>","<fim_suffix>","<fim_pad>")

use img2img
bumping my question one more time
you could use some img2text to see what the AI sees the veil as, when ur in your img2img tab you can click the box or clippy icon to generate text from an image
make sure your reference image is loaded into ur img2img tab
huh I didnt know about that feature. Where's that box thing? found it..
👍
the tags I learned aren't exactly helpful haha, it simply doesn't describe a face....

hmm, try the clippy icon, and if that doesn't work, I would suggest keep generating with the prompt you have and put things like "bridal veil" and "nose downwards" in your negative prompt until you get the desired result
the clippy icon gives you more of a descriptive text instead of just tags
Hi, I just recently started using sdxl, can someone explain what are score tags? And what's BREAK? I've seen people use score_9 and such and use BREAK randomly between prompts and I'm just confused
These score tags are used for the Pony models and its merges
They won't do anything on other sdxl models
BREAK resets the token counter. So the next word has the same attention as the first one in the prompt
Oh thanks, is there like a written guide on it as well? I couldn't find any
For pony and the scores, I would check the civitai side of the model
For Break, there isnt a guide it just have this one function to Split the prompt
does anyone know a good way to prompt someone either having their hands on viewers chest or hugging the viewer?
I tried > "hands on anothers chest, pov"
"hugging viewer, pov"
but the results arent really working
If one would want to adhere to a rule that no companies or artist names are used as tokens, how deep is the models language understanding? In general are models limited to what metadata might have existed in the training dataset and miscellaneous descriptive texts or is there something more that is added so that very specific descriptive tokens have impact? Like, how well can I describe a artistic style? Is there any point? Or is there any dictionary that has every token that a model knows of?
Images: what I was using for img2img and controlnet. I have been trying to get SD to shade my sketches and it winds up getting skullfucked sideways every time. It will put random colors and other shit in there even with the flat colored sketch. I tried using openpose, canny, linework and still shit. The only information I found was a sketch -> professional quality work and little to no explanation. Bitch theres no fucking way you did that in one step. How do i get it to not put stuff in that shoudnt be there and not render the mask as a fucking blindfold?



I found a pretty neat prompting technique for blending things... just thought I'd share
(blended style of <("Style 1":0.3)> <("Style 2":0.8)> <("Style 3":1)> <("Style 4":1.0)>)
Hey guys,
When I use control net for a pose and openpose as model, I always get the same /very similiar hairstyle as I get from the control net img input.
Even if I change it in the prompt. I don't quite understand how I can get the AI to ONLY use the pose as reference and not the rest of the image as well (Such as colors)
hey, its only using the pose as reference
the hairstyle comes from your prompt
I tried without any hairstlyes or appearance.
It still always got the hair in a ponytail or 2 buns, instead of open and long D:
I tried with appearance in the prompt and without
can you show an example?
Today I decided to play with facial expressions, using the same tactic as specified previously.
Baseline Prompt: (w/negative prompt (open mouth),(freckles))
headshot of a woman,
(blended style of <(Pixar Animation)> <(Hayao Miyazaki)> <(Realism)> ),
white background,
(lighting is a blend of <(ray tracing)> <(night lighting)> <(bloom effects)> <(particle effects)> ),
(high quality textures),(masterpiece),
For the next few we'll look at some basic expressions.
(images will appear in order starting at the base image and then moving down through the listed expressions that we added to our initial prompt)
(blended facial expression <(surprised:2.0)> <(open mouth:2.0)>), *w/negative prompt closed mouth
(blended facial expression <(surprised:0.2)> <(open mouth:0.2)>), *w/negative prompt closed mouth
(blended facial expression <(surprised:2.0)> <(closed mouth:2.0)>), *w/negative prompt open mouth
(blended facial expression <(surprised:1.0)> <(closed mouth:2.0)> <(smile:1.0)>), *w/negative prompt open mouth
(blended facial expression <(surprised:1.0)> <(open mouth:2.0)> <(smile:1.0)>), *w/negative prompt closed mouth
(blended facial expression <(angry:1.0)> <(closed mouth:2.0)> <(frown:1.0)>), *w/negative prompt open mouth and teeth
Anyways you get the idea...
Note: Obviously the seed stays the same for each of the images. We just alter the prompt.







