
#🏞|general-with-images
1 messages · Page 5 of 1
















looks amazing!
mind generating some space related stuff when you’ve got some time?
while I set up the model
sure!



lawsuit incoming

so no lawsuit against OpenAI, probably cause he know he will lose against them
"collage tool"
github pilot doesn't use a diffusion model for creating code, and it often uses code blocks from trained data verbatim. that lawsuit actually has a lot of teeth and microsoft stepped in a beehive there
it's unfortunate because people will think that one sets precedence for all AI systems














"I'm a little teapot Short and stout. Here is my handle, Here is my snout."

What prompts did you use to make the lego ones?


I wonder if SD is considered “remix culture”

There must be at least a few people who are salty and jealous about Stable Diffusion’s success 😂
I think the dislike is totally understandable and I would probably be commissioning art for this project I’m doing if
a) I wasn’t a broke high schooler
b) There weren’t about 100 images I needed.
Hi. Newbie here. I am training a dreambooth model with rendered images from an 3D engine.
thats like saying a paintbrush is a collage tool connected to your brain.
Good luck!
recite all the states in order, and don't be collaging them from memory of this copyrighted map.
You might not be the only one who sees price and quantity as benefits of ai art

Looks good
Are there any easy-to-use mobile apps on iOS based on Stable Diffusion technology?
The idea that comes to my mind is if SD can be used across the network from a browser maybe on iPad.
I mean, the IPad doesn't have the power to run SD, but it could connect to your computer using the web browser. But i don't know if that is possible.
Another favorite so far

Getting so many nice training images, that is just amazing





New embedding glitch is out now on civitai and hugging face.


Glitch is a finetuned embedding inspired by 80s and 90s VHS tape aesthetics (trained on SD 2.1 768 ema pruned). With it you can style images overall and affect skin, clothing and the general appearance of people, animals and more.Glitch generates both painted and photorealistic styles, where subjects and objects become more or less part of the V...
yes, its called Draw Things, here is the link:
https://draw.nnc.ai/
Just click on on the mini link (take me to Appstore) no need for phone number
Thanks















3d dart
Is there a place I could find some well engineered prompts I could give as example to ChatGPT?
something like lexica would work, or I just found this cool script on reddit and it made a really good prompt that I made an amazing image with https://github.com/526christian/SD-Prompt-Generator/blob/main/promptgen.py

GitHub
Personalized expansion on javi22020's Prompt Generator, that adopts its easy editing. For AI image generation (mainly Stable Diffusion, but can work for Midjourney as well). - SD-Prompt-Gen...
hope that helps!
Oh wow that's exactly what I needed
❤️
Much Appreciated
No problem! It's much faster than Chat GPT, and really customizeable. I barely know python but by the looks of it I could edit it really easily (though I do know how to code)
Very simplistic though.
I really needed the list of all the styles and etc. I'll try to force ChatGPT to combine them in an Epic way
Gosh I love Ai 😄
I hope it works out for you!
whats the best tool to use ?
tool to use for what? SD in general?
yeah
Most people use Automatic1111's WebUI, but there are others
I assume you mean to run locally
WIP

looks neat
Accidently generated something cool with Protogen.




Whoops, accidently found Google's supercomputer!

somewhat got decent eyes, and the start of a facial expression. Maybe ill work on it someday

or just face mask everything for my sanity
Look at what these guys are doing now https://twitter.com/JonLamArt/status/1614394690572517378

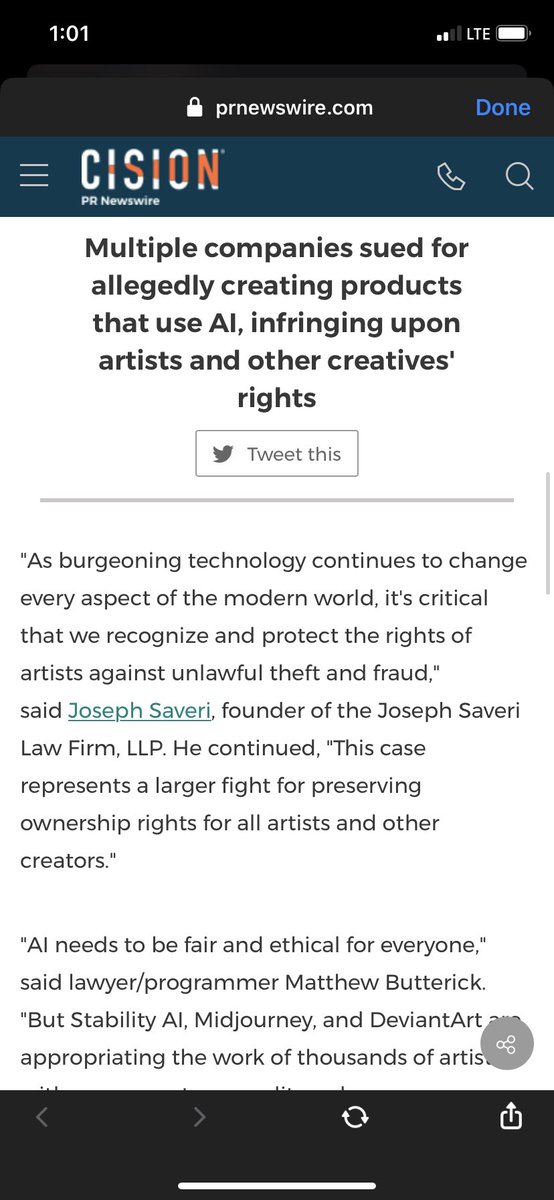
Today is a good day, Artists. We came together against being unethically scrapped and exploited.
The article below is from the Joseph Saveri Law firm that has filed a formal complaint in the Lawsuit against Stable Diffusion, Midjourney and Deviant Art!!
https://t.co/od2Bd6mVv8
Likes
10076
Retweets
2882



The actual amount of influence a individual artwork has on the input would probably be worth like 0,001 cent

we're discussing that in general chat, just dropped it here as a showcase.




