#🏞|general-with-images
1 messages · Page 2 of 1
I'm not sure how I feel about feeding AI-generated images back into the model
but if it was limited to good generated images it might be okay, to help feed the model with emergent qualities of the image
hmm
otherwise it's probably just going to over-fit what the AI already "knows"
any benefit for negative promting?
Good question. Honestly, the dataset could probably be improved by tagging negatives, too
specifically to help disambiguation it would be great
e.g. "turbine" could mean "wind turbine" or "turbine generator" or "jet airplane turbine"
which are all visually different
yea
so negative "wind" on a jet airplane turbine would help disambiguate
assuming the image isn't also windy, I suppose
thats kind of hard for a person to tag... makes them have to think
Yeah, that's why I think it's a Wikipedia-level project to make a really good dataset
So if an image was over exposed, the negative tag would be dark, gloomy etc. and the AI would learn more about that concept?
maybe? Especially "abstract" terms like gloomy could benefit a lot from a deep-tagging project
i mean gloomy is quite sepcific, makes you think of a dark cave with some objects slightly visible
though I've definitely found some do have real effects; try an A/B test on including happy in a prompt sometime
Havent large language models already learnt this stuff, dont we just need to plug on into it? or is that too compute expensive?
probably a dumb question, i bet that would be way overcomplicating things
But i dont code.. so i have no idea.
As a general rule, I find plugging "AI" into more "AI" to be risky in terms of getting clean data out
i see what you mean by the wikipedia thing, where its community contribution
people can just causally add to it in their spare time
plus community quality control, that's important!
just had an idea... what about node based prompting?
I'm not sure what that means
like in blender when i make a procedural material i will build a node tree, like a chain of commands,
just like simple building blocks
if you use blender you will soon get the idea
its just easier to manage than typing prompts
That could be interesting, though I haven't used Blender enough to really understand
because blender went from slider menus and dropdown boxes and stuff, to nodes, because nodes was so much more flexible and better
All my Blender stuff has been simple UV-mapped stuff for Minecraft mods lol
i mean i would be nice to have dropdown menus for things like art style, but that would be just a starting point. All the concepts we are trying to get the AI to learn could be displayed as node blocks
like having access to the latent space ?
if i understood right the latent space is concepts that the AI has learnt??
anyway i shall let you think about it. I dont want to confuse you with all these crazy ideas
Got to get going.
Cool, see you around
yep. merry christmas

do you know whats crazy, some loser on artstation who most of the world hasnt heard of is, is suddenly becoming more of a household name than he was before and he probably isnt bothered, meanwhile all of the non-commerical deviantart hack acyolites are claiming its ruining their nonexistant careers.
U talking about Greg Rutkowski? Most of the world still doesn’t know him, just AI folk now besides artists, which is still a tiny portion. 😂


f/16 bokeh 3/4 portrait classic woman on a city street, color grading, (glowing haze)+ (soft glow)+ octane render, anime style by Krenz Cushart and John French Sloan, 8k [poor bad amateur assignment glasses]
testing a new model

emoji this if you want to watch and I'll throw you a link to my art stream.
hi, can anyone tell me if there's an option for using a single image without training a model (like midjourney )... for modifying/ creating art from it
yes, img2img
but ... i am not getting good outputs
what are you trying to do?
in case anyone wants to watch me make art ^^^
it updates automatically
I just want to use my picture and modify the look
you can do it with img2img, with the right settings and prompt
can you tell me which sampler is good... for making portraits like this from my photo
what tool are you using? Auto?
samplers are more nuanced than big differences. euler is pretty good for art
the prompt is 90% of the art style
i m always getting ugly, deformed pictures 😦
it takes practice and experimentation
the img2img blend is really important

warm colors f/16 bokeh 3/4 portrait classic woman on a city street, fine pen lines and details, detailed long evening gown, color grading, watercolor-, backlit sun shines through hair, octane render, anime style by Krenz Cushart and John French Sloan, 8k [poor bad amateur assignment glasses]
this is beautifullll 😍
TY
hey everyone, anyone knows what is the technique to create something like this? the base is an owl with a wizard hat but it is filled with clouds and etc






Merry Christmas Everyone


f/16 bokeh 3/4 portrait classic woman dresses as santas helper, fine pen lines and details, detailed jacket, color grading, backlit sun shines through hair, octane render, anime style by Krenz Cushart and John French Sloan, 8k [poor bad amateur assignment glasses]

f/16 bokeh 3/4 fit muscular santa claus in his red coat and hat, presents over his shoulder, fine pen lines and details, detailed jacket, color grading, backlit sun shines through hair, octane render, anime style by Krenz Cushart and John French Sloan, 8k [poor bad amateur assignment glasses]
Hello☺️ I’m new, did last hours some stuff… thats my cyborgs




















Now some of my egypt robots















Now some city skylines









And some robot woman i did










yes
nah i'm trying to do good outpainting
HOOOOOOLLYYYYY
i changed the modal to "stable inpainting v2.0" and it is INFINITLY BETTER RESULTS
like damn perfect
first try






you need to use dreambot channels to generate images
They are #1047760914008522782
Etc
Please do check out our #✍🏼|rules-and-tos
And if you need help understanding the bot
You can check the quick guide here: https://docs.google.com/document/d/1aHJ9RBt_vlCwJQBVUUsb7VghKB-wynv7WGTxm9ozL1k/edit?usp=drivesdk

Google Docs
FRIENDLY STABLE DIFFUSION GUIDE by Atypical Consortium / Sunny LAST UPDATED: 12/22/2022 Please note this document is a work in progress! Thanks for your patience in this matter! PLEASE ALSO NOTE I DO NOT OFFICIALLY SPEAK FOR STABILITY! THIS IS JUST ME, MYSELF, & I! Hello, and welcome to Sta...


