#🏞|general-with-images
1 messages · Page 102 of 1
this shit come out good

The analog filter creates a disconcerting effect, its like uncanny valley.



the imperfection helps make it more convincing
Disconcerting in a good way i like the weird effect the analog filter has.
photographic style vs analog film style


good filmgrain
waltuh




pretty decent guitar
yea its pretty good! only about 1 generation behind midjourney i would say.

For comparison here is midjouney

SDXL can draw clean lines when it wants to

wow looks like an autocad archviz drawing

Victorian house, garden, brick path, lush vegetation, detailed sketch, architectural drawing, reminiscent of Frank Lloyd Wright's style
I actually felt something when I saw them 😄 like genuinely impressed

Deep-fried is a new negative prompt for me. What is it weighting out of the images?
This is amazing!
the overcooked look you sometimes get. it's a style of meme, so a good prompt to add to the negative since there should be lots of examples in the training data (in theory)


not bad, but SDXL is nailing that style
still get some meh stuff from SDXL but occasionally you find something it does really really well
this is from a 1.5 model. not exactly a drawing, more of a render


pretty house
Yeah, but notice the chimney?
good for leaning on

Thank you! I always enjoy learning from you all! So much talent in here 💜🙏


I got another 20 similar prompts from chatgpt using Frank Lloyd Wright's name. So I will try them all out

that's the house we all know from him



kind of reminds me of a landscape artist style


like a silent film


that's better! 🙂
Well, this was a surprise

all of these are the same seed

not sure why it makes the paper funky
that was 25 steps vs 20 and this is 50 steps

interesting
even has their signature and the dude is a lefty.





well... annoyingly it's late just as I'm getting into this. have to get some sleep now 






sdxl looks derpy now

jesus what is with your hate boner for sdxl
theyre testing things out with the bot its obviously not representative of the final thing



which part is confusing to you lol
why do you hate it so much i dont get whats wrong with it
then it's the perfect model and i'm just a fool, and you can ignore me
of course the currently being tested base model isnt as perfect as the current super-finetuned previous model but you can clearly see that when released and finetuned in the same way it will be much better
you don't see any issues in that picture?
i do
that picture was shared by the project lead to hype people up
so?
ive seen plenty better made images with this
a less than ideal advertisement choice doesnt mean much
🙂 i guess that means it has no issues, see earlier comment about me being a fool
thats not what im saying at all can you read
you are so pissed at me for having an opinion, i get it
what?
what can i do for you?
i asked a question and explained my opinion and you started being a snarky prick about it
you started the aggression
aggression? no way, i'm confused by how someone couldn't see the issues lmao
but then you said you do see the issues
so... i'm still confused
its just that ive seen you talk about sdxl only negatively
as if youre expecting it to be perfect
i don't think you've been here long
ive been here long enough to see you complain about it several times
cool
of course its still going to have some of the problems of a base sd model
oh, it has pretty much all of them
yes
because its a base sd model
but when you compare to previous base sd models its much better
yep
let's just leave it at "i don't wish to get into it" and "they've asked for this feedback"
some of us remember 2.x 🙂

the model architecture of SDXL is disappointingly banal

lmfao whyyy
why what
that morgan freeman is cursed
a little but he looks more like him than other peoples names ive tried
its the eyes going opposite ways for me
well yeah theres that
though i imagine when inpaint becomes available thatll be easy to deal with
teeth are hard for diffusion
also ryan reynolds works pretty well

ill try morgan freeman with sdxl then
they dislike 1.5
i havent heard particularly good things about 2.1
and btw i love sdxl, i hate how easily solved issues are ignored because other less important stuff now passes tests
sdxl seems to do faces pretty easily, there arent usually glaring issues with things like eyes and mouths

oh i agree with this
i think i was misunderstanding how much you were actually complaining about it
sdxl has the same thing about faces as 2.x and 1.5 actually
oh
portraits are amaaaazing
i havent had it show up nearly as frequently
but faces at a distance = gore
it was its own decision to give him the hat
it knows the man needs it
lmao
of course
interesting
a human artist drawing a tiny face in the background would struggle too
not as obviously as ai but still
its because they used the old vae architecture from sd 2 and 1
man i wish i knew what the fuck a vae did
its like compression

like jpeg
i thought vaes were like post-processing
they are
honestly i dont know much about what goes into making ai im really just a consumer, my only knowledge of vaes is that i put one on and my images stopped looking washed
they handle luminance and chroma and other graphics crap and fine details
the latent space goes through the vae to be decoded into rgb space
sorry just about backgrounds issues





vae is variational autoencoder and.it is trained by giving it an image and seeing how closely it can recreate it after encoding and decoding
the vae is lossy meaning it doesn't faithfully reproduce inputs
there are visible artifact patterns in the sdxl bot outputs because of the low precision of the vae. it is arguably the heaviest component of the model with respect to vram use, so keeping it small and shitty works well for most use cases while still running on consumer kit
all of the people wanting this to run on 8gb vram or less is why it is not better
im not even gonna try it on what i have now im just upgrading
ive been running sd on 6gb for ages
vae tiling can help but with dynamic thresholding it can.cause artifacts like brightness going all over the place for each tile.
so you see squares of brighter and darker sections of the image
so thats why sometimes two things in an image just seem like theyve been photoshopped in
they have weird mismatched lighting
thats possibly a text encoder issue
the text encoder captures relational semantics and the unet is trained on that embedding which the text encoder generates from the prompt. some overfitted concepts in the text encoder can make it difficult to have them appear in other contexts

