#Networking Protocol
1 messages · Page 5 of 1
But where ???
Correct
We can't add that into the event loop it self, because some call locations, including the one shown above, require the exception to bubble up and not be handled untill they do
I vaguely remember there was a patch in the eventloop handling swallowed exceptions, you should first try throwing an exception and see what happens. if it's swallowed we should wrap the submits
It is swallowed
And no we are not wrapping the submits
Well it is not swallowed
It is captured in the CF
But if you do not attach an appropriate handler it won't work
@velvet whale How about this: We add a third method to the work handler:
default void execute(Runnable runnable) {
submitAsync(runnable).exceptionally(ex -> LOGGER.error("Failed to process payload", ex));
}
That way the original API of the Executor is preserved
And people that normally know how to properly work with CF's can do that
But poeple that just want to run a task, get this handholding method
Mojang does something similar in their event loop
This extra method in the event loop has an exception handler build in
Do not get me wrong
I understand your concern
But blindly capturing all exception is a bad idea API wise
This should just be properly documented
And CFs and their exception processing behaviour is a known factor and component
As you yourself pointed out
Would it make sense to return the CF there so that people can chain off it?
Otherwise I'd think that would be fine
Maybe, but at that point I feel like the API differences become too subtle
If you want to chain of it, then IMHO you should know how it handles exceptions
Especially ones down the line
Because if you want to chain, then an exception can again happen in your next handler
Which is then again swallowed
If you want to chain, then IMHO the modder should use submit and be aware of the fact that he or she needs to add an exceptionally statement, or wrap his runnable in a try-catch themselves
@velvet whale Would that be acceptable?
So... these are the open todos:
- Implement registry sync failure disconnecting and messaging
- Discuss futher contextual components to the ServerConfigurationPacketListener, as this is the only piece of information given to the OnGameConfigurationEvent. We already exposed on that listener type if the connection is vanilla or not. Maybe the players UUID should be exposed as well? Please discuss this in the comments.
- Test further scenarios where mismatches can occur
- Is modlist mismatch testing even needed? Should we not more think about this in the form of content, aka network payload types, registries and their contents, tier sorting etc?
I think I got the first point now
I addressed @indigo hazel comments about registry revertal
And it should be fine now
It is nothing fancy
But it will just gracefully terminate and disconnected with a simple message
I found the reason why the registry sync can fail and it's indeed a race condition: https://gist.github.com/XFactHD/b85910268a091d9e0de87188ce251920.
Vanilla sends the brand packet, ClientboundUpdateEnabledFeaturesPacket, ClientboundRegistryDataPacket (the culprit) and the ClientboundUpdateTagsPacket outside of tasks (why Mojang, just why???). This means that modded tasks, including Neo's reg sync, start immediately instead of waiting for these operations to be completed. Because of that and the fact that all the mentioned packets are handled on the client thread while the FrozenRegistrySyncCompletedPayload is not, the snapshot application can happen while the ClientboundRegistryDataPacket builds the RegistryAccess to apply the transmitted data onto on the client thread, which calls freeze() on all registries. We'll have to move snapshot application and the response packet to a task submitted to the main thread.
This issue is a ridiculous pain in the ass to reproduce, especially once you add stack walkers and loggers for debugging. I'm lucky I got it to log that crap at least once, all subsequent attempts failed
Also, @mental ingot can you push your latest changes by any chance? I'd like to break more stuff after (late) dinner 😄
I fixed that laready
I would push
But

Heh, fair enough 😄
This should be after the Minecraft#disconnect() call so that the registry state is still consistent with the server while the level is torn down (which does fire a few events where people may access registries): https://github.com/neoforged/NeoForge/pull/277/files#diff-a78bbcf7c9cf4322bd0db6265da02751feb5736be58bf6966a54ca3dfe52b828R41-R43
Okey
Pushed
👌
I just did a quick test how the old and new network implementation interact. Here's the results (gist because Discord sucks and can't render MD tables): https://gist.github.com/XFactHD/9bc0fcab59b4cba2f8013ac41affed66
TL;DR: it's fucked and whether the ClientIntentionPacket is patched or not doesn't matter
(Tested with commit 0f066b3 of the network rework against NF 20.4.40)
Okey well that is fine by me
Nothing we can do
@velvet whale @fair sandal @indigo hazel Can you please review the PR again
Will probably take me a few days at least to do a full review
And @indigo hazel You still had an idea for the ClientPacketListener right, where I can patch the ensurerunningOnSameThread differently
@velvet whale @mental ingot #1170668658813575230 message 
camelot why you no reference
i'm quite surprised I remembered my message on that 
Camelot references only work if the link is the first thing in the message
ah
[Reference to](#1170668658813575230 message) #1170668658813575230 [➤ ](#1170668658813575230 message)a comment on the PR itself at this stage: why in god's good gravy does IPacketFlowExtension exist?
#1170668658813575230 message and the follow-up
[Reference to](#1170668658813575230 message) #1170668658813575230 [➤ ](#1170668658813575230 message)if the answer to that is for use as method reference, I raise Predicate.isEqual(PacketFlow.CLIENTBOUND)
There were originally more methods in that interface to deal certain logic that we had in place (particularly related to sidedness). I scrapped those methods, but left the extension in place, right now it is just a method-ref. And I personally consider code where the method ref is a proper name, better then the predicate option.
the method ref option involves a patch which involves adding an interface onto a class, which is one of the annoying types of patches because (as it happened before) it can lead to us forgetting to implement interfaces vanilla adds during porting
Yet we have nearly 100 of these extension classes, and this is the first I am hearing of that complained.......
We have several other locations where these kinds of methods are patched onto enums for the same reason
if the interface serves no functional purpose then we can have our code a bit less "clean" for the sake of maintenance
It is not just our code
It is everybodies code
And the maintanance is 0 in this particular case
If this was a class with a lot of interfaces, sure
But it is not
It is an enum, which we have regularly patched like this
I see no reason to change that now, unless you are arguing that a single line patch is too much, in a PR which touches 10000 LOCs?
I don't see the issue with the extension interface for those functions.
I am yes
do you have an example of such enum 
do you have an example of such enum
Any enum that is extensible gets an interface added
Any extension object that gets an interface added
in my opinion, that extension interface and its methods are superfluous -- they do nothing by themselves, are easily replaced with Predicate.isEqual, and therefore have no other reason for existing than your personal preference
do you mean to tell me that we can ignore the fine details of any PR as long as it exceeds some amount of lines of code?
The minecarts also have those, why are they not removed/allowed to exist
the minecart patches? the same patches which have existed since before 1.12 iirc, and only continue to exist, despite multiple people stating they need to be reworked, because nobody has put in the effort to rework those patches?
based on a patch spelunking, the minecart patches has existed in largely the same form since 2013, see https://github.com/MinecraftForge/MinecraftForge/pull/370
and at the time, those methods were made because the minecart types were based on an integer discriminator, rather than an enum (which happened around 2014, it seems)
they only exist because nobody has yet found the time to investigate the minecart patches and rewrote them to modern standards
this is not the first time the outdatedness of the minecart patches have been brought up (Curle knows; she brought them up a couple of times before), and I dare say it won't be the last
Fine I will remove it
I think we do modders a disservice
Because having properly named and documented methods to use a method refs
Seems like a good idea to me
Especially when the patch size is that small
Actually
I will leave it

This method is functionally needed
and the two methods above that method?
Do they really matter
?
I mean I would have argued that if the patch was only those two methods
you have to justify why they should exist over a simple == CLIENTBOUND
the enum is dead-simple -- it literally has two values, and a single method for getting the opposite value
there is nothing substantial to document on isClientbound() that could not be done by documenting the PacketFlow enum or enum values themselves
What is the downside to keeping them?
