#💬|general-chat
1 messages · Page 38 of 1
lmao
Horniness is the best motivator for learning new tools and skills
hey if its motivating lol
I already know I want a way to segment an image so that one portion is depth based and another is openpose based
Fucking around with a picture of a tree would not have helped me realize that lol
fair lol, memes motivate me, or turning gifs of michael scott into linus from LTT lol
{kind=link}
ctrlnet is way nastier than pix2pix
lmao
in another couple of weeks, something else will probably come along and blow controlnet out of the water 😄
I love the speed of development in SD right now
I'm so down for it
smaller Lora files to use with additional networks
lora extraction
I wanna play around with that, I havent yet
It looks like openpose doesn't wanna believe that certain configurations of limbs are possible
might be worth trying canny or depth then
and kinda just gives up
I see a lot of people using canny, but I'm not sure what that model is interpreting
so far I've only played around with depth and pose
yeah, I tried to do a dancer, and openpose had real trouble with her holding her leg up in the air
make your pose here, then use the screenshot tool on it to make an image, then process that for openpose
https://i.imgur.com/1FZeINJ.png you can disable floor grid and ground first to make it work better
{kind=link}
hehehehehehehehehe
as far as I can tell, canny does something like edge detection as a preprocess, then render using that
Let me fire up canny for a spell
That also has premade scenes you can play with and adjust
even without alkl the revolutionary new features coming out every few days, people need to chill out on thinking stuff is dead or slowing down. tech is 6 months old lol
i love so much that windows 11 lets me run a terminal quake style
"wheres the term again.. OH yeh! start+`
Hey all, does anyone if there's been a similar Dreambooth exploration for what are good Face hyperparameters in 2.1? Or is textual inversion / LORA the better way to go for this?
The face version of what's in this post: https://huggingface.co/blog/dreambooth
I've been trying some dreambooth Faces with the same parameters they have for v1-4, but it does not seem like they carried over...
hello guys
can you help me?
i how to find automatic1111 docker image link?
please help
thanks so much
Ok guys, every tutorial I watch and follow give me the worst results when I try to train a model or anything ... I did Dreambooth, I did LORA, I did Textual Inversion... I've spent hours and hours and NOTHING I do works, the results are horrible. horrible.....
I don't really know what else to do...
I have 12GB GPU but literally I followed everything step by step and this output looks nothing like me
I can get a style to work, but haven't successfully done a character yet
In the video tutorials, they say "follow these steps and get these results" and it's like... no it doesn't look anything like that
I guess I'll just keep trying but it trains for so damn long it's like wasting time 😄
Did you watch Software Engineering's tutorial?
it's over an hour, but he goes really in depth
even how to check when to stop training
can safetensors model be used the same way as ckpt models?
as long as it is a sd model. lora models also use the safetensors or ckpt formats so make sure you know what you're putting in the folder
I still have hard time understand training of Embeddings, most tutorials show how to train a face, but what if I have 150 black and white images from a concert and want to train a model for "Ilford Delta 3200 ASA" to get the film look but at the same time train it on "punk concert" so Stable Diffusion know tags like "3200 ASA" and "Ilford", how do I associate tags with my training?
How to use the ai?
Then?
What step are you on?
@twilit panther Do you have a plan on how you want to use AI, what you want to do?
what is ensd in generation settings ?
found it nvm,
How come I put in the exact settings for this https://civitai.com/gallery/112814?modelId=9942&modelVersionId=11811&infinite=false&returnUrl=%2Fmodels%2F9942%2Fabyssorangemix3-aom3 but cannot get the same image?
Do you have that checkppoint?
Unless they use clip skip I have no idea. sorry
Morning ☕️
morning !
Are there any models that can make a political cartoon style?
WTH is a political cartoon style
you could see if any editorital cartoonists are known to stable diffusion
I got tired of searching the db. sorry
The basic caricature stuff you see in newspapers where they mock politicians and label the things in the picture.
morning
Hello I haven't used sd since back when it was run in a bunch of channels here. I want to run it on my gpu, what is the name of the ui that people use to run it?
Good morning, everyone! How are we all today?
who know the best jok?
Is there any way to get my SD to start up faster?
Putting the models onto an NVMe SSD
hey guys, i keep getting an error in web-user.bat? saying i need to update pip but i already updated it.
did you update it from within the virtual environment?
sorry i'm not a programmer, don't know what that is
you on windows?
yes
ok we're going to do this step by step. open your windows explorer to and go to where your webui-user.bat is
yes
yes
type .\venv\scripts\activate
with the dot at the beginning?
what does it say at the beginning of the command prompt
you mean at the top?
at the beginning before the cursor
I want to make sure you're in the right folder
ok that's not the right folder. it should end with stable-diffusion-webui
ok so what do i do then
Have you ever had this problem
AttributeError: module 'tensorflow' has no attribute 'Tensor'
did you run the activate script?
if you did, it will ay (venv) in front of your prompt. if it doesn't, then type
.\venv\scripts\activate
it's a virtual environment to separate it from your main python installation
yeah it says venv at the beginning
ok type python -m pip install --upgrade pip
First good morning everyone!
When I try to run the lora that I installed locally it gives this error! what is it and how do i solve it?
morning
sorry for not understanding but can we start from the beginning again
ok in your windows explorer window for stable-diffusion-webui, type cmd in the address bar
Here's my tip:AttributeError: module 'tensorflow' has no attribute 'Tensor'
Oh, sorry about the mistake
i have windows 8.1 so it's a bit different i think
is ContorlNet
RuntimeError: mat1 and mat2 shapes cannot be multiplied (154x1024 and 768x128)
how i windows 8 still running?
ok the old fashioned way.
i guess yeah
webui on your c drive?
RuntimeError: mat1 and mat2 shapes cannot be multiplied (154x1024 and 768x128)
where do i see the path en for what
what are you using tensorflow for?
Never met,I don't know
i'm so confused
what folder were you in when you cloned the webui?
😣 i don't know
you have to activate the environment to upgrade pip in the environment and I don't know how to get you there in windows 8. the good news is that that is a warning not an error
I was just trying to help you make it go away
windows 10+ or linux I could get you there. I'm sorry
i'll look into it
how to open a1111 web ui if you deleted the pin? 🤔
hello! I have a question, do LoRA models work with like different models prior to what it was originally trained from? For example, if I trained a Blue Archive LoRA model from redacted v3 and used that on another anime model, would it still generate good images that adapts to that anime model?
Ye
How does one do a side smirk?
I tried, and all that it gave me was a weird creepy smile
sounds like most smirks
/ imagine
you cant do gens here
Does anyone know of a good free writer ai that you don't need to log into or download to use?
novelai?
it's not free
how do i make previews for the extra networks
Before i leave for the day, i just want to say that Windows 11's hidden feature, making a terminal window into a quake style terminal that comes up with start+`, is my new favorite thing about windows and has fully won me over. Theres no going back now
windows 11 was so bad i went out of my way to reinstall windows 10
i was on arch linux the past 2 years so i didn't get any of that first wave windows 11 stuff
i was using windows 10 until i got a brand new vega64 and eventually realizied that amd's shitty windows drivers were causing all my isssues and i moved to linux
classic
you try your very best, really give it your all
wow i have early member role
really is an honor
https://streamable.com/ticsfq very pleased with the ControlNet+EbSynth combo but can anyone help with fixing the weird glitchy artefacts caused by people moving behind the window?
I have it installed. When enabled, it doesn't run. SD acts as if ControlNet isn't there/enabled.
