#linear-algebra
2 messages · Page 311 of 1
careful. any two columns of this matrix will be linearly independent, but it's only when you consider all three together that you have a linearly dependent set
rref just happens to give you the left-most linearly independent columns
yes
only the left most columns are linearly independent -the columns of the original matrix-
ah i just repeat what u said?
no and im not going to repeat either, because it's not important
i am being pedantic with the phrasing


it'd be a lot clearer if you started with "R(cu + dv)" and ended with "cR(u) + dR(v)" just like you wrote in part (a)
oh
you've definitely written way too much
how do I handle the S(cT(u)+dT(v))? unless I define T(u) and T(v) as some vector and then back sub it.
this okay then

they are vectors so i don't know what you mean by "define as some vector"
yeah i get that but just from applying the rules
what you wrote is correct. you can skip two lines as the red arrow shows, those lines are redundant

this is just "applying the rules" since T(u) and T(v) are vectors
yeah
would this problem have any sorts of different implications if it wasn't T: R^n to R^n and then S: R^n to R^n?
like if it was R^n to R^m and then R^m to R^n
no
the solution would be the exact same
even for T: R^n -> R^m and S: R^m -> R^p, or for T and S defined on abstract vector spaces
nothing changes
I see


then rank(P) = 3?
meaning the columns are linearly independent?
@wintry steppe
ty
yes
i have a list = (e_1, e_2, e_3) , e_1 and e_2 and e_3 are defined as the columns of P respectively (left to right)
since i've proven rank(P) = 3 = dim_R (R^3) then that list forms a basis?
yes
nice
thanks TTera (1 hour ago or so late 🙂 )


stop pinging me for all your questions
Sry
assuming you row reduced it correctly, this is correct. use an online calculator to check yourself
Is it possible to find Matrix A in the Matrix equation Ax=b with just x and b given?
sure (you will have lots of Matrices that can get you from x -> b
if a matrix P(u,v,w) is invertible and u,v,w in R^3 does that mean that (u,v,w) is a basis for R^3,
u,v,w are vectors in R^3
@wintry steppe have any example numbers in mind?
rank(A²) = rank(A)?
A is a matrix
what exactly are you asking for?
so i have a matrix
P(u,v,w)
such that P²(u,v,w) = I_3
u,v,w are vectors in R^3
i want to show that (u,v,w) is a basis for R^3
so i want to show that rank(P) = 3
 but if rank(A^2) = rank(A) it would seem 1 example that would be I_3?
but if rank(A^2) = rank(A) it would seem 1 example that would be I_3?
ye idk
can't help much as we have not even discussed multiplying matrices
nor am I familiar with the terminology other than seeing it a few times before
makes sense
but really have not touched on that subject so sorry
basically the transformation needs to be bijectiive
oh and seeing you said matrix a and nothing about being a linear transformatino you could easily just make it some constant thing where all x's map to that b

not sure if this would be allowed or not?
but as x has no bearing in the equation I don't see and issue exactly
and then I suppose just scale your identity matrix correctly for whatever space b is in
I see
Well I took vector x as (1 1) and vector b as (2 1)
So there exist infinitely many solutions, or matrices A, to satisfy this Matrix equation right
I'm talking about linear transformations by the way, sorry for not specifying that out 😅
Yeah I mean the easy way for something like that would be 2 0, 0 1
Basically 2/1 and 1/1 in top left and bottom right
Oh
Will we work for any R^n to R^n just scale basically identity and then scale each 1 on the diagonal correctly to get that b you want
This assumes you x has all non zero values
Or else you would have to do something different
And obviously if it is linear transformation and x = 0 vector, we can't map to b unless b Is the 0 vector

Just curious if anybody can think of hint for the trick on this?
The previous exercise was to show M=M_{nxn}(F) is the direct sum of the set of nxn skew symmetric matrices and the set of nxn symmetric matrices
Things like dimension and bases haven't been introduced yet. Apparently there's a way to do this without using anything like that?
I'm thinking the trick is to pick A in M_{nxn}(F) and rewrite it in some sneaky form like in the previous problem.
One thing I had tried was to let A=B+C for B symmetric and C skew symmetric and then write B,C in terms of two more matrices each where one has the triangular form expressed in the defn of W_1. That seemed kinda promising but I think I'm missing some important detail that would lead me to the conclusion
You can get lower triangular matrices (take a symmetric matrix and remove the "upper part")
You have the complete set of lower triangular matrices and you have W_1
Using those 2 you can construct all matrices of M_nxn
I'm not sure I understand your thinking.
So take 2x2 as an example
Suppose you want
$\begin{pmatrix}
a & b\
c & d\
\end{pmatrix}
$
Drake

Consider
$\begin{pmatrix}
a & c\
c & d\
\end{pmatrix}
$
and
$\begin{pmatrix}
0 & c\
0 & 0\
\end{pmatrix}
$
Drake

From these two you can get
$\begin{pmatrix}
a & 0\
c & d\
\end{pmatrix}
$
and from W1 you have
$\begin{pmatrix}
0 & b\
0 & 0\
\end{pmatrix}
$
Drake

So extract the "lower triangular" part and add an element of W_1 to get any matrix of M_{nxn}(F)
Oh mb,I thought i<=j would be upper triangular like that
Doesn't one of the matrices I need have to be symmetric?
Well yes
When I fooled around with small examples I gave splitting up matrices into upper/lower pieces a shot but I kept getting stuck at producing a symmetric matrix 
Consider
$\begin{pmatrix}
a & b \
c & d\
\end{pmatrix}
= \begin{pmatrix}
a & b \
b & d\
\end{pmatrix} - \begin{pmatrix}
0 & 0 \
b & 0\
\end{pmatrix} + \begin{pmatrix}
0 & 0 \
c & 0\
\end{pmatrix}
$
Drake

This should work
Sure but can we look into this problem some other time? I was skipping some important concepts in between, so I'll look into them first then we'll surely look into this together 👍
In this text, are both binary operations specified here same or can they be different too?

