#🤝|tech-support
1 messages · Page 97 of 1
comfyUI is an interface that you run stable diffusion in. but don't you have photoshop? if you just want to enhance your photos a bit, adobe's gen fill in photoshop is a much better option than stable. it's a lot easier to use and integrated with all the other tools you probably use all the time
well i try to do something different with Ai i think that always is a way to make thing different
So you can look diffferent in the market when i say touch up meaning i dont want to make the person look different i could change clothes
i dont know yet because i dont much about this but that just an idea
okay, well - comfyUI is just an interface to run stable diffusion inside of. you can also run stable at the command line, or inside webUI, or auto1111, or forge - or online in a number of places. how much Vram do you have and what GPU do you have?
how i know the GPU i have in my computer?
do you have a windows machine, a mac, a linux machine, just your mobile device, something else?
mac
okay, you probably want to wait till @ornate elk gets back online and discuss it with him
why windows is better for this?
it's not necessarily better, but I don't know how to find out what hardware is in a mac as i don't use macs
the GPU for the internet or inside my mac?
gpu = graphics processing unit. so if you're going to run stable diffusion locally, you need one in your machine. if you are going to use something online, then you would be using the GPUS that belong to the site you are using.
but i don't know if macs have different requirements than windows machines, which is why i suggest wait till @ornate elk gets back online
Chipset Model: Apple M1 Max
Type: GPU
Bus: Built-In
Total Number of Cores: 24
Vendor: Apple (0x106b)
Metal Support: Metal 3
Displays:
LG HDR 4K:
Resolution: 5120 x 2880 (5K/UHD+ - Ultra High Definition Plus)
UI Looks like: 2560 x 1440 @ 60.00Hz
Main Display: Yes
Mirror: Off
Online: Yes
Rotation: Supported
how do you change the output temp folder for gradio? im not a programmer so ull have to say spcific instructions thank you ^^
i have some issues using HI red settings, its been fine for months when suddenly when i tried it today, the progress bar is stuck at 0% can anyone help me with this please?
how much RAM do you have? our Silicon Macs have a "graphics card inside CPU", which means there is no separate dedicated graphics card as we had on old Macs
they use "unified" RAM, which means it is shared between the CPU, graphics card, and neural engine
key point - sometimes is more important how much RAM you have than which CPU you have
M1 MAX with more RAM might work faster than M3 PRO with less RAM
hi again Viking, i thought i would give you an update from earlier:
i found out that, if I took the image I was trying to inpaint and copied it to a new .jpg file, then it would inpaint normally
this implies to me its something in the exif/metadata
anyway thanks for your help earlier, I'm going to try to figure out what settings are wrong on the image now 🙂
there is no "better" or "worse", they work the same
the key difference is speed
windows with newer NVidia (4090) works faster than any Mac
to install stabile diffusion webui on Mac follow my step by step guide or simply use my a1111-setup script that will do everything for you

GitHub
July 28th 2024 version If you want to install Stable Diffusion webUI on your Mac or fix your current Stable Diffusion installation as fast as possible, use my a1111-setup script that will do everyt...

GitHub
Install Stable Diffusion on Mac. Simple and easy Automatic1111 and Forge install script for macOS - viking1304/a1111-setup
yesterday i found out that the default model that was automatically downloaded by webui has been deleted (https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16457)
i will try to update my guide later today (i need to go now) and release a new installer version with a patch for that issue
you can manually download a model as described in the answer on that link
just be sure to put it in stable-diffusion-webui/models/Stable-diffusion folder

CS1o and Aryetis know much more about NVidia and AMD than me, but for Macs, it's always best to wait for me 🙃
Can you show the settings you used and the cmd log?


the problem was so sudden its quite surprising
months, alls fine
suddenly BAM! it stopped working
Ah I see, when using hires fix you have to set the hires steps to 10.
Also don't use a refiner
i see
but ive used the same settings for a long time
and it hadnt shown any issues for months
What's your GPU?
3070
Ah okay. Then also make sure you have --xformers --medvram-sdxl --no-half-vae in your webui-user.bat for the best performance
ill have that set up, and see how it works
thanks @ornate elk
Refiner is not needed at all as hires fix is better.
Refiner was only useful for the base sdxl model.
i understand
But never leave the hires steps at 0, better use 10-15
🙏
You used a shortcut here to launch. Make sure you add the commandline_args I mentioned there and in the original webui-user.bat
Hey everyone! I used to be able to run SD without much issue but I recently upgraded my PC and now I'm having trouble getting it to even launch. I’ve hit a wall with errors but before we get into that, I'd like to ask if it maybe is a compatibility issue with some of my specs:
System Specifications:
- CPU: AMD Ryzen 5 7600X
- GPU: AMD Radeon RX 7800 XT
- RAM: 64GB DDR5
- Storage: 1TB SSD
Software Environment: - Operating System: Linux Mint 22
Is any of those a big deal breaker? I'll send more info if needed!
Hey, what did you upgrade?
Or did you reinstalled the OS
Can't help much with Linux but checkout AMDs ROCm guide
the machine is different, like it's a fresh start basically
Quick start install guide
After Installing ROCm you have to git clone the stable-diffusion-webui
okay, out of the gate it looks like my kernel may be an issue, the website lists 6.8[GA] as the compatible one, but I have 6.10, I'll see if I can do something about that
thanks for the pointer!
can someone tell me how I can use LDSR upscaler here? Ignore the LDSR.ckpt in the list, I downloaded this and placed it in the ESRGAN folder but it's not the correct model. Is there a special version of LDSR I need to download to use it as an upscaler here? In Auto111 I was able to just chose LDSR from a list when using Ultimate SD upscale...

I have updated my guide for Macs https://github.com/viking1304/a1111-setup/discussions/2 to address the issue with the download of the default model
i do not have time to update the installer, it works, just the model needs to be downloaded manually, until I apply the patch
GitHub
September 14th 2024 version If you want to install Stable Diffusion webUI on your Mac or fix your current Stable Diffusion installation as fast as possible, use my a1111-setup script that will do e...
some how when i restart pc it del my added --xformers --medvram --no-half-vae
how to fix this

Add it to the commandline_args
i addded and save but when i resstart pc it become normal
that's problem
that makes no sense
but you can right click the file and enable "Write Protection" after you edit it
hey all hope doing well. Since to i am get lots of error like: Using pytorch cross attention
Using pytorch attention for VAE
ControlNet preprocessor location: F:\a1111-forge\webui\models\ControlNetPreprocessor
*** Error loading script: animatediff.py
Traceback (most recent call last):
File "F:\a1111-forge\webui\modules\scripts.py", line 525, in load_scripts
script_module = script_loading.load_module(scriptfile.path)
File "F:\a1111-forge\webui\modules\script_loading.py", line 13, in load_module
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "F:\a1111-forge\webui\extensions\sd-forge-animatediff\scripts\animatediff.py", line 10, in <module>
from scripts.animatediff_infv2v import AnimateDiffInfV2V
File "F:\a1111-forge\webui\extensions\sd-forge-animatediff\scripts\animatediff_infv2v.py", line 5, in <module>
from ldm_patched.modules.model_management import get_torch_device, soft_empty_cache
ModuleNotFoundError: No module named 'ldm_patched.modules.model_management'
any idea since i dont think i use anything with animation?
animatediff works only on the old forge version
hey cs. Do i need to do anything like remove extension or something or just error and let it be ?
To not get the error you need to remove the extension
is that extension forge_space_animagine_xl_31 ?
No its sd-forge-animatediff
sorry i think found it must be sd-forge-animatediff
super thks help again as always. You guys are awesome
no problem 🙂
Help me, please, what to write in webui-user SD Forge, so that it can see the ControlNet models that are in A1111.
Now it is as on the screenshot.

Hey, you have to edit the webui-user.bat of Forge like this:
`@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
@REM Uncomment following code to reference an existing A1111 checkout.
set A1111_HOME=D:/Programme/AI-Zeug/stable-diffusion-webui-amdgpu
@REM
@REM set VENV_DIR=%A1111_HOME%/venv
set COMMANDLINE_ARGS=%COMMANDLINE_ARGS% ^
--ckpt-dir %A1111_HOME%/models/Stable-diffusion ^
--hypernetwork-dir %A1111_HOME%/models/hypernetworks ^
--embeddings-dir %A1111_HOME%/embeddings ^
--vae-dir %A1111_HOME%/models/vae ^
--controlnet-dir %A1111_HOME%/models/controlnet ^
--lora-dir %A1111_HOME%/models/Lora
call webui.bat`
Will make a note of that 🙂
Thank you. Strange that it now see all controlnet models except this -diffusion_pytorch_model_promax.safetensors
https://huggingface.co/xinsir/controlnet-union-sdxl-1.0/tree/main

Hi could someone help I have difficulty installing sd I have never use GitHub and its really hard
What about just VRAM sharing?
Nope
Hey, checkout my install guide on the pinned messages
Okay thanks😊
And so when I’m here and I have type the prompt and click generate I just need to wait ?

