#🤝|tech-support
1 messages · Page 153 of 1
windows
ah which rocm+torch version are you on?
torch 2.10.0a0+rocm7.11.0a20251128
ah okay, and image generation works, it just freezes sometimes?
forge or forge neo?
Yes, it works and sometimes even give results, but ofter freezes everything so I have to reboot my PC
I don't know about forge neo, I guess it's just forge
ahh okay then the fix could be easy, in forge or forge neo just enable the Tiled VAE option at the Never oom setting in txt2img
This one, right?

currently rocm+torch on windows has an bug where it timeouts the AMD driver when the VAE step is done in image generation, so tiled vae can fix that bug
It didn't help, still freezed and I had to reboot my PC. But you're right, it happens after all steps of generating the image are done
do you use sdxl or illustrious models?
then try this fp16 vae file:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/blob/main/sdxl.vae.safetensors
also if you use hires fix then dont leave hires steps at 0, set them to 10 or 15
Yes, thanks, I'll try it
scam!
I haven't tried hires with amd yet, but I usually set it to 5-8, are these values ok?
It's both for IL and SDXL, right?
normal steps?
for sdxl/illsutrious 30 steps are the best
Where do I put it?
no, hires steps
models/vae
otherwise I'll get AMD issues like freezing?
no just for the better quality
the freezes will come if you set it to 0
I usually use 5-8 with denoising about 0.3. With more steps I see the same result and more generating time (well, on nvidia, but amd should be the same, right?).
yea it also depends if you make realism or anime etc
Most of the time, I do realism.. but logically it should require more hires steps for looking good. I guess it's either becouse I use low denising or just becouse custom hires model (but I tried standard ones like ESRGAN-something and it seems to also work fine on these amount of hires steps). It also take more/same time hiresing than generation image before hires, so, I tend to minimize hires steps
Here, right? Will Forge catch it automatically or I need to set this vae as default somewhere in the settings? How will I know if Forge use this vae or default one?

you need to select it in the vae dropdown

hmmm
gray or black?
gray
can you try add --upcast-sampling to the webui-user.bat?
Ok, i'll try
It's currently loaded something into the VRAM and doing nothing for a 2 minutes
Maybe I need to refresh browser tab and click "generate" again
It just become orange again, I'll try to restart forge and try again
Well, it again loaded something in VRAM and RAM and doing nothing (no gpu and cpu use), generate button is gray (interrupt/skip), but I don't see it's doing anything
ok, I'll try that
It's the same result with both --upcast-sampling and --no-half-vae. It seems that it also tries to use gpu for a split second when I click "generate" and then cycle nothing

remove --upcast-sampling and try again
your shared memory is full, how much normal system RAM do you have?
It's not full, it's kinda maximum from what was on this graph
I have 64GB of RAM
ahh okay
Strange, it's stuck again with something loaded in VRAM and don't making anything in the logs
wait a bit, maybe its compiling stuff or something
hmm
can you try without --no-half-vae again, but this time add this into an empty line of the webui-user.bat before the @echo off
set TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1
It seems to act the same. Now it's outputing progressbar before not doing anything, but that's may be just becouse I currently launched it via .bat (I'm not sure if Stability Matrix cares what I changed in webui-user.bat, so I launched it directly to be sure)
does stability matrix now has a amd rocm forge setup?
Hm, interesting detail, cmd doesn't react on Ctrl+C after it not doing anything
For me it seems it always has, is it isn't? You can choose which backend to use while installed.. althrough I had to delete and install torch+rocm (and also torchaudio and torch-something) manually for it to launch
yea that means they dont have it
i installed Forge Neo with rocm myself too
without stability matrix because that just adds a layer of potential issues
What is difference between forge and forge neo?
Oh, I probably should ask Google about that, not you 😅
forge doesnt get much updates anymore, and forge neo is the most up to date ui based on auto1111.
It has support for more and newer models like qwen, wan, z-image, and even supports txt2video
Can I move my reForge settings to Forge Neo by just copying settings file?
And does it have AMD setup? Maybe I'll try to use it instead in hope that my freezing problems will magically dissapear 😄
maybe, but it also could break stuff
i made a guide for it, but currently the rx9070 users reported that my suggested torch version didnt worked for them
so i was surprised yours worked so far
here are my Guides:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
It would be under Forge Neo with ROCm
Well, I'm not really good at python-dependencies things, but I just googled and pasted this line pip install --index-url https://rocm.nightlies.amd.com/v2/gfx120X-all --pre torch torchaudio torchvision after removing torch , torchaudio and torchvision, on python 3.11.13. This command doesn't specify versions, so it has less chance to error something becouse dependencies version mismatch, I guess that what make it work for me. And I didn't use zluda, becouse someone adviced me to never use zluda with RX9000
python 3.13 should not be used
forge and forge neo need 3.11.9
it's 3.11.13
thats okay
zluda works fine for your gpu
its more stable than rocm currently but not as fast
hm, I'll try zluda and forge neo tomorrow than
forge neo doesnt work with zluda, only currently forge and auto1111
ok. Didn't know it's something UI need support to
zluda emulates cuda for amd, so it has to be patched in
I though it emulates cuda so well that UI don't notice is it cuda or zluda backend 😅
yea but you need custom cuda/zluda files
i saw someone earlier mention doing it inside of the venv folder should i try there?
You can try
hello people, i need to know if i have automatic1111 or forge, how can i see what im using?
at the bottom of the webui in browser you can see the version
Its been a hot minute since i used stable diffusion. A lot has changed and I am confused. Google doesnt seem to be helping me find getting started tutorials. Where is the 'genreate' button?

which webui did you installed? xD
Ummm Vladmandic?
whats your gpu?
Im autistic and a little frazzled.Im trying to join the 'next' server but its got some weird are you human check that I have no idea
AMD
from memory vladmandic is for the amd/radeon gpos. I used to use it fine in the past. then switched to comfy but thats naff. so tried coming back
would suggest using Forge with Zluda or Forge Neo with ROCm Guide:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
boath have the typical ui from auto1111
do you mind my asking why. It took me ages to get it up and running. Once I get started i should be fine. I managed to find the generate button. it starts makin an image but then it vanishes
Comfy has broken and stopped working for some reason. And even then it was horrible. I couldnt do inpainting/outpainting and a lot more that I used to be able to do with vladmandic
because sdnext does everything different than the auto1111 baes uis. Its settings and usage is very confusing.
Also the Forge Neo is faster and supports new models day1 like Z-image and video gen
But Guides with ROCm require a gfx11 gpu or higher
I dont understand any of that.
whats your exact gpu btw?
Umm 1 sec. 6GB AMD RADEON™ RX 6800 XT - HDMI, DP - DX® 12
Ah okay, then currently you can only used Zluda bases stuff
Rocm is still wip until it supports your gpu
Like I said(or tried to with the tism)...
I was previouslt using vladmandic which I thought was the same as auto1111.
but Im struggling mostly because the Ui has completely changed from when I last used it. So Im struggling to even get started again. When I was using it regularly, I was what some people said was 'advanced' compared to just the average person who only used simple prompts. i was able to use the pose stuff, images as a 'reference', inpainting etc. But like I said its all a new UI.
I tried using comfy but just couldnt get on with it. I found I couldnt (work out) how to do any of the stuff I used to do. then comfy stopped working so i went back to automatic/vladmandic. but after launching the ui is so different
I was under impression rocm is what I need 9im in linux)
oh your on linux ahh, yea that uses and needs rocm
I think its just the new UI im trying to learn really. like how to ooad the safety tensors(where does it save them etc) just to get it working. Like I said. I typed a basic prompt, it started generating an image(I could see it) but then it vanishes

this is an error im getting
I might have launched it wrong, I might not have loaded models in properly I literally have no idea cos there seems to be no tutorials anymore
hmm, cant help much with sdnext sry :/
thanks all the same. pity I cant get into their discord
RuntimeError: GET was unable to find an engine to execute this computation
so close...
I should try a less demanding model first I guess