Well usually if we say one is a restriction of the other we mean they are the same operation just with a different domain. But nothing in this text says a*b=a°b for all a,b as a formula specifically, just a bit handwavy at the end
So honestly kind of a weird definition
I see, thank you 👍
How do I check for linear independance when there are more rows than columns in a matrix?
the same way as usual. solve the system Ax=0 and see if there is a nonzero solution

Consider the columns of the submatrix with nonzero determinant
Now The nonzero determinant part implies these columns form a LI set
because if you have a non zero linear combination that gives you zero,you can say the linear combination of columns in the kxk matrix with same coefficients is zero
@steep sandal
but you can't row reduce it to rref
why not
Got it if a col is ld then determinant will be zero we can make that col zero right???
yea'
so you have a LI set with atleast k vectors,rank can only be greater than or equal to this
could someone maybe explain me why every field is a vector space?
well it's a vector space over itself. the vectors are just the field elements which you add with the field addition. and scalar multiplication is just the field multiplication
thx 🙂
they are always equal
the hint almost gives it all away... anyway observe that 2A = (A +A^t) + (A - A^t)
what can you say about A + A^t and A - A^t
One is symmetric the other is skew symmetric?
exactly
so any matrix can be written as a symmetric matrix plus a skew symmetric matrix. to prove that its a direct sum, show there is no nontrivial way to write 0 as the sum of a symmetric matrix plus a skew symmetric matrix
I mean that's not the problem
Yeah, that's the last problem
I ended up generalizing what drake was talking about for the current problem.
I actually don't see why my approach would fail for field 2
We aren't dividing by 2 anywhere
I don't think it does fail for char 2.
Ok,I guess they expected you to do something like the symmetric ,skew-symmetric thing
And dividing by 2 would be necessary for that
Seems a little round-about to do that though lol.
yeah there A = (A + A^t)/2 + (A - A^t)/2
Is there some intuitive way to stumble on this identity if you're trying to write an arbitrary matrix as a sum of symmetric/skew symmetric matrices?
The best I can think of is that in order to write A as a sum of a symmetric+skew symmetric matrix you would have to know A+A^t and A-A^t are symmetric/skew symmetric and stumble on that identity by fooling around and adding them.
But idk if there's a better way to look at it?
Write A = B + C for B symmetric, C skew-symmetric. Take transposes to obtain A^t = B - C, and then solve for B,C
Ooh I like that a lot 

Mathematics Stack Exchange
For the function $f(x)$ we can write it as sum of even and odd functions:
$$f(x)=\underbrace{\frac{f(x)+f(-x)}{2}}{\text{Even}}+\underbrace{\frac{f(x)-f(-x)}{2}}{\text{Odd}}$$
My question is why ...




I'll probably need some time to reread and digest that but I find it very interesting. I haven't really spent a ton of time knowingly fooling around with involutions but the jist here is just that given any vector space V and any involution you can rewrite V as a direct sum of two spaces such that in one of the spaces in the sum every element under the involution maps to itself and the other space every element maps to its inverse. Then from there there's just a bunch of random places we can apply this by mucking about looking at various vector spaces and their involutions. Am I getting the big picture here?
Yeah, that's exactly the big picture.
That's weird and cool
goddamn u wrote a whole essay
You can even generalize this decomposition to any endomorphism of finite order f : V -> V. (i.e f is such that f^n = id_V for some integer n >=1). And the decomposition you get is in terms of the n-th roots of unity (as long as n is the smallest such integer for which f^n = id_V) which is sort of a finite analogous of fourier analysis lol.
Yeah, it is pretty cool.
The Z/2 grading of V obtained by an involution makes it into something called a super vector space
Which are interesting for reasons unrelated to your original question lol
But is worth mentioning I guess.

Well, if A admits an eigenbasis, then it is diagonalizable. Now, remember that a necessary and sufficient condition for a matrix to be diagonalizable is that each eigenvalue has equal algebraic and geometric multiplicity. Now, find the values of a such that the algebraic multiplicity of each eigenvalue of A (which you have already computed in number 1) is equal to its geometric multiplicity (which you have computed in number 2).
what did u find for the basis of each eigenspace of A?
I starting by considering different types of 2x3 row-reduced echelon matrices. Type 1 is $\begin{bmatrix} 0 & 0 & 0 \ 0 & 0 & 0 \end{bmatrix}$. Type 2 is $\begin{bmatrix} 1 & a & b \ 0 & 0 & 0 \end{bmatrix}$. Type 3 is $\begin{bmatrix} 0 & 1 & a \ 0 & 0 & 0 \end{bmatrix}$. Type 4 is $\begin{bmatrix} 0 & 0 & 1 \ 0 & 0 & 0 \end{bmatrix}$. Type 5 is $\begin{bmatrix} 1 & 0 & a \ 0 & 1 & b \end{bmatrix}$. Type 6 is $\begin{bmatrix} 1 & a & 0 \ 0 & 0 & 1 \end{bmatrix}$. Finally type 7 is $\begin{bmatrix} 0 & 1 & 0 \ 0 & 0 & 1 \end{bmatrix}$.

