#📝|prompting-help
1 messages · Page 4 of 1
You can put a png with the same name as the the ti in your embeddings folder I think
That's smart
Probably easier to generate an image. that way it's generated from the TI
Yep
Trying to figure out what I want to make. Already did a poster today
@wheat swift do something with a bat
another one?
how many did you make ?
Alright here is something I never seen anyone do
Do a Uganda knuckles but a good one
Like the live action sonic style
Oh just saw the bat pic looks wierd af
was that your attempt of a knuckles? @wheat swift
That was SDs attempt. Not my normal subject
any tips to get rid of the seem like line between the original and the outpainted pixels ?

yeah. just inpaint over them
make sure you turn off outpaint first though. been down that road a time or two
wait what ?
turn off outpaint before you inpaint or it will outpaint again
which part do i inpaint
inpaint over the seam. go a bit wide and it will smooth out the seam
With the outpaint is it fine for the denoise to be 1 ?
I've never set it that high. Usually about 0.75 is fine, is it working for you?
would be better to set the mask smoothing larger then the denosiing
I prefer mk2 over poor man's
did your outpainting work except for the seams? you have enough vram?
I'm going to talk you through using img2img as glue if both those are ture

how big is your picture? you have to do a small batch, but this will work
512x512 batch count 1 batch size 1
send the picture to img2img. don't change your prompt, set your denoise to 0.25, click generate
the low noise makes sure it doesn't change the picture too much, but it will bind it all together and make it fit
How wmuch sampling?
sample steps should stay the same. everything else the same as the original generation
except the resolution. that will change to match the picture you send
Seem is gone but now I have a somewhat different picture so I will rise the denoise a bit
no you want to go down on denoising to keep the picture from changing
Thank you for everything I have to go now I will miss with more later
what do I do then ?
inpaint ?
inpaint is a sure fire way to make sure it is the same and only fixes what needs fixed
it's just a lot more work. It's my normal workflow
What if I redo the outpaint the original pic but with the seed will that help ?
You may still get a seam. It's just the nature of the beast
Aight then see you later
Take care
Hello guys, do you guys use stable diffusion too?
I'm quite new to it and trying to make clothing damage image.
I was wondering if anyone know of a way you can manipulate the prompts to have more control on how a person's outfit is damaged, to what degree, in what way or if possible "what's damaged, and what's not"?
Anyway, thanks in advance.
have you tried adding parenthesis around damaged? i think it makes that term stronger. i think it also depends how far it is from the start of the prompt, so if it's at the end it wont have as much of an effect
hey there, i am looking for promts to generade a realistic 9ft tournament pool table, some ideas ? i have struggle with dimensions, to much pockets...
Have you tried making an image "clothing", then using the inpaint tool to draw over the areas and run it at full resolution with the prompt similar to "damaged clothing" or "frayed clothing" until the areas you want damaged look good to you?
Hopefully this isn't too redundant a question, but for the life of me I can't make 2.1 generate a "hypodermic syringe" for a medical job, is this somehow disabled within the model itself?
If so, is there a list of items documented somewhere that are explicitly disabled like this that I can provide as a reference for the reason the job was not possible to complete?
Hello skeddles,
thanks for the tip. I actually did try this before. This does have it's effect. In fact, you can go from (ripped) all the way up to (ripped:1.5). Anything above 1.5 makes the image look weird.
However, at the very beginning, I was having a hard time even getting damage on the clothes at all. Despite trying the () modifiers. After a lot of trail and error, I realized, the program was not reading terms such as ripped(they read this word as muscular) and torn. Turns out, something that makes a huge difference is the symbol underscore _
When you say ripped_clothes. This makes the program understand and adding (word:multiplier) does the trick. Which is where I am currently at.
However, the issue I face currently is.
-
You know how increasing the factor increases the subject amount. For example, if you put (((((dog))))), there will be a lot of dogs in the image. So, for my images of torn clothes, the clothes will be ripped. But SD would add a bunch of extra fabric to the clothes. And a simple shirt, for example, would not look like a shirt. It would look like a shirt with a bunch of extra fabric attached to it but is badly torn.
-
I am unable to control how the damage goes. For example, If I want a missing fabric from someone's right shoulder, entire right half of the shirt ripped off(like Goku tends to be like), or something very specific like the character just wears 2 shirts, the one underneath is fine, and the 2nd has only scraps left.
There would be very little control on what I can do, SD seems to affect either all or nothing.
- Lastly, the tear and damage always looks unnatural, but this is a nitpick as SD already does so much for you.(I'll try to fix this as the last thing)
coincidentally, I just happened to encounter a reddit thread that tackled these functions.
I did play around with image to image yesterday. I saved an image of Goku with his right side of the shirt torn off and did my usual prompt. Unfortunately, it changed the whole damage to the usual weird looking/uncontrollable tear my promps usually appear as.
However, what you said, is actually a good idea I should try. I actually didn't think of doing this at all. Using the inpaint tool in certain regions. Huge thanks for the suggestion, really. I will try it out and let you know how it goes.
Another tool you can use is ControlNet, which allows you to use a reference image for the purpose of composition. You can use it in conjunction with img2img or even txt2img. I haven't tried using it for details like ripped clothing but you may find it possible to replicate the rip patterns of images online and put them into your desired image.
Any tips for generating interior design photos? I want to try having Stable Diffusion make my dream house.
Hey I'm having a problem with a prompt, I'm currently trying to generate a single eliete female sci fi solider in an image but when I do it two always pop up
(extremely detailed CG unity 8k wallpaper), (one:1.3) (elite female sci fi solider:1.2) in sleek form fitting intricate power armor, sci fi assault rifle, professional majestic oil painting by Ed Blinkey, Atey Ghailan, Studio Ghibli, by Jeremy Mann, Greg Manchess, Antonio Moro, trending on ArtStation, trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, by midjourney and greg rutkowski, realism, beautiful and detailed lighting, shadows, by Jeremy Lipking, by Antonio J. Manzanedo, by Frederic Remington, by HW Hansen, by Charles Marion Russell, by William Herbert Dunton, (No Helmet:1.4), (sci fi city:1.2), walking in a warzone
Negative prompt: western, cowboys, hat, disfigured, kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, ugly, disgusting, poorly drawn, childish, mutilated, , mangled, old, surreal, text, (multiple people:1.2), multiple subjects
Steps: 60, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1161103013, Size: 1080x1272, Model hash: bc561295ca, Model: protogenInfinity_protogenX86

I usually have that problem when I change the dimensions. The AI was trained on 512x512 images so anything bigger than that and it apparently just starts tiling?
try inpainting to localize the area where ripping hapens, you may just "paint" the ripping trail just the way you want it with a finer brush size
you may have to tweak the prompt to just say (ripped_clothing) and get rid of the character and background description etc.
I always use a DOC to write the prompts, keep them in version numbers and then the images I keep always have a version number trailing them so i know what prompts I used to generate those in the future, in case I want to re-roll or make alternatives of those. I should probably make an excel file instead of a DOC.
I know there is a way to extract prompt info from an image, but i am not sure if they are good at extracting all the inpainting, outpainting, re-rolls that an artist may have prompted in order to create the desired image. Many prompts I see from galleries like the ones on playgroundai simply show the final prompt, which sometimes look so empty that it seems to come out of an inpainting process, like ripped_shirt colar. Whilst the picture show an epic battle happening lol
Hi! Can someone help me with the correct syntax for blending between two things, like if i wanted to mix a cat and a dog by percentage, or two different embedded face trainings together, or an embedded face and a lora - whats the terminology to do this precisely
[object1:object2:0.5]
it's called a prompt edit
There are other ways to do it too. hold on. Getting the docs

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
and here is the other one I was looking for https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#composable-diffusion

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
amazing, thank you, i will dive in and research this now
Second question; is it possible to restrict certain attributes to one object or character, so this prompt doesn't bleed in to other thing, like say you wanted someone on a green chair, occasionally it does stuff like make their hair green, or give them a green shirt or something, is there a way to ring fence attributes to only a specific set of defined objectds
Only way I have gotten that to work is work on a section at a time
obviously there's inpainting but frustrating to control an image, like if you wanted lets say a normal looking person in a blade runner style future city its hard to not get it to put cyber crap on the character
(actually not tested that example but you know what i mean)
In painting is the only way I have gotten that to work
even if you say "there are photos of X on the wall in the BG" it may still put X on the characters T shirt or on the desk they are at or whatever
sd in notoriously bad at color control
AssertionError: AND is not supported for InstructPix2Pix checkpoint (unless using Image CFG scale = 1.0)
interesting
hi, is there anyway to colour a bw image using img2img?
is there a command to prevent instructpix2pix from changing a specific element in an image, like "do not change the shirt" or "preserve the color of the hat" etc
You could probably do some creative prompting, but deoldify is a neural network trained to do just that
instead of putting text that attempts to say "do not change shirt" on the shirt lolllll

text is a no no
maybe that trick I have seen people doing with having an img2img input as well as the controlnet input, if you set it the same it should theoretically keep some of the stuff
Looking for a prompting or similar method where I can specify goals and constraints, such as performance, materials, and manufacturing. It could be useful for automotive, aerospace, defense industries...
How can I get this kind of result in Stable Diffusion? Similar style but long range photo. Tried few prompts but it just changes the cloths into random colors

test
Hey I'm trying to generate norman rockwell style stuff
but when I do it I keep getting weird extra limbs and stuff any suggestions here are my prompts
norman rockwell style:1.2) illustration, excessivism, (a beautiful woman:1.2) in a sundress while she drinks a bottle of soda on a Saturday afternoon, golden hour
Negative prompt: Deformed, blurry, bad anatomy, disfigured, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, (mutated hands and fingers:1.4), ((anthro)), ((animal)), crown, flowers, candle, fire, flame, hat, horse, riding, umbrella, snow, zipper, zip, logo, text, water mark, (to many fingers:1.3), (bad hands:1.4), (disconnected limbs:1.5), weird hands, (multiple legs:1.2), floating limbs
Steps: 60, Sampler: DDIM, CFG scale: 7, Seed: 704020129, Size: 616x816, Model: protogenInfinity_protogenX86, Denoising strength: 0.7, Hires upscale: 2, Hires upscaler: Latent

Hey! I'm looking through the documentation trying to find the difference between putting a comma ',' and an AND in a prompt. For example, how does stable diffusion treat "cat, brown" different from "cat AND brown" ?
I know AND is for 'composable diffusion', but I'm trying to figure out how it's useful.

This is what I was able to find, but I'm looking for more of an explanation.
is the difference that it diffuses each prompt separately? So it adds each prompt to the previous result? Is there a way to apply a set of prompts to all AND statements?
Such as:
(cat:0.3 AND brown:0.7), sharp focus, illustration, etc?
I might be wrong but my impression is that stable diffusion does not particularly consider commas.
Even withouth commas you get something very similar.
Hello there, I got a question,
How do you make the ai able to identify which anime character you are going to make it to generate?
for example for those characters who have a name only
like Reze from chainsaw man
it probably wont be able to create a specific character for you, especially an obscure one. I'd either describe the character to the ai, or do some finetuning
alright, thanks
You can download a model that has the character.
0.65-1.0 suitable,You may not be able to perform particularly complex positions
oh, almost forget something like that exists lel
I am trying this prompt : 3d render of batman in a shiny black armour with a bat logo on the armour which is glowing blue... unable to get a proper generated image ... all give a batman with a bat logo but it is not glowing and it is not blue ... any suggestions ??
did you try emphasizing like (glowing blue)
or try rewording it, like with a glowing blue bat logo
Thanks a lot for the suggestions, but they did not turn out as expected , also tried : 3d render of batman in a shiny black armour with a (glowing blue) bat logo
its often hard to get it to add details exactly where you want them. inpainting might help show it where you want it, or photoshopping a blue glow on and doing img2img. i havent done much of that though.
any one have a ghibli prompt i could use
Can lora models compatible well with the major realistic models?
if it is trained against a 1.5 model, it will be compatible with a 1.5 realistic model, but the results may not be exactly the same. you may need to increase the weight a bit
if i wanted to do a person in the spaceship from the movie "Alien" how would i do it without turning the person themselves into some stupid "gray" alien, like SD wants to
like whats the best way to use a specific movie as a reference
Hey folks, I’m working on creating an app for professional prompt engineers to better help them create, share, and track prompts along with their renders. Question for you: How do you keep track of your past prompts, settings, and outputs right now?
they are baked into the png files so i just load files into PNG info and extract them that way, so if i want to take settings from an image that worked well, load it in that way
I’m using image-to-image processing to modify pictures of room interiors. Any ideas which prompts I can use to NOT alter structural elements like windows, doors, beams, etc.? Maybe negative prompts can help?
get the controlnet extension
Yes, like the most popular images are made from koreandoll Lora on top of chillmix model
I trained one with as few as 15 my own photos and then one with 120 photos, both worked perfectly with chillmix. Orange mix models are best for anime
Hi, I'm new to AI stuff. Came from trying free Midjourney and now install a local SD.
My problem is that, no matter how I tried I cannot get a good result with SD compared to Midjourney.
I don't think at all it is the SD fault. But just can't get anything good even using the prompt from Lexica.art
What models are you using and what kind of effect are you trying to get? you can also try embeddings prompts and negative prompts are very important as well
Scroll down and you will see models and embeddings tab its like two below the one we are in now shows a bunch of different models and embeddings you can use on the side bar to the left
Sorry I might give you wrong info. pretty new to this stuff.
I use Stable Diffusion v1.4 original. I just follow one youtube how to install that locally.
you can use any model with stable diffusion one sec I'll find a video
Yes I actually onto that. as I understand the model, if it is .ckpt I could put them on the model directory.
But because I'm new and no coding background, I still don't know how to get other thing to work, like for ex. I have one .pt file and don't know how to use that at the moment.
ok you can put safetensors in the model folder too I hear that's best but I use ckpt as well one sec I'll look up the pt folder I think those are
files
Ia this an original stabel diffusion?
yes .pt files are embeddings
so I just put .pt files in the same place for .ckpt (model) ?
just put those in the embeddings folder
Nooooo sorry put them in the emnbeddings folder
Ah okay, I see it now. So those one need to be trigger, meaning use the trigger word in prompt, yes?
https://civitai.com/models/6543/old-fashioned-diffusion it is this one I want to try at the moment.

