#🤝|tech-support
1 messages · Page 86 of 1
Thanks a bunch. Just got a new comp and loved SD on my old one. Can't wait to see what difference an I-9 makes over an i5-6600k lol
It's actually longer but it wouldn't let me upload it
NP, for SD the CPU doesn't make to much of a difference
What model did you tried to use?
You're right of course, but at least I can load models in 20 seconds instead of 5 minutes now. 🙂
Okay delete that model and download any 1.5 based model from Civitai.com
For example Dreamshaper v8
I'm downloading now
SD-Zluda\stable-diffusion-webui-amdgpu\models\Stable-diffusion Am I loading the model to the correct location?
Yes
.safetensors Is it the right extension?
RuntimeError: "LayerNormKernelImpl" not implemented for 'Half'
I got a long error message again
Okay try add --no-half to the webui-user.bat
Then relaunch
The error seems to be fixed, I will share the result.
how do I run Stable Diffusion 4d?
Did it worked?
yes it worked thanks
No problem 🙂
Hey guys! Pretty new to SD and PCs in general. Right now I'm borrowing a friends PC for SD with a 1080 TI GPU. My other friend offered me to use his computer with 4090 instead. Maybe a stupid question, will I notice any other differances other than speed?
only speed, but the speed difference is drastic
Ah ok! Thanks! So no difference in image quality?


Oh god haha
45 it/s = 1 image per 1 or 2 seconds
yes
but, you need to have enough RAM too
The one im using has 64gb.
Which is guess is enough?
And would you say that 4090 is optimal for SD? Or is there anything "better"
for home users, no
NVIDIA A100 is faster 🙂
if you have spear $10000, go and buy A100 🙂
32GB of RAM and 4090 will work great
So A100 is better than H100?
no
Or maybe it's not for home/office computers?
H100 is more faster and expensive
But again, the only thing that will improve is speed?
yes
So like h100 would be for massive around the clock generation basically
yes
Its the best consumer GPU for Ai stuff right now so yes
The more VRAM you have the more advanced tasks you can do with ai
Not only speed is better but you can also do video generation on it as example
Ah I see! Thank you so much!
i am sorry, i had to urgently go earlier
hey guys so i have tydiffusion inside 3ds max now, is there a resource to explain all the special characters and symbols and what they do for sd. Like [ ] --1, things like that not needing a list of how to prompt but how to usde the special charachters and symbols to add more dept to your image, hope this makes sense?
you should check their documentation since that is not a "normal" way of using comfy
thnx
do you have any examples?
By using the {scheduler} keyword, you can control where (within your main prompt) the scheduled prompts will appear. If the {scheduler}} keyword is not included in your main prompt, scheduled prompts will be appended (rather than inserted) into the main prompt.
i was afraid it's something like this
in normal case you select scheduler from a dropdown
@sinful marten my advice would be to install https://github.com/AUTOMATIC1111/stable-diffusion-webui since it is easer to use than comfy, you will understand most thing very quickly, later you can play with comfy, and you will undestand your tool properly
this is great i certainly appreciate it, i will try it but i believe comfy is the only one tydiffusion works with but i will look into it, thanks again
i think for me confy is easy as hell but il check the other, its a built in gui inside max so its not a BROWSER BASED NODE SYSTEM....
its all internal within max

one click download for all models accepted

I tried running webui.bat today and everything basically reinstalled. Now it just seems to work for some reason. The first render took about 10 minutes but I remember reading that that is normal. I don't think I did anything to change the way the program runs.

Hi, I started using automatic1111 today, but when I try to generate an image, whatever the prompt, size selected, etc., I always get the out of memory error message. I've tried to read a bit about this error, but I must admit I'm a bit (a lot) lost... I was wondering if someone might have some time to help me solve it... Thank you in advance.
Is it possible to send or pull data in terms of a prompt to ComfyUI or have ComfyUI send out results to another program or process on your LAN?
How much RAM do you have? Also which GPU are you using? Also, what size images are you trying to make? Which model? 1.5? SDXL?
I generated this first image and it looks good but there’s some errors like 5 fingers on one hand and some other errors in the full original generated image (this one was zoomed in to hide most of the lewd stuff) so I tried doing img2img and it fixes a couple of things but one thing that’s been annoying me is that it won’t regenerate the hand the same as the original. I’m trying to regenerate this image with the same hand that has 2 fingers on her cheek and removing the extra 5th finger. Can someone plz help?
PING ME!!


I updated my Python and get this error, how do I solve it easy?

If you want to keep the face and part of the hand the same (the fingers) use masking, only mask the areas you want changed. Img2Img just uses the previous one as a refrence point and make something somewhat similar, and not identical
Make sure to have enabled the mask inpainting
in paint or image to image at at least 50denoise with some hand fixing negative prompts
Hi, thank you for you reply. Do you think I can dm you those infos?
sure, go ahead
I’ve never used the masking tool so I’ll probably need some guidance with that later when I’m on my PC. Thanks for letting me know
I’ve tried changing the prompts for fixing the hand but it doesn’t seem to work out so well cuz it gives me results like you see in the second image with the one index finger. What prompts do you recommend I add/edit?
inpaint/mask is the key bit
spare
this is a spear

one might rather spear somone for spare $10 grand
tbh, that's beyond overkill
unless you are doing a LOT of AI art nonstop as a business.
But even then, a 4090 or 3090 will most likely get the job done fine
If you have to question "Do I need that?" You dont need it.
Ah okay, but good that it works now
Hey, what's your GPU?
english is my 3rd language, so i should be pardoned for misspelling some things from time to time 🙃
Hi, I tried to convert a video into an AI video using controlnet and animateDiff, but seem to get this error:
"2024-07-30 09:56:55,808 - AnimateDiff - ERROR - [AnimateDiff] Error extracting frames via ffmpeg: [WinError 2] Das System kann die angegebene Datei nicht finden, fall back to OpenCV." (Btw, the sentence "Das System kann die angegebene Datei nicht finden" is German and translates to "The system cannot find the specified file") Does anyone happen to know what I have done wrong?
Btw this is the message that came before the error: "Attempting to extract frames via ffmpeg from C:\Users\Anwender\AppData\Local\Temp\gradio\42a37a1b2d90164defdf9f652dc6420cfb0e3cdb\ShortRandomTestVideo.mp4 to I:\A1111\stable-diffusion-webui/tmp/animatediff-frames\ShortRandomTestVideo-b5af14f8"
Do you have ffmpeg installed and in your Windows environment path added?
Tbh i don't even know what ffmpeg is lmao
where can I check if I have this added in my path?

Paints-undo tutorial. Make speedpaints and sketches with this AI. Free & opensource.
#aiart #aitools #ainews #ai #agi #singularity
TurboType is a Chrome extension that helps you type faster with keyboard shortcuts. It doesn't hurt to try it - they have a FREE forever plan.
https://www.turbotype.app/
Paints-UNDO
https://lllyasviel.github.io/p...
is there a way to download this for ZLUDA?
i need it to access my ROCM stuff
I can check it later
Where can I read about it? At least what environment to run it in, it doesn't work in auto1111( Direct at least...
Its not an extension
Checkout the github page of that project
coming here because auto update seems to have ruined something
I installed Forge last night and was surprised how much faster it was than 1111. I messed with some settings (directory defailts for models, dark theme) and then ran it, and it updated at least 3 different things, and then it said "import failed" and "press any key to continue", which ends webui-user-bat program.
When I run Forge now, it does this again, so I cannot use it. What went wrong and how do I fix it? Thanks in advance
Hey, can you show the cmd log?
how do I find that?
Ah never mind, I can run "run" and get in. Should I be worried that webui-user.bat doesn't work? Or should I assume "run.bat" is OK to use and ignore webui-user unless I want to update? I am eager to use Forge but I don't wanna shoot myself in the foot if webui-user doesn't work anymore
Copy the text from cmd when launching the webui-user.bat
Hi, I switched my Animate Diff motion model and now I can create Animate Diff videos, although I still get the ffmpeg error. Now I tried to generate a larger video and got another error: In Stable Diffusion it says: "OutOfMemoryError: CUDA out of memory. Tried to allocate 1.10 GiB (GPU 0; 8.00 GiB total capacity; 12.37 GiB already allocated; 0 bytes free; 14.65 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF"
seems that if I hit "ctrl+a" it counts as pressing any key to continue, and then it closes. I also cannot select text with mouse cursor. Should I just type it in manually?
ok I just typed it out manually, except shortened some long paths, can re-include those if you think they might be helpful
file "path"...params.py", line 4, in <module>
from pydantic.fields import fieldinfo, undefined
ImportError: cannot import name 'Undefined' from 'pydantic.fields' (path...webui_forge_cu121_torch21/webui/venv/lib/site-packages/pydantic/fields.py
Press any key to continue . . .
Hey guys quick question, which python version do I need to run stable diffusion? I have 3.10.9
i ran it on an older version for a long time and it worked fine, in fact even after my last update I'm still using 3.10.6 right now and it works great
(also there exists code to automatically update when you run it, if you want to not have to worry)
I'm gonna try to install it with 3.10.9 to see what happens
That will work but best right now is 3.10.11 64bit
Ah okay, I will try that then
Ahh the pydantic fields error.
Thats common for forge. I have to look the fix up again
@calm cairn
you need to do this to fix it:
put albumentations==1.4.3 and pydantic==1.10.15 in the requirements_versions.txt file
Then relaunch or delete the venv
I get an error when I execute the webui-user, it says this:
Traceback (most recent call last):
File "D:\ai\stable-diffusion-webui\launch.py", line 48, in <module>
main()
File "D:\ai\stable-diffusion-webui\launch.py", line 39, in main
prepare_environment()
File "D:\ai\stable-diffusion-webui\modules\launch_utils.py", line 381, in prepare_environment
run(f'"{python}" -m {torch_command}', "Installing torch and torchvision", "Couldn't install torch", live=True)
File "D:\ai\stable-diffusion-webui\modules\launch_utils.py", line 116, in run
raise RuntimeError("\n".join(error_bits))
RuntimeError: Couldn't install torch.
Command: "D:\ai\stable-diffusion-webui\venv\Scripts\python.exe" -m pip install torch==2.1.2 torchvision==0.16.2 --extra-index-url https://download.pytorch.org/whl/cu121
Error code: 2
I get it when the pytorch download is happening
I added the text to the requirements_versions file, but I don't know how to relaunch a virtual environment. Should I run the install again? (it was an automated package)
Where can I cancel my subscription
Then just delete the venv folder abd relaunch the webui-user.bat
Hey, what's the full cmd log
ok, thank you
Helloooo not sure if this is the correct channel but I wanted to know if there's a guide I can follow to install Stable Diffusion please!
Or if someone would walk me through the process I'd appreciate that more 🥲
guys
Amuse 2.0 is out and it has a video depth/line converter
my question is how to use the depth video , whats the workflow ?
Hey checkout the first link from the pinned messages of this channel
There are all guides
What's the difference between each of these and which should I pick?