I understand that you have a preference for == CLIENTBOUND
Or the opposite
And when I thought that those where the only two methods in that interface
I would have agreed, see here: #1170668658813575230 message
But given that it is not the only thing that that interface is used for
adding methods to our API surface which do not need to exist because perfectly working and readable alternatives (in the form of the Java-native == operator) exist
There are other places where this applies
having two ways to do the same thing is repetition of code, essentially
let those other cases be brought up and judged on their merits
but on this case, I think those methods are entirely superfluous and give no additional value other than preferring method calls to == comparison
You are now arguing that nearly every single extension method needs to be remvoed
I did not argue that
Yeah and that is a good opinion, but I disagree
I am arguing that isClientbound() and isServerbound() are entirely superfluous, because they can be 100% replaced with a normal == comparison with their corresponding enum values (or Predicate.isEqual(Object), if one wants to avoid writing a lambda for a simple comparison in functional programming)
other extension methods should be judged based on their context, and removed if appropriate -- that is the normal way for software to evolve over time, as new features are made and old ones are revisited (and rewritten or removed)
getReceptionSide(), I can see the merits of
but the other two methods have no such merits
Sure they are superfluous, but we do a lot of things to make the life of the modder superfluous, see runtypes, unit tests etc. And I am argueing that this makes the life of a modder easier. Is that wrong no. Is your opinion wrong, obviously not. Are they a maintanance burden, no. Is there any risk of these two methods becoming in issue during porting, no. So what is the harm in keeping them. They cause us no problems, make the life of modders easier, and allow for better readable code.
Hmm that is the method I added because it was there in the old networking api
I wondered why the other methods were there
does this make the life of a modder easier? I would say no. they are perfectly replicable with == and Predicate.isEqual() (and that presumes they have reason to ever need to interact with PacketFlow on their on)
there is no ease of use offered by these methods as compared to a bog-standard == comparison
"this doesn't have a maintenance burden" is not a reason to accept something which doesn't hold any value
every change adds a maintenance burden, make no mistake -- we should keep a critical eye on our changes to ensure that what we add, we add with reason and purpose, to avoid possible bloat
it may be a subjective opinion, but flow() == PacketFlow.CLIENTBOUND is no less readable than flow().isClientbound() (and the same for SERVERBOUND); in my opinion, the former is more understandable because it's a more simple thing to parse: "is this equal to another value"
and to note: nothing in the PR actually uses those two methods as method references, as far as I can tell
they're always used as if (packet.flow().isClientbound()), which makes them even more superfluous
Okey agreed fine
But I will do this only under protest
I find it rediculous that you are basically saying that my programming style is worse then yours, and that the two methods give nothign
They might give nothing to you
But they do to me
it's the concept of not wanting to put things into the API that don't need to be there
like, we both know and agree that isClientbound() and == CLIENTBOUND do the same thing here (particularly because the former literally just does the latter)
the question becomes, what is the worth or merit of that method versus just the straight comparison?
in my eyes, there is no worth or merit
I understand that comparison
But in my eyes there is
I personally find == CLIENTBOUND an order of magnitude worse in readability
Which is why I tend to add these methods to any enum I touch
So that I can have smooth code
Both in my if-switches as well as my streams
That is just me
And I understand that you think the opposite
And that is perfectly fine
We are basically on an impase
at what point do you consider adding is<value> methods on an enum unreasonable?
Realistically, never
I tend to put them on any enum I have created in the last year or two
Especially if I know that the enum will likely never change
to note: it is not just me who seem to be at least hesitant with regards to those methods: maty (as the person who left the review on the PR) and Schurli (see comment above about wondering why those other methods are there) both seem to lean in the same direction as me
That is fine
And again, if that other method did not exist
I would have removed them without discussion
Because then there is a whole other interface, patch etc that we need to maintain
I'm sorry, is someone arguing for adding methods to an enum... that check if a value is a given value of an enum, and nothing more? That's, like, the definition of API bloat
Also yeah can we please stop with extension interfaces when they're not absolutely necessary and just add methods to the class
No this is our programming design to reduce patch count
i understand its your personal preference, but our project style seems to veer away (according to the opinions of at least 3 maintainers above) from your habit of is<value> enum methods
it's not an indictment against your preference -- it's simply not a fit for NF and our (attempts at ) curation of our APIs
explain what you mean by "absolutely necessary"
It's... the same number of patches though...
Patch at the top of the class to add interface - 1 patch
Patch at the bottom of the class to add all the methods - 1 patch
When the same stuff is being added to multiple classes
...... You seem to have no idea what you are talking about.......
extension interfaces are meant to correspond one-to-one with their extension target
And have only default methods
that's how self() exists on these interfaces without fear of accidentally ClassCastExceptioning ourselves
I am confused then, because I fail to understand how those are different. A large number of injected lines in a patch doesn't make it more difficult to maintain, it's a large number or very specific targets for where it's injected, right?
The interface these methods are in, these default methods, is patched in with a single 1 line patch
And in both cases there's only one place targeted to inject stuff into
and one of the points of extension interfaces is to move code away from being in a patch, which is harder to read and review than regular code
particularly good when the methods being patched in are very long, and need no reference to e.g. protected or less-visible members of the target class
(when they need such references, they usually are defined in the extension and implemented in the target)
Now yes, that's a good point; can we make a spotless rule or something for patches not stripping vanilla interfaces, like there currently is for imports?
Regardless, my point about isSomeEnumValue methods still stands
I am not aware of any place were we strip vanilla interfaces
It's happened accidentally in the past
Because vanilla added one
This is not the thread/place to be having architectural discussions about extension interfaces.
#neoforge-github 
Yes, that's fair. The major, more relevant, question was around the isSomeEnumValue type methods - and for those I still think it's just API bloat
I honestly think its being blown out of proportion. The reasoning comes from a valid place: keep the api small. But your forgetting what these functions actually do, they do an equals check. These are standard in out enums (see Dist and others) and don't add any weight to maintaining them. This is pure bike shedding over 2 simple helpers.
Thank you 😄
i consider them superfluous regardless -- they add nothing
If it's standard in your other enums... perhaps it shouldn't be
And exactly, they just do an equals check
They're utterly superfluous
They are helpers for method references
and quick freehand
they are super useful for keeping code smelling good
Eh, not really all that useful. The only place they're useful and "cleaner" than an equals is as method references in place of a lambda. And even there the lambda isn't that much uglier
And they're also nothing someone can't add their own helper for if they really want it, since it's, as you've pointed out, a single equals check
I'm ending this discussion here. We aren't going to have a bike sheading argument over 2 helper functions. If you want them gone, propose it as changes to the general code style guidelines.
Regardless, you're right that the whole debate is bikeshed-y. Seems like the best bet is to just have maintainers make a decision on what you're doing about that style wise in the future, and then just go with that
But just saying the PR is good as it is because the issue is bikeshedding isn't really a solution. That just means you should have the relevant people make the decision, and the relevant people are "maintainers", not "Orion and us whoever else has popped by this thread"
I did a quick check, and out of the enums in NeoForge and FancyModLoader (+ Dist), here are the following enums which have the is<Value> method pattern:
enums in NeoForge which have is<value> methods (out of ~40):
ConnectionType--isVanilla()(noisModded()counterpart though)IFluidHandler.FluidAction--execute()andsimulate()
enums in FancyModLoader which have is<value> methods (out of ~17):
LogicalSide--isServer()andisClient()
model case:
Dist--isClient()andisDedicatedServer()
so by no means are they 'standard'
We aren't going to block a PR based on style decisions. If maintainers want the methods gone, propose actual changes to the style guidelines. This is not the battle to choose.
 gotta love the triple inconsistency between having these methods or no, having the I prefix or no, or having the is prefix or no
gotta love the triple inconsistency between having these methods or no, having the I prefix or no, or having the is prefix or no
If the style is up for debate...
