#🤝|tech-support
1 messages · Page 125 of 1

So they are different in the sampler used and in the cfg scale
And fp8 is enabled for sdxl in auto
And fp16 lora cache
Cfg shouldn't affect it that much
Sampler too
Right?
Unless something isn't visible in the Metadata
is it possible?
Yea Normaly not
But you can't generate the same images with different webuis
They work different in the background
I don't think so. Maybe in the config_ui.json
Hey all, this is probably classic. I downloaded flux.1 and get images like this
Details: I have an rx6700 12 gb card.
I close and re-open sd maybe 10 times and 1 out of 10 times, it renders properly.
It's the FLUX.1-dev q4 model I'm running. I can check the error messages when I get home, but is this a known issue?

probably trying to render at a wrong resolution
possible too but more likely wrong resolution when it looks like that.
hmmm the image you sent is 256x256 tho
512x512 should work iirc (havent messed with flux in months)
what settings did you use ?
Yeah, I copy-pasted from the internet, since I'm at work now. The very strange part, I see the render, it looks like that, then I get a 512x512 grey png as an output
I use default settings out of the box.
I up the image count to 20 though.
"grey png as an output", what s your gpu ?
AMD Radeon 6700xt / linux / ryzen 2700 / 64 gb ram
and what tool are you using to generate ?
Stable Diffusion, flux.1 model. What other info is needed?
"Stable Diffusion" is not a tool. You re using auto1111, forge, comfyui, etc ?
Auto1111 thanks for the clarification.
do you use directml or zluda for it ? what command line args are you using ?
I am using rocm + pytorch. No zluda afaik. Would pytorch use dml?
Sorry for the ignorance, but thanks, I am learning now.
windows or linux ?
ok sounds good then. Probably gonna need the command line args you re using tho to go any further.
(there should be a line for them in webui-user.sh)
and a complete log of one generation
I will check in 8 hours. thnaks.
Auto1111 doesn't support flux
welp that answers it then :p
because its weird, a1111 suddently made my loras worse
hey csio
do u think this is enough

i run stablediffuion on a portable drive (F)
should i do it to that too?
set it to 16000 min and 24000 max
and dont enable it for any other drive than C
then reboot
It crashes now
A lot
I get a low memory error on my browser
In your Browser?
yes
Where
opera gx
Hmm okay, then try set it back to system managed for C and restart
Ok
its back
i dont get the error now
but the generations are still messed up
it isnt suppose to be this detailed
with and without the masterpiece and source tags
Maybe because you have set them to be cached as fp16
Maybe revert that setting
whats that
A setting
isnt that a scheuler?
Nope
does it affect generation that much?
Haven't tested it


anything here?
i would have ditched a1111 a long time ago and moved to forge if it wasnt for a specific extention that isnt on any other web ui, except for a111, its the queue extention and its a life saver
What's your GPU again?
Reforge maybe works too with that extension
u should get it
itsa lifesaver
lets u queue different prompts with different settings
has support for the scripts, resolution batch count etc
does it ?
do i need to delete the venv folder even for forge ?
cuz i just updated it
man....
now i cant see my models in forge
ok so basically
it adds this button

to add your current prompts seeds negatives resolution etc, into a queue
u can add and add
a1 a2 and a3 are presets for style loras, same settings and prompt all u have to do is add the lora u want
im not that tech savy
thats why i use this extension
plus

its easier to edit since it just adds a textbox below
and u can edit it if u have a change of mine about a specific thing within the queue
ye
very
thats why i didnt ditch a1111 for that spefic extention
very handy for lora testing
no flux
which is good
do u know how scary flux is ?
its good
really good
and i dont like that
how realistic the images can be
now imagine if bad people got their hands on it
especially scammers
I got about half-way through converting this for Forge - I'll share if manage it all. It's actually a fairly trivial update in the sense that it just needed to have a few sections modified to conform to new standards in the more updated packages (pydantic ect.) I already finished that part. It's getting everything else down the dependency rabbithole to also play ball that is actually the challange. 5-6 dependencies deep into the friggin UI framework I'm not sure if I am qualified to follow the code anymore lol. It may be solvable by what I have already done + tweaking one of the package versions versions slightly so it doesn't break other stuff down the line.
I agree that life is painful without it - but right now Forge is the only one that even supports Flux for playing around with the new stuff
hello, I have a question stable diffusion forge or comfy ui works at good capacity with two gpu d (rtx 2080 ti)??
swarmUI can utilize two gpu's by running two generations at once but you can't use two cards for one image yet unless someone developed it recently
Hey I know 99% of stable diffusion used nvida cuda cores, and I have an amd gpu. I had to install a special version of webui a couple years ago for amd, and I can no longer find it
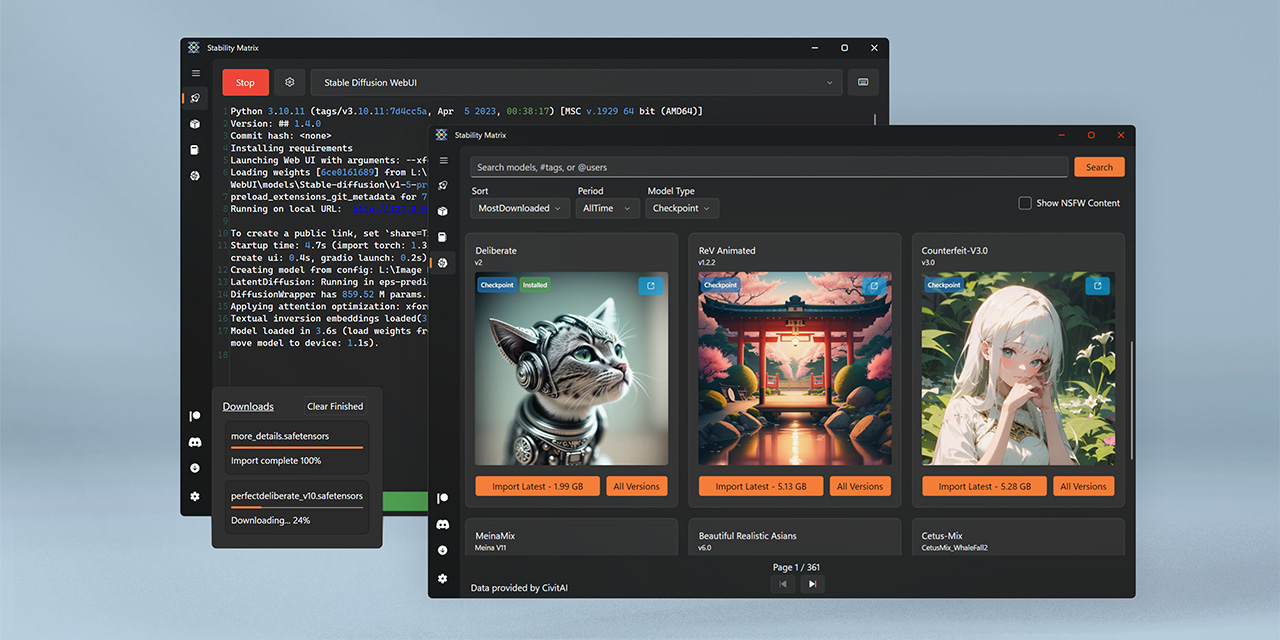
GitHub
Multi-Platform Package Manager for Stable Diffusion - LykosAI/StabilityMatrix
a friend sent me that one but idk if it will work on my amd gpu
go to the pinned posts in this channel. look for @ornate elk AMD GPU guides. everything you need is in them
I am back, #export COMMANDLINE_ARGS="" So nothing. In fact the whole file is commented out!
Ty
Hi guys, ive followed the guide to install sd on amd, added
--use-directml --skip-ort --medvram --opt-sub-quad-attention --opt-split-attention --no-half-vae --upcast-sampling
to the webui bat file but still getting the screenshot error
anyone know what to try now?
I tried adding --skip-torch-cuda-test into the webui aswell but no luck

