
#╭・artificial-intelligence
1 messages · Page 1 of 1 (latest)
I am actually interested in PaLM-E from Google.
does netapp has any involvement in genAI?

Mira Murati as CTO, Greg Brockman returns as President. Read messages from CEO Sam Altman and board chair Bret Taylor.
Practical question : how can we leverage the dataOps toolkit to import existing datasets into containers . most examples show how to use the toolkit to create new containers (workpsaces) with PVC but not how to bind existing datasets. This can probably be achieved with Trident but i don't see how to use the DataOsp toolkit for the same ina K8s environment .
@hot field is in here, let’s see if the ping gets his attention. If not, I’ll go chase him down for ya
@lilac trail - The DataOps Toolkit does not include any volume import capabilities. You would need to import the existing volume using tridentctl (instructions: https://docs.netapp.com/us-en/trident/trident-use/vol-import.html). After importing the volume with Trident, you will have a PVC which you can then attach to workspaces using the DataOps Toolkit.

WIRED
The airline tried to argue that it shouldn't be liable for anything its chatbot says.
Any plans to integrate this functionality into the DataOPs toolkit ? The main painpoint in my view is not building and starting container workspaces but rather handle the backend data that is used with the container which is often pre-existing or generated outside the containers used for training jobs. So snapshoting/cloning the existing data, provide versioning and so on is where the value is .
Posting this AI related blog here about doing LLM RAG development with NetApp, let me know if you have any questions, comments, or disagreements!
NetApp is the intelligent data infrastructure company. In this post, we will take a look at what this means in the context of the now ubiquitous technology that is Generative AI (genAI). Large language models (LLM) are at the center of genAI offerings. These models require months of time and sig...

Ai and Analytics exam is so tough 😮💨. Gave 7 attempts still not able to clear
Nice! I'd love to be there
@cunning barn you have some space left in your rack?


Space? Absolutely. Power/Cooling?

130 TB/s?! No way.


**Crysis
nothing ever will actually be able to play Crysis. it's like the inverse of DOOM
That is like the greatest thing I've ever heard, I mean they put DOOM on an electronic pregnancy test... Crysis I still doubt would run well on Deep Thought.
There's a whole subreddit on it 😄 https://www.reddit.com/r/itrunsdoom/

Reddit
This subreddit focuses on odd hardware that runs Doom. Calculators, ATMs, fridges, old video game systems if it has a computer in it, it can possibly run Doom.
Please note that /r/itrunsdoom has gone dark indefinitely in protest of the API changes by Reddit. For more info, see here: https://www.reddit.com/r/Save3rdPartyApps/comments/1476ioa/red...


Uber Blog
Machine Learning (ML) is celebrating its 8th year at Uber since we first started using complex rule-based machine learning models for driver-rider matching and pricing teams in 2016. Since then, our progression has been significant, with a shift towards employing deep learning models at the core of most business-critical applications today, whil...
Solid read! 🤘

I just downloaded Llama3 on Ollama and am impressed with the quality and speed on my MacBook!
NetApp AI Pod with NVIDIA DGX Systems - Architecture

We’ll be streaming live at 10AM PT Monday, May 13 to demo some ChatGPT and GPT-4 updates.
this is so sick, all these example-videos: https://openai.com/index/hello-gpt-4o/
🤯
I'm deploying the NetApp GenAI Toolkit Preview v0.4 - would this be the right place to make inquires about functionality ?
Sure! And we can ping @hot field with any questions!
After I've deployed and indexed some data - is it correct to assume that when I click on the eyeglass that it tries to open an explorer type window? Cause currently when I do that I get an error prompt. It does say above the prompt window "Explore with a prompt or select a folder"

perhaps its just a lack of a proper prompt..
the chrome console is showing a 500 error when it tries to open http://<ip addr>/apiv1/prompt/ .... looking for an index-CSBXXXX.js file
Mike is out on parental leave and will be back on Dec 2nd. Let me dig around and see if I can find someone to assist.
I found his backup, and he'll be here soon 🙂
thanks appreciate the help
no worries I'll check back in tomorrow

