#💬|general-chat
1 messages · Page 103 of 1
well mainly because after joining I can chat here ,, all the other room won't allow me to no matter what I do , bottom line I don't know how to get in the other rooms
the room I do go to is dieing lol
but I understand ,, I'll leave if you like , no hard feelings , I am not like that
i'm not asking anyone to leave, it's just that it's unusual for someone that doesn't have any interest in AI to join this server
AI is cool but myself that should make you aware that you are talking to AI and not a person
it's got to the point that you can't tell any more
i knew it. i had a feeling you were an LLM hooked to a discord account. or i'm going crazy and misunderstood things
LLM?
Large Language Model. you said in the above message that i'm talking to an AI, right? or am i misunderstanding and completely embarrassing myself here?
oh no I mint on phone calls you can tell if your talking to AI or not ,, I'm sorry
ah, alright. apologies
but see what I mean you can't tell
yes, exactly
phone brb
Hi guys
I'm coding a diffusion model on pytorch
and i need help with something
anyone down to help?
i'm not a programmer by any means, but i'll see what i can do
Are you familiar with it?
welll... there's different ways to guide image generation right? with text, images, classes,etc/
i want to do it with an image
alright. what problem are you running into?
How can i embed context ?
i'm sorry, but i have no idea.
is there any reason why you want to code it yourself?
Yes
also is stable diffusion open source /
?
i'm pretty sure it is!
as in, we have access to the weights to train our own models. that's all i know. i'm not an expert on this topic
so wasn't SD3 to be released?
we only had a vague hint which turned out to be false. we have no further info afaik
great. civit is down
Hey
I have an issue. Where can I change the image size in stable cascade ui
it's not allowing me to make big or small images
Only 1024 x 1536
I was just given a apple tree 🙂
it's dead but that's the best kind for fire wood , besides I won't cut down a living tree
well you all have a wonderful day , nice meeting you Yellow
you too!
"better for beginners" is a tough one... it is definitely easier to get started with A1111 but myself, i found i was really at a loss for what settings to tweak etc. until i switched to comfy. now when i come back for a specific task (using forge) i know exactly what to do.
would multiple gpu's be better than one dedicated gpu, thinking of getting the AMD Radeon™ PRO W7900 48GB but dont know if a few smaller cards would work better
is the primary purpose for stable difusion? if so, nvidia should be the only thing on your list
which sucks, but it's the truth
stable diffusion and a personal oobabooga based Bot im making with someone else
cool
are you planning on doing a lot of training, or just inference (image generation)?
looking into having it be constantly running as a server type thing, and was thinking about running linux but that has issues with Nvidia(which is my current PC)
just inference and api stuff
i dont understand how to train though that is something im looking to learn
i have a 4090 and that's def been a good experience, but it sounds like youre willing to drop more on a gpu than i was - 5k or so is fine for ya?
rtx a6000 is similar in price to the pro w7900 and much much better for SD
yeah, itll take awhile to get but i dont mind spending that much, my current pc is around 4-5k
if you think you'll get seriously into finetuning models, that's prolly the card to get in that price range
i thiiiink the 4090 is a lil faster for image generation, but the a6000 has extra vram, which is handy for training (not absolutely essential, and if you're just wanting to train LORAs, 24gb vram on the 4090 is more than enough)
Is it linux compatible lol, i see its nvidia(only asking cause Linux has been a PAIN to set up on my pc)
yep, nvidia runs better on linux than windows tbh
at some point soon i'm gonna build another pc that'll be headless with linux for that exact reason
I improved my generation speed 5 times for 130$ lol
how so?
oh? i was told otherwise. good to know
sold 1080ti which has no tensor cores and bought 2080ti
i mean, double check with someone with an a6000 before dropping 5k on it, but that's what i've heard universally
im thinking of doing that but i have spare parts so meh i can reuse without buying extra 
(reply to headless linux)
there's some memory optimizations etc that are only available on linux (at least officially - triton, flash attention 2)
that's a huge step up yeah
my current pc is pretty heffty ive been told but i have no concept of how good or normal it is
tbh im not much into the spec of PCs so thats why i need to ask around, still learning this stuff
(AMD Ryzen 9 3900XT 12-Core Processor, 128GB of RAM, NVIDIA GeForce RTX 3080)
and Vram still maxes out when running my bot 
really my whole gpu does
yep
here's the real question for you i guess. what is more important: inference speed, or ability to fine tune large models with the convenience of doing so at home? (the latter you can offload by renting time on A100/H100s if need be)
if you see yourself primarily doing image generation and maybe occasionally tinkering with training, get the 4090
i prefer all free once i set it up, which is why im going big
i plan to train a bunch once i learn how
its getting there thats been hard cause i dont really understand the stuff yet
im still new-ish to AI stuff considering most people
how big of training projects is the question though
it's annoying as hell to me but you can't just spend 5k vs 2k and get something that is just better
nvidia price gouges based on vram as they know it's useful for ai and they have no real competition
their cards wipe the floor with amd right now (ugh)
so the a6000 is slower than the 4090, but... has 48gb vram instead of 24gb.
if you're looking to train a full checkpoint, you might find that 48gb handy. if you want to train LORAs - single characters, styles, objects - 24gb is more than enough.
for the difference in price, it might be wiser to get a 4090 and sock away that extra 3k for time on runpod.io
as card prices will ilkely drop over the next year or two anyway and/or get more powerful
ill be using it for: Voice, Image, (Video once its out), and text bots, training wise: Pictures, Voice, and Text generation. probably stuff from grounds up
Im sorry for not being more knowledgable on this stuff, i really want to learn but its been tricky
another thing to consider: i'm not an expert by any means on LLMs (to say the least) but i believe you can split the vram on those between two cards
without the need to load eveyrthing into vram on a single card, dual 4090s would be cheaper than the a6000 and have 3x as many cuda processing cores
that would also allow you to dip your toes into it first
get one 4090, see if it's enough for ya
if not, get another, but make sure your mobo and your case etc are gonna be able to support it
that includes literally, as in physically suport it, these cards are so heavy they're prone to cracking if not supported with brackets or braces of some kind
wasn't sd3 launching on monday
was it?
oh yeah, ill be building the PC, so ill make sure to brace
the issue i'd be careful of is that you have the ability to brace two cards and there's sufficient space and ventilation so they don't just cook each other
and of course sufficient power from the PSU with enough cables to power it
either way yeah 10gb vram is not enough imo
i mean it works, just slowly 
i bought a gigabyte 4090 oc a few weeks ago, felt crazy for doing it, 3 seconds after starting the first sdxl generation it was done and i knew it was worth it lol
it displaced a 3080 12gb
i need help setting sdxl up cause i see nowhere to install it
i bought that before i discovered stable diffusion, and was so glad after i discovered it that i got the 12gb model for whatever reason
unless its a first come first server thing
cuz i was constantly running stuff that hit 10.8gb, 11.2gb, etc
what program are ya using
forge? comfyui?
neither
im doing everything manually via windows terminal
im using the normal stable diffusion webui
automatic 1111?
probably outdated by now but im not sure
this is a lot better IME with vram and inference speed
basically the same thing but with the back end code replaced
and a lot of common extensions already included
can't find it, guess I misread
pretty interesting take here though
https://fixupx.com/EMostaque/status/1763907760586916112?s=20
I have a dumb question. Will SD3 work with ComfyUI out of the box?
probably within a day or two max is my guess, if not at launch
oh that is def interesting
thank you btw
for the help
i might be back for more but idk
np
SO MUCH FASTER
i installed the lastest and i installed yesterday
im using the one click install of forge
yeah someone here was telling me early this AM that the newer versions of automatic 1111 fixed the speed issues... i was pretty skeptical
glad forge has improved things for ya
wonderful!
and yeah to use SDXL just donwmload a SDXL model and drop it in your models/stable-diffusion folder
https://civitai.com/models/133005?modelVersionId=348913 this is usually the first one ppl go to use
so pretty!
i second this! JuggernautXL is a phenomenal model!
Tell your friend that this isnt exactly the right server to ask such stuff 
ahh true lol, and i actually do mean a friend, i do the share thing. but yeah wont ask that again my bad
slipped my mind sorry
No worries, no one harmed or anything 
oh yeah is there any way to make Stable diffusion auto input a negative prompt?