...the decision should probably be made before more PRs in the old style are merged, to avoid breaking changes down the line and people complaining of breaking changes for breaking changes sake
Because people will use that as an argument against changing stuff in the old style
And my point is that if we know this is a style question that should have a decision made on it... why not make it now?
After all, are there plans to merge this PR in the next 24 hours? If so, you've got a point. If not, just open up a vote in one of the maintainer channels about the style stuff or whatever and call it a day
How many times do i have to state we are dropping this topic.
If you want to continue the debate, move to another thread.
You seem to be implying that the debate is not connected to the topic of the thread. It is - that style decision is one that ought to be made before the PR is merged, unless there're plans to merge the PR within the next 24 hours.
It is not connected to the topic of this thread. This thread is for the Networking protocol, not BIKE SHEDDING ENUM HELPER METHODS.
I'm sick to death of every single fucking thing we do turning into bike shedding. It HAS to stop.
If Matty wanted a reson for noone reviewing PR's. This is it.
It has been noted that there is an impasse regarding whether those methods exist: #1170668658813575230 message
I am simply questioning why the resolution seems to be "ignore it and go with what's in the PR". Yes, bikeshedding isn't good. No, the proper solution is not "ignore it and go with what's in the PR". It's "have the proper people make a decision and stick with it instead of debating in threads for ages"
I understand fully what you are saying, and im telling you to go pound sand in another channel.
Christ man, no need to be rude. I understand fully what you're saying and in saying that it is relevant to this channel, as much as you argue otherwise. However, I'll leave it be given that the proper resolution is for maintainers or whatnot to just decide on a style; my complaint has been about the heavy bias towards just doing whatever the PR author picked for something that takes breaking changes to change
Lol
but do you like to patch those kind of methods in vanilla classes
Given that they are not patched in..... I am not sure that question matters here
I don't really care tbh
@fair sandal and @iron ivy Can i get a review on this. Something more thightly please. I want to round this out during christmas
I can probably review tomorrow evening or the day after
I haven’t done any code review and likely won’t have time, but from the small amount of testing I have done it seems things work fine for mods in regards to custom packets and the additional entity spawn stuff
Only real comment that I will reiterate is it would be nice™️ if on server to client packets the optional was of the client player. That way in cases where the client is needed mods can more easily interact with and get the player without having to deal with worrying about class loading shenanigans and storing the variable as a ClientPlayer instead of just Player
I thought of that pup
But getting the player is not as easy on the client side from the listener alone
As the two things client side I sometimes have to access which are a little annoying and may trip up some new modders who don’t understand sides and class loading as much, is the client player and the client level (though level isn’t as convenient to provide)
Because you would have to handle the class loading prevention when creating and passing the optional? Otherwise why can’t you try grabbing it from Minecraft.getInstance().player which is what mods would have to do
Like sure for configuration packets probably not possible, but also the player doesn’t exist yet for those so it is fine to just be an empty optional
I can check if I can get from the client listener somehow
Given I agree avoiding the class loading shenanigans may be a bit annoying, but doing it Neo side to make it easier for mods to interact and not make mistakes with it would be amazing and worth a little extra effort our side
I just tested the approach I mentioned here #1170668658813575230 message with the modded connection check and our handling at the top of the method. NetworkRegistry#onModdedPacketAtClient() would return false for all the cases where it currently exits early and return true at the tail, which is only reached if the packet is handled. As far as I can tell that works perfectly fine as long as the aforementioned method bails early for packets with a vanilla payload ID namespace.
Also, I would really like to get rid of that netty "platform dependent" crap. This now prints in the worst possible place in the middle of the initial resource load
figured out how and included it in a review comment
Can you send me a patch for that?
Perfecto will address
would be slightly convenient to also expose ClientPacketListener.level as an optional but I don't think that would fit quite as well into the existing payload info that is passed, and only effects two spots I use, which can also potentially just be replaced by going off of the level of said optional player instead (but I need to look into my code more to figure that out)
Given that I am planning on making an additional player Optional
Making a Level Optional is not a problem
Orion, if you have time sometime in the next few days, I'd be available to sit down with you to go over the changes and update the docs
will look more tomorrow if I broke something or if it is an issue with this PR, but for some reason when trying to open a menu it doesn't have minecraft set so it seems like init isn't being called before it starts trying to render the screen
That's a bug in the PR which I also ran into last night: https://github.com/neoforged/NeoForge/pull/277#discussion_r1436174193
Minecraft not being set is actually a downstream failure from the actual error, which is RenderSystem throwing for being called off-thread during Minecraft#setScreen(). The actual error is swallowed by netty though
ah okay
i've been reviewing the PR on and off a bit (mostly off)
i'll try gather enough of my thoughts to a concrete review
I want to get pr publishing setup first before I review it
PR publishing is done 
https://github.com/neoforged/NeoForge/pull/277/files#r1436148407 why was this marked as resolved?
I feel like I am missing something
If that is an XFact message
Then I am about to commit those 😄
I am marking them resolved
So that I don't try to do them double
i need to continue my review
wait should I use ISynchronizedWorkHandler#execute or ISynchronizedWorkHandler#submitAsync if I don't care about the result? The javadocs are a bit confusing especially when it is run synchronously on the main thread when it has async in the name (and the fact that execute calls submitAsync in its impl
They are async executions from the perspective of the calling thread
If you want to do something on the main thread you can call either one
The executeAsync just does not return the future, but adds a log message when the async executions fails
The submitAsync returns the raw future, and you are on your own when it comes to handling exceptions
okay so I probably should use execute even if I don't expect any exceptions from my code. Thanks
Yeah
Forge uses submit everywhere
And then adds its own exceptional handler to disconnect the client with an appropriate message
https://github.com/neoforged/NeoForge/pull/277#discussion_r1437856063 uhh orion I just meant something along these lines: https://gist.github.com/pupnewfster/f85d13bf6de744626c039d10225d0533
I will comment that in response to your thing on the tracker as well (though it will just queue the comment for when I finish my current review, which is why I mentioned it here as well)
Done 😄
I just meant something along the lines of this: https://gist.github.com/pupnewfster/f85d13bf6de744626c039d10225d0533 (potentially slightly cleaner handling in regards to if the payloads length is 0 and erroring then and also maybe having it explicitly only allow calling the method for if it is client bound(?) but it at least shows the general concept)
is what I was going to write on my comment (in case you want to handle either of those cases that my quickfix example doesn't have)
you may also want to edit your comment saying it isn't possible to say that statement was mistaken 
Done 😄
well more comments incoming from me as soon as I finish looking at the NetworkRegistry (currently have 18 pending ones for this review, not counting the ones I posted a couple days ago that you are working on addressing already)
First pass is done
there you go
have a handful more comments
also you marked https://github.com/neoforged/NeoForge/pull/277#discussion_r1436146463 as resolved and a thumbs up but didn't change it
Fixed
what the hell
I am putting a break point in my deserialization code and it doesn't get triggered, but if I put a breakpoint in the handling code then that gets triggered and the data is fine...
though actually maybe that is just the fact that single player and netty
so ignore me
though interestingly enough... that means one of my variables isn't getting set, while I believe it used to get set just fine before the changes even in single player
so that is going to be an absolute nightmare to track down how many places I might have a variable for the client value get set in deserialization on an object... that I need to make get set while writing it or whatever as well
did the old system serialize it for single player for custom packets?
