#🏞|general-with-images
1 messages · Page 41 of 1
Probably user error then but I cannot check it since I just got off 😅
Ok let me know if it works later
You should be able to get nearly the same image with same settings
Oh wow, a BOY
something rarely seen in this server
Color me perplexed
very nice gen, he looks quite nice
Im sorry I didnt bring you something more unique /shrug
oh no no no, I was meaning these servers are always full of pretty girls haha
I wasn't being sarcastic, sorry if that came off that way 😅
its just usually conventionally attractive women/girls is all
yeaahhhh
I mean it gets repetitive 😹
I hate the current state of most models for SD
Hey there, I have the following use-case but I can’t figure out what could I do to make it work.
I have this dataset of artistic patterns, and I would like to apply “texture transfer” from the patterns to some objects. E.g: I have a camouflage pattern and I would like to apply it to a sweater.
Do you know of something similar that has already been done? I would very much appreciate your ideas. Thanks 🙂
Whys that?
Is it because they’re all anime girls
The sheer amount of young/illegal looking girls in very inappropriate situations
its just gross IMO
I definitely agree with you
100% agreed
models like chillout are so over focused on "barely legal" looking girls that even LoRA's of women in their 40's make them look like they are 14 with extremely sexualized proportions. Blegh
I am all for NSFW and freedom of generation, but not when its so blatantly in your face. Can't get a woman past like 22 in those models
Oh yea for sure
The amount of prompting you have to do to get a woman is just insane for most of these models
Its boring too
It all starts to look the same after a while
yeah, and I am not even just saying that cause I am not into women. I feel 100% the same way for models that do it for guys, cause some do
I like realistic vision primarily cause its extremely good at getting ages
if I say a man in his 40's, it nails it
Thats good
man in his 70's, nails it
I dont like any animes but I do like the art style most for AI so its a shame 90% of the models are for the same thing
I also dont really understand how you can be sexually aroused from a cartoon but that’s just me!
It's a side effect of mixing with anime models. Most anime characters look quite young by the very nature of the anime style (not even factoring in actual young characters in anime) and most models mix with at least some percentage of anime models
It seems, that it’s incredibly more common than I thought, looking at the most popular ai models
Ah true
Everyone in anime does look young huh
that's why it's less pronounced(sometimes even completely absent) in realistic ones. they aren't usually mixed or trained on anime
This may be because I dont watch anime but I kind of get the vibe that a lot of the characters look exactly the same from what I have seen
That is exactly why I made my own mix between faetastic (gorgeous colors, tones, and offset noise) and Realistic vision 1.4 (fantastic realism, detail, and compositions)
there are definitely dominant styles, but occasionally you find some quite unique ones
Could I check it out? I’m new to this stable diffusion stuff
I could try and send it some way. i am a bit busy at the moment with my guide paper tho
its not done, but I could see about it sometime soon
Well just @ me whenever
This new process demo image I am working on is really flexing how good this new process works, sheesh
honestly i'd say there is about as much variation in japanese animation as you'd find anywhere...it's just that a lot of the most popular ones sometimes share a specific style. there are exceptions though. take something like Mob Psycho 100 or JoJo's Bizarre Adventure and you notice quite a few differences between something like that and, say, My Hero Academia
I see
(all shonen examples, just to emphasize that even within the same genre you can have wildly different animation)


Yea i probably havent seen enough I guess
Most animes I have tried watching i have disliked
I continue to shock even myself with how much this new process is able to refine detail 😅
Danm detailed
Yea thats incrediblr
Incredible
How’d you do that?
thank you!
Working on a guide as we speak. Its gonna take a while, as I had a lot in it, then made a huge breakthrough that caused me to restart the whole thing 😅
ETA is hopefully within the week
this is only ~4k, I know I could go to 8k with some tweaks

and I have a 16k gen from a while back, but it has a lot of problems with seam issues
I cant even use hires fix so my pc def couldnt do it as good as yours
its 15360x6528 IIRC
Jeez
That's where you are wrong
this process I am doing can work on anything that can run a 512x512 gen
what it does is it takes the image, breaks it up into a ton of smaller tiles, generates them, and stitches them back together
I am doing these gens on an 8GB GPU
the upscale to 3072 took 98 seconds, or 1 minute 38 seconds
Wows
well, for the final upscale, all together its a sub 5 minute process from 512x512 base if you know what you are doing
but the benefit is it needs 0 high res fix, its straight out of base res
so you can do this
When your guide is finished, please send me a dm with it if you can
Im very interested
Bad timing but I have to go now
generate a ton of base images super fast, then find the one you wanna upscale

Thanks for talking with me though
no problem, and it should be uploaded into the official reddit, and hopefully pinned in the #1003034183716835418 channel at some point
oops, I deleted the hair close up
here it is again

miskicked when scrolling 😅


"Facerestore"


@smoky oak Well, Nvidia leaks talking about the new 5k cards is not good.
the leaks are probably just clickbait nonsense a youtuber made for ad revenue. the 4 cards had just come out and are nvidia's best sellers ever
Oh ffs. You sound like flowwolf.
What we do know from Jensen. TSMC. 3nm. Redoing from the ground up. 2-2.9x faster than 4090 for the 5090. Price? Unsaid but only a blithering idiot moron would think the price would be less. Pretty safe bet it will go up. Even TSMC said the die costs will almost double per wafer sheet going from 4nm to 3nm. Not rocket science there.
This is what i meant before. #1011228477954998273 exists. instead of dropping gas bombs about gpus in gen, knowingly trying to light conspiracy theories up, go there and do it. Bringing up a topic just to get offended about it. not uncommon gamer behavior around gpus in general.
 In most modern civilizations, it is believed that cows are the secret source of all magical powers in the world. Their spirits have the ability to connect together, and through the force of this mega cow-science, a magic milk is formed, source of all moo-diclorians.
In most modern civilizations, it is believed that cows are the secret source of all magical powers in the world. Their spirits have the ability to connect together, and through the force of this mega cow-science, a magic milk is formed, source of all moo-diclorians.
I post where I wish to post I will be be god damned if I allow any mother fucker to tell me other wise. I post in here because I know the people and I don't give two shits about any other channel or who frequents it. Besides, it wasn't directed in general to all only to one and if others wish to chime in great.
this is weird energy. i just replied about the 5 leaks. it's just rumors and conjecture at this time
dont have a cow man xD
I am saying what we already know
sorry
2+2 is still four no matter what core math says
nobody better lay a finger on my cow's finger
I suspect the rumours out there will be true but how true, especially about price, I don't know but damn Jensen as I suspect the prices may even +50% or worse +75%.
market value is a thing. If they're selling so well now, they're under valuing the cards. They're the best selling nvidia card generation yet.
He could get a way with it if he can get it to live up to his 2-2.9x faster
if the cards stop selling, prices come down. howthingswork.com
Dude, that is fanboy talk
its market economics
Outside the 4090 the others are rubbish
we are coming to an era where computing power will be really important to lots of AIs running; it should continue to increase, even with the downwind of crypto, as years go on
hell, the 4070 hit with a thud
and yet, still best sellers outside of 4080 which is still outpacing the 1080 generation
Not what the retailers are saying and what Moore's Law is Dead is reporting and he doesn't report stuff he doesn't have sources to back up.
4070 was a slow start. It's gotten going now. We got to recognize that jan and feb are the slowest retail months consistently too. unless you're just going to weave conspiracies then for those purposes, ignoring slow retail sales annually serves well
Copium? The 4070 just dropped as I said 4070 not 4070ti
People will wise up if they purchased anything short of 16gb as they are already starting to get mad.
Game companies said 12gb will be the bare min on future releases even for 1080 which is just wow
sad is they expect cards to have FSR and DLSS to take up for their non optimized code too but it is what it is
ooo you got me there. hahaha. not sure why a personal attack though? don't be so aggressive about gpu conspiracy theories. Exactly the gamer tude i'm talking about. These conversations lead to bans in general channels all across the discord spheres because gamers can't help themselves. it's always gotta be personal.
You're lucky you've got #1011228477954998273 here. The mods don't want to squeeze out the angry gamer crowd. Should maybe dial it back cause calling it copium or motherfucker this and that, it's just angry gamer energy that usually ends up booted out.
clearly i'm not a mod here, but i see this on so many servers and of course gamers come back an claim "i was banned because of an opinion!"
Know what? I don't game so I don't care about that aspect I just depise the situation and I don't let anyone tell me to go anywhere on a discord.
i only been here 3 days an its always nvidia is the worst company in the world conspiracy theoires when i pop into gen. gets old fast. like, a year ago.
Well, AMD is no saint
The thing is there is a video clip of Jensen in 2011ish saying what he intended for Nvidia and making it the people card we can all afford etc.... to seeing him today. SMH.
He changed fast when the mining craze hit
probably would be contingent on nothing changing in 12 years at all. or crypto. 2011 digs deep for a conspiracy about a corporate strategy
6 years before they got all that nintendo switch money
He got big and changed he got greedy and opulent that seriously needs to be taken down only no one yet has the ability. My hope is it will come.
"Businesses should never react to market forces" seems ilogical, but maybe that's not your actual position. anywyas, this is why its often good to boot conspiracy discussions to another corner of discord. It's just garbage usually. Almost like it parodies itself
As Moore's Law is Dead said AMD could run without their CEO but Jensen IS Nvidia. I see it the same way.
Moores Law is dead doesn't mean advancements don't happen. It means the transistor count isn't increasing at crazy rates anymore and we're entering another paradigm.
FLOPS are still on the rise
that is the name of the channel. He is VERY reputable.
oh. a youtuber. of course.
VERY reputable
popular channel probably pulls in 14k monthly tho
yes, unlike a lot on there or any of the legacy media stooges from CNN/MSNBC/BBC/CNBC/CBS/PBS etc...
300k subs. okay depending how pop they are maybe 5k monthly
You sound so bitter. Did you try and not make it or do you just have issue with someone who makes a career out of industry news and topics able to feed their family?
more with personal attacks? why? @glossy herald this is what i mean. gasbombs and then constantly trying to rope it back to a toxic argument. why can't we just stick to the topic? it's not just here. It's every gaming general chatroom.
Now i think i understand why. Popular channels like this "mooreslawisdead" are lighting up gamers like they're Keemstar. It's dramaalert toxicity in a different outfit.
gamer nexus is another keemstar style chan
You sound exactly like flowwolf. You attack his reputation, and you did, and you constantly talk down about youtubers, as flowwolf does, then I bring that up and I am attacking you? Pot, meet kettle.
Let's not attack both ways here. let's move the subject either to PMs or to something else.
The last few messages alone show animosity from both sides. I'm not going to decide who is correct in the argument, this is not my point, but language needs to be kept in check for everyone to keep in the conversation.
So let's move away from this subject if its hard to keep it cool, or move away from public chat.
i'm not about to pm this guy. he's figuring im' some other guy that he doesn't like. that's baggage i'm not about at all.
then block him and stop continuing to both feed the animosity of the other
this isn't a constructive talk you are having anymore
maybe i'm not feeding him and he's engourging himself? food for thought!! (see what i did ther?)
I'm saying this for both of you, but you are still returning what I'm saying against him. I'm asking for both of you to stop attacking each other. He has right now.
granted, i'm annoyed that he's got all this baggage hung up on some guy, but i'm lumping him in with all the cliche toxic gamers i'm annoyed by. I'll check myself surely. walk on the beach time
I'm thankful for this 🙂 and I do hope this doesn't come as too preachy. ❤️

