#🏞|general-with-images
1 messages · Page 7 of 1
I can understand it, well, depends why you're not a fan. I believe the most "off putting" thing about MJ, is how secret they are about their tech, I just want more people to be able to create cool stuff and keeping it hidden isn't making that easier in my eyes :(
I don't mind checking it out, just not exactly now, but I got no issue with trying it when I do get time a little later :)
That, plus I can't run it locally, and they charge people and those people who pay are beta testers they then turn around and use for their high paying clients.
Well if you insist, here is the page in the models-embeddings forum. https://discord.com/channels/1002292111942635562/1066559052328472596
Their entire setup stinks as far as I am concerned.
heh, I actually downloaded that one when you uploaded it the other day, or when it was, I thought it looked cool! ;P
But I haven't had the chance of trying it out yet, I can put it on top of my test list tho :D
I got into AI art from Dall-E 2, ran out of credits, then eventually found stable diffusion somehow, don't remember exactly. Have been here ever since
Oh wow! How cool. Well I would love to see what anyone can make with it, all I have seen are my own gens, and the two people that have left a review for it.
I never could figure out MJ on their discord so left to never come back. I tried dreamstudio I think it was and was hooked but as I was playing around figuring it out I used up all my credits and got mad. Came to SD. I mean I could figure out MJ now but I don't like the MJ style. I mean it is supposed to give me art, photorealism, etc... not inject its own style.
hehe, I believe a lot of people may download it, but then not give a review, or haven't had the chance to "grow on" it :)
Yeah, it has like 600 or 700 downloads now. Pretty surprised tbh, since I really didn't know what I was doing when making it. I must have done something right.
I don't like civitai so my embeddings are on huggingface and people are too lazy to figure that thing out and they sit and rot. Meh
I think I saw a plugin for blender that hooked into dreamstudio, used up all my credits, and then found out how to locally install.
PLUS most people are on 1.5 and I moved on from day one
I have a model on huggingface, but they don't really have a reccomendation system that I have found, or an easy way to find things at least.
Like me...
Well, I just used 2.1 today to help that one person up there
And it was cool, I must say
I don't like recomendation systems, or rating systems but I do like a way to find stuff.
Very photorealistic dogs
I dropped 1.5 like a hot potato the day 2.0 released. Yes, mad but CLIP in it is superb and I was the first one to find out it could count. OMG, that sold me instantly. 1 knife, two knives, three etc... I was sold. Model is stripped way down due to legal reasons and that sucks.
I had a lot of time invested in 1.5 with DB models I released and some I didn't. I would need to redo them for 2.x but meh
Woah it can do that? Is there a specific way you have to prompt that in or is it generally gonna figure it out?
I said a knife. It gave me one. I said two knives and damn 2 were there. I then tested to five and it gave me what I wanted perfectly. 1.5 could not count.
I found that out the day it released on this server.
so like "2knives" or "two knives"
I posted it to have everyone try it and sure enough it counts
Hmm
I spelled it out as two knives.
testing it now..
The major selling point of 2.x is 768x768 as the fabric, cloth, leather, fine hair is better than 1.5
I noticed the hair was much less grainy in 2.1
not perfect...

But more or less between 1 and 2
yep, it does know how to count
1.5 no way. that is the difference in the clips
clip got better model got worse
I find it interesting the knives look like guns
🧈
this is what is so bad that due to impending lawsuits they had to strip all the goodness away from the model while giving us a much more powerful clip. Had they not been forced to strip the model goodness everyone that could would have jumped over to 2.0
Which means less people making models for it, which would fix the issue
more or less
have you tried the primevalNova model?
I think it makes some pretty good results
Now we get a bare basic model and are expected, per emad, to make embeddings, and dreambooth, lora, hypernets to make up for what they had to remove.
if for 1.x no as I am strictly 2.x now
I should really start making stuff for 2.1
Just got this with 2.1 and double xposure embedding

I am a photorealistic guy so when I saw 2.0 do its magic my jaw dropped as the photo realism is so much better.
It is
We lost camera settings in 2.x though and that was a huge kick in my ass
lens speed, aperture, etc... just POOF
can't be done as embeddings can only do one concept
Custom model
I am not sure why that was removed.
lora, maybe.
possibly
Been having decent luck with it today
I know nothing of lora since koyha doesn't have a colab trainer
How much VRAM do you have?
It can run on like 8gb
6 and it required 40-60mb more
I only worked on subject training today with it. Going to be trying effects and styles tomorrow. My knowledge and access to photography is limited so I won't be touching that stuff.
oof
seems I have to let it rebuild the sd folder and my TI training will come back. Not sure why that is but imma try it. Still not sure what to use as a prompt so all trial now.
Another reason I wish I could train any thing locally but 1-3k USD for a 24 gig card isn't happening. No to used and new is nuts what Nvidia is pulling.
yeah. I got a 4090 when they were 'cheap' at 1600. still waaaaaaay too expensive.
they only went up and my poor 4060 ti I was saving for is now 200 more than a 3060 with less specs all around even 2 gigs less.
they spit on the ti making it a joke. Seems Nvidia is trying to ditch the gaming market and head strictly for AI/ML and let AMD have the gamers. If they get some gamers cool but that isn't their market it is corporate and AI/ML now. Charge double and sell half as many to equal the same in their minds.
less work for them
I got a free RTX 3070 with 8gb for my pc (I also have that in my laptop) so I can train locally, which is why I have been doing so recently. I find training the most fun.
For me I train as that is my enjoyment, then releasing it, but just making AI pics isn't as fun to me
That's the fun for me as well, which is why I also make video games. I love seeing other people do things with the stuff I have made.
makes me so mad so I tried Linux and everything is so broken in it I gave up. days I tried and lost a lot of stuff doing the transition too.
Linux I would have had enough vram but I couldn't get it/this to work in Linux
tbh, the 4060 ti as it currently is speced is a $279 card and no more.
they want 600
anything less than 16 gb is really going to hurt in the future especially when 1024x1024 hits with 3.x
Already 24gb is bare minimum for some things
My queen

Gonna outpaint this baby to get her whole head in the picture
That's 1.5 btw, still the undisputed king of models
@sick remnant


@dense tapir So i was using old version of stable diffusion for months now and updated to newer version and found that UI is completely changed, can't old settings like CLIP, hypernet,etc . Anyways to get them back?
(cant even see the what model is loaded like this)
show me what you are seeing


pm?
i had no idea UI changed this much since i last updated SD lol
okay

I did apply it but why can't I see dreambooth tab?

