
#📝|prompting-help
1 messages · Page 1 of 1 (latest)
and below something in the style i would like to reach ( a bit more complex i hope ) but i failed here to get my letters , each time i dont get all :/ :
What’s a negative prompt that y’all swear by?
"deformed, old, wrinkles, oversaturated, blurry"
You may add "jpg artifacts, jpeg artifacts, weird colors"
I never tried before, but I think that "unbalanced composition" is a good negative prompt. And "asymmetric faces"
anyone know of any models or even just good prompts for doing UI/UX design with SD?
How do I prompt a character of mine wearing a suit? Everything Ive tried is ignored by it
ChatGPT is just stupid sometimes.
Found a thing. https://huggingface.co/spaces/microsoft/Promptist

Good idea, but the execution is shit AFAICT; it literally just added by Greg Rutkowski to the sample prompt I fed it 🤦
Yeah, seems like it just adds stuff at the end.
A “thesaurus” sort of tool could be very useful, but this seems like someone just scraped the lowest common denominator from lexica.art or something
anyone have ideas on how to get rid of the larger more developed style of buildings in the background?

redshift style a small nomadic village during the jomon period, huts with thatched roofs, mountains in background, realistic, beautiful, 4k, octane, sharp focus --neg blurry, blur, out of focus
maybe try with huts on the ground, what model are you using by the way ?
redshift
Has anyone been experimenting with Christmas-style images lately? I'm looking for some help? Perhaps some example prompt,Thanks!
anyone have tips on how to get it to be night time?
starry sky is good, astrophotography if you want dramatic Milky Way stuff, moon can sometimes help but is slightly unstable …
If you’re not already prompting night, well, duh
Tried most of these but still often don’t get a truely dark night environment. Even tried something like ((((very dark lighting))))
Is this dark enough for that type scene? Just tweak your prompt in openmj1.4 model, so the image not so similar. But either way I think it needs multi generation.


lets say, I get a nice illustration of a horse that I like. and now I want other animals in the exactly same style, so they'd look like the same person drew everything in the same style. is there any way to achieve that?
hello I am trying to get 2.1 to generate skin imperfections like acne, is this possible? like I see people putting it in negative prompt but I want to force it out. I think it makes people look more real
I am trying it this way

anyone that can give me a prompt for clouds and ocean under the islands so it does fit?
if anyone has any tips on how I can make it look nicer more real.
Will writing too many negative prompts dilute the results from my positive prompts? I read something about 75 token limit. Not sure how this factors into it. Anyone knows?
I mean, it’ll suppress results where negative and positive prompts interact, e.g. negative wind on positive turbine will suppress “wind turbine” results but not, say, “gas turbine engine” or “jet airplane turbine” results, pushing your image towards those other sorts of images
Unfortunately, because of the keywords in the dataset, I can currently only think of two other suggestions I have - one would be to find a similar image of an island floating above water and interrogate it's CLIP data; this could give you some extra words to feed it that might push it in the right direction for your prompt.
The other would be the hard way - paint out a version of what you want in Photoshop, bashing the image of the island you like into a painting that shows clear delineation of the shadow and water; high contrast images are best. Then you would use a really low noise setting like .25 or .3 with your prompt and slowly work img2img until you get what you want.
Additionally, I don't know which sampler you are using but I've found recently that DPM2 tends to skew closer to the prompt (at the right CFG and noise) and Euler a likes fantastical things a bit more, though this also carries depending on subject matter. Also, I personally leave my CFG at 18.5 when I'm trying to force it closer to my prompt, especially in img2img, though YMMV.
If I get a chance later today, I'll try to mess around with some settings and see if I can get anything close to what you are looking for.
I want the island flying above water and above that clouds
Also I want those islands a bit more in a circle around the middle one.
anyone know a good method to turn something like an anime picture into black and white line art?
i'm trying to get some vesuvian man images out of SD, but its giving up a lot of jesus with that prompt
oops. Vitruvian man. maybe that's my issue
anyone have tips on how to get just one?

It keeps giving me doubles
"redshift style a powerful queen sits on a throne during the yayoi period, beautiful, sharp focus, realistic, detailed and intricate --neg blurry, blur, out of focus"
using the 2.1 model I was able to get about 2 out of every 4 generations to be floating in a manner that seemed similar to what you were looking for. The key prompt was floating islands hovering high above the clouds above the ocean, bird's eye view . I added in a few other key words like isometric environment and shadows falling on ocean . I think the main thing is to add in prompts that deal with the lighting of the scene - unreal engine 5 octane render soft light etc are all helpful in adding in those shadows over the water. For negative prompts I tried abstract, connected to ground, sitting, inorganic , high cliffs. From there you should be able to generate a bunch of images and then you'll have to use inpainting or something to get a composition you like. DPM2 and Euler a worked best between 12.5 and 15

It's a resolution thing, when it's trying to follow your prompt and sees enough space to make "more" of what you asked for, it'll do it.
Easiest ways are to either use a resolution where you don't get doubling, and outpaint it after to get to the desired resolution, or to use Img2Img to provide a composition for it to base the generation off of.
you might also try adding in the negative prompt of multiple people or duplicates. If you haven't already in the prompt, you can add portrait though that may end up cutting to just head and shoulders. If you use Automatic1111 you should definitely try hi-res fix - that usually helps a great deal.
you can try retaining your style prompting, sampler, steps, CFG and seed for the original illustration you like and replace the main subject with a new one (tiger instead of horse, jungle instead of pasture, etc). However, it may not be easy to get the results you want in that way. It is more likely that you will get more consistent results with a trained model in that style. But perhaps someone else has a better alternative. I know there was a link in here somewhere about consistent characters recently, but I am missing it for some reason. Perhaps someone else will have it.

oh shit, could you ping me next time wit this? thx, how would I be able to generate like 9 in total in circle formation?
12,5 and 15 being steps?
2.1 model gotta download that one
Sorry about that, I thought I hit reply but apparently my brain was falling asleep already 😂 12.5 and 15 are the CFG scale. I used anywhere between 35 and 50 steps, though with Euler a you can try anywhere up to 100 steps and get some varied results.
As for getting multiples, it struggled when I tried to tell it a specific number of islands to generate. I personally would find a good base to use, then go to img2img and paint in the areas you want new islands.
I can add multiple together using online tools but then the background etc looks weird.
Ye sometimes replies fail on me in discord too
Hello, how to separately detail different entities?
So the way I usually do it is either inpaint generating, or photobashing /painting by hand. Then when you have a composition you like, run it through img2img with a full description of the scene and your style prompt using a decently high CFG and a noise of like... .25. this should help start to blend the scene together and you can then take one of those images and run it again through img2img until you get the style and composition you are looking for. Getting an exact composition out of stable diffusion definitely requires a lot more hands on work.
Are you asking how to render two subjects in one image or how to add details to more than one subject that have already been generated?
it's not that easy to get such results without editing stuff. And it depends on how "different" they should be. As well as which model version you use. Words like twins gives copies of a person for example on 1.5, but I don't know if it works the same using 2.x
how to add multiple action with an image
Christmas postcard in tabular data of financial markets
Im having trouble getting stable diffusion2.1 to generate weapons. Any prompt ideas for fantasy bow and arrows?
maybe try wooden bow or longbow , holding a bow and arrow ? If you see anything you dont want it to be there try to put that in negative
I can't seem to get my character to do a specific action, here's my prompt:
A stunning full body jugendstil painting with defined contours of Goe3 playing the violin, white hair, defined facial features, ((vibrant)), 4k, matte finish, fantasy, by Arthur Rackham, Edmund Dulac, James Tissot
If anyone can tell me what Im doing wrong all ears
Someone can help me with SD 2.1 prompt: Beautiful pretty Cyberpunk woman with blue hair wearing tactical suit Purple and orange in cyberpunk city, portrait photography, 8k, 35 mm, DOF, Canon Mark III, highly detailed, cinematic light, Smile.

This is what I got
"hair wearing tactical suit Purple and orange in cyberpunk city"
in middle where says suits put or after orange ,
either write wearing purple and orange suit , in cyberpunk city
Thank you ❤️
I tried this
Beautiful pretty Cyberpunk woman with blue hair, wearing tactical suits Purple and orange, in | cyberpunk city:2.0 | punk:2.0 | , portrait photography, 8k, 35 mm, DOF, Canon Mark III, highly detailed, cinematic light, Smile. | in the style of <midjourney> | ugly, boring, bad anatomy:-2.0 | <TOKEN> in the style of <wrong>

My try with midjourney model way: prompt
" mdjrny-v4 , Beautiful pretty Cyberpunk woman with blue hair , wearing purple and orange tactical suits , in cyberpunk city , punk:2.0 , portrait photography, 8k, 35 mm, DOF, Canon Mark III, highly detailed, cinematic light, Smile , midjourney style "
Negative prompt: same yours:
ugly, boring, bad anatomy

Very nice render ❤️
except the ear, should be add in negative too 🤣 Tbh was not trying to copy you or anything. Was trying to see how it goes with cpkt model midjourney to see if it would pop what you wanted.
Tried with same prompt, using dreamlike-diffusion-1.0.ckpt, got a good ear 🙂
Beautiful pretty Cyberpunk woman with blue hair , wearing purple and orange tactical suits , in cyberpunk city , punk:2.0 , portrait photography, 8k, 35 mm, DOF, Canon Mark III, highly detailed, cinematic light, Smile , midjourney style
Negative prompt: ugly, boring, bad anatomy
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 42, Face restoration: GFPGAN, Size: 768x768, Model hash: 14e1ef5d, Denoising strength: 0.7, ENSD: 31337, First pass size: 512x512
GFPGAN visibility:0.88
Upscale: 2, visibility: 1.0, model:ESRGAN_4x

As you are using dream ckpt , If you add in prompts at end this will enrich it more if you want too: dreamlikeart
Yes I know dreamlikeart do a excellent work! But I tried to beat SD 2.1 😂



Some cool results
Jam! love the second with turquoise hair! 😄


Oh these are nice results aswell but I feel losing the purpose of using the purple and orange colors.
mdjrny-v4:2.0 , Close up portrait of Beautiful pretty Cyberpunk woman with blue undercut hair, wearing purple and orange futuristic tactical suits, in cyberpunk city, portrait photography, 8k, 35 mm, DOF, Canon Mark III, highly detailed, cinematic light, Smile , in style of midjourney:2.0 | ugly, makeup, boring, bad anatomy:-2.0 |
Yes a little
I am still trying and it also mess up with that orange purlpe thing 😄
Tried one more with sd model, at least orange is there ^^


does anyone have any suggestions?

highres fix
lower the steps to maybe 20 and choose DPM++ SDE Karras
Jeps, just don't go overboard on the weight, or do go overboard, that's fun to 😄

To 2.3 she evolve in new Pokemon 🤣
yes, I love how the hair gradually becomes rabbit ears 😄
Do commas have a use ?
Try with duplicate and/or identical in the negative prompt
I think it helps to separate tokens, i.e. "full moon, blue hue" vs "full moon blue hue", where the last have a higher chance of becoming a blue moon (example only, have not tried).
I will try with same seed later and check for differences
i need help with prompts for my oc , feel like her design is too complex for words
i just dont know how to describe her
I'm looking to get basic, clipart style designs with limited flat colors. Should I train a model specifically for this type of art, or maybe just work on better prompting? I get decent results as is, but trying to refine it the best way possible. Anyone got some ideas to throw at me
man
Maybe could you try to explain a bit more of what you want? oc what is that?
Usually OC means “original content” or “original character” or similar
It's basically a personification of Brazil
Let me send an image
This is her lol

I need some prompts to describe her
Uh hello?
i think this is closer to anime than anything else
have you tried clip interrogator?

