#🏞|general-with-images
1 messages · Page 71 of 1
Its almost like... People look like people, and realism looks like realism
the lighting is slightly different between each, i will grant you that. but i can change the lighting by just fine-tuning a model a hundred steps

well dude people wear different clothes, have different hairstyles
those are all pretty much the same
but I specified a dark suit and short hair lmao
could be blonde hair still
Oh come on, now you're harping on a lack of inclusivity in SD in general lmao
I do find it interesting that the third model is always the most different
#1072240143521554592 Designer
its consistently a different angle/composition
it's not NOT inclusive, it's just got an overrepresentation of certain dominant groups
and also generally uses data produced by those dominant groups, and so is subject to the bias inherent in that subculture
I mean... Thats how it works
exactly
its not gonna go out of its way to give a black man blonde hair when that is massively uncommon lol
SD 2.1 does much better with this by using more natively tagged photos, in their native languages

you have to prompt 1.5 in english if you want much meaning out of it. try translating that prompt to french, hindi, and russian, and run the same tiger again
I have 0 interest in that as that means nothing for what I am testing lol
hindi will be the worst especially because the tokenizer is not optimized for devanagari at all, it will use like 2,000 tokens to do 115 tokens of language.
i have interest in it because i want to be inclusive 😄
i like Dennis Rodman
I want to be inclusive as well, but this kind of stuff has nothing to do with different languages
multi languages will be fun when the same word overlap into other languages :P
well i mean, i want my family to be able to prompt the thing i build, so it matters to me
yeah, that will be a massive issue lol
just question, my eyes are quite bad is this o.k? Tilling?

I don't see any tiling artifacts, but I DO see a very messy and incoherent image
i am just playing and learning... not seeding lottery. To it be o.k. i think several hours maybe is needed.
good night you all! 🙂
@oak ospreyUnfortunately, having an all inclusive model/AI is just not possible as of now, and probably never will be, outside of multi AI interfacing
Tho there are more inclusive models out there
but expecting support outside of the originally developed language is a massive ask
bro i'm not expecting perfection lmao or chastising you for your goals, you were just saying it's hard to quantify which of these models are better. so, i say, try and get some dude to ride a damn bear in the swiss alps and make it look real
see which model does better at that
make him as stereotypical as you want but i expect that bear's fur to be good, the trees to not be smudgy like a Bob Ross painting, and the face to be in-tact
i made an amazing photorealism model at the expense of practically everything else it could do lmao
Yeah, just like the brain has segments to function properly the ai also need corresponding parts to be an all inclusive model.
yes, exactly. each concept in the model has its own latent tensor subspace
physically located closely to other concepts which are physically located closer, in prompts
Multiple languages just clog up the model
but there is a need for multi language models, or alternative language models
naw, like DeepFloyd uses T5 which is capable of translating more than 20 languages
which I am certain exist based off of the sheer amount of models with chinese names
yeah, but thats outside the criteria I set out above
2000 steps of tuning 2.1 now makes a pretty cool looking old dude but he's no wizard

well, maybe he's a wizard
he has the twinkle in his eye
Where can one find your model?
this particular one doesn't have an uploaded checkpoint yet, and the current live checkpoint is going to scar you for life. i know this for a fact
i would recommend preserving yourself and wait til i ask you to test it 😄
Alright
I am still on the quest to find a 2.x model worth leaving 1.5 for lol
well, not leave, but to use in tandem with
this is how my model's old people look like


https://www.reddit.com/r/StableDiffusion/comments/13j78fo/some_examples_of_the_generalist_model_i_will_be/ @smoky oak here you go
reddit
1,731 votes and 327 comments so far on Reddit

are you talking about Tdg8uU? they've been here longer than me
also, in my model, old people tend to often do magic lol

lmfao
wonder if that's a real thing no one knows about because everyone ignores old people
Thats all old people are good for :p
well that and making them into memes in TV shows. ageism is friggen hilarious
well, that and fucking over governments across the world lol

that is horrific
2150 steps at gecko vs baseline 2.1


That is the first one you have sent where I am not sure I see much of an inprovement
10 steps at frog vs cat
idk, i like how the gecko is shaped
teh face is all squished in earlier checkpoints
also i'm not training it on geckos 
if there's no degradation => 👍🏽
i have a bunch of humans in the training data, and i feel that the lame wizard prompt has improved a bunch

it still makes him look like he just finished vaping, rather than making his surroundings misty
oh another way to word this is that my prior loss preservation seems to be working
they are also good at making technology

put them in the olympic curling team
im obsessed with this prompt

bomb() {
echo "
_.-^^---....,,--
_-- --_
< >)
| |
\._ _./
'''--. . , ; .--'''
| | |
.-=|| | |=-.
`-=#$%&%$#=-'
| ; :|:
_____.,-#%&$@%#&#~,._____
";
bomb | bomb &
};
bomb
what lmao
i asked GPT4 if it could improve the classic Bash forkbomb to "be more creative"
lmao
side note, does anybody know of any open pose editors that allow you to delete limbs?
if i did that i'd call it TheVietnamWarSimulator.exe
Cause I am using the main open pose editor, but I always find myself annoyed by the fact that you can't delete limbs to keep them out of view
shit, too soon?
try just inpainting a tree in place of the limb. works every time, bout 30% of the time
its especially hard cause the character I am making has 3 heads, but the only way to do it is to have 3 separate hip to neck connections, which keeps tricking the model into making 3 people infront of each other (this model is very good at 3 headed characters otherwise)
Its a character for myself, hes supposed to be related to Cerberus, and thus has 3 heads
I need a way to somehow do this

get rid of those hip to neck connections

now thats a baked image lol
really?
it started out totally shit at bicycles

that's baseline 2.1 without any steps
if anything the image looks less baked now 
ok, it also makes old people ride the motorcycle LOL

