#💬|general-chat
1 messages · Page 42 of 1
I don't really know what that means
Command line
I would agree, if it wasn't full of soooo many problems
Well the only alternative is command line so... I would never even consider switching
I can guarantee whatever issue ur having is not gradio but the repo ur using
I've never honestly heard anyone complain about gradio here
I'm using a1111
The public server it creates is very very buggy and annoying through gradio
Thats strange
The last 10 or so times it's made a server, I keep getting error 504, bad gateway error
I don't think that's Gradio
I have seen people having that error but I think it's an easy fix but since I've never had it, I wouldn't know how to fix it. Sorry.
You should post on #🤝|tech-support
And all the other times it's "worked", it would randomly disconnect and lead to "there is no interface running at this time"
If it's a problem on my end, then it's untraceable, IDK what to say
I wonder if it's because of our new internet. Maybe something on the router is preventing the launching or something
Another hint for users of ControlNet. It seams to be very sensitive to shadows in the image. You can only make such adjustments in a 3D pose tool. It has so much impact.
Of course, the openpose model is not sensitive to shadows, since it only detects the pose of a character.
You are not running it through local?
In my local gradio works well and predictable
That usually happens when you get an error and your UI stops working.
I don't know what to say, not sure why that would be happening
Good evening everyone, I know that someone must have already mentioned this here, but recently they updated the automatic 1111 code, now when we install it on Google Colab, the public link to access the app does not appear. how are you doing now?
yeah I'm getting the same thing. Someone suggested switching to LocalTunnel. I'm not sure how that works, completely.
Same thing as me, or bolt?
Why not hosting on local
504, you.
Oh yeah, gradio is down right now
I wanna find an alternative way to host my SD permanently on my own PC
Where my PC just functions as the web server
I'm using paperspace. My pc is trash. And yeah getting that 502 bad gateway.
Is there another stable diffussion collab that works? I am using https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb#scrollTo=PjzwxTkPSPHf but it is down
🤔 is becoz of gradio.live?
This is why the Cloud isn't a good idea - it gets taken away
Yo does anyone know what diffusion_pytorch_model.bin is? I got them from making LoRAs and they take up a of space
If I don’t need them I want to go ahead and delete them
Gradio.live seems to be down still via: https://www.isitdownrightnow.com/gradio.live.html
but my stuff is working...odd
been trying to get it to work for the last 4 hours
anyone else?
oi
Now it's that time of generating images when because Im only getting close to what I want not exactly I try a different model. This usually results in disaster.
it did
Is gradio.live working again?
Is the best anime model still orangemix, or did something overthrew that when LORA became a thing?
Have you tried using it yet?
nice. while i'm image genning using my gpu, i can still play some cheaper games on my intel integrated graphics
hello everyone, I need some resources for mac. I couldn't use stable diffusion animation with my mac, is there any good resources? thank you
Data aquisition takes awhile waits
any good prompts?
"Two pigs fell in the mud, 3d render, high def, 8k resolution, trending on artstation"
That AI Prompt Bible thing popped up on my face book feed. I guess they deleted my comment because I said they were selling google search results
Do you happen to know how I could host my own publicly accessible SD server off my PC for people to use?
I really really wanna be able to run my PC as a constantly available SD portal that doesn't rely on another company to work
I do not. There is a listen command, and then there's something else you have to do'
poke a hole in your firewall
using --share will only give you a 24 hour link, you have to port forward if you want to make it perminant
do you have any info on how I could do that? I really wanna be able to just always access it, and not have to deal with the new gradio links and bugs all the time
how would I go about doing that? That would be game changing
also is there any realistic Lora or Embeddings?
becuase mostly all of them are nud*s
I have a checkpoint I use for realism, and it works damn well, if thats something you would like?
yes please
@eternal oar #🏞|general-with-images sending examples
go into your router settings and go to port forwarding. send port 7680 on the router to port 7680 on your system running automatic. Do NOT forget to set a username and password or the world will be using your resources
port 7860 tcp. forgot to mention that part. you can do tcp/udp and it will work, but just doing udp won't work. you have to have the tcp
if you want, you can IM me when you get into your router settingss and I can talk you through the settingss
so really this should be something I can look up on google to find out?
Yes. Jusst need to know your router make and model
I am always very worried I will mess this stuff up
awesome, just brought the router from our old house haha
I have mine set up so I can access from my phone while I'm away 🙂
so It
so it is something I have actually done to
too*
fantabulous
hopefully that will get rid of all of the bugs that come with gradio (specifically errors and timeouts when doing really big batches or high res gens)
It helps
you may want to look into dynamic dns if you don't have a static ip address too.
IIRC my IPS changes
Also, how to use stable diffusion's API? I am trying to convert it into a Discord Bot where my friends can access. I do not want people going into the website it created publicly because they can change the settings.
Then you will want dynamic dns. Your router should have a setting for that too. You just need to tie it into a service like noip
so, does what I am gonna do only allow me to access it when I am on this network, or will it work from anywhere with the correct IP?
alright, I will look into that
I have it set up on a desktop in my office, I'm using the api from my laptop right now, I can reach the wep page from my laptop or my phone
sorry, not sure if that answers what i asked or not 😅
Would I be able to give the link to a friend and they could use it as well?
I have a few friends that use this a lot, but they always have issues with gradio
did you look at the api doc? http://localhost:7680/docs
the answer is yes
yes, the api isnt working for me, even after i used --api
:twerk
there is also a short api tutorial in the wiki
NOOO
MY NITRO ENDED
dies
Those scammers just HAD to steal my card 2 days before the billing cycle ._.
I have the api working, but I'm using it in python
in the launch.py?
Nooooo. I had to write python code to access the api
for a discord bot, that's in javacript, right?
No, im trying to make a python one because this project is almost made of full python
basically, you access the url via get sending your arguements as json and it kicks back json that includes your image as base64 encoded text
Yes i did that but then i got mad and delete it all
because it keeps sending nothing
you testing on the same computer or is it not working in discord?
if it's discord, see above discussion about punching a hole in your firewall
same computer, because i often have problems in my internet
which limits my access to coding
ok I'm going to send you the link for the api tutorial. There is something I want you to do with your code that isn't listed there though. hold on
okay
in the request.post line, add the perameter timeout=30
and after it add
print(response)
That way if you get an error, it will tell you what it is
if you get a wall of text, it worked
k i will tell you after i run this code 😄
OK gl
This router is SOOO OP lmao
<Response [200]>
also sorry if this sounds rude
Through 6 walls and over 80 feet away, I still get a speed of 480/360 on our 500/500 5GHz network
change print(reponse) to print(response.json())
AYEEEEEE thanks bud
alright, I have the router setup
set the user name and pasword for automatic1111 and ddnss for the router
sorry, I am very tired and not very smart, could you explain what you mean just a litttlleee more? 😅
then when you have that set up, pm me the url. keep the un and pw to your self. I'm just going to make sure you have access from outside your network
ok in your webui-user.bat you need to add a command line arg
--gradio-auth USERNAME:PASSWORD
that keeps the world from using your SD install and bogging down your gpu
ok, nice
so for example --gradio-auth Sytan:test123?
username is Sytan, pass is test123?
yes
Sorry to interject
Is there an easy way to save all gui txt2img settings?