and when the embeddings dont mesh well, you get that pasted on look. tuning the encoder before tuning the unet is essential
if the text encoder has a crappy representation of a prompt it is an uphill battle for the unet to learn correctly

openclip for sd2.x has human deformities baked into it. the hands it produces and limbs in general are poor quality. so the unet struggles to learn a coherent image of them
tuning openclip on its own to produce hands and.faces, and then popping that into stable diffusion 2.0 without further training, ends up fixing most of its issues
Guys, I need some help. What am I doing wrong? I've followed so many guides, but I can't get this working with the tile ControlNet model. It works fine with a QR code model for ControlNet downloaded from civitai, but it doesn't work at all with tile. I've tried reinstalling all my ControlNet models, but it didn't fix it. I am literally using the same settings as the guy sharing his workflow. And this is the fourth different guid I try to reproduce:


use one of those free websites that lets you make the QR codes, problem solved! i don't think anyone scans them anyway
i dont think the images even work as qr codes

btw @rigid heron 2.0 can be fine-tuned pretty easily and i don't know why that guy has a baby or who is standing behind him - some kind of AI cryptid, possibly - but it's not as bad as people made it out to be, even for faces-at-a-distance

pop that into hires fix and watch the magic unfold

Can someone explain why when I put a prompt from Lexica into my local SD, I get this creepy ass little demon with like 4 arms that was obviously drawn by a 12 year old. However if I put the same prompt into Lexica website, I get a really well done image. Am I missing some setting?

different model or embeddings
are you running the default model sd-1-5?
if so, thats the issue =p
Yea 1.4 I don't recall seeing a 1.5
Another example lol... Any recommended model/embeddings?

try Artius v2.1, Illuminati Diffusion, epiCRealism
depending on what you're looking for it's those three ranked from adventure to photorealism
oh right, Vodka v4 is really good and on pretty even footing with Illuminati, and could be equal to Artius but i'm so in love with that mix it's hard for me to put anything in its league
epicrealism doesn't really need negative prompts (but it benefits from them)
i like to do additional post processing in gimp like unsharp mask, vignette, sometimes oil painting and canvas noise,
with unsharp mask i do it in several passes, i do like .5 pixels and then 1.5, 4.5, 15, 45, 150
and with every effect i reduce the opacity and merge down onto the original when im sure the effect isnt too much
i dont actually paint in gimp, it doesn't feel good to me
throwback to early april when i was working on a project whose code was entirely written by GPT4 to see if it can do it. it used DALL-E2 for the images, Elevenlabs for the audio, GPT3.5 for the script generation, and then the whole project ties it all together via a MELT XML file it generates, which is rendered into the mp4 file. all in PHP. god i hate that language. i had to keep correcting GPT4 "we're not coding in python, we're doing this in PHP" because it's not its default
they've definitely updated DALLE-2 since then
yeah neural net software has kind of reached a critical level of acceptability with image editing
not there yet with music
OpenAI jukebox was really cool tho

All Star by Smash Mouth, BUT an AI Continues the Song [Artificial Intelligence] Jukebox
This is just a fun experiment. The music you are listening on this video it’s generated with OpenAI Jukebox.
0:00 Attempt 1
0:52 Attempt 2
1:45 Attempt 3
2:38 Attempt 4
3:31 Attempt 5
- What is OpenAI Jukebox?
A neural net that generates music, including r...
i unironically enjoy all of these attempts
i just wish the codec were something better than 22kHz
i think it uses EnCodec but i've not looked
sometimes it's even lower fidelity than that, like an 8kHz AM radio station
anything that doesn't even run FFT on the signal is going to be garbage
fast fourier transform?
yea
not really "in the know" on the lingo, sorry fam
you knew it tho
have you seen RVC? retrieval based voice ?
i havent
my colleagues are the math wizards, they ramble on, and on, and on, and i guess something got stuck in there, but i wouldn't say i know what it means lmaoooo
it means they take the wiggles of the soundwave and turn it into what your ear sends to your brain
all the frequencies or pitches are separated
well, my basic (flawed, likely) understanding of FTs is that they can find a function to fit a waveform?
yeah the waveform is a big mess, so your ear, or the FFT function, looks for any cyclical patterns it can find, at every possible frequency, or pitch
that's like me saying "the parameters in the unet are updated", i know that concept but not the exact math of how it works. someone, at some point, tried to teach me. and it's like talking to a brick wall, let me tell you
i dont know anything about the math either
well i know "looks for" likely means "a derivative/integral"
if you look at a piano keyboard, every key is a different discrete pitch, it's like an integer version of it
nope that doesn't work for me lmao
i had trouble understanding the whats & whys of calculus until my professor explained the process of finding the area under a curve using smaller and smaller boxes until we have an infinite number of them and i was like hoooooooo okay i like this
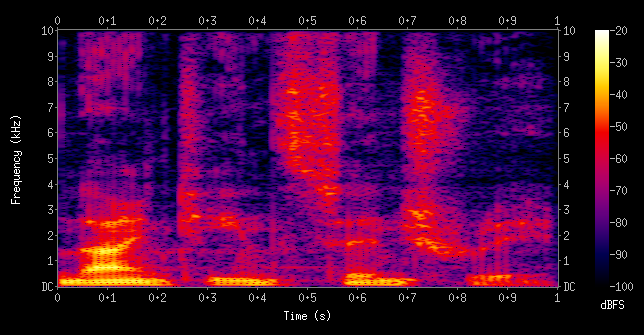
A spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time.
When applied to an audio signal, spectrograms are sometimes called sonographs, voiceprints, or voicegrams. When the data are represented in a 3D plot they may be called waterfall displays.
Spectrograms are used extensively in the fields o...
well i think that's how AudioLM is working, right?
or stable-audio-diffusion
can't remember which it's called but they trained it on text to image pairs that described audio waveforms