Hey, What's your GPU?
6950xt, I've uninstalled it all and followed your zluda guide instead so ill hang fire and see if this works!
But my zluda guide doesn't list the args you put in. You used --directml for example
nope I think i followed a different guide, ive completely undone all of that and done the zluda instead
Ahhh
Okay
Did it worked?
Let me know if not. But with that card it should work easily
It gave me a few errors but its finally loaded up the webui 🙂 do I just add models into the folder as normal with this then? its given me stable diffusion model failed to load in the cmd though
Can you show the full Cmd log?
I'm AFK, driving brb
ok
Do you have a log tho ? Meanwhile you can try uncommenting the line and setting --no-half argument in it. We seem to live in very different timezones.
Can you delete the model from the stable-diffusion folder and download an other model to test?
I had no models downloaded, it seemed to try downloading something for me to use, I'll try that in a mo tho thanks 🙂
@ornate elk downloaded a model and replaced it and still have this error
Zluda failed at start
Something is not correct with the path settings maybe
And did you download any gfx files?
Gfx?
Downloaded literally just the things in the guide
any idea why the quality is bad? like it's extremely bad, its blurry foggy, idk why

Can you show me the path settings?
Try an other pony model. The original is bad
i am open for suggestions :3
where its all downloaded you mean ?
C:\SD-Zluda
No I mean the environment variable's path settings
Nova anime xl is good
This?

hello where do i put ultralytics yolo v8 model?
no ultralytics folder in my comfyui
i do have the comfyui impact pack
Yep looks correct
Can you try delete the venv ans the .zluda folder from the stable-diffusion-webui folder?
Then relaunch
hey do you know how to get the ultralytics folder? i tried installing comfyui impact pact again in the manager but it doesnt let me uninstall
Delete the old impact pac and then reinstall
@ornate elk reinstalled python and made sure it was add to path, reinstalled zluda as this was C:\Zluda/Zluda as id added a folder, going to see if this fixes the issues and try
installing it gives an error like this, still says its installed tho
but the folders arent there like ultralytics



Hmm idk then
Maybe the Ultralytics gets downloaded when needed?


Have you tried updating comfyui?

idk why does it think
my email is that
Hmm
Found this on the impact PAC github

i did in the comfymanager
HM okay
but still
comfyui doesnt wanna update
it thinks me email is THAT
but its not
idk how to make it know my real email
It doesn't need an email
Its a bug
Sometimes it can occur when you have nodes that got removed fron github like the Reactor extension
yeah i have reactor node
What you can try is a seperate Comfyui install in the SD-Zluda Folder
@ornate elk reinstalling all, or changing the file path to correctly seems to have fixed it mostly, it loads in and lets me get started now and seems to generate, although it only generates a grey square ?

Okay good but, the model is not a normal model
Please use any model that is between 2-7gb
For example juggernaut XL or Nova Anime XL
you cant use hunyuan in auto-reforge right?
ima do it from your guide, with the zluda fork
its gonna be the newest version?
Yep updated a few days ago to the latest comfyui release
❤️ you're a legend, seems to work perfectly now, thank you!
Failed to create model quickly; will retry using slow method. is that message normal though? still lets me do images once its done the slow method but idk if id need to do that each time?
Yep that message can be ignored. Doesn't affect anything
No problem 🙂
perfect 🙂 thanks for all your help!
NP, let me know if you have any other questions
I've got loads but ill leave you to help other people for now xD
i did it and
i can tell i had an outdated version
things look so different
but still, no folders
i have this


i just created the instand id model folder and it works but not for ultralytics
Hmm idk. Will check how its on mine later
its okay i fixed it
i cant believe i just created the folders
and it worked
🤣
InstantIDFaceAnalysis error 😦 amd

this happens when i start a1111 with zluda
Have you tried it like 10-15 times like I suggested yesterday?
i tried it like 3 more times and then i went to sleep
Having reactor and instantID won't work together is my guess. As I had massive issues when tried to use face id while having reactor installed
Try it more
but it doesnt even say its compiling anymore
Its no joke 3 users with a rx580 reported it to work
im trying to get it to work😭🙏🙏
How much ram do you have?
i could have a possible source for it not to work tho
i do not have it, remember? i moved uis
i made a new folder and installed every node from scratch
just moved my models folder
maybe its because i use it on my secondary drive and my amd driver is installed on c:
would you like an error report?
No thats not an issue
Drivers always should be installed on C
Hmmm okay, can you give me a full cmd output and the workflow?
(this is a very nice workflow)
Yep exactly. When it crashes, just start it again. Until its done.
After the compile is done it should work normaly
i updated pip, pytorch and some other things
now this comes up
what kind of styles.csv does it need?

Is there a guide anywhere on any of the settings within sd that might be worth changing? and things such as what dampling method to use and when and so on? Trying to generate pixel art assets for a game and each time im trying with different settings and not noticing what is different
Hopefully to potentially stop me from getting errors like this when trying to make larger images also
OutOfMemoryError: CUDA out of memory. Tried to allocate 17.80 GiB. GPU
Time taken: 7 min. 6.3 sec.
Which settings did you used?

Ah well thats a to large resolution
Sdxl models are trained on 1024x1024
You normaly generate at half the resolution and then Upscale by 2 with hires fix to get Wallpapers
Ahh so as long as I stick to under 1024x1024 I should be fine? What about sampling methods and everything else, should I stick them all as default?
Nope it should be around 1024x1024 but a bit lower and higher works too
Like 720x1280
Aspect ratios i use a lot with good results:
1:1 1024x1024
4:3 1152x864
3:2 1248x832
16:9 1344x768
You can also reverse them to get portrait/landscape image
Id just made a 960x540 so I can upscale it to the exact size, but the image seems to change when i click create an upscaled version, is that normal ?
ahhh dammit, didnt even finish the upscale
OutOfMemoryError: CUDA out of memory. Tried to allocate 17.80 GiB. GPU
Time taken: 3 min. 35.1 sec.
id literally just clicked this ✨
Ah i dont use that. I sort of forgot on how to use hiresfix in that UI but with the right settings it will just upscale without changing and will be a lot faster
there a guide anywhere for what those settings are or what else I should be changing?
The denois needs to be 0.5 or 0.4 and you need the tiled diffusion extension.
That prevents it from going out of memory
OutOfMemoryError: CUDA out of memory. Tried to allocate 17.72 GiB. GPU
Time taken: 3 min. 26.5 sec. still fails, assuming I added the extension correctly, i reloaded the webui with it but still fails
After you installed it you need to check the tiled VAE option
Also don't run anything in the background like games or Wallpaper engine or twitch
it works but only if I turn the resize by scale from 2 to 1.5 which obviously means the image is smaller, not a massive drama tho
i didn't see it earlier but you are on a nvidia gpu right?
yep its fine
if it works with 1.5 thats good. if you use a smaller res it will work with x2
just wondering why its flipping out over a 2x upscale with thise resolutions though with that much vram
ive got literally nothing running in the background either
is your driver updated?
yup, although even 1.5 scale isnt working now after coming back to it again
OutOfMemoryError: CUDA out of memory. Tried to allocate 9.97 GiB. GPU
Time taken: 2.3 sec. and its trying to use less
can you show the settings again?
i feel like it has to be the settings. i ran a 1152x896 into a 2x and a 2x again (turning it into a 4608 x 3584) with only 8gb vram those times of 3min are also quite long
it took me 54 for the final refine and 18 for the first one. any special kind of upscaler model your using?
Okay the restart seems to have helped, it did 1.5 this time
im just dragging the image i liked into img2img and upscaling it from that, idk if thats how im meant to do it or not though, im a complete noob at this
you can use the sd upscale script in img2img for that too
theres so much to this its actually insane 😂 ill give that a try aswell
yup, failed trying the upscale by 2 again
54 😮 I feel like if it goes past a min for me its doomed to fail xD
you should also use the fp16 sdxl vae
it reduces the load a bit and the gen time
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/tree/main
its the sdxl.vae.safetensors
🤯 I dont even think I understood what you said let alone doing it 😂
is it another extension ?
nope its a file xD
first go into settings, User interface, quick settings, and there add sd_vae
then hit apply and reload ui.
download the file from my link (sdxl.vae.safetensors) and drop it into models/vae