/prompt
Is this different from the Clip Interrogator in A1111 or the same thing?
im not sure, i asume that the a1111 one is meant to used with sd 1.x
yes probably. i just saw that yours is for 2.1. what are the flavors?
sd 1.x is a very different model from sd 2.x so clip interrogator 2 should work better at finding keywords for sd 2.x
Png, flat, are good keywords
Hi Guys! Trying to find vaporwave/retrowave/synthwave models for Stable Diffusion, prhps you know any good ones?
hello, i am using waifu diffusion to make ai art of a boy and a girl together (anime style). i need help on how to make the tags correctly so that it doesn't mess up. the characters would always end up having swapped hair and it's confusing.
try increasing the attention to the word "and"
so “1boy and 1girl”
but sometimes it wil show 3 people or 2 girls
but i want to put specific details on both
like purple hair for the boy
and brown hair for the girl
anyway to generate visual novel images? like portraits
Can anyone help me build a set of prompts suitable for making images for children's story books? I'm willing to pay
I need some prompts that will give me the best chance of creating a suitable image on the first try. Most chance of creating cohesive cartoon faces etc and a nice style
so waifu diffusion isnt good for couple ai art
my idea was to bracket each character in the prompts
not sure if that will work
Is there a way to set up a prompt that makes the AI pick one of several options?
for instance, the AI must select one: yellow, blue, or orange shirts?
You could try this one https://github.com/Extraltodeus/multi-subject-render
GitHub
Generate multiple complex subjects all at once! Contribute to Extraltodeus/multi-subject-render development by creating an account on GitHub.
Can SD 1.5 recognize valorant characters? Can I just use the names?
generate separate images with a green background, make the characters back and front lit, key out the greenscreen, place the characters close, save image, run img2img with 0.30-0.40 or something and change their pose to what you want :p
roundabout way but still
I found an engine trained to create knollingcases. Would anyone have a suggestion on how to create this effect on Vanilla SD 2.1?
how do I weight an element in the prompt? e.g. I want to guarantee the subject is wearing eye glasses. Is there notation for this?
you can put brackets around the prompt like ((glasses))
the more brackets, the higher the priority
i've had 10 brackets on ((((((((((full body)))))))))) once, and it didn't work out
Something's wrong!! now everything is eye glasses! (just kidding, ((((thank you))))!)
1 or 2 will get the job done for something clothing related.
3 or 4 is suitable for overall themes like sketches or monochrome colors
6 or 7 makes my graphics card click and makes the check engine light blink
is there any notebook or anything with weighted prompts yet?


i always use "standing" instead of full body
full body gives me cropped bodies
i like actions like walking, jumping, swimming, etc
but typically they never work, lmao
"action photography" or "action painting" gets them moving around and a little zoomed out
thoughts on this prompt?
redshift style a nomadic tribe during the jomon period, they live in huts with thatched roofs, sharp focus, realistic, beautiful, ray tracing, 8k, global illumination
is "they live in huts with thatched roofs" best as its own element?
anybody know anything for getting better pixel art stuff?
im building a tool that helps small businesses generate images for social media, does anyone have any good models in mind?
Adriana Lima
after creating a model with Dreambooth+Lora the model is really good for creating consistent face, but it can not create anything else, like it refuses to create the character standing or sitting, the body is either messed up or the face is completely different. How do I deal with that?
Where do I type in the prompt to generate an image?
quick stupid question, what does enclosing a term in < > mean again
First time I've seen it
Go read #1014939219904450590 please
I would like to know how to keep the same face on different projects ?
It’s optional syntax for embeddings in a1111.
How does Prompt Order works in X/Y Plot please?

i think its for when u want to see what the same prompt does just not ordered the same
This is what I'm looking for but I get an error when enabling it, like I don't know what to put in the text box next to it
ur prompt
Oh
Makes sense now indeed, let me try
yeye
Doesn't work, it loads forever
lemme try myself rq
thx
i wonder why lmao
Oof
i think it works better for shorter prompts
mine was long asf
lemme try again with like 4 kwds
Same, and my PC suddenly crashed and switched to a 4:3 resolution
mine didnt lmao
but lagged it out
4 prompts

so either u have a godlike machine or u need to use short asf prompts
I will rather keep this script away 😂
Nope I don't even know what it is
When ya merge two or more checkpoints which prompt calls it?
depending on embedding there is a triggerword
but its basicaly merging 2 models togheter
On embeddings most times it's the filename
But with checkpoints
If I merge two of'em I have no idea how to "summon" it
Oh I see now
just write the 2 triggerwords in ur prompt
Appreciate it
base sd 2.1 512 model with basic prompt and 30 steps

same prompt as above but midjourney embedding

@dark shore u get it now?
especially the mj one is insane
i didnt change a thing only by midjourney to trigger the embedding

i discovered it yesterday lmao
lmao
where can I get it?
Yea, but I just wanted to generate variations of a good seed without tweaking the CFG Scale, Steps and Sampler so I wanted to play with the prompt order but I will do it manually

When the Stable Diffusion 2.0 & 2.1 models came out, it was a mixed bag that divided the community, it was very good at creating very realistic images but if you wanted to apply an artist’s style, you wouldn’t get similar results that you had with the 1.5… UNTIL NOW! Because very quickly the community realized that with the newest models, textua...
Thank you!🔥
write a python script that randomizes ur prompt
easy with chatgpt lmao
haha good gatch! Thanks for your help
npnp
hey
im new to stable diffusion. can someone give me tips or tricks to make my prompts better
more understandable and less "buggy" to the ai
a beautiful gir
i did that exactly, however later i found that wildcards+dynamic prompts did the job just fine.
?
describe it as much as possible
also order ur prompt right
https://lexica.art/ and u can look here for inspiration and so on

is that the only difference between the beautiful and pleasing to eyes arts I see on this server, and arts that I try to design
I mean just describing it good will do it?
like I am newbie so how can I get to know more about this stuff
@lavish tangle just look at those 2 i posted yesterday same prompt and sampler only added by midjourney on the 2nd one
When the Stable Diffusion 2.0 & 2.1 models came out, it was a mixed bag that divided the community, it was very good at creating very realistic images but if you wanted to apply an artist’s style, you wouldn’t get similar results that you had with the 1.5… UNTIL NOW! Because very quickly the community realized that with the newest models, textua...
is it for dreamstudio too?
or is it just for installation
hello there! Can someone help me out with prompting with sd 2.1? How can i generate arts in style of Beksinski with that new sd engine? sorry for such a noob question 🙂
what am i doing wrong https://i.imgur.com/lnky1yp.jpeg
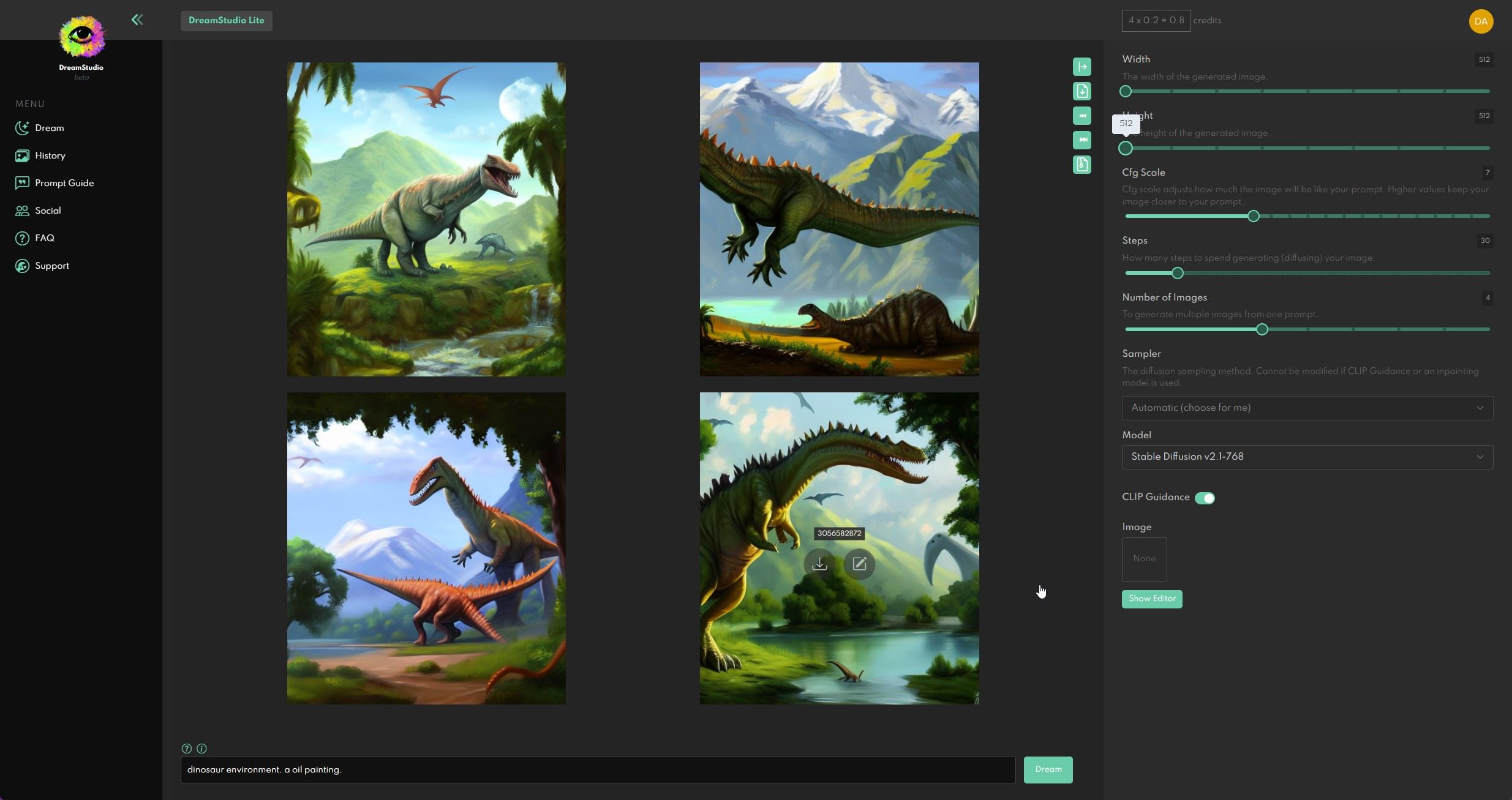
you may wanna be more specific with prompts to elaborate what you want
for example try
how come midjourney doesnt work with so many words as sd?
dinosaur, carnivorous dinosaur, bipedal, full body, jungle background, cinematic, realistic, high quality, trending on artstation
i dont know much about midjourney
but maybe try the prompt i suggested
not even close to mj quality ^^
yeah why its not as good as mj
dalle-2 is the worst option 😄 it cant make any dinos atall or animals or humans
mj trained on a different dataset with different weights
sd should have much bigger data no?
yeah, but some of it may be worse
does anyone have a collection with good stylistic prompts for anime models that work well together? i mean prompts like realistic, illustration, oil painting etc.
Is there a way to sort this by SD 2.X?
heyo what is this style called? https://cdn.discordapp.com/attachments/887074303852572692/1057737562548092978/wp9442456.png

im trying to generate something similar
i use it for 2.1 to its just trial and error
vectorizing mixed with high key
Anyone have a good negative prompt to prevent cutting off heads, out of focus. I'm using fairly typical, but still get far too often shots that are cut offf.
or just prompt, doesn't matter, figured it belongs in negative prompt
Using 2.0 right now
two tone maybe
I'm using 1.4 lol
how do i install 2.0? do you have the link?
Dead to me since 2.x. They need to bring on 2.x or just terminate the site.
https://docs.google.com/document/d/1_wBE8PGapaaKt8KuWtF1PTeAwG5Z-cRCWv2mCwcnpxY/edit?usp=sharing New category "DIRECTORS" feel free to use them to get that photorealistic look