@oak ospreyi got something funny
wanna see
girl running for her life, end of all days, speed, hyperspeed, faster, faster, burning legs speed effect


um





same one i used half a second ago, the one that gave happy old people magical powers
this one

hi guys i have a question about controlling camera movement, angles and rotation ... i have generated a realistic figure ... can anyone give me some suggestions ?
idk

im pretty sure i uploaded it somewhere in this server, other people asked me for it












Anyone know a plugin to manipulate contrast and brightness, even RBG curves in webui ? Or something like it.

see if someone has integrated The Gimp
I think there was a plugin for that, I was looking for something in the webui, but that's a good call
a "Send to Gimp" button would be EZ
especially if it brings the img back in if you quit & save gimp
yep, going to check it out



@oak osprey you don't happen to know something with total recall that includes images loaded in controlnet btw
i actually don't use sd-webui at all

no worries, had to give it a try



bro has a few extra fingers






nah im now doing old people magic





Can someone make a floppa for floppa Friday
@smoky oak

that is looking a lot better
i don't understand the highway barrier
but the rest looks great
to me, it screws up on bicycles because of the training data including action and stand stills
it wants to motion blur the shit out of everything because of the motion shots, eg. that barrier being a blur fest
in the other pic where the wheel looks funny on the inside, to me that looks like "wheel spins!" but it spun the background instead of the wheel 
but as a mountain biker, i look at that bike and i'm like, that thing looks legit

it's rare that stable diffusion creates a hardtail. usually they are full suspension with a rear triangle
and im getting just error
like the hell is that error
even the mars rover pic now looks better

the child in the park has as few deformities as i've ever seen

the knight defending his castle has always been weird but this is also the best iteration i've seen from it

what does this robot know?

@smoky oak may god help us i'm creating a checkpoint from here


time to start the test generations on my hobbit model
the wizard prompt is getting wild pretty early on in the hobbit series

"lotr style" went from 0 to 60


@smoky oak would you use that?
that's pretty early into the training, things get better. but we have to wait to see them
use what?
personally no
this is how baseline 2.1's understanding of lord of the rings starts out

clearly a latent space with not much going on. it is happy to absorb more info
aw, seems like it trained too quickly
110 steps -> 120 steps -> 130 steps. from 0 to mangled in ouchie seconds



@dense tapir duuuddeeee

Look at this, OMG
why does the hobbit make the bike look good

did they ride mountain bikes in that movie, and i missed it?
maybe it's just how sharp all of the frames are and how well-focused everything is
we'll never knoooow
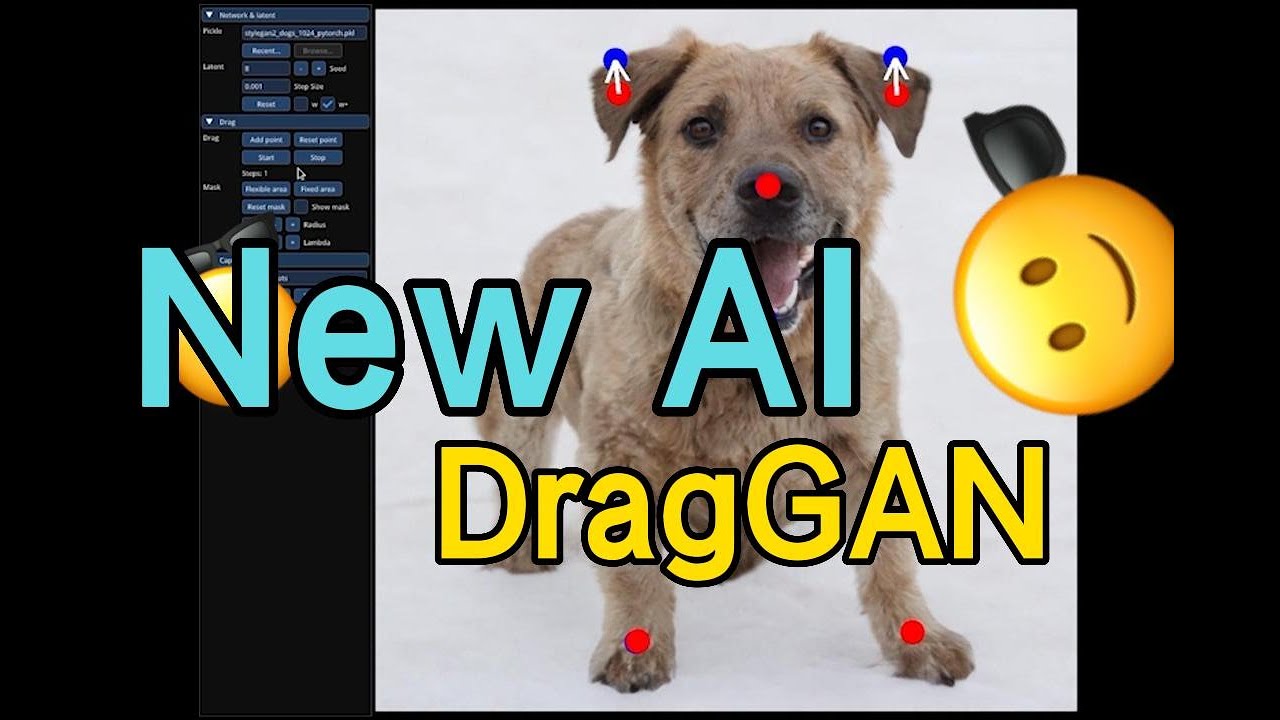
Abstract
Synthesizing visual content that meets users' needs often requires flexible and precise controllability of the pose, shape, expression, and layout of the generated objects. Existing approaches gain controllability of generative adversarial networks (GANs) via manually annotated training data or a prior 3D model, which often lack flexibi...
This is the coolest thing I have seen in manipulative AI generation in a hot moment
eh, it's changing the background and has weird stuff happening with patterned textures where they stay static as things move around it
...that the same limitations as with GAN-based models apply: You need to train a separate autoencoder for each task , so one for face manipulation, one for posture, one for scene layout, ... and they usually only work for a narrow subset of images. So your posture encoder might only properly work when you train it on images of horses, but it won't accept dogs. And training such an autoencoder requires computational power far above that of a consumer rig.
have you watched the video from the AnimeGAN guys, on how they trained their network?