The cmd wrote “stable diffusion model failed to load”
You need to download a model from Civitai.com
Put it into the models/stable-diffusion folder
Now it wrote “invalid argument to memory_allocated” 🥲
What's your GPU?
Can you show the cmd log?
It’s an rx6600
How ?
Copy and paste ^^
It’s too long for discord😭
Sorry I’m not really smart 😂
venv "C:\Users\mateuhla\stable-diffusion-webui-amdgpu\venv\Scripts\Python.exe"
ROCm Toolkit 5.7 was found.
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
Version: v1.10.1-amd-5-gd8b7380b
Commit hash: d8b7380b18d044d2ee38695c58bae3a786689cf3
Using ZLUDA in C:\Users\mateuhla\stable-diffusion-webui-amdgpu.zluda
no module 'xformers'. Processing without...
no module 'xformers'. Processing without...
No module 'xformers'. Proceeding without it.
C:\Users\mateuhla\stable-diffusion-webui-amdgpu\venv\lib\site-packages\pytorch_lightning\utilities\distributed.py:258: LightningDeprecationWarning: pytorch_lightning.utilities.distributed.rank_zero_only has been deprecated in v1.8.1 and will be removed in v2.0.0. You can import it from pytorch_lightning.utilities instead.
rank_zero_deprecation(
Launching Web UI with arguments:
ONNX: version=1.19.2 provider=CPUExecutionProvider, available=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']
ZLUDA device failed to pass basic operation test: index=None, device_name=AMD Radeon RX 6600 [ZLUDA]
CUDA error: operation not supported
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Is this enough ?
@ornate elk can you help me out with my question
i dont know if you swa my questions
Did you replaced the rocm lib files ?
Also show your environment path settings
What's the issue?
Didn't saw it
No I have just download it

Yea thats the issue then
You have to do step 4-5 of the guide at zluda setup
Replacing some files In a folder
Oh okay thanks 😊
i wanna know if i should install this on local or if any other way not too hight prices that i dont need to have that in my drive ?
or if can install that in external hardrive
You can install it localy on your Mac with the easy install script. Its listed in the pinned messages of this channel.
Then you can decide if its to slow to your liking
Online services like Leonardo.ai are good too. Or you can rent a GPU online too
But you should try it out localy first
Idk. For mac its a bit difficult I think. The install script installs it on the main drive by default
ok thank
@ornate elk also if i trying to level up my photography and video work what type of model pack should i loook for
or where can i read and learn more about this so i know what i gonna be doing?
I think I don’t understand this part well: 3.3 Go into C:\Program Files\AMD\ROCm\6.1\bin\rocblas folder.
There copy and rename the library folder to old_library
Open the .zip file and drag and drop all files of the library folder into the library folder. Not into the old_library folder.
Important Restart your PC after this Step before proceeding.
in your case its the 5.7 folder
And so I copy the library file so there’s two in robclas ?
yep
and then you rename one
to old_library
and then you move the files you downloaded into the library folder (not old_library)
And I replace or ignore the identical files ?
replace
Okay
and after that restart the PC
And after this it is supposed to work ?
This don’t work 🥲
Sd model failed to load
can you copy the whole cmd log?
mark everything and right click to copy
something isnt correct still:
ZLUDA device failed to pass basic operation test: index=None, device_name=AMD Radeon RX 6600 [ZLUDA]
try deleting the venv and the .zluda folder that are inside the stable-diffusion-webui-amdgpu folder and then relaunch the webui-user.bat
Okay looks like it work, thanks
Stable diffusion on my end is not generating nsfw rn and idk why.
Perfect np
Hey guys is if possible to do this with the image 2 image function?
Basically I wanna change a texture from a yellow like skin to pinkish

that would be an inpainting function, where you mask out the areas of the skin, and then prompt for a different color skin

For some reason when I use --medvram it'll be just about to complete the image and then Stable Diffusion just craps out
whats your gpu?
how much vram?
make sure you use --xformers --medvram-sdxl --no-half-vae
and enable fp8 mode for sdxl in settings
I'll give that a try
Does the order matter?
nope
So it's able to generate images without issues but my seeds don't seem to work :/

Should I try disabling the fp8 mode for sdxl?
huh, now whenever I try to disable fp8 mode for sdxl my instance crashes
show me the settings when you get this?

try load an 1.5 model then (2gb) and then try disabling fp8
I'll be back soon to test that
Im running forge with flux just installed upon generating the first image i get this error:
AssertionError: You do not have CLIP state dict!
which flux model did you tried? and which webui?

then use this model:
https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4/tree/main
the flux nf4 v2 (best for forge)
or the 16gb flux version:
https://huggingface.co/Comfy-Org/flux1-dev/blob/main/flux1-dev-fp8.safetensors
will the latter work with 10gb RTX?
yes but slow
the nf4 should work much better
whats the diference between the one i tried using at first?
its the 23gb base model
wouldnt try to run it on 10gb vram xD
yep
you dont need it
@frigid crypt also here is a guide on how to use different flux models with Forge:
https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/1050
you also need to download clip l and t5 for flux
Im trying to test out the flux.1-dev aswell as SwarmUI but i need a flux vae, where can i find it and where do i place it?
Downloaded both file in this image and placed them in models/VAE but doesnt work like that apparently.

whats the he flux1-dev-fp8 one?
drop it into models/vae
remove the other 2 files
Will do, thank you
?
flux1-dev-fp8 model
is it good with 10gb vram?
Oh God, my ComfyUI crashed and died yet again.
Trying to load a big Outpainting workflow, it downloaded lots of stuff and then died. ComfyUI will not start up. I'll start with the venv and get rid of some nodes or something.
which clip-l and t5-xxl should i download? or all of them?

Maybe.... @ornate elk since I installed the venv before I got my torch installed properly, that I needed to restart the venv and that'll fix everything? Wishful thinking, but I have no idea.
I dont suppose this is normal? Its crashing after maybe 2 minutes of generating an image. using swarmUI with Flux1-dev

only the clip l and the t5 fp8
which torch version did you installed?
whats your gpu?
I ran this: pip install -U xformers --index-url https://download.pytorch.org/whl/cu121
then you have to do this after the venv gets recreated
at the beginning of the install i selected amd version
that installed only the directml version of swarm and comfyui, not the zluda version.
which means it cant run flux as it takes to much vram
Okay, I'll let the venv finish recreating then I'll run that command again?
still following the guide:
do I need GGUF models?
nope
if you have the nf4 v2 and the flux dev fp8 16gb your fine
whats the best res for the model?
the default res currently takes 55 secs

i still have the zluda files from the stab-diff, any idea how i can get it to work?
thats already a good resolution. the higher you go the longer it will take
i currently dont have a guide for swarm, but i have a guide for comfyui and forge which both can use flux
with zluda
Guess ill just have to install comfyui then and learn it xD. WIll install it tomorrow
I got this error. Then I got a popup saying this: The procedure entry point could not be located in the dynamic link library D:Ai\ComfyUI_windows_portable\ComfyUI\venv\Lib\site-packages\torchvision_C.pyd.
got Swarm working with Comfyui Zluda
will update my guide tomorrow. But basicly you need to have Comfyui with Zluda installed first. then you can import it into swarm ui
Anyone can help me I downloaded extension which is wildcard gallery but when I add wildcard their preview doesnt show up can anyone pls help
@ornate elk Perhaps installing this file would help? That file isn't there
Not that I know where to even find that file
I looked and that file is in the right folder so the error makes no sense.
Activating virtual environment...
Running main.py with --auto-launch argument...
[START] Security scan
[DONE] Security scan
ComfyUI-Manager: installing dependencies done.
** ComfyUI startup time: 2024-09-14 19:30:09.370774
** Platform: Windows
** Python version: 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
** Python executable: D:\Ai\ComfyUI_windows_portable\ComfyUI\venv\Scripts\python.exe
** ComfyUI Path: D:\Ai\ComfyUI_windows_portable\ComfyUI
** Log path: D:\Ai\ComfyUI_windows_portable\ComfyUI\comfyui.log
Prestartup times for custom nodes:
0.0 seconds: D:\Ai\ComfyUI_windows_portable\ComfyUI\custom_nodes\rgthree-comfy
0.0 seconds: D:\Ai\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Easy-Use
0.7 seconds: D:\Ai\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Manager
Total VRAM 16376 MB, total RAM 32536 MB
pytorch version: 2.4.0+cu121
D:\Ai\ComfyUI_windows_portable\ComfyUI\venv\lib\site-packages\xformers\ops\fmha\flash.py:211: FutureWarning: torch.library.impl_abstract was renamed to torch.library.register_fake. Please use that instead; we will remove torch.library.impl_abstract in a future version of PyTorch.
@torch.library.impl_abstract("xformers_flash::flash_fwd")
D:\Ai\ComfyUI_windows_portable\ComfyUI\venv\lib\site-packages\xformers\ops\fmha\flash.py:344: FutureWarning: torch.library.impl_abstract was renamed to torch.library.register_fake. Please use that instead; we will remove torch.library.impl_abstract in a future version of PyTorch.
@torch.library.impl_abstract("xformers_flash::flash_bwd")
xformers version: 0.0.27.post2
Set vram state to: NORMAL_VRAM
Device: cuda:0 NVIDIA GeForce RTX 4070 Ti SUPER : cudaMallocAsync
That's when it crashes
@ornate elk Okay, new info. "Torch not compiled with CUDA enabled" ... I tried to start ComfyUI without using your .bat file but with the Comfy run_nvidia_gpu.bat and got that error
Oh damn, I may not have CUDA installed. I thought it was automatically installed on the PC
Anyone know if I need to install CUDA?
Okay, that was the wrong tree to go down. For some reason, there's a mismatch between my torch install and xformers
Can you use the Flux Lora trainer with a T4 GPU? I do have colab pro but I'd rather not use 5 compute units per hour

