
#🤝|tech-support
1 messages · Page 64 of 1

Please Stand by.

Part 2: How to Use Stable Diffusion https://youtu.be/nJlHJZo66UA
Automatic1111 https://github.com/AUTOMATIC1111/stable-diffusion-webui
Install Python https://www.python.org/downloads/release/python-3106/
Install Git https://git-scm.com/download/win
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
Download a model https://civ...
it can't be bad, says it's #1 right there on the thumbnail
I mean. It did help me get it working, where a written guide did not
Remove ever argument with -- there.
Then only add:
--xformers --medvram-sdxl --no-half-vae --autolaunch
Wait... sdxl? I need the sdxl pack for those promts?
No
And was it half vae?
Its for compatibility
it's a fix to a stupid issue that was introduced a few months ago xd
So... Its ready to be saved, once current batch is done, but what exactly do they do?
These let you generate images at the fastest speed and the lowest vram resources possible
So no more waiting 2 hrs?
The stuff you had isnt needed for a 1080ti and only slows down everything
also for the love of god look into img2img, don't just do text2img xD
I guess thats what u get for not being bale to afford the newest gpu's each year xD
You will be amazed how fast it is now xD
Its mainbly used to change the style of an existing img, ye?
Na I've used a 1080 a whole year with SD. It can do mostly everything
txt2img is what you use to generate a low resouliton image you start with, and then you refine it with img2img and upscale it to higher resolutions.
you shouldn't really be using txt2img for anything larger than 1000x1000 px, it creates issues
Wait... So txt2img = Prototype image. Img2img = production Image? (Using terms I am familiar with)
yeah pretty much
Thats not true for sdxl and hires fix. But for 1.5 models
So i should only do it for 1.5 stuff, but not sdxl/pony etc?
yeah but what's the point of generating 10000 pitures hoping to score gold instead of generating 100 and just refining the best one to be gold
No if you edited the webui-user.bat like I said you can use sdxl and pony and it will be fast

Depends on the GPU ^^ but yea better to gen lowres and upscale only the good ones
What are your settings ?

If you enabled hires fix then always set the hires steps to 10
Don't use 68 steps. 25-35 is mostly enough
i c
I'd set the initial size to 640x960, it's then easier to upscale to 1280x1920 and 2560x3840 which are pretty good resolutions to work with
And then swap them, should a landscape be needed?
yup
Guys amd 7900xtx or rtx 4080 for Sd?
Can those be saved somewhere, so they're default? Also 4080. Nvidia just works better
All i saw, while trying to find resources to install this, was amd needed extra files
amd has some hiccups but there are workarounds when you know what you're doing
amd has some lacking right they cant use hip so they have to install 3d part software for ad to use their hip which is similar to cuda
If you want it just for AI stuff then go for nvidia as the support is better
what is it called
how many steps can i go with 4080
@ornate elk Halp.
Wat dis mean? Came up after changing the promts, and now the Lora tab is infinity loading.

No we have hip SDK and rocm support but pytorch doesn't support it on windows right now.
So on windows I use Zluda to emulate cuda
Getting 16 it/s
yeah i wanted to say zulda
?
any updates on amd doing anything for sd for better support?
@cursive cobalt What's in Your webui-user.bat rn
to use HIP instead of zulda

its been like years what since people using zulda for amd
Yes they still work on it. Rocm development goes further and we hope to get windows support this year
Its since February ... XD
Before we only had directml
wow!so should i go with amd 7900xtx if support coming this year?
that vram wil work better than 4080 right
do 7900xtx and 4080 perform same in sd
I can't guarantee it. But if like I said if you want to do much ai stuff your safer with nvidia.
I bought my 7900xtx knowing that I can use it not as fast as with nvidia cards on windows. But now with Zluda I'm happy until full rocm support comes
have u used videos to convert into anime in SD?
i mainly want to use sd for that
or wait for 5080
this year
i want to convert 1 minute video of 1080p@60fps @30fps into anime in SD
how much time it will take with 4080
Like video onto frames, then using Controlnet and then put it back together as video?
Then yes I've done that
or 4080 super
how much time it took u
Looks good. Try restart and then check the lora tab again
Depends on the length idk rn
1 minute video
1080p@30fps
to anime
how much time with 4080
or 7900xtx
... I might need to move all of it so a quicker drive...
Can i just copy paste the main folder, pythin, git and SD (And Auto) is installed in, and just launch?
If you can send me a video I'll try it later
If you move the webui it will break the auto update (git path)
But its fixable
1 of the user said here i forgot his name that to convert 1 minute video into anime it will take 3 hours by some math he explained
is 7900xtx good for video editing?
Fairly ez, or bothersome?
It takes me like a solid 5-10 min launching the webui xD
so math he explained was 60 secs into 60fps
and do that into hours
anyways u tell me bud
how much time it takes for u @ornate elk
ill send u video here or dm?
Fairly easy
But don't move git and python
Only the stable-diffusion-webui folder
Once I've cleared up the space needed for my needs, could you guide me step by step?
You mean to fix the auto update stuff?
Is that the only thing thats gonna get broken?
Will it speed up the loading, moving the sd folder from hdd to ssd?
Wait... That is a silly question. Obviously it is, if the things its pulling `such as Lora's, is on the same drive
Yes
It won't affect image generation time
Cuz thats gpu
Cause spending 800+ seconds on loading all of my Lora's, is a bit... excessive xD
OH BOI! Thius is gonna take some time... output disc is hovering at ~40 MB/s
ETA: 2½ hrs
Trying to use Pixart Sigma, but getting this error. Ideas how to fix it? I should have all the filex downloaded and placed into correct folders. Trying to use the "Abominable Spaghetti Workflow - PixArt Sigma" workflow from Civitai.

I have been using the same drives since at least 2014, @ornate elk ... Except C drive.

Been using that since 2018 xD
Quite full xD
Make sure C has more free space
It doesn't help, that currency the drive of which i am trying to install this on (the Evo 870), has over 100 gb of unaccounted missing space
And i checked partitions
How does it look in the partition manager?
Everything is partitioned correctly, so idfk.

I QUESS that's what happens with 10 yrs of unaccounted random stuff on your drives, does to it

Speed*
If the 870 is a 250gb SSD its normal
Or where you miss space?
I do be missing the space on the 870,but the output (or where I fra copying from) is an old hdd
But is fix now. We good
I have the RXT 6800, I’ll look at your pinned messages
why cant i join mid journey server
Hii, what does that mean?

what happened to mask_mode in api?
I logged in VIA my Discord on Stable Diffusion. Now the loggin method isn't there anymore to do the API credits.
Anyone can help on that issue by any chance ? 🙂
I'm not 100% sure but it might mean that you use 2 different models that arent compatible (for example an sdxl checkpoint model with a sd1.5 controlnet model)
Hey @ornate elk fren.
Do you happen to know, whether its possible to bind the webui.bat file, to something, so I don't need to navigate to the folder each time, to start up SD?
Then follow my AMD Zluda guide and you will have a fast stable diffusion programm 🙂
Should I go through and uninstall everything I have already done?
Make sure you always start the webui-user.bat.
Make a right click on it and press Send to > Desktop
Then you have a shortcut
Oh nice
Is there a command to free up the VRam after each generated batch? Having the webui crash on me a few times cause it claims it doesn't have enough vram
If you already have git and python you don't need to uninstall them but delete the old stable-diffusion-webui folder
Wanted to bind it to my taskbar xD
Make sure to use batch count and not batch size
Wait... Thats whats consuming a shit ton of vram?`Oh
I assume it frees it back up quicker as well then..?
Tis' causing issues on new gen
Have you figured? I got this after the update.