Hey folks, I am fairly new to Stable Diffusion but not AI art. I am struggling to get something similar to a "Drider" from dnd. If anyone has any tips for promptcraft or model suggestions i'd be keen to hear it. (Pic attached for what i'm going for.)


The lawsuit is riddled with inaccuracies and straight up lies lol
I got an update this morning and now the generate button doesn't reset when done with an image or when I interrupt or skip. Images also don't preview when being generated. Anyone else getting this or know how to fix?



new mix




Well, Yea)






Arts Law Centre of Australia
Inspiration or imitation? Style of form? How much is too much for copyright? Part one of an article prepared by Arts Law.
from 2002. says it all
Has anyone dug into the Joseph Saveri Law Firm's past yet? They to have multiple lawsuits against tech companies going on right now, and they were the ones that the GME meme stock crowd used to sue Robinhood for blocking them from buying the stock
They seem to do a lot of anti trust stuff
Our Antitrust Lawyers Prosecute Cases in Federal and State Courts Throughout the United States - Joseph Saveri Law Firm
Well, WLOP module works)

That doesn't cover the use of artworks for training an AI, I assume it's the angle they are going to take
yeah the AI factor is all new so who knows
but in the end its still use of a style, which technically isnt copyright
I don't think it's going to be about the images generated by the model but how the model was trained with copyrighted works without permission
And I don't see it as an easy problem, it's a new concept altogether
so, i have been messing with the Easy Diffusion webgui on my gaming computer for weeks... all my pics still suck. First time trying midjourney, and the pic looks 10,000x better than anything i have been able to create with easy diffusion - and on the FIRST try. What am i doing wrong?
using easy diffusion, probably a normal model and basic prompts maybe?
My first embedding just finished training! Now I have to try out the 4 different ones at different step counts to see which is best, I hope it turned out well.
WIP

noice
Is there something you can guide me with so I can see and realize the potential I’m missing? Here’s my werewolf. The MJ ones look like pure artwork. This looks horrible.

what model, sampling method, steps and CFG scale are you using?
Im gonna try your prompt
That info is under my image.
Thank you!
idk something like this? Im using a cartoon model

kinda out of view wait
Guidance scale: 50
bruh
Ok so Id recommend using the WebUI and read about the options
Ok. Apparently I need to download/use new models and study my settings
I am using the webgui. I like it.
I just bookmarked the settings explanation earlier as well
welp it failed miserably, oh well.
It's at least nice knowing I can train locally now.
something less cartoonish

I could work to get better teeth
😄

First try, not too bad but lacks details around it imo

Second one


Damn. I really have to learn the tweak the settings. Everything you guys are sharing is epic.
highly detailed photograph of a menacing werewolf showing teeth, realistic portrait, realism, Canon
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 1430176969, Size: 512x704, Model hash: 0aecbcfa2c, Model: dreamlike-diffusion-1.0, Batch size: 8, Batch pos: 0
That's for the first image in the first block of 8, the others are the seven next seeds
highly detailed photograph at night of a menacing werewolf showing teeth, realistic portrait, realism, Canon
Negative prompt: 3D, glossy, fake
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 3407230357, Size: 512x704, Model hash: 0aecbcfa2c, Model: dreamlike-diffusion-1.0, Batch size: 8, Batch pos: 0
And that's the first image of the second block, keep incrementing the seed for the others
The last block of 4 is from img2img based on a similar prompt
Wow! Are any of those models ones that you had to download separately, or are they all included with the web gui already?
Downloaded separately, I also have bad results with the vanilla sd models
The one I use is this one https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0/tree/main

some of these merges aren't that bad. here's a good one of the standard deloreon mecha test i do

dreamshaper its called
another i coaxed out of it.

That's kinda dope


🤓
If I merge checkpoints do I need a yaml file for that new checkpoint?
Yes if the checkpoints are based on 2.0/1 and have a .yaml file
oh god dont merge 2.x and 1.x


dis u?

Why does my output seem to get darker whenever i use a low denoising strength? (Im using a loop back here so its just progressively getting darker)

Are you using a vae?
i think so
i think its built into the model or something?
Okay setting the vae option to none still has the same effect
Which model are you using ?
Normaly you need the right vae for the model (only if the model needs a vae)
anythingv3 + animevae
You should use the anythingv3 vae
thats animevae
well ive noticed in regular img2img aswell, its just more visible on loopback because its happening repeatedly
ultra widescreen generations are fun

I used soem stable diffusion to help make an enemy for one of my games, what do you think?