And then I realized you can't pick a base model for that trainer
Is there a colab that trains Flux loras and allows you to chose your own base model
Yup that fixed it!
What can you tell me about “search-and-recolor” in the “stability ai api”! It can be seen that the colors specified in the prompt are not uniform in the output for each reference image. Based on the above, is it possible that the color of the original image is affecting the output result, is this correct in your perception? In the future, we would like to make detailed color settings using color codes, but is there a setting that allows us to output the specified colors as they are?
Would someone help me HD'ify a picture's hair?
I'm trying to use Flux on Forge UI, but when I try and use DPM++ Karras, it crashes, here is the cmd

hi everyone. did someone use 3D photo inpainting node before ?
if i have an image which i know is ai generated, can i somehow know what model was used to make it? or in which software?
Flux doesn't work with most samplers
You can check its metadata. If the creator didnt removed them, there you get the info
Sick, alright thank you
Ill keep my eyes open
if someone removed them, can i still somehow have a clue?
could i send you the image in dms to see if you have an idea?
Hello, where can i find API organization ID?
cannot find it anywhere in API dashboard
Hi, does the Flux Realism lora work in SD Forge with flux1-dev-bnb-nf4-v2.safetensors? With the same seed I see no difference in outputs, however I'm not sure if there are trigger words to use alongside just including the Lora in the prompt?
No you only can guess, sure you can send it to me
I'm using torch 2.4.0+cul21, is this going to be causing me issues with some nodes?
I want to run some outpainting stuff but I'm really getting gun shy about loading nodes because of the crashes. I'd really like to get this working properly.
Checkout the nodes on github before installing them. Check for their requirements and how updated they are in general
Hmm, perhaps I should do a fresh ComfyUI install. I've been loading workflows so I can understand the steps better, but that means I was loading old nodes sometimes.
Okay, new ComfyUI and I see one warning but no errors. Being careful now to only install custom nodes that aren't depreciated or have other issues.
it has this warning: D:\ComfyUI2nd\ComfyUI\venv\lib\site-packages\torch\nested_internal\nested_tensor.py:417: UserWarning: Failed to initialize NumPy: _ARRAY_API not found (Triggered internally at ..\torch\csrc\utils\tensor_numpy.cpp:84.)
values=torch.randn(3, 3, device="meta"),
Using pytorch cross attention
[Prompt Server] web root: D:\ComfyUI2nd\ComfyUI\web
Loading: ComfyUI-Manager (V2.50.3)
ComfyUI Revision: 2695 [e813abbb] | Released on '2024-09-15'
Is that "failed to initialize NumPy" important?
So I made a new ComfyUI and used your Start-ComfyUI.bat and it installed torch 2.4.1 at first, then it proceeded to uninstall torch and now in the venv environment it says torch is version 2.3.0. Is this how it should be?
The bat itself says to install old versions of torch and I don't understand why it would do that.
you have to edit the bat
to install torch 2.4.0
by default it installs 2.3.0
Okay! I will do that. Do I go with 2.4.0 or 2.4.1?
I dont know
All good! I can test. Much appreciated
Well that loaded super fast and no warnings

Ienslnssj
Are you a damaged ai model sir?
Does anyone know how to setup the Hyper-SDXL-8steps-CFG-lora? I could not get any good results using it.
torchaudio and torchvision need torch 2.4.1 but xformers needs torch 2.4.0 . I think this is my big issue. I must not be pulling the most recent version of xformers.
then go for 2.4.0
I found a newer version of xformers but I don't know how to compile it properly. It's at https://github.com/facebookresearch/xformers/releases
GitHub
Hackable and optimized Transformers building blocks, supporting a composable construction. - facebookresearch/xformers
but I'll try to go for 2.4.0 but I swear I tried that earlier. I'll just try again.
My internet was no longer metered as of last week, thankfully. Here goes 2.7gb again.
Okay, I think I'm closer. I found I was installing torch 2.4.0 from https://download.pytorch.org/whl/cu118 but xformers from https://download.pytorch.org/whl/cu121 . These should be the same version?
yes that needs to be the same
best would be cu121
Okay
Even if you do have amd you should click no?

Yes
Alright thanks, got a bit confused as of why i should select no :))
Yea because when selecting AMD it would install the directml. And No, will install torch which we need for zluda later
Ahhh thats why it didnt work for me earlier aswell
Brand new error doing a simple image generation: Numpy is not available.
I did pip list and found numpy 2.1.1
I googled and changed the version and installed numpy==1.26.4
Success
I did copy and rename them like you wrote in the comfyui tutorial aswell.

Have you done the comfyui guide before?
I tried it before and it failed. Deleted the folders tho
I could reinstall the comfyui and paste it again see if it will work
Gonna try and reinstall comfyUI
bangs his head Using ComfyUI Manager, if I restart through the manager, it rebuilds the entire venv.
Then kills the venv and won't run again until I rebuild everything.
What failed?

What's your GPU again?
7900 gre
Aight, ill delete em and retry
hey im trying to replicate this app https://mnml.ai/ can anyone help me how to get it with sd

AI render and design tools for architecture and interior design curated by designers. Sketch to render in seconds
Hi guys i have nvidia 12Gb ddr5 and i install story diffusion but at the final says torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 864.00 MiB. GPU 0 has a total capacity of 12.00 GiB of which 0 bytes is free. Of the allocated memory 25.46 GiB is allocated by PyTorch, and 812.84 MiB is reserved by P
yTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. and i look all .py to find but i can't... were is located?? thx
hey, you need to edit your webui-user.bat
at the line Commandline_Args= you need to add: --xformers --no-half-vae
then save and relaunch
i use a external program to intall sttable difsion --- i use pinokio thx for answer me gonna try to do it im new in this world thx
ah okay, no problem
the webui-user.bat is inside the stable-diffusion-webui folder
thx but pinokio just download repo and execute just have the folder storydiffusion-comics.git then in sub-folder : app --- cache and some json files i use pinokio becouse i can have in order my repo i use note ++ and i gonna search to change i make troubles for me so easy... 😆
oh okay
i tought you installed stable diffusion
i think that is more easy than have a program that cant change anything thx for all if i can solve gonna put here if someone have my problems thx a lot
I am having a bit of an issue with generating pictures with Flux,
I have installed the VAE and text encoders like I'm supposed to and put them in the folders where they belong.
I mainly use SD 1.5, and I never have issues with wait times like this,
My GPU is a RTX 2080Ti.
The GPU weights, swap method, and swap location are set to what they are by default, so I don't know if they have anything to do with it.

When using SD upscale ESRGAN_4x i get very different time scales on generation. Up to 3,5x goes in less than 3 minutes. If I try with 4x, it takes 4-6 hours to finish. Is this because of some software setting or because of physical memory? I'm running a 4090 24 Gb.
make sure you only use the nf4 v2 or the fp8 16gb flux model
all other ones are very slow
you need to make sure to set a hires step value
like 10-20
Sorry, that flew right over my head. What is a flux model?
that message wasnt for you
I usually scale with 50 steps using DPM++ 2m SDE Karras (35 for the base generation, higher for upscaling).
I will try lesser steps.
Ooops, sorry
Alright, thanks. I will try the fp8 16gb flux model. I have seen some amazing pictures that people have made with the flux model/s and I would like to at least try my hand at making something. Hopefully this one works. Do you need something similar to a 4090 to be able to use the 22gb Flux model?
the nf4 makes also good images. its the same as fp8 just better optimised
could you give me a link to that one please, I looked and there are a few with the nf4 in the title
here you need the v2
https://huggingface.co/lllyasviel/flux1-dev-bnb-nf4/tree/main
Thank you.
Alright, followed your guide. Got a small different warning/error now. Am generating my first prompt as well so lets see if it works.

You can 1 click install SwarmUI on Stability Matrix
If you're having trouble with a manual install
I got amd so need zluda, also gonna follow CS1o's advise cuz been struggeling for few days now with all sorts of things
Was just a thought. Only just joined so i dont know the history of your problems. Apparently Stability Matrix only supports AMD on linux, for swarmUI also.
Ah alright and welcome to the club :)
Cheers 😄
Hmm ComfyUI execution error: Numpy is not available

guess numpy isnt installed correctly?
downgrading and upgrading numpy does not solve this (tried 1.26.4, 1,24,1 and now 2.1.1)
make sure your path statements are set up correctly
They are, also stable diffusion works fine
Nope, didn't work. Even with 10 steps it says 18 hours to generate.
Can you generate?
Yes it starts to generate by the looks of it and then comes up after 30 seconds or so with the error


currently on numpy version '1.26.4'
I had this error /just/ today. I think there's a change somewhere, but what I did was pip install numpy==1.26.4
Oh, I had numpy 2.1.1
sadly i am already on that version

Try install numpy 2.1.1? lol
Already tried that without any success
imma just reinstall numpy completely
Nope, its generating and then BOOM error

It crashes with numpy and then no image is generated?
Correct
22:38:00.926 [Warning] [ComfyUI-0/STDERR] Traceback (most recent call last): 22:38:00.927 [Warning] [ComfyUI-0/STDERR] File "H:\SD-Zluda\SwarmUI\dlbackend\comfy\ComfyUI\execution.py", line 323, in execute 22:38:00.927 [Warning] [ComfyUI-0/STDERR] output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) 22:38:00.927 [Warning] [ComfyUI-0/STDERR] File "H:\SD-Zluda\SwarmUI\dlbackend\comfy\ComfyUI\execution.py", line 198, in get_output_data 22:38:00.928 [Warning] [ComfyUI-0/STDERR] return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) 22:38:00.928 [Warning] [ComfyUI-0/STDERR] File "H:\SD-Zluda\SwarmUI\dlbackend\comfy\ComfyUI\execution.py", line 169, in _map_node_over_list 22:38:00.929 [Warning] [ComfyUI-0/STDERR] process_inputs(input_dict, i) 22:38:00.929 [Warning] [ComfyUI-0/STDERR] File "H:\SD-Zluda\SwarmUI\dlbackend\comfy\ComfyUI\execution.py", line 158, in process_inputs 22:38:00.929 [Warning] [ComfyUI-0/STDERR] results.append(getattr(obj, func)(**inputs)) 22:38:00.930 [Warning] [ComfyUI-0/STDERR] File "H:\SD-Zluda\SwarmUI\src\BuiltinExtensions\ComfyUIBackend\ExtraNodes\SwarmComfyCommon\SwarmSaveImageWS.py", line 48, in save_images 22:38:00.930 [Warning] [ComfyUI-0/STDERR] i = 255.0 * image.cpu().numpy() 22:38:00.931 [Warning] [ComfyUI-0/STDERR] RuntimeError: Numpy is not available 22:38:00.931 [Warning] [ComfyUI-0/STDERR]
Have you successfully generated an image with comfyui First?
Yea try to get comfyui work before using it in searm
Did you used the comfyui-start.bat ?