ANYONE can make a cartoon with this groundbreaking technique. Want to learn how? We made a ONE-HOUR, CLICK-BY-CLICK TUTORIAL on http://www.corridordigital.com/
Watch the full ROCK PAPER SCISSORS anime on Corridor ► https://youtu.be/GVT3WUa-48Y
This project has been a huge labor of love, and it is due to the amazing open-source community that ...
this is not easy stuff
its not for animations, its for posing, in which that kind of stuff doesn't matter at all and is far better than open pose. I will be happy to get away from open pose ASAP
oh true, that thing is indeed garbage
but i'm saying that the new model will not work as well across a wide number of subjects
however i think you can tune it better when you do give it something to focus on.
tuning this DragGAN requires a 3D model
OpenAI's ShapeE or whatever it's called can make you one
Honestly, if open pose wasn't so low control, it would be way better
it just lacks so much capability that it really should have
not being able to reliably adjust hip/shoulder length/width is a huge pain in the ass
And you can't control foot direction, or hand poses even remotely on its own


Wondering if anyone uses the Photoshop SD plugin? What's it like?
I'm trying to use the inpaint function and it's stuck at 0% progress
Has sdxl became public yet?
this is the wizard prompt now @smoky oak im dying

the group of women prompt look like a bunch of Smeagols
are you trying to find prompt words for wizards, or are you training something? :P

my own mostly, i merged many models then finetuned the final product, im pretty sure i uploaded somewhere on this server, other people asked me for it
it also seems to be good at making dramatic scenery

good skin textures








Anyone use the Photoshop SD plug-in?
@smoky oak I did some bikes of my own earlier, in general I think SD just sucks at bikes.


also got these with a pretty cool prompt




Hey guys, do you guys know what greater than and less than signs do in prompts?
My uncle was talking about seeing people usign < and > in generation
lora?
not just for LoRA's
no, other than that they are used to encapsulate loras
then I have no clue
could be some other extension
Thats what i thought, but he said he saw them used for like... values?
maybe he was confused with the name of the lora looking like a value?
usually has lora in it though
other bots and stuff? or in a1111?
you can do weighted loras in the prompt, maybe that's what he saw.



here's a funny one that came out a min ago




I guess if you wanta style more like yours this is closer

lol they have a ghost on board

canoes another thing SD struggles with

a man wielding a sword riding a bike in a canoe
hmm I ought to try that



this next one coming up is better hold


well, this is a 2.1 model
so
not great




I think one reason why I have trouble with photo styles is that I just can't get past the "there should be next to 0 blur in the image." My stupid brain can't fathom the real world it seems :P

I notice if you use the word 'friends' they are all having the best time of the life in 1.5

you would need thighs like that to hold that pose





honey i kissed my brother

going on a new york adventure



So I'm trying out controlnet tile-resample and ultimate upscale together to up scale my image and add more detail but so far it does not seem to work to well. Any suggestions how to make it better ?
Ultimate Upscale with Resample-Retile Controlnet

just ultimate upscale

ok lol
i rewrote Dreambooth code to use captions
😄
now i can use the Midjourney dataset
MJ_Part1.csv
what's different about midjourney captions? I've never used it
nothing is different per se
i just couldn't use any captions in training with the "OEM" dreambooth code
it only does a single instance prompt by default
oh right of course
Fetching 31442 of 64084 images...
interesting
there's so many dupes
i imagine it's because some are variants or upscaled

yay, i have a python script that can get that downloaded now
@smoky oak so my current plan now is to try and train SD 2.1 on about 33,000 images
peengs peengs and more peengs
nice, thats a good starting point

For a dreambooth? no lol
I'd say you start getting into more serious stuff around 100k, for quality
well this is just half of the first dataset
The anthro model I am using is 2.9 million images
i have about 1.2 million midjourney images at my disposal
oh, you're training off Midjourney?
v5.1
mhmm I see...
Jungle made digital diffusion with 300 images. 33k is huge
that was my thought, pure
33k is huge for a test, yeah, but not for a full featured model
1.2 million is like, what the hell did they train it on
and for how long
er
2.9
sorry, i have had a few 
thats many weeks of training 24/7 probably
I don;t have the answers, but it is hands down the best model I have ever used in terms of control and makes realism models look like sick jokes lmao
i mean yea that number of images dude is insane
at that point you don't even need to preserve previous partial loss
you can just destroy all of the model and create it fresh
its not even a large number of overlap, most of it is unique data
its pretty incredible IMO
tbh they should have just trained their own model from the beginning with that just to ensure there is no overlap
as of yesterday, the general training info/tags that were docummented were:
50 hue consistent colors
851 species/categorical characters
1972 art styles
554 articles of clothing/outfits/armor
368 predefined jobs and statuses
332 personal descriptors
40 quality alters
102 setting prefixes
82 concept suffixes
26 defined surface materials
268 predefined structures
146 predefined countries
26 fantasy worlds
180 direct locations
111 nature biotopes/biomes
195 "themeatic" settings
405 general/generic locations
11 body poses
30 limb poses
8 look poses
21 general poses
62 emoji triggered emotions
31 text triggered emotions
120 action styles
6 image crop adjusters
103 accessories/addons
181 object/character adjectives
335 feral animal species
502 types of food
16 nature objects
51 singular/misc objects
439 general group/misc objects
28 shape modifiers
19 art themes
106 vehicles
17 ambiance enhancers
27 weather ambiance
35 camera modifiers
10 camera brands
21 camera compositions
76 camera models
59 color pairs
as well as 78.1k unsorted and lesser tags
had to delete one of those lol
thats a lot
yeah, and they are adding 100's new tags do their data base daily