Nope
hmph
That has not changed
yeah I didn't think it did
It does as soon as you turn it into a LAN server
I patched that memory leak more then once 😄
that memory leak is so annoying
but I am 98% positive in the old system this code of mine functioned properly and set the client side storing of the value even in single player, whereas now it isn't functioning as the read/write never is being called. Which makes me confused how it functioned previously
You are right
I double checked
In old cases the Simplechannel did write and unwrite the payload
Even if the actual packet was send in memory
and I am guessing we don't want to do that?
No, even if I wanted to, I have no option to do that
given I am going to have an absolute nightmare trying to track down all the cases where I say set a client variable
That extra layer of indirection is simply gone
okay
I am very sad as odds are there are going to be a bunch of bugs introduced in my code.. and stuff but oh well
it definitely is something we need to document
as it is a very sneaky bug
that most people porting will likely entirely miss
I will add it to the PR
great, and yeah it is going to be super annoying to fix, but I do agree not having the added level of indirection is probably better. Though it does make doing initial tests of packets more annoying (and likely will cause a good number of modders to have things with broken read/writes as I don't know how many modders bother testing everything on a dedicated server)
do the payloads in single player at least get handled immediately or do I need to make sure to ensure all block positions and stuff in my packets are immutable? (I think they are but I don't remember)
Can we not introduce an option to test serialization by doing a pointless serialization and deserialization on the receiving end?
oh that's an interesting problem to bring up
how would you test reliably to see if it mutates the object?
hmm true
No we can't
I will check
We could add a debug option to always serialize packets
Vanilla has it but the if (false) clauses get stripped by javac 😦
Somewhere in the netty pipeline it must be possible
SharedConstants moment
which actually brings up another issue... of when things might have the serialization say read something from the server side block entity and wants to write it to the client side block entity... depending how it is done you need to be super careful to make sure you are modifying the correct object and stuff. (my case isn't necessarily with block entities but with different sorts of objects where I may want to mutate the client side one before a confirmation to sync back to the server happens... and if it is just a direct reference to the server side one....)
Nope it is a different Channel implementation
And no
They get added to the Netty queue
To be processed
In theory it is possible
which is what happened in the past as well right?
In practice they are processed as fast as possible
I have no idea what the stripped vanilla code does, I just know it's possible
Yes
okay that's what I thought
so I don't have to bother validating about mutable positions as I shouldn't have them in any of the spots where it would cause issues like that
but other stuff.. headache
imagine pinging a mojangster in fc to get a hint
The simple argument is: treat the payload in the same way mojang does
Because it is processed in the exact same way packets are
If mojang does not do any extra processing then we do not need that either
We don't need to, but it would be extremely useful for debugging
Yet it introduces a massive change in behaviour between production and dev
I vote no
The packet processing should stay identical
a debug option
Why would that option be needed!?
Like in what case would you need the debug option?
pup gave an example. your packet accidentally has a mutable BlockPos passed somewhere
Mojang already does it
The only reason not to do it is that I have no idea how to implement it
If someone knows we should definitely do it
and it's likely to be a problem with any mutable object in a packet anyways, so if you have no idea where, a debug option to make sure that it's not being mutated is useful
If you say "I don't know" maybe we leave it for later
But if you know please write it cause it's immensely useful!
An assumption I could make is that they change the connection channel implementation type
Maybe we ask a problem causer
question
when are packets normally serialized in multiplayer
in the same call stack where send is called, or later, by the netty thread?
I would like to see under what conditions the mutable blockpos situation is a problem
The only one that I can find
Is somebody sending a packet in SSP
In which a mutable object exists
And then they update the object
Something like a loop over positions
Which then get put into a packet
Interesting I can't seem to find a channel implementation
As if it is stripped
Or as if they added a custom processor or something
Something I have no control voer
Javac probably strips if (false constant)
But all classes and indicators of use are gone
Like I would expect there to be something
Anything
But nope
So
The Connection is simply not configured
I could add it
Probably
But not in this PR
It would require a significant amount of testing
does MC have any (visible to us) usages of the FAKE_MS_LATENCY and FAKE_MS_JITTER from SharedConstants?
I will check
No reference found
I assume it belongs to the same codeblock
Fabric API does it using a JVM flag and enables it by default in dev; its implementation can be checked.
Why do we no longer have the option to do this? Given the more I think about it the more I believe it will lead to cases where various mods have broken code or bugs that they don't realize, as now you definitely have to test on both dedicated and in single player as the two behave functionally differently rather than being able to rely on the fact that you have a function in and a function out
Like consider the relatively simple case where you want to sync the size of a map from the server to the client. At some point you need to store the size in a variable on the server now and keep it up to date rather than being able to just grab the already stored size from the map and then set that on the client side. Is it at least possible to potentially make some sort of method that gets fired when the memory transfer is occuring to then set any data that is needed clientside that the server does not have in the same form as the client expects?
I agree; this feature would be useful for developing Create.
yeah my biggest concerns by far are that:
a. it used to function that way so mods that are just being ported (especially large mods) are going to have an absolute nightmare of a time making sure everything still functions properly and it didn't break in some unforseen way
b. it adds a lot more states that mod devs have to actively test for to get a good sense of if their thing works as expected or not (which I doubt the average modder will bother to do)
Could that be solved by good documentation?
part a most likely yes, part b probably partially
Actually orion, is part of the reason both AdvancedOpenScreenPayload and AdvancedAddEntityPayload stash parts of the data as a byte[] (rather than just proxying the calls) to effectively force those to be serialized and deserialized?
So i looked it up. Turns out this behaviour is at best a implementation detail of SimpleChannel.
The way SimpleChannel worked is that your SC-payload would be written to a FBB, which then grabbed the byte[]. From there this data was added to the vanilla CustomPacketPayload instance with the int descriminator prefixed before the byte[].
This means that this only worked because you were writing to an intermediary buffer, not sure why it worked liked that but that is what SC did.
I can not find any evidence of this in EventChannel, where the raw buffer was passed.
This behaviour is additionally nowhere documented, to be honest I have heard to oposite more often: "Watch out for SSP packets, they are transferred in-memory." Now that might be because I worked a lot on networking memory leaks in SSP LAN Enabled worlds, but in reality I am not sure why this was never documented.
Now as with can we re-implement this: this exact behaviour of SC: No, the extra layer of indirection is simply gone, we use the native FBB that Mojang gives us. I also see no reason, as it was not done in EC and not in Fabric.
Now with respect to a debugging option: We can add it later on in an extra PR sure, probably only for in-memory-connections, in-dev, and with a big fat warning, since the overhead is a couple of orders. But we can do it as a channel processor probably.
Kind of yes, kind of no. I remember discussing this, the primary reason why it is a byte[] is the SSP-LAN world scenario.
There the same objective payload (as in the exact same instance in-memory) is send to all players. Important of note here is that this happens in the order of the players joining. Meaning that the local player is always first. This caused an issue when we kept the FBB there, because it ment that one thread could be reading from it, while the other was also copying its contents into another buffer (See the SC message above). In the end this was a bit weird of a behavbiour, and did cause issues with freeing up the buffer, or a significant increase in memory consumption due to over allocation of the buffers, and their immediate destruction. It was in the end considered simpler, easier and safer to write the entity/screen custom data once to a byte [] and treat that as an immutable data structure that is then passed to new FBB instances, or written to the network thread.
That way each buffer could be created and freed on its own terms
And without the memory thrashing overhead
hmm interesting, what times should mods end up writing objects of theirs in a similar way to how we handle the entity payloads and stuff?