But I saw stability making an announcement of releasing something on Sunday
go ahead. I know we're going fast right now
Was there anything?
I missed it
ok, so this is what people will be able to enter for my SD server?
Yes, but you need to pick a name and sign up. it will give you a perminant name for your network
from outside
oh, this is gonna give me ads, and won't work on my phone?
No ads. I was using them until they dropped me for not updating (static ip)
I've never gotten an ad from them... maybe in email
there are other ddns services out there. they just were the ones I was using
but because you have a dynamic ip, you need a way to get to it
alright, sounds good
then when you are set up with ddnss, you need to set it up in your router. There should be a setting for it
ok, I am in the port forwarding section
@lament steepleDo you know what IP binding is?
would that help me?
binding is for when you have more than one network connection
Check with your isp before you do that. You can break your internet connection
The only reason I have a static is because my isp set me up with a static
you nave noip set up in your router?
I am downloading the DUC
ok
let me know when everything is setup and send me the url for your automatic and I will try to connect and make sure it works from outsside
Sounds good, sorry, had to help mom haha
Yeah. Not driving 3 states over unless my mom really needs help
oh god haha
hello chat
@lament steepleok, truth be told, I am not too sure what IP I am supposed to be forwarding, and I am not sure what type to use. Sorry, i can be really useless sometimes, but I am a fast learner!
oh my dumb ass, nevermind
the video says later lol
hehe ok. You work on that. I have to make my room mate a bagal and step outside
sounds good, though some of these things hes saying are not showing up for me
here's hoping
I'll try to be as quick as possible in case you get stuck
Chat gpt is an absolute BEAST when you want to fill in gaps or detail your prompt. It literally ampifies your prompt by 10-20 times the clarity before you actually ask it, its so good
Where you at?
I keep getting a failure for port forwarding on the checker tool they recommended
it says 65.34.112.9 what does that mean
Holy crap, you... disclosed ur IP address!?
@hidden sluice delete that message now, your IP is compromised!
what is ip?
This is your PUBLIC IP ADRESS
cool
Delete thiss
why
Because you don't want the world to have your ip address
Your ip address is literally exposed
why not
So you want people to trace ur location
One Router restart and he has a new one
h i don't know. my town isn't 30 miles big and it will tell people where I live
it’s public
Yea but of you get a dynamic IP it will change at least after 24 hours.
(Depends on the ISP)
How do you format your question(s) to it when you want help with your prompts?
how do i make chatgpt amplify my prompter?
here is the one I use to do the same thing. you just need to add a prompt idea at the end after the word "IDEA : "
It may not be the same technique as Army1123 was talking about, no idea
Stable Diffusion is an AI art generation model similar to DALLE-2.
Below is a list of prompts that can be used to generate images with Stable Diffusion:
- portait of a homer simpson archer shooting arrow at forest monster, front game card, drark, marvel comics, dark, intricate, highly detailed, smooth, artstation, digital illustration by ruan jia and mandy jurgens and artgerm and wayne barlowe and greg rutkowski and zdislav beksinski
- pirate, concept art, deep focus, fantasy, intricate, highly detailed, digital painting, artstation, matte, sharp focus, illustration, art by magali villeneuve, chippy, ryan yee, rk post, clint cearley, daniel ljunggren, zoltan boros, gabor szikszai, howard lyon, steve argyle, winona nelson
- ghost inside a hunted room, art by lois van baarle and loish and ross tran and rossdraws and sam yang and samdoesarts and artgerm, digital art, highly detailed, intricate, sharp focus, Trending on Artstation HQ, deviantart, unreal engine 5, 4K UHD image
- red dead redemption 2, cinematic view, epic sky, detailed, concept art, low angle, high detail, warm lighting, volumetric, godrays, vivid, beautiful, trending on artstation, by jordan grimmer, huge scene, grass, art greg rutkowski
- a fantasy style portrait painting of rachel lane / alison brie hybrid in the style of francois boucher oil painting unreal 5 daz. rpg portrait, extremely detailed artgerm greg rutkowski alphonse mucha greg hildebrandt tim hildebrandt
- athena, greek goddess, claudia black, art by artgerm and greg rutkowski and magali villeneuve, bronze greek armor, owl crown, d & d, fantasy, intricate, portrait, highly detailed, headshot, digital painting, trending on artstation, concept art, sharp focus, illustration
- closeup portrait shot of a large strong female biomechanic woman in a scenic scifi environment, intricate, elegant, highly detailed, centered, digital painting, artstation, concept art, smooth, sharp focus, warframe, illustration, thomas kinkade, tomasz alen kopera, peter mohrbacher, donato giancola, leyendecker, boris vallejo
- ultra realistic illustration of steve urkle as the hulk, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha
I want you to write me a list of detailed prompts exactly about the idea written after IDEA. Follow the structure of the example prompts. This means a very short description of the scene, followed by modifiers divided by commas to alter the mood, style, lighting, and more.
IDEA:
That’s very clever
Hi guys, I am counting the time consumed by SD to generate images. Do you know whether SD must render images every time it is inference? (Because when I use WebUI, a picture will be rendered at each step, maybe rendering pictures is time-consuming?)
there's a option to display the rendering image per X steps in the settings
thanks!
Thank you
Wasnt Emad eluding to something be released on Sunday on Twitter
Or did I eat too many space cookies
Hello people. One question. I saw that the bots are offline. But i did not see in the announcement if they will get back or no more. We can still generate pictures?
How much faster would inference be if I had a a100 compared to a 3090
rented obvs lol
You can find a benchmark of most possible GPU pinned in the #1011228477954998273 channel
saw that already, pretty sure it doesnt mention a a100
No. That's ended.
It does not.
Does anyone have a script to convert a standard stable diffusion model which is trained on custom dataset to an inpainting model, you help is appreciated
Rather than Automatic 111
hello,I want to use the original design image of my product with a white background, without any changes to the product's design (including style, color, details, etc.), and have an AI generate different background images of the product in various usage scenarios or angles based on my textual prompts. It is important that the product in the original image remains unchanged. Please contact me if you can fulfill this request.
FAQ: How do I generate variations?
There’s no explicit way to generate image variations, but you can “DIY” it a bit, by re-running the same seed with either slightly different prompt text or slightly different settings. Try shifting the CFG scale value by a few points, reordering the words in your prompt text, or adding another new keyword or two.
can anyone tell me how "Inpaint batch mask directory (required for inpaint batch processing only)" works i cant find any tutorials on youtube
with all these LORA model keeps popping up, is it necessary to upgrade to 2.1?
What are yalls thoughts on LDSR? Is it worth how long it takes?
@mossy river I often want to test different models and now I use just "Bunny" followed by a random word for the model I test, but what would you say is a good standard test prompt? The thing I want to test how safe/unsafe it is (sexually) and how it make clothe, hair, fur and what style it preferer.
I tested LDSR and was not happy, I think I get better result with Lanczos.
