#🏞|general-with-images
1 messages · Page 115 of 1

and you should select a different upscaler methode, i use x4 ultra sharp, the best to me
I have not the x4 Ultra Sharp

the first step is to search for the right seed. If you click on the recycling logo, you'll keep the seed of the image generated just before, but if you click on the dice, the seed returns to -1, so it's random. So first close the Hires Fix tab to find an interesting seed, then once you've found one you can keep the seed and regenerate with Hires Fix.
this one maybe
https://openmodeldb.info/models/4x-UltraSharp
in stable-diffusion-webui\models\ESRGAN
I personally use between 30 and 50 steps
now i try
another thing to know, open a new tab in your web browser with SD, if you drag&drop an image in the prompt field (then press the blue arrow under the "generate" button), it will import the settings used for the image in question. So try this one, it'll import my settings.

cool
i find that chrome supports drag and drop and pasting images into fields so muhc better than firefox. i browser main with firefox but i load the various webui's into chrome
Has anyone managed to generate 2d characters for games at different angles consistently?
i'd start with 3d prototypes and then apply a character lora to them. there is a cool thing for 2.1 if i remember though.
https://civitai.com/models/3036/charturner-character-turnaround-helper-for-15-and-21 @fallen blade 1.5 too!
CharTurner Edit: controlNet works great with this. Charturner keeps the outfit consistent, controlNet openPose keeps the turns under control. Three...
https://civitai.com/models/104099/reference-sheet-model-sheet things like this too
My attempt at creating a reference sheet model. Trained on 120 images which were mostly manually edited by me to remove stuff like signatures or wa...
https://civitai.com/models/86207/character-head-concept-poses-openpose-3d-for-depth-maps tool kits like this too
Подписывайтесь на канал , я там рассказываю как работать со stable diffusion Credits for initial idea and 3d image goes to txanada and her reddit p...
@limpid lichen ty so much ill take a look at all when i arrive home
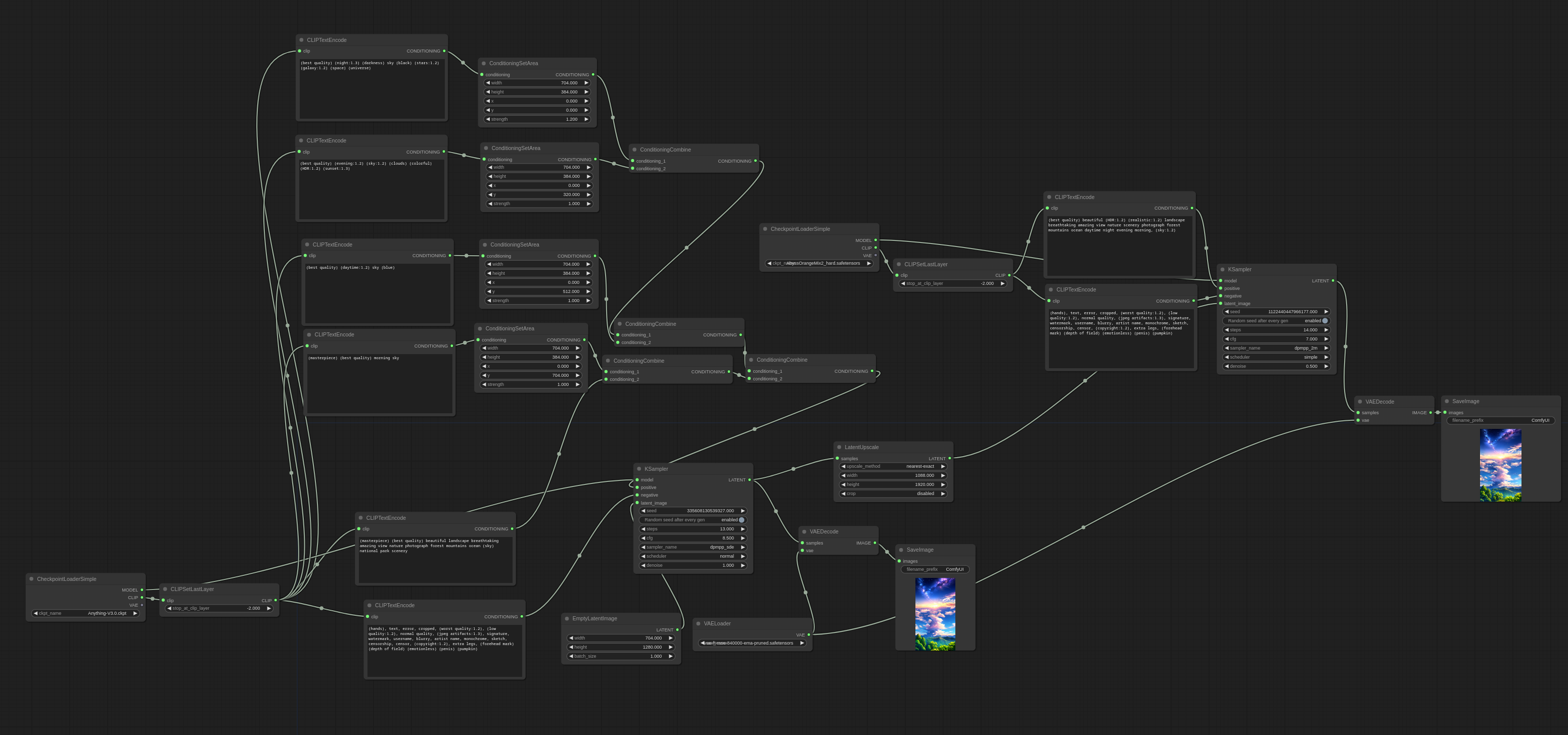
guys I was looking at a photo on civitai and I see "30 nodes" in workflow, what does it refer to?****

@bitter dragon 30 nodes in the comfyui setup they used to produce the image: https://comfyanonymous.github.io/ComfyUI_examples/area_composition/workflow_night_evening_day_morning.png

ooh thank you. And for you, which one is better? a1111 or comfy?
i prefer comfyui, but i have a software engineering background. i like the way the configuration can be saved, and the explicit nature of it (so you have some idea as to what's going on underneath)
i really dislike graphical node-based environments, though. i wish they provided a text-based interface. you spend about 70% of your time dragging nodes and wires around (this is a problem common to all node-based environments, blender being the other big one that everyone knows)
okay thank you!
What's up guys your Chengdu guy,Last name Dai,is back to Discord!The traditional German skirt dirndl, with beautiful design and pattern style, is capable and smart;A simple and refined headdress that shines on the girl's head;A brilliant emerald necklace lights up the silent forest between the mountains and rivers.


remove any/all embeddings in your prompts that are not for the checkpoint used : SDXL embeddings don't always work with SD1.5 checkpoints and can error out, vice versa
nvm i got it fixed
but i dont understand this whatsoever
can you screenshot the workflow before the error shows
hey
can you tell me
how do is search for a node in my workspace
whats the shortcut
doubleclick empty space
https://github.com/ltdrdata/ComfyUI-Manager add this to your custom nodes folder and restart comfyUI .. it adds a manager button letting you install missing nodes and install tons of nodes from within comfyUI

GitHub
Contribute to ltdrdata/ComfyUI-Manager development by creating an account on GitHub.

Models/Upscale models
ok i did it but will i loose my image when i restart it
i hope not
you will upon restart
Hey I was just wondering, what would be the closest art style to the one used in the APB Reloaded loading screens? It's some offshoot of graffiti, but I don't know if there's a more specific name or not.

Hi, does anyone know how I can use more power from my graphics card to generate in comfyui. it seems to only use 20% to 30% or less and I have a 4060ti 16gb.

that's normal, mine only uses 4% lmao
if you click the gpu and look at the bottom you will see it's using all it's VRAM tho
/Prompt:A beautiful sunset,carton

 where's carton tho
where's carton tho
is proper style transfer a thing yet? like turning a photo/3D render into a consistent art style but more or less keeping all details the same, the PhotoLab mobile app can do it (and says it's "AI", not sure to what extent) so there must be a way to do it locally, this is one of the PhotoLab presets but one day it could just disappear and I want my stuff to be consistent, the app requires an internet connection too so I can't just store it somewhere forever if it gets removed from the app


Yo,hello guys in Discord here and I'm Dai,the panda city's good boy!Today I'll show you the Dutch costume!