Does anyone know where to get the Euler a Karras sampler? I've been searching and cant seem to find where to download the sampler or which UI comes with it.
what ui are you using? afaik all uis ship with them preinstalled
thats what i thought too. I've tried a1111, comfy, and forge trying to find it. I can see it in png info from some images, but cant find where to actually use the sampler.
ahhhhhhh, okay i understand now. looked closer at the images that had euler a karras. they were in Comfy UI, but in order to get "euler a karras" you set the sampler to euler a and the scheduler to Karras.
ah, glad you figured it out!
are there any ways of getting the same charater without a lora or a character but with a different expression or pose? maybe even diffrent outfit?
i would like to try to make something using ai assets and such.
Hi, how can I find out how much SDXL 0.9 would cost on the Developer Platform for 1024x1024 50 steps?
I can see the XL 1.0, but not the price for the other Developer Platform models (here: https://platform.stability.ai/pricing).
what is the idea?
why would you use sdxl 0.9?
I build and AI app that can generate images, and I include every interesting models, do you think the 0.9 is not worth listing if i already have the XL 1.0 ?
I was wondering the same thing about SD 2.1,
it's part of the list of available engines on the Dev Platform, but yet it's not listed on the pricing page, is it not so good?
Also, does anyone know if Stable Cascade will be added to the Dev Platform?
Sorry for ignorant question - but is Stacle Cascade an official checkpoint release?
I think so, I've just saw this blog post https://stability.ai/news/introducing-stable-cascade
I've noticed when launching my stable console it says cuda stream: false.... this normal?
Does anyone have a sense of when the SD 3.0 model will be available in "beta" (by which I mean, running it remotely, without a local release available initially)?
all you can do is join the wait list
I'm assuming the waitlist is just for people running locally
if you get 2 running i THINK, someone correct me if I'm wrong, but you'll just put the .ckpt file in your stable environment once it's released
My understanding is that the waitlist is to run it remotely (since, once one can run it locally, the сat is out of the bag, so-to-speak). If they offer it remote-only, they'll have more control, such that nefarious persons can't do sketchy things or immediately create modifications of the model.
you might be right, I figured the waitlist was FOR those able to run it locally
I think, before they release the CKPT, they are going to do something like MidJourney, where they insert themselves between you and the model.
nah
doubtful
that sorta defeats the purpose of open source
but like I said I can't say anything with certainty
I agree. I hope you're right, and they'll just release the CKPT, but then...what would be the point of a waitlist? Limiting download bandwith on their website?
They're letting people super skilled with generative AI test it first
I mean it will have bugs
so they're going to want to release something as clean as they can
I'm hoping it's out this month, but I'm keeping my timeline releastic so april/may?
sup
Fair enough. I've developed some custom embeddings and such, and worked quite extensively with other tools (DFL, Wav2Lip, VideoReTalker, etc.), but I'm not some master GitHub developer with a million stars on my profile or somewhat.
Sketch
what is bro yappin about?
If you know you know lol
for sure
Primarily, about what sort of person(s) SD wants to have beta test the upcoming SD 3
okay
Also, StableDiffusion is on that R. Kelly math, that Microsoft math...
3.0, 3.1, 95, 98, 2000, 7, 8, 10, 11...
We have SD 1.0, then 1.2, then XL, then 3...
If you have any creative prompts that work on other models DON"T share them here, I think we have a rat. I'
So some nerdy stuff
Probably coincidence but I shared a prompt here that I was using to have Gemini bypass copyright protection and people generation. Got zapped 30 min later
what is this server about?
I made another prompt almost as wacky that SHOULD have worked. Well it did work, after my prompt, I asked it for bugs bunny in a dress. Got this.....
Primarily, this server is populated by persons whom'st've's'd'nt yet been banned for shilling crypto.
oh okay
Man, I need to set a profile image.
I made another prompt almost as wacky that SHOULD have worked. Well it did work, after my prompt, I asked it for bugs bunny in a dress. Got this.....
I put it in show n tell
Wasn't AI used to frame Roger Rabbit?
but you can tell they did something
I see what you did there
bro
I joined here
because I was looking for some big server
and I dont have to verify my phone
because I aint doin this
Like I said, sketch. Now, I'm also sketch. It takes one to know one.
wdym by "sketch"?
"Sketch", as in, if you wrote my username on a blackboard and then sketched over the underscores.
you joined here because you were looking for "some big server". My question is some big server for what?
alr
for big community
to not be bored
waiting a lot of time for respond
Well this is the stable diffusion dev discord
I don't use Discord much but I am quite framiliar with Telegram and the dominant form of SPAM there is for crypto projects, though I assume there's plenty of variety of SPAM.
you should check out open-ai art discord
oh yeah I remember
limewire
I dunno what he's looking for lol
rule 34 is a porn web side
Is talking about CivitАi generally permitted? I mainly use modified models from there. I don't do porn though.
basicly some people drawing some delusional-porn stuff
or more like delusional people drawing soemthin
Bigger server = more people who will read advertisements for SuperShitGoingToTheMoonToken
Do you know the meme image of "Mexican boy holding a Crucifix"? Create a custom keybinding for it, because you're gonna need it.
I thought that was a black guy
bro I aint clickin this
after I clicked some link on discord
The details are irrelevant; the key is, you will need to be able to invoke supernatural protection against sketchy people.
bro are you high or what?
No.
or you really into nerdy stuff?
So, I was in an AI model-training-related chat. Some dude started talking about how he was having trouble finding good training data because "women don't naturally grow cow ears". I called upon the Alpha and Omega, the God of Abraham and Issac, in the form of a Mexican child holding a crucifix, to protect me from the AI coomers.
I'm having a terrible time training on this style.
but idk why you want to call God bc of this
I built dataset of 50 decent images. Good resolution, some headshots, some body shots, some action shots with multiple people - even a handful of "detailed background" images
And the style is consistent
I captioned them as best I could, and I've tried a whole bunch of different configurations, but the results are inconsistent and rather poor
Any advice?
What style, specifically?
Triple your data set and see if it makes a difference
if you double/triple it you should see noticeable results, if not I'd say you're doing something wrong
I call upon the LORD to defend me against AI coomers because "artificial intelligence", in extremis, is a graven-image factory.
alr
Are you trying to train a subject (specific person) or a style?
I also wanted to create some nsfw stuff on some ai webside
but I had to pay something
it was only 10 bucks but I am not really into paying by internet
It's okay, trains leaving the station whether the boomers are on it or not
like nsfw stuff was for money
On a style. I've isolated a set of prompts which give me really nice traditional illustration style art. Well, about half the images are good. I want to wrap it all up into a LoRA so I can produce it more consistent
So I made 50 quality images with variety, captioned them, and now I'm training as best I can
I haven't started messing with training but what I said should work
Guhhhhhhh
at least to give you an idea
It took a whole day to build the first 50 images. Tripling it is going to suck
dude
@brave vigil So, the first thing I would say is, "the easiest way to complete a task is to have someone else do it for you". I would check on CivitAI for a foundation model that is as similar to the output you wannt as possible, and thenn train a LoRA from there.
Haaaaaaa!
Are you going with a LoRA or Hypernetwork? Custom Embeddings work well enough for subjects (ex. training a specific person) but not well for styles.\
LoRA
I'm gonna back out of this convo now talk to Dani lol he's way more knowledgeable
Still havn't really figured out what a hypernetwork is, and how if differs from an embedding
Hmm, 512x512 or 768x768 native?
I appreciate the help!
Mostly 768x768, some 768x1024 and some 1024x768
Headshots, body shots, shots with two or more people, shots with detailed background
Honestly, even though SDXL V2 is "better" and has 768x768 native, my rule of thumb is, "resolution (linear) has to at least double to see a difference", so I tend to still like to work with the 512x native forms.
Different body types, age groups
So I joined here a few days ago and have been using Gemini professional (free for 2 months right now) to teach me the different terms I see people throwing around on here, and teach me how to use them in my local SD2
are there people who already own stable diffusion 3? or stability ai not giving it away yet
It's a really effective system
@brave vigil So, the first note I'd say is, all the training data should be in the same resolution, which should match the resolution of the base model (which is almost certainly either 512x512 or 768x768). Otherwise, auto-cropping will occur, and it's usually bad. There is AI-assisted cropping available, but honestly with <100 images, you should just do it yourself in PhotoShop. Do your images contain the EurION Constellation (very important)?
