#🤝|tech-support
1 messages · Page 119 of 1
Ah that breaks the update function but can be fixed.
But this is a different error
oh
yes
venv "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\Scripts\Python.exe"
WARNING: ZLUDA works best with SD.Next. Please consider migrating to SD.Next.
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: v1.10.1-amd-18-ged0f9f3e
Commit hash: ed0f9f3eacf2884cec6d3e6150783fd4bb8e35d7
ROCm: agents=['gfx1101', 'gfx1036']
ROCm: version=6.1, using agent gfx1101
ZLUDA support: experimental
Using ZLUDA in C:\ZLUDA
Skipping onnxruntime installation.
You are up to date with the most recent release.
Traceback (most recent call last):
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\launch.py", line 48, in <module>
main()
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\launch.py", line 39, in main
prepare_environment()
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\modules\launch_utils.py", line 695, in prepare_environment
from modules import devices
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\modules\devices.py", line 6, in <module>
from modules import errors, shared, npu_specific
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\modules\shared.py", line 4, in <module>
import gradio as gr
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\gradio_init_.py", line 3, in <module>
import gradio.components as components
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\gradio\components_init_.py", line 3, in <module>
from gradio.components.bar_plot import BarPlot
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\gradio\components\bar_plot.py", line 7, in <module>
import altair as alt
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\altair_init_.py", line 649, in <module>
from altair.vegalite import *
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\altair\vegalite_init_.py", line 2, in <module>
from .v5 import *
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\altair\vegalite\v5_init_.py", line 2, in <module>
from altair.expr.core import datum
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\altair\expr_init_.py", line 11, in <module>
from altair.expr.core import ConstExpression, FunctionExpression
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\altair\expr\core.py", line 6, in <module>
from altair.utils import SchemaBase
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\altair\utils_init_.py", line 14, in <module>
from .plugin_registry import PluginRegistry
File "F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\altair\utils\plugin_registry.py", line 13, in <module>
from typing_extensions import TypeIs
ImportError: cannot import name 'TypeIs' from 'typing_extensions' (F:\SD-Zuldav2\SD-Zluda\stable-diffusion-webui-amdgpu\venv\lib\site-packages\typing_extensions.py)
Press any key to continue . . .
Try delete the venv folder and relaunch
What I do to safe space is to put the models on an other drive and link them in the webui-user.bat
My guide covers this too
i did that i linked my loras and models

appreciate all the help
No problem
Bump
it worked, now i just need to add my extensions
Anyone ever try docker containerizing all of this so things retain their states? Seems a lot like early days of skyrim mods. One change and it breaks stuff?
Learned a lot here but still lost months later
Hello, my subscription to StableAudio AI is expired on December. However, I still not downloaded all of my generated music in my dashboard. Is there any way I can differentiate the files I generated sing Free tier to those I generated using Creator License? Its just the dashboard for collection of generated music is just a scrollable window and there is no label or tags if that music is generated using free trier or pro tier
Would anyone care to help me work out why SDXL isn't training in OneTrainer please. I've put my settings in #🏞|general-with-images
Hi, i'm using comfy with python 3.11.8 what is the most recent version that i could install?
How to make animations?
Is there no folder called upscale?
Its in the same model structure as loras, stable-diffusion, controlnet etc
I think you should be using 3.10.11 https://www.python.org/ftp/python/3.10.11/python-3.10.11-amd64.exe
You said that you are using 3.11, that will not be compatible, only 3.10.xxx
I just installed Ishqqytiger's amdgpu webui based on automatic1111 and i also installed zluda using this guide https://github.com/vladmandic/automatic/wiki/ZLUDA however i guessed i didnt need to install SD.Next since i'm using automatic1111, i can launch the webui but upon trying to generate my first image without touching any settings and also not having installed a specific model yet i get this error: "RuntimeError: Input type (float) and bias type (struct c10::Half) should be the same"
anybody know what it is? i can give the full log if you need
i see peoiple saying indeed to make a folder called ESRGAN
models/ESRGAN
might wanna refresh the UI to make it show up (refresh the page or reboot the ui)
yeah remove the real
its what i see on the a1111 github solved/closed

GitHub
Checklist The issue exists after disabling all extensions The issue exists on a clean installation of webui The issue is caused by an extension, but I believe it is caused by a bug in the webui The...
hmmm
i mean its a guy with the same problem
but he fixed it by renaming
hmm
what version of A1111 are you using?
in the webUI somewhere in the bottom
hmm yeah your on the latest version. any reason your using A1111 instead of forge?
but stupid question did you reboot the web-ui
i recommend forge as its faster then A1111 for SDXL but yeah
in the pinned msg theres a guide
forge-webui
hmm it should show up after that
you could try closing the cmd and reopening it
just in case
and A1111 hasnt gotten a update since july
hmm yeah i would either recommend switching UI's to either Forge or Swarm (swarm has very usefull tooltips inside the UI)

but swarm can be a bit more confusing since it gives you more control
are you on a NVIDIA card or AMD?
ah then either forge and swarm are fine.
if you were on AMD i only know the guide for forge
there are some extentsions but forge and a1111 use the same backend iirc
ah Swarm UI uses "comfyui" as a backend. (noodles) so it has the benefit of an optional comfy ui use and speed of its back end
but without the noodles

i got it on darkmode but this is the UI you work with then

but theres more themes
Hey you should follow my AMD install Guide and dont use the sdnext webui.
Automatic1111 and Forge work much better with ZLUDA.
You find the guides here:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
If you want upscalers to work create an ESRGAN folder in the models folder.
Then put the upscale model In there
The folder also will get created automatically when you use hires fix and choose an ESRGAN based upscaler
quick question, there appears to be no C:\Zluda directory
You have to create one
Its stated in the Guide
quick ctrl+F says that that's the first time C:\Zluda is mentioned, unless you mean the installation path of the webui?

No problem ^^
oh wait i'm looking at the ROCm HIP SDK 5.7 with ZLUDA Setup: section, in which the folder is named SD-Zluda
Oh thats the wrong one. Only use rocm 5.7 if you have an RX 580 gpu
i do got a 580
Oh then your on correct with the 5.7 guide
but i've installed SDK 6.x version because trying to install sdk 5.7.x gave me a general error 215
bruh

my god im just going to try everything from the beginning again
delete the .zluda folder and the venv then relaunch
how to make animations?
why is some 10gb pytorch clip model being installed