Installed comfyUI manager, went to ComfyUI\custom_nodes\ComfyUI-Manager\config.ini and wrote security_level = normal-, restarted server, went to "manager", "install pip packages" and wrote numpy==1.26.4 even tho it was already installed
Now trying to get it working on SwarmUI
🥳

Thanks for the help and support CS1o! Been amazing
perfect! no problem 🙂
Suppose I had an instance that generates images all day, are there any automation tools out there that would allow me to swap out the prompt from a text file every hour?
I got juggernautXL working with webui stable diffusion, but I saw this error right after loading the model for the first time. Should I be concerned? It has some issue with the dimensions of the NN which seems important!
While copying the parameter named "model.diffusion_model.middle_block.1.transformer_blocks.1.norm2.weight", whose dimensions in the model are torch.Size([1280]) and whose dimensions in the checkpoint are torch.Size([1280]), an exception occurred : ('Cannot copy out of meta tensor; no data!',).
for which interface?
I guess the default stable-diffusion-webui
that would require something that would run inside webui that could edit the prompt - i'm not aware of anything that can do that
you'd probably need to run directly at the command line
My temporary solution right now is using the "prompt from file or textbox" option and using a firefox plugin Automa to hit the "generate" button every hour
So every hour it will spit out 5 different images from 5 different prompts
hello, trying to figure out where i put in command lines. (--xformers --listen --api --no-half-vae --medvram --opt-split-attention --always-batch-cond-uncond). do i put them in webui user.bat or something else? thanks for the help
Is there a way to use existing models folders with Forge?
Windows or Linux?
If Windows it's in webui-users.bat, and you add the line:
set COMMANDLINE_ARGS=--xformers --listen --api --no-half-vae --medvram --opt-split-attention --always-batch-cond-uncond
If Linux, it's webui-user.sh, and you add the line like so:
Hey guys, does anyone know what the difference between sd_xl_base_1.0.safetensors and sd_xl_base_1.0_0.9vae.safetensors is? They didnt mention it in the description
Only use xformers OR opt-sdp-attention, not both at the same time. And dont use --always-batch-cond-uncond
it would be best to use an internal SSD because it would work the fastest. you can move your models to an external driver later if you do not have enough space, but it is recommended that an external drive is also an SSD. I have M3 Pro with 1TB SSD + 1TB SDXC, and everything is on my SSD, since it is much faster than SDXC
Does anyone know whether SDXL has a minimum resolution required for inpainting and img2img?
Best would be 1024x1024 but 768x768 works too
How do i properly install these "missing nodes"? As they are not ones i get from comfyui-manager

Anyone knows why my flux1-dev is taking an entire hour to generate a single 1024x1024 image?
Sdxl and dreamshaper8 are max 30 seconds.
(SwarmUI with comfyUI)
Also it says "1 current generation, 1 running (est 1m 3s)..."
Output also looks incredibly weird and blurred/pixellated
Which flux model do you use ?
Make sure you use this one:
https://huggingface.co/Comfy-Org/flux1-dev/blob/main/flux1-dev-fp8.safetensors
Its the fp8 flux dev but as 16gb variant
Im using the 22gb version, ill try the fp8 16gb one
Yea dont use the 22gb
Seems like it tries to allocate more cuda cores than i have, got 16gb vram, and its maxed out in task manager (windows)
15:37:40.598 [Warning] [ComfyUI-0/STDERR] File "H:\SD-Zluda\SwarmUI\dlbackend\comfy\ComfyUI\comfy\ldm\modules\attention.py", line 407, in attention_pytorch
15:37:40.598 [Warning] [ComfyUI-0/STDERR] out = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=mask, dropout_p=0.0, is_causal=False)
15:37:40.599 [Warning] [ComfyUI-0/STDERR] torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.69 GiB. GPU
15:37:40.599 [Warning] [ComfyUI-0/STDERR]
"ComfyUI execution error: CUDA out of memory. Tried to allocate 1.69 GiB. GPU"
Must be something wrong with this model


Dreamshaper 8 works just fine

and now sd_xl looks weird aswell?



Looks like dreamshaper does work with regular swamui but not with comfyui? Weird
hi guys
I saw an interesting video from AI and wanted to start creating videos too, but after installing SD-CN-Animation nothing changed, help me solve this issue
I can send you a workflow for flux later
To test
Sure, would love to try
Here
Can someone ban this bot already?
Done
Hey guys new user here, what should i do?
I'm having an issue installing ComyUi manager. My Comfyui was coming up as a white screen after I clicked the update files in file manager so I uninstalled everything that had to do with comfyui and reinstalled it again. There may have been some files left behind because when I opened Comfy for the 1st time after reinstalling it, it still had my last prompt.
Now when I try to install the Ui Manager I get the error in the screen shot. Anyone know how to fix this? One thing that I notice is my terminal says _NVIDIA after windows protable, which in any other video I seen on installing manger, it does not say NVIDIA. I'm trying to run FLUX and I need to update my ComfyUi. Any help would be greatly appreciated Thank you!!

it can't find your git install.
Its so slow compared to SwarmUI "generate", the workflow takes about 5-10min for a simple prompt. Yet "generate" does it in 2-3 min
Any reason for this?
same model?
how do i make it so it's able to find it? I thought I was just supposed to right click the link in the terminal. Did I miss a step?
first question - did you install git?
Flux1-dev 6gb
6gb?
16gb, my bad
In the comfyUI workflow
Hello there, @ornate elk Can you link me your tutorial for the command line args please ? I've lost my saved links 🥲
hey, here are all the Guides:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
Thanks a lot !
np 🙂
the upscaler in extra tab doesnt work
it just gives a jpg of higher size
am i doing anything wrong?
you can try add --reserve-vram 1 to the comfyui-start.bat after the --auto-launch
https://huggingface.co/Kim2091/UltraSharp/tree/main
i decided to use a newer version of the upscaler but now it doesnt even show up

can you show an example?
that was with an older model
its not completely sfw but there is no nudity either
left is original right is upscaled


yep it didnt changed anything
what upscaler visiblity did you used?
upscaler 1 doesnt have any visibility option

how can i make Ultrasharp appear here


always use the .pth versions of upscaler
and the best upscale result is using highres fix or img2img sd upscale script
im doing it with highresfix
like this

your webui seems a bit outdated
and always set hires steps to 10
my version is this

ig its doing something now
nope its the same


what does the cmd shows?
Then something isnt working
Can you share the whole cmd log after the upscaling
No, but now I do. I got it to work now. Thank you!! Now I just need to figure out to get flux on there lol
you want to download a version of flux that'll fit in the Vram you have. how much vram do you have, and what GPU do you have? and are you running intel or AMD for the cpu?
I have a 7900x3d, a 4080, and 32gb of ram. I got flux working now and it seems to going fine. I got the DEV one. Takes about 40+ seconds to do the image.
yup. dev will work fine in that 🙂
do we have any tool to convert fp16 FLUX checkpoints into fp8 or GGUF-Q8?
What is the difference b/w Sd1.5 sdxl and flux? Rn I have automatif1111 is that just sd1.5?
Also can I use a pony Lora on a realistic checkpoint?
Does it generate smth meaning full?
Or do I have to find realistic loras for realistic checkpoints?
I'm currently aiming for that Korean idol look
With different poses, dresses etc
And I have found many of those loras but in pony
Wait can I use pony to generate semi realistic then?
Sry for so many questions

Similar to this one
If i import an image made with automatic1111 in comfyui should i have the same output image?
Can someone please explain to me what I'm doing wrong?

What does it mean by "negative values"

you could just download the models that are already quantized for that
when you desaturate, i.e. lower the number, your colors get less bright until finally all you have are shades of grey
The lowest it goes is 0
i know. what is it you're trying to acomplish?
Some images look like color vomit and I want to tone it down
Do I get set it a little above 0?
okay so i'd start by making sure cfg isn't too high, and adjusting your other values. what are you generating with?
drop it to 4.
Ok will try
I'm not an expert in pony and in fact have never used it. But I've seen many people generating realistic images with it, so I think the answer is yes. sd1.5 and sdxl are different models released by stability ai, in that order. The former was released about 2 years ago, and the XL release around july of '23. Flux just came out only weeks ago, and was released by an alternate company known as black forest labs. each new generation of model has shown pretty significant improvement in prompt adherence and possibly even other things such as better handling of rendering objects or people in the background (these have to do with the native resolutions mainly), but there are factors that keep the community attached to some of the older models. factors such as a wealth of community contributions (finetunes, loras), compatibility with extensions like controlnet, ipadapter, video creation extensions, etc
It looks much better
excellent.
Still looks a little weird so I'm gunna try 3
you might also play around with the samples and schedulers
very good. yeah, i think your screen shot is from an AI that thinks you're using photoshop, really.
Weird
classifier free guidance scale. decides just how hard the sampler should hit.
So could the problem also potentially be fixed by using a different sampler?
It would just look different
your samplers and schedulers are going to have a massive effect on the outcome, yes - and some don't work together well. and some don't work well with certain models but work well with others
they determine the math used
i dont see the error

the 8% i interrupted
should i use the command --medvram on webui forge i have 6gb vram
What can you tell me about “search-and-recolor” in the “stability ai api”! It can be seen that the colors specified in the prompt are not uniform in the output for each reference image. Based on the above, is it possible that the color of the original image is affecting the output result, is this correct in your perception? In the future, we would like to make detailed color settings using color codes, but is there a setting that allows us to output the specified colors as they are?
that's not how the AI works - you can prompt for a color, but it's not likely to give you the exact shade you're looking for - it's not photoshop, DaVinci Resolve, or Adobe Preimer

Running into this issue where I'm generating images and then towards the last image out of nowhere a ton of swap memory gets used up and my webui instance just crashes
maybe increase your swap space then?
(and make sure you're not running stuff like discord at the same time)
Using 8gb vram, with --xformers --api --no-half-vae --medvram --opt-split-attention --always-batch-cond-uncond
It's in a virtual machine on a hypervisor
it still has swap space
Completely seperate hardware and system
what os?
https://help.ubuntu.com/community/SwapFaq this might be useful
im having some problems when i try to merge checkpoints and keep getting an error message
Increased the swap memory to 8GB so fingers crossed
can you post the error log here
*** Error loading/saving model file
Traceback (most recent call last):
File "E:\AI\stable-diffusion-webui\modules\ui_checkpoint_merger.py", line 21, in modelmerger
results = extras.run_modelmerger(*args)
File "E:\AI\stable-diffusion-webui\modules\extras.py", line 213, in run_modelmerger
theta_0[key] = theta_func2(a, b, multiplier)
File "E:\AI\stable-diffusion-webui\modules\extras.py", line 97, in weighted_sum
return ((1 - alpha) * theta0) + (alpha * theta1)
RuntimeError: [enforce fail at alloc_cpu.cpp:80] data. DefaultCPUAllocator: not enough memory: you tried to allocate 335544320000 bytes.
not enough memory: you tried to allocate 335544320000 bytes. <--- that's an interesting number. where'd you get the models you're merging?
Okay... Are there any future plans to update the system with additional functions, etc.?
you could train a lora on very specific colors with specific color labels - and then use it when you generate
Can I get some help with this?
Thank you for your answer!
I am envisioning an API implementation of stability ai for a model that has been finetuned by LORA, is this possible? We are using only models that have already been trained, so we are not able to consider this in our configuration process.
i'm not sure if SAI would do that or not. You'd need to get in touch with Stability via their customer service email and discuss something special i think.
what are the diff for these 5?