models/vae
ive only got the stable-diffusion where i put the models and the VAE, do i just put it into both or am I looking in the wrong place?

Ohhhh fml my bad 😂😂 I was looking for models and VAE 😂
or use this link C:\SD-Zluda\stabe-diffusion-webui-amdgpu\models\VAE
I'll try it out in a few mins! Sorry just gotta pop out

eughh I dont get why sometimes it gets to 95% or so before it decides it will fail =.=
idk why it fails last min tho
Surely it can decide, I wont request any more, ill just take longer to do it ?
or am I just being naively optimistic xD?
I thought I had a reasonably good gpu aswell xD didnt think id be having these issues
You always need to have tiled VAE enabled
When using highres/upscale
Also in img2img use SD upscale script not resize by
Nan

Quora
Answer (1 of 3): Hey man,
1, mostly nan is caused by some math calculations.
Check if you are using something like tf.log or tf.sqrt in your network model.
If you do use them, clip the operands (or add small constants to them) to avoid the NaN.
2, learning rate too high.
If you are doing ver...
guys, im making lora for a style but im not sure which model to use. should i make it more sd 1.5 or sdxl??
made all these changes this morning, still getting the same issues
im basically training 1 art style using 71 images
amd zluda a1111 i used the guide in pins

Can you show the full cmd log?
i just installed the directml a1111
it works for now
Ah alright
i only am installing it to make captions for images
for a lora dataset
well then i did it all for nothing xD
amd for this ai stuff dude, kill me :D
Can you show what you try to do again?
comfyui lotus giving an error when trying to be installed
it shouldnt conflict with any other node
same with searge llm
Error message occurred while importing the 'Searge-LLM for ComfyUI v1.0' module.
Traceback (most recent call last):
File "C:\SD-Zluda\newest comfyui\ComfyUI\custom_nodes\ComfyUI_Searge_LLM\Searge_LLM_Node.py", line 13, in <module>
Llama = importlib.import_module("llama_cpp_cuda").Llama
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python312\Lib\importlib_init_.py", line 90, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
File "<frozen importlib._bootstrap>", line 1324, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'llama_cpp_cuda'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\SD-Zluda\newest comfyui\ComfyUI\nodes.py", line 2145, in load_custom_node
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 995, in exec_module
File "<frozen importlib.bootstrap>", line 488, in call_with_frames_removed
File "C:\SD-Zluda\newest comfyui\ComfyUI\custom_nodes\ComfyUI_Searge_LLM_init.py", line 1, in <module>
from .Searge_LLM_Node import *
File "C:\SD-Zluda\newest comfyui\ComfyUI\custom_nodes\ComfyUI_Searge_LLM\Searge_LLM_Node.py", line 15, in <module>
Llama = importlib.import_module("llama_cpp").Llama
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python312\Lib\importlib_init.py", line 90, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
ModuleNotFoundError: No module named 'llama_cpp'
is searge llm for nvidia only along with lotus?
llama.cpp can't work with zluda.
Zluda currently can't "translate" every feature that cuda has
what about lotus?
"comfyui - lotus"
Idk, haven't tested it. But I know depth extensions work in auto1111
Or controlnet works for comfyui too
Has depth and normal map and more
In forgeUI, does anyone know a way to keep PNG info (prompt etc) in upscaled version i.e. I lose it when i upscale in img2img?
I am adding it to imgtoimg from folder, not moving it using "painting icon" after txt2img
I think there is no way if you add I'd from folder
Does Flux on Forge not allow for negative prompts? The negative prompt section is grayed out.
Cfg on 1 = no negatives
And flux wants cfg of 1
How can i find the full logs? Is there an option from the web-ui. When I launch webui.sh, is it just the output to my terminal?
I am sick so in the correct timezone now.
Yep, its not available for flux
I need help! Whenever I use even a single LoRA in my prompt, my GPU usage drops significantly. Specifically, CUDA utilization gets stuck at around 10–20%, whereas without LoRA, it runs at nearly 100% full load. As a result, the speed difference is almost 10 times or more. For reference, I’m using a 4090 (24GB) with WebUI. Does anyone know a solution to this issue or if it's a known problem?
onetrainer flux training, this happens, i already have gguf installed (14.0) and i already have pytorch 🤔

bruh dont think gguf work for training
.safetensors also dont

Ok, after many reloads, flux.1-dev-uncensored-q4 loads I don't understand why, but it "works" now. I am sure I will have to re-load until it works again after a shutdown.
and i am logged in on chrome
i think u should try Opera GX, the sponcer of todays video
Why do some images come out like this? Some checkpoints just always seem to do this for me even if they are bigger and proper checkpoints, this was with artsyvibe

wrong vae issue
this?

yeah you need ae.safetensors for flux1d checkpoints
how do you know what you need for different checkpoints? does it say somewhere on each checkpoint? and also where do I go to get the different VAE?
actually checkpoints have vae, clip and unet included so you should have it already
flux does not use negative prompts. and it does not use CFG
thats all the ones i have