not sure the docker image is actually mounting the file system - cause I was able to get the prompt to show me an ls of /volumes/gcnv/<volname> and it returned a total of 12 files

given the bootscript - only the underlying OS would mount the NFS volume
but sure I'll create an issue in git
Thanks William! That’s the best way to get to some of those engineers.
Prabu is on my team so I’ll make sure to follow up with him
thanks gitlab issue created - https://github.com/NetAppLabs/genai-toolkit-terraform-deployment/issues/37
GitHub
name: Bug report about: Report a bug or technical issue title: "v0.4 release - web UI doesn't show directories of mounted volumes." labels: bug assignees: '' Describe the issu...


GitHub
Composable building blocks to build Llama Apps. Contribute to meta-llama/llama-stack development by creating an account on GitHub.
Keep an eye on this! Composable middleware that’s fully extensible!
This is super interesting. Looks like it is essentially a standardized API layer that can sit on top of any inference server (ollama, vLLM, NIM, etc.), allowing users to swap inference providers without needing to change any of their API calls. Only catch is it is “Llama first” (“Explicit focus on Meta’s Llama models and partnering ecosystem”).
Agreed! I’m trying to imagine use-cases where something like this would be implemented
Anyone in the NetApp community doing anything interesting with MCP and Agents on top of the ONTAP API? Likely needs some guardrails if allowing the agent to make any modifications. But would be neat if just giving it read-only access. Maybe an MCP server with an ONTAP API tool along with a BlueXP API tool? "Agent, tell me what people or orgs within my enterprise consume the majority of my resources?"
I’m tinkering with building a hardware universe agent, just need to verify I’m not duplicating efforts already in progress.
Not sure I would turn an agent loose on my data quite yet
Pair that up with the IMT and that could be a powerful tool for partners - "Agent, here's a BOM for NetApp gear and some other 3rd party vendor hardware/software. This is being installed in an environment with this additional list of hardware/software. Validate that this is a supported configuration."
And hope it doesn't hallucinate an unsupported config😂
That's sort of the entire point of using MCP underneath the Agent. You would expose HWU and IMT as either APIs or ingest the data from those tools into a database. MCP either exposes the API or templated queries as "tools" that the agent can then use. You just describe back to the agent what the tool can be used for and what parameters to provide the tool (the API contract or query templates). The LLM then has to abide be the constraints of the tools it has access to. You can then provide the lineage of the requests to understand how the agent derived its response. This is basically what Claude.ai is now doing (and I believe ChatGPT can do this now too) where you tell it to search the internet for an answer. When it creates the response, it also provides you with the sources it used for each part of the response.
Hi Taylor, i've built a workflow with n8n, using the NetApp api's. It needs some tuning but I can get basic info out of Ontap. This is in a lab environment 🙂
I use telegram to chat with the workflow
Nice! I've never heard of n8n before. Looks useful.
Once I get it 100% working, i'll create a video on it
Hi David, That's really great. IHAC who asked me a simple question related to get some information via thier chat. I think If we can get it using the workflow based on the n8n + LLM environment, of cour se we need to make some touches.
I'm going to work on a short video this weekend of how it's all working and showcase a demo, few people have been asking 🙂
Perfect! Many Thanks 🙂
If anyone has interested in the Trend report related to AI, please check this link. https://www.bondcap.com/report/pdf/Trends_Artificial_Intelligence.pdf
It's almost 340 pages.
Wanted to make sure this community saw a couple of blogs that were recently posted:
https://community.netapp.com/t5/Tech-ONTAP-Blogs/Zero-to-LLM-Inference-in-Five-Minutes/ba-p/461655
https://community.netapp.com/t5/Tech-ONTAP-Blogs/Zero-to-LLM-Inference-vLLM-Edition/ba-p/461836
Confused about where to start with LLMs? You've come to the right place. In this post, I will walk through the deployment of a basic LLM inference stack that will run on any of NetApp's NVIDIA-based AIPods. This stack is appropriate for smaller-scale deployments and POCs. Prerequisites You must...