There's a waitlist
i know ...............
So it's out for some
I joined I'm hoping to here something from them in the next few weeks
I don't know what that is. I'm using the FurryBlend checkpoint (link below) which is itself built of SD1.5
I've got plenty to keep me busy immersing myself in 2 so it can come whenever
also i hope my pc can run it
REDACTED
lol
why they made it with waitlist this time?
I've tried other models - more generally accepted models - but this one has given me much better results
i do not remember they published a model with waitlist
Lemme start with some basics, I guess. Do higher resolution images fed into the training produce images with better detail/fewer artifacts?
oh geeze. first day back so i can ride the sd3 preview, and allready the first link shown is a full on furry porn model
doesn't nsfw shit belong on other servers?
Well you are early. SD3 isn't out yet.
i'm mostly okay with furries. they're doing their thing and mostly not hurting people. but wow . WOW. they're the worst kind of exhibitionists
wait list asks for the discord user so i assume you've gotta be here
😐 I just wanted to provide the specs of the model. I gave y'all a disclaimer
Ah, forgot about that. Nevermind then.
i didn't even scroll. it was right there
I have the link, you can delete I suppose.
I mean civitai isn't exactly great about censoring their outputs.
if you're gonna go buck under your bathrobe in a room full of people, keep that shit tight
Sorry about that all. That's my bad
One message removed from a suspended account.
I'm still drinking my first cup of coffee -_-
@brave vigil Okay, back onto the tecnical side of things - that model is SD 1.5.x-based, which means it has 512x512 native resolution, which means you'll want only 512x512 training data.
settings are highly dependent on what your dataset and captioning approach is. what your goals are for the model. etc.
Where?
One message removed from a suspended account.
He's asking where the NSFW is.
One message removed from a suspended account.
Sounded like there was a link already here to me
He's talking about the civitai link.
lol oh. the civit link lol. i wasn't even that worried. just non chalantly surprised. didn't mean to rile mods babout it. he deleted i think
I'm glad I decided to ask for advice instead of just working it. I've got a number of questions based on what you're all saying.
Firstly - when I create an image using my current checkpoint at 512x512, the output is pretty bad. The concept is there, but there just aren't enough pixels to get details. Given the chance I prefer to have 1024x1024. Is there some way I can scale down the actually decent bigger images without losing quality?
often when people say "nsfw" i expect some boobies but not raging erections. just my gender bias outrage happening maybe
Feel free to report if you come across something similar again
it was pretty tame but thanks for the heads up.
Also - someone once told me that when training a LoRA, I should do so on the base model of whatever checkpoint I'm using. My checkpoint is built off SD 1.5, so when I boot up Koyha and give it a model to use in training, should it be the base model or the checkpoint?
See, I joined this chat, and mentioned using an image of a Mexican boy holding a Crucifix as a tool against sketchy NSFW content, someone rolled his eyes at me for doing so, but it turned out to be needed not five minutes henceforth. I posted it in general_with_images if anyone needs it.
its in #🌠|show-and-tell
Base model for a "clean slate". It's pretty easy to corrupt a checkpoint beyond recovery by making a silly mistake in training (like, not having the dimensions of your images be divisible by 8), I've done it many times, so I try to start from a clean slate when possible.
And a third question. If I'm having trouble with detail/resolution, should I consider moving to a different checkpoint or even to SDXL (not sure what makes SDXL different, tbh)
Oh. Its mocking autistic people. huh i'll report shit like that. I have friends with autistic siblings and people mocking them for who they can't change being is one of the worst parts of their life.
you're in the wrong discord
"Autism" is essentially a rebranding of mental retardation. Look at the statics.
This is where the sd 3 preview will be? i'll leave again after its over
WRONG
This is wrong in so many dimensions
Also, genome-wide association studies show essentially complete overlaps between retardation and "autism".
lot of hateful language around autism today. @slender fiber i think this stuff is worse than any nsfw content by a moon shot
Wrong by definition. Retardation refers to brain damage or malfunction. An autistic brain works totally fine, just very differently
There will be no plublic preview, just a release
you have to run it locally
there'll be an invited prview, suspected to run as a secret channel on this server
Also - I realize why I was so nonchelant about sending that link before. I'm in another server specifically for furry SD artists. The profile icon for it is also purple and abstract, and I genuinely thought I was posting in a furry oriented group. Like I said, first cup of coffee
While the model is not yet broadly available, today, we are opening the waitlist for an early preview. This preview phase, as with previous models, is crucial for gathering insights to improve its performance and safety ahead of an open release. You can sign up to join the waitlist here.
2nd paragraph
gotta read it
@brave vigil Evidence part 1: Look at statistical rates for retardation and autism among school-aged children in the United States (lots of good data). Autism rates "skyrocketed" exactly when retardation rates began to drop. Also, this happened first on the East Coast, in New England (the most WASP and wealthy part of America), then spread to the West Coast (the second-wealthiest area), and then the interior. In all three zones, the pattern was the same: diagnoses of retardation dropped as those of autism rose, such that the sum total of both rates stayed about the same.
ah yes. cross servering. dangerous times. you're all good bud. i was joshing you mostly. 😉 furries are all good with me
As John Oliver has said many times
Furries are harmless. And hilarious
right. i did. now go read where i said there was going to be a public release? i'll wait
@skywalker if he's really from germany he's going to have a fundamentally different approach to mental handicaps with regards to medicine
I'm not waiting I'll just block you because I no longer wish to provide assistance to you \
John Oliver was a great furry ambassador, but what got me to really stop caring about them was Violent J from the Insane Clown Posse. Those are another bunch of cosplayers that have fun and hurt no one and his daughter is a furry now, so he's an ambassador.
weren't really helping in the first place big gunner
touche'
none the less you seem opinionated and very eager to jump down other people's throats with regards to touchy social subjects. I wish you well.
I have an amazing ICP story (the band, not the crypto). It was my first contact with "the Internet mob" that is so common now.
I used to listen to ICP in high school, if you're still listening to ICP in your 20/30's you need a reality check.
Heh, it's all good, so did I.
used to watch em on wcw and wwf. fun times. wacky guys
I'm going to jump into #🔧|finetune to ask my technical questions
They had some good album art... The Great Malinko, Riddlebox. It'd be interested to train a model JUST to make ICP album covers. Take a prompt and turn it into one of those heads from their albums
Probably could just look up the original artist and find more of their work.
It's like how so many of the classic rock musicians all used the same artist: Journey, Boston, ELO, Foreigner, Asia, etc.
Found them: Shusei Nagaoka
Love those boston album covers!
Is there a plugin for Stable Diffusion that lets you apply different clothes to a character? Not IP Adaptor and inpainting, that doesn't work well. I mean like Reactor for faces. You upload images of clothing items and let the AI do the rest. Feels like something that should exist by now. Like Outfit Anyone.
SD3, tomorrow something is gonna happen: https://twitter.com/EMostaque/status/1764742280865284128
oooohhhh!!
https://x.com/EMostaque/status/1764743952526119380?s=20 "Tomorrow or Wednesday"
omg finally
Once upon a time, I read an article about how Juggalo make-up (cosmetics) was effective in defeating computer vision (sort of a precursor to more modern AI facial recognition). Basically, a group of researchers at Stanford University decided to paint people in Juggalo make-up to see if it defeated facial recognition, and it did.
So, learning this, and knowing about the famous ICP "magnets...how do they work?" line, I made a meme based on the "weak SpongeBob/strong SpongeBob" template, where the weak version was "Juggalo knowledge of magnets" and the strong version was "Juggalo knowledge of facial recognition algorithms".
I thought this was a harmless joke. I was wrong. I had angered the ICP army. Suddenly all my socials and inboxes were full of death threats for insulting ICP and Juggalos. I explained that the meme was actually sort of a compliment - like, that Juggalos had the foreknowledge to develop cosmetic face-paint to defeat AI facial recognition. But, the Juggalos were having none of it. My first experience of an Internet mob. I'll never forget it. Got Doxxed and legit lived in fear of a Juggalo attack for like a month.
am i allowed to ask about hobbies recommendations here or would that be better for off-topic?
i think off-topic would be better
just wanted to make sure...
