#🏞|general-with-images
1 messages · Page 29 of 1
this is objectively worse without canny
is it?

wait, what is your denoise
.55
that looks like artifacts from too highd enoise
trolol
oh thats wayyyy too high bro
no wonder its making things all weird
ima showcase it tomorrow
alright man, if you say so
.55 will guarantee to have unintended noise
they have a process, so I will just let them do their thing
we seem to be parting ways now in our methods, which is good :>
we have two people venturing into different things
I just know for a fact there has to be photoshop involved
and the image youre working on now isnt perfect is it?
u just cant click a button and have details in the image at high res
no but thats cuz I just did it quickly
tomorrow ima try something big
I might have to get blender involved for poses too
which sucks cuz I dont want to have to learn blender lol
there are easy online tools, and also a 3D poser you can download into SD
its called posex
The highest denoise I use is .35 and Ive upscaled hundreds perfectly.
Oh yeh I tried the web browser one but I want more control
for landscapes yes
but low denoise = mannequin skin
fair enough
which is my biggest pet peeve with 1.5
I haven't had that problem, personally
no, all subject matter. people, cars, everything
well I havent seen an example yet but then again I might just have a picky eye
Pure fire and I have a lot more experience with this, but I have little experience with people, so who knows
yeh im the portrait freak lol
I know I have done 1000's of test gens
so I can tell when something is upscaled and when something is legit detail
I can always add skin textures in photoshop but its time consuming
I mean, I am a professional portrait photographer lol. or well, professional as in it is my only real source of income
but I have been doing it for years, if that counts lol
This image I posted was half res of the original upscale. #1072010753462251521 message
6 now, maybe 7
that does look quite nice
cars dont have tiny details like faces do
did you ever get to see my absurdly high res upscale I did?
@static tusk
sorry for the ping, meant to reply
yeah saw that one
15360x6548 with basically pixel level detail 😩
was a lot of work, and it was not perfect, but it WAS worth it lol
r0fl
after even 4k you cant even see that amount of detail
but hey, its ur time lol
I upscaled it that high just to see, and also cause it is so high res, I can get several different high res views out of the same image for different devices
that makes sense
These 3 images (and way more) are all from the same extreme res upscale





and they are still 1440p+ each


granted, there are seam issues (the part that wasn't perfect and I learned from lol)
@stark vineOMG-
I followed what fire said with the lady gaga portrait, and the one that got rid of what i was saying (like he said) looks better-
like, considerably

I did not mean to send that, but it shall stay lol
ok, but cutting down the negatives did make it worse
original prompt

quality only

cut down negatives

trying no prompt
MY TAB CRASHED

ok, in order
Full positive/negative, cut pos/full neg, cut pos/neg, no pos/full neg, no pos/neg @stark vine
Cut pos full neg seems to be the best-





all identical settings, outside of prompt
Wait what?
Are those still with controlnet?
I'm on my phone now I'll have to check them tomorrow
No, I turned off control net
I wanted to see if what pure fire was saying was true, and it seems as though it is
I've tested it on a few different things
discord bots are offline

Apple
@twin falcon
FAQ: How do I generate images? Is there a bot on the server?
Currently, there is no bot on the server that generates images. However, there are plenty of other ways such as the official https://beta.dreamstudio.ai/ website or by running Stable Diffusion locally using your own hardware! Check out #1080946152318443610 for more details! You can also stop by #1025467151206854736 for any issues you experience while using DreamStudio or #🤝|tech-support for any problems you encounter while installing it locally!


Hey, I just linked you the FAQ saying we don't have a bot doing that currently
sorry but that won't work with any / you could try right now


Sad , but thanks for helping
tried volumetric lighting as neg?

its an omegalul 😆
Oh nice! NERFS are cool
It's a research paper that allows you to create 3D photos like the example above, but it only requires a couple photos. I believe they are so advanced now that you only require one
hm, what can you do with them?
It's not an actual 3d model , I'm guessing I can use anywhere else?

Since i reinstalled my A1111 on a new computer (using a 4080) a lot of my images come out desaturated. Any ideas why? This is using ReV Animated 1.1

desat gens are always VAE related. check you have the right one for the model, is my guess.
yes, that seems to be the case. I copied over the vae from InvokeAI and now it looks a lot better. But i didn't have these problems with past A1111 installs. Now i often get images that are either desaturated or overexposed
I havent experienced that, so not really sure why youre getting overexposed as well.
BTW, I enjoy watching your videos. Keep up the good work
thank you 🙂 feel free to write me if you see some new, cool tricks or things i should cover
Nice to see you there 
Best movies in the world





You know, hmmmm. Let me try that.
20 ton kitty on the prowl, now that had me laughing.
second is with volumetric lighting as a neg.





@static tuskI thought it might be seed related, but apparently not.





no image bots on this server @random rivet
FAQ: How do I generate images? Is there a bot on the server?
Currently, there is no bot on the server that generates images. However, there are plenty of other ways such as the official https://beta.dreamstudio.ai/ website or by running Stable Diffusion locally using your own hardware! Check out #1080946152318443610 for more details! You can also stop by #1025467151206854736 for any issues you experience while using DreamStudio or #🤝|tech-support for any problems you encounter while installing it locally!

My first Embedding based on someone else style, I used Brad Colbow style, you can almost see it is like his style but not even close to the original quality, if I self can say I think my embedding sucks.

this is your FIRST embedding. and it managed to capture the style. how dare you say it sucks ? it was a great learning experience, and it works mostly ! well done 🙂
It not my first, it is my second one, the first I made was on my own style.