Man, I am about to just give up when they can now flag you for "possible" training on their art.
I mean, that's just civitai trying their best to stay afloat- don't think they can really risk lawsuits in any way
even though they might win it, it's still way too expensive to make that gamble
i think that they should upload a folder with all the training data they used to train the model and thats it, if sda didnt draw any of those images then he can do nothing
I mean, the name might need a change at most
yes, any mention of sda should be gone
On youtube, for instance, being a content creator is hell as you can even write, and perform, your own music and some Copyright thief will claim it and forget it. I fear this is coming for thumbnails, arts, you name it (and not just on Youtube).
If that shit spreads making the entire Internet like Youtube we are done for as it is the most hideous system known.
i could see that happening, especially since that anti-ai campaign have The Copyright Alliance as an ally
Same
I am really getting depressed over this as I feel the luddites may win this one.
Ludites + copyright aliance VS multibillion dollar emerging industry
I think its useless to be depressed or mad about it, as much as I hate corporations, they have the resources
In the end I don't give two shits about copyrights, what I am sad, and depressed over, is the Great AI wars of 2050. Massive amount of luddites, and corps, depressed technology so they can keep their grasp on wealth, power, and control.
I'm not convinced disney on automatically on the anti-ai side because of stuff like this

Humanity will prevail, always.
Also, If I see a giant holographic ad in the sky, Im becoming a terrorist, in minecraft of course
Well, I hate to think it will be Dark Ages 2.0. Technological Dark Ages.
What a lot of people don't understand is that art style is already part of the public domain. What these people are trying to do is wall off part of public domain so they can collect rents on what belongs to everyone.
Well, look at Getty Images (that I despise) as they have all the PD images over the last 100+ years now and you get to pay them for what, 20 years ago, could openly be found. SSDD
also an association with only a couple hundred members like the CAA would be one of the smallest and most inconsequential organizations to join the Copyright Alliance
Even small, when numerous, wield great power. More join and more join we have a problem.
I hear you. I've looked at illustrated manuscripts from the middle ages and then find the exact same manuscript on one of the stock photo sites with their watermark all over it, charging $500 to use it. Ugh
Yes. I am not even sure how that is legal, but legality only works one way these days.
Universities, libraries, and other public institutes have generously made them available for free for everyone to use. It just sickens me to think that some people are paying for this and those institutions are not collecting a penny.
Exactly.
See, I am just saying that if it was available, on the net, as an image for free why do I now have to pay to have the same access to it?
I saw the same stuff for films that fell into PD and one house sucks them up.
We shouldn't. All this talk of stealing, poor artist, etc. smacks of the RIAA and other Corporate media working behind the scenes through these people.
Yes, they are shills or boot licks, or just rage mobs that do this then move on to the next rage.
Makes me sad they would sell out like that.
Doesn't me, but I am jaded as I see sell outs everywhere from politics to common Janes/Joes.
We can always have hope that they will change their ways. What makes me sad is that they haven't.
They will not change until wealth potential, and politics changes. What is bad is when they sell out their family for a dollar. Wait until the next recession/depression hits and they want some money.
I don't like to go down that path thinking about that.
This has been the way from the start of time as humans haven't really evolved in this respect.
You're mostly correct but there are a few and we can always have hope.
I think now there is even less, at least in Western Culture.
I don't know if it's any worse now than any other time. Nothing new under the sun.
I would say but we are veering off of the main subject.
I think we are doomed UNLESS we can get someone, some thing, BIG with trillions of dollars under their belt. WIth that sort of money you would have the money to fight, the power that wealth brings, and the clout in politics, et al.
Did I read you local GPU is a 16xx with 6GB VRAM.
1060 6gb
Don't you train models on it?
nope, too slow, but I am goingto attempt a lora
not sure if I understand it correctly, but does this count?
https://imagen.research.google/
:3
No, not really
Then you use colab?
Yes 😦 On broken TLB's automatic1111 barely stays working like a 30 year old junker car
I've been having so much fun generating images that I haven't gotten around to train yet. I'm hoping they can get it down to 6GB in a reasonable time so I can train locally.
Well, I was going to buy a 4060 as I upgrade every 3 generations though I have my doubts because Nvidia are pricks again. Now if what they originally said were still true I would. 4060 was supposed to be 16GB vram and $379 MSRP. EIther of those change I'm out.
AMD rdna holds promise though it can't do xformers (yet) it was generating in 6s.
LOL they got a taste of the crypto market and big bucks so it's hard to go back to reasonable prices.
4080 is a dismal failure so let them, and their shareholders, burn
Maybe one day we can all have a nice GPU but until then we make do with what we have.
yep
Another issue is my Nvidia card company for the last 20 years left Nvidia and I mistrust all others.
Gigabyte I will never ever purchase from again so they are not even a consideration.
I'm content for now to generate on my lowly 1660S.
Powercooler, and Zotac either
At least I can generate.
A new present every month. I can't keep up with it all.
Emad said they were on Holiday so it had to wait.
and it's important to stay positive, it'll all work out in the end! :D
Naw, tbh if it doesn't work out I really don't care it is just the hit to humanity overall that bothers me not any of this SAI stuff


any advice for cleaning up images while having 0 artistic experience?

i really dont like the white lines but i love the clothing
anyway to save this?
mery chrismas

Is that Gareth Bale?

.
It’s nice. He looks just like Bale too 😅

making particle system textures using SD 2.1 + Krita. Only minor overpaint required!
@brazen magnet if you're interested to see 😄
but yeah getting nice round or soft textures for game VFX out of photos is traditionally very hard. you have to paint a lot
with SD I can basically tell it I want it to be a "circular cloud", and also give it instructions to make it easier to color-key
Anyone else getting an issue where deforum devolves into total static, like this?

super rad.
usually when that happens it means my model is misconfigured, check if you have the YAML you need to go along with the model? Also you might need to update your automatic1111 if you upgraded to 2.0 or 2,1
It's outputting most of the images fine though, it's when it gets toward the end of the animation that it starts doing that
hmm... I have had decoherence from time to time, esp. when recursively iterating on the same image
But tbh I'm not an expert and I'm sure someone who isn't me can give you a better answer!
Thanks anyway!
Looks good, but yea I can see how that'd be difficult to alpha mask. Don't have an easy solution for translucency like that. Particle systems is actually probably a really good application for sd. I like it.
general textures and image elements I will probably use SD as my main tool before googling it
google search for images that don't exist
I've done a lot of handpainting over photo elements from Pixabay to make textures
but I can just direct SD to make me more usable photo elements 😄
yea and it works with non realistic styles as well, compared to realism only (probably the biggest category for game dev tho) for stock images
there is immense potential for game art all over the place. The potential for overfitting is worrying but this is just proxy art anyway
hmm maybe if you finetune a model to display icons on a certain predefined background image (something like the checkboard pattern) and you can use that to backcalculate transparency. Analogous to using lightness on black background as an inital alpha mask and how the transparency checkerboard pattern helps make it more visible.
like having a basis image 😮 then using difference to calculate transparency. Cool idea!
Exactly. Maybe a little bit of blurring/deblurring/signal processing to undo any artifacts from the background that show up in transparency if it becomes a problem (careful selection of basis image also might help), but overall might work better than a simple black background
This is awesome!
omfg I'm an idiot. I had contrast set to go down to 0 toward the end of the animation, and didn't realise that that'd render it as noise instead of pure white which is what I expected
At least, I think that's what it was. Waiting on a test render to confirm
@west sundial images are allowed in the other channels, heres some of the stuff I got from just replacing the raw desc