Correct, this chat is intented for discussion of how, and to what extent, Juggalo make-up interferes with facial recognition systems.
lol
This inspired me to set the newest #🔆|dailies to music album covers inspired by that style.
how can i convert a repository to a .safetensors file? Like, an model i want to use does not have the final .safetensors and I would like to make one
you weren't a victim. you're a dude who punches down. you were likely doing that intentionally to the fam you angered (they really do consider themselves a family) and laughing about it. "Death Threats" were almost certainly instigated. You're a giant cliche . "Reee" gave it away.
I would never claim that all (or even most) Juggalos are troublesome; in fact I've rarely met any. Perhaps the offenders were agents provacateux, engaged in a false flag anti-Juggalo operation. I wish them all the best - it was more a funny moment for me, especially in retrospect, and I wish Juggalos success in defeating computer vision. If SKYNET exterminates all humans except Juggalos (assuming it is unable to recognize the latter on account of their make-up), and my bones are condemned to the dust-bin of history as the Age of Men ends and the Age of the Juggalo begins, that would serve me right.
And, to be fair, I do know now that the "magnets...how do they work?" line wasn't intended to imply that ICP thinks that magnets are magic; it was really just an expression of the idea that so much of the natural world is amazing (magnets included), and that the "magnets..." meme is taken out of context.
Lol I see the convo has drifted to this discord
Ahhh ICP
I knew their music was trash, I just liked the Dark Carnival from a lore perspective
holy shit. wasn't expecting this to show up. https://www.reddit.com/r/StableDiffusion/comments/1b6ivqg/coherent_multigpu_inference_has_arrived/ NVLINK diffusion code
I'm thinking of using it as the basis for my AI dungeon master
At least the lore part of its MoE
Very impressive RE: Multi-GPU. Sadly I am likewise unable to test it 😭
I enjoyed them from the sidelines. Lots of juggs at my school but i thought their music was lame haha. couple good ones at least. To me they were always the clowns from WWF
Would be cool to have a pair of 4090s, but...I don't, haha.
4090s don't have nvlink
I have a 3080.... working on talking my fried into letting me offload compute to his 4000 series as needed
yehawwww i'll be getting a pair of 3090s someday then
i got a 4080. is good.
Is it like, a workstation-only thing? Like the thing about Martin Shrikelli (sp?), the "pharma bro", in the clip where he's hitting up the ghetto to buy some bootleg H100s?
General question, I just got a 4080 super and only downloaded drivers... I'm using ForgeUI, do I need to also download CUDA?
nvlink is on ampere cards. they left it off ada cards though
I think so too, but could be better to let StableDiffusion UI (like Automatic1111 or whatever you use) try downloading it, it will get the right version, I've had a million issues with wrong versions.
it helps to install the cuda sdk imo. i got 11 and 12 installed
Hm how would I know if it has?
@oblique edge Same, set up my shit wrong a million times. And what I said was what you said, let Webui do it.
I think "cuda:0" may just mean that the card supports CUDA (i.e., you're in GPU mode, not CPU mode, which is good) and that it's device zero (the first number).
use a package manager to install stable diffusion. easier than dealing wiht the terminal commands yourself. stability matrix works good.
Don't get me wrong though, I'm still generating fast but just don't know if I actually have CUDA XD
That's what I did with Forge
Ah that could make sense
scroll to the bottom of your webui and look at the pytorch version
As long as it's not bottleneck'ing anywhere and console shows it using VRAM your probably fine
top?
Python 3.10.6 (tags/v3.10.6:9c7b4bd, Aug 1 2022, 21:53:49) [MSC v.1932 64 bit (AMD64)]
I got this
all 64bit cpus , intel or amd, are amd64 architecture
@steel willow AMD64 is the instruction set (x86)
Yeah cpu
I don't see pytorch version 😮
It's not the newest pytorch I can vouch for that lol
API • Github • Gradio • Startup profile • Reload UI
version: f0.0.17v1.8.0rc-latest-273-gb9705c58 • python: 3.10.9 • **torch: 2.1.2+cu121 ** • xformers: 0.0.23.post1 • gradio: 3.41.2 • checkpoint: 912c9dc74f

It should dl the proper version
I thought you meant bat
Yes
you got the coods
Looks good
Thanks for the help!
Np
How do I avoid multiple instances of something in my output? For example every time I give it a simple prompt like "a toy soldier" it keeps putting 3 in each image
I've tried using sole, singular, individual... even.put things like many, multiple, etc in the negative prompt
Still having issues
I know this is inherent to sd2? should be less of an issue with3? Or am I missing something?
I'm also not well versed in sampling methods so maybe I'm doing something wrong there
Also need to brush up on my art terminology, has anyone found a good index of terminology I could reference?
Surely an "art dictionary" as it relates to generative AI already exists
Or at least I'd be willing to pay for one
Does anyone have an idea how to make A1111 use the shared memory as well?
I don't need it for normal generation but it appears 16GB VRAM is not enough for 4x hiresfix and it could use half (16GB) of my RAM there.
Even if the upscaling would be slow, at least it would work and not throw OutOfMemory
auto sucks
nvidia drivers provide this option by default. it has to be at the driver level. i assume you have amd. don't hold your breath for them to get there
skill issue
not skill issue, auto is for low skills
Yes AMD, and yes, kernel level. windows is able to do it, potentially via the system API, therefore it's possible.
so it isn't letting me run stable diffusion from the .bat file but it is letting me run it on the "launch" file. does this affect anything or nah
anyopne got sd3 yet
hey guys whats currently the best way to colorize/upscale old videos
so i found deoldify on forge
looks pretty good now i gotta find the bets video upscaler out there

Hey Guys,👋 as a part of my senior Design Project, I have created my own Image Generation Model and have deployed it on my platform, if anyone here wants to test it out please do : https://thetrazo.com/dashboard?show=1
topaz since i last checked, but i bet theres better now
workin on a custom face swap workflow... better than any node i've used at the moment (requires a lora, but a lot better than a naive lora swap)
Benefits of Forge over A1111 at 16GB VRAM?
A4000 gave me an extra 6it/s on forge
OK, how about benefits except the speed?
The supermerger extension didnt work for me, but the inbuilt freeu and latentmodifier are very nice
why doesnt stable diffusion say i have xformers even though when i run "pip install xformers==0.0.24", it says that all the requirements are already satisfied
I believe you need to set some sort of flag when starting WebUI
how so?
Do you have —xformers in the webui-user.bat file?
What ResidentChefAU said.
set COMMANDLINE_ARGS=—xformers
is that what it supposed to look like
Thats RCNZ to you 😉
or is there a space
I usually create a shortcut with the custom settings (actually I have several shortcuts, so I can launch in different modes).
Your shortcut would be like webui.bat --xformers
Question for y'all
its a driver problem. windows can't do it on it's own. it would rely on the driver.
amd windows driver are grade b
I want to make 2d illustrations, right? And honestly, I kinda want the quality (but not the resolution) to be low
wait but what should the notepad look like'
I want it to look like something an intermediate artist would make - not something polished
the unet patcher and the extensions that will inevitably be written for that
@Luke By "low-quality", do you mean low-poly?
Ah. I would just cut the number of iterations then...I have always been extremely successful in creating low-quality images, I don't mean to brag, but it's true.
I would also try different samplers, DDIM instead of Euler-A, for example. DDIM isn't necessarily "worse" but it's less predictable, which could be desirable.
Hmmmm
To be clear though, I think I'm maybe talking a bit more about stylization
On one end, you've got doodles
On the other, you've got highly photorealistic digital paintings
In between you've got your average art style, with exaggerated proportions, unique line work, etc
And that's what I'm trying to get (without borrowing from existing artists)
I've tried invoking prompts like "comic," "disney," "exaggerated proportions," or "cartoony"
With some success
But what I could really use is a primer giving the names of specific cartoon/comic artsyles
if you're using something like juggernaut or other photoreal models, gonna be hard to prompt them to toon styles.
Just normal SD 1.5 on Auto1111
"Disney" is the style really since they basically pioneered western animation. Other studios work too like style of ghibli, but each of their movies is so unique that it helps to go even further and "style of a movie name" too. Artist names help a lot. Bluth was big in the early days of disney and left to do things like Titan A.E.