Make images look like old fashioned illustrations with this embedding!Use the token "olfn" to create cool images in the style of old dead illustrators. I found the best results using Dreamshaper, but other models may work. With my small amount of testing it does not work on anime models.Try using any of these to get a more specific style:Allen A...
yes teh models work best witht he trigger word too Nitrosocke has some really good models
Ahhh yea I liked that one too
So, basically models will narrow the result down to what you are looking for, and those embedding will help at well? as my understanding.
Hi
Yea they both help with getting good effects there are a lot out there
I have to go take a shower and get ready for work I hope you enjoy and remember prompts matter a lot negative prompts as well
So just to let you know where I came from, the right pic is from SD1.4 I installed today, and the right is the Midjourney before I ran out of trial.
With SD the whole day I got these cheaper looking art see on the left image.


Thank you!
Not bad at all for y9our first images you should ahve seen mine way back lol
Alright, thanks a million!
Oh and certain embeddins will only work with the model in that how you say version like embeddings will only work with the 1.5 or 2.1 model so when pairing an embedding with a model make sure they are the same version or at least work together most of the time the creator of the embedding will say what version it works with 1.4, 1.5 2.0, 2.1
wait until you get to the point to where your merging the models its so much fun seeing what effects you can get
Yeah I saw that on youtube as well. I guess let's see if I get any decent with these one first.
you will it's not hard just remember prompt is super important
Yeah, at one point I ran out of word. I saw stuff like more than just "subject" but some symbols... I won't be taking more of your time atm before you late for work! thanks again!
@calm marsh think of Midjourny as Apple, and SD as Linux. Midjourney gives you everything slick and complexities hidden from you, but you get what they give you. SD gives you all the tools for you to use, including screw yourself up. But you have much more flexibility on things like what models to use, controlnets, etc etc
also, don't forget negative prompts
negatives are just as important as positive prompts
Hey, yeah I totally got that right away that's why I wouldnt say it is SD fault that I didn't get good result. But yeah I guess learning curve, but with other models+embedding now I feel I get a better result already.
I would suggest going to some place like civitai, see what models are out there. Most model pages will have images generated with the model, with the positive and negative prompts listed if you mouse over the !, or if you click on the image
that'll help with you getting started with prompting
Hi, what is the best negative prompt to avoid the face/head being cropped out? thx.
I'm am artist who wants to start using Stable Diffusion as a way to come up with ideas and compositions, but where I can later redraw those generated compositions myself. This also means that the generated images don't need to look good, they just need to have interesting "ideas". I however can't for the life of me get SD to generate interesting images that are still diverse. Prompts like "interesting composition" of course don't work, and whenever you do get interesting results it's when the prompt is so specific that all the generated images look nearly exactly the same.
The new --chaos feature in MidJourney seems really interesting so I might swap over to experiment with MidJourney instead, but I'd love to get some tips on how I could achieve the same with SD
I use "cropped", "out of frame", but not guaranteed
maybe ask ChatGPT to generate you some random prompts
Any suggestion of what model to use for the result like the bottom left, a painting style that looks like a retro Gi Joe action figure card? Thanks.

hello guys im using the sd and its working nice, the pictures are detailed but low quality, how to get them to proper quality? like ive seen 1080 or 4k these are really bad quality

like this

check off hires fix
Has anyone found consistent prompt words that tell SD to render a zoomed out view that show a whole subject? With many SD models, I keep running into problems with them showing cropped images. Is it because the models are trained with images of cropped subjects? Here is an example, using cars:
positive prompt: 3dmdt1, raw photo, a futuristic car, luxury, centered, (zoom out:1.8), photorealistic, reflective car body, intricate details, epic, beautiful lighting, best quality, hdr, dtm, (ultra hd:1.1), 100 megapixels, 10mm wide angle lens, view full car
negative prompt: (cropped:1.5), (out of frame:1.5), (zoomed in:1.5), (close up:1.5), washed out, faded, haze, oil, plastic, low res, (worst quality:1.3), (low quality:1.3), stretched, deformed, normal quality, jpeg artifacts, 3d, rendering, drawing, illustration, blurry, crown, hat, black and white, border, frame, lowres, asymmetrical, blurry, disconnected, duplicate, signature, username, frame, logo, (Watermark:1.5), (Text:1.3)



I get mostly images of the 1 picture: a cropped car. and in 1 out of 10-20 images I get a full car but only from front views. If I change the image aspect ratio, ie making the image wider/bigger, I get deformed or stretched cars instead of it showing the full car, despite deformed and stretched mentioned in negative prompt.
Leonardoai the webapp has a button for "zoom out" that fixes this. It is based on stable diffusion 1.5 and 2.1, does anyone know if there are magic keywords that SD immediately understands? because I typed zoom out, view full car, wide angle lens, etc in different orders of the prompt (way up front of the prompt to emphasize, with brackets and numbers), none of those strategies work. It make me suspect if it is due to the model being fed mostly images of cropped subjects.
i have the same problem with people. havent really found any good prompts or negative prompts that fix it. making the image rectangular might help a little.
i think it mainly stems from the images SD was trained on being autocropped from rectangular images, meaning they frequently had things chopped off.
outpainting might be able to fix the on the results you like (though i havent tried it).
you might be able to train your own embedding/hypernetwork to fix it. I've been training an embedding based on a certain style and make sure all the inputs were cropped, and I definitely get less cutoff things than before. so maybe you could train one on car images. (though this takes a while, and im not even sure SD would be able to pick up on something like that.)
lastly you might wanna try control nets, which you could use to force the car to be drawn in a specific place (im just not sure how far the design could diverge from the input without affecting the size/position of the subject.
yeah thanks for the suggestions. I've trained with other objects with images that I've carefully cropped to show the full object, and some close ups, in different perspectives, top/bottom/elevations and that my custom model is less prone to the constant zoom in view. Unless it is mixed with another subject that maybe trained differently. I will try your suggestions.
I am just curious as to how leonardo fixes it, maybe it is some form of outpainting and then merging the results to give you a "zoomed out" version of your creation.
its just a 1 click operation there.
yeah thats what i would guess too
Anyone got some tips for negative prompts I can use when generating a person with a white background ? It keeps rendering the background as a light source, so the edges of the person has a slight white glow. Is there a way to get around this?
try white plain background or white canvas/ white studio background?


i didnt have a ton of luck with getting a white background, it's whats i want too. except when I trained my own embedding on images that only had white backgrounds, then i get them more often than not
thanks guys I'll try it out 😄 Some things I render that has a white background turns out just fine, but with this one I got the white edges every time
is there a good way in SD to have say 4 embeddings and have it randomly use one or the other in the various images it generates? like an "or" command
a list of things this OR this OR this
maybe this will work? https://ericri.medium.com/smile-get-wild-with-stable-diffusion-wildcards-and-facial-expressions-83a52e4ca9fd

Medium
Quick share of two techniques: (1) using wildcards for variety in your prompt and (2) having specific expressions in your images.
I haven't tried it myself, so ymmv
dynamic prompts?
edit: just tried it, seems to work. install the extention then just do {embedding1|embedding2|embedding3}
where do i get this?
cool will check it out
https://github.com/adieyal/sd-dynamic-prompts, just add it in the extensions tab
both wildcards and dynamic prompts are in extensions
thanks yeah just installed
has anyone tested Dynamic Thresholding (CFG Scale Fix) and figured out what decent values are to use as starting point
it might be easier to look through model s and find one you want to work with rather than have a style picked out unless your an artist and want to train your own style or you want to collect some images and train a model but maybe https://huggingface.co/nitrosocke mo-di-diffusion or nitro-diffusion and playing in the prompt " retro GI Joe" comic book animated show or something like that might work not sur haven't watched that cartoon since I was a kid

has anyone figured out a clear method to getting a consistent full body render? 9/10 of mine are always from the chest up.
https://www.youtube.com/watch?v=xMmCZ1EqMVA Closest thing I have seen

I recently made a video about ControlNet and how to use the openpose extension to transfer a pose to another character and today I will show you how to quickly and easily generate a character turnaround or a character sheet with the same character with different angles using a simple open pose template!
Did you manage to create a character shee...
thank you. i will look into it
Thanks for the tip. yeah, I just like the art style on my uploaded example.
Maybe I rather need to find the right prompt for it as you said. Probably an artist's name or something.
I tried Alex Ross, not exactly the style I search for but maybe close. (example below)
I think his style is still too realistic comic drawing compared to what I want.

I went to Nitrosocke as you mentioned, but didn't get to download them yet.
Many interesting ones but models size are big, so I just didn't download everything I want.
Maybe the "classic anim diffusion" would work for what I want. I'll try later.
depending on how much source material you have, you could also train a model or a lora specificaly for it too
thoughts on a prompt to achieve this style?

As in, Im not sure what the style is called or what I would need to include to get a very similar style, so any words that relate to it you might think of could be helpful
hey does abyss orange mix 2 prefer danbooru tag prompts or normal people prompts
Thanks, I'm quite new (second day using it) and I heard about train a model.
I understand what is a model and an embedding now. But I haven't look into lora yet.
Will probably get into it eventually. Thanks!
well, all trainings work in the same way, you give them a dataset (a series of pictures you want it to learn) and some tokens to learn it on, and they produce a way to then prompt the things you trained on. All work the same on that front. bu all have their up and downsides, depending on what you want to do
LORA is the newest method, quite high on the quality side of things, while being also fast to train and light to share. it's the current craze from what I see.
Full model finetuning can be more qualitative imo, but is longer to train and higher size to share.
Text inversion embedings are usually faster but lower quality, but quite effective for style training (as opposed to subject training)
I'm a little out of date, so I could be wrong on some of those

i want to generate background of this picture
but i dont know wherre to start
do i use painthua or get sd infinity/invoke ai>?
inpainting?
anyone knows how to make background cleaner? My generated images always has some random around the character. I've tried negative prompt: messy background, chaos
Add noise, jpeg artifacts to your negatives and if you are using automatic1111 you can try adding a vae
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main

/ok

hey someone knows how to get this style? or even just flat 2d citys backgrounds?

synthwave?
thx will try
So control net keeps spitting out nsfw results even when negative prompting. Never had issues with the models like deliberate before. Any ideas?
describe the clothes more maybe
hmm might have been the model, stopped having issues when I switched to protogen
Is there a way to make it so that the Automatic1111 gui will pick between some parts of a prompt for each generation? Sort of like what | does, but for entire images instead of each step?
this is for instances where I wanna just let it cook for a while, but I want a few different variations on a theme
You can use x/y/z script with SR Mode as X
Select it and Hover over the name for more Information
ok great thanks!
Hey folks, I'm trying to generate people faces with skin defects like acne, pimples, chickenpox. Have anyone tried to do so?
Chickenpox is a bit of exaggeration, but I want to have faces similar to what I can see in a subway, not in Hollywood under heavy makeup
I tried to mention keywords above, but all I'm getting is people with smooth skin with no flaws
I use ControlNet on sd1.5 right now
Try intricate skin Detail, and maybe natural skin
Nope, doesn't work this way. At least for me
It feels like there is a strong bias towards photogenic people with flawless skin
yes, since the data was scraped from the internet for image knowledge, and there are probably way fewer "pimpled face" people than models
Got GPU busy for a while, but it probably makes sense to try DB/LoRA with something like this

Gonna try it eventually, but yeah, considering that the look of skin defects depends on skin color also makes it non-trivial
Can someone tell me what I am doing wrong? I think I have everything set up right, but the images coming out, even with super simply prompts, are terrible.