蓝色毛衣小女孩
Hello there! I'm curious about the cool image-making magic the bot uses – which stable diffusion model is it? Have there been any other models before this one? I stumbled upon a dataset called DiffusionDB with prompts and images that apparently came from this Discord server. I'd love to know which model or models were behind creating those images! Thanks😊
Please dont ask the same question in multiple channels 
ok sorry
Playing around with resizing old 2D sprites from the game Ragnarok Online following the instructions at https://www.reddit.com/r/StableDiffusion/comments/13f7jy7/i_remaster_street_fighter_old_sprites_using/. I'm not able to bring out as much detail in the upscaled images. Any ideas on how to add more detail to the upscaled models?



Reddit
Explore this post and more from the StableDiffusion community
increase denoising str
and use SDXL models, not 1.5
Can i add sdxl with aaaa1? Thank you btw 🙂
Obviously, its highly recommanded
will try it then 🙂
Anyone know why my images are finished like this as if they were interrupted halfway, I used sd before and the output was fine but now that I installed it again it does this, I used realistic vision v6, DMP++ 2, 512x512, 50 sampling steps

@uncut otter what noise schedule? any LoRAs used? i've seen this happen, but it's never been the same root cause twice
No LoRAs used and if you mean denoising strenght it is 0.7, I also have an AMD GPU so I had to make some workarounds in order for it to run but when I used it before it worked
for noise schedule, i mean that there may be a setting such as "normal", "karras", "exponential", etc
Oh I used SDE

i think those kinds of visual distortions you're seeing is where the system is constantly overshooting a solution when it reaches the end of the step count. if you watch the generation, you might see it kind of bouncing between what looks like two differently distorted faces
i'd see if the problem still occurs with a mindlessly simple setting like an euler sampler and a normal noise schedule
and 50 steps might be a bit much. you could probably get away with half that
Thank you I'll give some of those things a go and see how it turns out
Anyone else hungry for a new sdxl official update like a 1.1 or whatever it will be called.
Fine tunes are getting better but I feel like they are all pretty similar
@sweet thistle

this is with the default untrained NCNN upscaler for photo's by this program (4x upscale)
pretty good
how hard does it hallucinate details, or does that depend mostly on settings?
it just upscales..no hallucinations as in.. it doesn't try to detect things that isn't there
dang awesome thank you
https://pika.art/video/fa5d010e-42bc-4d09-9d46-b37448b18bab the girl with the magic pancakeplate 😄

Anime girl smiling as she gives you pancakes
2 ┬─┬ノ( º _ ºノ)

Thx
Two Chinese people are celebrate thier 50's birthday.

Jeez, looks so realistic, especially background
HAHA, its a real picture, i'm so dumb...
You never know here but yeah, pretty sure its a real one
With this name...

And background









lol trying out the comfyUI handrefiner thing using the whole meshgraphormer model 😄 results in baby hands sometimes

and seems to only detect 1 hand at a time so somehow needs a extra pass

ive been wondering, and trying with various levels of success
but could i give Stable Diffusion A1111 a sketch and ask it to finish the drawing for me? like what if i gave it something like this and asked it to ink and colour it in comic fashion, with a sick model or lora base:

ive given it drawings that ive inked and coloured and gotten great results btw
ControlNet? waht that, can you tell me more?

GitHub
WebUI extension for ControlNet. Contribute to Mikubill/sd-webui-controlnet development by creating an account on GitHub.
thnx, ill check it out
just found a sick civitai file but its not a checkpoint or lora, its EMBEDDING? where do i install and use it?
https://civitai.com/models/214976/comic-book-pencils
This is an embedding to get a comic book pencils style. One of my favorite parts of comic books is looking at the artist's pencils before the inkin...
You have to download it and put it in the embeddings folder of automatic1111, then when you open sd you can select it on the textual inversion button


thank you duuude. youtube and chatgpt werent helping at all

How do i generate with this style

@worthy shore


Hey guys, do you have any idea on how to make images in the same style than that ? What model to use, etc... The "kinda realistic but you can tell it's ai" style


For exemple, I tried recreating the pirate one but I only have results similar at this render : 😐

Im sure a lot of models are able to recreate that "style" but Im not sure what was the prompt of that images :S
Well, it was the same prompt for both the pirate images
I´ll look dreamsharper page too see if some images match that style
Aaa, do you have the prompt? so i´ll try it on that models
Yes, of
(highly detailed:1.2),(best quality:1.2),8k,sharp focus,(subsurface scattering:1.1) (depicting a character reminiscent of a youthful Will Turner from Pirates of the Caribbean:1.2),(detailed face and eyes:1.2),capturing the character in a sunlit tropical port with a ship turning its back in the distance, (mixed emotions:1.2), (warm sunlight:1.2), (featuring a captain attire akin to Will Turner's:1.2), (including a wider shot in an American plan style:1.2), (cinematic lighting:1.2), highly detailed, (Dungeons and Dragons:1.3),(Elden Ring style:1.3), (enhanced hyperrealism:1.2), RPG, artstation-worthy, smooth, beautiful, and sharp focus, incorporating two pistols and a rapier, with the character exuding a more youthful appearance and a friendly demeanor, drawing inspiration from renowned artists like artgerm and Greg Rutkowski.
Here you go
The first "good" image was made using this discord server's bot and the second was made using my local stabble diffusion and the revAnimated model
May be if I try with the SDXL model I'll get simillar results
this is dreamsharper 8

i gotta try a newer model, this was updated like 5 months ago
This already looks a lot cleaner

Which model did you use ?





hello, does anyone know why my stable difusion is white? i need a version with the blue one

i need this function

Just enable dark mode in settings.
And, this "function" is Depth from ControlNet extension
🫣 no white theme warning 🫢
Guys, any ideas why my renders looks like this ? What settings could I change/tweak ?
I'm using DreamShaperXL without Lora, DPM++ SDE Karras (I got same result with Euleur A)



While using the SDXL got fine results like this with the same prompt 🙄

I'm gonna loose my mind
SDXL models got trained on a 1024x1024 resolution, going for 512x512 will make them look like that
Can't believe it was just that...
Thx
The render looks way better now

Also, would it be possible to take the face from the first pic and kind of "copy paste it" on the second picture, or something similaire to the second picture ? What would be the working process to do that ?
Or at least get the pose and camera angle from the second pics with face from pic one



What happens when I let my five year old daughter control the prompts



Sorry I had to do it XDDD
yeah i thought i had a different version. turns it was just browser night mode plus some plugins
Could you download controlnet extension and the depth model?
This is the link to the extension https://github.com/Mikubill/sd-webui-controlnet
GitHub
WebUI extension for ControlNet. Contribute to Mikubill/sd-webui-controlnet development by creating an account on GitHub.
yeah already did
Here are the small version of the controlnet models, I think they are similar to the normal ones in quality but each one only weighs about 700mb https://huggingface.co/webui/ControlNet-modules-safetensors/tree/main

what is controlnet for? there are like 8 files of 1.4 gigs
There are different models, in that case he used the depth map model, so you can import a depthmap image and "fill" it with the image that you prompt
Btw you can use the link that I posted, I forgot to say that the "t2iadapter" are the smallers model, you can use that
Its 155mb each one
I´ll try generating something with it and show it in a video
mig23 ai art. needs improvement. idk why it has those symbols there

The one from the video is this one, the depth model, in the controlnet github there are images that compare the different models

here´s some example


you mean a depth map? That's in ControlNet, select enable, pick an image to use to set your map, click depth, then select the preprocessor with midas or one of the others, then the model will say 'depth' in it. Click the 'run preprocessor' exploding thing between the preprocessor and the model. Watch a video for details but that should get you started.
@frosty inlet it should look like this

If it doesnt work remove it, it may be another problem
Zara Haida
what's the GPU requirement of this model
Yeah, scribble is really nice :
prompt :
A woman



ZZtop bro, pilote just have good music tastes
can anyone tell me if this image is ai generated? there is a big discussion about it and i’m saying that it’s ai generated while others are countering me

certainly suspicious... found the thread on twitter about it and the artist "left the psd proof at work" or something
yes they said that they can’t pull up the layers until they get the file from work.. which leads me to believe that they’ll try to trace or fake a WIP.
these bits are what made me question the authenticity of their art



and people that say "I will never draw again" cause other suspicion.
too extreme... an artist is not going to just stop
someone faking it could
yeah they’re trying really hard to defend themselves 😭 all she has to do is admit she’s wrong and correct it.. because otherwise she is a great artist.. i don’t understand
I'm really not sure, not an expert on identifying 😐
trying to find older art... only see one so far and it is very different
this person is definitely a k-pop fan, that's for sure
I found only 1 other image of their other art, really... there's a lot of k-pop retweets to scroll through to get to any content. 😛
this one

interesting.. i understand style changes a lot but hmm
@wispy nest the Face i used for IP-Adapter