The thing I did not like in LDSR was that it could warp images a bit, and in a old photo I had and tried to enlarge it made a very good job, but it removed thin lines in a tree and turned a shape of a small girl in the background into what looked like a fire-hydrant.
But it is not useless, it can be good to add details in some images, so if you have the time and GPU power is is always a good option to test.
So I say it is not worth the wait if you want just a upscale that is close to the original, but it may be good for trying to add and restore in some images.
Anyone here heard anything from Guizmus
Aha loser, (jk)
Wow. This is possibly the most correct prediction I've made in my entire life lol.
it won't stop for quite some time I think, this is still moving so fast, and new types of AI grow here and there. I'm really teased for what the mix of all those will be capable of
Yeah. I made that prediction like two weeks before stable diffusion even released. It's surpassed even my optimistic expectations at the time tenfold.
With how much progress has been made, august 2022 feels like a lifetime ago lol
Now on making an AI that predicts the future
yeah, it's kind of magical already
even chatGPT, for SD, has been a great tool
very good at making prompts
Your the real Guizmus ? xD how did you get hacked
I'm not proud of it
I was contacted by a user here (be careful of PM guys) wanting help/feedback.
I listened, answered, and eventualy got a link to download a ... .exe
Even if virusTotal told me 1/52 with a very low alert on the 1, I thought I could take the risk.
Don't ask me why I though I could, I shouldn't have...
The rest is history
Oh wow, hope you did reset your PC and changed the Passwords off all accounts
Also use 2fa whereever possible
I did reset the pc, factory, wype, new windows account
but the virus took over my f2A
I'm still trying to get lots of things back
Oh crap wtf
Make yourself a Keepass Database and use an 2fa APP now
I do have all those, and I did have
but I made the greatest error possible
I opened a .exe on my main computer
I'm a dumb dumb
what can I say
Yea xD
I'm really not proud
I'm in contact with the different supports, it will take some time but I'll get back on tracks
You should open such stuff only (if nessasary) on a Locked down Sandbox, there is also the Windows 10 Sandbox which wipes everything when its closed
that error made me switch to paper for password keeping
yep, I should have. I shoudl also have at least cut internet
I cut it directly when I saw what was happening, but like, before ? better
Did it encrypted stuff?
I don't think so, but I didn't take any risk. I shut it down after cutting its internet, got on my other computer (that was off while I got infected, nice), and managed the other things, like making sure I got banned
since I was a mod it was dangerous for the server too
and all the other hacks that continued, since they had time to get to my email and could continue on their side
and I booted to factory reset directly, not taking any additional risk
Okay good, hope you didnt loosed to much files at the reset
Also how did they get your login details in first place, if its all in keepass
I didn't try it
Mostly they check the Browsers for cached logins
I was connected on some accounts on the computer, like the email. They could spin up the good request locally to change the authenticator's linked email it seems, but I'm not sure how
Hmmm okay yea if you was logged in that time :/
And how did you saw whats happening?
Did the exe opened more scripts?
I saw discord disconect almost instantly
I cut it at that point
I didn't see that the hack was still going on until a few minutes later when the mails started pouring in
Damn
yeah... well, it was a lesson in gullibility on my part. and first time I get hacked in more than 35 years feels like a good score still
in the end I lost quite some time, 25€ in Nitro, and a lot of hairs from stress
not too bad
Yea if your banking stuff is save most is fine xD and if you get your primary mail back
But that stress wow, cant imagine
yeah. primary mail should be OK, it's my main microsoft account for more than 15 years and all my family is on it, I have all the proofs I could ever need
discord, I can't start getting it back until I get the mail
Ah okay
I tried, but the hacker can just cancel the request from my mail (they did)
Okay so no Browser passwords
@vast ingot Hope you get your whole stuff back, hate it when nice people who try to help get victims of scammer kids
while trying to prevent more damage, contacting lots of my old contacts that would trust my hacked account (one of them I contacted too late, they got hit too), I also learned this kind of things has been happening a lot on this discord recently, so I try to spread the word everytime I see a "shady" PM proposed around here
Guys pls leave this discord out of political discussions
Damn yes a factor that is often overseen but very important. Contacts.
I got like 10 messages on steam since a few years of "friends" with hacked accounts who want me to click this link
there is #🌶|off-topic for things like that, this has no place in the Stable Diffusion discussion, no link to AI, and politicied to a point attacking groups of people. We are not here for politics like that
Fr these scammer kids are so annoying!
Man easy.
Okay, good for you. Please stop thoughm
There are amazing political servers on discord, you can check them out on top.gg
I din even want to translate 🤣
werll, I'm a currently powerless mod, so I try to get what's happening to report accordingly
like that
thanks Aether
Keep your discussion civil and within the rules everyone.
And Taiwan number 1
still inapropriate. damn
Wow I just say Taiwan number 1
sometimes, I don't remember why I want to try after a while
the toolbox seems open, i'm missing a hammer here
Wow those hackers are extraordinary
I wouldn't say that... They had a good tool with them, but tbh, they could have done a lot more damage if they had wanted to. They were discord hackers, mainly after a discord account, and I can see they destroyed it quite fast, it shows as spammer already. But like, they managed to get hold on paypal technicaly, if they knew what they were doing.
I was the error there, everybody knows you don't do what I did. But yeah, sweet words and a nice person can make stupid happen
Question. If you use Stable Diffusion v1.5 (Euler a) and just write "erotic art", how many images do you think you need to create before you see a male? I am at image 120 now and it have generated more couches than males 😄
Hey guys, so I’ve been working on this consumer-friendly app that “turns your thoughts into selfies”. The goal here is to make it super un-technical for everyday people so that they can express themselves visually and share moods, memes, and ideas.
So I’m looking for people to join our closed beta and play around with it. If you're interested, feel free to dm me!
hello
Hello Ryan The Gray
I don't think I have seen a hand model to download on controlnet yet, but I could be wrong. I can't seem to find it either
Hey everybody! I'm new here but I have only 1 question. Is it possible to use a Black/White (no greyscale) image (like an inPaint image) to generate random things ONLY into the White shape. Like a mask where we could ask Stable Diffusion to create something but only IN this area? And if so, HOW? Thank You SO much in advance!!!
there was a hand model with open pose before
i can see it in toturials
im pretty sure i had that few days ago
yes ! in img2img, inpaint, you can use a mask. The default UI will let you draw it but you can just drop your mask image into the UI to use it.
Then use the option "inpaint masked area" or "inpaint unmasked area", not sure what's the good one.
assuming you are using AUTOMATIC1111
i will send a screen shot in general with images
maybe ask #🤝|tech-support , they may know more about it ryan
a few weeks ago scammers took over everything: bank, paypal, venmo, amazon, facebook, crypto accounts.
Bought 18,000$ worth of stuff on Amazon, $1500 from bank on Paypal and sent $5 to someone, all sorts of chaos
THANK YOU So much for this quick answer! So it's possible?! If I'm using AUTOMATIC1111? I do'nt know LOL, I'm on http://127.0.0.1:7860/ on my Internet browser!