you actually can use cfg and negative prompts to good effect, it just wasnt designed for that use.
try none or automatic bc when you load the checkpoint it should have vae included
tried automatic and none and still didnt work
regardless of whether you can use it or not, it was designed not to allow negative prompts and bfl uses something different than cfg. that's why it is set with cfg not avaialble and no access to negative prompts becase negative prompts need classifier free guidence - which flux does not use.
https://civitai.com/models/1162948/artsy-vibe this is the 1 ive been trying to use, although theres a few that dont seem to work with me, this says checkpoint and base model so should be okay right?
you can also use a teaspoon to dig a hole in your backyard, but that isnt' what it's designed for
idk much about forge, i just know it barely does regular flux. and this is also a checkpoint merge
idk what forge is, sorry im a noob! Im on sd with zluda if that means anything
you can definitely increase cfg beyond 1 and use negative prompts, all im saying. it does increase generation times but it definitely has a profound effect on image composition/etc
forge is an interface to run the AI models in. so are auto1111 and comfyUI
regardless of whether you can do that or not, flux does not use it - een if you set it to 100, flux itself does nto use it. comfyUI might be doing stuff to modify things when you do that, but the flux model itself does nto use it
lol im telling you it can use cfg
different from flux guidance
and I'm telling you that while comfyUI might modify your out put, it's not the flux model that's using it. Robin Rombach, the author and inventor of both stable diffusion and flux, designed flux to use something other than classifier free guidance (cfg)
so when you turn on cfg, and force negative prompts, you are pretty much BREAKING flux
might as well just use sdxl
works great for being 'broken'
So how do i fix it not working? I tried it with flux checkpoint aswell and that didnt work either
yes, well - this discord isn't the black forest labs flux discord. it's the stable diffusion discord. so why is it even being discussed here?
what is it specifically that you are trying to do?
no idea, you keep arguing lol
Just trying to get pics to load with different checkpoints, just trying a bunch out but half of them give me that pixel artifact look and nothing else loads
this?

https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/ae.safetensors
heres the vae for flux models, unsure if this will help
yup
usually that specific issue happens when you use the wrong vae but youre using a checkpoint which has should have the vae included
yeah. you are using the wrong Variable Auto Encoder (VAE) for the model or checkpoint you are tyring to use
if you're using flux, you have to use the flux VAE
hes using a checkpoint though
if you're using sdxl, you have to use a VAE trained for sdxl
so? it's trained for a base model of some sort. what base is it trained for?
and does it have a VAE baked into it
if it does, you don't use a second vae
so how do i know which vae i would need in general?
bc its a checkpoint merge? lol
not in general. it's specific to the model or checkpoint you are using
so? which models were merged? there's a base model at the bottom of that or there's no checkpoint at all
where did you get it from?
civit
do you have the link to it?
Flux is not supported on Auto1111
lol thank you^^
You would have to use Forge Webui or Comfyui to use flux
Swarm is great with flux too***
Swarm runs comfy in the background
Ahhh ok, thats a pain! Can I use auto1111 and forge or comfy on the same pc ?
yes. but why?
Yes but since it has a different front end its nice to mention
yep and you can also share the models between them
Id like to try a bunch of different checkpoints so if I cant do it on 1 id like to try on the other
yes definitely, they each have their own usecases
you should probalby take @lucid yoke suggestion, install SWarmUI - and let it do all the technical stuff. and just focus on generating
damn remembering what checkpoint works on which is a pain, can i not just run everything from 1 interface?
sure. use comfy.
yeah ill probs try and do that if its easy to do! is there a guide somewhere?
Swarm does, comfy too but its more confusing
Forge supports more models than auto1111, and has the same ui
Swarm is drag and drop but once you feel confident enough to mess with comfy you can interact with the backend
but you still have to load the right stuff for the models you are loading. when you download a model, there will be an area on the page that tells you what base model it was trained for and if you need a vae, it'll tell you that too
whats your gpu again?
amd 6950xt
okay then you can use any webui from my guide
would still recommend forge/auto above comfyui for beginners
beginners need more advanced node support to make things easier
that's why i was agreeing with Euro and suggesting swarm.
trying to pickup old ui with no support can be difficult when the last people talking about it are from a year+ or more
Beginners need a drag and drop method where they can simply type a prompt and not worry about anything else tbh
especially me, im new to all of this and its blowing my mind xD
google tools like imagen work well for learning prompts
just strictly prompt 2 image
there's a steep learning curve, just take it one step at a time. you'll get the hang of it
local is prob a headache/not necessary for beginners lol
I mean, civit ai image gallery is a great way to learn prompts for specific checkpoints
Im kinda okay for the prompting side of things, when i find a checkpoint that works and i know how to make it work the images that come out are really cool and end up nice and clean so im happy with that
and like ill work using civit gallery and find images i really like and download the checkpoints and loras to try and see what styles I can make with it which is what ive been trying to do, just half the ones ive dled so far dont work for me
see for his case he needs to be able to run the latest things so i feel like a1111 would be a huge step in the wrong direction
I wish A1111's page got a big ol warning saying "I dont get updates, see a list below for alternatives" to prevent many such cases
so comfy or swarm is your recommendations then?
SwarmUI since that way you get both
with zluda or directML?
And most ||all|| options got a ? Next to it showing you what it means
I recommend following the guide of Cs1o in pinned msg
I can't troubleshoot amd for the life of me
yeah im on the guide, its just there is with zluda or directml and I have no idea what the difference would be
Zluda is better, directml is slower i heard
you honestly don't want to use auto1111 - it's not really being supported, it's not a very good ui. since you have to learn this from the ground up, please don't spend your time learning something you wont' really be able to use for much.
ill try that then 🙂 will this cause me huge issues with the auto1111 still on my drive or should I delete all of that?
just leave it where it is. install comfyUI, and then fill out the extra path's file with the paths to where your models and stuff you downlaoded for auto1111 are at
and watch scott's tutorials https://www.youtube.com/watch?v=AbB33AxrcZo&list=PLIF38owJLhR1EGDY4kOnsEnMyolZgza1x

Today we cover the basics on how to use ComfyUI to create AI Art using stable diffusion models. This node based editor is an ideal workflow tool to leave how AI art is generated, but also how you can really mess with the internal elements much more than you can with any other AI Art interface out there today. #comfyUI #stablediffusion
Install ...
Thanks 🙂 Ill look into it soon! You guys are stars ❤️ thanks a bunch!
and read @ornate elk 's AMD gpu guides...
always choose zluda
Yup will do:) that vid is going to probs need to be a favorite to set up that each time xD
tbf.. I only switched to comfy today as I've heard trying it all out ( controlnet wise on sdxl ) on webui / forge ( which I prefer ngl. ) is a bad idea or simply doesn't work as expected ( yep, same stick figure baking or whatever you wanna call it )
Does anyone know if Nvidia NV link is supported by stable diffusion? Is there any point in installing NVLink?



Try adding
--skip-torch-cuda-test
Do you know if StabilityMatrix automatically updates packages for Forge and Automatic1111?
Depending on what you have in your bat file I think
Usually they have a sperate bat file that u run to update
not sure where that'd be located.
@ornate elk can we try tmr start the conversation and finish it we always dont finish man😭
When you use Zluda, this error appears, with Directml it generates images normally, can someone help me?