Lmao that was a classic discord conversation
I'm still testing prompt tags, just now I took note that "sexy" + "Jar Jar Binks" is not recommended.

Damn sexy beast thing there.
And if Jar Jar Binks and Chewbacca had a child.

Now that is scary

Beautiful girl found on unprompt.ai

Darn those new advert bot's pushing for that scam site. It have many images, but it try to get access to clip buffer that may contain psw.

I was about to comment on the GPU scene as the two above were talking on it, but it seems neither of them can have an actually constructive conversation, so I'll leave it at the real world findings of how terrible 4xxxx series is outside of the 4090
The 4070 specifically is quite pathetic. There have been several benchmarks showing how the 3060ti is basically identically fast. But with less VRAM. Before anybody attacks me saying that's a stupid claim, that's what had been observed. It has more cuda cores and more clocks but that ≠ faster or better. In fact in this case, it means far from that as it suffers from a constricted VRAM bus width which, at those new much higher clock speeds, greatly choke the per clock calculations and lead to basically a bloated 3060ti with 12GB VRAM for about the price of a 3080
Jensen may try all he wants to say that VRAM bus isn't that big of a deal, but it very much is. VRAM speed is still 100% what you overclock if you want better render/mining/upscale/diffusion performance, as the calculations are not big,b it rather a monumental collection of small little calculations
The 4070 is a mediocre card at best for gaming. It offers on average 26 percent better gaming and computation over the 3070, for about 25% more money.
The only major benefit of the 47, of which I'm sure most people don't even care, is that it is a very efficient graphics card, offering around the performance of a 3080 for the power draw of sub 200 Watts
I thought was good result. First post here, be kind (or not, it is not my art anyway)

and with similar prompt:

These are good base generations, I would love to see them at higher resolutions
Safe to say I think you've stumbled upon a cool mix of styles
Almost like a watercolor photo hybrid
YAWN
They are ink and watercolour. How do I increase resolution? Shall I pass one of the above as input and...
I don't know how that happened but you are right
Each day I am inching closer to my upscale guide, ETA is currently within the week, but they should be excellent candidates for my upscale process
Where will I be able to find it?
I will be posting a guide to reddit, and I hope to try and get it pinned here in the #1003034183716835418 chat once I prove its effectiveness outside of myself
hi guys, today is my first day for using SD, I have a question with it, when I try to use the SD, it show (AttributeError: 'NoneType' object has no attribute 'memory_stats'), how can I fix it?

I change it to lowram, but still showing again
no
care to show the error message before the first line you screen capped?
btw, my computer is AMD
I read it briefly and it seemed a bit involved but I cannot help beyond that
I flow an youtuber using an AMD system
ah, AMD
so sad
that could be your problem right there unfortunately
oh, it is done I just do not know exactly how as it takes a different set of files
am i going to change to Nav?
On reddit I saw the thread on what AMD users must do
AI is a big crash for Interior design
one thing is you can't use xformers
😩
can you send me the link, pls

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
thank you so much!!!!!!!!!!!!!
saw it
Hi i have problem with installing 1111 . i did install python but i get these errors what should i do ?
ERROR: Could not find a version that satisfies the requirement torch==1.13.1+cu117 (from versions: 2.0.0, 2.0.0+cu117)
ERROR: No matching distribution found for torch==1.13.1+cu117
LONG CAT @glossy herald

El Naranja Flopper








New demo






When using control net, I only see the outputted image. I want to see the canny or open pose data as well. How do I enable that? I should be seeing an additional file created by control net.

You are not using a preprocessor, so I'm pretty sure it doesn't output it cause there is no output
also, are you making wedding photos of... children?...
What do you mean no preprocessor? How would I add a preprocessor? Also yeah...looks like the age is all wonky 🙂 Just trying out the pose, didn't really think about the prompt
ah lol
and nevermind about the preprocessor, I am not sure why that is behaving like that
It looks like when most people use control net, it by default spits out the map. But I'm wondering why it doesn't do that
Some setting here needs to be changed maybe?

With ControlNet, the preprocessing part is used to submit a normal image, then it transforms it into Canny, Depth, OpenPose, etc...
If you put an image already worked, do not choose preprocessing. You must leave the field empty and leave only the choice of the corresponding model.

Hey thanks for the reply. Looksl ike something is still missing. I tried your suggestion but am still just getting the result, but not the map info. Anything else I could try?

maybe update auto1111 (git pull), and update extensions in extensions tab
Can't go wrong with a little Lambo action.

tried that. Same thing. Using the latest versions.
uncheck restore face, maybe.
Either way, I really don't recommend using it.
Send us an image of all your settings.
Nice!
Where can i get ai to create image suggestions for me?
chat gpt can do it for you
BingAI (GPT4) is free
chat gpt cant create images
Clear, thanks!