Plegasus

Then I considered the solution space for each one and found out there were not equal.
So if R and R' have the same solutions then they must be in exactly one of those types.
I wanted to see I am heading in the right direction for this problem?
okay don't trust my opinion here since idk any linalg
but
i feel like
there is a better way
to solve that
yeah, that what I was thinking too.
there is absolutely no way the end solution involves considering seven special cases and proving the final result must lie in one of them
what I was thinking was, I can explicitly write out the solution for each homegenous system for each type.
So if R and R' have the same solution then I can just "compare the solution".
i mean
i don't see why it couldn't work
but that sounds like just
an awful process
unless there's some cute simplification that makes it easy
wait
im confused
how is there a 2x3 matrix with it's transpose also being 2x3
wdym? The transpose will be a 3x2 matrix.
Its R prime.
lol
consider the 7 possible rref 2x3 matrices
show that no two of them have the same soln
this is imo the most straightforward
this is hoffmann kunze?
yeah rref is unique so any solution given from it and some other matrix would be unique too
then it has to be the same
Thank you, that is what I was currently doing, just wanted to make sure.
ana does this work >.> im just starting linalg so not sure
thinking abt it
i think if anything this is an exercise of showing that rref is unique
so assuming it is kind of defeating the purpose?
imo yeah
Mathematics Stack Exchange
In Hoffman and Kunze they have two exercises where they ask to show that if two homogeneous linear systems have the exact same solutions then they have the same row-reduced echelon form.
They firs...
okay so im ngl i dont understand any of that
so i went hunting
and found this
which makes much more sense
wtf

answer the question ana or else it will eat you
The whale?
yep
if A is a matrix how do i write the n-th column of it?
like A^n looks like its power
Multiply from the right by the n'th standard basis vector.
row is from the left?
Yes, this will be a column vector.
i don't know if there's any truly standard notation but a_n is not uncommon for the n'th column of A
there's always the somewhat hideous but sometimes useful matlab-style notation A(:,n)
which is used in the likes of golub and van loan
hey, is this just wrong because two of the arguments are identical so φ(a_1, ..., a_k) has to be 0 to be alternating or am i missing something?
you are correct
Ok but I'm kind of lost here, do I have to prove for linearity?

so alternating map requires f(a,b)=-f(b,a) right
can you make something out of here?
i actually don't understand how i can interpret the φ(e_k, e_k) for all k
it's given for the basis e_k
like φ(e_1, e_1) = 0, φ(e_2, e_2) = 0?
yes
ah ok
and they have asked if that's sifficient for alternating map
I'm not sure...
you are free to set values for ϕ (e_1, e_2) and ϕ (e_2, e_1)
the don't mecessarily have to satisfy f(a,b)=-f(b,a)
Oh I see, but I'm not sure how to write that as a proof now
construct counter example
But φ isn't defined as anything?

xD
Well it's true tho
Oh mb nvm
It's false
I thought it was \phi(x,x)=0 for all x
So I can just take any vectors as long as they're not equal right?
can any1 confirm?
I think I have given enough hints. Here's an example for 2x2 || f(X,Y)=x1y2+x2y1||
Just to confirm my understanding of the algebraic/geometric multiplicities of an eigenvalue.
The algebraic multiplicity is the number of times an eigenvalue appears right? So if our characteristic polynomial came out as (x-5)^2, the algebraic multiplicity for 5 would be 2?
And the geometric multiplicity is the number of distinct eigenvectors that exist for a given eigenvalue? Or alternatively, the dimension of the kernel/nullspace of (A - xI)?
The algebraic multiplicity is the number of times an eigenvalue appears right?
appears as a root of the charpoly
Or alternatively, the dimension of the kernel/nullspace of (A - xI)?
yes, that's the geometric multiplicity
Sounds good, thanks
technically not "number of distinct eigenvectors" - that number is always infinite since any nonzero multiple of an eigenvector is an eigenvector. you could phrase it as "maximum number of linearly independent eigenvectors" for that eigenvalue
Yeah you're right, ty
if we are being technical, over finite fields there can be only finitely many eigenvectors
fair point!
How to prove that matrix addition is commutative?
calculate A+B and B+A and see that they are the same
It's probably interesting to consider an example that breaks this, e.g. pick matrices over something that's not a field, for example quaternions, and instead of addition use quaternion multiplication.
if you have commutativity of addition of the underlying object sure
calling something noncommutative addition is pretty disgusting
see near-rings
bah. disgusting
$\sum_{i=1}^{n} |x_i|$ \
subject to $Ax=b$
FantaSkink

How do I show that this object function is not a linear transformation
We need some help to get started
this function satisfies f(x) = f(-x), something that is impossible for a linear function to achieve unless it is the zero function, which yours clearly is not
Oh cool. That wasn't in our text book for some reason 🤔
That really helped. Thank you!
hi, anyone know how to search the equation of the cone surface? is there any math knowledge library?


this is not linear algebra, but the equation of the cone is x^2+y^2=r^2z^2/h^2, now plug in the ray coordinates for x,y,z
you get a quadratic equation in t, which you can solve in the usual way
Hey everyone, my linear is super rusty, I'm trying to remember the process for solving a system like this where the solutions are unknown constants

but I want to solve it for when the matrix looks like


V is a real vector space with finite dimensions. $f:V\times V\to\mathbb{R}$ is a bilinear function acting on V.
f satisfies the following property: for any $x,y\in V$, $f(x,y)=0\Leftrightarrow f(y,x)=0$
Prove that f is either symmetric or antisymmetric.
CollinGao-ALT

Take it as $(\begin{bmatrix}1&&\&1&\&&1\end{bmatrix}+x\cdot\begin{bmatrix}-1&0&1\0&0&0\1&0&-1\end{bmatrix})^n$
CollinGao-ALT



yes
yes
so D(sinx{0,1}) = cosx{0,1}?
what is that notation
sinx{0,1}?
just "D(sin x) = cos x" is enough
i have no idea what t is
the independent variable
lmao true. probably oversight
use t and x interchangeably here, it does not matter
😕 .
do i need to know about derivetaives to learn LA?
no
they're just a fun example
although otherwise the question is also very simple so that's nice. just three times 0