nah, this is almost definitely something I did
bruh
@pure tusk I think something's wrong
effing bot
Thanks. Ive managed to get things up and running now.
Thats a scam bot dont join
Ah oki. I also had a message from them. I havent clicked either thankfully
How do you organize a large number of images you've generated with image generation tools? I'd love to know what tools you use for categorizing or managing them.
aint gonna lie i was convinced first time one messaged me offering to help
Ive managed to get things up and running. Just need to know what model or samplers etc will help get better results.
Currently just poking it with a stick(changing random stuff) to see what works isnt getting me very far.
Is there some sort of guide as to what tasks(goal im trying to get to) works with what models/samples.
Being autistic doesnt help as I dont know how to phrase things

im sitting here talking with him and then next thing i know hes brushing off my question and asking for online wallet address
theres no set guide but if you download them at lets say civitAI theres example images showing metadata such as sampler, cfg, steps, scheduler etc
for example:"

not all images have this however
Unfortunately CivitAI is blocked where I live(UK).
So(sorry if im repeating myself). How would I go about finding how to go about what i want to do.
Goal: I want to use the left image as a guide to make images of that quality and style, but generate variants of it. As in male/female, diff clothes, race etc
oh hmmm flux kontext or qwen edit but those are pretty beefy to run, lets say my 5080 takes 30s for a flux kontext gen
the settings are not the problem in this case, the model rather
Ahh. I think I follow.Its been a long while. So different models are better at doing specific things? (at least thats how Ive always understood it).
yes definitely
I used to be able to load stuff in and do loras etc but like I said its been a lomg while and cognitive issues make the memory shit lol
https://docs.bfl.ai/guides/prompting_guide_kontext_i2i heres a good example what flux kontext can do


Black Forest Labs
is there a way to Dl the (safetytensor?) files from huggingface?
if you got the hardware to run it, https://huggingface.co/Comfy-Org/flux1-kontext-dev_ComfyUI
its pretty beefy and you might wanna lookup a tutorial

im not sure if sdnext can run it
hmmm
where am I supposed to click for the file?

files and versions
split_files
fp8 version but again make sure you can run the model before you run it
what gpu do you have?
definite maybe, but considering its AMD theres a chance you cant
yeah. Im using the romc thing in linux so fingers crossed
It really is a shame civitai is blocked in uk. pity they dont have the resources to to the safety stuff. that site was pretty easy to use. and had some amazing loras
with the age verification laws also coming to europe chances are they will comply one day
found a cool lora solely for doing klingon forehead ridges and inpainted one onto myself lol

Hmm I dl it and restarted the server and its not showing up in the list of models
hang on. saved wrong folder lol
Its in the dropdown now but getting this error
annot access gated repo for url https://huggingface.co/black-forest-labs/FLUX.1-dev/resolve/3de623fc3c33e44ffbe2bad470d0f45bccf2eb21/model_index.json.
Access to model black-forest-labs/FLUX.1-dev is restricted. You must have access to it and be authenticated to access it. Please log in.
you need an HF account to download flux
but you should checkout other flux models from civitai, they are better and oesnt need and account
Apparently there's a known issue with ComfyUI-Zluda where I needed to disable cudnn with a node, my lack of attention got me on a wild goose chase
Everything kinda works now, really glad
nice, good to hear!
I cant use civitai they(civitai) have blocked it in UK
damn, then you need a vpn and change your DNS
Im signed into huggingface(in chrome)
cba faffing about with VPNs
what?
TLDR: CivitAI isnt going to happen.
But you did mention about having an account with huggingface
Im signed into huggingface on chrome. So am confused why the model I DL from there isnt working
it should work but you should give more information whats not working exactly
also setting up a vpn is installing a programm and clicking "ON" and then civitai works again xD
Should be easy for someone who use comfyui
1 sec. Ill get a screenshot for you(thnaks)
[sorry] something else has bugged out now. none of the checkpoints dont seem to be loading.
https://civitai.com/models/2168935?modelVersionId=2442439 ppl in comments seem very happy about this model. Hmgm tried it?)
" This model just destroyed all others...RIP Flux, RIP Nano Banana, RIP Midjourney, RIP Seedream 4, RIP SDLX...Crazy revolutionary tech, same as DeepSeek did in early this year 💀💀💀 Big tech CEO's are jump from their windows 🤣"
"full pants" of happines? 😄
Cs1o investigate into this. This Z image what version is better. See they say depending on GPU fp16 might be faster or nah

Or its better cuz it run on lower vram gpus? than flux-qwen?
Im using the Q8 Version, its fast and good!
9 seconds for 9 steps
tell me . is it any better thqan flux-qwen ?
cuz kinda... need loras to be good ?
wait 9 seconds & 9 steps? that is really good speed hm
isnt quality & accurancy awful while at it ? 🤨
It performs so well, it beats flux in performance easily.
Its from the same creators as qwen.
Prompting is very easy, tagging and normal text works.
Text generation is crazy good
The Q8_gguf uses around 17GB vram when generating
So its kinda upgraded qwen? 🤔 And what about this fp16 turbo version on 11 gb? Wudnt it be faster than q8 gguf ?
The Q8_gguf uses around 17GB vram when generating
where dyu get it ?) - arent this version better mb ? - https://civitai.com/models/2168935?modelVersionId=2442439
do you also recommend zluda bases for my 16gb 7800xt? i am an absolute noob and my first try was with comfyui and im running into a ksampler error with z image
Lets not forget with the z-image its only a turbo version so its only getting better when the base model drops
forge with zluda will work, or forge neo with Rocm from my guides, or comfyui with rocm
dont tell me bf16 version uses more than 17gb vram ? o.o . And i guess the ones is on civitai site?
idk but probably
I run the bf16 model on my 5080 and i got 10s gens, though upscaling and refining bumps it up to 30 so it barely fits in 16gb
hello! was wondering if any kind soul could help me, all of my prompts turn into black boxes with random colors, i know i have something very wrong, idk if its a setting or if im missing something but i cannot for the life of me find anything on google, shoot me a DM if ur goated as fuck and can help 🙏🙏 ❤️
hey, which webui, which gpu ?
rtx4080, umm how do i check the Web ui version, followed a youtube guide hahah
hol up
sorry i am so lost on the menus its insane
can u tell what im on from this basic ass screenshot? i jsut reset everything basicly

thats auto1111, outdated since 1 year
please install Forge Neo, guide is in the pinned messages
A year feels so long ago, I used that first to play with image gens and it was outdated in less than a month
its installed and im just looking for a checkpoint atm, was a painless installation, what would be a good checkpoint? im still really new to all this, flux seems recommended but idk if it makes any difference depending on what GPU i have
yo anybody know what the folder is called in Forge Neo where the clip for flux goes?
text_encoder
i ragequit it and started with dreamshaper XL instead, its very chill to learn at a reasonable pace haha, got it working
will play around and see if i can get more familiar before going back to flux, wish it was more clear where to put the 3 extra files u needed
yea if you completely new start with sdxl or based stuff on that like Illustrious for Anime
since ur experienced, where would u turn to find like a good fantasy art generator? that is not flux etc, like a noobfriendly one, looking to make something similar to league of legends artstyles (the very clean fantasy style)
for styles you can download and try to use Loras, they are like addons that go on top of a model to help with specific styles or characters
yessir, and sd1 as a tag is probs stable diff 1.5?
nope 1.5 is old
is there any specific reason why dreamshaper XL loves to add extra eyes and mouts etc? im using the recommended settings from civit
do you have an example?
this absolute HORROR (i copy pasted someone elses prompt to see if it gets similar results)

it likes adding extra limbs or fingers etc, but most uploads i see are very clean
i mean can you show the whole webui page too
with all the settings etc

np
i really want to learn what everything here does to be honest, like i wanna understand every slider
the issue here is that you have hires fix enabled
and by xdefault its settings are wrong
hmm interesting, dreamshaper xl said they had built in refiner and all u had to do was to enble hires
yea thats not true ^^

I finally found out the problem why my stuff keeps crashing. Turned out I have been using SDXL checkpoint and my system is only 6.0 VRAM lol
Can anyone recommend me good anime checkpoint for 1.5? I'll make do with this for now until I get new PC in the near future
NSFW is a must as well.
Please
What's your GPU and which webui do you use? And how much system RAM?