Google Docs
This document is made for stable but it can be used with other ai services
How can I make SD look like midjourney?
You can install a custom model trained from midjourney images
you can try openjourney model one
Exactly what I'm looking for, can you DM me a link?
The new is still in beta: https://huggingface.co/prompthero/openjourney-v2
The old one is:
https://huggingface.co/prompthero/openjourney
Thank you ❤️
anyone here uses anything v3 ?
Hello, is there a way to do prompt to describe for example pizza in pie chart manner - 30% of the pizza is pepperoni pizza, 30% of the pizza is without toppins and 40% of the pizza is without cheese ? Can I somehow point out certain part of the image to be something else than some other part of the image ?
What about using chatgpt for prompts?
Anyone got some ideas for my prompt? I want to generate dense industrial areas. However it tends to want to general spread out islands (pockets of dense industrial areas). Any suggestions for words, "dense" doesn't seem to have much effect.
Anyone found a prompt that consistently turn the character backwards, with his back facing the viewer?
Hello Guys,
I want to generate ultra realistic photography like this
Do you what token i should use for this kind of results please ? 🙂

Just sent you a dm with the install I used. Very quick and easy
Hi, I created this left image and am trying to make it look like a woman standing in a medieval kitchen reading a book. I feel like I am close but there is something I am missing. any ideas and tips?

had to censor to send
has anyone been successful with getting people to display certain facial expressions? nothing seems to work except for getting them to be "laughing"
best to add weights, i typically dont focus too heavily on it but sometimes ill add a light smile and crank weights until i get what im looking for
Is there a good way to make colors and/or patterns stick to specific parts of the image? Like green eyes instead of green everything? Or striped hair instead of striped clothing...



eyes are easy, the hair is harder, would probably be best to use inpainting for stuff like that



And how are you doing these? 🙂
(selective color red dress) or (selective color orange hair) or (selective color yellow hair) or (selective color blue hair) etc... 2.x CLIP is powerful so I am not sure if that works in 1.x
So "selective color" is the magical word? 🤔
yep
Thank you! ❤️
You are welcome.
Here comes a more specific struggle from my list of things that dont work:
I try to make an image of a human with slitted eyes like a cat.
Cat-eyes, sliteyes, slitted eyes... Nothing works. Best so far is "almond shaped pupils", but this is more of a 1/20 succcess.
Do you (or anyone else) have a way to get this more consistent? 🙂
Never tried, but I have seen it done.
Any idea where?
on reddit
in 1.5 I've had a lot of luck creating a medieval feel with the terms renaissance setting, medieval european setting, and feudalism. I usually have to weight them around 1.3 or even higher sometimes.
thanks man 🙂 i will try those tags
doesnt seem to work in 1.x and i havent found a 2.x download
Yeah, 1.x clip is shite.
hi all, which is the best way to get photos very realistic with a perfect faces?
Hello guys,
I'm looking for someone who can sell to me a pack of prompt for my Avatar Generator Website, fell free to contact me in DM, i pay for this service, thank you so much
Ok, so i have a weird request. I am trying to create a fish, but with boobs. Please don't ask, just tell me how to tell SD to create this masterpiece.
Try to use the AND operator 🙂
Strange, if I type "blue eyes" it'll make the entire eye painted blue, like someone just painted blue over the eye with a soft Photoshop brush.
How are you prompting blue eyes?
What prompts do I use in SD for character Concept art?
And concept art in general
In mid journey I added concept art, concept sheet, character sheet,
In SD not as simple
hello, how do you make a text that is respected
I showed how. Instead of dress, or hair use eyes.
so the trick is to write "selective color blue eyes" and it'll only paint the iris, right?
2.x and you saw the result I posted above, right? That was done doing that.
Does anyone know how to img2img each picture in a folder using the prompts in each png file (in automatic1111)? I would like to first create 100s of 512x512 images and then choose the best for img2img with higher resolution. Like hi-res fix, but in two parts and only to some images.
oh my god I'm dumb (or tired and stressed). I thought the post with the blue eyes was from the person asking the question
LOL
I try to get striped hair like the fur of a tabby cat. Any ideas for that?
I failed with:
Tabby hair
Striped hair
Tigered hair
Hair with highlights
Multicolored hair
Twocolored hair
... And maybe some I already forgot about...
Beautiful realistic looking big mouth bass, wearing realistic Vitoria’s Secret bra, bra is red and with lace, bra is size 32 dd, full bra
Try that lol
It was too funny and bizarre not to try
Last night I played around with starting with a traditional art marble statue, then adding fantasy details to it (while it's still a statue). The details in marble have a lot of relief. it's easy to take those images up to concept art or comic art via img2img. Gallery showing the progression https://imgur.com/a/XLNjVlk. I am working with a trained model and trying to preserve the face in ways that work for each of the art styles ( alternating between comic book cover art and concept art photography)

ok so the #🔆|dailies bot wants a car driving through a rainbow at sunset. I cannot get stable diffusion to create this. No matter how simple or complex the prompts. Ideas? This is what i'm getting:

a car at sunset driving, rainbow
?
I'm brand new and can't get it to do a flower with three pedals so ymmv
is it just me, or do you guys have to negative prompt "watermark" and "signature" to prevent it from generating stock photo like watermarks on scenic nature prompts?
trying to generate some images and they're all too zoomed into the subject...any prompts to help ensure the subject isn't cut off/out of frame at all?
trying negative prompts of: out of frame, cut off, body out of frame, blurry
Sometimes I'll prompt with things like: rule of thirds, full body, centered subject, but I often have to augment with outpainting anyway.
good composition, golden ratio
Has anyone found out how to get Orthographic Projections consistently? Orthographic & Orthographic Projection don't work for me.
Character sheet sometimes gets me stuff similar, but neither consistently nor exactly how I want it.

hey, so can I use this with multiple subects?
e.g. a black man with (selective color blond hair) kissing an Irish man with (selective color black hair)
can I use this to control other aspects? e.g. I want a fat person and a skinny person... I find the concepts bleed
SD has never been good with multiple subjects
How can I make sure that the background is certain color? "... on black background" doesnt seem to work.
I wanna create "product studio shot" of a generated product - how can I make sure that the "product" is fully visible on the image (not just zoomed part of it)? And how can I determine how big the product is in the picture (can I somehow use % of how much image the product is covering) ?
what's the prompt like?
Highly intricate detailed photograph of [object] on beautiful black matte display stand perfectly centered in picture, product studio shot, on a black background, perfect lighting, extra vivid colors, centered picture,HDR, UHD,
64K, ultra realistic
what model do you use? can you share an example of the generated image?
and an example of what you want
Thx for helping out..
"Highly intricate detailed photograph of fire red bowling ball on black matte display stand perfectly centered in picture, product studio shot, on a black background, perfect, lighting extra vivid colors, centered picture,HDR, UHD,
64K, ultra realistic"

I would like to have black background (kinda void or empty space) and the object would be in the center. I would like to know how to control how close the object is
I assume that you are using a dreambot, right?
I have tried with SD 1 and 2. Different weights/models etc
I can use img2img but it determines too much the outcome
I guess that you want something like this https://huggingface.co/ProGamerGov/knollingcase-embeddings-sd-v2-0

but for product shots
you can probably get what you want by playing with the prompt and generating tons of images, but I think that results will probably be wildly inconsistent from object to object
I kinda would like to be able to generate good image every time and not need to generate 1000 images to find one what Im looking for
don't we all 🥲
but my best bet would be to train a hypernetwork or an embedding, like the one in the link
they'll shift the model to more predictable outcomes
the next best way is to do img2img, but it kinda kills the idea of getting a fast result by typing an object's name into the prompt
Yep kinda. Just without the box and just black bg
Yep, this is kinda working but it takes too much reference from the img.
Is there a way to tell in prompt where the object HAVE TO be in the picture?
Maybe I should look more into embeddings
Thx for helping out again
there is also such a thing like depth2img, but I am still learning about it, so I can't say if it'll be useful for your case
Im very new to SD and I have alot to learn still and I appreciate all the help.
ai's not very good with text 😅

It is just drunk 😅
Maybe I could create the stand and background image with white ball in it and then just use inpainting to replace the white ball with the generated object.. that might work well
Does someone have prompt for a human cuz sometimes I get weird fingers and weird faces
yea, I guess you could try that, I'm yet to figure out depth2img though, I have some problems with running it for now
if you use stable diffusion with webui you could try adding negative prompts like: "mutated hands, ugly hands, deformed hands, extra fingers" etc, it won't always help, but sometimes subjectively the results are better
webui also has a "restore faces" option with GFPGAN or CodeFormer (didn't try this one), and VAEs which allegedly help with the faces
Why is it so hard remove an arm, trying to amputate a image but no commands i try want to work with me, anyone got any advice, currently using inpaint with 0 negative prompts
it all depends on what you're trying. If there's one easy thing to know about the ai, then it's that nothing is easy with it! ;P
Yeah i was thinking of prompting out the arm in some way in intpaint but i get the feeling i have to use some other software to fix this,
go to paint, paint the arm in the color of the background and try to do inpaint again
Guess it it wroth a shot for this AI does not like me removing limbs
it's often very random, sometimes you save time by just brute forcing it like that
Yeah, some things you just have to fight like crazy i have noticed of past days of using this.
also depends on how far you'd go, like for example use variable seed strength to get a variation with no arm, then copy it into the other image using paint or anything you'd like to use :)
Yeah i think it will be easiest for i have currently painted it over and denoising on max so it gets free reigns on what it does
is there a reliable way to test seed variation or just ye olde trial and error?
depends on what you mean, it's super easy using auto1111 webui I'd say. But we might be speaking about different "reliable" ways :P
I believe it's super easy, but maybe you're making some super detailed masterwork my mind would never be able to understand, and because of that, my way wouldn't work. Mostly because my stuff is, well, not the thing I wrote before ;P
I mean like do you just use X/Y plot and go over a range of seeds to see how they differ? or maybe build a batch of 10 images relative to the original seed and see how they change?
Gotta love promting and trying to brute force, no hand, just the sleeve now he has a tiny little baby hand, i call this progress
cfg changes the image too though and so do weights, so are there benefits in manipulating a seed as opposed to the other ways?
I mostly use the batch count set higher than 1, and then toggle the extra button and change the Variation strength by something like 0.02 and let it roll a couple images to see how much the seed changes :3
some seeds are just bad
oh okay, I didn't know this method, what does variation strength do to the seed? is it like a seed-related incremental coefficient or something?
it creates super small changes (if you use a small number like above), it's easier to show than tell, so I'd recommend you to try it out, a super fun thing to try out! :D
thx, trying it right now
true that, I thought it would be fun to use the digits of pi as a seed, the first like 12 of pi are a terrible seed for most things I've tried, 😆
Hello everyone. I am trying to generate something similar to this style in SD using Openjourney since my friend made this in Midjourney, I can provide the prompt he gave but for some reason I just cannot get the same results in SD. Prompt he used: pirateship sailing toward the camera headon, freedom, freedom in an unfree world, this image is about breaking free of the new constraints to face the future with hope but a strong resolve to fight for that hope, ukiyo-e ink --v 4 --q 5