Is anyone able to use their stable diffusion to train and get images of themselves? I swear on the lord I have tried everything...
you tried the train tab?
yeah bro, it failed
Last night I literally ran it for 100,000 steps and saved embedding every 50 steps, they all worked like crap, they looked nothing like me 😦
(that's 2,000 embeddings that I tried today)
you probably overtrained with 100,000 steps
did you go back and look at intermediate embeddings to see if there was a sweet spot?
also, textual inversion embeddings are just super fancy prompt building. It can only get so close depending on what's in the model. Try different models and see if you get better results.
first if you got over 100k steps overnight i feel like you're traning wrong. i did it overnight last night and only got 1000. also did you preprocess your images to generate captions? did you manually fix the captions? what settings are you using on the train tab?
Hey can anyone tell me how can i make an brand logo for my shop herr which commands i have to use or something
Anyone out there use Kohya Lora as I am still having a hard time comprehending steps, epochs and was wondering what is this exactly in comparison?
override steps. steps for 16 epochs is / 指定エポックまでのステップ数: 544
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 600
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 34
num epochs / epoch数: 16
batch size per device / バッチサイズ: 18
total train batch size (with parallel & distributed & accumulation) / 総バッチサイズ(並列学習、勾配合計含む): 18
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 544
I am used to HN/TI/DB and this lora stuff I just can't. I know I need 3k epochs in DB, or 1200 for a TI so easy enough but in LoRA I still have no idea what I am really doing.
I see 544 steps but that cannot be the true total since it is over 2h to train it making it the absolutely slowest method behind HN that has no optimizations to it.
It was Euler I think that's how I got the 100k steps
hello, i want to install automatic 1111, but can i install it with amd video card
Only works on Linux. Which GPU?
when i try to install it, at the end it is written "torch is not able to use GPU" write --skip-torch-cuda-test...
Which OS are you on, and which GPU do you have?
Im with windows 10, video card amd ryzen 7
[1:32 PM]Occam: Only works on Linux. Which GPU?
That's a CPU, not a video card. And you can only get Automatic1111's webui to work on AMD on Linux... oh wait, there was some experimental way for Windows. Guess you could try that.
Hey guys, a quick question
Does stable diffusion works with 7000 series AMD gpus?
Or only NVIDIA?
Nod-ai's SHARK works on 7000 GPUs already. Webui on Linux AMD ROCm is not yet supported, has to wait for AMD to release ROCm 5.5
typically do you thinks good or negative to add alot information in a singular prompt? Would the ai be confused?
For example
"Dark forest woods' instead of having 2 prompts for "Dark forest" "dark woods"
Same thing with sea/ocean, beautiful/gorgeous/pretty
/prompt
inpaint area - only masked option
thanks
but it gives me error
when trying to generate with that option
ValueError: Coordinate 'right' is less than 'left'
not sure. never had an issue with it
maybe it has something to do with my install, as I can't do a proper git pull because it tells me that my "local changes" to some files would be overwritten
I haven't done any change to any files
but it allways tells me that
so I have to update manually by downloading from github page, But, if trying to git pull just after that it still tells me I have modified files.
it will say the name of the modified file. move it to another folder and git pull
it will get it again
yeah but its allways the same
I have to go delete a bunch of files
every time I want to do git pull
and then it doesnt work
If I do that stable diffusion doesn't work
it only works if I use the downloaded files
manually
maybe do a fresh install
Is there an automatic way to do that?
not automatic but its fairly easy
follow the steps from this video https://www.youtube.com/watch?v=VXEyhM3Djqg
thanks
oddly enough, I just removed the files it asked, did a git pull, and stable diffusion worked
after many times
maybe its because I reinstalled git and some other software the other day
and the full resolution worked too
updating git would have helped. yeah
Is civitai running on donations alone? I’m thinking of donating 20 bucks to them, but I’m not sure if they’re already profitable or not
Do we have explanation on what's the difference between controlnet preprocessors and models?
Preprocessor will turn the input image into whatever the model needs. For instance, if you want to use the depth controlnet model, and you have a regular image, you would select a depth preprocessor to turn that regular image into a depth map. If you have a depth map already made that you want to use the depth model on, no preprocessor is necessary. At least that's my understanding of it, I just downloaded controlnet earlier today and played around for like 20 minutes.
you don't have to use a preprocessor. they're just there to assist in creating the information that controlnet models want. if you get that info out of an image any other way, use it
anybody know how to use the k samplers? or am i just misunderstanding something, as I only see the regular euler and euler a etc. samplers
there's so much upgrading that can be done to the preprocessing bit. like parameters and all that. it's gonna get neat
somebody already made an extension that lets you pose your own skeleton right in the webapp, and use it as a control
update webui?
Hi. When bots welcome back for promt??
did you have k_euler and stuff when you first got it, I literally downloaded mine yesterday
Who know it??
So...ControlNet. I look forward to trying that out, so I might have to wait until if one of the web uis integrate that. As much as I want to use triple one, I don't have computer for it. 🙂
3060 for $200 usd for SD, worth it? I already have a 1080 ti
depends on if you get more vram
Its pascal vs ampere, im here for the RT cores and not the Vram
I get around 3it/s on 1080 ti
ok, then why are you asking?
Because im asking whether for $200 its a worthwhile upgrade
I have no idea the performance difference between the two
Gaming wise, its roughly the same. Im more interested in the inference strength of the 3060
Accelerating SD training and inference with RT cores would probably cut my time waiting by 2x if what i heard is correct, but im not completely certain on it
Wow; SD has improved a lot since I last checked out some of the better images
The #🏆|winner-gallery has really good image res, art-style consistency within the image, and less artefacts
Is that just evolution of SD itself, or other tools ontop?
ive seen lots of people merge models
https://twitter.com/_akhaliq/status/1627331099956240388 wonder what this is about. plug and play is useful but.. what is it?
Hi! Been testing out stable diffusion, is this a good place to ask questions about prompts or technical issues?
I'll take a wild swing and ask basic prompting question and if its the wrong place to ask maybe someone can point me in the right direction.
Question ; what is the syntax for blending between two things, like if i wanted to mix a cat and a dog by percentage, or two different embedded face trainings together, or an embedded face and a lora - whats the terminology to do this precisely
Try #📝|prompting-help and #🤝|tech-support
Second question; is it possible to restrict certain attributes to one object or character, so this prompt doesn't bleed in to other thing, like say you wanted someone on a green chair, occasionally it does stuff like make their hair green, or give them a green shirt or something,
thank you
with embedding it's [embedding1: embedding2: 0.25]
that'll do the first 25% of steps with embedding1, then the rest with embedding2
ok cool thanks
if you want to restrict something, try inpainting
and is there a good place to ask qustions about training embeddings?
then you can just mask out the subject and prompt specifically for what you want in the mask
regarding training, you can probably ask anywhere.
i have been testing inpainting quite a bit and the quality seems way, way worse than txt2img
make sure you have an inpainting model
yes, even then, i have tested multiple inpainting models
and you'll need to tweak your mask blur and paddings to fit how big or small your mask is
also, select "only masked" for inpainting area
that way you get more resolution
if you select "whole picture" you'll lose resolution on parts of the picture you're not painting
yes maybe I should let you know i have tested all of these things, and know the process pretty well there, the issue is getting images at higher res output from inpainting, at full quality, the uprezzing seems not as good as txt2img
appreciate the help though
ok who drank all my coffee
hello
@mild badge you can't block me from here, just tell me what I did to you so magnifically that upset you so much?
morning! 
oh, no, not K_euler., I thought you're talking about DPM++ Karras
K_euler doesn't come with update either, I don't have it.
Euler a, dont like it?
Im not you bruh
Hi, where can i find the available fine tuned models?