I will not publish it, I would not feel good doing so, I hope I can use it to just get better outlines on my work.

usually, using a lower learning rate helps me capture more details, at the cost of the speed of the training
so maybe adding some steps to your last version on a 10 to 100 times lower LR could help bring some of the details in ?
I am so sorry for this. Father, forgive him, for he have not known what he do", it is a combination of two styles and that scare me 😄



what model are you using for this? looks very real
lmfao
yeh I just tried this and the good news is that it works, cut pos full negs
the only tiny little itty bitty pwoblem is that it no longer looks like my girl l0l.
bruh we have optimized this tool so much lmao
it will have to do until we get a 1024 I guess, which probably isn't anytime soon
dog I just thought of something crazy
so crazy idk if I should share my idea 
here's the result that I got with this technique which is impressive

but still bereft of fine detail unlike the censored ones I posted earlier, although it is hella consistent
U know what fuck it. Ima share my idea cuz I aint a lil bih. and if someone snatches the idea before me then that's even better cuz it'll save me a lot of work
You know how this extension chops up the image into squares and processes them individually right?
What if instead of using a single prompt for the entire image, we throw in clip interrogator into each square and let it decide what the image is?
So we introduce a universal prompt which would be "hi-res, masterpiece, detailed, etc" and then mix it with the clip interrogator prompt for each square
So if it's just doing an eye and eyebrow the clip interrogator would do just for that square "photo of green eye and eyebrow, hi-res, masterpiece, detailed" etc
I'm gonna start working on this project and if anyone knows how to integrate clip interrogator into a prompt ur welcome to jump in. https://github.com/SenTheNastyDynast?tab=repositories

GitHub
SenTheNastyDynast has 4 repositories available. Follow their code on GitHub.



Welcome to the problem of high denoise. You're purposely setting it to change more than it keeps by using a denoise over .3


@wispy nest Imagedata:
steampunk cat, anime style, copper and metal, intricate details, gears, clockwork, 4k, masterpiece, highres, highly detailed,
Negative prompt: comic, blurry, deformed hands, deformed face, deformed fingers, multiple limbs, ugly, bad anatomy, bad hands, ugly hands, deformed, blurry, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limbs, ugly, poorly drawn hands, (grayscale), weird colors, censored, deformed glasses, lowres, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username,
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 2948040081, Size: 512x768, Model: Dreamshaper_332BakedVaeClipFix, Model hash: 637d5dcb91, Denoising strength: 0.3, Hires upscale: 2, Hires steps: 10, Hires upscaler: R-ESRGAN 4x+ Anime6B

@dense tapir Nvidia just dropped a new GPU you may be interested in
Not sure of the price, but it seems awesome
Ultra low power RTX A GPU, with 20GB VRAM
@dry crow i guess im good?

It's only 70 watts and delivers 3070ti performance
Wonder what it is?
its not the same but yea works 😄
alr yeah i got 331 baked and some diff things but it seems like everything is fine
It is a workstation card, so the price does make more sense, considering it has Quadro drivers and is focused on computation
Precisely
It does have 20GB ECC VRAM which is pretty nice
I used to use solidworks and on a geforce it was iffy and somethings locked out but stick a quadro in it and joy
But at the same time... That is very close to used 3090
See, tbh, I would buy that before a 4080
not even counting 4 gigs more so I wonder if this means a 4080 price reduction?
Not likely as this card is massively less powerful. It has much less CUDA, cause it's focused on ray rendering and AI workloads over cuda

I can see why though
way more stable than 6x and unknown about the upcoming changes to 7
cheaper too
It has 192 4th gen tensor cores, which bodes very well
tc is king
Even on a 4090, or A100 the TC waits on the ram to hand it more data 50% of the time cause it is just that fast.
Ok, so it is pretty beefy. It has 6.2k Cuda cores as well. It's just not competing with cuda on a 4080. But the drivers it comes with probably help it massively
I think this card is actually very interesting as a release
more ram, ecc, costs about the same, and uses far less energy. hmmm
It's an exceptionally low power card that seems to be pretty damn strong
It's so low power it doesn't even need a power connector
Oh, wow like the A2000
Yeah, it runs off of PCIE only
75w then
yeah, A2000 size
Very very interesting release
75w is max on the pci-e header so they are playing it safe. no o/c though
might can O/C it, as I do mine, where you limit the power to it but up the clocks
I am 85% power and +160 clk/ram
WHY, can't I get rid of this fog?
it plagues me
Ohhhhh, I see where it cuts the magic lmao
where?
Current estimates are showing it's similar to a 3050 in cuda lmao
even better
backwards
A 3070 in performance then with ecc mem, 20 gigs, and only 70w. Interesting
I know on the A2000 I saw a vid review with games and you could see it wanted to do more but still stood up for what it was in gaming it wasn't even made for.
limiting factor was the cap of 1100mhz I believe it was
I highly suspect some weirdness is coming like the same weird stuff on the 3k cards
when a 3060 had more ram than a 3070 kind of weirdness
I see something bad
160 bit bus with 20gb ram making it 320gb/s
if that were 192 it would have been good 256+ great


I've been thinking about systems for multiprompting multiple images. I think there's a lot of potential for prompting different sections of the image differently. there is ones that let you paint each prompt in. There are ones that do a batch of images all at once, blending the seams together, and that can be combined with different prompts on each image in the batch.
I think a big thing here is the UX. Some way to feed multiple prompts in needs to be standardized. Multiprompting would do well for so many purposes outside of upscaling too. Node based workflows i think will shine best here

yea...we already have comfyUI which can do multiple prompts on different image sections, there's an implementation on different prompts for different gens on TPU , probably should be something for GPU on normal SD too, maybe someone will make it less janky

this is why you should always edit the colors manually



any digital artist taking this gig seriously shouldn't just fire off a prompt/seed and call it a day
thanks for the feature, @scenic atlas! 🙂
https://stabledigest.substack.com/p/stable-digest-3