@tidal hawk

yup found it
lol what model made that
One I am working on called SmolOnes, should be ready sometime tonight or early tomorrow 😄
nothing
I was so mad yesterday
today it just works
very good
do people generate 2k x 2k images?
Or the results are too repeating?
I'm considering buying rtx 3060 laptop and I'm not sure If it's that necessary
with the hires.fix, or img2img upscaling, for the most part, or with images without people in them. things get weird at resolutions far beyond what the models was trained at.
I wonder if the new version will be trained on big images.
Is there info somewhere about that?
3.0 is rumored to be training on 1024. not sure how reliable the info is. seems reasonable, though.
biggest I usually render without upscaling is like mid-900's. larger resolutions work if you're doing patterns and things, but I stay pretty close to the training res for people.
How do I stop the buildings from being cropped? I have this in negative already: ugly, broken, distorted, hazy, (cropped), cartoon, zoomed-in, (close-up:1.1)

@hallow sparrow
Try adding clear sky
Make a caricature #1002292387051212860 kid having fun at the computer
Easy Diffusion UI has option to take an image through 25 more iterations. Is there a way to do that in Auto1111 AI?

Are you for long prompt to get exactly what you want, or short ones to get random images for inspiration? I am the later and here is "four funny feminine furry fursuit friends, fishing fine fish frantically for fun".

Incredibly detailed long black war astroship with tiny green light inside in the dark depths of a black ocean, HQ, 4k

how can i stop img2img from modifying it so heavily
i want it to still look as if its the same city
Try use low CFG Scale and as low Denoise as possible. I use Automatic1111 and can set (in settings) so it use colors from the original image.
okay thanks ❤️
And try Euler rather than Eulre a.
ill try it out now after the next gen, running on cpu cause im not trusting these random ass ckpt files lol
okay bet
But img2img can be a bit random, I some time get images that are easy to work with, then some days images that put up a fight.
only amd tut i found that includes img2img had the download on some shit like "aiinfra.visualstudio.com"
and ah okay i see
thank you for the help 😄

would you happen to know
if this is a safe place to install from? its for stable diffusion except compatible for amd.... link sus af
@still bobcat

coool
Found the golden long banana.


Lol
anyway thank you for the help
Thank you so much for your help. I really appreciate it.
np
as they should
Ive used Dalle for image creations and like the look, this "surreal", painted look I always get. How can I get this style( mostly for concepts) in Stable diffusion?
Ive tried so many different things but cant get it work. Would appreciate some tips or a hint. Thank you!


Hi, another newbie here looking for help! I generated the first image using F222, and I'm reasonably happy with it, except for the faces. OK, move to inpaint, mask the faces, load up the inpaint 1.5 model, run a DDIM at 10 steps and 10 batches and a random seed as a rough copy for face replacements, but nothing I try seems to give me anything near realistic. I'm using the same prompts for inpaint as for the original generation, namely: (Pos: two aristocratic women, beautiful, bored, looking at camera, sitting on antique couch, victorian, indoors, well dressed, casual pose, photograph, expansive, color, symmetrical, ((saul leiter)), (((radoslaw pujan))), (pier paolo pasolini); Neg: 3d, cartoon, sketch, blurry, disfigured, deformed, old, ugly, poorly drawn, extra limbs, missing limbs).
I'm using CodeFormer face restoration both in the original and the inpaints.
Is there anything I can do here to get normal looking faces?









huh... ok

prompt/model? That looks like dreamlike-diffusion tho...
With Photoshop plugin (Stable.Art); Generated an picture with New York, took a T-Rex toy picture, and used a layer and img2img in Photoshop to generate a new different one, works well, need to do an example with more work :


the result :

The trick :

i noticed discord had no towel emoji, so i went to SD and said to it "SD, give to me a towel emoticon of the highest quality" and it gave

Question for you all. Whenever I do a high res image with a resolution that isnt 512x512, my subject always gets duplicated and weirdly stretched out. Almost as if it is trying to stretch it to fill the resolution. How do I make the ai make one subject no matter what resolution I do. Or how to center the subjects in a certain portion of the image so they arent just floating around. THANKS!


can someone give me some advice to find a model that looks like midjourney and can generate pictures like this?

or just help me do something similar
it's just lexica and the prompt was pirate, centered, symmetry, painted, intricate, volumetric lighting, beautiful, rich deep colors masterpiece, sharp focus, ultra detailed, in the style of dan mumford and marc simonetti, astrophotography
crate a gamer controller futurist
seems to be a 512x512 generation, what are you using? I mean if you are using something like automatic1111 you can try a bigger resolution like 768x768 and upscaling.
Yes, it is 512x512. I’ll try a larger res, thanks for the tip 👍🏻
No prob, it happened something similar to me when playing with some models. And trying larger resolutions was the answer.
Are you using the default model?
watcha mean by default
Stable Diffusion 1.4, 1.5 or 2.1
it occured to me that maybe my random cuda crashes might be due to the nvidia overlay, whiich always just randomly pops up and disturbs me as a desktop user. it might be doing that to the training process too
turned that off. don't know why i didn't sooner tbh
mmmmm strange, what resolution values are you using?, normally they should be resolutions whose values are divisible by 256, or at least that is how I reduced that kind of problem
iirc values divisible by 128 also works
I trained it using 512
its cause 512 trained models create images in 512 sized blocks. its pushing the same seed into every 512 block it looks at, and diffusing what content is already there out some more
yeah, but the image with the orangutans seems to be 388x721
thats what the hires fix is good for. you do a small close to 512 image, then img2img it bigger with a denoise setting that gives a good rub to it
the attention isn''t fixed to a 512 grid. it's attention can be at any 512 block from any origin
so if the seed has a strong face to it, it'll want to create that face anywhere it can fit it
Daddy government said it's here to help me.


