#🤝|tech-support
1 messages · Page 47 of 1
G Morning,¿excuseme where i write the promtp here to make images whit sd xil 1.0?
Yeah! Got it working!
The bots are down
Ok thx
OK, we figured out where the problem is. this happens only on macOS 14.4 with Torch 2.2.0 or newer, downgrade to 2.1.2 fixed the problem
Hi guys, but you can convert Lora SDXL files to the format: SD1.5???
RuntimeError: mat1 and mat2 shapes cannot be multiplied (154x2048 and 768x64)
what does that mean
what image size have you tried to make?
1024 x 1024
it worked just before but now idk what happend
show me the settings you used to generate image

now it doesn't give me the loading percentage

if you disable hires fix and use 512x512, does it work?
it doesnt work
restart ui, put the same prompt, sampler... but do not add hires fix and use 512x512, 512x768 or 768x512 - do not use 1024x1024 with 1.5 models
yes it works now
now it works thank you
and any time when you get memory related error it is the best to restart webui before you try to generate something else
I will do it thank you
A question is ADetailer !After Detailer manipulations from th extionsions tool?
just as a sidenote, if you have a prompt that length you might want to try increasing the CFG value to maybe 9 or even 10 as its very specific. may or may not help, but just a good rule of thumb
thank you I will do just that
Bump. Can someone please help. Thank you
OutOfMemoryError: CUDA out of memory. Tried to allocate 9.77 GiB. GPU 0 has a total capacity of 11.98 GiB of which 0 bytes is free. Of the allocated memory 3.09 GiB is allocated by PyTorch, and 9.31 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
get this when trying to upscale with hires
My gpu memory usage was around 8 out of 12 so I don't know how its running out of memory
And usually its right when the image is done generating that this error pops out
are you on windows?
oh AMD, im not sure. i was going to say nvidia lets you fall back on system memory, im not sure of the AMD equiv
Dang yeah I don't know about amd
sorry, i was ready to help you, but i dont know about AMD. hopefully someone else does
Don't worry about it, you're good
make sure to set hires steps to 10 and it should work
Tried it but got the same error
Its being upscaled from 832x1216 to 1248x1824, maybe my 6700XT just isn't strong enough?
for that you need the tiled vae extension
Do I also need controlnet?
that will prevent the out of vram error
Alright will get it
ok installed it, do I just enable it and I'm good to go?
yes
but only tiled vae and not tiled diffusion
Alright and what sbout hires?
alright
for sdxl try upscale by 1.5
will do
looks fine?

NansException: A tensor with all NaNs was produced in VAE. This could be because there's not enough precision to represent the picture. Try adding --no-half-vae commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
got this error
ah okay, you might need to add --upcast-sampling --no-half-vae to the webui-user.bat
Alright will try that
There was an error with --upcast-sumpling
launch.py: error: unrecognized arguments: --upcast-sumpling
oh sry its --upcast-sampling
Oh ok
Dang same error
OutOfMemoryError: CUDA out of memory. Tried to allocate 9.77 GiB. GPU 0 has a total capacity of 11.98 GiB of which 0 bytes is free. Of the allocated memory 4.74 GiB is allocated by PyTorch, and 9.06 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
Time taken: 5 min. 8.8 sec.
then use a non sdxl model, or lower resolution
Oh bet, thank you
Hi, I can't find a solution to this problem other than having the old version of SD. As you can see my preview on the right is really too small. Is there a way to make it bigger?

The preview on the right is small in this screenshot because the generation is underway. See where it says 6% ETA: 01:46: that means the progress is ~6%, estimated completion in 1m 46s
what happen if you click on that small image?
i am not sure if it work by default, since i am on lobe theme
I've already tried waiting, even until 100%, but nothing
both pictures look the same to me, are you using the fixed seed?
what happens is that it becomes bigger, but the photo remains fixed. Below I see the sequence of images that continues, while the photo that I enlarged is still
No,i use: seed: -1
its img2img, i see now, but anyway, should not be the same, unless it is upscale, than it should be very similar
this and version 18 of SD.MA in version 17 I didn't have this problem. The preview of the photos was much larger. I don't know how to fix it. If it's bigger, I can notice first if errors appear and then stop everything. But such a small preview, I struggle 😦
Hey guys, I write an illustrate a sci fi comic series called system earth (found at my website tomgardenart.com). I’d love to be able to use stable diffusion to ‘ink’ my pencils using my drafts as its guide and my 100 + pages of my own work as a style guide. Could anyone give me advice on the best plug ins etc to make this happen? Thanks in advance
Here’s an image of my comic (human made) whilst also showing levels of drafts that I would like to feed SD so I can speed up my inking process.

I’d love to be able to use stable diffusion to ‘ink’ my pencils using my drafts as its guide
You mean coloring in the lines? I haven't done this myself, but this sounds like a job for ControlNet: maybe the lineart version. If you search "controlnet lineart" that should pull up some tutorials if that's what you're looking for
https://www.youtube.com/watch?v=Wl0JK5Ser28 <- start from here

Part 2 of a timelapse tutorial series on how to use Stable Diffusion A1111 to quickly generate images for a graphic novel project. Even if you're not making a comic, these techniques will improve both the quality and quantity of your creative output for your own project or commission.
Hardware:
I bought the computer I'm using to run Stable Dif...
If you want consistent coloring—again, just guessing here—maybe you could try loading a page into img2img, with half the page colored by you the human, and the other half pencil sketch. Then mask the pencil sketch for inpainting
tbh i dont really want them 'coloured'. these days i just go greyscale. To me, its all about SD copying my style
you should create a Lora Style with your drawing style

oh it'll do the shading etc well, but it will be very inconsistent in color, even if you tell it a green/brown pallet one image the background guy is wearing brown, the next green
This is a DreamArtist Textual Inversion Style Embedding trained on a single image of a Victorian city street, at night. You can get amazingly grand...
this is a Lora Style so to speak
you can recreate the style of other Masters etc
techniques to control colours only really work on fairly minimalist images consistently. what you might be able to do is use an SD1.5 inpainting model (the SDXL inpainting models barely exist).
ok. So if i give it more of a suggestion of values in the draft, would that help its consistency? ei:

they are their own master 🙂 its about inking their own work 🙂
I'm happy to keep it greyscale
oh then yeah SD can absolutely be used. i'd recommend controlnet canny with anime lines and inverting the image, but at a low level. its something you have to just play around with and from piece to piece you'll have to adjust
also, props for being an artist using SD as a workhorse and not a copycat 😄
Haha thanks. yeah I like comics but i really like the storytelling element and if this can help speed things up so im telling more stories faster, im all for it. I feel if i can just add enough detail to the draft, hopefully SD can get something similar to my final inkings. Here's another example

yep thats totally doable
ok thanks guys. And i can feed controlnet canny all my images to copy my style?
yep. you might need to tinker with its strength but you'll get the feel of it. i'd recommend doing it over panels rather than whole pages, it loses attention and tries to do too many things otherwise and you get kinda washy blurry faces etc.
ok good idea
maybe add text after the fact though, its notoriously bad at things like that, ends up writing that language the sims talk 😄
oh god, of course. It wouldnt be writing the script
oh i mean BLAM!?! action text
im not sure just how well it would work all the time and might cause awful results, but controlnet also has a reference feature and if you input an existing shaded image it should try to keep to that kinda "feel" of it too. you can have more than one controlnet. so you could try even adding that in too
haha yeah. best to add that in. But yes that would be a slight issue cos good onomatopeas in comics are ones where its built into the composition of the image, not just put on top
that said, if you have the text thick lined already over it, if you put that into image2image it will trace over them
so if sketch A already had !! woah!! in it, then it would know when generating to the render
Yeah it should just count it as a line like all the rest of the lines ae
mk. ill install controlnet and let ya know how it goes...
Do i need to install stable diffusion THEN controlnet canny? or can i just go straight for controlnet canny. sorry, newb here
i would install webui forge, personally, its a version of a1111 made by the controlnet developer