You need a resolution of 512x512 minimum because every 1.5 model is based on 512x512
that seems to improve things a bit, but still very poor results. I have an ok GPU, is that causing the issue?
I have a GTX 1660 TI on this machine.
You have no negative prompt
Would recommend 512x512 euler a for sampler and go with 20-40 steps
He also needs more Quality tags, also negative ones, also other models
can you recommend some good models? @silver valley ?
Depends on your liking, Protogenv2.2 or Dreamshaper are good ones to start
HELP, all the models i trained are looking great at 50-60% of generations and then starts to change to bad results, tried CFG an Steps but its the same, Does that have anything to do with over training??? i always like that range of my model but it starts looking old or changing to a different character.
ok. downloading both of them now... do I put those safetensors files in the same folder as the .ckpt files? or where do I put them to use them? @silver valley
Never mind, it is the same folder. This is much better. Thank you everyone!!
is there a way to tell Stable Diffusion to only use certain colors? legitimately just giving it a list of hex/RGB values (for pixel art)
not currently, no. I tried to make it output any flat color and it was already hard to get the full picture in the wanted color with prompt
which are the best samplers for photographic looking stuff? I mainly use EulerA and havent seen particularly better results from other samplers but not done exhaustive testing, what do ppl think?
can some tell me what style is this? (img2img)

Idk if this is the right channel but I've remade the picture on the left, my version is on the right. Trying to get the same sharpness and detail and quality when upscaling and it's really close! But there is just some blurriness still in the image I've created (right). You can only really tell when it's zoomed in so it's cropped here but yeah. I guess I'm asking for the best settings for upscaling realistic anime images lol. On this I did combo of SwinIR_4x and 4x_AnimeSharp (0,5 visibility).

honestly it's probably like the details in the hair that I think are less pronounced in mine, like the lines in the braid...
hello i need help
I want to generate images that look similar to these above
what i want is that gradient lighting, and really smooth surface.




i have awful results so i need help
Hello, I am trying to use inpant to change this figure to be explicitly hooded, but I think the "ukiyo-e" prompting is making it forcibly add a head to the image, could someone advise how i might go about encouraging the model to generate a hooded head rather than a visible one?

additionally, though not as important, I'd like to sharpen the image - either with the prompt or using an upscaler, if anyone had any advice on the topic I'd be grateful.
could try weighing the keyword like (hood:1.5) maybe, and maybe even do (ukiyo-e:0.8) if you think that's what's forcing the visible head to encourage it to make a hood!
ah ok, ty
@calm marsh this came out today thought it might help you with prompting a bit https://www.youtube.com/watch?v=HkLUmTJoyhw

How to create fine-tune prompts in Stable Diffusion with advanced functionality. In this video, I am explaining how they work and where to use them.
Very impressive AI driving image and video upscale https://topazlabs.com/ref/1514/ , try for free.
THANK YOU for your support!
Please subscribe and leave your comments, and don't forget to click o...
I personally use DPM++ 2M Karras. You may want to run the x/y/z plot and use sampler vs. steps to find something that fits your personal aesthetics.
😀
are there are resources with ready to go presets(automatic1111 calls it styles) i would love to check out some good ones to learn prompt engineering a little bit better
yes i second the x/y/z plot with different samplers and steps. I find that depending on the model/ti/loras used, the results can vary. There is no absolute best. I use DPM++ 2M Karras for photoreal people often, but sometimes it is "too sharp" (hard to explain), maybe due to the lighting. I try that with environment/buildings too. D-2-K is sometime producing very unnaturally sharp edges, and worst, thickens details to achieve that sharpness, it is very easily noticeable when i just zoom in a bit to find that, dont even need to pixel peep. Whilst on Euler, things like fine mesh surfaces on buildings look "finer" with more detail, although it is a bit more "blurry", it looks more natural, and we perceive that surface to be finer with smaller holes on the mesh, vs D-2-K that made very sharp mesh, but with thicker mesh lines and much bigger holes on the mesh.
Anyway get better hands ?

(modelshoot style), (from_above:1.3), (hand_on_hip:1.2), (modern punk clothing:1.2), bulletproof vest, intricate design, 26 year old, (black woman:1.5), (vampire hunter:1.2), (she's holding a sword:1.2), (muscled body:1.3), (a character portrait:1.1), art by artgerm and greg rutkowski and magali villeneuve, analog style, (mdjrny-v4 style), (blood stains on clothing:1.4),
Negative prompt: lowres, (bad anatomy), (error body), error hair, ((error arm)), ((error hands)), ((bad hands)), error fingers, bad fingers, missing fingers, error legs, bad legs, multiple legs, ((missing legs)), error lighting, error shadow, error reflection, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ((error eyes)), ((bug eyes)), ((bad eyes)), bad mouth, error mouth, (error face), (((ugly))), (nsfw:1.2),
Steps: 50, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3286114148, Size: 512x800,
Model: protogenInfinity_protogenX86, Denoising strength: 0.7, Hires upscale: 2, Hires upscaler: SwinIR_4x
you can either inpaint again and again the hand, use a TI or LORA or other training specificaly made on hands to help the quality of those, or you could try controlnet and its openpose that has a hand model integrated it seemed
but yes, out of the box, SD hates hands for now
I still get crappy hands with controlnet
I've almost given up and started just hiding the hands 😆
I only make turtles now, so I dodge the problem entirely
trying to go for some abstract art that kind that replace a dancer's body with a pattern/ material(clockwork, clouds, grass etc), do you guys have any tips on models/ prompts that are a must have?
I wonder if future SD will fix the hands
double exposure maybe ?https://civitai.com/?query=double exposure
Civitai is a platform for Stable Diffusion AI Art models. We have a collection of over 1,700 models from 250+ creators. We also have a collection of 1200 reviews from the community along with 12,000+ images with prompts to get you started.

let me give it a shot!
If you have a decent Nvidia card, you can start with https://github.com/AUTOMATIC1111/stable-diffusion-webui
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
Or, alternatively, https://github.com/invoke-ai/InvokeAI

GitHub
InvokeAI is a leading creative engine for Stable Diffusion models, empowering professionals, artists, and enthusiasts to generate and create visual media using the latest AI-driven technologies. Th...
This one's amazing, really worth the try
real good job by @fresh nest 🙂 happy to share
@winter ledge
FAQ: I'm new here, how do I generate images ? Where is the bot ?
Welcome ! There is no bot currently to generate your images on discord. You may want to start by taking a look at the #1014939219904450590 channel. You can access Stable diffusion in different ways : 1️⃣ the official website, https://beta.dreamstudio.ai/. The easiest and fastest way to access Stable diffusion with 200 free credits. For any question on it, you can find help in the #1025467151206854736 channel. 2️⃣ Installing Stable diffusion on your computer. There are numerous projects that let you do that, and you will find help in the #🤝|tech-support channel. 3️⃣ Running Stable diffusion in the cloud, through rented GPU services, using notebooks. You can find lots of them shared and discussed over in the #1011228442399883294 channel.
for a little more detailed answer, don't hesitate to ask
1/ is the easiest and fastest
2/ is the coolest and most fun to play with if you have the hardware for it
3/ is a cool fallback if you don't have the hardware for it
links given by happyfunball are quite good, the most popular tools for solution 2/
Any tips on making a consistent character in SD? I thought making a Lora based on several similar results would work, but how do I GET several consistent design results?
Not sure if you can do it with this tool but there are several options:
- Base the prompt on celebreties
- Train your model
- Use an image as input
.
.
.
Also got a question for help. I noticed some negtive prompts are using "::" can someone help me to find more info about this writting? I believe it is related to SD 1.5?
Only ::? Or word:: ?
It shouldnt do anything
Yes training on generated images does work. it's called using a synthetic dataset
This model is absolutely great when you just say a few descriptors and also I added a lot of comments on lighting etc (while it didn't turn that part out as I wanted exactly, still amazing. Like I gave a few ideas but this thing can think on it's own too tbf

Talking about models... This was supposed to be a model3 concept
So I am having trouble reproducing effects/ambeince like the design behind (and maybe the placement of the car) in this picture. Scale is a bit off but it isnt a problem since the finishes are way better than any other image I have gotten it to produce. What should I have requested to get this again? Just in general, the lighting, colors. I mean I put this "... with surreal and majestic lighting, making it look heavenly. The ambiance looks dreamy..." but only this image came out with that effect

Hey! I've tried to make these characters look like me and my friends ffxiv characters. Did many iterations to get the cloting and body detailes kinda right. But after that many masking and inpainting the image is blurry and inconsistent. How can I clear the image without loosing detail/transforming the characters too much?

https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#prompt-editing
[to:when] - adds to to the prompt after a fixed number of steps (when)
[from::when] - removes from from the prompt after a fixed number of steps (when)
:: is a special operator that applies to the block it's put on, and puts a weight on the prompt presentation itself
In other words, the prompt :
a duck (on a plane::0.7)
will act like the prompt "a duck on a plane" for 70% of the image geneation steps, and then will act like "a duck". the rest of the prompt will not be presented to the model anymore during the last 30% of the generation process
this is a really nice feature
that I discovered yesterday, it would really deserve a prompt guide one day
I'm not 100% sure, but I would try to downscale this to 512x512 and then try different upscalers. some are very good with sharpness, some are good with color gradients, ... you may not find any that fits for everything, but you should find a better base.
Then you can use inpaint, and the "inpaint at full resolution" option, masking only small details and remaking only those. for example the hand on the far left, you would just mask that, inpaint it at full scale (it would do a full 512x512 hand and insert it in your picture), and keep on doing the same on the other details you need bettering
talking purely about prompt tricks, using keywords of context where you could see such pictures could help. like this could be a "car showcase" or even the name of a specific car event where good photos of car are usually taken. Those can bring good qualities to your rendering too
But mostly I would use some image2image or controlnet to force the composition, so I'd be sure to have the car in the center, the pillar, ... and then I could focus my prompt on the style and not that much on the composition since it would already been taken care of
Why does my nature landscape turn out so bright, contrasted and saturated even though I directly specified not to in the negative prompt and added some "high-quality" tags in the normal prompts (if you need more context to understand ask me)
Hi, the idea if the text2img result is close to what you like, you'd use that as an img2img to get more variation from it yes?
And if so, does the original prompt from txt2img has to be in img2img prompt? or you can start new?
It doesn't have to be there, no
You can use a separate prompt for img2img to more detailed description of the desired output
Thank you!
Oh i knew the From when, but didnt know You can just use Word::0.8,
thx for the explanation
A trippy art piece with a celestial dreamscape portraying the solar system might feature a vast and expansive cosmic landscape. The stars and galaxies in the background would be painted with swirling, iridescent colors that create a dreamlike effect.
The planets in the foreground would be depicted as glowing orbs of light, surrounded by shimmering rings of gas and dust. Each planet would be uniquely stylized, with intricate patterns and designs that evoke a sense of mystery and wonder.
The overall effect of the piece would be ethereal and otherworldly, as if the viewer were floating through space in a dreamlike state. The use of vibrant colors and surreal imagery would create a sense of awe and inspiration, inviting the viewer to contemplate the mysteries of the universe.
how to use image to image?
#1011634831467221033 could lend more responses but let me give a little sum up
img2img (image to image) is the art of modifying a picture using a prompt. It uses most of the same parameters as txt2img, but some new ones are important :
- the picture input. this will be the base noise of your new picture and, depending on the next parameter, will inspire a little or a lot your new picture
- denoising : this goes from 0 (the output would be exactly the picture you put in, and the prompt would be ignored) to 1 (the output wouldn't follow the input image at all, it would just use the prompt)
there are some other "modes" for img2img, in particular "inpainting". It's the same thing, but this time you let SD modify only part of the source image by drawing a mask on it
Hello folks,
Need help! Here is a great opportunity for a skilled Gen AI artist.
We are looking for a digital AI art creator with a keen artistic sensitivity to help us with prompt engineering. We are developing an app to help people get present to their emotions with the help of AI (https://FeelsArt.ai).
The artist will work with SD 1.5 and custom models to write many prompts with an aim to generate emotionally-meaningful beautiful art. Being knowledgable, attentive, accurate and with high emotional intelligence would be just terrific. When you join our team you will be guided and well remunerated.
Do you know anyone who would benefit from this opportunity?
Cheers,
Nazar.
info@feelsart.ai