i think my destiny was with confyui.
i just hope i dont regret it.
and it seem they are arranged according to the best webui hehe
Soo Automatic1111 would be the best choice?
i think because of model manager of confyui , confy is the best.
the manager can download missing nodes, install models directly.
TBH i use confyui because Tydifusion is based on it.
Yes
Best for starting with SD.
yeah i think a1111 have all u need in one place especially if u r not a fan of nodes.
I don't know what nodes are 🙂
u are late to the ai party just like me ?
its been only 15 days i got into sd ai
i no longer sleep lol

these are comfyui nodes, a1111 have interface with tabs.
hmm
"RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!"
What is this?
This is the entire error log I was talking about in #💬|general-chat
Can't reproduce someone else's gen with prompt because of a strange error, please let me know what this means and/or how to solve it

Most likely they re running on some kind of laptop with igpu/video chipset. Force auto1111 to use one specific device with the --device-id xxxx argument where x is the dedicated GPU device id (usually 0 or 1)
@calm cairn
hmm. It's a desktop, but yeah I probably have both integrated graphics on motherboard and a video card. Will try solution, thank you
Oh--how do I check which number (0 or 1) my GPU is?
Hey guys, anyone remeber a guide / tutorial about model merging, and it explained some kind of different approach to normal merging. It was about block / segment / something merging of different models. Does this ring a bell to anymore?
Found it! https://rentry.org/BlockMergeExplained
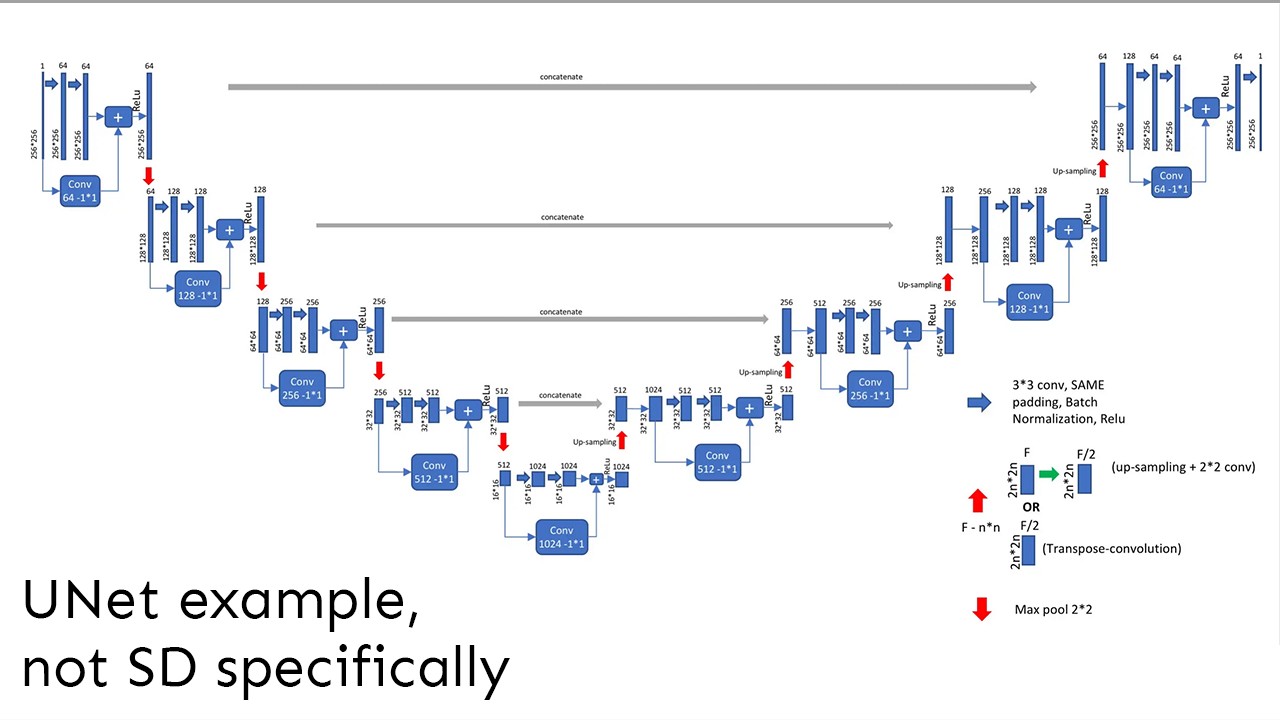
Please send me feedback
This guide is still work in progress. Any and all feedback is highly appreciated, it doesn't have to be suggestions, even questions regarding things you didn't understand can help me figuring out what to refine. For the moment I can be found in /sdg/-threads, but I might m...
I can't get a couple of Loras to show up in SD. Not sure what I'm doing wrong. I've loaded them into /stable-diffusion-webui/models/Lora and reloaded and refreshed the UI. Anyone got any ideas?
Should be indicated in the GPU tab of resource manager
1.5 model and xl lora, or vice versa

this will always show all, but... many will not work with incompatible model
1.5 model with 1.5 Loras
I'll try the setting
Ok, enabling the setting fixed it
thanks
how do I access stable diffusion remotely? I have it set to --listen, but when I try to go to my ip address instead of localhost, it doesn't work. yes I specified port.
Guys, what is wrong ? what can i do ?

alright this is driving me insane, i followed the pinned guide for installing webui on nvidia, did everything and got the panel open in my web browser but i'm having the exact same problem as @ivory bramble my computer just shuts off the instant i click the generate button on txt2img. i have the same specs as him too, gtx 1080 with 8gb vram and 16gbs of ram, and this is my command args in webui-user.bat
set COMMANDLINE_ARGS=--xformers --no-half-vae --medvram-sdxl --lowram
can anyone help?
I've been trying to install SD for years now, but I can't do it.
I got very close this time, but I got hit with a huge line of code.

It says 'timeout error.' What does that mean?

you installed python 3.12, you need to install python 3.10
find appropriate guide for your graphics here https://github.com/CS1o/Stable-Diffusion-Info/wiki/Installation-Guides
try to install in on D: or C: in some folder outside of your home folder
do not install in folders synced with one drive, google drive and similar
yes, but aparentely the SD is not recognizing the Python now... (i'm setting the right path)

I installed the file through an internet browser instead, and it worked. Where would I then put the file?


as you can see you are using 3.12
uninstall 3.12, install 3.10
remove vevn folder
run webui-user.bat
ok ok, i'll try
it will create new vevn with right version
i deleted the vevn, i think now will work
When I run the webui-user.bat file, it still makes me install it again.

do you have C:\Users\swirl\ synced with any cloud drive?
if you do not have onedrive, googledrive, dropbox or similar app, than its fine
let it install what it needs to install
But I already installed the file itself.
So where would I put it?


Oh, gotcha.
Sorry for your loss. LOL
but anyway, you should have more than 200 dirs in site-packages
This is what I see inside.

exactly what i said
let it install everything
it will take a while
btw, i would remove venv completely, and let it create a new one, so you can be sure that everything was installed correctly
The folder, venv?
yes
when you run webui-user.bat it will create a new one if not exist
installation takes a few minutes on my computer
but depending on you internet and computer speed it can take a while
i have 600Mbps

it should download 5-6GB in total
finally worked, ty @karmic crown
hmm, the fixes from here and from elsewhere on the web are not functioning for me.
Right now I am testing this:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
input_tensor = input_tensor.to(device)
output_tensor = output_tensor.to(device)
I just stuck it in webui-user.bat because I dont know what else to do with it
the hope is that it will do what it has to, putting everything on the graphics card (apparently can't have some on CPU and some on GPU or it wont work)
nope, code isn't doing it, although I don't know if its because the code doesn't work inside webui-user.bat or because the code is the wrong code
still getting error:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
can't gen anything, not sure what next plan is
Right, so I moved the stable diffusion folder to a USB drive, since I don't have room on my main PC. It gave me this.