Its one time for sdxl models
Can you show me the full CMD log when you launched auto1111
Looks normal. Can you show the stable-diffusion-webui models folder?
And the ESRGAN folder
hello, im havin trouble getting an extension to work. can any1 assist?
im trying to get faceswaplab extension to work. its not appearing in my webui

are you on AMD?
amd cpu, nvidia gpu
automatic1111, reforge, swarm?
automatic1111
Please help me with that 🙂
@lucid yoke
ah i dont know, these were some details nessacary so someone could help
the error shows a fix no?
But i dont get it,all i want is to install flashattention 😦
hmm any1 around that may be able to assist? @lucid yoke
open the file you use to launch it with notepad (probably its a .bat no ?) then change the line KMP_DUPLICATE_LIB_OK=FALSE
to
KMP_DUPLICATE_LIB_OK=TRUE
but that may cause crashes or silently produce incorrect results

hmm seeing how this isnt directly a SD Web ui problem but something else

GitHub
Fast and memory-efficient exact attention. Contribute to Dao-AILab/flash-attention development by creating an account on GitHub.
its for comfyui
id look into a more comfyUI dedicated space then. seeing how most of the help questions here are done by two people lately
im in 9 groups and waiting for the rescue xD
not that i dont want to help but its a very specific problem to a program that i personally dont work with
maybe create a issue on the github page
i have no hope on those pages when i look at the question asked 3 weeks ago and they still didnt answered him lol
i mean yeah its probably a small group of people doing this for a hobby
like im a K12 techie with some extra time on his hands but if i get bored of this i will probably move on to other communities/hobbies
its not like were getting paid for this
your original error says you have multiple copies installed. you can't just rename a dynamic link library like that
the error also told you to go to http://www.intel.com/software/products/support/ - did you do that?
you are probably looking at uninstalling a bunch of stuff, then rebooting, cleaning up your system, rebooting again - and once you're sure all the duplicate copies are gone, and out of the registry, instaling fresh
lol the intel site is just given as a generic "find support here" suggestion.
https://civitai.com/articles/9555/installing-triton-and-sage-attention-flash-attention-and-x-formers-win Step 2 there is about using a precompiled whl file. the generic error is something else entirely.
I would suggest they just have to restart and try again
but i said you need to create an ESRGAN folder
not realesrgan
and in this folder you need to put the upscaler
rename is fine
I did that so many times i don't want to count anymore
@midnight coyote honestly, i think you can skip triton for windows. Triton has never really been important for end users
What is your goal with using that guide? are you doing development work? You might be better off creating a proper linux environment for that.
yep I give up on triton on windows long ago
the torch compile thing claims to make things faster
i'm not even sure what the benefit would be of triton
u know what, I tried that triton stuff and torch compile
in linux
but unable to use it becoz out of memory 🤣
waste of time
to utilize torch compile to run generation faster
I think it only make sense when u have huge vram, and then you want to utilize them for faster speed
and then we also have deepspeed by microsoft that only works in linux, too, 🤣
but torch compile really speed things up, if u have the vram
that link says torch.compile doesn't need triton as a dependency. doesn't even mention it
i honestly don't think there's any benefit to it at all. it's more of a data center tool to get 0.5% gains
I think it needs, at least there is the error I am getting when trying to run torch compile
I'll said its more than 30% increase at least
i chalk it up to a massive waste of time from stock cuda
I think you are right, I think when I say torch.compile, i mean torch compile with inductor which claims to be the fastest

tensorrt still an options tho
yes it does. you spread allot of misinformation
demonstrate how to get speed boosts from triton on windwos then please
i'd love to know better if my assumptions are wrong
he is not wrong, if you using torch.compile with other options like tensorrt, you don't need triton
but of coz folks are talking about torch.compile with inductor which is also the fastest and default options
gotcha
do you know if can get compile+ to work efficiently on 3060?
i thought you were the expert. i guess you dont know after all. i'd appreciate if you'd come correct next time.
Who claimed I was an expert? Youre a fool.
it implies you know better when you tell someone they're spreading misinformation.
i never made a direct claim. i will actually own not knowing. i've drawn assumptions based on what i've found, but i do not know
I think you can, on linux, for sd1.5 and sdxl, however for flux it require 24gb vram to compile
Why is OpenPose not working?


No 🙂 If I select any Preprocessor, it doesn't even see the skeleton 🙂

BUT, if I insert a non-black background... Just a second
I ditched a1111 and forge cos it would break like this for no reason. comfy hardly breaks on me
so im unsure how to proceed to fix
is there anything whacky in the terminal when you run it?
@wicked widget 🙂


3070ti 8GB
This started happening when I turned on Conrolnet

you got the 8gb vram card right?

you may need to use vram lines args cos youre ooming. youre missing 500gb vram to run the process
turn off any wallpaper engine etc, run nvitop in console to monitor vram use and turn off anything not important
This is a warning error, can it really affect the generation?
How do I do this?
whats the openposexl2 model?
i tend to stick to the controlnet loras . usually the 128 rank version
add --xformers --medvram
youre missing xformers too
which you should alwags use as rtx user
I was initially advised of it https://huggingface.co/thibaud/controlnet-openpose-sdxl-1.0/blob/main/control-lora-openposeXL2-rank256.safetensors
But the result is the same

xformers alone will help prevent ooms
https://huggingface.co/stabilityai/control-lora/tree/main/control-LoRAs-rank128 these are the ones i have success with in forge ui

@REM set COMMANDLINE_ARGS=%--xformers --medvram% ^
Yes?
yep
think thars right format too, unsure cause your webui has allot more stuff in it than mine
Now I'll try it with new arguments and then download yours.
@wicked widget Did it trigger the argument?

i'm thinking that thibaud's model, which appears to be a lora style cnet as well, is not properly supported by forge.
it's a very hacky situation with the current version i find. unless you're using flux, i might recommend you stick to reforge fork of it instead
no
its still using normal vram
and no xformers
when adding it follow the format of the other ones
so take off that extra % at the end
I started another one.bat, launched with arguments, let's wait...

set COMMANDLINE_ARGS= --xformers --cuda-stream --cuda-malloc --enable-console-prompts
is my line. i'm not sure if you support cuda-stream or not on the 30 series. i also have console prompts on cause i think its neat
it does
use malloc and stream
should also help
biggest one tho would be xformers tbh
The main thing is that my VPN wouldn't suddenly turn off right now, otherwise it would be fun 🙂
interesting that it's reinstalling pytorch with cuda again, but hey. that can't hurt. maybe. lets see
Wrong Python Version
ah yeah 3.12 is the iffy one isn't it. you want a 3.11 version
good spot @ornate elk kudos for you.
I'm still waiting 🙂

It scares me a bit that the download is not continuing 2.1/2.4

you're going to want to gut your python install anyways. isntall the proper 3.11, and then either manually reconfigure your venv to point at the right one, or just delete it and let the bat file rebuild it. meaning, the whole download thing again.

there's going to be a lot of problems until you repair your python install. for stable diffusion use, you'll want 3.11 , not 3.12. python, that's just how it is
Which Preprocessor should I use?
preprocessors just convert an image into what the controlnet model is trained on. so an openpose model wants an openpose input. since it seems that you've already got an openpose style image, you wouldn't preprocess it.
if you had a photo of a character, you'd use an openpose preprocessor to detect the pose and pass it to the model.
If I choose Openpose, there are no models of yours, only mine, which does not work.


did you load the ui before or after copying them into the folder? there's the little blue refresh button next to the drop down. that'll refresh the list.
you don't need to select the radio buttons. that'll just narrow it down. you can just manual it and select the one you want from the full list.
I know about updating the list) But I even restarted the AI.
Excuse me