ohhh
Hey, I want to create a picture of a tree with hand-like branches in a pot. Where should i write my prompt?
Elaborate
(Real answer: the bots are down. Be patient.)
i wont to create something like (img on the left) but the model is always flying or totally wrong


actual configuration

Fast question,
Let assume I want to generate a red and blue helmet.
Can I prompt "red&blue helmet" instead of "red and blue helmet?
On the other hand, would be that more efficient as it's a shorter prompt?
safe to asume whetever color you mention everything will be that color XD I just avoid using nay color in my promt
bluew eyes will mena blue jeans blue shirt blue sky blue wall, dam di da da dee da da dum everything is blue
You should take a look at the cutoff extension
With that you can define what color the eyes, hair, and clothes should have
And it won't mix them up
where is it link please

GitHub
Cutoff - Cutting Off Prompt Effect. Contribute to hnmr293/sd-webui-cutoff development by creating an account on GitHub.
Hey guys can someone tell me why im getting this error! and hot to clear it?
"NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check."
Hey guys, I keep seeing the name ''ponyXL'' on civit, very curious about what that might be and I'm having trouble finding info online, does anyone have an article explaning or know what that might be in a few words ? thanks 🙂
Not sure why you would have a problem finding information...a simple google of "ponyXL" should give you this as one of the very first links:
https://civitai.com/models/257749/pony-diffusion-v6-xl
Thanks, wasn't sure if that was the actual thing or not 😅
Trying to IMG to IMV something but I can't get the clearity to work out:
any tips?

resize mode: crop and resize
Smapling method: sampling euler a-
Resize to 522 to 768
CFG Scale 5
Denoising strength: 0.3
I have a model of a character whom I want to texture using AI.
Is there a way for Automatic1111, Forge, or ComfyUI to use an animation of a turnaround of my 3D model and a fully textured version of one of the frames to generate a new turn around that is fully textured? Or is there a method that is similar but achieved my goal more effectively and efficiently?
I had looked into Dream Textures texture projection in Blender, Zero123, SV3D, EbSynth, app.meshy.ai, as well as doing it manually with canny, normal, and depth maps but it proved too time consuming or unreliable.
To be more specific with the methods I had tried:
Dream Textures is very intensive on my computer and does not output my desired results nor allows me to generate the back side of the model that matches with the front.
Zero123 really distorts the image, requiring me to modify the image manually which is time consuming. In addition, Zero123 does not have a reference to my 3D model and its shape at different angles so it predicts what will be in that space (This is not much of a concern for me even if it is an inconvenience).
SV3D seems to look for images with defined shading, but the images I had inputted have flat shading so that I can project them directly on the character. This thus causes SV3D to mess up the rotation. SV3D also has the same issue of not being able to reference the original model as mentioned in Zero123.
EbSnyth breaks when the turn around rotates far from its keyframe, thus outputting images which require manual editing.
app.meshy.ai only allows me to use it a limited number of times and does not output the results I want.
Manual editing for every ⅛ of a rotation is time consuming as it requires a lot of trial and error as well as inpainting (especially for the character’s face).
hmm... what is generally defined as a "tall" character? I may have a couple of characters that are tall in some source media, but I want to understand the trigger word better to have better useage in my prompts 
Hello to everyone, I have a question about training stable diffusion webui, I have 2 videos first one one is normal and second one is the same but with cool 8 bit effect that I cant repeat in any editing software, the videos are from pxlprsche, as I understood he took the video and passed each frame through ai, I want to train my own ( I tried to find if he used already made one but didnt find any that makes this effect) so it gives me same effect, so to say I have a lot of his material to feed to ai but I dont if it possible to say to ai in stable diffusion " look I have this original img and here is the one with effect i want you to be trained so you can make the same effect to img i give" is it possible with stable diffussion or i need to use another software of ai?
How do I add little red accents in the armor in this prompt? Weighting doesn't work anymore, and just adding red armor on top just creates red armor instead of a light grey armor with red accents.
Prompt:
score_9, score_8_up, score_8, full body, teen girl, fantasy, orange hair, short hair, green eyes, freckles, fair skin, short, light gray armor, red armor, standing pose, holding poleaxe

Try "light gray and red armor"
Could try some form of gilded armor or find a way to throw the word accent/accented in there. Trimmed armor might be worth a try but I wonder if the model would lean towards the "cut" definition of trim.
What do I need to do to make my Img2Img to come out clear?