I installed openpose, but its tab does not appear in the web-ui



update: It seems I can do normal txt to img gens, and I get the error on the img to img gens. I'm not sure why it wasn't a problem earlier today but I'll just do normal txt gens until someone comes by who might know how to resolve it
Remove --lowram and then you need to increase your Windows Pagefile
Check the cmd. That extension is outdated and requires that you manually install basicsr inside the venv
Can you shoe the img2img settings ?
Best would be to move it back. The webui itself needs only 8gb.
You can then store the models on the USB drive and link them in the webui-user.bat via --models-dir "D:\PathTo USB"
These are my settings that I used before btw



Yea too high resolution and with that much frames and 60fps + controlnet it will take hours
To test try 512x512 24 frames on 8fps
Context Batch size 4
If that works you can go higher in batch size
Or higher in resolution but not above 768x768
Btw what exactly does batch size do?
It defines how many images the GPU will generate at the same time.
That uses a lot more vram than a normal image generation and is the cause why it didnt worked for you. A GTX can't do 16 images at once at this resolution.
Wait, so setting batch size from 1 to 2 or 4 would work better for me?
Yeah, I thought it probably would take ages, was planning to let it run overnight, every time I go to bed, though sadly I keep getting these errors. I'll try reducing the fps though 60 is far too much and I'll also try to increase the batch size
No
A higher batch size won't work for animatediff
With 8gb vram
Oh, ok, cause my batch size is always 1 usually
Then I'll just try to reduce the quality, fps
Like I said before I'm not talking about the normal batch size.
Look at AnimateDiff
There is context batch size
You have it on 16
That won't work
Oh yeah you are right, my bad for mixing up the two, sorry
Np
Context Batch size of 16 uses 24gb vram on my AMD GPU.
So you should try it on 4
If that won't work lower it by 1 and test again
But always restart when you get the out of memory error
Ok great, I'll try setting the context batch size to 4 and I'll also reduce the fps a bit and then I'll try again, thanks for the help 🙂 👍
Btw, this will take longer then, correct?
Yep
does that mean "show"? if so idk how, you want ss of SD GUI? or cmd output?
I screencapped in client settings for img2img, if thats correct then cool, if you want something else (like from cmd) then let me know

while you are away, I'm turning color correction off to see if that matters
I mean the img2img tab
Your resolution, steps etc
oh ok



I am running forge (not 1111) which is why I have all the extra, unused settings at the bottom
maybe I am an idiot, but I logged in a few times now, and I can't see the first letter of my email to go to my account

Your using inpaint?
hi someone can help me run IDM VTON localy on google colab? https://huggingface.co/yisol/IDM-VTON

Are these speeds normal on a RTX 3080?

Your using sdxl?
Then its normal
Make sure you have --xformers --medvram-sdxl --no-half-vae
In the webui-user.bat
Yeah SDXL, im using xformers, what do the others do?
--medvram-sdxl speeds up the sdxl generation on GPUs with less than 12gb vram
--no-half-vae is needed for VAE compatibility
I have 32gb of ram
Ok thnx
Ah ok
And if you use hires fix make sure to set the hires steps to 10 or 15
Does it have a big difference? I have mine on 0 which would be 25
Those settings seem to be slower for me, the gen stops at every interval, if i batch 4 it stops at 24%, 49% etc
Yea with 10 its much faster and 25 is to much. Not needed
Use batch count and not batch size
You can also try to remove --no-half-vae
And see if it's still the same
Seems to be faster with just xformers, adding the others makes it slower
10 steps helps a bit though
Oh okay
Hey, I want to perform image reconstruction. I am trying to condition a diffusion model using the latent embeddings of the image I want to reconstruct, sourced from a pretrained encoder . Does anyone know how I should approach this task? Any suggestion on which Diffusion Model I could try to use? I was thinking of learning a mapping between the vae's encoder and my own encoder, then using the decoder from the diffusion model for the reconstruction
Is there a pretrained controlnet (with canny support) for stable video diffusion.
I'm sorry, I fell asleep. I value your help and didn't mean to.
Yes, I'm trying to inpaint and getting the same error over and over.
If your using inpaint you need to set the Inpaint Area to "masked only"
And then you need to set the resolution to a sqaure.
If your using an 1.5 model set it to 512x512 and for sdxl to 1024x1024
I often get the error on txt2img btw, so I'm not sure what is going on. Perhaps it started when I asked for help yesterday and had to remake the venv so I deleted the folder?
I'm thinking about deleting everything and reinstalling Forge to see if it works that way
have not checked if my 1111 install is affected but I assume it is not
I deleted Forge and am attempting to reinstall, I still had the self-install package on my desktop from 2 days ago.
ah, it also could have been when I installed adetailer, I've heard that some installs can give that error
It physically pains me to ask this cause it feels like a very stupid question but:
Currently I am trying to get ComfyUI. I downloaded the files okay, but something strange is happening.
I went under ComfyUI>.ci>windows_base_files to click on run_nvidia_gpu.bat... and an error message saying "They system cannot find the path specified" And shuts down.
Now, I've gathered that main.py is in the ComfyUI folder, but it seems no amount of moving of things fixes the issue... I'm pretty sure I have to change the file path, but copyxpasting the directory with main didn't seem to work... unless I did it wrong... So My questions is: What am I doing stupid?
did both, still shutting down
What's your PSU wattage?
did you ever put your directories into your sytem path?
Maybe it doesn't find your python path
Run the python 3.10.11 64bit installer again. Click Modify, Next, and select "add python to environment variable's"
I deleted Forge and reinstalled, and was able to gen about 6 pictures in txt2img, before I got the error again. I don't know what to do if the fresh install won't work right. Got any idea what is wrong?
Did you changed anything after the 6 image?
It appears that I do have enviroment variables.
Let me show you its current state
.\python_embeded\python.exe -s C:\Users\MYNAME\Documents\Coding\Python\AI Python Projects\NewProjects\ComfyUI\ComfyUI\main.py --windows-standalone-build
pause
show me your actual system path statement
This is the path to the run_nvidia_gpu.bat file:
C:\Users\MYNAME\Documents\Coding\Python\AI Python Projects\NewProjects\ComfyUI\ComfyUI\.ci\windows_base_files
This path has main.py:
C:\Users\MYNAME\Documents\Coding\Python\AI Python Projects\NewProjects\ComfyUI\ComfyUI
this appeared

you said you moved things around. what did you move?
The windows_base_files, but I moved everything back to be the way it was
did you reboot after you did that?
I did not, I haven't rebooted (the entire computer) in a minute.
I've run run_nvidia_gpu.bat multiple times though
I could try removing what I have, get it back off git, reboot the computer, and try running again. Do you think that'd work?
please do so, so that all the paths and stuff are reloaded into memory
Gotcha. I will give that a try.
i think what will work is for you to make sure everything is back where it should be, then shut down, leave it off for a minute, turn it on and then try running the comfy startup bat file
I'll give it a whirl
(thankfully, moving stuff around in windows doesn't change permissions)
nope, just went to CivitAI page for Animagine XL and copied positive and negative prompts, guidance, steps, sampler, and seeds, and manually pasted it in each time
Do you use a lora?
Or embeddings?
no, just text in prompt box, no special stuff
why are you runing the nvidia bat file instead of just running the main Comfy startup file?
I can send you the two commands to fix it later.
Also there is a better editor now.
Its included In Controlnet where you can use openpose and edit the Skeleton
Because the video told me to.
Also I have an Nvidia graphics card. 😅
Maybe that was silly of me. Let me try just running main.
well don't. just run the main startup bat file
i do too
in fact heres the page w image

as you can see it isnt even calling a lora i dont have
That seems to be making progress!
I got a whole host of test this time instead of just "Can't find file" so forward progress is forward progress.
so a couple of things: 1. don't move stuff around from an application install if you don't know what you're doing and 2. always run the main startup file
Good deal. I'll keep that in mind.
Nooooww... I have to observe the import fails.
what import?
nodes_audio.py
what's that for?
No idea, I've never seen it before. It came with the code I got from git.
go back and read the git page
Is there a pretrained controlnet (with canny support) for stable video diffusion.
ok, I'll wait
Good deal. There appear to be a couple steps I may have been forgetting so we;ll see.
Major progress!! It seems that I can gain access to the UI!!!
I guess atm I have one final question:
When I hit main, the python window pops up, some text scrolls, and it says "to see gui, go here"
I go there and Bing! I have a UI!!
My only question is if there's a way to pull that up automatically? 🤔
um, well, on my system it just opens that window automatically. loads my browser if it's not loaded, and opens it. so - make sure you don't have popup blockers in your browser. i'm on chrome, in case you're not
hello, does anyone know if it is possible to do 1000x1000 images with a 1050ti 4gb? whenever i try to do it i get this error