GitHub
Contribute to lllyasviel/stable-diffusion-webui-forge development by creating an account on GitHub.
thanks. ok, ill install this first then 🙂
it comes with controlnet installed you just need to download the models for it. https://huggingface.co/lllyasviel/sd_control_collection/tree/main you'd primarily want the SDXL models with 'canny' in the filename. the other ones are fun and useful just not for your task

but focus on those after, installing a SD client the first time can take a lot of effort and headscratching
comfyui might be a better idea long term for setting up a digital inking sweatshop on your computer, but if you havent used SD before start here 🙂
yeah there isnt a simple .exe after extraction. i might have to find a youtube video 😄
yeah theres a whole environment needs set up. i suggest olivio sarikas or sebastian kamph for handhold install videos
whats your system btw? what kind of graphics card do you have?
nvidia geforce gtx 1050 ti
ouch
hmm. im not sure if thats enough to run it. you might be able to get away with forge and using SD1.5 models. since you're not making new images from scratch that should be fine. but it will be slow
oh dam
for a decent speed, especially for a lot of images, you need at least something like nvidia 30xx
yeah you scrape through with SD1.5

with at least 16GB
he only wants to img2img shade/ink things
i got 32 gb of ram?
try it and see. the speeds might be monumentally slow but if youre just using it for touch up work it should be tolerable
theres lots of little tricks that let you squeeze all the toothpaste out of the tube
being able to run something and use something for work are two different things
if it works with intended purpose, id consider a pc upgrade
oh it 100% will
maybe 😉
just....maybe not on your pc. itll be like childbirth each generation
i know how frustrating it is to wait 3 minutes just to realize that the image is not what you want and to do a little tweak and wait again... in the and you spend 1 hour for a image that you could do in a 5 minutes with decent hardware
make sense
Yeah i have reservations if this process will even work. It might work, but might take more time cleaning the image up than me just drawing it. But also, i am due for a PC upgrade
hmm. after installing python, when I open 'webui.bat' I am getting text saying 'couldnt launch python' .

this is my python install folder.

Apparently it should look like this:

#🤝|tech-support message <- please follow this tutorial
at least for python and git
since you are with nvidia on windows, and you are installing forge, you can also try this one
https://github.com/lllyasviel/stable-diffusion-webui-forge/releases/download/latest/webui_forge_cu121_torch21.7z
that's >>> Click Here to Download One-Click Package<<<
from https://github.com/lllyasviel/stable-diffusion-webui-forge

GitHub
Contribute to lllyasviel/stable-diffusion-webui-forge development by creating an account on GitHub.
i dont think i checked 'add python to path' when installing python


ive already installed so i dont have that option anymore. plus python cant detect an installation file aso cant uninstall properly
run installer again
ok
i am searching for images on the internet, since i am on mac
but that is the deal, you need to check that littel box at the bottom
and be sure that is 64 bit version of python 3.10.11
ok so run installer again to unintalled? cos 'modify' option in the set up doesnt have the tickbox



should fix it, but if you already uninstalled, just install it

mk ticking that didnt work(run webui.bat) so will reinstall and tick box
might reset comp too
restart cmd
do not need to restat the whole windows (i hope)
in the last few years, i used Windows only a few times, so I forgot many things
the folder that python installer installed is still there after installation..
if you installed that for all user it should be in program files, or in your home folder (somewhere) if you installed only for yourself
i was expecting it to delete all files cleanly after running uninstall
not leave main file with its .exes etc
i can just delete that folder, reset comp and reinstall
if you are reinstalling at the same palce, no need to delete anything
ok
but i am little confused what it left

some weird directory...

that is fine
it should be there
that is default location for "use for myslef"
or whate that is called
if you type
python --version
does it work now?
also try
pip --version
if those two works, you installed python correctly

ok, 3.10.6, that should work, even 3.10.11 is recommended
and what about pip --version
awesome. it opened properly

looks fine
leave it like that
it take some time to download and install everything, depending on your computer and internet speed
i need to go, i am tired and need to work in the morning
but someone else will help if you need anything else
its 1am here
thanks so much for your help 🙂
come to the dark side and buy a Mac. I made a script for this - just one command and everything magically works 🙈
Hi, thanks to @glad fiber and @ornate elk I was finally able to download SD. I did it very late, closed the folder and went to sleep and now I don't know how to open SD! can you please help me?
Find the web ui batch file.
Sorry, I'm in the folder but find nothing...
C:\IA\stable-diffusion-webui
what do you see?
I've always wondered why when you generate two pictures with exactly the same parameters they are not absolutely identical to each other? They look almost identical to a human, but some small details are always slightly different. Where does this randomness come from?
Depends. If using a GPU vs a CPU, that can cause differences. Could also be that a parameter you're not seeing is causing the changes. If you truly have all the same parameters across the board, including hardware, then it generally will be identical.
the randomness is part of how SD works, it's trained to create the image from noise
interesting, didn't know.
I think it is on every setup is so. You just need to look really close to notice difference in pixel noise and very small details.
You can do a bit by bit comparison to prove that an image with all the same parameters ran on the same hardware is the same.
Hmm, I see I have param Random number generator source set to GPU. I wounder how much will it be different between different options here.
yeah, if I use CPU it actually creates two identical images, but my GPUs RNG gives some randomness between them.
Does it make no difference which generator to use? It only makes a difference in the starting noise and has no effect on the final quality?
Hello everyone, I saw this function on the official website, but I didn’t see this model in the interface, and the help document I clicked on was also a 404 page. How do I use this model?

Gm

I'm trying to train SD so that I can eventually make a video with certain faces, and I'm getting this error when I click to train... I'm pretty new to this stuff and the tutorials have options that arent on my panel. There's no "preprocess images" tab like the tutorial states. It says it's up to date, but do I have an out of date SD?



i amcoming back with the same problem now when i install new lora they wont show up now

- Install Python 3. 10. 6 (newer versions of Python do not support torch), and select "Add Python to PATH".
- Install git.
- Download stable-diffusion-webui 4. If your computer's video memory is less than or equal to 8G, please edit the webui--user.bat file and add the following parameters after set COMMANDLINE_ARGS=: -medvram (video memory is less than 8G ) or lowvram, (video memory is less than 4G)
這個怎麼使用
这个好像不用改,默认就可以
yes you do need them as stated by the vram requirements. And english please.
trying to install stable diffusion from this tutorial: https://youtu.be/mcqREz9xE74?si=uKPy-S95X3ZF76ER
It shows an error in mine tho

it s telling you everything you need to know

invalid python
use any python from 3.10.6 to 3.10.11
I tried using that version
then it just says no files found in python 3.12 folder
(if you have a venv folder in your stable-diffusion-master, delete it after downgrading to a compatible version)
probably because you didn't uninstall python 3.12 and/or didnt check the "add to path" checkbox during the install of the compatible python

ok
let me try all this
Wow what a bad tutorial
can you suggest me a better one?
Please consider doing a proper installation by using the guide of the pinned messages of this channel
ok
Chose the one matching your GPU type. Nvidia or AMD
yes
just did that
After running the command it says following:
G:\Stable diffusion 2>git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
'git' is not recognized as an internal or external command,
operable program or batch file.
You have to install git
https://git-scm.com/download/win
installing from here
clicked a lot of 'next' buttons
Yea everything can be default
its installing now ig
Its for downloading SD, (not as zip) and later to update SD in the future
Looks good