Hey, What's your GPU and what's inside your webui-user.bat?
i have been thru 2 gpus
the 1060 6gb and now 3060ti
and it s the same
it is a fresh install of the program
it used to work some time ago

What could be causing this issue? Its essentially crashing during generation

You need --xformers --medvram-sdxl --no-half-vae in your webui-user.bat
For the best performance
At the line commandline_args
so xformers being disabled generates complete jibberish?

is this a problem by any chance?
it is exactly the same...
1.5it/s untill the 50% mark, and then extremely slow!
and still random things

even with comfy ui it does the same
..... Excuse me wtf... Started getting grey squares genning... I look through my checkpoints... They're all gone. Wat
daamn
Hey guys, anyone know how to solve this error when booting a1111?
ImportError: cannot import name 'Undefined' from 'pydantic.fields'
ive been using a1111 every day for a very long time now and today when running it it wasn't able to generate anything so i ran "git pull" and now im getting that error
Hello! I am currently trying to train a character lora with https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer_XL.ipynb#scrollTo=OglZzI_ujZq- for use with PonyXL.
Everything seems to load fine, it picks up my dataset, all going well. Then, after about 5 minutes, I get "torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 480.00 MiB. GPU 0 has a total capacity of 14.75 GiB of which 307.06 MiB is free. Process 60818 has 14.45 GiB memory in use. Of the allocated memory 14.01 GiB is allocated by PyTorch, and 314.76 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)"
I tried running the line it suggested, but got a syntax error. Where do I go from here? I would appreciate any help, thanks!
A guide to torch.cuda, a PyTorch module to run CUDA operations

@ornate elk u finished with the video?or is it still processing?
I was at work till now xD
ooh
so can u do now the 1 minute video i sent u now or whenever ur free thx buddy
dm me ping me when u are finished with the video man
with the video or ur personal work?
i have got an old image i made last year
put it into PNG info
then transfered all of that into the txt2img
with the same checkpoint
nope. had to switch to comfyui
Oh alright I managed to do it
how?
It seems I was setting latent_mask in the request which I shouldn't be
Removing it managed to fix it
ah true. tbh i prefer comfyui. really good how you can send an entire workflow through the api. give you a lot more control

👍
Personal
ooh np

What's the model?

i was told karras was a good one
and i have been using it since
generated 400 pics with it
oh, okay
and why do everything i do
generate that stuff
blue image
even with confy ui
Because the model may be corrupt or your using the wrong vae
Have you tried other models?
What am I doing wrong with the api?
{
"session_id": "AB3A76D76053E20A6933A2B60797DA8E31553410",
"images": 1,
"rawInput": {
"prompt": "a photo of a cat",
"model": "cosxl",
"steps": 20,
"width": "1024",
"height": "1024"
}
}
to http://192.168.0.14:7801/API/GenerateText2Image
Generate:
13:48:22.835 [Warning] T2I image request from user local had request parameter 'rawInput', but that parameter is unrecognized, skipping...
13:48:22.835 [Info] User local requested 1 image with model ''...
13:48:22.837 [Error] Internal error processing T2I request: System.NullReferenceException: Object reference not set to an instance of an object.
at StableSwarmUI.Builtin_ComfyUIBackend.WorkflowGenerator.CreateStandardModelLoader(T2IModel model, String type, String id, Boolean noCascadeFix) in /src/BuiltinExtensions/ComfyUIBackend/WorkflowGenerator.cs:line 1348
at StableSwarmUI.Builtin_ComfyUIBackend.WorkflowGenerator.<>c.<.cctor>b__10_0(WorkflowGenerator g) in /src/BuiltinExtensions/ComfyUIBackend/WorkflowGenerator.cs:line 90
at StableSwarmUI.Builtin_ComfyUIBackend.WorkflowGenerator.Generate() in /src/BuiltinExtensions/ComfyUIBackend/WorkflowGenerator.cs:line 1308
at StableSwarmUI.Builtin_ComfyUIBackend.ComfyUIAPIAbstractBackend.CreateWorkflow(T2IParamInput user_input, Func`2 initImageFixer, String ModelFolderFormat, HashSet`1 features) in /src/BuiltinExtensions/ComfyUIBackend/ComfyUIAPIAbstractBackend.cs:line 627
at StableSwarmUI.Builtin_ComfyUIBackend.ComfyUIAPIAbstractBackend.GenerateLive(T2IParamInput user_input, String batchId, Action`1 takeOutput) in /src/BuiltinExtensions/ComfyUIBackend/ComfyUIAPIAbstractBackend.cs:line 701
at StableSwarmUI.Text2Image.T2IEngine.CreateImageTask(T2IParamInput user_input, String batchId, GenClaim claim, Action`1 output, Action`1 setError, Boolean isWS, Single backendTimeoutMin, Action`2 saveImages, Boolean canCallTools) in /src/Text2Image/T2IEngine.cs:line 255
any solution for this?
File "C:\Users\kevin\Desktop\ComfyUI_windows_portable_nvidia_cu121_or_cpu\ComfyUI_windows_portable\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module_ad.py", line 1112, in forward
x = x + self.pe[:, : x.size(1)]
^~~~~~~~~~~~~~~~~~~~~~~
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
Yea I know how to fix it. I'll send you a guide when I'm at the PC
try disabling the.. cpu rendering?
Having trouble while training a lora with google colab, can somebody who know's their stuff dm me?
how do I do that? I run the GPU
Colab pro?
I don t know your setup
i run this,

And what is inside of that

Can you try to use confyui's ui?
guys is StoryDiffusion part of stable diffusion?apparently it can convert 30 secs video into more anime looking quality consistent anime looking quality which we see in anime so any1 heard of it?
Thank you!
that pydantic error appears when using a not updated controlnet version.
Can be resolved by doing this:
Go into the stable-diffusion-webui folder. Click in the explorer bar (not search bar)
Type in cmd and hit enter.
Run the three commands one by one:
venv\Scripts\activate pip install albumentations==1.4.3 pip install pydantic==1.10.15
Then relaunch the webui-user.bat
and you can train ai on google colab?
they banned ai generation last year
training works still?
I guess not, since mine isn't working
Hi, I have an AMD 7900 XT and I followed the tutorial pinned for AUTOMATIC1111 with ZLUDA.
I would like to know if there are any optimizations in COMMANDLINE_ARGS that I can add to reduce VRAM consumption since when I generate with SDXL with hires fix it consumes all the available VRAM.
Now I'm using these arguments: set COMMANDLINE_ARGS=--use-zluda --medvram-sdxl --update-check --skip-ort, thanks.
hey sorry to bug you again, but i actually ended up doing a clean reinstall of A1111 and i tested it w/ one image, ran fine. but now while the UI boots, it won't generate anything and i dont even get any errors...

gets stuck like this:

Hey I have the 7900xtx and what you can do is to install the tiled vae extension to reduce the vram usage at upscaling
Also use the sdxl fp16 vae
which install guide did you followed?
the one on the main github page. i have a nvidia gpu (4070ti)

i would recommend installing it using my install guide
Here: #🤝|tech-support message
trying that now :)
final error, hel pls
still reacting the same way after re-installing: (now it gets stuck loading the model with the thinking icon)
make sure the webui is whitelisted in any browser adblocker
also try loading in an other model
i have no adblockers
nvme ssd where my os is installed
i dropped dreamshaper8 model into the folder and ran the ui. while it was stuck thinking i try to switch over and it lists the new model but its just stuck thinking with no error in cmd prompt
you dont think this error is anything i need to address right? "FutureWarning: resume_download is deprecated and will be removed in version 1.0.0."
that can be ignored
how much ram do you have?
32 gb
also make sure to not run any other heavy programms or wallpaper engine in the background
hmm... the thinking stopped and gave me an error. i refreshed model list, selected dreamshaper and was able to run an image
lemme see if I can get consistant restarts of the ui and generate things
what a bizzare series of errors ive never had before... been using a1111 for almost 2 years now
very strange indeed
reloaded ui and it locked up again...
I'm redoing some preview images for checkpoints and suddenly one of them started doing this. Weirdly they look completely fine during generation, it's something that happens as the pictures save. ideas?