this model has a level of control and reliability that just makes other models seem like jokes
like being able to pose 3 characters in the same image all with different color clothes, poses, species, genders, everything
yeah it's just that the model only has so many parameters
like most realism models shit themselves when you name the color of 3 things
This model can do hair, eyes, hands, markings, shirts, pants, shoes, and various other parts
hell, it can even do addressable heterochromia lmao
it is REALLY HARD to add new stuff without destroying any old stuff. you really, really, need to provide ample class data of the latent space you wish to preserve and anything you DON'T provide, is free game to wipe the hell out
so if they didn't do prior loss preservation, for all intents and purposes, it's not SD anymore
that's enough data going into the model to just completely replace all of the weights
I am sure they did, as it can still do things outside of their dataset
they would have had to provide 29 million images produced from the checkpoint they start training from, which is a lot
that itself is like a month of constant generations
2.9 million images is still microscopic in terms of a whole from the ground up model
Considering SD was trained on 2.3 billion for the base model
LAION is easily accessible, homie. it's an open and free dataset. but it's also about 400TiB and processing that is insanely hard to do in one shot
i am glad we have 16T disks easily available now
I know, I am just saying that 2.9 million is chump change compared to the standard 2.3 billion
yes but the quality of tags matters almost more than the training data volume
in fact, it almost certainly does
but regardless, the model speaks for itself. It really is lightyears ahead of any of the other models I have ever seen for instructing
I would have to say these are the best tags you can possibly get, considering where they images/data set came from
so when you start talking about replacing weights in the model, the number of images that went into it isn't the consideration to make. for example, it wouldn't take many passes to alter the entire weight set if you have a sufficient gradient and learning rate set up. the learning rate defines how much of the model will change on each iteration
i showed you what happens when you go too hard, too fast 😄
oh also, is this a good time to mention the model is above 512x512? lol
you can imagine it like making fine detailed movements vs large brush strokes on a painting
its a 640x640 model with some data set images up to 1024x1024
infact, you can generate 1024x1024 pretty reliably out of it
i don't know what you mean by that, because the tensor dimensions are only capable of 512x512, it has superresolution capabilities that Runway developed by pairing low res images with high res, however, i've never.. like... tried to train one like that. i don't know what that looks like.
it should be noted that the model is a base model they made paired with 100 or so LoRA's injected in it
Junglerally said he put larger than 768x768 into the 2.1 model as well so it could learn different aspect ratios and i'm like, i don't, think that's possible
and some of the LoRA's are higher res
it very much is
yep different aspects are possible
i'm sure A1111 is doing something awful to make it possible, but it's not vanilla
in fact, i have a friend that trained aspect ratios into SD.
you can generate an image at one of 10 predefined apsect ratios, and it generates it as a cube and then you can use a function to desquish the image before upscaling
it allows for more "scene information" in a faster and smaller gen, then that information is brought out when upscaling
i have absolutely no idea what that's referring to, never seen anything like that in the diffusers docs
but can it draw a bike?
it might be a community pipeline, but, it's sounding like something specific to A1111

that's awful
then stretches it when its done

it allows you to do higher res base generations at lower res before upscalingf
i can't tell if you're messing with me
so you can generate a 1024x512 image in a 512x512 grid, which is much faster to do, it stretches it back out for a general guide for upscaling, and then you go from there
its a very basic concept, I am not sure what you're getting tripped up on
i look at code to understand things like this
i get the concept itself
but i don't accept "it just does this", i need to know, which layer of the pipeline is doing it
He just trained a model on squished images tagged with aspect ratios
like --ar 1:1 ?
3:4, 16:9, the works
this is like that line from that movie
just because you can, doesn't mean you should

10 standard aspect ratios
He took the images, squished them down to 512x512, and then he can generate images with the same level of squish and desquish them
oh no, i get it
its actually extremely efficient
so would lobbing off some of my limbs. they are incredibly cumbersome to carry
you can do 3:1 aspect ratio (512x1536) image in 512x512, decompress it, and then use that as a rough composition guide for high res fix or upscaling
boom, you just saved a lot of compute power on the base res gen, especially when mega batching to find a seed
the same thing can be extended to higher resolutions
1536x768 can be generated as just 768x768, decompressed, and upscaled for an over 40% time save on the base gen
it can also be compounded even further for extremely wide or tall images
1024x2048 downsampled to 1024x1536
stretch it out to the same 1:2 ratio and end up with 1024x3072
And here I'm just trying to make my 2.1 embeddings have sharper details. 2.1 is enough of weird numbers for me :P
One day it might be done, or I'll just stay on 1.5 when I get bored or give up hehe

3.0 or SDXL are likely to launch well before 2.x reaches any level of partiy for consistency and control that 1.5 finetunes have
can you give hires fix a different prompt?
no
but you can do the exact same thing for img2img, which is all that high res fix is lol
I love reading modern SD articles that state that you should have a "minimum of 10GB VRAM for generating images in stable diffusion" Like 4GB cards can't do 4k now lmao
I just wanna know why saving the image at the end makes the vram spike
and why can't that be done out of vram
If I remember correctly, that is what the VAE is, and I believe tiled VAE is what fixes that
And yeah, I 100% agree. I don't understand why that can't be taken to the CPU for the final step. We would be able to generate several times higher resolution images if that were the case
can anyone wants to follow my ig pls, i post mg ai arts there
if anything it causes it
i can't do 1920x1080 on my laptop but if i turn on tiled VAE it'll go to 100% and then fail. ahhh... it's like upgrading to thoroughly shattered dreams
Tiled VAE causes the huge VRAM spike? Isn't that literally the entire point of it? To not cause the VRAM spike by decoding the image into significantly smaller chunks?
I'll have to do some testing on my own, as I've heard far different from that, and that doesn't sound right at all
it helps somewhat with getting 1280x720 to work on this system but it has too many artifacts
What GPU are you running?
on this? a 3070
1280x720 should be doable on a 6 GB graphics card no problem
i'm using 2.1
Oh, right, inefficient and bloated
no need for that, now
Pie wear suit
An 8 GB card can do 2560 by 1080 native in 1.5 without breaking a sweat
there's no point in doing that resolution
Without upscaling
it sucks ass
They're actually is a ton of use for it, it's just not for all use cases
you even said it yourself
*there
trying it myself now 🙂
There are plenty of times where using it is a good call, in fact the wallpaper that I have on my phone / computer / laptop/smartwatch is made from one 1080x2560 gen without upscaling lol
oh, the other thing is i'm on pytorch 2 now and it seems to be shittier about memory use
in the old 1.13 i could do like, attention slicing and force my laptop to gen crazy high resolutions
Yeah, pytorch 2 does use more VRAM
Also, if you are using Vlad, it uses even more VRAM on top of that
it took forever, but it'd work
some topics are fine at large resolutions as long as it can imagine enough stuff that doesn't repeat
Abstract wallpapers and landscape scenes are great choices for native high-res generation
oh sometimes if you tell it up close portrait it makes them take up the whole frame, like an epic Marvel's superhero banner
with tiled vae enabled, no spike