I'll try every process now.
@oblique walrus The situation is the same

youre trying to preprocess an existing openpose image, so i'ts detecting no pose there and converting it to a black image, sending that to the model. Use no preprocessor instead. you only need to do the preprocess if you want to detect a pose from an existing image. but youve got your own pose image already
for some reason my replacer extension isnt showing up, its saying im missing a infotext_utils.py file in modules. it was working fine a while ago and now it doesnt work anymore

did you upgrade to forge? it uses a newer gradio. that seems like a gradio 4 thing. i might be wrong. i dont want to spread misinformation
Do you have a full cmd log?
already resolved it, had to update my stable diffusion
Yes.
Tell me if I install ComfyUI, will you help me set it up so that I can do poses here?
yeah
install comfy, and comfy manager
and throw in my workflow, install missing nodes
I'll install it now, can I send you a private message as soon as I install comyfyUI??
yea if u want
I wrote to you)
well, i am learning alot due to the number of crashes/issues installing new nodes causes =p
Tell me, who here is good at working with OpenPose? Who can I write to?
Can you share an full cmd log + Screenshot how you try to get it working?
Which program is better for you? ComfyUI or Forge?
basically this is the 2nd time i ran the cmd, this is the error that also appeared on the 1st run through

@wicked widget helped me set up, Maybe he will add something, but it doesn't work or it works every other time with a drawing of a person, but I definitely need him to work with the skeleton with OpenPose edit...

do this @fierce hollow
can i generate pics in discord?
@ornate elk
Brother ellie said to post full cmd log too😭
Check artisan faq
I think its on you instead of the hardware, i get amazing results on a 3070ti
Show prompt?
then its not struggling to get good results but your struggling in general
mood
what im not berating you. but if you are struggling to get good results its probably a prompting or setting issue but if you cant reinstall it because your GPU is dying its a whole different problem
but to awnser your question. 5080 is a decent AI card yes. its worth waiting for as you dont have to use all kinds of tricks like you do with AMD
i am getting excellent results on a 3070 so hence the comment struggling in general to get it working.
sup, dont tell me my 1,3k dollars worth of gpu having a hard times to upscale a picture by 3, is there any option to boost it idk

Which settings and model do you use?
WAINSFWILLUSTRIOUS, upscale was by 3

and whats your gpu?
and does upscale by 2 works?
RTX 4080 SUPER
yeah, 3 work too but it make me lags and generate slowly
make sure you dont run any games or wallpaper engine in the background while it generates
i guess i just use discord and youtube videos in 720p
tryed with 2.5 upscale

Whats in your webui-user.bat?

Hello everyone, could someone help me achieve this kind of ultra-detailed result like in the second picture? I’d like to learn how to add more details to my photos and add a black outline to the lines for a more animated effect, like in the second picture.


This image is from MJ; I didn’t create it myself, but I would like to achieve the same level of detail as the one on the left. However, I don’t know how I can achieve this
The image was created using MidJourney, bro
Hmm, I don’t know enough about ComfyUI to answer that. I’m a complete beginner when it comes to Stable Diffusion, sorry
Haha, we’re in the same boat, bro
just the eyes? or you mean an overall style
oh depending on the lora you can get pretty decent results. tough i like to upscale the image first and then impaint the yes
eyes
but i use swarm ui so i can just <segment face>
tough it heavyly depends on the style and main model
oh wait are you using SD 1.5?
what is the model you are using?
well if you are using 512x512 pixels the ai has little space to work with but thats the downside of SD 1.5
whats your graphics card?
there are ways to utilize a AMD card for this
pinned messages show a tutorial on how to use stable diffusion with a AMD gpu. i personally use Nvidia so i cant help you on that one but again i dont know what graphics card you have so i cant say if its enough for it
Up 👋🏼
that is CPU
i replied to you initially but conronron replied to me lol
brb but after i can check
open task manager

Oh, I didn’t see it, sorry 🤣 How could I improve the details of my images like the second one above? I import an image and just want to enhance the overall details and add black outlines around the shapes in an anime style
with that gpu you should try out forge webui
hmm just "enhancing" a image i do not know but you can generate a image like that and upscale it
i would impaint it
to edit some things
but not the entire image
i wouldent say its bad. its a good GPU for general use
Enhancing the details, like making the hair, clothing, and outlines finer in a manga style, adding reflections, shadows, etc. I want the image to be ultra-detailed.
yeah thats something you either do with photoshop or do in advance
it does, but you have to mention it
What do you mean, bro?
well if you want reflections, thick outlines etc you have to tell the ai to do it
or you gotta after edit it manually
would you believe me if its different for every model
if you got the model from civitai.green (sfw) or .com (nsfw)
Do I need to install specific things? Can you guide me? Because I’m not sure exactly what to do.
a checkpoint on civit ai for example

whats your GPU
but CPU based generation is not gonna be really fast so i hope you got the patience
I have an RTX 4070 Ti Super
ah yeah then a LOT is possible
i could hop onto a quick call
yep there is even an extension for better eyes
I speak French, bro! If you do too, let’s go! Ahah
english or dutch for me fam
you can try enablen the never oom button at the bottom but only for tiled vae.
Also try the fp16 vae sdxl fix as vae:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/tree/main
but i will say all AI terms in english because i am NOT translating things into dutch
Oh, my bad… Can you explain it to me in writing? Maybe in DMs?
hmm i could condense it into a few lines
go on civitai.green
images tab
find a image you like (that looks good) lets say this one https://civitai.green/images/48136708
copy their resources used
copy their prompt
copy the negative prompt
edit the negative prompt and positive and edit as you go (so i would advice to keep the "masterpiece, best quality, newest, absurdres, highres," but change the rest if you want to keep that style etc)

there are also style loras in the "models' and "styles" but you need to use the filter button to match the model you are using (so like NightNoob in this one is a illustrious model)
So I need to use img2img and add these prompts then?
existing image: not possible as far as i know
new image: yes!
because you dont ADD detail to existing images
you can generate a image without a detail/style lora
and use the same parameters and to generate it anes
anwe
BRUH ANEW
but a random image without the parameters? tough luck as far as i know
It’s an image I already created on MidJourney, and I just want to add more details to the overall image, kind of like Leonardo AI.
ok thx
midyourney made it
so you dont have:
- the model
- the original prompt (midjourney enhances it iirc)
- the seed
4.specific style they used - image parameters, karras, euler, euler a, dpm ++ 2m etc
thus impossible
What Leonardo AI does, Stable Diffusion can do it even better, right?
its a different model
they excel in different things
online image generators work vastly different to local ones
So adding details to a base image using img2img is something Stable Diffusion can’t do?
hmm let me reiterate
you can apply a detail lora to pimp a image before its made
you cannot say
hey ai enhance the image in this way and keep all the things i want
reflections etc is just a tad too advanced to add in post
you can throw an image in img2img and keep the denoise low
its not gonna do what he wants
like this
hes better off adding those details using a lora before making the image instead of getting one off midjourney and then editing it
and why cant it? that image looks like it was ran through photoshop tbh
im2img with low denoide to add stuff
yhen ps to change the post processing
which is what that image has
if you dont have the parameters its gonna vastly change stuff
but he could try i suppose
tried adding cellshading and thick outlines (no same seed, parameters, prompt and sampler) (OG)

end result:

overal downgrade
but i said all that needed to be said. good luck though. i do recommend if you really want detail on a image without the parameters to use photoshop and edit away
Well, I’ll give up then if it’s not possible… I thought Stable Diffusion was capable of doing as well as Leonardo AI. At least that’s what I was told.
its capable pre processing, inpainting etc but its not fair to compare a detail editing feature if you have the manual and parts for leonardo but have nothing for SD
Its possible but it requires a lot of steps
What are all these steps ?
managed to change it into this in the meanwhile but getting a filter over it, ticker lines, cell shading, reflections while keeping the original image intact? nah