happens to me when I forget to turn off my vae
wrong vae mostly
rebooted pc, same issue. i randomly thought to try on edge browser instead of chrome and it worked again. gonna keep testing a bit and see
ty so much for your time btw. been pulling my hair out w/ this today lol. was working perfectly every day until last night
no problem
what changed since yesterday? any update?
i guarantee it was an issue with chrome. which caused me to delete the venv folder to reset it which is when that pydantic error popped up
which led to the a1111 reinstall and more issues w/ chrome
so far everything's working on edge
wish i had tried that before reinstalling it all and having to re-do everything lmao
true, but know you have a fresh webui
thats good too ^^
hello, solution for this?
File "C:\Users\kevin\Desktop\ComfyUI\ComfyUI\custom_nodes\ComfyUI-AnimateDiff-Evolved\animatediff\motion_module_ad.py", line 1112, in forward
x = x + self.pe[:, : x.size(1)]
^~~~~~~~~~~~~~~~~~~~~~~
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
@ornate elk I get to here in my command prompt "Launching Web UI with arguments: --use-zluda --medvram-sdxl --update-check --skip-ort" and nothing happens.
I follwed your ZLUDA guide, any thoughts?
wait...it took 2 min to load...ignore^^^
so it works now? ^^
SD opened in my browser, Im trying my first image generation with the knowledge that it could take 15-40 minutes. I will update if I make progress. thanks!
perfect 🙂 if the generate button is grayed out after pressing and in the cmd is showing no error, then let it load and you get an image
sounds good, ill be patient, thanks!
np, mostly its faster than 20 minutes
happend to me too today
we are all set, I think i saw somewhere that you can't train with AMD, is that true?
yes thats true
its only possible with the OneTrainer tool, because it supports zluda
good to know, thank you
no problem 🙂 wahst your gpu btw?
great for gaming 😄
for sd it will be good too, not as fast as nvidia but you can even use sdxl models and upscaling without problems
awesome, looking forward to playing more with it, thanks!
no problem 🙂 for any questions feel free to ask
will do, appreciate all the help. I will say, im not sure if it was just me, but the instructions on this site https://www.wikihow.com/Change-the-PATH-Environment-Variable-on-Windows were a little unclear because wherever it told me to click it a button, it was only showing special characters
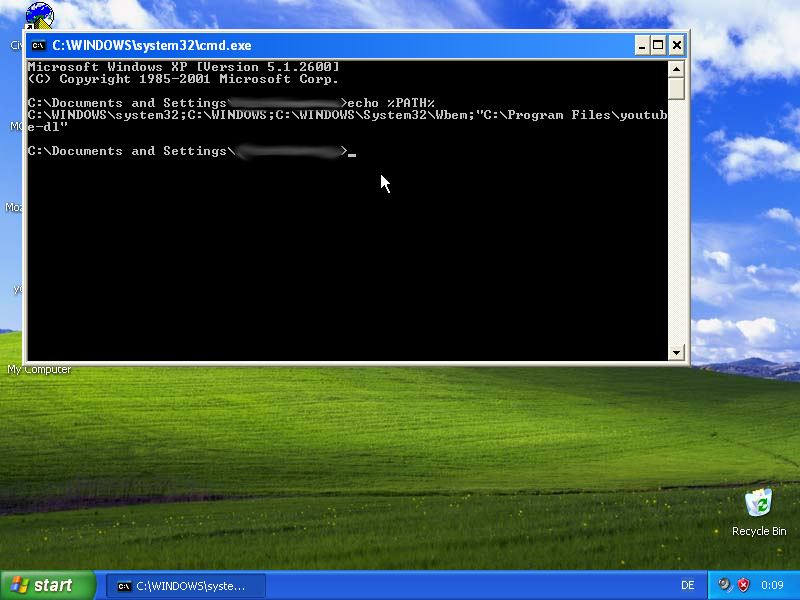
wikiHow
A simple guide to adding a directory to the Windows 10/11 path variable The PATH environment variable specifies in which directories the Windows command line looks for executable binaries. The process for changing it is not obvious, but...
I ended up getting it, but it was a little annoying, not sure if you want to find a new one

for me on firefox it looks like this:

so maybe a browser issue or browser extension issue
possible, good to know though
⚰️
What's your GPU?
1660 GTX 6GB
Okay, make sure your nvidia driver is updated
ok i go to check
Why does it take so long time to "moving model(s)"?
Have been around 1h and 30mins and still only at 50%
Using a 2060 12gb
updated, do I try running the program?
Yep
Where do you move them?
I am not really moving them, I just downloaded a model and put it in the models folder and tried to create a picture with txt 2 img but it said in the cmd that it was moving model(s)

But I read https://www.reddit.com/r/StableDiffusion/comments/15qwvo8/a1111_model_taking_forever_to_load_and_freezes_my/
That RAM speeds up the process a lot
Reddit
Explore this post and more from the StableDiffusion community
For sdxl models you need 16gb ram or more
If you only have 16gb you can increase the windows pagefile
same error
@ornate elk hey everything's running buttery smooth. one last quick question: after I install the TensorRT extension can I just drop the onnx models I backed up? or do I need to recreate them?
I have 16gb but I will try increasing it, thanks for the help ❤️
Wouldn't recommend using tensorRT as its not compatible with everything SD related.
But yes you can drop the models back in
hmm ok. been using it for a long time for non sdxl models w/ no issues. anything i should be concerned with?
No if it works then its okay, but it could be that some extension won't work with it
i recently upgraded from a 3060 w/ 16gb ram and back then had a hell of a time running sdxl models
gotcha. ty :)
it doesnt work w/ xl models or controlnet from my experience
but does wonders w/ 1.5 models and now its integrated w/ a1111 wonderfully and no longer have to embed loras to each individual onnx model
Hoi, is there a way in python code/comfyui/forge to make SD ignore steam deck's bios UMA frame buffer limits? As i am trying to generate images on the steam deck, but oddly comfy won't do anything past 4GB that i set in uma.
Can anyone help me w my account?
I paid for the monthly and there is no button that says Discord activation so I can use the bot here???
They will be in a text file that tells the extensions that "these are trained, use those", thus list them. So you can move them away as you wish. Only "recreate models" you need to do is per resolution/resolution range, as it still doesn't have a effective way to make the model entirely TRT
hey everyone, this is SD 1.5, right?

this is in the models folder of my Automatic1111 SD WebUI install
I checked, it is 1.5
how do I upgrade to SDXL?
i am having trouble setting up my stable diffusion checkpoint stuff, msg me i am like a newb when it comes to all of this. someone plz help
SDXL is not an "upgrade" in the traditional sense. Automatic1111 is the software. SD 1.5, SDXL, and others are different models. Automatic1111 can run both with no changes to the software you have installed. Simply place the SDXL models in the same place and ensure that you download the SDXL VAE and put it in its proper folder. You will then be able to produce images using either model. (I recommend using subfolders for each model type within your model folders.)
how is SDXL not an upgrade over SD 1.5?
thank you!
It is an upgrade in the sense of being a more capable model overall. It is not an upgrade in the sense of needing to change your software.
That's why I said it wasn't an upgrade in the traditional sense.
Yeah I knew that, I was just unsure if it was just as simple as downloading the SDXL .safetensors file and putting it in here
And I answered that.
Not a great way to get help here. You should share more specific information about what you are running into. Any errors, screenshots of examples, etc. will be useful for people to answer/guide you.
A model upgrade would more so be for instance SDXL models that doesn't need refiners, as they are finetuned to be fine with just one model. That's more a upgrade. SDXL is just it's own model capable of higher resolution. But even today, i find sdxl a "downgrade" over the better 1.5 models that can do so much more.
my 1.5 model doesn't get me very good images
I assumed SDXL would also have better image quality
I don't really care about resolution
how do I find better SD 1.5 models?
I'd prefer that to downloading SDXL which is like 7 gb
and then the VAE is another 7 gb
Show a result you've made. make a random dog/car/cat one for instance.
yeah one sec
As SD 1.5 can look quite good once you've stepped it up, as well as upscaled it
your using the default 1.5 model its just bad. you need to download community made models from civitai.com like dreamshaper v8
Oh yeah, default any model is complete ass by itself 
ah
that makes sense
let me download something from civitai then
Upload your gen, and i'll remake it in dreamshaper as an example of before and after :P
too late

