#🤝|tech-support
1 messages · Page 73 of 1
3.10.11 64bit
is python even available in 32 bit these days? lol
yea 😮
damn
when I try to use the text encoder clips on SD3 model it gives out of memory error... anybody have experienced this ?
What's your gpu?
welcome back cs n_n lmk when you got the time to help me out ❤️
what sd3 model did you tried?
the medium with 4gb one... it's on comfyui btw
it works if I don't use the triple clip thing
if I use --lowvram it proceeds but the images are generated black(with the triple clip that is)
heres a random question, just for curiosity's sake
can you download other sampling methods? 🤔
Try the 5gb model it has the clips included
yes like this https://github.com/redhottensors/ComfyUI-ODE
it works alone but I wanted to use the clips separated.. and then it's not gonna have all the clips I think?
it's strange that it's not working
which text encoder do you have? the t5- fp8 or the fp16 one?
i think sd3 is not worth it and not worth the time investment in it as it is now
wait for community release for it from civtai
meanwhile models for xl like the luma is good enough
or fooocus
I tried only the clip_g.safetensors and
clip_l.safetensors ones.. I don't have storage for t5
now I tried a dual instead of a triple with pure clip_g and it proceeded but the generation continue to come out all black
what do i do if my dev branch a1111 hangs at 95% in image generationand doesnt let me apply settings as its stuck at ‚loading model weights’ or smth like that
i think you need all 3

- sd3 4gb model
ive changed no settings its allways worked now suddenly this what is wrong with it? https://gyazo.com/b8ccce929bcda840d66fb28b903a111c

what are your txt2img settings?
whats your gpu?
3060 ti

also it dosent seem to change even if i change the width and height
nothign has changed besides like a windows update
also i did start using sdxl last week
idk if that is messing it up
whats in your webui-user.bat?

ok i dont usally do upsacles tho
okay den disable hires fix
and try a normal gen
in your screenshot its enabled xD
with wrong settings
so maybe thats your issue
oo just having it dropped down turns it on
your --medvram- thing worked
was it allways typed wrong and the program diddent care till now?
thank you for the helps
yea because your on an older webui version (in the new version it has checkboxes)
best would be to use or update to the latest auto1111 version if you dont rely on old extensions
--medvram is for every model type and --medvram-sdxl is only for sdxl. your gpu (8gb) only needs medvram for sdxl
Anyone ever seen an extension called "stable-diffusion-webui-simplefix" ? It appears to be malware and I'm having trouble finding anything about it.
I managed to fit all of them and it worked, thank you!!
nice, np 🙂
What's the proper syntax to make a venv which i call "comfyui" but creates a venv named folder in comfy's root folder?

here is my code for my custom Comfyui Launch bat.
https://github.com/CS1o/Stable-Diffusion-Info/blob/main/Resources/Start-ComfyUI.bat
it creates a venv and installs the requirements in there too. also it installs torch+cu118 (you can change it to your liking)
but i still use sd1.5 should i also put normal medvram?
nope, --medvram slows 1.5 down, so you wont need that
o ok
Thanks! Knew there was a step i forgot about. This shit xD
venv\Scripts\activate Just activate that shit, and i'm in it's venv where only shit for it appears :P
no problem ^^ yea always some little steps that are missing
never seen it, very strange
Yep lol. Now to copy pasta that one to all my A.I stuffs so they don't affect eachother :P
one result on A1111 issues, and talking to someone else who has been affected by it. Not certain it comes from A1111, might be from another malware he has.
i noticed this message yesterday, but dont know if its related:
#💬|general-chat message
yes that one
and the github discussion is this:
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/15931
we have to keep an eye open
yes, there was a discussion on reddit over if using docker would help against malware, this guy has everything in containers, so not quite.
ah well, guess thats answers it xD
whats the default ENSD?
0 (disabled)
@ornate elk For a tool that only has "setup.py" and "run_gradio.py", what changes should it have for the run part? 
https://github.com/Stability-AI/stable-audio-tools This is what it's for
GitHub
Generative models for conditional audio generation - Stability-AI/stable-audio-tools
you want that also in a venv?
Use this: (it has a venv)
https://github.com/diontimmer/audio-diffusion-gradio?tab=readme-ov-file
its made for stable audio tools
I want every A.I tool i have in a venv like this for conveniency, just some i need to alter as they are more just setup.py and gradio run ones :P
Ah, so the one i linked to is jsut the barebones, and the one you linked to is the more "here's all you need" fork?
loading the clips incorrectly would give you black image
the one i linked is more like auto1111, and the one you linked is the source like the first sd code (more cli etc)
ah ok, thanks :)
@fallen quail I'm new to comfy, so I could have done something wrong, but I tried installing your custom samplers but got an error on MPS during execution: Cannot convert a MPS Tensor to float64 dtype as the MPS framework doesn't support float64. Please use float32 instead. Is this a known issue? I can give you the full traceback if it would be helpful.
@ornate elk checked the one you sent, it's almost a year outdated :S
Uhhhhh. That's something that we'll have to fix because torchdiffeq prefers to work in double precision floats. Could you file an issue so we don't lose track of it?
he made changes last week, but yea the rest is 8 months back :/
but it works
For some reason, I'm not seeing the Issues tab on your repo. Just Code and then Pull Requests.
Fuck. Uhh, I don't own the repo, I will write it down somewhere
Nice. So as i got these, launched it though it's bat file, but it complains it has no models, even if they are in the models folder

you need to download the .ckpt version of the model
i tried it too but the safetensor wont worked
Ah shit. The insecure one 
yea xD
Though, is the diontimmer's fork as "unsencored" as the one i linked to? Or does sencoredness depend on the model itself? :P
it depends on the model
Hi. I am using stable diffusion webui with chrome, recetly it suddenly stopped working - its saying that I dont have enough vram. The model has about 10 GB, my vram is 16 GB. I tried reinstalling it, all together with python, torch, git and cuda but its all the same. I cant even load 4 GB version of models, it just says I dont have enough vram. I am honestly lost at what is the problem. Tried reinstalling drivers. Deleting possibly corrupted files, but as I said I even tried fresh automatic install
The error is
AttributeError: 'NoneType' object has no attribute 'lowvram'
hey, whats your GPU? whats the model? and whats your webui version
its 4080, the model is 10GB version of newest stable diffusion v3 (tried redownloading), webui version is 1.9.4, python 3.10.6, torch 2.1.2+cu121
Gotchu. So for this, do i just install cuda toolkit, and rerun? Or as it's in a venv, i need to add cuda toolkit to that?
"warning: User provided device_type of 'cuda', but CUDA is not available. Disabling
warnings.warn("
Just tried medium version - 4GB, but with no change
SD3 wont work in auto1111 right now
we all wait for an update ^^
ohhh
thank you, ill try the other ones then
no problem 👍
i dont think you need cuda for it
should be installed via torch in the venv
I got around to testing out an LCM model on ComfyUI with Zluda just now
ah nice
awesome!
Now to look for some LCM workflows I could try out