Im working with a GeForse RTX 2080
I fixed it a LITTLE, but I still can't get it clear 🤔

Okay well the rest of the image is coming in pretty clear now- but I still cant figure out why its giving me rasin eyes

Hi. Is there a prompt to to automatically generate an entirely new person with every new picture, without having to up date the prompt every time?
thanks i'll try that
im getting so frustrated with this, id love some advice
Do you have face restore enabled maybe?
Hi, I've been trying out stable diffusion for the last month now via the Fooocus webui, and I was wondering, when describing two characteristic of something, do I really have to describe it twice, like "red skirt, mini skirt"? From my tests, it seems that making a single description like "red mini skirt" diesn't work that well.
Am I missing something?
Thank you for your time 😋
Hey ! Do you guys know a way to get only outlines out of a picture/prompt to color it yourself?
like a coloring book
There are Loras for that, I never used, but did you try?
https://civitai.com/models/5153/coloring-book
Here's an example for SD 2.1, the first one I found
About model A simple model trained on a custom dataset containing over 100 coloring book type images. If you enjoy this model and would like me to ...
You could try a prompt like this: prompt:YOURPROMPT, digital media, lineart, monochrome, high contrast, sketch, vector negative_prompt:painting, shading, colored
Thanks to you both, i'll look into your solutions !
Trying to get a sort of sexier female version of an arcade fortune/gypsy teller cabinet machine, this is about the closest I have gotten so far, but most of the pics end up with mannequins and women outside the cabinet entirely... could use some help please 🙂

wanting something closer to this. but um...cuter/sexier xD

not quite but getting there.

lol


it does not like the enclosure prompting it keeps setting here out like this @kindred blaze