I'm in UK so not too early 😆✨ hope you're having a good Monday
is it just me or is civitai running like crap rn
took me like a good 30 seconds to refresh the front page
@bleak matrix
oh my
 didnt have time to check his account
didnt have time to check his account
Not an active member, from what I saw 🙂
Hey 
morning 🙂
been better, been worse, lol, yourself? chipper as usual?
still messing with mixture of diffusers, it's been getting some updates recently. my UI coding ability is poor but it's nicer than using the CLI.
I want my SD to generate 100 really bad sushis. I plan to use chatGPT to generate the ideas in bullet points. Is there a way to input those bullet points and batch generate them?
There's probably an extension for inputting a list of prompts and doing them sequentially, as well as maybe the command line interface can do it? I am not sure
Do we have a non-anime model , which can do magic?
Particles, effects , auras , e.t.c?
Just not anime , anything , game-ish looking is fine
any game artwork you're thnking of when saying "game-like"?
Final fantasy 15 comes to my mind.
Decent looking artstyle , not too far from being realistic
But there isn't alot of magic...at least not in a game , only in a movie
sent few screenshots in the channel with images.
https://discord.com/channels/1002292111942635562/1077246140191346729 New embedding released! I think it came out pretty good!
gm guys, greeting from China
How much of the popular prompt tags are just myth or BS? I tested things like 4K, 8K and so and they tend to work worse than 2K, and "detailed" just zoom in on a detail or add objects, I often try "add sharpness" to get sharper images or I try things like f18, long dof, sharp focus.
I often try to take prompts from https://civitai.com/ and then try to remove as much as possible to keep similar result and sometime I can remove more than half of the prompt.
yeah, that makes sense. There's a lot of cargo-cult prompting
As an example, I do not write "Two girls are hugging" but "girls hugging" then it imply it has to be another girl and the AI often understund that.
And the extra sharpness in the first prompt, I often fix that in upscaling and in post work.
I thought discord is blocked in China?
Lots of ways to bypass the blocks lol
True
Question is if some one want to risk that in China just to say "hi".
If they're a foreigner, then China isn't as concerned with stopping them from reaching the outside world
My best tips to avoid deformed hands, "wearing mittens", but it may look fun if you try to create a sexy lady pose on a beach 😄
Mitten kittens?
almost 😄
Prompting is 30 % trying to avoid bad hands, 15 % bad anatomy, 25 % getting rid of signatures, watermarks and so, then 12 % porn.
I don't usually try to avoid bad hands...when I get them, but like that gen , I just inpaint...oever and over again, there are other details I'd want to outpaint and fix anyway
And 44 % finding synonyms for shaved cats.
okaaaay...
I was talking about Sphynx felines, nothing else.
That is what we should get if we ask for a hairless Pu**y, https://www.wikiwand.com/en/Sphynx_cat
... I gave me a embedding idea.
hi, is it possible to have a metadata reader in the app of this discord ?
For everyone who missed the live session I did for AI/CC, here is the recording of the entire event. Where we talked about Environment concept art, Character design, 2D Game props & UI Icons for games and many other things. Using AI Tools with a professional mindset and goal. Hope what I've showed there will help many of you! https://www.youtube.com/watch?v=8wS4O9EojMM
Hey people, anyone going to NFT paris? I'm going Saturday and will send comments and contents (as much as possible) on my server.
( I want to know if i can meet anybody randomly there 😄 )
anyone knows a good guide to install chatgpt?
Start by buying 8 Nvidia A100 GPUs.
Then hack OpenAI and download the model.
Oh, and make sure to buy the 80GB VRAM variant.
step 4: profit
You can always pay and access ChatGPT plus 🙂
it's like 30 usd a month
Step 1: have a super computer cluster ready
it seems counter intuitive, but text language models seem harder to train then image denoising models
it takes a ton more computer to run chat gpt tech
i think you might be able to run just base gpt 3 on a home pc, but i'm not sure. it's kind of jank and not really as cool as SD
sorry i'm wrong. there are variants of gpt3 that have been made which can run on home hardware
they run more like gpt2 though
GPT3 hasn't been published, has it?
the code to train your own model has
I thought OpenAI's decision to keep that locked was what prompted so many open source alternatives to crop up, like GPT-Neo and GPT-J
yeah. that's what i'm seeing too. "open" ai is holding onto what they've trained, but have released the code that allows other people to make their own models using it
stuff that runs locally on a single gpu uses gpt3 level tech but performs more like a gpt2 model due to not using all the possible features that are responsible for driving memory use up
What code do you mean?
source code
my bad they didn't
nothing in there, just research data
but,, they did release all their research as a paper. i suppose that's what has been reimplemented
i'm not sure this is the argument you want to have. needlessly being argumentative is one of my giant pet peeves and it's too early on my weekend for that
It's Monday. 🤔
yeah like many full employed people in a job at somewhere that's open on the weekends too, my weekend tends to be irregular
again, another needless argument
Sure, sure. But why are you engaging in it then?
do me a favor and try to react to a comment of mine
What did that do?
nothing. ahhh. bliss.
Hi there! Did someone manage to train a lora with google colab?
I can't use imagine now?
You didn't let me respond
yo
I'm trying to use the fast-kohya-trainer, have you used it?
nope, don't think I should try training on 1050ti lol
it's a google colab haha
same, that's why im using (or trying to) colabs
free services going downhill
Just a week or two ago I could use collab for 6 hours , now 3 at best
Kaggle added afk check once per 40mins or something
paperspace...just sucks lol, too slow...
¯_(ツ)_/¯
I mean they all generally suck lol
I'd totally pay for a service where I could rent out a gpu to train lora/ti's
but if it's the horrible experience that is using google or kaggle then
no need
renting someone else's hardware vs using your own hardware. the shit that gets beat on by everybody that uses it is probably going to suck more
the rental companies are probably overselling capacity too, since why wouldn't you? supporting peak volume all the time is costly and usually a pointless endeavor
well, I can't train on my gpu because it errors out of memory, so literally anything that can train is better than nothing
no matter how beaten up it is
I think after a while more renting companies will popup...hopefully
rn it's just all google or owned my google
I mean, nothing is costly if the price is right; whoever does the business must know and chekck which price works and which one doesn't and just charge correctly
we have lots of hosting services , maybe they'll get the catch with GPU's someday too...
i've heard azure offers super competitive pricing and they provide serious good infrastructure, but there's nothing like a community building tons of free tools to launch on azure services right now
hm...hosting a111 shouldn't be hard
https://tenstorrent.com/ i'm waiting to see what jim keller's company does next to make any predictions about where infrastructure is going
right. just someone hasn't packaged it up and made an installer yet.
still it's useless to rent gpu's for training if in order to do the training you need a masters in computer science
lol
With good GUI, then everyone will jump right on
there exists an installer though
even the beefiest grayskull e300 from tenstorrent only offers 16gb though. probably meant to be used in clusters. i'm excited to see where he's going next. likely they'll license the designs they field test thorugh tenstorrent to all major manufacturers. keller is kind of a savant for that shit
for automatic1111 running on azure cloud services?
no, just 4 a1111
right. it should run on azure cloud, and should be easy enough for anyone to follow instructions and set it up if they know how to navigate those services. but you still hear more buzz from individual home hobbyists about these other services instead. word of mouth marketing is something that is a double edged sword for microsoft
https://vladiliescu.net/stable-diffusion-web-ui-on-azure-ml/ i found one guide and its barely been out a month. is linked by the wiki though on automatic's github
Hey guys! What’s the most interesting thing you find about stable diffusion? Have you tried other similar tools?