Also there are a few commits of xfact's you marked as resolved the other day but didn't address. Should I mark them as unresolved or add a new comment? @mental ingot
It is recommended that your payloads are immutable at all times
So.....
Unresolve them
unresolved the two and then added a few of more comments of my own
Addressed all of them
so @mental ingot is your trailing whitespace problem fixed after you imported the formatter config? if so you should remove it from the patches
No it is not
Me and covers tried finding as many as we could today
Anything that is left
Will stay
I can't look at them anymore
@fervent token Can I ask you for a rereview
just finished with an appointment
Okey
IServerCommonPacketListenerExtension
the send method has FQN in it
you can switch it to an import
the problem with spotless. If you move the exceptionally to the previous line OR if you move the () -> { of the submitAsync to the next line like it is in the advanced entity payload handle method it should hopefully look less derpy and bugged out
but other than that I think it is decent? Assuming nothing blows up in my face when I do a test on a dedicated server, and also the fact that at least a couple of my spots still have issues in regards to it no longer serializing and then deserializing so I need to fix that in my code
Fixed
okay, I am heading for a walk but will look afterwards
Okey
if you haven't don't forget to add the warning to the description about the serialize deserialize that simplechannel used to do not happening anymore in singleplayer
Already done on the registrar
As well as on the PR description
And I will add it to the blog post
is this meant to be translated?

I don't think you included english values for any of your new translation keys
Registering payload handlers outside of the event handling scope will result in those payloads not being known to the system and not being sent over the connection.
can we get it to error
Probably....
@velvet whale and @fervent token Addressed your concerns
https://github.com/neoforged/NeoForge/commit/fe2ce6fec066fca80e4acebb65fac70f4ea98841 uh I think you accidentally formatted the vanilla code in the first three patches
tbh I've always found auto import or auto format on save and co to cause too much trouble in any project, that's why I always disable them
it always manages to break something or format classes needlessly making contributing painful
Fixed
Added this as well
All registrars will become invalid immediatly after the event
I will look at it in a few hours
If self causes performance issues due to casts at times should the byte buffer extensions stash the self in a variable per method rather than retrieving it multiple times per method?
Realistically I would need to run a crap ton more tests to validate
I started patching in the method after the 1.18 phase when covers ama and I did research into a new chunk rendering pipeline and we noticed a significant hit to performance due to this.
Now how and when it comes into effect I don't know.
It could be because it of the class hierarchy
But I just go in a better safe then sorry route when I add new ones
We should really have an internal marker annotation we put on the self() method, and just strip their usage with a coremod, they should be replacable with a ALOAD 0 at runtime
not without a checkcast, and we should see some numbers first
It will work without a check cast
if the cast is required it's far faster than the invoke
The point is
Orion and I have numbers from when we worked on the alternate rendering system
I know from past experience that it does really influence the speed of the call sites
it is ungodly slow to have that self() call
Yes
But right now we have no hard numbers
However it is trivial to circumvent
WIth the implementation of the method in the class
There is still a perf hit to it slightly as its invokeinterface
Yeah
But the invokeinterface would also be hit on the default method as far as I understand it
Because it could be overriden / implemented
So that would be a constant performance penalty payed by every extension interface
I tried it already almost an year ago, a plain replacement of self with aload 0 requires a checkcast because aload 0 is the ext type
the cast would be faster regardless
We could probably also hois the interface default impls onto the parent class at runtime with a coremod
but we are into tin foil perf optimizations here
Yeah
The simple patch suffices for now
We need to do some more research later
And then figure out how to with all of this
I wish we had mixins for these
Would solve the problem immediatly
if we're targeting this for sunday (tomorrow, 31st, say 21 UTC) then we need to do a final RFC announcement today 
I am going to address your comments as fast as I can
Here or somewhere else?
#announcements (i wouldn't do #dev-announcements until after the PR is merged for the sake of better visibility)
Can you do that
?
My brainpower is currently exhausted from dealing with this PR and my sick wife, and afraid dog
I meant for the IFriendlyByteBufExtension write array and read arrays. Like do FriendlyByteBuf self = self() instead of having multiple self() calls inside of loops
if you are concerned that it might be a performance issue
I am concerned to the point that I patch the methods in newer extensions
But at the moment not enough that I go retroactively changing it in existing extensions
I am still on the fence about it to be honest
For the new ones I air on the side of caution
For the old ones I leave it be
in the past self was not overriden by the implementing classes, it was just left as a default method, right?
pup is specifically talking about the new stuff you added
And because neither javac nor the jvm had any idea that inserts a lot of overhead code to check cast ability etc
I know. Point still stands. If it is an old extension I don't really change the pattern of the old extension, unless a pr reviewer orders me to change it
Kinda, not default but private (at least since 1.17 since Java versions used before that didn't allow private methods in interfaces)
Mine also still stands since the method being referred to is a newly added one
Maybe we should work on a JMH test and determine a conclusion on the problem once and for all 😄
😄
I'm doing that right now
The introduction of private inferface methods might have made a difference
the perf will likely depend on the number of classes implementing the interface and how far deep the interface is in the hierarchy
^
Can you make a varint of both that has some hierarchy to it?
That is also not the test maty
Make the method on SomeExtension default with a cast of this to SomeObject
And remove the implementation of SomeObject
Allthough
I don't understand why in your test testPrivate is faster then testDefault
Well no
The private method is probably faster because it is not a virtual invoke
I am guessing
It is a vinvoke, but not through the invokeinterface table
We did not have those private methods when we did our testing
yeah
private method is probably good enough in J17 then
And some complex inheritance trees
as jit will inline it if its a hot path
Because we only really ran into this in BakedModel
Which has a really annoying inheritance tree
Yeah
And the point is, that it had to check for castability
the extension interface wasn't added to BakedModel itself?
It was
But that says nothing really
Because the compiler has no way of knowing that any given object returned from the self method is a bakedmodel at all times
Because the extension interface does not declare that
ohh yeah because bakedmodel extends the extension, not the other way around
For all it knows a modder added that interface to their random class
becaise its a invoke interface, it has to hit the invokeinterrace table on each concrete class in the hierarchy, etc
Yep
We did not have the time or the infra to dig deeply then
We scratched our heads for the bad performance
Got a trace
Saw the hotspot on that call
Patched it
Made a note
And moved on
Like 90% of the time was in a function that was using self() 3 times
Interesting
i moved the self impl into BakedModel, amazing, all went away
The interesting thing was that self() was not listed as a hot spot, the function calling self() was
I think private method for self() will work fine, it should be invokespecial
Should
as its not a virtual call with hierarchy then, jit will inline in hot paths
But if we are on the testing path now anyway
it will be 100% fine
We should just get the numbers
so the problem wasn't even the cast, it was the repeated virtual dispatch?
yes
🤦♂️
And then open a pr next week and fix it for every single extension all at once
or rather, just the overhead of invokeinterface
I am not 100% on that
regardless, numbers
you'll have numbers in 12 minutes and we can stop with this "it did... or didn't... or doesn't.." once and for all
can you gist that
Created Gist at the request of @velvet whale: https://gist.github.com/NeoCamelot/f96fc4a083f4f00289f46a2c5aa69bd7
use the 'button' 😛
I don't understand why that needs to exist, but okay
the reaction? for gisting duh
At least in bytecode it's still invokeinterface

and the self method is private?