Happy new year everyone
Could any one guide me to recent image to prompt colab?:) please
i've been finding you really need to peompt a lot differently from midjourney to SD
gents, anyone knows how I can make different style for foreground subject? ie "1 boy scout art by 3d pixar AND standing in a forest with big trees art by Stephan Martiniere" turns out using same style for both. Thanks.
Can someone suggest me prompts of creating images that look ultra realistic please?
I guess you can use inpaint, draw the mask over the object, set mask blur low and remove the style you don't want from the prompt
micro-details, photorealism, photorealistic, ultrarealistic, realism, realistic, detailed;
I don't really know if these work well though since I don't make realistic images
Anyone have any ideas on how to stop imagines from being cut off?
same its crazy how different things can turn out
Who is here the master on model training from a person face. i kind of did all the steps followed instructions, but they dont have LOARA in them, did a check point of my wifes face and she looks like nothing when i generate the pix.
or if you know a channel/person who i can ask about it that would be amazing. i'm just new and still trying to understand this whole thing lol i'm not gonna bore you just need some directions in a right direction.
@idle nexus I think maybe #🔧|finetune
Hi guys!! I have a question...hopefully someone can help me!: Is there a any way to write the negative prompt in the same field as the prompt with some sort of syntax?
What I want to do is to write a text file with multiple prompts to use it with the 'Prompt from File' script.
can anyone help to find all the command to use discord SD dreaming
If it's a person "full body" seems to work kinda consistently, if it's an object maybe just "full". Sometimes specific words accentuate the model's attention on the part of an object, like if you write "legs" you may get an image of legs, etc; so playing with weights might help. You can try adding "cropped" or "out of frame" to the negative prompt, but this usually doesn't accomplish much for me, so I just change the weights around or generate random seeds to hopefully get what I want.
--prompt "here the prompt" --negative_prompt "here the negative prompt

GitHub
An extension to AUTOMATIC1111 WebUI for stable diffusion which adds a prompt generator - GitHub - imrayya/stable-diffusion-webui-Prompt_Generator: An extension to AUTOMATIC1111 WebUI for stable dif...
What's dis
Anyone?
check what people are saying in the finetune subchannel, maybe they can help?
Thank you.
hey guys, some months ago I saw some kind of a cheat sheet that contained a table showing which keywords and artists result in which images. does anyone know if it's still somewhere around here? would be very nice to have! thanks in advance
has anyone found a way to generate 1 single cybernetic arm (think Deus Ex, Jax from Mortal Kombat, Cyberpunk, Shadowrun), When i try different related prompts i can think of, they usually give 2 arms and also add other stuff like armor plating all over the body and even then the arms usually look like robot arms from some 80s sci fi
Hey folks, what's up?
I would like some help to improve my prompt:
D&D Character, Male rogue goblin with grey skin and a scar on his face, crouching in attack position with a dagger and hand crossbow, wearing dark leather armour with hood and cape draped over his shoulders, in a Gothic city landscape, D&D, fantasy, by Greg Rutkowski, artstation, 8k, expansive, extremely detailed, cinematic lighting
Does anyone have a suggestion on how to improve it?
If you folks have tips on Models and embeddings to use. I'd be very grateful!
Currently, I'm only using the Dungeons-and-Diffusion model
These individual prompts are too complicated
Generally it's better to have a lot of small prompts that collectively have all the traits you're looking for
Like say I want to create an anime girl with green hair and brown eyes
I don't give it the prompt "Anime girl with green hair and brown eyes"
I give it the prompt "Anime girl, green hair, brown eyes"
@slender torrent So how stable diffusion models work is they're given a bunch of images, then it picks out the common elements in those images and is given a word to associate with those common elements.
Let's use your Goblin character and DnD Model as an example
Dungeons-and-diffusion was shown a bunch of pictures of goblins and told "This is what a goblin looks like"
So now when you prompt it to draw a "Goblin" it goes "I know what that is. A goblin looks like this."
But if you give it something where it doesn't know what it is, say "Elmo", it's like "Elmo? What the heck is an Elmo?" and it's likely to return a jumbled mess
Oh I see, so I'd better put the elements that I want to appear in the image, not the exact description of what the pose should look like.
But, for example, I wanted the character in the image to have a weapon in each hand, so I would put something like this:
"weapons in hands, dagger, crossbow"
No that's not going to work. Prompts are comma delineated so it's not going to interpret that as "Dagger in one hand crossbow in the other" it's going to interpret it as "The goblin should have weapons in his hands and also the image should have a dagger and a crossbow in it."
Also, be prepared to mess around and try different prompts for a few hours.
Whenever I'm designing a new OC I always have to mess around with the prompts for a few hours to see what works, but once it produces the general pattern of the sort of thing I want I save the prompt to a notepad file and then if I want to make a new image with that character I can reproduce it in a handful of attempts
Right, I got it, my notepad++ has several prompts already 😅. Thanks a lot @spiral crystal ! I will apply this new knowledge.
so that weighting (prompt:1.5), is there some good site with explanation or can someone please explaint it to me in a short overview? like what values should be used and can it be used several times and what does one under 0 do
What would be the best prompt foundation for outputs you intend to pass to a 3D printing wizard?
Is there a way to, after you get your perfect front-facing image, use that image as the foundation of following generations and ask the AI to produce the subject of the image from several different angles?
I'm thinking you may have to remove the subject from its background for starters and that would require some photoshopping
You're going to have to train the model to teach it what you mean when you say "1 Cybernetic Arm".
ok so theres nothing that SD 1.5 or any existing model has that would achieve that. Can't train models with my hardware
I recommend getting the Dreambooth extension. It allows you to train models even if you don't have a high-end GPU.
have to look at that, thanks. gonna assume extension as in automatic extension?
I don't know what that is
basically a plugin for the Automatic111 GUI
Yes
My new 3070 kept rejecting me on that
Find your VRAM and use this table to adjust your settings in Dreambooth. I think 3070 can do it

@wispy chasm try this, SD tend to upscale everything so this is the best i can do (at this moment):
prompt: a character portrait of an evil mage, 8 bit art, kieran yanner, fantasy portrait, low resolution, doom status bar face, daggerfall portrait, centered
negative_prompt: ascii, high resolution, detailed background, painting






then you can use this to maximise the results: https://giventofly.github.io/pixelit

has anyone here tried looking at the data set directly for prompt ideas? https://rom1504.github.io/clip-retrieval/
Clip front
i used to do it when sd was first released
now i use clip interrogator 2
but if I copy the text directly from something listed there, and put it in the prompt does SD actually reply on that reference or does it just go off and do random stuff?
I'm having trouble getting ai to make things the color I want them. For example, if I ask for a character with orange hair, pink eyes, red shirt and black pants, I'll usually get something like pink hair, black shirt, orange pants. Any advice on the prompt? I'm putting the color before the thing and comma delineating, so I'm not sure how it's getting lost
you can try negatively weighting the colors?
won't that remove the colors entirely? Or are you suggesting something like [black shirt]?
black shirt, black orange::-1 pants ?
I'll try that, thanks
worth looking up supercomposite & loab, but its a bit horrific to view. but a hilarious rabbithole of negative weights
FYI, it didn't work, but thanks for the suggestion!
Yo uhhh, I'm trying to basically remake a texture after giving it a prompt and said texture itself (fairly low-res too). Everything works fine apart from one fact: The pics generated are always blurry. Any help?
/dream prompt:high resolution remake of revolver texture, in parts, black grip, hd metal texture, colt. 3 5 7, 4 k rendering, 4 k texture quality, high fidelity, high detail, well focused, centered steps:50 number:4 image_strength:0.50 image_init:


this is what comes out usually
hey guys. I'm new to sd but i have some experience with midjourney. I've tried to generate faces with basic prompts, but all I'm getting with 50 steps and v 2.1 are horrible messes
am i missing something?

try lower your steps
with SD-2.1 it's enough like 15-20 steps and cfg around 5-9
30 steps and cfg at 5 😦

testing stuff with steps

it's not even that they are not looking bad, it's like they are mangled that tells me i'm doing something wrong
30 is to much, especially for DPM samplers
i use clip guidience, i have no idea what the other samplers should do
well, back to topic. use negative promts or weights in positive prompt to get rid of mangled stuff
Any suggestions for me?
sorry man, I'm not good enough to help you out 😦
I'm struggling with negative prompts. I've tried a lot but maybe I'm using the wrong prompts. Six fingers, three lege aso
i usually copy the whole prompt without editing to see what SD gives me first, i see clip interrogator just as an starting point
im having trouble creating a logo, any ideas?
https://huggingface.co/spaces/stabilityai/stable-diffusion/discussions/5290
I'm trying to figure out how these pictures were created as I'm looking for a minotaur/tauren but all i keep getting is dudes with horns or a picture of The Rock with a cow face. I'm quite stumped.

what does the vertical bar | do in the prompt syntax?
Separates multiple prompts I think
yeah, but im refering to this site... https://rom1504.github.io/clip-retrieval/ the photos on here have crazy captions scrapped from random blogs, I cant see how the SD thing actually is able to use any of it.
Clip front
Has anyone been able to get specific text to display in an image? Like "Peace Now!" on a sign?
You've probably moved on by now, but I found this embedding and remembered you, it looks like it could work really well in case you find yourself in the same boat again.
https://civitai.com/models/2748/kitchen-style