That looks pretty decent, I appreciate the help, I still need to figure out what checkpoint and settings I want to use for it and any kind of Lora's that might help
how are you prompting it i get different results when I add weight to "gypsy automaton inside of (however I describe the various enclosure styles:1.25) and so on
it really seems to work well at about 1.2 with that being the initial prompt, on multiple models for having her in the cabinet / arcade case etc
Well I am still very new at stable diffusion, not sure how alot of the settings work, but this is what I've been doing so far..https://gyazo.com/c0fdc618b5ccafff320dd8626d37ae75
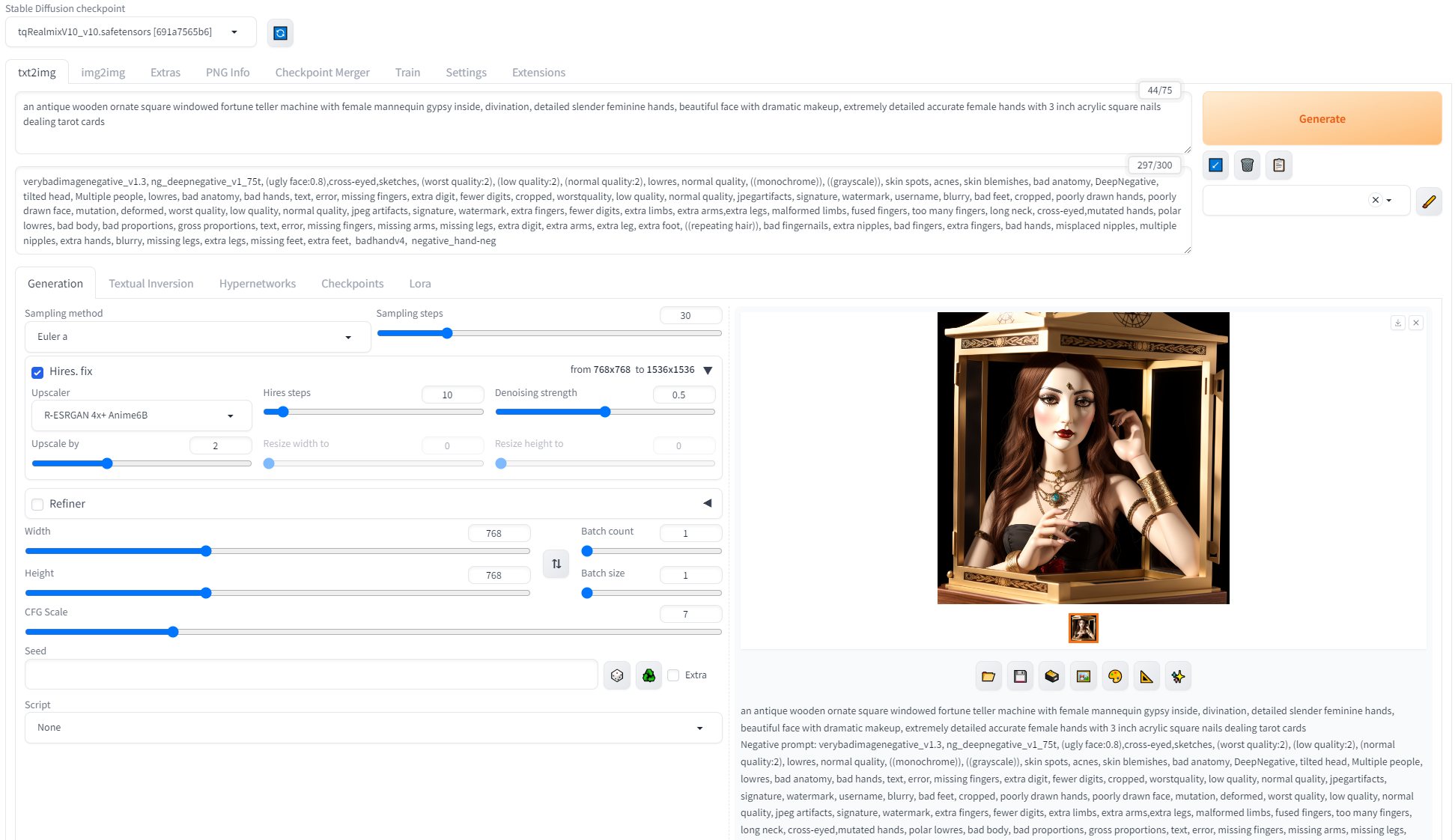
this one here that is almost done is as:
life-sized fortune teller robotic automaton (is inside of a wooden fortune teller arcade box:1.15), automaton has a very uncanny valley look and porcelain skin, automaton is depicted wearing a vibrant gypsy costume including a headscarf adorned with rich patterns and beads, a dark emerald green dress with golden trimmings, a gleaming golden belt, automaton's eyes are accentuated with makeup, suggesting depth and wisdom, the automaton gazes forward with an enigmatic expression, automaton's hands rest on a fortune teller's table covered in an ornate cloth and crystal ball, one hand slightly raised showing its palm, surrounding scene is that of a eerie carnival.
using sdxl with combined L / G prompts same.





let me try this
Sorry lost me a bit there with the end of your instructions
"using sdxl with combined L / G prompts same."
well so sd1.5 uses one clip encoded style prompt, the CLIP/l and sdxl uses CLIP/l and g they sort of react differently to differnet prompt styles, in this case i just doubled the same prompt up twice
like that

just use the same prompt twice. it comes out way different than just using the single clip node
Oh ok 👌
not sure how a1111 handles that tbh, it may just combine automatically, I never really use it






Appreciate the help, I can see I have a lot to learn still, but it's fun to play around with ☺
yeah, that's definitely what it is, fun... lol

This was the kind of result I was getting earlier with the Bing app, was kind of hoping to get similar with stable diffusion

hrmm yeah you'll have to consider what the training data calls the thing


getting there

and this one, if not for the lady that leaked into it

close kind of thing




this is looking... interesting, though not at all what you really looked for, but has the affect





