#🤝|tech-support
1 messages · Page 148 of 1
env?
Btw do you know you have Gpu installed?
ctrl+shift+escape -> performance -> GPU
Environment
I have radeon
screenshot the whole thing
SO which guide did you follow to run stable diffusion?
60 second guide

Here's the easiest way to install Stable Diffusion AI locally FAST -
Big Shout-Outs to Le-Fourbe for walking me through the process!!
GitHub Link here:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
If you enjoyed this video, please consider becoming a Member :)
https://www.youtube.com/@TheRoyalSkies/join
Or joining the Patreon Squad d...
aight
It does provide some installation guide on AMD?
lol no of course
Perfect!
i meant the gpu window
so I just cant have stable diffusion?
Not really

You can use that and should install the envrioenment first
yeah but how do I do that
also is there any other ai image software I could use as a replacement?
Ok there we go, you have a RX 6600 XT

and you followed a tutorial for NVIDIA gpus
so of course it s not gonna work
sigh

this is what it says
for amd
and its a lil too complicated for me
I went into python
and python wont even wana open
way too much work
I dont wana restart my pc either
obligatory reminder to not get scammed in DM
I have something running
Welp can t help you then. I can copy paste the same tutorial in smaller portions but the work will be the same.
alright thank you
im just wondering if there are any like
ai generators I can use instead
scam shazam
Localy only the ones from the guide.
Online are only paid services.
the one he sent?
There are multiple ones in the page I ve sent you. But yes
I might just be better off without any of it then
tldr zluda fast, directml slooooow
too much work and editing stuff
and I wana understand what I am doing
and not blindly follow tutorials
Then your out of luck because there aren't any YouTube videos about the correct or updated setup of stable diffusion on AMD GPUs.
Thats why I made these Guides to easily get it working.
The setup is not as easy as running an .exe file but you wouldn't understanding or control what an .exe does in the background too
Sure, no problem. Feel free to ask me if you have any questions about the setup.
RuntimeError: CUDA error: misaligned address CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with TORCH_USE_CUDA_DSA to enable device-side assertions. Unhandled exception caught in c10/util/AbortHandler.h 00007FF9D2FA805400007FF9D2F8C190 torch_python.dll!THPGenerator_initDefaultGenerator [<unknown file> @ <unknown line number>]
And what does this error mean?
Hi everyone,
I got a Question about an issue with some of my presets in SD A1111
After writing a prompt I save it from time to time as a template within the 'Styles' as preset
But I´m having issues with about 1 of 3 presets
If I place the Prompt (positive and negative) in my SD the pics look fine
But when I clear the Prompt (positive and negative) and select the preset, which has the same positive and negative prompt saved within and use the 1:1 same settings, the pics have issues
And if there are issues with the preset and I run the generation with my Adetailer it makes it even worse, but when I place the prompt (positive and negative) directly in my SD instead of the preset, the pics look fine even with Adetailer
Pic 1 = Prompt directly in the SD not as preset
Pic 2 = Same prompt but as preset without Adetailer (only with one time face detailer)
Pic 3 = Same Prompt as preset but with Adetailer (only with one time face detailer)
(Using SD A1111 with 1.5 Models)
Wish you all a good weekend



how does one unload models on forgeui manually? when switching between them, i often get stuck on one of them
uh what?
and why not here
sure you do, you are not even in that server lol
fk u want bro?
@light elm
Banned the scammer
If you dont switch between them while an image is generating it shouldn't get stuck
I saw this in SDnext ZLUDA. First, does this means FA2 works on AMD GPUs? (Chatgpt says otherwise cause). Secondly, How can I check if it's already enabled or not in SDnext?

Works fine for me, you don't need to manually unload models I think. Happens automatically when you switch to a different model. There still might be an extension for it ig.
I've tried installing a LoRA into automatic1111 but after setting everything up and reloading the webui the lora is not appearing in the Additional Extensions, any idea why??
Uh, the loras dont go into extensions
Hey hey, I am kinda lost actually. Does anyone know how to train LoRA locally? I want to make one that captures my likeness. I tried the native Lora trainer, the advanced lora trainer, and the FL Kohya LoRa trainer in ComfyAI. What I could get out of the native lora trainer was not good enough. And the advanced & FL Kohya Lora trainer had me trouble shooting endlessly. I asked Co-Pilot to help me through it, since I don't know much about it yet. But after installing version after version of ComfyAI, requirements, custom node versions, creating virtual environments and python versions, I think ai doesn't cut it when it comes to helping me through this. I've been at it for nearly 11 hours today. It's not for lack of trying, I just lack the expertise. I believe help from an actual person is my best bet at getting the results I'm after. 🙂
any reason this isnt working for me?
@ornate elk sorry for bothering, since i randomly get a huge memorly leak which fills up my 24gb vram, i enabled tiling again, but i dont see why it needs to tile upscale after every damn inpaint, simply slowing the process, and its not as if with it disabled that it uses much vram anyway

ive set this to that, and ill report back i guess

Ok so it still happens on its own out of nowhere, i wasnt even underload, i was just masking an image..

and yes i tried fresh venv too, idk if i should try, and fully wipe forge
Can you screenshot the settings when it happens again?
Sure
So as i said, i am not sure what to post this in. I am getting very bright skin and a weird red outline in every picture. It is very unflattering. I have tried doing ti with prompts, without prompts, with vae, without vae, with addons (like DT and adetailer), with refiners, without, starting from scratch with a new config, trying different checkpoints. they all give me the same issue. It can't be the prompt either because it happens without prompts. Its driving me mad. The images i will post have no Lora on them so they look bad. But yeah... https://postimg.cc/gallery/3KCf4Zt

probably an "issue" with the upscaler
depends how you ve set it up
it happens with and without an upscaler. but this is how i have my hires.

try to change the upscaler model
also if the outlines are here without upscalers at all
Try lower the hires steps to 10 and set the denois to 0.4
Or try Fatal Anime 50000 as upscaler:
https://openmodeldb.info/models/4x-Fatal-Anime

@mild flicker you need to start with the argument --listen to be able to access your sd instance on other computers from the same LAN.
I was wondering where would be a good place to ask for help with Comfyui I have a custom node with custom templates but they are not working in comfy. Like the templates show but they are greyed out and don't load and the nodes don't work either . I noticed that there are 3 custom node foldes the one under user the one in Local app data and there are 2 there which should I use?
well tried copying custom node folder to all of the other ones no luck
lmao
Just in case there was a link to some external discord or whatever. Don't follow it, the only official help you'll get is from https://stability.ai/ or their mailing system. This very channel is community driven
also usually you can install custom nodes throught comfyui interface itself.
that way you're sure that you won't mess up the installation
if installed correctly then look at the logs for errors.
aight so

which settings
I'm running an old script, but something's not working right
Flux

Base on this script it shows like you're using an old version of the training script
Which means the script won't actually train correctly unless you either run it with a supported gpu
I’ve been using SD1.5 but want to upgrade to another one. What do you recommend? I have AMD RX7600 (8GB), i5 9th gen, SSD, 32GB pc. My priority is prompt adherence. Was thinking of SDXL…
Yea that would work or if your into anime or semi realism then go for Illustrious based models
Thank you. Which UI do you recommend? I’ve always used A1111, would like to keep using it or something similar
Automatic1111 or Forge with Zluda should work fine
A screenshot of the whole page with to Settings you used, like resolution, steps etc.
I assure you nothing out of the ordinary there
Hello, I have a problem, I followed the entire tutorial for Forge with ZLUDA, AMD Ryzen 5 5600G Processor with Radeon Graphics, 16.0 GB RAM, years ago I had used automatic1111, and it worked although slowly, after removing it now I wanted to try the new ways, I have been trying all night between zluda, DirectML and it always gives me this error


Hey, can you share the whole cmd log?


The tutorial told me to use Python 3.11.9
Python 3.11.9 is okay
But rocm shows no agent was found
Have you downloaded the correct gfx files for your GPU?
I suppose, just in case, you can tell me which one it would be so I can check that I download the correct one?
Do you only have the igpu of the cpu and not a dedicated GPU?
I checked the the CPU and it seems that the igpu is not compatible with Zluda. Only DirectML would be an option.
I had tried it with DirectML and it gave me the problem, I will check and send what comes out

Full cmd log pls

For directml you need to change the launch args of the webui-user.bat to --use-directml instead of --use-zluda.
Then delete the venv folder and relaunch


also add --skip-python-version-check
then delete the .zluda folder and the venv folder and relaunch the webui-user.bat
I added and deleted both folders but it recreated them when opening the webui.bat


never launch the webui.bat
only the webui-user.bat
thats why it didn't worked
delete the venv folder and launch the webui-user.bat again
 Oh, I don't know why in my mind I remembered it being like that.
Oh, I don't know why in my mind I remembered it being like that.
Thanks! Now it works. It's a bit slow, I don't know if it's because it generated the first time, but at least it works.
no problem!, you can try remove --lowvram and instead add --medvram and make sure --attention-quad is also there
 I will try it, thanks for your help
I will try it, thanks for your help
Hey guys doing a 2049x1024 image and would like to be able to make it a little more crisp, what do you guys reccomend? SD upscale looks like shit:



Hi I've just updated comfy and all my nodes, I'm getting an annoying 2-3 second freeze every single time I click on my text encode nodes to change prompts. It only happens after I've already ran the workflow. If anyone else has seen the same issue and found a fix plz let me know. Not much to show, problem is as I said and removing nodes isn't really an option
?
why r u trying to get me to join this discord server like your life depends on it
seems sus asf
rofl
literal braindead
@marble python is trying to fish people into his discord server for reasons unknown
not sure who to @ for mods
took care of it.
Macbook Pro 16.2’’ M4 Pro - 14c - 20c - 48GB RAM - 512GB SSD
Is this good option for AI? I want to be able to handle Flux / Qwen or stable diffusion models locally. And maybe some smaller LLM
should be fine for SD (and probably flux/qwen too)
cf pinned guides for tutorial about how to install things on your mac
are there any arguements you recommend I use like ---usemedvram or something? i only got 8GB vram on my puppy, 32GB ddr4 ram
For Auto1111:
--medvram-sdxl
For Forge:
--cuda-stream
okay thanks. the link you pinned also advised adding --use-zluda --attention-quad --skip-ort --skip-python-version-check
Yep they are required too
Do you have one? How many seconds for image generation?
No I don't, if I remember correctly I ve seen viking having around 2it/s on his mac (m1 ?)
I see people having from 6 to 10 it/s on sd1.5 models on a m3
src : https://vladmandic.github.io/sd-extension-system-info/pages/benchmark.html (search for darwin)
Spreading the word that if your UI freezes for multiple seconds everytime you click on text encode nodes downgrading the comfy frontend to 1.24.4 worked for me. Just add this to your launch .bat file "--front-end-version Comfy-Org/ComfyUI_frontend@v1.24.4"
im getting warning messages about setting GPU weights, should i do this? how do i do it?