it's rapid pace of development.i've tried dall-e 2 but its' a hosted service instead of software on my machine
actually changing answer. How rapidly it's developing is awesome, but trying to understand where it's going is more interesting. It's a denoising algorithm right? that's not just pixel noise either. it's noise, that's it. How soon till software defined radios are using this tech on signal processing, to remove noise from analog data and usher in a new wave of analog data processing
stable balls
"new wave of analog" maybe a little bit of a pun. not sure if it works but i like it
hosted services just suck, SD's flexibility, extensibility and ability to try unlimited prompts are what make it great.
hmmm interesting
i prefer open tools, but SD is the only one in this category so it succeeds by default. the best kind of success
ive gotten better results from others but yeah SD is free and open so I'd rather get good at and support SD
i agree with this. lexica.art is a minor example. uses a custom sd model. That thing works VERY well and i want it but they're keeping it for themselves. jerks
As I'm sure you all saw in the #📣|announcements channel 
We have a short survey we'd really, really appreciate everyone taking the time to fill out to make sure we're keeping up with you on how you like to user this server & what you'd like to see in the future!
https://docs.google.com/forms/d/e/1FAIpQLSdpaL4lcXvdexbLEnAnP-G3w5e56nXuq_0-CfWDFKpmpAlSww/viewform
I'll be around for the next little while so you're most certainly welcome to let me know if you have any questions or run into any issues filling out the survey itself ❤️
(If you'd prefer to remain anonymous on the form, simply leave the first (optional) question blank)
My biggest feedback was to bring back Dreambot, as it was by far the best part of the server
Thank you! Feedback like that would be amazing if you had the time to fill it out sometime this week ❤️
(By your message I assume you might have already, so if you have, x2 the thanks!)
Yeah, filled it out thanks. Would be good if others who miss Dreambot could give their feedback on it too
I have filled it out as well :)
Thank yoouuu!
I was using ChatGPT for the lols earlier and got hit with the "too many requests in 1 hour" ratelimit error. Did 5 seconds of research and found out that even ChatGPT Plus subscribers will see this error. This is one of many reasons why I hate OpenAI
I'm amazed their website loads at all with how fast they've grown. cant really complain about getting their service for free. its far more forgiving than dall-e
hi can someone with a running version on mac give me some advice please? Im asking for a class of several students
TIL people run this on mac.
Hi. I'm... new here.
Welcome! Check out #1072220168534642768 to navigate our server 
yes I'm right there...
someone has shared to me before a link that is just a repository of ai made images i think from SD, anyone know it?
there are websites like lexica .art, publicprompts. art, prompthero .com, and openart .ai that have repositories of prompts of SD generated images, maybe theres a more specific site but thats all i know
Yeah mac got machine learning cores working in tandem with arm processors. they're doing insane things over there and i'd consider buying a modern macbook for this kind of work
how use this AI?
I have released a high quality 2.1 768 generalist model. I hope you guys like it:https://www.reddit.com/r/StableDiffusion/comments/117ih9o/3dmdt1_a_very_high_quality_generalist_model_with/
Feel free to submit a post in #1047197565365538826 for it as well if you'd like!
I'd like more 2.1 models, but idk about generalist, I'd prefer to keep different styles in different models, so I'm not getting styles I don't want in a general prompt and don't have to fill my negative or basic prompt with tons of specifications avoiding it 😦
how can i generate images help
Check out #1072220168534642768!
(Just to clarify, there is no bot currently active on the server - further context: #📣|announcements message)
This tends to happen. After several weeks without using colab, it gave me 6 hours for the first 2 days, then it halved to 3 hours / day, and now it's barely 1,5 hours. It seems that it goes downhill quite quick as you use it daily...
whats the best model for pixel art sprites?
You can try one of those, but I think default 1.5 \ 2.0 \ 2.1 should do the trick too.
https://civitai.com/models/34/all-in-one-pixel-model
https://civitai.com/models/21/pixel-art
https://civitai.com/models/22/pixel-art-sprite-diffusion
thanks
I didn't have collab errors
oh nice
The latest automatic 1111 isnt' switching models automatically, even if this feature is enabled. Anyone know how to correc this?
Are there any Mac users here? I had SD automatic 1111 up and running locally and it was working fine but then I closed Terminal and now I am getting a 'Cant connect to server error' so I have two questions: Do I need to have Terminal permanently open in order to run SD, and secondly, how do I get it up and running again as I cannot find anything on this via a Google search? Thanks
no mac users here, just schway individuals
they would have to drop their override "feature" that doesn't even work correctly, still waiting
i need a 3090 to use now....6900xt workarounds are very inconvenient
Hi all!
I have updated automatic1111, and was hoping that auto-load model was working again...but it doesn't for me? Can someone confirm this? I tried to enable it first and restart, and then disable and restart, but that doesn't help. I am referring to this option in the settings of automatic1111
When reading generation parameters from text into UI (from PNG info or pasted text), do not change the selected model/checkpoint.
You can find it under: User Interface
hey friends, the usual weekly post from me, this time I didn't have access to my computer so had to do a more theoretical write-up. I hope you find it relevant and interesting. let me know what you think. https://followfoxai.substack.com/p/3-limitations-of-stable-diffusion?sd=pf
Normalize deepfakes lets goooo
I want to try and read up and learn what ai/stable diffusion actually does
Does anyone know a good place to start?
Everything I've read is just so full of technical jargon idk wtf I'm reading
ask chatgpt broh
it just learns how to turn x image into noise and back
then learns the patterns and remembers how to do it. add some magic to make images congruent and voila. magic art in seconds
how do i generate a picture
a rare 2.0 model nice lol
oh looks like i was behind, was referring to artificialguybr new model
this is why I keep reverting back to dec 31 version, because it works. Another thing, Gradio, how can you fix the UI being broken? I've seen this a few times in the past, and eventually it panned out.
what part of the UI is broken, I missed that
the entire thing, when starting it up, you can't do anything, buttons are not in their places.
is this an Open source Ai server
@dire sun the most annoying thing right now is that in that some changes were made to the generations, and if you talk about it every single simpleton comes in the door with the "you sure that's not transformers?", it's like an eternal spring of idiots, but guess that comes with wider adoption
I see that a lot and I do use xformers, but does it have to be that bad? Even the older version messes up all my pictures. It's a big mess if you ask me, very unstable.
not getting that, just takes way longer for everything to be working. it's like a whole 6 or 7 seconds before things get populated
how do you kick in the pants to get it working
wait it out, 6 seconds
You are saying, refresh the screen? I've tried this as well.
I don't refresh it, it opens, 6 or 7 seconds after everything populates and it's off to the races
but it doesn't do that for me... windows 10
although it does say loading
has anyone found the reason why it changes the images we create so drastically?
some stuff was messed with in the way it processes, then some stuff was put back
and at least in two time periods, because of interactions, mostly with what info it recorded at the time
and some interactions with the pseudo random generator
those won't be able to reproduce
just wish they stopped effing with it, or at least provide all the compat options
but hey
move fast, break stuff
this is why I stay with a version for months on end. The one I have 'use to' make images flawless, but something happpened. It happened after I deleted my venv, however I can get them back, and it's a load of fish to do it. I have to delete the venv file, the config, and use the original files, setup, then let it make a new venv and hope it works. That's a lot of tooling.
yeah, automatic shouldn't mess with stuff so much. We don't need a rolling update every 3 days
dude, scunet pops in and out of existance and I have no clue what is going on
sometimes it's there, sometimes it ain't, it's like the tileable button, sometimes it works, sometimes it's radio silent
scunet, i've heard that word
I have it installed, once in a blue moon it gets detected, 90% of the time it's like it doesn't exist
but hey... control net
moving on
can you get control net to install in back in Dec 2022?
don't think so, even the extension stuff was diff
because if I could get it to install, I wouldn't change.
see, there's the kicker, we can't move forward
well, you can try
it appears that the most stable version of automatic is early Jan, which is just about where I am
Dec 31 was the last time I found a stable version
I stayed with something from around that time that didn't have the override and the broke load model on png info
but had to move on in the end
annoying af but hey
so the images that you can get now, are they are nice as before or just a mess?
but you can't recreate any seed?