This is a DreamArtist Textual Inversion Style Embedding trained on images of an intricate medieval kitchen. You can get amazing cookery themed effects in your images by calling Style-Kitchen in the positive prompt, and if you want to temper the effect, also call Style-Kitchen-neg in the negative prompt.If you'd like the effect to come through st...
What would make this prompt get a higher probability of having eyes made of flowers in the shot and have the man front and center, facing the camera or to the side, and actually shouting?
flower eyes, man shouting at the sky, city, cityscape, dramatic, ((catharsis)), high resolution, hd, 4 k, cinematic, realistic, ((vinecore)), no glasses, no sunglasses
Get rid of the flower eyes and inpaint them after; it’ll be so much easier
I'm having trouble getting SD to render a monstrous or super huge animal with a regular sized person or other animal next to it to give perspective
anyone have any suggestions?
Post work always helps 🙂
Love the idea of getting things done in a single prompt, but rarely does that happen for me.
I have had zero luck so not much work to post
I just get portraits of a single animal looking pretty normal regardless of model
You have to be specific, so find something that looks kinda like what you are trying to achieve. The size difference is where post will come in.
And joining two images if needed. I find animals are always a bit of a challenge. Been trying to get a snake to appear in a specific way and never can get it done.
hello. im trying to get pictures like this. is it possible with ai?



im trying to get em on stable diffusion 2.1 online
I making a video series to help the Average Joe better understand Prompt Craft. https://www.youtube.com/watch?v=iHEQz9uk-u8

#midjourneyAi #Midjourney花 #midjourneyart #midjourney薔薇 #midjourneyv4 #dalle2 #dalle #dallemini #stablediffusion #dreamstudioai #dreamstudio #aigeneratedart #aigenerated #aiart #AIArtwork #openai #prompt #prompts #promptcraft
I take a whack at cracking the Prompt Craft code for the Average Joe! First, I show how just using simple grammar and so...
I was wondering if anyone had some good negative (or positive) prompts to help with an issue I keep seeing, which is really long torsos


or just straight up duplicating:

I have this negative prompt already:
(ugly:3), morbid, extra fingers, poorly drawn hands, mutation, blurry, extra limbs, gross proportions, missing arms, mutated hands, long neck, duplicate, mutilated, mutilated hands, poorly drawn face, deformed, bad anatomy, cloned face, malformed limbs, missing legs, too many fingers, poorly rendered hands, low resolution, low-res, lowres, out of frame, error, cropped, low quality, duplicate, bad composition, disfigured, over-saturated, fused fingers, watermark, signature, tiling, skinny, fat, long torso, stretched torso
This might be a silly question, but are there any good checkpoints out there for figures and characters that aren't incredibly horny? 😅 I'm rustling up some NPC art for an RP session and it keeps coming out as ERP 😭
How do you prompt for a clean one colored background and full body pose?
Does anyone know for midjourney pulls this off? Typically you need to change the resolution to get full body shots
Interesting, I haven't learned that skill yet.
How do I start, once I have the initial image?
Is this something you can do here from Discord or must I run it locally?
Do we have any way to make good looking hands ?
so they don't look like mutated tentacles ?
Sorry, I don’t know about using the Discord bot; I use local exclusively
negative prompts work well for this: e.g. #📝|prompting-help message
Negative prompt:
lowres, bad anatomy, (bad hands), text, error, (missing fingers, extra digit, fewer digits), (extra arms), cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, (bad hands), text, error, (missing fingers, extra digit, fewer digits), (extra arms), cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,more then 5 fingers, less then 5 fingers

one hand have 4 fingers other is bunch of tentacles
well, technically, she still may have 5 fingers on the other hand, you just can't see her pinky
though, I've given up on perfect results from AI image generation (for now)
Something close should be possible. What have you tried?
progress will continue to be made on the models themselves (outside of my control)
if I need perfect, I'd probably just do manual post-processing
i tried it on midjourney it was easy to get but its hard to get something like that in sd
maybe i should try midjourney model for sd
I'm doing highres fix already, and SD 2.1. IIRC 1.5 didn't have as many issues with this, but I'm not entirely sure
the style I'm currently using for these is: elegant, 2d, ultra highly detailed, digital painting, smooth, sharp focus, artstation, pixiv, art by (samdoesarts:2), Ilya Kuvshinov, artgerm, wlop, greg rutkowski
can you suggest any other art styles I can try (I'm using automatic1111 so it's easy to play around with a lot of different combinations of things)
What's that 2 stand for?
Something like (word:2) is AUTOMATIC1111 syntax for “apply the keyword word with double weight”. Usually as little as 1.2 is enough, though.
Ah ok. Man seems I really need to move to locally running this beast
All the enhancements are there
Any prompts to help mimic this?

Hey, all, I’ve been trying to make a kemonomimi—juman with animal ears and tail—WITHOUT adding in human ears, and it’s been a struggle. Because the character is male, the hair doesn’t cover where the human ears would go. Does anyone know of a way to solve this? Inpainting is not usually rearing results as well. I have several cpkt models to choose from, but none are working in doing this.
hi all - i want to generate simple hand drawn black and white icons that look like this image, but i'm having trouble getting the simplicity. most of the images are very detailed and busy. any tips for engineering this prompt?
You could try this. I did it locally but it should be a good starting point.


keep it simple at first, it doesn't like fingers legs or toes. I'm using the latest UI version in Windows locally. Don't know what your 😄 means. Just used 21 year old blonde woman, long blue dress or skip the dress.







Here's mine: Black and white icons, simple, each icon is a food item, black pencil strokes over white background. I also tried Black and white icons, ((simple)), each icon is a food item, by Keith Haring and Black and white icons, very simple sketches, each icon is a food item + negative: color, complexity. Also tried: ((Black and white)) icons, sketches, each icon is a food item, hamburger, drink, fries, cheesecake, hot dog, fork, sandwich Helped to avoid pencils showing up while keeping the stroke style. You can see that in the last one. Though it seems to struggle accepting that I want a white background now.
Note, I am using a model I mixed myself which includes a decent amount of anime-based models. So that might be helping make things simpler. Not sure if it's quite what you're looking for, but maybe it helps push you in the right direction!






Im def not an expert but try some keywords like simple, minimalistic, aesthetic
just copy the pic into the UI, check off anime and an appropriate artist and bob's your uncle.










Is there a way to find out how well SD knows a token shown in a score? Like there should be a higher score for mundane things (e.g. chair) than exotic things (e.g. tony starks toothbrush).
This guy from reddit already did something like it, though there doesn't seem to be a script for it: https://www.reddit.com/r/StableDiffusion/comments/zc65l4/rare_tokens_for_dreambooth_training_stable/
reddit
95 votes and 38 comments so far on Reddit
oh this looks so cutee
what was your prompts or what model?
Hi Team, For some reason, I could not access the SD2.1 prompt book. Looks like the link is broken?

Metaverse
thanks! i use the gui version on the site
i lowered the steps as suggested and stuff, but i'm yet to get anything satisfactory. I'll keep experimenting when i get around to it
Hey... This is Awesome🤩
a cloud
o/ Hello guys , i'm trying to replicate the belows style but didnt get any near till now with SD. Appreciate your help 🙂

Hello, how do you achieve a clear white background of the product image? For example, I would like to generate a chair on white background in photo studio style.
The background is still gray or "non-white".

#queen working in McDonalds and eating french fries : catoon
#📝|prompting-help queen working in McDonalds and eating french fries with ketchup : cartoon
I tried a few methods right now and most cant quite replicate the colors, hypernetwork comes sort of close, but it's just not the colors your image has sadly, but maybe you have more luck if you can find more images with your style rather than 1?

hypernetwork learning rate at: 5e-5:100, 5e-6:1500, 5e-7:10000, 5e-8:20000 with style.txt as the template, rest pretty much default

have you looked into activating "face restore" with codeformers etc?
Had no idea where do I do that?
which UI do you use? dreamstudio, automatic, nkmd, ..?
Um I'm actually just using the dreambots in this server
.
oh no idea then sorry, maybe there's a help channel for those bots? like some kind of restore_face you can add to the prompt? 😄
Is there another way to use the most recent version of stable diffusion, I've seen some really cool outputs with beautiful faces but so far I haven't been able to get more than garbled faces. Any ideas?
can anyone help me describe this outfit?

dreamstudio should be able to, and automatic too, not sure about nmkd or other tools however
Can you please help me find these apps that you mentioned 🙏
here's another style example, when i try to replicate this with SD the watercolor bleeding effect is way to high and i dont know how to remove/lower this effect

is this all from different sources or do you have some way where there's like 15/20 of these?
dreamstudio is there
and automatic is this: https://www.youtube.com/watch?v=3cvP7yJotUM
and nmkd: https://nmkd.itch.io/t2i-gui but I'm not sure if that last one supports newest SD yet which you said you wanted 😄
i got this result without using img2img:
prompt: unfinished watercolor painting of [what you want to generate], by sam bosma, brush strokes, pastel colors



when you use this image at a very low img2img strength give you this results:
image_strength:0.1




you can go even lower, till 0.05 image strength
Alas not i created those with Midjourny only have a few variation of the same picture :.. The style is actually rather simple like those from Peter Sheeler or Catherine Gout
thats what a lot of people use as their dataset source, you could probably prompt for it to generate more? or did you run out of credits
the stuff comehu posted looks also really great!
could you elaborate on image strength? is that in dreamstudio?
Thx @quaint coral will give it a try 🙂
its here on discord using image_init (img2img), a lower number means that the image i feed will have less impact on the final result
the default is like 0.5 but thats too much
so you have to put 0.10 or 0.05
thanks! 😄
could someone please help me with my attempt to generate alpha planes with stable diffusion?
tuft of grass ((side view on a white background)), alpha card texture
is what i tried today
i've had little bits of sucsess
I can't reliable get the wwhite background though
i can do it for leaves and trees just not grass
maybe i should make custom weights for it?
Whats the best way to get face restoration without the eye help? E: spoilered as horror/mildly nsfw

Hi, I'm a newbie using SDGUI by NMKD. I have just generated an image that I really liked, but it has some problems. Are there ways to tweak the result?
These are my settings and that's the picture I liked:

Things I'd like to change:
- there are too many of them
- perspective doesn't work correctly (the Troopers in the back are bigger than the ones in the front)
- some of the helmets are disfigured
Can this be tweaked or do I have to rely on random generation until I get what I like?
About too many of them, usually it's because of original training set being 512x512 (1.x) or 768x768 (2.x) so SD works with those resolution, when you go higher than that it tends to repeat images at some part. In your GUI, try check High-resolution Fix (currently unchecked) and generate again.
It did work, although the image is completely different.