Yes
What happens if you have 2 interfaces, each with a private self() method, that does something different, and implement it on a single class
honestly I would have expected java to devirtualize an invokeinterface if the method isn't implemented anywhere except the interface itself, hearing that it doesn't is a bit disappointing
I guess, to be fair, it's likely nobody designed the JVM infrastructure around interfaces with this in mind
remember, @mental ingot and i tested back in J8
it works fine

think covers was probably more interested in the generated bytecode
And also potentially the case i2 extends i1 instead of being applied in parallel. Granted the parallel might be different yet given we are talking bytecode
it's still invokeinterface

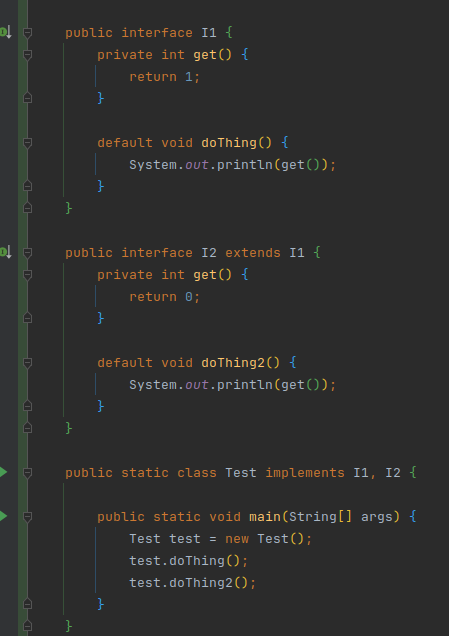
hot take: in Java 25 they should deprecate interfaces and just allow multiple inheritance
Wait when default instead of private is the invoke interface call referenced any differently in bytecode?
No, both of those get() calls are invokeinterface
Nope, looks completely identical
I assume when resolving the method call at link time, it see's its private and probably hotwires the table
as invoke interface is meant to search from the root of the tree down
but its clearly not here
Created Gist at the request of @iron ivy: https://gist.github.com/NeoCamelot/77fa497442adb23815b71cc1eaf189cd
the private method is faster when inheritance gets involved..
interesting default gets faster with inheritence too
default is twice as slow as override sure, but the private method is faster 
hmm? it's slower?
0.113 (override) vs 0.211 (default)
reading the wrong number
but yeah, the way to do it is with a private method
yep
very clear
oo
can you make a variant that does (Cast) this instead of an invoke at all?
so we can try and see if the jvm inlines the private self()
hm? wdym
oh you want a return (X) this in the runs?
So @mental ingot change the new extensions you are adding to be private on the interfaces for the impls of self instead of override
Only as companion to the Private one
doesn't make sense for the others, its the same test
the override is faster than private but only in the non-inheritance case
if I'm interpreting this correctly
great so i don't need to wait 14 mins 
Feels like there is a hotwire there at link time for the method always being default.
Somewhat releated, how do i search a repo on github for commit keywords?
So
Usually I just search and then choose commits on the "Filter by" sidebar
https://github.com/openjdk/jdk/commit/eb6d600333d93ede58e75814e267254fbe7554a8 https://github.com/openjdk/jdk/commit/21d9ca6cd942ac98a3be2577ded8eaf92dac7d46
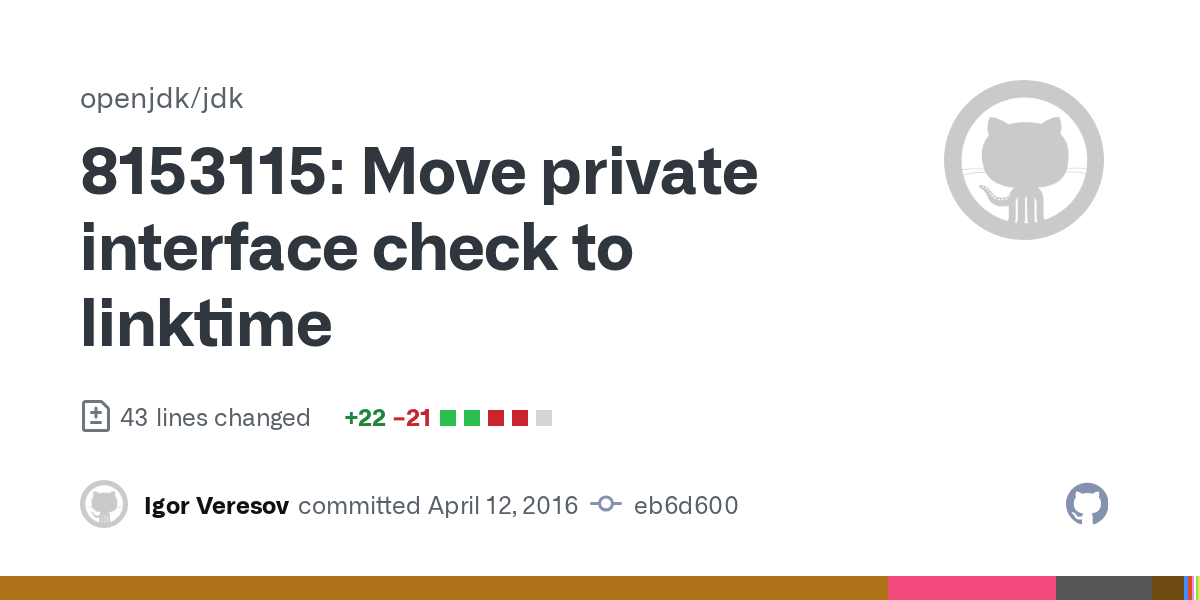
GitHub
Check for private interface methods during linktime instead of runtime
Reviewed-by: kvn, never, coleenp, acorn, lfoltan

GitHub
Reviewed-by: dlong, iveresov
neat, so we should be changing all of them to private, I take it?
The second one is the most interesting, if the invoke interface targets a private method, the jvm overrides it to an invoke special
looks like it was also backported to java 17
@mental ingot it looks like you forgot to reapply the change here: https://github.com/neoforged/NeoForge/pull/277/files#diff-170b6f1bf544127c7addf94404f1f1a1742403c3cf0463a802ee21f25a48d38dR8
Looks like lambdas actually use invokespecial if this javac commit is anything to go by: https://github.com/openjdk/jdk/commit/a8e63b82f1ebaa5ac1308d5893fa911e67fd3309
#announcements message punny announcement done
[Reference to](#announcements message) #announcements [➤ ](#announcements message)Hello!
As you might have heard, a networking rework was due for 1.20.4. And we're offering it to you as a New Year gift!
The Networking Refactor PR is in a final RFC period and is scheduled to be merged <t:1704056400:R>, if no critical issues are brought up.
Any comments and reviews are appreciated! If you want to test the PR, you can make use of our new (:Catjam:) PR publishing setup. Installer links, repository declarations and MDKs for this PR can be found here, so you can be ready for the LANding of the rework.
Happy... networking?
why does that announcement feel so cringe at the end
I just read through the PR description fully, very well written IMO. It doesn't seem to say what the final decision on modlist mismatch handling was - did we decide that?
After testing: Right now it is simply not part of the protocol modmuss designed
And for functionality it is not needed
As such it was left out of this PR
👍
so as a side effect: servers no longer know what mods a client has, just what payloads it registers, right?
Yes
Had this discussion with Orion last night. It's worth exploring as future work. Theres a few use cases for the server knowing what mods the client has. Server networks/public servers, etc, etc.
Personally I like the approach of going by payloads/registry contents
See the Follow up PRs section
Also thank you ;D I like my excessive PR descriptions 😄
what's this I hear of excessive PR descriptions
we still need a blog post 
blog post is just copy Orion's PR description, remove some implementation details that don't matter for a modder, fix a couple mistakes, 
btw Orion, since I can't complete my review, Imma make a comment here:
your doc comment for your overload in BundlerInfo#unbundlePacket is incorrect
I am writing that and documentation prs tonight 😄
Okey
somebody leave that as a PR comment somewhere
the method's logic isn't to write the bundle packet, the logic is to convert any bundle packet into the series of original packets it contains (with delimiting packets for anything downstream that cares about it), and pass through packets which aren't bundle packets
i had a pending review comment in the past, but it got wiped
Do you want me to leave a comment on the PR (or more so unresolve them) relating to this?