can anyone help me get started creating txt to img with comfy UI? I'm trying to generate images like the examples on this https://civitai.com/models/639937/boreal-fd-boring-reality-flux-dev-lora

Update 09/05/24: Uploaded a new version of Boreal-FD. This version includes a fix on the latent shift dot issue, while still using the better train...
different levels of ease of use, customizability, compatibility, speed
- Automatic1111 / A1111's stable-diffusion-webui : https://github.com/AUTOMATIC1111/stable-diffusion-webui/ the most popular solution out there, biggest community and support
- ComfyUI : https://github.com/comfyanonymous/ComfyUI : second most popular solution, more tweakable but more complex to use, usually the fastest option available by a slight margin when compared to a correctly configured A1111
- SwarmUI (previously StableSwarm) : https://github.com/Stability-AI/StableSwarmUI : a reskin of some sort of the two above but in one package
- Fooocus : https://github.com/lllyasviel/Fooocus : probably one of the easiest solution out there for people who just want a big button to press and generate "pretty" stuff, but also one of the less tweakable.
- Forge-Webui : https://github.com/lllyasviel/stable-diffusion-webui-forge a fork of A1111 aiming to make things faster but break a lot of A1111 extension compatibility and it's development has been paused/abandoned for a while and just recently started back for who knows how long
i see, thanks
damn thanks a ton
hello! Where is the best place to ask a question about ComfyUI and IPAdapterApply?
https://discordapp.com/channels/1002292111942635562/1204675216773619752/1285503094410444843
or else... is there a better more up-to-date upscaler for Pony or ComfyUI?
What is a good amount of Buzz I should use for a SD1.5 CivitAI bounty for a 49 character pack? I'll collect and supply the images
Oh oops wrong channel
Hello, i'm new to stable diffusion and wanted to set it up in my laptop, but in the webui-user.bat file i am having this issue. Can someone please help me with it, and also i'm using the .safetensors verson of stable diffusion instead of the .ckpt because i only found the .safetensors version.

python version
get 3.10.6
no
So do i have to do everything from the begining?
no just uninstall this
and install this
You sure?
yeah i also did once
Okay, i'll check it out.
Your Python should be installed here
C:\Users\your username\AppData\Local\Programs\Python
anyone can help me with this?

I tried two upscalers but they are not working.
Workflow-
txt2img tab
base, 512x512 resolution, 30 steps, 7 cfg
higresfix, 2x resolution, 10 steps, 0.5 denoise
extras tab
upscale
2x resolution,
model - SwinIR/UltraSharp



Ummmm.... Now i'm facing a new issue here. I installed python 3.10.6 and remove the old 3.12.6 version and when went back to webui-user.bat this showed up, help.

did u restart pc?
Increased the swap size and still crashing

yeah
anyone knows about PermissionError: [Errno 13] Permission denied: ?
I tried using ComfyUI Manager to install https://github.com/WASasquatch/was-node-suite-comfyui . When I restarted, it uninstalled torch and then did the same crash I was having previously. Here's my .bat that I'm using.

GitHub
An extensive node suite for ComfyUI with over 210 new nodes - WASasquatch/was-node-suite-comfyui
I carefully read about this but there were no depreciations and I didn't think anything was too crazy about it.
And this was my next error before rebuilding venv: Requirement already satisfied: numpy in d:\ai\comfyui_windows_portable\comfyui\venv\lib\site-packages (from torchvision==0.18.0) (2.1.1)
INFO: pip is looking at multiple versions of torchvision to determine which version is compatible with other requirements. This could take a while.
ERROR: Cannot install torch==2.4.0 and torchvision==0.18.0+cu121 because these package versions have conflicting dependencies.
The conflict is caused by:
The user requested torch==2.4.0
torchvision 0.18.0+cu121 depends on torch==2.3.0+cu121
To fix this you could try to:
- loosen the range of package versions you've specified
- remove package versions to allow pip to attempt to solve the dependency conflict
ERROR: ResolutionImpossible: for help visit https://pip.pypa.io/en/latest/topics/dependency-resolution/#dealing-with-dependency-conflicts
Running main.py with --auto-launch argument...
And trying to reinstall, here's the error. Apparently I have torch on my c:\ now and that's the conflict.
@boreal vector i restarted my laptop and it didn't work, i'm really frustrated right now. What am i doing wrong here.
check your python installation
Then what?
is it there
should be here
did you change your bat file after upgrading python
No
The only thing i did was type git pull in the notebook of the bat file when i had python 3.12.6
now relaunch web ui
that doesnt affect python its just for updating webui
it should redownload the missing files and you should be good

Reddit
Explore this post and more from the StableDiffusion community
if u need more help follow this
Are you talking about sd3 file?
😳 😳

You have to delete the venv folder, then relaunch the webui-user.bat
Sounds like this may be what I need too. Not sure tho.
Mine sounds like a very similar issue, but apparently I installed torch to the PATH install of Python rather than into the venv.
You installed kohya inside a OneDrive synced folder. Thats causing the permission issue
Comfyui does that
C:\Stablediffusion\KohyaTraining\kohya_ss its here
Hmm, so now there's a conflict.
Look at your screenshot again
yes?
There you see the path
Its inside OneDrive sync
So either disable OneDrive or move kohya to an other place
A yea i moved from desktop to C
maybe thats the issue?
Do i need to install from scracth?
Nope both wouldn't work as OneDrive syncs the Desktop too
Make a new folder on C: and then install Kohya in it
Dont move it
Then it should work
Tyvm
Did you see my issue above from a few minutes ago, trying to install WAS node suite?
Nope
Do you have thoughts on it? Looks like there's a conflict with installing a different torch version, but I also have no idea why it decided to uninstall torch with Manager restarting comfy
Open up a CMD and type
Pip cache purge
Then delete the venv folder and relaunch the webui-user.bat
Was this for me? Because it seems like a good idea.
Okay
The venv file is in the trash can, should i completely remove it for it to work?
Yep
You don't need it
It will get rebuild after launching the webui-user.bat
But now with the correct python version
I tried this, then I did venv\Scripts\activate but system cannot find path specified.
python got screwed up?
You don't need to run it inside the venv
I did the purge, but then went to try and rebuild venv but I couldn't get into the environment
then I remembered to do python -m venv venv sorry, painfully bad at this
I then did pip install -r requirements.txt and it's downloading torch now, but it didn't go to the right version I'm afraid. Gonna have a conflict.
unless.... I wonder if my issue is because requirements.txt is out of date..?
Hmm, yeah, I could put versions in the requirements.txt
Brothers, i'm still having the same problem and now i'm thinking about killing myself, there has to be a way to solve this issue.

AssertionError: Torch not compiled with CUDA enabled
Install python 3.10.11 64bit
Then relaunch the webui-user.bat
Currently it doesn't find your python so installing the latest compatible one should fix it.
Then if you have a venv folder again, delete it before relaunching
I'm trying pip install torch==2.4.0 torchvision==0.18.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu121 again. I have no idea why it didn't work before but hopefully the pip purge helped.
I made sure requirements.txt matches the version in the .bat so that if it runs through the requirements again it won't start uninstalling all my work
no luck


<- base upscale ->
@ornate elk I don't know what to do at all, I haven't faced this error before today. I'm stumped.
I don't know how to safely remove package versions from PATH
Can someone please help me get this to work?

still the same error

does stability still have the colab notebooks?
I'm used to getting image info pretty easily on Automatic1111, but I have recently moved to ComfyUI, is there a way to get PNG info there too?
Or with some outside tool that woudnt require me to launch A1111 (cant get it to work on my PC)
all the info is stored in every output, drop the image back into comfy and it will give you the setup complete
Okay then edit the folders permission and give yourself every permission
Can you try an other upscaler? Like latent bicubic ?
help plz

What's your GPU?
amd
7900 xt
i know have this line, but this uses my cpu instead of gpu if im right

Yea because you used the nvidia webui version
You need to use the AMD Webui with Zluda Guide from the pinned messages
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
Yes

Does anyone know if 2 minutes to generate an image is normal on an rtx 3070?
@ornate elk i am stuck at this part