You can't have things fixed and the keep image the same... SD generating works that way. Have to tweak your prompt/setting with hi-res fix enable from now on and see what upcoming generation looks like.
Thanks
Different question then. Is it possible to generate a lower res image and scale up the good ones later? I've tried that by changing 512x512, but the image was different on the same seed as the 1024x image.
I didn't want to use an upscaler, because I guess details would be lost.
I just need it to generate faster.
Well, for what I know, basically every settings/parameters you change lead to output image change. Even seed change by 1 unit, switch to different sampler, CFG scale, resolution, even steps... each of them affect the output. So have to accept that.
You said you want generate lower res and scale up, but the same time you also said you didn't want use upscaler. So I don't really know.
It'll be faster generating lower res and upscale, but the details is not as good as your directly generate high res.
Then I'll just ask it to generate 20 high-res images and I'll clean up my room or whatever. Thanks. 🙂
Yeah, if you system has enough performance then you good to go
Hello. I need a drawing.
"The shot inside the drinking well looks out to a clear sky. The walls of the well are made of dirty cobblestones covered with moss."
But AI gives out nonsense. You can prompt "prompt" to get in a style similar to this

How can I aks the bot to draw something in a style of the uploaded image (image_init)?
hey guys, do you know any "secret sauce" prompt words to make character portraits look closer to the midjourney style?
also, it might be a stupid question, but does steps == quality?
Steps = quality to a degree. This greatly depends on the sampler being used. I am typically using DPM2 at 50 steps. You can run x/y plots with different samplers and step counts to see how they affect your outputs.
Not sure what the 'midjourney style' would be. MidJourney and SD can both generate many things in many styles. I recommend checking out embeddings and custom models if there are specific stylistic traits you're after.
I'll try that for sure, thank you. I really have no idea about which samplers are good for what, but it is worth exploring that with the same prompt for sure
So i think i figured it out for now. The solution is very counter-intuitive for me because i come from MJ: I need to spam the prompt with words like facial symmetry and stuff like that. Over there, the shortest possible prompt usually provided the best result, but SD seems to like the verbosity
^100%
a man with a backpack walking through a jungle, in the middle of round ruins, artstation contest winner, craig thompson, sachin teng, brian kesinger, spotlight, full color illustration




kinda
Interesting! Could you give an example of what you had to add to bring SD nearer to what you saw from MJ out-of-the-box?
how I can create image with promts?
Hi everyone,
I need a little help for a prompt. I'm trying to generate a visual for a presentation. My slide is talking about Transformational Leadership, which mean a leadership that help employee to grow up and evolve.
So I have this idea of a manager watering a big tree with office employee sitting down on branches of the tree.
Unfortunately I'm a SD beginner and it seems that I have prompt issue since the images generated doesn't represent at all my idea.
This is the prompt I made so far
professional portrait photograph of some office employees sitting on a big tree watered by a manager., ultra realistic, character concept art, highly detailed, intricate, (sharp focus), 85mm, medium shot, mid shot, (centered image composition), ((professionally color graded)), ((bright soft diffused light)), volumetric fog, trending on instagram, trending on tumblr, hdr 4k, 8k
Deos anyone know how can I fix it plz?
use a referennce image
Hi all!
I'm an artist and I've drawn upwards of 80 character portraits in a particular artstyle with heavy inks and simple coloring. I was wondering if there was a way I could use these portraits as a type of model in order to generate new portraits of the same style from them.
I've tried mixing two of them in midjourney but the results were clearly pulling in from other artstyles and were a bit distorted.
Would a thing like this be possible with Stable Diffusion?
maybe negative promts
I don't have this kind of image. Do I try to sketch up and then use image2image feature ?
yes
you will need to train a personal model using dreambooth
its actually easy to use, theres a lot of tutorials in YouTube
oh cool! I'll look that up, thanks
So I made this sketch but the output using my prompt is very weird. How exactly does it work ?

Uhm, not trying to offend you, but i don't think that even an IA could recognise your drawing..
I'm not offended 🙂 do you have some advice of how to draw it to be recongnise from an IA?
I don't know exactly how an IA recognises an image, but i think it have to look like the model inputs when training it.
What ways are there to tweek my prompt to get character in an image to face a certain way? I'm making some NPC art for an RPG and want them all facing forward or in 3/4s view, but it keeps outputting people in profile or facing away from the "camera"
Maybe you should learn a program that actually gives you control over what you make, rather than just waiting for the algorithm to spit out a suitable image.
I'm not sure if this was supposed to be written in a mocking tone.
Graphic design is my hobby for like 15 years now. I know my way around the Adobe suite, Blender and others. I'm just adding another skill to my toolset.
I managed to get best results by combining SD with custom rendered 3D scenes uploaded as initialization images.
Pardon me, I didn’t mean to sound so mocking. But my point is I don’t understand why people play around with AI and essentially just wait for the algorithm to make something they like, rather than learning a program that gives themselves control over what they make instead.
Because it takes time and people can't just master every skill possible. For example I do vector graphics and 3D models most of the time. I never learned digital painting. It's a very broad topic. Using brushes is one thing but there's also knowledge like light theory and anatomy. You just can't learn everything. Currently I'm working on a game written in Unity and I need skill icons for the player.
I would learn for 5-10 years if I wanted to do them using traditional digital painting.
Taking shortcuts is okay.
Even if I learned digital painting there would be probably some dude going "that's not real art, use a real brush like an artist"
:p

Ok if i understand well I have to make a real draw, not a quick sketch. I'll try it this weekend
you have to imagine a real end product anyways. you can still throw blobs of color at it, just give it more to go on. those stick people wont help usually but the general shape of the tree and field did. if your bg was blue it'd probably have a sweeter sky
when i do it that way, i try to imagine the prompt first, then i throw blobs of color towards what i want the prompt to look like. then hopefully the prompt builds on those blobs well enogh
You can work that basic image out to a certain extend, like feed it to AI, with low img strength, get the output, feed that ouput again to AI with low img str again.
But the thing is AI works on your color area, like if you have some really separated color area with sharp border, it won't break those base color but only work from there (in early generation, like the 1st one, border almost keep intact). You have to make color area a bit messed up, not so clear and sharp in big separated area, that would lead to better output.
Here I don't modify your image, but only get it generate with short prompt and feed the output back to AI again.




After couble of generations of back feeding, AI will make color more variable
In this discord, you can try dreambots, all sample images above generated by it.

sweet examples
yeah, sure, for faces, i was able to get decent results with these: " photography, golden hour, award winning photography, beautiful, facial symmetry", this helped counteract the issue i had when SD would just generate roadkill without any additional words.
I recommend reading this: https://www.reddit.com/r/StableDiffusion/comments/xq1kp6/making_stable_diffusion_results_more_like/
Basically, you need to do the footwork that MJ does for you in SD. I'll share my "landscape" prompt as well if you are interested, but it's on my other laptop
reddit
5 votes and 8 comments so far on Reddit

He has 80 art pieces to train the model. Is that enough?
How to get good eyes and hands?
yeah it should be enough, the most important thing when training a model is variation more than quantity
i have never trained a style (just people) btw
Insane. I just experienced MJ.
So if you train it on those 80 pictures the model will be only able to create stuff similiar to what it already received in the training data, right? So if they draw people then there's no way it would create a robot, right?
This's what 1st generation looks like.

Cheers thanks for sharing!
It would be able to create a robot, but if you train the model TOO much it will overfit and only create humans tho
if you will use SD 1.5 you need to crop the images to 512x512, but if you will use SD 2.1 crop it to 768x768. In #🔧|finetune should be more info about it
How does the AI know what a robot looks like then? I thought it's all in the model.
Most of public models are finetuned not train from scratch, so model still have many things inside.
you will need to test it yourself to see if you like it or not, but dreambooth is very accurate
Yeah I saw that. How many redos did you need to do until you get to the latest result? If I understand it right you all have a program on pc to use the gpu and a web client to operate it? You feeding pictures locally stored and the sd ai learns from that material right?
SD is static, cant learn that way
the only way to make it learn is to finetuning it but its trial and error
But where it gets their principles from? Feeded data right?
Laion 5b dataset
Docs say only 77 tokens allowed for api. But my prompts are too big and then there are not enough tokens left for all the negative prompts. So the images look bad
What's the best way to deal with it?
And why is there a limit? In 1111 I seem to be able to paste whatever I want
Here's a script to help fix final product image
edit picture path on lines 59 and 60
59 path to image
60 output image to path
I'm trying to create a scene like this, with a muscular blacksmith working at the anvil, and someone, maybe a pretty girl or anyone really, watches in admiration, maybe one of those D&D models would work best; not sure

Lord Eddard Stark finds Robert's bastard son, Gendry.
From Game Of Thrones Season 1
I sometimes see prompts where people have separated the numerals for a number such as "1600" into "1 6 0 0". Is there a reason for this? If I use something like "Fujifilm Natura 1600" will it take the 1600 into account or is it useless?
what does that means?
how do i make a dark image
nothing works to make it dark
if i say like, "darkness" or "no light" it still gives me images with lights
https://www.reddit.com/r/europe/comments/105juup/results_of_an_ai_request_to_turn_countries_into_a/
What prompt should we use to create something like these?
reddit
67,179 votes and 5,348 comments so far on Reddit
anyone know how to separate a group of people
(4actors! in crowd of tourists),
actors as "yoga dancer+plush-mascot+joker+magician",
Hello all, I have a question, what is the best way to get images that have the same art styles between each other, im not saying like using an artist to be able to get consistency, I need moreover consistency saying LIKE = same sky color, same ground texture and color, Etc... Different shots of the same area Etc...
Let me know what is best workflow for this ?
Does anyone have a good prompt to get a dutch(the netherlands) flag ?
Is there any good and wide prompt library for stable diffusion online?
https://mpost.io/best-100-stable-diffusion-prompts-the-most-beautiful-ai-text-to-image-prompts/
Im testing these out at the moment, good to understand how to use them

With the help of the text-to-image model Stable Diffusion, anyone may quickly transform their ideas into works of art. You must perfect your prompts in
Thanks
https://lexica.art/aperture this makes prompting easy mode

Does anyone have suggestions or a video link to SD prompts and settings for getting my trained Photobooth model to look more like me?
https://docs.google.com/document/d/1_wBE8PGapaaKt8KuWtF1PTeAwG5Z-cRCWv2mCwcnpxY/edit?usp=sharing Small Update
Google Docs
This document is made for stable but it can be used with other ai services
All of them I posted in that example (5 or 6 generations and it reach the last image I posted at the end). I didn't skip a step on that post. You saw images from all steps. So it takes 5-6 steps to reach a decent output for that image.
About local or online, then both ways work. The 1st way is use this Discord Dreambots (free online services of SD for everyone generating images). The example I did, was done with this online free tool.
Another way, like you said, I have local installation of SD in my PC and I do similar steps (the popular UI implementations for SD to this point is Automatic1111, Invoke AI, cmdr2,...) All of them can do those steps.
That mean: this discord server is official SD server and they provide free online generating tool. This way you can generate images without installing anything (less customisation, but easiler).
You can scroll down to Dreambots (left side panel) and did all the steps I did and get similar results.

Have you tried using negative prompts, making things likebright, light, and illumination as things it avoids?
does dreamstudio have negative prompts?
im using dreamstudio to do it fast but i can run it on my own pc
Tbh I'm not sure. I know you can use negative prompts with local installations of stable diffusion, but I haven't really expermented with dreamstudio. I didn't realize you were asking specifically about that, sorry.
could domeone explain how ratios in prompts work like (walking towards viewer:1.7) or "(angry:1.1)"
"(angry:1.2)" etc?
its a multiplier for emphasis. 1 would be neutral. 1.1 is 10% higher emphasis. 0.9 is 10% less
does anyone have a list of prompt styles?? or is there a site??
draw a box
Ah okay thank you very much for your reply. Yesterday I've installed InvokeAI but I didnt tried it yet.
I'm working on a image to text AI tool that turns images into text prompts. Here's a link to our free model if you want to test it out. https://replicate.com/methexis-inc/img2prompt

Get an approximate text prompt, with style, matching an image. (Optimized for stable-diffusion (clip ViT-L/14))
morden art
I am trying to create a blind character for a prompt and can not find a phrase to evoke the concept. something like you'd see from a game of thrones white walker or irl blind people. milky white eyes.