https://discord.com/channels/1002292111942635562/1067710900187963504
new model, please check it out and show me the results 🙂
what dataset did you use for that?
it's included in the civit post but I scraped the midjourney images on the same topic from tophmagoph_ on instagram with his permission
66 of them to be exact
I see... yeah I was thinking something like generate related images then train. Its always nice to learn new workflows, thx
I have a lot of TI's with midjourney images and a few models, it works pretty well for helping SD catch up or pass MJ
I gotta try that! Never thought of using MJ to train SD...
So no one can help me?
seems to be the case
I can help you make one, if you provide a few more pictures
Hurrah!
Training SD models tends to focus in on a specific area, so that style would be doable in a model or TI but would be the limit of the model
Honestly, what was the MJ prompt, I can find the similar pictures myself even
Maybe this model could help https://civitai.com/models/1274/dreamlike-diffusion-10. You can find some prompts examples below in the images section

Dreamlike Diffusion 1.0 is SD 1.5 fine tuned on high quality art, made by dreamlike.artUse the same prompts as you would for SD 1.5. Add dreamlikeart if the artstyle is too weak.Non-square aspect ratios work better for some prompts. If you want a portrait photo, try using a 2:3 or a 9:16 aspect ratio. If you want a landscape photo, try using a 3...




Openjourney is trained on MJ Pics, try the 2gb model variant:
https://huggingface.co/prompthero/openjourney-v2/tree/main

Vivid green and purple tones fierce bear
I already tried this, it looks awful
Can you train a model or tell me where I can learn that?
I want to give it a try but here are two good videos for learning such a thing using automatic1111
https://www.youtube.com/watch?v=dNOpWt-epdQ&t for TI/embeddings
https://www.youtube.com/watch?v=Bdl-jWR3Ukc&t for DB
I will let you know my results 😄
Do you want more material for it?
I was going to search MJ but if you have more that would be helpful
Just finished a Lora model I was working on so I can run another training session now



Hi. Has anyone had issues with black edges on the output, when using video input in Disco Diffusion? Whatever settings I try, the first image output is fine, but the rest get progressively worsening warped black borders. any thoughts? Many thanks

It seems to have something to do with physical camera panning/movement - like it wants you to use a locked-off camera shot
yes, listen to daddy or otherwise you will kill yourself accidentally under mysterious circumstances one day
has anyone seen this? Fiverr is probably one of the few big sites that allows AI art

Protogen is not SD2, it's a merge of SD1.5 models

manual additions of prompts using the lasso tools and the Stable.Art (SD) plugin on Photoshop, incredible tool

ONG

One of these cats... is an imposter!

so, here's a fun game - prompt for something that gives you AI text, enter AI text as next prompt using seed of previous generation.
Like at quick glance, everything seem rather normal. However... Longer you look, the more you find... Just stuff wrong.

You may not like it, but this is what peak performance looks like.
oy! a fiver

how do i fix it?

add that "flag" --reinstall-xformers to your user bat and rerun the webui once, then remove it afterwards
Well, maybe I should have started with the question: which webui are you using?
automatic1111 ig
I can't remember for sure, but are you using the webui-user.bat to launch it?
yes
you wrote --reinstall-xformer, it should be: --reinstall-xformers

Already up to date.
venv "D:\ai\SUPER SD 2.0\stable-diffusion-webui\venv\Scripts\Python.exe"
Python 3.10.9 (tags/v3.10.9:1dd9be6, Dec 6 2022, 20:01:21) [MSC v.1934 64 bit (AMD64)]
Commit hash: 6cff4401824299a983c8e13424018efc347b4a2b
Installing requirements for Web UI
Launching Web UI with arguments: --medvram
No module 'xformers'. Proceeding without it.
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Loading weights [9ab3546b0f] from D:\ai\SUPER SD 2.0\stable-diffusion-webui\models\Stable-diffusion\AnightingV4.5+Yuzu3.5.ckpt
Loading VAE weights specified in settings: D:\ai\SUPER SD 2.0\stable-diffusion-webui\models\Stable-diffusion\anything-v4.0.vae.pt
Applying cross attention optimization (Doggettx).
Textual inversion embeddings loaded(0):
Model loaded in 47.1s (1.4s create model, 45.4s load weights).
Running on local URL: http://127.0.0.1:7860
To create a public link, set share=True in launch().
remove the --reinstall-xformers and add instead --xformers, it needs to be one of the args to be used in the first place


sorry, but I can't read that error as it's not in a language I understand. It's a lot of checking to see how you installed it, and I don't got that time sadly. You can remove the --xformers if it is causing the webui to not launch.
Otherwise, check the git page and see if other people have the same errors. Try and follow what the window tells you to do. Good luck :)
okok thank you
Try removing the OpenOutpaint extension (if you have it) and delete the folder called "vae" in the webui directory. I have seen that window pop up before and after a lot of searching on the internet I found that fix somewhere. At least I think it's that error, I can't read it either 😆
You can delete boath xformers folder in SD and then run the bat again with --xformers. It will install the new version
did today's daily as my first experiment with SD online - it's really cool to see the difference between the releases and how they use prompts

What happened to all the hot manga girls from SD 1.4? Look at the difference: prompt: "manga girl with red hair and a gun". And you usually just get a head shot with 2.1. LAME.