Neither can I
yep
someone needs to figure out why this happens
we'll always have 1424987 in October of 2022
it was not meant to be
there's a partial fix for one deviation, at least was, holded up in the pull requests
but it won't fix everything
there were at least two or three moments where things went berzerk
not sure what you mean. Isn't that a certain seed that made everything look good
that was a joke, homage to Humphrey Bogart
I should have known that, big fan
it was a movie star from the start of the "talkies"
anyway, wish I had frozen the system couple of times along the way
been watching old movies for years, in my 40s
nod
at least we get to see all this in the garage phase
before the ms's and the big tuna comes in and idiotifies it
true, it's a mess right now, so many ideas coming together.
was lucky to get on the personal home computer wagon back then
so the ride is pretty wild, guess this will boil down to a personal AI friend or something that will provide for every command
maybe through a cell or something
maybe even much before any sort of general AI is achieved
we'll have call you up, on your local computer ai friends, in a few years.
I run SD locally.
I need a 4070/4080
for heftier stuff
even if it's mobile
the vram is limiting and any txt2vid will be even worse
running 1650 super 😄
I bow to your patience
if you can wait 2 mins per photo, sometimes longer, you have it 😄
I know someone running diffusion bee on mac that has to wait a whole day for about 8 pics
wow...
it's exciting, the waiting.
they just go out, work day, come back to see what came out
@lilac reef could be...
I installed an external m.2 with linux, can boot from it straigh up
it's a little faster actually
I bet I know it is me having to delete venv
it must have a new xformers or some other thing
I'm doing grids now to explore ckpt/safetensors
I have this feeling that linux will run it faster, but it appears there is something like the version of python that is too high in fedora 37.
it's that bad
grids?
I got ubuntu running
x/y grids with checkpoints and seeds
saves all the manual switching, that is now even more annoying af because of the override thing
there are a lot of buttons and switches to this thing. It's probably turning a lot of people off.
let them be turned off, if they'll enjoy it more when it is a commodity on their cell phone, they get what they deserve
when this goes that simple, it's going to get really boring
lots of karens waiting to post their fake vacations and lots of chuds waiting to post their non existant gfs
it's going to be hilarious
the 2015 reborn 😐
hey guys! Currently APi is open source. Will it be opposite any time soon?
new to stable diffusion and AI art in general and i need a bit of help.
and premium version any time soon?
python.exe -m pip install --upgrade fastapi==0.90.1 does not stop the middleware issue, on local install of automatic 1111
You need to update your webui with git pull, the error got fixed
I did, because I updated earlier, still no dice
I will try again
If it wont work delete the requirements_versions.txt and run the bat again
that's a new one, thanks
well of course it says this :stderr: ERROR: Could not open requirements file: [Errno 2] No such file or directory: 'requirements_versions.txt
Okay then bring back the file (restore from bin)
Add fastapi==0.90.1 to the bottom of the file
But i think your git pull isnt working correctly
this worked
it checkout -b newbranch
git checkout master
git merge newbranch
git branch -d newbranch
git pull
Then it started to tell me to upgrade torch and xfomers
so it was stuck
Okay you can upgrade torch and xformers with --reinstall-torch --reinstall-xformers
well all that worked well, but now, like before the gradio UI is broken
I've seen this before, and eventually it panned out
but not this time
Broken?
yeah, it doesn't load right, buttons aren't in the right places, brokne
broken
but not able to take a photo of the image to show you
You can make Screenshots with Win+Shift+S
not able to show them here
please check general with images
Wow wtf xD
it's not the first time, and if I use another browser, the same thing
I'm trying to generate 4 images of 768 * 768 on A10G gpu that has 24gb vram. But running out of memory. any solution for this?
thanks, finally got it working. One should always start over when it gets that bd.
Yea now you can add git pull back into the webui-user.bat and also --xformers --autolaunch
I have a question. I'm thinking of buying a 3060ti or a 3070 for gaming.
Is resolution such as 1920x1080 difficult in the SD in local?
With 8gb vram yes but with upscale its possible
Is there a way to use controlnet and models in different drives?
Since I don't have room for the control net models, they will be stored on another drive
use the pruned controlnet models https://huggingface.co/Jemnite/ControlnetPrunedfp16/tree/main
still don't have room 😉
I might have room for 2 gb worth
A question: I have installed Controllnet and OpenPose through Git, and I use Git pull when I start Automatic1111, when I do so, will it only update Automatin1111 or do other things like OpenPose update at same time?
You have to look into symlinks, or a tool called (link shell extension)
only the webui will update with git pull. extensions like contronet will only update if you manually request an update
In the webui under extensions there you can search for updates and apply them
Ty.
so a simple in windows shortcut won't do?
shortcuts work with VSTs, for music
just install A1111 on your free drive. doesnt need to be on system drive
I hope it in the future get a update check script that can say if there is new updates at start, even for models and so. Just now I just forgot I can do so through Extention tab.
I do that already but I ran out of space on that drive.
I have space on another drive as well
No it has to be a symbolic link
You could also organize your drives and delete stuff or move it to an other drive
don't have the means to delete stuff at this time
but I"m in the process of backing up other stuff
I heard just two of these controlnet models are all you need, is that true
I need to start my day, can you come up with simple and fun prompt ideas or interesting words to use in the category "fun and happy" not "Porn and spank".
Mostly you want to use openpose and normalmap
thanks
vibrant, colorful,
Can someone help me, I wanted to start doing stable diffusion and wanted to install a model merger and it already gave good combinations of models that I should try but it says I need AnythingV3.0 huggingface pruned
[2700c435]「543bcbc21294831c6245cd74c8a7707761e28812c690f946cb81fef930d54b5e」but I dont know how I can find the exact model that is needed for that, any ideas how to get that?
Or is it even needed
If you use automatic1111 webui you dont need an extra model merger
I think I have the automatic1111 webui and so I can just download that and it would still work?
yeah but how can I get the exact version that is there listed? is there a way to get it or just searching?
So it doesnt matter what exact model I take? because this one is SHA256: 67a115286b56c086b36e323cfef32d7e3afbe20c750c4386a238a11feb6872f7 and the one that was recommended started with 543 so it doesnt really matter?
The original got taken down so it wont matter
Or maybe its from civitai
But its the same model so just use the pruned-fp32
Okay thanks then for the quick help I appreciate it :D
No problem 🙂
@storm river Here is an other upload of the same model, you can check its hash if you want:
https://huggingface.co/Linaqruf/anything-v3.0/tree/main
doesnt look like there is right one in there I guess it shouldnt change much anyways :D
Yea its all the same xD
Hi all.... Do you know what model that the result is looks like a real human photo? Generally this model used in pixiv or twitter that the result is cosplayer photo or something like this. Lately i looking for it in Hugging Face, but found nothing.
There is Realistic vision, Deliberate, Dreamlike Photoreal for good results
is realvision is same of realistic vision?
ok, thanks ...
Yea was a typo sry
#1072229057707659404 how to start?