Personally, I use this statement that I made, I copy/paste it into a new BingAI tab, then I ask him "give me a prompt from Legolas, in the Mirkwood forest, with a bow, the forest must be obscure and distressing, etc...", if the result does not suit you, you can suggest things like: Be more precise on the details, be more creative, while remaining coherent with the context.
`Voici ce que l'on appelle un "Prompt", pour designer par de simples mots clés une scene, situation, avec details : "Sylvanas Windrunner, an elf woman, with a bow in hands, quiver with arrows inside, a outfit with hoodie, light armor bra, armor, cape, glowing, helmet, holding, holding_weapon, navel, thighhighs, from Warcraft video games, surrealistic elven city, at night, moon, in a surreal forest, best quality, overgrown, highres, realistic, impressionism, epic, best quality, highres, close-up".
Dans cet exemple, cela décrit une image avec Sylvanas Windrunner, une jeune elfe avec diverses armes et armures, et un decors en arriere plan. Egalement, quelques traitements d'images sont indiqués.
Tu ne dois pas decrire des odeurs ou sensations, car les prompts sont fait dans le but de donner des instructions à une IA pour créer des images. Ne soit également pas trop narratif, les prompts doivent comporter tout au plus, de simples petites phrases comme « A dark skies in the background » séparées par des virgules. Tu ne doit pas mettre de point « . » dans tes prompts. Les prompts doivent etre en anglais. Tu dois, lorsque tu m'explique quelque chose : parler français, tout en mettant tes prompts en anglais.
`
upload un imgur or something else please, can't open them in my browser, bug and low res
Well, decided to say forget the Lambo and go McLaren instead....lol

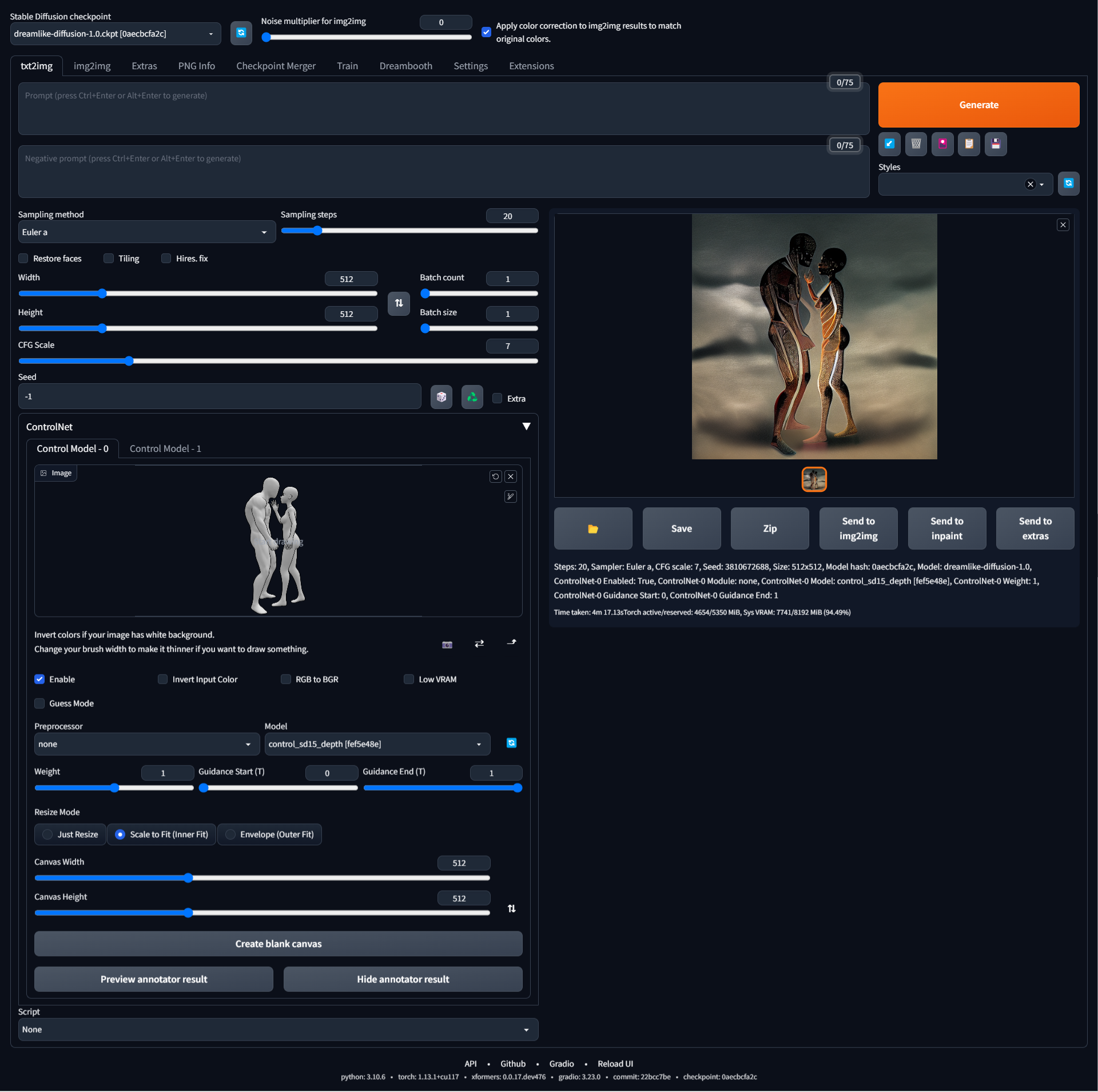
I don't see where it could come from, try my settings

Holy #$^& that worked. You are the man. People, respect this guy. He is awsomne!
One last thing. I've noticed that whenever I switch models in control net, it takes forever for the first image to generate. 5ish minutes sometimes. But then after that it generates images quickly. Any idea how I can speed this up? Issue is only in the control net models, not talking about the checkpoints.

pushing xl 2.2.2 to its limits 










desperate to get my hands on the actual model
Just hoping its not another 2.x failure
🤞
i did this on dreamstudio
its coming, the team is very focused on delivering a spectacular and usable model
The model may be great, but its useless if you can't train it like 2.x
I am hyped from what i tested. SDXL base blew all the others out of the water from my dozens of tests, but its gonna be worthless if you can't easily train it
once its open source there will be nothing stopping anyone from fine-tuning it
wish 2.0 and 2.1 were like that lol
instead, they are extremely difficult to fine tune
Mistress Mommy sexy in a black latex suite whit a whip above a slave petguy , 8k resolution , ultratexturized realistic scene
The more I look at these results, the more I am excited for the future of SD, but also skeptical to the usability. I am waiting for a bombshell that says that SD needs like 16GB VRAM now or something 
this is an XL model, so it will be 2.5 times bigger than the 900m parameter model everyone uses right now.
And there is the bombshell. Assuming anybody not on a 3090/4090 won't be able to run it then, as I suspected. What a shame
its in the name. It's marketed as an XL variant. it's not 3.0
So SDXL is based off the same stuff as 2.0? or am I misunderstanding?
XL is quite a different architecture from 2.x, lots of stuff added/changed. and the final model will be trained/fine-tuned on very different data compared to 2.x.
Ok, thats good to hear at least, even though almost none of us will be able to run it
Just to clarify, I am not upset with you guys for that, thats not on you obviously
stuff can only get so small
more upset that the purposely gimped VRAM on NVIDIA GPU's will now force people to have to buy even more expensive GPU's
Ahem...should be an easy fight, right? Boss is only level 150. No issue.

lol
Didn't we all think that about 2.x? 😅
I have tried to train 2.x so many times, but its just not worth it. I love 1.5
I am more interested in the text encoder aspect of SDXL than the parameters
cause if we could have 1.5 that just understands what we are saying way better, I would be over the moon
those things go hand in hand, no?
you can already do 4k gens in 1.5 no problem with my guide
No? 2.x is the perfect example. I believe its the same size as 1.5, but its terrible at listening to what you say cause its text encoder is all bad and stuff
However, that could just be a byproduct of not having good fine-tuned models for 2.x, but then again that comes down to the fact that it's nearly impossible to train it because the text encoder is such a pain to deal with
Please, feel free to correct me if I am misunderstanding why 2.x is so problematic for fine tuning.
I'd actually genuinely really love to know
On paper it should be better than 1.5 in every way, but in a practice it really just isn't, at least with what we've been able to do with it so far
In the works currently, should be released fully within the week
It will be released on Reddit, and hopefully pinned in the #1003034183716835418 channel. I could potentially make a video on it, but I'm not too sure how I feel about that right now.
It's an intricate process, however it's not particularly hard. There's just a lot of variables to understand in order to get it to work the way that you want
Here's an example of what it can do. Left is the base 512x512 generation out of stable diffusion, and the right side is a 3072 x 3072 upscale of the same image using my process