I don't like to generate images like these though
I usually do like
architecture or technology
Any will do, i just threw out examples :P
almost never humans or animals
Browse the output folder and drop in one of your liking/attempts
I made some space elevators a couple days ago


I think these were the best I had
Here's those results in a custom SDXL


Then we got dreamshaper 8 as mentioned before ;P Using prompts of the second image.
Model of the 2 above was with https://civitai.com/models/134338/sdxl-faetastic-details

This LoRA is used to enhance images, giving them more details, increasing saturation, and making things overall prettier and magical feeling. Unlik...
https://civitai.com/models/4384?modelVersionId=128713 Here's for dreamshaper v8
DreamShaper - V∞! Please check out my other base models , including SDXL ones! Check the version description below (bottom right) for more info and...

its not installed correctly, and also the wrong python version.
please follow my install guide:
#🤝|tech-support message
uninstall python 3.11 before starting the guide
it was just working until today
i have a different issue now
i just get this big ass error message now webui is open
ive followed all ur steps
it says out of memory and all im so confused
and my memory usage is at 0
No you didn't. In the screenshot it still says stable-diffusion-webui-master and not stable-diffusion-webui.
You also didn't edited the webui-user.bat.
Maybe you just launched your old install again instead of the new one?
It means GPU vram
i have 2 errors, help pls
hello, i wanna reinstall comfyui, so should i delete the whole package?

or maybe it has some sittings can make the software to default ?
if i installed new ram today would that cause the program to have to load for longer before use? or was it the new update have it set to git pull auto update upon opening the webui-user.bat cmd said everything loaded propberly but the ui was frozen/loading for 15 minutes before it decided it would work?
What would be a good parameter for inpainting/soft-inpainting so I don't get that halo? I'm trying to fix some upscalling seems.

working on Automatic1111
Just taken a look at this. Intended use: Making sure each individual in a scene, gets the correct hair color.
GitHub
set prompt to divided region. Contribute to hako-mikan/sd-webui-regional-prompter development by creating an account on GitHub.
Anyone used it?
I used it a little a while ago, with DS 1.5, it is good to try to make some kind of composition

But it is very evasive, it may do what you want or not
I used again to get different characters and it was completly frustrating
I mean your prompt "A boy AND a girl" and it does a random character in the middle, something like that
Is there a way to only reinstall the run.bat file for comfyui ?
I get a random unrelated software in my computer loading stuff midway through the start up log, and the log just stops for a moment until i close the pop up window of said software
Or should i reinstall comfyui 💀
The kind folks in Anime helped me :3
Oh I'm reading 🥸
But see, it seem to only work on changing hair on the 3 same duplicated girls 😂
I'm getting it to work, just learning the basic settings tbh
it works better to establishing features for one single character, but multiple different characters, it cannot handle, maybe after a lot of tries
hello, I was hoping someone could help me with an issue I'm having, I cannot get Stable Diffusion to generate anything, everytime I try, I get the same error message
AttributeError: 'NoneType' object has no attribute 'lowvram'
Stable diffusion model failed to load
*** Error completing request
*** Arguments: ('task(z84q6hy74ibixlo)', <gradio.routes.Request object at 0x000002827142A200>, 'boy', '', [], 1, 1, 7, 512, 512, False, 0.7, 2, 'Latent', 0, 0, 0, 'Use same checkpoint', 'Use same sampler', 'Use same scheduler', '', '', [], 0, 20, 'DPM++ 2M', 'Automatic', False, '', 0.8, -1, False, -1, 0, 0, 0, False, False, 'positive', 'comma', 0, False, False, 'start', '', 1, '', [], 0, '', [], 0, '', [], True, False, False, False, False, False, False, 0, False) {}
Traceback (most recent call last):
File "C:\Stable Diffusion\stable-diffusion-webui-master\modules\call_queue.py", line 57, in f
res = list(func(*args, **kwargs))
File "C:\Stable Diffusion\stable-diffusion-webui-master\modules\call_queue.py", line 36, in f
res = func(*args, **kwargs)
File "C:\Stable Diffusion\stable-diffusion-webui-master\modules\txt2img.py", line 109, in txt2img
processed = processing.process_images(p)
File "C:\Stable Diffusion\stable-diffusion-webui-master\modules\processing.py", line 832, in process_images
sd_models.reload_model_weights()
File "C:\Stable Diffusion\stable-diffusion-webui-master\modules\sd_models.py", line 860, in reload_model_weights
sd_model = reuse_model_from_already_loaded(sd_model, checkpoint_info, timer)
File "C:\Stable Diffusion\stable-diffusion-webui-master\modules\sd_models.py", line 793, in reuse_model_from_already_loaded
send_model_to_cpu(sd_model)
File "C:\Stable Diffusion\stable-diffusion-webui-master\modules\sd_models.py", line 662, in send_model_to_cpu
if m.lowvram:
AttributeError: 'NoneType' object has no attribute 'lowvram'
If anybody knows how to fix this I would greatly appreciate the advice
hi guys i need help, i have generated a very good emoji and i want to make more then 1 of it but with different face and so on can someone tell how?
Anyone facing xformers error while using --xformers?
Always when i try generate pic it fails on 90% and shows xformers and CUDA like error
Same thing while using sdxl safetensors
Hey, you need to install the webui the right way using my guide from the pinned messages of this channel.
What error do you get?
In the cmd

Nvidia RTX 2050
alright. let me take screenshot
Will sd3 available on replicate?
No one knows
We need to wait for the public release
Ok thanks, Hope that will be soon 🥲
Me too 🥲

Yup
Ah you installed it by downloadind the zip file?
yes correct
it worked fine yeasterday but today i got getting these errors
Then first run the Update.bat
Then delete the venv folder
Then edit the webui-user.bat and there add --xformers --medvram --no-half-vae
Then save and relaunch
alright i`ll try that one moment
and then... here is the another issue. i not find venv folder
bcs its not there
nvm found it and followed all steps but still xformers WARNING and errors.
WARNING:xformers:WARNING[XFORMERS]: xFormers can't load C++/CUDA extensions. xFormers was built for:
PyTorch 2.1.2+cu121 with CUDA 1201 (you have 1.13.1+cu117)
Python 3.10.11 (you have 3.10.6)
Please reinstall xformers
Memory-efficient attention, SwiGLU, sparse and more won't be available.
Set XFORMERS_MORE_DETAILS=1 for more details
No SDP backend available, likely because you are running in pytorch versions < 2.0. In fact, you are using PyTorch 1.13.1+cu117. You might want to consider upgrading.
What folders do you have?
What is "Clip skip" exactly, and why do i see a fair few items on civitai having them in the details section?


without --xformers it works fine with default sd models but still fails on sdxl models on 90%
3050 sorry typo
hm okay, i would then recommend to install the webui using my install guide.
then you get an venv where its easier to fix stuff
Here is the guide:
#🤝|tech-support message
git config --global --add safe.directory F:/Ai/stable-diffusion-webui
fatal: detected dubious ownership in repository at 'F:/Ai/stable-diffusion-webui'
'F:/Ai/stable-diffusion-webui' is on a file system that does not record ownership
To add an exception for this directory, call:
git config --global --add safe.directory F:/Ai/stable-diffusion-webui
that means your drive is not formated correctly
ah so i need deep clean format?
yep, it needs to be gpt formated in the diskmanager and then ntfs
alright
but save your stuff before formating ^^
okay bro 🙂
works now. thx ❤️
perfect, np 🙂
I tried sd 8 months ago. When the new game driver nivida wasn't working properly and it only working with 531.5 version. Did that glitch fixed in newer edition. And is there any other method created which can create result faster? Or anything new in that regard
Would need to see the complete cmd log
Its fixed because most people use the latest driver without issues
i have to say... ur guide is much better than one-click install
Thanks 🙂
i tried to cover all steps for the best way to install it
Hey guys, does anyone know a way to generate without meta data being saved?