A couple of weeks ago, I published a post walking through the deployment of a basic LLM inference stack that will run on any of NetApp's NVIDIA-based AIPods. In that post, I used NVIDIA NIM for LLMs as my inference server. NIM is powerful and easy to adopt, but it is not the only option for the infe...




The first two have gained a lot of mindshare. I've yet to see the latter two put into practice.
Hot off the press: https://community.netapp.com/t5/Tech-ONTAP-Blogs/LLM-Inference-KV-Cache-Offloading-to-ONTAP-with-vLLM-and-GDS/ba-p/461914
Today, we continue our series on LLM inference with an exploration of a more advanced topic, KV cache offloading. This post will build on my previous post in which I walked you through the deployment of an LLM inference stack using vLLM, a popular open-source LLM inference server. The vLLM deploymen...
Earlier this week, OpenAI released two state-of-the-art open-weight LLMs (large language models), gpt-oss-20b and gpt-oss-120b. These models have generated quite a bit of interest due to their reasoning capabilities, tool-use performance, and native efficiency. According to OpenAI, the gpt-oss-120b ...



Great posts @hot field ! I'm using a similar toolchain at home - Open WebUI with Ollama. Currently running on an RTX3060 with 12GB vRAM. Likely looking at an upgrade later this year, but having a hard time justifying $2,000+ for the higher end 50-series cards. Easier (and cheaper) to just use cloud-based GPU instances for the time being.
Every day this week I've had a conversation that involved creative ways to incorporate Graph into retrieval pipelines. Curious if folks are hearing the buzz like I am. David wrote a great blog about the value of graph based RAG in the enterprise. Check it out: https://community.netapp.com/t5/Tech-ONTAP-Blogs/From-quot-Trust-Me-quot-to-quot-Prove-It-quot-Why-Enterprises-Need-Graph-RAG/ba-p/462813
You are probably looking at the title of this blog post and saying to yourself, "I didn't know that you can build a RAG solution using other technologies besides a vector database." You aren't alone in this thought. There has been some great marketing out there for pushing vector databases as the on...