Maybe CS1o is a wizard
but at that point its a creative process instead of tech support
i test comfyui and i get no problem, the problem is stable sadly idk why @ornate elk
i used like three prompts
first the girl:
masterpiece, best quality, good quality, newest, detailerlora,
<break>
1girl, thick outline, cell shading, solo, (calico ears), two-tone hair, gradient hair, (white hair), medium hair, (orange hair tips), (long sidelocks:1.2), green eyes, yellow eyes, multicolored eyes, gradient eyes, (red berry hairpin:1.1), red scarf, black coat, raised eyebrows, wide-eyed, happy, open mouth, tongue out, (tongue stuck frozen), frozen tongue tip,licking popsicle, (looking at viewer:1, side view, close-up, glint, steam, daylight, sunlight, winter, snow, vivid colors,
then i masked the background. like 5-7 tries till i got a nice result
best quality, good quality, newest, detailerlora,
<break>
space, galaxy background, stars, dark background
no i used image to image
but i had the seed, main prompt and sampler (and model) so i could change it in the same style
its not done at once
i did it in like three to eight steps
you can
you use image to image
mask the background
change the background that way
🎉
Neither, i use SwarmUI
its not CPU based
so yes
i would assume so
if theres a setting to run it on CPU i dont know as i havent ran into that barrier
anything and everthing related to images will always be processed better on a gpu than a cpu as gpus were made for that specefic task
which gpu?
and how much vram
☝️
oh cool ty
oof 4
youre deff gonna need to use --low-vram and get xformers to help
yeep, conversation with him is always stimulating
yup
just slower
than what other ppl would do
theres a few 4gb vram users
can a 1650 run sdxl?
ah i guess the current ui's have them very optimized nowadays
back when it was new i couldnt run it with my rig lmao
So many wizards here. Truely a magical time in technology space
pretty sure yeah, esp on comfy
though the newer the user the less they need to use comfy ngl
depending on their background ofc
swarm habitual user here lol
sometimes i mess with the noodle but mostly i keep it simple
A lot of it is the libraries that are optimized. The UI's actually tend to mess up those optimizations fairly often. I would recommend swarmui as the king of the realm
yep
what i don't like about using non swarm workflows in comfy is that so many custom nodes are poorly coded and unoptimized
i just get really tired after work so i dont have the concertation left for the noodles and nodes but i FINALLY got my gigabit connection working after drilling a hole thru my floor so im gonna spend some weekends looking into it more
got a seperate comfy setup for the custom ones
giga internet is such a great experience
keeping the swarm lean
right. my previous house had like 300/30
okay but not too great
now 1000/1000 stable
for 15 a month extra i can upgrade to 4000/4000 but thats a bit much for me ngl
i've got 150/150. i've never had issue with it. I download to a 3TB hdd primarily which prbably makes the write speed fo the HDD the bottleneck. I could be wrong about that. Never really done the actual math
im the onedrive manager at my work i get like 100tb per licence of cloud storage
so no need for a nas
❤️ volume licensing
granted i dont trust my work enough to not randomly snoop here and there so i only store safetensors or files without a extension
upload ur nsfw folder u coward
i work in K12 rather not get fired lmao
boss makes 10 dollars and i make a dime so thats why i use volume licenses all the time - updated rhyme for modern days
but because of my work experience i can easyly translate the people skills to some of the users here
yeah some people need people skills xD
i got the full adobe licence for free :3
some people need reading comprehension skills
lmao
my bro used to work school districts. when kids found ways to bypass his protocols and get minecraft running, he'd let them do it. cause it was impressive
hey in my defense, i know how to read, im just LAZY TO READ IT ENTIRELY lmao
why not tfc? teach them the way
blocking the fortnite online copy tho
i only reward certain games, i consider a lot of it brain rot and just block it
hide a mounted image of brood war and see what happens
probably good to not get fired though
blocking tiktok on a few accespoints but allowing it on some (all the good light spots are blocked)🤭
really like to see them get annoyed by the tiktok but hey its a school its not for that
sooner than later the kids will realize their parents use tiktok now. and they will stop
yeah good thinkg tiktok is banned, shit is pure brainrot
alas im not the final decision maker i would have blocked way more on the school web

got minecraft for education though, its dope for projects with the local gov of designing new neighborghoods etc
kids love it
ECO?
its a minecraft like game but more depth, teaches cooporation amongst other things
ah id need to see if theres a interest for it with the more tech oriented teachers
most teachers however are better then the kids with tech and thats not saying much
dang yeah
version 6?
SDXL will fit into 6-8gb of vram. I'd suggest that as your bare minimum. Really depends on what your gpu is
Its not weak, its just not supported for sdxl
maybe if you used comfyui with high level of optimized workflows, like VAE tiling or whatever, maybe you could get away with SDXL models. Don't even think about SD3.5 or Flux models imo. Though i'd applaud you if you tried experimenting with GGUF versions of those.
If i were you, i'd focus most of your efforts on using SD1.5 ecosystem of models. There are tons of refines in that space
SD1.5 based64 has a plethora of solid loras to enhance style, concepts and more, you just have to upscale for nice results
For good speeds yeah but the quality will be lower. If you dont mind waiting. Potential crashes etc sdxl pony is fine
Pony is an SDXL refine so you've gotta have more vram to happily run it. You may be able to get away with it, but it'll be like 20min per image .. heh..
I prefer illustrious over pony for xl
i dont even do anime gens and i concur with that. PonyXL poisoned the XL refine scene with bad practices
"good" is subjective
Illustrious gets you nice images with low effort
Illustrious gets you great images with effort
go to civitai, to browse for models, turn on filters to only show illustrious or pony models
SD1.5 the best anime model is "Anything" and the merges/refines based around that
and look for a mdoel you like
so nice you had to say it twice
a lot of that is operator dependent
I used a different seed to generate that sentence:^)
sampler, steps, prompt, cfg, all the settings and inputs determin a lot of that. it's not just the model you use
It's a numbers game and frankly personal styles etc. its a whole factor of things you gotta try n learn. the prompts i do post are not the ones i keep to my self (call it gatekeeping idc)
I can show you how to do simple stuff but i cant shove the best prompting practices into your head as it differs per model merge etc
gatekeeping is like "you aren't a real ai user if you don't prompt the exact way i am" .. i think if you're keeping some secrets about your skills and approaches, that's something else entirely.
And in the age of youtubers stealing all the good tips they find online and acting like they came up wiht it all, i entirely recommend people do this. Break the meta and keep it to yourself .
You'll note that i rarely post any images publicly
Ive been accused of knowledge gatekeeping before lmao
For this sorta stuff i wouldnt worry about it unless you get a better pc to make your own model
But at that point youd have the knowledge
i often feel like 90% of the effort training a new checkpoint, or a lora even, is building the dataset and it''s captions.
The actual training is just flicking a switch and waiting.
Once you start into making loras etc you learn lot of terms and tags really fast
Yeah
And honestly its sometimes dang hard to think of a lora to make
For practice, i train instagram girls lol. I never publish the models i make though.
thats very shady
O actual good idea for practice, but it feels hella immoral somehow
is what it is. its all for private use and educational reasons
one thing i truely loathe of ai and SD in general is how easy it is to enable the bad actors
i draw the line at creating nude images, but in the tests i do a lot of the models will just bias that way on their own. I never publish any of that though. I dont even think any of it is saved
instagram just happens to be a very good source of datasets that i don't mind looking at
Yep, i unfortunately had to learn how easy it is to fake stuff with it. (I give workshops to teachers for awareness)
they're not all i train too. i find other sources and approahc other styles where i can. None of it is published either
I got ethics but i'm not going to lie to myself like i don't like looking at cute girls
Oh i get it and for training i get it. Easy datasets etc but alsong they stay sfw private practice
It wouldn't be the first time hearing from a colleague a girl ending it all bc of a fake
often when a nude image comes out of one button prompt situation (random prompt generator), i'll feel guilty. But then i remember i put (nsfw, explicit, nude, naked:1.5) into the negative and i'm doing my best. "No nuu, it's the models that are wrong"
I've actually stopped using cyberrealistic so much due to those strong biases
Yeah and like you said you don't keep them and delete them so you have done in this case the best possible steps
happens to guys too. "we'll post all these pics online" has caused many , not just girls, to end it all. sad and tragic.
Oh yeah definitely but you don't hear a lot about the guys. Its just the first time i heard it of a 14yo was so tragic i started the ai awareness workshop at my work
Hey, just want to let you know this is the tech-support channel
Fair, conversation just took off
Hopping to offtopic
Thx 
hey guys
a question
I was talking to a colleague and he said "Why are you still using Pony Diffusion? Illostrius is much better"
I wanted to ask... is that true?
yes. For that realm of work it is.
Pony is poorly trained and disaligns the model from the base substantially
But if that's the case... why are there more pony models than Illostrius? of characters
Pony has been out longer
"start"
lul
It's official name is the "Windows key".
If you're on a different OS, you'll see it called meta or super.
Whats the difference between illustrious and pony? will i still be able to use illustrious on A111 with all my lora's for pony? or do i need to get new loras?
beep
Yes + prompt
the one time i want to use comfyui 