Artist spotlight - Sagans join us straight from the studios of Linkin Park, Lorn and Die Antwoord for an AI animation deep dive
post-processing is near necessary


What model is this?

parameters: RAW Photo, Montpellier, France, cityscape, historic buildings, narrow streets, outdoor cafes, sunny day, trending on ArtStation, trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, realistic photography
Negative Prompt: cartoon, 3d, ((disfigured)), ((bad art)), ((deformed)),((extra limbs)),((close up)),((b&w)), wierd colors, blurry, (((duplicate))), ((morbid)), ((mutilated)), out of frame, extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), Photoshop, video game, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, 3d render, freckles, watermark, hat, gun firing
Steps: 50,
Sampler: Euler a,
CFG scale: 13,
Seed: 1403634710,
Size: 910x512,
Model hash: c35782bad8,
Denoising strength: 0.2, Tiled Diffusion tile width: 96, Tiled Diffusion tile height: 96, Tiled Diffusion overlap: 48, Hires upscale: 2.4, Hires steps: 60, Hires upscaler: ESRGAN 4x

Oh thanks~


anyone that wants to run this img through this google collab? I don't have collab pro and my credits are up 


Do you have the vae file for that model ?
wdym vae?
a lot of models come with vae's baked into them too. so by default they just look better and people use that instead

i see
some of the anything v3 remerges do that
Oh ok
i see. discords just puking
Ahhh
Yea thats what vaes do
For Anime models you need one. Most are based on the AnythingV3 vae
Not Anime models mostly have the vae intgrated
Where is the best place to find these models? I have the websui setup
@hardy tulip whats your model? I maybe can link you a vae to try
anythingv4.5
but i dont think i liked how they turn out
i think i prefer adjusting manually
what are vaes?
thank you very much.
You could adjust it after that too, but the image Quality overall gets better with a vae
No problem, best of luck
Here is it for v4.5:
https://huggingface.co/andite/anything-v4.0/blob/main/anything-v4.0.vae.pt
Has to be renamed to match the 4.5 model

A VAE is basically like a color processing algorithm that rebalances the image
Vae files are mostly needed for anime models for color and Detail correction
i think the need for the custom vae comes from merging novelai's model that used theirs
well it stems from that
over time people got new vaes to fix the over merging of anything v3 into models. it was sort of a gene correction lol
Wow, thanks!
No problem :>
They can make a monumental difference
Huge difference without and with


one of the pixel models has a custom vae and other scripts tied to it too, so the outputs are diffused into pixel perfect alignments
https://github.com/devilismyfriend/PXL8 here's his script side of things

GitHub
Pixel art diffusion. Contribute to devilismyfriend/PXL8 development by creating an account on GitHub.
@wispy nest
hello!
alright so I kinda get the deal, its like telling an artists to use these reference images

damn, thats sick
And this is the LoRA

so, I just drop the .safetensors file in the models/Lora directory, and use the trigger word?
wait you drew this 😲
Oh, still, amazing result
I also am working on a LoRA for the Na'vi from avatar

I keep getting a "couldnt find" error
You have to add it to the prompt, just a sec
These are some of my early results



the future is incredible 🤩

a1111?
You click that and it will open all of your additional networks. Then you can find the tab for LoRA, And if you click on it it will insert it into the prompt
ah I see them!
yours is red. mine's magenta
thank you
It should insert it like LoRA:NAME:1
The value after the color is the strength. 1 is 100 percent, .9 is 90, .8 is 80, so on
Some of them require high values, some really low, it's all experimentation
Oh, also made a LoRA for toothless lol

Oh my goodness, this is INCREDIBLE

Articles like this make me laugh, cause these people clearly know nothing about AI generations if they think that hands have been an issue up until very recently

And I did a LoRA for Jacques Chirac, alias Supermenteur

More examples from my Na'vi LoRA early tests


It's been paused for a while now after somebody here stole my thunder by directly copying what I am doing
All I have to say is, if you're gonna copy my ideas, at least make sure they look better than my results lol
Did you see Diablo IV beta is doing what Amazon Open world mmo did to the 3090? Bricking some of them.
3090 and 4090 stay away until fixed
@smoky oak how many images and what settings did you use to do good LoRAs like this?
Be my luck for a 2k card and BAM
For that early test, it was a 10 image data set, and I'm not comfortable with sharing my settings as of now, cause I have a feeling some people here are gonna take them and try to steal credit 
Not looking at anybody in particular... For now
ALSO
Just wanted to say, not AI, but this is insanely impressive to me lmao
They will, 100%

damn
Shockingly high fidelity haha
If you get the screen for another way from your face, it just looks like a really stylistic and neat painting
🥴 , I was just asking you for your LoRA generation settings, not your model (lmao).
I have my own inspirations, I don't need anyone x)
your LoRA train settings, sry
Yeah, those are what I'm not comfortable giving out right now, I'm sorry
Giving out my settings means that people who want to undermine me can do it at a higher quality. At least so far the person that likes mimicking my stuff isn't too great at it
A cheap imitation, as most would say lol
Bro, you need to chill with worrying about people copying you
The AI community it's all about freedom openness and generosity
Do not tell me how to feel. Thanks.
Being a selfish grump makes you no better than midjourney Devs
spiderman in china
I have given more back to this community than most people here have combined. I can be selfish when I feel like it. And for me that means not sacrificing my own personal enjoyment to cheap imitations
@wispy nest
FAQ: How do I generate images? Is there a bot on the server?
Currently, there is no bot on the server that generates images. However, there are plenty of other ways such as the official https://beta.dreamstudio.ai/ website or by running Stable Diffusion locally using your own hardware! Check out #1080946152318443610 for more details! You can also stop by #1025467151206854736 for any issues you experience while using DreamStudio or #🤝|tech-support for any problems you encounter while installing it locally!
hey, not again guys, please
mi art is spooky