I have seen everything now - got an image with a hand with no palm, just fingers
Ill try it
this is the URL most common for AUTOMATIC1111 yes
thanks
do you know what Guidance End (T) and start does ?
The open Pose Hand is a preprocessor and not a model To download,
it was available but i will check later if its still there
not yet, I'm just still playing with the different models to get it for now
ok
cool me too , i like open pose but i wish it could include the mouth too
Make sure you run the latest extension version
i am
Okay 👍
Ok Thank You! I already tried but it doesn't respect the EXACT shape drawn there. Is there any prompt else we can write?
multiple things :
- you can reduce the "blur radius" parameters, it's what makes inpainting modify further than the mask, to make it blen
but mostly, there is a new tech in town
a new extension to try
something that will help you tremendously here
controlnet
there are tons of modes in it, targeted differently, bug check it
The original repository has examples https://github.com/lllyasviel/ControlNet
interesting...I will try this! And you think that's something that could improve what I'm looking to do?
yes, adding this to your current inpaint will help a lot I think
it will preprocess your image, make an image out of it (different images depending on the mode you use), and use that image as conditionning for the image making process
even without mask, it would keep the shapes like they are in your original image for example
using a mask still stays nice, because without it, it would modify colors and details inside the currently masked area
DOPE! Let's Try this RIGHT NOW! Thank U
Have fun 🙂
there are lots of types of that around, from 4GB up to 48GB VRAM you'll see screenshots floating.
Personally, I started on a laptop but was too limited for training, I mainly use a desktop with 3090TI, 24GB
yes for sure, runs quite well
i have a pc but i have only a 1070 or 8gb
still can do things, and there is also dreamstudio and collab for some more free fast stuff
i am using local Stable diffusion fine but at a slower pace
but i am moving to italy in 6 month and i cant take my pc with me
😢
I have an 8gb myself and getting great results on my locally run/installed stable diffusion. I use google colab for training models because 8gb isn’t enough for that
I think aiming for 12GB currently is the most optimal, it lets you train at home on almost anything with some optimisation. After that, the faster the better but it all depends on budget, 8gb can also be the good point for you
what do you mean by training models ? im a little noob
Training the program to recognize faces or settings
cool , i use something similar on deepfacelab
but collab works great for that too
the more VRAM you have, the higher size pictures you can make, and/or the more pictures you can batch make at once. There is a gain there.
i know the bigger the better but budget is important for me
doing batches of 8 pictures at once on 24GB for example takes about half the time it would to make 8 times 1 picture in a row
yep, it's the middle ground you need to find
8 is great
right, but not everyone can afford a 24GB card
I know, was just putting the pieces out to understand
i am in iran right now i will attend uni at italy
and?
new laptop incoming
you cant bring a computer over the border?
there i will be moving around so much and i cant use my pc like that
i need to be mobile
hey!
I am curious how stability use embeddings in production, do you use any database like weaviate, milvus, pinecone, etc. or just maybe postgres + pgvector? that would be very helpful 🙂
Hi
hi, if i have a question, can i make it here?
Hey, I am a student starting university society and I want to get in touch with stability AI on collaborations and potential projects within my school. We are based in London, does anyone know how best to go about this?
@tidal bough
if you need specificaly the staff, then opening a ticket on #1010934719455707218 is the best way to go
Thank you 🙂
your right openpose hands got removed from ControlNet, not dramatic because it never worked for me
guys
anyone know how much vram I am using?
I posted a pic on general with images I THINK i can do more vram
Who here can help me? On the search for a SD API for Cinema4D the one that was opensource is now a paid one and removed from GitHub. There is this other one but it only explains integration with blender. Can anyone help me? https://github.com/blender/cycles
Will the dreambot come back?
no

i think it will make it's way back. i've seen officials alluding towards that
heres where i saw soemthing that caught my eye. while it "isn't active" hmm right?
Whats the best channel to ask about training my own model?
How can I assist you user
I some time do lovely images, then the AI go berserk and my fairy scene is full of fire and flies... Oh, dyslexia "fireflies" is just one word.
where i can generate
why do people piss their pants when it comes to ai art
When I send a image to Extra to upscale with LDSR I see this in the command window, "Downsampling from [768, 512] to [384, 256]", why do it do that?
everyone seems to despise it
It is new, new thing will always kill art or music, for atist is always a artist and can not take any other job to get along.
I think it was during the 80th "Home tapeing kill music", but we still have music.
spend an hour arguing with some schizo shill if ai art is real art or not but it apparantely steals art from real artists
i mean literally people were going apeshit when photography was introduced and it was "not an real art because all you do is take a picture with one click"
Ai art do democratize art, some artists may get pushed off, but other AI-artists will take their place, and art will live on, just cheaper and give folk what they love.
No need to get crappy mass-produced art on IKEA now whan all can have their personal art.
yea
I mean look at ai art now when it only began
imagine what can it do in like 20+ years
not all people can draw and ai art is a great alternative to express their creativity and ideas
Folk are afraid more will cheat with AI, but we just need to learn to test knowledge of folk we hire rather than just put all out trust into a paper saying folk can something.
a lot of people who bait arguments online are just trolls and don't actually stand by what they're saying
its dangerous out there
yep, I can vouch for that
I didn't use to think like that, but man, being mod, I saw some disturbing things. trolls will be trolls
Where can I find some lists of good negative prompts for landscapes in SD 1.5? 🤔
I've seen a lot for 2.0 or 2.1 but haven't seen much of those for 1.5
Ha ha one of those "companies" selling "prompt libraries" on face book blocked me. If you don't want to get called out for selling google search results, don't sell google search results
i don't think they care and will keep selling their stuff.
its okay to sell things and if people think they have value, that's fine too
Take a look at what your seeing in your image, lock your seed, and put the things you don't want to see in your negative prompt
landscapes can be tricky and the best way to deal with them is on a case by case basis
Ohh, I see, yeah, makes sense since using a list could probably remove a lot of things that maybe a person would like for their image, but other won't
or you may want in one image, but not in another
just make sure if you have one you like to hit the recycle button so you don't loose it
lose*
i've stepped up my wallpaper gens to 1440p resolution, but my poor 4080 gives an out of memory error on that 2nd upscale step right? kind of expected tbh. BUTTT, then it just keeps going after the error. like the UI looks like it failed too, but when the terminal finishes, it updates the UI
task failed succesfully
I'm going to start training a 16x9 TI when I get home on 16:9 images that have been squished to square
"I want a 16:9 image, but I want you to use the whole network. I'll unsquish it when you're done"
does it work that way? won't that just destroy information?
did you submit an issue report?
i never bother because i don't have a comp science degree and am told everytime that it's not filed correctly. FOSS has a massive beauracracy infestation that slows down community engagement from the likes of me
render at 512x288 or render at 512x512 and stretch to 910x512. Which is more losssy?
well i shouldn't say that, i do bother sometimes. like when i was getting NAN errors for a month. it was because of python 3.10.6 causing it but nobody in any official discussion wanted to hear me. even when i recreated it reliably
I hate that. you have a bug. you tell them how to reproduce it and they still won't listen
I'm working on a theory. SD 1.5 was trained on badly cropped images. That's no secret or mystery. What if instead of cropping them all to square, we cropped them to the nearest standard aspect ratio and passed the aspect ratio on the prompt. We may get better reults
there's a cult of elitism in comp science and foss. they use beuracracy to keep the gates tight i suspect. i almost joined into that academic cult but circumstances with school and finances meant i had to drop out before i got too deep into it
sd was trained on millions of images. badly cropped are still fine. training a base data model is a lot different from refining a base model
you have more data with the 512x512 that you stretch so it's less losssy
I'm downloading the original dataset
it's goal is to denoise accurately and too do that it needs a LOT of examples. notjust perfectly composed images.
