#Questions about Neo evals
1 messages · Page 1 of 1 (latest)
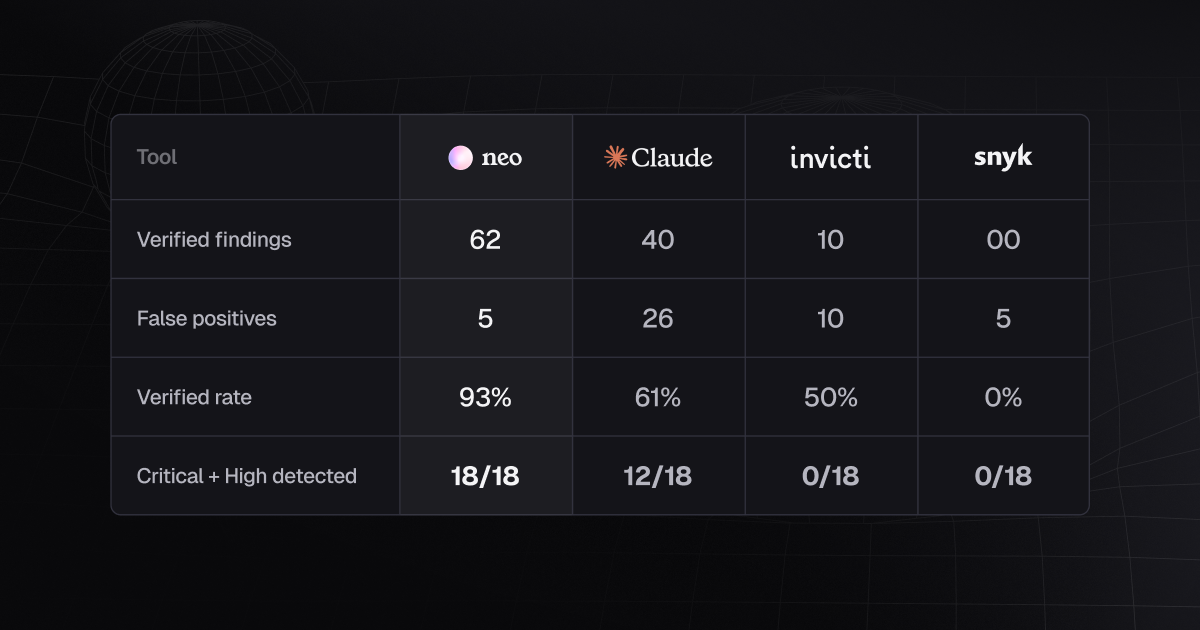
@slender mirage we got the source code and result published in 2nd part of the blog published today - https://projectdiscovery.io/blog/inside-the-benchmark-pp-architectures-finding-walkthroughs-and-what-each-scanner-actually-caught

ProjectDiscovery
This is Part 2 of our vibe coding security benchmark study. In Part 1, we compared how LLM-based security tools like ProjectDiscovery's Neo and Claude Code performed against traditional SAST and DAST scanners on AI-generated code. We found that LLM-based tools like Neo and Claude Code detected many high-value findings that traditional scanners ...