Sorry, I did the think a general statement like that was a problem
no problem, I'm just saying, let's not follow that same path again x)
Understandable. I've been working really well with them, and we even did some collaborative efforts last night. However if they keep telling me what to do/not do, I'll have to block them
Just for my own sanity
Anyways, moving in from that
making something simple is difficult xd



I am actually kinda obcessed with these spindly little guys
Please, feel free to share more haha
Just heard it's national puppy day on the radio. Pupper gens inbound from me

Some fluffer puppers


@glossy herald not sure if you are a cat only day, but apparently it's national puppy day lol
this is my puppy ❤️



I can't say anything but whoooo too x)
Haha
Bro, finnally i don't care your stuff.
Stop (or start?) smoke weed
What?
Save your settings, i'm not interest

and I wish you to have a real reflection on opensource, github, the people who made all these models. Because your talk about your settings.... There are 6 sliders max and 2 or 3 settings, you didn't invent nuclear fission either.
Bro, it's really not that serious. Please back off. If I don't want to give out my stuff, then I don't have to. I give out a ton of stuff, but I don't owe anybody here anything
Everyone doesn't care about your settings, it was just a small element of comparison, the problem is your big pretentious mentality, down 10 floors
I do not understand why you are attacking me for exercising caution with giving out details
it's not really a problem to want to keep some settings to ourselves, no obligation to share all either.
no need for going personal at them, they aren't the first one here that do want to keep some of that garden secret
It's not even keeping it secret. I am still working on the tutorial to do it, and I'm working on a huge project that relies on these settings. Of which somebody has blatantly tried to steal the idea of. I'm trying to keep my settings out of the hands of people who are looking to maliciously undermine people.
If anything, that sentiment is about as open source as it gets. Betterment of the people
Bref
The earth won't stop spinning tonight. Good evening
have a good evening too Seb 🙂

Hi there everyone, just dropping by to say hi and that I just now started experimenting with Stable Diffusion. Wooow I'm slowly becoming a nerd

It's a very fast plunge into nerdage haha
Kiss your social life goodbye! It is all text and images from here on :p
welcome around here !


Thanks a lot!! I now have a vision of creating some kind of abstract outcome including my both grandparents in a weird context, hopefully they will frame it and put it by the bedside 🙂 Also hopefully it is doable.. I'm thinking of them both riding upsized insects as vikings in the sunset or something...
Can Stable Diffusion get inputs from more than one image to better learn how to produce something creative to one new image (with crazy prompts)?
I know there are methods of blending songs, however I don't know them personally
Songs? Bruh lol
*images
well well well. the answer is yes, Stable diffusion can get multiple input image and learn from them.
but,and it's a quite big but, no pun
it's a whole other subject. You use SD to make picture, or you train SD to be able to make new pictures, 2 different tools and skilsets to learn.
Trying to first master making picture with less constraint would be best, that's my tip
I got that monkey music brain lol
I wrote an "intro to training stable diffusion" if you want, but tbh I don't want to scare you, this is a big tech to tame
Understood! Here we goooooo (I'll be back in like 3 months) 😉
They will for sure have 6 or 7 fingers, that I know for sure because all I created until now is very fingery

you can already try some extensions like controlnet, that solves that finger problem in some cases 😉

I'd love it! I will try to not get scared but this is a bumpy road in front of me :p
Oh thos make me feel unwell 😅
here you go mate 🙂 https://github.com/Guizmus/sd-training-intro
Omg that hand
It's shaped like
F
E
Hahaha it really is!
is it cat-dj time yet ?
Thanks a BUNCH Guizmus I'll get into that, slow and steady
I think it is
don't hesitate to ask if you need
one last non-dj cat

cause he's cool
DJ cat time now
and dj cat only comes in 1920x1080

Ooooh can I join in? Beginner style
of course
here are my settings
upper body, furry catgirl dj cat, colorful clothes , quirky, vibrant appearance, playful accessories, creative behavior, imaginative, spontaneous, dj headphones, mixing platines, music club, 1970's night club, indie theaters, people dancing on the dance floor background, underground danceclub, highest quality, fur texture, intricate details, (cinematic lighting), RAW photo, 8k
Negative prompt: airbrush, photoshop, plastic doll, plastic skin, easynegative, monochrome, (low quality, worst quality:1.4), illustration, cg, 3d, render, anime, asian, korean, japanese
Steps: 50, Sampler: UniPC, CFG scale: 5, Seed: 3445350518, Size: 960x544, Model hash: c4947fa2c4, Model: DB_mix_realbiter_v10, Denoising strength: 0.44, Hires resize: 1920x1080, Hires steps: 30, Hires upscaler: R-ESRGAN 4x+
Lmao I am really the new one here

Its like terminator meets
not terminator 🙂
Sorry for DJ cat spam but you started it!