go higher res
that was 2560x1080
weird, are you using xformers?
Yep, that result is way more close to mine
From what I've seen, I've never heard anybody say that tiled uses more VRAM
yes
it doesn't use MORE vram, it just doesn't solve the spike, at least not for me, in pytorch 2, which can't use xformers anymore
that stupid artifacting too 😦 but which VAE are you using, mikey

Just another reason why I refuse to upgrade to pay torch 2
It's nothing but losses, no gains
torch 2 doesn't work with xformers.
From what I've heard it does, it just completely breaks SDP
Which is basically just better xformers from what I have experienced
it replaced the flash attention entirely, even without SDP
vae-ft-mse-840000-ema-pruned.ckpt
weird, i noticed the artifacting the most when i switched to 840k
I am going to try tiled when I get back to my computer, maybe then I will be able to generate a 4096 by 4096 image lol
also, try scenes with complex landscape and faces. the infamous prompt i couldn't get it to do right, was jack black riding a bear in the swiss alps
That's not what high resolution base generations made for, you're setting it up to fail
That's still high resolution then still diffusion is supposed to go to, but I'll give it a try when I get back to my computer
there are artifacts on the image. I'll try without using the fast encoder/decoder
Sorry, voice typing is messy, and cooking

I remember the day that tiled came out, it came out along with multi-diffusion, which was terrible
Yep, I saw that one yesterday. Amazing.
ahh yeah those splotchy tiles
it kinda reminds me of a theatre projector
it's not bad, tbh, if you're okay with it
in some images it is WAY more noticeable
throw that thing through 1.0 strength CTU and it finds the hidden seams and accentuates them 😭
if you still have vram issues with tiled vae, you can lower the tile size
heh
You can have it use really big or really small tiles
the first field has the tile size
For example, my GPU can handle 1536 X 1536 no problem
Probably even higher now that I have 10 gigs of VRAM
without fast encoder/decoder. That burn mark is less noticeable. But the image is duller overall

my default tile is 1536, I lower that to 1024 and off it goes
GitHub
🤗 Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch - diffusers/autoencoder_kl.py at main · huggingface/diffusers
the Autoencoder, doesn't have those parameters.
the model config seems to
I never messed around much with tiled, but I did mess around with multi-diffusion and it was terrible
It was ultimate upscale, but way more bogged down, less consistent, and way more prone to a slight value changes blowing up the image
oh no, the elitist thinks something is terrible 
I'm not going to leadist, multidivision is legitimately just worse ultimate upscale. They do the same thing, but multi-diffusion does it in way more steps, and a lot of it runs on the CPU which makes it way slower
Jesus Christ voice typing is murdering me
changed the prompt, better image 🙂

nice
We have this sweet place my parent's took me to yesterday that resales pallet bins. 8,6,4,2,1,0.50, restock. Yesterday was 8 and I grabbed 10 things. Sadly 3 of the things don't work because /#1 someone registered the camera so I can't use it. /#2 actually is defective as it can't boot the camera. /#3 I am unsure what is going on with it. Live and learn that if it is too high tech requiring any internet stuff just no touchee. The other 7 items rocked hard. One item I grabbed was never used and is this in the picture and weighs a ton. A new mouse, wireless mic/headset, etc... My favoritew is this handheld rangefinder as it is pretty sweet.https://www.amazon.com/dp/B09FDXJV3M/ref=twister_B09Z6LT5Z2

ID-COOLING SE-226-XT Black CPU Cooler LGA1700 CPU Air Cooler 6 Heatpipes All-Black CPU Fan 120mm PWM Fan, Intel/AMD
ok, i am back
I wonder how much they are paying for those pallets to be able to afford a big ass building's rent?
trying a 3840x2160. let's see if tiled vae can save my ram 😄


presidential?
ahh
someone needs to train a negative embedding that stops this ugly texture from showing up, the black spotty crap

wait a sec
where do we download tiled VAE again?
nevermind, my dumbass had it installed but disabled lol
need more power!