i tried to manually pull it and it does this

so i guess something is wrong with the repo
Hi all, I am following this guide to learn how to train my own Loras in ComfyUI but I am stuck on this error message. I've followed every step. Installed the custom nodes, installed the requirements for each of them but I get this error when. I have searched and come up with nothing. Could anyone help please? Ty https://www.reddit.com/r/StableDiffusion/comments/193hqkz/lora_training_directly_in_comfyui/


Reddit
Explore this post and more from the StableDiffusion community
use onetrainer or kohya ss to train loras
Thanks, ill pivot to that
hello everyone, got a question. Can I use stable diffusion 1.5 loras in Flux comyui? or does the Lora needs to be matched with the base model for it to work?
No 1.5 loras dont work for flux
Yes the lora needs to be matched with the base model
1.5 with 1.5
Xl with xl
Pony with pony
Flux with flux
In some rare cases a xl/illustrious/pony lora works on another of the previously mentioned but rarely
Hello there, so I installed this a little over a year ago and used it just fine constantly throughout the last year with no problems. I then tried to update it and everything seems to have broken. I even tried a new install and I just get the same error.
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument in method wrapper_CUDA__index_select)
Updated swarm? Comfy? Forge? A1111?
A1111
I think, thats the only one that looks familiar
It seems to be because of the models I have. I guess maybe there old and dont work with this newer version.
The weird part is, I did this new install and waited for it to finish compiling and did a test run and it made a picture using the same model. I then restarted my PC and now its giving this error.
Yea I have no clue, no matter which one I try to load it gives me the same error
Doesnt matter how old or new it is
Can you show a full cmd log?
Zluda couldn't be found.
Delete the .zluda folder and relaunch the webui-user.bat
Hi, I tried to run the openvino accelerate script and this error pop up, everything is still working normally but i can't use the script.
I'm on intel i7 1360p, intel iris xe, 16g ram

You re probably best trying to use sd.next if you want to use openvino.
It s a fork from A1111, it should be easier to install. https://vladmandic.github.io/sdnext-docs/OpenVINO/
I have use SD.Next, it works well for 1.5 but I couldn’t load XL model with it due to low ram
Sadly, I doubt it will work any better with A1111
I know, I'm just going for false hope
intel iris are iGpu (understand gpu that does not have its proper memory)
A1111 actually loaded XL and pony though I don't know why
therefore you only have 16gb of ram for windows + SD
for sdxl models it can be tricky.
ComfyUI with some OpenVINO stuff might be more optimized but I still doubt it will work https://nolowiz.com/how-to-use-comfyui-with-fastsdcpu-and-openvino/
(haven't tried it)
I thought ComfyUI only support ARC and not Igpu ?
Also Node based stuff is scary
looks like it does support igpus

I get that ^^
Oh I have seen it before, it is very fast for cpu genning
you ll have to convert models tho.
It happens a lot for those hardware specific system.
That is why I'm a bit put off
same happened for using tensorRT on my nvidia
Thank you for your help, I'll check it out or if it doesn't work I'll just continue using A1111
That seemed to magically fix it and im honestly amazed at how fast it works now. I was lucky if I could get a pic per minute and now its shooting them out in 5 seconds.
does anyone know if i will be able to use pony lora's with illustrious?
unlikely, illustrious seems to be based on "Kohaku XL Beta 5" => not a pony model
oh alright thank you
to be more precise, it will probably technicaly work but results won't be good
whats the difference between pony and illustrious? so far ive only seen illustrious make better images?
Both are ultimately based on sdxl. But pony's training has been... let s say pushed to the point where it is very different from vanilla sdxl. So lora made for it are unlikely to cooperate with other sdxl based models.
regardless it s worth a try, but I would nt hold my breath
yeah so like putting aside loras, is there any benifit switching to illustrious or is pony still great to use?
Yep Zluda is really fast
And you can also generate larger images and use sdxl
Zluda has a better vram management
I should have updated it long ago, thank you so much for your help.
No problem 🙂
it s totally up to your taste
OH alright, i thought illustrious was just a better version of pony that came out. And i thought i would have to use it to get the best generations possible
@ornate elk What is an easy why to upscale your images on A111 stable diffusion? right now all the images i try to upscale through the image to image latent upscale and resize tool are very distorted
what parameters are you using ?

is there a good solution to multiple frames generating in the same picture? It keeps dividing it into 2 or 4 frames and generating the same subject with slightly different angles
oh alright? to 0.7?
what's more important the aspect ratio or number of pixels?
no more like 0.4 or even lower
also most people don t bother with the refiner
interestingly I was using 1024x1024...
I just changed it to 768x1024 and it seems to have resolved it
both don t strand to far away from your model's training resolution
sd1 : 512x512
sd2 : 768x768
others : 1024x1024
you can tweak them by 30% or so in any direction usually without getting too much "duplicate artifacts"
ok!
why not? my images always come out really strong? wont a refiner fix that?
it takes more time and people dim that the results are not necessarily worth it. You try it out and determine what works best for you.
Oh...I've been genning at 512 and upscale them is that bad ?
ok thank you!
For sdxl, sd3 and others. Yes. Outputs will be garbage at 512x512
straight forward
Yeah they look like smudge at 512 until i scale them up
Otherwise yes it s very easy to end up with stuff like that https://cdn.discordapp.com/attachments/1002602742667280404/1112151998586961920/twoheads.webp?ex=67879403&is=67864283&hm=cfddae3f954a679c2f1277c97f13d44d3de3ac23aacd0718a46a875ef415de85&

so set the initial output resolution to some resolution close from the training resolution and with the desired ratio.
And upscale it afterwards if you want higher resolution.
How to make animations?
i forgot did you have a 4070?
4060
theres a Text to image model thats really good but img2vid isnt there yet. with your card youd take like 3-7 minutes for a 6-8second video
kk but how to make one?