Got cuda working, sorry i didn't edit, forgot to
https://github.com/diontimmer/audio-diffusion-gradio/issues/2#issuecomment-2151127309

GitHub
I put new stable audio model with its json file to models directory - not recognized. I have only cpu as choice in "device", despite having 3090 The password thing ... not a fan. Is this ...
are you still here? tried stable diffusion webui with other stuff that worked before and I got the same result. I tired AbsoluteReality and EpicRealism_Natural, both about 2GB for my 16GB card and it still says "low vram"
idk why it keeps giving me this error

how to add --lowvram to ComfyUI on Pinokio?
and i can't run foocus even with 16 gb vram
idk what happened but it was running all good then everything starts crashing
all i found was this, but cant find it in Pinokio https://github.com/comfyanonymous/ComfyUI/discussions/3158

GitHub
This has been driving me crazy trying to figure it out . on the front page it says "Use --preview-method auto to enable previews." so I spent ages online looking how/where I enter this co...

AI Browser
i cant switch checkpoints for some reason
When I generate an image it gets stuck at 99% but the command prompt window says “total progress 100%”
After waiting a little bit, the image is finally complete but the quality is really bad like 360p for example. It’s pretty much the same quality as if it was still being generated. I can’t really send the picture here cuz I feel it’s a tiny bit on the NSFW side but not extreme
i have this too
OutOfMemoryError: CUDA out of memory. Tried to allocate 1.01 GiB. GPU 0 has a total capacty of 16.00 GiB of which 9.74 GiB is free. Of the allocated memory 4.75 GiB is allocated by PyTorch, and 331.25 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
check yr drivers are up to date?
yeah all updated
reinstalled everything today
did not had this issue but it started randomly
and sometimes i get no errors
i should not get this error at all with a 16 gb gpu
maybe the full log will help someone help you better
Sorry went AWOL and theres far too many messages to read lolol, did you figure out the issue? I think you said you were using an external ssd/hd to hold the models? If so what is the read and write speed of it? That would 100% cause your astronomically long model load times...
You're the second person in 24 hours to post the exact same issue. The person I just responded to was trying to troubleshoot theirs last night. I have no clue what it is but I feel for you guys
it was not giving issue for long time
even on my 4 gb laptop with med vram
it started randomly now i can't use AI to make game art assets lol
What GPU? 12GB VRAM I assume?
back to manually doing things 😦
Dur I cant read 16GB right there. Yeah something isn't right
on desktop its a 4060 ti
and laptop its 3060
i had no issue for long time on laptop but it just started randomly last week
Is this the first install you've done on the desktop?
issue started last week bascially
no i did before too
So it didn't just start after a new install? You just reinstalled to try to fix it?
no i did a fresh install of everything on desktop
and doing that on laptop too
even reinstalled python and git
So you did the manual install steps as opposed to the quick install? (just ruling out the install method as a cause here)
but as far i know python or git should not cause the problems
i followed his guide
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Installation-Guides#nvidia-automatic1111-webui-stable-diffusion-webui
GitHub
Stable Diffusion Knowledge Base (Setups, Basics, Guides and more) - CS1o/Stable-Diffusion-Info
although i can do it manually
but takes long time
Which fork did you use (A1111, Fooocus, etc...)
Hmm, well if you're willing you might try to use this guide (complete quick install) and see if it works. It's what I downloaded a few weeks ago on 4070 and worked just fine. https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
Again out of curiosity what Nvidia driver and CUDA version do you have? You can quickly see by typing " nvidia-smi " into command prompt
If you do try another install method though I would probably purge any other installs prior just in case it causes issues. You can copy and save model and lora folders before if you have any
also for some reason it keeps reducing my c drive space
i had like 70 gigs free on my OS c drive
now its down to 60
Depending on what you select when running it may just be from it downloading needed models in the background. I have no clue but yeah it eats storage for breakfast
That's rough... I'm already 600gb down on an ssd I got 2 weeks ago. Long gone are the days when 64gb was all you'd need for a lifetime 😔
so i updated to the new version of automatic 1111 and i cannot find the directory in the settings where my lora and checkpoints go to. Where is the setting?
Hi, I'm hoping I can get some help with ComfyUI, specifically trying to upscale the latent image for a second pass of ksampler. I've watched a few videos but I can't seem to get ANYWHERE close to what is expected.
I'm trying to basically run through my first KSampler at a lower res say 360x640, which does give decent results, then upscale the latent image to a higher resolution to run through another ksampler with less steps since it's a higher resolution in order to add more detail.
My problem is that I do a preview image of each step and the first ksampler comes out fine, I then upscale the latent image then preview that which then gives me a MUCH blurrier version of the first image instead of retaining the same or better quality, then I preview the output of the second ksampler image and I get a COMPLETELY DIFFERENT image of which every single time is completely malformed. I even tried upscaling the actual image of the first ksampler output then encoding it back to latent and running that through the second ksampler but I still get absolutely awful results.
basically I'm trying to do a HiRes Fix but in comfyui
@old sky do you as the developer have any suggestions I could try? Sorry if I am not supposed to ping.
I always get crap results
like if I do a 15 step first ksampler then on the second sampler I do a 1 step shouldn't I get a pretty similar image to the first? Cause I actually just get a crap load of noisy garbage that looks nothing like the original
do more than 1 step
Hey, I have a question regarding images from social media, are these generated with SD or another image generator? https://www.tiktok.com/@societiesr

TikTok
@societiesr 83.8k Followers, 38 Following, 2.7m Likes - Watch awesome short videos created by Societies-r
Models should be at C:\Users\Name\Desktop\ sd.webui\webui\models\Stable-diffusion and lora's are same path but "lora" as the final path instead of Stable-diffusion Disregard I'm an idiot and that was not at all what you were asking LMFAOOO
Does anyone know if you actually need this CUDA stuff installed to use xformers? "CUDA Runtime"/"CUDA Development"
thank you
I installed them last year and still ahve them
this prompt (tongue out, tongue:2.0) is 2.0 to everything inside the backet right? or no?
Feedback: Please make support for Stable Artisan to be universally available in Stable Assistant, there is a Javascript discord error some of us receive when having to log in the current way that prevents us from accessing Stable Artisan on Discord because it continually does a failed login loop. I've tried everything, and now I will have to drop my subscription because I can't access Stable Artisan specifically on Discord.
is this normal?
i only changed live previews to be jpeg