Anyone here good at Comfyui? I am new and I am running into an issue where, I upload a new workflow to COmfy, but the missing nodes that I need to install are completely hidden. I can't even see what I need to install, there is just massive gaps of blank space in the workflow. Anyone know how to fix this?
Will do, thank you
I'm pretty sure your a scammer
But it was a good try
Bro... stop. Im not falling for it
I love how you delete it immediately
!Help me please! I tried to exchange the wheel of the car using the flux kentext. But getting weird result. Could you give me any recommendation or any recommended workflow? Thanks

dunt fall for the Wumplus nitro bot scam, dunt add it, spread the word 💜 +-+
got a problem with getting controlnet to work on my new forge zluda. getting a controlnet.py error on the log :

looks like the code on this link could help but i have no idea how to use it other than to make a notepad file, paste the code in the error directory and rename it to a .py file type lol
https://huggingface.co/pantat88/ui/blob/3004933886514ae448e66ec8e925b4aedf0fcf42/controlnet.py

Hi, I'm getting NansException: A tensor with NaNs was produced in Unet. when I try img2img inpaint with illustrij_v8.
Tried "Upcast cross attention layer to float32" but the error keeps coming.
Tried --disable-nan-check but then I just get all black.
txt2img with illustrij works.
img2img with other models, even bigger size works (32GB cyberrealisticPony_v130 vs 6.9GB illustrij_v18).|
I'm using a Macbook M1 Pro.
Can anyone help? 
SOLVED: Fixed after using an external fp16 sdxl-vae instead of the checkpoint's embedded vae. Thanks to this post.
Hello, @nova loom ! Try reducing CFG scale to 3-5 (instead of the default 7). Higher CFG values can cause instability with some models on Apple Silicon.
Hi @safe fern . follow my approch step by step.
- Mask only the wheel you want to replace, not the entire car area
- Use "Inpaint masked" not "Inpaint not masked"
- Set Mask blur to 4-8 pixels for smoother blending
- Use "Only masked" padding mode with 32-64 pixels padding
??? i downloaded from automattic 1111 github in the install and run on nvidia gpus bit

rtx 5xxxx ?
i have rtx 2070
laptop ?
desktop
any iGpu on your cpu that might take priority over the rtx 2070 ?
run dxdiag and screenshot system and displays tabs


2 display tabs

how did you install a1111 ?

Please follow the install Guide from the pinned messages
oki
does anyone use sd-webui-ux? it doesnt have the normal env cmd prompt in the base folder and i dont know how to run the g it pull to update

or is there a run flag i can add to user.bat
hi people, is anyone able to run controlnet XL on M1 (MacOS)?
SD1.5 controlnet does work
but whenever I try a XL checkpoint + XL controlnet models I get Placeholder storage has not been allocated on MPS device
btw, I'm using automatic1111. I just saw that diffusionbee mentions support for XL and controlnet but it has way less github stars than a1111. what do you guys use on mac?
SOLVED: Worked once I used a controlnet model more specifically compatible with my checkpoint. Turns out being "XL" is not specific enough.
i might go back to a111 from my current ui
my sd forge is dead 🙁

Add git pull to an empty row/line of the webui-user.bat
Then relaunch
How am I wrong? I did it right a long time ago. What should I do then? Do you have a good link?
You downloaded forge as zip but not the correct one.
A correct guide is on the first link of the pinned messages.
Do you have the correct link you can send me?
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
ok, but is it still inside a winrar file? Is it good?
is ok?


Am I taking crazy pills? Almost every time I load a comfyui workflow, there are missing custom nodes, even after "installing missing custom nodes" via the manager. This time I'm trying to load the kijai workflow for wan2.2 animate, and I'm missing WanVideoAnimateEmbeds and FaceMaskFromPoseKeypoints. I've already updated comfy and I've updated the wanvideowrapper, what am I missing? Feels like I'm the only person with this issue.
in the a1111 nvidia guide where do i add the '--medvram-sdxl --no-half-vae' in commandline_args because i already ahve --xformers in but when i add the vram command it crashes and doesnt open, says it doesnt recognise it
anyone is familiar with IP-Adapter from controlnet to mix images together ?
At the line commandline_args=
Using forge (Zluda with HIP6.4) takes quite a bit of time to generate images. 4 mins for 832x1216 images (Later upscaled by 1.5 with Hires fix) using only 2 loras. My GPU memory usage also seems to be very low throughout

It spikes in between but mostly stay at around 3-4 gbs. Is this a problem?

Your system ram is a problem as its only 16gb.
You need to increase the Windows pagefile. That will fasten things up.
Here is the Guide how to increase it:
https://www.tomshardware.com/news/how-to-manage-virtual-memory-pagefile-windows-10,36929.html
Enable it only for C and make sure its not enabled for any other drive.
Set it to 16000 Min and 24000 Max for C
Then apply and reboot the PC.
Also 3-4 GB usage is not normal. Can you show me the full cmd log? It seems like its using CPU+RAM instead of the GPU
You've told me this before and I have it set to 16 and 24 gbs yes.
I'm outside rn sorry, I'll show you as soon as I get home
Alright
It's the total opposite in ComfyUI. There, the vram usage goes above 15.5 Gbs and crashes my display
😑
Same 832x1216 latent upscaled by 1.5x
Enable Tiled VAE Decode, that should fix the crash
I think it's already enabled or maybe it's missing somewhere. I'll verify it again
Unfortunately, nothing starts anymore. I followed the github guide (which I must say is a terrible guide), but nothing works anymore. I moved the loggers and checkpoints from the old forge to the new one, but it doesn't start anymore. The version of forge I downloaded doesn't have the COMMANDLINE_ARGS= line where you can add: --cuda-stream
The one I sent you? Why is it a terrible guide?
The commandline_args can still be added in the webui-user.bat which is in the webui folder
Also you showed me your webui-user.bat yesterday so what happened since then?
It only started once. I left because it was too late. I just logged into my PC, and since then it hasn't started anymore. 🙁
I'll have to do it all again from scratch
Yea its not that difficult, download the forge zip then run the update.bat and then change the stuff in the webui-user.bat in the webui folder
I did it, I edited this file: webui-user.bat

Okay
And what does happen when you launch the run.bat?
when I start with that file, it opens, but in the run.bat file there is almost nothing (I mean the command lines) do I have to write them?
No the run.bat just points to the webui-user.bat of the webui folder. So its fine if you only edit the webui-user.bat but always start the run.bat to launch it
ok, then I reinstalled everything and tried again
Alright, let me know if it works then 🙂
in your opinion, it's better this way: @echo off
git pull
set PYTHON=python
set GIT=git
set VENV_DIR=venv
set COMMANDLINE_ARGS=--cuda-stream --xformers --opt-sdp-attention --opt-channelslast
call webui.bat
or like this: @echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
@REM Uncomment following code to reference an existing A1111 checkout.
@REM set A1111_HOME=Your A1111 checkout dir
@REM
@REM set VENV_DIR=%A1111_HOME%/venv
@REM set COMMANDLINE_ARGS=%COMMANDLINE_ARGS% ^
@REM --ckpt-dir %A1111_HOME%/models/Stable-diffusion ^
@REM --hypernetwork-dir %A1111_HOME%/models/hypernetworks ^
@REM --embeddings-dir %A1111_HOME%/embeddings ^
@REM --lora-dir %A1111_HOME%/models/Lora
call webui.bat
editing webui user.bat?
remove --opt-sdp-attention --opt-channelslast as one doesnt work with xformers and the other one doesnt improve performance
ok
Dont do this:
set PYTHON=python
set GIT=git
set VENV_DIR=venv
leave them empty after the =
so is the second line I sent you better?
This one yes:
`@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--cuda-stream --xformers
@REM Uncomment following code to reference an existing A1111 checkout.
@REM set A1111_HOME=Your A1111 checkout dir
@REM
@REM set VENV_DIR=%A1111_HOME%/venv
@REM set COMMANDLINE_ARGS=%COMMANDLINE_ARGS% ^
@REM --ckpt-dir %A1111_HOME%/models/Stable-diffusion ^
@REM --hypernetwork-dir %A1111_HOME%/models/hypernetworks ^
@REM --embeddings-dir %A1111_HOME%/embeddings ^
@REM --lora-dir %A1111_HOME%/models/Lora
call webui.bat`
not needed, you can run the update.bat to update forge
but you can also add it to the webui-user.bat if you want
but Forge doesnt get much updates lately
@woven walrus You need to update your Comfy to the latest.
@worn oyster I use animated masks to drive the IPAdapter to mix two image streams together to form a video.
hi bro, i try to install stable diffusiion, my laptop with rtx4060, but problem with the torch version, i try download & instal manul for the correct version - torch 2.5.1+cu121, still not working.
I'm really unlucky today XD. keeps giving me trani errors: ModuleNotFoundError: No module named 'triton'
xformers version: 0.0.27
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce RTX 4070: native
Hint: your device supports --cuda-malloc for potential speed improvements.
VAE dtype preferences: [torch.bfloat16, torch.float32] -> torch.bfloat16
Installing bitsandbytes==0.45.3
CUDA Using Stream: True
H:\webui_forge_cu121_torch231\system\python\lib\site-packages\transformers\utils\hub.py:128: FutureWarning: Using TRANSFORMERS_CACHE is deprecated and will be removed in v5 of Transformers. Use HF_HOME instead.
warnings.warn(
Using xformers cross attention
Using xformers attention for VAE
that triton warning can be ignored
ok, but the program page doesn't open on the browser. I've been waiting for 5 minutes and nothing: Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: f2.0.1v1.10.1-previous-669-gdfdcbab6
Commit hash: dfdcbab685e57677014f05a3309b48cc87383167
Installing requirements
Launching Web UI with arguments: --cuda-stream --xformers
Total VRAM 12282 MB, total RAM 32694 MB
pytorch version: 2.3.1+cu121
WARNING:xformers:A matching Triton is not available, some optimizations will not be enabled
Traceback (most recent call last):
File "H:\webui_forge_cu121_torch231\system\python\lib\site-packages\xformers_init_.py", line 57, in _is_triton_available
import triton # noqa
ModuleNotFoundError: No module named 'triton'
xformers version: 0.0.27
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce RTX 4070: native
Hint: your device supports --cuda-malloc for potential speed improvements.
VAE dtype preferences: [torch.bfloat16, torch.float32] -> torch.bfloat16
CUDA Using Stream: True
H:\webui_forge_cu121_torch231\system\python\lib\site-packages\transformers\utils\hub.py:128: FutureWarning: Using TRANSFORMERS_CACHE is deprecated and will be removed in v5 of Transformers. Use HF_HOME instead.
warnings.warn(
Using xformers cross attention
Using xformers attention for VAE
hey, follow the setup guide from the first link of the pinned messages. Then you shouldnt have any issues.
very strange
thanks
can you show the full cmd log?

ah okay, i see, forge has an issue with xformers because triton is missing.
Close the cmd. remove --xformers from the webui-user.bat and delete the venv folder inside the webui folder.
then relaunch the Run.bat and it should start normaly
Do I have to install this Triton? What is it for?
its a module needed for xformers. --cuda-stream should be enough as forge is more optimized than auto1111 which needed xformers
I discovered something very strange. I was moving all my files to the new forge, but I noticed that it no longer starts when I move my checkpoints. How is this possible?