Hi, in this video I'll share the workflow and some quantized gguf models with which I have managed to generate hunyuan video in 8GB of VRAM. It takes longer than LTX Video but the quality and prompt coherency is amazing.
Links 🔗
Workflow- https://app.box.com/s/cdeuwc46gjwbio9e5sj5jl0gfxizuf35
Prompts -https://huggingface.co/Lightricks/LTX-Vide...
is there diffrent ui?
Swarm supports it natively
but youd need to know a bit more out of the box
its beginner friendly but theres less 24/7 chat support
i have no idea how to use this ui on video
i dont know what to tell you its well documented on the github on swarm
and i just sent you a whole video explaining it on how to do it on comfy
With cogvideo

Hires fix in txt2img and SD upscale in img2img
For anime illustrous is better than pony, also you dont need the score tags anymore
oh sick
thanks ill install the extension
SD upscale is already included but you could also install SD ultimate upscale
alright
thank you
hey everyone, doing launch.py and it wants to download a model from hugging face. but the download always fails. what do you guys do?
it always just freezes
Are you on Linux or windows?
Which webui do you use?
And if your from Asia you need a vpn for the setup
linux
usa
i can't even get to the ui
because it wants to download a new model and it won't complete
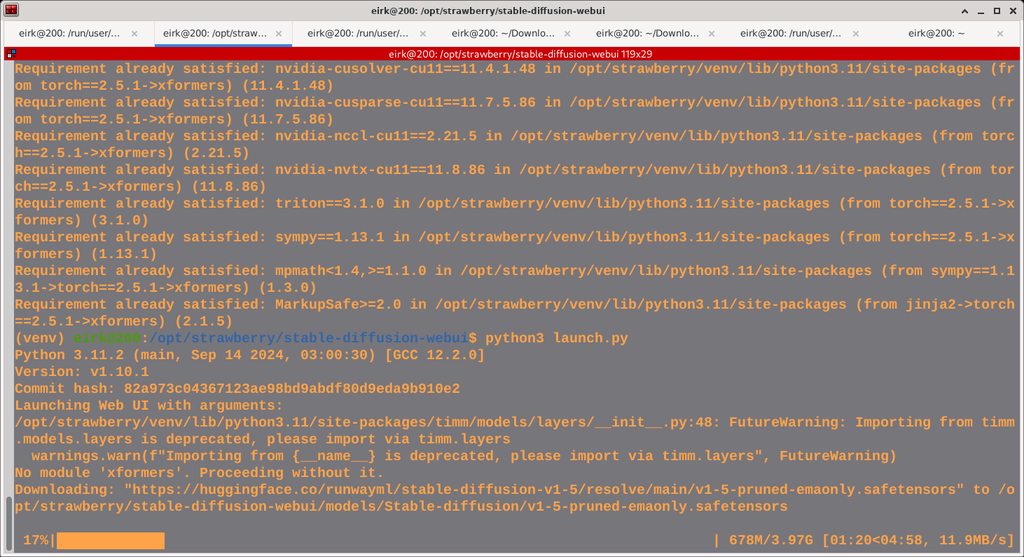
and it hurts that there is no resume on the server
got 300mb of it last try
Is it stuck on 17%?
it's python on windows that is the problematic download client. not the server.
why so many tabs open?
also, just download it manually and copy it into the folder then.
oh you're not on windows. probably still the cause
Use the Adetailer extension
that's linux, i can't get it with wget or browser either
just won't complete or resume
will do
have you confirmed that it has in fact stopped downloading? Like if you go look at the file folder and the size of the file in it, does it stop going up? or is the network traffic over your NIC dropping off?
yes
If pressing space doesnt resume then do this:
download a model from Civitai.com
Like Dreamshaper and put it into the models/stable-diffusion folder.
There delete the 1.5 model if its in there.
Open up a terminal and run
Pip cache purge
Then relaunch the webui.
It will skip the download.
heh dns server. atm machine. til learned
DNS probably isnt' the problem though. That'll only connect the domain name to an IP address, then it's purpose is done.
dns is fine
TIL LEARNED! always thought it was server
working on it now
which distro
debian 12
hmm ok i dont habe much knowledge with that one
basically ubuntu except more conservative
oh use sudo apt
forcing new line didn't work
civit ai also craps out on me
im wondering if it's my isp
that's the one
that i'm trying to launch
does it make any difference if I used the source_pony and source_3d prompts in stable diffusion?
CS1o wrote allot of good ones
ok
altenativsly i also suggest installing Stability Matrix for those who have nvidia gpus
will try
sure one moment
check ur dms hat
feels like days of dialup again
i'm loving Xfinity!
lol
the ubuntu iso 5.8gb is going strong....
are there torrents for checkppoint files?
Does anyone know the best way to generate 2 distinct characters on each side of the image? Not looking to load in specific faces or ip-adapters, just have them not use the same character prompts for both subjects (using comfyui preferably)
oh god xfinity
if u wanna try my distro
Pop Os
ubuntu
not "mine" but i use it lol
ic
ya
all ols
old
really fresh insall though
so i suspect computer less
i'm on ethernet
sadness on my end too
any torrent sites for models?\
not that i know of but i wouldnt be surprised if theres a rentry
@ornate elk know anything like that?
i know in days of old there was rentry with all the 1.5 model torretns
your trying to use a style lora as model, nut its not a model
I also dm'd them about better installation guide ytou posted
have you changed the dns of your router or PC ?
well a1111 is not gonna question the user input
your car doesnt warn you either if you put the wrong fuel in it :/
lmao
i mean it kinda does...by not starting
put disel in a non disel car
xD
yeah lol 2 yrs ago when was things started
you can download and use that model with your gpu 🙂
models (checkpoints) are the the core file you need to generate images.
there are different versions of it.
1.5 based ones are 2-4gb
sdxl/pony/illus are 6gb
flux can be 4-23gb
Loras are smaller and got into the models/lora folder
they are used to alter an image on the way it got trained on
they got my card, 3060
thats a lora
you need an illustrous based model for this lora
hires is the hires fix button
hires fix is for upscaling
with the correct settings it enhances the image
What is the last version of python that i can install for comfy
I use 3.10.11
3.12.8 generally speaking, some older developed things might have issues, i personally don't.
though my setup is specifically tailored for an AMD GPU with ZLUDA
Comfy Desktop uses 3.12.8 sooo...
How can i fix this?