now I restarted and pasted the same stuff in, and it generated an image. I really have no idea what to do
I'll just pay a lot more attention to what i am changing, if anything, when it fails again
I swapped to forge and holy moly its so much faster
Yes but you need to use --xformers --medvram --no-half-vae
And then you need to install the tiled vae extension
I've been running around in circles, chasing my tail on this for hours, days...
At some point, ReActor (CUDA) and InstantID ControlNet models both stopped working for me in A1111, Forge, and ReForge.
I get this error in CMD Window:
RuntimeError: D:\a\_work\1\s\onnxruntime\python\onnxruntime_pybind_state.cc:891 onnxruntime::python::CreateExecutionProviderInstance CUDA_PATH is set but CUDA wasnt able to be loaded. Please install the correct version of CUDA andcuDNN as mentioned in the GPU requirements page (https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#requirements), make sure they're in the PATH, and that your GPU is supported.
My build is < 2 yrs old - 4070ti on Windows 11.
- VS Community 2022 is installed.
- Current version of A1111 / Forge / ReForge
I followed the instructions for CuDNN: - Latest nVidia drivers
- Latest CUDA Toolkit
- Latest CuDNN
I check my environment variables, I have one CUDA version listed, and one CuDNN listed, both pointing to correct locations
I've looked around and for every instance where someone reported this error, they received no answer
What's the full cmd log?
And are the extension updated?
Yep, extensions up to date.
I'll share log in a moment...
If I delete the onnx related packages from site-packages, ReActor reinstalls them on next launch.
I then close and re launch the WebUI... same error.
Have you tried to delete the venv folder and relaunch the webui-user.bat?
I'll do it just for the sake that you are here and offering assistance, but it's not going to do anything - it's happening in all the webUIs
Shouldn't take long either... super fast speed here...
And it's not restricted to ReActor - same error seems to occur for anything using insightface (InstantID model via ControlNet)
venv rebuilt...
indeed, same error
@sand dawn On AMD I had the same error. Face ID didn't worked because reactor was installed. Reactor installs onnxruntime-gpu which is for nvidia but Face ID needs onnxruntime
I'll try disabling ReActor, deleting the onnx libs, and see what happens when I run InstantID
HMMM
Hmm that could be a thing. I will try having chrome open
So it said Module not found: onxx (because I deleted the lib, and apparently it won't install itself.
So I activated the venv and pip install onxx
InstantID is working
Okay... something got broke. Main.py is now flashing a Py terminal and then immediatly closing... All I did was change my default browser to chrome... even changing it back didn't fix it... what'd I do?
thankyou bro
go into the stable-diffusion-webui folder.
There click into the explorer bar (not searchbar)
type cmd and hit enter.
then you have to run these two commands:
venv\Scripts\activate.bat
pip install basicsr
then relaunch the webui-user.bat
Deleting files and then re-cloning git does not fix the issue 😓
Update: Running from a comandprompt appears to yeild that there is no module named "torch". So I guess I will try and fix that
yea and if you install reactor it will break it because it installs onnxruntime-gpu
Indeed. This is some BS XD
It worked, thank you very much
you made a mess. if it was me, i'd uninstall everything, including python, and reinstall. remember that comfy uses an embedded version of python. that's why people usualy set up virtual environments - so that what they have installed for comfy isnt' going to affect the rest of their sytem
alright I am beginning to think my problem has something to do with memory allocation
given I had no problem with gens in automatic1111, and now have the problem after swapping to Forge, which allocates mem differently
given that nothing I am doing seems to be causing it
It just started failing again, when my vram was stretched to the limit
I'll test to see if clearing out the memory fixes the problem, if you know any strings of code/settings that can help me with that, then plz let me know, could save me time
what forge launch args do you use?
there are some which can help
i dont use anything substantial, used more on A1111
--theme=dark --ckpt-dir "E:/Life/Projects/ART/Stable_Diffusion/Models/" --lora-dir "E:/Life/Projects/ART/Stable_Diffusion/LoRA/"
so just theme and directories
forge needs these for max performance:
--cuda-malloc --cuda-stream --pin-shared-memory
Awhile ago, I forked --sd-webui-ar-plus and improved it very much.
https://github.com/altoiddealer/--sd-webui-ar-plusplus
After checking out the new version of Forge, which is using Gradio 4, my extension is only one out of 2 from my extensions folder that is failing to load.
Seeing if anyone is savvy to what changes in Gradio 4 that could cause this error:
https://pastebin.com/iACS5udu
I took your que and that looks like it fixed it. I can now get to the UI. Still wants me to copy and paste a link to it... which is weird but maybe I should just deal with it for now.
I can see the UI so that's a win
you are running it on what? what's the link?
find an extension that works, and see how they created ui, do the same as they did
this is how I fixed mov2mov to work on 1.8.0
https://github.com/Scholar01/sd-webui-mov2mov/compare/master...viking1304:sd-webui-mov2mov:master
If I throw a link like this:
http://127.0.0.1:81##
(Two more numbers instead of hashtags)
It brings up the GUI. I can throw that into Microsoft edge
wha'ts the number where the hashtags are please
the entire URL it gives you. i want to explain what you're looking at
Of course, none of the extensions that are working have any ToolButton components 😛
this is not the same as
http://127.0.0.1:81/xx
this is the same as
http://127.0.0.1:81xx/
okay, to explain - 127.0.0.1 is the IP that's set asside for the internal local host of every network adapter. and the :8188 is the port that it's running on
To see the GUI go to: http://127.0.0.1:8188
FETCH DATA from: C:\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-Manager\extension-node-map.json [DONE]
and that is a drastic difference
that's the same that i get. comfy runs on local host on port 8188
not a clue what the /## you mentioned might be (other than typo?). but you can just bookmark http://127.0.0.1:8188 and just go to that bookmark if you need to
Ahh okay. Cool, glad I'm not the only one who's gotta copy paste that then.
I put in the ## signs just because I was weirded out about throwing it in normally, that was my bad.
So, dumb question, will me posting that link allow someone else to modify what's in my GUI?
i was a mixup with http://127.0.0.1:81xx/
I put the ## there, I was modifying it because it didn't feel wise to just post something that could be a vulnerability
no one else copies and pastes it. for most of us, the browser just opens a new tab and loads. again, make sure you don't have popup blockers and things that prevent your browser from opening new tabs
Let me check. It worked for Auto1111 so I am surprised, but I shall
127.0.0.1 is the local host IP of every single network adapter in the world and only reachable IF you are on the machine itself
Ahh well that's good news 🙂
when you see something like that with any ip, take for instance http://270.45.2.654:8877 you are looking at an actual website address then the : tells you what port the application you are using is running on
Hello! Not sure if this is the right place to ask, but can someone help me with LivePortrait Video2Video?
It works fine, but my output videos in the Video Combine window are only 5 seconds long, how do I get the full video?
Thank you 🙂
purz has a really good tutorial for this on his youtube channel
Cool I will have a look thank you!
Interesting, so then what in this case would the port go to? You said it was local
when you start up any application or process, you have to tell it what port to run on. you can think of ports like little rooms in a huge mansion. the local host ip assigned to your adapter is the house number that no one but you can use. but in that mansion, at address 127.0.0.1 there are 10,000 rooms. so in order for your machine to know which room the application you want to use is in, you have to tell it the room number (port number) - in the case of comfyui, when it's running, it's located at the home address of 127.0.0.1 (your private mansion) and in room number(port) 8188
normally, you just run an application and all the startup code takes care of assiging the room number(port) for you, but you could, technically if you wanted to, assign it to a different port. if you do that, make sure nothing else is running on that port, or you'll ahve a huge problem
I get it now. That makes sense!! Thank you very very much for the explanation!
🙂 you're welcome
How do I access SD from another machine? I've tried using ipaddress:port but it doesn't work, and I do have --listen enabled.
you have it running on a public IP - so you'd have to have a web server set up on your host machine and and your client would need to access it like you would any website OR you'd need to write some sort of server for it that could make it available to your client
im using A1111, so that's how I wanted to access it.....
you would be using that on your client. i don't think auto1111 has a built in server, however
well that kind of sucks.... i pretty much just wanted to access it from my windows machine
so i don't have to keep switching between my HDMI inputs lol
I have SD running on a linux machine in my bedroom
Launching Web UI with arguments: --listen --enable-insecure-extension-access
i know, standard client/server tech here. you have to have a server of some sort running on the host machine that makes the application available to the client. @ornate elk might know
well poop lol
not really that important right now though I guess
I'm a little curious why sometimes my loras all load under the lora tab, and then sometimes they don't and they don't show.
do you have them in the wrong spot?
Yo guys, can I use an RTX 3090 on a 650W 80plus Gold PSU? I would reduce the TDP by 10% manually, but before buying it I want to be 100% sure: I have a ryzen 5 5600G, 32GB of RAM and 4 1TB ssds
Shouldn't be, they're in the lora folder and they'
are loras
are they loras built for the model you have loaded?
that could be part of the problem, but it seems inconsistent in that they won't show sometimes when it is the right model loaded.....but this might also be user error. I'm actually trying to sort through my models, and put them in folders with their graphics and such, and make sure they're all in the right folders themselves, like checkpoints or loras.
ok so I think I need "LiberteRedmond SD 1.5" but I can't seem to find it anywhere? or im misunderstanding what that is.
okay, well, all i can do is guess, but that's the most common cause. you've got, say, an sdxl model loaded, and you're looking for an SD 1.5 lora
hey guys, kinda new to this and was hoping someone could tell me what an "activation token" is
where'd you see the phrase?
one of the models i wanted to try out suggested to use "4rchon" activation token
which model, please
idk if i can post links so i imagine this is what ya want?