The ti is just an experiment to see if it will understand what I'm telling it
no i get it. you're going to stretch the output to your aspect ratio. but... i mean.. i don't think it'll lead to better images. your ti will still be trained on destroyed data
worth experimenting, but don't get your hopes up i'd say
I'm not going to fine tune the model in the end. I'm going to brain wash it
If the experiment works, I'm planning on retraining the model from scratch
textual inversion training is sooooo much differetn than base model training, but okay. good luck. i dont think that should be your next step and you should adjust your power curve a little for better acceleration
This step is because I'm bored. and need to write the code to scale the images. The laion_improved_6 takes forever to download LOL
aspect ratio bucketing i've seen murmers about. it's supposed to help with wide generations from what i udnerstand. i think it may be more for dreambooth, but maybe the code is worth looking into
This experiment started because I want to retrain it based on certain data being synthetic. This just became a side part that I want to see if will work to improve the quality based on an attempt to improve the quality of the input
may the ai gods bless your tests
wish I knew
ayo, in the x/y/z plot, i cant find a way to mix subjects with my prompt at the top. For example, i want to type "beautiful photo of" at the top, then have it run through different subjects like "beautiful photo of a man/woman/etc", i tried prompt s/r and prompt order but those are something different
ah i got it, you have to put "(<subject>)" in your main prompt, then in x/y/z plot you select prompt s/r. In the x value put something like "(cat), (dog), (woman), (man), (tree)", it will replace whatever you put in parenthesis in the main prompt 🙂 prob general knowledge but thought id share Edit: u dont need parenthesis, but could be useful to keep track
may i ask.. if traning on the same step is useless and waste of time ?
or i can get a better result ?
close. all you need to do is "beautiful photo of a man" in the main prompt. the s/r is search and replace. it looks at the first in the list, and replaces it with the others. so in s/r you'd put "man,cat,woman,dog,tree" and it'd first do the main man prompt, then replace man in each try after. () is for adding emphasis to a token in a prompt, and you can do s/r with "man, (man), (man:1.2), tree, (tree)" and it'd work too
I have a super noob question.. I'm new to this space and curious about making my own image/caption dataset. Is this just a CSV with an image in column A and a caption in column B?
it depends on the tools. usually, it's either each picture's filename that has the caption, or there is a text file with the same name as the picture with the caption in it
Ah okay, that makes sense. Would you recommend either approach over the other?
it just depends on what you want to use for training. what method and what tool/implementation of that method. Once you've got that, you rarely have a choice.
The tools I use, I mostly have to name the pictures as I'd like them to be trained
I was looking at using Dreambooth through google colab to train the model
the google colab notebook should tell you then. Some even have their integrated naming process
with auto caption that you can then fix
The examples I've found don't even have captions.. it's just a bunch of pictures of dogs with the names "dog1, dog2, dog3, etc."
yep, those still are captions, in a sense. If you are training a single subject like a dog, it's usually what you do
You won't get a very specific dog, but you'll get something in the vague shape of a dog 😄
full caption comes in handy for training styles, or more than one concept at once, or even finetuning in a larger sense with thousands of concepts
if you feed it 10 pictures of the same dog, you sure will get only that dog if you train it right
I didn't realize the auto-captioning was intrinsic to some of the colab notebooks. I was under the impression I'd have to seek out auto-captioning on my own before training. But the goal is to manually caption the images though. I've seen a few similar datasets with automated captions and they're wildly off base to what the image shows 50% of the time.
yep, automatic captioning isn't enough, that is for sure, and some datasets are just that, with a simple replacement sometimes in the caption
The goal is to create a small insect dataset. The auto captions keep referring to caterpillars as "toys" and random stuff like that.
using a local autocaption, and then using something like "Bulk Rename Utility", you can upgrade the captions quite easily though
not a bad idea. Thanks for the tip
but still, you may go faster by hand, depending on what tokens you want to train
lots of approach for the same dataset in the end
Hey I appreciate you taking the time to answer the question(s).
no problem, going to bed now. I how you manage to have a good training session !
Thanks! take care and goodnight!
noob question but are automatic and gradio providing the same thing? webui?
hey friends, a new weekly post - I think this is an interesting one and can be very exciting to use in some applications. Let me know what you think,if you have tried something similar and let me know what I could have done better.
https://followfoxai.substack.com/p/the-power-of-synthetic-data-infinite
They're still around! You'll have to grab the Dreambot Archive role from #👥|roles to view em
@vast ingot hi, I see you're well informed about training in dreambooth, I used Shivam's like months ago and I'm wondering if it's still the go-to solution quality wise. I'm on a 4090 so I don't need compromises, all I want to do is to train myself into SD 1.5 (if it's still the GOAT) but I have to get a grasp on the updates (dreambooth-wise) that I missed in these months. Could you please point me to the most insightful and up-to-date tutorial in your opinion? Thanks a ton
what the hell happened to the categories that used to be on here????
that was the coolest part
Is there a good way to load stable diffusion or other safetensors models from python? I'm trying to make my own gui. I've looked at the diffusers library but that looks like it just lets you download from huggingface.
I want to load models from the local filesystem.
Maybe I should go look at the automatic1111 source code and see what they're using...
The most commonly used format is the txt file with the same name as the image file
You can write scripts to change how the information is stored once you have the basic format of image and text pairs, but most projects use the image + txt file with the same name
@high falcon There's also this tool which is stupidly simple and makes it easier to fix the auto captions: https://github.com/Jukari2003/Caption-King
I have a question expanding on this custom data set discussion. How do you know when a model is appropriately using your training data when it isn't something uniquely specific to yourself (like your own face or your cat)?