How come L(X) = A*X is incorrect?
would X->L(X)=A*X be the correct notation?
yes
the author is just being pedantic lol
you can write L(X) = AX and literally no one in the world will be confused with what you mean
that's incredibly pedantic. damn never seen something that pedantic before
what would 2X->L(X)=2X mean?
that you have a map I that maps 2X to 2X
and that you have a map L that maps X to 2X
kind of
weird notation
okay thanks
Anyone can HELP?
since V is finite-dimensional, you could assume that f(x, y) = x^TAy for some matrix A, and work with that
can someone explain to me how the hell this works
so I'm trying to modify a normal projection matrix, who's inverse transformation looks like this
This is too obvious
lmao


what do you want me to say then?
into one that has an arbitrary near plane and also transforms stuff preserving linearity
I realized that only the middle row is able to be changed, and so I set up a system of 4 equations and solved them

but, after doing gauss jordan elimination it says that this is impossible, saying that 0 = 2f(p1-p2)/n
however, if i'm understanding gauss jordan elimination correctly only the first 3 rows matter, and I can get two different results dependent on what 3 equations I put into the first four points. Additionally, it seems that if I only use the results from one it will only make the 3 conditions that I put in correct, like this:
blue is what the green should look like btw
so my solution is to get both matrices and interpolate between them, which somehow actually works
the issue is that this does not keep things that are collinear collinear
why, and how do I tackle this problem in a way that isn't janky and fucked up
because in 3d its even worse
is the function space a vector space?
what do you mean?
this is unrelated to ur question btw
ah
if the codomain if your functions is a vector space, sure. if S is a set and V is a vector space, then the set of functions S -> V becomes a vector space with pointwise addition and pointwise scalar multiplication
over what field tho?
what do you think?
functions arent "numbers" so i dont know
what does matrix transposition means in geometrical sense?
is there some invariant like angle proportion which stays constant if i transpose the 2d or 3d matrix?
"V is a vector space" assumes it's over some field, and...
over V?
V is not a field
V is a vector space over a field
field of V?
yes
but
then
oh
i guess u can multiply with it
if $f\colon S \to V$ is any function and $c \in F$, the field which $V$ is a vector space over, then $cf$ is the function $S \to V$ defined by $x \mapsto cf(x)$. (note that $f(x) \in V$ and $c \in F$, so $cf(x) \in V$ is defined.)
TTerra

this is "pointwise scalar multiplication"
wait functions == maps?
fine
call them maps and reserve "function" for things going to the base field
i wrote what i meant
no i mean are they the same thing?
the word "maps" in mathematics is usually reserved for a function between two sets equipped with extra structure (e.g. vector space structure, topology) which preserves that extra structure (e.g. linear map, continuous map)
but this is not universal
I use maps and functions for the same. no difference personally
they both

"function" is sometimes reserved for things that go from a set (possibly with extra structure) to some choice of field. this is especially common in differential geometry; "function" on a manifold usually means "real-valued function"
this is purely a linguistic problem
just call them mappings or functions interchangeably, and elaborate when you need to
ok thanks
$x^2(4)=16$
x->F(x)=x^2 then F4 = 16
Yes to your second question. Indeed, the transpose of a real $m \times n$ matrix $A$ satisfies for every $x \in \mathbb{R}^{n}$ and $y \in \mathbb{R}^{m}$ the identity:
$$
\langle Ax, y \rangle = \langle x, A^{t} y \rangle
$$
And is in fact the unique such $n \times m$ matrix satisfying the abovementioned identity.
MISTERSYSTEM :urs:

So both matrices A^{t} and A are very related when it comes to how they transform the plane via rotations or reflections.
i have to solve this task right now

this is what i got so far

anyone got an idea?
also V is a inner product space
Continuous function on closed interval [a,b]?
Or simply something about combinatorics written incorrectly?
Probably continuous functions
Since it involves calculating inner product space
Thanks for the help
Can anyone please help me remember how to take the transpose of an expression, ie $(y - X^Tw)^T$
HaleyVinton

transpose is linear, and (AB)^T = B^TA^T
Thank you! Do $y$ and $X^Tw$ also switch positions? This is the part I cannot remember.
HaleyVinton

nope
Thanks!
anyone got an idea?

for the previous question i had ideas, but for this i don't even know where to start...
the definition of projection is p(p(x))=p(x) right?
yes
so obviously it's equivalent to $x-p(x)\in\text{ker }p$
CollinGao-ALT

that is true
how do you get to that?
wait a minute let y=p(z) then (x-p(x),p(z))=0
it said $\forall$
CollinGao-ALT

after all if $p:V\to W$ then y may not be in W
~Martin

p(z) would be in z and y not
oh wait
you are right
didnt see that p goes to V
thank you
wait it cant have the whole V as its image
then it doesnt work again
Now I want to prove for every $t\in\ker p,\exists x,x-p(x)=t$
CollinGao-ALT

a straightforward way to see it is to decompose two given elements as the sum of something in the image of p and something in its kernel
then the fact that these two subspaces are orthogonal will help finish the proof
If $p=\text{id}$, then it is trivially correct
CollinGao-ALT


You didn't format it properly
You just proved that <p(x),y> and <x,p(y)> are equal, with both of them being <p(x),p(y)>
Going from what you wish to prove to a tautology is sound, but ugly
yo yo
I understand this definition of a shear transformation

But what does it mean when the given shear definition is for example:

What does the 45 degree represent?
Does it give the constant of proportionality in a convoluted way or something
ok i messed it up haha

this time it looks better
intuitivly it makes sense to follow that <p(x),y_ker>=0
Still not
<p(x),y_Ker> = 0 = <x_Ker, p(y)>
you proved 0=0
Here's how you might format it :
$$\langle p(x), y \rangle = \langle p(x), p(y)+y_\text{Ker} \rangle = \langle p(x), p(y) \rangle$$
$$\langle x, p(y) \rangle = \langle p(x)+x_\text{Ker}, p(y) \rangle = \langle p(x), p(y) \rangle$$
Syst3ms

