#🤝|tech-support
1 messages · Page 48 of 1
either i get no error or smth like server upload failed
image is showing in the img2img tab preview though
hi i'm new on stable diffusion. I ran it on Mac and got an error message saying: "TypeError: Cannot convert a MPS Tensor to float64 dtype as the MPS framework doesn't support float64. Please use float32 instead. I've read on forums that this can be fixed by entering the command: equalized_depth_tensor = torch.from_numpy(equalized_depth_array.astype(np.float32)).to(depth_tensor.device)". But I don't know in which file to enter this command. Someone else also said that they had succeeded in "Loading a different checkpoint" but I don't know what that means and what I should do. Thanks in advance!
Already pip install torch but still said module not found
I'm getting error 9009 but I have already set up the path as is in the directory for python.exe


Hey, what's your GPU?
And which python version did you installed?
4090 and python 3.12
ah
I need 3.10.6 sorry about that
Okay then remove the --skip-torch-cuda-test and instead add --xformers
Python 3.12 is not supported by SD.
Uninstall it and install 3.10.11 64bit
And check "add python to path"
Then delete the venv folder and relaunch
ty
Np
worked 
any idea how i would approach creating artworks which use the same artstyle of my brand's logo?
its pretty niche/unique and can't find any checkpoints/loras that go into that direction
enigmatic_e has an interesting video on style transfer adaptation for controlnet + ebsynth
ill watch the video
might be worth checking out, i have recently seen some stand-alone apps that do this, cant remember the name but searching
let me know as soon as you find out please
its frustrating not getting the results i want
i bet, have you dug into anything related to possibly doing your own model training, like maybe dreambooth
also checking this video out from SECcourses that is utilizing the T2I-adapter for controlnet
just tossing some stuff out that might be worth checking out that could spark an avenue for you to go down

Discord : https://bit.ly/SECoursesDiscord. New fantastic style transfer feature via T2I-Adapter added to the #ControlNet extension. If I have been of assistance to you and you would like to show your support for my work, please consider becoming a patron on 🥰 https://www.patreon.com/SECourses
Playlist of #StableDiffusion Tutorials, #Automatic11...
so i dont think the method he's using will help me much
my biggest problem is that i just wanna replicate the linework/shading work of something and use it to generate objects/people
cant find the standalone but i know it was something matt wolfe profiled recently, who runs futuretools.io
ill hit you up if i come across it sorry wasnt of more help
no worries
def dig around and start reading up on the functions of different controlnets, ie canny for outline/edges, etc
but in conjunction with other controlnets and a reference image, good luck mate
someone will def have better info than me, just tossing out some ideas
wonder how high these upscales can go
seems to really choke with 10k+ dimensions in forge (rtx 4090)
I'm having trouble with extensions
the whole panel kinda just doesnt want to work
in auto1111
cant Load from the extensions json nor manually add urls without it taking an unjustifiable time
actually they are working but adetailer aint
hi, Does anyone knows why it does that ?


Depends. Could be you have the wrong VAE. Could be you don't have Clip Skip set correctly. Could be too small of an image for the model type. Could be you touch yourself too much at night.
i'm gonna see abt that thx !
Next time you have trouble with your car, be sure that when you call the mechanic, you don't tell them what kind of car it is or what you're doing when the problem is happening...they love that; it's like a super hard puzzle they have to figure out.

Anyone have issues with A1

Reddit
Explore this post and more from the comfyui community
hi i am trying to use this but getting this error

what should I do
i have controlnet models, and controlnet installed in um auto1111,so i think it says me to isntall controlnet in comfyi?
“CIDAS/clipseg-rd64-refined” Please help me, should I download the entire folder or which part of the file in the hugging face, and which directory should I place the downloaded file in the local folder

When dealing with models from Hugging Face, you generally have two options:
Downloading the entire model: This would involve downloading the entire model along with its tokenizer and any associated files. You might want to do this if you plan on fine-tuning the model on your own data or using it for inference.
Downloading just the model weights: If you're only interested in using the model for inference and don't need to fine-tune it, you can simply download the model weights. This saves disk space and download time.
As for where to place the downloaded files in your local folder, it depends on how you plan to use the model. If you're using it in a Python script or a Jupyter notebook, you can specify the path to the model files directly in your code. If you're using a framework like Hugging Face's Transformers library, you can use the from_pretrained() method to load the model directly from the directory where you've placed the downloaded files.
My code foundation is relatively poor, and I don't know how to specify the path of the model
Can I just change the CIDAS/clipseg-rd64 defined here to my directory address

Are both modified
Yes, you can replace the "CIDAS/clipseg-rd64" directory with the directory address where you plan to store the downloaded model files on your local machine.
For example, if you've downloaded the model files and saved them in a directory named "my_models" located in your home directory, you would replace "CIDAS/clipseg-rd64" with something like "/home/your_username/my_models".
Hey Guys,
First of all Stable Diffusion is awesome❤️ .
We are getting consistent requests from our users to increase VRAM, 24GB VRAM is not enough & takes too much time with simple video workflows.
We have option for having bigger machine with 4-8 GPUs, but due to no support from SD apps for multi gpu, we can't do anything.
Any leads or information around multi gpu support would be great regarding A1111/ComfyUI.
stableswarm-ui is kind of based around multi gpu use if thats of any help
https://github.com/NimaNzrii/comfyui-popup_preview
guys this is a plugin which is supposed to pop up the comfy ui window. but how to do make it do it? there is no information on it. what the workflow is a custom node taking photoshop's canvas image and make it go through comfyui and giving a final output using controlnet and tiles. so how to i pop up the window, the 3 tutorials on youtube having this just show their window popped up, and no info on how they did it, I tried to contact owner of this node but can not reacch them out, please help
GitHub
popup preview for comfyui. Contribute to NimaNzrii/comfyui-popup_preview development by creating an account on GitHub.

Hi, I'm trying to understand the limits of resize with my GPU (RX 6700 12 GB VRAM), and tiled VAE settings
As I'm using SD XL I set the encoder Tile Size to 1024 (with the default it tells me it [Tiled VAE]: the input size is tiny and unnecessary to tile.)

I'm able to resxize in img2img to 1.2 or 1.3, images of 1344x768, 832x1216
But I don't see "hi-res fix" effect, usually it seems like it is bigger and with not added detail in texture


but I guess it is just trying, it adds texture sometimes but it seems the upscale is not enough, it seems SD upscale would be better. But I wanted to do the maximum resize in img2img and then use Ultimate upscaler

The thing is usually when I like an image it has some good textures already with the resolution it has, I just want to improve it but I find that this img2img process sometimes kind of breaks in some parts the image and enlarged it with artifacts, I guess it just trial and error maybe.
On the other hand SD upscaler usually kills some details but doesn't add artifacts



well low denoising kind of does it

Looking at his watch
to be on time
but I can resize to 1.3 with or without Tiled VAE, I don't understand what's the deal with that
I can't resize to 1.4, with or without Tiled VAE
what's the deal with it?

I have just one question, what is difference between these two?
one is 136 mb, and other is 1.5gb (also have 13 same for canny lineart etc).
But what is special about this rank128 lora tile... it does good stuff controlling image
so i am surprised what it acutally is because there are 30 others there along with these, i wnder what they do

@vocal burrow do u know ,sry for ping but i hope u avaialble
the image on the left looks very familiar
that happens with Euler A and some other A samplers on macOS 14.4 with PyTorch 2.2.0 and later
if that is the case, just revert PyTorch to 2.1.2 with
venv/bin/pip install torch==2.1.2 torchvision==0.16.2
form your stabile diffusion folder
since that blue-colored noise is very specific, I am 99% sure you are on macOS 14.4
if he drove a Mercedes in the official Mercedes service, mechanics there will know what car that is, and they might guess what the problem is based on common problems that occur to owners of the same car model 🙈
so, similar to that, I am sure that it is macOS 14.4 with Euler A (or some other ancestral sampler) 🤣
I will never forget that blue noise 🙈
fortunately, that happens only in specific combination of os and torch version, and can be fixed by reverting torch to older version. also other samlpers (non ancenstral ones) works fine
You're making an assumption that he'd be calling the right auto shop, though. Imagine the results if he was driving a Mercedes and called a general auto shop that wasn't brand-specific...then he just said that the car "makes a sound". That's closer to what's happened here. You can get that type of noise result from more than one circumstance.

don't get me wrong, i agree with you 100%, but i can't forget that _____ anytime soon, and my frustration from that day - THANK YOU APPLE!!!!

i got blue one 🙂
that guy got this
wait...

mine was the same
hmm, where i saw that blue one then
There are 2 things that just bug the shit out of me on this server that happen constantly.
- People who come in to get help and only give you one tiny slice of their configuration as if there is only one variable in the equation. (Similar to the above.)
- All the people who join the server, hit some random channel with a "command" to prompt for an image. These people took absolutely ZERO time to read anything at all on the server, including the list of channels and assume that they can just pop in and get a free image without reading.
i am on windows and i still get this noise actually. never got whole blue color though.
and then after 4 hours of you trying to recommend them, they feel lazy to solve it, or give up, and then leave like there is no error in life.
the 3rd group is the worst of all
people who do not want to listen
it bugs me when the error does not get solved and they dont even try basic thing.