:/
For 2.1 u need to use negative prompts
Like blurry, deformed, lowres
I see. But I don't understand why the cartoon women are less hot 😂
So your negative prompt has to be the opposite to your positive prompt? So "red haired manga girl" the opposite would be "blue haired disney prince"
Yea but dont make it to specific
idk, i'm not convinced by this latest version yet. But I'll try to get better at prompting
For positive Prompts try masterpiece, highres, highly detailed


anyone ever just mess with the base SD model for scifi shit? it looks legitimately epic af

A friend asked me to generate Saul Goodman and this is the result

(very short prompt)
good lord i dont have to deal with indepth prompts

this plugin uses gpt3
i just command like human instruction like u give to chatgpt

what plugin? awesome
Pix2pix on github
This one?
https://github.com/phillipi/pix2pix
is not available in auto111 yet?
I think this:
https://github.com/timothybrooks/instruct-pix2pix

GitHub
Contribute to timothybrooks/instruct-pix2pix development by creating an account on GitHub.
this is where all the cool kids hang out
I am getting this error whenever I click on dream button

oh I never used what ever that is
I cant help
sorry
do you have anything in the prompt?
Yes I do
then I dont know
Here is what it looks like

I got it
so a positive prompt is like
Table:1
Example: A cat doing a backflip. 4k, Best Quality, Ultra Detail, Table:1
Wow, thank you so much. What effect does it have with creating the image?
It adds Intensity
if you made a house and said Grass:1.5 then there would be more grass than if you just said Grass
not sure what Negative prompting would do
I think negative prompting makes sure it doesnt include what you specify
oh I guess its different in this one
since there isnt a seperated box for neg prompts like stable diffusion (local)
Oh okay, thanks for helping me out, really appreciate
Yes, is in the available extensions list in auto1111. You have to download the model manually. Here's the extension link.
https://github.com/Klace/stable-diffusion-webui-instruct-pix2pix.git

GitHub
Extension for webui to run instruct-pix2pix. Contribute to Klace/stable-diffusion-webui-instruct-pix2pix development by creating an account on GitHub.
r there specfic settings for not getting blurred final images or distorted portraits
in this plugin
Guys, do you know a good prompt to have the "Aerial perspective" effect?
What does it do? What is it used for? I don't understand.
you can change specific parts of an image in natural language

AH
heres a demo: https://huggingface.co/spaces/timbrooks/instruct-pix2pix
I take it it will not run with my GTX 970
neither in my GTX 1050, but its really cool
I am trying the demo you linked. Thanks
would it work with other .ckpt s, or do you absolutely need the pix2pix one?
only the pix2pix model works but the embeddings made for SD 1.5 are compatible
with the pix2pix model





we get it bro stop lmao
Faces I generate looks similar even with different seeds. Any idea on how to change
use a different model
use img2txt
use names of known people at different weights
describe facial features
are you using a custom model?
NO,its dreamlikediffusion photoreal
thats a custom model
its a common issue cause the dataset used to train that custom model is not broad enough
protogen also have that issue
auto1111 emphasis is supported
so if, for example, the prompt "make it blonde" changes the image too much, you can try "make it (blonde:0.7)" or something like that
drone shot
You don't understand, Aerial perspective is supposed to be this effect

Yes, I don't understand

have you tried what I told you ?
it is this effect that makes the colors paler in the distance, on the most distant layers, an optical effect due to the atmosphere
that's atmospheric distortion, called distant Sfumato in painting
that has nothing to do with height of the camera
Ah, thanks, english is not my native language, so
You're french ?
yep
I figured that part
x)
go try it, tell us how it went
works well ! 🙂

nice
i need to use it in Photoshop plugin on a creature, but hard associate with something i think
Why don't you do composition like the "stelfie" guy does it ?
working on this, generated the left on SD, and working with Satble.Art and drawing with Photoshop

is stable.art working ok ? been meaning to try it
WOrking perfectly
Nop, WIP
weird, someone posted something very similar to that
???
it had a godzilla on the right side though
I was writing a pavasse to prove that this is my project but a video is much better xD
yeah dino on right side
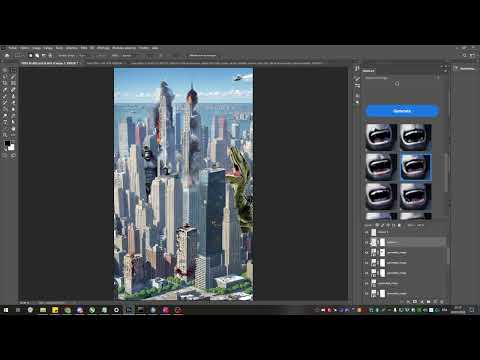
If you have a link of this post on reddit please, have to talk with this guy

we knew you like sfumato, so we put some smufato in your sfumato dawg!
inceptsmufato?

My AI/Animation Playlist
https://www.youtube.com/watch?v=1g2q-hKDXcs&list=PL8G7-J1OZZnT60bZ0hX3GI6nYQfFhguIv
Playlist of some of Best AI Stable Diffusion Videos on YouTube https://www.youtube.com/watch?v=uo6iPeFHk4A&list=PL8G7-J1OZZnS205o_9XbNhmp6JPSi58-n
#stablediffusion
#artificialintelligence #ai
#animation
#midjourney
#openai
#automat...

lol i thought it would be like chagpt prompting







Guys, anyone doing blender or low poly renderings here? Trying to render something like this. What model and sampling methods etc would you recommend?

Just as you can see, soft, sort of blender style.


what's the best upscaler option?

got your nose!

the boring and probably what most would answer: it depends on what you want to create :P
I've not even named half of the ones I liked. Their default names tells me nothing other than that they have no idea what words mean! That, or I have no idea what it's supposed to mean ;P