Ah okay, do you have --xformers added in the webui-user.bat? Thats needed for the best performance. It goes at the commandline_args line.
Also for 16GB RAM you need to increase the Windows Pagefile.
Then you can easily use the sdxl and Illustrious models
Here is the Guide how to increase it:
https://www.tomshardware.com/news/how-to-manage-virtual-memory-pagefile-windows-10,36929.html
Enable it only for C and make sure its not enabled for any other drive.
Set it to 16000 Min and 24000 Max for C
Then apply and reboot the PC.
Also update your nvidia drivers.
I'm off for today.
I have set the pagefile. It worked for a bit before the same problem rose again.
The webui and chrome crashed on me and closed itself. The black cmd panel also closed itself.
So I didn't even have a chance to take screenshot of what happened.
XD
hello, i just installed forge and im getting the CUDA error: no kernel image is avalible error, i got a RTX 5080 and im pretty sure i didnt download the automatic1111
Hey, forge doesnt have native rtx50 support.
Install Forge Neo instead, it is the most up to date
Guide can be found in the pinned messages, first link
No problem 🙂
its this one right

@ornate elk sorry for the ping but quick question, with forge neo you launch it with webui.bat right?
Webui-user.bat
ahh gotcha
nvn i figured it out :>
Yo Cso1 sorry to highjack the convo, just a quick question, ima try to get flux running today again and i just had another question about the 3 extra files.
Do Text encoder5xx something and Clip go in text encoder?
And then Ae.safetnenotors goes in VAE?
Sorry for the spelling im typing at work hahaha
Yes exactly.
i got forge setup now but after generating it says "failed to recognize model type". i got the z image files from this site: https://comfyanonymous.github.io/ComfyUI_examples/z_image/
is this why im getting an error?
You have to use Forge Neo, as old forge doesnt support newer models
forge neo with ROCm?
What's your GPU?
7800xt
Okay, yea then that
i think i messed up somewhere but not sure where. i got forge neo to generate an image but its all black

You have to set it to Lumina
And then sampler, Euler simple, or multistep
I installed ForgeNeo with ur guides, but have this error while launching webui-user.bat:
There's also an output of the last step before launching webui:


Hm, is it using my system Python instead one inside ../venv?
you didnt installed it with my guides because it shows stability matrix there and python 3.12, which i boath dont list in my guide
best is to uninstall python 3.12, and install python 3.11.9 as main python.
Then reinstall forge neo in a seperate folder
I put it in stability matrix folder and renamed the folder for convinience, but for other things I strictly followed your guides.
yea putting anything in stability matrix folder will cause issues
How do I set main python for this folder/project/webui?
only for forge neo?
edit the webui-user.bat and there you see a PYTHON=
then open up a cmd and type
where python
Then copy the path to the 3.11.9 python.exe into the wbeui-user.bat
and then you need to delete the venv folder after that before relaunching.
Hello, can you help me with the problem I said yesterday? Should I switch to use SD1.5? Or is there a way to make it work?
have you increase the pagefile ?
and added --xformers to the webui-user.bat?
As I have said above, yes, I have increased it a while a go the first time you helped ne
It worked for like a little bit before same problem rose again
Did that as well
I can’t even generate one pic
does it freeze?
Nope, it just crashed
okay, then i would suggest you try setup Forge webui, as its better for gpus with low memory.
With that it should not crash
The chrome either closed itself or turned into “aw snap”
Is Forge UI as easy to use as a1111
yea its based on auto1111
Nice
guide is on the first link of the pinned messages
Because I also read from somewhere that Forge is superior
it has its advantages yes
Okay, I’ll see to it. Thank you very much my friend
no problem, let me know if it works 🙂
yea, but save the models first so you dont neet to redownload them
Which forge should I use? Neo or normal?
normal one

you didnt downloaded the forge zip or you renamed it
I unzip it into the folder
is your F drive internal or external?
Is this normal?



Those error lines look ominous
No
Make sure you Dont run the update bat or start bat as Admin
Also make sure you placed the forge folder not on Desktop, downloads, documents, programs folder
It has to be in a newly created folder
Wait, dang, I ran the update bat. The instruction said so.
problem is running any of them at any point as admin
Okay, I unzipped it again. Now what should I run? run.bat or webui-user.bat?


What HIP SDK is reccomended for 9070XT on Forge Neo with ROCm? The lastest 6.4? And what drivers are recommended? I currently have 25.10.1, is it fine?
6.4 and 25.11.1 is needed
Also ROCm is currently a bit unstable on windows
You need to enable the Tiled VAE option to not get freezes
do you know of any other possible causes for the onnxruntime error.


If you mean No model named "optimum.onnxruntime" error, they has a recomendation for it in their instruction:
Go inside the stable-diffusion-webui-amdgpu-forge folder.
Then click in the File Explorer bar (not searchbar) and type cmd then press enter.
Then you copy and paste these commands one by one:
venv\Scripts\activate.bat
pip install optimum[onnxruntime]
Then relaunch the webui-user.bat
yeah but that dont work for me for some reason
wrong reply
You can try remove --skip-ort from the webui-user.bat and delete the venv folder.
Then relaunch and apply the fix again from above
i wanna ask just to make sure but is the zluda folder i put on my drive meant to be empty
No it should include the zluda files
tf
just making sure but when you add something to a cmd you put spaces right
Grok GPT said that for 9070XT (unlike RDNA3 and earlier cards) don't really work faster than DirectML. I wonder what real 9070XT users experience with performance between DirectML and zluda, because GPTs are currently really bad at knowing what "9070XT" is (and I don't blame them xd).
just asking because i havent been putting a space while doing step 3
Grok talks BS. Because that was before hip SDK 6.4 was released xD
It added native support for rx90 cards
Yes
maybe it slow becouse some of the launch parametrs and I should try to remove some of them, like --cuda-stream --attention-quad --skip-ort?
They are okay
The only thing that could broke it is stability matrix
That thing only causes issues
SM doesn't do anything to webui, it only helps managing files and may cause some issues becouse of symlinks (never did I had any issues becouse of it), but it doesn't do anything with generating process at all
It's really handing for having different python version for webui than the system one, because I don't really know how to install a specific python version and manage packets specifically for it and not for the system one outside of stability matrix. And it's also good for automatically creating symlinks for checkpoints and other files that can be shared between webuis
for me it says "module" instead of "model" is that the same?
I guess it's just a typo in the instruction
ah
i just dont understand why ive been having issues prior i installed this once before and it worked but now its just being goofy
still didnt work so im guessing somethings wrong on my end
Hm, it actually don't generate anything at all if remove --cuda-stream. Without --attention-quad it shows "4.43 it/s", but actual speed is below 1 it/s
think it did something new
ONNX failed to initialize: module 'optimum.onnxruntime.modeling_diffusion' has no attribute 'ORTPipelinePart
i got this message and now it says compilation in progress
i uh think i know what i was doing wrong
i wasnt hitting enter again after adding pip install optimum[onnxruntime], sorry for being difficult
Ohh xD I will add that to the guide lol
Compiling is good, it will take a bit
Is the webui stored on an external or internal drive?
And what about the windows pagefile settings. Is it set to system managed?
Which one? xD you can check on the taskmanager under performance tab
Ah yea thats good
on iternal SSD. It's surely something to do with amd adhocks, because it was fine on 3080Ti and cuda
would i need to run the fix everytime i use sd or was it just this one time
Is it set to system managed?
What does it means?
lowkey finna paste the fix in my notepad
Only one time
ah yeah youre right
you mean pagefile's size?
Hmm okay, can you show the settings of txt2img tab while you generate the image?
Maybe its because of a to large resolution or refiner, upscaler etc
There's a pagefile settings, SD is on N drive

Any reason why its limited for C?
im confused how vram works, like do loras and models take some of it, and do i delete images to get more back
No its temporary, like ram.
Models and loras will load into it.
When the image is generated you get the vram back.
it's can't be limited. And I don't have much space for C, so I set ~6 GB as optimal maximum
Ah alright. Then yea please send the settings you use while the image generates. Screenshot of the whole txt2img page

so im guessing its normal for the load bar to not be present first gen?
kinda takes away the suspence
It should be present when it will start to generate. But before that, it should compile zluda, what takes a lot of time in the first gen. It should write something like "compiling cuda..." in the console
yes, I tried sdxl 1.0 base, but didn't tried other sampler
with euler a it's still ~1.3 it/s
Strange
Have you tried the ROCm forge neo guide?
Yes, it's speed around 4-5 it/s, but it crashes the driver or reboots/freezes my pc when progressbar is full
Have you enabled the Never OOM setting ?
For Tiled VAE
And here, in amdgpu forge with zluda, it also sometimes shows numbers like this, but with actual speed much below 1 it/s. I find it out when experimented with launch parametrs, but it actually happens just randomjy, disregarding launch paramtetrs. It's also freezing a lot while this happens.
Also, zluda use a lot of VRAM, more than cuda used on 3080ti. And there's OOVRAM peak in the end of the generation.