What's in your webui-user.bat and what's your GPU?
3060ti and I got --xformers --no-half-vae
Thats good, but for a ti you should add --medvram-sdxl
Also check the GPU vram usage when generating
In taskmanager under performance
Then on gpu
24gb is not the actual vram, thats with shared memory
Make also sure to always start the webui-user.bat and not the webui.bat
And yea add --medvram-sdxl for a speedup in generation when using sdxl models

Np 🙂
Hello, I'm expecting my new computer shortly. It's not very expensive, but it's better than the one I had. I've installed a 16GB VRAM graphics card; the previous one had 4GB. Now, let's get to the point. When creating images with SDXL, it can take up to 15 minutes with the following settings: 1134x833 upscale x2, hires steps 15, denoise 0.3, cfg scale 7, steps 30. How much do you believe the time will decrease with the 16GB card? For me, if it goes down to one minute, I'll be very satisfied. I know it might sound like a lot, but 15 minutes to 1 is a huge difference.
Hey, what are the GPUs?
4070ti super
That will be really good for sdxl models. You should generate a 1024x1024 in seconds and with upscaling by 2 maybe 1 minute
Make sure to use --xformers
I'm looking forward to trying it out
Grok went open source with public release of their weights and codes
around 318gb downloadable size
how do I fix this? CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1. Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
I have tried restarting but I got the error again
using a1111 on a 3080

ur using the wrong vea
tnx bro i will download sdxl so i can fix right
anyone know why its saying I dont have python when I have python????


probably didnt set the path when installing
wdym
I did though
and it says 311 when I have 3.10
I tried installing 3.11 but I can't have both 311 and 310 installed but I need 310 to be installed so I can use kohya but I can't use SD without 311 but I also can't use kohya with 311
do I need to just completely reinstall SD???
delete your venv folder wherever you installed SD
itl recreate one when you start up the webui-user.bat and that will resolve your issue
pretty common issue with that additional information, happens all the time
okay thanks I will try that
well it's what I was using lmao but it won't let me use kohya with it so I installed 3.10
oh okay i probably did read the message correctly then lmao
yeah so youll want to uninstall 3.11 then do the venv deletion step above
so the kohya gui is what I use to train models right
yeah I'm now reinstalling torch

looks like youre good
thank you also after I install the kohya gui do I use that for making my own model?
yep thats right
Hello, I have recently just started using automatic1111 and it has been working fine for the past couple of days but today, it has been using all of my memory and crashing my pc just from starting up. What can I do to fix this? I have 8GB of VRAM
hey, are you using an nvidia gpu?
if so you need some performance arguments in your webui-user.bat
--xformers --medvram-sdxl --no-half-vae
Add them to the line COMMANDLINE_ARGS=
Then relaunch the webui-user.bat
trying to get it setup but have an issue where cudnn only installs to torch but not as a folder so I don't get the 'upgrade.ps1' file
is there any other way for me to install cudnn or do I have to use kohya > cmd > .\setup.bat
hopefully cs1o or someone else knows, im unfamiliar with kohya setup
how do we write a propt? and which channel
this can happen for 2 reasons - wrong vae (as someone already wrote) or too big CFG (might happen if you are using lcm/lightning/turbo... those require very low CFG (usually between 1 and 2)
Hey guys,
I wanted to use this upscale method. Is there a way to set the settings? or does it automatically use premade settings?

Yes I am, I will give it a try and see how it goes
it uses the hires fix settings you can select
The settings are different from my img2img settings that I usually use for upscaling.
not that much, you have a denois, some upscalers, set the hires steps to 10. and upscale by X depending on the resolution.
is it strictly needed that the training images for a lora be the same size?
moved this here since I believe it's the right place

the tool for PT to SAFETENSORS
has some screwed coding errors
I did set gdrive on my pc and put the right path
allowed it
installed all the requirements
pfew
so uh ...all in all can you give me some troubleshooting advice ? :))
Hello, can anyone recomend a good setup for someone getting started making video work with stable diffusion 1.5? Approximately $2500 budget, whether it's a laptop, desktop, or using service like RNDR. I'm a beginner, would appreciate any advice. Or if anyone can point me to a better place to ask these questions.
would say a 4080 super
but where u from
because that changes with prices
4080 by itself is over 2000 euros here, for example
and he said 2500 for the whole computer, not just gpu
hello
does someone know what this error might be ?
I'm trying to fix it around
but it
it's just not going anywhere , like I am not into coding
for me its 1300
so thast why I ask where he's from
Choose Your Parts
thisis for the us amazing
I did this and it’s still freezing my pc. I also see in my task manager that’s it’s using 100% of my memory every time now.
nvm its 1100 for me in the us its 1300
i agree with you that price depends on the local market


How much memory do you have?
like
uh
someone told me to use forward slashes
instead of backslashes
and I think the coding language it's python
is the writing in red generally a bed deal , like it announces an error ?

sorry to repost i am having the same problem again now all the new lora are now not showing up even when i refresh

are they for sdxl? while using a 1.5 model?
both
change the model, loras are either made for sdxl OR 1.5
16 GB
you may need to increase your windows pagefile then
when ysing a 1.5 model u can only see 1.5 lora and vice versa
@late cove @ornate elk how do I do either of these? I'm sorry, i don't know much about software.
Means it should have either started using system ram or storage to make up for the ram usage being 100
Which is why it slows down to a crawl
i would agree with you but some of my 1.5 arent showing
oh I see what you mean. Yeah it does that but it takes 30 minutes to actually go to normal speed. Is that normal for it to take that long?
you can do that by following this:
https://www.thewindowsclub.com/increase-page-file-size-virtual-memory-windows
set min to 16000 and max to 24000
make sure the pagefile is set to C and disabled for other drives
make also sure to have 15-20gb free space on C drive
and restart the PC after that.
Doesn't go up to normal speed
Uses system storage as ram
And painfully slowly generates the image
Okay, I will see how this goes
how can i just fix this
This my setup : 💀

Why is it doing this all of a sudden though? It was working fine but now it’s so laggy and I have to wait so long. Before, it only took like 5 minutes for a big generated piece.
You got to many loras
Causing overflow of ram probably
Base sdxl is very easy to run
make sure to also disable Wallpaper Engine before using SD, as WPE causes freezes
even my emdedding arent showing up\