I used the pxl8 model to create the base image which looked like this
Which it then turned into this
Which I then turned into the first image.
Maybe add texture to the torso but otherwise that's pretty cool
The torso has some texture, the little lines that are slightly lighter.
really cool... Are you using the allinonepixel model?
no, the one that comes with the pxl8 plugin. It's not great tbh, but what the things turn into is really nice.
I am using img to img from some enemeis already in the game to keep the same colors and style mostly.

That new pxl8 model looks so powerful for pixel art. I am going to get it set up today to play with. cool that you can so easily create new game assets now. Production ready really! nearly anyways
It's nice, but the model itself doesn't make great pixel art, rather the plugin does. It's still a nice model to have I suppose.
Look at the difference between the two.
whats the plugin? is that for an editor
It's the pxl8 extension for Auto1111
My bad, I meant extension/script not plugin
I'm just dragging the pixelated stuff into aseprite and downscaling it
Though it can still do some nice stuff
AH i haven't started playing with it yet so i didn't realize it has other tools in the ui. i know i had to add a script
Reminds me of old color cycle animations. these things demo'd on this page http://www.effectgames.com/demos/canvascycle/
oo those are pretty
With a little work you could probably create something like those with this tool
i learned the basics of how to create color cycling animations back when my school had amigas. it's a neat very technical art form


i knw there's some pixel artists who absolutley hate pixel filters, and i'm sure this model is going to face a ton of their critiques too. It does seem like it just adds random noise for details much like the last generation filters would
the random noise is probably an artifact from the color pallette picker thing, if I were to add more colors it woulndn't be as noticeable.
That's probably fine

I think it will be the boss for the game, so it will like summon stuff I guess.
I guess the best part of using this tool is getting a good natural shape for things, and fixing up the detailes yourself.
Here's my first neat result. i used "reference pose" in the prompt and it did this.

Oh that's neat
I got these with a little trial and error
very niiice
it does scenes very well
Generated with intel HD graphics 4000

Yes. Torture
poor thing is doing its best tho
My ThinkPad screams in agony with this. But it's fun
Yeah
I have 2012 era E530
nope. It was generated with the cpu. the igpu i don't think has a ml library to execute the model with
thats what matters... Having fun
cpu only generation mode is still super valid. i dont mean to bring it down. excited for you. the future is now
yeah I was thinking that also... The main page for the WebUI says only AMD/Nvidia + Intel HD graphics dont have enough vram
wait 1 year and this technology will be as smooth as running blender, looking back to first versions of 3DS max, comparison is quite close 😄
did you consider colab?
Wym

runpod is also quite cheap, i train around 50+- embeddings with 10$
No, I will check it out. Thx
👍
When I launch Automatic1111 (Win 10) now it gives me this error...it's been working fine lately... ideas how to fix? I did a reinstall (Git cloned, as I usually do to update it) and it still happens... 😦

what error
btw you can just click the .bat files
That is what is causing this. I just launch webui.bat and get this instead of it working like it used to work...not sure why.... (see my screenshot)
get what theres no error in the screenshot
It won't open. That IS the error. (not working), but I think I fixed it. somehow I had a git clone command in the webui.bat after my set COMMANDLINE_ARGS=--xformers line before my @ Echo lline.
It's installing/cloning stuff now so it should work.
tbh Im not sure what youre doing. Parameters for the webui should go in the webui-user file... No need to keep everytime parameters. Then just double click the webui file. I think call starts the program in parallel so maybe thats why no terminal output
man, i'm higher than bird pussy. Chillin, making art n listening to Palmer Squares

How you all doin?
I think that was an older webui.bat I had saved as a backup before updating, and it was one that had that line in it from a YouTube video to auto-update the installation every time you launched it...apparently that doesn't work....I'll move the parameters (which is only the --xformers line to that other one, but it seems to work in either.
I'm using invokeai's web-ui. works great.
hmm, do you think its better than auto1111?
fine... Training a model


i censored the picture
but yeah, shit works great
remember, there are no mistakes in art. just happy little accidents 🙃
heheh ok bob ross
the questions is
which one is better?
auto 1111
or
invokeAi

but you cant use invoke+AMD on Windows, the main page says you need ROCm to use AMD. ROCm only works on Linux... So you must be on Linux and therefore can also use 1111
I don't use windows
last time I touched that OS was win3.1, I still hate it, XD
I use lots of things, stick man
relax
O_O
but like I think this would imply you cant use 1111 with AMD
Correct
yeah but thats what Im says, you can
I can't, others might, idk
card?
linux was hardly functional at the time of windows 95 through xp. but i'll believe you still. there was apple os still i suppose. and amigas.
instead of the 5.1.1 one
i used a1111 with a vega 64 for months on garuda linux
but that's just me
yeah ikr I used garuda before
it took a little tinkering
everyone's PC is different
that's why I view tutorials and the like, as suggestions
and I ad lib alot of shit
but I'm also confident and not afraid to edit code
it's just code
if I fuck it up, delete it, and start again XD
I don't like garuda
There is no reason to hook timeshift into a btrfs fs
btrfs already has built in snapshot tools
so..... if timeshift fails, so will the entire backup functionality of garuda
(been there) even got in there forum to tell the dev this
they werent intrested
¯_(ツ)_/¯
its the bloatiest of the arch i've heard. and i wanted to explore all the cool new systems available for nix. i found lots of good tools in their bloated kit. btrfs was one of those discoveries.
I'm pretty sure the garuda backups tie into btrfs' own snapshot abilities
tbh i didn't even look who i was talking too lol
just chatroom life. even more if you run discord in irc mode
or just irc from the terminal
Here's some word art, for your ears
Enjoy


