
#🏞|general-with-images
1 messages · Page 110 of 1

AI now able to do bad photo shop jobs, excellent





wait a few months until i have my new laptop xD


needs some fishes eating other fishes early 2000s gameplay

perhaps one day


Anyone have a prompts that I can generate this character?
My models and my prompts cannot correctly generate an image of him
And my friend requested me this too
I don't wanna fail them
have you tried textual inversion?
One fun thing is to use "dressed in ?????? suit", here is a man dressed in "tight unicorn suit", "zombie suit" and a "deer suit".




For Baldur's Gate fans. Shadowheart herself. lol

Been using SD for a little less than a week now, thoughts?






Comparing 3 different upscaling models.. which one you think did the best?
you may need to download and zoom in to see difference



This can be one of those old RTX ON/OFF jokes (Second Life - img2img_AI)


Smooth areas look better in realistic rescaler, detailed areas are enhanced by ultrasharp. But swinir seems to be a good compromise of both.



too basic honestly
What would you do to improve it?
I would make it not too basic
Yeah but how? Add more detail?

Hi guys, my models have often a nose piercing.. a very ugly one. it never looks good. Even though i don't write anything about piercings in the prompts.. How can i get rid of this?
probably remove the mile long negative prompt, and use the negative prompt box to remove things you don't want? 0.o
ps [] de-emphasizes a word, () emphasizes, I assume you mixed that up because de-emphasis of 5 is basically just an ignored word. I don't think you'd be allowed to post the image if you hadn't messed that up though.
wait.. can you see what prompts i typed in?
lol.. but long negative prompts are good. stop lying about that.
what does that mean.. i don't understand 😢

#1072220168534642768 the tarot in the looking glass, behind it a mirror maze from which the senior arcana of the tarot look out


Truly a work of art






Just a comma difference.. if you put at the end of the last prompt



Blip and clip

How comma this happen
Is she like
With the comma looking more at the viewer and has warmer lighting?
I'm too stupid to see the difference
the comma at last doesn't do a big change but it definitely does a subtle change
i like her forarm band though.. using the comma
you can experiment yourself.. you'll get two different results using it so why not!
one with last comma looks better, lol other one has artifacting in the hair, lol
yeah comma makes it better sometimes, and sometimes worse
That's literally something from those "spot the difference" games
Haha
interesting username, lol

it's fun to experiment
I usually put comma at the end
comma has a special value within the prompt i guess
However, I've never used commas to separate Lora model references
Since I unusually put the reference at the end anyways
I always do
It looks like something I don't need to
But it gets on me if I don't separate everything with a comma lmao
How can I take a 2d image and make it 3D rendering? I've tried img2img with low denoising (0.1-0.5) and it is barely changing the style. The higher I go, the more other things change but the style is not changing much. I really need the details of the image to stay together as much as possible and just become 3D instead of a flat 2D image.



need help
if an image is generated full body for others but only half body for me for all same settings then what could be the reason?


There is some other setting that differs. Could be nearly anything.
or maybe they used a controlnet pose
I mean...nearly anything at all can cause differences. Different seed, different CFG, different prompt, different VAE, different anything.
they only used text2img+hires.. not sure if controlnet was involved or no
Here's the data:
1girl, photo of nude model 18 y.o, tanned caucasian 18 yo, situated near Kilimanjaro in Tanzania, final fantasy still, extremely high quality RAW photograph, detailed background, intricate, Exquisite details and textures, highly detailed, ultra detailed photograph, warm lighting, 4k, sharp focus, high resolution, detailed skin, detailed eyes, 8k uhd, dslr, high quality, film grain, Fujifilm XT3,
Negative prompt: FastNegativeV2
Steps: 20, Size: 512x768, Seed: 2680399189, Model: aniverse_V12, Version: v1.4.1, Sampler: DPM++ 2M Karras, CFG scale: 7, Model hash: 4393bb4b9b, Hires steps: 20, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+, ADetailer model: face_yolov8n.pt, ADetailer prompt: "photo of a blonde girl, (film grain)", ADetailer version: 23.7.11, Denoising strength: 0.53, ADetailer mask blur: 4, ADetailer confidence: 0.3, ADetailer dilate/erode: 4, ADetailer inpaint padding: 0, ADetailer negative prompt: BadDream, ADetailer denoising strength: 0.25, ADetailer inpaint only masked: True

If there are different versions of that model, you might want to try a different version.
Unfortunately, the information showing on Civit is A) not complete and B) not always correct.
i used v12 and v13 and all are coming the same way for me.. half of the body
Sure, but they could easily have done something else that isn't explained in the generation data summary.
They may have used ComfyUI and you might be using A1111. Without the proper care, the images will be different.
Hell, I've got images on Civit with wrong generation data simply because Civit doesn't have the 3M samplers available in the dropdown.
ooh so those examples are pretty misleading.. i see
I'm not saying that specific generation data is wrong, I'm only saying that it's possible.
disappointing huhh
thought i could learn from them but no i guess
i'll have to scratch things out myself
You have to understand how this stuff works. Basically, the rectangle created with the dimensions you give it is filled with random pixels...the latent noise. The sampler & schedule will then essentially "infer" the image via the prompts over a series of steps. (I'm simplifying here just to speed this part along.) So anything that changes any part of the latent noise, the calculations, (or anything, really) can change your image in either dramatic or subtle ways, depending upon what changed and how.
could be a reason with different automatic version? like he used 1.4.1 and i'm on 1.6.0
I haven't toyed around with differences in A1111 versions to see if something like that changed generation output, but I'd assume there's some possibility of that, yeah.
probably.. who knows..

which looks more correct?


and these two


pompt was: (best quality, masterpiece, colorful, dynamic angle, highest detailed)upper body photo, full body photo, fashion photography of cute girl with iridiscent pink hair, in lush beach, gold bikini, (intricate details, hyperdetailed:1.15), detailed, moonlight passing through hair, (official art, extreme detailed, highest detailed)
i think second sets of pics followed the prompt more accurately
but as there's body upper body and full body prompts given so i'm not sure which is correctly done
i cannot even tell the difference im not gonna lie
ill say
number 1
because the extra hair
nah it's the hand in the shadow

did you install some extension recently?
Why posex ui not showing ?

first off, you don't even have "Send this image to ControlNet" checked, then make sure ControlNet is even enabled before hand, and then make sure you have "canvas-zoom" extension.
Hi, visual maestros! I'm working on a project that requires 3D camera tracking, replacing a floor, and inserting a few objects into the scene. I tried using stable diffusion/controlnet and applied EBSynth for animation, but the outcome wasn’t satisfactory. I'm considering using After Effects with Mocha for planar tracking but am unsure about masking around columns. Could you recommend a quick and effective approach or software solution for this? Thanks!