Let me know how it all plays out 🙂
with End Step set to 1 (no change in expression)
and with End Step 0.7


i gotcha!
thanks will try it
Np, you need the IP-Adapter Plus Fave full Controlnet model
The other ones are good too. But thats Made for faces only
Thank you, looks great :) I played with Faceswaplab a bit and it suited my needs very well
But will have a look into the IP-Adapter stuff for comparison
oof, feeling a bit lost. I was following this tutorial using counterfeit for checkpoint and vae, to create anime girls, added depth and open-pose and the quality is crap. anybody know why? Dall-e does a much better job surprsingly

improve cloth quality and bike make fancy
@wispy nest

Didnt know if alrdy mention, look closer at the eyes, even if not full ai it uses ai and then maybe PS, eye is too blur and even more notice compare to any of their other images
Artist can change style but they won't make it worst


@wild sorrel
oh, I see, images wasn't even loading for me without vpn lol
bizarre
idk , maybe older images
so probably they used a different scale before
Are you going to generate using dreamstudio or other webuis?
ultimately probably comfy but I want to work my way through them so I understand everything better
not sure about comfy, but in automatic1111 - usually going above 1.7 isn't good idea
Will overcook
I usually keep everything below 1.4
I read through #1072220168534642768, #1072229020520947753, and #1080946152318443610, but it seems that Stability.ai never created documentation for DreamStudio, and there's no glossary even for the terms I see like cfg and checkpoint. So I'm looking at YouTube for explainers on those, automatic1111, comfyUI, theory, etc. to try to understand this.
But I'd like any recommendations people have
@dry crow and you all guys, do you know a good SDXL model for Skribble/Sketch?
I don't really get how people understood any of this when it first came out
well...read few things, started testing things out, then some new guides on youtube, few there...
https://stable-diffusion-art.com/
it's a mess anyway, alot of stuff outdated, some tutorials are straight up bad, but eh, you'll figure it out, focus on something simple first
yeah a lot of these are a year old so I'm sure very outdated, but it's crazy there's so little out there to actually explain the theory, terminology, etc
I was using realisticvisionv6 that´s based on sd1.5 so im not sure, Im running it on a 3gb gtx 1060 but it can even run on cpu (but it will be very slow)
I'm trying to use the imag2img mode to modify an image but it's not working. The image with the transparent background is the input, the one with the white background is the output, and the prompt is "A golden retriever sitting on the moon". How do I make it follow the prompt?


I tried both 1.5 and XL 1.0 and my hardware is a 4070 GPU and 14900KF CPU with 64GB of ram
I added something to the image and it kinda worked, sometimes if the background is completely blank it doesn´t add anything

thanks, using an actual background fixed it
Would anybody happen to know why none of my controlnet models show up in the adetailer controlnet models dropdown list? I have controlnet itself working fine and can use the models in the controlnet tab. But in adetailer, there are no controlnet models listed in the dropdown.

What's everyone's favorite LoRA?
I try some lora with planes. I would say I would remove all bombs, gas tank, weapon under the wing. It will give you better result. Once you have a good model, you can try to add more systems under the wing.
A golden retriever walking across the woods in Costa Rica.
I am trying to install Reactor but as you can see i am getting errors stating that the I am having trouble installing Reactor for Stable Diffusion.
I followed all the installation steps and as you can see in the CMD window it gives mainly the error that the insightface==0.7.3 is not found.
But the strange thing is that i do have it installed as you can see in the screenshot...yet still it says that it can not be found...????...
As you can also see that i have Visual Studio installed and also the community build tools
And you can also see in the SD extensions tab that Reactor is installed.
What could be the problem?...
Thanks in advance for the help.




Can someone tell me how can i get the sub tab "Preprocess Images"?
Have you selected the build tools for c++ in the community build tools?
Also post technical questions in #🤝|tech-support
Then more people will see it that can help
Create 3D illustration featuring a realistic young Albanian boy with a blue backpack containing the blue and yellow flag of Kosovo walks down a narrow cobblestone street lined with Spanish colonial buildings. Many locals and tourists fill the street. The boy smiles excitedly as he holds up a camera to take a photo. He has black hair and wears green shorts and a gray t-shirt. Behind him, a woman in a red flamenco dress crosses the street. The surrounding buildings have clay roof tiles, iron balconies, and arched windows in classic Spanish style. People talk outside cafes and restaurants under green awnings. The scene is full of life on a sunny day.
thats for the bot channels #1080261341362786384
Supergirl photo of the day. I think it came out alright for what it's worth.

I was having the same issue earlier tonight. This ended up fixing it for me. https://www.reddit.com/r/comfyui/comments/18ou0ly/installing_insightface/

After that the reactor node successfully imported without error.
Though its actually pretty cool despite how ugly the workflow layout is. Here you can see what is going on. I set up nodes so that you can load any video, and it will automatically generate keyframes with animation skeletons matching the movement of human shaped figures in the video I am using. So in this case, I loaded a tiktok dancer video, and am stealing the animation data to replicate the dance she is performing.

The detection is working much better than I thought it would, and its even picking up frames for more complex fast moving motions that I thought it would have a problem with.
And its pretty quick too since Im having it use latent consistency models
Why are you talking like you set up that workflow? I know exactly which .json file that is lmao
any img2img specialist?? #💬|general-chat #🏞|general-with-images #🤝|tech-support
You misunderstood me. The workflow is from a tutorial. I was just excited that I got the worldflow to work. Not sure what I was doing wrong.
Took me days lol.
I dont know why I have never had much luck with comfy. But now I am finally starting to like it. But maybe the alcohol made it work. That was the only thing missing before tonight.
One thing I am still confused about though is how the LORA stacker works. Does the order in which you load the LORA's in the stacker make a difference? Like do the ones loaded earlier have more priority?
Nobody? 😔
What u need
@prisma iron

does anyone know fooocus
Hello!
Do you know any models or prompts to create images with this art style?


Anyone know of any models/LORAs that could approach this sort of style?

You can use ipadapter with that image to copy it's likeness.
That doesn't really seem to work XD
Hmm give the image to chatgpt to describe it then use those as prompts plus look for lora with those keywords chatgpt gives 
Yay Firefly

Sadly the bot doesn´t have img2img option (I think)
Generate a cartoon avatar in an anime style based on an uploaded image
Generate a cartoon avatar in an anime style
Generate a cartoon avatar in an anime style
@nocturne creek there´s no option to edit/use an uploaded picture in this server
you can use the bots like #1100170312106127410 for example but to generate images from 0 with a prompt
Yes, you can use the command "/dream" on the bot channels and enter the prompt after that
"After uploading the image, do I complete the image generation function using the '/dream' command?"
There´s no option to upload images, to do that you have to run a local installation of sd, you can use the command like this for example

Then the bot will generate the image that you prompt

just made this. Thought it was cool. Not perfect but came out pretty closely to how I envisioned it

A painting of a cute goldendoodle in the sky, wearing a suit, natural light, with bright colors, by Studio Ghibli



Hey Guys, I am looking for some online tutorials on how to take line artwork that I created and apply any style to it and then output some sort of vector or layered file. ANy help is appreciated.
You can generate images with the bots channels like #1100170312106127410 , you have to use the command "/dream"
I working on the node of hand refiner, and after one week settings most of time the result is really good in photoreal images:

Nice job!
Who is interested in stablestudio?
Hey for that you should use the controlnet lineart model
Or the lineart anime
Hey Guys, does anyone know what the issue is? in the first pic, that is what it looks like when generating, the second pic is when its finnished, why do my faces become so ugly? 😦


Satan speeds towards heaven with a group of devils. They collide with burning meteorites

Refer to this picture. The picture is clean and the overall style is a meditative state.

/bee
Satan speeds towards heaven with a group of devils. They collide with burning meteorites
Satan speeds towards heaven with a group of devils. They collide with burning meteorites
made a little motorcycle-themed profile picture for my brother :) he liked it

this is how it came out of SD

i am only new into SD (auto1111) .. but get this into session:

and more (^_^) -> http://maitag.de/semmi/stable-diffusion/ (my first tryes)
totally amazing (and stableRunningSURE!!!)*hugs!
I am tryed also to make some walkcycle into variations by (but failed there into at now ... also controlnet+lora) ... -> the .blend and png here: https://github.com/maitag/peote-samples/tree/master/anim/walkcycle/assets)


Provided to YouTube by Ingrooves
Nirvana For Zeroes · The Legendary Pink Dots
The Museum of Human Happiness
℗ 2022 Metropolis Records
Released on: 2022-03-18
Writer: Edwared KaSpel
Writer: Philip Knight
Auto-generated by YouTube.
have only this at now: http://maitag.de/semmi/haxelime/peote-view-remaster/anim-walkcycle/ 💧
(wanna make it walk into SD-style ;:) [my "goal" for this year ;:)]
someone tryed to generate UV-maps here ?
Try adding some realism prompts in the negative prompt
Also this vae is for anime (in case you dont have it) https://civitai.com/models/23906/kl-f8-anime2-vae
I FINALLY UPDATE THE FILE! This file is VAE, it's one of the best so use it if you like! Many models here at Civitai use kl-f8-anime2.ckpt I upload...
it goes on your models/vae folder if you are using automatic1111
Hello everyone

Hello everyone,
I have a hard time finding a workflow who would help me transforming mediocre 3D characters into photo realistic humans (see picture attached).
I would appreciate any help achieving those results (A1111 or ComfyUI).
Thanks !