Jay explores an incredible visualization method used in speech recognition technology and in the analysis of animal communication. Spectrograms show which frequencies (high-pitch/low pitch) are active in a specific sound. They reveal a lot about the nature of sound, aid artificial intelligence, but more excitingly, inform us about the intelligen...
it's a really cool technique and i'm curious what the impact would be of training a model from scratch on audio waveforms vs fine-tuning stable-diffusion checkpoints
i am now curious if i can improve the audio generation capabilities by applying zero terminal SNR noise schedule to their models
the inference process of SD leaves behind some trash that we can ensure is gone about 90% of the time, which would mean the audio we hear is more precise
SDXL doesn't quite have this but instead would result in overly smooth outputs due to the "ideal denoiser" from k-diffusion
but the increased parameter count of SDXL... 
VAE replacement whennn
funny sometimes look back, probably 1.4?


that could honestly just be them testing SDXL at smaller resolutions
it's interestingly working VERY well if that's the case, kudos. not easy to do
you have to evenly display a number of image sizes to the model during training if you want to do that. you can't just give it different aspect ratios at one base resolution. you have to do that, with multiple base resolutions. i assume they used 256, 512, and 1024.
the 768 model for 2.0/2.1 end up heavily artifacted at 512 because it was trained exclusively on 768 for about 800k or more steps and the transformers inside the unet begin to expect to express details they commonly see at 768
i've trained the 768 model on 1024 images for 100k steps at a high batch size and it similarly loses the quality at 768x768
i'm tempted to do that style of multiple resolution bucket training, but i'm not ready to put that work into the training code
Holy shit, remember when it couldn't reach the same quality as an extremely fine-tuned 1.5 model? This is insane

Man, this is an insanely good model

I have no idea how they managed to implement 2 text encoders in a single safetensor, but this is awesome. I can't wait until it's released

they increased the dimensionality of the text embedding layer
i haven't looked to see whether it's concatenated or if it's stacked
I don't know what it is, but I gotta tell you, I was never able to make this level of detail with ANY AI model
probably easier to concatenate but that's speaking as a noob
It's just so seemles
the text embedding size is more about coherence and overall "knowledge" but you have to train the unet on that stuff or else it just shows up as confusion
one thing i'm curious about is how much the parameter size of the model increases the requirement for training data or if it's learning rates that get adjusted, or what
like their dataset emad was mentioning has 12 billion image in it and they've captioned it using, i believe BLIP2/a finetune of it, or something similar that leverages the dual embeddings
I have no idea, but I must say, SDXL is the greatest AI diffusion model I saw yet, and it's not even finished OR finetuned
i hope they replace VAE with something else before 1.0 but there's a fat chance of a major change like that
they might fine-tune multiple VAEs, which would be awesome
there's ways to fix its remaining issues but not much time
that said they plan on regular updates
so not just YOLO'ing a release like 1.5 and 2.1
can you elaborate for me what kind of details you're seeing in SDXL that you can't make in legacy models?

we're using it already on the bot and clipdrop though, that VAE isn't useful on 1.x or 2.x models
the size/architecture or advanced capabilities of the VAE itself hasn't changed, only its training schedule - it could be better simultaneously at photoreal and anime now, for instance. but there's issues with how it expresses patterns of noise still
It's not compatible, different architecture
it's literally the same architecture, comfy has said it, mcmonkey has said it, TwoDukes has said it

it's such a heavy (VRAM-wise) component that they're really not interested in increasing the size of the VAE or the tensor space it operates in
Really? I tried to use the SDXL VAE on A1111, it fucked up my UI
yeah it doesn't work and i don't know enough to explain why but i know it's the same VAE architecture
It can't be the same architecture, if it was, it would work=\
i'm telling you lol it is the same >:| unless SAI devs lie to me
But regardless, Automatic 1111 will be forced to update the webUI to support all SDXL stuff like ordinary models, so I don't give a fuck rn. I can wait, it will be so worth it for this model, this model is by far the best diffusion model
apparently if you retrain a vae from scratch on a different data distribution, it will be incompatible with the learned data in the older model
I have access to it, it doesn't work. It literally can't be the same
could have a different loss function it used during training, but i'm not sure how that would interact with the unet/text encoders.

Also, how the heck did they manage to implement 2 text encoders in the model?
the VAE is just a encoder/decoder @cyan snow it converts into a lower dimensional latent space and then back to a higher dimensional image representation
VAE is Variable Auto Encoder
i don't know where to begin explaining this one because i don't know how much of it you understand already
if you know how a single one is used to guide diffusion it's not that big of a leap to guess how two of them work, especially if they're concatenated. but they could be stacked and averaged etc too
it probably helps that they were both trained on 77 token captions and they can either be padded from left or right or both
Maybe, whatever vodoo magic SDXL is it's fucking amazing
text encoders are hard to train because you can't directly do inference from them, you have to build a unet as a backbone on top of the embeddings produced by the text encoder, and that doesn't / can't happen concurrently, you first train text encoder and then the unet
you can fine-tune the text encoder and try again but it's a great expense and by the time you discover you've been fighting a cursed text encoder quanta, it's a few hundred thousand dollars in
i've messed with reverting a unet to an earlier checkpoint, and using a more-tuned text encoder, which works very well. i assume at Stability's scale, this would work better, and be even easier
the "showdown" seems like such an apples vs. oranges comparison
yeah it's like the highest level of a weird tournament
it makes sense though once you see the charts they've produced from the data