I especially love the guys that don't bother to thank you after you put work in giving qualified answers.
Imagine moderating all this 
A cat.
Yeah...but at least in the above case, they did thank me...even with my initial sarcasm. 😄
I've been in that situation before. Used to handle several large communities. It's a job in and of itself.
Much respect to you guys.
and above all these, the people who think you are purchased by them and its your legal obligation to help them, else they will shout and curse at last.
Those are just straight up Karens.
even karens are polite than them lol
Yeah, we are a community and not a customer service. I like to help out but....
This is one of my favorite google image searches to demonstrate Karens:
https://www.google.com/search?client=firefox-b-1-d&sca_esv=cdc18846ebd0314a&q="I'd+like+to+see+the+manager"+haircut&tbm=isch&source=lnms&prmd=ivsnmbtz&sa=X&ved=2ahUKEwi2z5Gbo4WFAxUcIUQIHTxIC74Q0pQJegQIERAB&biw=1773&bih=907&dpr=1.09
lmaoo
excuse me dear person can you answer me why this is not making the image? (screenshot included)

now it is doing this. please help.

...or how about the ones that are just:
"HALP!?"
if anyone familir with this pls let me i am still thinking about this 😅
to be honest, i can eyeball quite a few things, doesn't angry up my blood as much. and a lot of people have never worked with open source projects or anything beyond polished, push button apps. 🙂
i wish discord had a feature that if i click and drag over text in a jpg it just did some OCR and let me copy it.
Well, I'm going to guess that the one that isn't listed as fp16 is a larger file than the one that is. (I'm not looking up the files or anything, just basing this on name.) So I'd imagine the fp16 is a lower precision file to reduce vram use.
Just a guess, though.
Yea not here but at other places, It made me more polite. since even if they shout or curse, act rude, I just smile laugh and continue... earlier i used to get upset. Dealing with more rude people just gave me more patience or a laugh i guess.
oh that makes perfect sense. since small one is way faster and result is almost close. i guess its lite version of main.
did anyone here had problems with the civitai browser+?
When i try to use it, i keep getting error. I already restarted the webui, updated it, reinstalled it, i keep getting error
1girl, not reading the rules, not getting an image, bot is down, masterpiece
totally true ^^
You forgot the negative prompt, though.
woman, girl, ugly, old, fat, slight, disgusting, Unflattering, Distorted, Poorly lit, Blurry, Grainy, Overexposed, Underexposed, Cluttered background, Distracting elements, Inconsistent theme, Unfocused, Harsh shadows, Glaring highlights, Mismatched colors, Unbalanced composition, Crooked, Tight framing, Excessive noise, Low contrast, Washed out, Oversaturated colors, Undersaturated colors, Awkward pose, Forced expression, Unnatural skin tones, Red-eye, Motion blur, Incorrect white balance, Uncomplementary background, Obstructed view, Uncoordinated color scheme, Dull lighting, Unappealing angle, Lack of depth, Disproportionate features, Unsympathetic expression, Incoherent theme, Overwhelmed by props, Lacking focus point, Disjointed composition, Inconsistent lighting, Unharmonious colors, Overprocessed, Underprocessed, Lacks emotion, Non-engaging, Stereotypical, Clichéd, Predictable, Uninspired setting, Misaligned elements, Disconnected from viewer, Unoriginal, Repetitive theme, Jarring contrasts, Uncoordinated elements, Stark lighting, Excessive editing, Unnatural enhancements, Overdone effects, Lack of authenticity, Artificial atmosphere, Forced theme, Unintentional subject, Unrelated elements, Incongruous style, Misplaced focus, Inappropriate mood, Overstated drama, Exaggerated features, Lack of subtlety, Inharmonious composition, Unnecessary distractions, Overcrowded, Simplistic, Unrefined technique, Lacking sophistication, Amateurish, Inelegant, Non-artistic, Lacks narrative, Unconvincing portrayal, Unpolished, Unprofessional, Inconsistent with theme, Muddled colors, Uncomplimentary lighting, Inadequate exposure, Imbalanced elements, Disproportionate composition, Overlooked details, Lacks depth of field, Unremarkable, Forgettable, Unimaginative, Monotonous, Tiresome, Uninspiring, , Tedious, Lackluster, Unattractive, Aged, Overweight, Underweight, Repulsive, Disheveled, Scarred, Detestable, Unpleasant, Wrinkled
😄 😄 😄
haha xD
Just for giggles from Juggernaut XL v9 with that +/- prompting.

The bot is down portion of the image made me lol.
haha and shes reading the negatives
Technically, she's not reading them, as your prompt requests; her eyes are closed.
Good job, Juggernaut.
lol
true xD
thought shes looking down at first
but they are closed ^^
I feel like my work here meant something today with that image. I'm gonna consider today a win. 😄
Yeah...it did well with that one.
Coming back to this...are you running Windows?
i am
You should install PowerToys. Among the many useful tools, they have Text Extractor, which is pretty much exactly what you're looking for. You hit Win+Shif+T (which is configurable, if needed), and it will OCR pull text out of anything on your screen that you drag the box over.
id just like to quickly grab people's goddamn error codes, might give that a whirl
Powertoys is amazing
It's fantastic.
Fancy Zones is my favorite thing in the pack...super useful for anyone with multi-monitor or 4k monitors.
so true, thats why i got it too, for fancy zones and an portrait mode 24inch monitor, so i can split stuff on it
and power rename and locksmith saved me too sometimes
Locksmith is a nice tool for the toolbag for sure. I also frequently use the color picker.
and "Awake" on my laptop for work xD
thank god theres an exe for it. ill be damned if im going through windows store for anything.
omg that is EXACTLY what i had in mind.

thanks so much guys
now i just need to append it to lmgtfy urls 😄 jk
ok, and fancyzones is immediately going to help me too, im always working from a window into another
Spend the time to check out every feature...there's so much buried in there. At this point, I don't know why Microsoft hasn't just incorporated it officially.
oh i am, its sort of like when i used to get stocking filler gifts as a kid at christmas
one of the pose editors integrates with controlnet and doesnt live in a tab
make a controlnet pose in controlnet and see if you have an edit button appear on the output image with the pose skeleton
know what i want now? similar hotkey, take a screen snip but a CLIP/BLIP interrogation. might be a fun little diy project
you dont need any of those
its integrated and also supported by photopea
you just need to load an image into controlnet
then select openpose preprocessor and click on the Explosion icon
then you get a Preview of the pose, which you can edit when clicking the Edit button or the Editp button
Hi guys, i've been trying to installing SD on Paperspace gradiant on Pythorch, but everytime i keep getting the same error that checkpoint isnt loading, can someone help me fix this?
or if there's a guide for it, i looked for it but couldn't find
I'm sorry, I'm asking again. After changing the address, I still reported an error. I tried to find the answer through GPT, but I failed
@scarlet igloo plz share your screenshots.


It still failed to load on my cloud server


This is my error message and the file I downloaded
Thank you very much for your help. If you need me to provide other screenshots, please let me know
good
Where do I download the installer for Stable diffusion 3?
Not available yet

Question, does anyone know the extension to show generated images as gallery? I can't find it after a reinstall.
oh there was one i remember it had masonry in the description card, but it doesnt seem to work anymore
gpt is too stupid for that...lol... the Python traceback errors were best dealt with by Github Copilot. phind can also git it. Just send the traceback error to www.phind.com.
i would like to ask for help. i tried cascade extension on SD Auromatic1111 but it says error. i also tried to delete it, but it downloaded the models somewhere in my c drive (i have the webui on D drive) "https://github.com/blue-pen5805/sdweb-easy-stablecascade-diffusers.git"

quick tip: any time you see module <something> has no attribute <something> the first thing you should do is update both the extension and the client you're using. That's nearly always a symptom of one big of code, expecting another bit code thats not there anymore after an update, for example an updated package version.
thank you i will try but i don't think that's the issue. also my biggest problem is that i don't know where did the extension downloaded the cascade models in c drive and it takes a hell of space
if you have absolutely no idea where they could be in C:. Install windirStat which shows you the folders and files with the amount of space required and also shows you the big files.
hey thanks.
windirstat is going to give you a heart attack, its like looking at your bank balance and seeing where all your money went 😄
You can also display the big files on C: using the CMD or in powershell, but I don't have the necessary knowledge about Windows when it comes to the command... but just ask Google.
for samplers do you or anyone have an opinion on what tends to be more detailed/realistic?
SDE karris seems to be potentially higher quality output then 2m karris, requiring longer processing
also then does 3m sde karris > 2m sde karris > sde karris?
I also find the color block display in Windirstat extremely intense... I definitely like the circular display like in Linux better. He should just look at the file path to find the modules.
https://stable-diffusion-art.com/samplers/ honestly, it depends on how many steps and if you want the steps to build closely on the ones before or not. its salt to taste and like wine sampling and talking about expensive headphones, anyone can say, oh i DEFINITELY perfer chateaux de SDE karris ++ --, but its likely something you convince yourself of.