Where do I find wallpaper engine at?
hp r dell?
Dell
thats where it goes wrong
If you dont know, you mostly dont have it
Make sure to close heavy programms in the background
I might have a hate against dell
Eh ?
Hi, it's me again.
I'm trying to open SD with webui-user but this is the result...
it has to be --xformers not xformers
i dont know how well xformers works with v1.8, or more specifically the torch and cuda versions it uses
Thanks, so I have to open webui-user every time I want to use SD, isn't there a more direct interface?
You can make a shortcut to it
How?
Right click the webui-user.bat and press Send To, Desktop
curious is there a reason why img2img tab does not support different upscalers too (r-ersgan, swinir, etc)
It does
You have to select SD upscale script to use them
not in forge then?
it does, open the scripts dropdown menu 🙂

its at the very bottom of img2img tab
just be sure to set your denoising level low, otherwise it will wrestle with you to make a new image over the current one 🙂
thats what i do for best results. i normally only scale factor 1.5 or lower each time, it keeps things consistent. a bit more work but on photographic prompts it adds in crazy detailing for pores, eyebrows, skin creases
i'm gonna go all out just to see what the detail is
2048x2048 r-esrgan 16x
i wonder if 4090 can handle it
it works by breaking the image into tiles and works on them as individual jobs so it can, itll just be a longer job.
so it'll be 32k wow
and you wont be able to use your computer for half an hour 😄
already 2048 x4 is taking over an hour
as i say though, low denoising is the key
60 steps is kind of pointless for an upscale
its not creating anything, just filling in and making things bigger, you could easily half that, but go hog wild and feel it out. i'd recommend youtube tuts on it too, theres a bit of a feel for it you'll get watching someone else use it
why? there can be significant changes to the image between 20, 60, or 150 steps
really just depends on if the output is good
are you saying higher sampling is also like a denoise?
yes and if youre upscaling what you want are LESS significant changes and only subtle ones.
the problem is getting perfect arms/hands on people before upscaling
steps cfg and denoise settings are all something you'll have to play around with. theres no specific scale

yeah work on that first 🙂
if i use a hand lora would it be good for distance shots
any good guides on getting perfect anatomy? may have to check civit
esp. when the scene contains many people
think it's pretty achievable reliably?
the more people the vaguer it gets, and inpainting is a bit crap on SDXL
yikes
theres an extension called Adetailer which is useful
id honestly suggest walking before running, a busy tableaux type image upscaled to the size you could put it on a buildings wall is achievable, but you're best getting there in steps.
Is there a way to make the preview image closer to the final image? I'll have an image that looks perfect in the preview, and then at the very end everything gets messed up and the final image is an abomination.
are you using latent upscaler by any chance?
because that can trash a perfectly good image.
Yes
Which one should I use instead?
try one of the other upscalers instead, its utter rubbish
what kind of image is it?
my spider senses tingled, it happens to me once in a while when i forget to set the upscaler and i get so mad 😄
What's a good all-round upscaler?
these are my ones, i only have 2 you need to download manually

4x-ultrasharp is really good for photorealism and esrgan_4x i find best with vectors and illustrations. but you might just find your own favorites
there used to be an upscaler model wiki for downloads but they've moved it or something
yea, is there a guide how to install it
oh you just pop it into a folder in your models folder

when i checked the site for it seemed to involve editing a py script
image isn't loading
its just an image of forge\webui\models\ESRGAN where you can put the models in
https://upscale.wiki/w/index.php?title=Model_Database&oldid=1571 heres an old version of the upscaler database
nice
shows when i click it
discord is being weird these days
anyway, 4x-ultrasharp is my fav all rounder model
What would you do in order to better this face?

bit of a broad question. do you mean with settings or prompts?
Anything you can consider if that betters the face, since the rest of the image is pretty nice
However, I've already included lots of prompts for the face in here

It is understable considering this is the reference image (controlnet included) and the face is just a drawing witch is not blended so well. But it should be a way to better results

is this an SD1.5 or SDXL model you're using?
i would chop so many of those prompts out if its SDXL
https://discord.com/channels/1002292111942635562/1011743094309396631 this is a good channel for promptcraft btw
here is primarily "why computer no go brrr?" type questions 😉
So let's go there?
https://civitai.com/models/118086/3d-animation-diffusion My checkpoint
3D Animation Diffusion 3D Animation Style Model Do you like what I do? Consider supporting me on Patreon 🅿️ or feel free to buy me a coffee ☕. A ❤️, ...
if you're using controlnet, you could also experiment with cutting its ending step down to 0.8
I don't understand, why does it go under esrgan/
then where are all the other upscaler models
Are you meaning I set this down?

yep, just to see. also things like reduce or increase your CFG as that is an enormous prompt
if you drop the ending control step down then it lets the model try to generate the last bits on its own and add in little things
Yeah it may work!
might make it worse too 🙂 its like letting go of the handlebars
Talk about this point
in #📝|prompting-help if you want, but I'm interested on that
sure
Hi guys, now I have this problem
SafetensorError: Error while deserializing header: MetadataIncompleteBuffer
The upscalers you can download on openmodel db are all based on the Esrgan technique, thats why they go into that Folder
When do you get this?
A bit more info would help
Ok, finally SD is running, I wrote some prompts and this is the result.
Maybe you can show your settings or the full cmd log
Ok.
Hello, can someone please help my dumb ass make a lora? I already make the dataset and all, I was trying to do it in kohya and I was following a yt tutorial, but I can't do the training part
thank you


What's your GPU and what's inside your webui-user.bat?
Also what model did you tried?
Where is the issue?
But remove the space in the image folder name
set PYTHON=C:\Python\Python310\python.exe
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers --no-half-vae
call webui.bat
NVIDIA GeForce RTX 2050
I don't know the model, just followed your installation guide step by step.
You need to add --medvram
Hey guys I have a big problem. I asked someone and he kindly helped me out to understand SD better and how to generate just like him. My SD did not do the same results as his. I used 1:1 the same parameters, vae, prompt, neg prompt, everything. Our results are very difficult. The outcome is very difficult. My version is 1.8 and his 1.6. That is the only diffrence
So I delated SD completly, download it again, and it still does not work
this is my out come of the image with the same lora etc

and this is his. We tried everything but I still get it so diffrently as you can see above

1.8 had a change that is "seed breaking" I'm not at PC rn to tell you which. But its listed on the github changelogs.
Also you both need the same GPU type or it won't work. Also you need to both have RNG CPU selectet or it would be still different. Also xformers makes minor detail changes
As I know we have the same VRAM, is that important too?
In COMMANDLINE_ARGS?
so that means I first need the same Version which is 1.6 . But how is it possible to get that version back again?
So it's not possible to generate like his image at all even though the lora was created by him and the outcome should look like that
How do I or we select the same RNG CPU
No it wouldn't bother at this point. 1.8.0 is the better version.
You won't get 100% the same image but the lora should work the same for you as for him
You can select the CPU RNG under settings and then search for Seed
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Install-and-Run-on-NVidia-GPUs I downloaded it from here

GitHub
Stable Diffusion web UI. Contribute to AUTOMATIC1111/stable-diffusion-webui development by creating an account on GitHub.
And that is what i also wonderd. Why is my image not even near to his? I understand if its not 1:1 but at least the character should be regognizable
Do you have the meta data of his image?
And yours?
I could compare it
Nvm its included
Okay (I dont know what that is but I'm happy you found it
We tried to find out what it could be for at least 4 hours or more
Okay so it seems you didn't used the same settings as him. Even the seed is a different one
We really used the same settings. Same Prompt, same neg. prompt, same vae, model etc.
But what is the diffrence in these two images
I did everything he wrote so we have the same settings
No your seed is different also the denois strength is different
And more
What should I change so I have the same as his. It's weird because I copy pasted everything he send me. I was sure I did everything just as the txt.file
@solemn atlas To check for yourself do the following:
Drop his image into the PNG-Info tab in auto1111.
Then you see all the Settings he used.
Screenshot it.
Then drop your image in and compare
seeds dont work on different computers. i think theres one old sampler where it does
but you will not get identical images.
its not the same as random seeds for map generation on say a video game
Seeds work if the RNG is set to cpu
yes on both sides
@solemn atlas if one of you have nvidia and the other do not, you wil NEVER get the same image
unless you switch to CPU generator
I put it into the PNG Info and then just "Send to txt2img" and used his parameters but it's still as mine