This is dope
thanks. My chatgpt prompt was "Write me a highly illustrative and specific matter-of-fact visual description of a still image that captures the essence of your scp in a single sentence"
and then a list of custom weighted embeddings at the end
those seems to work similar to the random artist names and tags from 1.x, but the results are better imo
oh my god
metaprompting by prompting chatgpt to write you good prompts 😂
how many layers of meta can we go here? maybe we can meta-metaprompt chatgpt
training sd to produce chatgpt prompt request screenshots would be the next level of meta
if only it produced proper text in its current form




@wispy yarrow outpaint with auto1111



oh my goodness, I'm terrified lol

I'm a little late but merry Christmas to you wonderful people 🙂
To you, and yours, as well.
@small plover its definitely very hard to achieve


Thank You very much for your attempt ☺️ the second one is not that bad
Personally, I have never seen a Jewish cat which may be why it has a hard time.
AI draws upset Traditional Artist 😂









AI or real?

Looks dead to me
What
Like a weekend at Bernie's type dead
AI, I can tell by the pixels
Bru guess my camera sucks then
This one has to look real

what was your prompt for that?

"Phone Selfie, Android UI, vertical video. centered framing, flash photography"
If you throw video in there you get this
Is doxxing myself worth it to confirm that my face is not AI?
I looked at the full sized image and that was a potato camera (no offence).
My front camera is a patato
Hell, both of mine are. :/
Compared to the rear I don't like using it cause it's just awfull
Oh
Not ever going to spend 800-3k on a cell phone.
I spent only 500usd on my phone
Well it was previous green when I got it 1 year ago
So now it's like
3 gen old
My GPU was 700usd💀
I hear ya. I rather spend 700 on a GPU than 500-700 on a smartphone.
The problem is that now the GPU is 200usd
4090 1600 at launch. 2 months later is 2200. Damn.
4070 specs was just released
4060 specs I think next month so I will see. AMD, as always, has driver issues. AMD hardware for gpus has always been so damn good but their software driver's division sucks ass.
How does it do SD?
I mean the onnx version takes minutes but I assume there are things that take seconds
Hey quick question, who else thinks these are AI generated? Did we start verifying ai generated images on captcha now

I'm not sure why but the thought makes me a little worried. I mean obviously Google is gonna push their own image AI... But they'd be able to get so much free training data with this
If it is what I think
OK so
someone posted on r/stablediffusion about it 2 months ago so it's definitely real
However these ones are obviously way harder to tell apart from actual photos
Like that top left duck one? Makes perfect sense in context. Could fool me if shown apart from the rest.
everything's ai generated, nothings real!
runs away screaming
The bottom left is a dead giveaway- but I mean, it's a smart way of doing captions (left not right, I just woke up)
Just like they had words from books in their captions at one point, to help them decipher things their algorithms were having a hard time with
it's a win win of sorts
Yeah some of these seem 'too pretty' to be actual photos. There's some level of authenticity to bad image quality, you know?
imperfection is perfection as the saying goes
Gnh
I don't know why, but I have a bad feeling about AI trained by unlimited hours of humans selecting rectangles mindlessly.
I'm not sure why tho - Like the whole point is to get ai images to the point where we can't tell the difference, right? But it just feels like with captcha training it's going to happen before the world is ready for it.
Like in a few months
We're still only starting to wrap our heads around how ai image generation is gonna affect commercial art world
for sure, we're in the infancy years of AI right now in general
The only reason I could tell these are even fake is that I'm even aware that ai art is a thing
It's not really a widespread knowledge at this point
Sure, Photoshop has existed forever but with the critical thinking skills of the general populace I'm not very confident 💀



SD don't know a hang drum, its a problem.
Can I learn to SD this object you think?


8k portrait of beautiful young woman with brown hair dissolving, face half submerged in water, intricate, elegant, highly detailed, majestic, digital photography, art by artgerm ruan jia and greg rutkowski surreal wet paint gold butterfly filigree, broken glass [lowres, cropped, jpeg artifacts, bad anatomy, text error, worst quality] [amateur, m...
Can i use Textual Inversion in 768x768? Or i should use 512x512 images?
768
how many images i should use to train a hang drum, by exemple? 10, 20, more?
6 min, 20 max
Hmmm, ok, thanks general 🙂
you are welcome.
I sometimes cheat for styles and do 4. I did 1 and everything became the old man that I used. :/ Learned my lesson with that though it was funny.
don't understand how to use


watercolor f/16 bokeh 3/4 portrait classic woman on a city street, fine pen lines and details, detailed long evening gown, color grading, backlit sun shines through hair, octane render, anime style by Krenz Cushart and John French Sloan, 8k [poor bad amateur assignment glasses]
Ah, I don't understand why it didn't work, I had CUDA crash
Is it possible to create embbeding with 8GB of Vram?
I can, and do, with 6
what settings?