I did not color grade them, they are only different in color because I'm not utilizing any form of image to image post-processing color correction
bear with me but as far as I know one of the differences between 1.x and 2.x is attention heads? I think there were differences in the UNet but the biggest difference is the use of OpenCLIP, which just doesn't have the OpenAI magic "sauce" which might be what you are referring to.
I'm not Robin so take my analysis with a grain of salt but it might be that you are referring to just the lack of cohesion from whatever OpenAI had going on. SDXL is very different in this regard.
Yeah, I get what you mean. I tested the hell out of SDXL compared to specifically 1.5 and was able to see that SDXL missed less than base 1.5 hit. It really was quite impressive
SDXL seems to listen astronomically better than all of the previous ones, so one can only hope that translates into being able to train it, unlike 2.x
I haven't trained 2.x, but I'm not sure why you refer to 2.x being hostile to train. Nothing suggests that it would be more "difficult" to train, quite the opposite in fact.
it should be slightly more capable
hi Sytan
I as well as the vast majority of people that train are never able to get it working properly
in fact, even a lot of the mods here are vocal about choosing 1.5 over 2.x cause 2.x has an insanely high loss rate, and often errors out
2.x also has a problem with stretching
ah I see
As Dogu Cat pointed out, he trained a LoRA for 1.5 and 2.x, and the 1.5 LoRA came out way better, whereas the 2.x one is squished for whatever reason even though it uses the same images
You can see it here
one of his 1.5 test images

vs the 2.1 ones

they are very stretched for some reason. 2.1 has a huge problem with warping things

you can use specific techniques like bucketing to help this i believe

even if that was the case, all I am saying is you do need some extra stuff ontop of 1.5 in order to get something as good, which typically isn't how I go about an "upgrade" 😅
but there has been specific work done on SDXL to fix this problem
thats very good to hear
again, I am super super into SDXL, I just reserve my feelings on training it for now is all
I have seen the amazing results I and other people have gotten out of 1.5 and its crazy to look how terrible the base model of it is (I understand that its not meant to gen on, but rather finetune)
so seeing how good SDXL is out of the box only makes me imagine what it could do if we finetuned it to the same extent as 1.5
Is repeated faces even a problem anymore? I have had no problems with that really ever
not quite sure what that entails
oh, its a base model. If you saw how terrible the other base models were, you would understand how much better SDXL is 😅
I would send my comparisons again, but man that would take a lot of time and flood the chat again 😅
blegh, high res fix
I will never touch high res fix again
Its just really bad for any form of consistency or coherence, and it also produces some pretty poor looking images on average
was that the image before high res fix?
the one above I mean
here, I can show you why high res fix is bad
Base image

High res fix of that image

it changes the whole composition and adds stuff where I didn't want it
if I am gonna high res fix an image, I want it to look like the base image
and then we have my upscale technique:

basically the exact same composition, but higher res/detail
mine is a drastically higher resolution photo
like, thats pretty high res 😅

thats only 1024
also, out of curiosity, what model are you using for such realistic images?
I could give my process a try
Very interesting, I use realistic vision and it never looks that realistic
very very interesting
lets see how well their negative works
Wow, what the heck am I doing different lol
like, my results look good, but not exactly like photograph photographs
those images would look incredible with my upscale process
investigating
@stone cipherWould you be willing to give me some insight into your prompting in DM's so I can use it to test my guide? Having such realistic images could be a very useful thing for beta testing
What's the (current) best way to get a consistent character across multiple images and poses, including character design, coloration, and style?
Sorry, to clarify: on a potato.
H
Potato = weaksauce computer. In my case, 8 gigs of ram and a Nvidia GeForce MX 3300.
I'm not sure but I think I do more in Virtual memory than VRAM when I generate an image.
Is it a nice smartphone?
You win. yours is worse. How long does it take to make a 512x512 image?
Guess I should look into using these free hosted solutions, huh?
Use Google to train a LORA or whatever.
Let me ask this: What if I already have a moderately good Daz or blender scene I can just make renders from. Is there a way to use SD to just give the existing image a glow-up? Like not change the content, proportions, colors, shapes, silhouettes or subjects of the image at all, just wrap what's already there in better lighting?
somehow i feel like its not using my gpu

eta 12 minutes just to generate "apple fruit"
🥴

atleast i got it to run somehow
🎉

Here are some of the prompts I explored today using SD and RealisticVision 2.0 https://docs.google.com/document/d/1BAC4sJyETUnuADf-vEOy1h0BYe7tie8QVaB79VtYNHQ/edit?usp=sharing




I tought about controlnet_tile 1.1 to make skins more realistics then I saw that the example doesnt keep the vein :(

Termina-child



when i tried a realistic approach based on makima

@glossy heraldI made a super out of my comfort zone little bass demo
fun time
my friend made a super cursed sound, and I decided to loosely sample it into a demo
His sound he made lol
And what I very loosely transformed it into with the use of other sounds I have made
A final version before I sleep with a weak intro and a little more ambiance
goodnight y'all
Denoising str is for that.
Use hires fix, set denoising at 0.2, it will be really closer than original.
Original :

0.2 denoising with hires Fix

@smoky oak
resize: from 640x512 to 1280x1024
spider-gwen

a tip for realistic vision is to look up the models it is merged from and use the keywords those models thrive on. raw photo tends to work well in RV i think that comes from dreamlike photoreal.
is it Euler a or something?
adaptive?
@crimson dawn
I don't see a correlation there...
Yea, I can see higher cfg making image "better" , I guess, unless you go too high, but it depends.
(different seeds might give different results)
Why are you saying "Higher cfg benefits from higher steps"?
i deleted the examples i posted because you're clearly one of those "i have to argue everything" toxic types. Stop @'ing me. I'll consider it harassing going forward.
You saw the example too. so i don't know why yo'ure pretending it didn't exist now
jeez...
Another good example of Hires Fix (0.2)


please block them then. But don't resort to attacks like those. You can not want to answer if you feel those are not genuine, I don't know there but it doesn't seem like trolling imo. I could be wrong
In any case, don't start calling people toxic for asking questions here, and a ping there.
i did block them and stopped engaging. The guy tattled on me dropping him immediately? wow
take any reports from them going forward with a grain of salt. that was retalitory
this is coming from me, not any report there, don't feel attacked by them. I would do the same for any one going on this vocabulary against someone else directly, to try to follow the tos there
i'll note that calling out toxicity is against the tos then. weak but okay. i guess corporations dont want to approach that topic with a 100ft pole
anyone got a 101footer?
damn.
1/ I'm no corporation here, I'm community.
2/ You're attacking on questions that do feel genuine. They are a regular that ask questions like this and get answers. They discuss those types of things.
This is not calling out toxicity, this is calling someone toxic. If you feel they were, then "tattle" on them, I don't know, or block them
TOS 2 Respect the community
Be mindful and respectful towards fellow members of this server. Do not harass others!
disagreeing with someone and stoping commincation can be respectfull. calling them out on nothing isn't.
TOS 5 Don't reproduce more toxicity than you see displayed
Do not engage in negative/hateful speech
Be sure to escalate rule-breaking content to our staff by clicking the 3 dots on the corner of the message you’d like to report or right click > Apps > Report to Staff.
one of my recent landscapes, to appease your morals

I did report btw 
It just felt right, instead of trying to explain something and probably escalating it even further 🐧
That was...interesting


I've seen your portraits recently, and you achieve unreal levels of realism, you've really got the hand for those




at first I almost asked you if you were cheating and posting real person tbh
guys any ideas about how i can improve my membership tiers?! all ideas are welcome, this is how it currently looks:

My last tier would be TOS tier 




yeah i love this series, nice prompt so far
ah kool
Guys
Did you outpaint though? like the built in outpaint.
gals
How to use Stable diffusion in Android?
@flat pike
long nails are so hard to do

normal generation with automatic .vae


https://toyxyz.gumroad.com/l/ciojz blender SD rig updated. It combines openpose with canny and depth hands and feet like before, but includes mediapipeface face rig for custom expressions now, all which automatically export to their respective folders from whichever distance and angle the user wishes by pressing F12. Extremely powerful

Gumroad
-Blender version 3.0 or higher is required.- Download — blender.orgCharacter bones that look like Openpose for blender Ver7 Depth+Canny+Landmark+MediaPipeFaceAdded MediaPipeFace controlnet model support.Download the appropriate controlnet model file and place it in your extension's model folder.CrucibleAI/ControlNetMediaPipeFace · Hugging FaceHi...
Haven't had a chance to try the update, as my brother is still ill and quarantined with my desktop...feels like having withdrawal symptoms









That one is weird, but that makes it better

Someone made the thing
https://civitai.com/models/24728/chimeramix

This mix is more focused on (un)realistic creatures/monsters , merging concepts, but seems to be a quite versatile/creative base model. Can be merg...
@glossy herald

so, that's my input to a1111 with controlnet

but with canny edges it just confuses things
this is worse from a distance:
I haven't touched at all on how training controlnet works though
I have no idea how all this works

where the lower resolution (and zero color data) end up completely obscuring the needed information
that's okay.. main thing in this case was me updating sd to a version higher than 1.4, that'll still run on an 11gb card 🙂
training.. well.. I've not yet figured out a good training set that'd apply. some type of segmentation model (the current segmentation one they provide also fails miserably)
that'll be a future step, if I can come up with a clever way
@glossy herald what about pruned vs pruned-safetensors?
I imagine stabilityai's own models are safe to run :}
anyone have ideas on how someone can make a diagram, like the skeleton, with an original image (my first skeleton image with the very clear lines of muscles between the spine and leg) without SD (or optionally controlnet) getting so confused about what's what?
the original is a 3d model I made