ugh im an idiot i thought that was specific to one of the samplers
Then it should be a different image to your last one
Because it would have used an other seed and denois
I just looked it up. I have Nvidia but it is on GPU

if you both have nvida and both on gpu it is fine
Is there a text channel for developer based question for Automatic1111’s webui repo?
i learned that lesson the hard way
theres github
Ohh I understand. I never heard of that. I'll try to change to NV and look if maybe that was the problem all along
i am on mac and i was desperately trying to recreate image from civita (made with nvidia) for 2 days 🙈
i do think though that seeds across clients should be a thing for the future as a standard. i like the idea of collaboration
then i tried on my sons pc (with nvidia) and got the 99.5% identical image from the first time
I have Nvidia but my settings were on CPU I guess maybe that was the problem. So how did you find it out and could you generate them just like on civitai?
It still reloads. I didn't know it takes so long
civitai prompts are weird. so many photos of a beautiful unicorn have crazy prompts and you could tell the creator was going for a horror scene but missed
can't wait to try it out
Maybe my question is generic enough for here. I’m curious about tile based Upscaling with img2img and ControlNet through an API. Mostly want to know what the flow should be, e.g Generate image > ESRGAN upscale > img2img ControlNet > ESRGAN upscale > img2img ControlNet
Maybe I’m wrong in how I’m thinking about it
If it was on CPU and his setting not, that is a big difference yes
I added and the result is
Can you go into the stable-diffusion-webui/models/Stable-diffusion folder?
There check the file size of the model pls.
does any of these other settings help

@golden arch I guess the model could be corrupted.
Best is to download this one from here:
https://civitai.com/models/4384/dreamshaper
And put it into the models/Stable-diffusion folder.
Then select it in the checkpoint dropdown and try again
DreamShaper - V∞! Please check out my other base models , including SDXL ones! Check the version description below (bottom right) for more info and...
you need to press both of those


Hey, what webui do you use?
I dunno if this question goes here but...
How can I link the models from my Automatic1111 webUI folder to the Stable Swarm UI (or a custom folder located on another drive)

@ornate elkpinokio installer
For auto1111?
Ok, I think there's no model...

Thanks for answering
I don't really know where is the problem, I got stuck in this part from the video
I left the space because the guy from the tutorial also left it (2nd image)
Something I have to highlight is that I reached min 46:17, saved the configuration, and closed Kohya, logged in again and loaded the lora configuration as it was.
I don't know if my mistake is that Kohya no longer detects where I put my image dataset???



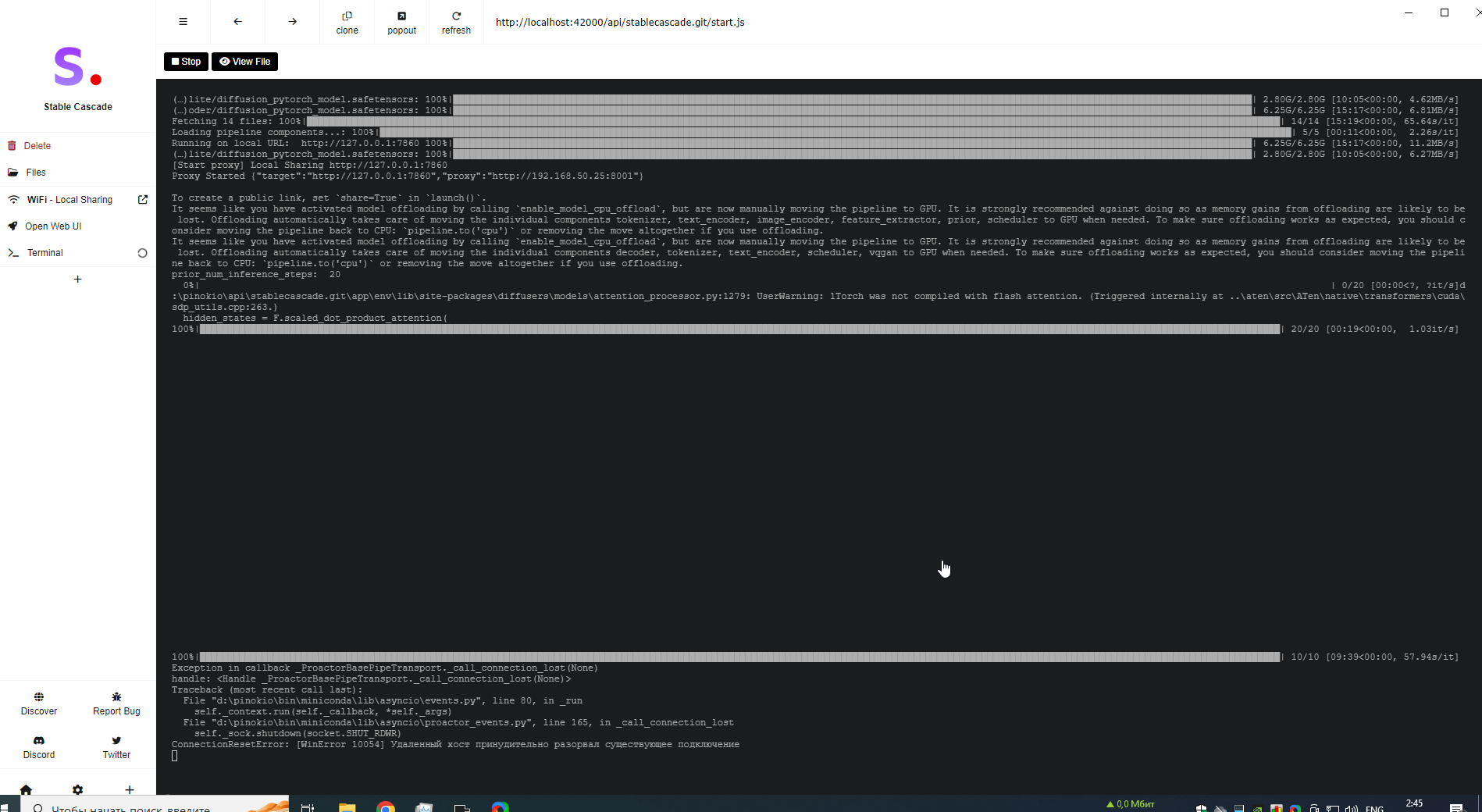
Oh stable cascade. Thats a special new thing. Thats not the normal Stable-diffusion webui.
So yes it could be normal that it takes so long
Its in there but the file size is not correct. Please download the one I linked you
@ornate elkcan u recommend anything else with faster renders?
Coming
comfyui or stable swarm could work
Sure, if you want to use the normal stable diffusion webui most people use then follow my guide:
#🤝|tech-support message
Its much faster
And easier to use
@ornate elk do you think you can help me with this problem?
okay will try it now thanks
since I am having difficulties with configuring it
I dont think stableswarm has args for adding paths. So your only option is to use the good old Symlinks

it does have this tho
doesn't this work?
since I tried placing windows paths but it didn't detect them
E:/ai/stable-diffusion-webui/models/Stable-diffusion/
This doesn't seem to work
I really don't know. So i changed from RV to GPU and to CPU and the outcome is still the same. Shouldnt that at least look at bit diffrent? But it looks the same

I even restarted the backend
Look near the bottom it locked your RNG settings
You have to click the X
To remove the locked setting
Or it won't change

where is the X ? Sorry i cant find it

yeah I just needed to set the root path for models and everything else was picked up automatically
Ohh okay, should i remove both?
Good to know
Its like comfyui then (as its the same Backend)
It's still the same. Didn't changed a bit
Need to go off now gn 😴
I'm really confused

i am off too its 1am, and i am awake from 5am
good night
It worked! Thanks!
trying to get kohya setup but have an issue where cudnn only installs to torch but not as a folder so I don't get the 'upgrade.ps1' file
is there any other way for me to install cudnn or do I have to use kohya > cmd > .\setup.bat
Hey guys, so I've successfully run the webui.bat using python. Im unsure what to do next 😄 does that mean its installed?