welcome around, nice presentation, and also a thanks for putting in the effort to explain it like that, clearly, and not spam every other day. I hope you got some contacts last time ?
cute cat too 🙂
Still relevant 👆
If I would like to get a littlebit "straighter", "cleaner" lines on my results, what are some prompts that would help with this, but not affect too much of the other stylistic stuff? (this is snipet example, 1 current 2 desired)


you may have tokens in the prompt that call for brightness indirectly ? like asking for a lion would force fur to generate too ? not sure, the full prompt could help (or could also stay a mistery, but we could try things)
I asked for gentle sunlight and visible sunrays, i don't think anything else was related. I deleted the prompt anyway now, I will try again later
Are there a good prompt for "axe" or "hatchet"?
I try to use inpaint to add an axe on the hand of the character. However I try the axe won't be there. I tried hatchet in prompt with no luck.
When I use prompt "axe" to generate new (txt2img) I only got something that looks like a short knife or sword.
i second this problem~
Hello guys so i have a picture with a white blank background that i want to change do you have any tips of how to approach this ?
inpaint with a denoise scale of 1
What about the mask blur?
um probably can stay at default

looks good to me
@tired vigil thanks for the info, gonna try it out 😁, I saved the original text at home but I dont think it had any weights just the word and ::
I read it again later and I made an error in my example, please do use the doc I linked instead, I don't want to spread misinformation
happy to help :=)
Jup gonna check the doc for sure.😁
@tired vigil small follow up question (if you dont mind). What would you consider to be the best way of writing a negative prompt inside the actual prompt?
Should I just add a weight 0 or do you think about something else?
adding negative prompt inside the prompt is a bad idea.
weight 0 will make it ignored, it's also a bad idea since it will make no difference and still cost you tokens
some older implementations let you use negative weight, but I don't know how this behaves now. even back then, it was quite glitchy, outputing pure glitch picture more often than not.
Why not use negative though ?
I don't see solution directly to your question to be honest, maybe using tokens close to the "opposite" of what you want to exclude ? but using the token you don't want, in any way, inside the prompt itself, should only push it more inside than repulse it
Yeah I am also trying to figuere it out. It is for a project where I only want to use pthe positive prompt
If it is only affecting 1 or very few areas, I would try in painting with a new prompt for the area, adding emphasis: straight lines. Sometimes it works. You may have to use a different sampling method, from my past experience. However, I would also like to know if there is a better way, more consistent way to avoid these wobbly lines in Stable Diffusion. I've used positive prompts like straight lines, sharp lines, fine lines, negative prompts like wobble/wobbly lines, curve lines/shapes, badly drawn, scribbles, etc. There is never consistent results, and like you say, sometimes they affect areas where I want curves, so it is not a good solution. Other times, SD just straight up ignore my calls for straight lines, drawing wobbly lines all over the image, despite everything is based on rectangles, and end up drawing a whole page of soap like bars.
In those cases, in-painting wont work since I need SD to completely redraw it. I've tried image2image to try to save the work since I like the color, lighting, composition, but that does not work 99% of the time. I will draw something new to get straighter lines out, and if I control it so it says true to original image, the soap bars reappear without being straightened out.
This is one of the most frustrating problems in SD. switching models, aspect ratio, sampling method, prompting, nothing fixes it. Either get a completely new picture for straighter lines, or live with the soapy looking images.

case in point, i cant in-paint my way out of this mess...i like everything about it, except the wobbly lines

again, verticals are straight, but the horizontal grid/mesh, wobbly
Is it just me or is stable diffusion not good with generating a lot of basic items such as sword, staff, pickaxe, pen, hat, arrow, bow, crossbow, etc. I’m guessing it hasn’t been trained on a lot of things? Everything like this that I try generating gives me disfigured objects or very zoomed in close ups that don’t resemble these items at all.. is there a way I can get these to generate correctly or somewhere I can report this bug?
SD does not like violence. we talked about guns a few days ago
you may want to train your own loras and name the bows axes etc into other names
I could imagine guns but a lot of this stuff might be for recreations of the past like medieval times
@smoky totem Thank you for comprehensive response, appreciate it. I will try to remember to let you know If I find something that helps with it 🙂
Need somebody to help me w/ making an image to a prompt (kinda confused how to replicate the art style, dm me (NSFW))
Thanks! Can you make me a simple example of any car you want its all ok
For NSFW what I do know is u need special models or something idrk
sure, let's try those tips, but I'm not into cars that much personally, I'll be worse on prompt itself.
1/ using CLIP on your pictures, I got some tokens and added mine to get the prompt
a silver car on display, car showcase, square picture, Dahlov Ipcar, ue 5, a digital rendering, panfuturism
first picture as result. problem is, it's not consistent. I get around 6/8 cars in frame still, quite OK to me
there is no real lighting, and the "car showcase" token put it inside if I don't add anything for describing the outside
But also, using the first pic I sent in img2img with 0.75 denoising and some new tokens like "surreal lights, lens flare" and adding "outdoors" to the display at the start of the prompt, I get the grid I sent. Lots of consistency, cars stay in frame, lights get better.
2/ let's start again with the black car this time, using controlnet. I used interrogate to have a new base prompt and added kind of the same modifiers :
a black rolls royce parked in front of a building, Andrew Law, luxury, photoshoot, car showcase outdoors, surreal lights, lens flare
this time, we get the grid I sent. Like said, there is no more question about composition : the composition stays exactly the same as the original photo, but you can play with all other parameters now and get it just as you'd like.
This was done using the "canny" model of ControlNet


all on 1.5 model
I don't get the majority of it, my appologies lol. Im basically only skilled enough for the basic playgrund on the online versin (also hardware constraints) so basically do you have any tips for me on just using that?
mostly the 1/, I'll rephrase
useful tokens in my tests : outdoor car showcase, square picture, digital rendering, lens flare, surreal lighting
You can also use the "Image" field in the bottom right, and put an example photo with the composition you want : a car in the middle.
When using that option, you have a slider named "image strengh" that appears at the top. lower it a little, like 35%. This is how strong your input image will inspire the output. If it's too high, it will have a hard time changing too much things, but you can play around with it.
Using the prompt :
a black rolls royce parked in front of a building, Andrew Law, luxury, photoshoot, outdoor car showcase, square picture, digital rendering, lens flare, surreal lighting
I got this :

from automatic1111 github: "Adding a BREAK keyword (must be uppercase) fills the current chunks with padding characters. Adding more text after BREAK text will start a new chunk." what does this mean? whats the use case?
I suppose it might be to do with doing prompts like :girl riding a bike BREAK sunshine, street, cars. So seperating concepts and foreground and background . This is what I want it to be though I don't actually understand the explanation lol.
check the thing just before it in the doc, Infinite prompt length. it's made so that you can manage "batches" of token in their weird way of making infinite prompt possible
Typing past standard 75 tokens that Stable Diffusion usually accepts increases prompt size limit from 75 to 150. Typing past that increases prompt size further. This is done by breaking the prompt into chunks of 75 tokens, processing each independently using CLIP's Transformers neural network, and then concatenating the result before feeding into the next component of stable diffusion, the Unet.
For example, a prompt with 120 tokens would be separated into two chunks: first with 75 tokens, second with 45. Both would be padded to 75 tokens and extended with start/end tokens to 77. After passing those two chunks though CLIP, we'll have two tensors with shape of (1, 77, 768). Concatenating those results in (1, 154, 768) tensor that is then passed to Unet without issue.
oh okay, so it needs some help breaking it up. Is token= single word or is token what's inside two commas? ,girl riding a bike, = 1 token, or 4?
it's a little more complex than that... a token is around 3/4th of a word usually, and is broken apart automaticaly by the interpreter there. You see the number of tokens grow as you type your prompt in the UI too
I can't check right now, I'm running a training, but your example could be around 4 to 6 tokens maybe
this also can depend on some other things, like if you had a TI loaded that would weight 8 token and would be linked to the word "bike"
"it's a little more complex than that" it always is haha! Easy enough to keep track of it though in the UI. Ty!
What does a colon and underscore do to a prompt? Ive looked through the automatic1111 doc but didn't see it mentioned. I've heard some explanations for it like ":" can link two concepts like so : cat:girl. But I see no mention of that. I've also seen underscore described as a way to limit a keyword to only affect another keyword like so: white_dress. And the explanation was that it is done in order to prevent the keyword white from "spilling" all over the image.
I got a special model, if you have a specific request I could try to run it once, but cant promise anything. Just for comparision.
Question how to prompt color or not just red,green etc simple colors is it possible like hex codes?
you can try to trick the AI into it but there is no real command for it, you'll ask for a prompt that would describe such things. Using terms like the HEX code, the pantone name, .... copying how such picture could be titled if it was found online, can help, and did for me to some degree, but there was no consistency, I could get a picture of a pantone book in the middle of flat colors... this isn't the best tool for that.
I realise that
testing diffrent samplers in img2img and the image looks normal while rendering but then at the last second turns to this mess on the right


whyyyy
Dm me
afternoon! been trying to recreate this style in SD img2img but i cant seem to figure it out
tried a mixture of prompts and models but no where close to what i want. anyone got some insight on how to achieve this?

i cant even describe what im looking at so idk how an ai would

how about: a black and white photo of a person made out of metal parts, cyberpunk art by Steven James Petruccio, cgsociety, afrofuturism, dystopian art, steampunk, future tech
Credits to image2prompt AI model
This happens to me a lot. The image looks great during the sampling but the last sample turns out too sharp and saturated, just like your image.
Is there some kind of tutorial on the basics of creating solid prompts that produce okay or decent results that you can use to refine going forward?
how do you even get to this level of quality in the first place?
usually, a really good model
maybe this is prompting help, so i'll ask here
i struggle pretty hard to get ControlNet to work
it functions, it copies the pose of a source image, but the generations that come as a result of it are invariably awful
The model is neverending dream made by Lykon and yeah model+prompts lol https://civitai.com/gallery/114071?modelId=10028&modelVersionId=11925&infinite=false&returnUrl=%2Fmodels%2F10028%2Fneverending-dream-ned check the comments - the creator kindly explained his workflow to me.
But one trick for detail is in this video https://www.youtube.com/watch?v=4u-Ytioi3DM&t=1s. Result is like this. Obviously the left face has TONS more detail.