In a1111 it can be done with img2img and a cfg of about 0.5-0.65

You can also use controlnet
(example stolen from reddit)

Black background, dark Q version, IP image, blind box hand office, pink purple fashion skirt, medium long hair, headphones, publicity sexy, big eyes, open mouth smile, legs standing, arms folded, rich in details, blind box, bubble mat, 3D, HD, C4D, fashion, with impact

you're using codeformer or some sort of "face restore" option


Isnt that a render? 

I guess if you wanna define render
I just used the automation photoscene
im changing up the headlights a little. Just a little more modern touch



No, he says it's good
so good, that artists who make stuff that AI can do should stop complaining and quit their jobs if they can't adapt
Ai Weiwei said: “I’m sure if Picasso or Matisse were still alive they will quit their job.
he criticised art teaching that focuses on creating “realistic” images. “It takes AI a second to do it. So that only means what they have learned very often is meaningless.”
Oh wow I completely missed a word in that headline lol
Or all of them…
tested both bing image creator and sdxl discord bot, say less microsoft


Hey guys I have a question please help me how can I generate a photo using AI but using an existed photo that I have
I have photo for a girl she passed away long time ago I want to make her mother happy to make this girl look like as if she's sitting at a table talking to angels in heaven do you have a way to make this visualization or imagination happen please
INterestng, would you know where i can find that?
it would be somewhere in the settings tab. Something like Settings->User Interface->Face restoration model
I don t have access to an auto1111 instance at the moment
I see, thank you!!
This is what it looks like, cant find it 😦
wait i might have found it lol
Thank youuuuu it did the trick!!!
for the future, keep in mind that those are features for realistic human faces. So it will mess up anime stuff
Looking for help. Did i get my settings right? Its not generating the right pose

please continue in #🌶|off-topic this doesnt really belong here

This looks pretty amazing. can you share with us, how did you actually made it happen ?
your input image is already a pose, so you need to set the preprocessor to "None"
Someone just fixed a problem that was bottlenecking my pipeline for over a year - PROMPT 2 MOVEMENT 🌈
https://meyourhint-momask.hf.space/file/cached/12138/sample_repeat0_759737885.mp4
near real-time prompt 2 movement-openpose to create a de facto 3D model by running it through stable diffusion every frame. SD just killed blender & co for artistic stuff and small anime productions
testing pipeline:
agent _> storybook and movement prompts (sb)
sb _> memo_gen _>memo_gen gets sliced into frames (sf)
sf _> openpose + depth map _> stable diffusion
frames _> video
=
aka autonomous prompt and scene; aka fully ai generated visuals for comics, anime etc.
this is insane
this is 2D - no fucking blender - no fucking polygons - fuck nvidia

Any tips on how to improve the photo realism, I use sdxl V1 the prompt is here: https://app.bench-ai.com/workbench?id=4c417077-b0c7-11ee-8ba3-6aef6c450620
I upscale using esrgan after



It is the first time I use it, I downloaded a trained Lora but when I put it in collab it generates black images. What am I doing wrong? help pls



A lora is like an add-on you combine with the base model checkpoint. So you need to load a base model checkpoint, look at which one the lora creator used for a start. Then put the lora files in the lora folder and you add lora:SugarOP to the prompt to load it
https://aieasypic.com/inspire/models/detail/sugar-one-piece-v10-62457 He used SD 1.5 and this lora, it doesn't say anything

AIEasyPic
Try Sugar (One Piece) for free and many other models at AIEasyPic.Sugar from One Piece LoRAWeight 0.7 - 0.9 for best generation.
looks like the use something called cetusmix as the base checkpoint

where did you find that information?
click on an image and it shows the metadata on the right
It doesn't come out, but it doesn't matter, I'm downloading it from https://civitai.com/models/6755?modelVersionId=20229
NOTICE : LET ME KNOW before you put this model on commercial usage . My twitter account: @eagelaxis :) Contact me if needed. Discord Account: Eagel...
So, I put the cetuxmix in: path to model. right?

And where do I put the SugarOP.safetensor lora then?
I create a folder called lora on the drive and put it there without selecting it? Would just writing lora:SugarOP be enough?
it looks like you are using A1111, which should have a models folder and inside that folder there should be a lora folder
the cetus mix file goes into the stable-diffusion folder
I have these sites.

I guess use model download for cetus mix and then the download lora for the sugarop
but in download lora asks me for a link not a path:(
maybe click the /content/drive link and have a look in the folders?
Well, I'll try it another time, thank you very much for the help!

turned ai art into wallpaper

@dry crow hey im in here now
hey, here my input image from the internet

and here the output after using reactor

you can load any image in there and it will apply the face to the output image.
you can also add a batch of images in a folder and it will create one image per face

that looks like exactly what i need
yes thats what i thought too ^^
@livid tapir if you want to install the Reactor extension, please follow this install guide carefully:
https://github.com/Gourieff/sd-webui-reactor#installation
can you take that same face and say create 10 images of that same face perfomring electrical related tasks or something liek that and it generate them
yes
for that you only need to change the prompt and set batch count to 10
then you get 10 images
i need to develope a workflow around that process. that is perfect
you placed the lora in the wrong folder
it needs to be in models/lora
then select in in the lora tab
the heck is this?



Yes it is.

https://media.discordapp.net/attachments/1100170312106127410/1195772124552515706/Three-dimensional_space_very_black_background_the_corner_of_the_black_space_is_visible_the_silhouette_of_a_man_is_standing_seed-0ts-1705164688_idx-0.png?ex=65b53492&is=65a2bf92&hm=44db68c9952f3101b799505cfb9ca6f75182cbca86fb40156f33be44434ff3e1&=&format=webp&quality=lossless&width=582&height=582 https://media.discordapp.net/attachments/1100170312106127410/1195772124216967168/Three-dimensional_space_very_black_background_the_corner_of_the_black_space_is_visible_the_silhouette_of_a_man_is_standing_seed-0ts-1705164688_idx-0.png?ex=65b53492&is=65a2bf92&hm=00e52839ea869d64ee0e74e0879bc90c8f04be20bdfc7f2ee882a3f677adf163&=&format=webp&quality=lossless&width=582&height=582



#😊|co-creators como puedo crear imágenes
hi, i want to change my character hands inpaint mode, as u can see but it does not change for 6 pictures, why?


hey, are you sing an AMD gpu ?
yes 😦
okay, which one and whats in your webui-user.bat?
rx 7900 gre and set COMMANDLINE_ARGS=--use-directml --opt-sub-quad-attention
AMD cards need these Args:
--use-directml --medvram --opt-sub-quad-attention --opt-split-attention-v1 --no-half-vae --upcast-sampling
to make inpainting work you have to change --no-half-vae to --no-half
but using --no-half will result in a much higher vram usage so be aware of that.
Also for inpainting you have to set the Inpaint Area to "only masked", then also set the resolution to 512x512 (thats not the output resolution):
Then it will inpaint really fast
oh thank you so much i'll try, I searched for a long time on the internet and could not find a solution, thank you very much
no problem, i have an AMD card too, so for any questions feel free to ask
❤️
i am getting error when i use this args: --use-directml --medvram --opt-sub-quad-attention --opt-split-attention-v1 --no-half-vae --upcast-sampling
i changed from --no-half-vae to --no-half, it fixed but this time, inpaint mode doesnt work
i dont know 😦
what error did you get?