[WARNING] Image path does not exist: /datasets/midjourney-c/fullbody_pose__dynamic_pose__perfect_blend_of_beefy_teyana_taylor_and_beefy_janet_jackson_as_perfect_goddess_sekhmet_the_goddess.png
midjourney users
god bless that image for being too small and getting deleted.

i know what's likely to replace those donuts once you do 
a jar!
a jar full of shiny apples with multi-dimensional fractals embedded within their essence
Yeah, I will make some crazy shit with that model


training SD 2.0 is so fuckin easy

2.1 is like getting punched in the face and asking for more
stellar at composition, really bad at denoising
And SDXL is a fucking legendary model
By FAR the best, it has so much potential, and SAI will make specialized fine-tuning tools
The unfinished and not finetuned version on clipdrop already CRUSHES everything else
yeah the base SDXL feels like Bing image gen and the refiner just blows away expectations
and i don't mean Bing in a bad way, that thing is really, really impressive
Bing's image generator isn't that close to XL
It is as good as 1.5 finetuned models
what are you talking about when you say "XL". it is two models, and you can run the base on its own, which is what we've seen tested in the bot channel vs the refiner before
i've been seeing mcmonkey's pictures he shows which he repeatedly says are just the base and it's like Bing image gen
The refiner should already be in one of the variations on release, the version with refiner should be a single safetensor
it's not a single safetensor file, at least i don't think it is, that doesn't matter much
it's an img2img model
They confirmed it to be 1 or 2 safetensors
What?
the refiner.
Isn't it like just more parameters in addition to the base?
It's something new, isn't it? I bet it's a new component, just like versions of 1.5 have VAE baked into them and some don't
it is its own model with just one text encoder and a vae, but you can reuse the vae among two models in like, ComfyUI
ComfyUI?
Huh, does it have all the extensions?
Like making game shaders and materials?
it has nodes and community members do write stuff for it but i'm not sure if they're called extensions or what
for example it has ultimate upscaler as of a couple days ago
If it has hires and CNET and Adetailer, I'm sold
bingo like the blueprints system in Unreal Engine
That's awesome, I'll try that when I'll return to my house in 2 weeks after SDXL is finally released
Also, there is a new A1111 extension that allows LLM integrated prompting
It can in fact get instructions
Oh shit, it does have hires fix =]
And Adetailer
And even prompt gen
Oh, it has the ability to fuse 2 images together, this is insane
it's got everything but i honestly can't answer generally whether "does it have extensions" covers your needs 😂
I might switch to it when I get back
well i hope you like it, it's probably the best tool for doing local inference at the moment
And I'm familiar with that kind of node interface, this seems to be just right for me
i don't mean in a "it's the best, period" way, i mean in a technical sense
so an interesting feature is that you can drag images from the examples page on the Github into the ComfyUI and it loads the workflow up
Idk, next time I will use the AI will be after SDXL releases. We'll see
So far I'm impressed with ComfyUI, I really like the node design, it will be much easier for me to work with
Thank you for introducing me to it =]






i can't wait to see what weird shit you do with it
you can load Kandinsky alongside your model and alternate steps of denoising between them
@sterile temple did something like that, i believe
@cyan snow trying kandinsky

might need to check on something in a sec to fix that
oh it's pretty good






it has an interesting take on the girl with the pearl earring

can't say i've seen that one before
@wispy nest kandinsky does your oil digital real thing
for such a simple model it's very impressive

a little toasty on certain stuff

I doubt anyone will make a fanart of Hu Tao
some more RDFX-PRO images










surprisingly coherent on human photoreal subjects in Kandinsky lmao what the hell

You know, I see why AI is taking over news reports when humans are still using shitty grammar like this:
"Much faster than by using"

What the don't mention is it has less params than 1.5, it can only do 256x256, and it's from Novel AI lol
And it's results also look pretty terrible lol

It is a cool little piece of tech, but once again, just click bait to try and make people click to see if there is something new better than SD
maybe it's trained on 10% of the hw
emad said something like that was coming and impressed him






i love the kodak commercial about saving moments in life where the little girl's flying toy like that goes straight into the fireplace
yesss lmfao

Also just wanted to share this snippet of a song, cause this has to be the single biggest and punchiest kick I have ever heard, and I am not sure how you get something to sound so massive while not being any louder than the rest of the song
(Loud and intense warning)
Like, I checked, and the kick is no louder than the rest of the song, its just that fucking saturated 😩
And now I am working on the new and extremely over engineered mounting system for my AC unit lol
Looks like I am taking a break from AI, which I can't believe I am saying lol

she just lets it happen

Gady laga





one of these uses that artist's name, the rest don't. Which is it? ;P





Who else hyped for Biortsmer coming out later this year???🤩🤩🤩

@shrewd trench
i meant to send the picture of this supermodel first responder rescuing someone from a mud pit

lmao thats epic
looks like the netflix adaptation of biortsmer 2
she's gotta go in or they're gonna die maybe

supermodels just love getting stuck in pipes 😦

oh not only pipes...
the clothes dryer?
driar
get back to your desk, champ
do you know regional prompting
i had dinner with them last week
ill go to sleep in a bit. its 2.30 here
that is good to know
can you try making 4 pipes?
like with regional prompts
with many stars
like this but 4x
@smoky oak A new sampler just dropped and from what I am seeing half the steps of SDE.

wai wut
how is it?
oof, old reddit
I have no idea we must now wait for Auto1111 to get it
ok!
in the meantime i will go to sleep

Their example images don't seem to show literally any benefits IMO
who generates at 100 steps
gn guys
night
I mean, if they are gonna make claims about being faster and better, show me some 20 sample comparisons, with times listed lol
dont get lost downloading loads and loads and loads of loras bc of the previews : D
I haven't seen them over hype before.