Do you mean like caricature? That's a distinct (and, I think, pretty cool) form of art, created by Italians in New York to sell to tourists. I don't mean this as a knock against it; the fact that it's popular can be evidence that it's good. There's also overlap between caricature and propaganda, very interesting.
Titan A.E. was AMAZING by the way
Maybe not so much for the story, but from a production level
Woah, you know what would be cool? A CupHead-trained model.
This is an interesting idea
why use the base 1.5 model? it kind of sucked imo. Runway ML rushed it out to piss off Emad for some reason. All the drama was contained behind closed doors but they got fired for dumping it on hugging face
There are a number of "niche" or "hyperstylized" art styles which, if turned down to a simmer and paired with regular disney animation, might help spice things up
Graffiti style
Oooh, that's another good one.
You're using words I don't understand
yeah i agree. The story wasn't badbut it sure was campy. SO MUCH HIGH QUALITY PRODUCTION. Bluth knows his shit
I've been doing this about 2 weeks. I think I'm doing okay, but all I can do is use the resources I'd found to work so far
Daddy issues. Daddy issues everywhere
buzz lightyear
you should look into community refinements. Theres been a lot of work done
Fun Fact. Don Bluth is working on getting a Dragon's Lair movie made
"Base 1.5" is a 512x512-native model. It's not the most up-to-date, but probably has the most support in terms of LoRAs (though that will change). FlowWolf is correct, SDXL is technically superior in every way.
What I'm trying for is a delicate mix of western cartoon and realistic-ish
This is going to sound extremely stupid, but...sometimes the easiest solution is to hide hands (hands-in-pockets, etc.).
not just sdxl. All the community refinements like anything v5 or dreamshaper or protogen
I like the exaggerated artwork from comics and cartoons, but also the realistic proportions and relatablity of realistic work
Sometimes the easiest approach to a problem is not to solve it, but to cover it up and pretend it doesn't exist. If you have a problem you need not solved, I can help not solve it.
Oh man
This gives me feels
Nobody cares that a dragons lair movie staring ryan reynolds is on it's way ?
The front of my brain knows that in 99% of situations this is totally correct. My background is in software development though, and this is something that's beaten out of us pretty thoroughly
how do i keep it so my settings save? its annoying having to re-set it up everytime i relaunch sd
hethens
Errors should never pass silently unless explicitly silenced - which is I suppose what you're talking about. As a general rule, I prefer the philosophy that "if the problem is to hard to solve, change the problem"
if (error) continue;
I believe that not-solving problems is key to success in the AI industry, especially as pertains to moderation. Concerned that your AI produces "objectionable" text when asked about certain issues? Just get between the actual AI and the user, and set it so that, if certain tokens are detected, the AI will never even activate, and instead a static output of "I'm sorry, but X is a sensitive issue. One should always be respectful when discussing X..." is returned.
The same thing with Gemini. Not enough diversity in source data (arguably, an actual and significant problem)? Instead of changing the training data set, just "get between" the user and AI, and inject certain terms into the prompt in order to "diversify" the output, regardless of what the prompt is and regardless of whether this makes sense logically. Then, when people complain about this, just disable the ability to generate images of people entirely.
Non-solution of problems is a key approach at the highest levels in software development, finance, and government.
@brave vigil https://civitai.com/ peruse this website. There are 100s of community refines of sd 1.5 and sdxl . just be careful of all the community nsfw obsession
Ahem 😓
My older sister always says - and I believe this too
Perversion is its own reward
Indeed; intercourse is one of the few activities that cannot be engaged in ironically. Almost everything else can be done ironically.
Ohhhhhhhhhhh that is good
I was raised "anti catholic." My parents were what you might call refugees from devout catholic families. They raised us to believe that hedonism is NOT sin, rather, it is the wine and olive oil which give life its true flavor
So go ahead - enjoy your shoe fetish! Squeeze every bit of flavor you can from the lemon that is life
I think it's important to remember that the most important use of irony, is inspiring online arguments about whether something is actually "ironic" or not.
And the fact that 90%+ of instances of irony are related to Internet arguments about whether something was actually "ironic", or just "unexpected" or a "twist of fate", is itself ironic.
Everything in moderation. Being catholic and then going full hedonistic might've been an over correction. I see the same thing happen to JW kids. They grow up and hate being "proper" so they swing the other direction hard.
Enjoying yourself is fine. We're in the 21st century age of abundance. We aren't quite at 31st century hedonism bot levels though.
disagree. Singing Morsette is the highest calling
I'm exaggerating a bit. Or at least, I'm only explaining the part about the hedonism. Common sense was another important theme
lol hedonism bot is an exageration too. i love the guy
So, "reading the room", it's my sense that there aren't many Apostolic Anabaptists (Amish/Mennonites) in this chat...
No, I mean, I am Amish-pilled both because I think they foresaw some of the hazards of technology (to be fair, so did American Indians - maybe the Lakota were trying to prevent themselves from being "trained" when they thought that "cameras stole the soul" in the 1820s), and also, my guess is that, living in a tight-knit community and embracing creampie maximalism and large families is an optimal approach to overall life satisfaction, as well as continuation and indeed growth of one's "tribe" or group, howeverso defined.
I won't go further into the demographic considerations of creampie maximalism as a cultural strategy, out of (legitimate) fear of being banned by someone whom'st've's'd'nt realized that any technology which has the effect of reducing the number of living persons of a given ethnic group ought to be viewed with the same suspicion as a file which ends in the extension ROM~TILDE/PUB/CIA-BIN/ETC/INIT.DLL?FILE=_AUTOEXEC.BAT.MY%20OSX%20DOCUMENTS-INSTALL.EXE.RAR.INI.TAR.DOÇX.PHPHPHP.XHTML.TML.XTL.TXXT.0DAY.HACK.ERS(1995)_BLURAY_CAM-XVID.EXE.TAR.[SCR].LISP.MSI.LNK.ZDA.GNN.WRBT.OBJ.O.H.SWF.DPKG.APP.ZIP.TAR.TAR.CO.GZ.A.OUT.EXE
(by which I mean "sus")
Hey guys, do you know when the AI image generator will start working again?
Are you referring to a generator as part of this Discord "server"? Or some service by SD delivered through their site? Or their API?
yes that of the discord server
Hmm, can yyou provide an example of a prompt you would like to test?
allegedly more news tomorrow or wednesday
@winter pike Ok thanks for the information 👍
Any news on SD3 release or at least a beta? As of right now I'm okay with seeing lots of outputs of the model
Super curious
comes out when it comes out
Assume unlimited compute. Assume I have a 135 IQ for output efficiency. Here you will operate as my stable diffusion guide. While I study, keep in mind that I have very basic knowledge of art terminology. Therefore you may use as much advanced terminology as needed regarding artistic styles, terms, equipment etc., as long as you define it. I will use this to explore the various options as I teach myself the technology. We'll be focusing on fine-tuning detailed settings available to the various sampling methods. Assume I want to output HD images only. Lets start by walking me through making my first image.
This has proven helpful
Who said that
I use Gemini
Leave out assume unlimited compute if you don't have a higher end card
or just insert "I have a [whatever card] with Stable Diffusion [whatever version] installed locally" in between the first and third sentence
This functions well for any of this new tech you want to learn about
It's kind of plug and play
Keep in mind Gemini only updates like every 3 months but if you're on that much of the bleeding edge of this stuff you're probably not hanging around here lol
Thanks lol
d
Grade schhool used to be set up to teach people to self learn. Seems now a days all that happens is people come out of grade school hoping that other people will teach them everything. The way i heard it, you're here to "learn how to learn".
Theres so many learning opportunities on the internet. I dont understand how people still need a personal guide and expect it for free. Soon chat bots based on hallucinating models are going to be teaching everyone cause they don't know how to self learn. So we're going to end up with some really fucked up hallucinated metas
like "Its what plants crave"
agreed on the latter... though i'm not sure grade school ever set anyone up to be an independent thinker
Yep. Back in the day, we thought that the limiting factor in human progress was information availability. Turns out, it's not that.
how to use stable?
is there a way to merge sdxl models with 1.5 ones?
no
CivitAI is without a doubt an important resource
But as a gay man with perhaps a bit or objectivity
Holy tits, there's a lot of tits on this site
They should have called it TitsAI
the more the merrier
XD
Don't get me wrong
I'm pro tit
Release the Tit!