I tried:
a cute magical flying DJ cat, with mixer table, fantasy art drawn by disney concept artists, colorful, high quality, highly detailed, elegant, sharp focus, concept art, character concepts, digital painting, mystery, adventure
most admins are cats or other animals as profile pics
That feels safe, I'm home
Banned in 2 days - what did he do? Spammed cats in general all night

I'd feel really bad banning for cats
to be fair I prompt "furry catgirl dj cat"
I thought they are their real pics 😮
it's a secret, we aren't supposed to :mooooooo; show our real 🐮 nature 
This is a cat friendly zone lol
Did you know that cows are secretly obsessed with stable diffusion technology? In fact, they are known to spend hours on end watching mesmerizing videos of stable diffusion patterns, and some have even been caught trying to replicate the patterns with their spots! Farmers have reported finding cows huddled together, hypnotized by the swirling colors and shapes, completely oblivious to the world around them. It seems that stable diffusion technology is just as addictive to cows as it is to humans!
(and I swear, when the 🐮 thing gets out, you'll all be mooing with us)
removing "girl" from the prompt now

just the good amount of fingers there
I was just starting doing nerd cows for some reason I don't know

Oh yes this turns out to be a really good day!
Nightmares will enter my life tonight probably, worth it
Not sure why she is so angry

Exciting!
upper body, furry cow hacker, black clothes , dangerous, Matrix appearance, computer, hacking, surprising, dark, headphones, keyboard, dark bedroom, dirty bedroom, computer screens, soda cans, underground, highest quality, fur texture, intricate details, (cinematic lighting), RAW photo, 8k
Oh!
DAMN
The soda cans will be nice to follow up on
Have you guys seen the amazing brain wave reconstruction Stable Diffusion interfacing?

OK WOW he is serious

I too like to use that small screen and have a wall of huge screens behind me

This is so cool
My brain cant figure it out
It feels like the whole concept of "art" is changing
Everyone and noone will be artists
the paradigm around art evolves for sure. but this isn't good on its own, it's full of things that make no sense and need touching to be good. like in the first one, look at the keyboard.
It goes up to F25 at least
Yeah there will be lot of keyboard buttons and fingers if robots are to decide, for some reason
Lmfao
like, is that a keyboard for cow ?

Lptp
I'LL DRAIN ALL YOUR ACCOUNTS

These guys are crypto scammers!
Im doing a bunch of cows with your prompt now, one will need a really good chiropractor... (any prompts on chiropractors?)

Hahahahaha
I have a furry dedicated model, let's see what I can do
Is he using the small laptop screen? The bigger one is just for show maybe

Is that the new theme?
woman in automn light is my theme :p
I'm on it! Prepare to change background!

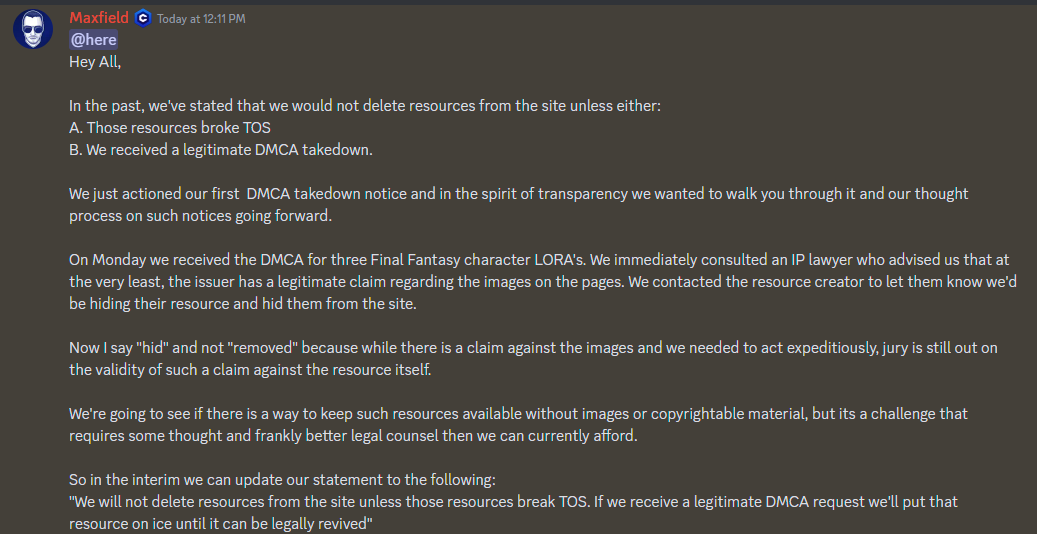
The first ever DMCA take-down just occurred for some models on CivitAI: https://i.imgur.com/qXPhatt.png

I should stop doing them in 512X512, not the best wallpaper format



it's quite a lot harder to do 1920x1080
Try 768x512 and later upscale
Oh it is!

Anti-AI artists are also apparently setting up malicious bots to target the Stable Horde and LAION (Anyone know the username of the person running Stable Horde?): https://cdn.discordapp.com/attachments/1006139459860975716/1088501275898941520/image.png

@winged dragon
Saw this on the LAION Discord
Oh ok here we gooooo


man, don't, do little things ^^ I use extensions and 24GB VRAM and still take more than 30 seconds per picture there, but without some things you'll just end up with duplications in there
Understood, thanks
(in before connecting to the server room at work going ham with 300+GB RAM and destroying the whole electricity grid for my city)
Oh right for the graphical card
300 of VRAM?
yeah, I have 128GB ram and can't use it
I'm more the DJ cat
x)
the largest good one I did, my current background

ok, the girl is technically in the water
My first and maybe only try for 1920x1080 had a lot of leaves :p

we see the autumn come out there
I'm having so much fun from all this
For how long have you been into this?
And for how many sleepless nights have you all been creating DJ animals?
hum, I've been around since public beta
so around summer last year
I mostly spent time making pictures, then doing animations, then training models
@glossy herald using a furry model

time for bed here, that's a good night cat to you people, hope to catch you all soon !