Auto and forge have some extension for that
no clue. I basically ran any errors through chatGPT o1 until I got it working
No i don't understand how to do that
There isn't a folder called cache_setting. json.
No, there is
Idk
just so others may be able to help you better could you please paste the entire log in chat?
yes
Here

maybe a conflicting node, did any say import failed or anything at the end cuz that's still not the full log
copy the entire text in the command log and paste the entire text in discord
step bro im stuck in the loading

bruv

btw ur off topic, Community support channel for questions related to local/cloud/colab installations.
yeah maybe but rules is rules people need help (like me) and u make message and helper cant see my message
ugh.. anyone know how to access the comfyui navbar on mobile when its not showing? I need to save my workflow
figured out a solution.. open a new browser tab with the comfyui address, and it will load your current session without resetting it. The menu will display momentarily as long as you dont click anywhere else, but will let you save the workflow
go into settings, user interface, quick settings, there add sd_vae
then hit apply and reload ui
then you have a dropdown to select the vae
if the file is in models/vae
yep but if you dot it as i mentioned then you dont have to go in the settings everytime
you will have it in txt2img at the top

there add sd_vae
illustrous needs an sdxl vae
not the 1.5 one you downloaded
vae, aswell as loras always are only compatible with models that have the same base version
no problem
that is cursed
Hey! Anyone experienced with Trellis node extension up here ? 👀
i guess not
Then my question will be, is it possible/recommended to change python version from Comfyui from 3.10 to 3.12 since it seems i installed all the xformers/triton/wheels etc... for Trellis in 3.12 version of python or something like that
you dont want to use 3.12
or 3.11
3.10.11 is the one because the others break
ah thats a vpred model
youll need to run it in forge for that one
forge has the extra stuff to run it
download the 3.1
see if its not vpred
if its not vpred youll be able to run it as normal
Forge is A1111 but with extra tweaks to it pretty much
a whole other webui installation
im downloading comfyui with hunyuan and im wondering what hunyuan model should i install? to do videos in 720p at least constistently for like tiktok and insta reels. I can choose from the bf16 model to like q3 even to q8 (q7 skipped). i have a rtx 4060 ti with 16 gb vram and 16 gb ram
all the models are from the hugging face website
hi what make this picture? I want to %100 same picture

why is this happening?

Good question, if you got their model, seed, prompt and workflow its possible
Otherwise its not and it's gonna deviate
Hmm its possible they didn't fully list all tools used like clipskip? Or a comfy node changing stuff, euler a + karras etc.
Or even a variation seed that they didnt list
My images i need to manually add all tags/meta data on civit
Cant tell from the image but are you using the exact same aspect ratio?
it worked perfectly before :/
Can you show the full report?
absolutely
File "C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\execution.py", line 174, in _map_node_over_list
process_inputs(input_dict, i)
File "C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\execution.py", line 163, in process_inputs
results.append(getattr(obj, func)(**inputs))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\nodes.py", line 568, in load_checkpoint
out = comfy.sd.load_checkpoint_guess_config(ckpt_path, output_vae=True, output_clip=True, embedding_directory=folder_paths.get_folder_paths("embeddings"))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\comfy\sd.py", line 825, in load_checkpoint_guess_config
sd = comfy.utils.load_torch_file(ckpt_path)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\comfy\utils.py", line 36, in load_torch_file
sd = safetensors.torch.load_file(ckpt, device=device.type)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\python_embeded\Lib\site-packages\safetensors\torch.py", line 313, in load_file
with safe_open(filename, framework="pt", device=device) as f:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
OSError: The paging file is too small for this operation to complete. (os error 1455)
Prompt executed in 0.02 seconds
there is more, just a second
here that is everything
i mean if you just want the same image, just use image to image? or is that not what you mean?
Paging file is too small for this operation to complete. I am no comfy expert but the error should be the same ish
thanks, i will check!!
IT WORKED!!! THANK YOU SO MUCH!!
another error showed up
D:
C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable>.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build
Total VRAM 4096 MB, total RAM 16294 MB
pytorch version: 2.5.1+cu124
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce GTX 1050 : cudaMallocAsync
Using pytorch attention
[Prompt Server] web root: C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\web
Import times for custom nodes:
0.0 seconds: C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\custom_nodes\websocket_image_save.py
Starting server
To see the GUI go to: http://127.0.0.1:8188
got prompt
C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable>pause
Press any key to continue . . .
Ah you are using a 1050
Amd vram state to normal,
Set to low vram?
Its like that on other ui's
Scheduler on yours is automatic, hes using sgm uniform. Ensd?, cfgrescale. Isnt that a extension within a1111/forge nowadays
i know i change that in Main.py right? but there is a specific line?
In other ui's its in the launch script iirc but comfy users correct me if im wrong
Or uhh google i suppose
i tried to google it, i found the commands but not where to put it
which line?
Not a checkbox, you missed the scheduler setting (euler a + sgm uniform) a ensd setting but that might be comfy specific, and a extension for cfgrescale
C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable>.\python_embeded\python.exe -s ComfyUI\main.py --windows-standalone-build
Traceback (most recent call last):
File "C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\main.py", line 2, in <module>
comfy.options.enable_args_parsing(--lowvram)
^^^^^^^
NameError: name 'lowvram' is not defined
C:\Users\igorh\Documents\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable>pause
Press any key to continue . . .
i put this lowvram everywhere possible in everyline i could try nd the result is the same
did you add lowvram or --lowvram.
i googled the thing but i see you also revived a year old reddit thread bruh
even this?

https://www.reddit.com/r/comfyui/comments/15jxydu/comfyui_command_line_arguments_informational/ (see top comment for readble ver)

yes, but i might have fixed it
by changing for (["--lowvram"])
yes, i fixed it, it is now working!
hi i have this issue when i swap between multiple ckpt checkpoints i get 100% ram usage and then it starts using the c drive up too
Why are you using the old format?
The old pickle format needs to be uncompressed first when loading into memory. Hence explaining the ram issue
Then again how much ram & vram do you have?
i use ckpt because if i try to merge checkpoints then i get the error pystring/float etc. But if i change it to ckpt format i get no error and the merge works
i have 32 gb ram and 16gb vram
automatic
i can see it loads sd_vae thingy a lot
and something called optimizing dogtex?
Hello! I have a question: when I use the "img2img" function, the colors always end up being dull and grayish. How can I fix this issue? Is there a way to adjust the colors or download something to correct it?
I'm using Illustrious.
Also, where can I set the "Clip Skip: 2" parameter in Forge?

dang nvm

Clipskip for sdxl is a meme, you dont need it. Also are you using a vae?
Also clipskip was hidden in a settings submenu cant recall where
I couldn’t find a VAE for Illustrious, so no, I’m not using one.
Use sdxl vae
As its based on sdxl
th
No vae = no colours basically or really dull
All of them will do, right?