Hope you all are having a good day
<3



mmmmm, yeah. I like using InvokeAI Xp
nothing I did looked this good or worked this fast when using automatic1111
i couldn't get it to install. all it's requirements were failing. the install wiki's instructions didn't match the files in the folders. i'm sure i could've wrestled the install into submission but i had it working on another instance already and went there. when i finally migrate to docker, maybe i'll try to make a docker image for that too
i read something about it having 2x model support now so i'll try again sooner than later
yeah, that happens with fresh software, there's prob been updates n shit, it's github stuff so
an easy way to update if you use the terminal and git clone $URL is to cd into the $dir you cloned it to and run git pull --ff . Now everything is updated
no with invokeai, all you do is run ./inokeai.sh then just press enter on every question
and it works
If you need help the actual developers of it will help you.
on there discord
so. If you can't get it to work, It means you didn't try and you realy probably don't care if it works or not.
Or I'm totally wrong about everything I say, idk, ya know.
¯_(ツ)_/¯
and even better I made a desktop launcher

if I want it to always launch the browser i could add echo "2" | /usr/bin/bash /home/mrgfy/invokeai/invoke.sh --no-nsfw_checker--safety_checker --no-patchmatch --embeddings (the echo part, so it will auto answer #2)
oh and & at the end to turn it into a background process
then ; exit at the end of that to close the terminal
🙃
hmmm, no
works best just like this /usr/bin/bash /home/mrgfy/invokeai/invoke.sh --no-nsfw_checker--safety_checker --no-patchmatch --embeddings
so it's taking me about 30secs at 5 images with 300 steps each, image strength at 0.73, k_euler_a, random seed, noise 0.3, perlin noise 0.05, cfg 7.5, 512x512
config using: v1-m1-finetune.yaml
300 steps is 5 to 10 times the amount of steps I use

this is all i can show
but I get great results
in a bit i'll upload my new images to my gallery site (found in my profile)
i'll still post the sfw ones that get made
need to do a lil more work on fixing that smirk

unless you like that derpy look

"An extraterrestrial invasion has taken over New York City, and the streets are filled with chaos and destruction. The aliens, who are technologically advanced, have brought with them advanced weapons, and the city is on the brink of collapse. The citizens of New York are fighting for survival, and the military is struggling to contain the extraterrestrial threat. The image should be highly detailed, realistic and in high definition, with a focus on the destruction and fear caused by the invasion. The image should also convey a sense of chaos and despair, as the city is overrun by the extraterrestrial forces."

i run win 11 now so i'd use their bat fiile and have to select all the files that configure it for nvidia on windows
oh yeah, windows .... (shivers in disgust)
man, too bad i'm banned from art servers that DO allow nsfw
I'm making some kick ass art right now
ayyy they are starting to turn more pixie like.. nice
omg, the bot wont even allow an uncovered BACK
who the fuck gets aroused from a back?
really?
lame
I'm trying to find "Additional Networks" in the Automatic1111 GUI to use some LoRa models... I feel like an idiot and can't find that anywhere, least of all "a panel from the left bottom of WebUI...
Can someone screenshot this and share it? Thank you.

that's discord's nsfw filter. it's not so much detecting a back, just patterns. maybe her shoulder blade is too cleavagy
server owners don't have control over the filter's thresholds last i checked. its either on or off
i just tried to dm u the pic
and even your shit is blocked from seeing a womans back
😂
are you all like .. Mormons or something?
its discords own filters bruh...
nah dude
i can get what ever i want sent to me
weird
discord put child locks on you adults
😂
i mean, u be u
but one thing i do do (heh doodoo) is immediately block people who act like anything less than extreme hedonism is religious devotion.. i'm going to go ahead and not do that for you though since nsfw seems like your whole thing to begin with

Anyone?
OOooOoOo so sexy
hahahahahaha
i actually lol'd
man, guess I'll have to make my own disboard discord server
So the Adults can post there art
Don't want to get all you ppl all sexed up for more pictures of bare "Backs" 😂
I'm just teasing you guys
Looks like the tutorial is for sd-webui, just try to place the files in your stable-diffusion-webui/models/ folder and it should work (after restarting automatic)
Sampling with k_dpm_2_ancestral starting at step 75 of 300 (225 new sampling steps) 🙃
unicorn going super saiyan

its at the bottom of txt2img
@red plover

Alright, my second attempt at making a textual inversion embedding just finished. It's of a person this time, not a style.
I hope it works
Well it works better than my previous one, but it has a lot of flaws
The last one looks the best, right?

But see, in this one the first one looks the best

I think I am going to go with 2000 steps being the best. I don't think it is overfitted, would you say it could be not enough steps? Do I need to train more?