in the cmd pls

ohhh, you installed the webui the wrong way (by downloading it as zip), so it never got any updates. so your using an older version of torch that get the error, also the newer version is faster
i installed so much another version and i got some error, so yes
best is to checkout my AMD Install guide in the Pinned Messages of the #🤝|tech-support message channel
and install the webui into a new folder. you can then copy your models over
oh thanks, ill look
@dry crow hi again me sorry 😄 i installed this time it works with these args, but inpaint mode does not work, still same 6 pics,i have selected only masked mode

just a second, ill change it to --no-half
yea with --no-half it should work
should i add --lowvram because of getting RuntimeError: Could not allocate tensor with 9994240 bytes. There is not enough GPU video memory available!
10gb vram is not enough
that should not happen if you used 512x512 and inpaint only masked
maybe you forgot to set these settings again after restart
also every time you get an out of memory error you need to restart the webui to clear the vram

restart and try with 5 or lower
but like i said --no-half uses more vram. so you should only add it if you want to inpaint or make 2 different webui-user.bat shortcuts
i changed like that set COMMANDLINE_ARGS=--use-directml --opt-sub-quad-attention --opt-split-attention-v1 --no-half --upcast-sampling, it works perfectly now, thank you so much, I know I'm tiring you out. thanks
so you removed --medvram? thats trange cause that normaly helps for AMD gpus
but good that it works now
yes i removed otherwise i am getting error, i dont know why but it works
can anyone simplify how extensions work?
I downloaded an extension for better hands and feet because I am absolutely lost on how to make them better and not mutated
GitHub
Depth map library for use with the Control Net extension for Automatic1111/stable-diffusion-webui - GitHub - jexom/sd-webui-depth-lib: Depth map library for use with the Control Net extension for A...
I downloaded the zip file, after I unzip it do I just throw in all the folders? or every individual file?

maybe there is a better alternative
but I'm trying to get rid of this "shadow" effect I keep getting on hands and feet


extremely detailed and sharp background, massive sparks and fire particles effects
8k, hi res, shallow depth of field, dynamic angle movie grainy still, 35mm, kodachrome, 1990s broadcast quality. (extremely detailed textures)
a knight from dark souls with a machete made of fire, standing in the night

monkey
d
which model did u use?
So I'm messing around with trying to get images generated quickly. This set is from the Dreamshaper 8 LCM, generated in about 25 seconds on a laptop RTX 3070.

With these parameters used in mind:
parameters: high quality photo, one car, sports car on asphalt, facing camera, fully visible, in daylight
Negative prompt: noise, letters, numbers, low resolution, compression artifacts, race livery, off-center, warped, deformed, driver, people, blurry, oversaturated, multiple cars, watermark, logo, asymmetry, license plate
Steps: 10, Sampler: LCM, CFG scale: 2, Seed: 3839933948, Size: 512x512, Model hash: a4f3e1526c, Model link: https://civitai.com/models/4384, Model: dreamshaper_8LCM, Version: v1.7.0
Is there anything you reckon should either improve speed and/or image quality without sacrificing the other?

I used the sdxl model nightvisionXL
Try many cars and not multiple cars for negative


Lmao
Hi, im trying to find models more suited to graphics illustration preferably SDXL based, found this one but most images seem to sugest its used as Lora? Also its about 70Mb, but no further info is provided: https://tensor.art/models/624412542015405514

Generate your images in vector art illustration style Recommend weight 0.8-1.0
Anyone knows of a Lora/Model that could output things like this?:

Then its a lora. Models are always bigger than 1.98gb
Sdxl models are always bigger than 6gb
Hey, What's the model size and what's your GPU?
https://github.com/TencentARC/PhotoMaker
Can this be used in comfyUI or auto1111?
GitHub
PhotoMaker. Contribute to TencentARC/PhotoMaker development by creating an account on GitHub.
Any recommendations to take old facebook photos and remove the noise in them
What do you mean by noise? Do you mean there's too much stuff in the background? Or the resolution is too low?
you know what, its not really noise. Just a picture on facebook that is poor quality. Bad resolution older camera
You could try upscale the images. Theres so many different upscaling methods. I used this guide, it's simple and uses already built in options in the Automatic1111 webui that this Discord has instructions for installing in the tech support pins:
https://www.howtogeek.com/894661/how-to-ai-upscale-any-image-with-stable-diffusion/

I don't think any single upscaler produces ideal results in every situation though. You could Google or maybe YouTube guides on how to upscale blurry photos if you don't get the desired results.
The guide does provide multiple options though (like using two upscaling models at the same time)
Yeah ideal methods of just photos and just text are different
I imagined so, but for some reason A1111 doesnt pick it up, np, searching for models more suited to graphic/vector art
hey guys, i keep seeing these images where they add detail or completely change the style of an image, is this possible with sd?

hey, yes thats possible
but not easy
i made this

do I need a specific extension or how exactly do you do this?
actually looks amazing haha
yes thats done with controlnet and IP-Adapter
This is an example: but a photo with bad quality like this:

Is there a way to make it crisp. Upscaling in extras just makes the same thing bigger really
I can take an IP adapter of an old facebook photo and even txt2img and it retains that bad quality of the original
I found that using the upscaling in the extras tab does tend to remove the lossy compression artefacts (e.g. those rainbow coloured distortions) to make some things more crisp, mainly things that were initially monotone. But it doesn't create new details that were not in the photo to begin with.
For faces specifically, the guide I linked to does describe GPFGAN and CodeFormer which are also options in the same extras tab. They will add new details to faces to make them more realistic at larger resolutions (the guide says CodeFormer is better at skin details and GPFGAN is better at eyes, but you can tick both at the same time and adjust strength of each method).
bacon trees 😁


What i need to do, what is Terminal&? i use A1111

It shoul give you gradio link to follow (above this message), just paste it in your browser.
You can ignore this message

I heed to host it forever
How to gradio deploy?
YOu want a local install?
I have a1111 on my server
I need to share it
And keep running
I put --share into webuibat
But it says that link will expire in 72 hours
share?
You mean just install on your desktop computer?
Every free "forward" service (gradio,ngrok,etc..) will have some sort of somewhat short relay time , if you want permanent you need need to install something like DDNS service or static IP and mess with port forward to router or have a paid solution
I use AnyDesk because of straight IP TCP Tunelling and 2FA , but if I wanna share it use Gradio or Ngrok
Using Gradio (--share) means disabling managing extensions remotely
If it's a host server, there's no need for DDNS, it's a static ip.
I think he's talking about the --listen launch argument, which enables external traffic.
@old marsh
You can also change the default port with --port xxxx
Remember that all ports below 1024 need root/admin rights, for this reason it is advised to use a port above 1024. Defaults to port 7860 if available.
Maybe its a "home server" no idea what passes by server this days 😛 , Also , pretty sure "listen" is for local only , "share"generates a public (Gradio) link
Use --listen to make the server listen to network connections. This will allow computers on the local network to access the UI, and if you configure port forwarding, also computers on the internet.
they are talking about OTHERS computer locally, by example, from 192.168.1.2 to 192.168.1.3
and, internet obviously

Of course you can TCP tunnel with listen , heck you can do it without any if running in "server"
I don't see the point, especially if you have no control over the link.
by opening tcp traffic, you access the same server, without bridging to the gradio site.
Share with a friend or colleague? If your workplace computer is behind some firewall or you don't have control over port forward? No idea, but I guess the thought behind it is for short term share
Good evening.
Tell me how you can generate large size images. When I install it manually I get an error.

mfw a server says AI art is banned, so they hyper analyze every image

Install what manually and what kind of error?
steak
Not sure what interface that is, invoke?
all these i generated




despite being here since the start, i havent been catching up with SD for half a year, so now im a redarded user that has fell off. this is some of the last crap ive done before i ended it all
Have any big and popular extensions come out? Is 1.5 still relevant? Is auto1111 still relevant? Are there any YTers other than MattWolfe and MattVidPro AI?

I just want to know what is Graio deply and how to make link not to expire so fast




Left looks Picasso but cant remember the phase name, top right definitely Cubism and so is bottom right, but probably one of the many variations like sintetic Cubism or whatever
Surrealism probably for the first one left
If using A1111 you could probably use Clip interrogator extension:

Thanks alot ❤️
Tha page looks busy, extension works really well on fast mode (be sure to read the about tab)

GitHub
Stable Diffusion WebUI extension for CLIP Interrogator - GitHub - pharmapsychotic/clip-interrogator-ext: Stable Diffusion WebUI extension for CLIP Interrogator

we findin aliens today

i just downloaded the program and it makes me crappy pictures like this, anyone know whats going on?