Thus $\langle p(x), y \rangle = \langle x, p(y) \rangle$
Syst3ms

ohhh, i got it the other way around
this would be my reasoning, but i dont think it is a proper prove since it is like "think about it and it becomes clear"

Right, a projection is orthogonal iff its image and kernel are orthogonal
So what you need to show is that $\forall x\in \text{Im}(p), \forall y\in\text{Ker}(p), \langle x,y \rangle = 0$
Syst3ms

Hint : if x is in Im(p), what is x equal to?
p(x)
if $x\in Im(p)$ and $y\in Ker(p)$ then $\langle x,y\rangle$ would turn into 0
~Martin

Yup, so that means Im(p) and Ker(p) are orthogonal
That is, p is an orthogonal projection
should have gotten it from here already haha
oh wait is it trivial that $\langle p(x),y\rangle$ is 0 if $y\in Ker(p)$?
~Martin

i mean that is kinda the thing i wanna prove after all
how do you get to <x,0>?
oh yeah
i had:
$\langle p(x),y_{Ker} \rangle =\langle x_{Ker} ,p(y)\rangle $
here y is not in the Kernel, but $y_{Ker}$ is
Hello, and sorry to barge in. It seems I do not have permission to create threads. I only have a short question.
What is the most informative introduction to Linear Algebra? I want to teach myself this topic but I already understand Mathematics overall so I am looking for a dense book with a focus on proof, not intuition or calculation. The more depth and generality the better for me.
~Martin

in my problem y_K is not the same as y, thus y is not in the Kernel
This isn't for x and y in general
This is for y∈Ker(p)
y=y_Ker if you want your notation
but if it's not in general what is it's use?
Because you're not trying to prove <x,y>=0 in general for x,y∈V (good luck with that btw)
What you're trying to prove is that Im(p) and Ker(p) are orthogonal
That's what being an orthogonal projection means
And the definition of two subspaces U and W being orthogonal is that for all u∈U and w∈W, <u,w>=0
if x is in p(V) and y in Ker(p)
<p(x),y> = <x,p(y)> = <x,0> = 0
but i dont think i had <p(x),y> = <x,p(y)>
or better put i never had an expression whith p(y) where y is in the Kernel
but i dont think i had <p(x),y> = <x,p(y)>
IT'S THE HYPOTHESIS
not with p(y) where y is in the Kernel
Tell me what the kernel is a subspace of
of V
y doesnt have to be in the kernel though right?
No?
Just like when I say that f(x) > 1 for all real x, it works for x=0
But x doesn't have to be 0
It can be anything, in particular it can be 0
so you assume it to be in the Kernel, then the output clearly is 0
Yes?
but i dont think that proves it for all possible x and y
thats where im stuck
I spell out this restriction right there
what are you even trying to prove for all x and y?
i want to prove that if this is true, then p is an orthogonal projection
I think you read that wrong
"p is an orthogonal projection if (for all x,y <p(x),y>=<x,p(y)>)" does NOT mean "for all x,y, (p is an orthogonal projection if <p(x),y>=<x,p(y)>)"
Your hypothesis is that the formula holds for all x and y, not just some fixed ones
And you use that to prove p is orthogonal
yeah, as you say i dont want to fix my x and y
that's good, you don't have to
i suggest you brush up on quantifiers again, because you're getting stuck on some rather basic uses
sry but what do you mean by quantifiers? im not a native speaker
like operators?
the thing is that i wanna show that if:
<p(x),y_K> = <x_K,p(y)>
Then <p(x),x_K>=0
ok thank you for your plentiful time^^
it really means a lot to me
i actually think i understood it after reseting my brain real quick
Hey guys can someone explain what ∧ does here, how did we get the e3?

^ is the vector product @visual hedge
You can see $\varepsilon_3 = \varepsilon_1\times\varepsilon_2$, @visual hedge.
jnkena

I can't see it, lemme see
It is sometimes used as a notation for the vector product. Just be cautious, because it is most commonly used in the modern mathematics literature as a notation for the exterior/wedge product, which is a different notion. In this case, they are using it as a notation for the vector product.
The relationship between the vector product and the wedge product is given by Hodge Star Operator, where given two vectors $u,v \in \mathbb{R}^{3}$, we have that:
$$
\star(u \wedge v) = u \times v
$$
And this is one of the reasons why some people when talking about vectors in $\mathbb{R}^{3}$ use both notations interchangeably.
MISTERSYSTEM :urs:

I keep reading and trying to understand and watching videos, I just don't get how it was calculated
It is the vector product one learns in precalculus or prealgebra
$(v_1, v_2, v_3)\times (w_1, w_2, w_3)=\begin{vmatrix}i & j & k\v_1 & v_2 & v_3\
w_1 & w_2 & w_3\end{vmatrix}$
jnkena

$=(v_2w_3-v_3w_2, v_3w_1-v_1w_3, v_1w_2-v_2w_1)$
jnkena

Thanks
Thanks for explaining guys, but I just never came across these ever before
Oh, that's weird if you just run into that, isn't it? I mean, why?
Are you actually studying Numerical II and you didn't ever studied x product? It's so interesting the difference in curricula between countries. In my country the vector product is studied with 17 years old at high school
I encourage you studying the definitions and properties of the dot, vector and mixed products
If you want to know more you can revisit the theory if inner products which are a generalization of the dot product
Do you suffer from that?
Idk man I just hate it, north africa is pretty f*ed
Oh, North Africa...
What's more annoying is when teachers don't provide material such as PDFs for you to study with
:O
This semester sucks for that reason
If you need stuff ask us or maybe in the Internet
I know indeed people have been very helpful especially here
But us studying in french is also annoying
Kinda
Thanks man
Yo man thank you so much, finally I could calculate it
I guess in $v_iw_j$ the index "i" is always the current column or row +1 and it loops so that when we're in the last column or in the 3rd one the index "i" for v is 1
Lionasty

¡No problem! Thank you for asking!
I don't get what you mean with this.