Thanks for your time and creations tonight! Night night
Ok wow my recent hacker cow just forgot the hacking part completely and decided to become some kind of end game boss in dark souls instead lmao

I posted it there 😄
hello, could someone do pixel art fox for me? i wanted to see what basic it can do
like could midjourney create something like this?

This is not a commission server, and it is certainly not a midjourney server, but best of luck@tired nymph
cute little girl
I made an embedding where the negative prompt "blurry" may struggle 😄

It was based on images taken with high ISO Ilford film.

@glossy herald he's so handsim

With them big ol peepers
The floor flopper sunlight fun time

Good image, AI often struggle with lights going through thin skin as in the ears of a cat.
Lol

Well, no nude, or anything bad and the same prompt I used on SD1.5 that I showed here gets me this on the new Bing AI

Far too censorious like MJ
@smoky oak
What do you post?
Nothing, I was trying to gen an image
It didn't like my prompt YET I posted the image in here many times with various outcomes. Not for me and they can go pound sand.
I did report it though
Oh, I looked at their content policy and it passed every last one.
@dense tapir did you see how bad adobe firefly is? Lmfao
I saw it on a vid but never tried it. I gotta say about the Bing one it is a MJ knock off though it did do my other prompt more to the vision in my head. Still, censorship like this I want no part of it.
Firefly is horrible lmfao
I still do not understand why an app like photoshop need AI, the only place I can understand the need for IA is with "Content aware fill".
Pleas misunderstand me correctly, I think AI is good, but not in a Editor, that should be in a own app.
Well, like it or not it is here
even if you think it is not needed they will tell you why you need it
I have seen results from people who didn't cherry pick, and oh my god firefly is asssss lmfao
It's giving dalle mini levels of quality. I swear lol
oh, ugh


Looks like it was pasted on
And even that SD gen is the very good lol
isn't firefly still beta though?
Yeah but Jesus it's bad lmao
These are the images that adobe themselves are putting out




Like bro lmao
Dalle mini called, and it wants it's artifacts back lmao
It's giving SD v1

Artifacts, artifacts, and more artifacts
This, right here, ruins it for me
Is that not during the test?
Not sure, but if not then lol
I'm pretty sure that is specifically put there because the product isn't fully released yet
So Adobe is just uploading these pictures to their Twitter, and they don't want anybody to like download them and use them
Kind of ironic
I just find it funny that one of the most hostile and problematic companies in the world is preaching ethics about their data set lol
I did hear something that they had used images from own database that was under CC0 and therefore have to follow the same license during the test.
Of course. Hypocrisy reigns supreme.
Like sure, you guys may not be affecting artists through your data set, but instead you're going to hike the prices of your products that artists rely on, which is a thousand times more detrimental to their well-being
@stoic pivot If that is the case then I would suspect their dataset is tainted and legally would be allowed ever
AI image generation does not hold a candle to the amount of damage that Adobe causes to their own community by abusing their power to price gouge them

CC = Creative Commons, CC0 "No Rights Reserved", but I think I said wrong and that it would be the "CC BY-SA" Adobe used.
Just now not 100 % sure, it was some told me.
There was a time when Adobe was good, but few remember that day.
btw, on bing AI this is not allowed

It surely hasn't been within the last decade or two lol

Win11 was installed on the PC I got and I hate it so I'm going to sail the high seas to downgrade to 10 again
web-ui's masking works like a charm but I get low quality renders with a custom mask. what am I doing wrong?

Spent a bunch of time installing stuff and taking out unneeded stuff, then it reinstalled the default trash it came with. Also kept deleting a program even though I disabled the security
Fun is not allowed with any of the big corporation AIs

ironic that you will end up having to pay for the service too
your mask is too precise. needs to be more loose, similar to this. give it more room to work with

I forget but in 1.5 how do you push the subject away from the camera?
I tried long shot, medium shot, extreme long shot
Almost never works for me either
Nothing I do moves them only changes them.

Starting to regularly see AI generated advertisements
Same
Specifically from this game "bloodline"

If you want it to look that the girl is in the background, say what she wearing on the feet.
IDEK know what the game is. That's legit the whole ad lmao
Oh? Let me try that
If you specify body parts, it usually helps
If I want a cowboy shot I usually specify upper torso, and hips
Then it typically backs the subject up at least far enough to show those items
much easier these days to use openpose CN
Funny cowboy shot is a wd1.4 tagf
When the AI cut of the legs you can say "wering socks" and the Ai try to make socks by showing the feet too
That's how I do it too
the pose stuff is just not for me as I am waiting when the AI can do it, and it will eventually do it I just hope not on some damn paid service as SAI sleeps.
trying "wearing greaves" now
wearing greaves

wearing boots

in pink socks


looking at old gens ive used ((distant shot)). worked sometimes
full body portrait.
I have to say cowboy shot is interesting
even changed from female to male
full body portrait

(wideshot:1.4)

(full body:1.4)

Just look so you do not have any conflicting prompts. If I write something like "female" that the AI do that, but if I add "detailed face" that it zoom in on the face so more details are visible.