I guess we will see when it gets implemented
All academic and just like opinions, and assholes, we all have one so I just wait to see. Might be like UniPC, lol.
Yeah, I remember how much people thought UniPC was gonna be good lol
Its just slower and less efficient DDIM lmao
ffs, no tensor core cards can't even use it, like my 1060
Restart?
I am unsure what restart is as I have never seen it before.
oh, so what was that statement referring to then?








I am still wondering if the right course of action when training is to use the base mode from SAI?
for dreambooth
Help




Gold.





is this the house md guy

Cybernetics have come a long way.




This ghost says hello.




Nope. Kinda looks like Hugh Laurie though.

My power supply arrive tomorrow so I can finally spend all day on Sunday moving my entire system over to a new case. Next up will be a new video card and I can hold up to 400-430mm long cards.

the hat looks so impractical

it does but also there are like 4 hats I could think of that look like that
so I guess it's not unrealistic

Action Figure

Well, damn. Sexy beast.

I think this training was a success.

for some reason I always default with sdxl to just casting actors as characters they didn't play



I tested what would happen if I did a character as another character instead of a person as a character
It almost worked

Prompt was ("iron man", "as Doctor octopus").and(0.9,1.0)
Im really running out of ideas I can do with this clip drop I need this thing to release



Yknow in this drought of creativity in my brain I also may resort to funny ai boob
Also every time I try and get a skull wearing a helmet it just makes a skull helmet
















"A young lady looking at her cellphone in her lap. The glow of the cellphone is becoming a small pegasus, with its wings spread out flying through the magical glow of the cellphone. Realistic, but magical."
I don't get it. Whenever I use SD (this is Invoke), it just mixes up my terms, like it doesn't know grammar at all.
any of you have any insight (or especially solutions) for this?
i gave it a shot in the bot channels and got this

ill fiddle some more and try to get the pegasus on the phone
getting closer, maybe?

which one of these is closer to what you're imagining?
@green socket hey, thanks for helping :)) .. this was because my wife was hospitalized and stuck awake for 5 days straight.. she saw a friend of ours sitting there (she was actually there)
but she saw the glow of the friend's cellphone which turned into a pegasus flying above it (kind of small.. like, dunno, 1 foot tall or less.. )
after that it turned into a narwhale

it might be something where you gen the lady and then inpaint the pegasus
i like this one even though there's no pegasus lol

Prompt to try: Realistic portrait of a smiling woman looking at cellphone, (small pegasus:1.3) crawling out of cellphone screen, realism, volumetric lighting, octane rendering, hyper realistic, intricate,
Negative: angel wings, blurry

oh stable diffusion 2.1 really sucks IMO.
use a better model. I like deliberate but there might be another one
rev-animated or dreamshaper are the more popular fantasy models. I would link to them but Civitai is down... again.
@green socket i've not yet tried the alternate models .. just getting back into trying SD after a lot of issues in life.. civit's neat
yikes. why's my stable-diffusion-webui come up all in chinese??
i tried revnimated and dreamshaper and they just wanted to make a random lady with no phone. :\ might need to play around with weights.
I think the language embedding we use is garbage
it really doesn't have enough capability to understand what the sentence(s) are saying
GUYS GUYS
Who knows how to make stable diffusion concept files?
With .bin extension

Comfy UI is genuinely pissing me the fuck off
it works, then I try to run it and it tells me I need an A100 in the error message? I assume it installed wrong, reinstall
now xformers is broke, so I update it
it can't update cause now torch is broke
I follow their doccumentation on the page to fix that error
It can't cause it says it doesn't have torch to rebuild torch
What in the actual hell happened to comfy UI, why is it so convoluted and such a pain in the ass to use now?
I have used it several times in the past with 0 issues
@smoky oak
What?
If you have perma trouble with a100 ypu better use...(i ll send in you dms if you dont mind)
Oh, my apologies, i thought you re not satisfied with sd webui
But this is different stuff you re talking about
@smoky oak by the way, do ypu know how to make stable diffusion concept files?
(With .bin extension)
no idea
Crap
Just trying to find my way around the dubpster fire of comfy UI right now
It has you install torch vision and torch audio, but they require torch 1.12.1, yet it has you install 2.0.1, which breaks everything
IDEK what to say
Im trying to become a god of nsfw arts(i cant tell any further since rules are against it)

m'kay, you do that I guess lmao
I just said im nsfw creator, i dont discuss it any further so im safe
great, now stop talking about it lmao
Plenty of us here do tons of NSFW, no need to bring that into the server
Also i cant say anything bad about xi qingping since i dont want my xiaomi explode when i get a call


I just use the portable version of comfy with no issues
I have used comfy plenty of times, but my god this is pissing me off
the xformers it auto installs needs torch 2.0.1, but the torchvision and torchaudio it installs need 1.12.1
update the vision and audio, break xformers
Update xformers, break audio and vision
so now I am having to back one by one through the X formers versions until it auto installs a torch version that works
oh yay! Now it broke torch again! Woohoo!
alright, uninstalling all of the messed up shit they installed
did you use this one?

huh weird
installs torch 2.0.1, needs 1.12.1
I intall 1.12.1, not xformers is broken
Downgrade Xformers to 0.13, now torch is missing
Install torch, its already installed
try again, no torch found
oh wait a sec, I did NOT try that link
trying now
I tried the direct zip download, not the portable one
time for my CPU to off itself uncompressing all of this haha
hope it works 🤞
ok, it at least LAUNCHED this time
time to see if what I am trying to do will work
@sterile templeIT WORKS YOU FUCKING MAD MAN
WOOOOOOOOOO



did clip drop get more servers or is there just nobody using it
Every time I press generate the queue is like 10 images
Guys please, can someone please help me with textual inversion training?(i only have 6 gb vram) I just need one trained .pt file