Talking about how to choose the indexes of v and w
Can anyone point me to a good resource on projections of continuous funtions onto subspaces
?
It's not explained very well in our course book
@wintry steppe R^2
the t,u plane is R^2
yes
is there a mapping like that?
thank you. i got it.
is $A \in \mathbb F^{n\times n}$ correct notation for saying "$A$ is an $n\times n$ matrix with entries in $\mathbb F$"
anamono

yes
dope thanks
how can you prove that the wedge product of linearly independent vectors must be nonzero?
pretty basic question i think, but somehow i jsut cant figure out a proof
Mathematics Stack Exchange
Given ${e_1,\cdots,e_d}$ a basis of $V$, we have $e_1\wedge\cdots
\wedge e_d$ is a non-zero vector in the exterior algebra $\Lambda_d (V)$.
Given a decomposable element which can be written as ...
uh yeah i've read that, thanks icy
Why wasn't it helpful?
Oh
Oooooooooooooohhhhhhhhh...............
Why didn't I figure that one out?
is this what’s commonly called a “Jordan block”?

usually jordan blocks are the other way around lol
the 1s are on the wrong diagonal
hmm yeah that’s what i saw online lol
wolfram mathworld says “The convention that 1s be along the subdiagonal instead of the superdiagonal is sometimes adopted instead (Faddeeva 1958, p. 50).”
Well HK has a different definition of Jordan block
Conceptually both are equivalent
gotcha
is this true ? $$|Ax|\le |A||x| \implies |AB| \le |A||B|$$
Fractal

and Im not taking A to be an induced norm
I know this is true for induced norms
but I wonder if this other one is
otherwise, Id appreciate a counter-example
basically saying that if || does that with a vector norm, then it is submultiplicative
how are you taking the norm then?
Since induced norms tkaes into acc the multiplicative structure of L(V,V), it is not necessarily true that any other norm would
because the "definition of a norm" do not in general see the multiplicative structure
sure, but this is a weaker condition
so my guess would be no, but I'm also curious about a CE
Im wondering if it is sufficient
yeah
I suspect thats wrong
I was givne that in an exercise
I think they just wanted the norm to be induced
couldnt find anything about that elsewhere
but cant find any counter either

,rccw

Anyone???

oh, so the determinant of the gram matrix.
Yeah
right so maybe this is easier to show if we write it as G(v_1, ..., v_k) = |v_k^N|^2 * G(v_1, ..., v_k-1)
G(v_1, ..., v_k) should be equal to G(v_1, ..., v_k-1, v_k^N) but i cannot think of a way to show this right now that would not involve tedious matrix fuckery
I got that what uhh are saying and even know it is true by just observing gram matrix but how do we show on paper
Same I m also not getting that
well ok let's package our vectors into an n by k matrix V = [v_1, ..., v_k]
so the gram matrix of {v_1, ..., v_k} is V^T V
now v_k^N is v_k plus a linear combination of v_1 through v_k-1
so if we let $V' = [v_1, \dots, v_{k-1}, v_k^N]$ we will get that $V' = VE$ where $$E = \bmqty{1 & & & & \alpha_1 \ & 1 & & & \alpha_2 \ & & \ddots & & \vdots \ & & & 1 & \alpha_{k-1} \ & & & & 1}$$
.
shit
i fucked up the typesetting hold on
Ann

I didn't get what u did still I will pretend I got it
$v_k^N = v_k + \alpha_1 v_1 + \alpha_2 v_2 + \dots + \alpha_{k-1} v_{k-1}$ for some coefficients $\alpha_i$ whose exact values i dont care about right now
Ann

do you understand this?
Yeah
right
do you understand why V' = VE as i wrote above?
i fixed the matrix typesetting now
Yeah
Ann

on the one hand, this is equal to $$\det(E^TV^TVE)= \det(E^T) \det(V^TV) \det(E) = \det(V^TV) = G(v_1, \dots, v_k)$$
Ann

on the other hand, because v_k^N is by definition orthogonal to span{v_1, ..., v_k}, V'^T V' is block diagonal
it has one block of size (k-1)×(k-1) which is the gram matrix of {v_1, ..., v_k-1} and one block of size 1×1 whose element is v_k^N · v_k^N, or |v_k^N|^2
do you understand this?
Ok got it
does anything else need explaining?
@keen sierra actually, it isn't obvious for me how induction is used in the case despite me understanding induction itself quite well.
There was another theorem in the book regarding multiplying a row/column by a scalar and getting determinant multiplied by the scalar as well. The proof involved using induction as well but I had understood the property by imagining a "call tree" where each minor is decomposed into other minors and is multiplied at a moment and only once. Should I do it another way?
They are simply the components in order.
the proof expresses the determinant as a linear combination of determinants of smaller matrices (the minors)
the induction hypothesis applies to the minors because they are smaller
Then in my opinion it first should be true for n x n matrix
And only then for (n - 1) x (n - 1) matrix
you're proving it for the n x n matrix, under the assumption that it's true for (n-1) x (n-1) matrices
that's how the induction step works
Hmm okay
It is just not obvious to me that if something is true for a 2x2 matrix, then it is true for a 3x3 matrix and so on...
it's true for a 2x2 matrix by explicit calculation
Yes
then you can prove that it's true for a 3x3 matrix because you can express the determinant of a 3x3 matrix as a linear combination of determinants of 2x2 matrices
and similarly the determinant of a 4x4 matrix is a linear combination of determinants of 3x3 matrices
it's not automatically true for a 3x3 matrix just because it's true for a 2x2 matrix, you have to prove that, and that's the main part of the proof
I am not sure that when going from a 3x3 matrix to a 2x2 minor all just the right minors will be chosen which will result in determinant changing its sign
well that's why the proof makes the distinction between the case where the minor corresponds to one of the rows that was swapped versus the case where it does not
Can we get specifically to the case when i doesn't belong to {1, k}? Why is it obvious that A(i, 1) = −B(i, 1)? Because when decomposing the sigma it will have the same both cases when i doesn't belong to {1, k} and when i belongs to {1, k} inside. The first case is just a recursion and the second is not proved yet. Besides, when decomposing sigmas again and again at one moment we will get rid of cases where i doesn't belong to {1, k}. Should I try to comprehend the "i belongs to {1, k}" case first?
Gonna send the pictures again.