wherever i look i only find the terms "token merging" not sure that's what i'm looking for
also if it helps: using webui
okay, that's the keyword you put in your prompt. so your prompt might be: 4rchon a man eating a hot dog
without that keyword, the lora will be ignored
oooh, alright! tought i had to download smth. thnx
make sure you put lORAs into the LORA folder, not the models folder
Zluda error
yea, ik that part, was only missing this detail
you might search this discord for that error, it looks familiar
hey gang, i used Nightcafe's "creative upscaler" to get this result, anyone have any idea how i can do the same thing in stable? (auto1111)


(image on left is upscaled, lol)
Hello. Does anyone here know how to generate a specific objects and apply in the prompts? I'm struggling with this.
I'm new in generating AI images, so, I tried to put some ideas in the generator but it didn't work.
I was trying to make an image of a prussian soldier, and it didn't recognize the helmet - it has a lot of details - and I want the most similar possible.
This is the helmet.

zluda gives an error saying that a file is missing, but it is in the folder


that's going to depend on the model you're using, whether it was trained on data with that specific label or not.
Who knows why it goes Red and Cursed at the last 5% of rendering?

maybe because of vae it could be thou
Anyone know why my speeds seem to be flucating so wildly? These are same prompt, models, and settings. Just different speeds:

Colab Lora trainer gives me this...

I swear it was working yesterday. What happened to it?
Anyone have issues when installing SD with pinnochio? I can't get realistic faces anymore... thinking of installing manually again
Better install it manually via the guides from the pinned messages
Made a ticket, we sorted it out, I was making a rookie mistake with my cehckpoints resolution
ty tho
I'm using the wget command to get files from Civit. Sometimes the get works and then other times it asks me for a username and password. I tried adding my username and password as paramaters to the wget command but it still failed with the issue. Anyone know how to get around this?
give me the link that gives you the error
--2024-08-01 14:41:56-- https://civitai.com/api/download/models/424720
Resolving civitai.com (civitai.com)... 104.22.18.237, 104.22.19.237, 172.67.12.143, ...
Connecting to civitai.com (civitai.com)|104.22.18.237|:443... connected.
HTTP request sent, awaiting response... 401 Unauthorized
Username/Password Authentication Failed.
https://civitai.com/models/288584?modelVersionId=324619 hi i want to use this checkpoint and when i downloaded it, it said i had to install xformers. I installed it then it said i need CUDA for it to work and i installed it. But then i ended up with this message


Mix of pony with some stuff. It's an attempt at making pony more predictable and less dependent on schizo negatives without removing its comprehens...
i need help pls
i also get this message

amd 7800 xt, trying to run this https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-AMD-GPUs
everything works fine but when i try to generate an image, this error happens
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
if i upload a image can someone tell me what is the model or style?
Please follow my AMD Zluda guide.
You can find it in the first link of the pinned messages
Can you show the full cmd log?
@ornate elkbtw i installed the newest version of python but it says i have the other one which is weird save with cuda i got the latest version and it shows the wrong version
do you know how i can fix it?


You need to uninstall python 3.12
Then install python 3.10.11 64bit
Then delete the venv folder
Finally launch the webui-user.bat
why can't it work with the latest version of python?
because its not coded to work with it
3.12 is not supported same goes for older versions like python 3.9
oh okay
@ornate elk btw i'm downloading the correct cuda version i also wanted to ask
why do i have to delete the venv folder?
because if you wouldnt. it would always still use python 3.12
the venv folder needs to be rebuild with the compatible python then torch and xformers will work too
maybe in #📝|prompting-help
i see thanks
i'm installing pytorch now and it should be good to go i think
whats your gpu btw?
rtx 3070
ah then make sure you have --xformers --medvram-sdxl --no-half-vae in the webui-user.bat
for the best performance and compatiblity
i'm gonna downlaod xformers after my downlaod is done
you dont have to download and install aynthing manually
dont do that
the venv will do this all for you
wait really?
i saw videos of people explaing it was mandatory
its not
but feel free to share me that video
just deleting the venv and having the right commandline args in the webui-user.bat is enough to setup everything.
and of course the right python version

We go over how to use the new easy-install process for the XFormers library with the new AUTOMATIC1111 webui. I achieved huge improvements in memory efficiency and speed using this.
XFormers is a library by facebook research which increases the efficiency of the attention function, which is used in many modern machine learning models, includi...
this video is more than a year old and even there it was outdated after 2 months xD
dont follow old stable diffusion videos, everything changed
@ornate elk https://civitai.com/models/257749/pony-diffusion-v6-xl btw this is the checkpoint i want to use but it says i had to use xformers

Pony Diffusion V6 is a versatile SDXL finetune capable of producing stunning SFW and NSFW visuals of various anthro, feral, or humanoids species an...
yea that will work with your gpu but only if you use the commandline args i mentioned
also you need 16gb RAM or more
i have 32gb ram
then edit the webui-user.bat, delete the venv and your ready
okay so i just need to insintall pytorch now?
Python 3.10.11 64bit
not pytorch

you didnt editet the webui-user.bat
or didnt editet it correctly
then do that and then delete the venv folder again
then your fine
set Commandline_ARGS= --xformers --medvram-sdxl --no-half-vae

it tells me this now...

full cmd log pls

it seems you have added a space in the webui-user.bat after the line
set VENV_DIR=
delete the space after the =
then save and relaunch the webui-user.bat


thats fine
its rebuilding the venv now
and will launch then
ah okay it launched
now i need to see if the checkpoint works
@ornate elk thank you a lot for the help btw
no problem ^^
This error appears when I open the web-ui with zluda
I looked in the folder, and this file "nvrtc64_112_0" is there
yes, I copied the library folder and renamed it to old library, downloaded the 6600 rocm files and placed them in the copied library, without the old_

You need to install rocm 6.1 instead of 5.7
And then add the hip path again and replace the Library files again
Which of these Path's should I put?

In the bottom one
Its system variables
The top one is called user variables
Can I ask about stable-fast-3d here? Or is this not the correct discord for it?
Does it take time for the authentication of the model (Gated model You have been granted access to this model )to propagate?
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
...
...
raise GatedRepoError(message, response) from e
huggingface_hub.utils._errors.GatedRepoError: 401 Client Error. (Request ID: Root=1-66ac054e-2c8906bb336f3fb337447d7f;905cdb37-e025-49cd-9092-3f68190982f7)
Cannot access gated repo for url https://huggingface.co/stabilityai/stable-fast-3d/resolve/main/config.yaml.
Access to model stabilityai/stable-fast-3d is restricted. You must be authenticated to access it.
You have to download the model manually from huggingface because its behind a login
Oh, okay. Even though I have logged in with my token/account?
Do you know where to put it?
What service/Programm do you use?
Windows 11, just CMD client thing ^^
I've set up a venv, installed all requirements (and some more that wasn't listed), and logged in with my HF account from this env. And it still displays that error message.
I have also downloaded the model now, model.safetensors, but not sure where it is supposed to go.
Here's the complete console log
Hmm I don't know where the model goes into
Sry
like this?

Yes
Its around midnight here I'm off.
I can help tomorrow if you have any issue.
Make sure to restart the PC after Installing HIP SDK 6.1 and replacing the Library files.
Hi, I'm trying to set directory for CLIP models for Automatic1111 in another folder, for SD3, it always try to download the clip models anyway

I'm using --clip-models-path /media/mario/Ultra-Zen/SD3/models/CLIP/
but I don't know if I'm doing something wrong there as it doesn't seem to detect the models or use the folder
It detects the checkpoint model in the other disk just fine with --ckpt-dir /media/mario/Ultra-Zen/SD3/models/
mmm it seems it is trying to use other models as I put the clip sd3 models I have and it started downloading this one instead

So maybe I let it download the clip models and then test with the alternative dir
Hey, I need some help.. I am not able to use certain ControlNet function anymore and I have tried to update ControlNet but still getting this weird Error..
RuntimeError: The size of tensor a (80) must match the size of tensor b (64) at non-singleton dimension 3
I have been trying to google but cannot find any working solution..
Can you check to make sure you are using an SDXL ControlNet when using an SDXL model, and SD1.5 ControlNet when using an SD1.5 model?
Uhm, how can I check that.. I have been able to use this controlnet before with the model.
Or are you refering to this one?