Could it be that I have a checkpoint file that is giving me an error?
He does it to me even when I marry my Loras

the program starts even without the vens folder which I don't have
Forge doesnt need a venv
Ok, but the fact is that if I move my time and my checkpoints, then maybe it won't start, look.

if I remove them, it starts, why???
how much models and loras do you have?
can you try just move the loras into models/lora folder and then relaunch?
I have 849 Lora
what: ControlNet preprocessor location: H:\webui_forge_cu121_torch231\webui\models\ControlNetPreprocessor
the folder is empty, I don't understand why it goes out
If I then remove the time, that error no longer appears
i'm trying to mix two image into another image but for some reasons the image given to the ip-adapter is not considered, it's generate colorful patch and nothing else, do you know if the IP-adapter is supposed to launch in the webui-user.bat ?
probably forge needs to calculate the lora hashes for all of them and that takes very long. Try adding only a few to see if it still starts up with them or not
controlnet models go into models/controlnet
ty will try this
Hi, in the end, nothing to do, I no longer have the energy to check 850 lora and find out which one is defective. Maybe it's the version of Forge that doesn't work for me. Is there another type of version I can download?
it said this and then just didnt update

Updating d8cc7ad0..df7045bb error: Your local changes to the following files would be overwritten by merge: extensions-builtin/sd-webui-ux/javascript/anapnoe_sd_webui_ux.js Please commit your changes or stash them before you merge. Aborting
not sure how to p[roceed
is there a --force-update flag
You could also try setup ReForge
Okay to fix that:
Go into the **stable-diffusion-webui-ux **folder.
Click in the File Explorer bar. (not in the search bar).
then type cmd and hit enter.
after that type and run:
git reset --hard HEAD
hit enter and then
git pull
Then rerun the webui-user.bat
oh shoot its doing it thank u
Is ROCm available on Debian 13?
Hi, I don't know what this ReForge is. I've tried over and over again, but my Forge never starts. Is there another version I can try?
Hello folks, I've got a question and im not sure where to ask it but i figured here would be a good place to start. I've been using Automatic 1111 for the past few days, just got into it and started playing around. I installed the dreambooth extension from the webui's extension tab, and now when i try to run the sd.webui i get a runtime error : RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check. I am very new to all this and I'm not sure how to proceed.
I've got a 5070ti and its been running sd.webui beautifully so far.
There is Auto1111, Forge, ReForge, Forge Neo
But have you tried just not moving the loras over and just adding --lora-dir "PathToLoras" to the webui-user.bat?
Hey Dreambooth is outdated and breaks the Auto1111.
You need to delete it from the extensions folder and then delete the venv folder and relaunch the webui-user.bat.
Then you need to do the steps again to change torch for rtx 50 series.
no. should I add --lora-dir / to the webui-user.bat file?
my a1111 suddenly stopped booting with error "Cannot find empty port in range: 7860-7959". i retried multiple times. it was okay just yesterday and i don't seem to have changed anything in my system
I see no folder called venv
Oh right the sd.webui has no venv
I went to the extensions folder and removed the extension.
Would it be easiest to fix by just moving my Models out, deleting the entire folder, and re extracting the initial automatic 1111?
where should I add it?
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
@REM Uncomment following code to reference an existing A1111 checkout.
@REM set A1111_HOME=Your A1111 checkout dir
@REM
@REM set VENV_DIR=%A1111_HOME%/venv
@REM set COMMANDLINE_ARGS=%COMMANDLINE_ARGS% ^
@REM --ckpt-dir %A1111_HOME%/models/Stable-diffusion ^
@REM --hypernetwork-dir %A1111_HOME%/models/hypernetworks ^
@REM --embeddings-dir %A1111_HOME%/embeddings ^
@REM --lora-dir %A1111_HOME%/models/Lora
call webui.bat
To the commandline_args=
Where you also added --cuda-stream
since strangely enough it's already there but it's useless
ah,ok
Best would be to install Auto1111 the normal way or Forge by using the setup guides.
You find them on the first link of the pinned messages here
now


this is what happens if I insert the lines like you told me
and yet I did everything right

You have "--lora-dir" as an argument, but you don't tell it what that directory is. If you're not going to specify that in COMMANDLINE_ARGS, don't put it there. Otherwise, give it the primary directory where you would store your LoRAs.
Is there anyone that has managed to get InstantID working within Fooocus? Without InstantID, it works just fine, but when enabling it, gets stuck on "Preparing task 1/1", then does this


tried doing a fresh install of auto111 but for some reason xformers wont install, i did the stanard winnividia directions on their github and then tried --reinstall-xformers flag
actually i just looked and it does look like it started with xformers

but when hit render theres an error and says xformers is not defined
sdp works though it was defaulting to doggetx
Remove --reinstall-xformers and --force-enable-xformers
Just add --xformers
Then delete the venv folder and relaunch the webui-user.bat
Also upgrade to python 3.10.9 64bit before deleting the venv folder or delete it afterwards again.
ah ty
Trying to get my friend up and running with comfyUI. We used the same workflow and settings, but his video gets blurry near the end for some reason. Any idea what is causing this?
I installed Stable Diffusion WebUI AMDGPU Forge on Stability Matrix
I'm getting rocBLAS error: Cannot read C:\Program Files\AMD\ROCm\6.2\bin/rocblas/library/TensileLibrary.dat: No such file or directory for GPU arch : gfx1032
Dont use stability matrix for AMD.
Follow the Forge with Zluda Setup guide from the first link of the pinned messages here

looks good to me
ok thx 🙂
Are there any commands to make startup faster? I would also like to know if I need to enable any options so that I can see all my checkpoints immediately, since now I always have to press: refresh page
Is your H drive an HDD or SSD?
And how much RAM do you have?

Yep looks good
ohhhhhhhhhhh yes
https://github.com/lshqqytiger/stable-diffusion-webui-amdgpu/issues/628
How do I fix this error?

GitHub
Checklist The issue exists after disabling all extensions The issue exists on a clean installation of webui The issue is caused by an extension, but I believe it is caused by a bug in the webui The...
hello i have a problem with my comfyui all works but at the moment of the VAE decode it put me this error

the error log
someone can help me please ?
@ornate elk my lord can you help me please?
if you want you can again take control of my computer
hey, follow the updated AMD setup Guides from here and then let me know if which exact error you get if any:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
Therefore, it is like this.
can you paste me the cmd log you get in here? Because on the Github Link Logs there are multiple issues.
Sorry
I restarted PyTorch? and launched it after reinstalling...
okay, can you just copy and paste the whole cmd log in here when you launch the webui-user.bat?
then i can check for any issues
looks correct so far
Let it compile, it can take a while
also whats inside your webui-user.bat ?
I made a mistake when opening it.
If it's webui-user.bat, it's this.
set COMMANDLINE_ARGS= --use-zluda --update-check --medvram --no-half --opt-sub-quad-attention
wait
remove --no-half
that just slows down everything
just wait its still compiling
can take up to 1 hour max on some gpus
Hmm...
It threw an error...
Checking with GPT...
Can you show the complete cmd log again?
Please don't use chatgpt for zluda stuff
Thats not the complete cmd log
But can you try just generate 1 image at default settings without using a lora?
Does that work?
You may need to relaunch the webui-user.bat first
Because chatgpt doesn't know about custom webui amd forks with Zluda. And will output stuff that breaks it even more instead of fixing it.
I see...
A similar error was generated.
The issue comes from the dynamic prompts extension it seems
Also you added a lot of embeddings which all didnt load because they get blocked because they are .pt files (insecure)
There are several other issues involving extensions. For me it seems you copied them over from an old install?
I installed it from the official GitHub.
yes
Then try generate an image again but dont enable the dynamic prompt extension
If that outputs an error post the cmd log again
おk
Also Umi-ai extension is not compatible with AMD GPUs. I looked it up right now.
So that could be an issue too
thank you
To fix the webui, delete the umi-ai extension.
And then also delete the venv folder.
Then also add --skip-ort to the commandline_args of the webui-user.bat and then relaunch it.
ok
I'm off now, its late here. Let me know if it worked. If not we can fix it later
Thank you.
Please wish me success.
I'm getting the same error message
This isn't working either/
Nvm.. I believe it's because I'm using 6800s and went with 6800+ guide
Recently when i launch Auto1111, the startup (terminal) gets stuck loading on some lines for a really long time. Is there a way to soft reset this, such as deleting the venv file or something?
ZLUDA device failed to pass basic operation test: index=0, device_name=AMD Radeon RX 6800S [ZLUDA]
CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when callingcublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)
...
TypeError: '<' not supported between instances of 'NoneType' and 'int'
Now I'm getting this
Yes deleting the venv can help.
Can you show the complete cmd log?
It didn't work out.
Okay, then please send the new cmd log
Here it is, though it's late.
Okay do these steps:
Edit the webui-user.bat and add git pull to the 2 line below echo off.
Then add --skip-ort to the commandline_args=
Then download and install Python 3.10.11 64bit.
Then delete the venv folder and the .zluda golder.
Boath are located in the stable-diffusion-webui-amdgpu folder.
Then relaunch the webui-user.bat
ok
error…
You still have python 3.10.10 and not upgraded to 3.10.11
Okay can you screenshot your webui browser with your settings like model, resolution etc?
Is this okay?