that isnt a complete cmd log
Are you talking about comfyui? You can startup the server with an argument --disable-metadata then no metadata is included in the image.
make sure the video file names dont contain special characters, also do you have ffmpeg properly installed and in path?
No A1111
I forgot to mention
TROUBLESHOOTING TIME again @ornate elk 😄

what have you done before ?
installed any extension?
Please stand by. Might have fixed it
Ah yes. It had ommited to copy a specific file from when i was moving it, but i was smart, and copied it into another folder, before i formatted the drive. I found the files, and put them back in, and it launched
Can i add an image for this, so it doesn't show "No preview" but has an image instead?

yes thats possible in two ways
if you generate a image you can then click on the right corner of the lora or embedding, then press the edit icon and there click Replace Preview. then it will use the latest generated image
Oh really..? Nice
or you can manually place an image into the lora or embeddings folder and name it the same
np for the names but not sure about ffmpeg, how can I check?
hmm if you run the install_bat it should have already made the ffmpeg path
yeah I did before
but still the same error
Some extensions also download pictures and info automatically
btw CS, I resolved my issues, thank you for the wise words!
GO on.... Auto1111 😄
For example https://github.com/BlafKing/sd-civitai-browser-plus
But keep an eye out after installing it, I think the extension may have upset some of my files or something. At least when I downloaded wildcards through it, then I got errors because it downloaded the pictures, json files and preview info
GitHub
Extension to access CivitAI via WebUI: download, delete, scan for updates, list installed models, assign tags, and boost downloads with multi-threading. - BlafKing/sd-civitai-browser-plus
That doesn't bode well
@ornate elk what should I do
yuuussss
any1 skilled in QR Art?
you should open an issue on the roop-unleashed github, they will know where the problem is
Let's say I have an extension, and it downloads extra files upon being used the first time, and now I cannot find these files. Is there a command in terminal that can delete everything related to those files, so I don't need to role play as a detective?
you can open up a cmd and type
pip cache purge
and to fully delete those files you would need to delete the venv folder.
but after the first launch every file needed will be redownloaded
I'll try the purge
Last part sounds a bit scary lol
only scary if your internet connection is bad yD
I live in Sweden so should be no problem xd
Is venv in appdata? Its not in my forge folders lol
its not in appdata either wtf
suppose it's this bad boi

i thought forge has it too
I'll look it up
Hey , coming acorss this problem.
It was running and installed all fine and dandy until I got a windows update, now I'm stuck with this issue.
I thought I had broke it playing around with comfyuis new fork, but even after a restore to previous state it still has the same error
webui-user.bat looks like this
`@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS= --xformers --autolaunch --pin-shared-memory --cuda-malloc --cuda-stream --api
@REM Uncomment following code to reference an existing A1111 checkout.
@REM set A1111_HOME=Your A1111 checkout dir
@REM
@REM set VENV_DIR=%A1111_HOME%/venv
@REM set COMMANDLINE_ARGS=%COMMANDLINE_ARGS% ^
@REM --ckpt-dir %A1111_HOME%/models/Stable-diffusion ^
@REM --hypernetwork-dir %A1111_HOME%/models/hypernetworks ^
@REM --embeddings-dir %A1111_HOME%/embeddings ^
@REM --lora-dir %A1111_HOME%/models/Lora
call webui.bat`
But I don't have A1111 😳
looks normal
Ait well, I didn't find venv on their github so I guess I don't have it at all
it normaly gets created at the install
its not in a repo
the files im looking for is not in models either, this shouldn't be that hard right?? fuck
idk what files you are looking for
ops 😳 mb
C:\Stable_Diffusion\Forge\webui\extensions\sd-forge-layerdiffuse this extension downloaded a bunch of files before starting, then proceeded to not work and give me errors, and in the end not generate nothing. So I figured might as well delete it fully and try fresh
Shouldn't one of these create the venv folder? 🤔

forge has a venv folder for me

WHY THO
Where would .pt files go to? https://civitai.com/models/159990?modelVersionId=179964 That is a .pt file, when downloaded.
Auto1111 UI
How can it not install the venv for me when I installed it via the friggin one click installer
stable-diffusion-webui/embeddings
found it C:\Stable_Diffusion\Forge\webui\models\layer_model xd
I'm kinda tired that forge is making me troubleshoot my webui every other day.. Thinking about installing the normal one like you suggested. I'm a little bit hesitant though, cause atm I'm generating images pretty fast, that's why most ppl get forge I suppose. Any idea if I will notice a big difference if I change versions?
whats your gpu?
NVIDIA Geforce RTX 3070 Ti, 8gb
32 gb ram, not sure that matters though
thats perfect to run sdxl models
should work good with auto1111
forge makes sense for 6gb or less vram
wouldnt use it with 8gb
it makes more problems that the little speed increase helps
Okay, I see. Maybe I'll just do it and follow your guide. Need to find a way to save the stuff I want to keep first
you dont need to delete forge for auto1111
you also can share models between them
That's more of a memory issue
can you que up to batch processing?
What on earth is going on here?



Its ignoring both a negative, and a positive promt as well
Wrong vae
Wrong? Eh?
OOh
Going the Lora way now, or trying at least, and the checkpoint way xD I be back if that doesn't work either
There a way to bookmark specific promts?
You need extensions for that. Or a really big txt document 😄
Right! Which extension, and compatible with Auto1111? 😄
I'm using this https://github.com/namkazt/sd-webui-prompt-history
GitHub
Automatic store your generation info with image and apply back anytime. - namkazt/sd-webui-prompt-history
it works with forge, so should work with a1111 afaik

gozaimasu
I'm getting this error about facexlib. I am using python 3.10.11
Traceback (most recent call last):
File "D:\stable-diffusion\ComfyUI_windows_portable\ComfyUI\nodes.py", line 1879, in load_custom_node
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in call_with_frames_removed
File "D:\stable-diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\PuLID_ComfyUI_init.py", line 1, in <module>
from .pulid import NODE_CLASS_MAPPINGS, NODE_DISPLAY_NAME_MAPPINGS
File "D:\stable-diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\PuLID_ComfyUI\pulid.py", line 10, in <module>
from facexlib.parsing import init_parsing_model
ModuleNotFoundError: No module named 'facexlib'
Cannot import D:\stable-diffusion\ComfyUI_windows_portable\ComfyUI\custom_nodes\PuLID_ComfyUI module for custom nodes: No module named 'facexlib'
i used pip to install facexlib
C:\Users\Eamon>D:\stable-diffusion\ComfyUI_windows_portable\python_embeded\python.exe -m pip install facexlib
Collecting facexlib
Using cached facexlib-0.3.0-py3-none-any.whl.metadata (4.6 kB)
Collecting filterpy (from facexlib)
Using cached filterpy-1.4.5.zip (177 kB)
Preparing metadata (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [7 lines of output]
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "C:\Users\Eamon\AppData\Local\Temp\pip-install-13q0izce\filterpy_456c11648240483cbf0da1cb5e214a09\setup.py", line 18, in <module>
version=filterpy.version,
^^^^^^^^^^^^^^^^^^^^
AttributeError: module 'filterpy' has no attribute 'version'
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.