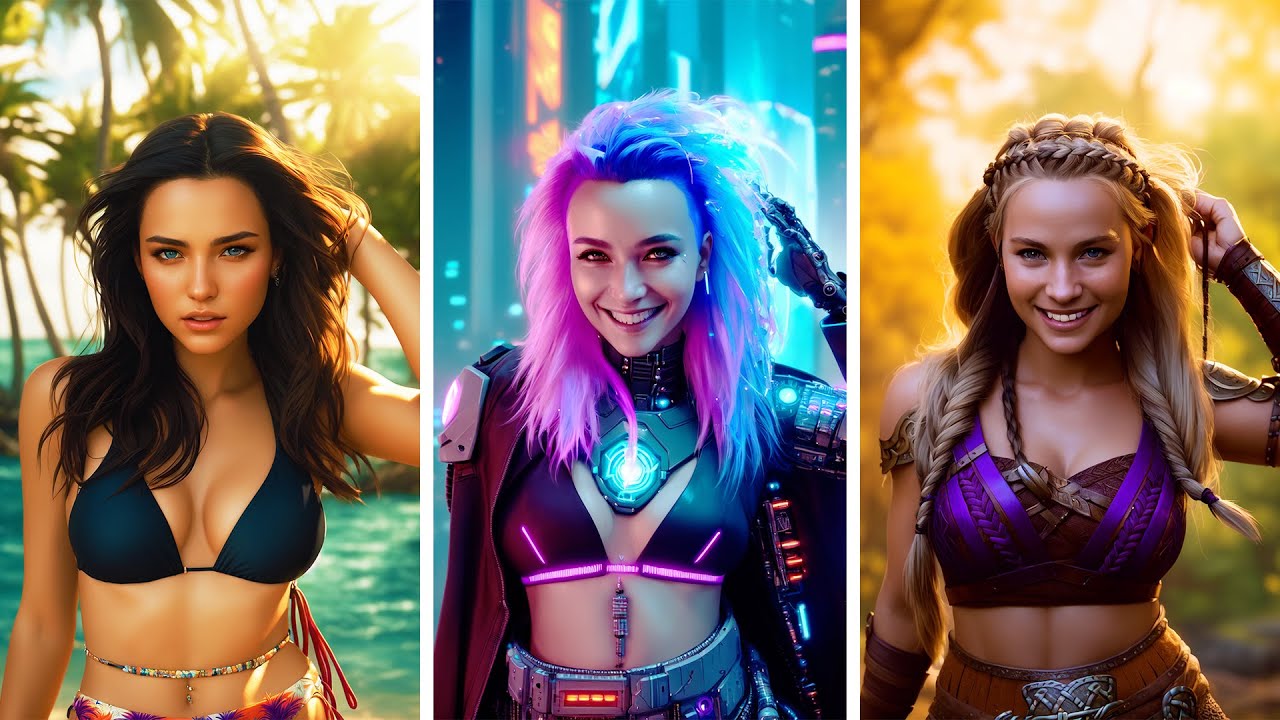
I reveal my never before seen workflow to achieve the best images possible in Stable diffusion together with the ControlNet extension. ControlNet lets you use any composition or pose when creating Stable diffusion images.
Support me on Patreon to get access to unique perks!
https://www.patreon.com/sebastiankamph
Chat with me in our community d...
it's a safetensors file, does this work with SD?
yeah, safetensors work
the pruned versions of ControlNet models are safetensors iirc
yep with automatic1111 it works
so I just save it into the stable-diffusion folder like all other models?
exactly the same
I'm excited to see how this model differs from the default
not sure if this workflow is applicable for people using computers without a ton of ram
i'm using a 3070 which is 8GB, i cant render above 1024 in any dimension
I've experienced this, what I tried to fix this is lower/upper the CFG little by little. Usually within like 2 CFG steps the good image shows up. I am not too knowledgeable on this but the image on the right that is screwed up is either over/under "baked" (edit, sorry not CFG but steps, I usually start with 20, but most models can produce "acceptable" images from 15 steps, then you start to see pose changes every 3-5 steps. Sometimes I watch the scenes change from 20-50. If the eventual image looks bad, I step back a couple of steps or forward a couple of steps, usually I'd find the image that I want.)
I would capture the prompt, seeds, settings, and redo that image with small decreases/increments
I'm on a gtx 1080 and I'm ok starting generating at 512x768 then doubling it and then inpainting into that.
weird, mine always hits me with a CUDA error
you running optimization code or anything?
nope just standard everything. But yeah that happens sometimesbut as long as i stick to that res I'm almost always ok. If it absolutely refuses a reboot does the trick but it's rare that I need to do that.
lemme give you a life example for ControlNet just sorta shitting itself for me
But slightly higher res and it's CUDA errors all day
i want to use this D&D char ref as a pose

easy enough, you'd think!
How did you even get this clothing so similar? I understand how one can take certain key features of an image and sort of replicate it, but I could never get a specific type of clothing like that
i dont exactly want anything funky so the prompt is basically just "greg rutkowski, elf"
cause i just want to see a re-rendition of the image in his style
instead it gives me this

So do you want to only save the pose?
my intent is to have the same image but to have basically changed the art style, i suppose?
but what often happens is i just have the "outline" of the pose remain, while everything else just becomes random colors
Interesting
I just copied the generation data. I had to generate some images to find that pose though. But since that image used a Lora of the character it pulled from a kinda limited dataset. BUT what I gather is that same generation settiongs = same image IF on the same machine. Like when you press generate and then generate again - same seed, same image.
even when i lower the CFG and even the weight of ControlNet, it still gets obscenely funky

Ah, alright. I can't imagine making up a prompt to replicate the original image so closely without yoinking data from somewhere.
Ok so the colors will not transfer by controlnet. What contorlnet model are you using for this? If you give me the prompts i can try it out.
dreamlikeart, greg rutkowski, elf, beautiful, handsome, male, masculine
Negative prompt: feminine, woman, female
Steps: 20, Sampler: Euler a, CFG scale: 3, Seed: 552418222, Size: 512x768, Model hash: 0aecbcfa2c, ControlNet Enabled: True, ControlNet Module: canny, ControlNet Model: controlnetPreTrained_cannyDifferenceV10 [ea6e3b9c], ControlNet Weight: 0.4, ControlNet Guidance Strength: 1
the model is dreamlike-diffusion
Now I feel pressured to look at different models, because I use automatic111
i do not have that model but ill try with another one see what happens
Wait sorry I'm interrupting, but for example in the automatic111 webui, are the LMS, Euler A, etc different models? What are they?
sampling methods
ok so I would go up on the weight in contorlnet. And it needs more prompts I think, the AI doesn't 'get' what those clothes should look like. But your image look almost like a VAE issue - try a diffrent one or none at all maybe?

weirdly enough i got better results by dropping the weight to about 0.4

not great
but workable with some inpainting
i forced him to wear clothes but it took some additional prompting

The left hand looks interesting
Huh, actually both hands
Even ai has tough time drawing hands 
interesting hands - the stable diffusion classic
THIS one got BEAUTIFUL hands on accident

Wait this is pretty fire
The fingers look as if they are connected but it's almost perfect
They are close enough that upscaling would fix it I think, it's still a pretty small image
shockingly good for low res like this
It seems it's much easier to generate landscapes and nature than humans and objects. I wonder why
how do i manage to get SD to give me more detailed texturing? surfaces like skin and clothing tend to come out flatter for me..
I am really having a lot of trouble with controlnet: it just mangles faces when the character is not immediately in focus and it's driving me crazy. Is anyone else having a similar problem?
inpainting to the face afterwards

Recently the ControlNet extension for Stable Diffusion was updated with the ability to use multiple ControlNet models on top of each other, which is fantastic because this brand new neural network structure allows you to combine multiple special ai models, and create even better and more precise images than before! In this video, I will not only...
5minutes in
thank you so much. I realize how little I use any tab except txt2img
you are welcome, for more advanced control on how to fix faces using inpainting, ask someone else here. I rarely make portraits of characters
Hi guys, how can we get the past prompting that we've made?
does stable diffusion pref working with models agains a white or black bg?

finding that im getting weird artifacts when isolation a subject on a black background
you can drop the image made inside the "PNG Info" tab in automatic, or look at the image metadata. If you didn't change the options, the prompt is saved there with the other parameters, like the seed
Thank you! Will try for that!
Perfect! I got it!
Can we use parameters in stable difussion? Like in midjourney, exampel ::1 ?
there are lots of parameters and options yes
you use Automatic from what I got
check that wiki, it"s really well done page and shows most of the features. https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
In particular, some of the features pertaining to prompt edition
FAQ: What is Stability AI?
Our vibrant communities consist of experts, leaders and partners across the globe. They are developing cutting-edge open AI models for Image, Language, Audio, Video, 3D and Biology.. AI by the people, for the people. Learn more here 
Thank you so much!
you're very welcome 🙂
I had a lot of help from the PromptHero website in the beginning understanding the Parameters and Options by checking out the stuff there on the website and what prompts were used to achieve those. Check it out maybe it'll be of help.
i always get bad eyes in my disney artworks -> they look more like human eyes
any idea how i can fix this?

have you tried prompts for simple/cartoon/disney eyes and/or negative prompts for human/detailed eyes?
i might try this again, in general my eyes look always similar, also in different anime styles, it always feels like i have a specific style with a humanized face
-> in other models too
I have a question on attention/emphasis I don't see in the FAQ: can you nest groups? For example, (a (tall man:1.5) with an (umbrella:1.5):1.5)?
Any similar webs like prompthero?
is there a way to tell if the model you're using is trained with a given tag?
I'm having some trouble building a prompt for a description I've written. I can get close, but nothing quite matches the "image" I'm envisioning in my head. can anyone help me out or give me suggestions on how to convert the following description into a coherent prompt?
The city is a labyrinth of towering, concrete buildings, their facades marred by the scorch marks left by years of industrial pollution. The streets are lined with rows of identical gray buildings. The sky above is a sickly shade of yellow, and the air is a thick smog with the stench of chemicals and pollutants. One building stands out: Nutri-Synth's headquarters, a towering structure that looms over the city like a monument to greed and power. The streets are filled with robotic drones, carrying packages and delivering synthetic food to the masses.
How would you describe a dryad as having bark for skin? I have been trying "bark on skin" "wooden skin" and such, but not much luck. Or is that something that would probably require an embedding?
skin off bark and moss worked when I did it
Thanks. I will try that.
Took some work and a bit of img2img, but I now have a portrait for one of my rimworld pawns.

Hello~ I have a question about the resolution. I am using other people prompts to create an image, it's ok with low resolution such as 768 with 1024,etc. But when I am using around 1024 with 1526,etc or higher, there'll be extra legs occur with image. Do I need to install a plugin something to solve this? Because it's actually others prompt with no problems. Thanks if you give me a helping hand 
upscale after you generate the initial image if you want a higher res image, use outpainting if you want more background to show up beside your portrait subject, do not just up the resolution from initial generation. all kinds of floating limbs and weird stuff will show up if you go too far above a model's initial training resolutions, most are 512 for sd1.5 or 768 for sd2.1 (edit spelling)
Will do! Thank you so much! ⚡️⚡️⚡️
hello,I want to use the original design image of my product with a white background, without any changes to the product's design (including style, color, details, etc.), and have an AI generate different background images of the product in various usage scenarios or angles based on my textual prompts. It is important that the product in the original image remains unchanged. Please contact me if you can fulfill this request.
Is there some documentation or maybe a youtube video somewhere that gives an overview of the ins and outs of prompt generation? I see prompts posted with things like (monochrome:1.3) [out of frame] (((extra fingers))) and I'm curious to know more about them.
how can i prompt on google collab notebook v.05. I dont see changes in animation , and do I need to rpompt everyframe
thank u @tropic topaz
you are welcome 🙂 (Aaron is my currently unavailable account, sorry, it was named Guizmus)
Random Seed a Batch of Identical Images
I'm using Automatic1111 stable diffusion webUI. My goal is to take a still image and create a sequence where it cycles through different AI treatments, basically a different seed per frame. I was hoping to avoid the manual task of generating all the images separately and sequencing them in video editing software.
I was hoping I could do this by making an image sequence that consists of the same image each frame and then using Batch img2img. However, I'm finding that there is very little (if any) variation between frames, even though within the Extra seed settings with a Variation seed of -1 it made me think there would be a different seed each frame.
Why is it the case that a batch of 4 images in img2img can turn out so differently, but my frames in Batch img2img are coming out so similar? I'm obviously missing something. Please could someone point me in the right direction? As you can probably tell, I'm extremely new to all of this but keen to learn!
anyone has an idea to get better eyes? always when txt2img, my eyes look not really great. messed up. even when i rework them. Im using classic anim atm and trying to create classic disney stuff.
as an example

even worse

you dont use any negative tags, thats your problem here, try add stuff like:
blurry, low resolution, deformed, bad anatomy, etc to the negatives
this is with my negative tags, same model, tags and steps,