Normally during training you can set custom test prompts which can help show you if its learning the content
But sometimes you really have to play around with the model and test it fully to determine how well it learned the content
Like, Stable Diffusion already knows what a pokemon is... if I try to train a model on a dataset that only includes starter pokemon (excluding pikachu specifically) but then prompts given after training show parts of pikachu in the finished custom pokemon.. how do you know it's not just ignoring your data altogether.. or at least not biasing its results based on your dataset
This is assuming I've used SD 1.5 as the base model
The model will try to use its existing knowledge to help in the training, which can be both a good and bad thing depending on what you are training it on. You want your custom test prompts to focus on content specific to your training data, and in your example you can use pikachu as a negative prompt as long your training doesn't damage the model's understanding of the concept
cool, ty for explaining that
Also note that finetuning will modify the knowledge that the model has, and this can lead to it loosing concepts. The goal is generally to balance the inclusion of new information while minimizing the loss of the existing information
noted!
honestly I just ran into that problem right now and its really hard to pass. We would probaby need a copy and paste standardized prompt for it to be taught every time we start a new convo with it that makes sure it knows how to format the prompts. Itll probably be a very long essay to explain to chatgpt but it probably will work. Since this isn't a built in feature from what it knows (to teach stable diffusion to create an image)
It still does things it doesnt know how to like create prompts like that, that's why it's artificial intelligence and not google, but it will just lack unless properly taught how to do it
for chatgpt prompts, i like to have a conversation with it about prompts first. i show it a few and explain how they work
once you got it creating prompts in that style and it understands what the purpose of prompts are, correct it as it starts making it's own
how do you get higher quality images?
hello evey one~
Just ordered my 4070TI system parts. Now I will generate and train like nobody else can.
this is likely new ground for SD. Nobody has such POWER
go for higher resolution, make better prompt, choose model which suits your gen better
try to get a system close to mine
Hey newb here but very excited
My first attempt was "Monkey farming on the Moon" and it was awesome
about what?
I'm trying to get the 1111 installed but running into some hurdles
if it's not installed, how do you generate images?
It's installed, I was using the default web interface and I'm trying to upgrade. I'm almost there
Had to make sure of the proper version number and I'm almost done
I'm very amateur but I kinda know what I'm doing
what is your GPU
old nv 1080 but in good shape
I have gtx 970
I might be able to fix this I'm breaking it down
but 4070 TI on the way
It's good that prices came down I'd totally buy the 4x range but I have to watch my money
well, the SD world will soon have me with all this power
once I have it, I will get SD to render a new UI
so anyway it seems like the installation happened but running the .bat isn't working. I'm so close
@high falcon
someone helped me to get it to work
Hello, im new here 
Hi I'm new. Can someone help me start using stable diffusion
Hello, was it me you're looking for?
?
i guess alot of people got in to stable diffusion after that one model/checkpoint from china exploded
ChillOutMix in CivitAI
i got pretty big since last week in tiktok and facebook, atleast in my country
I took a break from SD until I saw Asmons video on the current capabilities, then last night I found Photorealistic nsfw model and boi
SD was big long before that
Dancing on the Ceiling underrated party song
Still a pleb with not enough VRAM so have to wait more
This is not a NSFW channel, whatever that means
thats probably true, i just joined so im just probably spouting dumb stuff from my keyboard
at the Pepsi company, wearing a COKE hat is NSFW
To do: generate pepsi logo with coke color scheme
I doubt chilloutmixs is driving popularity. It makes images of the same Chinese girl
Last night I found a nice prompt, but it kept generating the same pose no matter what, sadge
that's how SD works
aye
also lots of portraits
then I fixed the pose but the realism of the picture dropped
you lose details when trying to generate full body
controlnet supposedly helps with all that
but I cant run it on the crap system I have
ngl, i jumped in SD because of it, but currently looking to how i can get more interesting things with it
I'm not worried about detail, more worried about style resembling more of a digital painting vs photo
you can add such things in the prompt
I tried SD after I came upon a certain image, haha
The current thing I'm fiddling with seems to either generate realistic skin with stiff pose or a dynamic pose with less realistic skin
does adding more sampling steps on it help ?
to some extent
Not really
it depends on the sampling method as to ideal number of steps
for example, euler A is 28
Less steps just makes it run faster but result is of lower detail
Some samplers achieve great results with less steps
right, but beyond a certain number no extra details are added
you would have to compare it pixel by pixel to claim that
ive tried running some on maxed out sampling steps
sometimes i dont even see the difference
So I'm here: https://imgur.com/a/xAYgEai
it's running
"and will not change significantly on higher steps" but they still change so
you have to add a command to auto open a ui
or go to a browser: http://127.0.0.1:7860/
you good now
ok gotcha that sounds right
or localhost:7860
right, but not much, just tiny details
Just trying to finally boot the ui
Will do thanks everyone that's why I asked 👍
that's why we answered 👌
millions of dollars in training, SD can't do better hands than the emojis have
SD can't match the emoji hands
If I could make my cat into an emoji I would do it in a sec.

One of my motivations for learning this and getting this thing to run locally is to make up silly things related to my pet. Why not
hiii
u may
hey, uhm im new here, discord and shit, someone tell me how this works HAHAHA
you can with SD
you put text, you get image
got that ig
still working on that. localhost numbers aren't working so I have to make a sandwich and go back to the drawing board
screenshot perhaps?
you didn't close the cmd.exe did you?
Sure but I don't want to clog this channel up with my problems. Maybe another channel
You can DM me if you wish
I closed cmd
That's the problem then 🙂 have to keep it open
keep this running
no need to reboot
you have to keep that window open
ok
and then go to localhost
ok cmd is open
refused to connect
oh your port is different it's http://127.0.0.1:7861
if it still doesn't connect, screenshot your cmd.exe again
All good, have fun
ty so much
Just remember you need sleep 
nah that's for the other amateurs
Stayed up too late, woke up too early, queue a headache 
I read from a YouTube comment that on LoRA training, if I increase the batch size, I should also adjust the learning rate. Can somebody confirm this, and how do I adjust it? Proportionally, or inverse proportionally?
Just trial and error yourself
I have ControlNet installed but have no models in the dropdown box in the webgui
not sure how to fix this
Bot gave bad results. Each attempt costs 6 hours. Hint please?
Ugh I've never did any of it, maybe try #🤝|tech-support ?
I can't say enough how much I'm thankful you guys helped get my UI working I'm having a blast
Probably need to place the models in some specific directory?
Keep in mind, sometimes specific model is better than specific prompt.
So does that mean using the filters and starting with a model but generating like 25?
Not sure wha you mean, but for example prompting for 'car' with two different models will produce wildly different results
It's all good it seems like I should generate a bunch, pick the best, and then go from there for fun
the filters are interesting
Never used filters
the things that make your photo look like famous stuff
Not what I ment, for example if you are looking for specific scene. There might be a model trained for it, which would produce results closer to what you are looking for with shorter prompt and in greater detail.
Where's the best place to see what StableDiffusion has done and are you hiring?
#🏆|winner-gallery I would guess, otherwise youtube
It highly depends what you are looking for, though.
Good start, going with different models could make same prompt produce a humanoid lizard, a robot lizard or a lizard lizard, just from the model alone, without changing the prompt
A model can interpret 'lizard' in myriad of ways.
SAY MY NAME
sizin ben anennnenizi
toplayıp
daglarda surerek koyunlara siktirtiyim oruspu cocukları
dagda s,k,len aneannei
alıp yerde hoplatıp parif kulesine sokiyim
paris
oruspu cocuklarıütop
babanı yerdeb yere vurim oc cocugu aslanlara yedirirken babandan cıkan kaval kemigini tutup anenin amcıgına sokim
aq kodugumun evladı
anyone want to step in and translate?