No I am already on it
@fervent token Addressed your request
@velvet whale and @indigo hazel Addressed your requested changes as well
@buoyant pagoda Addressed your changes as well
Sorry geo, wrong person in the box
don't edit the ping, it will be more confusing
I will take a peek in like half an hour
"opinions on networking refactor were requested from modrinth developer"
i can already see the drama headlines /s
Where did I write that?
hmm? it was just a reaction to you pinging geo 😛
lolol
Blame IDEA
Well and VanillaFlower
Turns out vanilla flower will add the indents when it deals with inner classes, or lambda callbacks
Idea detects them
And then thinks that the rest of the file should have that as well
so I don't have like 30 comments on your PR can you search in files on the patches that you are modifying for \+\s+\n (using the regex find in files) and then fix them
Vineflower
No there are 160+ files I touched
And as already talked through with Maty
I spend a good several hours with Covers trying to fix this 2 days ago
I won't be further touching those whitespace changes
Either institute a global formatter over both the MC and Forge code
Or fix VineFlower to not output shit
fine, though there are only 23 files total (when doing a find in files on the patches folder for \+\s+\n) that have this issue some of which aren't touched by your PR so it would just be a subset of it and not 160+ files
I might consider doing it tomorrow if I have the time
But do not hold your breath
I will only do it if I have the time
that's fine, still have other comments I will post after I finish going through files that have changed since I last viewed them
do you mind if I make a commit fixing the spacing thing orion?
Maybe better to fix it after all changes have been made and before merging then
yeah or given some cases aren't touched by this PR I can just make a PR after the fact that fixes all the cases it happens
I would do it after the fact
Personally I would like to discuss having a formatter run in NG7 to standardize the entire sourcecode
That way shit like this where we depend on the formatting of an external tool on which we have no, or extremely little, influence has no influence on our patches anymore
Does that mean the patches get polluted by the formatter's changes though?
Or does the formatter run before patch application
Run before
It would basically be as if the decompiler was formatted in that way
Or not it
but its output
Seems reasonable to me
two things. One the reason doesn't seem to be localized, and second is the reason it shows the modid as the channel name so many times that it shows once per registered payload? (and if that is the case should we maybe show the payload's rl?)

Good question.....
That is indeed wrong XD
That should be the payload id
Not the namespace
Adding a record field effectively removes the vanilla constructor, which as far as I know Neo isn't supposed to do
https://github.com/neoforged/NeoForge/pull/277/files#diff-219ac03f1741431b7467ef49a7a37fcb50e5bb022b9e165ccc0c9b15206a0f50R8
This can be fixed by adding a constructor which takes the same values as the vanilla one
Yes and no
Yes it can be easily fixed
But no the rule on ensuring compatibility has been weakened
We try to stay compatible where possible (and here I missed adding the field, so I now pushed the change as you indeed suggested)
But if there is no direct obvious way, like in several other locations in this PR to remain compatible, then we will patch method signatures.
Alright
meh in this case if we patch in the other constructor it would allow removing the patch in the same class to createInitial and iirc remove a patch adding the , false in one other class
so maybe worth it? idk
I was indifferent so didn't make a review comment about it
okay so locally you are removing the now unneeded patch to CommonListenerCookie#createInitial and ServerCommonPacketListenerImpl#createCookie(ClientInformation)?
okay great
I'm almost done fixing the things in my code that were relying on the serialize/deserialize of SimpleChannel . Though the last few cases are definitely super annoying logically when it comes to deciding how to address them
oh also do I need to leave a comment on the PR in relation to this? Or is it aso something you are already addressing locally
No I am adding that still
Okey
Test past 😄
We now have a fully working packet splitter in NeoForge
For all packets 😄
Modded or not 😄
@fervent token All addressed
I can check when back at my pc but at a glance I don’t think you fixed the missing translation key from my picture (just the payload name thing)
nvm seems it is localized now, so must have missed it in the commits I skimmed
is this opt-in or are all packets that are too large just automatically split now?
I just spent far too many hours trying to find why a Neo tests client can't connect to a Neo tests server. Turns out the packet splitter has two bugs which meant the oversized registry packet wasn't received:
- It doesn't actually write the prefix data (i.e. the "state" and, in case of the first packet, the vanilla packet ID) to the packet slice
- It doesn't trim the state off the received packet slice, so the decoding of the collected slices then produces nonsense
Here's a quick patch: https://gist.github.com/XFactHD/489fafc6986cc3c410e1f9843a561c29
Your bottom hunk can be replaced with Arrays.copyOfRange(payload.payload(), 1, payload.payload().length) :)
Right, good call 👌
So.. staring at the write-up. Lots of noise. In dev voice proofreading.

Also.. I'd argue that implementing the functional interfaces for payloads via constructor can be messy, and they could be final fields on records instead.


You can breakpoint the FI version, and it looks similar to how I've seen quite a bit of modder packet code (less wrestling everything into one line)
Is it possible to just offer up a codec, and have the reading+writing handled by that internally?
ChannelHandlerContext#sender - mentions this is a player optional. Does the platform have a player UUID yet, during configuration? If so, passing it here as well means mods can do some lazy init for when the player gets fully constructed. Also means that ban lists and similar features are more possible.
Proofreading/thoughts. >.>
is this Obsidian
yes
Nice, although I wint be using everything, i will be using some of it
Wtf i worked for me, did i forget to push before i feel a sleep, i am going to check later
Not yet
It is eventually planned
But not as trivial as you might think
@mental ingot I sanitized registry snapshot a bit so we are not creating and copying FBBs everywhere, should I commit to the branch or send it to you as a patch?
Commit
Sitting in FC Voice chat
Did you push?
not yet
Testing
Weird it worked for me
pushed
I'm not in FC
okey
@indigo hazel I applied your patch and now I have a broken ref counter
@errant summit Your PR be broke 😄
I think I got it 😄
You released the snapshot buffer before grabbing the data array
You fucked something up
Oops (that happens if you refactor the same code twice and forget what you did in the first)
I also now have a netreg error all of a sudden with unknown packet id!
Weird because the read and write code are the same except for the try-finally block
I'll fix it after lunch
Fixed
You used the wrong reading and writing methods on the FBB to write and read the snapshots
Just a PSA: Do not use readBytes / writeBytes if you want to write a bytearray
It does not do any size, prefixing or terminating
So you frequently end up reading and writing over other data
Which is what happened here
Properly using readByteArray() and writeByteArray(...) fixes the problem
I did that on purpose because I am reading the data directly and not wrapping a byte array in another FBB
That does not work with FBB
And in reality it does not matter
That is what it did before except it stored an FBB instead of the contained data in a byte array
Yeah
But as soon as I used writeByteArray()
and readByteArray() it was fixed
The problem with readBytes and writeBytes() is that it has no termination logic
It will read and write as long as it can
Which is problematic
Hmmm how did that ever work then
It did not for me 😄
As soon as I added the writing and reading via the byte array it was fixed
Because it was ByteBuf to ByteBuf
I just know that Byte[] are really problematic
And should only be used with their corresponding methods
writing bytebuf to bytebuf does the same as writing byte array to bytebuf with writeBytes
It does not 😄
it uses setBytes under the hood for both which copies the data over
(at least for unpooled which is what is used here afaik)
No it does not
writeByteArray writes the length of the byte array first
where writeBytes does no such thing

ik the old code never used writeByteArray
Basically writeByteArray should always be used
Unless, and only unless you know exactly what you are doing and want to use writeBytes without its terminator
I think there is another issue at play here, Schurli's intention was to append the raw buffers together. provided you still read in the exact same sequence it should be fine. Something is not incrementing/resetting reader/writer indexes, or there is an issue with readRL
but it technically isn't a byte array but just the cached versions of the buffer write operations
I don't know what to tell you man 😄
I am doing exactly what the old code did but storing it as a byte array instead of the FBB directly
Yeha
Supposedly there should be no difference between writing a byte[] and writing a FBB
Figured it out 😄
There is a significant difference between readBytes and readByteArray
In particularly because readBytes reads as many bytes as will fit into the buffer it is given
So if you do not make exactly sure that your BB from which you copy and the BB to which your read the bytes again are of the exact same size
It will just copy anything
Causing it to misallign
That can not happen with read/writeByteArray
Because it prefixes the size on its own
@errant summit Does that explain the issue?