WEBINAR: BUILDING THE AI READY ENTERPRISE
NetApp webinar featuring NVIDIA and IDC
@runic wadi - This has been a big part of my day-to-day for the last year in working on the Amazon Neptune team. Our team created an opensource library to assist with building GraphRAG applications. https://github.com/awslabs/graphrag-toolkit. Primarily supports Neptune, but we've opensourced it and have been accepting PRs to support other Graph databases/datastores, There's also a really good website being curated by Neo4j on all of the different implementation patterns for GraphRAG: https://graphrag.com/
GraphRAG
Design patterns for improving GenAI applications with a graph.
Very cool Taylor! @old jewel it might be interesting to look at integrating Neptune.
will need to take a look! the other project which looks pretty interesting is https://github.com/getzep/graphiti which is next on my list to take a look at. it's a general purpose library that might be an easy button for a simpe version of what I have proposed in the GitHub repo in that article
GitHub
Build Real-Time Knowledge Graphs for AI Agents. Contribute to getzep/graphiti development by creating an account on GitHub.
thanks for posting this!
Please do share with us what you find out about graphiti!
Similar in nature to graphiti, we've integrated Neptune as a backend graph store for mem0 and cognee. We've also looked at integrating with graphiti, though there are some things we need to address on our end to support it.
... and now supported with Graphiti: https://aws.amazon.com/about-aws/whats-new/2025/09/aws-neptune-zep-integration-long-term-memory-genai/
Amazon Web Services, Inc.
❗ @old jewel check it out...
Just posted my recent blog post and this might be an interest to some here...
We’ve all heard the phrase "treat infrastructure as code," but what if I told you it's time to give your datasets the same respect? In AI and machine learning, tiny shifts in data ripple through models, causing unpredictable behavior that can lead to compliance nightmares. Our latest blog explores a fundamental shift in mindset—treating data like code—showing you how immutable commits, provable lineage, and policy-driven pipelines can transform your AI from opaque magic to transparent, audit-ready solutions.
As regulators increasingly scrutinize AI applications (hello, EU AI Act!), understanding exactly what changed in your models is no longer optional—it's essential. Whether you’re a data scientist tired of explaining mysterious drifts or an AI stakeholder who needs to keep auditors happy (and lawsuits at bay), this piece aligns perfectly with today’s urgent conversations around AI governance and compliance. Imagine confidently pinpointing every decision to a specific data commit—no more guessing, just receipts.
Dive into the full article here: https://bit.ly/4ncqnRa
.
PS: If you are interested in some of the things that you are protecting yourself when taking your AI Governance seriously, I am re-presenting my in-person API World session this week for Virtual API World Week:
📅 Wednesday, September 10 at 11:00am PDT
🌏 VIRTUAL API World -- Workshop Stage A (PRO)
📖 More info: https://bit.ly/460Ryri
In my last blog post From "Trust Me" to "Prove It": Why Enterprises Need Graph RAG, we discussed why Enterprises need explainable, provable AI at inference because regulators, auditors, and risk teams demand verifiable answers. If you can't show why a model decided something, it creates legal, finan...