Maybe try inpainting white eyes iris pupils
hello
i'm trying to make simething but it is not giving me as i wants
can you help me to make it?
you see this greec statue with flowers

is it possible to get something similer
Cannot get SD to understand the idea of a ringing bell in a belltower. Depending how I weight the prompt I either get a distant shot of an entire bell tower (with no or little visible bell) or just a huge bell without a tower. Done a couple hundred images with variations on prompts and cannot get close.
house stone cabin mountains
Hey! Can anyone give me negative prompts to avoid pixelation?
and get a good pic
And to remove that grainy texture
does anyone use chatGPT to try and create prompts? or is it not worth the tiem?
Hoy i can do a beautiful logo?
best negative prompts for figures to remove mutation? SD 1.5 model
Yea its fun, if you ask it correctly it gives a few tags but its not that good on a main subject, but you can also ask to focus on certain things
I used it for a couple tries and it gave me some nice stuff to start with. Initially I fed it an example prompt and it used that as a template though. Haven't tried it from scratch
But this came out #1010577750077210726 message which I liked
Ah nice, AnythingV3 ?
is there some kind of guide here I can follow to help my prompts? I just keep getting 9 things of what I asked for or weird humanoid versions of it all meshed together. Or a video guide?
I tried it, it does not work, Chat gpt does not know SD
Is stability ai working on any open source alternatives to Chat gpt?
since they are soon going to paywall it
I don't use chatGPT for prompts, but it is good for general inspiration. If you are doing a horror image and normally referce a 'deamon' you can get chatGPT to suggest other variants: Tell me some mythical creatures like demons

here's the very next query on that discussion. it's that versatile from a simpler primer and explanation

i intend to gen these once i get the system loaded. rebuilding it all to stop crashes
Hey guys! Does any of you maybe have tips on how to improve the faces i occasionally get on my landscapes? Honestly, if i have a figure on my landscapes i prefer it to have their backs to the pic so i don't get stupid faces or hands, but maybe there is a solution
Eg:

"/dream prompt:blonde girl in front of a tall tower, yellow skirt, white blouse, environment art, fantasy art, epic, intricate, hyper detailed, concept art, sharp focus, photorealism steps:50 cfg_scale:8 width:1280 height:704"
facing away from viewer, back towards viewer
that is all good, but is there a way to get a decent face maybe?
i mean, i could technically use image_init, turn up the image weight and roll 50 images and pray to rngesus
but i'm looking for a more professional solution 😄
adding "realistic face" improved the face quality noticably
If the character is too far away, the face cant get better cause it has too less Pixels for details
here's this prompt with "CHV3CKnight" added to kickstart the embedding

This is neat too. just fed in the chatgpt prompt directly with some charhelper keys

so when you say i sahnt use chatgpt for prompting well i very well shantll do that.. because i cant write gooder nuff for ai. but ai can


this one took a little wrangling. highly technical


i was right, but sometimes i think it just agrees with me no matter what


A high-speed car chase through a neon-lit cyberpunk city, with sleek, advanced cars weaving in and out of traffic, the streets are crowded with people and the buildings towering above them, the cars leaving trails of sparks behind them as they skid through tight turns, one car, a futuristic police car, is in pursuit of a sleek, black sports car that has a skull symbol on its hood, both cars are driving on two wheels, through an overpass, in the background, a massive holographic billboard advertising the latest virtual reality experience is visible

this one isn't really matching the prompt at all. even afte ri told it to rewrite with less action orientated language. it makes great prompts still. lots of detail in them to get a great scene started. i wouldn't write the tool off entirely yet

You could try it to give you only tags like car, Cyberpunk, neon lights, etc
To much description and the ai dont get what to focus on
thats sort of what i told the chatgpt. I had told it to remmember what i said earlier, and also that too much action orientated description is bad for image generation. it was trying to describe a car chase
In that case I'd suggest you work with image init after you're happy with the rough environment
Just don't set image strength too low
Hey, I'm working on making action sequences for my anime character using protogen 2.2. At current, my best efforts have gotten my character to shoot fire off screen, and I'm trying to get it to show her burning zombies with her fire. I've spent most of 2 days trying to get this to work and have 700 non fighting pictures to show for it. Can someone please help?
keep getting weird faces and malformed body any ideas to fix this kind of problems?, using 1.5 pruned ema

@dusty urchinnegative prompt: disfigured, kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, ugly, disgusting, poorly drawn, childish, mutilated, , mangled, old, surreal, text, blurry, b&w, monochrome, conjoined twins, multiple heads, extra legs, extra arms, fashion photos (collage:1.25), meme, deformed, elongated, twisted, fingers, strabismus, heterochromia, closed eyes, blurred, watermark
much appreciated for the neg prompt man !!
another question, i've seen some prompt use spaces when refering to some era like 90's, so they put 9 0 's / 8 0 's instead of 90's and 80's , is this true?
@solemn sphinx Can you please pin it
does anyone have a list of studies or comprehensive keywords to make the output better
There was a post on the subreddit, r/stablediffusion
Did anyone see it?
Hey! hi! i created a breakdown of my prompt engineering workflow and how i usually blend artists using alternating keywords
https://www.artstation.com/artwork/QnAbwE

ArtStation
Stable diffusion Collab used for faster iteration : https://colab.research.google.com/github/ddPn08/stable-diffusion-webui-colab/blob/main/automatic1111.ipynb#scrollTo=Ao2t5h5qG9HD
Stable Diffusion WebUi by AUTOMATIC1111 : https://github.com/AUTOMATIC1111/stable-diffusion-webui
Checkpoints downloaded from : https://civitai.com
List of suggested negative prompts for future reference as per requested:
negative prompt: disfigured, kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, ugly, disgusting, poorly drawn, childish, mutilated, , mangled, old, surreal, text, blurry, b&w, monochrome, conjoined twins, multiple heads, extra legs, extra arms, fashion photos (collage:1.25), meme, deformed, elongated, twisted, fingers, strabismus, heterochromia, closed eyes, blurred, watermark


My latest Prompt Tutorial: https://www.youtube.com/watch?v=QIefoODVEuQ

#midjourneyAi #Midjourney花 #midjourneyart #midjourney薔薇 #midjourneyv4 #dalle2 #dalle #dallemini #stablediffusion #dreamstudioai #dreamstudio #aigeneratedart #aigenerated #aiart #AIArtwork #openai #prompt #prompts #promptcraft
We launch from the basics of the last video and enter into the world of Styles, Artists and Mediums. With just the addit...
All my 2.1 images are turning out bad in dreambooth
Yeah same , has anyone pulled off dreambooth or LoRA well with 2.1?
They are all a little different , and unfortunately there is no hard and fast rule
Saw a good comparison vi a while back , lmc if i can find it

I wanted to see if there was a huge difference between the different samplers in Stable Diffusion, but I also know a lot of that also depends on the number of steps used when the AI draws the image. In this video I show the results from each of the Stable Diffusion samplers as well as the optimal range to get the best results. To do this prope...
is (collage:1.25) , 'extra negative' or is the positive weighting syntax absolute?
OMG, this is the best breakdown I have ever seen. Man, congratulations and THANK YOU. Awersome material. 🤯🤯 🤯
The LAION tags are so bad, it's a miracle any of this works
use "realistic, photo realistic, 3d," in your prompt to make things look more real. as for the sampling method, i usually stay with eluer_a or euler for everything i do, and i get results like these...




it prevents fragmented images from popping into your pictures.
suppose you want to create a scene with specific details, for example a woman working on some magical device, next to an injured templar, in a medieval house. how would you do that ?
1girl, ((inventor, white uniform, magical tools, fixing strange device, blue aura, focused on device,)) | 1boy, (((laying down, wounded, templar, blood, white sheet up to torso, looking away,))) sharp focus, octane render, highres, 4k, 8k
it takes a few pictures to get it to hit... but... and you could probably add more descriptors for each character to pretty it up... but yeah...


Wed design ui for Blog
Is there a decent prompt to keep a character in the centre of the frame?

Like, I'm getting good results otherwise, but the top of the head's always clipped out
"shoe on head" will ensure that a shoe is visible, thus the head. hope that helps 🙂
im in the process of reworking my stylesheet, can i get some feedback? https://rexwang8.github.io/resource/ai/modifiers
I am inferencing an anime version of person sd2.1 base but I am getting random images.Any suggestions??
Looks good on mobile, you could add a drop down collapse menu for each section if you add more stuff like camera angles or pose etc.
So i could collapse the color section for example
Also can you add "iridescent" ? 😄
what ui do you uses ? and what is the | operator ?
He means the |
it's a separator for characters. its something i learned from using wonder ai
Ah ok, I dont know if this works in automatic1111 webui
i've used it in sd 1.5 for weeks... it usually hits 2 - 3 times in 10. for the 2 pictures i posted, i had a batch size of 6 and it hit twice, but that's using protogen 2.2
I'd say : dark mode please and avoid repeating patterns that gives eye cancer
Has anyone some tips to create realistic phone photo (ideally the kind of lower quality from older iPhone or android)? Did some simple tests but everything looks way too instagramy.
Tq
Sure
There's a drop down for modifier groups for other stuff that will be added later since I already have like 50 groups, I'm just rebuilding it to have a better UI
Dark mode is a good idea, but I'm not too sure how to do the non repeating patterns, do you mean on mobile, I push one column down a bit?
Ah okay yea the drop down is good!
I mean you background would certainly hurt my eyes badly on my bad days
I have a condition where I can +/- randomly get dry and hypersensitive to light eyes. When that happens, I really just need to go to sleep. But sometimes, it happens with less intensity. In those cases, light modes and high contrast stuff, even on dark mode, and especially with repeating patterns, hurts my eyes a lot
and can trigger a bad episode, in fact, where I need to keep my eyes close for +/- 1 hour (so, go to sleep basically)
heya. Trying to create a character a little like Samara from The Ring. Any ideas for prompts to create long dripping wet hair in front of the face?
prompt: greg rutkowski looking at greg rutkowski while facing greg rutkowski, trending on greg rutkowski by greg rutkowski
thanks. super helpful.
Missing negative prompts tho. "Not Greg rutkowski"
Anyone know how to get long hair that isn't "flowing"?
I want the hair here to just be straight and follow gravity