I am going to train some that are 100-400 steps
nope thats just dream builder model. it really nailed the symmetry there though
definitely

A friend who was curious about AI challenged to make a picture like he wanted, here is the result:

This is something I still can't wrap my head around. If it's this easy why dont all pytorch programs just also tap into RAM too?

well unless its a new feature its not working for me lol and I have 32gb ram 24gb vram

are you using invoke or 1111?
did you build your conda env correctly
i have 32Gb ram and 12Gb vram
cd invokeai
conda init --all --user
conda env create -f environments-and-requirements/environment-lin-amd.yml -n inokeai
conda activate invokeai
source .venv/bin/activate
and your venv and conda are now setup
@tame forge
make sure you also installed all the correct ROCm packages
🙃
we're going no where, somebody help me, ya
well..... I thought it was funny 😒

thank you
i run at 300 steps
yo thx for the tip. I will definitely try this. I usually only use invoke for inpainting
thats 300 steps? ur wasting GPU power
I use inpaint and img2img

i'm not wasting shit lol
4 image(s) generated in 162.27s
Max VRAM used for this generation: 3.40G. Current VRAM utilization: 2.25G
Max VRAM used since script start: 3.40G
@tame forge
Let me see what 300 steps can do
barley even touching the 12Gb of vram
regardless
i'm using like 3.4 of 12gb of vram
at 300 steps
per image
still think i'm wasting vram, please enlighten me on a good step number to use @tame forge
Ugh 40 steps? Lol? Depends on the model
Yea do a 40 vs 300 I'm curious
because I've never head of anyone using beyond 100 steps outside of joking purposes
i won't be able to post here
why
Then do a sfw prompt
this fucking server even thinks my sfw is nsfw
dayum
yeah, that's why i bitch so much about it
just add "wearing a burqa" and that will cover her up

I just want to see the quality dif
so thats 40 steps right

da fudge?
ya
ooooh ya lol
doesn't work if its randomized, my bad
prompt
(tattooed body), (tinkerbell with long hair over her shoulders and smirk smile)+, photorealistic, full body portrait, shadow depth, intricate details, (large breasts), trending on artstation, intricate details, highly detailed, (fantasy)++ (nude), (realistic), (photorealistic), (NSFW), [poorly drawn face], [poorly drawn hands], [poorly drawn fingers], [poorly drawn breasts], [poorly drawn body], [disfigured], [ugly]
running
(don't judge my prompts, i'm a single male in a town of 2000 ppl, and no single women my age)
nah its kool I only do chix as well
I told u to cover them up
my art is SFW fuck you discord
put a shirt on em whatever
they are clothed

i assure you, she is wearing clothing
but this server is re tarded
Ok so 300?
sorry not sorry
no
this is 40
running 300 now
running at 4 images per so give me just a min
it has to be the same seed to make a fair comparison
if its the same seed then the 4 of them will look exactly the same
if not, something is wrong, I suspect its not actually steps that setting is changing

If it really were 300 steps, your img would be garbled and overcolored

Why seed 0
Any normal number lmfao

and these are uncompressed? Thats how they look like in ur pc?
That is bizarre. There is probably some cap that is setting a limit on steps. Like, look at this one
This is the detail 40 steps does

It is either 40 steps or 70 steps, I can do some digging
Its a failed generation but it is just an example of why u dont need 300 steps
u really think im lying to you huh?
If u want to I can do the max 100 steps in the regular webui and show u why 150 steps would look awful
no, invokeAI is lying to you
It is probably capping your steps at like 70
{'prompt': 'black leather lingerie, (tattoos), (7ink3Я8311 7uЯn3d in70 4 53xy 5uccu8u5 wi7# 4 10ng 810nd3 p0ny74i1 0v3Я #3Я 5#0u1d3Я5 & f4iЯy wing5 wi7# 4 51ig#7 5mi13), photorealistic, shadow depth, intricate details, (large breasts), (sitting on the forest floor with her legs spread wide)+, (facing the viewer), (realistic)+, (photorealistic), [disfigured], [p00Я1y dЯ4wn f4c3], [poorly drawn hands], [p00Я1y dЯ4wn fing3Я5], [poorly drawn breasts], [p00Я1y dЯ4wn 80dy], [poorly drawn pussy]++', 'iterations': 4, 'steps': 300, 'cfg_scale': 5, 'threshold': 0.3, 'perlin': 0.05, 'height': 512, 'width': 512, 'sampler_name': 'k_euler_a', 'seed': 2428777163, 'progress_images': False, 'progress_latents': True, 'save_intermediates': 5, 'generation_mode': 'img2img', 'init_mask': '', 'seamless': True, 'hires_fix': False, 'init_img': 'outputs/00137.png', 'strength': 0.75, 'fit': True, 'variation_amount': 0}
300 steps
{'prompt': 'black leather lingerie, (tattoos), (7ink3Я8311 7uЯn3d in70 4 53xy 5uccu8u5 wi7# 4 10ng 810nd3 p0ny74i1 0v3Я #3Я 5#0u1d3Я5 & f4iЯy wing5 wi7# 4 51ig#7 5mi13), photorealistic, shadow depth, intricate details, (large breasts), (sitting on the forest floor with her legs spread wide)+, (facing the viewer), (realistic)+, (photorealistic), [disfigured], [p00Я1y dЯ4wn f4c3], [poorly drawn hands], [p00Я1y dЯ4wn fing3Я5], [poorly drawn breasts], [p00Я1y dЯ4wn 80dy], [poorly drawn pussy]++', 'iterations': 4, 'steps': 40, 'cfg_scale': 5, 'threshold': 0.3, 'perlin': 0.05, 'height': 512, 'width': 512, 'sampler_name': 'k_euler_a', 'seed': 4029563337, 'progress_images': False, 'progress_latents': True, 'save_intermediates': 5, 'generation_mode': 'img2img', 'init_mask': '', 'seamless': True, 'hires_fix': False, 'init_img': 'outputs/00137.png', 'strength': 0.75, 'fit': True, 'variation_amount': 0}
40 steps
I believe you that you are entering 300 steps, but I know it is not doing 300 steps, let's get a second opinion. I'ma wait for some expert to come in here and pitch their opinion
What you can do is do an X/Y prompt and do 40 steps, 60 steps, 80 steps, etc.
You will see after some point they will all look exactly the same
on it
i'm changing nothing but the steps
since i did 40
i'm upping in incriments of 20
Aight I'll be back since I gotta finish troubleshooting my card. But I am curious to see that joint and prove to u it is not doing what u think it is lol
kk
running 60 now, same everying as in those posts above with the {}
sorry if I seem agro, I have really bad ptsd, and I can't help it @tame forge
so please take my attitude as with a grain of salt
nah its kool, also pick a 8-digit or so seed and stick with it
Im not fighting u I'm just pointing out what I think is wrong, which I am sure it is lol
no, i mean in general
i have no control over it
and i can't work because of it, and prob why i'm single