API is alot faster today too, nice



























getting the squid robot vibe from the matrix movies
clockpunk




















dancing house, and gaudí, maybe Hundertwasser. If not, try him @sterile temple
yes gaudí 🙂




fift remind me dancing house.
Gaudí was giant 🙂
was blown away by these frank lloyd wright images last night





yes i like architecture as well. I think i love some sort of architecture most, because kindergarden was in that style.
sdxl does architecture sketches so well

I found a odd thing, larger images follow the prompt better, I wanted to test models and made a prompt that was not very specific other than it should be small creatures floating in space. at 512x512 the character just stood on the floor, but at 1920x800 I got images of floating animal characters that I later could crop out.
AI is strange.








Now I also want to make scary images

Sorry, here is a nice image that is not soo scary.

A monster under the bed.

Dr. Brenden Williams, CTO of Three Corporation, 2047
Born Jan 3rd, 2013, Dr. Williams was a top student throughout his education, getting his Ph.D in computer science while minoring in Business, he became known as the "Ruthless Programmer" due to his no-nonsense attitude towards handling situations and his education.
Sometime in 2040, he befriended the CEO of Three Corporation, a Technology Megaconglomarate, by pure chance and due to his charismatic charm, he was appointed CTO of Three Corporation.
He was eventually fired in 2051 as a result of his behavior and involvement in the cover-up of the Baton Rouge Teleportation Experiment Incident.
Despite the fact that during these events, he terrorized the rural town of Huntington, shot a Public Law Enforcement Officer in the knee to prove a point on who was in charge of the situation, and his Machiavellian handling of the situation, he was not charged of any crime by either Public Law Enforcement or Pyramid Security Solutions.

Thoughts on this Character?




He looks like mr blue eyes from cyberpunk 2077
Interesting
It's a butthole.



SDXL seems to have a very long token input limit...
you know, the unfortunate thing about the SDXL fine-tunes that are coming out is that they're all going to be based on SDXL 0.9
works really well at incorporating every word you give it.
the 1.0 release isn't available for fine-tuning yet, and so the base model at release time will possibly be better than the fine-tunes
im going to post a bunch of images... same prompt but different filter styles in clipdrop.
i don't get why they did it this way because there's zero motivation to actually fine-tune it











this one looks weird to me, am i the only one?

like some of the detail to me looks like artifacting until i look closer and then it... doesn't?
something uncanny and extreme is happening but i don't know what
i think thats the photographic filter. The detail will tend to artifact like when you run an AI upscale and it comes out like reptile skin
the styles are prompt keywords that get added to the end fwiw
its amazing that they are just keywords, because they feel like fine tunes or something
prompts are very powerful in SDXL but as a result, you can go really far in various directions eg. too smooth, too crusty, etc
you have to somehow be very precise in what you mean
know what i mean?
i can tell the prompts are reacting different to the old versions. i like it
it gives you what you ask for.
it does and it doesn't. you can ask for watermarks and you don't get any, which is why the negative prompt for watermark won't remove them
you can't mess with negative prompt or seed gen in clipdrop
i have local copy of the SDXL weights and run it in Python
nice... i would run it on my machine but its just a GTX 1070
you can probably still do that, albeit slowly
there's many layers of optimizations you can attempt, as this is a modular architecture, not all of the model has to be loaded at one time
yea.. its pointless running up an electricity bill tho rather than paying for clipdrop
oh true, true. you should try StableStudio or DreamStudio. they can plug into the SAPI and give you more control
i have dream studio as well.
does it let you set negatives and seeds etc?
dream studio does.
i got this prompt from ChatGPT Psychedelic alchemical garden: A realm where psychedelic plants and magical elements intertwine, creating an alchemical garden of vibrant colors and surreal shapes that invite viewers to explore the mystical depths of the subconscious.
i added Alex Grey style to the end and it worked... cant believe the input token limit must be high
they've been messing with that stuff in secret
idk if they're going to keep the current prompt parser in the end
@prisma iron any details on that prompt parsing implementation yet?
Nice prompt

Thats pretty good.. usually AI will totally screw up windows and such.



idk lol the reflections are weird


a chorse











can someone tell me how can i generate more images like this? What's the style

How can i find the seed
Unless it is in embedded info or a .txt with the info the seed is lost forever.
do you know what style this is
I don't as I don't know Anime.
if i find the seed, how should i format the prompt to use the seed

I don't think you can as most of us do this locally.
maybe someone who uses those discord bots can help more
thanks








that is SDXL?
it looks a little more cooked than i'd expect but some of it has "the look"
tbh it's more like a very good 1.5
yes SDXL from clipdrop
damn, wouldn't have expected that kind of halo'ing from clipdrop
whad do you mean?