What's your GPU?
Can you show the full cmd log?
Also what's your GPU?
I feel stupid for asking this. I have tried to move over to comfy a million times but I never feel like I'm getting the same results I get using WebUI for "hiresfix". I want to use an ESRGAN model as part of that, so decode into image space, then scale up using a loaded ESRGAN model. I think with the nodes I have I also have to scale the image back down if I don't want to use the default multiplier of the ESRGAN model.
Then, I pass the image back into latent space and feed it back into another k-sampler with a low denoise and the same text conditioning.
Am I missing something? Is that really all hiresfix is in WebUI?
Hi, can you tell me how to fix artifacts when generating images? Adjusting the image with the parameters

Hey this is a VAE issue
At the generation stage, the image looks in the preview without artifacts.
1.5, sdxl, flux etc have their own vae
I used klF8Anime2VAE_klF8Anime2VAE
Ah thats an illustrous model.
Pony and illustrious are based on sdxl
Which vae are suitable for this model?
So you need an sdxl VAE like this:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/blob/main/sdxl.vae.safetensors

Thats the one I use mainly. Works for every sdxl, pony, illustrious models
Okay, thanks, I'll try with her.
What settings can be used to speed up generation? rx 580 2048 sp on 8gb vram, when installing medvram, there is not enough video memory even for the minimum resolution, and with lowraw it generates for a very long time even with the minimum resolution. I put a 30gb swap file.
Webui
Windows/DirectML
Yea that won't be fast with any larger model.
Would recommend using my install guide with zluda
That is much faster
How is zluda better than webui?
Is there a way to turn a non vpred checkpoint into a vpred one?
Zluda is better than directml. Both use the same webui.
Zluda uses less vram and is faster as it "emulates" cuda
I don't think so
😭😭😭😭!!!!
For the rx 580 2048sp, you only need to install ROCm HIP SDK 5.7?
2048 native wouldnt work (the models are trained on 1024x1024)
but you can generate at lower res and upscale
Can't Zluda be set to 2048sp?
it can but your vram is not enough for that native resolution
Is 8 GB not enough?
not enough for 2048x2048 yes
1024x124 is quite enough, but if I put that much, it will take an extremely long time to generate
2048 is the name of the graphics card, I'm not talking about resolution, maybe there was a misunderstanding.
yes because you use directml. its really slow
what is a 2048 ?
I'm trying to figure out how to install zluda.
and yes i tought you talk about resolution
Radeon rx 580 2048sp
I have an 8 vram graphics card. rx 580 2048sp (8gb vram)
Does the processor have a strong effect on the generation rate? Or maybe RAM?
Now I'm trying to figure out how to install it, there's too much in the instructions.
cpu nope, but RAM is important for sdxl based stuff.
If you have only 16gb or less you have to increase the windows pagefile to 16000min and 24000max for the C drive
hey does any of you know can you run fluxgym on amd and train a flux lora there?
I have 16 GB of RAM and I have installed a 30 GB swap file.
thats good then
6750 xt, I fixed it tho
ah okay, i hope you use zluda and not directml as backend. You would miss out a lot of performance.


nope
Just to a new empty folder?
can you reload the page, there are words missing in your screenshot
thats how step 3 should look


Okay
zluda isn't in the options
only cpu, cuda, DirectMl, Rocm, and mps
yea its not in options, its an install method you have to do to get the best performance with AMD on Windows
directml instead is really slow and runs out of vram constantly
yeah would you mind helping me find it then?


sure but its not on pinokio
i made AMD Guides for Zluda and DirectML. You can find them here:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
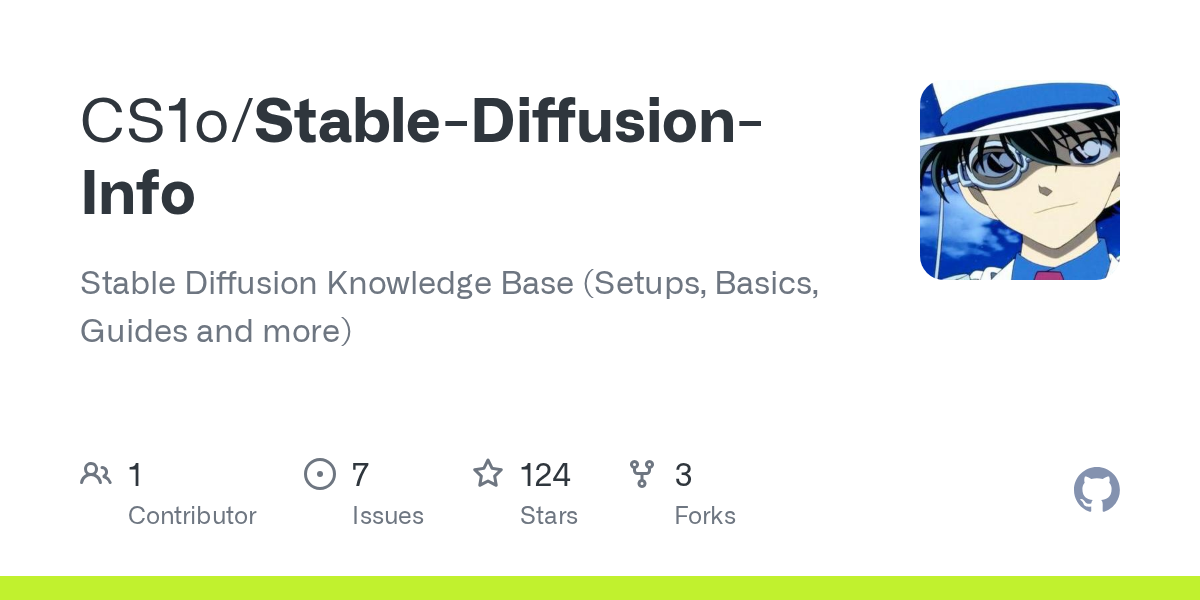
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
I'm using stability matrix, idk what pinokio is
oh right, its nearly the same
both dont have the correct amd setups
only the slow and old directml install
is there any way to patch it in? cuz everything else is really simple
its not recommended, you could do it but it could break more easily
My setup Guide is a bit more complex but stability matrix gives AMD Users no advantage anyway
so better remove it and then do a clean install
He doesn't want to ship models to zuda. The built-in 1.5 couldn't boot at all


its still compiling... xD
you have to wait
give it 15-40 minutes
There was no such thing in directml, is this how it should be?
yes
zluda needs to build a cache file
Okay, But the built-in 1.5 model just gave an error, and mine is still loading.
which webui do you personally recommend for amd users
with 12gb vram i would recommend Forge Webui or Auto1111 with Zluda
you get the best performance and usage on them
you can still install comfyui later too if you want. but as start its not recommended as its more complex
how complex
I installed the og webui a couple years ago, can't be as complicated as that process
its a different ui system (node based)
Forge and auto1111 have the same webui you already know
try restart the webui and then let it load until its done, also add --medvram to the webui-user.bat
is there any benefit to comfyui other than personal pref
Another model is being loaded

I have set up such settings according to the manual

i think more complex posibilities the workflows can give you
error(

forge and auto1111 are better to optimize for the vram usage than comfyui.
you can easily upscale on them as they support some extensions to lower vram usage.
Comfyui supports more complex workflows and more models and you can change anything you want in the process. but that also gives you unlimited possibilitys of errors that can appear xD
goooootcha
on rx580, the webui needs a few restarts like 15-20 everytime you get that error
at the end it will launch
I'll install it in a bit, currently cracking my adobe installs cuz adobe wants 60 bucks a month for their shitty apps
genp my beloved
they are crazy with their pricing wtf
Do I need to restart 15-20 times?
I'll update you on what happens when I install it
can you first show me a full cmd log?
Do I need to select a model at startup so that it starts loading it?
sure, let me know if you have any questions about the steps
in the dropdown on the left
I've already closed it, and I'll delete it next time I make a mistake. Should I attach screenshots?
yes please
then i can see whats causing the error
It's closed again



that is not correct, but could still have worked
Can you show me how to do it? I added what was in the manual.
Right?