With which settings
You can ignore step 3
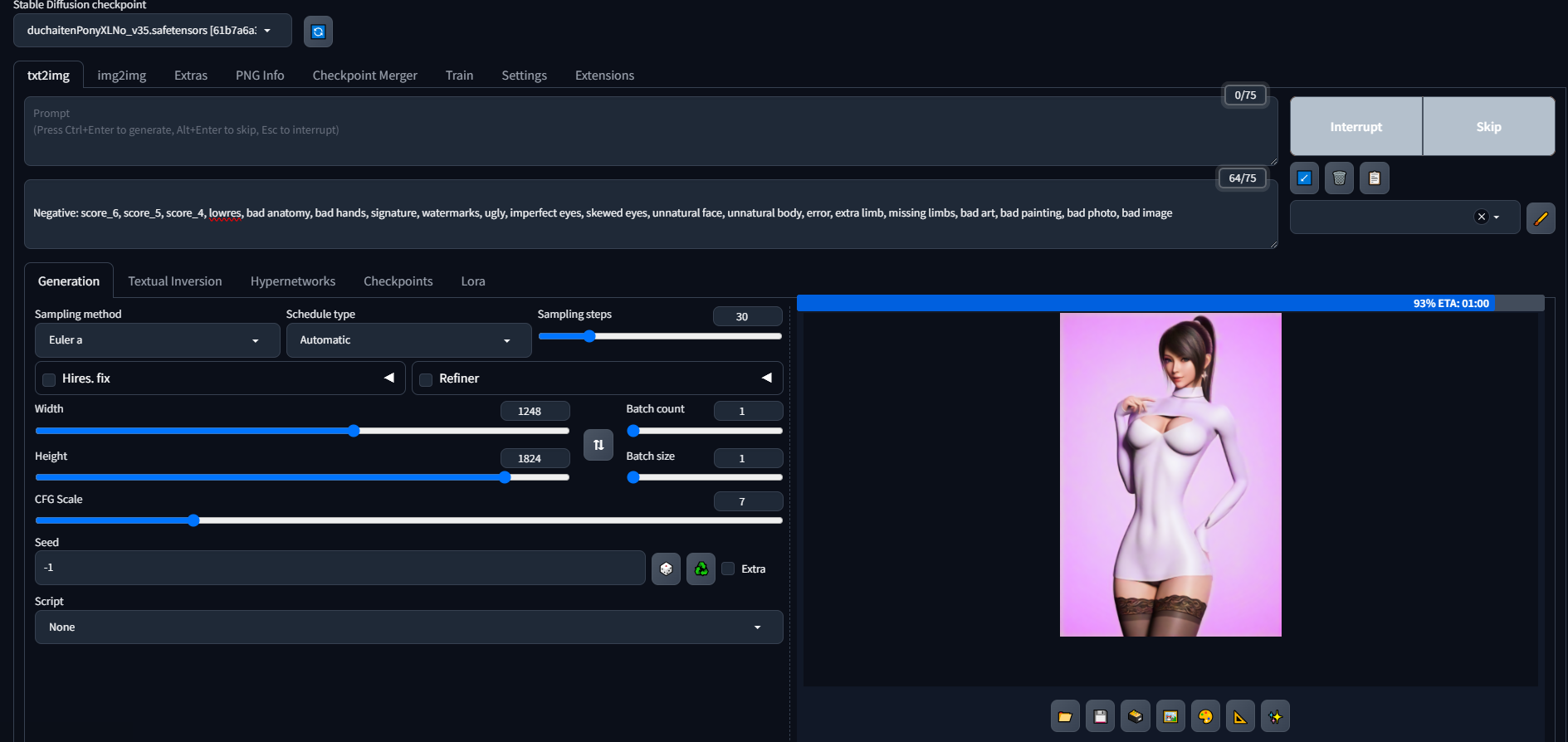
also its making hideous monstocities
like whats in the picture

yeah im right there yes
Its and sdxl model and pony too. And your generating at a very large resolution.
But first show what's inside your webui-user.bat?
but i don't understand what they mean with this

i'm so sorry. How do i get inside to look at that?
do i have to copy word C:ZLUDA and %HIP_PATH%bin
You need to create these as 2 new entrys
Right click and edit it
i can't edit or do anything at system variables



Thats the webui.bat not the webui-user.bat
The VAE is missing
Can you screenshot it?
sorry it says this inside
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
git pull
call webui.bat
Okay your missing the performance args.
At the line Commandline_args=
You add: --xformers --medvram-sdxl --no-half-vae
Then save and relaunch the webui-user.bat
like so?

Yep
Yep should be really fast now
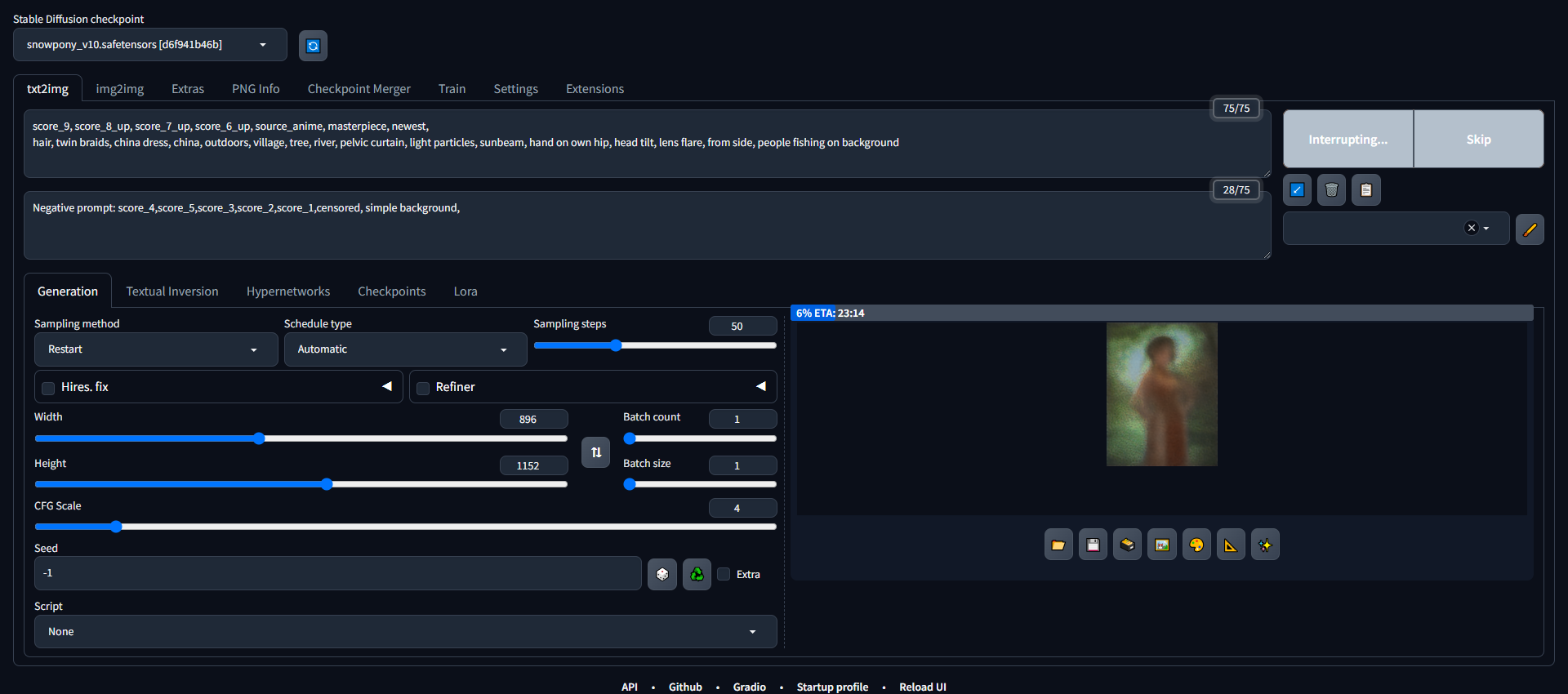
That makes no sense. Do you run any game or Wallpaper engine in the background?
Also use sampler Euler a or DPM++2m
no just chrome


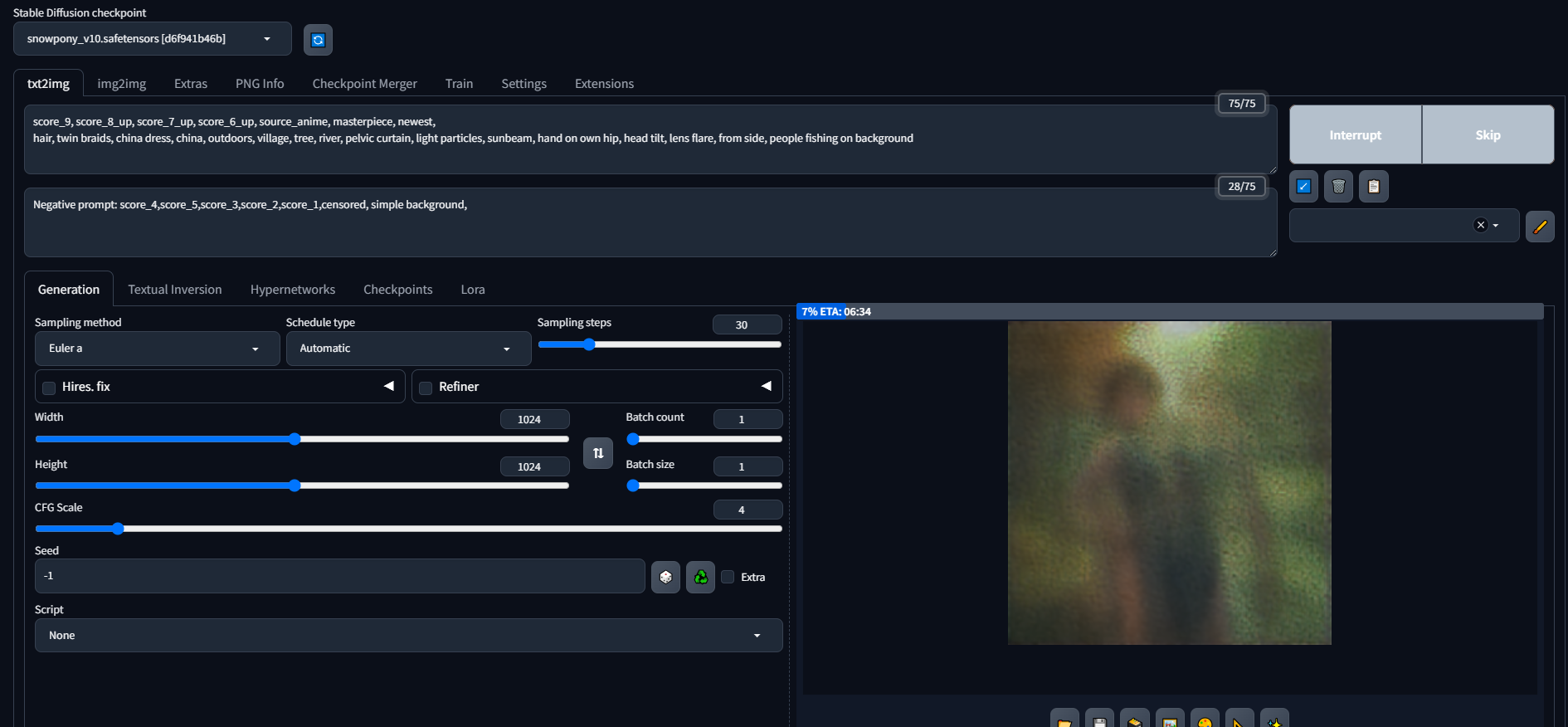
still says 6 minutes
so crazy it was working totally fine yesterdauy
a friend said to clean install after i was having issues with the VAE
since reinstall its been so slow
okay the VAE worked

now i just need my regular speed back
im cool with 1-2 minutes for a high quality image, but 5-6 feels kind of weird
and i just put in a new card
Yea 6mins isnt right
Make sure you always launch the webui-user.bat and not the webui.bat

i just installed adetailer too
im sorry about all these questions
for every fix there seems to be a new problem
does this face look fine considering i installed adetailer?