View more about this event at API World + CloudX + DataWeek 2025
New blog: DocumentRAG Using OpenSearch: GraphRAG-like Structure Without the Graph Overhead
GraphRAG has exploded in popularity for its structure, but it forces teams to maintain a full graph ontology and schema. This post introduces the BM25-based Document RAG Agent (or what I am calling DocumentRAG), a practical middle ground between VectorRAG and GraphRAG that preserves explainability while avoiding graph overhead.
Read the full blog post here: https://bit.ly/48kWHvC
Vector embeddings changed how teams build RAG systems. They made it easy to scan large datasets and pull back passages that feel semantically close to a question. And for a while, that was enough. You could drop your documents into an embedding model, compute vectors, plug everything into your favor...
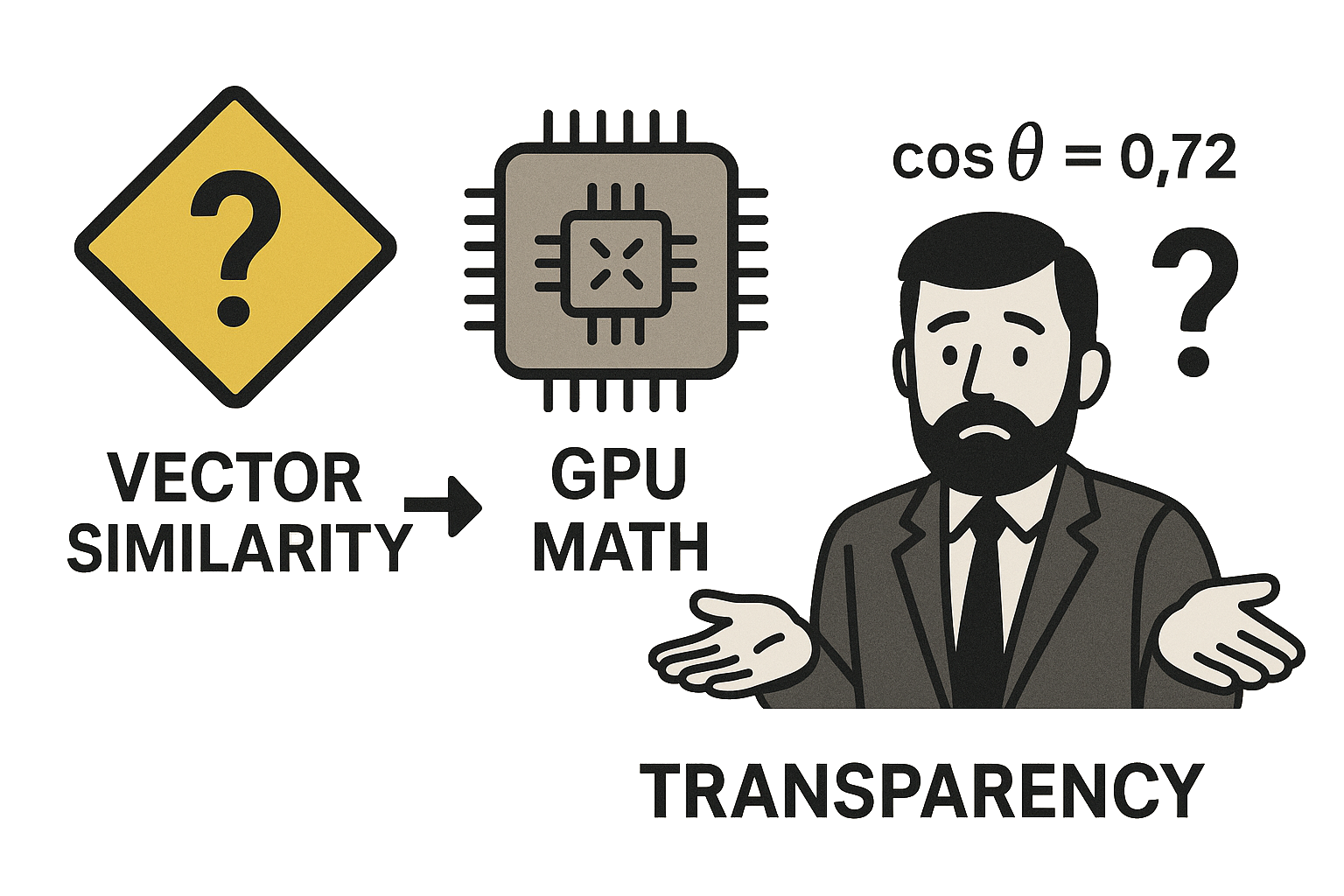


Forgot to post the follow up to the blog above called: Hybrid RAG in the Real World: Graphs, BM25, and the End of Black-Box Retrieval
We discuss why Hybrid provides a 96% factual faithfulness on answers when compared to plain vector embeddings and we also provide an alternative to the Hybrid RAG (Graph + Vector) you typically see out with an alternative BM25 + Vector Hybrid RAG solution. This BM25 + Vector variation provides an in between solution that doesnt require the heavy lift of using a whole new database and maintaining graph ontologies/structure, while still getting most of the benefits that Graph portion provides: factual data grounding in answers.
Take a look at the blog post here: https://bit.ly/4pz0D3b
In the earlier posts in this series, we talked about what happens when Retrieval-Augmented Generation leans too hard on vector search. The first post, From "Trust Me" to "Prove It": Why Enterprises Need GraphRAG, walked through why enterprises need retrieval that behaves more like a knowledge graph ...



Today, we continue our exploration of KV cache offloading. If you missed my previous posts on this topic, be sure to check them out here, here, and here. In this post, I will further explore the benefits of offloading your KV cache to shared storage. I will show the benefits of a shared storage tier...