if you don't see it, i don't want to point it out lmao i love the images
i can see things i want improvement on such as details being more realistic and not looking blatantly upscaled but its still good, i can live with it.
i've been playing with it in some toy python scripts but it's not very easy to tweak and re-generate that way, so i'm working on getting it going in my Discord bot code











































before I actually started reading the text I thought it was some sort of real chart for a moment and wondered why you were posting it here.
I agree.
Mlued tlhe biee lardre cont?
21.4%
1.4 on scare
velb a3%
10 caa
veri .S3%
7.5.3%
The bard yflne
war Yre o werßt
hale gh.?'
38.%
Hae srades fof eprile preotk
it is better than 90% of infographics i find
it doesn't have an axis that doesn't start at zero, has no unlabeled axis
(shoutout Windows Powertoys for being able to transcribe XLesian text)
things are, if anything, over-labeled
one neural net giving another a helping hand
feed that thang back through BLIP2 and get the text perfectly too i bet













still clipdrop?
yup its all clipdrop because ive subscribed now,
how did you know i put giger in the prompt?
Because I art.
Very awesome! Did you happen to save the prompt for this one?
Decaying Interdimensional Rift: A grungy, crackling portal reveals terrifying glimpses of alien realms. The stark contrast between corroded metal and cosmic swirls creates a blend of ancient and futuristic aesthetics, ominously suggesting the risks and unknowns lurking beyond the boundary. By H.R. Giger.
Also, dood, seriously? Maybe the f* xenomorph.
just kinda hoping it's not lol
they're not great looking to me
yea true. its a dead giveaway.
i don't know if it's the prompt or their upscaler on clipdrop
Masterpiece, best quality, Apollo Berrun, handsome young man, detailed short golden hair, detailed blue eyes, slender athletic build, DND, monk, digital painting, by Akira Toriyama, lora:akiraToriyamaStyle_toriyamaAkira3:0.7
Negative prompt: Sexy, Big Breasts, NSFW, lewd, risque, nude, hat, laser, lightsaber, showing skin, lowres, bad anatomy, bad hands, bad faces, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blind, bad eyes, ugly eyes, dead eyes, blur, helmet
Steps: 20, Sampler: Euler a, CFG scale: 12, Seed: 390771138, Size: 768x768, Model hash: 22c84a4a0a, Model: mangledMerge_v3, Version: v1.3.1
it's a 2.1 diffusion.
Who TF uses Euler a?
I do still

DPM++ 2M
Why TF 2.1? I just loaded it up and I can't get a good prompt for shit.
try my 2.1 model 🙂
I use DPM2, and avoid Karras unless I'm stumped.
mangled merge is a good 2.1 model
or UniPC when I'm broke.

Where do I get these 2.1 models? Does civit have them, or do I have to learn how to use huggingface properly?
https://civitai.com/models/73341/pseudos-journey?modelVersionId=78058 < this one is midjourney-trained
https://civitai.com/models/97808/pseudo-flex-base < this one is more photoreal and does portrait and landscape and a base res of 1024x1024
Disclaimer This model applies Terminal SNR to its training noise schedule, as described here. This will not work out-of-the-box (as of June 2023) w...
Capabilities Widescreen & portrait up to 1536x1024 and 1024x1536 1920x1080 sometimes works, sometimes not. This is a limitation of pre-SDXL mod...
apparently they're both 5 stars now
Is SDXL going to gradually improve or do we need to wait for an entirely new model to be trained?
people are using my model as a base for merging now with fantastic results
i'm pretty happy about that because i have no energy for taking my model further at this moment
Thats above my head i dont know how you guys manage to combine models and stuff.
i honestly am not a model merger, i am a model trainer. there is a major difference, both are their own form of art
It's a four-click process. I'm trying to learn the dreambooth extension if anyone has advice
Introduction: Mangled Merge V3 has been a labor of love side project for some time. I finally feel it's strong enough for a new iteration. It is gr...
^ that has pseudo-journey-v2 in a high percentage as a merge too
mangled merge is possibly better than journey v2 as a result
i think it 'knows' more stuff but has a lot of 'magic' from my model weights, no idea though really
whoa!!
Nope. Need photorealism.

Clipdrop you cant use any deep controls i dont even think negative prompting works.
is this photorealistic though to you, i don't know. to me it looks like studio portraits but not what 1.5 models refer to as photorealism, which itself is like an AI art style.
sorry I've been inactive for a minute, got covid. how y'all

here's one with better contrast

yeah someone else said it looks like the prompt involves the terms 'juggalo convention', i don't know what that means but now i do. thanks

anyway these are the results of pseudo-flex-base



works best at 1024x1024 or like 1280x1024, 1366x720 is really cool and the widescreen vibe feels very different
portrait mode at 960x1280 is great too

nowhere near the number of deformations but honestly i have to admit, some subject matter that isn't in my 480k training images doesn't work well in portrait. stormtroopers mostly 
none of that uses hires fix or img2img, LoRAs, textual inversions..

I like this mangledmerge
I'm pretty shit at prompting and it still spits out awesome stuff.
yes! it works without negatives because of the pseudo-journey-v2 text encoder being slowly/carefully trained on midjourney image-caption pairs successively freezing the layers of the text encoder until just the last two were being tuned for a few weeks straight
I'm using negs anyway as I'm using it.
the freezing happened pretty early on, like, you want to do it within a few hours of starting training or you'll be having problems later
used to it*
negatives still work very well yeah
Yes, he put a lot of effort into that
i can tell
im hoping clipdrop will improve.
you can do that for clipdrop, too
well
i mean sdxl's text encoders
i'm nervous to try tbh but tuning the text encoder is something i can begin now and still have that work apply for 1.0 (i think)



Yo I love it when the botto spits out non-Euclidean geometry








Mangled merg ftw

So I have been messing with SDXL's base weights after I finally was able to figure out how to get them working, and I amr eally hoping that SAI is purposely giving us bad models just to try and still leave some improvement for release day, cause these models are both pretttyyy... blegh 
The refiner is the star of the show, and its still pretty disappointing
It cooks anything ever close to realistic, and the base model is basically 2.1 but a little less bad
VRAM requirements are a bonus tho, I will say that