Nope you don't need cuda installed for xformers
In Auto1111?
Can you show the full cmd log?
Can you show the txt2img settings when you get that error?
Make sure your nvidia driver is updated.
If you changed your gpu in the recent time then you need a complete driver reinstall.
Models/stable-diffusion and models/lora
You can't change these paths in settings
But you can define other folders with the launch args:
--ckpt-dir "D:\Path\To\Models"
--lora-dir "E:\Example\Path\Loras"
Everything in the ()
Can be normal yes
Is ist sdxl or 1.5 model?
What's in your webui-user.bat?
how do i check?
it could also be that i'm using a laptop perhaps cuz it was working again a bit later
Check the model file size in models/stable-diffusion
And for the webui-user.bat just right click and edit it


oh i thought u meant there was a file with "1.5" in the name
what about this?
Thats the first 1.5 model made by stability ai
it seems most of my models are 2-3 GB's
These are based on 1.5 then
No problem at all ^^

is this fine?
What's your gpu?
uhh.. does nvidia rtx 3060 laptop help?
i'm not the biggest tech gal xd
like in terms of specs and shit
Okay, yea the settings are correct for that gpu
Thats an good idea 🙂 more power for SD
But for your issue from above, recheck if it happens only with the sdxl model selected or any other model too
A 6gb vram gpu has a hard time with sdxl and pony (which is based on sdxl)
it happened with a model only 2 gb's
earlier today
which is when i came to the server
Ah okay. Then make sure you don't run an other heavy programms in the background, like games or Wallpaper engine.
Whitelist the webui in any browser adblocker
yeah i don't normally do PC games and i don't have wallpaper engine for now
i have the ad blocker extention for chrome tho
also another question, i tried generating some images earlier today and when i tried some negative prompts like ||bare skin||, ||uncensored breasts|| etc. it didn't actually to what i asked sometimes which means it had the opposite of what i wanted in the pics
shit
Also did you used upscaling, hiresfix or any extension while getting that issue?
i pressed enter on accident
yeah i tried hiresfix sometimes
If you use that make sure to always set hires steps to 10
If not it can error out
ok
i fixed the message now
It depends on the model. Dont use the base sdxl or 1.5 model as they are not trained for it
But other models do fine
i used "yesmix"
Okay that should do it
it still had the opposite of what i wanted most of the time tho


You can also add sfw into positive prompt ^^
true
one weird thing that also happened is when generating images it somehow brought 2 girls into a pic when i believe i only used either 1 character lora or "1girl" so idk where the other one came from but it actually looked sick as in the end. so basically i got lucky but i would've liked for results to appear as often and accurate as the random pic i got
That can happen if the resolution is set a lot higher than what to model got trained on.
1.5 models are trained on 512x512
So doing a 1024x1024 can cause duplicates and deformations.
Thats why hires fix is needed for 1.5 to gen like 512x768 and upscale by 2
oh and that reminds me, i tried using 2 character loras to get them into one image but most of the time it would only add 1 character and not the other. i was using the "BREAK" method thingy and the regional prompter from this guide https://civitai.com/models/339604?modelVersionId=403892

How to Generate Multiple Different Characters, Mix Characters, and/or Minimize Color Contamination | Regional Prompt, Adetailer, and Inpaint | My W...
ah ok cuz i did 1280x720
Yea that likely caused that behaviour
this?

wait lemme double check
ur saying if the dimentions are too high on a 1.5 model then it can cause 2 characters to appear for example?
cuz i had a bit of a brainfart and thought u were referring to this 😅
Yes
alright thanks
also do u possibly have a solution for this?
For that I would use the tiled diffusion extension which has regional prompt control

GitHub
Tiled Diffusion, MultiDiffusion, Mixture of Diffusers, and optimized VAE - shiimizu/ComfyUI-TiledDiffusion
just looking at these sample pictures it seems very complicated
nvm i assume u mean this

Yes that one

guys i need help with a model and a lora don't showing in the UI aftere refresh and restart it. Did i do something wrong??
whats the models file size? or whats the model name
is every region supposed to be 1 character each? cuz i generated an image with 2 regions and both sides had 2 of the same character doing the same thing and it seems the background has been split in half just like the red and yellow boxes

region 1 and region 2 were both 2 different character loras
https://civitai.com/models/377060/retro-fantasy-style
and the relative model suggested anything else v4

First i just wanted to make the Faceless warrior from Manowar. But i made it into a style inspired by Art from Frank Frazetta and Luis Royo. Trigge...
Hi, I am facing an issue when I try to change a model, it returns this error:
attributeerror 'nonetype' object has no attribute 'lowvram'
I saw other people mention that here before but it seemed to me that the solution is GPU specific. My GPU is rtx 2080 super and my args are --listen --medvram --no-half-vae
thats a lora not a model
it goes into models/lora folder
add --xformers and change --medvram to --medvram-sdxl
then try an other model
you need to make a region for the background, and 2 other foreground regions 1 for each character
ah ok
I've put it in the lora folder and the anything else model in the modello folder but, Nothing. I'll send you some screenshot
still the same :(
is comfyui better then a1111 or and is it also deprecated like forge?
whats the model you try?
better if you have a hand on nodes
None of the models work, it's stuck on sdxl turbo if it matters
how much RAM do you have?
is it also possible to make 2 or more characters interact with each other? like lets say i would want one character to place their hand on the other character's shoulder or something else that's more advanced? if it's possible then i'm not sure what i should type as a prompt and in which box
yea its possible by overlapping the zones
so like this?

ah ok one sec

so what do i type in region prompt 1 and 2?
just any example is fine
i would assume in both region prompts i have 1 character lora each at the start?
you need 3 regions
1 for background
1 for character 1
1 for character 2
ah shit yes my bad
and in the character prompts just add the loras and describe the char
describe it as in looks and what it should do?
yep
ok
i should probably mention that sometimes when i describe a character it tends to have some bugs like extra legs for example even tho i've added things like "deformed" "poorly drawn hands" "mutated fingers" etc. in negative prompt
yea that can happen sometimes
is there a method to be more likely to avoid it?
more negative tags, other resolutions, using sdxl or pony models
ok
and when using hires fix lowering the denois can help too
denoising strength?
i generated an image with 3 regions but both the characters look like twins when it's 2 different loras
16, I managed to fix the issue by deleting the venv folder. But now it gives me 1.5s/it :(
make sure you always launch the webui-user.bat and not the webui.bat
and if your using sdxl with an 8gb gpu, thats pretty normal speed
nope, 1.5 dreamshaper
args or screenshot of the webui?
both
what would i have to type in a region prompt to get one character interacting with the other?
With that I now get ~2it/s is that normal?