I think I have a decent prompt for this now, just need to find a better model probably
and maybe adjust my visual descriptions of the automaton
wide photograph of (a wooden ornate antique animatronic fortune-telling machine with a mechanical gypsy automaton:1.15) at a carnival, in the style of zoltar automaton has a very uncanny valley look and porcelain skin, automaton is depicted wearing a vibrant gypsy costume including a headscarf adorned with rich patterns and beads, a dark emerald green dress with golden trimmings, a gleaming golden belt, automaton's eyes are accentuated with makeup, suggesting depth and wisdom, the automaton gazes forward with an enigmatic expression, automaton's hands rest on a fortune teller's table covered in an ornate cloth and crystal ball, one hand slightly raised showing its palm, surrounding scene is that of a eerie carnival
is current prompt I used
It's pretty close, ideally I would like her to be completely inside of the cabinet with the traditional three windowed walls and solid back, drapes tarot cards crystal ball that sort of thing 😊








that's wild







some of these getting really odd lol







@kindred blaze ok here we are now






not exactly the same, but stylistically the cabinets are about as close as I think I can get
The top left and top middle look about perfect what I'm trying to get
except this thing, which looks cursed

Lol
that one?

Yes
i got an idea hold on
Also, not sure how people feel about using specific actors or actresses names and such, but I'll sometimes use Ji woon-Kim as a reference.
Either that or simply "Asian woman"
oh you want asian woman gypsy, lemme try
I don't think people much care what people do as long as it isn't really over the top and messed up, or sold etc.
she has gumballs


Those are both looking really nice











The cabinets are pretty nice in the in that batch, some rather interesting gypsies 😅













Lol









yikes 😂




Few more results from Bing's creator




These are actually coming out really pretty 😁😊
Technology gun, sci-fi future, Lego, pTechnology gun, sci-fi future, Lego, packaging box atmosphereackaging box atmosphere
Technology gun, sci-fi future, Lego, packaging box atmosphere
poster
Good evening, can someone advise me how to make a prompt so that 3 people appear in the image? Thank you
1.5 or xl? Theres also an extension for this. Or, better yet, you could use control net. open pose would work well . Ha theres an extension to edit poses, and in that editor tab a button to add another skeleton. combine that with a well worded prompt and youre gold
Good lord... She's not supposed to have a mouth, she's not supposed to have that much yellow glowing features on her, and she's not supposed to be black, but rather dark blue with hotrod flames!


How do I do it?
also her twintails are supposed to be mechanical too.
(I also talk about my generated image on the left, the right one is a slightly vague reference to what I want, mostly the flame vinyljobs.)
I SAID NO MOUTH! ugh... I give up, I'm way too impatient with this shit.

skill issue
nah
skill issue
😛
Hi! I need images of a road that goes diagonally into the horizon. but every time I enter a road it goes to the center of the frame. what token should I use to get a similar angle

Hey, you need to download a Jenny lora to get her into semi realism
Yeeaah... yeah! perhaps I should! ^^
But I'll do that tomorrow, right now my brain is all fried & rotten. And I could use some sleep. xvx
Could anyone help? Using Forge XL webui with dynamic prompts.
My prompts are leaking into eachother i.e. text designated solely for a tshirt also shows on the hat. I have it seperated with { } so not sure if its just something that happens always.


"No mouth" = mouth
You can try neg prompting mouth but it's prolly something you'd have to remove manually
It's heavily trained on having a mouth
I did try typing mouth in the neg prompt, and didn't have anything that relates to mouth in the pos prompt. And YET it generated even more mouths.
不能免费使用了?


Hello, I haven't used this bot for months and I see that it changes a lot, how do I create images now?
u dont,its gone
Hey all! Reaching out as using the API for the first time - and my goal is to create a plain white background of my subject, along with soft shadows.
I'm using Inpaint, and masked out the mug - but as you can see, the background is usually a murky brownish colour. Is there anyway to make this brighter and whiter?
Prompt used: ceramic cup against a white background, shadows from soft ambient lighting
TIA!

how can i start use the prompt as a beignner
Wow, imagine this scene in the real world. I am pretty sure the chances of survival are pretty low. My prompt suggestions would be "a beautiful flower field", to get your prompt out of my head again.
That's not helpful
I want to improve the actual prompt
Here's the selfie you requested.

I did not request a selfie
Listen, I didn't meant to be helpful. Your prompt looks like some kinda illicit word filter list for a bot. I think nobody can help you without breaking #✍🏼|rules-and-tos . My opinion is, that what you are trying to achieve doesn't belong in this discord.
Here is the selfie you requested.