(well, I didn't make the skeleton myself)
i just told it to do more stretches and exercises and that built up its muscles.
@glossy herald training looks easy enough (famous last words): https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md

GitHub
Let us control diffusion models! Contribute to lllyasviel/ControlNet development by creating an account on GitHub.
they provide a small test dataset to get started.. did a nice job on that page/instructions too..
I'll check it soon but right now, it's late and I'm loging off sorry
later bud!
I can't think of a good way to build a training set for this
I was thinking I could take original images and quantize their colors to form a segmentation-type thing as input
@glossy herald can I share sexy fantasy images of men? (no genital)
If the intent of the picture is the sexualization (aka the sexy fatasy part is the focu) then no
That being said, Guizmus is offline now. Please direct moderation questions (even when Guizmus is online) towards #1010934719455707218 . So if I'm not around, you still get a response
sexualization is part of it not the goal of the image
could you kindly tell me whether you think this image might be considered more sex than art?
I need to focus the second line of what I said
It's 9 PM
I've been moderating since 6AM
lol
If you are unsure if an image adheres to our rules or not, you can send a ticket, or simply not post it.
i have created a ticket
most of my images are artistic form of sexy men.
beautiful images of male physiques with artistic elements. I have created a ticket with an example.
i have submitted one at #1073085702927024128 but maybe it was too early to post it there


finally got it to use my gpu

generated some lopsided 512x512 apples in 1:36
3.59 seconds per iteration
god bless technology
Nice!
o yea an update: since the amd rx500 series (gfx803) is pog and can use half precision, i disabled those flags and enabled --medvram
practically doubled me performance
went from 1:36 to 30sec @ 1.6 seconds per iteration
i have the power of GOD

a god that make nice birds and fruits mostly, but yes
Bro im sorry i dont speak this language😹
all u need to know is that you dont need the --precision full and --no-half flags for rx500 (and amd rx6000) series gpus
You’re playing with me
nop
and the best part is that disabling those flags saves alot of vram
meaning i can then use --medvram on my 4gb card
No i mean i actually dont know what ur saying
Idk
Would a 3060 12gb vram be better off with or without --no-half?
I would say without no-half
as no half just makes it run at full precision which tends to be slower and use more VRAM
also, I know I shared this last night, but I wanna share it again cause I am pretty happy with it lol
Turned this super cursed sound my friend made into this little demo last night lol


pretty proud of this one, though a bit frustrated that i can't seem to get better fingers and face. just don't look too close and i think it turned out great 😛


spend 2 days trying to fix hands on that last picture i posted, and today it just outputs this on a random sculpture that i'm not even TRYING to get hands on -_-

Actually... weird question. Can anybody show me a picture of what an image's "latent space" actually looks like? I'm not certain what it is, exactly, or if it's such a thing that can be displayed visually, but if there's a way to do it, I'll bet somebody around here could figure out a way to do it.
While much of what we use has been recently developed, latent space as a concept hasn't really changed since the inception of AI tech. here's a pretty good reason on why it isn't easily visualized
https://stats.stackexchange.com/questions/442352/what-is-a-latent-space

Cross Validated
In the context of machine learning, I often hear the term latent space, sometimes qualified with the word "high dimensional" or "low dimensional" latent space.
I am a bit puzzled by this term (as ...
basically it's like trying to imagine something 4 dimensional. we can come up with a concept of it that fits our headspace, but we probably don't really see it correctly
i personally think of it as a kind of a city? blocks and streets are essential to it, but then inside those are buildings and floors and rooms, and inside each of those are business, made up of groups of people, many of which have families, etc. but it's more like how things interact than that...so i dunno. it's just the easiest way for my old man brain to understand it a little lol
If I were to copy and paste the latent space from one image to another, and both images had the same prompt, seed and environment, but they were img2img of a character in two different poses, would the new character produced by img2img be more consistent than with the (apparently random? or arbitrary? Or based on the input image somehow???) default latent space?
i think you may be thinking of the noise, rather than the latent space. you can't exactly copy latent space 😕
noise is actually trained from normal images to begin with. basically the model learns the noise from a picture and then, once it knows "hey a thing can be made from noise like this" then it can turn noise into those things
Is it true that there's a sort of 3D model of what a human looks like somewhere inside Stable Diffusion, that arose organically from the training data? Or am I thinking of a different AI?
latent space isn't an image. it's all the possible images that a model can generate after it's been trained
it's a metaphor describing all the inbetweens an ai builds out of training sets.
it never saves the training data. i'ts only building a latent space using that training data
That definition doesn't mesh with keyframer's description of what it does with the latent space: https://github.com/LonicaMewinsky/sd-webui-keyframer
GitHub
Automatic1111 Stable Diffusion WebUI extension, increase consistency between images by generating in same latent space. - GitHub - LonicaMewinsky/sd-webui-keyframer: Automatic1111 Stable Diffusion ...
it's a metaphor so you're going to find a lot of different definitions.
How can latent space be different from one image to another if latent space, by definition, is all the data connections?
that guy is probably just throwing a buzz word into his description
it's a metaphor is why
Okay does img2img use the source image to 'sample" the latent space in some way?
latent space is really how the things connect, not the things itself
i probably didn't describe it well with my city analogy
So "skirt is associated with woman but (somehow) has nothing to do with legs," is an example of how the AI connects concepts differently from how a human would. Is that association part of the latent space?
the association itself is it, yeah. about a billion times(literally) more complex but that about sums it up
I picked a colorful example. Somebody wrote a plugin once to use layer-aware to sample what was behind the skirt. AI was like "the trees and rocks are behind the skirt." It's just a big curtain that sometimes exists instead of legs, not in front of legs.
Do you happen to have a link to that plugin? sounds like a fascinating read
you may be thinking of Loab? the AI cryptid?
I don't have a link, sadly. It was a talking point mentioned in passing in a youtube video that I saw once and will never see again because youtube is floodded with desperate sweaty clickbait if you search for "Stable Diffusion" right now.
bummer. thanks anyways. I may try to find it later, but as you said...youtube can be a mess lol
If anyone knows an alternative to trusting youtube to help you find content on youtube, please let me know.
(I feel like I just said "change my pants; tie my shoes for me." What has become of our modern internet?)
read papers and tap into academic news channels. youtubers will typically pander for views and money
I've found that the channel "AI Explained" does a pretty decent job of covering a lot of the big AI news and explains a decent chunk of it pretty well...though even that channel is prone to sensationalism https://www.youtube.com/@ai-explained-

YouTube
Covering the biggest news of the century - the arrival of smarter-than-human AI. What is happening, what might soon happen, what it means and what we can do with it.
Business Enquiries: aiexplained@outlook.com
"BUsiness Enquiries" speaks a lot of his channels' goals and aspirations. He's not there to report news. There to pander until an investor pays in
Look people that break down actual research papers for you. 2min papers is a great start off point as it introduces you to the world of papers being published and gives some insight into how to navigate them.
koi boi does a lot of thorough explanations of actual papers.
people who just read off headlines to their audience offer nothing of importance
Aitrepreneur is one of the worst
his information is reliably unreliable lol
Like sure, he is the reason I learned how to train LoRA's, but hes also the reason why the first 3 weeks I did it, I got trash results lol
I didn't say he was the best out there, i said he simplifies a lot of the big news. which he does.
bad info
i immediately found that aitrepreneur was flashy and glitzy and that indicated to me that they're there to pander for views . so i've never really watched their videos. I got strong biases
so his videos each week are just summarizing the top reddit posts that week. not very contributory. just pandering
channels will do that. doesn't mean there isn't good info in some of them. i feel like if you watched at least one of the videos from the channel i posted, you wouldn't have that opinion, but everyone is entitled to their opinions
not gonna continue talking about it because i'm not here to advertise for him. it was a response to someone looking for easily digestible info
i can read the news on reddit as it comes out. When i'm trying to learn ML i want actual explanations. Not a hot take on SDXL
The channels that are most about the shine and view counts are absolutely culpable for spreading bad information in the community.
you can learn a lot of wrong information by leaning on the channels which aim for the highest view counts
Aitrepreneur is probably responsible for a majority if the bad info in the community honestly
@crimson dawn everything you're saying is true. irrelevant to what we were discussing, but true anyways
I find I just see what he is talking about and then just watch a video by somebody else who doesn't talk out their ass 😅
Like I went from what he taught, with wayyy too many steps, overtrained LoRA's huge amounts of time dedicated to training and tagging, and mid results... to literally a few minutes of work and insanely high quality results just by watching videos from somebody who knew what they were talking about lol
This was my avatar result after like 5 days of following his process. Well over 10 hours in total dedicated to it