Many sampling methods are available in AUTOMATIC1111. Euler a, Heun, DDIM... What are samplers? How do they work? What is the difference between them? Which
from comments: `
Here’s a decent choice:
Good speed – DPM++ 2M Karras.
Good quality – DPM++SDE Karras
` I can't really disagree or add more
skill issue
care to elaborate?
playground vae wont load
ok, we're up to four words now. do you have errors, screenshots? logs?
sorry about that  next time i will give you more information but for now its fixed so thanks you 🙏
next time i will give you more information but for now its fixed so thanks you 🙏
biased sampler tierlist:
s: dpm++ 2s karras
a: dpm++ 2m karras | dpm++ sde karras | ddpm
b: euler a
c: all others
well maybe not all others
but most
Do you mean 'infinite image browser' ? It's available under extensions, available at default location, just search it with CTRL F or in the search bar

So yeah, turning off the nvidia setting that swaps to ram after vram runs out didnt seem to help. Still 6 hour render at 600 max frames... Im assuming this isnt normal?

and cpu is hovering around 50 to 70 percent, took the screenshot right on a 100% spike accidentally
What are you trying to do?
its a deforum render, 600 max frames
if thats what youre asking
havent attempted a render in weeks but the last time i did i had the same issue and was told to change that nvidia setting i mentioned. Doesnt seem to have sped anything up
Okay, do you use xformers ?
that sounds familiar and i think i am but where can i check again?
Changing the nvidia setting isnt good. Because it won't help in speed, it just crashes if it runs our of vram
Make sure your using --xformers --medvram --no-half
In your webui-user.bat
interesting, the other person i replied to in general said it would make it faster, unless i misunderstood him
ok will check right now
For the best performance for your gpu
yeah for some reason my actual gpu utilization is only around 4% rn
You have to check the Cuda graph in taskmanager
When clicking on 3D
If cuda usage is at 100% its normal
these both look alright?


Yes looks good
dang
so do you think that render time is normal then or what
so i guess im not running out of vram either right? Since it should be crashing due to turning that setting off?
Yes should be normal with that GPU.
Yes in the screenshot you see the GPU vram is not maxed out
So no crash, but better to have the ram swap enabled
In any case, its better if you do higher resolution images
oh really i would have assumed the opposite lol
No I mean not I general
oh youre saying better results
I mean its better to have the ram swap enabled if you do higher resolution imagrs
gotcha
yeah ill enable the setting back on after this generation
or do you think it would be fine to do during it
i mean wont really matter cuz the eta wasnt different with it on or off lol
Idk, but I wouldn't run 6hour task now. Make that over night if you can xD
true LOL but these are reall my first ever attempts so i want to get like a good handle on how to control the results if that makes sense
just wish i could do something much quicker even if its low wualkity just to basically practice deforum prompts and settings and stuff if uk what i mean
Yea but everything video related will be slow on a 1660
@wheat helm Idk what your goal is but maybe you should try out the Loopback wavescript.
It needs lesser frames and with interpolation you can double the frames as often as you want
my final final goal with diffusion is just to make relatively short (30 to 60 second) videos to go with music for like instagram lol
never heard of loopback whats that?
LOL thats alright i can wait
Loopback wave script is a script where you can alternate an image to an animation. So you input an image in img2img and then you can prompt for changes the image will get
Then you get multiple frames and a small video file of it
Its pretty aweseome when used with interpolation (video frame generation)
interesting so it sorta sounds like a mini deforum with an init image?
Yes exactly
i may as well give that a shot too also yeah sounds cool
Here is the setup doc with the script:
https://rentry.co/sd-loopback-wave
Its not as difficult as this may look like ^^
The loopback wave script is an img2img script which modulates the denoising strength in a sinusoidal fasion, then produces a video from it. The effect this produces is a "stable" image, followed by a gradual then drastic change to another image which then also stabilizes.
Loopback Wave...
Would love to show you my example but discord upload hangs on 75%
ahh thats anoyying but thansk anyway definitely gunna check it out!
at the very least it sounds like it would be useful for quicker exports to test different ai styles or whatever theyre called
checkpoints? forget what theyre called
Yea checkpoints, but to compare stuff in auto1111 you can use the x/y/z script in txt2img
xyz script?
Yes
Its a function to compare everything with everything
Checkpoints, loras, steps, cfg,
well that seems useful lol where is it? Im under txt2img and dont see it
is it just the prompt box?
At the bottom at scripts
ahh got it x/y/z plot
thanks
do you know if you can use that whilst a deforum is generating or no
Nope
alright thats ok
Deforum is its own task
yeah i figured
thats ok tho that will help with getting some practice
not exactly sure how the script is different but ill find out haha
thanks for the tips
No problem ^^ if you have any questions feel free to ask.
I'm not at home but I can send some example of the x/y/z script later
Will do, appreciate that 👍
@wheat helm finally
Upload worked
That was a fast one, but you can do slower transformations too like here
oh nice thats loopback right? That could be cool, though i would prefer something longer like 30 to 60 seconds and camera movement etc (which is why deforum is so interesting to me) but i can certainly make good use of that as well
@ornate elk yo that piece is gorgeous, i barely learned about this tech like yesterday, very intriguing
the buildings in this kinda remind me of inception lol
100% inception lol he’s world building!
Yea thats with loopback
Thx, did you find the guide for installation?
If you have any questions feel free to ask here
I did! I’ll take a crack at it tomorrow
@wheat helm here is an example with x/y/z script, comparing different steps and the cfg scale:

Hi.
Help! What's happening here?
AttributeError: 'NoneType' object has no attribute 'mode'
cool thanks
would need full log to understand what s happenning there
hey guys i've installed inpaint anything but the tab is not showing even though the extension is activated in the extension tab
hey guys can anyone tell me here that we will do manually in blender to add stable diffusion if i buy stable diffusion api then it will work in my 3D model to convert real time image ?
check for erros in the console
I m not sure I understand what you re trying to do here.... blender's camera point of view -> stable diffusion -> image output ?
i dont think they want to use the 3d model as a reference image for an SD generation. either a) plausibly, some jiggerypokery where it textures the model which i think was being worked on or b) maybe, in a few years, generate from an image a 3d shape.
@light oxide work out very clearly what you want and what you expect before putting money down.
(in any case, forget about real time unless you have infinite tech startup money. Or you consider 10 fps with lots of temporal inconsistency to be ''real time'')
or a GPU farm and can work with postage stamp resolution.
i understand the need to generate a lot of images fast if youre doing animation, but for actually creating an image it seems pointless. reminds me of a woman i used to work with where she would take literally ~100 identical photos of herself over her break times, and delete all but one of them.
the only thing that i got is that: no module 'xformers'. Processing without...
did you restart sdwebui after installing the new extension ?
Also send the full log (in a .txt) so we can take a look at it
there you go
what extension are you trying to make work ?
(also what s your gpu ?)
@pastel cargo
Does more steps always mean more better? (Using SVD model and euler sampler).
I'd assume there's a limit where'd you go overboard with the numbers just like when training voice models
inpaint anything and my gpu is an RTX4070 laptop
uh no ? I answered you already ? Anything beyond 50 is bonkers. 20 / 35 is usually enough.
Hey everyone, when doing img2img with replacer extension, ive been having great images, but when i introduce imgs that are not square-like i get this error, any config to go around this? (im on amd but as i said square images work just fine)
the res i output is 512x512 usually

Sorry you wrote "no, cf" and linked to this tech support channel?
ok might as well throw --xformers in your webui-user.bat command line arguments then. it won t fix it but it will give you free performances boost.
I linked to a specific message.
Oh, I totally missed that. I rarely use Discord for servers/channels. Sorry
try clicking it again, sometimes discord can be messy with links
np
It worked now lmao
k i'm adding it what next ?
Hmm odd, I see a huge difference between 20 and 200 steps (doing img2video though)
extension hasn t had any updates for the past 5 months... looks like it needs to be updated/fixed. https://github.com/geekyutao/Inpaint-Anything/issues/141
uh okay
is there any other way to modify clothes on a character ? i made my avatar but i want to change its clothes
nvm i found a tutorial
if anyone could help i'd appreciate 🙂
what s the full log ? and what do you have in your webui-user.bat ?
have this in user: set COMMANDLINE_ARGS=--use-zluda --medvram-sdxl --update-all-extensions --update-check --skip-ort
this is the log
and it just crashes at the end of that
try delete venv folder an rerun
and when running again even if img is not squared should i keep res at 512x512?
oh god, groundingdino/segment anything were hell for me to install, even on cuda proper.
also, install_goundingdino ?? (e: nevermind, the typo is consistent for the function in the code)
Does anyone has any idea while trying inpainting in A1111 I get this error?: NotImplementedError: convolution_overrideable not implemented. You are likely triggering this with tensor backend other than CPU/CUDA/MKLDNN, if this is intended, please use TORCH_LIBRARY_IMPL to override this function
I'm on Mac
where and how do you set TORCH_LIBRARY_IMPL ? Is it a start command line argument?
are you running on cpu?
Everything seems to work ok but Inpaint:

I guess Mac (ARM) is somewhat diferent , it does run on GPU but not the usual way
I think one can set that argument at start, just dont remember how
Same error happens still 😦
What's the replacer extension?
I don't even know where this is, or how to do it, can someone explain it to me
Hi 👋 Any suggested latest command arguments for 6700 XT? I'm only using --use-directml
What's your GPU?
Okay, then you need to use:
--xformers --medvram --no-half
In the webui-user.bat at the line COMMANDLINE_ARGS
Then save and restart
Hey, did you also installed Segment anything?
Hey, you have two options.
First checkout my Directml guide for the needed commands.
Guide for directml:
#🤝|tech-support message
Second option:
You should switch to the zluda directml version, its much faster and has no vram problems like directml.
Guide for the zluda version:
#🤝|tech-support message
Yes 😄
Hmm I've tried using local groundino and disabling controlnet but neither work
strange that only occurs on photos with high height vs widht
Try making the height by width resolution divide by 64.
hello, i have a question, if i try the img2img Inpaint feature with Realistic_Vision_V2.0-inpainting.safetensors model, everything that i marked with the inpainting feature just gets turned black. I don`t know what to do
Could you explain a bit more? You mean I should tweak the output resolution?
Or edit the original image?
Hi, i'm trying to inpaint with a mask that's grey according to these instructions:
"The image passed to this parameter should be a black and white image that represents, at any pixel, the strength of inpainting based on how dark or light the given pixel is. Completely black pixels represent no inpainting strength while completely white pixels represent maximum strength."
But the final product just spits out the original image with all the grey areas still grey. It seems the API only interprets black or white pixels, nothing in between? Or am I missing something.
Hey gang is there a video that yall can direct me to for general knowledge and terminology regarding stable diffusion? I am figuring out I know absolutely nothing about this
hey guys, I delate my SD and now install it again because it has some problems
what do i need to be aware off after installing it
https://github.com/lllyasviel/stable-diffusion-webui-forge?tab=readme-ov-file do you recommend me this?
GitHub
Contribute to lllyasviel/stable-diffusion-webui-forge development by creating an account on GitHub.
Is it possible to queue a bunch of renders without running out of memory? (Using Comfy).
Have no issues running 1 render at a time, but if I queue e.g 10 at a time it "crashes" with error "Allocation on device 0 would exceed allowed memory. (out of memory)).


I downloaded roop extension but i just cant find it
But it is definitly there
any updates/info on controlnet functionality within WebUI Forge?
so i just dealte roop?
I'm curious if anyone knows how to recreate Wolfram's code for generating an image from the average of two text embeddings, as with the cat/plane hybrid in this essay. He's effectively generating an image that is halfway between two concepts in latent space, which is a fascinating thought.
The article links out to this code for a Wolfram notebook but it won't properly run on my computer because I don't have a GPU.
textEmbed[text_] :=
NetModel[{"CLIP Multi-domain Feature Extractor",
"InputDomain" -> "Text", "Architecture" -> "ViT-L/14"}][text,
NetPort[{"post_normalize", "Output"}]]
cat = textEmbed["A cat"];
dog = textEmbed["A plane"];
GraphicsGrid[
Partition[
ResourceFunction["StableDiffusionSynthesize", "Version" -> "1.0.0"][
Table[x cat + (1 - x) dog ->
BlockRandom[SeedRandom[254345];
RandomVariate[NormalDistribution[], {4, 64, 64}]], {x, 0, 1,
1/11}], BatchSize -> 5], 6]]
I'm not sure if this is the right channel for this so point me in the right direction if there's somewhere better
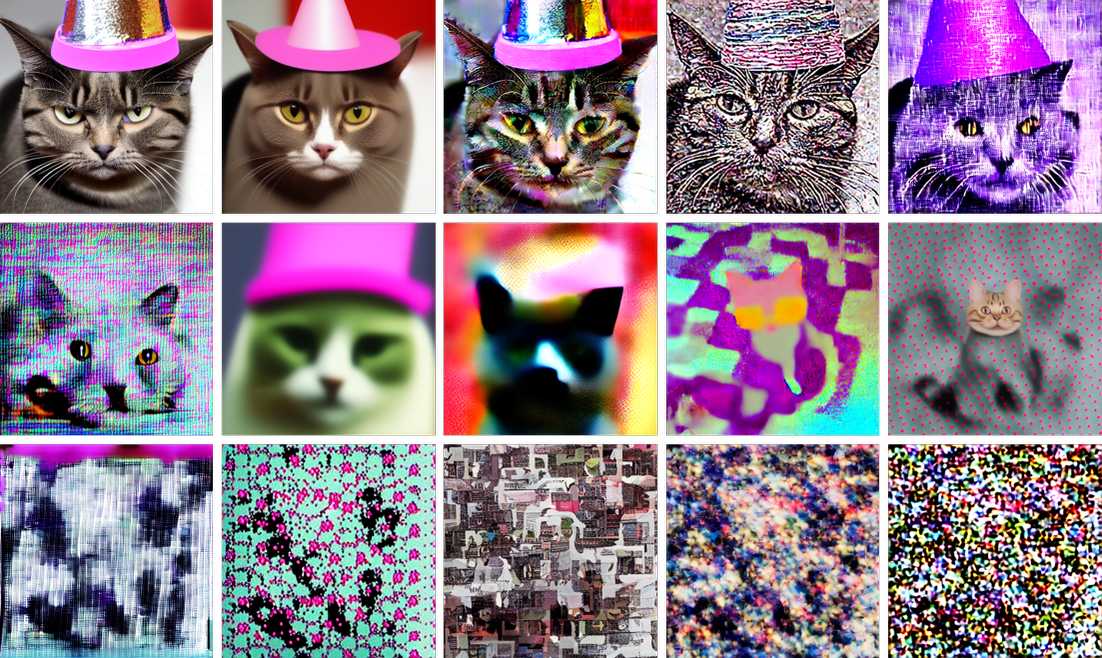
AI and the ruliad in the Wolfram Physics Project provide a new way to consider how alien minds might perceive the world. Stephen Wolfram explains how this artificial neuroscience experiment works.
>sees 16xx
> "use --no-half"
i dont blame you
just that auto decided to make the one thing that fixes 16xx not on with 16xx
i already following step by step in pinned chat but found this eror, can someone tell me what's the problem?

Your not following my guide step by step
My guide says to use Python 3.10.11
Also I didnt mentioned anywhere to use --precision full or --skip-torch-cuda-test
@smoky cape
The problem you have is already pointed out in the screenshot.
It says "Your Graphic card driver is to old"
So you need to update it.
Um I use 3.10.6 and the cuda test I used because I found eror torch is cannot use gpu (something like that) , and I found how to solve it from chat above
Alright I'm gonna try thanks dude
Np, what's your GPU btw?
Nvidia geforce rtx 3050 and and Radeon tm graphics
Oka then you only need --xformers --medvram --no-half-vae in your webui-user.bat
ok thanks again dude
suddenly It stopped showing embeddings and most of the lora. Doesnt matter if I refresh, restart or whatever. everything worked well in the morning

fixed lora one but embeddings still not appearing
fixed everything

hey there everyone, i hope this general chat is the right place to ask. So i got forge from Git into a folder, batched it, and indeed the webui showed up, but it says error and connection error. Anyone knows what to do? i never installed stable diffusion before, maybe that was a mistake to start with the ui?
hey, you need to make sure that you dont closed the cmd window
as this is the actual programm, and the browser is just the UI
Oh! damn thanks ill try that for sure! what a chad
I downloaded visual studio installer because of rope. Now that i shouldnt download roop, should I delate it or do i need that for something else?
And is reactor the same as roop?
if you dont want it you can delete it, for Reactor you either can use visual studio or the vcc build tools:
guide for the Reactor installation:
https://github.com/Gourieff/sd-webui-reactor?tab=readme-ov-file#installation
and yes reactor ist pretty much the same, its used for faceswap
nice
how to get decent hands 
Um I found a eror like this one
Importerror: cannot import name 'exposure' from 'skinmage' (unknown location)
What is exposure and skinmage?
try delete the venv folder and relaunch the webui-user.bat
okayy
anyone anyone know where I can find endpoint docs for comfy ui?
What do you mean by "endpoint docs"?
for api access
Is stable cascade still supported on Stable Diffusion A1111?
I'm looking for a little help to solve this error I get every time I want to generate an image with stable cascade

hey guys, I'm looking for learning content for using diffusers,
i've been using it for more than a month, and yet I've never succeeded in using it to the fullest with Civitai models and its resources
What tool are you using?
what do you mean by tools?
I mean how do you tried to use diffusers?
google colab
Most people here use so called "local webuis" to generate images
Or do You mean "how to get better results?"
yeah , you are right
the thing is I'm developing a service that generates image automatically, so i need to do "code" not web ui
api for what?
you means like a pipe from hugging face , or you mean rest api?
Rest API maybe
i'm aiming to use open-source services, so i host the stable diffusion in a certain machine and pass to it the work by an API
do you have any suggestions regard the diffusers thing?
maybe this is where I neede to be lol. sorry for posts in the wrong zone
Hey friends... Im on the struggle trying to figure out what I did wrong here. learning the video end of life and used the basic workflow.... but it breaks at ksampler. anything you see fast that im doing wrong?

Does anyone have any issue with using DreamshaperXL model? I'm fairly new to Stable Diffusion, A1111 and Forge, but the SDXL models, such as JuggernautXL and DreamshaperXL are giving me issues randomizing images even on low CFG scale (literally on 1). It gives me really similar images, no matter what I try. Same goes with negative prompts, eventhough i put wings in it, it still creates them with wings.
Using the Dreamshaper 1.5 model works flawlessly, so I feel like I'm definitely doing something wrong
for example, with a simple prompt using DreamshaperXL i get this:

settings:

any help to make it more random would be greatly appreciated!
Anyone able to clarify a few things for me?