#roles image
I'm so dumb
I dunno how to use this
what causes images in SD to sometimes become overly sharpened looking
Why is controlnet in my txt2img tab? what's the use case of it?
you can use the body pose or camera angle for easy gens
is controlnet included by default now?
its an extension
morningggg
no real need to go over 7
No real need to even touch CFG right
I like to use 6.5 a lot, but 7 will give you good results. For 2.1 you want to go down to 4 or 5
How did you ever figure out you need to go lower? Just ugly highly-saturated results?
that and hovering over the CFG Sclae text. it mentions you will get more creative results. I found it to be better
Good morning, everyone
morning. its evening here
It's morning here, but I'm nocturnal. almost bed time
Yay for nocturnal!
why can't i see anything in the #✍🏼|rules-and-tos Rules-and-TOS canal?
good morning
And if I try #1072220168534642768 it only give me .png's
any idea what I could do?
it seems that civit often suffer from internet issue...
Restart Discord, if you're on mobile, restart the app
Hey guys, I am getting a HeaderTooLarge error for ControlNet. Any idea how to fix it? Thanks!
thanks, but i have always had this problem from i started on SD a few month ago. So thats properly not the problem, but you could not know that, thanks for the input.
You can probably try cleaing your cache after force stopping the app.
(if on mobile)
Discord is just finicky. But you can always file a ticket with support (Discord)
np
thanks, i will try
Hope it works!
GM. New here. Just downloaded stable diffusion. Is there a guide to certain settings for realistic images of people?
Hey all - has anyone built x-formers for WebUI on Windows 11? The walkthrough specifies to deliberately install an older version of Cuda (v1.3) but it only supports up to Windows 10
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Xformers
I have a 4070ti so I don't think I need x-formers for most operations... but I'll be trying out Dreambooth soon enough, x-formers seems to be required with GPU < 16gb
still need help on this
Hey all, is anyone running a 3090GS KFA2? I was wondering how the card preforms, thanks. 🙂
What was the chat where I could create drawings?
I googled how it compares with the 3090 ti, seems to perform very similarly? So, probably performs as well as benchmarked here https://cdn.mos.cms.futurecdn.net/iURJZGwQMZnVBqnocbkqPa.png
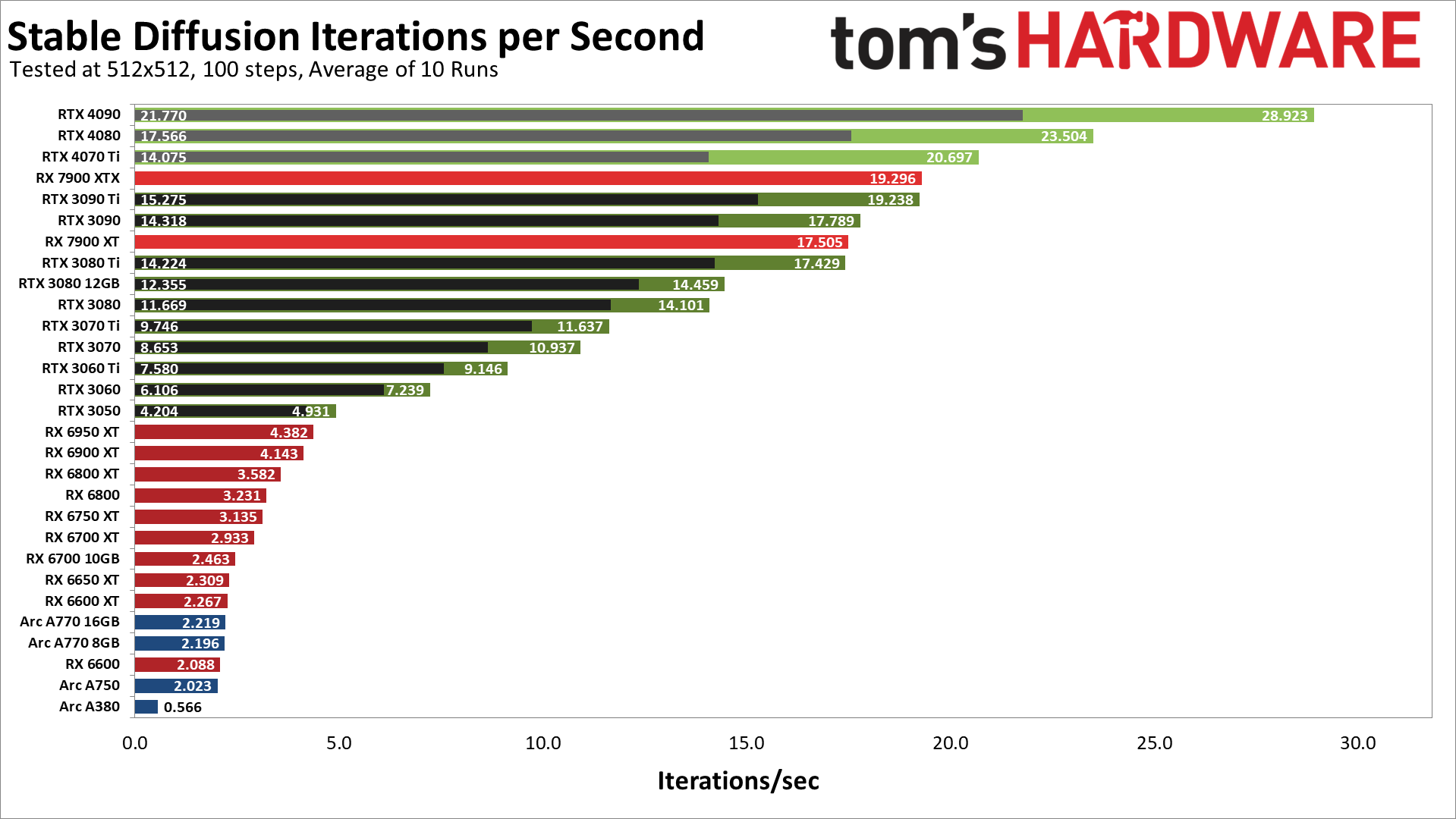{kind=link}
Sweet thanks i was more hoping anyone had it installed can could tell me temps also. I'm thinking 2 step over from a 3080 Strix 2 that card and want to be sure it's properly cooled. 🙂
How can I use stable diffusion paint feature.
in painting?
Wait where can I generate pictures
not here
I feel lost in this server
they dont generate images here like a few other ai bots (which is a weird way to generate images to be honest). this is just a support server
Hi! #1072220168534642768 should help you get started on the server. We currently don't have a bot in here (#📣|announcements message).
HI sorry for bothering everyone where do it put a .pt file
Is this on local webui ? if it is a textual inversion put it in the embeddings folder, you can even organize with further sub-folders if you want, mostly to separate 1.5 embeds from 2.0 and higher that are not compatible.
if you do an xy grid of increasing cfg with increasing steps, you'll find a zone of quality on the grid as steps get higher for higher cfgs. its a neat artifact.
Not much need for it, but you can get good results out of cfgs all the way to 30, according to the last of these generation grids i spotted. haven't ever made my own though
its good to test ,but yeah in my recent test from 1-20, everything on the 20 side got ugly
It depends from model and what you're doing, on most model there's usually no reason to go above 15.
I'd say for most generations 6-12 is fine
From my experience going higher mostly ensures that everything you prompted will be on the image and will be in focus, everything else - probably cut off.
if something not on the image, SD probably either have no idea what that is or prompt is filled with too many things...
also, if the prompt is long, then high CFG gives it indigestions as it tries to fit all the prompts in
not exactly true, sometimes you want more precise output, that's the case for higher cfg
I find the longer my prompt, the lower my CFG should be (9-12 maximum)
RTX 3090 with 24 GB VRAM or 4070 TI with 12 GB VRAM - benchmarks show 4070 TI is faster with SD, but 3090 has the 24 GB. Which is better for SD?