No worries :>
Glad it worked!
I have to manhandle the AI to give me what I want frequently lol

Prompt - "silly fast rainbow girl run on a street sneakers and hairband , digital art, motion lines", then I added my "by BradC" embedding when testing a new model called CarDosAnimated.


I did read it as CarDosAnime first and thought it should be good doing cartoons, but the background is always realistic.

It going forward, looking good.
I often like less details and bright colors, so I am not good judge dark fantasy.
See, I want more details and duller colours
are my colors correct tho? it should pure black and pure white right?

yep, you want the white to be what is generated, just black and white
haaaaihooooo

are you using Chempunk TI? It sort of looks like it, not sure. I found that embed to be very difficult to control










When you add one to many words in your prompt.

I feel that this is what God looks like



heh
Gaming Grandma Series 🙂 👵




Last for today, it feel like I am still addicted to sleep and have to do it at least once per day.












Nope, no tis with these
/hazme una portada para la guia de un taller de live streaming en alta resolución con mucho detalle y de aspecto moderno, minimalista y profesional
hazme una portada para la guia de un taller de live streaming en alta resolución con mucho detalle y de aspecto moderno, minimalista y profesional
Je ne peux pas commencer à vous dire dessas línguas hablar de estos idiomas
I don't think thta made a whole lot of sense
which gives it a bigger point
If the same clocks were to be applied to the RTX 4060 non-Ti SKU, one could expect around 15 TFLOPs so 5.5 times less than RTX 4090.
5.5x slower damn!!
Hello, I have a question, I want to make a AI learn to help with my art style, but I don't want to share publicy so I can use my art in the way I want. Is that possible with Stable Diffusion?
of course. train whatever you like and use it on your pc. no need to publish online
How can I do that?, but the machine will learn locally or the style gets memorized on the internet?
you need a local installation of SD on your PC, then the extensions to be able to train. This all depends on how good your PCs GPU is
So I need a powerfull pc?
a good graphics card is important, the rest not so much
Thank you very much! I´ll search for tutorials then. Is there´s a good Youtube video with an explanation for training locally?
there are some but I dont know they are good. Just search on youtube for training, there will be a few
Thanks!






hai





https://prompthero.com/BalrogDx my promthero gallery, feel free to copy handsome ideas

PromptHero
BalrogDx is on PromptHero! Join them and thousands of other prompters in generating breathtaking AI images using Stable Diffusion, DALL-E and Midjourney!













Don't mind if I do, those seem top tier, wel done
thanks, if u need some more information about a pic, just write, but there open and readable with all needed infomationein SD (via png info)
adapting your fox cat hybrid right now

I need a good cat for #1023999442338201721 :p
have a better version ready, im working on it right now
and more cat with better fur
wait a sec i upload it






ok, so i will check ur submission if its posted 🙂 great that u like my pics
always loving good prompts tbh
you don't have the same prompt style that I have at all, and it's refreshing to learn

nice one, good lightning
Unfinished but verified functional AI generated texture map

生成能量的海报


As a stable diffusion main for months, I have to admit the new dalle has a ton of detail, raw output



the prompt: One complete, centered, dark black jade green, Italian muscle car, designed in Italy, in 1975, coolest car ever, cinematic, long shot, 4K, HD, depth of field, long shot, bokeh.
the neg: signature, autograph, watermark, out of frame, duplicate, people,
the result

but why the black and white background?
because it looks cool, emphasis on the car for your eyes, etc...
I have noticed "cinematic" loves b&w
/bull dog akita
ok so that's it

kinda looks like a challenger
Hi. I have a pretty crappy mobile picture of two musicians which I would like to let SD do it's magic on. I don't have an exact vision of the results, but maybe something cartoon-ish. How would I do that in SD webui?
I know there is something I can add to my prompt to get rid of the extra merged car but what? prompt: (One car) complete, centered, ((dark black jade)) green, Italian muscle car, designed in Italy, in 1975, coolest car ever, cinematic, long shot, 4K, HD, depth of field, long shot, bokeh.



Help. I am getting results of this kind all the time while trying to use Latent couple + Composable LoRA. SD completely ignores my prompt and loras and does random things. Anyone has some experience with this?


that kind looks like a washing machine using pants
kinda*

I KNOW. And it had to be a photo of two people...
The extension I downloaded had to make it but instead it completely fd up my loras and is doing nothing
I downloaded an extension that did the same thing and also fucked up my venv as I had to completely start over
Damn
I had no choice as nothing else worked
what is the best sampling method for architeture and horror images
Welp, I was trying to do it without the extension but SD gave me an amalgamate of the both lora trained people
my suggestion is to rip out the offending extension and delete the venv to start over
Depends
If you have a powerful video card DDIM 50-100 steps is actually the best.
ok
Bruh. I just realised something. Seems like that something happened with sharing LoRAs between my LoRA training account and my main SD one so the LoRA isn't actually here
Well, no extension can do that and survive for long as the crowd would report it
you are right
My 1060 I do 20 steps but a more modern I would be doing 50-100 almost always.