btw, which card cause on mine it is omg slow. I only do it to test 100 epochs
takes hours
768x768 png


change from 2 to 16
Now, make it 8 or make it 10 for the source pics
? don't understand
Don't do odd number of source images
okay
Now comes the hard part
Learning rate change it to (god I wish this shit had a save as defaults) - .001:50, .0001:100, 1e-5:500, 1e-6:1800, 1e-7:3000, 1e-8
Batch Size I wonder. This is a trial because you have 8 so you may be able to pull this off, or might not. Batch Size = 2. Gradient = 4
i put this whole chain instead of 0.005???
- .001:50, .0001:100, 1e-5:500, 1e-6:1800, 1e-7:3000, 1e-8
yes
weird
once you have done the BS and grad tell me
Now here is why you crash. EVERYTHING must be turned off that might even touch the card. Turn off hardware accelerations from discord, browsers.
no exceptions
i'm low usage, everything is closed
you are in here and this is default using hardware acceleration until you turn it off
even the browser used for the webui must have hardware accel off
we don't have the ability to afford such luxuries
why? to gain 300 mb of Vram?
with 10 you could but not with 6 or 8
now in 1.5 days 8 was good enough because 512x512 but you just asked for 1.5 times the mem that 1.5 needed from the gpu
done, disabled on discord, have only SD openend on chrome
i could kick explorer too
I use edge for this but same same and hardware accel is off in it
that way I give it a browser that is fast, and only used for it
with H/W accel off
now take a pic of the settings again and post it
sorry, done. took time to sacrifice my shit edge to disable HW acc

on LR kill that first -
LR?
Learning Rate
ah
should not have a -.
001:50, .0001:100, 1e-5:500, 1e-6:1800, 1e-7:3000, 1e-8
?
yes
done
now at the very bottom change from once to deterministic
done
Now here comes the worst saved for last. We can't help it. Save image to log director and save a copy of embedding must BOTH be 0.
Being 8 gigs you might can change to save the emb every but let's try this first to see if it runs
?
yoKill those 500 and make 0
don't understood a word
done
now give it a try
i will give a screen 1st 😄
CUDA crash
alright
then you are stuck like me. This requires shutting down the cli and starting it again (don't restart the browser)
mah, forget this parasite of Steam
what this means is the BS 2 must be 1 and the Gradient from 4 to 8
done
closed him
anyway, show me your new settings.

Those work for me with 6
Hi
CUDA crash
oh, and did you close SD and restart it completely over cause once CUDA OOM you must

I just ctrl-c the thing and Y
Now add this line into webui-user.bat set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:24
if you add that line after all ofthis and it still doesn't work for you, but does me, you have something draining out your gpu vram
`@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:24
set COMMANDLINE_ARGS=--listen --port 7860 --no-half --medvram
call webui.bat`
?
no
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.6,max_split_size_mb:24
done
restart it
as I said everything we did is what I had to do so if it doesn't work with you having 2 gigs more something is not right with your system
:\
show me a screen cap of your settings fo webui


BINGO


your training section should be exactly that
i have to clic on this to save and restart? right?

Yeah, just to be safe
done
although it needs to be rstarted since CUDA saw an OOM. It is a PITA
ok
not refreshed page of training, but crash cuda
he didn't savec my presets in settings
in trainning
oh god... i didn't clic on "apply settings" on top...
nope, always must be reentered (hence my saying it doesn't save as defaults)
Overwrite yours with that in the webui folder.

replace you config.json with the above one
last hope for you
once replaced restart everything
a new error
??
https://media.discordapp.net/attachments/976881252667887647/1051481391797379182/image.png
@errant leaf someone with who I discussed this a while back made this drawing about it.

probably because of this
"sd_model_checkpoint": "v2-1_768-nonema-pruned.ckpt [e1542d5a]",
mine is :
"sd_model_checkpoint": "v2-1_768-ema-pruned.ckpt [4bdfc29c]",
I still use the pickled one so just change it
same or another one error
i think i'm gonna give up it's sad but i have to go
Anyway, thank you very much for trying to help me 🙂
what happens when you cross dutch golden age paintings with modern macro photography?










Probably never been done before in the history art... But still the Artists complain that AI art should be banned



Daniel Radcliffe?
Elijah Wood?
Oh shit








inpainting? or maybe lama-cleaner
I figured out what I painting is, but what is lama-cleaner?
Ya know I try all sorts of different wording and come no where close to what you guys get at times. Is it due to me using the browser attachment and not using the direct coding in the DOS Command prompt?

That is a compilation for one of my NFTs on Opensea. as you can see it is still not as clean looking as I would think it should be, Still having issues with hands and feet also.
Hi
Assuming you mean Automatic1111's GUI when you're saying browser attachment, you could look into custom models, embeddings, and depending on what you're looking for some people have the prompts embedded in their images if you want to learn from them
Hands and feet will be more of a general issue though, there is no one easy fix that always works
Any users of HassanBlend1.4 here? Faces are always bad (top pic). But all of this model's images I see posted online look perfect. If I use the "inpaint the face at full resolution" trick, then I can repair the face (bottom pic).
Would it be accurate to say that all Hassan generations need the "inpaint at full resolution" trick to be fixed? Or is there other setting I don't know about.

does anyone know how to make videos with stable diffusion like @iagenerator666 on tiktok?



@errant leafSorry not a programmer here gave up on that back when we went from DOS 7 to C+. I start the SD program, open my internet browser and use the interface from there is what I mean.
@shut quartztry this video link seems worth watching.. https://www.youtube.com/watch?v=rvHgcOa9gDk

How to create Videos with Stable Diffusion. Learn how to create Prompt Morph Videos in Stable Diffusion. Learn how to use Video Input in Stable Diffusion. Create Music Videos in Stable Diffusion. Create Video Animations in Stable Diffusion.
Join my Live Stream: https://youtu.be/0mEJWCYJkfg
Deforum SD Google Collab: https://colab.research.google...
thanks
I always hunt google before bothering folks here. But at times it all comes down to the wording you use in the search.
My issue is normally updating and such as I know jack squat about a lot of this modern programming stuff.
Back in my 30s and 40s maybe, now days at over 60+ I set my objectives a bit lower than I use to on knowing PC stuff.. 🤣
That's fair! Do you know what version you're running? You can see that at the top left of the interface; it will probably be either 1.4, 1.5, 2.0 or 2.1.
If you're not using a version 2, you could consider upgrading. You'll get more pixels (768x768) as native resolution instead of 512x512, but artist names work less well. 512x512 won't work as good either. Generally, in 2.0 and 2.1, the quality of (photo)realistic things is in my humble opinion at least a lot better.
I'll try to explain a few small concepts as simple as I can make them, not being a native English speaker.
💠Embeddings are tiny files you can place in your embeddings folder (which you can find in your stable diffusion folder) and you can kind of think of them as magnets. They push the result of your text input towards a certain style or subject. So, for instance, I can say 'A photo of a cat, art by VintageHelper' if I have the VintageHelper embedding in my embeddings folder, and it will make the result very close to an analog photo. You can also use multiple embeddings together, and use that to create even more unique styles.
All you have to do to make them work, is download the file to your computer, place it in the folder, and use the filename (but without the
.pt, you don't need the extension) in your text prompt. Be aware though, that embeddings for version 1 do not work on version 2 and vice versa.
💠 Models are bigger files that actually contain the data Stable Diffusion uses to build your image. These are less flexible than embeddings are, but the result is sometimes more accurate. You can switch models by going to the top left corner and clicking on the version you're using, and if you have other models installed, you can select those. Usually, a key word like the filename of the model isn't needed to get the model to work. Instead, every output will be biased towards what the model is supposed to do.
The way to use models is to download them, and place them in your
/models/stable diffusionfolder, which is inside your mainstable diffusionfolder. Sometimes you need a.vaefile as well, but you can just place it next to the model and forget about it. They're just there so the model can function better.
If you're not running 2.1 or 2.0 but want to upgrade to a model that is based on 2.0 or 2.1, you might need to update your stable diffusion so it can handle the version.
If you'd like to see what models and embeddings can do, click on #1047197565365538826 and check out what some of the community has made so far 🙂
There's also websites like civitai.com that contain a lot more embeddings and models, but let's just say a lot of it is for a not-safe-for-work audience, so I don't know how interested you'd be in that. However, there's also a lot of good stuff to be found there, and the interface works well.
I hope this helps, you can tag me if you have questions of course!
Stable diffusion at 4K then upscaled to 8K