I usually go for low prompt, but often do higher cfg is I want to get exactly what I prompted, was doing up to 15 cfg on protogen
I would love to find a prompt that gives a clear, full body image, so I can have someone walking or running, while seeing who it is, with it not changing the character to some weird looking, lower res character
just "full body" should work with higher cfg, but you probably will have to increase resolution, otherwise face will be messed up probably
try hires.fix and inpainting the face
SD needs resolution to work with facial details
I do 512 x 768...more than that?
idk , depends on model and output.
For anime model should be enough , for realistic - probably will need even higher
Ive4 never done hires fix, not sure my crap card can handle it
then do inpainting with just the face and "only masked"
which is why Im looking for a new computer GPU, but can't decide between 3090, likely used, and 4070
it doesn't just low detail the face - it's everything
Another idea would be is to make upper body and then outpaint
if I could paint a figure, I wouldn't be using SD
when it does do full body, everything loses detail
generally, the figure also becomes skinnier, sometimes almost stick figure like
3090 used if you're willing to go there. 40xx has some cool new features but theyr'e not a big deal
just do upper body and outpaint down, it'll do the thing
i loaded up atomic heart the new videogame last night and noticed it had supprot for dlss3 on my 4080. i'm like "sweet if i need frames then i got free frames here with frame synthesis tech!" but then the 4080 runs this brand new cutting edge unreal engine game at 120fps 1440p maximum "atomic" settings with ease anyways
so the new high tech feature wasn't needed. lovelace is just that good and software quality standards are rising thanks to engineering work that epic has done on unreal engine
you mean just paint the legs etc?
yes
4070 benchmarks is faster than 3090 on SD and many other apps/games
just outpaint downward, and it should add in more details
If I could do that, I'd paint the whole thing
given your prompt
right. but the memory. you'll want that more than the speed maybe. i love my 4080's generation speed but still wish i had the 3090 for the memmory instead
Are you talking about in Photoshop or something?
then you send to img2img (or use another tool with open canvas like InvokeAI)
and you extend the picture by asking SD to "outpaint" downward
Ive tried taking a portrait, torso only, in img2img
no, it's done in SD
stable diffusion has a feature called outpainting, you can extend the edges of an image. downward means extending the bottom edge
it's almost impossible to get it full body than, and that's when the low detail is the worst
I don't think you're understanding what we're saying
I somewhat agree with this, however if I was paying $20 a month for ChatGPT+, I would certainly expect not to get rate-limited.
It would also be a lot better if it actually told you how how much longer you are being ratelimited for (it always says "too many requests in 1 hour" even if you only need to wait 5 more minutes of the 60m afaik).
It also doesn't actually tell you anywhere how many requests is "too many", you just eventually hit the limit. Additionally, by adding a rate limit like that, they also add an incentive to creating alternative accounts because it makes it so that having more accounts effectively means that you don't get rate-limited.
shared a screenshot in #🏞|general-with-images
from A1111
it's in the img2img scripts
You can outpaint image im any direction (increasing image size), it will add legs, e.t.c
You can use SD outpainting scripts for it , or use invoke ai, or use https://www.painthua.com/
there's a script in img2img
there are many ways to outpaint in SD, depending on what kind of interface you like
I see it. I'll see if it works with my crap card.
I dont like cloud
invoke ai pretty cheap for VRAM on outpaint, it's also pretty quick...but not as comfortable to work with 😦
I see, so I can outpaint down, and it will add legs...
basically
Ill see if this works with the crap card I have
you may want to outpaint slowly though, over several iterations
do I put the original prompt in then, or just about the legs?
If you will be limited on vram - just do it in invoke ai, I can outpaint here even with 4gb vram, just giving it less info to work with, reducing chosen area
yea
Do I write the original prompt, or just prompt about what's being added?
original should be fine.
If you have additional details you want to see on your legs - add it to prompt
you can use the original if it's a continuation
but if your original says "upper body", you'll obviously need to correct for it
yea
or if you want to add something else, like "fence in front"
OK, I tried adding 128 pixels down
I was doing it with original model usually, same as I used for gen
dont they all support inpainting?
nope
but you can make your own
if you have a particular favorite, but it doesn't come with an inpainting version
well, it worked with protogen anime
if you get weird output like another head or something, then you likely need inpainting version
now trying with the model that made the original image
if it works, then all good
it worked fine, added part of the legs
with the original m,odel, vintevivid, it shows him standing in a concrete block
instead of adding legs, it just added the concrete block
Im trying with more iterations. The script suggests 80-100
sampling steps, that is. 10 minutes to generate
78%]
I ignore the script recommendations, works fine with the same settings I originally used
Hi guys, i have the problem with controlnet, that with every rendered frame the model gets more and more nude. Very strange.
also, sometimes it will be creative and add things like concrete blocks or pillows or whatever, just do a batch
ah, now he's behind the concrete block, nmot in it
Using img2img batch processing. Single frames are ok, but in the batch process it drifts to nude.
add "nude", "naked", and "nsfw" to your negative prompts
Seems to help a little bit, but finally not.
I am using the RealisticVisionV13 model. Maybe it is the reason.
Now it made his hips longer, so they go down further like some kind of freak alien
loading up the model on my potato now. I'm curious if I'll get the same
I am newbie, can someone help me the link for stable diffusion for prompting. thank you
Say, what's the name of that AI program which can simulate an inputted voice?
there's a cool editor called graphite, it's all made in RUST so it's very "stable" heh... an alpha preview right now, all node based. it can connect to a stable diffusion server but since i got automatic1111 running, it doesn't connect to that wrapped set of stable diffusion. i need to figure out what it wants still. runs in a browser for now while it's being made. entirely open source so i think you can download it and build it yourself.
it's a very node based editor and preview software, so only use it if you're a tinkerer who likes to custom tailor tools to your purposes. https://editor.graphite.rs/
the "imagination" tool is the node that SD would connect to
I am a newbie, can someone help me the link for stable diffusion for prompting. thank you
looks interesting, thanks for the link
@bitter marsh If you like learning by discovery, this website: https://lexica.art/ is like Google images for Stable Diffusion.
thank you very much
Type the sort of thing you want, they click on the images you like, and the prompts used to create them will be shown. 🙂
since, right now I am prompting using my image at midjourney suddenly there is a limit, thats sad
Best to download a program onto your computer and use your own GPU, if you have the power.
is my own pic possible to create?
where to download?
There are a few. I have one downloaded, though I haven't used it much lately. Give me a minute.
I've generated 7 images so far with batch using controlnet canny model and RealityVisionV13 and I don't see any nudity drift at all
sure thank you
using (nude, naked, nsfw:1.3) in my negative prompt
kek
@bitter marsh I have this: https://nmkd.itch.io/t2i-gui Not sure if it's the best, but it seems pretty good.
I want to generate results of a specific face everytime
the face isn't in stable diffusion as it isnt a popular person or character
so should I finetune it to generate the same face everytime ?
is a specific face someone you have photos of? If so, yes, textual inversion or lora probably your best bet
Maybe i have the same issue. It is a specific face, some models are more trained on it and some less. I am using a lora already.
hello! 
Is it possible to seperate the main image and a masked area output in Auto1111?
for example
Cat with red eyes
-inpaint over eyes - prompt "blue eyes"
-2 images result, one is full image with blue eyes and another is seperated blue eyes based on mask
Hello
was it me you're looking for?