66
that is really cool
Cool.
nice



Really hard to not get leather based armour it seems. A lot of it seems BDSM related.
Not that one but a few I can't even show



lol




Nah, you didn't release 3 new models while I was away, no way
Are these good people ? Enjoying ?
Can't test right now but so hyped !
Quick question - does gen and gen with highres fix produce same image if prompt and seed are the same?
I mean, can I just re-gen something I previously generated without highres fix, just to add more details with highres fix or it's not how it works? Will images be the same or not?
It will depend on how much denoising you put in the highres
makes sense
High-res is supposed to create more details
But it can change composition too, especially if you use latent upscale imo
eh, so best way is to keep just doing gens with higher resolutions then still
highres fix takes longer to gen then just normal gen at higher res
Well, for pow, i ran a lot without high-res, but still in quite big res, and looked for a good seed, then ran high-res on it while trying multiple denoising
And then ran the same with lots of steps
yea that might be an option too, but if it's not as consistent idk what's the point, lower denoise will probably do less details then normal gen at higher res too
0.45 is my best value for it
hmmmm...steps might be the way at low denoise too with DPM++ , right
It very rarely details the composition, and still let's a lots of details in
aight, ty
Using unipc mostly on my side but yeah, it converges on the same thing anyway

Prompt was "super cool unicorn" and then I added my new Embedding "CraiyonUnicorn", I start to get the hang on doing very bad and silly Embeddings 🙂


Some time I think AI was just made to confuse me... SD v1,5, prompt "art GigaChad CraiyonUnicorn".

This artist uses stable diffusion to render their drawings. When I try to do this using controlnets canny and depth, SD just butchers my drawing. Maybe someone could point me in a direction of how to achieve this process.

here is another example


decided to upscale a bit old gen
probably will do more attempts on same theme at some point ^^

Good idea, have 10 Gigs of old gen
lol
I keep finding more and more gens from firefly, and it's really striking me just how bad it is lil
Firefly should be renamed dumpster fire







looks like my attempts at 2.1 model...

I find out how everybody seems to be praising the most corrupt company in the creative space for practicing "good ethics" for training on their own shit. Like... They screw artists over every single day. They are probably the most unethical company in the scene
probably painted the details in photoshop
I believe first image is painted in photoshop, second is image to image SD
then in that case maybe used image to image with low denoising strength. Check this art walkthrough maybe can be helpful. https://www.youtube.com/watch?v=R7ywLyOoBuE

Walkthrough creating anime style character concept art using Stable Diffusion Img2Img.
kk, thanks ill check it out in a bit
Wow so many different nice results! 😮
I thought it was always cat days in here!
but i'm already eating all my bandwidth uploading models
it is always cat day
but model cat day is something else
I forgot to sleep last night because of cows, cats, hackers etc
here is the showcase

#1088926673644290058 if you want to check

what shpeed?
I have a lot, it was HF that was slow as hell
it's online now
but I have symetrical 8MB per second

ah, not too bad at least
also, I am still not properly understanding what this weekly challenge is I think
I tell it "wearing full body armor"

cats
but you guys take the submissions and train a model on them? or am I misunderstanding
me guy, but yes
DDIM wouldn't do it but Euler_a did

ok, so that is how it works
and then everybody was tagged, so calling their token does what exactly? I just wanna make sure I understand this all properly 😅
the model is just me trying to make something fun around, it is not even mentionned in the #⭐|pow-info
I'm about to go to bed so I cut everything out already
but here are one or 2 examples
that's 2 original ones from the submissions


that's some variations with just 1 token





you could also use 2 tokens at once, and it would "import" both inspirations
I'll bother you some time about this, cause I don't think I am asking right
ohhh, wait
so its trained on them as inspiration, ok
that what I was confused on
each token is linked to only 1 pic
so yeah, it's a weak token, and acts as inpiration mostly
the token "SDArt" is different
it's trained on all of those, so it makes some kind of "mean" art


it's a strange way to tackle training, I'll give you that
its like a multi style inspired model
a little yeah
ok, that makes more sense
and people like to play around their submission a lot it seems
i thought it was trying to teach the AI how to make cats, and I was really confused lol
nah, cats are quite already known
yeah, that is where my confusion came from haha

yeah, I get it now, awesome
lol
well, civitAI is down, the model will have to stay on HF for tonight
have a good evening !
you as well :>
or over part of the day !


Are you also doing this to test things out? :p I just waited 2 hours and I'm not even sure why really lmao


I think I forgot "Ultra realistic", "8k" and "Trending on ArtStation" and that's the reason it didn't turn out as I wanted.







lmfaooo hahaha
who was that one dude that made the most useless prompt ever
let me see if I can find it
"A stunningly beautiful girl. Cinematic in nature, this hyper-detailed scene is filled with insane details and beautifully color graded using Unreal Engine. The use of DOF, Super-Resolution, Megapixel, Cinematic Lightning, Anti-Aliasing, FKAA, TXAA, RTX, SSAO, Post Processing, Post Production, Tone Mapping, CGI, VFX, and SFX has created an insanely detailed and intricate world. The hyper maximalist approach and hyper realistic Volumetric and Photorealistic rendering bring out the ultra photoreal and ultra-detailed aspects of the scene. With 8K and super detailed visuals, this scene bursts with full color and Volumetric lightning, using HDR to create a realistic and breathtaking environment. Powered by Unreal Engine and rendered in 16K with sharp focus, the intricate details of this scene are truly mesmerizing."
That prompt lol
I admire the dedication to the craft haha
thats some passion, if I do say so muself

Black guy wears a black coat And brown pants, sleeps on the floor, and cardboard paper is underneath him

Black guy wears a black coat And brown pants, sleeps on the floor, and cardboard paper is underneath him
Bigfoot drinking beer and wearing hawaiian shirt



{kind=link}
{kind=link}
{kind=link}
{kind=link}
@dense tapirI am playing with fire
I edited the config to let me go to batch 16 hehehe
the higher the batch, the more time efficient it is so... fuck it
it works!
woooo

that means I can do a 1600 image generation in one grid lol
Oh, snap