its talking about the C: drive
first open up a cmd and run
pip cache purge
Then get a tool like WizTree Free and scan your C drive for stuff thats taking up space
hi i cant get webui bat to open python
guys my PATH is set to 3.10
3.10.11
yet
whenever I open webui bat it says 3.11 could not be found
how do i change this
How does one purge the ram being used? Is a bit excessive
Delete the venv folder and relaunch the webui-user.bat
ty
and python 3.10.11 is the correct version right
as u said in ur guide
Yep
@ornate elk
venv "C:\stable\stable-diffusion-webui-master\venv\Scripts\Python.exe"
fatal: not a git repository (or any of the parent directories): .git
fatal: not a git repository (or any of the parent directories): .git
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)]
Version: 1.9.3
what dpoes this mean?
that means you didnt installed it correctly, meaning you didnt cloned it with Git
did you downloaded it as zip?
i did download it as zip
- Error loading script: main.py
Traceback (most recent call last):
File "C:\stable\stable-diffusion-webui-master\modules\scripts.py", line 508, in load_scripts
script_module = script_loading.load_module(scriptfile.path)
File "C:\stable\stable-diffusion-webui-master\modules\script_loading.py", line 13, in load_module
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 883, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "C:\stable\stable-diffusion-webui-master\extensions\openpose-editor\scripts\main.py", line 14, in <module>
from basicsr.utils.download_util import load_file_from_url
ModuleNotFoundError: No module named 'basicsr'
yea thats not the correct way, my guide has the correct steps to install it
i tried cloning and ti says
$ git clone github.com/AUTOMATIC1111/stable-diffusion-webui
fatal: repository 'github.com/AUTOMATIC1111/stable-diffusion-webui' does not exist
the link is incorrect its missing https://
you need:
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
oh
openpose editor is broken since last year as it didnt got an update, the extension can be fixed by installing basicsr manually or can be deletet because controlnet has an openpose editor too that works
same error after i cloned it into new folder
can you show it?
nvm i was opening wrong folder
@ornate elk
i cant install
whenever i install i just get errors
this is on a clean inmstall in a new folder
how much RAM do you have?
and how much free Space on the C: drive?
16gb ram and around 20gb free on c drive
okay make sure to close every other programm on the PC, the installation needs a lot of RAM
k
also maybe restart the PC before trying again
if it still crashes you need to increase your windows pagefile (or check if you miss it)
File "C:\Users\Zain Raza\AppData\Local\Programs\Python\Python310\lib\threading.py", line 1016, in _bootstrap_inner
self.run()
File "C:\stable\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py", line 807, in run
result = context.run(func, *args)
File "C:\stable\stable-diffusion-webui\venv\lib\site-packages\gradio\utils.py", line 707, in wrapper
response = f(*args, **kwargs)
File "C:\stable\stable-diffusion-webui\modules\ui.py", line 1154, in <lambda>
update_image_cfg_scale_visibility = lambda: gr.update(visible=shared.sd_model and shared.sd_model.cond_stage_key == "edit")
File "C:\stable\stable-diffusion-webui\modules\shared_items.py", line 175, in sd_model
return modules.sd_models.model_data.get_sd_model()
File "C:\stable\stable-diffusion-webui\modules\sd_models.py", line 620, in get_sd_model
load_model()
File "C:\stable\stable-diffusion-webui\modules\sd_models.py", line 748, in load_model
load_model_weights(sd_model, checkpoint_info, state_dict, timer)
File "C:\stable\stable-diffusion-webui\modules\sd_models.py", line 393, in load_model_weights
model.load_state_dict(state_dict, strict=False)
out of memory
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacty of 8.00 GiB of which 3.19 GiB is free. Of the allocated memory 3.68 GiB is allocated by PyTorch, and 94.77 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Mmmm Out of memory. THat is what i live for.
Not even regular ram (32gb), can keep up. (12 gb VRAM).
@ornate elk Has u told him to do the low/medium vram tweak in the bat?
whats your gpu?
2060s
and what model is in stable-diffusion-webui/models/stable-diffusion
okay and whats in your webui-user.bat?
base model
That is dangerous. Never know if they are compatible
you need --xformers --medvram-sdxl --no-half-vae
and you get the error when pressing generate ? or just by opening the webui in browser
make sure to always launch the webui-user.bat and not the webui.bat
generate
hmm and nothing activated?
thats really strange
anything running in the bckground? like epic game launcher or wallpaper engine?
or hundreds of browser tabs open?
Can you sit the default resolution, the webui will always open up with? This is more in case of a crash, and i forget to re-do that specific setting
set the*
yep if you edit the value in ui-config.json
Excellent
hey if anyone could help, I seem to be getting some very bad images, but with no errors.

haha,i find something funny~
i got this error early and dont know how to fix it.

today i restart my computer
everything is ok~~so the bast way to fix a problem is restart?
Could try to specifiy the amount of each gender the scene has? 1 boy, 1 girl, 2 boys, 2 girls, etc, and see if that fixes? Am also really new to this, but i use those promts frequently.
I've tried that as well, it seems like the image is just being fried, as far as I can tell this isn't a prompt issue
Denois to high, set it to 0.5 and hires steps to 10
Hey yall, I've been trying to diagnose and fix a really persistent and damaging issue, that's got multiple levels of weird behaviour, but always has the same outcome where the final generation is just completely toasted - or turns into some sort of horrorscape. I've tried everything from fiddling with Nvidia drivers, changing args, updating python, reinstalling auto1111, using comfyui, even waiting a month for new drivers and updates - nothing seems to stop my pc from just frying the image. At this point I'm contemplating if my graphics card is just busted, and I simply don't notice it while gaming.

Sometimes I'll get a barely usable image (even though the generation completely ignores half the prompt), and then for each generation it just declines in quality - never reaching the actual potential of the model. - There should be a paladin with a bucket on his head in this image, half of the prompt is dedicated to his description, but all it spits out is vague scenery.

Hello
I reinstalled my OS and cannot remember what I'm doing
Stable Diffusion is 'installed' but I'm missing Python
What version do I need
I remember latest is not a good idea.
... Why isn't the latest a good idea?
Oh right, incompatibility. 2 sec, i installed this stuff like 2 days ago
3.10.6, i believe was the version u wanted
That's the one thank you.
I am having an issue with automatic1111 where it is using close to 100% of my system ram all the time. Does anyone else have this issue?
Yeah... Mine will frequent end up capping out on my ram (32gb), as well.

Is there anyway to mitigate this? I am coming to automatic1111 from forge where I was not experiencing this issue.
My reason for switching is issues I was running into with forge's built in controlnet version
3.10.11 is the latest you can have it seems just FYI
Fairsies
.. Well this sucks.
At least you get an error code
I'm assuming it's because I'm using an old install and my prior user account had a specific token associated with it or something
I'll just make a new one, oh well
ayyy

32 gb of ram
Me too
I think I've been maxed a couple times too
I just reboot the program.
I think it happens when you interrupt a job or something gets stuck
Why is it spamming this, despite what seems to be it reading the tags? (Forest and landscape was added AFTER that grid)



Anyone else having trouble disabling soft inpainting via API?
Kek. Electri Boogaloo
been having a weird problem since the last git pull update from yesterday, after everything loads correctly from the webui.bat and it auto opens web ui it will sit there frozen/loading with timers above the checkpoint/clip and anything else pinned to the top for 500s then error connection pops up like 6 times then its useable like normal. happens every time if i close the window and reopen a new one from the local url. have to wait 500s if i reload the ui to change something have to wait the 500s. Was fine before the update so idk what happened
ive installed reactor extension but it doesnt swap faces what problem can be?
Hey, can you show your txt2img settings? Also what's your GPU?
To start fixing stuff open up a cmd and type
SFC /scannow
That will fix corrupt system files
Missing insight face
What's your GPU and what's inside your webui-user.bat
Where can I download the missing file?
This is just what it will normally use for me regardless of if it interrupts or not.
You have to follow the instructions by Reactor:
https://github.com/Gourieff/sd-webui-reactor?tab=readme-ov-file#installation