Not in zluda webui. I don't remember if I checked it in rocm one
Its needed for the rocm one to not get freezes and crashes
I sure I enabled it when tried rocm for the first time, but don't remember if it's still enabled on the last generations and crashes (I saved settings in default tab, but I'll try it again later with ensuring it's enabled to be sure)
I tried it with "Never OOM", it still crashed my gpu driver, there's console logs and webui settings:

it also telling me that not able to install nunchaku every launch, should I do pip install nunchaku?
Nunchaku is not compatible so no need to install
im getting a low vram warning how do i fix that
Its a warning not an error, what gpu do you have and what are you trying to run
Found it nvm
im not using any loras im just trying to mess around to try and generate decent images and then use those as base settings
Upscaling & refining could consume more vram
all i did was crank up the sampling steps to 60 everything else is how it starts out
so am i just outta vram or how do i replenish what ive already used
Crank the steps down to 20-30
I almost never gen with more then 30 steps
Changes are minimal
damn bro how do you make em look good then
Proper prompting, face fixing etc
face fix is an add on right?
Sure yeah for forge, adetailer or something
I use swarmui and segmenting (built in) no idea how to set it up for amd
i could probably figure it out
thanks for the info
huh yeah really no difference the eyes just look a little whack
Thats what adetailer is for 

use it like usual, and wait for about 45 to 60 minutes
6 is not enough
I have +20 on other drive. And why do I need much anyway if I have 64GB RAM
vram or ram
hmm its not showing up as the models though even after putting it into the models folder
you need to load it with a gguf loader I think
and there's a bunch more stuff as well, a good tutorial would help but I don't know enough to recommend one
Hiii! I have a question: can sd run on mobile??
Text from a reddit post i just made:
||I'm pretty new to the ai generation system, and heard that SD offers many opportunities for free if you run it on local, so i really look forward to give it a try!
The problem is: my pc is pretty bad and can't afford a new one rn, but my phone is kind of new with 16Gb RAM so i think it would somehow run easy to mid generations. Is there any way to download and run SD on my phone with all the features it has on pc?
Thank you very much!!
PS: please use simple terminology as, as i said, I'm pretty new to these things and have only surface understanding of computers||
Short answer no, long answer even if it could it would take a long time since image generation works on vram, normal ram is painfully slow (and mobile ram is probably different aswell) maybe maybe the old 1.5 version could work but im not aware of any mobile platform
So not with all the features thats for sure but even the basic image gen is a probable no, maybe apple devices have a chance iirc
anybody have a proper guide for installing kohya-ss?
I actually have 16Gb of vram too, is that enough? (I don't really know how vram works)
anyone got this error when running the default z-image workflow?

Hello,
I just installed Stable Diffusion, but I’m running into an issue when generating an image: TypeError: 'NoneType' object is not iterable.
I did make sure to select the Stable Diffusion checkpoint NoobAI-XL-v1.1.safetensors [6681e8e4b1].
Hey, can you show the complete cmd log?
Can you show the workflow?
First link in the pinned messages of this channel.
You installed the webui the wrong way
Please follow the setup guide from the first link of the pinned messages here.
If you have a rtx30/40/50 GPU then install Forge Neo,
If you have an older GPU or low vram then install normal Forge
for NVIDIA GeForce GTX 1070 is older version ?
Yea for that go with Forge
Anyone here have a DGX Spark? Is it as good as it sounds for SD?
How to launch z-image on neo forge? Ive got errored out after an almost of minute trying to create image
pretty sure i dont have to do this ? - Install the latest version of diffusers, use the following command:
Click here for details for why you need to install diffusers from source
pip install git+https://github.com/huggingface/diffusers
import torch
from diffusers import ZImagePipeline
1. Load the pipeline
Use bfloat16 for optimal performance on supported GPUs
pipe = ZImagePipeline.from_pretrained(
"Tongyi-MAI/Z-Image-Turbo",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=False,
)
pipe.to("cuda")
GitHub
🤗 Diffusers: State-of-the-art diffusion models for image, video, and audio generation in PyTorch. - huggingface/diffusers
No you dont need to do that
Can you show your webui interface?
You only need 3 files or the all in one model

downloaded all 3 files that are within this model in link
You have to set the preset to Lumina
You can also try the All in One Model from here:
https://civitai.com/models/2173571?modelVersionId=2448013
Then you wouldn't need to select the text encoder and vae.
did u tried lots of them?)
and what u ended up liking. if yes.
the 9gb or 11gb gguf?)
I tried the Q8+qwen3 encoder + vae and the all in one Q8 (9gb) boath work fine.
have u tried inpaint anything extension? Is it working? Btw ive noticed dpm2m can let u do inaccurate inpainting because it doesnt change that much or adapt to surroundings more than Euler A =\
I didnt tried inpaint anything
how did yu get an 9-10 sec generating result? because gguf 9 gb ?)
it generated imagee in about 15-20 sec & errored without saying why or where -_-
error at the end of generation =\

Shud i just try the version u suggested ? or whuht? 🤨
these one worked for me:

or just this one, from the link:

is this discord server for StabilityAI? assuming no - but their webiste has link to this server
Tried BF16 version from here. Ends up just same. after 40-50 sec of trying to create image. error at the very end. withou saying any reasons why -_-
ppl seem to use it even on lower vram-power gpu's 🤨
am i missing smthing ?
The rock updated today 🤔

i had flux running no probs -___-
You need to enable it always for therock
Because if not it will likely crash the driver or the webui
RuntimeError: [enforce fail at alloc_cpu.cpp:121] data. DefaultCPUAllocator: not enough memory: you tried to allocate 9437184 bytes.
[enforce fail at alloc_cpu.cpp:121] data. DefaultCPUAllocator: not enough memory: you tried to allocate 9437184 bytes.
lol ?

and i just get an black screen o.0
2nd time generation 20 sec . nice. but... black screen again -_-
Which sampler,?
you need to use the Lumina ui preset.
Then Euler Simple, 9 steps, cfg 1
I'm off now

Hey people
I just recently moved to Linux, and I'm currently encountering a reccuring problem. I get this error message quite frequently
||"OutOfMemoryError: CUDA out of memory. Tried to allocate 1002.00 MiB. GPU 0 has a total capacity of 15.47 GiB of which 313.50 MiB is free. Process 4829 has 134.62 MiB memory in use. Process 175903 has 6.10 MiB memory in use. Including non-PyTorch memory, this process has 14.08 GiB memory in use. Of the allocated memory 12.36 GiB is allocated by PyTorch, and 1.52 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)"||
I really wonder why, because I never had such problem when on Windows. The checkpoint/model I use is 6.9GB and my GPU is a RTX 5060 ti 16GB.
I can encounter this problem randomly, in almost any situation (during a generation batch, when generating a single image, when using ADterailer, when using ControlNet, when using none)
I use a venv with Python 3.10.6, Pytorch 2.10.0 and CUDA 12.8
A guide to torch.cuda, a PyTorch module to run CUDA operations
yeah if i leave it defoult its not black anymore but ... 😄

nah when switch to euler later it either errors or black sreen. w.e the model is. lower fp8 or bf16

It almost feels as if it's a memory leak or something. It just keeps taking more and more VRAM until it cannot do anything
Launched kinda, need to pick theese 2 right . Not sure which one is optimal tho