this ones better cause i upped resolution i think

sorry if its rude to post these dunno if this is the right chat
will delete if its cluttering
Its okay to post them if its not nsfw
And how?
lowered resolution like you suggested
also restarted and made sure to use webui-user
do these look good to you?

just made this
took about a 2 minutes to make this
thats prolly normal right?
2 minutes with adetailer

with these settings
oops sorry, i didn't see your previous message, no im gonna continue another time, but thanks anyway
whats it mean if i get shit like this?

tried to make this

it says its for flux right?
@ornate elk have you got a tutorial on how to download flux?
alright, let me know then ^^
whats your gpu and do you have a webui already installed like comfyui or forge =
flux doesnt work in auto1111 currently
amd radeon 480, id like comfyui but i havent got it installed yet
with 4gb ?
vram
no 8gb
but your gpu is supported by ZLUDA it seams which means you could run sdxl models
yeah i have SD already
but apparently flux is more relistic
realistic
yea but we have to weight for AMD to support bitsandbytes on windows. so we can use the smaller nf4 or gguf models
also thank you so much for all your help again dunno if i said that
no problem 🙂
they not here

then try Nearest


can i have comfyui and a1 on the same comp? I know that sounds dumb but like they don't conflict or anything right?
try updating your extensions and then relaunch, make sure the webui is whitelisted in any browser adblocker.
And if its still not working try deleting the config.json and the ui-config.json and then relaunch
yes you can have them both without problems
i have all webuis in one Folder
you think i can make decent stuff on FLUX with 8gb of vram?
yes but for that you need comfyui or Forge webui. and the nf4 v2 flux model
doesnt work
i was using it jsut fine, was making charcter art. btu then something happened an dnow it just makes blobs of color
how do i fix it. as now no matter what i do its doing this
can you show an example with the settings you used?
then you could try a clean install with my guide and test again. and dont install any extensions at first

the lora for the chaaracter i want was workign perfectly fine last night witht he exact same promt
wrong resolution for a sdxl/pony model
these need a highre base resoltuion
then why is it still doing it after making the res bigger
and why did ti work perfectly fine last night
looking at the screenshot again it seems that your negative prompt is not recognized
make sure the webui is whitelisted in any browser adblocker
ad blocker hasnt chnaged since it woreked
your sure? they update their blocklists in the background
yup.
the 0/0 in your negatives is caused by something blocking it or not updating/sending it to the cmd
so how do i fix it?
first thing i would try is to relaunch, or to whitelist the webui in any browser adblocker xD
can you show the cmd log, maybe we can see an issue there

i mean the full cmd log
also why do you use 150 steps with an sdxl/pony model? ^^ 30 would be enough
Nope
Thats just the end of the log
You can relaunch and then generate one image and then copy the whole cmd log



Okay 5 things I can see:
- Your webui is not updated since Dec 23 (9 months outdated).
And since it was not installed the right way it can't be updated easily.
Your on 1.7.0 while latest is 1.10.1 - Your not using the recommended performance Arguments for your gpu, meaning you could generate much faster.
- You have Roop Extension installed which is deprecated and causes errors in your log.
- Your using Lycoris extension, but its not needed anymore, even on 1.7.0.
- you have other extensions that cause a flood of requirement checks at the start.
What I would recommend is a clean reinstall of the webui.
Its hard to fix outdated stuff.
But if you want to keep using 1.7.0 then you should remove Lycoris and roop and any other extensions you don't need and after that delete the venv folder and relaunch.
For a better performance you should checkout the install guides in the pinned messages. They show the right args for your GPU vram.
how do i find those?
The extensions or guides ?
In the pinned messages of this channel or directly here:
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides
but.. i followed that guide when i did it tho o.O
But the console says commit hash none. Means it was not installed via Git 😮
Or maybe it was moved, that breaks it too
Also the performance args are not in your webui-user.bat
Or dont get recognised

I'm still running into the issue where even after increasing swap memory, the application is still crashing
Should I just keep increasing memory (not vram)? The recommended is 32GB but I can increase it further
I'm starting to think there's something wrong with Stable Diffusion not releasing memory
it wouldn't be stable not releasing, it would be the interface you're running stable in. and that could be the case.
Do you try sdxl or pony models?
Then you need a swap of at least 32gb
uhhh it says for nvidia thers no gpu
lioek when i cloick thte option for that int he guides it dosnt do anything
I use both
I'll bump the swap to 32gb then
What about regular memory? Leave that at 32?
Your correct, I broke my link it seems. Let me link you directly to it.
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Webui-Installation-Guides#nvidia-automatic1111-webui-stable-diffusion-webui
ty
Np, will fix the link tomorrow
Do you use nvidia or amd ?
Nvidia
A friend of mine used a 6800xt on Linux and had massive RAM issues.
Because on Linux the webui seems to use or need more RAM.
He increased the swap to 32gb, that helped but in the end he bought 32gb additional RAM
I'm also referring to non-vram
Yep ik
I'll keep you posted, and thank you for the assistance so far!
Np, also when does it crash?
At upscaling ? Or launching ?
Make sure you also use --xformers
Yup using --xformers, so it crashes towards the middle or end of generating a small batch of 3 images.
Most likely during upscaling
I'll click generate and it will generate the 3 images no problem, But there are times by chance once it nears the end of the 2nd image or end of the 3rd image it just crashes.
I don't know what i'm doing wrong https://i.imgur.com/BRDv1N9.png
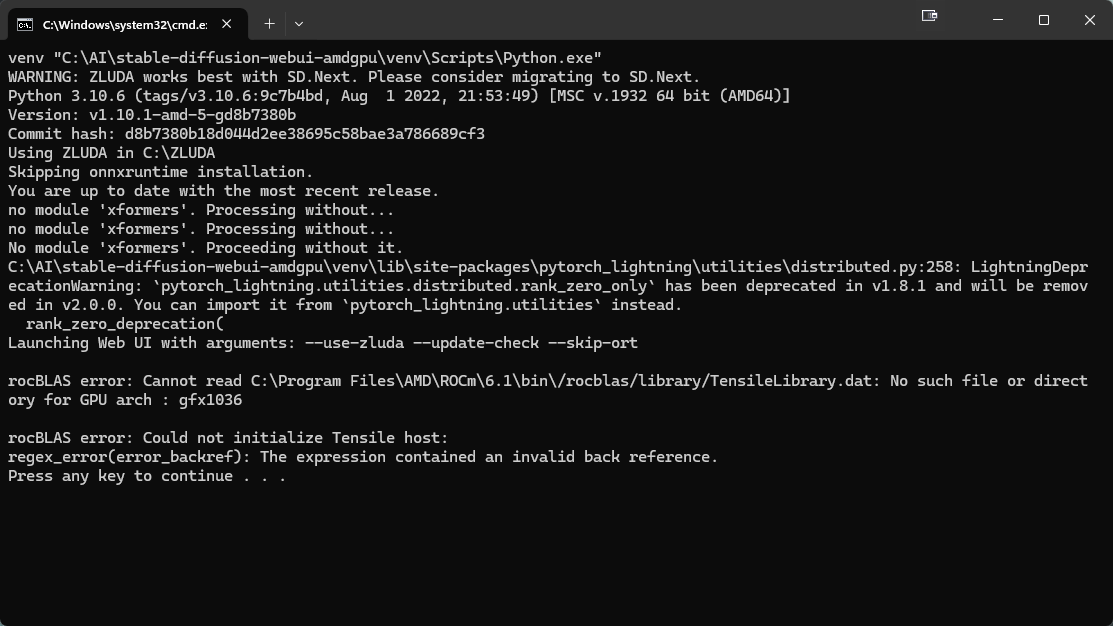
Make sure to always set the hires steps to 10
If its on 0 it will most likely crash
And then there is the tiled VAE extension. Which can prevent crashing when upscaling too
Should I try this first before changing the swap to 32gb?
You did everything correctly. But zluda found your CPUs integrated GPU before your normal GPU xD
So you need to disabled Radeon TM Graphics in the device manager
Under display adapters
Sure, maybe it will fix it
Help with this issue please in webui-user.bat