8GB will definitely be enough for 1024x1024 with SDXL base
and if you use it strategically, like with comfy UI, you should be able to run base and refiner just fine in 8GB
also, whichever mod said that SDXL uses barely any more VRAM when going to higher resolutions, that does seem to check out!
1024x1024 uses 6.4GB VRAM on average for me, while 4096x4096 only used 7.1GB, though the VAE decode did push it over 10GB VRAM, but when it switched back to tiled decode, it was able to complete in just over 8 GB at 8.2GB VRAM
Very very interesting how they did that



I would have been able to share this all sooner, if my dumb ass wasn't having problems installing comfy UI
whut
Looks like a big difference between the API model and the weights you have just based on running the same prompts
they're allowing just anyone in to the beta now 
looks like lmao
Yeah, that was very interesting to me. It does seem to run artistic stuff about as good as the API, but its shit at realism
I actually play D&D, thank you very much :<
I have for 7 years >:C

i didn't even know you did. but i knew
i knew, the lady at the grocery store knew, the librarian knew
base SDXL 0.9

after upscaling and adding the refiner

I am quite happy with this models artisti stuff, but flat out pissed at its realism. It does about as bit, if not maybe even worse than base 2.1 with photo realism
base 2.1?
yeah, that bad lmfao
what
no way
2.1-base or 2.1-v?
2.1-v is overtrained gore
i have not tbh tried 2.1-base a whole lot
like in some ways, it can do good, but man, tyou really need to beat the shit out of it with CFG finetuning and some extremely specific settings
Honestly, I am not too sure which ones I have used
just know this base is not good for realism, like at all lmao
Its all smeary, and blurry, and full of what looks like MJ V4's artifacts
2.1-base might be the best of that series considering it's "middle of the road" in terms of training step count just like 2.0-v
but the added benefits of the reduced LAION filtering
ohhh
are you able to put a custom text encoder now?
How do they run it with the two clip models?
you can use the file from my pseudo-journey-v2 branch and the one from the pseudo-real branch, with any 2.x model, and improve coherence
like here for example: 1.5 finetune wolf

@sterile temple they're combined in a single huge layer on the input


Can you do the same in comfy?
you talking to me?
tis such a weird combo of realistic and digital look
if so, I am using comfy UI exlusively for this test lol
right, the refiner cannot do realism at all
@smoky oak pfft give it a human from EpicREAlsim
or whatever that model is called
i have faith in this refiner 
otherwise what's it all been for
more bouncy lighting, i guess
Like that game from stranger things? 😛
E.T. the board game?
ask the refiner for an image that is realistic, with an extensive negative that tries to discourage being artsy
get this:

the refiner cannot do realism at all lmao
don't give any negative at all, what happens?
negatives i find, tend to hurt SDXL bot outputs
it just leans more into artsy stuff
this was no neg

with SDXL some of the realism terms from 1.5 days are counterproductive
I tried several different ways of prompting it, all of which 1.5 understood, and base SDXL understood, but not the refiner
gotchya
i hate how slow the sd_xl branch of diffusers is to start up, it makes it a real pain to test all of this
same prompt in SDXL base got me this

far more realistic, but it really just looks like MJ V4 up in here
that looks like what i get from 2.1 with controlnet tile on a 1.5 model
i was waiting 15 minutes for torch to start up

turns out the GPU crashed
the patterning on its forehead wasn't that bad before on clipdrop





yeah, those images lead me to believe that the 0.9 SDXL beta weights are just a bad version to try and validate training, but not make great images
there's uh, different upscalers on clipdrop paid?
yep
sigh
just different models, like sharpen, denoise, remove compression, then the smooth or detailed option

2x clipdrop sharpen upscale
on scrutiny it looks bad
that does not look very good at all, so thats reassuring lol
patchy and what not
As a paid service, I would mega pass lol
thanks for burning your credits for us, for science
clipdrop is unlimited IIRC

it's confusing keeping track of DS, Clipdrop and SAPI
imagine having to pay to render images lol, stable diffusion my dude is the way to go
this is stable diffusion

that's stability AI's paid service for SDXL use
currently the only way to use the model for most
the bot is here, but... uh... YMMV
#bot 1 through #bot 10
yeah, used to be good, recently got neutered lol
that thing is junk 😄
excuse me?
yeah, Auto is rough, its what I use day to day, but its not very good lmao

it's not a reflection on you
comfy UI is luring me in, I really do hate to say it
you are fine, Poly
ya but yall are paying for something, ya really don't need
Yeah, Auto is fine, its just not made well for what it does
Its inefficient
oh, i don't pay for clipdrop
no? lmao
sono does and that's their choice to do so because they saw value in SDXL
I have like 300k local image gens at this point, and I train my own LoRA's
mysticago made 14,000 image gens using the SDXL bot here so far
for free
no need to heat their own computer/house up
it's okay if others are fine with using even Craiyon to make their AI images if they're really happy with it
I have never paid a penny for SD
in fact i'm going to test Craiyon again lmfao
i haven't used that little boi in like, 3-5 months
oh it has negative prompts now
and art styles 😮
and it uses some language model to predict your next prompt
annnd it has an upscaler
yeah this is totally different now

{kind=link}
{kind=link}
{kind=link}
{kind=link}
wow, that looks WAY better than when it was just dalle mini back in the olden days lmao
i know
i feel like there's more you can get out of it but i don't know* how and it takes a while to gen lol
ahhhh the prompt is too extreme
simplify it, and results are way better

Interesting, I am trying wombo dream directly against base and refiner SDXL
dude why lmao
it actually did pretty damn good lmao
shouldn't have said that lmao