Cfg scale needs to be 1 here
Hey, on Linux you need to have a large swap file. Check that you have one or create one and set it to 32GB if not
Do I need to recompile ZLUDA after driver update? How?
It will compile again after launching the webui if needed
It seems to haven't been recompiled. Is it means it don't needed it? I hoped that with new driver I won't have this 1 it/s speed. Can I manually clear the compiled things?
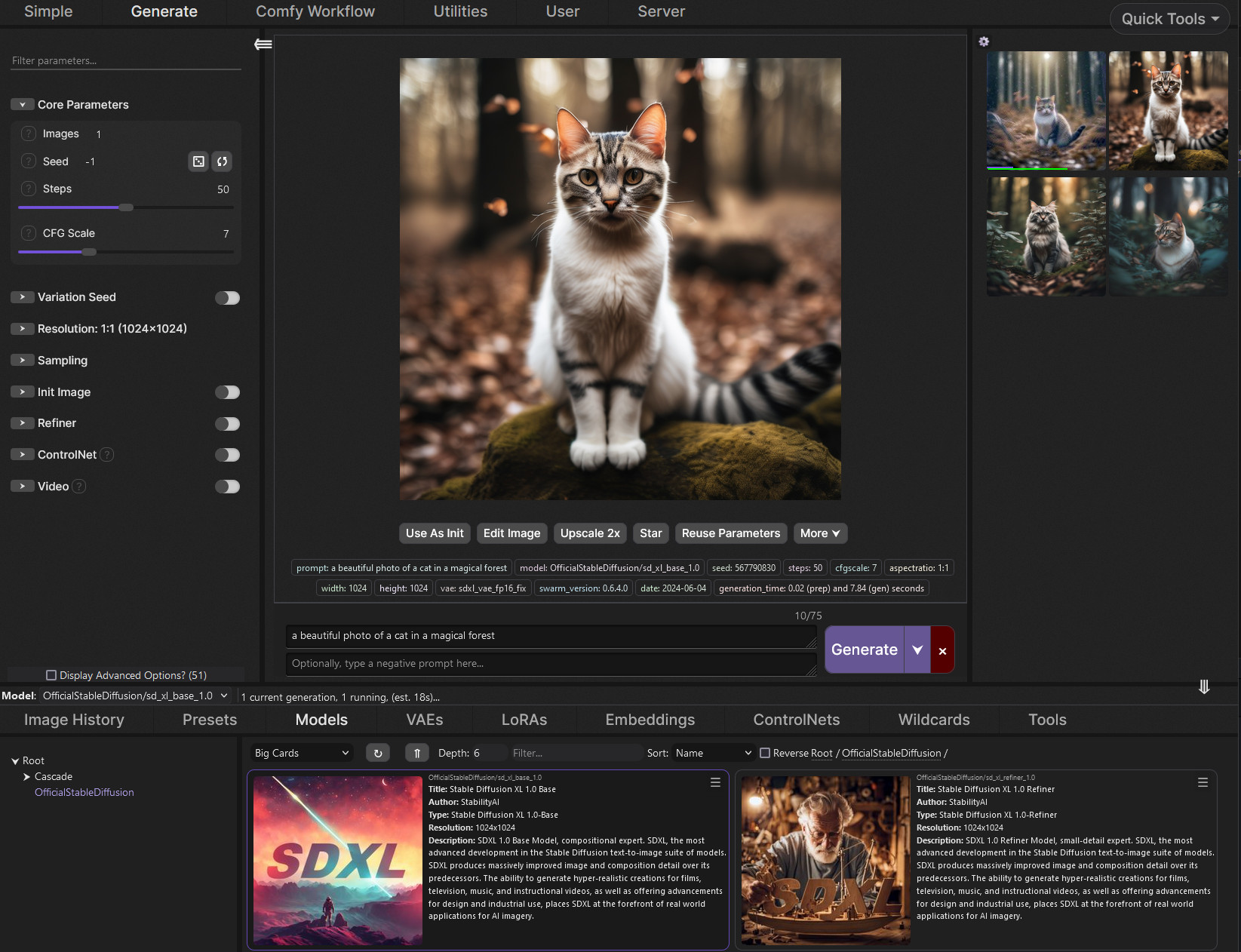
is there a setting here i can change to avoid crashes when generating higher resolutions? its able to generate 512x512 image for about 2mins but once i increase the resolution it processes until it says 10s left then my PC freezes and have to restart.

yea you have to always enable the Tiled VAE option at the Never OOM setting at the bottom of the txt2img tab
that will prevent crashes
and use the smaller Q8 gguf version or the all in one model which is 9gb
it will work much better

(about ROCm in Forge Neo with 9070XT). I tried it with a newest driver. Surprisingly it don't freeze my pc forever while generating, it takes few seconds for it to complete 30 steps (1024x1024, SDXL), but then it stops, adds ~3 GB of "VRAM" in RAM, all PC lags a lot about 2-3 minutes and then it completes the image. It also caused driver crash one time, but surprisingly, it still completed the image after driver crash. And after that, it crashed driver again and also crashed webui.
Also, my videocard does "pi-pi-pi" sound every time while it generating from 0 to 30 steps, I wonder what is it.
my videocard does "pi-pi-pi" sound every time while it generating Coil whine ?
Not sure it is. If it should sound like in this video: https://www.youtube.com/watch?v=HP73edpQwgc , then it's not it, it sounds kinda like old printer printing, but with a higher pitch, not as high as in the video. I never hear it in any other cases (even when generating with zluda instead of rocm). I'll try to send a file if I can attach audio in discord
probably coil whine yes.
Ok. I'm glad it not as disguasting as in the video and happens in extreme rare cases
Anyone know why when I'm using rgthree fastgroup muter, my groups are all squished together like this?

Hi, everyone, I am working on stable diffusion + comfyUI. We are making AI animation pipeline for making animation from the storyboards.
Does anyone expert in it? If then, please contact me. Thank you
So i just learned about image Z turbo... this need a text encoder... but i don't have a folder for that in my webUI... where is it supposed to go?
text_encoder
or sometimes clip
yeah but i ddon't have any of those
which webui?
auto1111... i did find a clip folder deep in another one, but i dunno if it's the same
aw that's too bad
i tried to switch to another webui a while ago but it was just too different and not as intuitive as all my stuff and settings i have now
thanks anyway
have you tried Forge Neo ?
its based on forge which is based on auto1111, all have the same UI
really? I'll hve to check it out then... can it install all the extensions the same way too? like tiled VAE and so on? (a life saver this one, wouldn't be able to use them otherwise)
yea you can install all the extensions, but controlnet and tiled vae are already integrated
cool
@shut apex have you followed the setup guide from the pinned messages?
Yes, I pretty much followed him. I just had a problem with AMD HIP SDK 6.4.2 (the version was not compatible). And what's more, I didn't understand why I had to have a ZLUDA file in addition to the SD-Zluda
then at the end you see the fix for the error you got
with optimum onnx
I don't understand. What can I do to fix this ?

Ah ok. I will try this
anyone know of a node that i can use to load an mT5-small model? I have a custom built model that works, but using it with sdxl for example isn't working. making me think that a node with a different architecture is needed.
@compact fulcrum Huh? lol i didn't understand you question.
oh, i see. lol no not really. the model works, but i'm under the assumption that the architecture is so different from t5XXL that a new node is needed. mT5-small doesn't output a dim large enough for flux, from what i understand of things. so i'm currently trying to sort out how to work it in with some sdxl stuff. I figured using it with Pony models would be a bonus.
anyone knows why my deforum results are so bad with SDXL and not SD15?
That kind of looks like animatediff. That means you're using different motion models when you switch from SD 1.5 to SDXL. SDXL motion models never got out of beta.
then SD works, it opens the window for me, but now when I try to generate an image I get nothing at all. Do you have an explanation?
hmmm I dont think deforum works that way. It doesnt try to animate whats on the pic,, it merely generates different seeds
Can you show your webui and cmd log
problem finally resolved. Thanks anyway
Died anyone know how i to add stable diffusion to openwebui?
So all the main problem that was on THe rock still persists it seems? only tiled vae & compiling when changing resolution 🙁
does anyone have a good inpainting worfklow for qwen image edit (not edit 2509 model)
I have got AMD up and running, but I cant install any nodes cause of security, I've changed it to weak in the cfg but It still wont allow me to do anything in comfyui and Im very lost right now ,I cant install nodes or templates, how can I disable this permanently?
Fixing Permission Error if installing Custom Nodes or Pip packages:
Install the Comfyui-Manager, then Click on Manager > Try to install the custom node or pip package.
If you get a security warning you have to go into ComfyUI\user\default\ComfyUI-Manager and there edit the config.ini.
Change the Security Level to Weak, then save, restart ComfyUI and try install the custom node or pip package again.
After that set the Security Level back to normal and restart.
It should work like this normaly.
posting here since general chat dont allow images. I created https://sdmarks.com/ to compare inference speed of 1000+ gpus and checkpoints. It is based on Vlad's data.