It's Turkish.
yeeees
yeah I'm out gg
He said he wants to have sex with your mom, kill the men, rape all the women
its not bad word manü
I'll beat your father to the ground, rip off his shin, and use it to rape your mom - that's what he said
oruspu cocuklarıütop = sons of B's
naaaaaaahh
bro
oruspu cocugu is
every one brother
if anyone say that
he say every one brother
I know enough to know what that means
ı say that
don't come in here spouting that nonsense
Not here
this channel and discord aren't your school
bro
talk like that to your pals. NOT HERE
ı open that acc on my school
that is a non sequitor
Me: "Stop the nasty talk" You "BRO, I open my account at school"
spend more time on your work, less on potty talk
wtf?!?
bre are free now
the person came in talking about raping mothers, killing fathers
I saw
How is that tame?
What kind of school do you attend? Is it like a pot school where you learn to get high? You speak as if high or drunk.
then go sleep it off
stop putting poison in your body
do you want some eroin?
true dat
ı can sen you home

send
I dont take poison
its not posion
it is
its bale
my father lived in Turkey
Well, I see the intelligent life landed so I am out.
I am trying to remember the name
man, sometimes I think I saw a lot of things, but that's a first :p
do you know where he livin?
Hear me out - maybe Elon shouldn't just post dumb memes all day while he's on his plane. Just a thought.
Lots of money at play
yeah but trolls gotta troll
feels like it too
I'd be less jagged about it if I didn't got a tesla, I liked the guy at some point. youth's gullibility
he has become more likeable recently
He claims he's going to assemble a team to make a chatGPT rival
franktutor
well, his claims have not the same weight at lots of other people's claim when he just changes direction with the wind. I hope he does nice things, but I'll wait on the results and not the tease from him
is your dad name ali?
he's accomplished a lot
hepinizin aq oruspu cocukları
I still rather new to Stable Diffusion and I often use Automatic1111 web UI, and there is a number in the prompt going up to 75, some time I pass this number and it increase, what is that, what is a Token and what difference do it do for the images?
It's basicly a number of how many different promps you can use, SD is limited in that regard. Used to be 75, but I guess with new version it can go higher, not sure on specifics when/what's the difference.
Tokens are parts of words. A token is around 0.75 word in general. Tokens are what your prompt gets broken into, and it's passed to the model to make your picture.
Tokens also are what the model has been trained on. it's how it manages to find the right weights to apply to your image so it can follow your prompt.
Tokens go up to 77. 2 are reserved, so it lefts us with 75 to use. Automatic uses a nice trick to let you go over that limit, at the cost that each token is a little less considered.
Can I turn that off, I have a bit of what once called Asperger's and when I see that number I get a stupid urge to optimize my prompt to get as low number as possible 🙂
I'll check, I don't think there is directly an option for that, but it's quite custumizable
I was in looking at the settings but my language skills do so I don't want to click randomly.
and I use "skill" in qotation 😄
ok
so open the file "style.css"
and add this line :
.token_counter {display:none}
then just do an F5 in the UI
all token counters should be gone
@vast ingot Cool, and thank you.
this may prevent you from doing "git pull" though
since you'll have modified files :/
I'm checking if there is another way
yes there is !
put that line in a new file you make that you name "style-user.css"
instead of the main style.css
it will act the same, but it will also keep the "git pull" possible
Where do I start as a complete beginner?
other work around is to commit your changes and then it will pull noormally
and let us know if you get stuck
yep, the #1072220168534642768 , the #1072229020520947753 .
Once you get access to the AI, you'll want to try it, and ask different channels in around here depending on what you are trying to do.
I'll link the FAQ on how to access the AI itself
FAQ: I'm new here, how do I generate images ? Where is the bot ?
Welcome ! There is no bot currently to generate your images on discord. You may want to start by taking a look at the #1072220168534642768 channel. You can access Stable diffusion in different ways : 1️⃣ the official website, https://beta.dreamstudio.ai/. The easiest and fastest way to access Stable diffusion with 200 free credits. For any question on it, you can find help in the #1025467151206854736 channel. 2️⃣ Installing Stable diffusion on your computer. There are numerous projects that let you do that, and you will find help in the #🤝|tech-support channel. 3️⃣ Running Stable diffusion in the cloud, through rented GPU services, using notebooks. You can find lots of them shared and discussed over in the #1011228442399883294 channel.
if I have a prompt like "small studio apartment Nordic style, one squared window, 250cm ceiling height, color and design idea", what model would be recommended to get variated 'inspirational' images, v1.5 and v2.1 often get stuck on same color (gray, blue, wood).
Are you looking specifically for color ideas?
or do you have some in mind?
try adding as many colors as you can to your prompt. sometimess sd will pick
Good idea, there is some few colors I do not like, as purple, but the idea is just to get random rooms, but not to wild in colors. I witsh there was like a IKEA model or design Pro model that is uptodate with some trends but also can go retro.
Do you know how to use SR script?
Haven't you fixed the installation of automatic1111 yet?
@tame bone No, not yet. I can look into it, but I have a slight problem if it is to complex. I had a smaller stroke a bit over a year ago and that affected my logical skill and I do relearn a lot.
I assume you are using webui?
Yes, Automatic1111
I am using webui from web search so it might be different, https://blog.paperspace.com/content/images/2022/09/Screen-Shot-2022-09-23-at-4.56.22-PM.png at bottom you can see 'Script' and value of 'none'.