Dreamshaper v8 should work. Have you tried just using the default values to gen 1 image?
default? This should be the original settings with no modifications.
Since it seems like a CUDA-related error, should I reinstall it?
AMD doesnt support cuda. Zluda emulates the cuda instructions.
Can you open up a cmd and run:
Zluda --Version
Unrecognized argument: --Version
Run zluda.exe --help for more information.
Oh try zluda --version
ZLUDA 3.8.4
I can help you
@lapis raven Then I would recommend the following steps to update Zluda:
Delete the content of C:\zluda but keep the folder.
Also make sure your AMD Adrenalin Driver is updated.
Download the latest zluda 3.9.5 rocm6 zip (not nightly) from here:
https://github.com/lshqqytiger/ZLUDA/releases/
And place the unpacked files of zluda in your C:\zluda folder
Open up a cmd and run:
Pip cache purge
Then in the webui delete the .zluda and the venv folder again then relaunch the webui-user.bat
hello i hear you ^^
Okay can you try remove all extensions from the extensions folder.
Then delete the venv folder and relaunch the webui-user.bat?
Zluda didnt found the GPU gfx version
Have you downloaded the custom gfx1032 files and put them in the correct folders?
I did this
Go into C:\Program Files\AMD\ROCm\6.2\bin\rocblas folder.
There copy and rename the library folder to old_library
Open the gfx .zip file and drag and drop all files of the library folder into the library folder. Not into the old_library folder.
If the zip contains a rocblas.dll, copy that into the C:\Program Files\AMD\ROCm\6.2\bin\rocblas folder.
Should I have kept the files from old_library in library?
I got the files from rocm.gfx1032.for.hip.sdk.6.2.4.navi21.logic
Yes you should have kept the files from old library in library and then add the new ones to library and overwrite
That worked! Thanks
Perfect, no problem 🙂
Getting this error + a crash. Dedicated 8.0 GPU. Tried lowering GPU weights
I had to reinstall webui, and I chose a different folder without deleting the old one. Now the lora tab is acting weird, showing the loras from the old installation instead of the new one. Even weirder, new loras won't display even after adding them to both installs. Is there a cache of it outside the install folder or something?
how did you install the webui?
and which one?
the joblib error can be ignored or you install it inside the venv
you need to show your settings when you get the out of vram error
Show my settings?
like resolution, steps, model etc
git cloned lshqqytiger's amd version of webui
okay, and now you see old loras? are any loras in the new installation?
did you linked something in the webui-user.bat?
I see the loras I had yesterday before reinstalling
but not the loras I added today, to both folder
are the loras made for the base model you selected?
also whats in your webui-user.bat and can you show your cmd log when launching it?
512x512, 20 steps, ealismIllustriousBy_v50FP16.safetensors
unsure, I tried a bunch and none worked... but I even deleted one and it's still not showing the change in the ui. It's like there's a cache somewhere
have you reloaded or restarted the webui after removing them?
yes
okay then please cmd log and webui-user.bat content
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--use-zluda --update-check --skip-ort --skip-python-version-check --precision full --no-half
set HIP_VISIBLE_DEVICES=1
call webui.bat
remove --precision full --no-half, they just slow down and are not needed for AMD
PS C:\ai\stable-diffusion> .\webui-user.bat
venv "C:\ai\stable-diffusion\venv\Scripts\Python.exe"
WARNING: ZLUDA works best with SD.Next. Please consider migrating to SD.Next.
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
Version: v1.10.1-amd-45-g3e1758c5
Commit hash: 3e1758c509354f44c1bc2aab06891ddfb433259f
ROCm: agents=['gfx1100']
ROCm: version=6.4, using agent gfx1100
ZLUDA support: experimental
ZLUDA load: path='C:\ai\stable-diffusion\.zluda' nightly=False
Skipping onnxruntime installation.
--------------------------------------------------------
| You are not up to date with the most recent release. |
| Consider running `git pull` to update. |
--------------------------------------------------------
W0923 14:51:57.564000 18784 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
C:\ai\stable-diffusion\venv\lib\site-packages\timm\models\layers\__init__.py:48: FutureWarning: Importing from timm.models.layers is deprecated, please import via timm.layers
warnings.warn(f"Importing from {__name__} is deprecated, please import via timm.layers", FutureWarning)
no module 'xformers'. Processing without...
no module 'xformers'. Processing without...
No module 'xformers'. Proceeding without it.
C:\ai\stable-diffusion\venv\lib\site-packages\pytorch_lightning\utilities\distributed.py:258: LightningDeprecationWarning: `pytorch_lightning.utilities.distributed.rank_zero_only` has been deprecated in v1.8.1 and will be removed in v2.0.0. You can import it from `pytorch_lightning.utilities` instead.
rank_zero_deprecation(
Launching Web UI with arguments: --use-zluda --update-check --skip-ort --skip-python-version-check --precision full --no-half
Loading weights [dd240b5bb5] from C:\ai\stable-diffusion\models\Stable-diffusion\unstableIllusionPRO_pro.safetensors
Creating model from config: C:\ai\stable-diffusion\configs\v1-inference.yaml
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 16.4s (prepare environment: 25.5s, initialize shared: 0.8s, other imports: 0.2s, load scripts: 0.5s, create ui: 0.4s, gradio launch: 0.3s).
Applying attention optimization: Doggettx... done.
Model loaded in 3.6s (load weights from disk: 0.2s, create model: 0.9s, apply weights to model: 1.4s, apply float(): 0.2s, load textual inversion embeddings: 0.2s, calculate empty prompt: 0.6s).
can you try again and send the full cmd log if you get an error?
why is your webui outdated if you said you installed it today?
thats not possible
your sure thats the "new one" ?
yes, 100%
This time it didn't crash\
yeah, I made some changes in git, so I guess it's just using it to check for updates
did you installed the new version in the last few days?
old version yesterday, new version an hour ago
then your log is from the old version
in git, I made a new branch, removed some stuff from gitignore, and made some commits
but it's not an outdated version
can you try to setup the webui again the normal way and dont mess with the git stuff?
then it will probably work normal
reverted back to master, ran it again... same problem
venv "C:\ai\stable-diffusion\venv\Scripts\Python.exe"
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
Version: v1.10.1-amd-43-g1ad6edf1
Commit hash: 1ad6edf170c2c4307e0d2400f760a149e621dc38
ROCm: agents=['gfx1036', 'gfx1100']
ROCm: version=6.4, using agent gfx1100
ZLUDA support: experimental
ZLUDA load: path='C:\ai\stable-diffusion\.zluda' nightly=False
W0923 15:02:50.668000 6476 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
C:\ai\stable-diffusion\venv\lib\site-packages\timm\models\layers\__init__.py:48: FutureWarning: Importing from timm.models.layers is deprecated, please import via timm.layers
warnings.warn(f"Importing from {__name__} is deprecated, please import via timm.layers", FutureWarning)
no module 'xformers'. Processing without...
no module 'xformers'. Processing without...
No module 'xformers'. Proceeding without it.
C:\ai\stable-diffusion\venv\lib\site-packages\pytorch_lightning\utilities\distributed.py:258: LightningDeprecationWarning: `pytorch_lightning.utilities.distributed.rank_zero_only` has been deprecated in v1.8.1 and will be removed in v2.0.0. You can import it from `pytorch_lightning.utilities` instead.
rank_zero_deprecation(
Launching Web UI with arguments:
C:\ai\stable-diffusion\venv\lib\site-packages\torch\onnx\_internal\registration.py:159: OnnxExporterWarning: Symbolic function 'aten::scaled_dot_product_attention' already registered for opset 14. Replacing the existing function with new function. This is unexpected. Please report it on https://github.com/pytorch/pytorch/issues.
warnings.warn(
ONNX failed to initialize: module 'optimum.onnxruntime.modeling_diffusion' has no attribute 'ORTPipelinePart'
Loading weights [dd240b5bb5] from C:\ai\stable-diffusion\models\Stable-diffusion\unstableIllusionPRO_pro.safetensors
Creating model from config: C:\ai\stable-diffusion\configs\v1-inference.yaml
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 17.0s (prepare environment: 24.8s, initialize shared: 2.1s, load scripts: 0.5s, create ui: 0.5s, gradio launch: 0.1s).
Applying attention optimization: Doggettx... done.
Model loaded in 3.3s (create model: 0.9s, apply weights to model: 1.3s, load textual inversion embeddings: 0.2s, calculate empty prompt: 0.7s).
Compilation is in progress. Please wait...
this messages is very strange:
W0923 15:02:50.668000 6476 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
can you delete the venv folder and relaunch the webui-user.bat?
and now it doesnt show launch args, dont forget to add --use-zluda --update-check --skip-ort --skip-python-version-check
stupid venv, I don't want to go through that again... the mirrors I get are like 20 kb/s, it's a pain
its cached dont worry
just let it rebuild clean
a corrupt venv can cause much trouble
that's the reason I had to reinstall everything
I've always hated python for their terrible package manager
yea but something is clearly off with your installed version, so better get a fresh venv
looks okay, zluda just needed to compile fully.
But as you only have 16gb of RAM you need to increas your windows pagefile to speed up sdxl/illus gen time
Ah, I edited the bat a little before I ran it this time. Lemme run it again and see
Right now my pagefile is 40960
ah okay
should be fine then, but you can recheck it later. make sure its only enabled for C drive and disabled for any other drive and then set to 16000min and 24000max or 32000 if you want
Ok I'll change it to that and see if it fixes crashes
a PC restart is required after chaning the pagefile
fresh venv, same issue
venv "C:\ai\stable-diffusion\venv\Scripts\Python.exe"
WARNING: ZLUDA works best with SD.Next. Please consider migrating to SD.Next.
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
Version: v1.10.1-amd-43-g1ad6edf1
Commit hash: 1ad6edf170c2c4307e0d2400f760a149e621dc38
ROCm: agents=['gfx1100']
ROCm: version=6.4, using agent gfx1100
ZLUDA support: experimental
ZLUDA load: path='C:\ai\stable-diffusion\.zluda' nightly=False
Skipping onnxruntime installation.
You are up to date with the most recent release.
W0923 15:17:54.633000 1852 venv\Lib\site-packages\torch\distributed\elastic\multiprocessing\redirects.py:29] NOTE: Redirects are currently not supported in Windows or MacOs.
C:\ai\stable-diffusion\venv\lib\site-packages\timm\models\layers\__init__.py:48: FutureWarning: Importing from timm.models.layers is deprecated, please import via timm.layers
warnings.warn(f"Importing from {__name__} is deprecated, please import via timm.layers", FutureWarning)
no module 'xformers'. Processing without...
no module 'xformers'. Processing without...
No module 'xformers'. Proceeding without it.
C:\ai\stable-diffusion\venv\lib\site-packages\pytorch_lightning\utilities\distributed.py:258: LightningDeprecationWarning: `pytorch_lightning.utilities.distributed.rank_zero_only` has been deprecated in v1.8.1 and will be removed in v2.0.0. You can import it from `pytorch_lightning.utilities` instead.
rank_zero_deprecation(
Launching Web UI with arguments: --use-zluda --update-check --skip-ort --skip-python-version-check
Loading weights [dd240b5bb5] from C:\ai\stable-diffusion\models\Stable-diffusion\unstableIllusionPRO_pro.safetensors
Creating model from config: C:\ai\stable-diffusion\configs\v1-inference.yaml
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 38.2s (prepare environment: 65.4s, initialize shared: 1.1s, other imports: 1.1s, load scripts: 0.4s, create ui: 0.7s, gradio launch: 0.4s).
Applying attention optimization: Doggettx... done.
Model loaded in 3.3s (create model: 1.0s, apply weights to model: 1.3s, load textual inversion embeddings: 0.2s, calculate empty prompt: 0.7s).
can you remove any lora of the webui and relaunch and then check if you see any?
if every lora is removed of models/lora you shouldnt see any of them after the relaunch
on 512x512 resolution?
Yep
7152 but I’ve lowered it to 2000 and it also doesn’t work there
I’ll try updating drivers and going into overclock mode etc
do you havy anything open in the background like twitch, wallpaper engine or games?
Maybe that will fix
Nah I close it all
But will try everything next time and report back
Thank you!
okay, no problem, now its only a vram issue
you can also try to enable Never OOM for VAE at the bottom of forge
that kinda helped, at least I'm seeing different loras now. Thanks a lot for the help, I appreciate it
No problem, good to hear, but your seeing loras now even if you remoed all of them from the new webui?
I've already readded them
ah okay
Still crashing lol
Basically my laptop fan begins to get louder and louder and at 100% the entire PC blinks off
Set your cpu to 80-90%, its throttling it but might help? 🤷♂️
What's your pagefile set to? And how much space do you have left on your C drive?
anyone mess with openoutpaint, its pretty neat