60 steps
now running 80
i fucking hate living on the edge of fight or flight, i really do
my family has to knock on the door of any room im before they enter in so i dont jump up
it sucks
(Fuck you discord bot)
Not on mine, for some reason...

Hey admin! I'm trying to post a picture of a clothed pixie, so wtf!?!?!?
Trying this....
same as the pic above just better detail
fucking art nazi's
😒

now it looks even more naughty
but i guess thats how they like it here
running at 100 now
man... i see how my mouth combined with ptsd gets me into shit ... smh
srry

running at 120 now
(I hope the admins understand my ptsd is bad, and why i can't work)
i hope they don't take what it writes/types as me typing it, cause well, it is, but it's not
most the time, i don't have this quick clearity
as i do rn
because i'm focused on it rn, so i'm able to catch myself as soon as it happens

running at 140 now

running at 160 now
(personally they are improving, even if it is, ever so slightly)
and i'm not really noticing the 1 or 2 seconds longer they are taking
i'm not addicted to instant gratification

running at 180
and notice, her hair bun
it's also getting better at trying to make my image match my prompt
"tinkerbell"
and, i am ONLY changing the step

running 200
then we will compare 40 to 200
(i really hate living on edge 24/7, you all have no idea)

fin
idk what happend to step 40, but here's step 60 to compare

STEP: 200 above, 60 below
i ran 4 images at the same time, others i can't share so you will just have to believe me when I say, there is a different
and if you look at the OG SD wiki, all of there tests range from about 40 - 200/300 steps
also if you look, some of the info on the models at civitai.com say they run at 200 steps
which is why I usually run at 200 steps
on the wiki page look at the grid showing the types of SAMPLER's
you'll notice they are doing what i'm saying
showing example images of each type of sampler ranging from 40 - 200 steps per example image
if you do, you'll also notice the change happens around the 200 step mark
please correct me if I am wrong.
(I could be wrong, but I don't think I am)
200

80

300

60

👀
see the diff
@tame forge
i choose 300
imo, step 300 beats all of them

300 <--------------------------------> 60
what do you all think?
I choose the one one the left.
with proof i did no fuckery
(I just want people to know, i'm on the ball, and not trying to fool anyone)
changed prompt, image and seed, starting at 40


moving up to 80


moving to 150


and finally 200
last 2 im doing
then you all can judge them for yourselves
2 sets of images only thing changed are the steps


imo step 200 is the breaking point when shit gets better
but I did this so you all can do own assessment and make your own informed discussion
I believe this is due to the model ur using
I think its kinda like midjourney
Its hard to make something look like shit with their models
Sadly this troubleshooting has taken me all day but tomorrow I'ma post an X/Y plot with the protogen model

This mixed model is a combination of my all-time favorites AND new-found favorite, Dreamlike (thanks to JustMaier for the heads-up). A genuine simple mix of a very popular anime model and the powerful and Zeipher's fantastic f222 mixed in with Dreamlike (minus sd1.5).What's it good at?Realistic portraitsStylized charactersLandscapesFantasySci-Fi...
and ima tag u with it and I'ma show u wassup
the model i'm using ☝️
this is the config i am using as well
@tame forge so do you concur with my hypothesis that step 200 is when the major change happens?
or are you still fighting (possibly bad choice of word) that steps 40 - 80 are all you "really" need
honest and sincerely
🙃
I have seen an image suddenly transform itself after a random amount of steps occassionally
and @tame forge ty for being able to handle my energy, it means alot
But I am telling you, 300 steps is not the norm, not even 100 steps is the norm
Something is wacky with ur model or with invokeAI and ima show u why tomorrow
My head hurts from all this bs I'm doing with python rn
norm, is boring and idk what norm anything is fren
What I mean is that any other model would look deepfried after 150 steps
Its not pythons fault, is its dependencies especially SD that uses a ton of moving parts
like, if your prog lang breaks the versions its replacing, you might as well call it an Apple product
lol, am i right
lol, burn
(reffering to the devastating python2.7 to 3 version upgrade and the BS it still causes today)
when software devs have to introduce, virtual environments or version managers, is when you know, something, somewhere, someone fucked up 😂
and they ran with it.
🤣
because, programming hard sometime
@tame forge mind you as well, everyones pc is diff, so steps for you compared to JimBob and I, will never be equal
and that's ok
we have nothing to "prove" to anyone
(but it is fun to try)
lol
we all love the gratification of validation through other people
it feels good, though it just shows we're all kinda broken inside
wrong. images can be reproduced exactly between computers if all parameters are the same, steps included, they are no different
so what have you found
maybe, i'm not computer scientist
idk
but ok, lets roll with it
are you still gathering your data to show me?
(I was showing my data as I was working in real time [ he mumbles quitely to himself])
No I will do that tomorrow. I'm exhausted
I just wanna chill and play some OW2 then hit the sack
tomorrow I'll tag u and post my chart