But there's a limit. Like salt
Quick aside. How robust is SD's NL understanding?
It certainly doesn't have the juice of, say, ChatGTP (though I don't see why)
You're joking, right?
I came for the fur
XD Yeah, I'm that guy
Maybe you can help me understand
Why is it
That with every model except for one that I've ever used, no matter what prompt I give (even ones copied word for word from other posts on civit), all I get is garbage
can you guys take tht kind of discussion to dm if nsfw
Not NSFW. Just dicussing the fandom, and how the tech can be used in a general sense
cant really recommend people civit without warning them
stable should make a host
we can talk about the safe host then
"Hugging Face" is not one either, since the bar is civit. For the community purposes. Capiche?
i can't talk about it sorry
Every other model I've ever used, and I can give the same prompts and get nothing but garbage
Lemme rephrase in more community acceptable terms them
Anyway, I use this one model - X. Every other model I've ever used takes the same prompts and gives me nothing back. What's the deal?
cfg too high or low. steps too high or low.
Or maybe just bad prompts? Not speaking the right language?
any prompt should make an image thats not just noise and garbage crap
couldnt agree more
hi, not sure if it's right channel but we paid $20 for commercial membership (twice!) but don't see the same reflecting in our account. It's still the basic 25 credits account. Stability have specified their support emails but getting no response at all (been 3-4 days). Would anyone have an idea or faced something similar? Is there a way to subscribe from within your account (membership payment was done via https://stability.ai/professional)
I am not sure whether this goes under off topic, but I am wondering whether there is a way to customize your own voice without needing to use someone else's voice? I am looking for voice modifies with settings such as for timbire, pitch, masculinity to femininity, etc.
S o r a
@admin
brother
I'm sure you "didn't notice"
but this baguette
has veins.





{kind=link}
trump commemorative xbox mountain dew gamestop collectors edition coin
XL with pineapple
why no make image???
I'm following an auto1111 tutorial using tiled vae + high res fix to output a large 4k image. I'm using a 3090 with the same paramters that they used with a 3060, problem is i left it running over night and the image was stuck generating for 330mins and never complete. I'm wondering what I can do since my spec should be more capable, maybe one of my command lines is making performance slower? "set COMMANDLINE_ARGS= --autolaunch --xformers --no-half --disable-nan-check"
Yes your slowing yourself down with using --no-half and --disable-nan-check is also bad
You should add --no-half-vae
Then Tiled VAE should work
For more help feel free to post in #🤝|tech-support
ay what exactly do you use ControlNet for
Largest size SD3 8B on the 4090!!! In early, unoptimized inference tests on consumer hardware our largest SD3 model with 8B parameters fits into the 24GB VRAM of a RTX 4090 and takes 34 seconds to generate an image of resolution 1024x1024 when using 50 sampling steps.
Sure, that's longer than Cascade takes for 4K, but we're talking about 8B parameters.
Hi
can anybody please help me fine tune my lora/dreambooth model?
I'm using abstract art like my profile picture so I think it's a bit tricky for the AI to figure out
any help appreciated!
Since SDXL is trained to maximize an aesthetic score, it has a really hard time learning to make ugly art.
(LOL sorry I'm just kidding. I have no idea how to train loras.)
noo don't call it ugly
wym
It was just a joke I promise. I can't help.
try asking in #🔧|finetune
i actually believed u for a second about the aesthetic score
Lol
or is that part true
ok i will thanks
The aesthetic score part is true. But it can definitely learn amateur/ugly anime in a second. Training isn't a problem.
Yeah, but I'm new to all of this
I mean I'm excited it's just that this is probably harder to get used to the whole fine tuning thing
it s definitely harder to finetune than to generate
I mean yeah
totally ok to get lost at first
but I meant like my goal would be easier if i was just inputing my face or something
this art style is kinda fucked
if you look at my training data it's a bit too harsh i feel like
I have'nt watched it yet but you can t go wrong with aitrepeneur https://www.youtube.com/watch?v=1BCYdd9r1To
yeah i found his channel yesterday
thanks
i'll skim through it can't listen to audio rn
but hmm how many epochs should i train with 287 images and 15 steps
can you give me a rough number rn?
i'm trying my larger image set again
d
Hey guys! If you're looking for a different image generation UI, check out: https://www.practal.ai/
Hi, does some one know how to get a API key for image inpaint? It is for a schoolproject 🙂
When will the bots be back
Question for the Stability AI team, if you are reading this:
Now that the SD3 paper has been published, can you provide some more guidance on the VRAM requirements for both inference and LoRA training of the 8b parameters model?
I saw a table toward the end of the paper, but I'd like to double-check. Thank you!
You can check this out: https://platform.stability.ai/docs/features/inpainting#Python or use https://www.practal.ai/
Yes but can't click on inpainting?
They said the full fp32 version will work on a 4090 24gb vram so fp16 should work on 12gb cards
this is for the 8b model, correct? Thank you.
Correct
Which makes sense as you can get sdxl on a 6gb card with some room to spare and thats 3.3B
Haha no, but if you have that much spare $$$ burning a hole in your wallet feel free to send a 3090 these ways!!!
😛
Are you able to XYZ Plot Mask blur settings in In painting ?
I’m still new to SD. What is this fp32/fp16 thing ? If I download a checkpoint model, how do I know which one is it and how will it influence my generations?
Another question is regarding sdxl. There seems to be several versions. If I download a Lora for the base sdxl from civitai, will they work for lightning or turbo versions?
Fp = floating point - the 32 and the 16 refer to how many bits (ie how accurate) is being used to store each number. Will influence but its a game of wheres wally to find the change usually.
Turbo no, lightning probably
Lots of barley grains bouncing against a gradient dark brown background
Hi, is there a way to set up Focus to open in a specific browser without having to have that browser as default in windows? How, if it's possible?
i don't think that's possible
afaik it generates a url in the form of an ip which windows recognises and then opens with the default browser. i could be wrong tho
interesting, I've found this but I dunno where to put that line
--disable-in-browser
looks like something I'd put in the webui-user batchfile if it were A1111 but can't find anything like that in Focus
i'm afraid i can't help you with that then, as i don't use fooocus
thanks for trying tho
Thats pretty long, damn
Got a source?
Sit tight and wait for their answer, they probably have a lot on their plate right now. If you dont get an answer within the next few days, feel free to open a #1010934719455707218 ticket and ill try to elevate your issue!
Check announcements they released the research paper last night. (Source.)
Time should come down with xformers. If a lightning version is trained, it should drop to 3 seconds.
hi
heya!
Hi Guys, are you saying that today will be the lucky day where they will let us access the preview of sd3?
I hope they do 🥺
yeah 😦
according to what Emad said, either today or tomorrow. source: https://x.com/EMostaque/status/1764743952526119380?s=20
Let's hope so 🙂
but needless to say, that will be a private discord with a bot running SD3. if you let people run it locally they can just go around sharing the model
Do you think it will be the discord bot?
I mean if they will do a preview with the bot
not necessarily the one in this server, but rather a private bot for people who joined and got accepted into the preview
that's all just speculation tho
I understand.
On Twitter I saw that a person had been accepted
wait really? do you have a link?
yeah
I don't know if I can share the posts here on the group but just type #sd3 and go to latest
i see. i'm skeptical tho, since the image quality isn't anywhere near what others have shared
I agree with you, in fact it seems very strange to me
Oh maybe those images refer to a past technology
that's also a possibility
man, i hope the requirements for SD3 aren't too high. at least for the smaller model. i really don't have money for a new gpu right now
i have a 3gb 1060 xD
Maybe you should be able to handle the 800m one, I hope 😄
that would be the ideal outcome. anything higher than that isn't going to be it
We can only wait and understand. In fact, 3GB is very little nowadays
no way to know unless you work there 🤷♀️
very true. if it weren't for the fact i wasn't into ai when i bought it and it was a great deal, i would've gone for something better
Are you sure that the image was done in sd3? The person who post it said "VQGAN + CLIP" in the end
🤔
ill direct this to the ml engineers team at sai so they can send you a memo next time they come up with an improved training script
Until last year I had a GTX 1080 8gb, then I switched to the 12GB 3060
It depends on whether they buy the hardware or just rent it
i almost bought a 6700xt, boy am i glad i didn't
You did well 😄
now imagine if amd improves rocm on windows
that would be great, i don't think it's going to happen anytime soon tho
and if we used 100% of the entire worlds wafer capacity, it would still take close to 2 full years
dam emad exposed
I have a feeling they are measuring in a different way that isn't being explained right
My guess is they are referring to their total systems FLOP potential in 1 second multiplied by the number of seconds trained, then flattened down to a number in total
Do they menction this in the new paper?