Those are both for SD1.5
What checkpoint/base model are you trying to use to generate the image with?
It's called TFM_Cutesy
It's an SD 1.5
Okay, then it should work.
The error of the size of the tensors not matching is sometimes because you're trying to use incompatible models.
You're not using a <lora> for SDXL or something in your prompt, right?
Just making sure you aren't loading any incompatible models anywhere 🙂
Might have found the issue
I had a --non ..something .. Because I had issue with AnimateDiff
I removed it and now it worked.
Nvm.. It's the .. Sampling Method
I can't run Euler SMEA Dy with OpenPose. ...
Ah, good to know!
I'm trying to run SD3 on Automatic1111, it seems I'm 28 mb short

how much Vram do you have?
12 GB VRAM
I tried to run it with "lowvram" and got a lot of errors, it seems it doesn't work for AMD or soemthing
ouch. @ornate elk might have a solution for that
I don't know if it needs different flags or if it isn't supported for AMD yet
I have a RX 6700, running on Ubuntu
auto supports it already? Sweet
same error again :\
Hi there, I fell asleep last night receiving tech support from CS1o. I was advised to add
--cuda-malloc --cuda-strea --pin-shared-memory
to my arguments, but upon running Forge, I am now told that it's launch.py error, unrecognized arguments
What file am I supposed to put these arguments in? Did I type this wrong? I thought I copy/pasted
he hasn't been on today, can you wait till he's back online?
yeah, I'm assuming he'll probably be back tonight, seems like thats the pattern
he also works, so he's here when he's not at work
Anyone know where the PBRemTools Segment Anything & Clip Model needs to be placed? Or how to install the relevant models with stability matrix?
I've tried adding "sam_vit_h_4b8939.pth" and "sam_vit_l_0b3195.pth" to a 'sam' folder and the 'CLIP' folder in D:\Stable Diffusion\Stability Matrix\StabilityMatrix-win-x64\Data\Models - but I'm more just guessing at this point

nothing on the page you downloaded it from?
not really, I just installed what I found in forge extensions. This is the only doc and it doesn't really explain where the models go/where to get them https://github.com/mattyamonaca/PBRemTools
GitHub
Precise background remover. Contribute to mattyamonaca/PBRemTools development by creating an account on GitHub.

doh, lemme give that a try
noice, we got it - thanks @ruby yoke (I might need to invest in some glasses xD)
🙂 you're welcome
I think I scrolled down to the installation part and just skimmed the rest haha
we all do that I think. just glad you got it working
i cant seem to get stable to recieve my controlnet sketch prompt, it says it does but the little sketch image wont appear next to my finished generations, also none of the sliders on controlnet seem to affect the output image

Thats a different error. Try delete the venv folder and the .zluda folder.
Both are in the stable-diffusion-webui-amdgpu folder
It goes in the line with the Commandline_args= at the top
With what i can train Lora using AMD RX 6600 XT?
Any suggestions? I was trying OneTrainer, Kohya...but no luck since i have AMD and not Nvidia.
Oh hey, your from Github.
With OneTrainer it should work because it can use Zluda.
I haven't tried it myself but I can this weekend and then make a guide for it
I've tried to use OneTrainer.
First of all it throws error
Second it can't generate captions (text files that generates pormpt for each image)
And i've tried also Kohya and that works on Nvidia
Im trying to swap the head out on a photo, but without manual inpainting cause i want to automate the process. I found this post on reddit: https://www.reddit.com/r/StableDiffusion/comments/18z70b1/roop_but_for_the_whole_head/
Now how exactly do i keep the body but place the new hair+face from my reference images on top of it? Here are my current options and results (face swapped but ne hair and body):

Reddit
Explore this post and more from the StableDiffusion community
You have to not use Face ID plus.
you need to use Face Full to get the hairstyle etc or additional IP adapter plus
Face ID is like Reactor and Swaps only the face
helo guys can anyone help me how to fix this problem?


Not sure if the result can be considered any better. Cab you give me some hints with the settings? The hair looks different, some random mutation and the body/clothes shouldnt change

I assume i have to choose a different preprocessor too? But i feel like i have a bunch of settings set wrongly
I can try later and send you an example. But I'm wondering what's your webui version
And why it takes so long for you to generate

that would be awesome
Oh your on the latest version vut your not using xformers
Edit the webui-user.bat and at the line commandline_args= you add: --xformers
Then save and relaunch. That will increase the speed alot
alright, lets see
Open the .bat file with notepad
already replaced, about to make a new run
Also interesting that you got Roop to work
Its outdated by 10 months now
Normaly people use Reactor for faceswap
i actually had a error with roop:
NansException: A tensor with NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
--no-half fixed it
should i use reactor then?
Oh dont use --no-half
It slows down the generation speed a lot and uses more vram
Yea better use Reactor
alright
Its does the same but gets updated frequently
And has more features
So you only should have --xformers and maybe --no-half-vae
In your webui-user.bat
is there way to make stable diffusion go idle when no promp ahs ben send for 10 min and to dump from vram
I removed --no-half and now im getting this again:
NansException: A tensor with NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
Will --no-half-vae fix it?
it did fix it
also --xformers made it significantly faster lol
Hi there, I fell asleep last night receiving tech support from CS1o. I was advised to add
--cuda-malloc --cuda-strea --pin-shared-memory
to my arguments, but upon running Forge, I am now told that it's launch.py error, unrecognized arguments
What file am I supposed to put these arguments in? Did I type this wrong? I thought I copy/pasted
Also I believe the errors I am having (cpu cuda:0 thing) is probably something to do with memory/VRAM, because when I swap to Edge (yuck), the errors go away (normally using Chrome when I got the errors)
can you show the content of webui-user.bat?
At what point? Do you mean get it to crash in Chrome, then post that?
oh nvm
you wanted the txt not a log
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--theme=dark --ckpt-dir "E:/Life/Projects/ART/Stable_Diffusion/Models/" --lora-dir "E:/Life/Projects/ART/Stable_Diffusion/LoRA/" --cuda-malloc --cuda-strea --pin-shared-memory
@REM Uncomment following code to reference an existing A1111 checkout.
@REM set A1111_HOME=Your A1111 checkout dir
@REM
@REM set VENV_DIR=%A1111_HOME%/venv
@REM set COMMANDLINE_ARGS=%COMMANDLINE_ARGS%^
@REM --ckpt-dir %A1111_HOME%/models/Stable-diffusion^
@REM --hypernetwork-dir %A1111_HOME%/models/hypernetworks^
@REM --embeddings-dir %A1111_HOME%/models/embeddings^
@REM --lora-dir %A1111_HOME%/models/Lora
call webui.bat
there is a typo
you have: --cuda-malloc --cuda-strea --pin-shared-memory
but you need: --cuda-malloc --cuda-stream --pin-shared-memory
ok will try that, one minute
launch.py: error: unrecognized arguments: --cuda-malloc --cuda-stream --pin-shared-memory
Press any key to continue . . .
in case it is relevant, it is Forge, not normal A1111
im using your guide for comfyui with zluda, i just did the first steps, and this pops up

hmm maybe he removed these launch args in the latest version
hey, at which step are you?
launching comfy ui , step 6 🙂
okay then read step 7 ^^
zluda needs to be setup
then it will work
let me know if any step isnt clear
yeah but i didnt try generating an image, the webui doesnt even open
yea i will edit that part. in the past it launched. but now it does not it seems
also im installing amd hip sdk right now and i dont see an option amd pro driver
its at the bottom. its disabled by default so your fine
i dont even see it but ill trust
whats the latest version? I only recently installed Forge, but I don't know how old the installer was, only when I got it
I can say my Python is 3.10.6, torch 2.1.2+cu121
your running the latest version
1.10
thx for letting me know about step 6/7 , i editet the part that launching fails.
btw whats your gpu?
ah ok, well then I'll assume my problem is, tentatively, solved
I have not had any trouble running it in Edge, although I don't like Edge, it is functional
Thanks for your help, I don't understand the problem really (cpu/cuda:0 error message), but using Edge is a successful workaround, so I'll just keep using that, unless you really want to solve with more troubleshooting
okay, maybe check if you have extensions in chrome that could cause errors. sometimes adblockers do
also if you want you can try if it works on firefox
yeah I'll try firefox later, i have no addons for chrome because I prefer Firefox but I have a lot of tabs in Chrome right now so I'm closing all of those first, before I go back
Again, thanks for your help, I'm just gonna gen all day now 😛
guys, how can i change the settings used by this function ?

Enabling hires fix
Changing the vaules
And then disable
thanks!!
its rx 7900 xt ^^ thank you for the help btw, i launched it and it showed up in my browser now ima get the manager
is this how its supossed to look like with the manager? can i somehow make the ui more friendly like it is in automatic 1111?

The UI in Comfy is friendly. But it's node-based. If you're not used to it, take time to understand it and you will be able to wield a more powerful tool than A1111. If you don't want to do that, go back to A1111 (or use tools that mask the ComfyUI interface; though by doing that you're defeating the purpose).
is there a guide to the interface somewhere? im up to learn it
The official documentation is here:
https://docs.comfy.org/get_started/introduction
There are a ton of YouTube videos out there to walk you through it. I suggest starting on this page of the docs:
https://docs.comfy.org/get_started/gettingstarted
Also, many people embed their workflows into their images when they post here. Download and save the original, full size image, then drag and drop it onto a ComfyUI instance and if the workflow is embedded, it will open up that workflow for you.
do you have any workflow recommendation?
Here. I get asked this every once in a while. This should be enough to start with, giving you an SDXL image. The missing pieces/stuff you'll need to change will be the drop-down for the Checkpoint and VAE. After that, just put text into the prompt and queue up the image.
That flow used only nodes included by default, so you don't have to download any custom ones to get it to run.
I step you through it in numerical order for how a human thinks, but the other thing to understand is that most node-based systems actually logic-check backwards, in a sense. They're going to look to make sure you have everything from the end moving back to the beginning to fill each step's prerequisites.
can i run stable diffusion xl too?
i got 20 gb vram
That's what the workflow will do for you; create an SDXL image. You've got more than enough for SDXL.
I only have 10GB of VRAM and generate SDXL images all the time.
so i download what you sent, and ill drop it into the website right? and then i do the rest you told me
Yup. I recommend putting all your workflow files into a directory that you know where it's at so you can easily access it when needed.
this normal?