remove the -sdxl
so that its nonly --medvram
then save and close
then do this:
Additional Step ONLY for RX570/580 Users:
Go into the main folder of the webui and click in the explorer bar (not searchbar)
There Type cmd and hit enter and then run these three commands one by one:
venv\scripts\activate
pip uninstall torch torchvision torchaudio -y
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu118

I didn't really understand where to enter these commands. To the console in the folder?
Ah, yeah




Hey all, I've recently formatted c:, but I have all my stuff on a P: drive (programs) for SD. I did a quick reinstall of python, git, and downloaded SD via: "git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git" but I can't get GIT to be reconised by my path:
Okay
hey, try reinstalling git and then do a reboot, then check your environment variables path setting



yep
everything is setup correctly
now you need to relaunch it a few times until the compile in the bckground is done
Okay, I'll try.
all rx580 users that followed my guide relaunched it like 15-20 times then it worked
the first image will also need to compile again, but after that your fine
yep 😄
I have GIT in my path, but I keep getting:

hmm thats strange and you reinstalled it too and rebooted the PC ?
Yes sir. If I had hair, I'd pull it out at this point.
can you show the git in path?
sure one moment!

correct
you have to uninstall it and reinstall it on its default path on C
stuff like python and git should always be on the OS drive
to not get wierd errors
gotcha, Python worked fine, just Git bein' complicated
then also create a folder and name it like Ai or soemthing and then git clone into that
that mitigates permission issues
seems like permissions issues now... sonofa
While installing on C or what?

Oh
Did you created the Program Files folder by yourself?
If its a system created folder then it wont work
yeah system created...
I could move everything over to a backup drive, and then slick it and move it all back...
Thats why I said to create a folder called ai
Yep you can backup the drive and reformat it
It's been loading without errors for about 30 minutes, is everything okay?

yes looks good
its nearly done
@ornate elk Oh, you really earned it. And the speed has become much faster, it also now works with medvram, thank you very much.
@ornate elk my sleep deprived brain thought I did steps 1 and 2 and skipped straight to 3, where would automatic1111 go if my dumbass possibly forgot to make a folder for it

happy valentines day everyone :3 💜
perfect no problem 🙂
You can still make a new folder
I figured, just didn't know where it installed otherwise so I can delete it
anybody had problems wioth rtx 5080?
Ryzen 5800x3D
RTX 5080 16gb
32GB RAM
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
If you opened the Cmd without not in the folder its probably in system32
Or on C directly
Hey, make sure your webui is updated.
Then delete the venv folder and relaunch
ty
If its there delete it. Then start with step 1
so I'm on this portion.

found my gpu here
but what exactly do I do here?

do I just get this one?
it wasn't in system32 or the c drive so I just installed the regular one on my nvme drive
ty
Hello everyone,
I’m sorry if this has been brought up before, but I’m experiencing an issue with the upscaler in the extras section
They just stay on uploading forever, can someone land a hand to this lost soul?

Hey make sure the webui is whitelisted in any browser adblocker
Np, let me know if it worked
I did it but same thing happened
thank you for helping btw
do I only need the first one

and which of these do I click for it, I tried the rocm6 zip

I'm assuming the zip but I just wanna make sure
Leave all default
You need all but not the bottom (pro driver)
Yes only rocm6
Not nightly
alr
What does the cmd shows when you upload them?
Okayy so I installed comfy ui as per instructions and everything seemed to work fine, except it gets to 29% of an image, closes the cmd window and just says reconnecting in the web ui
just keeps saying compilation in progress

hey guys
having some difficulty with connecting stable diffusion to owui



also both are running on docker containers.
After several generations, such an error occurs and the generation does not work until it is restarted

Can you show the workflow you tried when it closes?
Should work after its done
Will as soon as I get home:) CMD closes though so I have no logs for that
Does it just take that long?
Yep first time only
Gotcha, thought I did something wrong
Did it worked by now?
Hi does anyone know if its possible to manually add Samplers to Forge? I like the 'Gradient estimate' sampler that is in Reforge but it does not come with Forge, is it possible somehow to copy into the folder or install it somehow into Forge? Thanks
@ornate elk this is the log before I try doing anything in the webui


Ive tried this with a bunch of different models, it just does this each time
Numpy error:
Numpy fix:
If you get a NUMPY Error do the following:
Install the Comfyui-Manager from below, then Click on Manager > Click on Install PIP Packages > type numpy==1.26.4 > Click OK and restart the server as prompted.
If you get a security warning you have to go into ComfyUI\user\default\ComfyUI-Manager and there edit the config.ini.
Change the Security Level to Weak, then save and try install numpy again.
After that set the Security Level back to normal.
Ahh god dammit, I thought that error would pop up in the webui, didnt even see it there! Sorry my dude 😫
no problem, yea its only in the cmd
Im never too sure what im looking for in the cmd so I kinda avoid it as its all jargon to me xD
@ornate elk this when I type in numpy==1.26.4

ERROR: To use this feature, you must either set '--listen' to a local IP and set the security level to 'normal-' or lower, or set the security level to 'middle' or 'weak'. Please contact the administrator.
Reference: https://github.com/ltdrdata/ComfyUI-Manager#security-policy
How do I do that?
ready my message from above again (the fix)
doh! Sorry dude! Feel free to tell me to piss off xD
Still closes at 29% even after the pip install thing and rebooted through cmd and everyhing
Same reconnecting error even without it saying numpy error
ohh it tries to use your cpus igpu instead of your dedicated gpu
god dammit xD how do I tell it to use my other?
you can disable the Radeon TM Graphics in the Device Manager of the PC.
or you can try edit the launch bat and at the end behind --auto-launch add --cuda-device 1
Changed that now, still stuck at 29% but CMD hasnt closed so im assuming this counts as the first time where it can take like 50 mins or so ?
yea the compile will take a bit again. but it wont show it in the cmd
so if nothing crashed, let it load
Alright 🙂 Ill leave it running and hope for the best! Ill let you know how it gets on, thanks again dude you're the goat for real!
which option did you took?
disabling the igpu or the edit of the bat?
--cuda-device 1
alright
everything else on my pc is set to use the dedicated so i doubt it would make much difference
but thought this seemed easier
yep
how much RAM do you have?
32gb
okay thats enough
and when does it crash?
after you hit generate or just by launching?
at 29% always, its when its green on the bottom negative prompt
so assuming its when its loading that section
is it empty?
Yeah, it wasnt yday but I cleared it to see if that was the issue
hmm should work no matter what
just tried it with some info in it and still crashes out
should I try making a new workflow and starting again with it all? or is that unlikely to make a difference?
try this workflow (drag and drop into comfyui)
What do i do with that?

yes
here is the sdxl vae fp16:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/blob/main/sdxl.vae.safetensors
the model doesnt matter, choose any sdxl you have
where do i save the vae?
models/vae?
crashes out, this time at 38% but idk if thats just because theres more or less steps than the other

but crashes out at negative prompt again
hmm and the cmd doesnt show anything?
is comfyui whitelisted in any browser adblocker?
i disabled adblock for this yday when I was in the search someone else had a similar issue
current log, ill try and copy or do a screen recording before it crashes when i try
can you try an other browser without any extensions?
it does a bunch of python stuff before it crashes
where do you see that?
the cmd desnt get the prompt to even start genning
something might be blocking between browser and cmd
i filmed it when i clicked start
hangon ill find it
that was until it crashed

ive got no idea if thats normal or not though
was the 1 in the link, 3.10.11 64bit I can try and find out exactly incase its wrong