GitHub
Fast and Simple Face Swap Extension for StableDiffusion WebUI (A1111 SD WebUI, SD WebUI Forge, SD.Next, Cagliostro) - Gourieff/sd-webui-reactor
Sure thing!
I run everything on a gigabyte 3090ti
Parameters for the weird minimalist cubic failed image:
score_9, score_8_up, score_7_up, score_6_up, score_5_up, score_4_up, (close-up) of a large radiant human paladin, wearing (huge plated armor, bucket helmet, bucket on head, large shoulder pads, blue cloak on back), holding a stick in his hand, striking a pose, mountain peak, sunny day, clear skies, castle in background, concept art, realistic, fog, volumetric lighting, depth of field, macro lens, <lora:Concept Art Twilight Style SDXL_LoRA_Pony Diffusion V6 XL:0.8>, lora:xl_more_art-full_v1:0.6
Negative prompt: face, food
Steps: 25, Sampler: Euler a, Schedule type: Automatic, CFG scale: 7, Seed: 3675776181, Size: 1344x896, Model hash: 67ab2fd8ec, Model: ponyDiffusionV6XL_v6StartWithThisOne, VAE hash: 235745af8d, VAE: sdxl_vae.safetensors, Clip skip: 2, Lora hashes: "Concept Art Twilight Style SDXL_LoRA_Pony Diffusion V6 XL: e5fe96cd307b, xl_more_art-full_v1: fe3b4816be83", Version: v1.9.3
I'll try the SFC /scannow
4070 super and no commandlines inside it execpt for git pull and pause at the top
Then you should add --xformers --no-half-vae to the Commandline_args=
Also make sure to always launch the webui-user.bat
And not the webui.bat
And if you still get an error check what model it tries to load
Ah pony model. These models can break easily by using a wrong word, not compatible lora or a wrong setting in auto1111
Yeah, I've noticed the model breaking quite often - but that usually appears like a completely different kind of artefacting. This is just straight up every single model - both sd and sdxl getting crunched.
It also just happened quite suddenly, and has meant a complete non-progress of any stable diffusion on y pc
And your using a fresh Auto1111 install?
Is there a plugin, that allows you to re-name Lora's, in the Lora list, without having to go into the Lora folder to locate it?
Maybe try a normal sdxl model without using any lora or embedding
Yep
Tried completely fresh install, re-downloaded all models and loras, tried without loras... all sorts
I use to have those in the command lines but tried uninstalling and reinstalling to see if it would fix it so currently didn't have them in the commands problem happens with either, but if i leave the url open after its already loaded i don't have to wait
Tried to run the SFC /scannow - it found some corrupted files and repaired them but results are still the same

What can I do to either fix it, or abandon my current generation and moveo n
Lemme guess, it gets stuck on 4s?
Well
And slowly adds a second eveyr ~5 sec?
Was i guessing correct?
CRYING IS NOT AN ASWER! 
It's an admission of the painful truth and reality
Kek
Mine does the same
I let it sit. But because my gpu is a bit old, if it surpasses an added 60 sec to the timer, I assume its frozen
And reboot the webui.
I switched mine to run in Firefox... Well, I've made it my home page, on firefox
Also check out a different browser. Someone had problems in chrome since an update
What happens when you use an 1.5 model?
i use brave which runs on chromium tested out edge real quick seems to be the problem is chrome based browser
Did it worked in Firefox?
I can generate a 512x512 image mostly fine (bear in mind i don't use 1.5 much since switching to sdxl, so i don't know whether the quality has tanked) but slowly for each image generation it becomes more unstable (like the sdxl images i showed) and if i do a batch generation of 8 images at once (something that my pc used to be perfectly fine with, never had any problems) i can literally see how it's completing less and less images for each generation, using the same parameters every time until it spits out vram errors
I'm trying to replicate a picture from CIVITAI but some reason my output is a lot different
You could try to pull the meta data from png info?

Is it because I don't know what these are and I'm putting them in the wrong location?
I think I'm adding them all as LORAs
I'm using Automatic1111 by the way
Checkpoint is the top left spot, Lora are added as lora ofc. Embeds go in the embed folder, X:\A1111\stable-diffusion-webui\embeddings
Lycoris... However, I'm not sure what, and how they work. CS1o would know
Idiot
Scuse me?
Of course I put them in the LORA folder olol
I'll put them in the other one and try again
Me not you
Ah, i c 🙂
CS1o is awesome, he's super helpful

Lemme know when you find out what lycoris is, and how they work
so upon further testing it looks like it wasn't any of the browsers chrome, firefox, edge all work its an extenstion i have in brave my main one and its the Malwarebytes browser guard extension that after the newest update is causing it to load in slow taking the 500s timeout connection before being useable. disabling it allows it to boot right up disabling causes the issue now why its causing an issue and why after the newst git pull update i have no clue lol
Well

I got these things like Realistic Vision, BetterFreckle etc that was spat out for prompts
Yes the webui has to be whitelised in any adblocker browser extension
Problem is, it seems I need to add them myself from the LORA tab.. but I don't know their weighting.
LOL ;d
is that a new change? because i've never had the issue before
Really strange
Neither and I use uBlock and stuff.
Imo, just get a seperate browser, and change that browsers home page, to the webui 😄
Allows a clean client, without any interference from anything
Goddammit it keeps going to tits.
Generating tits doesn't sound too bad... Unless its a male character
I wish the layout of information spat out from CIVITAI was easier to understand.
I mean tits as in.. it's bad. ';d
What drives me up the wall is so many LORAs and so on have confusing names, and don't show up the same way in the client.
It depends on the browser extension
Thats why i spent like 2 hrs yesterday, making preview thumbnails, and re-naming all of my LORA's

Gah, idiot again..
I should have started with 0.4
I thought 0.8 was enough
Maybe even less
Btw, @ornate elk Happen to know of an extension that allows me to re-name Lora's IN the webui?
Wait, is there a standard / default weighting when CIVITAI uses it?
Doesn't png info tab show all of this info, if you're trying to replicate an image?
Yes that'd be nice.. also how to make the LORA's either have pictures or smaller icons. I feel like I'm playing YU-GI-OH
Sadly it just says what's used, but not the weighting
Wait
..... Ooooh..
It should if you send it to txt2img
As long as its a png file, it should have all of the meta data it can draw information from
HELL-E-YEAH
There is a setting in the webui which makes it display the original file names, then you can rename it I guess
Wait nevermind, it still failed lol
I mean the prompt reverse worked, but the LORA info or SOMETHING is still missing..
You see, the issue is i May have named a few things, the same, with minor variations, such as Lora1, and Lora1,2
Is it possible some CIVITAI stuff is omitted from users or something unless specifically published?
Or Lora.1, lora1,
Wait
And i wanna clean up my lora folder, cause i have a few... invalid ones

Settings > Stable Diffusion > Clip Skip

Trying to find an easier way to do it
What does it do? :f
No idea, but i see a crap ton of images from civit, using clip skip, so figured having it easily available would be beneficial :;D
Well god damn it this whole time this might've been my issue.
My python. AND taskmanager both crashed 😐

So Python crashed so bad, i can no longer close the cmd window
Usually what I do is I just press X, anywhere on the window, then click 'cancel' on the popup window
Yeah, the window that asks if i want to end the process, doesn't even work xD
I mean it pops up, but doesn't work
Yeah clicking cancel for some reason is what makes it proceed
At least for me. Like don't press 'OK'
Nop. Cancel just closes the box xD
It's like some weird reverse psychology thing
Weird.
I must have some tweak in my PC that set a registry entry to have like 0 wait time on hanging programs or something
Because the moment I press cancel it just kills it
Right. Nothing works, brb rebooting pc i guess
Or not... Reboot doesn't work either
Hard rebooting it then
what does that mean

Humm
Are you still here
Try to do a safe one.. :<
:C
Yep
It's without a doubt the fact I don't know the correct LORA weightings.
How annoying. CIVITAI doesn't say what they are.
CS1oooo!!!!!
I have returned. FOr some reason, my gpu refuses to display over displayport, after a hard crash
So gotta unplug it, wait for it to boot up via the hdmi, then reboot and plug DP back in
:c
Unplug what
over Displayport, after a hard crash, so i gotta unplug it 😉
No no, that won't work
Well I give up. :C
.. Stupid LORA weightings
You suck ;U
I'll try again later.. maybe we can learn how they work better sometime together. :x

I just figured out how to fix this and my results changed crazy.
Incompatible stuff used together
Btw @ornate elk my issues got solved by just deleting the ui-config file and move my wildcards before civitai+ updates them and adds html's and pictures. (???) lol
ahh okay
Will git checkout dev fuck up my forge you think 🤔
it probably does
its dev
I HAVE LEARNED! To actually ask someone first before I do something that I have a bad feeling about
Feelsgoodman
Man I wanted to try that sweet euler a karras
is this controlnet?