Oh maybe it didnt work given what its saying in the text above
Hey, what's your GPU?
Hi, @ornate elk

Okay, make sure you update your nvidia driver to the latest version, and restart the PC
Then relaunch the webui-user.bat
Any local open source tools describing images and generating texts?
Nice! I have webui forge going (web browser based, didnt know that), now i am tring to add some models for it. Noob question, how do I add them from here? Im used to github and adding its url, but this, unsure.
https://huggingface.co/lllyasviel/sd_control_collection/tree/main

referencing this message from Wit 🙂
how do I put a max on the amount of vram sd uses
You can try add --medvram to the webui-user.bat
I already have that
These models have to be downloaded manually and place inside models/Controlnet
but I mean like a slider or something
nope
becaus normally I can just use everything, its jsut that I now need to have my wallpaper enginge on because clock
Wallpaper engine causes stutters and freezes and even PC crashs when used at the same time while SD generates images.
Good morning guys, about my problem yesterday that we can't generate the same images with the same settings
These are his version: version: v1.6.0-2-g4afaaf8a • python: 3.10.6 • torch: 2.0.1+cu118 • xformers: 0.0.20 • gradio: 3.41.2 • checkpoint: 354b8c571d
and these are mine: version: v1.8.0 • python: 3.10.6 • torch: 2.1.2+cu121 • xformers: N/A • gradio: 3.41.2 • checkpoint: 354b8c571d


yeah ik
thats why I ask for the slider
Why do I get different results from civit.ai/my friend/alien lifeform examples :
1/ --xformers (and some other flags but mainly this one) will make stable-diffusion non deterministic. Meaning for the same prompt+settings running on different hardwares you'll get different results. The output should still correspond to whatever the prompt is.... It might just be slightly to very different if you're unlucky. So yeah, some command line arguments can alter the outputs of your prompts and your hardware might also do the difference.
2/ Do you have all the loras, embeddings mentioned in the prompt ?
3/ Are you really using the same settings ? Copy pasting manually what's inside the "Generation Data" boxes is not enough. Civitai is hiding a bunch of data there. If you want to get the exact same settings you'll have to click the "Copy Generation Data" button at the bottom of the image page, paste its content into Auto1111's prompt field and then click the blue arrow under generate to automatically apply each value to the correct field. Hidden values can be; clip_skip, ENSD, token merging ratio, etc
4/ Did you have any overrides set beforehand ? They should show up at the very bottom of the page (some will probably show up too if you use data from civitai like I mentioned in 3/)
5/ Maybe it's using some extensions that does not record its settings in the metadata
6/ Maybe you're using different versions of some extensions/auto1111/lora/models/etc that yield different results
7/ Are you using the same random number generator ? GPU / CPU / NV (Settings->Stable Diffusion->"Random number generator source")
8/ Maybe you're using a newer version than OP. One that includes a "seed breaking change", cf https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Seed-breaking-changes
tldr don t waste too much time trying to replicate images exactly
the thing is, the Lora is the character I want to create. He created a Lora for that specific character. I don't want to copy 1:1 his image and pose but at least get the same hair, expression etc which is recognizable for that character but when i use the lora it looks completly diffrent. I only want to generate her as she is (with a few diffrences ofc but to get "her" into the image" And I don't know why it doenst happen
Is there a way to adjust xformers?
There is no slider. What you can do is to get yourself Rainmeter and a simple clock widget for it. And then disable WPE
ok thanks
(or look at your watch, smartphone, clock in the start bar, open a browser page with a clock on it, etc)
where can I do that? I looked at SD but I don't know where to try it out
oh xformers are just the NV GPU and stuff I understand
Xformers Is on when you added --xformers to the webui-user.bat
is this on settings?
set COMMANDLINE_ARGS=--xformers --whateverIsAlreadyThere
So I go to webui-user.bat and open cmd
these things are in my black window thing when i open sd

there are a lot of errors
what s in your webui-user.bat ?
that s your log, not what s inside your webui-user.bat
Oh I#m sorry it's this

so yup you have litterally no arguments whatsoever ....
what s your gpu ?
I'm not sure but GPU is this right

set COMMANDLINE_ARGS=--xformers --no-half-vae
then
okay I did and then open it again
Okay I opend it. Should I now put this too and remove the other one
use this one .... set COMMANDLINE_ARGS=--xformers --no-half-vae
I did
then there you go
xformers is on
(and whatever error you had at startup because of some extension is probably still there)
The outcome is still the same and yes the errors are still there. It says that " Unable to load ESRGAN model" and this "RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory"
hi, i cannot find any # dreambot in left hand side, may i know it is normal?
I even re-installed SD and still have problems. I don't understand what is wrong. Even after downloading Comfyui there is not bat.file. Something is off with my whole system
Can you screenshot the whole cmd with that error?
it's this
Does the webui open in browser?
Do you have access to the Extensions tab?
Yes it opens and I also have acces
Then click check for updates, let it load and then restart the webui-user.bat
click apply update before restaring the webui
In Stable Swarm UI I have a problem where my controlnet preprocessors aren't being showed I am just stuck on having canny as an option.
I did
It's still these problems
Unable to load ESRGAN model
RuntimeError: PytorchStreamReader failed reading zip archive: failed finding central directory
I think i know where the problem comes with the ESRGAN model
I copy pasted these folders before delating SD and when putting all files back there was not ESRGAN folder and i just created a folder and named it that way and put all upscalers in there
You should have had this folder in models/ folder
When installing sd
Otherwise something is broke
It was not there, I also wonderd thats why i created it
Maybe you should do a clean install of the webui
So I need to delate SD again?
What you can do first to try to fix your webui:
Rename the Extensions folder to _extensions
Then delete the venv folder.
And restart the webui-user.bat
And then check if you get any errors
anyone manage to get stable diffusion run on intel core ultra integrated gpu?
You mean Intel UHD 620 ?
That won't work
SD can only work with Intel Arc or maybe IrisXE GPUs
no
*it should be called intel arc graphics
i tried using the accelerate with openvino script but it isnt using the gpu at all
So I did and the error is still there
I got CUDA runtime error
and it's like, felling all my RAM and VRAM...
I found out this issue when I searched about the commandline too, any fix for that?
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with **TORCH_USE_CUDA_DSA** to enable device-side assertions.
When will the bot be fixed?
Okay, then for Intel arc you need to use the SD.next webui
Then you need a reinstall
What settings did you used?
which settings?
from which page? I did that yesterday too
Here is my install guide:
#🤝|tech-support message
I'll start it later, I'm updating a driver xDD
Or let's do it on weekend. I will message again.
I forgot I have an exam I need to learn for
Resolution, model, etc
Hmm
Try a restart and test again
Make sure wallpaper engine is not running in the back
my wallpaper is literally a 768^2 image I generated xDD

can it maybe because I install a plugin?
Yes, which extension?
Some of them can break stuff