at that point just 3d model something in Blender, lol
then you'll get exact reflections, lmao


took about 10 minutes to make mate
Also SD can benefit from 3D modeling as well. If ya don't want to make just a 3D animation and bother creating all the textures, UV maps, etc., depth/normal images can be used to help with animations for SD to render. (Using ControlNET of course)
Wow! Thank you for the advice! I'm comfortable with 3ds Max, but I'm not up to date on making a 3D scene from the source footage these days. I've tried using the aeTransfer_v2.1 script to transfer the scene into 3ds Max, but the camera doesn't seem to match what's in After Effects
Here's what the scene looks like in After Effects and in 3ds Max https://drive.google.com/file/d/14W1sDn0lIWIPT-_uAVKiEbkDPyBPQiOU/view?usp=sharing
Google Docs
Seeing that you managed to recreate something similar in about 10 minutes is impressive! Would you be willing to assist me in building the 3D scene? I'd be more than happy to compensate for your expertise and time 🙏
Unfortunately I've not ever used 3ds Max, I have used Maya and Substance Painter but for a short time back in community college, lol. Pretty much all paid/subscription based 3D software I don't own myself. In summary what I would do is create a 3d scene very similar to the real footage like what I showed you, render a normal pass (just a normal render) to get similar floor reflections, lighting, etc, then another pass rendering the floor white and everything else pitch black to use for alpha channels (so you don't have to manually mask the pillars over the ground again). That's just coming from a mostly blender user's point of view  (like me) but that's probably what I would do. I can't help since I've already got alot of other projects going on but yeey.
(like me) but that's probably what I would do. I can't help since I've already got alot of other projects going on but yeey.
Same kinda technique used for fluid simulations on real people and real scenes.
Thank you for sharing you ideas! Initially, I wanted to leverage the Tokyojab technique with Stable Diffusion Controlnet and EBsynth, generating 4-8 keyframes for EBSynth. Post achieving a desirable result with EBSynth, the aim was to derive masks for the columns, possibly through ControlNet Segmentation preprocessor or Mocha's planar tracking. Your mention of rendering a normal pass for accurate reflections and lighting, followed by another for alpha channels, was also something I've been considering. While I have my concerns about closely replicating the original arch while constructing it in 3D, your input gives me some direction... but still - I'm currently concerned about how close I can go to replicating the original arch in 3D



Hey guys,
Will one day it be possible to use LoRA made on 1.5, in SDXL?
nope probably never.

lets simply it. imaging like, sd1.5 is a bunch of random dots on a grid that make up one pattern. and you make a new pattern by adding dots to that grid. so when you overlay your dots, your intended pattern shows up. but now put your dots over another entirely different set of dots. it'll be meaning less in that context
loras are basically a set of numbers that change the original model's numbers. they only work if they match up to the same architecture
brub


Icecold what's with the Star Trek distorted dance spam, lol
this nails it. dead on.
i just discovered visioncraft software. ui for animatediff

takes about a minute for 3 seconds. i can use any 1.5 model
opening his n64 on christmas morning
he's so stoked

he looks like one of those chinese generals from those tv shows 🤣
Nice to know that the bot is still as bad at composition as ever.



I wonder if anybody here has managed to generate a grown-up photo of Jenna Ortega as she looks like now. I guess it's because of the training data but the images major AI models generate of Jenna Ortega are of her as a kid, mainly because that's the only images they have of her
Something like this

Just look on civitai lol






The AI keeps generating light poles or something similar to alien light sources rather than a city in the distance



@kind quartz the settings im using right now, and the prompts


you can uh... see some of the nightmare fuel im getting out of these on the right 
I matched the image generation resolution to the original image as well
im also gonna make note that I am fairly new to messing with stable diffusion as well
try lighter denoise strenght or go higher to change image very

lemme go to .3 like you suggested
the lora im using is meant to emulate the renaissance style as well
oh hey what do ya know, moving the denoise down made it almost perfectly recreate the image.... thats progress, it doesnt look renaissance though 
wouldnt lean on lora. O.3 change image just slightly
Should I get rid of the lora in this case?
the checkpoint im uisng is SD V1.4 full

actually this aint half bad
tbh
didnt realize adjusting the denoise value would have such a drastic effect
i would and in img2img description would write renaissance painting or renaissance still life 🙂
you mean up here? or is there another place i can add words for

Im glad you didnt question the thing im trying to make 
what about do not describe banana? It is in image
I did that at first cuz i was getting women instead of bananas xD that was before i messed with the denoising though

Ill try taking the word banana out and see how it does
you have some image putting in img2img.
just put it as image there
Wait you mean just type image in the prompts?
no put image in img2img tab. What picture are you putting there? Banana?

this
I addded the description on top of that though because originally even with this image there i was getting a person instead xD
yes so no needed describe banana


😄
Thank you for the help i appreciate, ill continue tweaking the denoising and stuff ot see if i can get something i lioke more but this is really good
see you!


does swapping the from and to inputs make a difference?


This should be the same as the ATJ LoRA example pic on civitai - but it looks completely different although all parameters and the model are the same. why?

一个中国仙女

I'm not really familiar with how those "styles" work, but that's the one unusual thing I'm seeing
are there any example images that have simple prompts you can try to recreate
no additional loras or styles
I just can generate some simple pictures like a cat with a hat or a mushroom with eyes - but I don't understand what's wrong here. I've deleted the first installation of SD, cleaned the cache and er-installed it - but... no changes
Don't know to be honest, looks alright other than those "styles" and also the lora appears twice in the generation info for some reason
perhaps one of the "styles" loads the lora a second time
or something weird like that
Ok, thank you...
/iagin a car pink


Subscribe for good luck - Most Popular videos - https://www.youtube.com/watch?v=72qmtr41iWU&list=UULP3MF3KCtKQkCudSvNpk3BOg
#chatgpt , #ai , #art
_
Artificial Intelligence (AI) has been a game-changing technology that has revolutionized the way we live, work, and communicate. In recent years, AI has made significant strides in various fields su...
@dense tapir A1111 feature, but feeling not safe with it very.


how so?
I see by hand is still needed but the brunt of the labour it did
it is automaticaly imagine b&w images, extension, but something must be done in webui-user and i dont believe it so much.
That torn must be done manualy. This is only colorizing 🙂
I am not much into colourizing old b.w images
yes but i think it is working very well, will try coloring video today
I do believe combining controlnet with clipvision and ipadapter will vastly decrease labor time in these sorts of endeavors
guys, you need to check out the stable audio website. type in an image prompt or something. be impressed and terrified at the same time

cool post it in #🎵|stable-audio not here, lol
is this channel called image chat, or general chat? if I were to post in the channel that's called "stable audio" would it not be a bit off topic? this isn't general image chat. it's general chat with images. and I don't see a multimodal channel. so I guess I'll just have to not post anything else with more than one style of media
thanks for the pedantry