You're confusing FLOP/s with FLOPs.
But not per second, right?
Maybe that´s the catch (or not, english is not my first languague 😁 )
all I know is this number doesn't make any sense, unless they are counting total compute flops/s x seconds run
But literally no one here understands or cares about the paper details. We just want it to run on our PCs
There could be a typo in the paper, or you could be misreading.
Where did they menction it? @near silo is it on the paper or their twitter?
we have a few reddit university graduates here that may care about it
finding it really fast, just a sec
I closed it
yeah, ok, they say it on page 12, first paragraph under 6. Conclusion
Aaa thanks, i´ll see it rn
Yeah I'm at work or else I would at least open the paper. He's obviously just confusing FLOP/s (operations per second) with FLOPs (operations, plural). E.g. 60 teraflops for 1000 seconds (less than an hour) is 60000 teraflops.
they claim it has used 5x 10^22 flops
which is 50,000,000,000,000,000,000,000 FLOPs
That had to be a typo then?
I myself already said that's likely what they were meaning
"Finally, we performed a scaling study of this combination up to a model size of 8B parameters and 5 × 10^22 training FLOPs"
tera is 10^12, so that's 10^10 seconds
10^10 seconds is 317 years...
11574 days on 1 H100.
Assuming 100 H100s, that's 115 days.
So they probably had around 150 H100s and did a few months.
Alright, in that case it WAS that measurement of flops/s x seconds
Wait a sec, you missed a 0
10,000,000,000 = 115740.740740740745
114,740 Days (317 years)
so likely 1k H100's
assuming ~115 days
my guess would be around 1.6k H100's for about 2.5 months worth of compute in total
@grizzled palmoh wait, we did the math at 1 Tera Flop, its actually a lot less
any word what type of hardwares will be required to run this or no idea yet?
i mean sd3
there are various different models, but all of them will run on 24GB VRAM or less
the biggest one will run on a 24GB VRAM GPU
you could also get a second hand 3090 for less than half the cost and end up with about 80% of the AI perf
even more for LLMs
for 1 H100, it would take 2,083,333,333 seconds to reach 5 x 10^22 FLOPs, which is 57,870 hours
Which means 2411.25 days nonstop on an H100, or
24 days on 100 H100's... Which seems shockingly low @grizzled palm
well now we just need the release. hopefully in the next month but maybe that too optimistic idk
thats likely not actually that much money, just a sec
lets say based off run pod (I know this is not a very good benchmark), you can get 8x H100's for 37.52/hr
Thats 12.5 of these systems, so 37.52 x 12.5 = $469/h
469 x 24 hours x 24 days = $270,144 around
Thats very little compute cost, honestly. Very very interesting. Now I am sure they actually get it for a lot less due to guaranteed renting time and bulk ordering
I hope nvidia will add more vram to its 5000 series, 16gb is now not enough for mid range
yup
when is 5k series due?
They didn´t announced it yet, i think
later this year
oh ok
if they follow their normal release, at least
its usually every 2 years around October-December
1 things for sure, no consumer grade GPU will be able to train the higher end SD3 models. Likely not even a chance of making LoRA's for them
yeah not if they need 24 gig! wow. i think 4090 only thing even has this
or is 4080 too idk
3090, 3090ti and 4090 are the only NVIDIA consumer grade GPU's with 24GB VRAM
all of their other GPU's are 16GB VRAM or less
oh nice. i thought only 4090 was that much
😭
AMD has many more high VRAM GPU's, but they are far less VRAM efficient and slower for image gen, so they aren't an option either
if they can get ROCm to work better, man, the 7900XT would absolutely dominate the budget AI scene
I hope that i can run it with my 12gb 3060, or i´ll have to buy a second hand 3090
$800 for a 4080 performing GPU with 20GB VRAM that uses like 150 watts less power
dont worry im sure they will release new scripts so we can train on cosumer gpus
i have 3080 12 gig so i can run a lower model maybe
They are releasing several different sizes of SD3 models, from 800M params (1.5 size) to 8B params (3x bigger than SDXL)
For the smaller models, for sure. But there is just no way a 24GB VRAM GPU will be able to train an 8B param model/LoRA for one. Its just not possible unless they quantize down and lower the quality considerably
24GB VRAM isn't even enough to properly finetune SDXL, which is a 2.6B param model with 2 text encoders. SD3 8B is an 8B param model with three text encoders, one of which is several billion extra praameters on its own
T5 XXL is almost double the size of all of SDXL on its own
Oh I skipped through it but must have missed that part 
they give any hints for a release?
34 seconds on a 4090 💀
Its done when its done is all we know
lots of cool stuffs going on with ai
I mean has there ever been a silent week in AI since the release of SD
haha true
It looks like people would have to use at least a6000 to tweak it (unless nvidia adds more vram to the new GPUs)
We can pray
If they dont I have no reason to upgrade at least
Would be kinda pricey, one 4090 for work and one for games
yea just wait maybe they will release scripts that can do it on 24gb
bro think's they are gonna release scripts to let a 24GB VRAM GPU train an 8B param model
its ok maybe one of the engineers will release something good
its just the price of these models increasing way faster than consumer hardware
Someone surely will develop something for lower end hardware, also since the model isnt finished yet, maybe they will have some breakthrough with VRAM reqs. A man can dream
gonna have to ask one of them tho i dont see any here
they didn't for SDXL, and its like 3x bigger than SDXL. I am just saying be reasonable. Don't get your hopes up for something thats almost guaranteed to not happen. Instead be pleasantly surprised on the 0.001% chance that something DOES happen. thats my approach at least
I think it'll run normally on 8GB, but without T5 XXL model, that thing adds 19GB to the VRAM requirement, just for text😮💨
Wait the T5 is just for text?
they have smaller versions down to 800m, and they will still benefit from tne new arch, cog captions, 16 channel vae etc... even the small ones will probably need to run with TE's frozen on 24gb cards tho for full finetune, at least the big fat T5
I do think very small LoRA's for 8B might be possible on 24GB VRAM. Like maybe rank 4 or 8
yea i thought the small one was gonna run on 6gb but just gotta wait and see
exactly. I don't think there is hardly and hope for any training with T5 enabled on ANY consumer grade hardware on any of the SD3 models. Its just not efficient enough for consumer hardware. Could be amazing for professionals and businesses tho
honestly, I could see the 800M running on like 4GB VRAM (without T5 of course)
T5 = text + a little bit better at very complex images. Aesthetics don't change. It's in the paper released
you can already run SD1.5 on less than 4GB VRAM, and Sd1.5 has a few more than 800M params
yeah, T5 seems like an additional little toy for people who have workstation cards/huge funding. Not something any reasonable consumer should even worry about
My biggest hope is that SAI finally started using a better training dataset (which it seems they have) as their horrible dataset is what held back SDXL so hard. I have spent months training 100's of LoRA's for SDXL and found so much out about what it responds better to
You candeactivate t5
yeah, I know. I am saying its not for us
for art styles etc probably dont need to tune the T5 anyway, the smallest openai clip is also the one that handles art styles best probably due to being trained on a really good dataset, so might get away with freezing the other 2 when finetuning.
Its for me
yeah, that seems like a reasonable assumption to me
Clip alone is justnot very good
yeah
Wasn't this something openAI did with dalle3? and also have human-written captions
So im doing a img2img batch for a video but I want the prompt to stay consistent instead of flickering, can anyone help?