Hey, what's the model you tried to use?
Also the resolution needs to be at least 512x512 for good images
when i put it in 512x512 it says i dony have enough space
What's your GPU?
Also what install guide did you followed?
Intel(R) UHD graphics family total avaible graphics memory 4107 MB dedicated video memory 128 mb shared system memory 3979 mb
Only that? No nvidia or amd GPU listet in the task manager under performance tab?
where is that information?
Open the taskmanager and click on the performance tab
On the left there should be listet
CPU
RAM
Drives
Ethernet
GPU 0
GPU 1
yes
If there is only GPU 0 and thats the Intel and no GPU 1
Then you can only use the CPU for image generation
Ahh okay
https://stable-diffusion-art.com/install-windows/ heres the installation guide

We will go through how to download and install the popular Stable Diffusion software AUTOMATIC1111 on Windows step-by-step.
thanks for helping me btw!
Np, can you check what's inside your webui-user.bat?
Right click to edit it
You need some settings in there for better performance. These are not Included in that guide from above
k gotcha
im on the .txt file
it says:
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --no-half
call webui.bat
Okay, remove the --no-half
And add --lowvram --no-half-vae
Then save and relaunch
Then try again a 512x512
Perfect np 🙂
For better speed stay with models (Checkpoints) that are 2gb
Like Dreamshaper v8
You can find many models on Civitai
my goal installing stable diffussion was to use control net to color my lineart drawings using my colored drawings as reference
dont know if it will work tho
you better get some better graphics first
Oh that could be hard, and if it works it would be slow.
Idk if controlnet even works with 2gb vram.
But when you want to try it let us know in #🤝|tech-support
how?
i meant, you need better graphics card for that
something like 30xx with at least 8 GB of VRAM
just do not get nvidia 16xx, since that works too slow with stabile diffusion
my son's 1660 SUPER is super slow with stabile diffusion, even it is decent for gaming
Radeon on windows is not fully optimized, so it better to get nvidia for now (CS1o know more about that)
ok so i opened an sketch on controlnet and marked it as lineart, then on unite one i opened a diferent picture with colors in shuffle mode, thinking it was going to take picture 1 and give it the colors of picture 2

but it ended up giving me that abstract picture

i also tried to write "male face" on the text to image but it gave me a hiperealistic black and withe picture that also had nothing to do with what i wanted

you need to have a proper contronet model selected
did you donwload them?
i have a meeting in 5 minutes, so i need to go, but someone else will help you



see you later guys
@finite hound
You need the controlnet models from here:
https://civitai.com/models/38784?modelVersionId=44877
STOP! THESE MODELS ARE NOT FOR PROMPTING/IMAGE GENERATION These are the new ControlNet 1.1 models required for the ControlNet extension , converted...
Select the model at the top bar, for example Lineart, and download it + it's config file below the download button.
Then move the two files into the models/controlnet folder
Then restart the webui
thank you both"
are those smaller than those on hugging face?
Yes (700mb)
hey diffusers. what prompts would you suggest to get something like this- specifically that lighting setup?

@dry crow

What webui is that?
its fooocus
Ahh okay
the only program that isnt giving me trouble with this lol
i could probably do it with comfyui but its daunting
Then I would suggest set the VAE file to None
As that can cause the most Problems when used together
i did sadly :/ i will try to force it in the settings rather than per checkpoint
ohhhh this could be it

that checkbox
ill find out in a few mins
best would be to get this setting on the front page. to do that:
go into Settings -> User Interface -> Quicksettings, there add sd_vae and then hit Apply and reload. (onmly if not generating)
so its not turning yellow anymore except for 1 frame, and the shirt takes that information and turns yellow lol



what in the world is going on
you sure? Im getting more animerealism or atleast cyberealistic 2.5D from this. the ones you suggested are photorealistic models...
I think that wasn't meant for you ^^
yeah i dont think so hahah my images are decent besides that color swapping
Cyberpunk, neon city, and an anime model
That swap is interesting xD
its blowing my mind, like am i just gonna have yellow stuff in all my images now or what LOL
this is the reverse, with the 1.5 checkpoint going first and SDXL as the refiner. its doing the same thing


this one doesnt fix itself lol
i cant understand why this is happening
I reinstalled the webui with git recently, so I could update with git pull in the future. When I use safetensors as checkpoints, it produces stuff like this for any prompt

wondering why and how to fix it



Some of my favorite images, that I made using SDXL on bench AI









Please let me know your thoughts
i would try something like "rim lighting" cause thats what that is
scenic long shot, a river through a valley,view through the trees, a bear in the distance next to the stream
@valid pivot

the idea is to make something else the main subject of the photo
scenic long shot of a gigantic ancient cedar tree, bear scratching his back in the distance


@dry crow So I downloaded the lineart and shuffle models for controlnet and i tried to merge my lineart picture with my color picture but once again it says that i dont have enough cpu memory
Can you post a screenshot of the error in #🤝|tech-support ?
that works, thank you
Hello, guys when installing SD on pc, i am getting this error, can anyone help?

Hey, it seems like your provider or DNS is blocking the connection to github.
If your from Asia you may need to use a VPN for the installation.
For more help come to #🤝|tech-support
thanks. i'll write you there!
Check also if you have a dedicated firewall or proxy that may blocks
Can anyone help me? I've attempted a simple prompt with all of my models, and the result is consistently like this. Sometimes, it even becomes low-resolution images, although I specify an HD prompt. I'm using an RTX 2060 Super. Can anyone assist me in resolving this issue? thankyou for your help

Just someone's basement retro gaming collection...

the thinkdiffusionxl is an sdxl based model.
so the resolution has to be 1024x1024, for it to look better
hello


I LOVE the images of Herne. They are fantastic!
Anyone has access to this discord server?
I'd like an invite, thanks

Links to it are expired
Appreciate it
I think I put this in the wrong chat.
Have a question. I have a very low resolution image from a photoshoot that I'd like to try upscaling with A1111.
https://i.imgur.com/QvD0rQk.jpg
There is an image from the same photoshoot that has a relatively larger resolution;
https://i.imgur.com/UKWNhlK.jpg
Is there a way I can use the higher resolution photo somehow to assist in the enlargement of the low res photo? Can ControlNet do something like this?
Thank you.


I can't bring myself to pay $40 for Magnific and this is just an example. I'd like to do with other photos as well.
The image is not low resolution, it's 3000x3000px...
It's very grainy
Anyone know where the preprocess images tab went in A1111

when i look it up i dont see anyone talking about it or any reason why it should be missing
Extra ?

I don't think so. There probably was an update that removed it because it does it automatically ? Can't guarantee, but that's how I've seen things working, these days
does it do it automatically? I haven't tried yet so
Try it
yeah one sec
There is a way, just img2img it, then faceswap with her face.
I'm creating her model right now, just to check how it will work, but I got this already with img2img

By the way, I'm creating Lora's now, because I never got how embeddings work. What's the difference ? How easier/harder is it to make ? Is it usable for creating a specific person ?
I've never done this before so idunno 
Gotcha
i just slapped some pictures of my dog in there and wanted to see what would happen
Please tell me the results
dunno if this is normal or not
Auto1111 ? Yeah
been like 400 seconds and not a single image has been made
ill just leave it i guess, see you in 4 hours
Not sure this is what you wanted, but here we are

I keep seeing images like this posted online but can never find what model was used
I've found things that were close but not quite there




Was wondering if any of you know...
Cuz I keep seeing this style but the posts never have any details (pretty sure it's ai most of the one with hands are often fused)

@fresh canopy This is what I get after 10 seconds for 5 steps 💀

i just saw ur cfg comment
Use 512px, CFG 1 and Euleur a or SDE Karas
Too many steps and it starts "tripping"
real
pretty good
mine dont look good though
best i get

and it takes 10 seconds each
do people still use --xformers
10 is ok , sampling method has a great influence
does anyone know why when i put my clothing into brackets like this {jeans|shorts} for multiple options, the quality nosedives, look this is with brackets and without


im on automatic1111
same goes for the background or anything else i put into these brackets {}
i fixed this. turns out you have to enable the combinatorial gen in the dynamic prompts plugin. i dont know what the syntax was doing previously to drop so drastically in quality lol
i cant tell with just one image. but i want the output to be random based on variables, instead of it weighing them all
i think its fixed tho im not sure
a do you want random background?
lets say i do {at the beach|in an apartment} i want it to randomly choose between those two each time
not both
one would be at the beach, one would be in an apartment
but in the same prompt
aa if you put [at the beach] ,decreases the force, doesn't it?
yes, but i want them all to have the same weight, so it chooses randomly, not one over the other
but then you put them all in []
but i dont know if that work in SD, in PixArt that works
no i put them in {}
oh i see what you mean, i dont think that works
ahhh i found out what was wrong. dynamic prompts was disabled when the quality was bad. i need to just have it enabled but not check the combinatorial box, then its random and not in batches. i need to check the quality when its finished rendering now lol

yep if you try to do random combinations in brackets without this enabled the quality nosedives
its fixed with dynamic prompts enabled
weird how it would work in the first place without it turned on though
brackets are just letters like any other letter. Automatic1111 adds additional filtering to remove them and process them before sending to the image generation.
Also, A1111's bracket processing rules are a nightmare built ontop of spaghetti
I dare you to try to understand the difference between
[cat|dog:1.0]
and
[cat|dog:1]
Hint: you'll get completely different images
The scene is full of tranquility, warmth, and soothing atmosphere. It can be a study room or a living room, with a hostess or family members.
thats so messed up lmao
hi! what woudl be the best method to recreate that symbol?