And then I had these results within 30 minutes of listening to somebody who knew what they were talking bout lol




was surprised to find that "amputee" in my prompt was contributing to my "people having legs" problem(was trying to generate legless, armless, headless statues). would generate people with artificial limbs . definitely wasn't expecting that
oh interesting
I have been really wanting a model that can do good looking synthetic/human cyborgs
I've been wishing there was a mod for automatic-1111 that would just list literally ALL the known prompts and let you toggle them positive or negative, since that's how my prompts usually end up going anyway. I'll get 7 images deep and then suddenly realize that I need to add... I don't know, let's say "back to camera" or "has three feet" or something stupid and bizzare like that nobody would ever think of to my negatives.
I wish there was an addon where you can write notes on models you use, to remind yourself of their quirks or optimizations
just a little notepad you can access when you load a model
You could use the styles menu to save/load model quirks
I suppose I could do that, yeah
Curious what differences you heard? I always love seeing what the community goes with vs what actually works. So much mystical thinking about models out there haha
Short and sweet explaination is:
Tag things that aren't consistent, not the things you want it to hold onto.
If a character always has red eyes, don't tag them overwise it will defayult to something else if you don't tag them. My general rule of thumb is to try and aim for 2.5k total steps (1250 with BS2) and 2 eopochs
I went from doung like 10 epochs to 2, from 48 minutes of training for the worse result to 6 minutes for the bottom one
Hmmm. New txt2txt model I downloaded seems to be speaking the language of the gods lol

Your beam search is wack, probably. Use the presets for llama-precise.
this looks important. https://github.com/huggingface/peft
GitHub
🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning. - GitHub - huggingface/peft: 🤗 PEFT: State-of-the-art Parameter-Efficient Fine-Tuning.
Can you link to or give channel names of the people who knew what they were talking about?
It's been such a long journey, but I do have a very long video I watched that helped me a lot

polishing for too long my dataset

Dukes ! can I ask you a question on training ?
I have one that I can't find any answer with, and my thinking seems to be opposite to what Emad or the devs are doing/saying

no obligation to answer, but if you know, I'm really curious
Why is it good for the base models like 2.1 and above to be "so much overtrained" ? I saw Joe being proud of it and saying it with those words on reddit, and it felt like something bad for me, and the source of my problems with training on 2.1
I would say XL is no is not "overtrained" in the sense 2.x base was and I am the one training XL for Joe heh (the new XLs). 2.1 was more work to train due to missing knowledge and dataset duping (that said people still are able to make insane stuff with careful training and good data).I will say XL (if you can tune it hardware wise) is much kinder to picking up new concepts and plays very nicely from smaller training tests we have run with it 😄 The one we are attempting to make is generalized, versatile, and tuned with human feedback to make it at a baseline feel great to use regardless of what you want. I am hoping it will suprise some people when they get a chance to try it. There will likely always be a bit of bias towards certain concepts that tend to be over represented but newer XLs will be much better about this. When the weights are released I feel pretty dang confident in people go wild with it. We are just trying to make the best base version we can for now with it haha. it has some fun little tricks up its sleeve
ps: we did a large normalization run across the dataset between .2 (current DS/Clipdrop) and .3(pic-a-pic) version so that whole concept locking is pretty much history. New versions feel like a whole different model (much better listener)
hey guys can someone please help me with stable diffusion i need hlep (someone help me with stable diffusion ineed hlep(
that feels really reassuring.
XL may be taxing on hardware to train, and keep on spliting the training community because of it, but those methods and changes seems very promising for the next "regular" size version to be a new version "unifying" everyone once again.
The splitting of the community model gets frustrating ^^
I do hope I'll be able to tune it for sure ! I'm quite excited :p Some people working on it with you are also giving some very teasing vibe, in how they feel about this new gen of model 🙂
A big thank you for this detailed answer Dukes 🙂
need help[ weith stable diffusion but no one can seem to help me its very shckinmg
I expect a lot of colab training at first until the community as usual gets it training on a smart fridge in a week
haha
@daring crow #🤝|tech-support is usually the best for help on getting it up running. I'll come around there to check if I know what to do, but I'll need more details
it keeps saying python cant be launched
Raw output

the last time I asked you for details on this, you wrote me blocks of 50 lines to tell me that you weren't sharing this, so that you wouldn't be copied, blablabla.
That is not what happened
What I said was at the time I didn't want to share the information because it wasn't fully completed, and I actively had a person in the server who was making it their sole purpose to copy every single thing I was doing. That has since stopped, and I'm much more open to sharing my information because I don't have to worry about somebody taking it in order to compete with me
I even said that at the time, but you insisted on making it about yourself, and called me all sorts of names even though I owe you nothing, and I can choose to share what information I want to

my ass bro
So what you're saying is that I wrote 50 lines about not wanting to be copied, and what I just said was how I didn't want to share my information because somebody was actively copying me...
But you are saying that what I just said is false? So then that means what you're saying is false, cuz they're both saying the same thing
Anyways, I'm not going to waste my time with this conversation. I share plenty of information in this community, and I've been dedicating the last couple weeks of my life to sharing my biggest breakthrough yet. If you want to hold my temporary reserve about sharing against me, by all means go ahead
FAQ: How do I generate images? Is there a bot on the server?
Currently, there is no bot on the server that generates images. However, there are plenty of other ways such as the official https://beta.dreamstudio.ai/ website or by running Stable Diffusion locally using your own hardware! Check out #1080946152318443610 for more details! You can also stop by #1025467151206854736 for any issues you experience while using DreamStudio or #🤝|tech-support for any problems you encounter while installing it locally!
yes, and probably full of bad ones too; but I guess you haven't seen my previous message that I replied to you, for example.
I'm assuming you're talking about your upscale results? They looked good
Yup, hiresfix is not so bad as you think
//imagine
It definitely has its use cases, however it's extremely limited outside of those use cases. For example you can't selectively upscale certain sections like you can using ultimate upscale, and it's also extremely dependent on the prompting, CFG, seed, and various other factors of the model. For example certain models need extremely high denoise value such as .7 in order to not have the blurring artifact associated with high-res fix, which drastically changes the composition of the image.
I never said that high res fix was unusable, only that anything that it can do, a dedicated ultimate upscale workflow can do better
Honestly the biggest limitation of high-res fix in my opinion is the fact that it uses more VRAM the higher the resolution you upscale, which is not a problem with ultimate upscale
I agree, but it's not his vocation, his goal is to do a quick img2img with upscale (when we've found a decent seed), and we have to admit that he avoids going through more taking time.
Or use topaz
hires fix is adding more chaos to the mix and honestly doesn't work that well
That's why I use TiledVAE (multiDiffusion) with it.
it was good for the earlier days when we didn't have good models but these days there are tons of better alternatives
I can agree with that, really the only thing that high-res fix can do better is speed / ease of use. If you don't need a really high resolution image, high res fix can work just fine assuming you have a model that plays well with it. But for people out there who want 4K resolution generations are higher, high-res fix becomes prohibitively VRAM intensive to use
@elfin nacelle see this post
Tiled VAE is pretty cool, and works in a similar way to ultimate upscale, however from my testing personally, I find that it introduces a lot more potential problems. Although I don't have nearly as much experience with it as I do with ultimate upscale
So does tile VAE do the same thing as UU which is chop up the image and reform it? I would love that rescale if it wasn't for the fact its using facefix which will ruin specific subjects
face fix is shit
If you can keep your subject consistent tho then I'm all ears
ur telling me that upscale isn't using facefix?
cuz it sure looks like it
TiledVAE is simply used to img2img zone by zone, suddenly, it avoids a huge consumption of Vram, and allows to greatly exceed its maximum potential of Vram. Without that, I'm max 1400x1400 pixel (8 GB Vram, 2070 Super), with TiledVAE, the only limit is the time I want to wait, I did 4000x4000, working.
vram isnt an issue with these upscalers unless u have peasant vram
what I care about is quality
I actually tried the updated UU and it seems they made it worse lol
I mean sure it still works at 0.1 and 0.2 but honestly, controlnet works WAY better for upscaling
ima show u what I mean if u want pic examples
Just take a look my posts in history, all my post are in more than 1400x1400 is done with TiledVAE and HiresFix
UU at anything less than 0.5 blurs out faces
what model is this
was that done with tilledvae too?
Cuz looking at those examples it looks like it blows UU out of the water
Even tho u have people on reddit still claiming UU is better https://www.reddit.com/r/StableDiffusion/comments/11tuzov/comment/jcm4386/

reddit
1,547 votes and 127 comments so far on Reddit
I haven't tried UU yet, I will see that tonight, but I can only say that the results with HiresFix and TiledVAE are very good.
so tilevae works only when using hiresfix?
Personnally, i do a 910x512 base, Hires to something like 1920x1080
Yeh honestly thats all you need
No, it can work with everything.
A native 1024x1024 is good enough to be upscaled to 4k with basic upscaling
But u say it works better with hiresfix?
Im telling you UU is shit at maintaining details in faces, but I'm interested to see how this one was made