My understanding is that Stable Diffusion prefers you use python version 3.10.6. Kohya ss however is complaining that I need version 3.10.9
Is this folder here a seperate installation of python that kohya exclusively uses?
Cause if it is then I guess the fix is simply installing the version it wants here.
You can run 3.10.9 just fine with A1111 or ComfyUI.
Hm, I thought I remember hearing something saying pytorch was incompatible with any other version
PyTorch works fine with pretty much any subversion of 3.8-3.11.
ah ok
perhaps the issue I had back when I first installed has since been fixed or became outdated.
I'm reinstalling A1111 and kohya on a new faster drive.
Hello, how come I am unable to use Stable Diffusions any longer? It says I am unable to message on the channels anymore
hi there, I am trying to train my own embeddings but failing. I followed this guidehttps://civitai.com/articles/5/beginners-guide-to-textual-inversion-and-publish-170-updated and have good source images but the results give what i call "clip art" images (as seen in the preview).
i get....


wtf!?
Topaz Video AI currently have a RX 6600 XT fps is really low would getting a MSI GeForce RTX 3060 Ventus 3X 12G OC increase fps a lot??
I have a AMD Radeon 5600 xt. Am I able to use deforum stable diffusion?

Hello, dear readers! Today I am pleased to bring you an exclusive preview of the new images generated with the incredible technology of Stable Diffusion 3. For those who are not yet familiar, Stable Diffusion 3 is a groundbreaking tool capable of creating impressive images in an innovative way. In this article, I invite everyone
Is this something new?
SD 3? and how can I download it
hey guys how does the SD upscale script work in img2img?
first time trying to do it and im not sure what tile overlap is, and is scale factor just the upscaler?
SD3 paper just came out in Feb, its on a waitlist right now
Probably yes but it would take hours
Got nthn but time yfm
Set the Denois below 0.3
Set the resolution to a square because the scripts uses tiles.
Then choose an upscaler and thats it
should i leave overlap @ 64?
Default is ok
ok thanks! 😄
i thought i had isolated this problem down to a specific extension in Forge, but apparantly I haven't. I have been having issues with Forge crashing while rendering lately, any insight or help would be most graciously accepted, thanks. going to post the error messages and then the contents of my webui-user.bat
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "D:\AI\stable-diffusion-webui-forge\stable-diffusion-webui-forge\venv\lib\site-packages\uvicorn\protocols\http\h11_impl.py", line 407, in run_asgi
result = await app( # type: ignore[func-returns-value]
File "D:\AI\stable-diffusion-webui-forge\stable-diffusion-webui-forge\venv\lib\site-packages\uvicorn\middleware\proxy_headers.py", line 69, in call
return await self.app(scope, receive, send)
File "D:\AI\stable-diffusion-webui-forge\stable-diffusion-webui-forge\venv\lib\site-packages\fastapi\applications.py", line 273, in call
await super().call(scope, receive, send)
File "D:\AI\stable-diffusion-webui-forge\stable-diffusion-webui-forge\venv\lib\site-packages\starlette\applications.py", line 122, in call
await self.middleware_stack(scope, receive, send)
File "D:\AI\stable-diffusion-webui-forge\stable-diffusion-webui-forge\venv\lib\site-packages\starlette\middleware\errors.py", line 184, in call
raise exc
File "D:\AI\stable-diffusion-webui-forge\stable-diffusion-webui-forge\venv\lib\site-packages\starlette\middleware\errors.py", line 162, in call
await self.app(scope, receive, _send)
the errors continue along this same path for another 20 lines or so....
*webui-user.bat
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
@REM Uncomment following code to reference an existing A1111 checkout.
set A1111_HOME="D:/AI/stable-diffusion-webui"
@REM
set COMMANDLINE_ARGS=%COMMANDLINE_ARGS% ^
--ckpt-dir %A1111_HOME%/models/Stable-diffusion ^
--hypernetwork-dir %A1111_HOME%/models/hypernetworks ^
--embeddings-dir %A1111_HOME%/embeddings ^
--lora-dir %A1111_HOME%/models/Lora ^
--controlnet-dir %A1111_HOME%/models/ControlNet ^
--cuda-malloc ^
--cuda-stream ^
call webui.bat
i kinda think that these issues started around the time of trying to utilize an extention called "Custom AutoLaunch Script" which allows Forge to launch in a non-default browser, but i have since unchecked the extention, removed it's folder. my last action was to delete VENV folder and allow it to rebuild, but am still stuck with this issue. thanks for any insight and Happy Saturday!
Is there an API call for A1111/Forge that can confirm which client is running?
if that was meant for me im not sure i understand, apologies
nvm I think I got it...
can anyone help me with issues with my SD?
i think i am going to have to do another full reinstall at this point, i wish i could figure out what is going wrong with Forge......even with every extension removed, and VENV delete, on an RTX3060 with 12GB of VRAM it is all of a sudden taking like 5 min for a single EulerA at 30 steps using COPAX XL model
toss out your question, hopefully someone can
define "wrong"
automatic1111? etc? forge/ which? any messges/errors in your command window? using vpn?
tried copying the 127.0.0...etc to different browser completely?
foreign language to me
what webUI are you using for stable diffusion? automatic1111?
lmao how do i find out?
from what source did you install stable diffusion? did you follow a YT video? an instructional page online??
yeah sure
dmed it to you
what video card do you have?
so you go to your StableDiffusion-Webui folder, you click on webui-user.bat to launch, then it opens up in a browser and this is where you get the connection errors?
yea
okay so in the command window, it is posting the status as it launches
so you get any type of error messages or other content which might be useful in helping to diagnose the issue?
There are three "no module"s but nothing else seems wrong
did you install Python before installing stable diffusion, or do you have it installed?
yea i have it
type python -version in to a command window
Traceback (most recent call last):
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py", line 488, in run_predict
output = await app.get_blocks().process_api(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1431, in process_api
result = await self.call_function(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1103, in call_function
prediction = await anyio.to_thread.run_sync(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py", line 807, in run
result = context.run(func, *args)
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\utils.py", line 707, in wrapper
response = f(args, **kwargs)
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\call_queue.py", line 95, in f
mem_stats = {k: -(v//-(10241024)) for k, v in shared.mem_mon.stop().items()}
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 92, in stop
return self.read()
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 77, in read
free, total = self.cuda_mem_get_info()
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 34, in cuda_mem_get_info
return torch.cuda.mem_get_info(index)
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\memory.py", line 618, in mem_get_info
return torch.cuda.cudart().cudaMemGetInfo(device)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
any1 wanna help me out with this 1 xd
ive given up when i see big error codes
what version of python?
3.10
it doesnt let me type into the command window
you would need to launch a different one windows-r CMD
3.10.6
i recommend wiping your install and then follow along with this video instead of the 60second version you used: https://www.youtube.com/watch?v=kqXpAKVQDNU&t=2s

Part 2: How to Use Stable Diffusion https://youtu.be/nJlHJZo66UA
Automatic1111 https://github.com/AUTOMATIC1111/stable-diffusion-webui
Install Python https://www.python.org/downloads/release/python-3106/
Install Git https://git-scm.com/download/win
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
Download a model https://civ...
k good deal good luck
 👍
👍
make sure that python gets appropriately added to the path evnironment variable (usually done at time of install with a tick box), otherwise YT or google this for more info
delete your venv folder after changing python
got this while following along

i do have space on my D drive but i think it might be trying to use my C drive
might go ahead and update pip and see if that helps, then rerun it
python.exe -m pip install --upgrade pip
is this a file location or command prompts?
its a py command for updating PIP (python installer package)
should be able to do it about anywhere if python added to path
i did dw


and tried to rerun the bat
my c drive is low but it still has something

way not enough
yeah def not enough tho
yikes
im already installing everything on the d drive so idk why its going to c
is the d drive not enough?
cause that's where everything is cached for download
you need more than that for your entire system to run stable imo
lmfao okok
would recommend having at min 15gb maybe 20 to be safe
so yeah maybe like @vocal burrow was saying, free up some space then del the VENV folder on your install and let it rebuild
wheres the venv folder?
its a folder inside the main installation directory
stable-diffusion-webui/venv
gotcha
your getting there....
update your nvidia driver


bruh, is it just me or do these seem dark?