I usually use Remacri or Ultrasharp, depending on the image https://upscale.wiki/wiki/Model_Database#Universal_Models
I got almost every upscaler from that site, it's such a good addition :D
there are too many to te4st for each image so I only use a few. even then its a little fiddly
yeah, some does almost nothing as they are are made for super specific things or areas of the image, but the horder in me wouldn't let me just get the ones I needed! ;P
@wispy nest here for example. model and vae from the same creator

ooooh ok i'll keep an eye out for those
also "Oh" for realizing this is the chat where i wanna be, i figured it was for chatting while posting SD images 
its general so yea we could post created images also xD
thanks again! time to play around with it!
Been hatching a phoenix fox 🙂 Love Stable Diffusion, really addictive stuff

wow really nice! which model did you used?
latest one, hatched from an image

#stablediffusion #dreamstudio The evolution of an Image starting from something in made in Canva a while ago for my game Halloween Hunt VR.
official SD 2.1?
yeah
ahh
Ive been creating a pick a path story using google sites, gtp chat and stable diffusion. Only been doing it for a few weeks, but starting to get the hang of it now
100%, its crazy fun when you strike a good seed, almost like a win on the pokies lol
How do you do it? I kind of follow the composition. I see a composition in an image and then create a prompt to try and hatch it, some timjes just upping the steps, other times getting the new image and starting from 15 steps and 4 images to try and improve it
What's that?
so you mostly use img2img ?
I start with prompts sometimes
but usually I get better results from other iomages
using tehir colours and composition
ah okay
that makes you image resolution higher while creating, it creates and image of 512x512 and then upscale it automaticly by 2x and you get 1024x1024 as result
Oh awesome, yeah I knew that was out there but haven't done much with it yet. I'm trying to get a heap of images so I can pick the top ones to do that for
would be a lot better for the pick a path pictures, thanks, I should get it into my workflow now
okay have fun 😄
Cheers!
woo, so i think i will finally switch back to 1.5 from 2.1 🙂
so whats new here ? 🙂 haven't checked the 1.5 stuff since 2.0 came out

What's the best way to reduce (or eliminate) the glow/halo you often get around faces after you inpaint them?





anyone got any idea how to "force" CodeFormer or GFPGAN to use the whole picture?
it's not even able to fix/upscale the neck
Working on a hyppernetwork to fake plastic miniature , happy with the result 🙂

I wanted "A cake with the text stable diffusion" and I got a SUS cake lmao

You can´t do that on codeformers/gfpgan as far as I remember, you have to use another AI like srgan/bsrgan/remacri/etc. You can also try using img2img in stable diffusion with a low denoising strength

Groly lol
Ok since you like girls... Way more interesting in my opinion than what you have there.

Also I didn't need a massive set of prompts and wall of negatives. Can you even prompt with your using greggy?
IN case you are in to milf or gilfs


Not judging!
they look like oil paintings
They are supposed to
I dont dig the painting look
well not really...
Thats why I always put greg rutkowski in the negatives
They are supposed to be in the realm of old film reel and painting.
Kinda like old school matte
That is what i am going for
thats kool. I just dont do that style. I do modern photography
Well if u like 2.1 just keep using it. I just dont like it cuz it doesnt do what I want it to
especially with celebs
Well you could at least try modern photography techniques...
Like art photography is all sorts of interesting
They try and do all sorts of shit
Like IR and UV filters. Polarisation...
Hell lot of them have gona back to film since it allows you to do things digital doesn't. Maiinly due to how the exposure works.
That's a pretty cool style. That's one thing I really like about this AI art is that you can actually develop a style with it, just like with painting or photography
Well yeah. I take my best generations of some style. Make a style embedding - not always as easy as you'd think. And then keep iterating that
Style embedding....that's on my list to look into. I only just discovered SD this past weekend so still lots to learn. Happily consuming info at a voracious rate though lol
Instruct Pix2Pix is very nice

Thoughts on this by the way?
Based on the Creation of Adam by Michelangelo, of course
just found this prompt on civitai, and, well, maybe if we ask with this level of kindness, SD will generate good images? hahahahaha

hahaha nice one xD saw also prompts with very very very good eyes or five fingers!!!!!!!
i have to admit that I already used the "five fingers" one, hahaha
did not work very well
hehe 😄
if there is one thing I learned about hands, is that... when you put "biomechanical claws", there is no right or wrong, so it will always look cool

yea with my cyborg prompts its also very good xD
hahaha

hi 1.5 guys 🙂
hey 1.4 guy 😛
😉
thx i discovered better results with model merges


which model is this? 1.5 ?

frozen cherry trees

looks like an old photo
sometimes stuff goes into ... unexpected directions
model merges? you merge them by yourself in webui?

yes i merge a lot and test with them

amazing colors and composition! I would easily frame this to put on a wall
🙂 thanks
@analog goblet do you use the 1.5 VAE ? im not sure

sorry to ask but, is there a tutorial that you would recommend to watch and learn this? I just have no idea, haha
this is v1-5-pruned-emaonly.safetensors
i dont know if this answers your question
i downloaded that VAE file, but i have no clue how to apply it
yes thx i would suggest to use the vae to get rid of the tiny pixelation
you need the vae.pt file of 1.5, then rename it to match the model file, the vae goes into the models folder
the webui will then be apply it automaticly if its set so in the settings
like here:

so i rename it to ... ok
its a safetensor right now
so i rename that, too, yes ?
v1-5-pruned-emaonly.safetensors is my mondel
*model
v1-5-pruned-emaonly.vae.safetensors would be the name then
v1-5-pruned-emaonly.vae.pt would be the vae name
ok, so do rename to .pt
i downloded it somewhere i think, but it was name .safetensors
how big is it ?
then restart the webui thing ?
yes
i can give you a short explanation, idk if there a tuts
NVIDIA GeForce GTX 1050TI, 4 gb VRAM
I would appreciate, hehe
thats right.. too sad that here in Brazil the GPU prices are insane
I can never make high resolution pictures
you should use --xformers and --medvram in the webui-user.bat
maybe pay for a monthly midjourney ?
what exactly does it do?
it then uses less vram of your 4gb and you will be able to generate better
nice
ill sure try this
yep, thats it, hehe