Ah nice I have the same GPU.
Works great with Zluda.
Yes thats Comfyui with the manager.
If you want a Ui similar to Auto1111 you would need to install Stable-Swarm UI.
But I don't have a guide for it yet
Yes you can even run SD3
your guide was THE ONLY one that worked, literally everything else gives an error
Ah...I had some legacy group data in there for some reason. Gimmie a sec.
stable diffusion 3 medium?
Yea there are so many guides out there. Most have missing steps or are outdated. Thats why I made these guides and tried to get them all working before.
Try this one.
which one should i download? sorry im really new to this

But only use the 5.9gb sd3 model. It has the clip text encoders included.
I can give you my workflow
sure, i will try both workflows of soul and yours
I do appreciate that you're willing to take the time to learn a bit and not give up. The curve for Comfy is a bit steeper than A1111, but once you're past that, it's tremendously easy and powerful.
here is the SD3 Workflow
and here is an sdxl workflow
thank you dude this is much easier with people like you and cs1o to do
without his guide i wouldnt be able to run it, and you guys respond really fast too which is nice, when ill have trouble ill message here
thank you a lot
can i ask where you found my guide? was it here in the pinned messages?
yes it was when you told me to check it out
ahhh right
how do you import characters? i mean the safetensor file, where do you put it?
into ComfyUI\models\checkpoints
if its a lora it goes into models\lora
Caution, though; are you downloading a full checkpoint or a LoRA?
LoRAs are not able to be used properly as full checkpoints (models); they are applied on top of checkpoints.
i got no idea how to see it
Where did you get what you are downloading?
nevermind im blind
it says type: lora
😭
civitai
Ok, so start by just trying to create what you want via text and the base model, then graduate to adding the LoRA into the workflow.
Just make sure that the LoRA is for a version of model that you're using in the workflow. (1.5 and XL are the most common versions. If you see Pony, that's a special thing for XL based on a popular model that has some quirks to it; I'd recommend staying away from that at the very beginning until you get familiar, then go read up on Pony.)
where do images save?
i wanna show you what generated
its very accurate
Many workflows will save in the "output" folder. If you can't find them there, look for a temp folder.
what is 1-5 pruned emaonly?
whats the difference of
emaonly and just pruned
im trying stable diffusion 1.5 emaonly and it gave a bad result
Long story short is that the pruned emaonly one is smaller and uses less VRAM.
this is not ankha from animal crossing 😭

FYI in case you haven't seen yet, SD 1.5 images should be ¼ megapixel (variations of 512x512) versus SDXL, which is 1 megapixel (variations of 1024x1024). Between size differences and the different VAE, you can get garbage output if incorrectly configured in your workflow.
can i use a sd 1.5 model in sdxl?
SDXL and SD 1.5 are models.
They're 2 different model versions. Careful not to mistake the model version with an application version. 🙂
LoRAs only apply to the model version they're made for.
hey guys good morning, so i was hoping someone could point me to the file i need to edit to be able to use all my cpu cores, its telling me when i start the server its set itself to max of 16 cores to be safe and this is the txt i copied from the cmd prompt
NUMEXPR_MAX_THREADS
where do i put v1-5 pruned.safetensors? in the vae folder?
No don't download the default model
Which one should i get
For example download Dreamshaper v8
Its an 1.5 based model.
And for SDXL try albedo base xl
Or juggernaut xl
Is there a site for those? Like to see the other models
Yep
Civitai.com
Its the biggest model database
There you also see if a model or lora is 1.5 or sdxl based
do you know how to select loras?
my last 5 images look like this

You have to make a lora node
is there a vae for dreamshaper? i cant find it
and it needs a vae
do you always need to use a vae?
Some models have them included. But better use one
why after inpaint, on image in mask area is a lot of blurry mess?
tried a lot of settings, nothing helps
Your AMD user?
has sd created a model that will actually take text input and make a legitimate 3d model for use inside apps like blender. i read an article from dec 23 that they were working on one for making polygon models?
would love to talk to anyone using tydiffusion in 3ds max , pretty amazing
no, but there are plenty of others out there working on that
and no one working on 3ds max
thnx crystal
well the hottest thing is tyflow for effects and its the only legit thing for 3d and only for max so id look again because im using everything in a real gui insiode 3ds max with no browser at all
now it is not for model creation just effects


i know, but no one i've seen is doing anything for 3ds max. most of them are doing text to 3d in their own interfaces.
🙂 it's fine. i know you really would like this, i wish i had better news or somewhere to point you to
ehh all good itl happen
its so new that tyflow doesnt even have but install instructions thats it, they dont have a server or forum or anything so i created a server here and ive been the only one in the room,
Is there a way i can .. make my stable diffusion XL model into an API? this way people cant download it, but they can use it, as long as i let them?
or is there a way i can provide the model without downloads?