I'm struggling a bit with inpainting... I'm trying to patch up this little spot of exposed skin which should be the black dress.
I'm adding "black dress" to the front of my prompt, and "skin" to negative. Masked content: Original. Full Picture. I've tried various combinations of denoising strength + CGF scale
I must be doing something blatantly wrong, just not sure what that is yet 🙂

oh ok , thank u 🙂 -> is it possible to read any info from my pics? 😄 haha didnt know that. still looks a little too humanlike, but the bird looks great in general, way better than mine
yea generated images contain exif meta data with all infos you used to generate 😄
ok so the problem here is that img2img morphs pixels, and it can be hard to go from full flesh to dress like that.
Open your source image in paint, and add that black spot to it too. then go back into inpaint, put a mask over the bad black you added, and you'll make it a lot easier to the AI to modify it
you can load your image in PNG Info tab in the webui to see all settings
thank u so much for the advice. im really completely new to everything. in general when a model is based on something is it literally like SD 1.5 with an addon? or how does it work?
im wondering i can generate similar images with models that are like 1 GB and specific for something and then i have those big 10 GB ones. Are they just trained with more stuff?
there is SD 1.5 and 2.1 as base official models, now the community can train on top of this base with their own images (fine tuning) to get better results. So it has the core model + extra trained stuff in it
nice, i see 🙂 thank u
All models are over 2gb, if its smaller then its mostly a lora or embedding, these are like (additions to a model that go on top)
Aha - thank you very much for the tip. I'm on track now, I think I just need to fiddle around with the sliders a bit to get it perfect now
or hypernetwork too, I know they aren't the most popular right now but I still love them
well done !
(just had the time to see)
This was the end result 🙂

yep just painting a black blob there before inpainting did the trick
hi, I am using automatic1111 webui. What does < and > tags do in the prompt? like <cinematic light> thanks
does word case matter to SD ?
they do nothing, here are more information how to use () or []:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features#attentionemphasis
what do you mean?
it wont matter, it just reads them, but it could be that it gives you different outputs for Tree or tree
also should I use | rather than commas ?
no you need , for seperating. | is used for other stuff (Alterning Words)
Ah thank you
Trying to start using Loras more. I frequently get this 'overbaked' look that occurs, and it seems like it's there even if I turn the strength down on the loras, Wondering if the total lora strength needs to add up to 1, or if I can have 2-3 loras turned on at high strength levels like you can for embeds?
any tips for improving blending of seams between the original image and inpaint-sketched generated content? I'm using auto1111 for reference.
I've had some success with increasing the 'blur' up to 20 or so. Also decreasing the denoising works pretty well. Usually 0.4-0.6 is what I use for getting rid of seams. Unsure exactly what blur does, but it seems to work in blurring seams for me.
Nbbnhj
Can someone explain me the difference between lora and embeddings?
2 vagina
any tips to make 1male and 1female with specific characteristics each?
use inpaint
Does anyone remember a MJ prompt guide that had a ton of resources sorted by style, lighting type, pose setting, etc that had a bunch of examples in each categories drop down? I SWEAR I had it bookmarked but I can't find it anywhere 😦 Open to other suggestions if you have one
I was using it on SD and it was super helpful for prompt words on the scenic set up of the image
your aspect ratio is way off for this figure. shorten the height by a lot to fix this. otherwise your fig will either stretch or 2 bodies show up (even if you neg prompt to control those). If you want higher res, upscale afterwards or use highresfix during generation. if you want more background, outpainting afterwards, do not just raise the resolution
do you want to have entire legs visible? are you using prompt for full body?
I'm using the stabiliy API img2img. I would like to set one of my pictures as input (init_image) and edit that picture (prompt) so that the output will be that picture of me wearing a golden armor or a suit, or with another picture style. But the face of the person in the output image is totally different of mine.
I don't know what I'm doing wrong !
What is a better way to keep the face of the person in the init image. I would like to create avatars using the API.

Hi👋🏼
Any idea who to get really empty backgrounds with nothing but white? Tried prompting it but it only works about 40%.
Impaint does work, sure but that's just for one picture, i need it to work in generation
you could use img2img with a very high denoising, like 0.8 or 0.9, on an image with just a white background and a basic stickman, or sketch of a person, maybe colored in a color you like.
since pixels get morphed during that denoising process, they start from that while background, and won't move far from it since the prompt doesn't allow for it. As for the pixels of the stickman, they'll change quite a lot. The base picture will just be a "composition guideline", pushing in the good color patern as input noise (input image is input noise) and the good picture composition through that stickman.
If you want to control more the composition, like the pose or even some details of the character, you could also use controlnet, but your question seems to indicate you want variety, so I would go with the method I described
ask if I wasn't clear, there is a lot of terminology in there
So basically a prompt saying "just use 500500 of the 768768 isn't possible? Will try your approach, thanks
yep, you cannot just control the pixels color through the prompt. it's really not thinking like that.
It was trained using how pictures were described/named on the internet in part. so try more to think of a prompt that could describe the image you want if you found it on a forum for example
like, character on white background, I'm thinking "character sheet" would be powerful
you need to find examples in your mind of how you would find your image "in the wild", and describe it how it would be described
like, when doing realistic photo, you can add "taken on iphone 6" or "70mm" and it will work quite a lot, pushing SD to make only realistic looking photos
same goes here
Hm, will test around more later. Anything background helps but not good enough. Not touching border did nothing at all. Clip art just a tiny bit
But won't i lose the randomness wirh img2img?
with very high denoising, no
if you had 1.0 in denoising (don't do it it crashes) it would be the same as if you didn't use any input image
so there is a right spot, usually around 0.85 for me, where the input image is no more than a suggestion for the composition
you still may want to check the example uses of controlnet if you didn't yet, one of those could be of help, like Segmentation or Open pose


Sounda promising, thanks. 3 more hours😅
this is txt2img, the image on the left gets preprocessed to only use the composition, not the colors or details, depending on the mode you use
I got CN. Didn't do as i wanted for this issue. At least mit yet
i'm still learning how to use it correctly, so I stay a little shy giving tips on it tbh
hard thing, lots of possibilities
Don't paint over your face in the img2img
We are all new basically
Anyway, will test later, thank you
How can I do to avoid painting over my face ?
When using mask just don't use it on face.
It means a mask for each image.
There is not a way to automate that ?
I suck at explaining, watch this https://www.youtube.com/watch?v=3QPt_dPnmGk&ab_channel=Colinfreeman

This video builds on the previous video which covered txt2img ( https://www.youtube.com/watch?v=Nu2T2G_Aa8o ) This video covers how to use Img2Img in Automatic1111's stable diffusion web UI to modify and inpaint images using the options in the web UI.
hi, i connected the diffusion.gg bot to my discord serwer, but when I try to draw it keeps saying that "the app doesn't react"
Hi guys, how can i get rid of texts as much as possible when generating? Trying with negatives (watermark:1.2), (logo:1.2), (barcode:1.2), (UI:1.2), (signature:1.2), (text:1.2), (label:1.5), (error:1.2), (title:1.2) but they still generate
im still looking for guides for pose prompts, stuff like angles etc, are there any public guides for it out in the internet ?
https://www.youtube.com/watch?v=ZCJX5ZAk9SA&list=WL&index=64&ab_channel=OlivioSarikas I haven't tried it myself

The BEST Tools for ControlNET Posing. This Complete Guide shows you 5 methods for easy and successful Poses. OpenPose Editor is very easy but pretty limited. A great beginner Tool for Posing. Posemaniacs gives amazing Poses and Camera Control. Posemy.Art offers easy webbrowser posing and loading of scenes with perfect poses in full 3D. Daz3D is...
I only use (words) (text) (copyright)
What command create pics?
Any, you can even get a pic with empty prompt
Why it send me to this channel instad of prompts
@formal ember here some views:
https://www.reddit.com/r/StableDiffusion/comments/y46k9t/comment/isd3xqd/
reddit
296 votes and 24 comments so far on Reddit
Hello everyone, I'm Vega, I'm an animator that's interested in learning Stable Diffusion and all of it's features. Are there any guides anyone would recommend? My goal is to use my own art to feed into a style on top of an animation through image sequences. But for now I want to learn how to use the features and the basics.
hey and welcome around Vega 🙂
I don't have a good guide, but there are multiple resources and paths I can point to you, to discover SD. Each path can take a long time and have lots of other subpaths, it's like an hydra, it feels like you can't really learn everything, but keep cutting heads, one after the other, and you'll progress for sure.
1/ there are lots of tools to use SD. Some can be installed localy and give you more freedom to explore it without limits that you'll find online. They can still be used online if you can't run them on your computer. The main two people talk about would be
1.1/ Automatic1111 (https://github.com/AUTOMATIC1111/stable-diffusion-webui/)
Lots of features, lots of sliders, lots to learn. There is a quite good wiki that can also be a good thing to check, all features (almost) are showed and give a good idea of what you can do in SD. (https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features)
1.2/ InvokeAI (https://invoke-ai.github.io/InvokeAI/)
Less feature but very high quality UI with a focus on inpainting/large canvas. here is a good example use (https://www.youtube.com/watch?v=IuJv4EMFq1s)
This first steps should give you a good idea of the possibilities. Then choose one, install and try.
2/ prompt making. It's a real thing to learn, it takes time and experiment, and asking around here, or using some prompts you find online on sites like https://lexica.art/ to learn from. Also, chatGPT is a great friend when it comes to making good prompts now, I put an example on how here: https://discordapp.com/channels/1002292111942635562/1002292112739549196/1079658399366643712
another guide was published by one of our mods, and is pinned in this channel, very nice explanation of one way to make prompts
https://discordapp.com/channels/1002292111942635562/1011743094309396631/1030121511845101638
3/ training. You can train lots of new things into your IA model, teaching how to make things it didn't know, or refining concept it did know of. This can be very efficient in animation, to help keep stability from frame to frame. Here is a guide on style training. subject training is a little different but very close https://github.com/nitrosocke/dreambooth-training-guide
There are lots of other things, especially pertaining to animation since it's what you are interested about. In particular, the tool Deforum is specialised in animations though SD : https://deforum.github.io/
Lastly, the big game changer that came around recently is a complement to SD, conditionning the output to help you control them, to help "tame the beast" that is the model and make it give you the intended results. It's name is "ControlNet" and it's very powerful for animations too. https://www.reddit.com/r/StableDiffusion/comments/119o71b/a1111_controlnet_extension_explained_like_youre_5/
WALL OF TEXT POOOOOOWAAAAAAA
I reformated a little
and added more guide links
no problem, I can link other people to it in the future, it's a common question and there is a lack of detail on it around, easy to access
ControlNet sounds really cool

so could I use my art as a means to using a style?
like my idea is to animate in 3d, use my paintings as a style
you could yes.
Either you could use you art as base, and have SD change the style on it
or you could teach you artstyle to sd, making it understand "painted by Vega" in the prompts you would then be able to make. And it would mimic your art, if you managed to train it well.
how many images do you think I would need? 100s?
I trained some styles, on specific animes, videogames, ...
I would usualy say a style needs at least 30 to 50 pictures, but will benefit from more.
The important thing is to keep it diverse. If you repeat the same art or composition too much, it may pick on it too much too, and put it in all the outputs.
Last style I trained https://civitai.com/models/1158/mosaic-art
I used 46 pictures. I don't have examples of lots of types of subjects, like for example I have very few "landscapes" or "sky shot" in the dataset, and because of that, the model is not very good at doing those.
So the more diverse subjects you have, the more your style will adapt to any prompt you give it
But if you have a very narrow style, you still can train. it won't need as many pictures, and it will just be able to output in your narrow style
it all depends on what you want to target
training is really taking the Pot in witch SD already is boiling, putting fire on, adding small pieces slowly and baking a new model
you need to know though that the model doesn't "grow", it will forget things, become worse at things you are not training it on
it's "specializing" the model, so it's important to keep the limits in mind
(that being said, there are numerous training methods, and some can purely add new data in some kind of post processing too)
Paintings!! Just for some who don't know I also use to paint a lot back in the DA days. I'm hoping to finish something soon while working on animation projects.




here's a small sample
so would you say as diverse like this?
something in this style yes.
I would be very careful in how I train on that though
the pokemon ones in particular
more humans then
pokemon token is quite powerful in the model, it can mess things up
no, you can go monsters too
but taking something like yoda or pikachu can pull on weights in the model that are quite strong, and that can mess up the training
basically, your style would get trained faster on a random thing than on a very strong thing
so avoid fan art?
or go full into it in one category, and you'll train enough to "cancel" what was in the pokemon token
but don't go half Strong token + half weak tokens
I did that error with the manga death note
Riuk is very well trained already, some others aren't
I couldn't get every character trained correctly at the same time in the end :p
I should try again
but, like, with just a few pics, it's hard to say, but even if I had your full dataset it would be hard.
I have made around 20 quality models now, and I can't know for sure before I tried, before I checked the training curve, before I tested the first trained model to see what went wrong. And then I would come back to my dataset and change pictures
and do it again until I get something of quality, that isn't all pokemon because of 3 pics, or that isn't all blurry because I made one pic to blurry, or hasn't some text (try to NOT have watermark in your dataset), ...
lots of biases can show up, and are hard to anticipate
it comes with experience
(I do have 2 friends that have made that their real job, this is a real complicated subject)
I can't wait to start playing with it tonight
someone have an idea why my faces always look more 2D especially in more 3D anime mixed stuff.
i always have a body with more depth and it looks like a 2d face is set in
thank you, i will look into these links
hey, back again.
That did kind of the trick.
But i'm using https://github.com/KutsuyaYuki/ABG_extension.git now as well. works great in 90% of the time.
Thanks for your feedback, really did help me

GitHub
Contribute to KutsuyaYuki/ABG_extension development by creating an account on GitHub.
what should be the prompt to make her face this way?