Should I try reinstalling it?
yea maybe something wasnt downloaded correctly
or wait
this is always before it crashes?
that was just before yeah, after i click queue and tab into that quickly thats what comes up each time, just tested it again
okay and your not running anything heavy in the background ?
like games or wallpaper engine?
literally just discord
334gb
open up a cmd and type
python --version
and then
where python
Microsoft Windows [Version 10.0.22631.4890]
(c) Microsoft Corporation. All rights reserved.
C:\Users\seanb>python --version
Python 3.10.11
C:\Users\seanb>where python
C:\Users\seanb\AppData\Local\Programs\Python\Python310\python.exe
C:\Users\seanb\AppData\Local\Microsoft\WindowsApps\python.exe
C:\Users\seanb>
ok open up a cmd as admin and run sfc /scannow
that fixes system bugs.
running it now
and then disable the Radeon TM Graphics in the Device Manager.
then relaunch comfyui
Microsoft Windows [Version 10.0.22631.4890]
(c) Microsoft Corporation. All rights reserved.
C:\Windows\System32>sfc /scannow
Beginning system scan. This process will take some time.
Beginning verification phase of system scan.
Verification 100% complete.
Windows Resource Protection found corrupt files and successfully repaired them.
For online repairs, details are included in the CBS log file located at
windir\Logs\CBS\CBS.log. For example C:\Windows\Logs\CBS\CBS.log. For offline
repairs, details are included in the log file provided by the /OFFLOGFILE flag.
C:\Windows\System32>
okay it found an issue and fixed it
gunnu restart quickly because its not opening the webui at all atm
brb
okay with AMD Radeon(TM) Graphics disabled it doesnt open the webui at all
ahh okay
do i need to edit the .bat again?
then remove the --device-id
--cuda-device 1 this bit?
done and disabled but crashes out again at the same spot
enabled it again and tried again and crashes still
okay then do a reinstall of comfyui
also redownload the launch bat, i updated it rn
okay 2 secs
just back to this part, be a few mins
Go into the C:\ZLUDA\ Folder.
There make copy of the cublas.dll and the cusparse.dll and nvrtc.dll repaste them inside the folder.
Rename the copies to cublas64_11.dll and cusparse64_11.dll and nvrtc64_112_0.dll
Copy these three files into ComfyUI\venv\Lib\site-packages\torch\lib and overwrite if asked.
okay all done, the launch bat is this right?
https://raw.githubusercontent.com/CS1o/Stable-Diffusion-Info/main/Resources/Start-ComfyUI.bat
okay still crashing out, i tried disabling the driver again and still no joy :S
can you check your windows pagefile setting?


okay, can you try with an 1.5 model?
just tried uninstalling python and reinstalling and it wont even let me reinstall that now
fml its doomed 😬
whats the error?

okay then check in system control if any python is still there listed
and uninstall
also uninstall stuff thats called conda
or anaconda
did that, hang on i got it
ran it as admin and it let me install it
okay whats a 1.5 model ?
you then need to delete the venv of comfyui
how do i do that?
this for example
https://civitai.com/models/4384/dreamshaper
those 3 zluda files do I leave them in the zluda folder or delete them once i copy them over?
you leave them there
okay I have been so just wanted to make sure
just waiting on the cmd to install it all again
tried with 1.5 and still crashes
hmmm and which webuis do you use that work?
id only used the auto1111 a few days ago which worked fine for a few days then i deleted it all to use this as only half the models I wanted to try worked
ahhh dw dude, ill try 1 of the other uis or go back to auto1111, ive taken up way too much of your time already!
hmm okay, yea comfyui is the hardest to get working from my guides.
But the issue you got is fixable.
can you show me your environment path settings?
where do i find that?
my guide listed how to get there and how to edit it
here is a quick way
and thats how it should look like:


remove the C:sd-zluda and the C sd zluda comfyui from there
and then recheck if your zluda folder on C is called ZLUDA or Zluda

i ticked add to path when installing
rerun the python installer
click modify,
click next
select "add python to environment variables"

is that it at the top ? and yeah okay

was already ticked, idk if that means it was already active or not?
click install then check the environment path again

yep
added both, that correct?


can you show me the full cmd log?
yup
ill show you it before i queue anything up
then ill send you the vid of it after i queue
file size too large to upload dammit
can you go into comfyui/users folder and there copy the comfyui.log file?
hmm there is no python error
yep but the error exception code 0xc0000005 is acces violation
so like my pc doesnt let me have permission to run it?
it can access some files hat need to be run
as its windows 11 maybe it has a problem with the C:\ZLUDA
try moving it into SD-Zluda and then alter the path in the environment path variables
moving the launcher into there?
ohh wait i misread that
move all of zluda into sd-zluda?


done
also have you any antivirus programm installed?
nope
still crashes, lemme restart again
ima install this windows update real quick just incase this somehow magically fixes it
That took ages holy, right ima try again!
Seen this just now in the cmd, think it was there before but does it matter ? Warning, you are using an old pytorch version and some ckpt/pt files might be loaded unsafely. Upgrading to 2.4 or above is recommended.
should I try adding all those things to variables for me?

instead of system
Nope
And nope torch 2.3.1 is needed for AMD with ZLUDA
@spare crow
I'm out of ideas. Other than a windows reinstall (which fixes mostly issues by 100%) I don't know what else to check.
Its either a permission or RAM issue.
Would suggest using either Auto1111 or Forge Webui.
No worries dude, ill try going on forge and hopefully that lets me try a bunch of other models and works for me
I really appreciate how long you've spent on this trying to help me dude ❤️ you're a legend
Forge let you use flux as addition.
And no problem 🙂
Is flux like a different model type or just a standalone model? Cause I downloaded a bunch and flux was just 1 of many that wouldn't work
Flux is a model type
Like sdxl, 1.5, pony, etc
Auto1111 can use
1.5, 2.0, SDXL (pony, illustrious, both are based on sdxl), SD3.0,
and forge Flux in addition
I installed swarm, worked straight away 🥲 all that time spent
works fine but feels slower to generate
ahh okay I need to make myself a list of model types so I can keep track of it all then and what can use what
swarm is just that good tbh. but the "feel slower" can be a thing of first loading in the model and some zluda/directML wonkyness
I read back at your message and because of the comfy vid id saved I thought it was comfy you said to try so I went to that first 🙃
i couldave labeled it a bit better probably
Naah that was just me trying to do 20 things at once, not reading things properly as usual and watching the vid for comfy while I was trying to do it xD
Hi! sorry guys I´m having trouble to mimic the configuration of flux Dev of Civitai in my Forge Console, anyone knows wich sample methods and schedulle type they use? I´m using same Loras and a flux1-dev-fp8.safetensors checkpoint . I´m breaking my horns trying to get the right configuration, but i keep having weird results.... thx!!!
Because it uses directml and thats really slow
And vram limited
Ill try getting forge setup and working aswell later, hopefully that works because id like multiple options!
Just realised I have a 1080ti sat doing nothing in my attic, I could probs add this to my pc and use both for this and save myself some headache right?
yes
With most of these, like forge comfy and swarm, can I use the nvidia card as a 2nd card, set it all up with that and use both cards to work at the same time? I know swarm can because I just watched a vid on it
which loras are you using ? I've been using beta for some time and its working pretty good.
oh CS1o h1)
it seemed like 1 guy managed to use hi res fix on flux. to make from 960-1280 a double 1920-2560
with that 10-12 gig of vram... but ive ended up failed with always too low vram message. advising to low vram used. which ive tried up until 16gb but still nothing. Is it like with fp16 and need of 48-64gb of usual ram of wtf ?
yeah flux very bad optimised and eats alot of vram when trying to upscale. but he managed to do it on 3080 =\
dont tell me that amd is still that bad optimised compared to nvidia... shudnt be a thing as of now... pretty sure... espec on forge
im using one of my own and 2 dowloades from civitai that worked ok in the site. Now im testing Euler and Simple (quite Vanilla) and worked on de distilled cfg and looks good! thank u!!!