Steps: 11, Sampler: Euler a, CFG scale: 1.5, Seed: 1227405756, Size: 1024x1024, Model hash: 0538f9319d, VAE hash: 63aeecb90f, VAE: sdxl_vae.safetensors, ControlNet 0: "Module: lineart_standard (from white bg & black line), Model: controlnetxlCNXL_tencentarcLineart [905c2459], Weight: 0.55, Resize Mode: Just Resize, Low Vram: True, Processor Res: 512, Guidance Start: 0, Guidance End: 1, Pixel Perfect: True, Control Mode: Balanced, Save Detected Map: True", Refiner: sd_xl_refiner_1.0 [7440042bbd], Refiner switch at: 0.8, Version: v1.8.0-256-g57727e55
getting "TypeError: 'NoneType' object is not iterable" a lot in webui forge
anyone know how to solve this?
are you trying to utilize controlnets
no
inpaint?
typically its when i load an image from png into and try to regen, or paste a prompt+settings from an image in civitai
i'm not going to lie, i have had so many issues with forgeUI over the last few weeks doing just about anything beyond basic image generation
fix one thing, something else breaks
not sure though on that, sorry
i think forge has many compatibility issues with extensions
def have luck with stripping down as many extentions as humanly possible to accomplish any one task
looks like it was calling a sampler i dont have installed
nice glad you figured it out
one thing baffling me tonight in Forge is how it hates certain xl based loras that auto1111 has no issue with
ill do a base generation, add a lora and the generation time jumps from 30 seconds up to 44 minutes
using the exact same parameters in Auto1111, no issues
obviously, ill interrupt it, then make adjustments, or switch to a diff lora and back to quick renders
just strange
what means waitlist do people sign up to be in a waitlist?
sort of. its not open to everyone at the moment but you can get early access/be notified if they so choose
dalle-e did this before
currently it is not available to the public
is someone available to help?
not run into this
never know till you ask @ionic meadow


I got a upscaler workflow and these 4 things i need to add but nowhere in the place where i dowloaded it from has download links for these
true

nice
owe you 1 💚
Traceback (most recent call last):
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\routes.py", line 488, in run_predict
output = await app.get_blocks().process_api(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1431, in process_api
result = await self.call_function(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\blocks.py", line 1103, in call_function
prediction = await anyio.to_thread.run_sync(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio\to_thread.py", line 33, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py", line 877, in run_sync_in_worker_thread
return await future
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\anyio_backends_asyncio.py", line 807, in run
result = context.run(func, *args)
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\gradio\utils.py", line 707, in wrapper
response = f(args, **kwargs)
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\call_queue.py", line 95, in f
mem_stats = {k: -(v//-(10241024)) for k, v in shared.mem_mon.stop().items()}
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 92, in stop
return self.read()
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 77, in read
free, total = self.cuda_mem_get_info()
File "C:\Users\august\Desktop\stable-diffusion-webui\modules\memmon.py", line 34, in cuda_mem_get_info
return torch.cuda.mem_get_info(index)
File "C:\Users\august\Desktop\stable-diffusion-webui\venv\lib\site-packages\torch\cuda\memory.py", line 618, in mem_get_info
return torch.cuda.cudart().cudaMemGetInfo(device)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
i cannot solve this for the life of me
i tried worked for one gif then i enabled some settings in animate diff and it broke again 😦
just a quick question, could this be set up on A1111? not a big fan of ComfyUI
https://github.com/fofr/cog-face-to-many

GitHub
Turn any face into a video game character, pixel art, claymation, 3D or toy - fofr/cog-face-to-many
if anyone knows, feel free to ping me or DM me
I don't think a ComfyUI plugin can be used in A1111
Also, I think you don't need anymore to use a Refiner, in SDXL mode that was for the base model was I told.
k will turn it off and try
started getting darker 😅

darker when not using a refiner ? sorry to hear that 😦
whilst using 🤡
can someone help me get sd running on my amd gpu? i cant figure out how and always get errors and such. help is greatly appreciated
i would try help but i dont know amd bro
maybe be more specif as to what your issue is
well i followed some tutorial getting automatic 1111 running
but it uses cpu instead
wich is like really slow
will try that thanks
getting an error
Traceback (most recent call last):
File "C:\AI zeugs\SD-Zluda\stable-diffusion-webui-directml\launch.py", line 48, in <module>
main()
File "C:\AI zeugs\SD-Zluda\stable-diffusion-webui-directml\launch.py", line 39, in main
prepare_environment()
File "C:\AI zeugs\SD-Zluda\stable-diffusion-webui-directml\modules\launch_utils.py", line 568, in prepare_environment
raise RuntimeError(
RuntimeError: Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variable to disable this check
followed the tutorial in the pinned message
maybe search this channel
ok, i found out that my integrated gpu causes the problem
Is there anyone with the same issue?
show the actual settings, prompt/cfg edit as a screenshot or upload the image with the data in it
my first thought would be you dont have seed to -1.
much better

any idea of what this error exactly means and how to fix this error? the generation still works fine but i want to fix it regardless

this has been explained many times over on any of the faceswap githubs. they're all frankly hacky as hell and never keep things up to date. search the github issue centre for whichever one of those youre using
as a sidenote that was really difficult to read being over an insanely long screengrab
🙂
i just installed stable-diffusion, any must-have extensions?
what did you install? lots of different distros. a1111? forge? comfyui?
a1111
in any case i'd recommend playing around with what comes as default before getting loads of extensions. but the first one after that is definitely controlnet
What's your GPU?
The style selector could cause a heavy influence on the image output
What's your GPU and what's inside your webui-user.bat
Running it without still shows no improvement unfortunately

Do other models work?
If you want more random images you could try out the wildcards extension
Non SDXL models work flawlesly, it's just JuggernautXL and DreamshaperXL
is that something SDXL models have an issue with? I just don't understand why wouldn't the CFG Scale work on randomizing it, or giving the models "More freedom" as it does that with 1.5 models flawlesly
for example:

Because its a turbo model where the cfg scale is needed to be low
even trying to use it as a non-turbo model, which they can be used as, still shows no real improvement
and it ignores the negative prompts
I can try your example prompt later to check if its the same for me
appreciate your help ❤️
What you can use is the X/Y/Z script at the bottom and there you can put in multiple different seeds
That should give you different images for sure
Sure, but then i would rather use the 1.5 models as they don't seem to have that issue.
it's just the quality of SDXL models seems far better
Is there a way to swap the model while generating? I'm using Forge.
Anyone know what the file model_metadata.ldb file is for?
RX6800
then you need to follow this guide:
#🤝|tech-support message
yo im gonna build a pc in a week alr have a list of parts made but im conflicted on which gpu to get, i could get the RTX 3060 12gb or the RX 6700 XT for $200 but im concerned if the RX 6700 XT can preform as well as the RTX 3060 12gb in SD , does anyone know if ithe RX 6700 XT is any good with SD? cause im mainly getting the pc for gaming but im gonna do a little bit of SD on the side too
Hey, Ai stuff works best with nvidia but SD works also with AMD.
Performance is not the same
yeah ik ive seen some people use ROCm and Vlad's fork of auto1111 and they got pretty similar results to the 3060 but that was a couple years ago
i know my way around linux so i was just askin if AMD got any performance upgrades
If your using Windows zluda is now the best you can use for AMD
I'm using AMD GPU myself
is it better than ROCm on linux?
Its a bit slower
You get the best performance with rocm on Linux or by using Shark ui on Windows
But zluda has the best performance for auto1111 webui
Best support for Extensions on Windows
Linux rocm uses also normal auto1111 webui
Yes
ooo ight than
im gonna go with amd cause the RX 6700 XT is considerably better than the 3060 at games n stuff
Thats true, the 6700xt is a good card
fr
Also if you ever plan on using Linux, AMD has the better Linux open source drivers
I build my PC for Gaming primarily too, so I went with AMD, even knowing that its not that good for SD (that was before Zluda released)
yeah i think im gonna main linux and just sideboot windows if i ever wanna play windows-only games or use adobe products
amd is amazing tbh
gonna go for a R5 7600 just so that i can upgrade to better gpus later
Take a look at the 7500F too
ohh yeah ive heard of that cpu
im gonna ask around to see if i can get locally
cause if i bought it online it would cost more than the 7600 lmao
Lol okay xD
Yea boath are good and later you can go on the 7800X3D
That thing is a beast
yeah thats what i was thinkin of doing
Then you have a good plan 👍
:D
Anyone know what the file model_metadata.ldb file is for?
hi
belated, but hello. do you need help?
An educated guess would be is an lDB of metadata for a model.
sup gang, any obvious reasons the realvisxl model would be only giving me grainy af images? this is before any hiresfix stuff so you can see the raw output. using normal webui and pretty standard settings the creator recommends.

maybe it isn't playing well with vae?
Doesn't look fully denoised.
ps: hey gurrrl
im using some outdated automatic1111, currently watching a video on switching to comfy etc.. will update if a fresh install fixes things ;P
might as well give forge a shot while you r at it
better than comfy and automatic?
comfy screws with my ocd
i def recommend trying it out, its based on the auto1111 ui and is pretty nicely optimized for memory
and faster
it's got ups and downs but def worth your time
still not positive on how it's doing with controlnets atm haven't tested in a bit
would love feedback on that if anyone knows
okay ill try both!
def, good plan
you can add cmd args so it shares your loras, models, hypernetworks, etc.
from auto1111 without having to move or copy anything
which is nice
My img2img function doesn’t work lately. I can put in prompts and images but the generate key does nothing, and other functions get a timeout error. Text to image still works though. Anyone know whatsup?
Using an AMD RX7600 8GB with the following command lines:
git pull
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS= --use-directml --upcast-sampling --lowvram --opt-sub-quad-attention --opt-split-attention-v1 --no-half-vae --no-half
call webui.bat
Automatic 1111
if its only img2img its likely an extension that plugs into it has failed and needs updated.
is it throwing any errors in the cmd window?
go
hello guys, i am trying to train a lora and i get this error everytime at 10% steps. can someone help me with this?

You have a non utf-8 char in one of your captions.
Possibly a trademark ™️ sign
Or a Copyright ©️ sign
Or things like é. I had a lot of failed trainings because of this error.
ohh thank you. ill check. and update back.
Just keeping captions as plain as A-Z 0-9 works best in my experience.