SD.marks
Compare GPU performance for Stable Diffusion AI models. Benchmark RTX, AMD, and Intel GPUs across configurations to find optimal hardware for AI.
hey guys, my 3060ti is making around 5 s/it using this model: hesperidesIllustriousV1_v10
is this an ok speed, or should it be measuring in it/s ?
wehich webui and how much RAM?
i have 16gb of ram, and im using auto1111
ah okay then you need to edit the webui-user.bat and add --xformers --medvram-sdxl to the line set COMMANDLINE_ARGS=
then save.
and because of the 16gb ram you need to increase your windows pagefile.
Here is the Guide how to increase it:
https://www.tomshardware.com/news/how-to-manage-virtual-memory-pagefile-windows-10,36929.html
Enable it only for C and make sure its not enabled for any other drive.
Set it to 16000 Min and 24000 Max for C
Then apply and reboot the PC.
yea thats okay as long as minimum is set to 16000
and isnt the medvram setting for 12gb? or am i mistaken?because my gpu has only 8gb
no its especially made for 8gb vram
oh ok
ill try it
is there a way to save my prompts so i can exit the webui and come back to the same prompt later?
nope but you can reload the last one you used when you click the lbue white arrow below the generate button
ok
its faster but its still in the s/it territory
about 3s/it now
have you restarted the PC after chaning the pagefile`?
i didnt since its higher than what you said, and it already was enabled only on c
you mean the web ui?

can this converting from VAE to 32bit be the thing that is slowing it down? or is this expected?
ok
if you use this vae it wont error:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/tree/main
also can you show your txt2img settings when generating? maybe something is wrong there
ok\
when i find a prompt i like i only increase the batch count

i should download this one to the VAE folder in models?
Ah the resolution is the Problem here
Illustrious best size is 832x1216
It will be much faster on that
ill try it, i just ran 2 prompts with 768x768 and hires fix 2x, but it didnt get faster, ill see if this res fixes it
its running 1.5s/it now
can it get faster than this?
How long does it take for a 30 steps, Euler a image?
i ran one with the same script, took 1min flat, ill try a prompt with just "guy in street"
it actually took longer lol
1:22
i did a second pass with just "1 boy" took 49s
Okay what you could try is to setup forge webui. It should be faster than Auto1111 for your GPU
A guide is in the pinned messages
the ai was really proud it even tried signing it lol

ill liook into it
I'm trying to follow these instructions for gguf but I don't have the text encoder folder https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/1050

GitHub
The old Automatic1111’s user interface of VAE selection is not powerful enough for modern models. Forge make minor modifications so that the UI is as close as possible to A1111 but also meet the de...
do I need to create a text encoder folder?
If you dont have it, yes
whenever I try to load in the flux model, it seems to refuse to select it. I assume an error occurred. where would I find that again? would it be in the command log of autoatic1111 cmd screen?
that comes along with the loadup of forge automatic1111
Auto1111 doesn't support flux
damn.....is there any other way for auto1111 to support gguf or is that not a thing
aka the web version of forge (which i i think auto1111 is)
Nope Auto1111 is outdated since over a year now
damn I need to update then....
You should switch to Forge Neo if you want the latest feature and support
does forge neo run through the same steps as auto1111 and does it support gguf
out of the box?
Nice I will take a look when I can. didn't know auto1111 was that outdated
Yea forge was the successor of it. But its also not updated anymore.
Now we have Forge Neo xD
too many editions I see
It supports the latest models like flux, chroma, wan2.2 14b, lumina, Qwen, and z-image
*never mind it is lol. I will bookmark it for later and skim through the instructions. Might not get to it for a couple of days tho, busy with some stuff.
shouldn't be too hard tho
Sure, checkout the setup guide pinned here. It makes it simple to setup
But if your on and old GPU with less than 8GB vram, its not worth.
Best is to have something like rtx30/40/50 with 12GB or more vram
No it also supports AMD
oh ok, so ignore the nvidia label
If you checkout my setup guides its there under ROCm Forge Neo
I'm using it with my 7900xtx
I'm off now, let me know if you have any questions about it.
will let you know while skimming
since the instructions are pretty short and simple so far, I can get this done quickly @ornate elk set COMMANDLINE_ARGS, what do i put there
I only see the options for rtx
can I just use "--cuda-stream --sage --fast-fp16"
Here is the correct guide for AMD:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides#amd-forge-neo-with-rocm
guys, i already install python 3.10.6 but when i run webui-user.bat, it state like this, can somebody enlighten me with this ?

Which Webui do you want to setup?
Best is to upgrade to python 3.10.11
Or uninstall 3.10.6 and then install 3.11.9
best you coould go with if you dont wanna mess with stuff is using the forge https://github.com/lllyasviel/stable-diffusion-webui-forge one click package
what is the best place to post my own made extensions?
probably #1092446741984444416
For rocm, will the option for 7900xtx work for my 7800xt. I assume it should
Yes
hi, i tried to ask something on the subreddit but my account was too new. it should be okay here, right?
i am new to this genre of ai stuff. i knew about colab and i stick with the free version for inference since it's okay for me. i got interested recently about z-image, and i can run it in there but i can't make a lora. i heard about modal on the subreddit so i'm trying it out but i can't get ai-toolkit to work in there. does anyone here have tips or a notebook?
i did try to ask llms, i used grok and gemini while making the colab notebook to import in there. but no success
the issues are that the ai-toolkit github doesn't have an updated notebook for z-image training yet, and i couldn't get grok to adapt the notebook that is there to make it work. i couldn't get the webui working either, which is what i'd have preferred. ended up wasting away credits trying alone so i hope it's an alright enough question to be asked here
Most people ask here about local installation stuff.
Can't help with collab or notebook stuff sry
oh yeah that's alright
is there any resources you could point to instead though? if not, it's fine
lmao
but i dont have any resources on that stuff sry :/ can only help with local installations
wait, are specs stuff related? i could use some advice on what would be the ideal stuff so i can set it up on modal later
grok suggested a10g with 0.5 cpu core and 16gb ram, is that a common option for training?
a10g ?
z-image is pretty fast so the colab t4 is fine for that, but i'm really excited for the lora journey
yeah, gpu stuff. i can look up what is the equivalent for that
okay, i think z image doesnt need as much as flux or other big models
a10g is apparently comparable to rtx 4070
ah okay
yea for training the more vram the faster it is
12gb is the minimum while 16gb would be okay
cpu is not that important
ram at least 16gb
that helps a lot actually
the other option grok suggested would end up costing more credits so i'm glad this will work
i've heard of those too but i can't spend money right now. that's how i saw the post about modal on reddit, $5 free credits is enough for training a lora there
i'm gonna look into those, perhaps the setup is similar and i could port it into modal
ah okay, didnt know about modal
it looks like it doesn't need to be notebook-based either, but i'm very confused about it since i'm new to this stuff anyways
How accurate is "Install Missing Custom Nodes"?
Is it possible it's returning the wrong custom node?