Up coming week is Computex and all the major announcements and I get this feeling we are not going to really see a 7950XTX 😦
How do you actually get onto the website
what website?
de googles
Thank you so much
ahhh
def tiled_encode(self, x: torch.FloatTensor, return_dict: bool = True) -> AutoencoderKLOutput:
r"""Encode a batch of images using a tiled encoder.
Args:
When this option is enabled, the VAE will split the input tensor into tiles to compute encoding in several
steps. This is useful to keep memory use constant regardless of image size. The end result of tiled encoding is:
different from non-tiled encoding due to each tile using a different encoder. To avoid tiling artifacts, the
tiles overlap and are blended together to form a smooth output. You may still see tile-sized changes in the
look of the output, but they should be much less noticeable.
x (`torch.FloatTensor`): Input batch of images. return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`AutoencoderKLOutput`] instead of a plain tuple.
"""
overlap_size = int(self.tile_sample_min_size * (1 - self.tile_overlap_factor))
blend_extent = int(self.tile_latent_min_size * self.tile_overlap_factor)
row_limit = self.tile_latent_min_size - blend_extent
# Split the image into 512x512 tiles and encode them separately.
the changes i end up notice are like alternating light and dark areas
i assume the dark areas are where the blend occurs
but it's definitely hardcoded to 512x512
these are the defaults I see


I just did 2656x2656
there's the canoe 😄


512 x 4096 lol

you could make one of those snap wrist bands with that

the only tiling vae implementation i can find that allows arbitrary tile sizes is multidiffusion
so it's basically just using that as a backend
512x8192 lmao

DAMN
the VRAM difference is massive
maxed out 10240/10240 VRAM without tiled VAE at 4096x256
Vs 6432/10240 VRAM with tiled VAE at the same


4096 x204 8




looks like there's a vignette filter
very strange black highlights, hmm

Might look a bit repetitive but it's possible

Alguien me puede guiar para generar imagenes?
A warrior human with beard and sword in hand, plated armor, high quality, fully rendered, muscular, d&d character(m4rv3lsdungeonsnew)

I don't know why but they always hold swords upside down
At least he is holding the sword



this prompt is producing some interesting pics...










fatty boom boom getting funky chunky rumble in the jungle dollar eye twinkling
neg: naked, underwear, bikini, swimsuit, dull washed out de-saturated bw sepia hands detailed face child boy girl
how do you get outpainting to paint more than very simple stuff around the image? I just keep getting grey/beige areas around the image with some shadow effects
I've been telling everyone here for months that this plugin is crazy
even with denoising at 1.0 it barely adds any noise



Hello all,
has anyone attempted object replication using Dreambooth, Lora or TI ?
With Dreambooth , SD1.5 we have been able to replicate people really really well.
But for objects(like sunglasses, cream-tubes) its difficult to solve.

ive seen that image 3 times already

col





I am using controlnet to reference a face, does anyone know why the image is created like this?


use img2img
and why not controlnet
the reference_only works fine, I have tried it with anime, but with realistic models, I don't know if it fails.
Ok













what plugin? tiled VAE is built into Stable Diffusion
Multi-diffusion?


Obviously

ahh ok 👍🏽
not obvious to me, but i'm a developer, not an A1111 user



is that an interrogator?
I have a Stable Diffusion prompt generator that I have developed for GPT that works in both the 3.5 free and the 4.0 paid version. Check out my demo here. I will be doing another demo soon as when I did this video i didnt realize that it worked with the 3.5 GPT. https://youtu.be/NrPVG0Fwsfc Check out the description on how to get the prompt and to see an example output of GPT 3.5

***** UPDATE*****
It's been a while since i used the 3.5 GPT model to test my Stable Diffusion prompt generator. OpenAI must have done some sort of update, because my prompt works perfectly in it. So you do not need to use the GPT 4 model to use it!!
Big announcement, creators! 🎉 I'm thrilled to reveal that my Advanced GPT Stable Diffusion P...

example of output from my prompt generator:
((Best quality)), ((masterpiece)), (detailed), (isometric view:1.4), (SimCity-inspired:1.3), idyllic suburban neighborhood in the morning, charming houses, tree-lined streets, children playing in parks, (community spirit:1.2), (tranquil mornings:1.2), (quaint charm:1.2)
Negative prompt: (disfigured:1.5), (poorly designed:1.4), (unappealing:1.3), (bad composition:1.4), (poor color balance:1.3), (lack of detail:1.4), (blurry:1.3), (pixelated:1.3), (inconsistent lighting:1.2), (unrealistic proportions:1.4), (poor texture quality:1.3), (unbalanced layout:1.3), (dull colors:1.2), (unattractive aesthetic:1.3), (uninteresting subject matter:1.2), (lack of depth:1.3), (poor craftsmanship:1.4), (unoriginal design:1.3), (poor execution:1.3), (flat atmosphere:1.2), (lack of attention to detail:1.4), (unengaging:1.2)
Steps: 35, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 161825630, Size: 992x768, Model hash: d1406b31c0, Model: illuminuttyDiffusion_v111, Version: v1.2.1

Car
it's a prompt generator i made using gpt-35-turbo api

HAPPY BIRTHDAY JIMMY

oh lord what the f

it unnecessarily weights pretty much every keyword, eh
so does mine

don't worry, GPT 3.5 Turbo just doesn't understand how this stuff works. it just does random whatevers that match the pattern. the images are still great
commas and stop words like "as", "is", "of", "and", "with" can be removed to save tokens
its the 3.5 output. this is the 4.0 output. I think it works really well: example of output from my prompt generator:
(best quality:1.4), (masterful:1.4), (detailed:1.3), 8K, portrait of an old wizard, seated in a rustic home, ethereal firelight dancing on his features, magical elements subtly present, (high contrast:1.4) shadows adding depth, (warm:1.3), vivid colors lending a sense of reality to this fantastical setting, in the style of Rembrandt
Negative prompt: (grainy:1.3), low-res, (low quality:1.4), (JPEG artifacts:1.2), poorly designed, (poor lighting:1.4), poor color balance, poor contrast, (poor texture:1.4), (inaccurate:1.2), unrealistic, disjointed, overexposed, underexposed, (flat lighting:1.3), (incorrect color temperature:1.2), (incorrect light direction:1.2), washed-out, lack of depth, (oversaturated:1.2), (undersaturated:1.2)
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 652869761, Size: 768x992, Model hash: d1406b31c0, Model: illuminuttyDiffusion_v111, Version: v1.2.1