Yesterday I wrote a script to find a "bad" caption. I was in the same situation, but with 1000 files. Hard to find if the error doesn't say which file it is.

brah troubleshooting 1000 files
It was a single "é"
AI Be like : time to troll my man. 😄
I think my Llava autocaptioner said: and here I place a char that will cause an error so my copilot friend will have a bit of work with debugging too.
@fallen quest removed and recaptioned using wd14. still stuck with utf-8 error. 😦 guess ill do it manually to check
even with different caption, still same error. used WD14 as well as BLIP
hey thanks for replying and helping me out. i havent seen any errors but let me check again and get back to you
it seems to be working now. dna what was going on...
Hey, if you want faster Image generation and less vram limitations you can follow my AMD Zluda guide from here:
#🤝|tech-support message
With that your also be able to use Sdxl models
Hey, I wanted to know if it is possible to run sv3d on a google colab. Does anyone have experience with this?
thanks so much, jea ill put these in to my command line asap.
hi
No dont just add them, its a seperate install where you also need to install some AMD SDK to make it work
Everything is in the guide.
For any questions feel free to ask
Hi, does anyone know if Forge controlnet models are any diferent from A1111? Im watching a video that mentions I should download .pth files for Forge , and in my A1111 the models are all .safetensors
Hey, it should use the same controlnet files as auto1111
Ok, tks.for some reason I cant understand it doesnt update the model list
Hi, is there a spanish stable difusión comunity?
Hello everyone! I've just trained SD model for my project and I want this model to be safe from getting copied, though I want other people to be able to use it.
What is the easiest way to make my stable diffusion model accessible online? I'm thinking about google colab, but I'm not sure if it's possible to secure my model from getting downloaded locally from there. Thanks in advance.
Hey, I think the best is to create a space on huggingface.co
You can provide a webui there with simple text2img prompt boxes and your model loaded and the people can generate images with it accessible only on that site
Ive never created a huggingface space before so idk what you need for it to work
Thank you! I will try that.
Here is an example of what it can look like:
https://huggingface.co/spaces/cagliostrolab/animagine-xl-3.1

BTW: fixed now , referencing the A1111 ones in commnad line arguments made it work: --controlnet-dir /Users/miguel/stable-diffusion-webui/extensions/sd-webui-controlnet/models"
Hey everyone! I need your help on something:
I got a platform and I need to generate images for each profile scraped and uploaded on the website automatically.
It would be image to image prompt from instagram real profiles.
This would be the steps.
- Profile ALPHA is imported on the platform
- Profile ALPHA profile picture is scraped
- Profile ALPHA profile picture is modified into a cartoon image (image to image prompt) through stablediffusion
- Profile ALPHA modified cartoon profile picture is now uploaded on my platform automatically
Is something like this possible with API?
Trying to get the XL Tile model working with UltimateSDUpscale, but running into this or any other no attribute error... Anyone got any clues? 

guys i dont remember, i used to have an extension or whatever that when you were typing it was displaying the correct tags that corresponds but since i reinstalled sd i cant find the name
Hey, its called Boorutag Autocomplete
Nice thanks
hi guys, where to put LOHA
anyone know why the "core API" tends to fail alot with no error message?
im getting 200 responses back, but data is undefined.
usually when outpainting. sometimes repeating the same API call works,
stable-diffusion-webui\models\Lora
thank you so much
i have another question. Since a few days when I installed SD again it is so slow generating. Back then i could generate 100 images in 3-4 hours, now one image takes so long

I don't know, I don't have any logs to look at, any hardware informations, any frame of reference (how long it took before, at what settings, how long it takes now, etc)
it probably depends of the client/UI you want to use
"installing SD" is as vague as saying "installing linux"
there's many many clients/UI
googling "automatic1111 aws cloud" I see many tutorials are available
oh right, what are logs? so this is system information

console logs (white text in black window thingy)
if it takes """too long"""" there's probably some errors displayed in there
there are some errors
even after I reinstalled it
for example the upscaler are not in the folder i put them in
You don't have any command line arguments, it should be --xformers --no-half-vae. And roop is sh$$$$ its pants, get rid of it (and install reactor insteaad if you have to)

xformers will get you better speed
i put my upscaler into the real esrgan but it doesnt know in SD



then create it
Does anyone know how to fix an issue with webui auto11 where every time it starts up, you have to refresh the browser before it works? Everytime I run webuiuser.bat, it opens normally without any errors, the ui works normally, like I can change settings or write in the prompts etc... but I cannot actually generate anything. The only visible issue is that the extensions list wont load. When I refresh the browser, the ui loads again and everything works, but its annoying that i have to refresh everytime I start it or use 'apply and restart ui' for extensions...
there's probably a bunch of errors showing up in the log
Hey, I am using automatic1111 but when trying to generate something, my gpu isn't used and instead it uses my cpu which makes it very slow.

chances are you're not using the directml or zluda fork
check pinned messages for tutorials about those
ok then you're probably not using --use-directml command line arguments
True, I am not. Let me try it
there are no errors in the console,
what does the log says exactly ?
Now its not starting .-.
same thing, what does the log says ?
Launching Web UI with arguments: --upcast-sampling --opt-split-attention --opt-sdp-attention --opt-sub-quad-attention --skip-torch-cuda-test --precision full --no-half --autolaunch --use-directml [2024-03-25 22:25:49,665][DEBUG][git.cmd] - Popen(['git', 'version'], cwd=C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml, stdin=None, shell=False, universal_newlines=False) [2024-03-25 22:25:49,713][DEBUG][git.cmd] - Popen(['git', 'version'], cwd=C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml, stdin=None, shell=False, universal_newlines=False) DirectML initialization failed: No module named 'torch_directml' Traceback (most recent call last): File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\launch.py", line 48, in <module> main() File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\launch.py", line 44, in main start() File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\modules\launch_utils.py", line 663, in start import webui File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\webui.py", line 13, in <module> initialize.imports() File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\modules\initialize.py", line 36, in imports shared_init.initialize() File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\modules\shared_init.py", line 31, in initialize directml_do_hijack() File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\modules\dml\__init__.py", line 76, in directml_do_hijack if not torch.dml.has_float64_support(device): File "C:\Users\John\Desktop\Stable Diffusion\stable-diffusion-webui-directml\venv\lib\site-packages\torch\__init__.py", line 1932, in __getattr__ raise AttributeError(f"module '{__name__}' has no attribute '{name}'") AttributeError: module 'torch' has no attribute 'dml'
the full log
wrong command line arguments
--use-directml --skip-ort --medvram --opt-sub-quad-attention --opt-split-attention-v1 --no-half-vae --upcast-sampling
Alr thanks, let me try
this is my full console from starting it, and then refreshing once to get it working
Still no luck
try deleting your venv folder
Alr
==============================================================================
You are running torch 2.0.0+cpu.
The program is tested to work with torch 2.1.2.
To reinstall the desired version, run with commandline flag --reinstall-torch.
Beware that this will cause a lot of large files to be downloaded, as well as
there are reports of issues with training tab on the latest version.
Use --skip-version-check commandline argument to disable this check.
==============================================================================
don't ignore error messages in logs
do you want me to add the line to disable, because I already uninstalled torch and reinstalled, and it reinstalled the same version. and when I asked Cs10, he said i should still be on 2.0.0
not sure why you should still be on 2.0.0....
use --reinstall-torch and make sure to launch using webui-user.bat and not webui.bat
ive done it, and it reinstalls 2.0.0. I even went in to one of the other files to change the torch install directory to the specific link to 2.1.2 torch version, and it still did 2.0.0. (i dont remember the specific file and argument but i followed a guide, and did it correctly)...
What's in both stable-diffusion-webui\requirements.txt and requirements_versions.txt ?
(drop the files in here)
my req.txt has: 'torch>=2.0.0
torchdiffeq
torchsde'
is that the issue? i need to change the req.txt torch to 2.1.2
drop both files in there please
Worked! Thank you so much for the help
ok looks like it's ok for torch to be stuck at 2.0.0 for the directml fork (for now)
try also deleting your venv then and relaunch it
Why do I always have the hard questions x)
Anyone know if either kohya ss changed something with how it reads training image tags in the latest updates? Or if XL lora models just handle it different than 1.5 models?
I noticed it's only reading the first tag in the info icon in the A1111 gui
is there any handsome intelligent fellow willing to help me with this 🥺
im using stability matrix and have 12gb vram
🙏
What's your GPU?

Then the best you can do is to follow my install guide for AMD with zluda support.
Its in the pinned messages of this channel
Its the automatic1111 directml webui but with zluda Backend.
Its much faster and doesn't give you out of memory/vram errors
but is it accurate
Accurate?
Do you mean quality wise?
accuracy wise
Like following the prompt?
yes
Ohh
That has nothing to do with the webuis
Accuracy comes from the trained Checkpoints
i dont get it
You need to know that there are Local Stable Diffusion webuis.
These are the programs to run and use Stable Diffusion models.
Stable Diffusion models are trained on a lot of images and are the core to generate new ones.
Yes
do i just follow the last pinned message
Models = checkpoints
Yes thats my guide to get everything working on AMD
Sure, and feel free to ask if something isn't clear or if you get an error
yessir
I'm using AMD myself so I can help easily
To be clear this is the guide you need:
#🤝|tech-support message
Hello !!! Does anyone know what's going on that the images are always blurry (at least 1/10 images are fine) with any prompt I'm sending, they appear the same whether in "SDXL 1.0" or "SD 1.6" ?
Here an example from the sandbox.