Do you have any errors in the cmd?
I only see this
For the Photoshop plugin you would also need to add --API to the webui-user.bat
Easy photo extension won't work on your gpu
ah, sadge
Or wait how much vram does it have?
RTX 3050 Laptop 4GB
Okay nope
lmao, sadge
You can delete it from the Extensions folder
Boorutag autocomplete is also a good extension
btw, how do I know what version of SD do I use in AT1111?
And you should get the tiled vae extension
or it can automatically use any SD version?
interesting, what it do?
With the auto1111 webui you can use any SD model version (1.5, 2.1, sdxl)
It helps when using Hiresfix upscale to not run out of vram
Making it easier to upscale higher

but it is intel arc on intel core ultra cpu? can it still use ipex?
you're in core ultra now? how's the iGPU performance?
Yes it supports Openvino and ipex
I can't guarantee that it will work, but its your best chance
Yes
alright. i will try it with sd.next
Best is to read on their github for the Intel instructions
still haven't got it to actually be used in sd
oh ok
i couldnt find documentation made for it, those intel arc guides out there are made for their discrete gpus
On SD.next it says igpus are not supported with Ipex. Use openvino instead
do I need to restart the AT1111 or ReloadUI is enough?
Best is to restart
hmm, okok
oh nuts, apparently I have to turn this on xDD

yes, the extension really useful, thanks
Yes enabling it is enough. Also you dont need to enabled tiled diffusion
I don't even know what it does, so I'm not enabling it xDD
Hey I've got an issue with the fetch_uri for my queued images
if I call it with curl I get
{"status":"error","message":"Invalid API Request","tip":"1. Make sure you are passing Content-Type: application/json in header. 2. Make sure you are doing POST request with valid JSON. 3. Make sure your JSON does not have error, use jsonlint to validate json array"}%
going a bit mad with this one, the api key is definitely correct and is used earlier to generate the images in the same package
hey so I trained a lora model using kohya but its a JSON file instead of a 'safetensors' file
I got the following error every time I want to generate a slightly higher resolution image. I'm using openvino acceleration
BackendCompilerFailed: backend='openvino_fx' raised: InvalidCxxCompiler: No working C++ compiler found in torch._inductor.config.cpp.cxx: (None, 'g++') Set TORCH_LOGS="+dynamo" and TORCHDYNAMO_VERBOSE=1 for more information You can suppress this exception and fall back to eager by setting: import torch._dynamo torch._dynamo.config.suppress_errors = True
here is the full error msg

So there are so many versions of ControlNet canny, depth, lineart etc. for SDXL 1.0 and from like 10 canny models, only 2 work good out of the box. I tested them all. Why is that and why the controlnets for 1.5 models were better?
Stable Swarm UI problem here. It isn't detecting any of the controlnet preprocessors only canny no matter what other model is chosen.


Any tips guys?
https://github.com/danielgatis/rembg
This is supposed to show up at the Extras tab, however it simply doesn't.

GitHub
Rembg is a tool to remove images background. Contribute to danielgatis/rembg development by creating an account on GitHub.
use this one instead https://github.com/AUTOMATIC1111/stable-diffusion-webui-rembg
if I use the lora and the wb17myself in the prompt, the output image is nothing like what i want

how can i fix this?
dont know that model so don't know what triggers it best or the best strengths to use. look up wherever you got it and see how examples use it i guess
for stable diffusion theres a nice little civit model helper, but im not sure if it works for downloading anymore as the site changed things around and requires auth. but anyway what it did was fill out your lora with information like how to trigger it
this another version I have the lora is applied


wait, is this a lora you trained yourself? just looked at your name

oh right. damn there could be a dozen different things causing that which happened during your training
i guess it is related to my prompt or the captioning
olivio sarikas' discord has a pretty good training channel, i could send you an invite if you'd like to ask there, they're good with in depth things like that
send it
Can I ask about those online models which generate text exceptionally well, how do they do it?
compared to SDXL models
are you asking how the models work?
if you want to make them locally i could link you a really good video that dropped today, but its comfyui workflow
How can I train pix2pix in SD to apply a style based on training data that consists of paired images, where A is a piece of artwork, and B is an image based on that artwork that is potentially very different. e.g. the 'style' image is outlines traced on the artwork. or the 'style' image is normal maps that were manually painted to match the source image.
i.e. I have a piece of software that animates images, and uses multiple textures based on that image. I want to train SD to be able to generate each of the different texture types, based on those which I have already done manually.
hi guys, anyway to get more credits for stability . ai? I think will need more to test the app
controlnet has a good feature, 'reference', you might want to read up on that. its very good at translating the feel or style of an image over to another. https://github.com/Mikubill/sd-webui-controlnet/discussions/1280
its essentially pix2pix
Hello, I keep getting an omegaconf error regarding a missing key for ddconfig. I'm trying to get SVD running on a M1 Pro Macbook
Here is the traceback, I'm using the stable-diffusion-webui
any help on this? thx
whenever I use embeddings such as "easynegative" in the negative prompt I get the "RuntimeError: expected scalar type Half but found Float" error.
how do I actually use this. It just seems to be a discussion about that feature? Is it just in SD if I update to 1.1.171?
controlnet works in a1111 and comfyui
both have seperate extensions, that was just a quick overview with pictures in case it looked like something you'd wanT*
lol i accidentally typed want with another character and got blocked by the server!!
So then to have SD take an existing artwork, and generate the different versions of it, I would train a style that is all of the texture types I have manually generated. Then use a new image I want transformed in the same way as controlnet image?
I feel like something where training accepts both 'original artwork' and "texture based on that artwork" is more likely to get the results I want "X artwork changed to Y texture in this way". So that I just give a new X artwork, and it changes it in the same way. But I"m not sure what functionality in SD trains "image A turned into image B".
whenever i run lora script, this also happens. any clues why?
hey just starting out using fooocus and im currently trying to recreate a generated picture on civit.ai
i tried copying the models, prompt, negative prompt, the seed but my image is entirely different, not even in the same artstyle
anyone care to help me out figuring out what the problem is?
you wont get the exact same image, the generation from someone elses random seed is different to if you run it on your own. also a lot of civit generation data isnt easy to copy over, they might have used other upscalers or inpainting.

oh hell no, thats a completely different model lol!
yeah im confused because as i understand it, im not allowed to change the basemodel to the "vixon's fantasy mix" checkpoint
so i tried to understand how refining works
i assume theres the problem, but no idea
the one on the left seems to be using an anime trained model, you wont get anything even a mile close to that. the two model flavours interperet the prompt differently too. anime models wouldnt know what to do with a photorealistic prompt and vice versa
huh, isnt the "resources used" category telling me what models they're using?
by "not allowed to change" do you mean its running on a server?
no it gave me the error "You have selected base model other than SDXL. This is not supported yet." when i tried to
after googling i came across this:

so i went onto the vixon's fantasy mix model's page and it says "base model SD 1.5", due to the look i assumed it counts as "anime"
so i figured i put 0.667 on the refiner
what client are you using? is it local or running off someone elses computer?
its local
if its local you can literally just download that model
thats what i did
wait, which client are you running? a1111?
fooocus
ooooh right
so as i understand it, it doesn't support changing the basemodel or something
im clueless
im just trying to recreate similar images 😦
also unsure if i should change something here?

or whether i should use a style
its a bit undersupported, i dont know many people that use it that could talk you through settings mate
so im better off looking for SDXL checkpoints?
at least i assumed using the SD 1.5 as refiner it would at least get me closer to the result i want
no i mean rooned. not many people use it so dont come across problems and can help you. you could bump this again tomorrow maybe during the day
i say during the day, i mean its late in US and europe
maybe thats why
yeah using lora based on sdxl 1.0 it works much better
u could join the sd sub reddit discord the developer of foocus is in there
with the help of @noble belfry i just switched to forge and having great results so far
that also works XD
anyone successfully build https://github.com/Stability-AI/generative-models on Apple M1 pro? keep getting this error and related issue (but closed) https://github.com/Stability-AI/generative-models/issues/125
ModuleNotFoundError: No module named 'torch'
isn't torch python module?
try pip install torch
What's your GPU and what's inside your webui-user.bat?
my gpu is a gtx 1660 ti and this is inside my webui @echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
git pull
call webui.bat
Okay for your GPU you need to add
--xformers --medvram --no-half
To the line COMMANDLINE_ARGS=
Then save and relaunch the webui-user.bat


still dosnt work
Thats strange, it should work.
Does the cmd shows any error?
Make sure you always launch the webui-user.bat and not the webui.bat
Hoooooolyyyyyy shhhiiiiiiiit im stupid 😂 thank you so much its fixed now.