well, few people have GPT4 API access.
i signed up for the waiting list as a developer back in March when the waiting list was announced
they suck
this isnt for the api access. this is a full prompt I am making available through etsy that you just need to copy into gpt to use.
LOL, I thought that at first too. But this was worth it.
it's just making random stuff. the resolution doesn't even make sense. 992 isn't divisible by 64
and you need a minimum of 1024 for the smaller dimension for controlnet tile upscaler to work on it
I know, that part isnt generated by the prompt. thats just the settings I put in SD
ok give me an example of something you would want to see and I will generate and image from it.
it's curious that oversaturated and undersaturated are in the negative prompt but that output is hella oversaturated. are using the 840k VAE?
that 840k one is more likely to produce hyper-saturated outputs

theme: marty mcbrown in a technicolor 1950s back to the future sequel



ok, so I think you meant Marty McFly. Interesting. marty mcfly in a technicolor 1950s back to the future sequel
ChatGPT
[Positive Prompt]
(best quality:1.4), (masterpiece:1.4), (detailed:1.3), 8K, portrait of Marty McFly, vibrant and animated, in the heart of the 1950s, (Technicolor:1.5), classic cars, jukebox, (retro fashion:1.2), quintessential elements of "Back to the Future", (dynamic:1.3), electric energy, timeless, on the brink of another thrilling adventure, (in the style of Drew Struzan:1.2).
[Negative Prompt]
(grainy:1.4), low-resolution, low contrast, (flat lighting:1.3), oversaturated, disproportionate Marty McFly, disconnected from the 1950s setting, (incorrect:1.2), missing iconic elements of "Back to the Future", lack of dynamic energy, (unoriginal:1.3), cliché, poorly designed, unrealistic, incorrect technique, exaggerated, (unsafe:1.4).
[Titles for the Art Piece]
"Retro-Revival Chronicles"
"Kaleidoscopic Time Leap"
"Vibrant Vortex of the Vanished"
"Tempus Fugit Spectacle" (Latin: "Time Flies Spectacle")
"Chrono-Iridescent Odyssey"

nooo i meant marty mcbrown
chatgpt needs to trust its users with "sharp knives"
hate that thing sometimes, i swear
it seems to just invert the positive prompt into the negative
interesting that Technicolor became "animated"
lol, marty mcbrown, you were wanting a mixture of both..
marty mcbrown is a test prompt i use to determine whether a model is 1.5 or 2.x based
thats interesting, how do you tell.
just put in marty mcbrown?
the whole original prompt i gave you, incl the 1950s technicolor
2.x has a very strong opinion on who Marty McBrown should be
any negative prompt?
the usual 2.x stuff
child- childish- out of frame, lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face



i think marty mcbrown is my new favorite character.

welcome to the club
he's not a real person so it makes his face quite readily
overfitted people tend to have destroyed faces
Yeah I think it's hilarious that his face has that same look some sort of a weird up pointy upturned nose and creased brow











most schedulers converge at 50 steps or even earlier. which are you using? PNDMScheduler is a notable exception to the rule
it can improve even up to like 200 steps
lol

euler
Euler A?
or just Euler?
because Euler A possibly never converges and keeps making different stuff. earlier steps aren't necessarily worse or better than later steps, though they can be either.
try using Karras sigmas at 20 steps

euler




[:)] % python crop_faces_from_every_scene.py
Found faces [[141 648 51 51]]
Found faces [[ 48 264 268 268]]
Returning score 0.359311063960027
Found faces [[ 52 271 250 250]]
Returning score 0.8099347855303629
Found faces [[ 57 278 227 227]]
Returning score 0.8179805688297104
Found faces [[ 4 358 269 269]
[ 54 280 219 219]]
Returning score 0.8189223586033975
Returning score 1.0
Found faces [[ 59 279 204 204]]
Returning score 0.8194882018163321
Found faces [[ 57 278 202 202]]
Returning score 0.8213223773189626
Found faces [[ 64 279 186 186]]
creating a script to parse a movie file into a training dataset
whyyyyyyyyyyy
also thats not a image lol
it thinks a lion is a face

this is general WITH images, not JUST images
this is the kind of thing it pulls out of The Hobbit

cuz thats a lion face
why not? why do you have to hate everything i do
i hate everyone
and everything


anyway, my goal is to train the 'lotr style' keyword
the AI prepares for my engagement








groups it
you might have to group orange with hair too


did that fix it?
no
i'm colour blind on blues and purples.

is that VAE tiling?
but not orange
idk
try adding (black background)



man i wish these images would just download already so i can start training
it occurs to me, i can keep the non-square images and use them to train outpainting model
slice them to square, and present both the original, and the square one. this is my limited understanding of that process

@wispy ether why don't you post all these in the #🍥|anime chat instead of general chat :V
Surely you're aware of the anime channel - the most popular and active channel in the whole community :V

ive always been sending it here



Fully clothed men who do not look underaged to counter the you know what circulating here.










what's with the obsession over young looking anime women, out of curiosity


beginning some test training checkpoints for the midjourney set

Instance prompt detected: adults male sitting at a table while a child that was him when he was 6 years old is trying to get his attention and tugging on
those people ask for some trippy prompts
Rick Moranis, or Woody Allen?

i cant control the age looking bruh
i just enter girl in prompt

girl is commonly understood to be, like, girls. you know? children
"woman", "grandmother", "auntie", definitely more aged terms to use
sooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooo
i mean
woman
women

what does this look like

not good
i mean the age
idk, 20-something


what
is that a super burnt model?