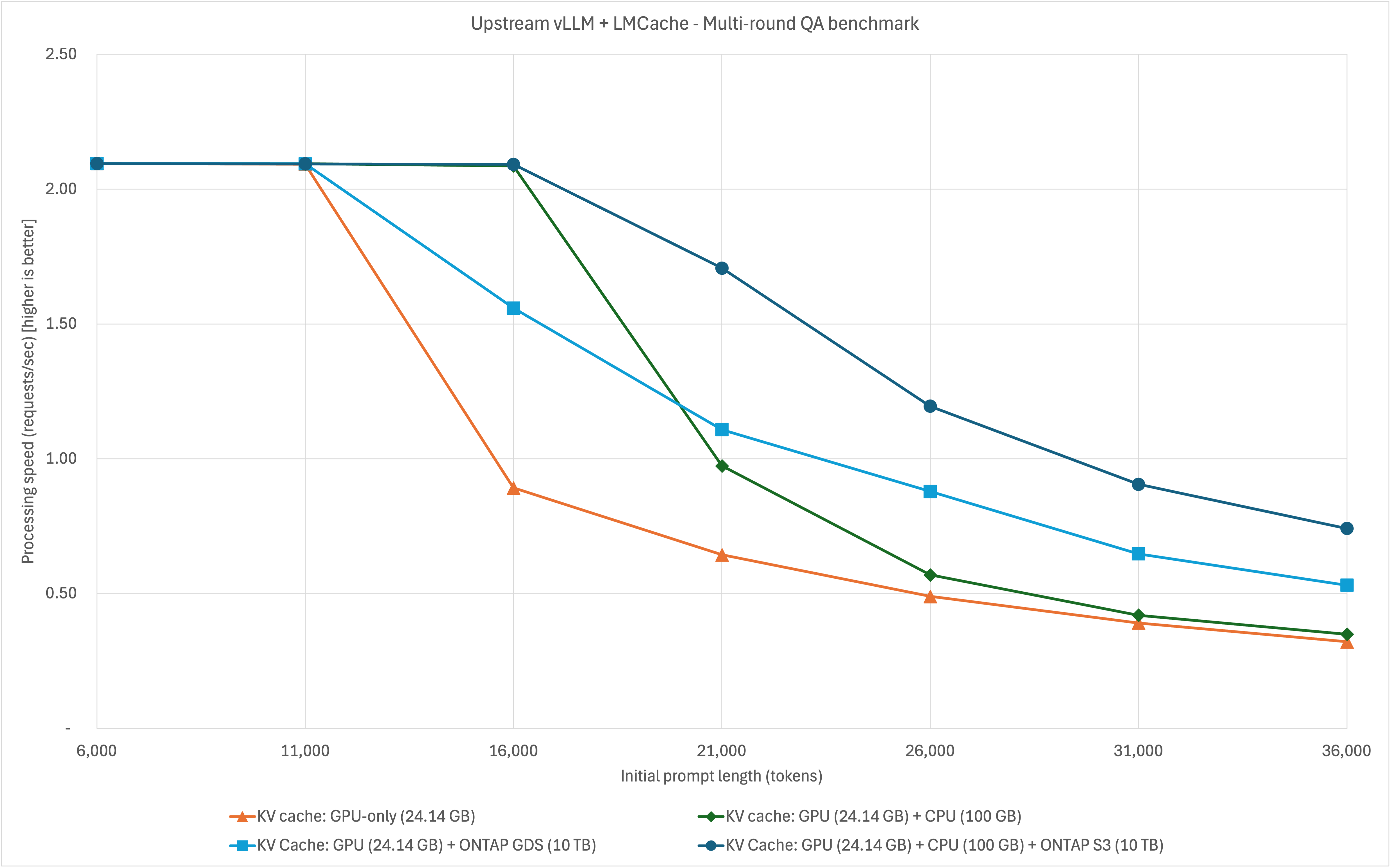
Killer posts @old jewel and @hot field! Love the research and demo content! Very well explained!
Dropping a new blog hot off the press titled:
Less Compute, More Impact: How Model Quantization Fuels the Next Wave of Agentic AI
Bigger models used to win headlines. Now they win (in not good ways) with power bills. This post looks at what changed after DeepSeek R1 made it clear that smarter engineering can compete with brute force. Instead of chasing parameter counts, we look at quantization, fine-tuning, and specialized Small Language Models that focus on one job and do it well. We also unpack what this means for agentic systems, where multiple focused models collaborate instead of one giant model trying to do everything.
This shift is happening for a reason. GPU costs are rising, data center power demand keeps climbing, and inference is now the line item that finance teams watch closely as token costs rise. NVIDIA’s recent inference-focused deal with Groq signals the same trend: latency, efficiency, and cost per token matter more than raw size. If you are building AI systems today, the question is no longer how big your model is. It is how much value it delivers per watt and per dollar.
Dive into the full article on the Open Data Science blog: https://bit.ly/4s6iKye
PS: for those interested in this topic, I will be presenting this topic at 3 different conferences (SCaLE this week, in April I have Devoxx France and a workshop at ODSC East) and 1 podcast due out Friday.