another 4k example

edited and downscaled

Hello, excuse me. I am beginner into webui. What does multiplier do to img2img?





@errant leaf


@errant leaf Yep, I am listed as a 100% Disabled VFW. I have permanent damage at the brain stem so I have issues with my hands and such anymore and free hand drawing is simply no longer possible. As such I wanted to use SD as a sort of baseline for making my art. Create a picture of what I would basically want, then using GIMP. Paint.net, and Inkscape to refine and remake them so they are originals. I have been doing ok so far with basic dual layered work but as i progress more into more detailed work I am having issues. Thanks for the info... This is some of the stuff I have done so far. Not as good as I would like but i have them all listed on Opensea as basic NFTs. https://opensea.io/Galwin?tab=created





(dark dim dramatic atmosphere)+ beautiful woman portrait symmetrical, swirls of rich silk color, thick brush strokes, love, 3d depth, closeup, insanely detailed, photorealistic, studio photography, hdr, 8k, cinematic lighting, dramatic lighting, Cannon EOS 5D Mark III, 85mm, volumetric lighting by ayami kojima and ewelina kowalczyk and alessio ...
going to hang out in voice and make some art, if anyone wants to hang out.
my art stream is here: https://seek.art/users/coreco

(dark dim dramatic atmosphere)+ 8k portrait of beautiful young african woman with brown hair dissolving into liquid gold, face half submerged in water, misty evening lake, intricate, elegant, highly detailed, majestic, digital photography, art by artgerm ruan jia and greg rutkowski surreal wet paint gold ribbons filigree [lowres, cropped, jpeg a...


Would anyone be able to give me some insight into what kind of art this is? Or name artists doing similar work?
Thanks

eerm
perhaps a hint of dutch golden age, and a hint of Giuseppe Arcimboldo going from that hat
id say maybe some fractal art influence in the neck part, and also CGI digital art in the face, perhaps Zbrush
maybe a bit of macro photography and undersea/oceanic influence
color composition could be Picasso




Also... a character portrait by Christian W. Staudinger, behance contest winner, gothic art, behance hd, rococo, aesthetic




Nice
thats awesome how do you do that
fine tune im working on



Are you using the vae file?
Btw what was your prompt?

@quiet moat this 4 photos were generated with this prompt: woman wearing random clothes, masterpiece, best quality, (ultra realistic photorealistic:1.3) soft lighting (8k photograph:1.2) global illumination, portrait photo"
And negative prompt: 3d, render, doll, plastic,painting, drawing, 3d render, blender

Is this 2.1 model? 👀

Basically, it's a loopback starting with the sketch and 8.5 cfg scale and 20 steps with Euler a (I think changing this would have various effects, but it's not as important as the other parameters). Other parameters are: desnoising strength between 0.01 and 0.1 and between 10 and 20 loop iterations. Setting the denoising strength change factor to anything else than 1 can be done, but it should not be set to a high value if the number of loop iteration is high. For example setting it to 1.1 with 25 loop iteration would yield a denoising strength greater than 1.08 for the last iteration, completely changing the image, and you don't want that. And anyway, setting that change factor to 1 or less than 1 already give very good results.




those look amazing, what model/embeddings did you used? 🙂

That one you hearted took me a LONG time to generate. If I had a faster card it would look even better as I would double the steps to 40. it is FHD.
Aww I see, well very nice , love all them. Keep it up! 
40 steps is so much nicer

Yeah indeed! You actually could make a big panorama city with all these.

Love those details especially on clouds
Straight diffusion, or have you got an embedding or something?
My embedding I made is driving a lot of it I think. Bit funny as it is not how I envisioned it but if I remove it it all falls apart


Diffusion can be tricky like that.
Yeah.


These last ones look a whole lot like NIR photography







I like this one
I feel like this needs something else in the image, but I'm not sure what.

For some reason this feels melancholic
Good! That's the intent I had, it just also feels too empty 🙄
a chair?
FTFY





















Stable diffusion discord general with images thread - #🏞|general-with-images message


These are wild


This time I used Andy Warhol, Sandra Chevrier, and Bob Ross as the artists

a portrait of [a cat|infinity] in a scenic environment by [bob ross| andy warhol | sandra chevrier], hyperdetailed, trending on artstation
This was the best one yet. Originally, I was just using Sandra Chevrier, but decided to throw in a bunch of extra artists

Since this is my new favorite prompt, I'll have my GPU generate 27 of them. RIP GPU

Tried using old manuscripts for textual inversion training, just as an educational excercise for myself... Started out pretty good.

Yeah, you would be surprised what can come of embedding styles
but somewhere it went off the rails and just started turning everything into high octane nightmare fuel as well as giving it the manuscript look I was going for.
Everything gets transformed into some sort of horrifying meat manual.