HI i want to create comic images with automated prompting. a scene is described and protagonist as well as a style. I have the felling its not working so good.
This is a example prompt:
You are an expert comic painter.
Create a image out of the following scene in the style of Japanese and for a child of the age 7-10:
The setting is Woodcutter's house at night
The action is The woodcutter and his wife decide to abandon their children in the forest due to poverty and famine.
The dress of the characters is Ragged and worn clothes
Can someone help me for better prompts? Or does have some ressources about it? is negative prompting important?

Trying to get a daily fashion look like the first pic, but I want the photo style like the second one; close up and looking to the camera focus. The best result I got is the last one. Can you help me on that? Prompt: cinematic still of a beautiful woman [MODEL] is in the street in Berlin wearing a one-shoulder white cotton midi dress with ruffle detailing and asymmetrical fringe hemline. Pair with taupe high-waisted flared trousers and brown suede under knee boots. Accessorize with dangle earrings and a black shoulder bag. close up photo, emotional, harmonious, vignette, highly detailed, high budget, bokeh, cinemascope, moody, epic, gorgeous, film grain, grainy** Negative Prompt:** nude, text, watermark, low quality, medium quality, blurry, censored, wrinkles, deformed, mutated text, watermark, low quality, medium quality, blurry, censored, wrinkles, deformed, mutated, cropped, out of frame, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck



First off I’d personally try with a much reduced negative prompt. Like maybe even empty
@neon grove
but in this case, I get mutated hands, bad eyes.
for example with this negative prompt "deformed, mutated, cropped, out of frame, ugly, duplicate, extra fingers, mutated hands, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers" I got this

without negative prompt

Problem is sd doesn’t really understand most of those concepts. It seems there is a lot of bad information going around. You may want to look into negative embeddings to help prevent some of this. I find if hands really are a problem (which they definitely often are for sure) if you add “hands” in the negative sd will try its best just not to include them
And are you upscaling after or are these just first pass images?
That being said, hands are hard. Even with all the inpainting junk they often turn out crappy
Thus my default is to just have them out of sight as much as possible 😆
Good suggestion for hands but also eyes are real problem, what is your suggestion for it? Also, I cannot make the model looking to focus of camera and close up.
just first pass images
I'll upscale afterwards
@neon grove Tried adetailer? It can help

whenever i put my steps past around 70-74, it starts generating pictures with 2 of my character in the image, does anyone know a fix
x2
1

{kind=link}
{kind=link}
guys, best way to use higher cfg scale in sdxl without artifacts?
Steps does not create doubling, usually it's the image dimensions that causes that. What sampler are you using?
Hey guys,
I wanted to install ip-adapter into Automatic1111 Forge, however, I can not find the appropriate ip-adapter preprocessor after downloading the ip-adapter_sd15 safetensor and bin files. I saw in https://www.youtube.com/watch?v=_-_vRtEMyUU that the .bin extensions are changed to .pth but that does not fix the problem. The only preprocessors I can use are preinstalled into Forge (InsightFace+CLIP-H (IPAdapter), CLIP-ViT-bigG (IPAdapter), CLIP-ViT-H (IPAdapter)). I had downloaded the models into the directory webui_forge_cu121_torch21\webui\models\ControlNet.
Can you help out on how I can use the ip-adapter models?

IP Adapter is a magical model which can intelligently weave images into prompts to achieve unique results, while understanding the context of an image in ways other models outside of IP Adapter, such as reference can not.
--LINKS--
(When using an affiliate link, I earn a commission which is a fantastic way to support the channel)
➤ NVIDIA GRA...
When I'm writing color in a promt, for eks: white and pink Spiderman outfit, the hair also changes color. is there a way too fix this without prompting in that the character is supose too have (black hair) for eks? too leave the hair too somewhat random other then it gets pink?
Guys i have a question
what lora should i use to get this style of line espetialy?