wondering how important using an inpaint model is for the base gens
i got the controlnet part of the extension working with its inpaint model but i dont relaly have that many inpaint like sd1.5 models
Can anyone please answer me my forge ui lora is being detected but not being used in images and there are not error massage
with sdxl/illus inpaint models are not needed anymore
is it compatible with the base model?
@ornate elk yes it is compatible with base model i just changed some setting on my display after that it stopped working
Name of lora is manga illustration
for which model version?
Sdxl
and you already restarted the webui ?
can you try generate an image with the lorad added, and then drop it back into the PNG-Info tab to check if the lora is mentioned in the meta data?
No I didn't do that I will get back after I do that .
I restarted webui and did fresh installation also for what I did not do was checking png info
https://civitai.com/models/1255751/manga-mode-illustrious this is the lora
ah this one is for illustrious models not sdxl
But when I used this before it worked perfectly
compare the images meta data in PNG-Info maybe it was with an other checkpoint?
because illustrious is based on sdxl but that doesnt mean it works with every sdxl models or not at all with them
I used this lora with anylora checkpoint, and checkpoint named WAINSFW-illuatration-sdxl
For both of them it worked like wonder without any issues
wainsfw is an illustrious based model, so that works
but anylora isnt, or which did you used?
Both and it worked best with wainsfw
Wan Animate native works with 640 x 640. But when I change dimensions, it bizarrely no longer uses the reference image - anyone hit that?
yes, because the lora and the model match the base version, can you share the link to your anylora one?
i havent used a1111 in a while and tried to launch it... it just stops doing anything after Launching Web UI with arguments: --xformers --medvram... I havent touched the install since the last time i ran it, and it was working then.... is there any reason why it would stop working?
as i tought, thats an 1.5 model, it doesnt work at all with sdxl or illustrious loras
i cant or havent been able to run xl models so still on 1.5 but it seems to be sortof working
you mean in general? whats your gpu?
hey, can you share the full cmd log? then i find the issue
Python 3.10.8 (tags/v3.10.8:aaaf517, Oct 11 2022, 16:50:30) [MSC v.1933 64 bit (AMD64)]
Version: v1.10.1
Commit hash: 82a973c04367123ae98bd9abdf80d9eda9b910e2
Launching Web UI with arguments: --xformers --medvram
gtx1060, 6gb. its like just on the edge i think of being able to run xl. but i just have been using 1.5 models since i started
it might just be loading sometimes it takes a beat
ah well ,yea it can run sdxl models with Forge webui but it will be much slower than 1.5
ya due to that ive avoided them and just try to improve my results with 1.5 , so i should try to find some inpaint models to get the most out of this?
hm okay looks normal but the webui version is not updated.
do this:
edit the webui-user.bat and in the 2 row/line below echo off you add git pull
then download and upgrad to Python 3.10.11 64bit
Then delete the venv folder and relaunch the webui-user.bat
i tried launching it without the arguments and it does the same thing... just stalls out after the launching command.... are there any logs for a1111
webui version is at the most recent version
oh true lol
sry
yea then just upgrade python and delete the venv + relaunch webui-user.bat
python 3.10.7 and 3.10.8 were a bit buggy back then
will it recreate the venv ?
yes, with the latest torch and xformers version
hm if you want to use inpaint then yes, but i dont think there are that many
but most semi realism models dont need one
i used UNIGetUI to update some random things like torch and transformers but i dont know what directory its updating but it didnt break anything
unigetui doesnt update webui stuff because its inside a venv
ah i figured
i have no idea where all these packages are installed that its detecting lol but i had a feeling the gradio servers like a111 were basically compartmentalized

can someone help me
the openoutpaint thing is sort of working it gens like 4 essentially irrelevant sections and one that actually fits in context
probably denois to high, but if you want to improve your 1.5 images more then go for hires fix upscaling + adetailer
i do not think
yeah
because of birds?
no waffles
u know what they say
it aind dumb if the ends justify the means
:((((((
@wild tendon with what do you need help now?
Wan Animate native works with 640 x 640. But when I change dimensions, it bizarrely no longer uses the reference image - anyone hit that?
I would advise walking outside the front door for a while
bye spammer
I tried a bunch of different permutations. Rn it's 40-64 GB
But I have 215 GB free on my C drive
It seems like this may be a solution for nvidia users but I have amd: https://nvidia.custhelp.com/app/answers/detail/a_id/5490/~/system-memory-fallback-for-stable-diffusion
Can sopmeone elaborate why dfq is this happening to me (at random)?

Could be an out of vram error maybe.
I think your GPU is running out of memory when trying to allocate space for model operations.
This is my approach:
1.reduce batch size.
2.clear GPU cache regularly
3.use gradient checkpointing
4.kill other GPU processes
I hope this is helpful for you.
24gb is not enough for 1mpx hrfix generation??
24gb should definitely be enough for 1 megapixel hires fix generation!. 1MP is only around 1000x1000 pixels, which is quite modest.
But even though , 24gb is enough, there are some issues can cause errors.
-Multiple generations without clearing cache
-Denoising strength too high → more VRAM usage
-Upscaler method → some use way more VRAM than others
-Hires steps too high → try 10-20 instead of 50+
im using 0.35 denoise
remacri model
10 hr steps
ALTHO, i set 0 in tiling size
(because of inpainting reasons)
a friend of mine is having this issue what is it?

For about 2 days comfy just will not work. I been using it for 2 years and havent had this issue before. Whenever i queued something it just crashes. no errors nothing. when i rarely do get errors it says i am out of memory. I even tried setting the res to 30 by 30 and nothing.
I feel like my account will get hacked if i join lol
I join but ima make an alt real quick lol
Yea i joined the server with an alt and yall asking for my wallet lol @shy falcon

Thanks for the hint, we banned him.
What's your GPU and what does the cmd shows when launching Comfyui?
I fixed it, it was a really dum issue that I would have no figured out without someone help
Ah alright xD
I had to mess with this to fix it. Tho I might have another question, anyway to lower vram usage? Am trying to use wan at a higher res but my 4070 sorta struggles