Is there a way to rollback training an embedding? or do I need to re-train?
Oh, I' sure AF surprised.
There is a way as what you do is grab an earlier epoch then change its name to remove the -xxxx into embeddings and start from it
you really can make styles with 4-6 images. If you use 1 it locks on to something. In my case I tried 1 to see and suddenly everything changed into the old man that was in the picture. Was them and they aged if male.
Thanks, Voynich batman cranked out at 2500 steps, and was kinda awesome/adorable.
I'll hang on to meatmanual generator in case I need creepy pages for halloween or something, but I don't want to run the training further down that track until I figure out what I screwed up.
I've got a big dataset, full scans of a few hundred old manuscripts, engineering manuals, illuminated bibles, etc.
Dagnabbit.
Don't give it too many
I know what it was, I just realized I have some 1800's anatomy textbooks in there.

Man I hate anime. Well, not hate but I do despise Waifu crap.
I wouldn't mind it so much if it were so overtly sexualized, and if so much of it were just the same tropes over and over and over again.
yep. What I despise about waifus are the ones who can't, or don't, want to get a real woman so fanaticize that a cartoon character is their lover/SO.
What model is that?




Thanks

YUP, it was the medical texts.

Note: do not include late 1800's medical textbooks in your training data... unless you want nightmare fuel.

so that is anatomy imagery? lol
some of them were more obvious

there are some other ones with humanish forms but a couple look kinda NSFL
was hoping for more stuff like this

but I need to cleanup my dataset first.


LOL, with a reaction like that maybe I should train a model on nothing but the anatomical texts for you weirdoes.

Just not sure the world needs an AI specialized in flayed limbs and exploded torso diagrams.



hello guys, I'm trying to recreate something like this. I think it's some sort of "redraw" based on another image, anyone keen to help me or guide me to the right direction? ❤️


Gundam Mew


Hi, how may I increase the detail SD paints? Using img2img using Anything v3

Got it thanks

Those eyes




Thank you, figured it out. If Clip Skip is at 2 instead of 1 you get awful faces.
hey guys, I would like this one to continue upwards basically, so that it generates the upper half, ist that possible?

What model is this? Anything V3?
yes



Some more new pokemons


Message #1040615021316681850
y you keep saying channel names
what happens if you set up lots of automated cameras to collect nature pictures for training a fine tune model of SD? surely the anti-AI folks cant complain about that.


meanwhile Im printing pikachus
They’ll complain that base SD isn’t “vegan”
go ahead.. i would say you won the copyright
own
midjourney claim everyone owns their copyright
I dont own copyright to pikachu 😦
oh yea,... well theres rules for that. as its fan art
thats only true if the gen doesn't already violate copyright
i forgot about fan art for a sec
If you use mj to make a darth vader thing, its still owned by disney so you can't just publish for money
humano ¯_(ツ)_/¯




why do people over on midjourney think they are using a pure artist style when they prompt and artist. When they are actually getting midjourney style + the artstyle they prompted
on the other hand SD does not have a default style so we can get a pure art style if we prompt and artist
The MJ art style says it all to me at least.
I don't want my generator to have its own style
exactly
I always giggled when people were training SD to have the MJ style. ffs, lol
All models have their own unique styles though, its just MJ's is particularly strong and hyperfocused
in the style of midjourney is a thing, btw.
limits it as a tool.. if you were generating references and wanted different artist styles.. you would definetly use SD
I am so pissed as I spent a long time with my new embedding training it only to find out it refuses to put people in it.
r/Art on Reddit is going into full meltdown mode after attacking an artist who's art they though resembled AI art: https://i.redd.it/dibekv0ogn8a1.png
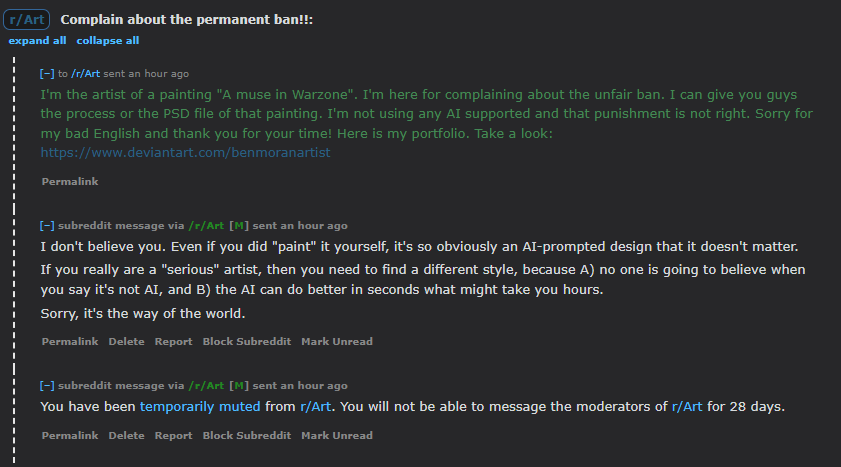
r/Art mods: AI art is bad because it's stealing from artists who have practiced hard to learn their skills.
also the r/Art mods: Why did you even bother drawing that when AI can do it in seconds?
madness
this is so out of hand it is making me mad so I try to refrain from that noise as much as I can.
i've not used reddit in a long time. seems there are a lot of authoritarian ban hammer type moderators on there these days
I see this from the left (no offence to any leftists in the room) a lot on various subjects. Damn if you do and damned if you don't. Get that then time to do the Homer Simpson back into the hedges meme but irl.
reddit admins are even worse the mods will tell you. 99% are pure authoritarian dicks.
I wonder how an embedding can zap SD so it can't make people? I mean the TI isn't touching the textual encoding so I don't get it.
same with the right though, it just depends on which color glasses you choose to wear
human nature at its finest
Well, I don't hang out with the right much and I run into the left more than ever on line so I based on that. Fact is that be they right, or left, people in large groups, ESPECIALLY if anonymous, are the absolute worst. Mob rule.
That, and positions of power 
even if that power is really just in their own head.
I am a middle of the road type so I based my beliefs on a subject by subject basis. That used to be what people admired as it helped everyone then after 9/11/2001 we became hunted, scorned, etc... pick a side, etc... NO. I refuse to pick a side as I want to hear from all sides then get the best out of their views to make a final decision so we can all go forward. Seems that is now a dead trait.
Rightists and Leftists do it the same which is so sad.
The internet and social media make it really easy to get lost in the worldview you choose to be your bubble, and will reinforce beliefs a lot- especially in places like the US, where a two-party system really limits the amount of possibilities people root for
although here in Europe it's not always great either lol
Yeah, I used to be for a parliamentarian type system (except for president) until I saw what happened 2016-2020. I watched and came to the conclusion that too many chefs spoil the broth is what was happening so nothing got done.
In the USA we currently have a need for four parties. It is real, but supposedly will never happen even going so far as to say the Constitution disallows it. I dunno about that but this two party system I am not for since 1992.
We have people in the dems, and in the repubs, that do not belong but they would never win so get shoved in there.
we have socialists who should be in their own party not in the democrats, and we have nationalists that should be in theirs not in the republicans.
Eventually this two party system is going to implode as both are having MAJOR strifes internally due to it
There's a fine balance between too little choice, and too much- currently the US doesn't have a party for actual left wing politics as you mentioned, just the democrats who are still center right by European standards
Oh well, there's little we can do at this point- just hope for the best
I do agree
For the sake of all of us 😄
for the record I am a classical liberal and on the chart slight left of center which means in the current paradigm I am Hitler. LOL.
According to godwin's law, we all are 
@errant leaf Why would my emb not do people? Never seen it this bad before.
I do not know, I'm questioning all of my knowledge about embeddings right now with how my own training is going
Does your training material contain people?
I am amazed as it is a beautiful 3k epoch embedding but will NOT do people. You can't get people for this training but we aren't messing with text encoders with embeddings so that shouldn't even be a part of it.
it is as if we ARE messing with textual encoding for Embeds and we shouldn't be
I can sort of get a person (close) if I stop the emb at step 6 out of 20.
Stopping at 6 out of 20 steps. I called emma stone and got that thing.