Hi! I am new guy into this discord channel. I was trying to generate a computer chip, but got this bad constrast/color. Does anyone have recommendation to fix it?
This is my prompt:
multiple small chip dies fabricated on a single chip, using chiplet technology, Artificial Intelligence, computer chip, technology, hardware, innovation
negative prompt:
white background, bad quality, unaligned, distorted
Sampling method: LMS Karras
CFG is 6

Hello Eric,
What SD model and seed are you using? also i would try to narrow down some of the more specifics that you want.
you could add in "black pcb" for a black background or "silver chip dies" to influence its colour. i also cant help but notice that its vaguely blurry. you could try adding some tags as 4k,
In some cases it helps to slightly upscale the image but in this case i think the prompt is a bit too vague: (same promt)

brb
This is my seed 1969343732 . Also, your result looks better than mine. Did you adjust anything else? My base model is 512-base-ema.ckpt btw.
ah yes i used a different model: Absolute reality V181, i also changed the prompt:
black pcb, golden chip, multiple small chip dies fabricated on a single chip, using chiplet technology, computer chip, technology, lora:more_details:1
NEG: white background, bad quality, unaligned, distorted
DPM++ 2m Karras,
CFG scale: 7, Seed: 2716502994
i also changed the resolution from 512x512 to 768x512 as wider pictures are more common for these kind of pictures ( as portraits are more common for people so it has more refferences)
with SD you want to make some things very specific, if i tell it to make a t shirt. it doesnt know if i want a blue, red, white or black tshirt.
that is helpful. I guess if we don't tell it what color to use, it would just randomly use anything that may make it look bad
granted my result isnt the greatest as the checkpoint i used was trained on real people
Yeah, I was going to ask as well. Most of the models are trained on real people images. I am looking for models that are better at this kind of stuff (objects)
you might wanna use stable diffusion XL for this lora but it requires a pretty beefy setup https://civitai.com/models/197869/chipx
granted it produces chips a bit better. i did a quick search but theres other options too i suppose. i think if you used a model thats a bit more trained youd get a long way


Silicon chip processor Lora
yeah i either recommend absolute reality or something like CyberRealistic for this use case but its still something niche
could work. just takes a while im rocking a 3070 Ti
Why do my colors look so... bad???

like there's this weird effect on them and it's making me upset

changing sampling method didn't help

and it's worse

what am I doing wrong?????

do i need to just...crank my sampling steps?? what the hell is this? the others were on 40, and this is on 20

60 steps isnt much better than 40.

like the previews look fine, and then when it finishes, it looks like ...garbage
If it is in comfyUI, you can try using 'conditioningConcat' and place the contaminated prompt in a separate 'ClipTextEncode'
hi
so what should I do in automate 1.1.1.1 if my goal is for the character to change clothes in random while im making 100 batches
should i write
wear shirt, coat, jacket, full sleves t-shirt
or
wear shirt, wear coat, wear jacket, wear full sleves t-shirt
or
wear shirt or coat or jacket or full sleves t-shirt
You can try using wildcard
yes. jus checked. good stuff. though there should also be the option to do this in prompt. imo
Rabbit
how do I fix the eyes

i found that 10-20 is the sweet spot
fixed it

With upscaling or with the adetailer extension, or by inpainting manually
thanks
How could I fix these parts? 🤔

/prompting help
Beep boop! Here are the corrections you requested.

/dd
Here is the image you requested.

Hey everyone,
I could really use some assistance with something. I'm trying to figure out how to create a new artistic style by combining influences from multiple artists using stable diffusion prompts. I've experimented with various examples, like Artist Name 1 and Artist Name 2, as well as trying to emulate the styles of individual artists like Artist Name 1 and Artist Name 2. However, despite my efforts, I'm not achieving the results I hoped for. Any suggestions or guidance would be greatly appreciated!
Also, does anyone know of any straightforward stable diffusion prompts that I could use to test and experiment with different artist styles?
Thanks in advance for your help!
hello
Does adding [feral dragon] to my positive prompt decrease the chances of a dragon being rendered?
Because it seems to have had the opposite effect.. I'm trying to generate a dragon humanoid lady but sometimes it'll just make an actual dragon instead of a girl with dragon horns and wings.
#🏞|general-with-images cloud,sky,science fiction,scenery,day,outdoors,building,science and technology sense city,(mechanical structure:1.2),(hard surface:1.2),car,BJ_Gundam,, masterpiece, best quality, complicated details,extremely detailed CG,perfect lighting,RAW,Masterpiece,Ultra High Resolution,(Dynamic Perspective),Sharp focus,(Masterpiece, Best Quality),8K,oc rendering,hd rendering