need cuda 12.x or +
activate venv
then
pip uninstall torch torchvision torchaudio
pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118
not sure why this wasn't included in the instructions lel. so I need to download cuda 12.x? but isn't htat for nvidia tho?
which gpu
7800xt. was following the forge neo for amd gpus with rocm
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides#amd-forge-neo-with-rocm
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
do you need specifically neo? neo is highly optimized for Nvidia
try looking at this

u can also use DirectML or whatever it's called but its slow
also make sure to set command line args
set COMMANDLINE_ARGS=--skip-torch-cuda-test
anything thatsupports gguf
and its neo seems to have more features and more up to date to compared auto1111
comfyui supports it and its easier to install for amd
or swarmui
if you want to use it with forge you will need ZLUDA fix
so the instructions given in that link won't work or something?
that I was following with CS?
doesn't help that I never used comfyui before either
im not sure i never tried running on amd
zluda is very easy
and swarmUI gives you an frontend UI aswell so no need to use comfy backend
i mean try it and you will see if it works
me personally i dont like comfy workflow aswell
altho it gives you all the control over gens u want
okay so which one do you recommend that allows me to gguf, checkpoints, and safetensors out of the box?
and easy to use and local + allows the use of my GPU
zluda sounds nice
so is forge with zluda recommended for my use then?
it is your only option since you are on AMD
zluda requires some knowledge to setup but nothing hard if you want to use a111 or forge
swarmUI / ComfyUI is your best bet for out of the box. It has native oneclick installation for DirectML. But DirectML won't be as fast as ROCm but for GGUF they are actually very efficient so its okay. Try swarmUI first.
is this located int he pinned notifications of this thread
@minor latch
oh yeah it is im an idiot
GitHub
SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
should be oneclick install just run the BAT
i'M FOLLowing the one int the pinned notifications
is that ok
never tried it, on phone rn. But i guess It doesn't get easier than one click installers
how do you disable autoloading the browser upon clicking the .bat
find the launch-windows.bat or similar and --launch_mode none
for neo or a111 its COMMANDLINE_ARGS=--use-directml --no-auto-launch
I see none of that
I'll deal with this tommorow, gotta do stuff. Hopefully I don't need to migrate to a different alternative the 5th time
Still was hoping neo would work tho. Hopefully CS1 can assist further with that (will keep swarmui in my directory tho)
I get a message that says NVIDIA GeForce RTX 5090 with CUDA capability sm_120 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_50 sm_60 sm_61 sm_70 sm_75 sm_80 sm_86 sm_90
Which Webui do you tried to setup? Because that error mostly comes from outdated ones.
Try setup Forge Neo from the pinned messages.
Yes thats the cuda error. You can do the next steps then.
hello, can someone check if this script does anything to their gen
i've had issues with disabling tiling but it still wont work
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides#nvidia-automatic1111-webui-stable-diffusion-webui
Hey guys, im tryna install this but when i did this yesterday on W11 i kept getting an error saying something about skipping a cuda test in regards to my gpu
Im trying again today on W10 but wanted to know if theres a specific Nvidia driver i need to update to first
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
Torch is not able to use GPU, add skip torch cuda test...
Automatic1111 doesnt get update anymore. 1.10.1 is the latest version
If you have a rtx30/40/50 you should switch to Forge Neo
What's your GPU?
Its a 3070
Damn tho i just got it workin
And youre tellin me this no longer supported?
so trying to use faun q4 gguf but this error keeps popping up. I assume Im' missing something

note i removed disable bnb from the launch parameters since the cmd wasn't recognizing that
this is the model im trying to us https://huggingface.co/OlegSkutte/Faun-GGUF?not-for-all-audiences=true
It works but doesnt get updates anymore and no new model support etc
What's faun?
Can you share a link to it?
Ah okay
It seems like no webui currently supports it.
Thats why you got the error
Only a tool called dreamio, but I never heard of that.
hmm I do use dreamio and hoping to use the faun model outside of the game (which the author does state it works for kobold so I assume the same for neo forge)
still going to use neoforge for other models tho if that doesn't work
How long has this been the case? And what are some beginner friendly alternatives?
I see its based on chroma and chroma should work on forge neo, but its based on Chroma-Flash. Maybe forge neo doesn't support that currently
hmm interesting...i assume I need a plugin
Yea flux, wan, qwen, z-image and sdxl/Illustrious work without issues
Since over a year now.
The best alternative is Forge Neo
It has the same ui as auto1111
Okay thanks, what makes it so good?
I find a lot of this complex to get good results, so i dont mind me some guardrails
Its actively supported, and supports the latest models and has the latest performance improvements build in
Its as easy to use as Auto1111 and also supports community extensions
Okay thanks, ill get that then
so forge noe possible won't work with faun then due to it being chroma based?
Also if anyone is in my situation
Install chipset drivers (amd cpu) and then ddu my gpu drivers and reinstall latest
Then it worked
Yep probably. But I can test later if thats really the case
In the pinned messages is a setup guide
Has setting up the models themselves gotten any easier in the last year?
I remember finding good configurations for them was very timeconsuming and i never really got the hang of it
Yea forge neo has presets for the model types
cant test as i dont have enough space left xD
this error seems morel ike your not using or missing the right text encoder
i got this extension

however it dont appear


GitHub
Inpaint Anything extension performs stable diffusion inpainting on a browser UI using masks from Segment Anything. - Uminosachi/sd-webui-inpaint-anything
i am using sd-webui-forge-neo
ig it uses automatic's11111
so idk
Do you know what im missing? Tho i don't expect you to know 100 percent
Might have to ask the faun dev (creator of dreamio)
also how do u update
--------------------------------------------------------
| You are not up to date with the most recent release. |
| Consider running `git pull` to update. |
--------------------------------------------------------
got it to work on automatic1111
however pc freezes and crashes everytime i use it
running 9070
there are lots of issues with forge neo though
maybe comfyui?
It works good for me and most others too
Sure, but its not as easy to use
currently installing python 3.11.9 but it say to download with microsoft store but only have python 3.12, when using it, got problem with torch...can somebody help me 😩

USE ONE CLICK INSTALL ? it creates a local python enviroment so you dont need to download python at all
Don't use the Microsoft store for python. It breaks the webui.
Uninstall everything from python and install 3.11.9 64bit from the python website.
Then delete the venv folder and relaunch the webui-user.bat
thanks a lot bro
why is this ?

It would need you to have visual studio build tools installed or you to manually install insightface
But if you dont want to use faceswap stuff then you can ignore it
so i just installed forge neo but as always with these tutorials it's like missing several steps and assume everyone know what they're doing
I've been told tiled VAE is auomatically installed in it, but i can't find it, and like how do you generate video? Selecting WAN at the top still only shows txt2img or img2img
Tiled VAE is at the Never OOM option
i see, so it's just a check now? No option to set stuff? (i had to go down to 1024 and 64 for exemple, don't remmeber the name right now)
i have soooo many question, would be nice if someone could set some time in private to help me...
Like i downloaded the new ZimageTurbo thing... isn't it supposed to generate stuff faster than other checkpoints/models? It's the same speed or even slower...
You only need to enable it yes
It needs 9 steps and Euler simple.
Ui preset lumina
that's what i mean, is there a full tutorial telling you all of this? How was i suppsoed to know, lol
and it says forge neo works with video generation, but even if i click on the wan thing i don't any options for it
here is the wiki entry for each model type:
https://github.com/Haoming02/sd-webui-forge-classic/wiki/Inference-References
when i follow what you said, the image are super blurry... but they were good when i tried them on wan (when i was trying to find videos, lol)
and also the speed wasn't faster
faster than what?
other checkpoints/models
its definitly faster than qwen, flux and chroma and wan
but of course slower than sd 1.5, sdxl illus etc
oh, i thought it was faster in general, i've been using illustrious most of the time
and how do i use video generation? i don't see the option in the WAN settings
txt2video is txt2img
why doesn't it do a video then
You need at least 17 steps
And wan 2.2 14b as model
but then how do i control the length of the video, amount of frames, and all that?
the wan 2.2 16b model has a fixed fps rate of 16
so 17 steps will get you 1 second of video
33steps = 2seconds and so on
is there a limit?
idk
also can i use other wan 2.2 models? like lower gb for lower ram? i need to find one cause the first one i found doesn't work
you can use gguf versions of wan 14b
https://huggingface.co/QuantStack/Wan2.2-T2V-A14B-GGUF/tree/main
you need to enable the Refiner in settings, then set highnoise as model and low nosie as refiner
refiner is not present in forge neo, guess i have to download it as an extension?
No as I said you have to enable it in the settings
Its under refiner I guess
there's a lot of different files, which one do i pick?
apprently i also need a text encoder... what do i pick? ther'es not one in these files
finally managed to do a generation... but it's not a video
okay i didn't notice the frame slider... used that, but then the generation fails after trying to do one for 10 minutes...
i really need help, i probably downloaded the wrong wan model among all the ones in the link, and the generation slows down everything even with Lowest resolution (i have 10 gb ram), only to produce nothing at the end
and does this save some stuff on your main drive? i have the webui installed on another drive than my C drive, but my C drive still lost like 20 GB from nowhere after these tries...
how much gpu Vram do you have?
guys, need help, has been stuck here for a long time now, i already install visual studio insiders 2026 but it wont do