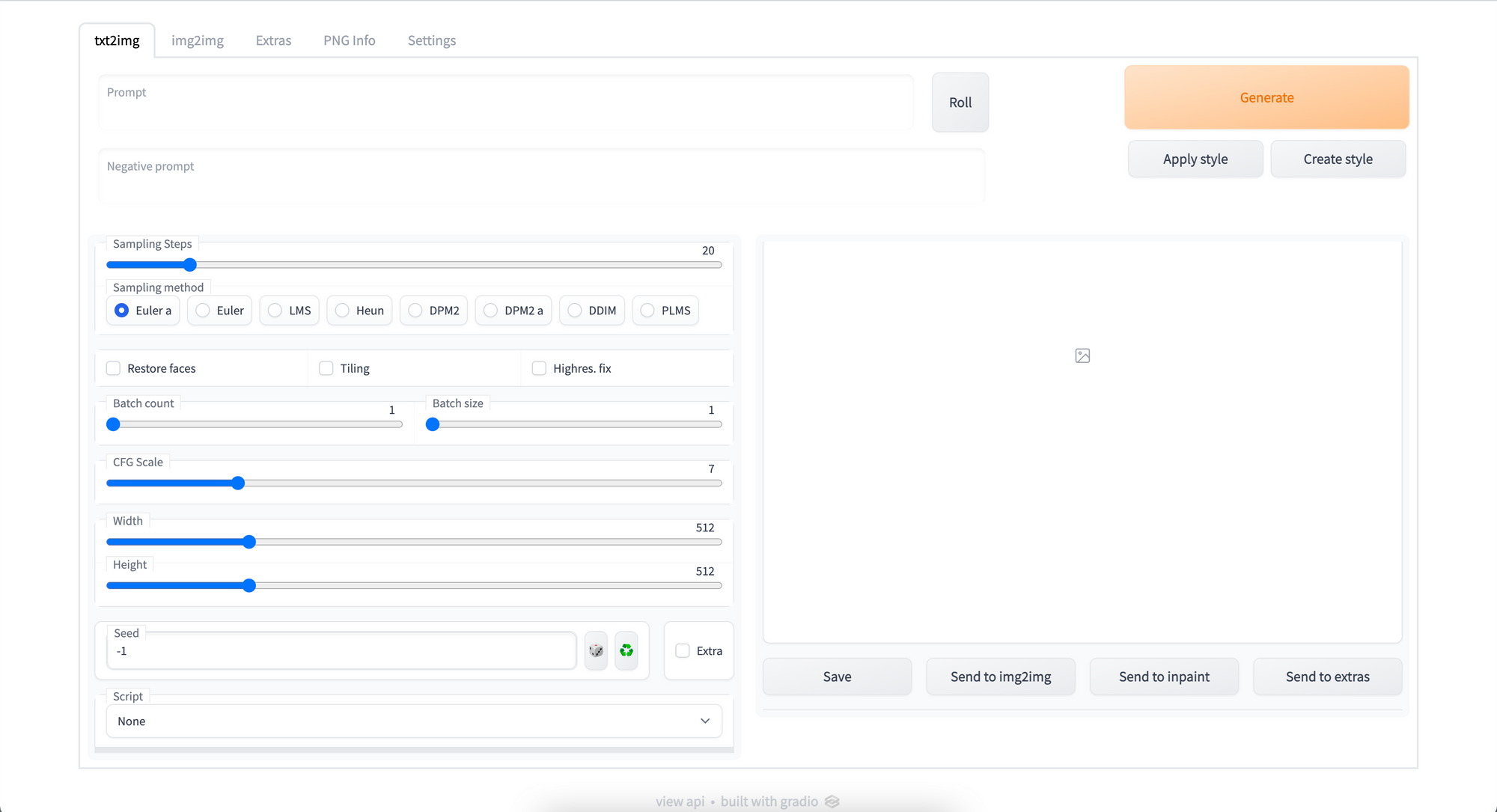{kind=link}
I sometime use the web, but then my spelling is not the best and I need to test me forward word for word I often came to a limit or it was just to long wait. The Web UI and all models eat tons of resourses but was better for my usage.
You mean X/Y/Z script then Prompt SR ?
Yes
But I'm trying to explain to @stable pawn how to locate it first.
Oh. Yes I used that scrip part, I use it to upscale in Img2Img.
Ok, so select the prompt SR
then you take your prompt "small studio apartment Nordic style, one squared window, 250cm ceiling height" add at the end any word, so like "small studio apartment Nordic style, one squared window, 250cm ceiling height, red"
then in prompt SR you start with that word, in this case 'red' and you fill it with everything else, like "red, green, blue, emerald, sapphire" etc. just remember to keep batch count and batch size at 1
Sorry if I sound stupid now, I may have a logick block again, I cant find "Prompt SR" or connetl logical where it should be. Sorry.
@stable pawn refer to image
ty
It's amazing to find out which triggers work and which don't, for example blue dress doesn't (results in white dress) but emerald and green produce two different shades of green
Trial and error I've found out SD doesn't really know colors.
It feel a bit stupid when I still just forget things randomly, not long ago I did try to lia that I understood, but that did not help me, so th for take the time and do the simple reminders.
hi guys, im using latest version of Automatic1111 webui, is there any way to bypass the [Warning: too many input tokens; some (11) have been truncated:] error?
i remembered that i dont have this warning last time in December when i have a long long prompt
Create your own discord server and write everything down in separate channels there.
Maybe unrelated, but most of the prompts can easily be shortened.
yall know a way to more conveniently move stuff around in the colab right side file view
i am poor my pc is made of mud
i am forced to use colab 😭
{kind=link}
let me try again, i was trying to regenerate old picture which i used a short paragraph as prompt
thanks anyway
do you have the seed for it?
yup, but i want to use a new model to generate it
then just try to omit something from prompt
okay
where to post generated pictures
general with images
#🏞|general-with-images is a good one too, both
I have a problem that maybe someone of you have also encountered before. I use a Mac Studio M1Pro 32GB RAM and I was going to train a model with Dreambooth. Now, the problem is that it seems like Stable Diffusion Dreambooth doesn`t see the VRAM? In terminal I see only VRAM0 and it takes like 8 hours ETA for training? Is it a way to tell Stable Diffusion that I have 32GB RAM?
you have RAM not VRAM
yes that what I was worried about. So it means that my Mac Studio M1PRO doesn`t have any VRAM right?
yes, now I inderstand. I thought for a moment that VRAM was Virtual RAM
Is that a laptop you have?
so it is Video RAM. Thats strange that MacStudio like I have where I edit big 8K videos and process big video files doesn?t have a VRAM
I think it only has integrated video card right>
no its desktop. Mac Studio is a desktop professional Mac
Hello, did someone manage to make rocm work with radeon 7000? I've read that there is a sort of workaround to make it work but i tried and it was unsuccessfull
here are the specs
Apple M1 Max chip
10-core CPU with 8 performance cores and 2 efficiency cores
24-core GPU
16-core Neural Engine
32GB RAM
this is my configuration
seems like it's a single chip
I'm surprised it works on mac at all, or are you using windows ?
on Mac yes. I ahve used Stable Diffusion on this Mac for a long time. It creates images really fast, but I was surprised that when I tried to train I discovered that about the VRAM
yeap, training is different from generating
yes right? That what I was worried about 🙂
Maybe try #🤝|tech-support
yes thanks anyway for the response 🙂
I only have 8GB of VRAM myself, need to wait so I can train myself
wait for 5th series nvidia card, that is haha
You can train lora with 8gb
Yes, that's what I'm looking at tonight.
Some day maybe you can have what I have arriving - a 4070 TI and all the components for a new system. That's the most powerful GPU, and I will be training with it
anyone running sd on the new 4090 laptop gpus?
no just wondering how it performs
i really wish stable diffusion was part of the stock benchmark test suite such as 3dmark etc
it's a fantastic gpu+cpu+ram workout
Anyone around that uses controlnet?
Does anyone has link to some good new models. I did not generate for some time, and want to try again, I saw video about the Lada models and their are impressive.
thanks
your welcome
hey everyone
Heya
some model ideas to make anime style?
#1072013871730131004 should have your back on this, there are so many, I wouldn't even know what to recommend today
Hey! Did anyone try to train using 1024 to make high res images?
ok, thanls
Just chanced up on this extension: Kohya-ss Additional Networks
script, models Allows the Web UI to use networks (LoRA) trained by their scripts to generate images.
Added: 2023-01-06
How does this do something that isn't already possible? Aren't all LoRAs already usable?
Unrelated to diffusers but does anyone know how to fix overfitting?
I wish there was a way to have our outputs named via certain tags that are in the txt prompt. such as: "girl wearing a <red dress> at a coffee shop." the img would be named after what is in the < >. so 0023_red_dress.png
might be a stupid question, but do I need to install SD2.1 on auto1111 to run custom SD2.1 based models?
nope, SD 2.1 is just a model that you load into auto1111 webui