Editor’s note: David vonThenen is speaking at ODSC AI East this April 28th-30th. Check out his talk, “Less Compute, More Impact: How Model Quantization Fuels the Next Wave of Agentic AI,” there! Early last year, DeepSeek dropped R1, and the market reacted as if someone had pulled the fire alarm....
If you are interested in the blog post above on why Small Language Models and Quantization are going to going to see a dramatic uptick in Agentic solutions....
I recently joined the Open Data Science Conference (ODSC) AI X Podcast with Sheamus McGovern to talk about what's actually happening inside production AI systems. Not the polished demos. The messy reality is when models meet budgets, latency limits, and infrastructure constraints.
We covered a lot of ground in this conversation:
• Why many RAG and agentic AI demos fall apart in production
• The shift from bigger models to smarter-per-watt systems
• What quantization really does when you move from FP32 to INT8 or INT4
• Why Small Language Models (SLMs) often work better for multi-agent systems
• Hybrid RAG architectures that combine vector embeddings with knowledge graphs
• The growing need for governance and observability in enterprise AI
🎧 Listen to the podcast:
Spotify: https://bit.ly/40jPqsq
Apple Podcasts: https://apple.co/4bfx3tu
SoundCloud: https://bit.ly/4s0UrlV

Spotify for Creators
In this episode of the ODSC Ai X Podcast, host Sheamus McGovern sits down with David vonThenen, Senior AI/ML Engineer in the Office of the CTO at NetApp. David is a seasoned keynote speaker and open-source contributor with deep expertise in Agentic AI, deep learning, model optimization, cloud-native architectures, and retrieval-augmented generat...

ODSC
Podcast Episode · ODSC's Ai X Podcast · March 6 · 48m
New Blog Post Alert:
Engineering Inference: KV Cache, Shared Storage, and the Economics of AI
Large language models burn through GPU memory and compute faster than most teams expect. Every prompt creates key-value tensors that sit in GPU memory, and that memory footprint grows with every token and every user. In this article, I walk through what is really happening inside KV cache systems and why architectures like vLLM and LMCache exist in the first place. Instead of treating caching as a performance trick, the post looks at it as a memory strategy that changes how inference systems are built.
This topic matters right now because the economics of AI are shifting. Training made the headlines, but inference is what drives ongoing cost in production systems. Techniques such as KV cache reuse, memory tiering, and shared storage are becoming critical for controlling GPU spend and data center power consumption. As companies deploy chat systems, RAG pipelines, and agent workflows at scale, engineering the inference stack is becoming more important than adding more GPUs.
Dive into the full article here: https://bit.ly/4bl87kn
GitHub
NVIDIA plugin for secure installation of OpenClaw. Contribute to NVIDIA/NemoClaw development by creating an account on GitHub.
7k starts and over 700 forks already in what.... 24 hours?
I'm curious... who's gonna drop this in their Enterprise?
Nobody 😀

We’re on a journey to advance and democratize artificial intelligence through open source and open science.