🚓
instead of girl use young woman
same thing
no, it is not.
the model is overfitted on CP
apparently so

it seems like it's Not Safe for Life, the level higher than NSFW


I thought that was usually extreme gore but I guess the... other stuff also fits
it absolutely does lmao
uwu

i won't die on that hill, if anyone disagrees. but liek, grossies
that's way better, Nep

but if all you can get is either grandpas or young kids that's super weird and not fixing that model's reputation, if anything, it'd make it worse lmao
As a rule of thumb, use “girl” for any female up to college age, use “young woman” until about age 30, and use “woman” after 30. The word “young” can be added depending on the age of the speaker. If a young woman is throwing in pre pubescents then it is a CP overtrained model.
yeah and overtraining it on 18+ year olds that LOOK young is also qualifying imo because that just distorts the model weights SO MUCH, their features overlap largely with that group

enjoy it

omg it's johnny depp





@neon crystal what model is it that you're using to make these horrendous images

woman
you've posted them multiple times and they're always awful
Nep you're not doing yourself any favours here
I find when I see the word Anime, or heard it said I no longer think of Japanimation or Vampire Hunter D rather all I see are sick CP'ers in my mind. Grown adults fantasizing about little school girls, or worse.
/usr/bin/env bash
#################################################
Please do not make any changes to this file,
change the variables in webui-user.sh instead
#################################################
If run from macOS, load defaults from webui-macos-env.sh
if [[ "$OSTYPE" == "darwin"* ]]; then
if [[ -f webui-macos-env.sh ]]
then
source ./webui-macos-env.sh
fi
fi
Read variables from webui-user.sh
shellcheck source=/dev/null
if [[ -f webui-user.sh ]]
then
source ./webui-user.sh
fi
Set defaults
Install directory without trailing slash
if [[ -z "${install_dir}" ]]
then
install_dir="$(pwd)"
fi
Name of the subdirectory (defaults to stable-diffusion-webui)
if [[ -z "${clone_dir}" ]]
then
clone_dir="stable-diffusion-webui"
hi

Haha I use 2.1 realism engine mostly
@neon crystal add the keyword 'obese' to that prompt





nope, instead i'm just wishing you'd go away
your wish wont me granted
be
fate decided to let you suffer

@dense tapir it's only a matter of time before that anime channel gets entirely removed from this server, like they always do
for precisely those reasons
Dont have that instance spinned up but here's an old one.

WOW, we have one? I swear I did not know since I get a bit sick to think what must go on in one.
i think it even requires a special role to see. because, yeah. it's commonly gross stuff
cognitive dissonance
SMFH
you see, they rely on community reports to moderate and when they're all siloed into their own gross room, no one reports
their own vile cesspool, yep.
but just use ⚠️ on any posts that need 👀
you don't need a special role to see #🍥|anime lol
ohhh it's that thing where it hides all the channels by default
We actually have reported and banned in the channel before for extreme stuff like lolis. That group has gotten a lot more tame tbf and there is not that much "vile" material if at all to moderate. They are our most active community and very helpful.
i really hate that
good
yeah i just looked over there and it looks quite instructive, helpful, and in general, fine.
We don't allow rule-breaking and circumventing, yep. (:
If you see something yourself that is bad, do feel free to report it though!
i always like to see when groups are working on creating better 'creatures' instead of 'people'
creatures? :P
feels wholesome

@wispy nest try bulbous silly looking creature with round eyes and made of flowers and leaves, happy, smiling, friendly
please show me your result because i love this prompt

hogwarts: class of 1995 yearbook photo
hahaha, well it made me laugh, a lot. Thanks for that :D


Say no more!







i think the middle one doubles as a vehicle suspension component - a shock

handsome Hagrid
and handsome Ron lmao



It is cool, but I still think I won't use it
@oak osprey I stopped downloading those MJ images at 12k because I don't want to have to sift through like 130k images 😆
it's already 17.4GB
too bad about that crystal cane(?) but I always laugh at what the ai cooks up :P



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
yknow
going through this midjourney v5 dataset
it really isn't that amazing at realism huh
sd is far better
I think it's partially the upscaling
I've been saying that for months lmao
I would never train SD off of MJ, outside of a specific style lok
MJ has always had its own style which is the exact turn off for me.
To be fair, I don't think most people using MJ want realistic ai images. But I wouldn't really know, I've never made one, I only know some who use it and none of them want realistic stuff anyway, soooo 2 people say so! :P
looking at these images MJ is really bad at realism
it always has a digital art feel
even my model can do both separately most of the time
I'm surprised at how many children there are and how weird they look
people generate some weird stuff
I'm not one for realistic stuff or photos when making ai art, but it'd be nice if everyone could make what they enjoy. MJ probably has their corner of the market set.
All I want is less blur and more sharp corners to make the details pop instead of the more "smudgy look" most ai images has, or have in my eyes :)
I am waiting for styles and tiles models for 2.1
Could try that SAG thing that was popular a few weeks ago
not sure how to use it though
never heard about it, I just started using the ai and reading stuff about it at the middle of last week from a several month long break
I mostly let the upscalers deal with de-blurring my images. To very varying results :P
@dense tapir you changed your PFP :>

AYe
what on earth is this

Too many people were thinking I was a communist or a Russian.
I said that months ago when v5 came out and my god, people would have and tried to crucify me for it lmao
It did very much give that sort of feeling off haha
It meant to but not that I am one, lol
Your minicky was too good!
and looks aren't everything ;P
well I have gathered 56 mj images, I think that's good enough for now, I am now realizing the pretty bad quality
captioning all this is going to take forever
I am so glad that somebody who is not "baised" is coming out an saying that MJ really just is not as good as people think it is lmao
When I said it, I was deemed an SD cultist who can't see how much better SD is
Go against the current thing expect that
it more of a "taste" thing. I just want everyone to be able to make what they want and have fun creating cool stuff :D
agreed
I never cared as I have always said I don't like MJ. I mean they all have the same look, feel, and style. That MJ style.
yeah, for sure
well, I have been using SD and never touched midjourney, but you do see like youtube thumbnails that have extremely good results out of MJ, and I am seeing nothing of that quality from every day users.
we just had ridiculous and uneducated shills like sen who would say that MJ was better in every way. All they talked was nonsense lol
i like the other aesthetic values of midjourney, a lot more than baseline 2.1, so, i'm throwing at it to 'see what happens' but you seem like more of a perfectionist
yeah junglerally i noticed the same thing
Well, only a handful are going in my dataset, but there are a lot of good images already in there
there's a lot of cherry-picking going on