training models is so much fun
going to hang out in voice 3 and stream my new model using InvokeAI.



so
nijijourney vs waifu diffusion
which ones better
in terms of coherency at least
I CLICKED ON THAT GALLERY
THINKING IT WOULD BE NORMAL THINGS
I SAW NOT SO NORMAL THINGS LMAO
also does mrgfy stand for mr. Go fuck yourself?
nice name man
yes
I'm just experimenting with all the models from https://civitai.com/
Civitai is a platform for Stable Diffusion AI Art models. We have a collection of over 1,700 models from 250+ creators. We also have a collection of 1200 reviews from the community along with 12,000+ images with prompts to get you started.
@fierce crest my handle come from my tattoo, Go Fuck Yourself - across my throat
-- one day, I just got tired of peoples bullshit
sounds legit
damn free nsfw
do you just download a model
or?
yup
and then


i was using getimg.ai

I'm self hosting
using inokeai, on my pc not a website
the gallery is one of many of my websites
that's a lot of steps to create a image :O
I got made it quickly randomly one day because I got tired of every single "art" place online, has an issue with using the femal body in art
is it
Might be different in the workflow, but using steps over 60 seem to cause the image to become too blurry in my experience. :/

yeah, the important part is the outcome. I just haven't seen people use those high steps in a long while :)
¯_(ツ)_/¯
if you look at SD's wiki on explaining samplers, it shows a grid in the range of steps, 40 - 200
with progression images
and you can see that around 200 steps, is the change between ok, to wow happens
I'm sure they are good as well, I have a couple of my own which I tested when 1.5 was released
I don't think many ppl even look at the wiki on github tbh
I've made a couple thousand images using over, well 1000 steps, but I found that the ones I liked the most was around 20-44 steps in general, there never is a set number, I like some at 50 steps and others at 9, etc :D
sucks for them ya kno
most wiki's an tutorials are behind as the technology and discovery happens too fast, which is a good thing in a way as it means we get lots of new stuff all the time! :D
I'm just longing for a time when it's easier to get shaper/crisper images. Blur is my nemesis! :P


The trick is to use a higher resolution or an upscaler xD

yeah, but that's cheating, I want to be able to do it using only txt2txt and img2img :D
crazy how even the simple shit can entirely change the final image
I dont think its cheating when you just make a 1024x1024 xD
too bad the wiki don't show the other samplers, Euler a and DDIM are the only one I sometimes use of those :/
and honestly, if I were getting the results i want at 80 steps, i would be using 80 steps
yeah, I don't really think so either, I just want to strive for it :D
Try DPM++ 2m Karras, its realy good too
but so far 4 images at 300 steps per 1 is only taking 30secs a piece
which is fine
i'm in no rush
I use DPM++ SDE Karras the most, not because I know it's better at X or Y, but because it's the longest worded one :P
Would suggest always to go for 512x768 for portrait
Same mostly Euler a
switching between those 3 are always gonna be ok
then change to ddim for inpainting
I haven't had time to learn inpainting yet, I'm still learning how to "perfect" what I want using the txt2img, so much to learn, and it's so much fun. Was a long time since I was this set on a goal! :D
once I get a txt2img I like, i use it in img2img
getting 1 really good txt2img can be an uphill fight
It all depends on what each person want in the end. :)
I'm happy with the results straight out of the txt2img most of the time
I started to make a README file with each models trigger words, and tag words, so it helps me get an image i want
auto1111 has an extension that does that as well, but I'm too lazy for it, I just rename the model file to include the keywords inside a ()
For models i rename them to Inkpunk(nvinkpunk) for the triggerword
can u send all ur websites
i use inokeai, i dont use auto1111
to my dms
https://www.cursedcode.com all my sites end up here

Where once there was fire, molten sulfur, and rock. Now be it cold. Void of all light & the purest of dark. A Torment so great; even Gods have no words. For only the most evil. This place is reserved.
or begin here
that's also my favourite model, how'd you know?! ;P
basedlabs isn't rendering correctly so, ignore that page
Haha its a realy good one ! 😄
it worked before, just fine, then idk wtf happend, maybe jekyll got an update or who knows, i'v recompiled that site with ruby gems idk how many times and it still wont fucking work like it used too
😒
so i been slowly building a new website for that 1 page
its slow going cus i'm not all that motivated to do it
like imagine being on the production dev team, you finish and upper managment comes over n tells you were switching to a new framework, trash whatever you just finished
non nonnegotiable
🤮 🤬

its not even like jekyll is hard but idk, i have no clue what's different
you make a _config.yml and a Gemfile, bundle install, then bundle exec jekyll serve -d public
it compiles and serves the site, then you make your edits n what have you.
easy, but ..... maybe its just the theme im using that's broken, idk