If this one was made with tiledvae then I'm never wasting my time with UU again
HiresFix is not a simple upscale like in Extra tab.
Its an Img2img AND a upscale
but it only works well when using tiledvae
No
Or I could be wrong, I havent used it in eons because it always used to be shit
things could have changed tho
let me try one real quick

TiledVAE just avoids having CUDA Crashes, because it does things sector by sector
thats not what it does according to the reddit article
you can use TiledVAE in normal txt2img, img2img, hiresfix
its an upscaled like UU
etc
aight let me try it out to dispel this mystery
if I get something as detailed as the one above im gonna shit my panties
If you want my opinion, don't really believe what people have said about it on Reddit, I spoke a lot with the Dev of MultiDiffusion (TiledVAE), he explained to me what it was like. Do your tests, you will see that the images generated with it are identical to those without TiledVAE, TiledVAE is simply used to consume less VRAm, those who say that the results are less good have understood nothing.
Ooh I will post my results alright
We can do a pepsi test
I want to settle the upscaler wars once and for all lol
wondering which of my dreambooth gals I should choose for this challenge
Personnally, with my 8 gigs, i use theses settings, but if you have more Vram, you can increase decode tile size, and gain time generation

wait wut
is the tile size in pixels? damn I hope I dont have to read pages worth of documentation
I'll try those and see how it works
Just search extension in list, install, don't check anything on the TiledDiffusion tab, it's another function, keep the same settings as me in TiledVAE, launch the generation, it's as simple as that
What GPU do you have?

Mah, not sure its usefull for you, you probably never had a crash CUDA for high Vram usage.
its not about cuda
its about image upscaling quality
I cant natively generate a 1024 image no matter how much vram
should I not enable the Tiled Diffusion tab?
I can native gen 1024 on my 10gb card. Maybe you dont have xformers in your launch arguments?
what I mean is that it wont look good
because of the native 512x512 picture
unless you're using controlnet
which is my current preferred method but this method appears promising from the samples
That's normal, generating directly in 1024x1024 will rarely give good results, it's because of the 1.5 models, which are based on 512x512; I advise you to make an image in 512x512, or like me, for example 910x512 and then use the hiresfix to 2000x1000 with 0.2 of denoising for example. You will have a well-arranged image at the base, then much more detailed thanks to the Hiresfix.
Im excited to see the results
Its all about keeping the details
ima post some blind tests here
But, this is not because of TiledVAE, its because of methode
What settings do you use for hires fix


remember Denoising is important, lower he is, closer from the original it will be. And of course, you have to save your seed if you want the same image as your previous good one
gawdayyuuuum
guess they really have buffed this tool out of the water
it looks way better than it used to
0.2 - 0.25 - 0.3, play with it
yeh its good now I gotta try it in conjunction with tiledvae
with a 3090 you could probably do 4x without tiledvae
lolol im already struggling to find a 2x upscaler that will preserve details
once I do I might consider moving to 4x
Yeah, one time was enought
tiledvae either is not working or Im not noticing it
I can take a quick vid if u wanna see
but im getting the same stuff as with the hiresfix
You not understood what i said, read again
Tiledvae doesnt change details its to save vram
fuuuuuuuuuu
reddit
1,547 votes and 127 comments so far on Reddit
This post says its used for upscaling
omg dude stfu ^
someone report that bih
@glossy herald please ban this idiot
blocked that bish
and what ?
lol
that's not acceptable
thanks for the ping
sorry I wasn't around
these guys confuse, TiledVAE, and Tiled Diffusion, read the dev's post, you will understand better. They did not understand anything about this extension
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
so in the reddit link, they named it incorrectly. Mutidiffusion upscaler does the upscaling using an upscaler. Tiledvae is just for vram
Thanks to you bro
both came in the same extension
so maybe thats the confusion
correct
Yeah, but if you use both of theses functions, they are complementary
doing a 4x upscale rn, never seen my gpu sweatin like this lol. But what will the deetz look like?
I have them enabled, we'll see if they work
4x upscale with 0.2 denoise will be very small change
so more denoise?
see the result first
Kk
not impressed.
I mean it has details, but even at 0.2 it did change some stuff, and it has that characteristic "stretched" look
I'm not 100% sure the upscaler is even working or if I'm doing something wrong but I suspect it's one of those too-good-to-be-true moments
Because you have a 3090, otherwise believe me you would be 🙂
with what model?
my own blend of realistic vision, uberporn and another one I forgot
but its the best model I have
I need to mess around with this a bit more
They are often updated, if you not checked
It has a lot of tools I haven't explored yet, so I'll give it the benefit of the doubt

Cyberrealistic is really good too
See the github link i sent to you.
well if whoever created this one @stone cipher I could drop him a tip or anything his majesty desires
I would rather wait until that guy comes on and explains his secrets
I got some pretty good results but nothing I couldn't create with controlnet upscaling
he wont say anything. Assuming you will steal his work
rofl. then he's a kid and a hypocrite since he is stealing A1111's work as well. checkmate.
as well as literally everyone from OpenAI's work.
steal his work
Something that always makes me laugh with 100% opensource soft, models
yesterday he said I used his images to make a model for the portraits I posted
if he doesn't want to reveal his "secrets" then I am assuming he literally just grabbed that picture straight from google search.
maybe not just stolen pictures if not giving out their dataset
sure it does happen a lot, and in mix models too I'm sure
but disclosing stays not mandatory, and some weeks of work on a dataset can make someone feel they should keep it private.
I don't, I share mine, but it's something that could be understandable imo
then he can just say its a privately trained dataset
yeah, blank model cards don't inspire confidence and honesty
he's making it look as if he's using currently available tools in ways that he's refusing to share
If he really had spent the time creating a TI or something then he wouldn't be bsing like a kid
I know a certain someone I could name who does this
let's not start with personal attacks though. I get it, you don't think he knows his stuff or that he cheats at the discipline in some ways
but personal attacks is really not something that make a server nice for people to participate in
So let's drop those, or mute them if it's too much of a bother
wow
civitAI is up !
wow !!!
it finally happened !
x)
gotta go snatch those models before they shut it down again
damn, they even seem to have fixed the indexing problem
although frankly im just patiently waiting for xl
@elfin nacelle
personally, his image doesn't impress me more than that, go see the posts on civitai, what people post on models such as RealisticVision, CyberRealistic and others, you will quickly find prompts adapted to effective photorealistic
I can find my models at last, they weren't showing in any research
there still seems to be quite some road before XL on local GPU though https://www.reddit.com/r/StableDiffusion/comments/12m169y/my_team_is_finetuning_sdxl_its_only_25_done/
wut. not even a 3090? 😦
plus I'm scared of what the "XL" will mean on hardware requirements
no idea what it will mean in terms of cards, they haven't say
anything needing more than 24gb is trash
but I meant, it's not for right now
unless the RTX 50 series plans on releasing more, which I doubt
I'd be surprised if they didn't at least target 24GB as a possibility to run it
but even if not, I'm sure the model will be cut in half or something sooner than later, and require half of the base a few weeks later
when I remember that, last summer, you couldn't run a 512x512 picture under 8GB VRAM
that is very very true
I might bite the bullet and update my models. It does look like its gonna be a stretch until the next model comes around
let alone when its dreamboothable, which is what matters 😏
Kej himself told me it's gonna be about 2.5 as big as 1.5, but he has faith the community will find a way to get it working
what are your models about ? 🙂
I shudder at the thought of how much VRAM that would take
all people
thats the issue tho. I would have to retrain all 25 or so of my subjects into my new model
which is why Im saving up for Xl but yeah..probably not gonna come around soon
you have managed to find common parameters to train each of those subjects, or do they require different LR/epochs ?
ahh thats a good question
you could merge the dataset on some key steps of the training slowly, to train all in one
(I worked a lot on multiconcept models)
Ive experimented with merging and never got it to work properly
and some people say theres always loss, so I rather just train each model separately
yeah, merging when your subject are close to each other impacts a lot the quality
with how fast dreambooth is these days its just like less than 40min.
it stays the most reliable option, it works almost every time, wheras multi concept takes a lot more tries to have all concepts learned well
I think comfyUI lets you use multiple models in one prompt tho? I havent tried it but its what people say
so if I have X person in one model and Y person in another then I can just keep them in separate models
I got an example there
the only issue is each model is 4gb a pop but hey thats the price to pay.
First Screenshot is the first step : the controlnet picture that I build, and pass through a canny filter
Second screenshot is the first step of the real image, using a new model, a new prompt, and the first picture as controlnet. Still in 512x512, same shape
Third screenshot is the second step, the highres fix (aka latent upscale + img2img, like it's done in automatic), using a third model and still a new prompt. 1024x1024, new details
4th screenshot, I add some post processing
5th screenshot, I use a classic upscaler (RealESRGAN 2xplus) to go to 2048x204, and I save the picture
last screen is an overview of the full workflow