hey, can you share the complete cmd log?
can i share it this way ?
the facefusion extensions is outdated and wont work anymore
you have to install and use the normal Standalone Facefusion version
any step how ? newbies here
one thing, any link for me to download controlnet model ?
u really are so helping, thanks a lot !
whats your gpu btw?
RTX 4050 with 6GB Vram
can i use this for SD1.5 ?
nope thse are for 1.5:
https://civitai.com/models/38784/controlnet-11-models
with that gpu you should better use Forge webui instead of auto
its more optimised for lower vram/ram amount
any idea how i can start with it ? 😅
yea, you can find the setup guide for it here:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
it already has the controlnet extension included
10
Hi i just dowloaded Stable Diffusion. Ive trouble generating images. Its taking too much time idk why (10 to 15m). Ive 16go vram. Can u guys try to help me and maybe give me the best settings i should be already using ?
Thank u !
hey, whats your gpu and which wbeui have you set up?
thats not enough for wan 2.2 14b
maybe wan 2.2 5b can work, but that only works in comfyui. Or ltx video
but with 10gb vram i would stay at image gen not video
RTX 2070s and im using A1111 ?
ah okay, then edit the webui-user.bat
at the line set COMMANDLINE_ARGS=
you have to add --xformers --medvram-sdxl
then save and relaunch the webui-user.bat
i cant wait for an easy webui to use to be able to do video... i tried swarm a while back and it was working but such a pain to use
like that ?

no it has to be after the =
ok
one more things, with my spec RTX 4050 6GB Vram which is suitable ? forge or forge neo ?
forge or (forge classic, which i have to the guides)
Its working tysm.
Do u have a video to config fully Stable Diffusion i could follow ?
nope sry :/ but get yourself the Adetailer extension and boorutag autocomplete extension from the extensions tab
also go into the settings under User Interface -> Quicksettings -> and there add sd_vae
then hit apply and reload ui
then your ready
TYSM have a great day
thx, you too!
so apprently you can use wan video on forge neo with as low as 6gb ram if you use a lower Q model?
yes that can work
but you just told be it couldn't, xD
the normal wan 14b yep. and the lower gguf versions have a bad quality and will still take ages for a 3 second video xD
you can get the lower gguf files and test. but i cant quarantee that it works. you would also need to have a lot of system ram and a large pagefile if not
or you try comfyui with the much smaller 5b model of wan2.2
i have 32 gb ram
is there not a list somewhere on which model is recommended for vram? Q3, Q6? I dunno
it has to be a bit lower than your actual vram
so if you have a 3080 with 10gb i would go for a 8-9 gb version
if that errors out of vram, then go lower

it should work
its audio to video lol xD that wont work in forge
oh lol, yeah
why this error appaers ? in webui it says typerror ? 😩

can you screenshot the whole webui site?
okay, i think i got it, i set the Hires steps to 0.5 😅
it should be an integral no. right ?
yep xD
😆

complete cmd log pls
where do i find that?
just copy the whole cmd text, there is no log
you probably dont have ffmpeg installed
its required for video stuff (converting images into video)
ah okay, thanks
you need to download it and add it to the system path
yeah just did that, currently generating we'll see if this works
welp... same error as before
can you open up a cmd and run
ffmpeg -version
I:>ffmpeg -version
ffmpeg version 2025-12-10-git-4f947880bd-essentials_build-www.gyan.dev Copyright (c) 2000-2025 the FFmpeg developers
built with gcc 15.2.0 (Rev8, Built by MSYS2 project)
configuration: --enable-gpl --enable-version3 --enable-static --disable-w32threads --disable-autodetect --enable-cairo --enable-fontconfig --enable-iconv --enable-gnutls --enable-libxml2 --enable-gmp --enable-bzlib --enable-lzma --enable-zlib --enable-libsrt --enable-libssh --enable-libzmq --enable-avisynth --enable-sdl2 --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxvid --enable-libaom --enable-libopenjpeg --enable-libvpx --enable-mediafoundation --enable-libass --enable-libfreetype --enable-libfribidi --enable-libharfbuzz --enable-libvidstab --enable-libvmaf --enable-libzimg --enable-amf --enable-cuda-llvm --enable-cuvid --enable-dxva2 --enable-d3d11va --enable-d3d12va --enable-ffnvcodec --enable-libvpl --enable-nvdec --enable-nvenc --enable-vaapi --enable-openal --enable-libgme --enable-libopenmpt --enable-libopencore-amrwb --enable-libmp3lame --enable-libtheora --enable-libvo-amrwbenc --enable-libgsm --enable-libopencore-amrnb --enable-libopus --enable-libspeex --enable-libvorbis --enable-librubberband
libavutil 60. 20.100 / 60. 20.100
libavcodec 62. 22.101 / 62. 22.101
libavformat 62. 6.103 / 62. 6.103
libavdevice 62. 2.100 / 62. 2.100
libavfilter 11. 10.101 / 11. 10.101
libswscale 9. 3.100 / 9. 3.100
libswresample 6. 2.100 / 6. 2.100
Exiting with exit code 0
okay then idk why it has that error xD
maaaaaaaaaaan there's always something wrong that nobody knows what the issue is with me... my luck sucks ass
maybe restarting the computer instead of just reloading the UI?
worth a try
and as you said yesterday, if i select 33 frames, i must put 33 steps?
oh no they added the frames slider so you can leave the steps at 20 and only use the 33 frames
finally it's working
took 5 minute to generate 2 seconds, could be worse!
now to find some good lora for it... do you have recommendations?
also thanks a lot
no problem, but nope no recommendation, as i dont do video stuff that much, only for testing
well i just tried this one and it just give me a jumbled mess, any help for settings when using a lora with wan?
not from me :/ maybe someone else knows
i guess there's nothing i can do much about the video quality since it's a lower vram model? Can i use hi-res fix with it?
otherwise it might be better to just use image2video?
img2video might be easier
i guess hires fix wont work
no change in setting for img2video? i just need to get the i2v model and that's it?
check the wiki, i didnt used img2video
what're all the different types of stable diffusion things?
like, the comfyui, swarmui, forge, etc?
and which is probably the best to run on an amd card?
depends on your amd card
7800xt
different ui and model support etc
oh alr
are these basically the same things?
as in are there many/any differences between the two
It can be confusing but the core behind all of them is the same. After all, they load the same stable diffusion models (or z image, flux, whaterver).
What change is the way they load the models, the way they use your hardware, the specific knobs and settings they expose to the users, their UI.
Just like different cars can share the same engine but feel and look totally different.
Some are made to be more intuitive for users and therefore hide a lots of settings, some have a graph / node based UI, some are made with specific GPU vendors (Nvidia / AMD / Intel) in mind. Some implements specific optimisations.
It can be a mess and quite often those choices are mutually exclusives.
rocm and zluda are different backends. while zluda is more stable, it is a bit slower compared to amds new rocm support
no problem, feel free to ask here if any step isnt clear
yeah i'm gonna need some help with I2V, the image just becomes noise immediatly
it does a video, but that's it
hope someone can help
any advices on Zimageturbo loras? I downloaded one on civitai, but the generation doesn't take it into account at all, like it doesn't exist
@ornate elk Today, I encountered a problem in my friend's shared session and so as in my Local SD that loras used for image generation distorts the image result. Also, when I use Forge Couple, it often occurs that the prompts prioritize the secondly added character into the image and the first one doesn't even appear on the image or she becomes almost non-existent despite her detailed prompts. Is this normal? No such thing happened to me before.
My own Colab sessions are unaffected, but what exactly is this?
Hi people! Quick question. I'm using comfyui portable. I've a 9060XT and 32ram. I'm trying to make some clothing workflows work. Would you recommend me flux, Qwen, or any other workflow? Total noob here. Thanks in advance
Can't help much with that but it doesnt sound normal.
Check the cmd log and that all extensions are updated
Forge Couple is the only extension that is not updated due to the newer version is inconvenient with certain of my characters depictions. The newest version is v5.1.0, whilst I'm only willing to use the v4.0.4 one.
what exactly did changed in v5 ?
Basically, Leaves out certain elements from main prompt line and the first character lora entirely. The second character becomes the main focus somehow. In v4.0.4 it generates both characters with no problem and not willing to leave out key prompts that I added.
sometimes may cause the engine to ignore certain text-based negative prompts like english/chinese/korean texts.
you should open up an issue on the forge-couple github then, the dev answers within a day.
i cant imagine it breaks anything that much in v5