Ah the Pagefile.
There aren't many nodes that help with vram usage.
There is Tiled VAE Decode which can help with large resolutions.
And there are some vram cleaner nodes that can be added in between tasks to reset the vram.
Then there is stuff like sage attention and nunchaku which can help too.
But video gen on 12GB vram is not that great. Even with more its not that great xD
I am using sage attention but never heard of nunchaku before
It got a hype lately:
https://github.com/nunchaku-tech/ComfyUI-nunchaku
But idk if it works with video stuff
I've figured it out, so in case somebody will be also looking into it:
If webui cannot find empty port in the default range 7860-7959, it means the ports are reserved/used by something else. on windows, it can be checked via powershell:
netstat -ano | findstr :7860
to check if a specific port is in use. if nothing pops up, it's vacant; if you see a PID and want to know which process it is:
tasklist /FI "PID eq xxxx" # replace xxxx with the PID
Then you can stop that process (but only if you know what you're doing) by:
taskkill /PID xxxx /F
But it might be launching on every boot anyway.
And you can see the reserved port ranges by:
netsh interface ipv4 show excludedportrange protocol=tcp
You can then safely set a different port by adding argument --port=xxxx with any bigger number in the webui.bat
The ports are often reserved by networking components like Hyper-V, WSL, Docker, NAT
In my case, everything from 1300 to 8018 was reserved. By looking into windows optional features, i figured that Windows Sandbox could be the culprit since I enabled it recently. So I disabled it, rebooted and the reserved range disappeared, and I was able to launch webui on default port again.
scam, it's redirecting to something else most likely
Hi there,
I would really appreciate some quick advice. I have no interest in making videos, so please could someone let me know which checkpoint to use for Wan txt2img, and which VAE, text encoder, Sampler/Scheduler etc.
I am running the new version of forgeNeo and have the following, but I get shit images:
Checkpoint:
wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
VAE:
Wan2.1_VAE.safetensors
Textencoder:
umt5_xxl_fp8_e4m3fn_scaled.safetensors
Sampler/Scheduler:
DPM++ 2M with SGM Uniform.
Any help would be appreciated!
can i ask? when you said it should be enough. You mean 1000x1000 before pressing hrfix? and ussually what do you mean hrfix? 2x resolution or 1.5? what should I assume when people talk about hrfix? thnx
Webui has been really slow lately when I generate for the first time or switch to a different Lora any way to fix it?
Old laptop but it's never been this slow
I got my local install of forge working on Nobara (Linux!) Here's how to do that:
running stable diffusion webui forge on nobara linux (or fedora) if you already have a pre-existing installation created in windows:
(be warned, this process will modify parts of the environment and do things beyond my comprehension, you will not be able to generate images identical to those you had before. back up your stable diffusion instance before proceeding if you want to do that.)
starting within linux, run sudo dnf install python3.10
go to the folder your forge install is in, find webui-user.sh, open it in a text editor (like kate), change python version to 3.10,
(optionally, you can also add --xformers to the launch parameters, and any other parameters you may already be using)
for instance, mine has these two lines:
export COMMANDLINE_ARGS="--xformers"
# python3 executable
python_cmd="python3.10"```
save it
open a terminal (like konsole or gnome terminal) in the same folder as webui.sh
run `./webui.sh`
it will rebuild itself to work with linux, and that's it!
run at any time by changing directory to the /webui/ folder and launching `./webui.sh` from a terminal.Whats your GPU and what's in your webui-user.bat?
spent over an hour arguing with chatgtp on how to enable xformers. new old python... this that... bat file changing... nothing worked.. gave up...
4090 32gb ram, ssd, 7.5it/s at 1080p render speed with sdxl 1.0
I tried using cuda malloc command and no mem attention but same speed...
fallback disabled in nvidia
hardware sheduling disabled in windows
ive heard others have much higher speeds..
any tips?
which webui do you want to use?
normaly adding --xformers into the webui-user.bat is enough
i tried all, and as a beginner i found a1111 forge never crashes, no problems.. that command line does nothing for me, i think even chatgtp gave up, told about a1111 having its own python and not using mine which would support gpu, im not sure what it told but it was over hour it giving me advices that did nothing to fix it lol
yea thats normal for chatgpt xD
so your using auto1111 or forge now?
and which python version?
forge. not forge used to give oom messages, forge is just super trustworthy.
how do i copy paste text? discord prevents me to write what a1111 shows
3.106 2.3.1+cu121 gradio 4.4
mark the text and press ctrl+c and then in the chat ctrl+v
it wil maybe create a text file if the text is to long
i think i had higher python version but gtp downgraded it in hopes of making xformers work, maybe xformers would not boost my peformance? im not sure.
ctrl c ctrl v doesnt work even for a single letter on discord ( i have web browser version) it works if i turn the "legacy" version somewhere, but legacy version bricks other discord channel commands
oh okay then paste it inside a txt file and send that
version: f2.0.1v1.10.1-previous-669-gdfdcbab6 • python: 3.10.6 • torch: 2.3.1+cu121 • xformers: N/A • gradio: 4.40.0
if you installed forge by downloading its recommended .zip file it does come with its own python version 3.10.6 no matter what you have installed on your PC
dont remember how i have forge, been some days ago
the cmd log would help to figure it out xD
when i launch forge?
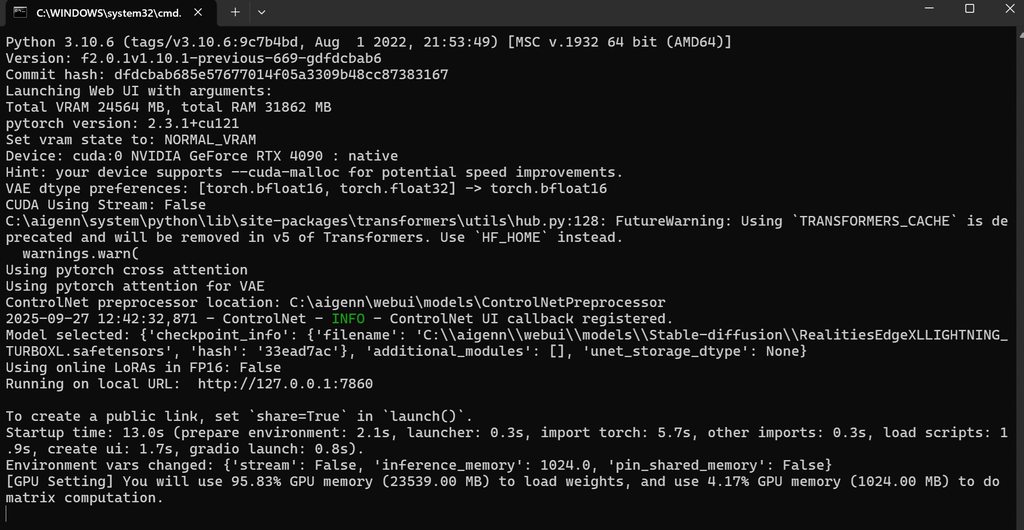
looks normal but you didnt have --xformers --cuda-stream added to the webui-user.bat
anyway as forge doesnt get much updates anymore and you have a 4090 you should go with Forge NEO.
Its more updated and supports newer pytorch and xfrormers versions which makes it faster on your gpu than normal forge.
It can be found here:
https://github.com/Haoming02/sd-webui-forge-classic/tree/neo
For this you should have Python 3.11.9 64bit installed only
And dont download forge neo as zip, install with git
https://imgur.com/a/mHn26dG now with added both lines like you mentioned.
second picture bottom
cool i will try force neo!
it doesnt list them
but yea forge had always issues with xformers... forge neo should work much better
i got neo i can choose where to install, i dont want it to hide in some obscure folder
make sure you used its recommended git install command to get it:
git clone https://github.com/Haoming02/sd-webui-forge-classic sd-webui-forge-neo --branch neo
if not you wont be able to update it
how do i install in c:/a1111neo folder? it would be far better, or any other?
yea make a folder on C for it
then while in that folder, click in the explorer path bar (not searchbar), type cmd and hit enter
then paste the command from above and hit enter
https://imgur.com/a/KIFMUd9 need help sir
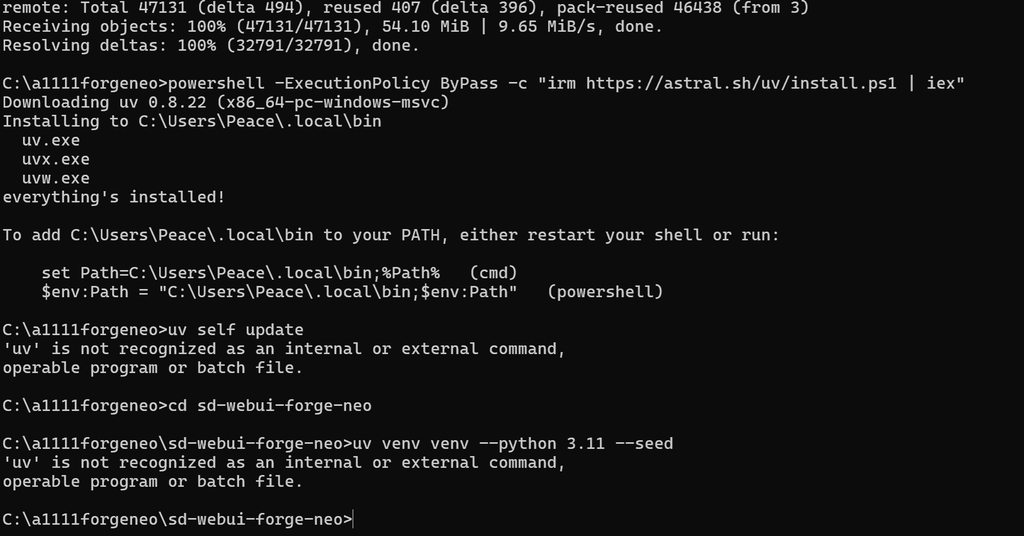
what have you done exactly?
why is there powershell mentioned xD
you dont need to follow the uv install guide from its site, just git clone the repo, edit the wbeui-user.bat and launch it
Woah sounds good!
maybe i could somehow figure out how to make videos now.. what speed i can hardly believe, it renders too fast 😄
nevermind,, default settings! not 1080p
~8.5it/s so its a boost so far, no idea how to install wan or why people use qwen or flux kontext but maybe i will figure it out.. any website blog talks about these things?
I don't know any :/ as they are all pretty new
what pc you have?
RuntimeError: CUDA error: no kernel image is available for execution on the device CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
What the problem?

I have a RX 7900xtx with an Ryzen 7800X3D
What's your GPU and please copy and paste the full cmd log when launching the webui-user.bat
RT 5060

Full cmd log please and not python console. Nvm its all installed the wrong way.
Automatic1111 doesnt support the rtx 50 series nativly so you need to follow the setup guides from the first link of the pinned messages to get it working
wanna thank you... without i would have stuck with sdxl, now i just trying flux cos with neo it just somehow got easier for me and i aint going back to sdxl.. flux soo nice.. watched long tutorial while it was downloading flux about presets and stuff and its super exciting
no problem 🙂 yea flux is great but needs a lot of vram, there are also smaller models of it out there like a Q8 gguf version.
whats weird it doesnt crash! older a1111 used to crash a lot, a1111 forge almost never crashed but it was sdxl, now flux and i can even use discord while its running! its trully epic
thats awesome! yea auto1111 hasnt been updated since a year and Forge also haven't got much updates or support for newer models lately
will update my guides today to include the forge neo setup
Need help to find some way to remove a character and keep the background, already tried many tools online and inpaint, but it akways generates random shit, no matter how much weight i put into background and empty, it keeps generating random stuff.
Where are Adetailer's default values located at within the "ui-config.json" file?
@ornate elk
Not in ui-config.json because its an extension
Hi, sorry to bother you, but I had to format my PC, and now I have to redownload everything. I wanted to ask you which CUDAs should I download for Forge?
this is my sd forge: webui_forge_cu121_torch231
What's your GPU?
Hello guys, could someone please help me with the Krita Stable Diffusion Plugin?
I am trying to install it but getting this error. I have installed it before on my PC before formating

Does this have any significance?
yea and nope, AMD is currently working on their project called TheRock which this driver is probably based on now.
Would wait for the official support before installing this driver.
Also TheRock works too without it. Im currently using it
I see
But good that they are going forward
rtx4070oc
would recommend trying forge neo then, as its more updated and supports the latest pytorch 2.8.0+xformers 0.0.32
or you install 2.8.0 manually into forge
where do I find it?
Its on my Guide list:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
ok,thx
Brother this is the same issue I am having right now. Did you solve this, or can we try to solve this together?