Use Google image search, find some vector/image but at better Res, upscale with anime model, could probably get close to 8k sharp Image
unfortunatelly i cant find this symbol anywhere

idk, I found few
https://cdn5.vectorstock.com/i/1000x1000/42/24/throwing-trash-icon-on-white-background-vector-27794224.jpg
I recently did for fun a screenshot of around 1k from a vector imagebank (I bought the model after because it was work) cleaned in PS watermark and got to 16k probably as sharp as real vector





It was 5 EUR so bought it anyway
Didn't need to...
yeah, ive found similars, but not the one on my picture
@broken linden If you have that Screenshot with more resolution I'm sure would help in search, as it is: https://lens.google.com/search?ep=gisbubb&hl=en-PT&re=df&p=AbrfA8orTiSV3ySHBbnQT5x78zha31-3u9oWu5RhlEbCN9fU4v7bhLgav3BjSrEwe3qFuMtWFCnGo_BP4EuYz49imb22AKhVSBObSMHVG8t5KztZWotdSNN2qlFfoRc0lRiCiF9IjS5iZjEPUnkFVFf3I-t7Wk21itRRKfoa5F-DKgiZgVVQC87IeR6TE2b8ucbW4MeTGvwl4FPmbA%3D%3D#lns=W251bGwsbnVsbCxudWxsLG51bGwsbnVsbCxudWxsLG51bGwsIkVrY0tKR0k0TW1Zek1XWTVMVE5qTXpNdE5EVmpPQzA1TW1GakxUaGhNalUwT0dFek9EaGlOQklmTUROeU1WRTFZMHBYVXpSalRVbG5SM0JuU1V4dVVETkpiMmxJWmpCb1p3PT0iXQ==

gatos bailando
super scarmario



Pitch of a fictionary dystopic movie about the Roman Empire, in the style of Warhammer 40k, for AI lovers (Morgan Freeman cloned voice)
https://youtu.be/N9itVxjBE7U?si=YB6awmwNRTeDddv4

Men always think of Roman Empire? What about futuristic dystopian Roman Empire.
Original creation and world inspired by Ancient Rome and Warhammer 40K
A gripping journey through a Rome unlike any you've known – a city where ancient grandeur meets a dystopian future
In this captivating episode from our dystopian series, we reimagine the heart ...
That’s awesome

this is the image with the pasted in hand from gimp i was trying my last few attemps to make look better
is it just too small? the image is 1024x1024 and i tried inpainting at 2048x2048 res
controlnet with lineart, controlnet with depth, canny, ip-adapter, and various combinations of those
idk, I inpainted smaller parts, just need to make really high pixel padding thing, whatever it's called
just takes some attempts
Only masked padding, pixels?
im doing this for more than 4 hours now so yeah i already have like 1000 pictures of that hand
I usually inpaint bit by bit , like
get image slightly better - reinpaint it, repeat like 50 times lol
i also tried various hands from the depth library
i did that for like a few hundred attempts but the hand only got worse i got no progress whatsoever
i did that succesfully on other pictures too, but here it just doesnt want to work
yea, this will need really high value, so it can "see" more things around, make it somewhat similar

well i have whole picture activated, so it sees the whole picture...
maybe it sees too much
it thinks its a horrible looking supergirl so she needs horrible hands
😄
higher denoise, less controlnet power, end controlnet earlier , and umm. maybe throw some artist names at it? thats a more complicated fist pose for sure. knuckles out is a lot of lines. plus it looks like its small too so that makes it tougher
which controlnet should i use even?
the hand is already perfect actually, only the seems arent and the texture isnt either, and maybe the color could be improved aswell
if i use lineart on 2kx2k, the thumb isnt seperated enough and it just garbles it together with the other fingers....
maybe i should draw a fine black line around the thumb in gimp?
I had pretty weird way to adjust color, making it as I want, but that can make your image only worse...
Just copying part of the image from somewhere else and put it on hand , let it inpaint and figure out what color it should be (again, lots reinpaint iterations)
there should be better way, idk
that's an option too
i'm getting decent prompt understanding by using "front of fist" , "palm side of fist", "arms out palm fist" . Those get me pics with the right side of it more consistently
making sure the prompt has an idea of what you're inpainting helps blend pixels really well
1.5 understands fist positions so much less. i'd inpaint with sdxl instead. juggernaut has a very decent inpainting version
i just got disconnected...i will try that, thanks
you mean a specific inpainting checkpoint from juggernaut, or just the regular juggernaut checkpoint?
specific inpainting of it
FOR Automatic1111 -> inpaint, please read that this is not yet fully implemented @KandooAI (confirmed thx) original: https://civitai.com/models/...
i had problems with inpainting checkpoints aswell to the point i gave up on them -.- they wouldnt draw me anything...
but i will give it a try, thanks for the link
sdxl on it's own has an inpainting layer, but something about these models extend it? i'm not so sure. the base sdxl inpainting model was put out by the diffusers team https://huggingface.co/diffusers/stable-diffusion-xl-1.0-inpainting-0.1

You only can generate images in the bot channels for example #1100170365604483202
With the / dream command
Dude, just use Stable.Art.
you'll save an incredible amount of time, and it's so much more practical and precise... Etc
whats that?
An inpaint/img2img/txt2img tool for Photoshop
Stable.Art load in PS, and connect to A1111
i dont have photoshop :/
Depending on your "values" about having something you don't, I can help you x)
(i don't know if its a good translation)
check your pm @feral sluice
ty but I'd rather use some open source software 😅
Oh yeah i understand, that's almost all I use too. But sometimes you just have to admit defeat, the work of certain large companies, and the federation around them, can't be overtaken like that.
what even is the upside of using photoshop? you mean for the whole process? or just for inpainting? i dont get it
The inpainting on the A1111 web page is disgusting. imprecise. etc.
With photoshop, you can use the lasso: boom inpainting. You can even use blend masks to erase the outline of a layer of inpainting that's too intrusive, or only half satisfactory. And do it very, very fast
It's Firefly only much better, with Civitai models 😄
you can do the same thing with automatic1111, just need the right extensions
Trust me, not like this :
https://www.youtube.com/watch?v=utjxgMQbshk
with a simple stamp to use the smoke on the background to cover that ugly piece of wood right in the middle then: inpaint with a prompt like this:
a man's shoulder, with blue fog, smoke and shadows in the background, trending on CGSociety, Intricate, High Detail, dramatic, psychedelic painting
The piece of wood has completely disappeared. It took me 2 minutes

The image before all inpainting :

So cool
a 4 floor modern house on a sloping land with under garage and a pool on the second floor
is there a better faceswapper then faceswap lab or reactor?
Depends. For faceswap in other styles. IP-Adapter on controlnet is better
I mean photorealistic faceswap


Midjourney has more details, but I like the lighting in the anything model
Tbh its hard to compete with midjourney unless you use a lot of loras
i dont know if this is the better model XL for background
Do you have the prompt? I´ll try it in the sdxl model that I have @shell plover
entirely a subjective choice. technically, both seem very competent at what they do. Stylistically they've gone different ways.
Anything XL, never heard of that? Is it another situation where other people made a model and named it after the anything v3 model that was really popular ?
anything v4 was so bad but everyone started using it because they thought it was the next version. it was just some jealous kid who hated that his models weren't as popular as Av3
official civit anything page, you'll note how they skip over v4, its because of that jealous kid. https://civitai.com/models/9409?modelVersionId=90854
不要问为什么别的模型能出这个模型不能出,或者为什么细节/画面不丰富精美,你先看看你写没写或者写了什么奇怪的东西,没写的东西别指望模型给你出图。 ———————————— Anything-Ink hugging face: X779/Anything_ink · Hugging Face 1....