@potent hornet your webui-user.bat should look like this:

i think there's even a --lowvram options, isnt there ?
yea but with 4gb you should use medvram
ok
did the vae work malicor ?
make sure in the webui settings under Stable Diffusion the vae is set to Automatic

just did this
autolaunch is for...?
autolaunch is starting the webui in browser after starting the bat
I found that switching vae's manually is easier than naming them after the model, less headache for me anyway :P
yea if you have many vaes or models then yes
What's the most appropriate channel for prompt / model assistance. Trying to replicate an artstyle I use a lot on midjourney.
and for some reason I don't trust myself with changing the web-user.bat, instead I just made my own bat @echo off cd /D E:\stable-diffusion-webui REM git pull OR git checkout master OR (before highres fix change: git checkout fd4461d44c7256d56889f5b5ed9fb660a859172f) REM --precision full --no-half --api --xformers --disable-safe-unpickle --medvram --reinstall-torch --reinstall-xformers set COMMANDLINE_ARGS=--xformers --api start "opens a new incognito chrome browser" /MAX "chrome.exe" --incognito call webui.bat :P
nice xD with the commands to remember
wow
well, i think i somehow bricked my system with that vae thing
yes, no way in hell I'd remember then, my memory is so bad that I don't even remember it all!
what okay yea never saw a .vae.safetensor file xD
since i'm no dev, this is crazy for me, i'm really struggling to learn all this thing, hahaha
when i try to train on a embedding i get "KeyError: malior_wild3"
i got malicor_wild3.pt in my embeddings/ directory though ... i was training it before the vae thing
hey @dry crow , just tested the --medvram thing, and wow this is a gamechanger

i now cannot pick ANY embedding to train anymore
also with xformers ? glad it worked
yes
top
thank you so much
np i help where i can, you mostly see me in #🤝|tech-support xD
any idea whats wrong with my installation now ?
yea, you already saved me sometimes there, hahaha
an update could broke it. or you can rename the vae back like it was maybe it works
no, doesnt work at all now anymore
the training or the whole webui?
i dont think the vae has something to do with it
did you try a fresh new training embedding without continuing from another one?
i think the git pull updated 2 files
try to search for updates in the extensions tab
i m not sure how to see what happened
i cant see the 2 files anymore
(closed and restarted the cmd.exe )
can i somehow with git revert all changes from the last hour ?
yes there is a tutorial
its for pix2pix but in the first minutes he explain the whole git update and revert stuff:
https://www.youtube.com/watch?v=0fkGd9wIhrA

Get ready to revolutionize the way you edit images with the new AI model, InstructPix2Pix. This cutting-edge model allows you to edit any image simply by using simple sentences, just like chatting with a language model like ChatGPT. In this video, I'll show you how to download and install the model inside your local stable diffusion webui and al...
should maybe be git reset --hard master@{1.hours.ago}
i m not sure if i'm at master, but i suppose so
you can try idk but yes you should be on master
AI is not that good at generating the "text" you wanted it to do.
@potent hornet here is a quick explanation of the Merge tab:
If you have 2 Models (A, B) always use Weighted Sum: It will merge them with this formula where
M is the Slider Scale: A * (1 - M) + B * M
It will merge the two with the Percentage of the Slider (0.5 = 50%).
If you have 3 Models (A, B, C) always use Add Difference:
It will merge them with the formula where Slider is M: A + (b - C) * M
In Fact it will erase all of the C Model of your final Merge.
Interpolation is only when you have 1 model (its for making ckpt to safetnesor, baking in a vae or just renaming).
ckpt and safetensor are the output files you can choose for the model.
Choose dont copy config if your models are based on 1.5
also dont check fp16 if you dont know what it does.
I have yet to find a model that show significant difference in inteference qualities between 32 and 16.
But what it does - for those that don't know -ä just means you can store 23 fractions instead 10.
Basically every number is twice as big.
i heard that gtx cards can only use fp32
C:\Programmet\AI\stable-diffusion-webui>git reset --hard master@{2.hours.ago}
HEAD is now at 9beb794 clarify the option to disable NaN check.
any idea how to fix this ?
i dont get anything to work right now :/
looks like now my webui-user.bat is broken, too
its empty, i dont have the --xformers and i dont know what else i had in there
oh crap, --xformers and --autolaunch is all you need if you have much vram (8gb+)
got 24, yes
it asked me to reinstall torch and xformers
no idea why, but i tried to let it by doing
set COMMANDLINE_ARGS=--reinstall-torch --reinstall-xformers
Successfully uninstalled torchvision-0.13.1+cu113
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
xformers 0.0.14.dev0 requires pyre-extensions==0.0.23, which is not installed.
open-clip-torch 2.7.0 requires protobuf==3.20.0, but you have protobuf 3.19.6 which is incompatible.
Successfully installed torch-1.13.1+cu117 torchvision-0.14.1+cu117
how to fix that one ?
you need to delete boath xformers folder and only use --xformers. it will then download xformers again
both xformers folders where ?
this will take ages
found them in stable-diffusion-webui\venv\Lib\site-packages
and there's a second directory i need to delete, too ?
whats the difference between folder and directory ?
in venv/lib/site-packages i have a directory xformers and a xformers-0.0.14.dev0.dist-info
delete those two ?
yes
then restart webui-user.bat
these two and then run the webui only with the --xformers --autolaunch
it just opens the webui in your browser after you launch the bat
so you dont have to type the ip or copy it
okay, it says "installing xformers" now
i still cant choose -any- embedding under train
hmm do you get an error? then post it in #🤝|tech-support maybe someone knows it
no error, just an empty dropdown list
uh, on startup it said TI embeddings loaded: 0, and skipps(229)
so it skipped all
but why?
hmm, maybe because it was the 2nd time it tried to do that and it had them already
i try restart
make sure you select a model that is compatible with the embeds
then make an image with it and then restart so it will load the compatible checkpoint
what do you mean with "make an image" ?
txt2img
ah, just a picture ?
doesnt help
i switched back to the v2.1.ckpt
and created a picture
it even said it loaded all embeddings
So Shutterstock has their own image generator now.




okay, after a lot of back and forth and restarting i can now choose the embeddings again in the 2.1 model
i m pretty sure the 2.1 embeddings worked on the 1.5 model, too though
hmm, then this is a bug probably
is it free?
so if you do:
- kill the cmd.exe
- start it again with a 2.1 model active
- create an embedding there
- train that embeddig 5 steps
- switch to 1.5model
-> the 2.1 embeddings are still available under "train"
ahh okay seems like a bug then
Free to generate previews, paid to download.
paid to download xD wow
i could have sworn that i trained those landscape images on a 2.1 embedding while using the 1.5
but i cannot prove it in any way unfortunately
Cat generated by the ! token.