I mean they made a #🎵|stable-audio channel for a reason but idk bro you do you.....
bro had a whole paragraph ready
I was just having fun with something new and thought I'd share. I didn't know where to share. it's people like you that suck joy out of the world
Sounds like you did a good job of that yourself, I also noticed you deleted that comment, nice
Anyways, moving on
well I mean, I didn't engage with you. how about you do some self reflecting and stop worrying about me
kind of a shit ass attitude tbh
treating chatrooms like a meangirls highschool situation is just so not fetch
Left or right, what you think is the best for a ring-shaped architecture on Mars, that can turn in rotation for an artificial gravity ?






mars has gravity, just over 1/3 of earth. so if you are 50kg, you'd be about 15-20kg there. Also centrifugal force creates a force perpendicular to the rotational axis, not top down like gravity would expect to work. but i like the one on the left one better.
Realistic mars colonies are likely going to be similar to total recal. Excavated underground, sealed and pressurized. Domes like those would be for bringing in sunlight or entry points. Rotation may work for logistical reasons like a train switch yard
i love the colors on this. using animatediff?

@wispy nest fascinating tech but man are they garbage compared to other stuff
if you mean runway ml's gen2, yup. or pikalabs. yeup. But these are open models that can run on a home GPU.
Anyone can train a motion model too. Give it 6 more months and they'll be the standard
standard for what? 😄
for general animating not at all
for some fun play around for a niche of consumers eventually
I do 3d animation and I can tell ya there is no way it's replacing it that soon.
that soon to say the least
it doesnt even replace 2D static artwork
let alone 3D and especially animating
simply not comparable to animating in Maya, 3ds Max, Blender or in 2D animating as well
what kind of 2d static artwork?
kinda all kinds
anime art is at biggest risk tho imo
but even there
the thing with anime just like with comic art is that you can hide and thats what is actually something artists (including pros) do is to hide hands or other parts where someone might not be that sufficient or just spares the time by hiding those
you dont have to draw and paint full body with every part of it on the canvas
which comes in handy for people within AI art community that like to generate anime stuff
but yet, there are still major issues with AI art even in that sector
as someone who used to draw i dont hide hands if they come out deformed i just fix whatever deformity is on the pic by drawing on top of it
but there are those who hide em if the situation allows it ofc
i mean artists as well as people who use exclusively generative AI
yea if u generate and post a lot of images is better to hide them,its faster instead of spending like 30 mins per image
yeah
unless you can work on them by "hand"
Photoshop or whatever
most people in the community cant likely
which is part of the reason why i say 2D isnt and is hardly going to be replaced either at the current state
do you know if i works to draw some ketc to use as controlnet?
I noticed that when there are mountains, negating mountains with negative prompt doesn't work
that womans head tho




hey which file i have to dopwnload


Just want to say that I find it highly impressive that SD was able to spit out this image without inpainting or after the fact editing


Lol people coming here just to argue if it will replace animation
Nah, but it got to that topic after someone claimed that generative AI animating will become standard (in general animating?) In 6 months 😄
yes I was thinking that, like it only works in low gravity right? and also the perpendicular thing. But the thing is it wouldn't even work on not low gravity, so it doesn't matter how it is built. But it would make more sense perperdicular. https://youtu.be/1wJQ5UrAsIY?si=K48EnDK6mas1nCSV

Many ask in the comments: But isn't this Centrifugal force?
On centripetal motion:
(Google Definition: a force that acts on a body moving in a circular path and is directed toward the center around which the body is moving.)
By definition, all accelerations are due to a force. Yes? f=ma. So, for there to be a force, there must mathematical...
I mean if they put you on a giant wheel on earth, you will just drop, right?
Bah, it could work but it would be completely unsafe
go to a fair that has a gravitron ride. same principle
when it spins up it pins you to the wall
oh I see
He didn't say that
Standart for this tech. He is not saying it will replace all animation
Dunno, if thats the case then its different. Although i see someone else being the standard: Wonder Dynamics
That one is already going to be bridged with Autodesk Maya for example
I believe tho it wont be cheap to use

well you're on the inpaint tab, you should be on the sketch tab
managed to use IPA while maintaining AIT =]

also figured out how to make IPA's blend function more refined

Sure. But it's insane that you can even do this stuff considering where we were just 1-2 years ago.
While now you can already make short gifs on your home PC


Yeah that's pretty close to the sort of stuff I've been able to generate

I've switched over to a different ratio to avoid the bulky look (which works a bit)
still mech, i think you cant get a robot 🙂

@kind quartz https://imgur.com/vvJPXW6
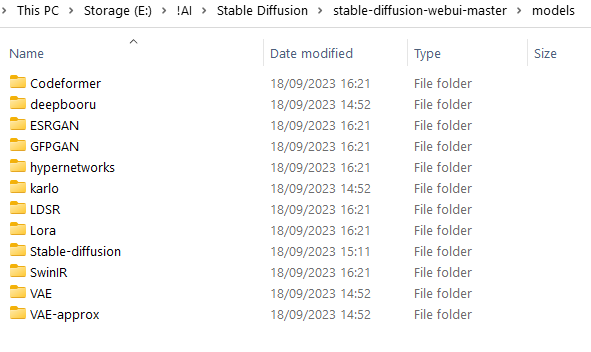
yes, Stable-diffusion, there should be models @fringe spindle

ckpt is model, suggesting you download file with safetensor extension, it is safer
Er... wut? lol
those are on civitai.com or huggingface
mmnt i will send you some link for 2.0 model.
Thank you

DreamShaper - V∞! Please check out my other base models , including SDXL ones! Check the version description below (bottom right) for more info and...
try this
Yes, which is why i said the tech is still fascinating
And also not everyone will want to play around with Blender and co.
So the specific niche of users will find a use definitelly in this one
@fringe spindle when dl, put it in folder models/stable diffusion. And choose it from dropdown menu in top left on first screen.
Thank you - going to do that now.
also check then what you have in VAE folder
Where is the VAE folder?
Hi all, I'm new to the discord, but have been putting hundreds of hours into building LORAs, and exploring machine learning. Love what I've seen here, and I want to start sharing too.