Hi, im new here. Do you have a composition guide somewhere? Sd ignoring prompts like "central composition" or something like "Samuel l Jackson standing in the middle of the frame"
Also im pretty happy with face portraits, but full body dont work for me. Corpses are deformed (negative prompts don't help) or not in the frame




maybe long hair, straight hair, (wet hair), (covered face),
Well, I will copy + Specify question here - what are generally good negative promts if I want to make anime character ?
@gaunt sail can only recommend to use an anime model, but when u use SD1.5 try
the tag (pixiv fanbox) as positiv tag, it will help a lot
@gaunt sail here are some negative tags:
comic, blurry, deformed hands, deformed face, deformed fingers, multiple limbs, ugly, bad anatomy, bad hands, deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limbs, ugly, poorly drawn hands, grayscale, weird colors, censored, deformed glasses, lowres, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username,
nice thats a good idea
And I use 1.4 module xd
i would recommend 1.5 or 2.1
I heared that 2.1 is bad
2.0 is bad, 2.1 is still good, images in #1045349359044280360
Oh, well, I have difficulties in downloading big files from browser ((
why that? it should work normaly
Thanks)
My internet is slow (
try the emaonly version its 4,2gb
https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main
And browser lowers download speed even further
Like
400 KB\s
From torrent I usually get 1.7mb\s
what xD which browser ?
Google chrome
okay, can recommend firefox but in chrome it should be also alot higher, but depends also on the source website
Well, I also have Opera GX actually...
nah wouldnt use that chinese browser xD
Oh , Is this Chinese?
chinese corp bought opera
Well, I need to delete this then
yea you should xD
like i said, can recommend firefox, its opensource, no big tracking corp behind, and its stable, also the best Extensions available
Are there free vpn extensions ? I know that free VPN are bad, but I need them for simple tasks and I really have no money to spare
not like in opera, for free vpn i would suggest proton vpn or hideme
okay, yea then know sense in keeping opera xD
and thanks)
no problem 😄 did the negative tags work ?
the hotspot shield extension is available in firefox too
ah okay try 2d and pixiv fanbox as positive tags
So now I try to include 3d rendering in neg promt
yea 3d or render as negative can work


ouh Mordred

haha to much going on there
I will try her again tho)
you can also try to ad (Anime:1.5) to your positive tags
OMG, Ai really can't get her arms
I think I should find better pick
Oh, and I really should download 1.5
For better art
Oh, from hugging face download is fast !
Even from chrome
10 MB\s
Nice!
Seeds are like Minecraft Seeds. Every image batch has its own seed. So if you type the seed and all settings the same as someone posted you will get the same image.
If you use seed -1 each image will be generated with a random seed
Ok, thanks)
Yeah, tried that. 'Covered face' trends towards face masks. I'll have to do img2img i think. Thanks anyway!
try playing with negative prompts, the model will jump through a few hurdles to figure out how not to have facial details in shot, and if you exclude say glasses it'll slowly run out of non-hair options 🙂

(this image is absurd but a quick example of what i mean)
That's kind of a thing I hope is explained in the new prompt book for 2.x, that you're not just erasing an element with a negative prompt but drawing what isn't to be there.
dark mode button added on the top bar, see if that helps
really belated but add wind to negative prompts
Hmm, I'll try it out. Thank you.
I did some quick changes with the developper tools of edge (so it's very imperfect, but it gives you the idea)

I also changed the background for another darker hexagonal one
Hi everyone, How do you think is better to teg dark elves? like drow or like dark elves?
Hey guys. Any advice on how to prompt away the dead, souless, flat eyes on portrait photos?
Does anyone know if it's possible to comment out a part of a prompt for a quick test?
would suggest dark elve,
frens , is there a hugging face model to recover the prompts from a SD generated image ?
Hey guys, I tried generating an image of this creature (monstrous crow from elden ring) (https://eldenring.wiki.fextralife.com/file/Elden-Ring/er_crow.png) for a pen and paper adventure
I want to have it sitting perched on a branch of a dead tree in the mids of a dead forest.
I am using openjourney embeddings in a Google Collab (ca 40 steps, 512*512).
I cannot generate a sitting bird with these proportions. (they are always flying or without a giant head/eyes)
My prompt is something like that:
Scary concept art of a sitting bird monster, black feathers, giant head, long black beak, huge sharp break, large piercing eyes, sitting on a dead tree, diseased, side view, evil, high contrast, view from afar, mountain range in distance, very detailed, bleak atmosphere
Negative prompt: frame, pixelated, human, flying, humanoid
How would you change the prompt to generate a similar monster without using hyper networks?

Run it through https://huggingface.co/spaces/NoCrypt/DeepDanbooru_string to get an ai breakdown of the image, then toss out what doesn't apply, add in what does and adjust as needed.

That sounds great, thanks, I'll try it out
can you list out what you changed and why?
i can see the top bar being dark-moded which makes sense
and did you shrink the cards and enlarge the description font and shift everything to the side more? not 100% sure about that
Hi everyone, do you have any ideas how to make elf dark in fantasy stables, and more RPG-style?

fantasy, detailed face, white haired, dark elf:1.6,holding sword, at battlefield
Negative prompt: low-res, deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb
promts that I used
@gaunt sail hey again xD i tried it in SD1.5 with:
adult female, portrait, (dark elf:1.6), fantasy, detailed face, (white hair), long hair, red eyes, holding sword, at battlefield, masterpiece, highres, highly detailed, volumetric lights,

wow you should really get SD2.1, same prompt:

/imaging firestation old fashioned like in a children book
Looks little too realistic
I would like smth more drawn-like
ah okay maybe try painting or pencil strokes
I only changed the colors of background and text, and the background image, that's all. anything else (related to size) must be a consequence of resolution and zoom in edge, I think.
Hi, if I use brackets () like this it means that i want to emphasize this specific word? Can i use brackets in negative prompts?

ahh ok, designing it to be responsive makes it funky sometimes (i'm no expert)
can you send me the color codes? i want to take a look and see how they look on my end
yes you can use them
Does someone has an excel table of artists that MD-1.5 recognises?
SD 1.5?
should be an artists.csv in your folder if youre running it locally otherwise i think theres a list up somewhere
Yeah, I run lockaly
then look in the main directory you have automatic installed
if you want to flick through them theres a little extension called inspiration i like to use
worth playing with just to quickly peruse without running back and forth online. i use it like a little pinterest of artists and styles. (though i rarely put in artist names)
i think its neat.

BTW, when I finish and finally get good drow art, I want to ask - what are good promts for character images in SD 2.1
?
very broad topic but if you go say, here https://lexica.art/ and on the right of the search box theres a filter button, switch it to 1.5 and look through the prompts i guess
oh sorry, 2.x i misread. i dunno if the 1.5 prompts are as helpful on this as they dont have any negative prompts afaik
actually helpful, thanks so much!
Not for 2.1
But for 1.5)
BTW, I made some progress

And lexica actually upped my self-esteem
Dark elves are not good on 1.5
Not bad for SD, but not a dark elf

you mean elf-esteem surely
if you're doing img to img, is there some trick to getting it to completely change up the colors?
you can try things like "gradient effect, gradient background, (pastel shades, purple, lavender, powder blue),"
I feel like hte inpainting masking isn't doing as much in the newer versions, at least not on straight img2img
So, I have a question about prompts and what might work best for cyberware parts in my pictures?
prompt: moon: full moon, pointy ears, night, 1girl, moonlight, weapon, solo, night sky, diamond shaped face, drow, dark elf, full lips, pale skin, plate armor, glowing runes on sword, armor, braid, red eyes, sky, sword, gauntlets, cloud, long hair, red moon, castle, cape, elf, holding weapon, holding, white hair, standing, lips, outdoors, cloudy sky, realistic, looking at viewer, silver hair, nose, glowing, holding sword, single braid, shoulder armor, sun, pauldrons, mountain
negative prompt: hat, disfigured, kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, ugly, disgusting, poorly drawn, childish, mutilated, , mangled, old, surreal, text, blurry, b&w, monochrome, conjoined twins, multiple heads, extra legs, extra arms, fashion photos (collage:1.25), meme, deformed, elongated, twisted, fingers, strabismus, heterochromia, closed eyes, blurred, watermark, wedding,group

Thanks)
I filtered 3 types of words for how good they are in making an image better, without adding to much bias/baggage (like adding lens-flare from too much light-transport, or adding carpets/fabrics from too much "detailing"), even when only rendering in 10 steps for rapid prototyping of common environments : "detailed-thesaurus" and "light transport" and "science fiction illustrators" that (even AnythingV3, an anime model knows well enough , sorted all terms by utility/efficiency/beauty in https://www.reddit.com/r/StableDiffusion/comments/109ebkf/a_10_steps_only_test_run_for_1_day_taught_me_many/ the findings of this EASILY turns a model, that preferably only does one cg/cartoon-style, into making photorealistic imaginary landscapes. "science fiction" themes mostly are useful for variety and tolerance , because the genre is more lenient to uncanny/physics errors.
reddit
34 votes and 8 comments so far on Reddit
Bookmarked this
Has anyone found a way to force SD to prefer generating images in the frontal camera angle?
used chat gpt for promt generating. Looks not as bad as i thought.

prompt: moon: full moon, pointy ears, night, 1girl, moonlight, weapon, solo, night sky, diamond shaped face, drow, dark elf, full lips, pale skin, plate armor, glowing runes on sword, armor, braid, red eyes, sky, sword, gauntlets, cloud, long hair, red moon, castle, cape, elf, holding weapon, holding, white hair, standing, lips, outdoors, cloudy sky, realistic, looking at viewer, silver hair, nose, glowing, holding sword, single braid, shoulder armor, sun, pauldrons, mountain
negative prompt: hat, disfigured, kitsch, ugly, oversaturated, grain, low-res, Deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, blurry, floating limbs, disconnected limbs, malformed hands, blur, out of focus, long neck, long body, ugly, disgusting, poorly drawn, childish, mutilated, , mangled, old, surreal, text, blurry, b&w, monochrome, conjoined twins, multiple heads, extra legs, extra arms, fashion photos
How did you do it?
Hey folks, I am fairly new to Stable Diffusion but not AI art. I am struggling to get something similar to a "Drider" from dnd. If anyone has any tips for promptcraft or model suggestions i'd be keen to hear it. (Pic attached for what i'm going for.)

Can you feed the prompt links to photos somehow?
you can only upload photos using image_init
hi im trying to get something like this

it was done in md journey
im trying on anything v4
anyone can help?
Does anyone have any idea how to prompt for images that turn out like lensa ai or these
https://twitter.com/thelordbasil?s=20&t=2EiCcMpubls0FCasdyipeg
having a hard time getting it to generate an empty street without a character despite using negative of people 1 girl 1boy and saying "empty street" any ideas?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
"person", "people". if you say no people it will go for a person, if you say no person it will go for people. its trixy
I found my mistake, I still had shirt/shorts in the prompt from the character which of course was forcing a person
mask
i want to generate 2 chara, man and woman in 1 picture. is there any prompt that make it happen?

yes
try putting each in parenthesis
like (agirl with blonde hair sitting at a desk) (aboy wearing a suit standing behind the girl with dark hair)
usually even if you add 1boy and 1girl to the prompt youll get 2
what about the facial expression and body build and pose? can i make it in each parenthesis?
you'll just have to try in general its very difficult to get very explicit posing options on multiple characters
there is a multiple characters plugin but it essentially puts two renders into the same image and looks bad most of the time
thanks for the tips man
usually following the above youll get two characters but sometimes the things will be switched
like the guy might be blonde and the girl dark hair at that point just roll the dice on generating a bunch
once you get the "poses" in the right place to work on details swap over to img2img
then if you use a .3ish denoising strength you can iterate on the details while keeping your basic layout
is there a reliable way to get a solid background color (for purposes of easier compositing)? I have tried solid background color, solid gray background, etc but nothing seems to work. Anyone have experience with getting this to work? Thanks in advance 🙂
try the tag photorealistic,