What if i get only greyscale images using controlnet (i am using a simple grey dummy for the poses)
Well...outpaint experiment was a failure. It extended the image, I did it 128 at a time. Made the legs look like cylinders with all sorts of weird seams where each down extension was done. When it gets to it, the feet have 12 toes each
show us in #1019361238234443776 =p
I found out why my images where grayscale. I have enabled the "apply color correction to img2img results" option. Since my pose images are greyscale...😂
yeah, the UI could be designed better to have that option in the img2img tab, instead of in the settings tab.
Just putting this out there: please stable staff, don't let krikey pull y'all into crypto/NFT/MLM/pyramid schemes.
Have anyone seen this "Self Attention Guidance" stuff? i think it's similar to what controlnet is doing, just using the generation process to get the control information each loop back, maybe? i need to read more about it still and also, be smarter
Hello, has anyone tried the new "Use PNG alpha channel as loss weigth" feature in embedding training?
I made an easy SD hypernetwork training tutorial for those who are interested:
https://www.youtube.com/watch?v=E9vh4hgA4Qw
@fervent thunder Is this about the new feature, or just generally about hypernetwork training?
It's my attempt at helping beginners who don't really know what to do to get their first training working
I remember when I started, I was lost for a while
Thats quite nice.
Did you try training with the "Use PNG alpha channel as loss weigth" ?; It got recently added to automatic1111 and is supposed to make training on specific features easier.
ooh, I'll add that to my list of things to research, thanks
I don't know what that is, but it sounds like de-emphasising the transparent areas of the images, which makes total sense
Yes, I would actually like to use it, for my next embedding, but are stuck with my Photoshop knowledge :x
i cant use the program, can someon help me with a request?
i have an image macro and need background generated for it
woah. woahwoahwoah. nobody told me that the smaller controlnet models load near instantly. i just started using them and woah!
hello guys, i just joined out of curiosity
i have 0 idea where to start but I'm reading faqs and stuff
should i start with any of the links in #1072220168534642768 ?
I'll try Arki's Installation guide then
No xD start with this:
https://m.youtube.com/watch?v=VXEyhM3Djqg
oh thanks
Any one know how a art style lora dataset looks like?
Can only found character/person lora dataset example, but I want to make a art style one.
why didn't anyone tell me about this
week now i been using the big models cause i thought it made little difference, but, this is instantaneous loads
which models are you referring to?
ahh. I posted them a few times in different channels
oh i've known about them, the smaller models. i just had already gotten the larger ones and i didn't think one of the biggest benefits was instant load times
as opposed to the longest 1:05 ever
I never even installed the big ones, I was downloading them when I came across the small ones and used those instead.
life changing really
and the HDD space saving
i got tons of room to stretch out for storage and i plan to build a big honkin NAS too
you all been getting instant loads on controlent models while i been here loadin a minute like a chump?? this whole time?
yep :)
finally Im seeing attachments as a grid now on discord. I heard others saying it changed but only today it did for me
much better than long long posts
how do people make +18 content with stable diffusion? (like ones on pixiv)
they probably install stable diffusion directly into their computers because websites have ToS against displaying such
just my guess
Well pixiv is known to be for anime/manga, so you would use an anime/manga model.
that doesnt explain anything
Did you use Stable Diffusion before?
no
hi, I have stable diffusion and its awesome. Heard something about openjourney. Its working? I need to update stable? Where find more data?
Did you use AI for image generation before?
only midjourney
Okay , so you know about prompting and settings a little bit.
Stable Diffusion is free to use and open source. You can run it on a google collab or locally on your PC if you have a good setup.
Stable Diffusion has more than one model you can use and they are all free to download. Some are better for photorealistic stuff and some are better for illustration , anime etc. and some are specifically trained on adult themes. ; While every stable diffusion 1.5 derivative should be able to do nudity. Some do it better.
Since im not very 'smart' about installing and what not, is this ok?
cuz with the 'normal' installation im supposed to install 30 different stuff as pre requesites and what not
and apparently this is 1-click option
I honestly just followed this. It was like 4? installations and it seems promising
currently downloading a Model tho
https://stable-diffusion-art.com/beginners-guide/ This is quite useful.
apparently what im installing is a local installation
Install Python 3.10 and GIT for windows. Go to the sd-webui github page https://github.com/AUTOMATIC1111/stable-diffusion-webui and you will get it running.
for outpaint down, for example, is there a way to go more than 256? If I type in a bigger number, it goes back to 256. Then I have to do one more outpaint to get all the way to feet, which then can look a little off, not exactly even with the leg above, so there's a seam
For a better outpainting experience , you could try openOutpaint ( If you are using Automatic1111)
i am...how do I get openoutpaint?
Extensions tab ; Then load the standard extension url ; and in the list there should be openOutpaint somewhere. Install and restart your webui.
standard extensions url?
bot's been retired
one moment
I found it
👍
trying to install it caused SD to crash
restaring
eh...openoutpaint not working. It doesn't populate the model window
had to enable api
Did you get it to work?
When I use the regular outpaint, I add more pixels. It extends the image.
With openoutpaint, I cant start with an image like img2img. I generate an image, generate below it...the images are related, but the top image isn't extended
original is portrait of a man...extended is his lower body, but not of the same guy, not connected to the top
It'
It's doing something, but I don't know what....trying to extend an existing image to add what's below, like the legs
in many cases, it just gives me another image below the first when I add the box below
Since openOutpaint is integrated now you can just do your normal txt2img first and then use "send it to openOutpaint" from there the model and the settings and the prompt are added to their text fields. And from there you can either change the model into an inpainting model for better results. Or just start by using the txt2img tool for adding and the img2img tool in combination with the masking brush for changes. ; Masking brush and txt2img tool can also change things, but more from creating something new instead of changing something existent. The Txt2img tool adds over the "edges" and is necessary for outpainting. Txt2img tool doesn't change unmasked things, so not adding too much at a time is better for models that don't have a good inpainting function. If there are seams you can fix them afterwards with masking and the img2img tool. ( Just to avoid confusion everything after the first sentence are steps you can do with openOutpaint)
yes
but when I make an img in txt2img, send it to outpaint
then extend the canvas...what's drawn in the new part isn't the original extended
maybe Im doing too much
With models that are not specifically for inpainting, just adding a square beneath is most likely too much. You can take smaller parts by extending only over the "edge" it will just add the nonexistent part instead of changing the existent square, unless you decided to mask it. If it's masked it can be changed.
when I try to extend barely over the edge, it wont add
I am trying now the minimum it allows
What do you mean with "it won't add"? Could you provide a screenshot?
I am generating an image so I can show
well...now it's generating
if I make an image 512 x 512, then I have to extend at least one square below or above or right or left
It wasn't starting a new image when I did it only one square
https://youtu.be/4qVwlqGwR5I?t=64 this is the easiest way I could find to explain the situation. This is how it's normally used. You can see the tools that are used and how to not extend too much.
Yes one square below or above or right or left; The amount and the size of squares might have been lost in the communication.
cant watch the vid right now
for some reason, Discords changes my audio device, and then I cant get audio back inside a browser
I hope that this answers your questions. I have to log off for now. If you have any questions you can DM me and I will answer as soon as I come back again.
You don't need the audio, it's mainly visual.
then I wont be able to follow it
Then if you any questions. Just ask me per DM and I will try to answer when I'm back online.
I wish you good luck.
all the video is showing is the inpaint box extending out 2 rows of checkers, the rest of the box is overlapping the original image so the inpaint knows what its generating
I just posted with general with images...notice what's extended, what's in the extension, is not a continuation of the original
/setting
You need to apply your first prompt