@kind quartz Found the VAE folder - it's empty

where are models
hm you will have to find most probably 1,5 VAE
Try generate something
I re-did the cat looking at mouse image usinf the model you suggested - it's much better

if you have good gpu, try 24 or 30 steps, if you have weaker put sampling method to EulerA

it is 8 or 6GB?
Does this help answer that?

it looks o.k.
What should go into VAE?
vae file, but it looks it is working without it. May be baked in model, but it wasnt written on model.
If you realy need put something in it, try ask in tech support, i dont know where it is.
OK, Thank you for all your help - I really appreciate it!
np, @fringe spindle have to go sleep now 😄 good night!
G'nite!
What is deepbooru
Dreamshaper has baked in vae
I'm very new at this. I've just installed SD today. Do I need A1111, and if so, why?
A1111 is the webui you use to create images.
It uses Stable Diffusion
When would one use A1111 in preference to SD?
Also, what do "headLeaf" and "arstation" do?

SD is the core mechanic to generate images. A1111, comfyui, invokeai, are webuis (tools) to use the SD mechanic.
Artstation is a tag used to get images that are likely similar to the ones on the artstation site.
Headleaf no clue
Thank you. But I'm still not clear on when I would use a webui as opposed to SD itself?
SD don't have a user interface. Its a Programm running purely as python scripts.
The webuis are user friendly Programms we use to generate images. In the background still works SD
Your using SD by using a webui
Understood. Which webui would it be that I'm using? (Sorry for being so ignorant). I'm using what popped up as a browser window during the SD install process.
Automatic1111 (aka A1111)
Thanks.

Is there any form of lexicon of what SD can understand in prompts? I'm thinking that I might use a term familiar to me but which means nothing to SD?
In A1111 go to img2img and interrogate a image, it should make you txt files with styles, artists and most common words or similar.
I think SD knows very much "words".
Can anyone recognize model used for this? It's used in Tokio Lo-Fi Healing YT channel

@kind quartz Thank you - that was interesting. This was the image I used:

CLIP returned this:
a train is traveling over a bridge in the mountains and hills of scotland, with steam pouring out of the top, Andrew Henderson, award-winning photograph, a storybook illustration, magical realism
Deepbooru returned this:
building, field, forest, grass, ground vehicle, nature, no humans, outdoors, road, scenery, tree
CLIP sounds better, I think?
I have to wonder though - how did CLIP know it's Scotland? To me it looks like it could be any hilly or mountainous part of the world.
@fringe spindle you should have generated 3 text files, somewhere in A1111 folder, with what i say before.
The text I copied above appeared in a prompt box in the img2img window. I believe I'm using A1111 but only because someone told me that I was - I haven't seen anything that actually says so. I don't see any A1111 folder anywhere here. This is the folder structure I have:

no i mean text files that should be generated using clip, check interrogate folder
should be 3 files flavor something, authors and styles or medium.
Yes, I have the following, which look like they contain the lexicon I was wanting before - but don't seem related to the specific image I was interrogating?

i think just small fraction 😄 but yes, can be inspiration.
it is not, it is generated when you interrogate any image.
Oh I see. If I interrogate more images, will I get more content in "Interrogate"?
no, thats the point 🙂
Er, sorry -- what is the point?
it is generated just once, sorry my english is very bad, never had it in school, too old, so sorry if i am confusing. Thing is interrogate how many pictures, those files will remine same
Thank you (and your English is very good - it's my inexperience that is the problem!).
So, is there no way of getting more of that content?
you can check authors with pictures or tags used. On some pages.
OK. Thank your for your patience 🙂
A comparison of all 1,833 artists in Stable Diffusion. Each artist is tagged and 4 generated images per artist are shown.

proxima centauri b on Notion
prompt 1-3: “a portrait of a character in a scenic environment by [artist]”
prompt 4-6: “a building in a stunning landscape by [artist]”
work in progress (ノ*・ω・)ノ*. ☆゚ @proximasan @EErratica @KyrickYoung @sureailabs
For information about this project see: About: Image Synthesis Studies Database 🦜
Navigation:
- use Ctrl+Shift+L/ Command+Shift+L...
@fringe spindle happy to help 🙂
Maybe thats done with the flat2danimerge model


I am trying to get an art style I made in MidJurney in SD. is there ANY way to figure that out? Any help would be great.
train a lora
Yeah I was thinking that... just it comes out as horror when I tried. I maybe need a better Lora method.
or you can try interrogate image to get some idea, can give you combination of artist and so @sterile ether
interrogate as in what?
lost me on that one.
in img2img, clip interrogation. Upload image here in A1111 and click on it, it gives you description of image. Probably i wasnt understand well.
Ohhhh
@fossil kayak hello. Please can you share how you come up with this prompt?

I was looking for the "Tiling" checkbox (and others). Has it been removed from the main window? I see it's in Settings, but I'd prefer it to be in the main window, for easier "as and when" access. Is there something I can do to get to appear like in this screenshot:

My SD window looks like this:


if you have it in settings, try turn it on in quicksettings. It should appear on first page on top.
Er... quicksettings? I don't see that...
in settings show all, i probably misspeled name of it, mmnt, going to run A1111 it starts with quick, so search in all settings for quick
yes it is called quicksettings, search for it 🙂

I must be looking in the wrong place - I'm in the Settings tab's window, but I don't see a search box?
show all. and then ctrl+f quicksettings should get here in screen i posted
only not sure if tile is there
it seems it isnt there
OK, found it - I'm sure I looked there before... but anyway 🙂
supposed when you find it in settings, it should be here 😦
OK, so I have quicksettngs now... what do I do?
it isnt there. It is total fail to remove it and keep in settings only.
I have not find it there. There are only tile for resizers...
Er... but I found "tiling" in quicksettings... or have I got the wrong thing?

You have right, i couldnt find it by typing 🙂
I have another question, please, about NG deepnegative?
NG deepnegative? I dont know what is it
It's an embedding, supposed to help prevent malformed images
aha, and what you need then? How to use it?
You put "NG DeepNegative" in the negative prompt box, and it should prevent many malformations, bad anatomy, hands with 6 fingers, etc. It's on CivitAI.
i checked it now. And what help you need. I think there isnt universal solution to solve all bad anatomies
No, not universal, but they say it should help - it's been trained of bad anatomy, so putting it in nagative prompt basically says," Avoid these".
The file is called "ng_deepnegative_v1_75t.pt", and I've seen it referred to in other AI image generators, but only as "NG DeepNegative" - not the whole filename. So I was wondering, is it sufficient to use only "NG DeepNegative", or must I use "ng_deepnegative_v1_75t"?

ng_deepnegative_v1_75t
on page where you downloaded it, there is on right trigger words which should be you as well mentioned
Add different flowers and make her in princess style
Ah thanks, I missed that 🙂
It's in uppercase there, but if you click the copy icon, it's puts a lowercase version on your clipboard - I suppose it doesn't matter? But, it seems you need the whole file name ("ng_deepnegative_v1_75t")
Thanks 🙂
no problem, hope it all works well for you!
👍

You ever had a prompt be misread but in a cool way?

what's uh.... going on here?