thinking about how he'll eat it
yes , "a photo of a very beautiful white castle with clouds all around, close up, beautiful windows made of shiny precious stones, red tiles and pointed roof, with beautiful angels flying around the castle"

i love that
which model do you use?
This is with nightvisionXL photorealistic

I wish there were more loras for SDLX :p 🥺
RealVisXL
same prompt?
Yes, 20 steps, 7cfg
Does anyone here
know inpainting only changes a face
and not add what i want to implement
If you scroll up, i was talking about inpainting, i posted a video, just take a look
how do you connect it to photoshop
the euler anscestral is better for XL models?
?
Cause thats epic
? huh
I installed it a long time ago, I couldn't tell you, look at the Github description
And yeah, thats epic
DPM++ 2M Karras is better in my opinion, it has more details, the same with DPM++ 2S a Karras
Its a bit slower to process tho
i gonna try with both
anyone experimenting with face swapping ; )



🤔 maybe it depends on the model
B
I tried with roop on sd but it lagged so I just sticked with facefusion and gpen 512 model, Its the best in my opinion
i use react-webui, facefusion looks good, will try it out



why is this happening? left is txt2img adetailer, right is img2img adetailer, same settings

i want the results on the right to be in my automated workflow in txt2img
i dont know what the deal is
What are your settings in both?
same exact settings in both

I dont have any of these settings in txt2img or img2img
im using automatic1111
Same
sorry i forgot to mention this is adetailer
lol, do you know what could be going wrong?
Nope didn't used Adetailer with these settings
its weird, its literally perfect on the right. and when it zooms in to show it rendering its a lot clearer
theres a checkbox in adetailer to completely bypass img2img
so it just activates the adetailer

so i know its not my img2img settings
Ah okay, and you use both 1st, 2nd settings
In adetailer
yeah exactly. it should give the same result
i use 1st tab for face and 2nd for eyes. but in img2img i just do one tab for the eyes
cause the face was already done in txt2img
So its not 100% the same settings
not EXACTLY but ive also tried doing eyes in the 1st tab so they run first, and same result
im going to run it again with face off completely
but if this works that would kind of defeat the purpose, cause then id have to run the face in img2img
no its the same result
hmm strange
could you grab the adetailer extension and test it for me? just make a random chick and try to improve her eyes just by turning it on
i want to see if it really is my settings or if its just like that
no worries if you cant i would appreciate it tho
only enable it with default settings?
in txt2img?
yeah even with default settings i cant get it to work so if you can thats a huge improvement
besides the face model
for the adetailer model pick this one

thats all i changed, just so it would pick up the eyes
ok
you should have it by default
oh fml i have hiresfix on also with these settings

im thinking its not picking up the hiresfix, cause when it zooms in img2img the quality is crazy compared to txt2img
thank you btw ❤️
okay now ive mde 2 images in txt2img with adetailer. first is with yolo8s and the second with the face mesh eyes only:


Wow, I like the details. Can you share the info if possible? I'm a noobie
were the eyes messed up a bit before generating?
thats kinda crazy though they look pretty good
i noticed i get the same results in img2img when i dont resize the image to the size it was upscaled at. if i could figure out how to turn that on in txt2img i think that would fix it
thank you for trying that for me
you mean in the preview?
yeah
like after the hiresfix but before the eye fix
idk, havent looked at it
Haven't used ai in a long time tried checking out stable 1.5 i still had vs bing's new ai thing and oof it did the prompt so much better lol


how's stable diffusion 2 these days? It was controversial when it was new
Everyone tells me to "stay the hell away from it" so I don't think it's bright
But maybe I'm just prejudiced
If you mean 2.0 id rather use SDXL these days
Everything is either made for 1.5 or SDXL now
maybe sdxl can keep up better, midjourney and bing have gotten crazy good
I really like SDXL, but some 1.5 models also stand out
would you mind running the prompt I used to compare with bing's ai on your SDXL? i'm curious how it handle it out of the box
SDXL takes a lot longer for me to generate, so I stick with 1.5 these days
Because I'm not on my main device, it's only 6gb gpu in this
I don't mind longer times, I just want quality
do you want me to test your prompt on sdxl?
yeah that'd be nice thank you i'm curious
A highly detailed drawing of an knight with a fur cloak with nautical suit elements and a lantern, drawn, inktober, sketch this was the one i used to test
any loras or models?
no just base
sure
🫡
Oh wait, I don't have the base sdxl on mine, where can I import it fastest?
I'm using sdxl models time to time, but never used the base tbh
ah tbh I have no clue, if you don't have it's fine, thanks for trying
Dont have the base model, but tried a few others. You probably have to adjust the prompt for SD and use loras and other models maybe


ahh thank you for trying, that seems similar but crisper
yeah you'd probably have to to get similar results
tbh for now i'm just going to use.. bing's free tokens when i want to mess with ai prompts
lol
I prefer having a local install with full control 
Added a Lora and negative embed. Kinda tends to make wolf heads or similar, dunno why



me too, also img to img and other features. But I just don't have the energy to fiddle a ton, just for inspiration this'll work fine if I don't use it a lot anyway
oh that's a different result but pretty neat lol
one day we will go back to the glory days of crotch lanterns
one day


And fried egg lora 

Trigger: ral-friedegg ☕ Buy me a coffee: https://ko-fi.com/ralfingerai 🍺 Join my discord: https://discord.gg/g5Pb8qNUuP

has science gone too far
Not yet
you're right, we need a whole breakfast assortment lora
omg they're so cool!!
And they're both for 1.5 and xl
I'm in love
With revAnimated model + extra details 1.5 lora

I now have an enourmous failed bicycle collection
canon event
the thing is I tried installing kohya ss for lora and failed on that either
instead, i'm making forest pictures now.. simple
needs some impaint, i guess

||mountai top view , moutains surrounded by fog style : realastic||
The lora lora:drow_armor-000003:1 i made. Its my attempt at getting Minthara's armor from Baldurs Gate 3. Since she is the primary model in the lora the figures resemble her in some form or fashion. Yes, my prompt is crazy i know. I ran it through several models with the lora settins at 0.6, 1, and 1.5.
cowboy shot, 1woman drow, elf, pointy ears, (light purple skin), (vivid red pupils), detailed eyes, black lips,white hair,black circlet, priestess, elegant, ((drow armor)),breasts,buckles, leather,blood, sword, candles:2, white marble columns and braziers, (hyper realism, soft light, dramatic light, HDR), ink scenery, (perfect body), jewelry, (seductive, sexy, alluring), perfect lighting, perfect shading, volumetric lighting, subsurface scattering, (photorealistic:1.6), (fantasy art), (beautiful, stunning, gorgeous),dark backdroplora:GoodHands-beta2:1 lora:drow_armor-000003:1
Negative prompt: (bad_prompt:0.8), (artist name, signature, watermark:1.4), (ugly:1.2), (poor details:1.4), bad-hands-5, badhandv4, blurry,young,teen, child, loli, kids,FastNegativeV2, (worst quality, low quality), EasyNegative, (BadDream, UnrealisticDream),[([mutated hands | mutated fingers]:0.65):([mutated hands | mutated fingers]:1.3):0.40], [([extra limbs | missing limbs | floating limbs]:0.4):([extra limbs | missing limbs]:0.7):0.5]:0.8)]:bad anatomy:0.3]:[[([mutated body : ugly head:0.25], [([mutated hands | mutated fingers]:0.5):([mutated hands | mutated fingers]:1.3):0.40], [([extra limbs | missing limbs | floating limbs]:0.4):([extra limbs | missing limbs]:0.7):0.5]:0.8)]:0.8], horns
Steps: 80, Sampler: DPM++ 3M SDE Karras, CFG scale: 7, Seed: 874930416, Size: 512x768, Model hash: 3699d7fa76, Model: luminaverse_v10, VAE hash: c6a580b13a, VAE: vae-ft-mse-840000-ema-pruned.ckpt, Denoising strength: 0.5, Clip skip: 2, Hires upscale: 2, Hires steps: 40, Hires upscaler: 4x-UltraSharp, Lora hashes: "GoodHands-beta2: c05ed279295e, drow_armor-000003: 704320b78683", TI hashes: "bad-hands-5: aa7651be154c, badhandv4: 5e40d722fc3d, easynegative: c74b4e810b03, BadDream: 758aac443515, bad-hands-5: aa7651be154c, badhandv4: 5e40d722fc3d, easynegative: c74b4e810b03, BadDream: 758aac443515", Version: v1.7.0


I have a 1024 x 1024 lora of her armor i built yesterday but havent tested it yet.
Thanks! I will definitely play with this
i wonder if i should post that lora to civitai....
I mean... why not?
Im testing the 1024x1024 ones now. ill show some results and get yalls opinion first
ive only made a few lora's so they may not be great. 😦
You made "a few" more than me, which is 0
so be proud


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
this is with nightvisionXL