Hey folks, I'm a software engineer working on a app for professional prompt engineers. I'm looking for a few people willing to try out some early versions and provide some feedback. I have doordash giftcards! and would be really appreciative. DM if you're interested please.
do u have any neg prompts for avoiding double belly buttons? or some weird lines on the belly?
Hello, i have this photo edited fast in GIMP, i would like to do it more Realistic, like they're really fighting, all prompts like "one white man fights one black man and one white man with guns, 8k, realistic," only give some vague characters, thanks for your help


Have you tried getting a decent result then inpainting that? Usually the best way in my experience, usually I get like one good out of 5 so gotta do a decently sized batch
Hello guys, kinda new here 🙂
Do you guys now what prompts i have to use to make an specific character?
The character is Dehya from Genshin Impact with the sky on Fire
(sorry if my english is not good at all)

short of using a lora, you just just try to use that specific description Dehya from Genshin Impact, background sky on fire, as starting points. I bet there are many images of Dehya in the database already since genshin is recent and well known.
thanks buddy, any recommendations about where i can find Lora models?
civitai
Can someone enlighten me to as what {tag} does compared to (tag) and what doing (tag:1.5) do?
What prompts would you recommend to generate a picture of a bengal cat (the house pet)? I keep getting bengal tigers, or cats that look like bengal tigers. Left is what I'm going for, right is what I get. Using the 2.1 settings on the huggingface website.


tried negative prompt tiger? also positive prompt bengalcat and bengal_cat
How is DDfusion different in SD than Google colab
Try "domesticated Bengel cat" or "Bengel Longhair" or "Cashmere Bengal"
wow ! nice and well done ! I didn't manage to make that one work
Is there a way to assign different colors to a subject and a background? If I write "purple background" the subject often also turns purple and the other way around
anything diffusion 4.5 just gives me dull images and faint colors, only with cherkpoint or Loras to get more vivid color results?

you need the .vae.pt file from anything v4
copy and rename it to match v4.5
I am using colab, can you tell me in which folder on google drive I put it?
dont know how the folder structure looks like, but normaly it goes inside the folder where the models are stored:
Rename the vae to match the model like:
Example.safetensor
Example.vae.pt
thank you very much
no problem 🙂
Do u guys have any ideas to get the same or similar style like in midjourney ? i tried several models / prompts but it doesnt really bring that midjourney look , it looks more painted/ soft in midjourney
as an example of a midjourney pic

did you try openjourney?
I guess they are trained on the data of midjourney
yes, but feel like the faces are more versatile, unique and it feels more like "art" less photorealistic
ah
just an overall different look
I'll try a few prompts w it if i can get something similar then would let you know the prompt
oh nice ty 🙂
how do I get SD to put the eyes of an image into sharp focus ?

Negative prompt: (deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck
Steps: 50, Sampler: Euler a, CFG scale: 7, Seed: 4186429302, Size: 600x600, Model hash: c35782bad8, Model: realisticVisionV13_v13, Denoising strength: 0.5, Hires upscale: 2, Hires steps: 25, Hires upscaler: 4x_NMKD-Superscale-SP_178000_G```Hello. I am trying to generate an image of a burger. The burger looks great but it's always cut off on the edges. Is there a way to prevent that?
put cut off image or cut off subject in negative prompt, and/or try to use outpainting to "complete" the burger image by adding to an existing finished image.
try put focus on eyes earlier in the prompt and soft focus/out of focus earlier on neg prompt
your neg prompt right now looks like a standard one I've seen from a model maker.
try sharp focus on eyes too
Oh my god thank you
@tribal spruce can we see ur result? 😄
Things like this. It's really in love with tomatoes. I wanted to take the focus off of the tomatoes and next result I got was tomatoes on the burger and ON the burger, as in on top of it

h nice
Now it burnt the tomatoes for some reason...
Thank you very much but How to inpaint it?
It started cutting off again. Also it's in love with tomatoes and I don't know how to reduce it and it started building towers...
Prompt: burger with a few tomatoes, onions, cheese, salad, front view, center, subject in center
Negative prompt: cut off, cut off image, cut off subject
This is what it produces

your prompt in realistic vision:

Medium rare
Currently it just cuts off the burgers in every single run. Sometimes the burger has 5 patties or too many tomatoes or stuff like that...

Right one even features fresh imported tomatoes right out of the heart of Tschernobyl (Ik that it's AI and things like that happen, I just think it's funny. All I want is the burger to not be cut off)
It did not cut it off for a while but went crazy with tomatoes. I use Heun btw, if you mean that
Yeah, just realised. sd v1.4
yea, i would suggest you try 1.5 or 2.1
or community made ones like: Realistic Vision or Illuminati Diffusion
My only big issue is just the cutting. The burgers look great. I will download another one I guess but they just need around 2-3h with my internet
I mean, look at this one. It's perfect! ... but cut off


yea thats kind an issue of official models, they can do everything but not everything right ^^
This one is not cut off but it looks too clean. It has this artificial look
Or is that a sampler thing? Because I think mine looked the same in the beginning but on Heun they look great
It looks like there is a straw on the burger. I learn a new way to enjoy them now.
It just reaaaallly loves tomatoes XD

Any improvement suggestions on the prompt? Otherwise I would try to download another model but my internet is really slow.
Prompt is burger with one patty, a tomato, onions, cheese, salad, front view, center, subject in center, padding around burger <- Desperate try to prevent it from cutting
Negative prompt: cut off, cut off image, cut off subject
I fail when try to simplify the prompt.

And then the tomato cheeseburger with extra tomatoes.

Fuck it, I'm gonna include that burger into my UI project (if I`m allowed to?)
XD
I added "trending on artstation".

What model is that btw?
The first (tomato) one was Deliberate and the last was V1.5
I guess I'm gonna download v1.5 then because all of the images v1.4 generates at the moment are cut off and I desperately try to fix it in the prompt but it just adds tomatoes
"one center placed tomato cheeseburger seen from front, with (extra tomatoes:1.2)"
And V1.5 do fail from time to time and place it out of frame, it AI so it isn't smart.
And can give images like this too :/

v1.4 fails all the time to fully place it inside. It did for a short time but now it doesn't anymore. I just generated images where it took the burger apart and it looked like salad
Now I seem to get a burger and a building
Changing the prompt was not a good idea

I just wanted to make a UI with AI generated assets and needed a burger. Now I spent half of my day generating burgers...😭
I'm trying. They look good but are always cut off and idk why

You can also try to say what is on the top and bottom to try to frame the subject: "one (center placed) double cheeseburger with tomato on a napkin seen from front (extra tomato) flag on top".

How big is the file?

it's a ckpt, 2GB. sorry, it was done before LORA was a thing
Currently downloading v1.5 hoping that it can center it better than v1.4. 2h left...
I only have CKPTs atm
there is the ckpt https://huggingface.co/Guizmus/SD_PoW_Collection/resolve/main/291122/ckpts/Burgy.ckpt
and here is the dataset if you want to check what I trained on https://huggingface.co/Guizmus/SD_PoW_Collection/resolve/main/291122/dataset_Burgy.zip
token to use in prompt is "Burgy"
lol never thought this model would be of use again
The burgers v1.4 creates look bautiful (maybe it adds too much tomatoes) but it just cuts them off most of the time. The one I replied too would have been at least close to perfect, but it's cut off...
do u use automatic1111's version?
Downlaoded 1.5 now but it just doesn't get any better. I think I got the best result in the beginning and from then on it has just gotten worse and worse...
please how do i find the right model for making drawing sketches
#1047197565365538826, civit.ai, google, make it yourself
im a bit slow please tell me do you mean a model called google or you mean i look it up
i mean do a google search for something like "stable diffusion 2.1 sketch style embedding"
oh thanks the thing is i dont even know the keyword to search something like this. like this " style embedding" for example
there are different types of "models" (idk if that's the right word), which improve stable diffusion prompts. embedding is the simplest / smallest / easiest to install (though probably the worst results)
I know brackets give words more priority, is there something similar to give words less?
thanks for the info! sadly nothing on civit.ai and a google search didnt bring anything up thats why i was asking here if someone used one
square brackets []
i tried mid journey and it made some nice sketches and i was wondering if i can do it in SD
if theres a very specific style you want, that no one else has done yet, you might have to train your own
no not really specific quite the opposite but i dont know how to train
how many images approximately do i need to train it
oh niice
can you link me a tutorial please

reddit
10 votes and 1 comment so far on Reddit
I was generating goth models and after seeing your cheese burger I took a shot at making them hold a cheese burger
what are some key words I can input so that my legs are fully clothes and not showing skin? doing impaint job.
I have tried naked, nude, skin, but they dont do the trick
Maybe mention the clothing piece you want them to wear. Like trousers, jeans, long dress, etc.
Assuming you mean what to put in the prompt and that you tried naked, nude, etc. on the negative prompt
thanks will try that.
Also, does anyone know what I could add to the prompt it so this picture doesn't look so pixelated? And also so the architecture is a little bit clearer instead of a visual buzz that doesn't make sense haha

The pixelation is not that big of a problem since I can fix that with resizing with ESRGAN, but the architectural nonsense is a problem I can't seem to get rid of
Even if I add words like "sharp details, extremely detailed" etc
what resolution did you set it too ?
W 768, H 576. The pixelation at least didnt show up in previous results. I must've messed up the prompt or something
My concern is the architecture. Do you think a higher res will provide better results?
A little bit more could help are you using high rez fix?
Nope
Should I?
it can raise the resoution much higher
so give it a try see if it fixes your problem
if not then we can start messing with some other settings
also how many steps are you doing
A low number for now, between 15 to 20 with DDIM
try going up to 40
I've always written my prompts like: "medieval, knight, heavy armor" but lately I've seen people write something along the lines of "medieval knight in heavy armor swinging huge sword" is there a difference how SD interprets both prompts?
Hey, I left it for a while and I tried again and your tips actually improved the image by a lot. I used the same settings by using PNG info and then I did 40 steps with DPM++ SDE and applied hires fix. It looks way better now and after further upscaling I think I'll use this one. Thanks a lot!

@silver valley

I am trying to run a list of prompts on a custom model I made and over several ckpt’s saved on different steps for that training session.
Each ckpt has the same token: shbdg
Ah okay
Your Problem is you need a replaxer word before your tags
Replacer
The word dont need to exist.
Type for example
lolol at the start of your prompt.
Then add lolol, as first word in x values
Only add it one time but first?
This word will then be replaced with the followed words
Ok. But there is no issue that shbdg is repeated in every prompt?
I thought that was the issue
No that shouldnt be an problem
You can also hover over S/R Prompt to get more Information
Aah! Didn’t know that 😀 thanks x2
Yea its not known but most stuff is good documented
But should I also add that word first to the regular prompt?
Yes like i said
Prompt S/R stands for Search and Replace
So it will look for that word to replace it with your stuff
But I mean: put it both in the regular prompt and in X values where I keep all following prompts?
Yes it searches for it in your prompt
It needs a match
Then it will replace it with your stuff
Awesome. Now it works 🙂
Hey Joachim 🙂
In your case, you could have a prompt like
shbdg a woman wearing a brown jacket in a city closeup portrait shot bokeh photo
then have params like those ones for example, to test 9 different combinations of prompts on your checkpoints
(sorry was very very slow :p but CS1o rocks)

I don’t understand.
Yea thats next level S/R
the prompt has 2 words that will be researched in this case : "woman" (that will be replaced by man and child), and "brown" (that will be replaced by red and purple), so 9 total prompt
and the lot is run once per checkpoint
giving a grid for each checkpoint
Another thing: if I want to use commas in my prompt, should I then put “” around them?
🤔
not sure I see any trick for using commas in S/R
why would you replace the comma though
I don’t want to replace commas
you aren't supposed to replace the whole prompt, just some words to make it cycle through some tokens ^^
I get what you are trying to do though
I want to use prompts with commas in them without confusing it with the comma that separates the prompts.
i think they want to exchange a string of words like "cat, photo" with "dog, drawing" for example, but ye not supposed to replace a large section, usually single words
What do you mean “supposed to”? I want to try out some basic prompts throughout my different step ckpt’s from a training season. What’s wrong with that? 🙂
there is another script that does something maybe more fitting, "stresstest a list of checkpoint on multiple prompts", never used it yet though.

o ye u can put the prompts in a text file then run a prompt batch i think
the "prompt S/R" is "supposed" to, I meant the feature has been thought for, replacing parts of a prompt, not the full prompt. if going for a list of prompt, other tools won't have problems like the comma thing
but yeah, outside of the comma thing, your way should work too
I will have to get into this on another occasion. 🙂
Found it, discord breaks the Syntax when i copy the Text