you have batch size on 4
thats slows down because it generates the images at the same time and using more vram
Images began to be generated for a long time. What could this be related to? 3070ti + 32 GB ram
with 1 I get ~4.8it/s. Would you consider that normal for 8GB VRAM RTX 2080 super, 16GB ddr4 RAM?
make sure you close every other programm like games or wallpaper engine etc
is your webui updated ?
check the version at the bottom
@ornate elk
any interaction, like touching, kissing, hugging etc
oh i meant like only one character interacting. for example lets say one of them is pregnant and the other character rubs or hugs the belly etc.
then only prompt the interaction for one character, like hugs.. or waves etc
mostly the interaction will come automaticly when the regions overlapping
so what could i type for something like this? (this is what i meant by more advanced btw since it's only one character interacting)
help
more information needed
long time? how long?,
what model is used?
what settings are úsed?
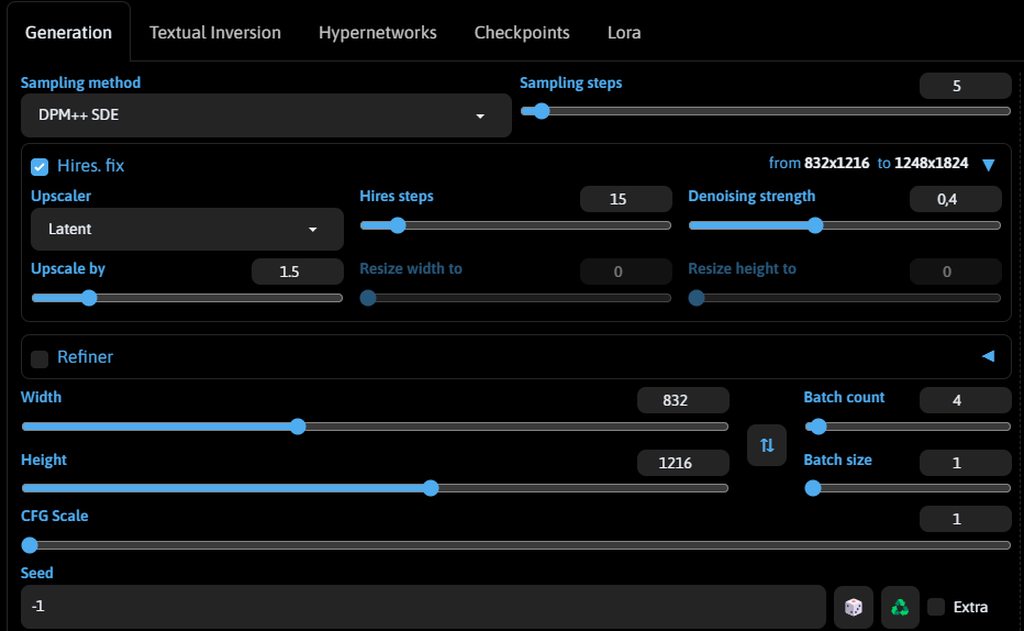
An 832x1216 image with Hires has been generated for 5 minutes already. fix that is, the final image is 1248x1824
Model - realvisxlV40_v40LightningBakedvae
The settings are as follows: Sampling steps - 5
Sampling method DPM ++SDE
CFG - 1
It took me about 7 minutes to generate one image
i'm only getting 1 character in the image now. here are my prompts and settings to give u an idea



SDE samplers can take double the time then non SDE samplers, so try DPM++ 2M or Euler a.
Also when using Hires fix, set the hires steps to 10
should i maybe not have posted this cuz it's too lewd?
forgot about this btw

nah its fine
but i cant help much with difficult positions
its mostly more luck
you can also try/use the regional prompter extension, but i find it a bit difficult to use
Milking this model requires exactly such settings to create a realistic image. It used to take less time
hello there, i started using stable diffusion about a month ago with automatic1111 but for some reason suddenly it was giving me "cuda out of memory" error. Even after fixing that error, a1111 was still running really slow, like 30 mins per image. Then i installed forge UI which is crazy fast but i am facing troubles in img2img. Even at low denoising strength it is distorting the body and instead of upscaling the image loses detail and quality. I am using rtx 2060 6gb vram graphics card. Can anyone help me fix this?
hey, i can help you fix auto1111
you can screenshot them, maybe there is some wrong setting there
or try a restart
thank you!!!...plz tell me what screenshots i need to provide...
your content of the webui-user.bat
and your txt2img settings when getting a slow image.
looks normal, whats your gpu again?
@ornate elk yes its a new install of gpu drivers and sd A111
where can i find the full logs of errors?
ok
how do u change to dark theme? i've always wondered that
3070ti
Oh... somewhere in the settings, I'm sorry, I don't remember anymore, I switched over a long time ago...
add --theme dark
to the webui-user.bat
thx
and you have --xformers --medvram-sdxl --no-half-vae in your webui-user.bat?
my errors started appearing after this error btw
J:\AI Apps\SDA111\stable-diffusion-webui\venv\lib\site-packages\huggingface_hub\file_download.py:1132: FutureWarning: resume_download is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use force_download=True.
warnings.warn(
@ornate elk
OutOfMemoryError: CUDA out of memory. Tried to allocate 1.01 GiB. GPU 0 has a total capacty of 16.00 GiB of which 9.23 GiB is free. Of the allocated memory 5.50 GiB is allocated by PyTorch, and 81.35 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Time taken: 1 min. 10.6 sec.
A: 6.81 GB, R: 7.09 GB, Sys: 8.3/15.9961 GB (51.7%
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--autolaunch --xformers --medvram-sdxl --no-half-vae
call webui.bat
what are you trying to do?
it seems like your using a tiling extension in img2img or seomthing
okay looks good
yes i use that always it did not give errors before
creating seamless tiles from my images
can you show the whole img2img settings then?
I started having these problems after installing ComfyUI (not immediately, after some time ...)
you can try to delete your venv folder and relaunch the webui-user.bat
that can remove unwantedd changes



you need to remove --always-batch-cond uncond and instead add --xformers --no-half-vae
then relaunch the webui-user.bat
delete the whole venv folder and relaunch the webui-user.bat
how come some of the words in the prompts are in brackets?
Sorry, but what is this folder responsible for?
nothing fancy just making some textures from images
thats for getting more attention to the word
can be used like (((word))) or (word:1.3)
it stores librarys and stuff from extensions. also the whole torch and xformers stuff.
when launching the webui-user.bat it will get recreated automaticly
okay, i will try that....but can u help me with forge tho? i would really like to use forge but the img2img is generating weird bodies even in low denoising strength..any fix for that?
I got it, I'll try it now, thanks
Forge is deprecated for normal users. with the next update it will break. so i dont recommend using it
but you can use img2img in auto1111
no clue what could be wrong here :/
i got no clue either
By the way, a question about SD3, has the automatic111 update been released that supports these models?
and i feel bad for being a computer techniciain and i can't fix it sigh
its in development but not stable release yet
Is there an approximate time when to expect? At least approximate dates
nope, but my guess is a week
Understood, thanks. Will this be notified in #📣|announcements and #1010934719455707218 ?)
nope
i tried ((hand on shoulder)), just as an example and it didn't work. here's my regions