And ther is a 75 token limit because of clip
I am sure they more likely made an in house auto captioniner similar to a state of the art COG
yeah, after 77 tokens, prompt adherance lowers. T5 has a 500 token limit IIRC
I wonder how it is with sd3 it has both
I am personally in the boat of hoping that SD3 comes out looking much better than it is now. I think training on it is gonna be one hell of a task, and the less stuff that needs to be fixed, the better
on what
But i dontlike astetic fine tuning
?
sdxl?
In my opinion, it should have an aesthetic score rating on its captions, something like Ponydiffusion or Midjourney
They did that with SDXL, and I don't really think it helped anything. Granted, SDXL used a pretty bad data set, so maybe that was more of why it didn't work
I don't know, something just feels off about SDXL. Like I don't think I've ever seen it ever replicate any of their demo images in terms of quality, not even remotely closed. And looking back at the original demo images for SDXL, I think those images look better than what they're showing for SD3 right now, which is not exactly the most promising to me
you can use multiple gpus
as somebody who uses multiple GPU's for AI, it is not anything to aspire to do
but damn sd3 inference looks really slow
Yeah they should show images that show the "maximum potential" of sd3, in civitAI there are some sd1.5 images that look better
for my system it might be like 10 minutes per gen LOL
and I have not found a single trainer that can actually utilize more than 1 for SD
Good morning, everyone!
yes, for SD
How are we all today?
guess what's easy to do for transformer based architectures?
I think they will be adapted
yay scaling!
you'll very likely be able to do tensor parallel sharding on SD3
that could be promising at least, though I am sure that will slow it down even further, and its not exactly fast as it is
Also, Joe Penna doesn't work at SAI anymore, so I likely won't be getting the early access to SD3 that I was supposed to
oh well, seems like a fair trade for him not being around anymore haha
I think the community was pretty burned with SDXL, so I think the SD3 reception this time around is a little more luke warm
or should I say more cautiously optimistic
I just hope that SD3 can do better photo-realism out of the box than SDXL, cause I have spent months fixing SDXl's realism and the dozens of issues trained into it. Having a cleaner slate to work with from SD3 would be worth it on its own to me IMO
I think the fact that there is still a pretty big lack of any really good realism models for SDXL is a bit of an architectural limit, or maybe an approach limit, but it definitely isn't as receptive to fixing its baked in issues as say, SD1.5
Am I the only one who thinks that they should train a model ONLY using real photography? or it would be unefficient to do? (also more costy)
(not to say I prefer 1.5, as I very much do not, just an observation)
They easily could, and it would likely be fantastic, but it would also be too locked down to a demographic that most people aren't interested in. They release general models that can be turned into decent at any specific thing rather than focusing on being extremely good at 1 thing
Are you sure the problem isn't that almost all models are a merge of other models?
ill wait for nsfw finetune... for the fuzzy times...
for SDXL? Thats not really the case. I do a lot of model training and work with a lot of model trainers. I have worked a little behind the scenes with Juggernaut, as I am partnered with RunDiffusion, and I can ensure that they train their stuff, not merge it
Almost all "photorealistic" models look...idk too plastic, like some anime images were in the training data or something, or so many asians XD (withouth offense to asians)
I am currently sitting on several different versions of a realis mmodel that absolutely wipes the floor with Dalle3, MJV6, all fo them. But I have spent months trying to fix some fundemental issues that come with making SDXL good at realism, which have stopped me from being able to sell this model/open it to the public
My model specifically targets fixing that issue, and its done by far the best job out of all of the models I have ever used, but it has some pretty severe issues that I haven't been able to fully solve (been making much better progress since I restarted recently)
popping over to #🏞|general-with-images for some example images, if you would like to see
Sure 👀
Reading the paper now
Very interesting, although some choices are confusing
5x the cost of SDXL is going hurt thou
34 seconds with 50 steps with 8B SD3 on 4090; SDXL on the same setup for me takes around 7 seconds
You're using tons of optimizations to run SDXL at those speeds. XFormers and fp16 are the biggest, but you also have faster sampler than DDIM. I'm hoping it'll be ~2x slower than SDXL at worst.
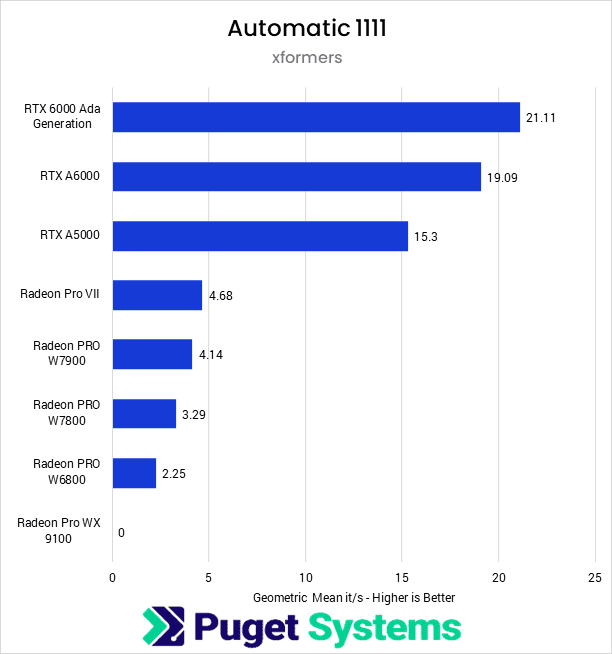
What about an RTX 6000 ADA? Do you think it would be enough to train decent LoRAs?
48GB VRAM should be enough for LoRA's, yeah
IDk about a full 8B param finetune
Is Stable Diffusion open source or only free to download? Cause in youtube someone told me it isnt open source though everyone said it was.
probably not. But I'd be content to do LoRAs for the 8b model
SDXl is 2.6B params and you can abrely do BS1 full unet tuning on 24GB VRAM, and SD3 max is 8B params, so assuming the same scale, it would likely need more than 48GB VRAM
I am not lawer not have time or undertanding of the licenses
different models are under different licenses
What about sdxl and 1.5
SDXL is free to use, Cascade is non-commercial, SD 1.5 is free to use
So none is open source?
Open source =/ free
I believe 1.5 is open source, SDXL, I don't believe so
or well, you can edit them both into whatever you want and use them as you wish, if thats what you mean
you can clean out their weights and re-train and use them however you want
Hmm.
@rose sedgeIf you can give me some better context as to what you have in mind, I might be able to answer better
Well I wanted to know just that
If its open source or not
Cause Emad allways talks about open source
And now it seems sd is not
Technically all of them are open source @rose sedge
Though eveyone presents it as it was
AFAIK, all of them are bus SDXL 0.9 and Cascade
SD3 is pretty unlikely to have an open license
SD cascade also is open source but has a non-commercial license
SD3 will be non-commercial too right?
it doesn't bother me but that's how its gonna be right?
pretty likely, yes
I'm not sure why it would be non-commercial
if so, that will likely be a pretty huge reason fot it to fail
you'll be able to pay to use it commercially
yeah
Anyone know if dalle and midjourney have comertial licenses?
but guys
it should be non-commercial so that they can charge services that use SD3
but we can still generate "paid" images, its only non-commercial to host it
not like I think it's ethical to make paid images with Ai image generators but yeah
idk this is what I remember
Who would notice though
notice what?
non-commercial to host the model, but the generated images are commercial
You use it commercially
"Mark.... This is good news."
I work with a company, and we have seen the quote for how much SAI charges for commercial licenses, and let me tell you, it is not cheap by any means 😅
I thought it's like $20 monthly
for a single person, yeah
if you are using it commercially then you are probably working a lot anyway
not for an entire company
yeah for a company lol
some enterprice license or whatever probably
but its good for stability
they deserve it
you need to go up a few orders of magnitude to get to small company level
companies can host a model as good as ideogram and DALLE3 and still probably save money in comparison 🤷♂️
idk about DALLE3 API price for commercial use
and Stability gets some income
All I can say is I have had multiple companies come to us asking how much it would be to make their own in house model, as they don't want to/cannot afford SAI's prices
I personally think they should be getting the money, they trained those huge models using expensive server GPUs and suddenly companies could use it for free? Wouldn't sound good for stability.
damn
so its THAT expensive then
🤔
I don't think it should be free, but their prices are insane
One that I can mention was $350k per year for a single company with a couple dozen employees
DAMN!