Nothing in my prompt asked for the dnd style thing
Masterpiece, best quality, a large but old man, Darth Purgatus Dark Lord of The Sith, fantasy, Star Wars, detailed Sith yellow eyes, detailed red skin, villain, Sith Pureblood, short white hair, wearing detailed full cybernetic armour, sci-fi, wearing an eyepatch,
Negatives: Vader, Maul, wings, shield, horse, riding an animal, weapons, ((exposed skin, Big Breasts, Big Breasts, NSFW, lewd, risque, nude, sexual, skimpy clothes,)) hat, laser, lightsaber, lowres, bad anatomy, bad hands, bad faces, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, bad eyes, ugly eyes, dead eyes, blur, helmet, username, monochrome, face, showing face, gold, double, two characters,

I'm going to cry... I've had 20 regenerations, this is the best but it has 3 legs (spoiler because of suggestive tone)



I don't know

hello everyone, sorry to bother, just want to ask for your advice..
i really want to copy the lighting of this photo because the beauty of the skin really stands out but i can't get it
i have tried = softbox lighting, overcast, outdoor lighting, frontal light, front light, dawn, neutral light, natural light, early morning,
but the light still appears to be coming from left side, but i can see a little improvement in "overcast"

just make stuff like this instead

can you tell me what prompt for lighting did you use?
oh I don't use prompts anymore. sorry
ok, thank you
in all seriousness, I really don't know how to achieve what you're trying to do or I'd tell you
I can't believe how clean these all are
yeah, first time i saw something like this on youtube, i really thought that, it was a real girl and i was like "what a goddess"
I just make weird stuff so not sure how to make regular stuff
what do top p, nucleus, and top k do in this context?

has anyone trained using BLIP2 AND/OR WD14 captions without editing them? I wonder how the results were


These are slightly oldschool looking but they are part of a recent project!! This is actually an incredibly quiet and chill discord isn't it!! it makes sense that is !! 🙂 🙂 So i will try not to post too many, but i have found many different shapes that it is good at making!!


ok!! i will find a new project for next time but i had forgotten about these!! I think what's interesting about Stable is that, most of these would take many months to make in a CGI program and, i know i personally couldn't yet have visualized these types of scenes. But now that i have seen them who knows!! That is a sometimes overlooked good aspect of art visual light synths!! (which ai art programs are, they make light shapes like a synth keyboard or computer makes sound shapes!! and they correspond to emotional shapes in their infinitude!!)



Hey you, make sure to use a highres resolution than 512x300 for example 512x768
Also use some negative tags like mutated, multiple limbs, blurry, lowres,
It's an image for a bot on SillyTavern, it's a test more than anything
Ahh okay
hey rid of all the negatives. Inpaint, maybe using controlnet especially if you had some idea where you wanted his hand to be.
Idk how to :(
I assume you know how to get rid of the negatives. That might already fix your image.
For controlnet, easiest way is to probably download someone's controlnet template. You got manager? You know how to install extensions?


Noob question, please. I'm a new user. I have a few models (absolutereality, cyberrealistic, dreamshaper, juggernautXL, rpg). I've read good things about SDXL - what can it do that the others don't? Or, when would I use SDXL in preference to any of the others?
it is trained on higher resolution. So with no SDXL your generate at size 512x512 or 768x768, while with SDXL it is trained on 1024x1024 and other 1Mpx resolutions.
Thats just one thing
Thanks @kind quartz
If you have gpu powerful enough, sdxl is superior.
What happens if I close the SD browser window, and the cmd window? How do I run it again?
I've been too afraid to turn my PC off!
Should be run browser and then (cmd window) <- run webui-user.bat

im not able to get stable diffusion to do anything. currently im trying to get img to img to do anything but it doesnt work.

after i click generate nothing happens but it claims to be complete
any help would be greatly appreated
but most of the newer 1.5 models are trained on 1024x1024 images...
and SDXL takes way longer to generate a 1024x1024 than SD1.5 does... so I wonder what the actual benefit is... if there's something inherently better about the architecture.
I still get better results from 1.5 mixes, but maybe in the future when SDXL has better models, that'll change.
there are different advantages as well. You can go way higher and generate full hd wallpaper or even more.
is the benefit just about pixels? I make 2048x2048 on 1.5, but generally I prefer not to. So in that case I have no use for SDXL?

yuou can make 2048 images withn 1.5, but it's thinking about them like they're 512 images and just filling in the details with it's 512x attention span.
SDXL has more parameters to understand prompting context better, plus a 1024x base attention. More fine grain details since the model has a higher native attention.
https://arxiv.org/pdf/2307.01952.pdf here's the technical report on it. It goes over a lot of the changes and what the goals are
https://www.youtube.com/watch?v=qgLme4eHJvk&lc=Ugw5-6-l3QVpqsFS3z54AaABAg.9umjm6A4ygh9uzsIQpWlve this is in Thailand I think. Great to use as controlnet

Go Out Working In The Rain Unclogged Flooded Street For Safety Driving .
I make this video I hope that joins in doing good deeds for society.
Jion us on facebook link below
https://web.facebook.com/1m2023/videos
making Vergil, might make the lawnchair meme and try the white monster one


from where are those almost perfect numbers from? CN model?

Qr module
It's controlnet I think
Haven't used it yet, it's cool
it is for old sd now only
Thank you

it even generated names for car 🙂

hello! I am new in this discord, can anyone help me with this new version of AU1111? thanks in advance!

I tried to update it by editing the code with
git pull
and turns out it just says error 1 and does not do anything after I type any key
ask in #🤝|tech-support with reference to this picture.
thank you, sorry for interrupting!
not problem at all @open parcel
Sorry for my ignorance but what tools offers that node interface?
Oh I used the original one
with something called https://github.com/WASasquatch/was-node-suite-comfyui

GitHub
An extensive node suite for ComfyUI with over 190 new nodes - GitHub - WASasquatch/was-node-suite-comfyui: An extensive node suite for ComfyUI with over 190 new nodes
thanks
Mondrian images are fun to play with CN


hello guys
i need help finding R-ESRGAN-4x+ upscaler, where can i get it? i searched everywhere
That's one of the standard official models:
https://upscale.wiki/wiki/Official_Research_Models#ESRGAN_Arch
@nocturne oak they are moving slowly to different place.
https://openmodeldb.info/
But you are right. They seems to be stay on both places

OpenModelDB
OpenModelDB is a community driven database of AI Upscaling models. We aim to provide a better way to find and compare models than existing sources.
was really hard to hide him at least on this level, still very easy...