i read through that link u sent btw
so far it seems to be the interaction that doesn't wanna work
@ornate elk i was getting cuda out of memory errors beacuse of cuda fallback system on new nvidia drivers which enables the gpu to use my pc's ram as extra vram...according to some reddit post this causes massive memory leak and was the reason of slow genaration..they recomended turning it off...but when i turn it off it gets even worse, u got any opinions on this?
Dont turn that off!
Like you said it makes it worse
btw, this kinda helped to reduce the genaration speed a little..tnx...
You need the tiled diffusion extension if your going for higher resolutions
It has an Option called Tiled VAE
Thats what you need for higher resolutions or upscaling
And its normal that it takes longer for your gpu if your using sdxl
For sdxl models you also need to increase your windows pagefile if you only have 16gb RAM
i get the cuda out of memory with 16 gb gpu
@ornate elk
OutOfMemoryError: CUDA out of memory. Tried to allocate 1024.00 MiB. GPU 0 has a total capacty of 16.00 GiB of which 8.21 GiB is free. Of the allocated memory 5.03 GiB is allocated by PyTorch, and 1.56 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Time taken: 2 min. 28.0 sec.
A: 6.79 GB, R: 7.12 GB, Sys: 8.3/15.9961 GB (52.0%)
ohhh! i see....i will install that extension then..tnx for all these valueable tips man!!!!
how do i do that? the windows pagefile thing....
It didn't help
95% processing takes a long time (1 image) Without increasing the quality. The standard 832.
I'm sorry, it was the first generation, I tried the second one - everything is OK, now I will try to zoom in
No problem.
Its under extensions tab, available, load from, then search for Tiled.
Then only enabled tiled vae and leave its settings on default.
@thorny dragon for pagefile look here:
#🤝|tech-support message
Make sure its enabled for C drive and disabled for any other drive.
Then set the min to 16000
And Max to 24000
And make sure you have 15gb free space on C
Here where i put the models, is it ok??


As you can see it doesn't show them


your webui version is to old
and remove this file from the models/stable-diffusion folder

ahahah damn, can i update the UI from the UI itself?
not with the ui. you have to do some more steps.
first in the webui click on the extensions tabs and click "check for updates" then let it load.
after that.
close the whole webui and cmd.
right click to edit the webui-user.bat
in an emtpy row you have to add Git pull
then at the line Commandline_ARGs= you add --xformers --no-half-vae
if it isnt there already.
Then save the file.
After that open up a cmd and type
Pip cache purge
Then delete the venv folder.
And finally launch the webui-user.bat

Then it should download the updated files
ok i've done, i'm not sure of the next steps, i don't understand well

looks good, dont forget to save
whats your gpu btw?
if it has 6gb vram or less you need to add --medvram
if it has 8-11gb vram you ned to add --medvram-sdxl

how much dedicated vram? scroll down a bit to check

just next to xformers?
yep, like
--xformers --medvram --no-half-vae

Then the next step is to Open up a cmd.
click on the windows symbol and type cmd
then launch the cmd.
in the cmd type
pip cache purge and then press enter.
that will remove old temp files from the first webui install
ok
done

and then delete the venv folder
that folder will be recreated at the next launch with the new files
this one?

yep
ok, then i restart?
yes, now launch the webui-user.bat
still the same issue, it didn't show the lora and the model
make sure the lora is only in models/lora
and not in model/stable-diffusion
and then selecte and 1.5 based model
and delete the 1.4 model from your models/stable-diffsuion folder (its really old and bad)
here the models, i need to delete sd-v1-4?

yep
ok, than as you can see should be all ok, right?

okay and what model is selectet at the top left?
in txt2img
still mantein the old setting

not showing the one i need and showing the deleted one
the lora should be on the lora tab
also click the blue refresh button
then the 1.4 should be gone
i've clicked multiple times but nothing happens and the lora tab is empty
and extensions installed? that could mess with loras?
can you try download an other lora to test if the lora is the problem?
yeah, now i try
for example this one:
https://civitai.com/models/58390/detail-tweaker-lora-lora
It's been like this for a while now, it doesn't give me any errors but it doesn't do anything. Does anyone have an idea, or do they just need more time?

what even is this? 😄
what tool are you trying to run
Srry XD Im trying SD with Zluda in windows with AMD, text to image
ohh, so your trying SD Next i asume
whats your GPU?
Yes


RX6600XT

then i would recommend not trying it with SD Next and instead following my Automatic1111 AMD Zluda Guide.
im on AMD too and ive made many guides.
you can find them all here and feel free to ask if any step isnt clear.
https://github.com/CS1o/Stable-Diffusion-Info/wiki/Installation-Guides

ok so i'm moving back to a1111 since forge is apparently going to shit the bed
it told me to update xformers, so i did, and now it's saying this shit

hey whats your GPU?
I can try, which one do you recommend?
RTX 3070, i was previously using a 1070 though and moved to forge when i got the 3070, so i never used the 3070 with a1111
the Automatic1111 with ZLUDA guide
it covers everything you need. i helped like 3-4 guys with a 6600xt getting it to run ^^
so it should work for you
okay, whats in your webui-user.bat?
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS= --reinstall-xformers --xformers
call webui.bat
it said xformers was out of date so i put that arg in there
my A1111 is also up to date on the stable release, i did a git pull before anything else
okay add Git Pull into the second line thats empty
then remove --reinstall-xformers
then add --medvram-sdxl --no-half-vae to the --xformers
then save.
Now install Python 3.10.11 (because 3.10.7 has some bugs)
https://www.python.org/downloads/release/python-31011/
after that delete the venv folder
then relaunch the webuio-user.bat
I tried it but from what I see is that you have a few more steps added than another one that tried to install. I have tried several times to install it, is there anything you would recommend I clean?
man why did the forge dev have to ruin it, this is so complicated 
you can remove the sdnext (automatic) folder and in a cmd run
pip cache purge
then your ready
I'll do that, thank you very much for the help!!
and make sure your AMD driver is updated
and for any question feel free to ask
i'm just going to keep using the current version of forge until there is a genuine reason to move on
why not fixing your auto1111 install?
most stuff from forge will get into the next auto1111 releases, thats why he forge gets back to experimental state, to improve auto1111
for example SD3 will not be usable with Forge
someone said the dev branch of a1111 has the same performance improvements but the comments on the forge announcement say otherwise
you have a 3070, thats work great with auto1111 preformance wise
until last year i used a GTX1080 and had no issues even with SDXL
nothing my man
Isn't torchmcubes gotten from pip? As i'm missing that module for a node
i feel like maybe i should just completely re-install a1111 because this install is from like 2022 and i've only kept it up to date using git pull
would you raccomand a fresh install?
yep, that could solve it.
because your install was really old
follow the guide from the pinned messages
so, there's something i can keep?
you can keep your models and loras
and outputs
i don't remember if i installed python using bucket or scoop or whatever it's called
yea then start fresh ^^ youll find an easy guide for that in the pinned messages of this channel (it will take like 10 mins max)
ok, i change folder for those and then i delete the webUi1111 folder and start from 0?
yep
can you link me a new guide please?
i don't remember where i installed python 3.10.7, can't find it in the start menu, and it isn't in the default install location for 3.10.11
guys any idea why my images are taking 5 minutes to generate? i have a rtx 4060
then uninstall via system settings /apps
or open up a cmd and type
where python to get its path
hey, whats in your webui-user.bat?
ah, that's where it is