in shutterstock?
Yes.
on the other hand, being confused is basically my normal state in the stable-diffusion-game 🙂
Seems like it's treated similarly to regular stock photos. Subscription or on-demand. Expensive either way.

oh you always used 2.1 before?
or did you meand your first image of SD ?
because i tried around with some nsfw stuff and that worked out and wouldnt have at 2.1
but i think the embedding training i did was probably 2.1 only
i was just confused that all embeddings seemed gone while i thought i used them on the 1.5 model
but maybe i just -thought- i used them, while they had no real effect to the ai
xD that can be possible

yea with constant updates new features and the community with extensions xD its a lot to test and watch
wow nice also the texture looks like a real painting
yea, i love that we can use SD local for free
Shutterstock AI logic:
Anime? Ok.
Woman? Ok.
Girl? Ok.
Anime woman? Ok.
Anime girl? Hol' up.

hahaha xD
woo, 1.5 is again a whole new world 🙂
And "anime woman" looks more like 3d game characters than anime. You have to use "2d anime woman" for something decent.
i m not really sure if it's a nice world yet 🙂

1.5 is really nice and support the most stuff
wow, did they trained their model on shutterstock photos or what xD
i wonder if embedding training works about the same as in 2.1
but we're about to find out 🙂
it should, but yea let us know ^^
i m not convinced yet 🙂
1.5 seems to be more into the longneck / foureye / twoheads stuff

ohh xD

They work the same way as you can navigate London with map of Paris. Both are maps of a city, and might lead you to somewhere, but sure as hell not to the right place.
Also due to the fact that 1.5 uses CLIP VIT-L that was pretrained, 2.x OpenCLIP vit-h which they trained themselves. Totally different models and structures.
So you navigating London with map of Paris written in German.
If you have trained a model, like with Dreambooth and touched the text encoder, the embeddings are most definitely absolutely porked and must be retrained for that model. If you only touched Unet, then... chance that they do something approximately correct however no quarantees on that.
makes sense 🙂

this is pretty hard
embeddings are stubborn in 1.5



getting weird stuff 🙂

this is pretty nice actually 🙂
it looks to me though has if doesnt give an F about what you give it as training dataset directory when you train an embedding in v1.5
"Save a copy of image before doing face restoration."
Where is it saved? I thought it would be in Log/images but nope

Hi, if you have an image of an dog on a blank background, how do you inpaint a background (like some flowers) behind the dog? I kept getting almost nothing in the background.

I'm using a mask of the dog during img2img inpainting
You will need to either use a denoising strength of like 1 with (maybe latent noise?) or you could add color paint to where you want the flowers to be.
say, is textual inversion embeddings completely broken for 1.5 ?
it seems that it compleeeetely ignores the dataset directory training images
Tell me if i'm wrong but, to use pix2pix locally, 18 GB of Vram is needed? Right?
I only have 8 GB (2070 SUPER), i suppose there is no way?
wrong, it works with 8gb vram for me xD but you should have xformers
anybody know how to use wd1.4 e2 on automatic 1111?and then this happens

i have the model and the yaml it wont work
tried visiting the link i dont understand it
you have to name the .yaml the same as the model ckpt:
Example.ckpt
Example.yaml
same file right?
here?
yes
still same thing happens
oh nvm
my goofy aaaah also coppied the file format
xD
hi @dry crow 🙂
say, do you know if textual inversion in 1.5 is simply completely broken ?
hey, i dont think so, but who knows xD
i was doing about the same as in 2.1 and from my tests it completely to 100% ignores the training dataset pictures
whats the best webui in yall opinions?
hmm thats very strange
try it out, its easy to see
My fav is Automatic1111 webui, it has the most Features and also support Extensions.
For the Design the win goes to InvokeAI. Very pretty interface
put "create embedding -> initialization text" to *, and then give it 10 pictures of dogs
@analog goblet maybe watch this tut based on 1.5: Maybe there are some steps you need to change?
https://www.youtube.com/watch?v=2ityl_dNRNw

Textual Inversion is a method that allows you to use your own images to train a small file called embedding that can be used on every model of Stable Diffusion. You can train any subject you want (a character, a pet, an object, a concept, a style, etc..), all of that with a few images. These small files are very easy to share with the community ...
isnt there one that lets you see prompts that would work? like if you type a part of the prompt it completes it i found it when i used a colab but i cant tell what its called but there was a big "nocrypt." watermark on it
thats about the idea, but try it out, doesnt seem to work
@outer moss i use the extension Booru tag autocompletion. That gives me autocorrect of anime tags
how do i install it?
in the webui there is a tab "Extensions" then click on Available, then on Load from, then search it and install, then apply and reload the webui
is it confirmed to be safe tho ?
its on github, so you can check the code. but i use it for like weeks and its working good:
https://github.com/DominikDoom/a1111-sd-webui-tagcomplete
the closet ive been to coding is editing game code and minecraft command blocks
same xD and a bit c++
got a few min to try the textual inversion thing @dry crow ? help would be really nice here, i have no clue whats going on
if you give me the instructions sure
idk man seems pretty sussy i might get coronavirus on my computer
init text: *
its up to you, like i said its working for me and friends and other community members
how many people have used it?
then -> create embedding
approx
i think like the whole anime com
then tab : train
 seems safe enough that a entire website uses it
seems safe enough that a entire website uses it
yea its just scrapping tag data of danbooru, nothing special
do i just paste the gethub link in it?
no its listed there under extensions when you click on load from
next step?
embedding: pick the one you just made
emb learning rate: 0.01
dataset directory: c:\somewhere\dogs
i have no dogs xD
make a directory c:\somewhere\dogs and put 10 dog pictures in there
can i use random stuff
okay
not one dog, one cat, one house
ok give me a min
Save an image to log directory every N steps, 0 to disable : 1
you set the save-image to 1, yes ?
how many pictures did you put in the dataset dir ?
14
how much vram ?
done
(or 3 and 4, depends what the system can handle)
then "train"
"train embedding" that is
dont understand how to install the extension still put it in cave man terms

this and click it?

yes
extension index url put: https://raw.githubusercontent.com/wiki/AUTOMATIC1111/stable-diffusion-webui/Extensions-index.md
then press "load from"
what do i check here?

check, localazation, and ads (these then get not listed)
sort by a-z
then look for Booru tag autocompletion
@analog goblet how long does the training goes?
ples send a video or something i still cant find it out lmao
no i pasted the link on it
training goes forever @dry crow
but it shows you the generation pictures (epochs)
and those should convert towards your training dataset
so what to do now? wait a bit?
yes
worked now which one do i install?