Ok. So I will have to do it like this in prompt then \,\
Yea maybe that works
Ok
Never tried it
Ah ok
How do I get the basics to work without Models-Embedding and all that jazz?
I do admit I am new to all this stuff, I for instance don't even know if I am working with 2.1 or 1.5, I think 1.5, because of the SD15New in the top
The thing I am trying to achieve is somewhat correct proportions, as in, a classing dungeons and dragons dragon in this case.
There are a few things I suspect, like putting a list of dont do ugly things in negative, or maybe it has some difficulty because it is less experienced with drawing dragons than say humans, however what is the best way to get started to achieve more consistent results?

just adding modifies apparently really helps, still not fully satisfied with the silly looking head and fore limbs, but a lot better

heres a negative prompt i found that usually works well, usually for people tho:
blurry, rendering, photography, painting, signature, (ugly), (duplicate), (morbid), (mutilated), (mutated), (deformed), (disfigured), (extra limbs), (malformed limbs), (missing arms), (missing legs), (extra arms), (extra legs), (fused fingers), (too many fingers), long neck, low quality, worst quality,(Wireframe),Polygons,Screenshot,Character design,Software,UI,(watermark),(text),(overlay),getty images,(cropped),low quality,worst quality
and a very basic prompt i usually start with, just start adding stuff:
photorealistic, highly detailed, beautiful, 4k, 8k, trending, award-winning
also, is there a way to combine elements,
I started off with red dragon on a hoard of gold,
It somewhat resembled a gold dragon with a red background,
Is that just a fluke, if not, is there a way to make it do something like that?
try running it in a batch of like 4, usually i get 1/4 good ones
I dont know if this is the right place, however:
One of my goals with stable diffusion is to easily make dungeons and dragons character portraits, is there a good model that specialises in drawing fantasy characters (as in, wizards, necromancers, knights that kind of thing), preferably in a semi realistic or not anime style?
Try Dreamshaper or Protogen
Does it matter if you use (by x artist:1.3), (by y artist1:3) or by x artist, y artist
So does (:1.3) do anything?
Try RPG4
Yes. There's a few. Depends on if you're more into illustration/drawing type or if you're into realistic portraits
RPG4 is freaking good. But! It's kinda complex to use, there's a guide that fully explains how. You can find it here https://civitai.com/models/1116/rpg

Originally posted to HuggingFace by AnashelAvailable on:Mage: https://www.mage.space/u/AnashelSinkin: https://sinkin.ai/m/vlnWOO4RunDiffusion: https://rundiffusion.com/StableHorde: https://stablehorde.net/STATUS: RELEASEVERSION 4.0I have built a guide to help navigate the model capacity and help you start creating your avatar.Download the User G...
And for more illustration/painting type of art I use Dreamlike Diffusion (https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0) or Dreamshaper (https://civitai.com/models/4384/dreamshaper)


DreamShaper 3.31 and 3.32 (clipfix)Please check out my newest model: NeverEnding DreamCheck the version description below (bottom right) for more info and add a ❤️ to receive future updates.Do you like what I do? Feel free to buy me a coffee ☕Live demo available on HuggingFace (CPU is slow but free).Also available on sinkin.ai with GPU accelerat...
I made this with RPG4. The one Fran suggested

Amazing
Thanks
nice, ill look into it
Having some trouble getting an earth genasi rendered (stone or cracked stone as skin)
positive: face portrait earth genasi, gray cracked dirt and scales as skin, cosmic background, yellow wizard robes, black smoke hair, photo, kiss, 80s
neg: woman, cropped, lowres, poorly drawn face, out of frame, poorly drawn hands, blurry, bad art, blurred, text, watermark, disfigured, deformed, closed eyes
I'm getting stuff like this which is awesome of course, but not exactly what I'm looking for

Maybe I can get cracked skin in with inpainting, but I haven't had much success with that either. I got closer with stable diffusion 1.5

Hello. I`m trying to figure out why I dont get the same pictures in SD when following the exact same promts and seeds model etc from Civitai. Could anyone please explain ?
Are you using xformers?
So I’m trying to generate swords but no matter what it never generates a good looking sword, I’m guessing stable diffusion isn’t trained on a lot of items? This issue happens on a lot of items. Staff, pickaxe, pen, wand, etc.


we talked about this a couple of days ago, and earlier than that. search and read up on it. not discouraging you asking, just do not want to explain again.
guys im having this issue, i get greyish outputs instead of what im supposed to get copying prompts from internet

that is an example, do some1 know the reason why this is happening? Ty in advance
@tranquil folio hi, what is the trigger word for your contrast fix lora(s) for 1.5 and 2.1? When I look at your examples and others from the community on civitai, I did not see triggers like lora:theovercomer8sContrastFix_sd21768:1. Is it automatic? I tried to use it with a 2.0 model (dont know if that was a problem) on a bright day scene, and its effect seem minimal if at all. I tried to bump up to :1.5 as well.
I put lora:theovercomer8sContrastFix_sd21768:1 on the positive prompt section at the end.
the 2.0 model does robots but trained at 512x512 so that maybe a problem?
I can't really tell if contrast fix is applied. I had to use a white mech to test the shadow and contrast since dark ones come pretty contrasted by standard. However, with noise-offset influenced models, I can see distinct vignette on the images, and this one does not have it. As such I am assuming that your lora is not triggered.

to8contrast style is the trigger word i listed on civit. i generated the samples using the additional networks plugin which doesn't put the lora into the prompt. it should have the same effect by putting the lora in the prompt and the trigger word
thanks, have you tried it on 2.0 models? are 2.1 trained loras backwards compatible with 2.0 (not 1.5)?
i haven't tried it on 2.0
i'd guess it'd only work on 2.1
was there a 768 for 2.0?
You are probably missing vae,
Edit:
read through model description and files included and see if you're missing something
no sorry that robo model is 2.0 trained at 512x512
i doubt it 😦
ok thanks anyways I will find a solution. I will make my own lora based on the robo checkpoint images I generate to "upgrade" it to 2.1 (since it can generate 768x768 images with no problem), then I will use your contrastfix for 2.1
I'll try dvmech as an alternative, its style is a lil different from the 2.0 robo one, but it is trained natively on 2.1 at 768x768, should play well with your contrastfix lora
So I’m trying to make some beautiful oc character sheets for personal use, but the Ai is giving me weird looking people?
has anyone worked out how to make SD2.1 reliably render a couple where the woman is taller?
I totally get that it's only going to find nearest paths based on ingested data so it's not trying to be sexist, but I've been tinkering for about 20 mins now trying to make it produce this, and the closest I've been able to get is a woman dramatically in the foreground and the male partner in the distant background lol
annoyingly, even when I feed it img2img with a bunch of different illustrations in the correct pose I'm trying to produce (a gender reversal of the famous ww2 "soldier kissing nurse on may day" portrait) it forces the existing female character to become male and vice versa, even on super low denoising strengths
interestingly, I can kind of get it to produce platonic "standing side by side" images, but the second I introduce the phrase "kissing" it spikes hard in the way described above
would love any ideas on how to trick it out of it's gender stereotypes lol
Hey I'm trying to create something like this in SD

any idea how I can do that I wanted the female character to have golden finger tips like this with the gold all liquid
then another image more like this

Where the fingers are just gold
Perhaps inpainting or photoshop? Generators aren't usually good with very precise details
What you could do is inpaint the hands, use multi ControlNet with Depth and Scribble to ensure that the hands are in the exact position you want and prompt it to make the new hands with golden fingers
The alternative (which is wayyy simpler) is just using photoshop
I'm sure you can find a tutorial to make this effect
that's called "outpainting". there is a script for it at the bottom of the img2img tab
also, the other tool outthere, invokeAI, is really good for this kind of things, let me find an example

Using Stable Diffusion and Invoke A.I. and nothing else. Still Learning
Go for the dislike button and,
SUBSCRIBE FOR MORE BAD, FAKE, EVIL, A.I. ART!
Outpainting with the openOutpaint extension or the outpaint script, but you need a special model for it (You can also convert the others to use)
What prompt would generate identical faces as per the source image?

It literally looks like its made by a person, there's almost no AI artifacts
Congrats!
what's your best negative prompt to help with bad anime eyes?

no matter which model I use I keep getting anime and can't prompt my way out of it
Try realistic vision or deliberate model
yeah deliberate is usually my go to and sometimes the results are great, but keep getting the same characteristics as anime e.g. big head, eyes, pointy chin
its almost like the closer the picture is, the more anime it becomes, the more zoomed out, the more f222 it becomes
e.g these were in the same batch


anyone know what prompt for artstyle like this? and maybe the model too

This was a marathon but finally got there by starting with two women (which was the closest it would let me get with txt2img), then inpainting the male character slowly in parts 😮💨

Hello! Anyone know a prompt/model for this sorta rough hand drawn artstyle? I'm in love with it.






did you try to "Interrogate" CLIP to see if you find some artists name that would fit ?
Yes I did, and unfortunately the results weren't too great. I'm not sure if it's because of my model, but it mostly resulted in these sorts of images.


Hello! I am very new to Stable Diffusion, in fact just learned about it earlier today and managed to install sdwebui and played around with different models. I'm very interested in copying screenshots of video game characters (Lost Ark right now) and upscaling them to look realistic and very detailed. I attached 2 pictures of someone basically achieving what I'm looking for, staying extremely loyal to the source material, which I don't seem to be able to find out how to do (left is in game, right is the output). Any tips? :D
I know the model used is anything-v4.5-pruned.safetensors with anything-v4.0.vae.pt, other than that, nothing really hah


hum.... maybe yeah... I'll try to see what I can get to
what I got through all pics as useful style keywords :
, Dan Content, official art, a storybook illustration, sots art
, Clara Miller Burd, sepia, a character portrait, synthetism
, Caroline Chariot-Dayez
, a detailed drawing, mail art
I can't get anything coherent either....
sorry, I'll try again later, but yeah, a model could help, I'll look on civitai
"upgrading" the art for more details and upscaling will be 2 different things, maybe try to focus on the details first. The techniques used here seem multiple :
img2img to keep the colors and initial composition
controlnet with canny mode (not sure on the mode) to keep the shape close to the source and not stray too far in the changes that happen
a good prompt to help push the AI into adding the good details
the good model to fit with this fantasy realistic style
potentially embeddings and/or hypernetwork to push the quality of results even further
its latent upscaled, so you can also upscale it with img2img sd upscale script
Does anyone know of any models that are focused on generating objects/items? I'm trying to make images for an RPG campaign. When I try to generate a wooden staff it generates this kind of images

Or this

I'm using dreamlike diffusion
Which is cool and all but it's sort of useless for what I'm tryna make
Gotcha! Installed ControlNet and playing around with settings, which finally stays true to the contour of the original! Will play around with stuff to see how to keep the color scheme perfectly the same and only add detail, then when I have a good output, I'll stray into upscaling, as @silver valley suggested, thanks :D
Any suggestions on how to get blending between two nouns? For instance if I just use "giraffe daffodil" or expand on that with '"giraffe made of daffodils" or "giraffe wearing daffodils" I still tend to just always end up with either a giraffe, a field of daffodils, or both in the same scene. On a rare occasion, some attempts produce some flowers replacing the tufts of hair on the top of the giraffes head, but that's about the extent of it. This is just one example, but I've found that whenever I use very distinct nouns, I never have much luck getting them to blend together somehow.
how do i deal with the top of the head getting cut off EVERY time

try cowboyshot or portrait
doesnt help much, just changes the style 🥀
which model? its also missing the vae file for it
vae?
and the model is anythingAndEverything
a vae is used and needed for anime models for color correction, i can you show you an example shortly
what tags are you using and what resolution?
try a resolution of 512x768 and then use for example:
portrait of a girl ....
res is 512x768

so you need to get the vae of AnythingV3 for your model
it goes into the models folder, then you have to rename it to match the name of the AnythingAndEverything Model.
Example123.safetensor
Example123.vae.pt
for your cropped problem, try to describe her hair more
like straight hair, streaked hair,
and i assume you have to apply it in the settings?
no if the setting for vae is on Automatic, it will automaticly apply matching vaes to models with the same name
oh
oh wow that looks way more vibrant
also is there a way to get rid of more annoying small details that refuse to go away, such as this on the right arm

you can try img2img to get similar pictures or you can inpaint and maybe remove it
@silver valley i used outpainting and after (quite a bit) of trial and error i got something that worked well
nice 😄 👍
but why outpainting and not inpainting ?
for the head being cutoff, i mean
i'm using inpainting rn to alter some other stuff
ahh yea good idea with outpainting then
ended up with this

When you are using prompt editing with A1111, does SD take into account the how the prompt will change before it starts to generate the image? I am adding something halfway through generation, which should be late enough that it doesn't affect the composition, but depending on what I try to add, it totally changes the whole scene.
It is almost as though the presence of the elements to be added affect the weighting of other elements even before they start to be drawn.