im sorry but how can i find whats in there?
right click and edit it
i don't remember why i ever installed python using scoop
this one?
the rxt4060 has 8gb vram right?
yep
i'm just going to delete the whole scoop folder, surely nothing bad will happen
if i did install it for a reason, it's probably irrelevant now since i can't remember it

put med vram
at the line commandline_args=
you need to add:
--xformers --medvram-sdxl --no-half-vae
then save and relaunch the webui-user.bat
you need that sdxl command to run sdxl models?
no but for 8gb vram cards --medvram-sdxl is better than --medvram
because --medvram slows down 1.5 models
yea probably ^^
is the venv folder on my a1111 install supposed to be 10 GB
hey i got a new problem now
😔

photos are turning out like this
what's your cfg and steps
whats the model your trying?
its a model i got from civitai
yea check if its made for sdxl or 1.5
one time i accidentally cranked the cfg to 30 and didn't notice and i was like "wtf why is everything turning out like crap"
and yea make sure cfg is set to 7
it says 1.5
okay can you show your txt2img settings, like steps, resolution etc?
it honestly really would have helped to have the image with the metadata

like when it is generating it is fine, looks normal, but when its at the end with the final result it fucks it up
make sure you also use an 1.5 vae
or when its sdxl based you need to use an sdxl vae

whats bis?
big
oh it was around 6gb
Then its mostly an sdxl model
That needs an sdxl vae
can you send me a link for one?
Like this VAE here:
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/tree/main

i don't think i've personally encountered a checkpoint that didn't have a baked vae
i use mostly pony derivatives though
thanks man it worked
is it normal? or do i need to write something special in the command line?

what file contains the settings again? i want to move them from my old install to my new one
You need to edit the webui-user.bat like stated in my guide
I wouldn't do that. But its ui-config.json and config.json
someone help me even after having 16 gb vram it says out of memory
do you think i can copy and paste my extensions at least?
You can but if they are that old I would recommend to just install them fresh
They dont contain much data anyway
i launched it once and it worked, closed it, launched it again, and now it's doing this


or batch size?
batch count
batch size will slow down the process
did you moved an extension over? or the configs?
i did move the extensions, but i tried deleting them and it's still doing this
you then need to delete the venv folder
because the extensions can break the venv
most likely what happened here
is there like a specific part of the venv i can delete to fix it? i have really slow internet
dont worry, the files got cached at the first download so it wont download big stuff again
there isnt a specific part, as the extensions could mess up any folder in there
i think it most likely messed up because i copied my extensions from forge and forgot to exclude forge couple
ah well xD
i'll try copying them over again without it and if it breaks again i'll just reinstall them
hey i am unable to use sdxl and also it is giving me cuda out of memory can you help 😅
but i got latest driver and everything for the 16 gb 4060 ti
using A111
whats in your webui-user.bat?
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --medvram-sdxl --no-half-vae
call webui.bat
i did the one without the medram
same problem
forge has specific modified extensions that wont work in auto1111 because they were made for auto1111 and modified for forge xD
example is tiled diffusion and controlnet (please dont copy them)
okay looks good, what yre your settings
no txt2img settings, like resolution steps etc

none
okay then please try txt2img first

gave me connection timed out and press any button to continue
was there something happened with some update
everything was working just fine before
Nope, are you on the latest Version ?
Make sure any other programms are closed, like games or Wallpaper engine.
Yea something isnt right
We had some people with the same issue two days ago. They fixed it with a complete nvidia driver reinstall
You can also try to delete the venv folder
ok
i did a fresh install yesterday including drivers
sometimes it works but most of the time it goes cuda out of memory
what is the sechedule type dropdown for?
just did that still cuda out of memory
this is comical
it took 6 minutes to spit out the image

i am using a RTX 3070 with these commandline args
--xformers --no-half-vae --medvram-sdxl
what was it doing?
it took like 2 minutes just to start the hires steps
forge does the same thing in way less than a minute
ah thank you.
forge might work better for your configuration then. use that.
I tried offering help but you argued. now i'm just annoyed
i'm just confused and a little frustrated because i've been told to move back to A1111 and i just spent the last hour doing that
why can't i use sdxl on my automatic a111?
it seems i can make 512x512 images fine but not 1024
Hoi, any idea why comfy manager just stopped working after i updated it?

how do i switch to the dev branch of A1111, and can i switch back to the normal one?
git switch dev
git switch master
hayo, bois!
I have some serius trouble using A1111 AnimateDiff.
Whenever i try to use it, i'm welcomed by this error

and i seem to be unable to fix it.
I tried on my setup, as well on a new fresh install.
no diffrence.
Now, clearly, i'm doing something wrong. but i do not know what
Hey, what's in Your webui-user.bat?
And what's your gpu?
3070ti
Thats strange

also i can't load any sdxl models
and that's my standard one

before in my laptop with 4 gb ram everything ran smooth even sdxl
Ah okay. At the line commandline_args=
You need to add
--xformers --medvram-sdxl --no-half-vae
Then at AnimateDiff set the batch size to 8 or 4
Lemme see, one sec
How much RAM do you have?
RAM, sdxl needs a lot to load
it sucks that forge is going to die because it would instantly solve this issue methinks
do you know if forge has any equivalent to --share=True?
i'm going outside of my home network for a bit but i still want to be able to generate on my PC from my laptop
And the models are on HDD or SSD?
SATA SSDs aren't that expensive these days and they are still way faster than HDDs
No change. the settings.