My current and only theory is that that the absence of people in your training images and possibly the SD dataset taps into a part of latent space that just heavily discourages human forms, and due to the amount of steps you're usually doing for training that is only reinforced
But honestly that feels like a stretch because it's still photography related
This happened once before but so long ago I forget now. Still, you would think it would work since we aren't touching the text encoder.
Hi guys, Im seeking for help with some Table game (dog boxing) box visuals. Please see pic and promt - (Portrait of two animated fighter dogs in a boxing ring with underground boxing arena background, Boxer vs Doberman with muscle human bodies in boxing shorts, wearing boxing gloves, standing in opposite positions 3 d modeling details, high resolution, 4k). Im just a newbie trying AI for the first time 🙂 But maybe some one could help us out for some reward? Thanks

That looks so funny, what would you like to do? Generate another thing like this or have better details in the same picture?
basically I would like to generate another picture with the same motives 😄 I just cant do it on my own, its too funny looking 😄 (Digital art of modern in the style of (ARTIST), two animated fighter dogs in a boxing ring with underground boxing arena background, Boxer vs Doberman with muscle human bodies in boxing shorts, wearing boxing gloves and boxing shoes, standing face to face to each other, underground colors and arena lights, 3 d modeling details, high resolution, 4k effect, glitter, smooth skin....
something like this 🙂
🙂 I´ll try generating this on my sd installation and if it looks good i´ll post it here @marsh gale 🤗 😊

Thank you







these two guys complaining about stable diffusion https://www.youtube.com/watch?v=maCqaAtlvtg

Go to http://joinhoney.com/itdaily to get PayPal Honey for free.
Go to http://masterclass.com/newsday to buy one annual membership and get one free.
■
Follow Us Here:
http://twitter.com/internettodaytv
http://twitter.com/eliotetc
http://instagram.com/rickyftw
■
Timestamps:
00:00 - AI Art Hits the Masses
20:51 - Trump Org Guilty on All Counts
23...
First they say oh look how bad it was with deep dream and now its actually pretty good and come a long way, then they start mocking it saying all SD images look like a mid-level deviant art artist, and that anyone who respects their craft can easily surpass it.
But they don't think for a moment that by next year it will look like a high level artist work
SMFH
of course there is drama because that is how they get clicks and views and $$$$$$$$$
realisticblondegirl
I think a lot of people are just pissed because they don’t understand there’s a new form of medium. They just see it as something that cheapens or steals from others
At least, that’s my opinion
bro who tf I have 7 friends mutual with







Ko Wavchyume, just like grandma used to make.

😏⚡️


Help please! What the prompt should be if I download the image with person and don't want to AI modify this person, but only background???
You would want to use inpainting for that
Where is it? in dreambot too? Could you give an example how and where to do this?
Hi
Oh I have no idea about doing it with dreambot, I thought you were running a local or colab version
Some image to image abuse results. Love that we can take the style of the painting via img2jmg










And photorealism!!! It is sooo Good at it as of 1.5. Still can't figure out 2.1 and I don't even think I have to




Generated these here in bot?
Im want to know how I can generate an upper half to this collage. Is that even possible?

for those who had an issue with getting black images only - how did you resolve this?
nvm resolved now lol

let there be light














Did u had any success? 😬🤗
you can feed your 1.5 image into 2.1 as a finishing touch, make it do the last 10%
Impressed with this one!!

Ok,


I haven't been having success with outpainting mk2. What should I do when I see this?

Some options: 1) try refining your outpainting prompt to refer to what you actually want outpainted, i.e. hair 2) try expanding the image manually with "broad strokes" and refining with inpainting 3) use a different outpainter because the AUTOMATIC1111 outpainting's never worked particularly well
Took a break for a week or so over the holidays. What's the scoop? 🙂


Any new models people are loving or anything? New styles that are popular people are messing with?
Any news on tool updates and such?