No problem 🙂
Hellow
I have a mainboard with 2x pcie 16 slots
I have a rtx 4080 running in it
can I use a rtx 4000 ada together with it?
Does someone run two different gpus in their system?
only one gpu can be used at a time.
(but you can run one instance on each of your gpu, stable swarm UI might help you with this)
Oh ok thanks
I wanna do dreambooth training and maybe I can do that on two gpus simultaneously
I'm getting an error when trying to generate, it goes through the whole thing but then fails at the end saying:
Cannot set version_counter for inference tensor
does anyone know of a dataset that has just one person's face in a lot of different poses and angles?
ty
is there a torrent for automatic1111, installing the portable version always fails and trying to use git fails as well
if you are still wondering, i got about 1.3it/s on openvino and 1-2s/it on ipex
hello !
I need help regarding Stable Diffusion, I have installed Python and stable diffusion, i follow all the instructions but now i still can't launch it. and the first time it launched automatically I got an error message and I couldn't generate.
If someone can help me pls 🥹🥹
what webui did you install?
hey, whats the error? and whats your gpu?
Here is a full guide to install auto1111:
#🤝|tech-support message
you would need to install python onto the external drive aswell as SD
my problem is that all standalone portable versions of automatic always crash for me, my internet connection over VPN is not stable enough and keeps crashing
that's why i am hoping for a torrent that doesn't restart every time your internet connection gets lost
it’s a red error msg up to the right in the screen
my GPU is nvidia RTX 3070
did you followed my install guide?:
#🤝|tech-support message
you can also screenshot the whole cmd output for me to check
Ooh, wow ok
I'm getting this error with Ultimate SD Upscaler. Only with "ultramix_balanced", for example not with "4x-UltraSharp"

Any link to install Kohya_ss on .MAC if possible at all… if not any other tip for training model through dreambooth / SD?
Thank you so much! 😄
“CIDAS/clipseg-rd64-refined” Please help me, should I download the entire folder or which part of the file in the hugging face, and which directory should I place the downloaded file in the local folder

Ok ! i succeded to install SD in the good way I think cause now I can lauch it, but, when I try to genere i have this grey screen, i don't know what to do

Any advice for changing in stable dif webui adapted for latest M3 Pro configured to max 16 C CPU / 40 C GPU with ANE 16C
Is the model you try to use 6gb ? (Sdxl models are 6gb, 1.5 models are 2gb or larger)
Everything smaller is not a model
My guess is your trying to use a model as Lora.
I think old anime style xl v3 is a Lora for sdxl and not a model itself
If its a lora it goes into models/lora folder
As model try out aamMix
i'm sorry to ask, i searched on the web and didnt find. Where can I dl it pls ?
You can get all the models and loras from here:
https://civitai.com/models
You can choose between 1.5 and sdxl models and loras.
1.5 is trained on a 512x512 resolution while sdxl is trained on 1024x1024 resolution.
For example this is AAM Mix
https://civitai.com/models/269232?modelVersionId=303526
An sdxl model for Anime
Oh thank you so much, now i understand better (i think myself so dumb now too 😅 )
no problem ^^
in img2img you can use the sd upscale script
at the bottom
set denois below 0.3
set the resolution to square
select the upscale script and an upscaler
hires fix is still better, but it uses the same technique
in img2img upscale you cant set the denois as high as with hiresfix
so best is to generate the image with hires fix and then inpaint and upscale it with the sd upscale script in img2img
anyone mess with adetailer before?
trying to run adetailer over this image to fix the face but it just messes it up


are you on AMD?
whats your GPU?
ahh okay
then you may need to add --no-half --upcast-sampling
to the webui-user.bat
alright ill give that a try
also: any idea why i have to reload the ui after starting it in order to do anything in it?
like the first startup is always unresponsive; won't generate, load extensions page or even PNG info
until i do "reload ui"
thats strange, maybe a gradio issue, make sure to whitelist the webui in any adblocker
oh wow lol i'll try that, i didn't even consider that it could be my adblocker
yea, we had such issues here before, if its visual (and no console error), then its mostly the adblocker
erm, so before i could add these flags to my launcher i did a complete fresh install of the webui to make sure there wasnt any funny business going on (also to fix that weird reloading issue because at the time i thought maybe a fresh install could solve it (it didnt ofc))
and for some reason now adetailer is working fine?

i did a lot of shit that was almost 100% unrelated, like installing rocm sdk and not installing the insightface module so i really have no clue why it's working normally now
hmm, yea normaly it should have worked on rocm linux without issues before
good that its back to normal now ^^
it is!! but i'm also scared because it's just randomly working now xD
ok. i disabled my ublock origin completely and lowered firefox's security settings and the first launch is still buggy for some reason
web console errors from the ui
might be related to the agent-scheduler extension..? either that or it's a symptom. im going to try disabling it and see if that helps.
@ornate elk any thoughts on this? you see lcm lora works with 2-8steps and 1-2 cfg, and within those same parameters lcm lora has both sd and sdxl versions, while sdxl lightning lora too works with 2-4-8 steps wit cfg 1-2, what exactly is the key difference to them?
there is a lightning lora?
yes
can you share a link?

{kind=link}
{kind=link}
{kind=link}
ah interesting
also have a sdxl model merged with it
i guess the difference is thats its locked to steps?
no
you can go from 2-4-8 with either
hmm

technically you could just work with lcm for both sd and sdxl for decent output
after - detailer
why do you need adetailer to work before hires fix?
after detailer kicks in after the image has processed
its a way of correcting the image
you cant assess correction method before image is processed
dunno
doesnt sound logical what you are asking
hires fix does some correcting too as far image quality goes
hires fix sorts out image depth, adetailer works on image content quality specific to faces / hand attributes
they are entirely different in their function
or think of it this way, adetailer is sort of inpainting, it does its work when you have an image fully rendered
no not possible
due to their functional criterea


np once you understand their ussage concept its easy to understand how they are applied
what's the difference between tiledvae and ultimate upscaler? which one is better for upscaling higher than you normally can?
and is ultimate upscaler still a good/viable option for sdxl?
Tiled VAE is for getting higher resolution
SD upscale script is for upscaling
If you get out of vram errors enabled tiled vae
gotcha ty
does anyone ever use non SD images in img2img tab? would it be of any use?
it can be any image in img2img, you dont need a generated picture for it
@ornate elk sorry to bother you but i figured you'd want to know this. i think i figured out why adetailer was failing.. and it seems like it has to do with styles not being applied by adetailer
i was using a style for my negative prompt which worked fine for the base image, but not adetailer
after manually adding the negative prompt, adetailer worked normally again
oh good to know thx
strange behaviour still