Hello, can anyone make Medieval version of this image?
Will be much appreciated

anyone know anything about animatediff

it only does these
idk why


when i disconnect the animatediff model injector it just makes normal images
Anyone have any ideas on how I can prompt SD for blog article photos?
adding "blog article photo" is surprisingly not bad, but I need a prompt more solid/scalable
what qualities does a blog article foto have
No text or humans since those are distored
Just something that can accurately describe the blog title I suppose
probably 10 steps and gif can be issue? Gif has limited color, hasnt? Try different format if same @wispy nest
i did try other samplers and steps, doesnt work
i gave up on it
other people have the same bug without solution
or apparent cause
i mean gif, try png if you can
o.k. didnt knows that
your model has baked vae, you dont need load vae imho.
Can you share this workflow?


sd-webui-discord Support setting with ui, multi image gen, retry and delete image, multi ControlNet now! This is a opensource bot !



GitHub
SD-WEBUI-DISCORD is a Discord bot developed in Go language for stable-diffusion-webui. It utilizes the sd-webui-go to invoke the sd-webui API and supports cluster deployment of multiple sd-webui no...
any idea how to fix this part?

I'd like to carefully inspect the full image for research purposes in my DM
And to know what's wrong 
i want to understand outpaint workflow. currently i do this very ugly way
1/ i got my original picture

2/ i want to outpaint on the left, so i copy/paste it in Paint in a large empty area, and i screenshot a new picture with a empty space that i want to outpaint

3/ Finally, i put this new img into a1111/i2i/inpaint and mask the white area and prompt

but is there any better workflow ? 1/ it is annoying 2/ i doubt about quality, i mean, i just do a screenshot from paint
there is openoutpaint for A1111. I like it is very creative, but not sure if for your purposes. If you want try it, then in webui user bat add --api in commandargs line.


looks smooth asf
though there's certain issue always there.. like in second image his right foot glitch
Yes interpolation is made with Rife, not perfect yet
did you fixed this? I'd try another sampler and scheduler, some combinantions produce garbage
dpm 2M, 3M with Karras works good
also eulers
A lot of tbh
For fun its usable tho
i'll reinstall it and try later, thanks for the tip
nope

it's vaaled
oh it seems to work with the base model
just not with any fine tune





old yard 😦



What ai model is that generates images like that
it is model for sd for controlnet, called qrmonster, it is on huggingface
it isnt classical AI model, working with any 1.5 ai models, not with sdxl now
Link to huggingface?
oh, i would have to search it as well. huggingface qrmonster. thats all

should be 723MB file + yaml
What about one of the model pages?
?
Sorry my english i very weak
you will have to install controlnet, and model any 1,5 you can search on civitai.com, seems bit more readable.
This is one of them https://huggingface.co/spaces/AP123/IllusionDiffusion

no, i am using jugernaut final
i think this isnt 1.5 model. Illusion diffusion i dont know what it is
Oh
I'm get this error, any idea what I should do? Whats "ModelPatcher"

Can i somehow save all saved images with the seed for each pic?
If you throw the images in the PNG info tab you'll see the seed
They are automatically saved with all generation info
Most of the information
Only as pngs?
 maybe idk if they have to be PNG to have info
maybe idk if they have to be PNG to have info
I'm noob
FAQ: I’m missing credits/having issues processing payments. What do I do?
If your account balance is incorrectly showing 0, please wait 2-3 minutes to see if the system auto-corrects. If not, please confirm with your bank to ensure the transaction completed successfully & then fill out a request using the following form on DreamStudio so the team can investigate it further: https://beta.dreamstudio.ai/support
i think it is A1111 working only.

@wispy nest or simply give seed number to name of image in A1111. Not sure how in Comfui, probably similar

Hey can someone recommend a good laptop that will run stable diffusion smoothly and fast enough?
Budget is 1k
Honestly, any "gaming" laptop in that price range should be 'good enough' for your purposes.
You would need a Laptop with at least a nvidia 2060 rtx graphics card @timid yew
how would i make images like these. What is the process?


controlnet, 1.5 model, and QRMonster model for CN. And A1111
thank you so much.
also does it work with words too? i saw some images of dogs that made a word if you squint.
yes but you have to made those words
ok thank you for your help!👍



Most time I've spent on a single thing in a while. Took forever to upscale, too 😦

How did you generate that? Is that img2img with a given text and a small noise?
it is with high denoiser. Premade manualy TEXT and in SD controlnet in A1111 used qrMonster modul from hugging face. There soon will be similar i hope for SDXL
Ohhh, cool!







@wispy nest can you read it? I always move with something crucial and cant get back...


what a large shaft thing on top. Glass ball probably?

I asked him for a magician's staff with an orb at the top, he went a little overboard xD

i cannot  maybe im just dumb
maybe im just dumb
it is not letters but numbers 🙂 same as in bottom one @wispy nest
oh lmao then yes
🙂
im trying to figure out how to make it more visible with xl because .5 seems too faint and the entire image gets messed up at even .51
maybe should use this instead of the other

i got too much numbers and always forgot some get back and i am stuck.
Strength used to be about 0,7 in rare cases up to 1 in old SD
there is one value 0-2 set to 1, which is best, probably this strength.
yeah i put strength to 2 and it was just noise, seems like 1 looks like noise too





https://imgur.com/QwoPSJO motion modules have really invigorated sd1.5. this is cyberrealism and i got open pose on a few key frames pulled from a dancing gif

same prompt new gen

i love this shader style ❤️
objects in mirror are closer than they appear



我在『#原神園遊會』幫可莉裝飾了漂亮的蛋糕,快來一起品嚐吧!參與園遊會,還可以獲得原石等獎勵!
/icecream images
#🏞|general-with-images give me high quality mango ice cream images
@fringe shell but it is not much top down as well worthless...

worth less rather than worthless 😀 what ckpt are you using?
Jugernautfinal. safetensor
you can play in img2img to get some new fresh original idea. 🙂 Second image is original rendered. And first image is based on it, just it should look like bedroom in 18th century. I think same things can be done for exterior, been image guided <- if proper word. You need controlnet and some models, canny, depth, MLSD and as well probably QRmonster, which can boost imaginery very @fringe shell


@fringe shell there are first two your prompts if it is what you are looking for?