Hi! I'm in the "--skip-torch-cuda-test" bucket of people, is there another way to force it to use my GPU? As far as I understand this makes it use my CPU, and it's slow. I'm waiting 5-ish minutes for an image.
:CriesIn1080TI: @ 1-2 min 😦
Hey, what's your GPU?
Hey guys, what's the deal on using the API for adult content? Is that a content policy issue?
AMD Radeon RX 7700 XT
Then you need to follow my AMD Zluda webui install guide.
Its in the pinned messages of this channel
With that you can use Stable-diffusion on your GPU
You're a good person, I appreciate you!
No problem 🙂
Feel free to ask if you have any questions
@ornate elk Friend! I think i made a boo boo.
I installed https://github.com/lllyasviel/ControlNet-v1-1-nightly first, then after reading (After importing it), that its NOT for A1111. I then, installed the correct version (https://github.com/Mikubill/sd-webui-controlnet), and restarted the UI... Now i can't boot it back up

Does anyone use Replacer addon with SDNext?
that pydantic error appears when using a not updated controlnet version.
Can be resolved by doing this:
Go into the stable-diffusion-webui folder. Click in the explorer bar (not search bar)
Type in cmd and hit enter.
Run the three commands one by one:
venv\Scripts\activate pip install albumentations==1.4.3 pip install pydantic==1.10.15
Then relaunch the webui-user.bat

Must've made a typo, this time it installed
Is still not liking it @ornate elk 😦

Running the cmd's again, yields this

Hi, I'm getting this error with Kohya. What can I do?
File "E:\AI\Kohya\kohya_ss\sd-scripts\sdxl_train_network.py", line 185, in <module>
trainer.train(args)
File "E:\AI\Kohya\kohya_ss\sd-scripts\train_network.py", line 272, in train
train_dataset_group.cache_latents(vae, args.vae_batch_size, args.cache_latents_to_disk, accelerator.is_main_process)
File "E:\AI\Kohya\kohya_ss\sd-scripts\library\train_util.py", line 2080, in cache_latents
dataset.cache_latents(vae, vae_batch_size, cache_to_disk, is_main_process)
File "E:\AI\Kohya\kohya_ss\sd-scripts\library\train_util.py", line 1023, in cache_latents
cache_batch_latents(vae, cache_to_disk, batch, subset.flip_aug, subset.random_crop)
File "E:\AI\Kohya\kohya_ss\sd-scripts\library\train_util.py", line 2428, in cache_batch_latents
raise RuntimeError(f"NaN detected in latents: {info.absolute_path}")
RuntimeError: NaN detected in latents: E:\AI\Regularizacion\Maru IA\1_ohwx\ohwx (1).png
Traceback (most recent call last):
File "C:\Python\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Python\Python310\lib\runpy.py", line 86, in run_code
exec(code, run_globals)
File "E:\AI\Kohya\kohya_ss\venv\Scripts\accelerate.EXE_main.py", line 7, in <module>
File "E:\AI\Kohya\kohya_ss\venv\lib\site-packages\accelerate\commands\accelerate_cli.py", line 47, in main
args.func(args)
File "E:\AI\Kohya\kohya_ss\venv\lib\site-packages\accelerate\commands\launch.py", line 1017, in launch_command
simple_launcher(args)
File "E:\AI\Kohya\kohya_ss\venv\lib\site-packages\accelerate\commands\launch.py", line 637, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['E:\AI\Kohya\kohya_ss\venv\Scripts\python.exe', 'E:/AI/Kohya/kohya_ss/sd-scripts/sdxl_train_network.py', '--config_file', 'E:/AI/New Training Data\model/config_lora-20240519-191339.toml']' returned non-zero exit status 1.
19:15:40-249264 INFO Training has ended.
Trying to crop my img but this happen 😦


#🤝|tech-support message Fixed it by deleting the Venv folder, and launching the Webui.bat file to reinstall the venv folder
I just create an embedding for training a new model but there's nothing in the embedding drop list, ive restarted and refreshed it. There's jsut nothing 😦

can anyone help with this🥺
Alright, another edge case with my AMD gpu. Is there a way to run rembg (remove background) in A1111 on cpu instead of it trying to use gpu? It keeps trying to use cudnn...
foocus running slower on my new gpu 16 gb than my 4 gm one lol
Is it possible to get support for Stability Platform API from somebody from the team here? Been trying to reach out over email and helpdesk with no success. We got some billing issues which prevent us from giving money to Stability 🙂
Hi everyone, I am trying to install SD and I am getting this error
RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
What is the best way to solve? I am quite new to this so plrease excuse my ignorance. Many thanks in advance...!
@woeful pendant Are you here by chance?
I have been having a VERY windows specific error for Months and you are the only one I remember in the past being able to help me fix it. It has been driving me absolutely insane because it makes literally negative sense. If you could spare a little time, I would appreciate it immensely
Its not specific to SD, just installed programs as a whole (been affecting LLM's the most)
yes
Would you be willing to take a look? I have exhausted so many options and it makes no logical sense at all. I would be immensely grateful 😅
what is happening or it doing it shouldn't?
its such a simple/stupid error

this has been haunting me for MONTHS
I can't build anything at all on my system
It tells me it can't find it, but then when I ask it to print my CUDA_HOME var, it prints it

This has literally been ruining everything I do with AI for well over half a year, and I can't find any information on how to fix it or what would even cause it
I have reinstalled python, cuda, my GPU drivers, VSC, C++, everything so many different times, and its never fixed or even changed it. Its just never worked on this PC
Cuda 11.7/11.8/12.0/12.1/12.2 all do it
Same with python 38/39/310/311
I don't use that but in a cli type echo %CUDA_HOME%
wait...

remove the type, lol
type?
as in typing just type echo %CUDA_HOME%

there it is
I even tried manually setting it for the operation in windows using the set function, but it STILL tells me its undefined
have you installed the cuda toolkit?
over 10 different times
clean installs
I can re-install again
Hello, anyone knew how to install stable diffusion on computer?
You use conda?
I do not use conda, but it does seem to work inside conda for whatever reason. Though I have some programs that specifically say they are not compatible with running in conda
auto install scripts work fine
but if I run the individual commands manually to install in my own venv, it never works
I forget how censorious this discord is but I did find this
As I think other people may end up here from an unrelated search: conda simply provides the necessary - and in most cases minimal - CUDA shared libraries for your packages (i.e. a bunch of .so files). I don't think it also provides nvcc so you probably shouldn't be relying on it for other installations. (I ran find and it didn't show up).
If you need to install packages with separate CUDA versions, you can install separate versions without any issues. The downside is you'll need to set CUDA_HOME every time.
The error in this issue is from torch. So you can do:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
and it should load correctly.
Just revise to current versions.
that last line is me. conda and torch can be problematic
unfortunately I need NVCC for a lot of these
conda has its own evironment variables
I just don't understand why windows can't seem to find a file it points directly at
it isn't windows at fault here
It seems I have a problem with my A1111:
I switched my base model from SD1.5 to SDXL and wanted to select the Fantasy Warriors LoRA - only to find out it isn't displayed there despite it being located in the matching folder looking in the Windows Explorer. Is that a display bug that can be solved with a simple re-start of A1111 or is that a deeper problem?
it is Conda it can't find it
What do you think is at fault in this case? I am at a loss
oh, this is not using conda
yes it is
I have other programs that do use conda, but this doesn't


you keep typing type

I never went past 12.1 as it had issues
When I try to build files, they all error our in conda, venv, and base PC saying they can't find cuda and that I do not have cuda installed
And some packages that I download say they can't find the DLL while looking in the exact folder with the DLL. If I disable the check, they work fine
I have had this on 11.7/11.8/12.0/12.1/12.2
Alright, I can send it
k