hello all. Hope somebody can help. I am getting error after i want to generate image. Last week i reinstalled comfy but now again error After restarting ComfyUI, please refresh the browser.
FETCH ComfyRegistry Data: 25/33
FETCH ComfyRegistry Data: 30/33
FETCH ComfyRegistry Data [DONE]
[ComfyUI-Manager] default cache updated: https://api.comfy.org/nodes
nightly_channel: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/remote
FETCH DATA from: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/custom-node-list.json [DONE]
[ComfyUI-Manager] All startup tasks have been completed.
got prompt
Using pytorch attention in VAE
Using pytorch attention in VAE
VAE load device: cuda:0, offload device: cpu, dtype: torch.bfloat16
F:\comfyui\ComfyUI_windows_portable>pause
Press any key to continue . . .
after press any key the CMD screen just closes
why is this a thing in zluda a1111

Would need the full cmd log + what you tried as settings
nvm it was in directml, im trying to use zluda a1111 now, wrong thing turned on
too many uis
Ah well xD
swarm is using my other gpu by default atm, I dont know why but its using the 1080ti, which is fine because its letting me upscale and do more than the 6950xt does, but how can i get both working at the same time to increase the limit and speed? I tried adding another ComfyUI self starting to the backend with GPU_ID to 1 but then nothing seemed to load at all, not sure if I did it wrong or it doesnt work the way i thought it would?


You can't use 2 GPUs for one image output
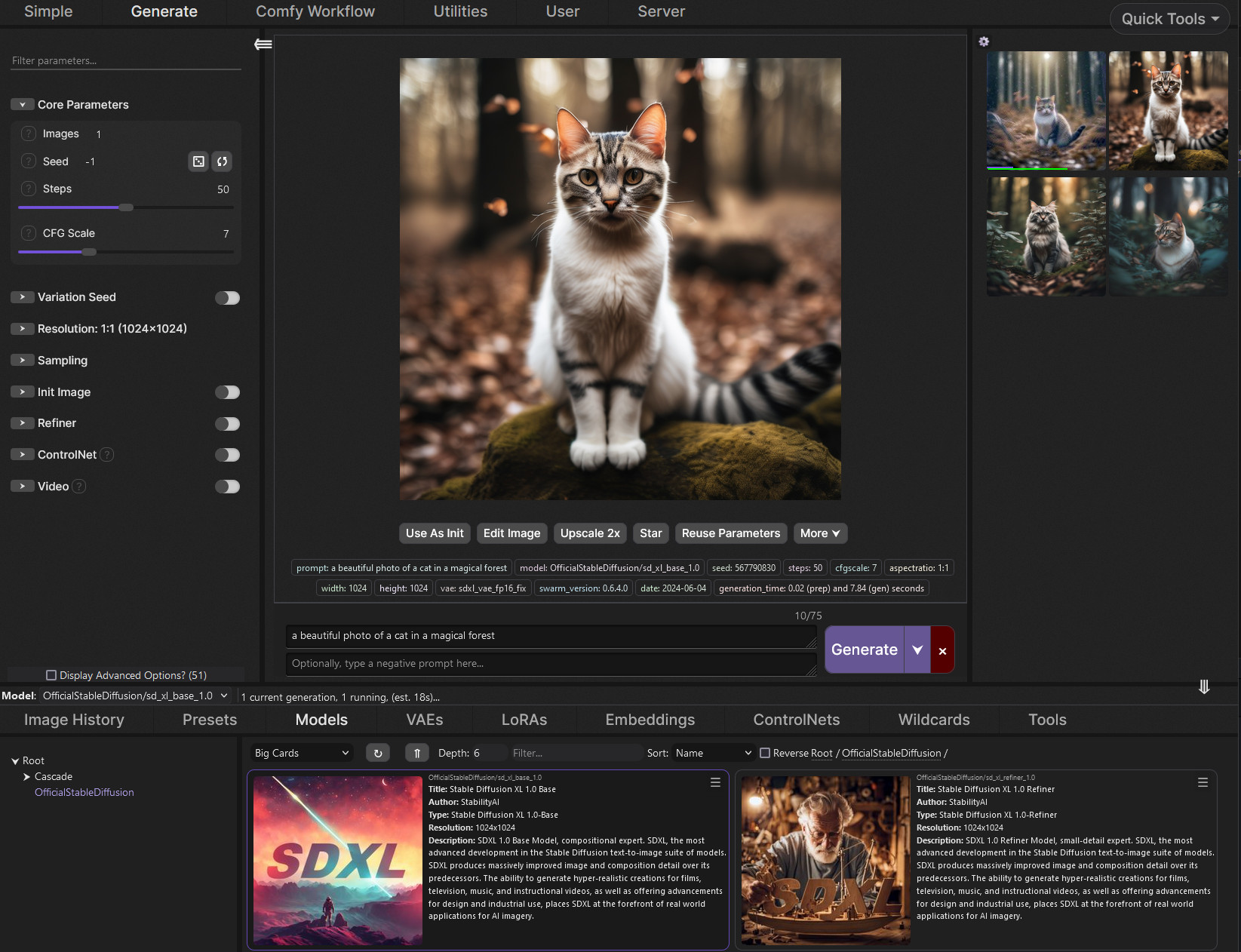
GitHub
SwarmUI (formerly StableSwarmUI), A Modular Stable Diffusion Web-User-Interface, with an emphasis on making powertools easily accessible, high performance, and extensibility. - mcmonkeyprojects/Swa...
you can use both gpu's at once to generate/do different things but you cant combine the vram
i wish though
Ahh that sucks! that would be so handy! I feel cucked, 16gb of vram available to me and I cant do shit with it, but my old 11gb vram card works better xD
Yyyyy. with zluda bad amd vram optimization shudnt be a thing anymore but im still not sure it is...
Csss111ooooooooooo
With Auto1111 and forge you can use 16gb really good but yea xD its much easier with nvidia
Gunnu set forge up in a little bit so let's hope so! I feel like my amd card just decides to use it all straight away regardless of what it's doing
it feels more less as if its uses all vram legit. but calculates wrong...
also some vram is always used up even if u close everything
I couldn't even upscale an image on swarm 2x earlier with 16gb but with my nvidia I've done 2x 3 times to each upscaled image already lmao
ive read some ppl even connect their monitor into motherboard so it wont use 1-2 gb of extra vram 😄
That sounds like Directml
I think on windows you can go as low as roughly 500mb used doing nothing, from what I looked up earlier
@ornate elk ? Can say smthing about this?
This
I did set up swarm with zluda thought so didn't think it would still use it