I'm so impressed with your work bro.. really great. I'm trying to catch up to your skills but, I'm stuck on the first steps. with my version of SD only producing static or grey squares. any suggestion on where to search for the problem. I get no errors on the terminal
oh i dont know. Try post errors in #🤝|tech-support
my skills are basically 0. If you mean animation, non static images it is not me 🙂 if hidden images, i played with it curently
@undone kite picture you are refering to is isometric livingroom i believe original one. Luck and time is needed.
I need some advise, Im trying to create an image with ONE hallway in the center but all the time im getting thid:


suguestions?
center, symmetrical?
I just added that in the last one
my promt: one centered symmetric straight long hallway with neon blue volumetric lights, aesthetic, mysterious, videogame, modern, neon, minimalist, liminal, backrooms, empty panels
Negative prompt: people, persons, silhouettes, multiple hallways
Steps: 78, Sampler: DPM++ SDE, CFG scale: 23, Seed: 4119121761, Size: 1024x576, Model hash: 6ce0161689, Model: v1-5-pruned-emaonly, Version: v1.6.0

I want something like that
a tunnel with neon lights, runway, purple and blue neon, violet and aqua neon lights, neon ambience
guys i just installed stable diffusion today but its only generate this blank picture what should i do?

can you post whole screen? of A1111?
What is your gpu, any error in cli? That black icon most right on bottom
@torpid rampart how about neonpunk theme or neon noir theme?
tunel is good idea
I will add this
here btw i have a 1660ti gpu and i didnt have any errors

and can you show what you have in Webui-user.bat? specialy in commandlineargs

luffy sounds like a lora and not a checkpoint
i have no idea how this thing work i just installed it an hour ago lmao

checkpoint is the main file you use to make images, and a lora is like a style or character you can apply to get a particular look
yes dl SD checkpoint and put it in models/stable diffusion folder
well y'know its was the model's name i downloaded from civitai but whatever i generate it give me a blank picture
can you help me?
download for example non XL version of model called dreamshaper, on civitai.com. Make sure it is labeled checkpoint and size above or equal to 1,99GB
i realized i have instead of neon origami 😄



DreamShaper - V∞! Please check out my other base models , including SDXL ones! Check the version description below (bottom right) for more info and...
if model 1.5 then o.k.
yeah its s.d 1.5
so yes
This model is very well known, I have used it forever
btw i have 1660ti gpu is that good ?
i think you will be able, but not suggesting you SDXL therefore. Should work
Enough for 1.5 models yeah
ok thanks
You will need to use the --medvram or --lowvram arguments
An example of what i did, i have a 2070 Super (8 GB Vram)
set COMMANDLINE_ARGS=--medvram --xformers --api --port 7861 --always-batch-cond-uncond --ckpt-dir "D:\SD\MODELS"
@sterile kiln and if you put model in original folder, does it sees it or only in path you specify?
this is closer @torpid rampart but not much 😦

I did not try
o.k. np
thankssss
it wasnt for you 🙂 @torpid rampart
yes classic me 🙂
anyway im aslo istalling some models xd
installing*
Is possible to make small gifs/videos with automatic 111 UI?
A1111 is dotted with extensions, some of which allow it. But be careful, this is the kind of thing that can require a lot of GPU performance
Hahaha my laptop can get toasted?
It can end in a CUDA crash or be very, very long
or out of memory as well
I have 16Ram memory (15 avaibable) and Nvidia GForce Rtx 3060 plus intel core 9
u think it will survive?
Literally I need to make something like a like an still images with a little movment
It's the Vram that counts, your ram will only be used a little
Also im seeing that there is checkpoint and checkpoint XL
Can I put anyway Checkpoint xl models in stable diffusion folder? Or needs to be another folder
There are 3 types of models. Those based on 1.5, those based on 2 and 2.1. Then SDXL
Extensions do not work on all models.
1.5 is less demanding, but is the one with the most extension, and which allows the most for those who have little Vram, but SDXL has fabulous results, but requires much more Vram, therefore takes longer.
I advise you to avoid 2.x
yes
ok
thanks that dreamshaper thing worked do you know have any method i can make it faster to generate?
How many Vram on your 3060?
its a 6gb 1660ti
Oh, i melted you guys x)
I thought some people were saying they could use SDXL with this card
less steps, hurts quality, medvram instead of lowvram, xformers you have, Sampler EulerA or try uniPC could work on lower steps 🙂
thanks
how many steps is enough?
and resolution 512x768 or other way round or 512x512 or 768x768 no higher
not enough steps, but let say for your HW 20-32?
xd
btw what is CFG scale?
cfg scale is how it follow your prompt and using ai creativity.
suggested say 5-15, play with it to see.
ok
The CFG Scale is the strength with which SD will listen to your prompt, the more CFG scale there is, the closer it will be to your prompt, with potentially more quality, but if you use too much, SD loses its creativity, and it often becomes very ugly. Personally I play between 7 and 12
ah Bernix was faster x)
then i will let it be on 7
actually yours was longer and more detailed....
10 is often the happy medium
hehehehe
now me
How do I install an extension

GitHub
Official implementation of AnimateDiff. Contribute to guoyww/AnimateDiff development by creating an account on GitHub.
in extension tab.
I downloaded it and put it on the extension folder
yeah yeah
and I have an error
is it possible to generate more than one pic at once?

@sterile kiln i saw you type, so i didnt write. Then i dont see you typing so i wrote it, but you for sure write it more precisely
of course. and greatly better
but how?
just spam the generate button?
not for your hw i think, you should render more in series, not in parallel
mmmmmm
okay....
but this link is for animateddiff?
To simply generate multiples ones with the same prompt, just use Batch count
oh
Nope, its the list of extensions
Oh, srorry, you're right
Not use batch size! @astral patrol
ok
just batch count
you just have to click on load from, most extensions are listed there, but there may be some that are not listed
what smapling method is good?
Euler A, DPM++ Karras, DDIM, UniPC
ControlNet with models
Stable.Art (Photoshop plugin with A1111 implementation)
MultiDiffusion (use Tiled VAE Fonction can save lot of Vram)
Posex

Here's what you can do to better understand your models
In one go, A1111 generates everything and does the fresco himself
(X/Y/Z plot)
not really a portrait person xd
It is not the content that is interesting, but the methodology.
How to get what you want most easily
Do a X/Y/Z grid can help you to know if your Ckpt model, or LoRA model support more or less of CFG or else

how much vram do you use ?
8
If you have CUDA crashes or out of memory, you can use the Tiled VAE I talked about above to exceed your max Vram, but the generation will take longer. Use only if you have crashes.
And first you probably need to put --medvram or even --lowvram. Otherwise your tests will be biased
what if it use all the vram?
--medvram is must for you
I think too, he should use --medvram
Once you have found the prompt, the CFG scale and the ideal seed, you keep the previous seed by clicking on the recycle button, then you use the HighresFix to generate the same thing bigger.
This is how with low resolutions, we can achieve very beautiful results in very high resolution
(an old one with 1.5 based model)