Test it out or compare to the old forge and decide.
But as you have a 40series GPU and that supports sage attention and fp16, neo should be faster
In fact, I generated 10 images in less than half the time it took me with the normal forge 0_0
Sounds good then 😄
I see no "out painting" where i could drag drop image, cover it with tool and generate image around it to blend it in.. i tried many combinations with the buttons here and nothing worked so far. i probably need some extension

GTX 970 and it's slow no matter what I use haven't tried it without a Lora tho
Should be done by now
Maybe you should try using Forge webui as its better for older gpus
Mb that's what I meant when I said webui
Oh okay, and your using an 1.5 based model and lora?
Idk I've just see a Lora I like and download it. How do I check?
You have to check the info box on the loras page on civitai
It shows "Base model:" and then it can be 1.5, sdxl, Illustrious etc
Same goes for checkpoints
As sdxl based stuff will take much longer than 1.5 on your GPU
It just says illustrious
Ah okay and your also using an Illustrious checkpoint (model) with it?
Illustrious models are around 6GB on size but your 970 has only 4GB.
So it can't fully fit inside nor an lora too.
So it will get loaded partially and stored in RAM
So what you can do to improve the speed is to increase the windows pagefile.
Thats needed if you have 16GB or less of RAM.
Hi, I had to format my PC. I was in a hurry and didn't save the upscalers. Can you tell me where I can download the good ones?
From here:
https://openmodeldb.info/
OpenModelDB
OpenModelDB is a community driven database of AI Upscaling models. We aim to provide a better way to find and compare models than existing sources.
thx a lot
Hello! I have suddenly developed a strange problem... when I try to generate anything I get this error:
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1024x64 and 1x98304)
Any way to fix it?
hey, thats caused by incompatible model+lora
Can u get a mod to get this guy out, he's the scammer type, since he hasn't posted in this server yet, but did in another


how many scammers are in this damn server?
Hi, just out of curiosity. When I start Forge Neo, it still takes a long time. I then noticed this strange message: Legacy Preprocessor init warning: Unable to install insightface automatically. Please try run pip install insightface manually.
I need to install something, right?
Insightface is made for controlnet IP-Adapter face ID or reactor faceswap.
If you dont use them or any other face swap stuff then you can ignore that.
Or if you want to install it then go into forge neo folder and there click into the explorer address bar (not searchbar).
Then type cmd and hit enter.
Then copy and paste these 2 commands one by one:
venv\scripts\activate
pip install insightface
Then relaunch forge neo.
mmm,ok,thx
hellooo im trying to use local stable diffusion with the amd gpu fork but it seems that i am unable to do that i have searched alot but it just refuses to open i tried installing it thru github and stability matrix still not working mind you i have an rx 580 and i know it needs some tinkering to work but can anyone atleast point me to a documentation?
Hey, checkout the setup guides on the first link of the pinned messages.
There is an explicit guide for the rx580 with Zluda
Thank youuuuuuuuu
NP, let me know if it works.
Alright will do
How do I use img2img to generate while keeping the same artsyle as the image and how can I get a prompt from it?
Tried integrate clip but the prompt it gave me was awful
found out this tool works great https://tensor.art/template/890082907731814649
can someone help me instal control net: open pose to Forge UI SDXL? I tried the other one but got mat1 and mat2 errors (they are for SD1.5 not sdxl thats why). i tried this link but it instals to the wrong folder, and even moving it doesnt help because no models appear in the ControlNetIntergrated tab...
Hey, try these:
https://civitai.com/models/136070?modelVersionId=267493
Controlnet union+ promax should be really good for sdxl.
For noobai or Illustrious you need other ones.
i almost exclusively use illustrious models: i use stable D as an illustrator and 2D animator.
its working thank you! any advice for a dw open pose model? i love how it maps complex hands and facial expressions
Here is the Illustrious controlnet openpose model:
https://civitai.com/models/1359846/illustrious-xl-controlnet-openpose
I update comfy and dependencies and my vram requirements shot up for some reason. I could regularly make 800x1120 videos previously and now it can't even generate 768x1024 videos without spilling over... 64gb of ram and 3090, this is how it looks like mid gen

Hm thats strange. I would recommend updating your GPU driver first and then test again
What text to video platform is the best
Does anyone else experience ComfyUI's venv crashing and not recognizing dependencies when trying to open a new pod in Runpod?
I've been working with storage (1 TB) for a month now, without any issues, but since Runpod crashed 2 days ago, this garbage is useless.

Anyone find Wan Animate gives slow motion even with the ComfyUI native defaults?
anyone have any experience with comfy ui / stable diffusion? I'm running into a bunch of missing nodes when I'm trying out new workflows and I'm not exactly sure how to solve the problem without breaking everything lol
hi guys good morning, afternoon, or evening. im been trying to install stable diffusion and i go this error "AttributeError: module 'torch' has no attribute 'dml' "
does anyone know how to fix it?
hey, it sounds like your on AMD, whats your GPU?
Hi im on Rocm with an AMD card and im having an issue with Hidream where the preview in Kasmapler will show that it is worker correctly but when it goes through VAE decoder in comes out compeltely black in all cases. Are there any alternative nodes or fixes? Sorry if this has been asked before, done a search cant find an exact fit as it doesnt error or anything

When i use the first inmage generation model, it works fine, the difference being theres no decoding stage
hey sorry i didn't reply. a black out happen
here my gpu
with control net do i prompt to the image or just randomize it ?
Thats your CPUs igpu. Are you on a laptop? Any other dedicated GPU installed?
no im on pc.
wait let me check how do find my gpu
is this it?
It said its on my task manager
any other GPU?
because thats not a dedicated gpu, which is preferable needed for AI stuff
it could look like this:

nope.
so i cannot use stable diffusion?

whats your cpu model?
ah okay that explains why you dont have a gpu.
But with this you can only use the slow cpu mode
Automatic1111 with CPU Mode:
You need to have Git 64bit and Python 3.10.11 64bit installed.
- Make a new Folder on your Drive (not on Desktop, Downloads, Documents, Programms, Onedrive) and name it Ai for example:
C:\Ai\ - You go into the folder you created in this case Ai, then click in the File Explorer bar (not searchbar) and type cmd then press enter.
- Then you copy and paste this command:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
Press enter and after its done you can close the cmd. - Edit the webui-user.bat (right click, edit),
At the line COMMANDLINE_ARGS= You add:--skip-torch-cuda-test --use-cpu all --no-half --precision full --opt-sub-quad-attention - After editing, save and close the bat. Then launch the webui-user.bat
After the Installation, that can take a while is done, the Webui will autolaunch in your Default Browser.
alr i'll try it
thx
Np, There is also one thing that might work:
As you have 32gb of RAM you could allocate more RAM to your iGPU as VRAM. Thats done in BIOS.
If you give it like 8gb you could also use the DirectML Version of the setup instead of CPU.
But the best would be getting a dedicated gpu in the future.
oh ok thx fo the info
Good day, people. Looking for some help with "cg-use-everywhere" in regional prompting as I am trying to have a different set of lora applied to a different inpainted region (e.g. Region 1 and Region 2 groups). Currently, most parts should be connected correctly, yet I am having an issue with finding a way to connect the MODEL output from " CR Apply LoRA Stack" to have it received by the KSampler model input as it's currently using the model output from "Attention couple" in Combine regions group to the KSampler model input. I have a feeling that I am trying to over-complicate it and there's a more simple means to have this archived, yet my brain isn't there rn  looking for any suggestions or workarounds.
looking for any suggestions or workarounds.

hi guys good morning, afternoon, or evening, i got this error anyone know what does it mean?


nope i followed what CS1o said
and i got this error
alr
anyone know how to fix it?
the support sever i joined earlier suddenly disappeared after i made a ticket and explain the issue
it seems like it somehow broke as it tried to get some stuff from XL.
you need to probably git clone the normal repo again and only adjust the webui-user.bat then relaunch
the "suport server" are scammers that want money and personal data, report them to us and discord if you see them and block
git clone the normal repo?
how
oh ok
- Make a new Folder on an internal Drive (not on Desktop, Downloads, Documents, Programms, Onedrive) and name it AI for example: C:\AI\
- You go into the folder you created in this case AI, then click in the File Explorer bar (not searchbar) and type cmd then press enter.
- Then you copy and paste this command:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
Press enter and after its done you can close the cmd.
but delete the other webui first
do i have to put the same commandline_args =?
omg it worked i came back and im on the site thx for helping!!!
Perfect np
Hello, my OpenPose was working for like a day but now i get an error when i try run it on my ZLuda Forge SDXL or Illustrious models

Please, help me. WHY???

that looks like the same issue im having.
Can you show a complete cmd log?
Which preprocessor did you have selected?
Hi! I'm kinda new to SD and read that Zluda was good with AMD gpus (I've a 9060XT) but when I tried installing it I got this error after trying to run the .bat

I was following this steps: https://github.com/patientx/ComfyUI-Zluda?tab=readme-ov-file

GitHub
The most powerful and modular stable diffusion GUI, api and backend with a graph/nodes interface. Now ZLUDA enhanced for better AMD GPU performance. - patientx/ComfyUI-Zluda
hey, probably the antivirus flagges the zluda files
its a common issue with that repo
Thanks. I'll try reinstalling everything with the antivirus turned off
it will probably flag the files as soon as you enable it again, so better set the .zluda folder inside comfyui to the whitelist or ignore list but not the whole comfyui folder
Gotcha. Should I set an exception for the zluda folder and then reinstall it?
Good and bad news. I got a new error

looks like torch is having some troubles, not sure why 🤔 , maybe I've a wrong version of something.
I just formated my pc today btw, I installed everything from 0 so I'm not sure that I've an "older version" or something like that, but I'm no experto
you have the wrong python version
python 3.11.9 is required

Oh, ok
I'll replace the versions realquick
should I reinstall everything or just restart pc
Gotcha
I'm having troubles with the HIP. I tried installing HIP 6.4.2 but im getting this message

I'll try reinstalling it rn. Lmk if im doing something wrong
have you added hip to path?
I'm having troubles with this step

https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU/releases/tag/v0.6.2.4
If i've a 9060xt what should I use¿


GitHub
Rocblas and library for hip sdk 6.2.4 (for Windows)
Some prebuild with rocm6.2 package also works on 6.2.4 .
ROCBLAS packages based on GPU Arches:
By GPU Arches (Alphabetical Order)
gfx1010:xnack-...
I managed to add the path btw!
you dont need custo mfiles
hip sdk 6.4 has native rx 90xx support
Oh. Gotcha
What should I add to path then? I was doing the 6.2 way but looks like that's for older gpus. I'll try removing that and going with the 6.4 again
yea uninstall everything of 6.2
on it
What should I add to path for the 6.4? I added C:\Program Files\AMD\ROCm\6.4\bin but idk if that's correct

thats correct


oh an you have to run the patchzluda2.bat , and dont run the patchzluda.bat
inside the comfyui-zluda folder
thats needed when switching to newer hip sdk versions
You're 100% right. That was mb for changing the version
is asking me for a URL. Post says i gotta get them from here: https://github.com/lshqqytiger/ZLUDA/releases
Should i use the newer? 3.9.5

GitHub
CUDA on AMD GPUs. Contribute to lshqqytiger/ZLUDA development by creating an account on GitHub.
if you used the -n .bat files you need the nightly version
if not then the normal ones
Im using this url: https://github.com/lshqqytiger/ZLUDA/releases/download/rel.5e717459179dc272b7d7d23391f0fad66c7459cf/ZLUDA-windows-rocm6-amd64.zip
And is giving me this error:

I tried using the N version too but no luck
Should I re-install from scratch? Takes me like 6 minutes
Looks like I didn't fully uninstalled the hip 6.2
I'll see how to do it properly
Uninstall every module of hip SDK 6.2 then reboot the PC
On it
Done. Trying again
It gave me the same error. Im reinstalling the whole thing
I removed every module of hip 6.2 and rebooted. I'll try to stick with the normal bat file (not the N one)

It worked!
Thank you so much mate. You're the goat
Perfect! No problem 🙂
Comfyui now has native support for AMD GPUs and patientx says the performance is similar to his comfyui zluda fork. Would you try it or wait for a later version?
Using PYTORCH_TUNABLEOP_ENABLED=1, the first 512x512 took 37s for the default prompt but the subsequent ones only took 3s avg. Then I upped the resolution to 1024x768 (16 words prompt). First one took like 11 mins and the subsequent ones took only 12s.