How much vram do you have ?
i have 8gb
i have no clue what is going on
I am positive a 3060ti can render this


@livid crystal

no

Would suggest using the WD1.4 vae for proto
Close every window on your pc, check task meneger
I fixed it
It happens to me from time to time
Well, thanks for advice) But I just wanted to experiment , I had anythind v3 vae for wlop model, and I changed to protogen so I thought that leaving anything vae active would be fun
Yea try to experiment with it. I figured out that using anything vae on non vae needing models can cause The image to get pale(desaturated)
Yea its good! Just sharing tricks ^^
xd

Bloody bullet holes wtf
@vast cape here, i have compared them very quick: ProtgenX2.2. See how anything vae makes it pale xD.

Hmm, I see)
AnythingV4, ACertainModel, also Eimis Anime Diffusion maybe
Is anything v4.5 better than anything v4 / anything v3?
its different, depends on what you like
the creator said in dc higher number = better 😛
Btw, what means prunned ?
Thanks)

@amber leaf














When is STable Diffusion going to have their own version of Chat GPT?

very nice! but you should use a vae, if its anythingv3 then the av3 vae
then its not using it correctly
okay 👍


yea!
make sure the vae selector is on automatic
then it will choose the right vae for the model
Loading weights [67a115286b] from E:\stable-diffusion-webui-master\models\Stable-diffusion\Anything-V3.0-pruned-fp32.ckpt
Loading VAE weights found near the checkpoint: E:\stable-diffusion-webui-master\models\Stable-diffusion\Anything-V3.0-pruned-fp32.vae.pt
Applying cross attention optimization (InvokeAI).
Weights loaded in 110.1s.
It said that so it's probably choosing automatically
yes, ah youre using invoke ok
Yeah I noticed. Is there a way to change that
change what?
ahh, its not other AIs, they are just webui's
There is Automatic1111 (the most used with the most features), InvokeAI (best outpainting and ui) and SD 2.0 (didnt tested it yet)
Right. I'll check it out. Thanks
no problem, automatic1111 webui is not as easy to install like invoke, but message me i can send you a tutorial if you want or just look up Aitrepreneur on Youtube
I'll try my best ig
So fp16 is just less precise version of fp32, but what is the regular one?

@outer spear fp32 is the "normal" one you should use
also you need the vae for anything
whats just pruned then?
thats also fp32?
@outer spear yea pruned is compressed for a smaller filesize, always use them
im asking what is the difference between these two

the file size, oh weit
no its same
yea i see, he uploaded the 32 and 16 two days ago, so use either the non fp32 or the fp32
it shouldnt realy matter in this case
keep in mind that you also need a vae file for 4.5 if you dont manualy select them
yea its like night and day with anythingv3
Yeah. The colors are much warmer

GitHub
Is there an existing issue for this? I have searched the existing issues and checked the recent builds/commits What happened? Whenever using img2img, the output images always turn out darker (every...
anyone know whats causing this
Vote

GFPGAN is the most accurate, both face restorers smooth too much the skin for my liking tho



mofu and mofu

its something in your prompt or negative prompt. do you have anything like overexposed, underexposed, contrast, high pass filter, hdr, cinematic lighting, etc

this dreamshaper model keeps impressing me with how well it is doing abstract prompts i'm throwing at it. i think i'm going to keep on this one a bit, pausing my 2x exploration, so that i can get a good set of desktop wallpapers








Hi ya, I am noticing a bit of a trend on pisstagram. I can tell they are using film stills with their prompts. I would love someone to shed light on this. What's the diagram of operation, you think? Is there specific model/module they run their prompts to achieve these? Is it even Stable Diffusion?






theres lots of cinematic style embeds and models









poolsuite is a model trailed on kind of late 80s 90s cheesy magazine lifestyle glamour.
https://github.com/Firework-Games-AI-Division/dmt-meshes Anyone else checked this out yet? I am downloading it now, supposedly it works really well.
(It's a Blender plugin to generate 3D meshes from text)
I'm trying it out right now in blender
"A corgi" at 15000 steps...

It was really fast tho
An alien spaceship

Alright, one more txt2model, then I wanna try img2model
A windmill

Definitely not

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Online image library Getty Images has filed a lawsuit against Stability AI, accusing the Stable Diffusion developer of infringing its intellectual property rights.
Learn more: https://t.co/D71TNlqB4A
#stabilityAI #stablediffusion #AI #ArtificialIntelligence #gettyimages


Anybody know if you can blend two images like in Midjourney ?

It is Getty Images’ position that Stability AI unlawfully copied and processed millions of images protected by copyright and the associated metadata owned or represented by Getty Images absent a license to benefit Stability AI’s commercial interests and to the detriment of the content creators. <--- see THIS is an actually well worded filing. Because getty absolutely own the shit out of their images inside and out and took pains in doing so.
for some reason invokeai doesn't like the the textual inversion files

Getty Images Press Site - Newsroom 2 - Getty Images
sorry but by looking at this halo flare you now owe getty 100 million dollars.
😂