4128x4128
i would prefer resizing in extratab. I have always issues in hires, i must missed something crucial 😄
for example latent isnt lossless, other needs plenty of VRAM. But probably only my problems.
Resize in Extra tab is upscaling, HighresFix is Img2img + upscaling, a complete difference. HighresFix will add details, create another one, upscale don't
i know
but it will not create exact same image? I will test it again iam in A1111
what method do you suggest @sterile kiln latent?
4x-UltraSharp or ESRGAN4x
is there a way to save the prompt when i launch the webui?
Depend on what Denoising Str you set, lower is Desnoise, closer from the original image it will be
o.k.
png info, keep pictures in png and you keep prompts that it was created it with, or you can use style save it in first page @astral patrol
yes denoise i know very played with it last few days 🙂
Or you can simply drag&drop an precedent generated image in prompt field, and then clic on blue arrow, it will apply your settings of the image
have to do it on a clean tab
i used that --medvram and this happened wtf

can you show your webui-user.bat?
and copy paste error on https://pastebin.com/ and share link here, better to read
i used that --disable-nan-check and got fixed
hm, this is bad solution. Ask in tech support.
Have you put that --medvram in commandlinearg =
got fixed by itself lmao btw its it possible to use multiple loras at the same time?
It just hide error messages, not solve them. So it should work before as well
Its possible,
but be sure to use LoRA compatible with your ckpt models. If you have LoRA 1.5, don't use SDXL models and vice versa.
This generally happens when you keep the same prompt by just changing the ckpt.
Because A1111 does not allow loading LoRA incompatible with its current ckpt (the graphical interface)
nah i deleted that --disable-nan-check from the bat because my generates got black then i run the webui again and it got fixed somehow
i think i got lucky
maybe
AAHH I dont know what I did
and now im having an error
in CMD
So web UI is not opening
can you post what do you have in webui-user.bat?
where is that? Like in CMD?
in root of stable diffusion, the file you double click to run SD
and copy paste error on https://pastebin.com/ and share link here, better to read
To do it, select all text of cmd by a right clic, (not ctrl+c, Ctrl+c is kick process in a terminal)
sorry i am bit slow 😄

Another great Grid

but idk what does that mean
Same answer, just use pastebin, as i said before
me too, probably some extension you installed?
Yeah for sure thats the problem becaus eit was working before
but I took all of them out of the extension folder
it is not cleanes way. How about cmd?
Pastebin
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.
I took all the extensions out and still nothing
show what you have in webui-user.bat 🙂
or you will have to reinstall probably. Delete VENV folder and run webui-user.bat -> it will install again

How long have you installed A1111?
ok
and I was just testing extensions and this happend
What extension did you installed?

where is VENV folder I dont see it?
Stable Diffusion\stable-diffusion-webui\venv
all seems to be related to video = demanding
in root. It is folder, but ask in #🤝|tech-support if good idea?
You should remove suspicious extensions you installed recently. You can just remove folders

I delete everything of the folder
don't
there is some default extensions
of extensions I mean
and do you installed it with git or with zip file?
I just move it to other folder outside in my desktop
zip
automatic installation
hm i thought so, do it again, and with git
well
zip is BAD way
ok
go with a1111 installation for windows nvidia if you have those
I did this one

Is the zip one you mean right?
and you are saying to do it this way right --->

yes i think so. Use method with git. It has many advantages and less troubles.
ok
and to unistall completley is only deleting the folder?
oki thankkkks for all the help guys
Hello everyone. I'm having an issue of my results fading when I do the run. May I post for help here?
send one of these images here
Starts with left image and after a few frames becomes realistic again


starts with left and then fades to realistic after a few frames


No, send the result image, i need EXIF data
not a screenshot
File Name : POS New Lora 2(0)_000074.png
Directory : /Users/jacksondoran/Downloads
File Size : 771 kB
File Modification Date/Time : 2023:09:28 11:08:20-05:00
File Access Date/Time : 2023:09:28 11:11:36-05:00
File Inode Change Date/Time : 2023:09:28 11:11:34-05:00
File Permissions : -rw-r--r--
File Type : PNG
File Type Extension : png
MIME Type : image/png
Image Width : 1280
Image Height : 704
Bit Depth : 8
Color Type : RGB
Compression : Deflate/Inflate
Filter : Adaptive
Interlace : Noninterlaced
Image Size : 1280x704
Megapixels : 0.901
I feel like this is not what you're looking for. Sorry very new to this
just send the image here

I copy the png in here and it comes as screenshot
Go in stable-diffusion-webui\outputs\txt2img-images, and drag&drop your image
Hi, i have a question. My teeth looks sometimes like this, way to often in my opinion... Is there a fix for this? in the prompt, or negative promt, or after detailer? Something like bad-hands-5 for example..? Any solution?

I've been experimenting to improve AI-upscaling with sd.
FreeU helps a lot to add fine details:
Left: original 128x128;
middle: ESRGAN NMKD 8x upscale model;
Right: Details added with stable diffusion.

workflow and test pic:


i made cursed while i was trying to get something something roblox

what beautiful eyes! 😄
gordon freeman be like in HL3

haha
two goblin fighting

ok that is amazing

ok this one have made a m16 pretty good

ok a last one i dont want to spam


just merged my first model, what yall think

😍
is the stable diffusion bot entirely free?
I made a mistake.
I meant to generate 150. I think I generated 1500. This has taken 7 days thus far.
Also, yes it is
both local and online
Local is much harder to set up, but is definitely far more superior in the fact you can change model
Turns out, nope! It's just a beefy model. Furrydiffusion.
 what are you even doing
what are you even doing.png.webp){kind=link}
why is it stuck like this?

i finished first round on training and would like to continue with second round
but it stucks on waiting...
well i used local and it did not like that lmao
Your computer might not be able to handle local


it's a beefy pc so im sure it's not that
can someone suggest me something that will target and remove the text like thing appears on the top right without modifying anything else in the image?
Mix something cute and something fun and throw in some puppies; what can go wrong?

The prompt was: "retro circus poster showing a baby clown and a small puppy dog standing in a colorful candy landscape, wearing clown outfit and knee-socks, a circus tent in the background"
Model; "Stable-diffusion-xl-base-1.0"
i followed the auto1111 steps
what was it you didn't like?
the images had fucked up colors