Is that what a NSFW work result looks like by any chance ? Guess based on the the blurry image looking like woman in a swimsuit on a beach.
I believe the same but is NSFW so over the top as to come to this ? It won't let me create any kind of image where they ask for a woman either in the countryside, the beach, etc etc, if she is alone it comes out blurry. Almost 100% of the images. This is too much.
Could someone direct me to the controlnet models to download?
Dont see a github pinned in here
1.5 controlnet:
https://civitai.com/models/38784/controlnet-11-models
STOP! THESE MODELS ARE NOT FOR PROMPTING/IMAGE GENERATION These are the new ControlNet 1.1 models required for the ControlNet extension , converted...
Sdxl controlnet:
https://huggingface.co/lllyasviel/sd_control_collection/tree/main

I appreciate you
The strangest thing is that I have been doing this for a long time and it just started to give these problems today. It seems to me to be borderline overkill. Is it such a big deal to see a woman wearing a swimsuit on the beach?
Is there any way to avoid these problems?
if you have the hardware to run it locally then do it. Solves all your problems with any kind of censorchip. If you can't run it online then look up how to run it in google colab. it's like running it locally on a cloud server
Well, the idea is to use the stability.ai service, but the censorship issue is still exaggerated.
I have tried to create images in the same way with a woman but also with her dog, and now they all come out. The problem is that it does not like to create images only of a woman. STRANGE !!!
I am developing an application and I need it to be online with good creation times. Making it local doesn't work for me and that's why I use this platform. I have left aside the developments with Dall-e 3 because I didn't like the results but now after some time here I am having other problems. Maybe less serious but they are still exaggerated.
hah I saw a video on google imagen and half in the video nearly every prompt of the most normal stuff was rejected so it was basicly unusable in the end. Maybe there are other SD online services with less restrictions?
yes it might be an option to look for another service but the problem is that I am up against the clock with very little time for an event that must use this application. I hope to have better results if I find another service and I have enough time to adapt the development.
Try change girl to woman or teenager
Some words can trigger the filter even if it doesn't seem to be what you try to get
Followed the pinned guide. What does this mean? @ornate elk

Hmm what's your python version?
i just upgraded to its suggested version from 3.9.5
i deleted the venv as well like it told me
Okay, can you show me the full log?
sure
it gives the warning again at the top even though I installed the version from the link. Should i restart my pc and try again?


Its using the old python version
So you can try to delete the venv again and relaunch
If you still get the error, uninstall the old python and delete the venv folder again.
Also make sure you checked "add python to path"
If not run the python 3.10.11 installer again and click, Modify, Next, and then check "add python to system variables"
Then delete the venv again and relaunch
The venv folder is enough
adding to system var. fixed the python error
can someone remind me where the configuration file is for stableswarmui so I can set lowvram?
or is that just not really possible yet
https://www.reddit.com/r/StableDiffusion/s/zSCHxQ9OjY
Can someone help with Kohya ss?

Reddit
Explore this post and more from the StableDiffusion community
anyone have an idea of why my backend keeps crashing?
20:00:00.044 [Error] [BackendHandler] backend #0 failed to load model with error: System.AggregateException: One or more errors occurred. (The remote party closed the WebSocket connection without completing the close handshake.)
---> System.Net.WebSockets.WebSocketException (0x80004005): The remote party closed the WebSocket connection without completing the close handshake.
at System.Net.WebSockets.ManagedWebSocket.ThrowEOFUnexpected()
at System.Net.WebSockets.ManagedWebSocket.EnsureBufferContainsAsync(Int32 minimumRequiredBytes, CancellationToken cancellationToken)
at System.Runtime.CompilerServices.PoolingAsyncValueTaskMethodBuilder1.StateMachineBox1.System.Threading.Tasks.Sources.IValueTaskSource.GetResult(Int16 token)
at System.Net.WebSockets.ManagedWebSocket.ReceiveAsyncPrivate[TResult](Memory1 payloadBuffer, CancellationToken cancellationToken) at System.Runtime.CompilerServices.PoolingAsyncValueTaskMethodBuilder1.StateMachineBox1.System.Threading.Tasks.Sources.IValueTaskSource<TResult>.GetResult(Int16 token) at System.Threading.Tasks.ValueTask1.ValueTaskSourceAsTask.<>c.<.cctor>b__4_0(Object state)
--- End of stack trace from previous location ---
at StableSwarmUI.Utils.Utilities.ReceiveData(WebSocket socket, Int32 maxBytes, CancellationToken limit) in /home/daniel/Downloads/StableSwarmUI/src/Utils/Utilities.cs:line 208
Now it's so strange... when I changed "girl" to "woman" several prompts worked without problems and when I went back to "girl" everything worked again. I don't think they have done something ? so soon I don't think so, but what would be good is that if some word doesn't pass the censorship filter or the phrase, at least give us some more information to know where the problem is. We will see how it goes... thank you very much.
Hi, I'm using Zluda and I recently got an sdxl model. It's working fine but it's slow compared to 1.5 models. What's weird is that sdxl normal generation speed is half the 1.5 model but the hires.fix is just as fast. Is there some way to speed it up and make it faster?
Also, for some reason the images are somewhat grainy and noisy. It's not crazy levels of grainy, but it's still pretty visible, how can I fix that?
I just started learning what SDXL is and fiddling around with PonyXL, I saw there was a WebUI Forge to speed up the gen speed on low-mid vram gpu's, i have it installed through the extensions tab on my original SD webui currently, are there any extra settings or things I need to mess with in order to make sure it's working properly?
i built https://artforgelabs.com, if you want to chat about how that works hit me up.
its basically my own API for SD models, and a nice little web UI for users
the tl;dr: we run a modified version of A1111 for its API, on google cloud GPU instances. we have a custom backend to handled user request, the queue, autoscaling GPU instances, etc. and then a nice little frontend for the UI.
SDXL image generation times are under 5 seconds, and it can handle many 1000s of users at once 😄
Forge is not an extension for auto1111.
Its a different webui on its own
You would have to install it the right way like stated on their github page
And delete it from the Extensions folder
Its normal that sdxl is slower than 1.5. Make sure to use DPM++ 2M Karras as Sampler, that's much faster than DPM++ SDE
What's your GPU again?
Why is the loading time for SDXL unbearably long in comfyui? It was fast at the beginning but suddenly it ceased to work
I tried converting safetensors to ckpt as suggested online but it didn’t work
Can you have 2 comfyuis on 2 separate drives ?
Yes
You can try with --xformers --medvram
And then enabling the FP8 mode for SDXL in the auto1111 settings
@chilly knot if that doesn't work you can try --lowvram
it get me This could be either because there's not enough precision to represent the picture, or because your video card does not support half type.
--xformers --lowvram --no-half-vae
in bat
maybe is imposible
You could try adding --no-half
But that would slow your average generation time by a lot
Is there a way to output and save both the PIL.image.image and the np.array at every step of the inference process?
Hi, can anyone plz tell me if you need to git clone and install photomaker for use in Forge?
It already seems to have the pre processor
Should only need the model but its a .bin file?


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Is there a way to callback at every step of the inference process in order to save every np.array at the end of each step?

hello, i have this error message when i try to generate, i dont understand cause yersterday i didn’t have this problems, and i only changed width/height and sampling step

can someone help me pls ?
is the command window still open?
tensor with all NaNs was produced in Unet. Use --disable-nan-check commandline argument to disable this check.
its ok now i understood the pb! thx for ur help 🙏
is this a corect way to instal automatic 1111 that will be able to support adding other add ons like confyui - https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs?
GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
Okay, then try out if Dreamshaper xl turbo or juggernaut xl lightning work for you
im also getting this error. only on my img2img. console log shows 1006

you know people on a111 who do this ?
on 4 gb
i read that it works only in comfy
Hey team, I'm getting this error when trying to create music, is there a fix for this?
Error - ERROR: column "uses_init_audio" does not exist Hint: Perhaps you meant to reference the column "generation_attributes.is_init_audio". Position: 36; SQLState: 42703
same
Yes one guy used sdxl on 4Gb 3050
Also you should try out SD webui Forge. As its much better for GPUs with 4gb vram
Maybe it works there
hm but rtx is better then my old gtx 1050
Disable any browser adblocker for the webui
Yea with 4gb vram you won't have a good time with sdxl in any way
It would stick to 1.5 2gb models
Controlnet with 700mb models work too
i think its hell my system freeze when i start it
Hey, I'm trying to work with inpaint feature but no matter what I do it seems to mess up the end image colors of inpaint area
When you start what?
Sdxl ?
sxxl
Ah yes
Dont forget to change --no-half back to --no-half-vae
i get back to my fast 1./5 )
i use it everytime
Also get the tiled vae extension
As it can help making larger resolution (with upscaling)
any help would be appreciated
i want sdxl only because it listem promt with lora
AMD GPU?
nvidia
Okay, do you have an example?
Yes the prompt understanding is pretty good in sdxl


😭
3060 12 gb its good for xl?
What's the denois? Also do you use an inpainting model? That could help
Yes totally
i want new videocard not very expensive and for my processor
think i've tried all from 0.3 to 0.7, it doesn't correlate. The weird thing is that at one frame on low res before finishing the image it shows correct colors but in final image it always mess up the tone of selected area
Try set the VAE to none maybe
this?