Okay then check your Windows pagefile.
It needs to be enabled only for C and not for any other drive.
You can increase the pagefile by setting it to 16000min and 24000 max
i haven't been able to find if forge has any way to create a public link
normally on my home network i just RDP from my laptop to my desktop but i can't do that from outside the network
For real? Can you recheck?
5 to 1 minute is huge
I never saw that decrease in forge
any ideas CS1?
forge takes like 45 seconds for me to generate a 1024x1024 image at 30 steps with 15 hires steps
i feel like something is probably just wrong with my A1111 install
even though it's literally a brand new install
sure enough, only 48 seconds

Yea thats the strange thing. But we had that yesterday too with someone that upgraded his gpu.
And his auto1111 thought its still using the old GPU with limited vram until he reinstalled the nvidia drivers
Is your webui updated?
Is your extension updated?
we should not use the gaming ones, right?
The gaming ones are fine
And I would recommend using them
i think my old install from 2022 that i had kept updated with git pull actually performed better
Sure thing. When launching I at the end get this error

At should I try to generate, it lists error with "low vram"

btw for upscaling i suggest using a tool called upscayl
instead of wasting time using A111
its free and its local install
its a nice tool but it cant use latent upscale
so upscaling via hires fix is still better in auto1111
your trying to use SD3 in auto1111. Its not supported yet
true, but lowering the denois can help a bit
yes.
still, when you try to make a image that is gritty, as in
like, damaged helmet or dirty something
it does tend to clean it out a little bit.
okay, newest drivers installe.d
let's try again
strange. I actually was using stable diffusion v3 for like 2 days. But randomly at one generating it stopped working with this error. So now nothing with SD3 can be used until its updated. Does it update itself or do I check the website from time to time? Thanks!
if you have git pull in your webui-user.bat it will auto update
if not, then you have to manually run it
nice, thanks
you can also add --update-check to the launch args to get notified (this wont update, just notify for an available update)
Okay. Got a clean install, new drivers, and installed the animateddiff and control network. Should be good to go, with the command liknes you recommended, right?
yep
the model for animateddiff (mm_sd15_v3) goes into i\extensions\sd-webui-animatediff\model
right?
stderr: ERROR: Could not install packages due to an OSError: [WinError 5] Access is denied: 'C:\new sdg\stable-diffusion-webui\venv\Lib\site-packages\cv2\cv2.pyd'
Check the permissions.
...and it crashed when i try to make an animation again.
for the sd3 model you also need to use its lora
try the sd2 model
roger.
it should work easier
downloading.
So I'm looking into a desktop in the $1300 range without peripherials, and I want it to run AI stuff smoothly. Do you have any build suggestions? Didn't know if this was discussed elsewhere also.
no change.
all that console said.
C:\actions-runner_work\pytorch\pytorch\builder\windows\pytorch\aten\src\ATen\native\cuda\IndexKernel.cu:92: block: [89,0,0], thread: [66,0,0] Assertion -sizes[i] <= index && index < sizes[i] && "index out of bounds" failed.
Shows up quite alot.
what resolution did you tried?
and which model
you need an 1.5 based model (2gb) and the resolution should be 512x768 max
512x512, mm_sd15_v2 o arUniverse_V8,
wait, ti's doing maths now
like, mega slow, but it's not crashing

what was your gpu again now?
batch size
i assume you mean this?

hmm... should it be taking multiple minutes per frame? Alot more then a normal image, of that size?
i guess, makes sense.
yes its very slow and takes very very long

you need to enable a setting in auto1111 to make animatediff work
and better try with 24 frames to test
good test values?

in the settings go to Optmizations and there enable this:


disable FILM
and check webm
then try an other model
best working for me was Photon
sampler euler a or dpm++2m
no problem 🙂
Radeon and AMD and it's a laptop
ah you had the integrated gpu
AMD Ryzen 9 5980HX with Radeon Graphics, 3301 Mhz, 8 Core(s), 16 Logical Processor(s), Radeon RX 6800M GPU with 12GB GDDR6
okay, are you located in US or EU ? price related question xD
US! N.W. Arkansas to be more precise.
okay
hello
I am getting this error
ImportError: numpy.core.multiarray failed to import

Skytech Blaze4 Mini Gaming PC, Ryzen 7 5700 3.7 GHz (4.6GHz Turbo Boost), NVIDIA RTX 4060 Ti 8GB GDDR6X, 1TB SSD, 16GB DDR4 RAM 3200, 650W Gold PSU, Wi-Fi, Win 11 Home
Nope
Dont buy anything that has a GPU with only 8GB Vram
You want 12GB or more
The more the better for Ai stuff
Ah right, gotcha.
As processor go for AMD
Cool, is there an Amazon seller you like, or should I consider Best Buy?
is there a way to make comfyui fallback to shared gpu memory if dedicated gpu memory fills up? working with 6GB dedicated but 16gb shared
Have you enabled the fallback in the nvidia control panel?
Idk sry, im in EU so its very different
But I wouldn't buy complete pc builds on Amazon
cuda fallback yes
yes I have
Are you trying to use sdxl or sd3 ?
idk I'm using a different model. it's an NSFW model. Pretty sure it's SDXL and not sd3
since not using any sd3 specific latent images or things like that
Oh cool, danke sehr. 🙂
i guess you can just replace that with RTX 4070 TI SUPER 16GB, everything else looks fine to me
Good day to all, please tell me the analog of the model realvisxlV40 for creating REALISTIC images of people.
it should not be drastically more expensive than NVIDIA RTX 4060 Ti 8GB
I was disappointed with the power supply, but it's such a small part. I should rip stuff out of my old desktop.
How much normal RAM do you have?
32GB
A 4070ti is great but pricey.
Also go for 32GB system ram. You'll need it
I'm working off my poor mans 1660 super XD
https://arstechnica.com/gadgets/2024/01/review-geforce-rtx-4070-super-makes-a-good-gpu-even-better-still-costs-600/ <- check out this, you have comparation between similar cards here

Ars Technica
Remains pricier than past xx70-tier offerings, but the performance bump is nice.
I'm being lazy and don't want to build it myself. Been there, done that.
Have you tried Auto1111? Does it behave the same there with sdxl
you do not need to do that, just find the card that is right for you, than buy something with that card
I immediatly moved away from A1111 for comfyUI, I only had the allocation error happen once I was just asking to see if anyone had any info
but would like some help in dms since I am working with an NSFW model and don't know if that's allowed here to post images
specifically with HiRes Fixing
getting crap results even tho last night I did get some pretty good results but now it's just trash
also comfyUI just seems overall MUCH better. on A1111 my entire pc would come to a near standstill and sometimes even lock up entirely. I haven't had any issues like that on comfyUI
you can try to generate SFW image by adding "nsfw, topless, nude, naked...." in the negative and something like "girl in white dress" in prompt. that works with some nsfw models, but not all
I can probably just switch off this model too but. idk it's whatever. I'm just confused how I was getting pretty decent results HiRes Fixing last night but now it's trash
since this is so garbled I think this is safe enough to post as an example:

Finding the right Gb size in the right processor takes some hunting
this is my second pass ksampler

comfy said to put start at step to 5 last night which gave me the decent results but then today it was just trash. tried at 7 but same thing
for PC - you want as much VRAM as possible and decent amount of RAM, and Nvidia works better with AI than Radeon. for Mac its much easier - just get one with most unified RAM you can afford 🙂
cfg is too high
but that is so low
I have become well acquainted with Radeon issues, I'm sorry to say. This laptop is heading to be the new work laptop.
running now with cfg at 1
If I'm using a turbo, 2.5 cfg is as high as I dare.
wdym by a turbo?
SDXL turbo model that allows few steps and gives good results
I'm using dreamshaperXL_turboDpmppSDE.safetensors right now
mine doesn't have turbo in the name
i like lightning more than both turbo and lcm
I stopped DLing models a couple months ago. I'll have to try lightning. What model do you recommend?
any with 8 steps

variant of blue_pencil-XL LCM-LoRA / SDXL-Lightning
its a merge of lcm and lightning
Nice, but I only use realism

This checkpoint is designed for a specific Workflow but you can also use it with just A1111. You can find it here: https://civitai.com/models/33200...
this one is experimental
lcm version is stable and you can use slightly higher cfg than with "standard" lcm (up to 5)
https://civitai.com/models/200061?modelVersionId=256258

This my first full LCM model. Its also the first model of the NextGenXL version of Hephaistos. Its trained on a merge of Hephaistos and Colossus Pr...
Nice
i haven't use a1111 for months, didn't have time and was busy at work
I just LOVE the modularity of ComfyUI and the fact it doesn't lag my computer at all is a MASSIVE W
on my mac a1111 works faster than both forge and comfy (with default settings) 🙊
but i managed to make forge to work slightly faster
comfy runs pretty fast for me but I think it's mostly model dependant.
with same model comfy should work faster on most computers
I haven't even considered forge. I just do a1111, tried comfy but didn't really go deep dive at all.
it's awesome honestly. much prefer it to A1111
other than hires fix being super finicky
Should I get the 13gb version or is the 6gb version okay?
for which model exactly?

This checkpoint is designed for a specific Workflow but you can also use it with just A1111. You can find it here: https://civitai.com/models/33200...
usually I tend to go for the larger versions so the model has more data to work with
FB32 vs. the BF16
I'm not sure what the actual difference is, and bandwidth issues. 😛
FP32 says it's slightly better
in general, smaller models need less VRAM, so always download smaller first
if it works, great
if not, get bigger one
6.62 gb it is
i will download that one when i finally install a1111 properly
i always have like 10+ experimental installations
since i need to test my install script and some issues
anyone willing to hop into a VC with me to help me get my HiRes Fix working properly again? NSFW Warning
did adetailer just get an update recently? i swear it had a checkbox to activate it that was separate from the dropdown toggle


Does anyone have a recommendation for where I can learn the basics of installing and learning to use stable diffusions weights? I'm finding it difficult to find a simple step-by-step tutorial and am finding it difficult to wrap my head around it. cheers.
How about the 4070 rather than the 4070 Super? 12gb. It's difficult finding the PC I want for the right price
i said separate from the dropdown toggle, it used to have one inside the menu itself like this
and i remember seeing it like that just yesterday

idk why they changed it
4070 super has more cuda cores than 4070, but if that is make price too high for you, go for 4070
I'm facing issues again with a1111, 12gb of vram but I can't do a single generation on SDXL without running out of memory
I'm looking at task manager and when I generate something without a Lora, it works, but when I use a Lora, it shoots up to 12GB of VRAM utilization
Any ideas on how to fix this?
fatcat pls save me 
i see you typing
That's normal as it holds the lora in VRAM alongside the model. I don't think there's a way around that other than using Forge or Fooocus
I am using Forge, it was working perfectly up until a few days ago
now i cant generate using LoRA without my a1111 crashing
due to no memory
Did you reenable sysmem fallback policy in NCC after you nuked drivers?
no ill do that rn oops
The 4070 to 4070 Super is the most cost effective upgrade/choice in the 40 series. 10% price increase for nearly 18% more CUDA/Tensor cores. Regardless, you'll be incredibly happy either way and both have 12GB VRAM so it's just generation speed that is affected (although the 4070 Super can pull some serious O/C...)
enabled it and lora is still mkaking it crash
Moving model(s) has taken 0.64 seconds
To load target model SDXL
Begin to load 1 model
Reuse 1 loaded models
[Memory Management] Current Free GPU Memory (MB) = 4211.08544921875
[Memory Management] Model Memory (MB) = 0.0
[Memory Management] Minimal Inference Memory (MB) = 1024.0
[Memory Management] Estimated Remaining GPU Memory (MB) = 3187.08544921875
then its gone
What is the file size of the lora it's trying to load
65,400 KB
is the size of the .safetensors file
im about to just switch to comfyui atp 
Are you missing a 0 in there by chance?
Huh that's a tiny lora
The other day I think you mentioned something about using an external drive or similar? I wonder if that may have something to do with it
yup i have literally no clue why stuff is breaking
yea so
my C drive is where my python is installed alongside other windows stuff and pip
and my D drive is my main drive
where I have the stable diffusion folders
will that cause an issue?
i really dislike comfy and anything node based stuff like that
When you say folders is it just the lora and model folders or is it the whole sd.webui folder package?
i guess most artists may like their nodes and spider web of wires connecting nodes
the entire stable diffusion folder
me too, thats why im trying so hard to make my a1111 work without breaking lol
i hate blueprint in unreal too
or those any node based softwares or programs
i wish all those comfy features would be in A111
minus those nodes
And you made sure the file paths are correct pointing to the models and loras?
yes, 100% correct
the lora appears in the ui and everything
I just made a generation, it finished in like 20 seconds at 1.38 it/s
now if i try with a lora, same prompt same settings, it will not work


yup, out of memory instantly

also programming is faster than visual scripting xD
What does your task manager show for dedicated gpu memory usage when this is happening
ill do it again and take a screenshot
btw i still get that cuda out of memory in A111
everything works good as long i make 512x512 images
but to describe it, it shoots up to 11.8/12 for dedicated GPU memory and then dies
i did all the steps cso said
the generation doesnt even get a chance to start
but idk why i can't use sdxl models on a 24 gb ram and 16 gb vram rig
i checked performance it don't even use half of the rams
a1111 is so broken
it sucks
but its the best for my asset development
a 16gb vram rig shouldnt run into cuda out of memory
forged don't have a seamless tiling
it simple don't make anything seamless
i can't run foocus idk why
and i refuse to use comfy
no way screw that
and forged is becoming obsolete

same lol
it works fine for 2 months and then breaks randomly
i thought i can make my assets to sale faster with AI
i make stuff based on my doodles 😄
i am doing a workaround atm
Yikes and you're sure high-res fix is off and no other controlnets or anything else
using upscayler to upscale
everything is off
same