@outer moss Booru tag autocompletion
you know how the dreambooth extension effect the webui or the program itself since im running on low vram
it says optimized for low vram
wow xD with my 8gb i cant use it too
@analog goblet hey how long should it run? how can we test if it works?
its at 50 steps now
50 steps should be enough
do the images look remotely like your training dataset ?
i used a blue parrot and every image is a blue birdlike thing
did you put an init text or set * ?
and which ckpt ?
what wait
where

at "create embedding"
can you send me 1 of the dataset and 1 of the ones you got from training ?
you scroll down and click on "interrupt"
ahh thx
okay what now
ill try an txt2img with my embed? but how to trigger it
is it * or cs1o_dogs
now you go to c:....\stable-diffusion-webui\textual_inversion\2023-01-28\nameofyourembedding
okay
there you find those training images, right ?
send me #1, #20 and #40 pls
it starts with 2
sounds fine 🙂




no problem
ok
ok, now take 12 pictures of some-other-thing
like dog / cat / house / whatever
make another dataset directory
and do you use the v1-5-pruned-emaonly.safetensors ? exactly that one ?
need they 512x512?
not for this test
no where do i have to select it for training? or do you mean for generate?
its just topleft stable diffusion checkpoint
no there was a custom merge model selected
boath are based on 1.5
i m training on portraits like this:


and these are some of the outputs i get:


lol


? It's used in the Automatic1111 graphical interface, I didn't quite understand how and where to install it, isn't that right?
https://github.com/timothybrooks/instruct-pix2pix#other-ways-of-using-instructpix2pix
GitHub
Contribute to timothybrooks/instruct-pix2pix development by creating an account on GitHub.
@sterile kiln watch this 😄
https://www.youtube.com/watch?v=0fkGd9wIhrA
Get ready to revolutionize the way you edit images with the new AI model, InstructPix2Pix. This cutting-edge model allows you to edit any image simply by using simple sentences, just like chatting with a language model like ChatGPT. In this video, I'll show you how to download and install the model inside your local stable diffusion webui and al...
@analog goblet so should i train again? i have 10 anime pics of the same person
but udk if 1.5 ema will work that good with it xD
can you try with the 1.5 ema ?
sure
for the next test pls make a new embedding
again with init text *
rest the same
by the way, the pix2pix thing doesnt work remotely as good as promised in that video
it works very good for me, changing hair colors and stuff, but not for big changes like weather. its limited by only changing the surface of an image
it cant make a portrait photography to a cartoon for example, but thats a whole different thing 🙂
i d be happy if i could fix this embedding problem
thats only possible with img2img
curious if it works with the emaonly 1.5
its saying preparing dataset and it loads ages
how many images in the dataset dir ?
ah, that may have just used too much vram then maybe
yes its seems so
you can try interrupt
100% gpu, 7,8 of 8
might work, might not work, maybe you have to kill the cmd.exe
if you want to go with this, reduce batchsize (and up the grad.accumulation thing)
like to 1 batch and 12 grad-acc
instead of 3 and 4
How do you generate stockphotos that actually look like real photos?

I can always recognize that they're not photos
I've tried prompting with "photo, realistic, real person, 16k" etc.

change the resolution to 512x768 and tag portrait
so i interrupt and start again?
and ? 🙂
does it look close to anything ? 🙂
but very close to the original
i gave it an anime girl with the same clothes and hairstyle
the colors always are used but randomly
so i guess its working



maybe not the nicest output but defintively works
do you have the 4gb or 7gb ckpt ?
well, then i dont know 😦

{kind=link}
{kind=link}
{kind=link}
wrong channel, pls #🤝|tech-support
thanks
does anyone know how to get DreamShaper to work? i'm not sure what im doing wrong, but im getting results like tihs



posting this in case it helps

You need a minimum resolution of 512x512 also use the tag dreamshaper and dreamlike
i turned the resolution down cause it gave me an out of memory error
How much vram?
i think 4?
i have a 1650
it says RuntimeError: Not enough memory, use lower resolution (max approx. 384x384). Need: 0.0GB free, Have:0.0GB free
Do you use xformers and medvram ?
i have xformers but most of the time it says it's starting without them for some reason
i don't think i have medvram on tho
Try edit your Webui-user.bat and behind Commandline_ARGs=--xformers --medvram
like this?

Yes
i'll test it out, thank you :)
Np hope it helps 👍
Xformers works with RTX, not GTX
Wrong
ah
It works with boath
is "set PYTHON=" where you can specify a python version? it's trying to launch in 3.9.12 and xformers isn't supported by that
Yes there you can set the path
3.10.9 is the highest Version that works. But 3.10.6 is recommended
Guys I'm going crazy, I'm pretty sure that a lot of people manage to create an Embedding with 8 GB of Vram, personally I can't do it and it's driving me crazy, someone nice who would have 8 GB and who would have managed to give me a hand?
If you scroll a bit up, @analog goblet gave me an short instruct how to train an embed
CUDA crash, each time

Lower the batch size
yeah, i just did what's in the video
Ah okay
I have 9 images
How much vram?
With 10 images you could try 5 / 2
Yes
CUDA crash

it is
Okay

Okay should work
What ARGs are better to do this, some peoples says --medvram create problems
I use this :
--no-half --medvram --xformers --api
dont use --no-half
its not needed for 8gb vram
also dont use --medvram for 8gb xD
your capping yourself
Yeah but without it, i had black pictures
i will try to remove it
Yeah, it now works without --nohalf 🙂
(txt2img)