but it did not do any readBytes or readByteArray it only wrote
Hmm
Weird
You are right
Then I am out
And really I don't have time today to further investigate
I'm investigating rn
If you figure it out, I would be really interested
I know what the problem is... the .array() call returns an array that is longer than the actual data in it and thust increases the writer index too far
.array on an array backed BB will return the actual backing array, not a buffer of the readable data
that's probably documented behavior but the method is so tempting
It is.. https://ss.ln-k.net/6a2b1
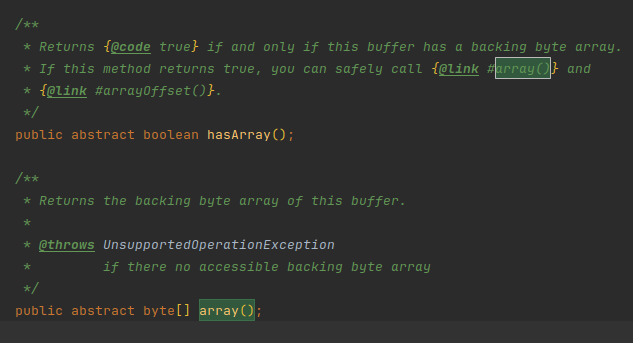
Are you going to patch it back
Or is the PR okey for now
?
I'm going to patch it back if I find out why the client is missing the damage type registry
It was not on my end.....
did you test with testmods?
I'm getting Unknown registry ResourceKey[minecraft:root / minecraft:damage_type]
Does it happen without the test mod?
during handleUpdateTags
works without testmods, it seems like ClientboundRegistryDataPacket#handle is not called either
when testmods are enabled
I pushed, it works in neo idk what is wrong with the tests I'll check later
@mental ingot Would you be available sometime tomorrow (evening) to go over the changes for the docs?
I am writing both blog posts and documentation now
Not sure how far I will get before the deadline
But yeah sure
alright
ping me when you're done, then I'll have a look over it and give some first time reader input
The error you got is exactly the one I ran into last night. It was caused by the bugs in the packet splitter
But given schurli’s second commit is after Orion’s that mentions fixing the bugs you mentioned, does that mean it isn’t actually fixed?
Depends whether he pulled before testing
No i fixed that
Can you join world?
btw orion not sure if they have been resolved or not but according to the PR there are still two unresolved conversations
one I am fairly certain is out of date and is resolved, the other not sure
are they resolved? if so I can try
given I can see the buttons for them
looks like they are
marked them as resolved
though there are still the comments I added this morning that need to be addressed
Yep on it
I forget if spotless disallows wildcard imports but if so it will be angry at you for the change you just made to GenericPacketSplitter
also I didn't get an answer to #1170668658813575230 message (doesn't really matter from a PR ready perspective, it is more me being curious and wondering for the packets I have that can be on the larger side)
It happens to all packets
No opt-in
okay
Given that the new limits for packets is 8MB
I doubt it will be used much
So..........
Both ways btw
Combined
Mojang upped the protocol limit
But due to the new way we transmit stuff we are not limitted to the max size of the "unknown" custom payloads
Because technically we are now known custom payloads
useful
Yep
just a few conversations

😛
I just pictured like, a bloody sword, and orion like "ANYONE ELSE HAS SOMETHING TO SAY?!"
Yes and no
I am happy that a lot of people are involved
But I kind of slowly have enough
if it makes you feel any better orion, you are at 190 comments (according to github), the registry rework was 199, and the cap PR was 250
then it sounds like we must go even further!
let the nitpicking begin
Is the configuration packets in general for use cases where you would previously instead send a packet from the PlayerLoggedInEvent?
(getting to the point where I am evaluating if any of my packets should be moved to configuration)
Yes
why does SyncRegistries not capture the listener and notify as a completed task but the other two syncs we add do?
Because the Sync sends acks
And the acks can just complete the config task via the context
The mod phase start and end tasks, call internal methods
so for modded tasks is it recommended to do the listener thing or is it not necessary?
Not needed
also is it recommended for mods to include the if (event.getListener().isVanillaConnection()) return; if the mod is expected on both sides?
No
Because configs don't run if your channel is not set to optional
So as long as your channels are configured properly that is not needed
wait what? So if I have a nonoptional channel then configurations don't get ran?
so then you can't actually make use of configuration packets for those mods?
if you have a non-optional channel, then it will only allow the client to connect if that channel exists the other side
ah so it won't get to the configuration phase
I am still a bit confused on when to mark configuration tasks as finished. As in:
- registries have a packet sent back from the client that it is complete, which then that packet being handled marks the task as complete
- configs just immediately mark the task as complete as soon as the packet has been sent
- tier sorting does some weird (which might be a bug??) thing where the task is only added for modded connections but then if it were to somehow be a vanilla connection when the task runs it finishes the task or disconnects. And otherwise sends it and then the client sends a packet back that marks the task as complete
but given the config one just marks it immediately is the proper approach to have a packet that is a response or can we get away with just marking it as complete immediately?
Also is the fact the tier sorting task doesn't get added when it is a vanilla connection a bug (I am guessing yes? Given otherwise the disconnect thing wouldn't be a branch in the configuration for it)
You can basically do all of it
You can capture the listener and immediatly complete
You can send a packet and complete in the handler for the ack packet
You can do weird combinations
It is up to you
And your needs
okay
and is the tier sorting thing a bug
in terms of the task not being added for vanilla connections
No that is correct
I think the extra check in the task it self
Is just out of pre-caution but is really not needed
but
if the task doesn't get added and TierSortingRegistry#allowVanilla is false
then the client won't actually get disconnected for it?
that was my point of why it seems like a bug
Fixed
I did the testing before rebase so the fix was not in
okay, and yeah I tested after and it seemed fine
yay for last minute bugs
join world works yes
so we are good to go for the deadline in 2hours 40minutes
well the blogpost still has comments to address
I am on them
well I will be back in a couple hours (not sure if before or after the target deadline), so hopefully nothing more is really needed from me
@velvet whale Addressed your comments
you didn't push
Oeps now it is pushed
Don't break everything while people are out celebrating new years eve 😄
there you go, also un-resolved some previous comments that we're actually addressed
uh @mental ingot you may want to consider batching the changes

you have to go to the files tab
unresolved stuff from the previous review, for reference https://github.com/neoforged/websites/pull/28#discussion_r1438902014
https://github.com/neoforged/websites/pull/28#discussion_r1438900996
Did I mark that as resolved?
yeah, i unresolved them
@mental ingot hi cpw https://pr-28.neoforged-website-previews.pages.dev/news/20.4networking-rework/