Flux 1 Schnell by Black Forest Lab is the BEST SD Model to date. It rivals Midjourney in quality and artitic Style. Flux 1 is also very good with Text and can even create multiple Texts in the same image.
Links from my Video
https://huggingface.co/spaces/black-forest-labs/FLUX.1-schnell
https://openart.ai/workflows/maitruclam/comfyui...
huge memory hog atm but quality is what they aimed for with SD3, so it seems
not usable for average users, it requires 24gb vram, and 64gb ram
can anyone help me out and list the top models for photorealism
im having some problem using xformers, when running appears this:
PyTorch 2.1.2+cu121 with CUDA 1201 (you have 2.0.0.post304)
Python 3.10.13 (you have 3.10.14)```
and when trying to generate something appears this:
```NotImplementedError: No operator found for `memory_efficient_attention_forward` with inputs: query : shape=(2, 3840, 10, 64) (torch.float16) key : shape=(2, 3840, 10, 64) (torch.float16) value : shape=(2, 3840, 10, 64) (torch.float16) attn_bias : <class 'NoneType'> p : 0.0 `decoderF` is not supported because: xFormers wasn't build with CUDA support attn_bias type is <class 'NoneType'> operator wasn't built - see `python -m xformers.info` for more info `flshattF@0.0.0` is not supported because: xFormers wasn't build with CUDA support requires device with capability > (8, 0) but your GPU has capability (7, 5) (too old) operator wasn't built - see `python -m xformers.info` for more info `tritonflashattF` is not supported because: xFormers wasn't build with CUDA support requires device with capability > (8, 0) but your GPU has capability (7, 5) (too old) operator wasn't built - see `python -m xformers.info` for more info triton is not available requires GPU with sm80 minimum compute capacity, e.g., A100/H100/L4 `cutlassF` is not supported because: xFormers wasn't build with CUDA support operator wasn't built - see `python -m xformers.info` for more info `smallkF` is not supported because: max(query.shape[-1] != value.shape[-1]) > 32 xFormers wasn't build with CUDA support dtype=torch.float16 (supported: {torch.float32}) operator wasn't built - see `python -m xformers.info` for more info unsupported embed per head: 64```
i have no idea what to do, please helpno
you're running the wrong version of pytorch
how do i install the correct version in a colab? im using sagemaker
normally, at the start of any colab notebook, you'll find a section that installs stuff, like the version of python and pytorch. your error is "xFormers was built for: PyTorch 2.1.2+cu121 with CUDA 1201 (you have 2.0.0.post304)" <-- that tells you that you are going to need to use PyTorch 2.1.2 - is this your notebook?
can share the github of the colab
i have no idea what version of pytorch is using neither know how to install the one i need
if it's not your notebook, you should probably go to the author of it and report the error
Hmm. Well then. Is it possible to rent a GPU. Say vast.ai where it costs me like 15 cents per hour, setup a login for them but only to the webui?
you can't very well run a google notebook somewhere else.
huh????
oh i see, yeah you have no idea what youre even saying, you can easily run PCs elsewhere, ill figure it out.
no, i replied to the wrong person. but you have a good life with that attitude
I did, but it gave the same error
so is juggernaughtxl ass?
running it now, insanely slow, at just 20 steps
like 10x slower than pony
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_CUDA__index_select)
help
I save cool prompts from CivitAI when I see them, into folders so I can find relevant stuff later. There are a lot of archived posts online, but IMO all the ones who promote themselves are pretty bad, and image gens with prompts available are better. Hope that helps.
i've got a spreadsheet full of prompts and stuff you can have a copy of if you'd like
you've got to set your system up to use just your gpu or just your cpu. let me guess, you're using an AMD card?
I would also like it, is there a link, or is it a DM thing?
i need to DM you, if that's okay
yeah man, of course
Thx bro u can post here or dm me
Do you know if not functions or just (real) slow?
Do you run the latest AMD driver?
it works fairly ok for a large model, i'm using it on rtx 3060 with 12gb vram along with 32gb ram, its not fast but not dead slow either
thks thats the card i have also so can try. Have amazing weekend
np, this is the quality for this base model

-
Flux Schnell is a distilled 4 step model.
You can find the Flux Schnell diffusion model weights in the link below and the file should go in your: ComfyUI/models/unet/ folder.
https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/flux1-schnell.sft -
download t5xxl_fp8_e4m3fn.safetensors and clip_l.safetensors in your ComfyUI/models/clip/ directory you can find them on:
https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main -
The VAE found in the link below should go in your ComfyUI/models/vae/ folder.
https://huggingface.co/black-forest-labs/FLUX.1-schnell/blob/main/ae.sft
source: https://comfyanonymous.github.io/ComfyUI_examples/flux/
thks
Sorry if this issue happens all the time. I just downloaded the automatic stable diffusion and during its start up in the command prompt, it failed 86% of the way through saying that there was no checkpoint. So I downloaded a checkpoint, but cannot put it in the stable diffusion checkpoints Notepad++ folder due to it being over 2GB. How on earth do I set this up if everything I need is over 2GB? Do I have a fundamental misunderstanding of what to do? (I’m not a tech nerd)
Is there a guide how to run stable diffusion 1.5? It gives me VERY bad results, just like dreamshaper
You have to put the model into the stable-diffusion-webui/models/stable-diffusion folder.
Dont drag and drop it onto the information text file there
Oh ok I’m doing that this time, waiting for results
use a good negative prompt, use quality tags for postive prompt. and the rest comes with upscaling
Now in command prompt it says Error: could not find a version that satisfies the requirement pytorch_lightning==1.7.6
No matching distribution found for PyTorch_lightning==1.7.6
can you show the full cmd text?
how to upscale?
in comfyui its a bit difficult for AMD
is there a special workflow for that?
if you have a 1.5 workflow i would apprieciate
Like idk what I did wrong I followed a guide step by step then did what you just told me so
I feel dumb
You followed a wrong guide it seems. (Downloading as zip isnt the right installation method)
Please follow my install guide for nvidia from the pinned messages
Ill try this, thanks
Lol already on step two, typing cmd in the Ai folder search bar does not do anything
press right click and open with cmd
or copy the directory and type cd and then paste the directory
it works the same
do I right click open with terminal?
yeah anywhere inside the folder
and if it says the directory when the cmd starts up its good
copy pasting the github link gave an error though
PS C:\Ai> git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
git : The term 'git' is not recognized as the name of a cmdlet, function, script file, or operable program. Check the
spelling of the name, or if a path was included, verify that the path is correct and try again.
At line:1 char:1
- git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
-
+ CategoryInfo : ObjectNotFound: (git:String) [], CommandNotFoundException + FullyQualifiedErrorId : CommandNotFoundException
PS C:\Ai>
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
dont use search bar lol
i didn't after that, but once I got the cmd working it's giving me that error when I copy paste
you have to install git
and python 3.10.11
the links are provided
I did python, I didn't see the git link ig my b
Nope it's still not working even after I set up git
and set up python to path
getting the same error
im losing my mind
bro if this is a hint of what comes after step 2 i give up
can you show the error again?
did you installed Git with the default settings?
after reading it again, you cant.
You can only generate a new image wit hthe hair+face but you cant swap an existing head without inpainting it
Like there is noooo way at all? No other techniques?
There are some extensions that detect the face+hair and automatically create a mask for I painting. Only problem, if the hair length will always be the same since the mask dictates the hair length ... Maybe you have a solution for that?
Hello, after installing pytorch 2.3 I have this, what could be a problem?

and if I use the command --skip-torch-cuda-test i get this

Hey, what's your GPU?
nvidia rtx 4070ti
Okay then open up a cmd and type
Pip cache purge
Then delete the venv folder.
And then relaunch the webui-user.bat
seems like it's worked, thanks
And edit the webui-user.bat and add only --xformers
As commandline_args
Don't use skip torch cuda test
I'll try, thanks again
@ornate elk just in case you didnt see it since i didnt quote you
Your meaning Segment Anything ?
Have you tried the extension Inpaint anything?
Maybe that can do it
Cant remember, tried one of them many months ago
The problem is, you cant replace a short hair head with a long hair head. Since the mask will be just as big as the hair.
Not impossible but would require someone with a lot coding experience
To manually make such a script that can do it
No problem
No, Nvidia
That's what SAM is for
Ok, that's weird, usually you get that with amd
I'm using linux btw
Hi.... I am a dumb architect who have no knowledge in coding:
I already habe installed swarmUI and I need to install A1111. How can I use the same models that I have of SwarmUI models folder in freshly extracted "stable-diffusion-webui-1.10.0"?
Oof. And I use windows. I'm also not at my desk, I'm going to have to research this and get back to you. However we've had the error before here, and the solution might be in this channel. Use the search function for the specific error and give me an hour or so. Please
Yes you can edit the webui-user.bat of auto1111 and there add --ckpt-dir "D:\Path\toModels"
--lora-dir "D:...."
Many thanks....I will give a try now
Like this?

It needs do be after the =
From commandline_args
And you have to use your path to the models
My path is just an example

Looks good
ok, thx, I appreciate it
And the loras?....Pardon the annoyance

Thank you.....Its working !!😃
Perfect no problem:)
are you using comfy, auto1111, or webui?
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
okay, read through all the replies in this thread https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/2373

GitHub
When I try to use txt2image the first image is generated normally but when I try to generate the next one it shows "RuntimeError: CUDA out of memory. Tried to allocate 58.00 MiB (GPU 0; 4.00 G...
oh no thats the error I have been having
update: Using a different browser does not, in fact, fix it
Some of the people in the thread are saying add command line args
"--precision full --no-half --lowvram --always-batch-cond-uncond --opt-split-attention"
which I can do, but the other people are saying disable sd refiner, and I don't know what that is or how to disable it. I'll try putting in the command line args now, but I would appreciate help disabling refiner
no, the browser won't. there are command line settings and arguements they discuss
@ornate elk is our Auto1111 expert and might have a solution
im mentioning the browser because CS1o previously (yesterday) helped me with this and swapping from Chrome to Edge worked, for around 12 hours
that sounds sort of like a caching issue then
I also assume it is related to memory in some way, and actually generating the error happens inconsistently, but often after multiple gens, or after swapping models, which is consistent with a memory caching problem
Dont add these args. They won't fix anything
ah ok
What is the uninstalling refiner thing? I don't know what it is or how to uninstall it. Would it possibly help?
Hi, why is that?







I think it happened after I launched Kaspersky antivirus but I'm not sure. I can still run A1111 but it annoys me.
Kaspersky app didn't warn me about anything.
And there is another problem.

Should I delete and reinstall it?
just ignore it - if it helped the one user on that thread that said they did it, something else is wrong on their machine
ok, then I still have the error he has, but neither of the solutions in that thread (command line args, uninstall addon) can help me? Definitely looking for a fix so I can gen again
can you poste your entire commandline interface error log please
sure, let me start it up and recreate the error, will post it shortly
it just means you should not have this enabled:

yea you should install it the right way via git clone
a guide for that is in the pinned messages
yea on that link you find all guides
I think it was because OneDrive.
what about OneDrive?
Just stopped syncing and all my synced files gave error but I only noticed webui first.
Just deleted OneDrive and problem solved. Megamind. Tired of OneDrive.
yes OneDrive cause issues with SD
cs10 this is the message
Windows PowerShell
Copyright (C) Microsoft Corporation. All rights reserved.
Install the latest PowerShell for new features and improvements! https://aka.ms/PSWindows
PS C:> git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
git : The term 'git' is not recognized as the name of a cmdlet, function, script file, or operable program. Check the
spelling of the name, or if a path was included, verify that the path is correct and try again.
At line:1 char:1
- git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
-
+ CategoryInfo : ObjectNotFound: (git:String) [], CommandNotFoundException + FullyQualifiedErrorId : CommandNotFoundException
PS C:>
Update from PowerShell 5.1 to PowerShell 7 for your Windows platforms.
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
you have to run git clone in a cmd not in a powershell
thats the issue
@ornate elk can i run Flux on ROCM?

I right click on the AI folder and the only option I have is “open with terminal”. Is this not what I’m supposed to click
If it’s not idk how to open a cmd
Dont right click the ai folder
Go into the ai folder
Then on the explorer bar where the path says C:\ai
You click in that bar. Then just type cmd and hit enter
Should work yes
But I didnt tested it
ill try it out imma reinstall SD since i installed too many stuff on it
i mean comfyui
I've got a DevOps question and it's stumped me.
The ComfyUI AI-Dock image has sample init scripts for HF token passing (https://github.com/ai-dock/comfyui/blob/main/config/provisioning/sd3.sh). I want to extend that functionality to the A1111 script (https://github.com/ai-dock/stable-diffusion-webui/), and wouldn't even know how to start doing that.
Unfortunately, when I contacted Vast.ai support, the person I spoke to wasn't familiar with SD-web-ui's init script structure.
Are you on Linux or windows with WSL/Zluda?
Windiws ZLUDA
Does stable diffusion save the prompts I’ve used before in the past? I’ve noticed it saves my image generations so I was wondering if it can save my past prompts too.
PLZ PING