I already tried it yesterday,
Speed test:
SDXL 1024x1024 on a 7900xtx OC/UV on Adrenalin 25.9.1 on Windows:
Comfyui without changes with rocm 6.4.4 and torch-2.8.0 gets 3.6 it/s (using sub quadratic attention as pytorch attention doesnt affect it)
TheRock and ROCm Nightly with rocm 7.9.0 and torch 2.10.0 gets 4.6 it/s (using pytorch cross attention)
Haven't tested Tuneableop but set TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1 is needed for nightly and pytorch cross attention.
hi, friends. nice to meet you
I have a new idea to collaborate with you that could be profitable.
how about it?
Wrong channel
what do u mean?
Read rule 3 and 5 of #✍🏼|rules-and-tos
okay. first i used the explosion and i t read the control net and showed me the result:

but when i tried to generate an image with it i got the same error:

i managed to get this model working as an alternative tho https://civitai.com/models/135552/openpose-sdxl
takes fucker long though, maybe thats just the price i have to pay
You should use controlnet union++ promax
That should work and fast
yes, i have been to this link before but im not sure how to download/install it. i think i pasted the link in webui extensions url installer and it downloaded the files to E:\SD-Zluda\stable-diffusion-webui-amdgpu-forge\extensions\controlnet-union-sdxl-1.0 but the models don#'t appear on preprocessor>models
Dont install it as extension
Just download the model and put it into models/controlnet
Hello good fellows!
Wonderful to be here.
I have managed to not only install automatic1111 on fedora with al lthe broken instructions out there but I also got rocm working and everything's great.
I just can't generate anything at 1024x1024 with sdxl -.-
Running into torch.OutOfMemoryError: HIP out of memory. Tried to allocate 9.00 GiB. GPU 0 has a total capacity of 11.98 GiB of which 8.04 GiB is free. Of the allocated memory 2.60 GiB is allocated by PyTorch, and 894.80 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
Now I am on an older RX6700XT witth 12gb vram so it is pushing the limit but surely I can find that 1gb it's SO CLOSE or hand off some of the processing somewhere to get this to work?
already using --medvram and --medvram-sdxl
Processor is a 5700X3D not really a workhorse for this kind of thing.
Much love out there guys
Which version did you install ? What command line args are you using ?
standard automatic 1111 webui via python install
sdxl1.0
export COMMANDLINE_ARGS="--no-half-vae --skip-torch-cuda-test --medvram --medvram-sdxl"
smaller models work fine
Is it even using your gpu ? Can you you check its usage during a generation with rocm-smi ?
Any setting that would reduce that vram use by like 1gb or let it spill into the 64gb normal ram (ik that's not how it works and it's wildyly frustrating 🤣 )would be great
yes it is defionitely using my gpu I did all of that earlier
Went from 45s/it on my processor to 4.5its/s on my gpu it's definitely working
probably is indeed
the py script calls the HSA_OVERRIDE now for my gpu class which is quite nice
I know I need a new gpu but I thought I could spit at least an image or two out of sdxl with 12gb vram.
With the 0.04GiB and the 894.8MiB that's so damn close to the 1GiB it needs
It's like smelling the finish line
You not gonna like it... But I would not recommend using A1111 nowadays. It hasn't seen any updates for over a year. Forge is more updated but also on its way out because the dev is quite busy. But still it would probably do better regarding memory management than A1111.
Also Forge Classic or Forge Neo are probably the best ones out there for now but I haven't fully tried them yet.
ComfyUI too but that s a whole another beast.
Check the pinned comment for install guides on those.
bags
They re windows based guides but there s still some knowledge to apply there for linux stuff too.
Don t bother with zluda if you re using linux
run things using rocm directly.
not without running much much slower
bags
you can try using --opt-sub-quad-attention but I would nt hold my hopes
i need to free up a total of 0.1GiB
until you add a few words or lora and then it will be 0,5gb or whatever :p
not sure what resolution you re using too but you could try lowering it.
1024*1024
the kind of basic sdxl size I thought?
yes, you can lower/increase it by 30% without too many issues
Hi people. Has anyone experienced prompts being completely ignored when running Qwen-Image-Edit locally?
I'm using the GGUF models in ComfyUI and trying img2img. E.g., with a prompt like "add glasses to her face" I only get unrelated, slight changes to the image: a bit more saturation, eyes pointing elsewhere, etc.
I'm using these models:
Qwen-Image-Edit-2509-Q3_K_S.gguf on "Unet Loader (GGUF)" node
Qwen_Image-VAE.safetensors on regular "Load VAE" node
And these models on "CLIPLoader (GGUF)" node
mmproj seem to be correctly associated:
Using mmproj 'Qwen2.5-VL-7B-Instruct-mmproj-BF16.gguf' for text encoder 'Qwen2.5-VL-7B-Instruct-Q3_K_S.gguf'.
Tried with and without Qwen-Image-Lightning-4steps LoRA.
Btw, txt2img does align with the prompt, the problem is only img2img 🤔
Appreciate if anyone can shed a light 🙏
SOLVED:
I was using the wrong "Lightning-4steps". There are specific ones for Image vs Image-Edit vs Image-Edit-2509.
Now my output image is a bit messy but that's a different problem.
SOLVED:
Upgrading models from Q3_K_S to Q4_K_M fixed the messy output.
took your advice. ComfyUI would work if it accepted the HSA_OVERRIDE argument as easily as A1111 because it uses neag 2GiB less VRAM. :/
Different problems are not the same problems it's all progress
VAE load device: cuda:0, offload device: cpu
would be nice if Comfy just used the gpu but that would be too easy
comfyUI should be using your gpu by default
And you can just set HSA_OVERRIDE before running comfyUI, it s a system variable, not a a1111 argument.
So something like HSA_OVERRIDE=xxxx python main.py should work.
automatic1111 anyone know how to get all old / new smaplers i wanna have them all to run test anyone know how to restore them
easiest way is probably to just revert to an old version if you just want to run some tests
dang nabbit thanks well if anyone knows how to get all versions that would be very nice. Thanks for the recommendation tho will help me out a bunch
Hi, in webui-user for sd neo, are there any strings to make it faster at startup?
Is it installed on an SSD?
yes,Corsair Mp600 Elite 1tb M.2
but I noticed that it was always slow to start up honestly
Even photo generation doesn't seem very fast. The PC was formatted only 2 weeks ago. I also updated to the new Windows 25h2 update.
Latest drivers installed?
Correct launch args used?
Also add git pull to the webui-user.bat to auto update it
where should I write: git pull?
@echo off
:: set PYTHON=
:: set GIT=
:: set VENV_DIR=
set COMMANDLINE_ARGS= --cuda-stream --sage --fast-fp16 --xformers
:: --xformers --sage --uv
:: --pin-shared-memory --cuda-malloc --cuda-stream
:: --skip-python-version-check --skip-torch-cuda-test --skip-version-check --skip-prepare-environment --skip-install
call webui.bat
Add it below the @echo off line
The rest looks good
Yes
ok,thx
What about faster image generation? Maybe it's just my impression that it's a bit slow XD
What was your GPU and how long does a illustrious 832x1216 30 step Euler a image takes ?
hi everyone,
i'm looking for help using my character LoRA to create t2v animations with SD 1.5 and AnimateDiff,
the results i got so far are mediocre at best. t2i works fine using my LoRA(s)
i feel like its a training issue and i can share examples
hope this is the right place to ask
Hi! I'm trying to use zluda with an AMD card (9060XT 16vram) and 16RAM. I can generate images with checkpoints from civitai and the standar SD ones but flux seems to hate me or something.
I tried reducing the ram to --lowvram but when trying to create any image with flux (txt2img or inpaint) it just freezes my pc and I gotta restart. I don't care if it takes longer to generate but idk why it crashes? The SD with 512x512 generates images in just like 10 secs. Is it that bad with flux?
I took the pic with my phone for obvious reasons


Hello I am experiencing difficulties with my Stable Diffusion installation but my english is very bad. Does someone here speak german?
Hello. I'm pretty new to this. I followed a tutorial only instead of the 3.5L I used 3.5M from here
When I try to load in the workflow, SD3.5M_example_workflow.json, I get this error.
How do I resolve this? Where can I get this SkipLayerGuidanceSD3 from?

I believe I solved my own issue. I'll leave the question for anyone else, and I will update as to whether this fixes it or not, but I'm updating ComfyUI and python dependencies now...
Well, running that made it so pytorch isn't working, because it "wasn't compiled with CUDA enabled". Probably worth pointing out haha
The update did resolve this issue.
Hey, make sure you dont use the 23GB large flux model. It doesnt fit in your vram and will freeze everything.
Use a smaller gguf variant like Q8 gguf
Hey, yes I do, feel free to DM me ^^
Can anyone recommend me any easy to install all ai platform?
The only one I know is Pinokio
i dont recommend them but there is also stability matrix, but its only for image gen and traning webuis
Heya my discord got hacked but im back now
hey CS1o i helped him install comfy and stability matrix set up api key for civitai and redirect the extrafolderpaths.yaml
but then he got a cuda error
he got a 1070 8gb which should be fine
like his cuda cores couldnt be accessed
the installation went good
i mean we used comfy ui portable straight from the github
yes i love stability matrix but for some reason the search function is still bugged as hell
i feel like only very few models get displayed on search
the previews get bugged and need a long time to get redirected
and then sometimes when i reach the end of the search results and load more models it loads a lot more and mixes them with the models i previously looked at
its extremely comfortable for browsing models and loras
he should check if he has the latest drivers from nvidia
thx
ill tell him to update his drivers when i see him
but with a 1070 comfyui is no fun, i would suggest using forge or forge neo instead
is forge like auto1111?
i see
more updated and some more features, better optimised on low vram or older gpus
back then i started with my 1060
and sd1
damn it was slow and the images were bad
but when i swapped to comfy and the gen time got reduced to half the time
if he installs forge
does he need the --lowvram stuff?
i forgot how to do it
thats long gone in my memory
nope not needed
epic
also idk if this is the correct chat for it
but atm i am stuck at pony models
and maybe some flux
is there any big upgrade? like sd1 -> sdxl, sdxl -> pony?
whats your gpu currently?
Illustrious based models are currently the best for Anime stuff, newer training data on booru tags and no score tags needed.
And there are also semi and realism models of it
i have a 4070