The state of Civitai rn...
Far too many horny people out there.


its been that way for a long time, places like deviantart, they use Daz3D models.
"places like deviantart"...thats all you need to say really, lol. My eyes are still bleeding from the time a couple years ago I sorted by new on that site. From what I hear, it hasn't improved since.
nudity has been a big part of art for a long time.. The question becomes where is the line between artistic nude and porn
by a long time i mean thousands of years, look at ancient roman statues and paintings from hundreds of years ago
I wasn't referring to nudity, but rather the... interests that people have on deviantart.
i never saw anything odd on there when i sort by new. just nudes and normal art styles
checking now

No UnU only 2 images looked good but they were not as good as the image that you posted, most of my images were 2 human boxing, instead of 2 dogs 🥺
Sowy

it has been mentioned to the dev in their discord 🙂
Bring it








only AI would think to turn a housefly into a sci-fi retro futurism spaceship

it goes beyond human creativity when it comes to applying styles

This HIGHLY reminds me of early 1960s children's tv.

hmm that reminds me



maybe that didnt work very well but theres styles and artists based on old tv shows
such as Garfield John Martin Roy Lichtenstein Kate Greenaway Adolph Menzel
Scooby Doo Ron Walotsky Keith Parkinson
Powerpuff Girls Vincent Van Gogh Georgia O’Keeffe
Spongebob Squarepants Yuumei Francis Picabia
Shrek Andy Warhol Maxfield Parrish
and many more
Interesting as I used no artists
SD is an amazing tool for studying art styles and combining them
yes, it takes a piece of each (which piece we don't know) and combines them to make its own style with a hint of each. Just like real life.
All artists were influenced either knowingly or unknowingly with each art piece they ever looked at, or film, etc...
Hell, looking at something in nature influences.
Do anyone know how can I do something like this? I don´t remember the settings 🥺 🥹

ok so the #🔆|dailies bot wants a car driving through a rainbow at sunset. I cannot get stable diffusion to create this. No matter how simple or complex the prompts. Ideas? This is what i'm getting:

Describe the rainbow sunset and the car separately using commas. Append the sunset part with "behind" or "backdrop". Maybe start at a lower res too


still hving trouble. it keeps creating more than one car.
What model are you using and what resolution are you trying to generate? Sounds like the standard issue of trying to generate at higher res than the model was trained for
using SD15NewVAEpruned and rendering at 1920x1080
Unfamiliar with that model, but generating at such a high resolution with a non square aspect ratio is gonna do that
that's the one that came with automatic 1111
If so its made for generating at 512x512
Youd have to outpaint sideways and upscale for more resolution
If you are set on using that aspect that is

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
Outpainting is explained here (ive never actually used it so best i can do is the link lol)
Id definitely just try generating at 512x512 and building it up from there


Never mind, thanks for tryin 🤪🫡


Not here but from SD. Being able to use photo reference is something they should add because look at these
That makes sense. I will try it



The moon means this photo is facing west, and it's early morning. yay AI + Astronomy!
How do you know?
The moon is upside down when it sets from where it rises, that crater pattern is a setting moon, I think it looks like a jumping fish. It's a full moon, so the sun has to be exactly opposite the moon. Setting moon with opposing rising sun = early AM
but with two moons, all bets are off, I don't know what crazy universe you pulled this from! 😄
no wonder I feel so at home there! lol
Hehehe
I got told that people in the northern part of earth see a skull on the moon and the people on the southern part see a bunny :P

Noice



Add a howling wolf in the foreground, and they'd make amazing gas station T-shirts!
don't know if I can post links here, just search Amazon for "howling wolf tshirt" and you'll see roughly what I mean.
gas station versions take them up a notch though.


When you misunderstand how matrix works and get... unexpected results.

I'm pretty sure I had this playset as a kid.
This is my new gaming machine, the ϴ77 Aicb Niᴧins

I love the copyright warning in the corner.
What I find maddening is when I am training the trained images have shit like that while none of my images do.
Generated case of murder

Just ran a few hundred loopback iterations using the wrong checkpoint. 🤦🏻♂️ not 2.1 after all, I guess.
How may I improve and increase the level of details with blurry images like this? I'm using img2img. Increasing cfg didn’t help

Want to save me some reading and explain in a sentence or two what loopback script does?
Sure, takes the result image and uses it as image input for the next iteration with a factor that makes the noise tend to converge on a particular image or get more chaotic.
Interesting, thanks for the explanation. I'll have to try it out if this Lora training ever finishes with satisfactory results

How can I force a character start to look to the right? She keeps looking at the viewer

It's her choice!
(don't get offended just a joke lol)
"Looking away" is a booru tag that will trigger it iirc, add some emphasis if it doesn't work

How do I use an image as a prompt?

gennerate flower
help

with lora, stable diffusion
since i got 6gb vram
i can create a model, but when i try to train it this happens
looks like it's not loading cuda. 6gb of nvidia vram?
okay so that's covered. was worth mentioning
i got cuda ver 12

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
but then i realised that there was another method
there should be a lot of guides around to get lora working on a1111's. i intend to dig some up tonite and start lora training. I have 16gb but I think its worth learning the ins and outs
I just finished my first successful Lora model but I definitely need to mess with settings more next time, as it took 54k steps
i've trained 2 models and tehy're both jank and inconsistent
Everyone I ask says "Experiment" lol, trained a lot of embeddings but only a few models
so like.. what should i do
install the whole cuda again or sth
after the xformers installation, it shows the concepts
Did you set it to use xformers in the advanced settings on the dreambooth tab?

{kind=link}
{kind=link}
{kind=link}
yeah its a lot of "experiment" since this stuff is all so new and buggy and very much a "minimal viable product"
Turn on Train Text Encoder for Lora, see if that helps maybe? Idk how much Vram that takes though
gpus dont really die from software. something would have to be doing some horrible driver level hacking to kill one. reboot will save most of the time

so basically the previous model i set it to "use EMA"
but this model i didnt do the same mistake
so now
ignore the name for my checkpoint

if you know you know
experiments win the day again. hurray
you guys are awesome
@grizzled sage @fervent rune
ima come back with more "Experiments"
Glad you got it working!
what I said: "A potato, orange background, in studio photograph style."
What the AI heard: "An orange/potato hybrid, orange background, in studio photograph style, I love oranges, do you love oranges?"

@gloomy elbow i would first get the potato, then use the potato and get an orange background, but cool hybrid
You're right, that would probably be the best strategy. For now I'm just playing around with X/Y plots and the prompt S/R function It's the only iteration of all the colors that had the possibility for such confusion and it amused me. 😄
if only I had listed "violet background" instead of "Purple background" we might have had another botanical mashup
These are from my 54k step Lora model



that's cool, I'm getting like between CGI anime and action figure vibes.
Happy New Year, everyone. As a photographer, I minted a free edition for all of you, open till midnight EST today. Enjoy! https://app.manifold.xyz/c/Happy-Holidays

Feeling grateful for all the friendships we've created this year and proud of what we've built together. Wishing you well!
Wim Van Cappellen
Now when someone reads my long posts, I can offer a rainbow potato:

It was trained on a friends NFT collection who was only just starting at 3d modeling
interesting, the prompt set hit the "gouache painting" style and now it's making me potato characters...