Just sdxl yeah, i use the basic one
How much RAM do you have?
☝️
Asking in advance even if i cant solve it :^)
What's in your webui-user.bat?
Also how large are the model files?
what do u mean model files they are the 6-7 gb type of checkpoint merges. And i have this webui-user.bat
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS= --use-zluda --skip-ort --theme dark
call webui.bat
Guessing but dont you need to set
PYTHON=<YOUR PATH OR VERSION> GIT=<YOUR PATH OR VERSION> VENV_DIR=<YOUR PATH TO VENV DIR>
? Shot in the dark from my end
this won't show in the controlnet dropdown


there's no models folder in the controlnet extension folder itself
where do controlnet models go if not the models/controlnet folder
ok for some reason i had to manually add the path to the models/controlnet folder in the settings
Hello, I'm trying to setup Stable Diffusion w/ an RX 7900 XTX GPU (preferrably on Windows), and I'm not quite sure how to go about it
I've heard conflicting view points as whether to use Microsoft Olive, ZLUDA, or DirectML - and I was wondering if someone would be able to give me some advice on which approach I should go with?
Thanks in advance, I'd really appreciate it 🙂
Follow the Zluda guide for AMD gpus in the pins
Does it perform better than the microsoft olive approach? I keep reading that using olive is 10x faster?
thanks, in that case I'll prob go w/ zluda since this is gonna be my first time setting up stable diffusion locally
is automatic111 the recommended ui to go with, or comfy?
i dont even know what this microsoft olive is either tbf
id have to look into it
i personally use comfy, its all a matter of preference, each ui ahs their pros and cons
the general concensus is that forge and swarm are the main easy to use and comfy is for advanced users
cool thank you, if forge/swarm are easier maybe I'll start off with one of those haha
and yeah I think microsoft olive is able to convert cuda models to run in a different format optimized for amd cards etc
would u recommend one over the other, between forge and swarm? ie. does one have more support
Pinned messages has a amd guide for forge. Havent checked/seen one for swarm but since its a comfy ui back end its basically the same steps as a zdula comfy ui build i think
But theres more support for forge in this server
My previously trained lora's that worked fine are now producing black screens and this error
NansException: A tensor with NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
thanks, im gonna actually end up just doing comfy ui I found it in the guide for zluda, but I noticed here they recommend installing python directly, is that neccesary or can i use miniconda?
Okay looks normal.
With 32gb ram this issue is strange.
Does the ram fill up completely when switching models?
Hm sorry i used python directly, no idea about miniconda
Miniconda is not recommended by the guides as you can install python 3.10.11 and use it for every Webui without a problem.
But if you know what you do you can install python 3.10.11 with miniconda and shouldn't get a problem.
Also for beginners I would recommend using Auto1111 or Forge.
gotcha thank you! I'll be sure to install that version then ❤️
NP, feel free to ask me if you get any questions.
Also zluda will be a much better experience than directml with onnx
Thank you, although the setup had quite a few hiccups along the way, the end result is significantly faster than DirectML ❤️
And one more question: does it turn out that all LoRAs and embeddings made for SDXL work with Illustrious? Where can I read about compatibility?

What's your GPU and what's inside your webui-user.bat?
Hi I'm getting confused trying to install Stable Diffusion and google isn't really helping
A lot of the information is from about a year ago
I have a Rog Strix 3080 and I'm following the step by step guide in the pinned information
But I'm a bit lost now
I'm trying to follow these steps

Is this correct?

RTX 4070, inside idk, just run
Yep thats correct
Thanks! I've since managed to figure it out and it's now working. Just trying to understand how ComfyUI works
Np, If your new Auto1111 or Forge is easier to start with than comfyui
That's okay I'm excited to learn how it works. I'm completely new to this. This is Day 1 for me in terms of learing Stable Diffusion
Sdxl loras only work on sdxl, pony on pony, and illustrious on illustrious
Idk about embeddings
yea when i used X Y Z plot/test each checkpoint it does it if i just add 1 or multiple of CKPT checkpoint files. but i will try to disable add vae
@ornate elk when i choose a merged ckpt file
Loading weights [d0c6b4a29f] from D:\Automatic1111 Stable diffusion\stable-diffusion-webui-amdgpu\models\Stable-diffusion\OmniRillusmNoobAICyberRealistic-0.3.ckpt
Loading VAE weights specified in settings: D:\Automatic1111 Stable diffusion\stable-diffusion-webui-amdgpu\models\VAE\sdxl_vae.safetensors
Applying attention optimization: Doggettx... done.
Weights loaded in 11.7s (send model to cpu: 2.2s, load weights from disk: 7.6s, apply weights to model: 0.5s, load VAE: 0.3s, move model to device: 1.0s).


if i set "VAE Checkpoints to cache in RAM" to 1 and disable "Selected VAE overrides per-model preferences" would that work?
If I have a image of my wife and I want to run her into forge ai how hard would this be
Took a photo of her and want to change it up a bit
i cant move this popup (properties panel) even i zoom in zoom out.

img2img tab
I wanna copy the pose and stuff ... and make her anime style
train a lora on her images, roughly 15/30 of them on different angles etc. then you'll be able to do a generation of her with controlnet and other model styles
if hardware allows, sdxl
How many do u select to test?
quite a few like 6 or something but today even just 2 ckpt files takes up all ram dunno why it takes Ram it uses ram and then continues to use up my C drive virtual memory since thats where python are
Is there a way to set Clip Skip: 2 in Forge, and where can I find it in the settings? I think the absence of this setting is why I can’t achieve the same results as in A1111. 


@halcyon zodiac @dreamy token @jagged idol @ashen plume @light elm Hey guys, I have the following script for in-painting when I upload the mask (as showen in attachment) on the the-man.png image, most of the times it doesn't perform well, I changed the seed number to different numbers, without seed (randomized seed) most of the time, it doesn't perform well with the prompt in the script, I wonder if there is something wrong with the code or it's the stability's bug that cannot perform well in in-paint.png feature.
I also have uploaded a sample result.png generated by the Stability.
Any help/guidance or intuition is really appreciated, we put some great hope on using the Stability in our production.
@quartz ferry FYI



Can you check the pagefile settings?
Also open up a cmd as admin and run
SFC /scannow

{kind=link}
{kind=link}
Is anyone here experienced with prompts? I am trying to get an image generated but everytime i generate the image it looks worse than all the other images on civitai even though i use the same lora's and strenght
does anyone know how to fix this or whats going on control ui

nah generation is still horrible
Please paste the whole error so someone can better help you
just copy and paste the text in the cmd prompt into chat
did you find any good youtube videos or sources of information to help with prompting which i could use? (if you dont mind)
@ornate elk hey i did it before but i cant find out how to do it again but i figured you might know but do you know how to manually change the defaults for forge/a1111
Hey, you have to edit the ui-config.json
oh hella, thanks man 🙏 youre the best ong
@ornate elk Sorry to bug you, just had a quick question about ComfyUI 🙂
I notice some models run fast and state:
CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cuda:0, dtype: torch.float16
Where as other models state current as "cpu", and run slower:
CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cpu, dtype: torch.float16
Is this an issue where the GPU isn't being properly utilized, and if so can it be fixed, or is it just a downside of using ZLUDA with some models not being compatible?
Can anyone tell me why all the loras i train in kohya produce black images?
I have not tried onetrainer but I will give it a shot.
Ill send my settings rn
this is the settings
I've tried bf16 and fp16 both only give black images.
prolly cos ur using a vae model as the training source lol
check ur training model
try a different one
What confuses me is i've used this model before and the models worked, but now they don't.
strange indeed
Well regardless of it being strange, I just tried onetrainer and it works great the lora isn't just producing a black image. I used the same base model as in the settings as well.
AI is weird.
onetrainer is my prefered
change the learning rate warmup to 200 and this should serve as a good starter settings for training xl loras on a 3060 12gb vram
I have a 4090 should I crank it higher?

these were my settings and i got pretty good results
if you want speed nah leave it as is, one thing you could mess with is the lora dim and alpha. high dim will eat more vram, i pushed my besties 4090 up to 256-128 just for lolz
well actually
the batch count will affect the quality too
while yes with the 4090 you could do 4, make sure the dataset is.well balanced for it
I don't really know how to balance it, is there a method?
i have an epoch helper calc i wrote you could use if need help
the link is in my bio