final pic

daaamn I gotta learn that
I'll have to check out some tuts on comfy. Maybe I can do some better upscaling there than I can do here
it's long to learn how to use efficiently
and even then, such a workflow takes an hour to correctly prepare and test
but it's the most powerful in terms of feature
daaaaaaaamn hell naw
https://comfyanonymous.github.io/ComfyUI_tutorial_vn/
the visual novel tutorial is a good place to start
and the examples can all be loaded directly in your UI
https://comfyanonymous.github.io/ComfyUI_examples/
well I guess until I see a result good enough to motivate me I'll keep using controlnet upscaling
you can even plug LLMs into it 😉

controlnet upscaling is quite good yeah 🙂
it helps a lot

Anyways the results are in if anyone wants to take the pepsi challenge
Each of these were upscaled using a different method - Topaz | Hi-Res Fix | HRF+Tiled Vae | Controlnet




Go ahead and take your pick as to which one looks better in full res and we can help settle the debate, obviously I'm not saying which is which. Also I left out Ultimate Upscaler to avoid another flame war
I really dont want to mess with that thing anymore it's such a massive timewaster
oh yeah and here is the original base

I haven't seen the base so hard to say
x)
thanks
the goal was just to upscale ? (I got no horse in that race, but I only see 1 that I would qualify as an upscale. The other change the eyes and face too much)
yeah there will always be a change if you use denoise
even 0.2 changed a lot when using tiledvae which is what the guy suggested
yeah but I mean, on an upscale of the face, fidelity is important
New details is ok, but those are big changes from a latent space upscale without enough control after it imo
for such a subject, If we are talking about a real person, I wouldnt take any
if we are talking about generating someone fake though it's different
yeah I think that's the point a lot of people miss
also depends on the number of steps used for the base vs what was used in the hires fix
It's easy to generate ANY face in high-res, but not so much in generating a SPECIFIC and consistent face in hi res
I think I used the same amount of steps for hires than for original
so to answer here, I would take the last one personaly, because of the subject
@sterile kiln @stone cipher if you guys think you can upscale any better than the 4 examples I gave them lmk and I can give you the prompt data + the model etc. and we can expand on this pepsi challenge lol
why pepsi btw ? x)
its just a generic term for a blind test in which people are tested to see which is better without knowing which is which
like how pepsi used to do to convince people pepsi > coke
ok, thanks 🙂 didn't knew the use of the word as a kind of challenge because of it. nice
if someone here thinks their method is better then put ur money where ur mouth is
Can't do anything before tonight, have kids
the last gen is Topaz and suffers from the problem of not being able to fix problems, like the eyes and the dark marks on the teeth. A bit of inpainting will fix that.
don't confuse upscale with hiresfix.
The upscale is done in the Extra tab, and uses some models, while the HiresFix is img2img + upscale. Inevitably, the HiresFix will add details, while the upscale will mainly refine existing details
hires fix can be used with like 0.05 denoise for almost no change
yup u got it. funny enough the mod voted it as best
personally, I do not recommend using it under 0.15, otherwise it is useless
but thats how you upscale without changes. It can still upscale
thts also how UU does it
it ends up looking buttery af but its still better than just clicking and dragging in MS paint. lol
not quite. UU uses the denoise slider in the main img2img settings
nah I mean in terms of results
Has anyone improved Clip Interrogator by adding entries to it? Or simply messed with its settings?

im trying to generate something but generates like this
What no negative does to a mf
yeah add "scary bubbles" to negative
Sent a pretty standard negative prompt to your DM 🙂
thanks
where are some good prompting resources?
Your resolution is also really high, many models struggle with making coherent images like that



https://lexica.art/ has quite some
And here is a guide on how to build interesting prompts #📝|prompting-help message

thank you I've checked the pinned messages from there (and stolen the negative prompt too)

Going after the Skyrim logo
if anybody wants a controlnet to play with me

not easy to make the wings stay inside
double head

which model is that?
realbiter
I was quite surprised, it went on its own to the "war/violent protest" kind of photos
realy nice results
i'm looking for a 1.5 model that can get me realistic stuff
then this one is quite nice for it imo
downloading
some of my best on it (you may have seen some already)






























I have so many from it, it's one of my prefered model, top 3
since i burned out from trying fix colab issues so i run it on my pc

I burned out thanks to Colab too though I did make kohya_ss work on it just all text though since Colab is headless it means no display possible for open file/message boxes. Worked fine but Colab just sucked the life out of me.
i am pissed that i need put command arguments to launcher but colab kinda ignores what i wrote...
what do you mean?
set COMMANDLINE_ARGS=--autolaunch --xformers --no-half-vae these settings, kinda colab dont even work with that
Oh, you mean for automatic to gen? I never do that I only train with colab and gen locally
i bought colab pro just to test out more
now i today i cant even do anything just because asking me put those lines
and colab dont even bother run it

colab is Ubuntu Linux so if you understand Python and Linux you can easily do it. If not then yeah.

That is why I am super depressed because I have to buy a 4080 or more than likely a 4090 only it doesn't stop there. I had to buy more ram, a new cpu, a new case to fit any of the new cards as 12 inches is not long enough, and probably a new power supply too. Just too much, so I am doing one by one. Next up is a new case.

3060ti is a good card for even training on
faster than a T4 on Colab too
just 8 gigs vs 15
oh, so you are one of those who paid 50 bucks per month?
lucky because if you read the groups as time goes on you will not see that A100 for 10 USD per month you will only get a T4. The A100 is to entice you that when they no longer give it to you that you pay 50 USD per month for it guaranteed.

T4 sucks even if you had it in your own PC it is very dated now
So? The people who pay 10 per month never get the A100 so you are damn lucky.
It does depend upon region they said
You may be in a region that you get it all the time so lucky. Some other regions have to pay 50 USD per month for it.
its scam service
not even worth
u get those computing numbers once u use it up u go back to free gpu
in txt2img dropdown menu for scripts don't show up anymore, all good in img2img, any idea why?

yeah settings for each script
they don't show up in txt2img
did thta to no avail
i installed few extensions and i think some of them broke it
i really don't want fresh install so trying to fix it if possible
it's not the version problem i haven't updated it
it was working before i installed extensions
seed travel, prompt travel etc
ok i restarted pc and it fixed
probably installing extensions fcked up something in gradio
and it needed proper restart
restarting webui wasn't enough


{kind=link}
uu love this one
Why not 🙂
anyone got any clue on how to get a giant turtle under them?

with the pow model?
? I used the skyrim logo than Guizmus linked, scroll up
oh okay
damn
I didn't manage good at all
and lost interest earlier since I was alone on it
I'm training a model now though x)
Bah, I find them not terrible compared to yours. I don't know how you did it but it's great
Yes, and it doesn't take long either. If you do get an A100 it eats up the credits like 4 times as fast or it was 8 (I forget now).
I was looking at AMD and AMD still hasn't released rocm 5.5.0 for the new gen of cards plus the older gen (6700XT for instance) are slower at generating than my 1060. :/
can anybody help?
probably this one :
https://civitai.com/models/23669/temari-naruto-wrise-lora
and what checkpoint?
Ahem
huh?
I saw that before in here but do not know
😦
thats lora model
a lora model to produce image to look like her
rest other ur idea what u put on prompt
wdym?