Like i've done everything that's required me to do but there's always seem to be a problem
Make sure your nvidia GPU driver is updated
And?....
And then relaunch.
And maybe restart the PC too.
The webui-user.bat file?
Everything else looks correct in the screenshot
sucess thanks my man
Perfect np
@ornate elk I'm trying some stuff to get my ComfyUI running again, but it's very challenging, and I don't understand why it keeps breaking. Is there something in my system that's going wrong, do you think?
I was careful to research https://github.com/WASasquatch/was-node-suite-comfyui and then restarting through Manager it uninstalled torch and started reinstalling it. I have no idea why it did that.
I believe i've hit another wall https://i.imgur.com/B2IhPcA.png
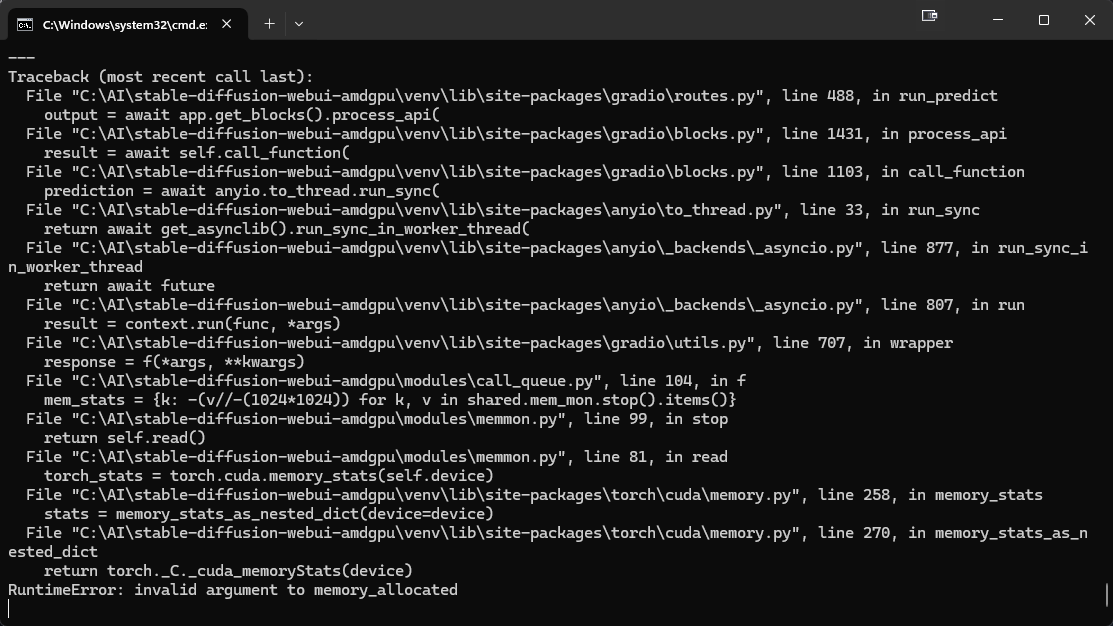
Can someone help me please? Why am I just getting noise?

What's your GPU ?
Havr you tried an other sampler ?
6900xt
Okay so you have hip SDK 6.1 installed ?
Restarted the PC too?
And how do your environment path settings look?
yes yes and yes
The last one is not a yes or no question xD
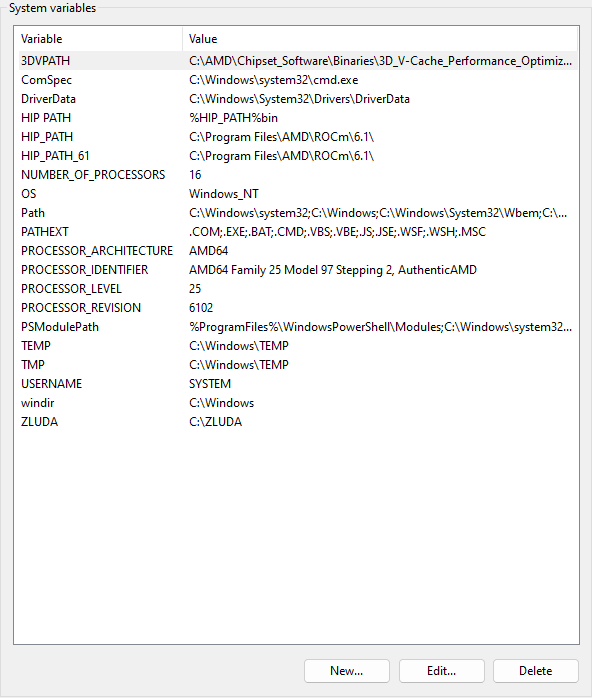

does this look correct? https://i.imgur.com/QGk9Cl7.png
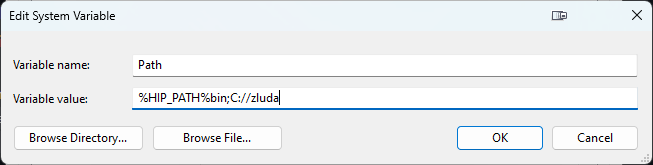
No
Look at my screenshot
Find the left Path entry in the red square. Then click edit

shit
Then you need to recreate it
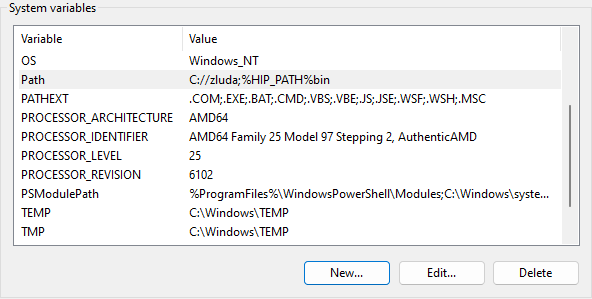
Can you go into edit mode again?
And screenshot it
Why does it look so strange
Normaly you should get a list view
You also need the first 4 entrys here in Path, to not get windows problems

But you need to go into the right edit mode
@ornate elk Sorry but i have a very dumb question. I just downloaded comfyui and followed all the instructions, so its working but it only opens in its own program what do i press to open it up in browser like stable diffusion?

Seems like you installed it via stability matrix or pinokio.
You can just copy the URL you see at the top right into the browser
yes the tutorial advised pinokio for easiest install
thats cool you'd say?
or is there a better way?
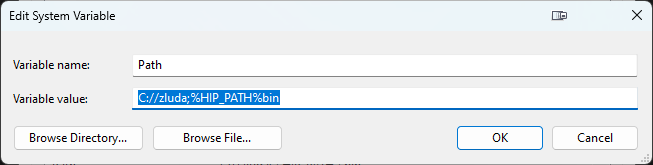
this is the edit mode that I have https://i.imgur.com/aq9s3xo.png

i just reinstalled stable diffsuion. follwoed the steps in guide exactly. can anyon ehelp me confirm its all working right before i go further?
Sure

just finished its download and i have the stable diffusion thing open in my brioweser
There is a // instead of a / at the zluda path
does this look right?
Check the bottom of the webui
for what?
There you see the version numbers
version: v1.10.1 • python: 3.10.11 • torch: 2.1.2+cu121 • xformers: 0.0.23.post1 • gradio: 3.41.2 • checkpoint:
Yep looks good
does this look right? https://i.imgur.com/CQo0rQD.png

it using my Nvidea gfx right? and not my laptops intigradted gpu?
Now your missing the : after the C
this looks correct then? https://i.imgur.com/Yuk5nmD.png


No problem 🙂
Btw what's your GPU ?
nothing super fancy. just an nvidia geforce rtx 4080 laptop gpu
Ah okay, but thats a nice GPU for stable diffusion
Only a bit sad that the laptop version has 12 instead of 16gb vram
yeahh
oh.. jutst relized. I have to redownload all my stuff again >.<
43 models and like 320 loras
😭
You can move the models over
Or did you deleted them already ?
i deleetd and wiped it all before reinstal. did the same gor graphcisdrivers and evrything jsut to be 100% sure
Oh okay
i wanted to be completly sure, it wasnt something else thart was the problem
Yea thats good now it should be as fast and clean as possible
Lycoris can be dropped into the lora folder and instead of roop you can use the Reactor extension
dumb question. it is the wbui-user batch file i use to open table diffsuin every time right?
Yep and only the webui-user.bat
@thin cave
Let me know how it goes.
But I need to sleep now. Can help you tomorrow if its not working.
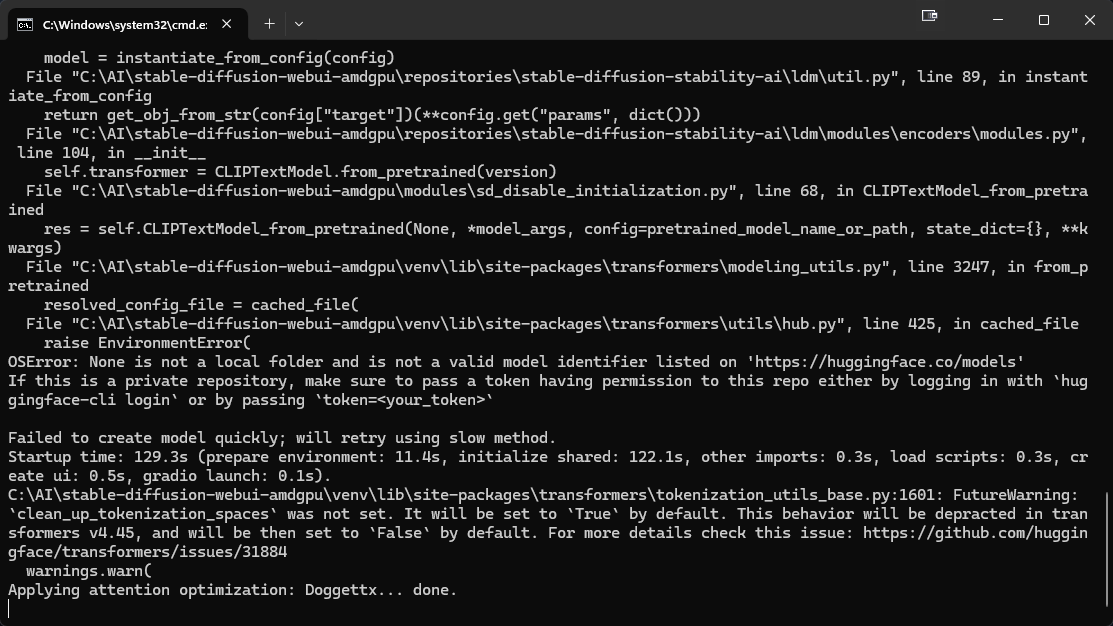
seems to be stuck when attempting to generate https://i.imgur.com/gvZzD1I.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

After changing high res steps to 10, it looks like it crashed again
Gonna change swap to 32gb
It almost looks like it isn't releasing memory from swap
It says that five tracks are pending, but it's three. The three have been pending for 2 hours.

@ornate elk I got it going, so far so good! Thank you again for your help.