Actually I didn't understand fully will try
Are you done with me?

Well for something to be linear both f(av) = af(v) and f(u+v) = f(u) + f(v) has to be true
You have to find a function where the first part is true but the last part isn't
$P_{y, x}=\sum_{\zeta=\max {y-k, 1}}^{\min {y+k, N}} \sum_{\xi=\max {x-k, 1}}^{\min {x+k, M}} \omega_{y-\zeta+k+1, x-\xi+k+1} O_{\zeta, \xi}$
FantaSkink

How would this type of image convolution handle convolution of the original image $O$'s outer edge pixels?
Where kernel $omega$ is of size $2k+1\times 2k+1$


Is this linear algebra?
It's a linear transformation on a matrix
maybe think along the lines of f(x,y) = xy...
No that doesn't work because then neither of requirements are true
Lol ok, where should I ask then?
it's non-linear and I didn't say that was an answer, it's just similar to an answer I thought of
some kind of rational function
Can anyone help with this, I'm lost

I think you are more likely to get meaningful help in #numerical-analysis tho
Fix any nonzero vector v in R^2 (say take v = (1,0))
Now, for any vector x in R^2, denote by M(x) the matrix whose first column is given by x and whose second column is give by v.
Now, define f(x) = det(M(x))
Notice that a satisfies the above mentioned property.
since the det(M(ax)) = a*det(M(x)). So precisely f(ax) = a*f(x)
Notice that since v is non zero
then there exists at least one vector x in R^2 such that the determinant of M(x) is non zero.
Thus f defined in this way is not identically 0.
Moreover, it is not a linear map (check this).
You can generalize this example to any dimensions.
is there any more information?
Need some help on this

what have you tried?
Well I get that the codomain is R, so I will need to use a 3×1 matrix. However I have no idea how to find the rank of that matrix
@hexed bronze for (i), can you explain in words what the kernel of T is describing? what property/properties the elements in the kernel have in common? i.e., what does it mean for a•x = 0?
Orthogonality?
wym orthogonality?
Yes, I'll reply with it later ❤️ Thank you!
a must be orthogonal to x
yes
yeah but how do I find the rank of x?
Aren't there like many vectors orthogonal to a
do you really need that?
I need the dimension of null space
rank T = dim of the image
Image?
image of T
Sorry, kinda losing you there. By image you mean the transformed space right
What order tho? I just noticed that the number of the column doesn't appear in the index that's why in column 1 there is no index 1
so null space is all the vectors that are perpendicular to a right?
Yes..I got it dim must be 2 ig
i.e. (x, y, z) such that a1x+a2y+a3z = 0
ye
Yeah
Is there any mathematical way to say this tho?
From rank point of view
^
dim W + dim W\perp = n
you can use this
if you know why this is true
W = span(a)
Isn't that the rank nullity theorem itself? Like nullspace is orthogonal to row/column space iirc
no it's not
kinda mix of Gram-Schmidt and basis extension and shit iirc
anyway
given you have ax+by+cz=0
you can determine value of one given other 2
with this you can find a basis of the null space, which will have 2 elements so dim = 2
Oh and the last part, what about the basis? Can I take a cross product
With some arbitrary vector, cauz all I need is 2 vectors along the plane for the nullspace
Anyone know what is the difference between a discrete time Markov chain and a time homogenous Markov chain? Im only familiar with the first of these where the probability of moving to the next state depends only on the current state and not the entire history

yes
Thanks

For proving that the set of symmetric polynomials is a subspace of the space of all real matrices of size $n \times n$, which we denote by $\mathcal{M}{n}(\mathbb{R})$, notice that the set of symmetric matrices is precisely defined as the kernel of the linear map:
$$
f : \mathcal{M}{n}(\mathbb{R}) \rightarrow \mathcal{M}{n}(\mathbb{R})
$$
Such that $f(A) = A - A^{t}$ for every matrix $A \in \mathcal{M}{n}(\mathbb{R})$.
MISTERSYSTEM :urs:

Now, in order to find a basis for this space, notice that each symmetric matrix is precisely determined by the number of entries on or below the main diagonal (since the (i,j)-entry is equal to the (j,i)-entry), and there are (1/2)*n*(n+1) on or below the main diagonal.
This can give you an idea of how to proceed from here.
*space of symmetric matrices
that's a smart way of seeing things
but personally i would just show it's closed under linear combination
they're both just as short and easy
That notation with bars | A | is the determinant of the A matrix. And i=(1,0,0), j=(0,1,0) and k=(0,0,1). Look for determinant of order 3 and Sarrrus Rule, @visual hedge.
I can see it now man, thank you so much man!
does any non zero matrix M over a field F have an infinite number of row equivalent matrices?
is F infinite?
mhm
then yes, all the scalar multiples of M are row eq to M
alright thanks, I was having some doubts on that assumption
I was worried it wouldn’t work for all fields
it doesn’t work for finite fields obviously since there are only finitely many matrices
yea
what is a determinant
like i know how to calculate it, but in practical terms what does it actually mean
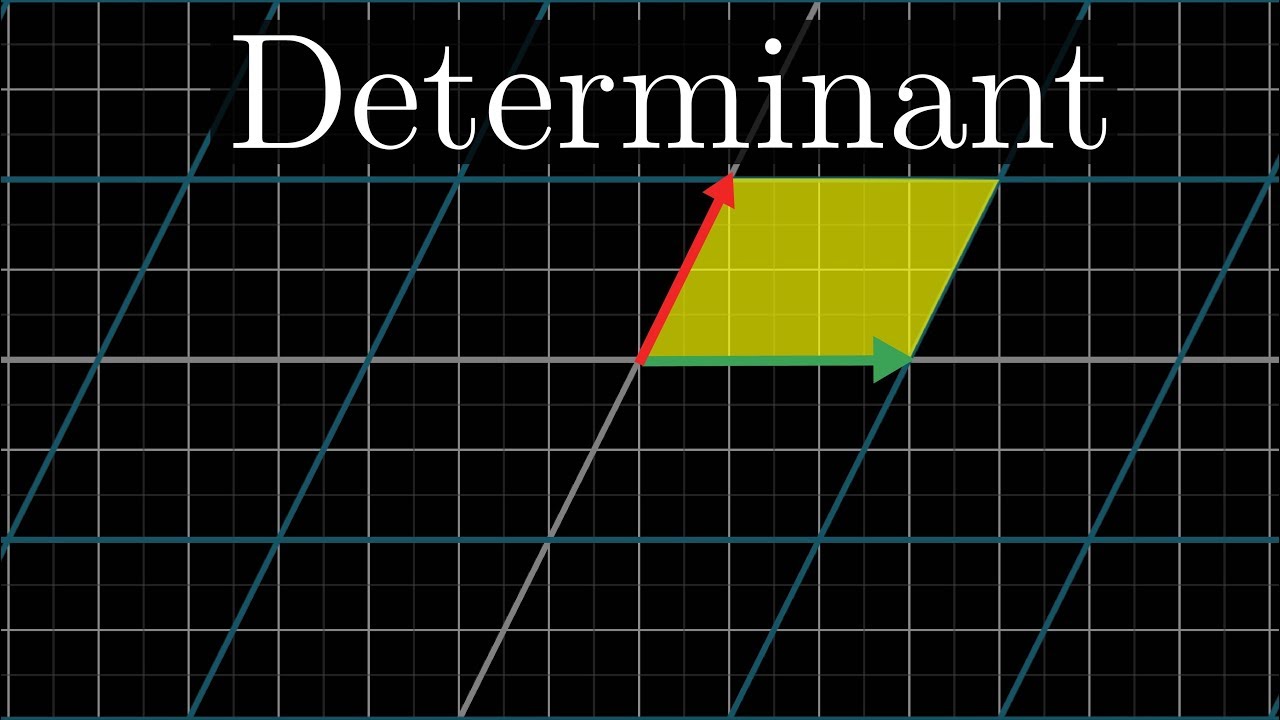
The determinant measures how much volumes change during a transformation.
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to simply share some of the videos.
Home page: https://www.3blue1brown.com/
Full series: http://3b1b.co/eola
Future series like this are funded by the community, throug...
ty
the determinant of a matrix is the signed volume of the parallelepiped its columns span
you can derive just about any fact about the determinant you'd like just from this nice geometric definition
For nxn matrices A,B if AP=PB where P is an nxn matrix does that imply A and B are similar or does P also have to be invertible for A and B to be similar?
notice that P doesn't have any condition given on it
can you pick one P such that AP=PB for all A, B?

"the composite linear map" here refers to the composition of T and S, as they say immediately after the phrase.
and surely you are familiar with the concept of "matrix of a map"?
@steep sandal
the composition of T and S
Like function?
yes, composition like functions.
"compositeness" is not an inherent property that some linear maps have and others don't, just so we're clear on that.
in fact they even use the same symbol: see that $\circ$ in $T \circ S$?
Ann

Yeah
How could I construct a 2x2 matrix that has 2 specific eigenvalues?
Hi, if I have two (square) matrices A and B and A arises from B by increasing the diagonal elements do I have A >= B (eq. A-B is PSD)
put the eigen values in the digonal and rest to 0
isn't then A-B just the factors you have increased B and all off diaginal =0?
Yes provided off-diagonals are the same, right?
you are changing only the diagonals, so rest are same
so the diff would be 0
(off diagonals)
I'm suddenly seeing notation where a matrix is an exponent, like e^A
What is actually happening there?
power series
matrix exponential 
since e^x = 1+x+x²/2!+..., you define e^A = I+A+A²/2!+...
3b1b has a video on this
https://www.youtube.com/watch?v=O85OWBJ2ayo

General exponentials, love, Schrödinger, and more.
Help fund future projects: https://www.patreon.com/3blue1brown
An equally valuable form of support is to simply share some of the videos.
Special thanks to these supporters: https://3b1b.co/mat-exp-thanks
The Romeo-Juliet example is based on this essay by Steven Strogatz:
htt...

I am thinking if $V/W$ is equivalent to ${\vec{v}+\vec{w}:\vec{v}\in V$ and $\vec{w}\in W}$
Trenton

the second set is V + W, which is just all of V
the first set is not even a subspace of V, it's something entirely different
Umm the first set you mean is ${\vec{v}+W:\vec{v}\in V}$ and the second one to be ${\vec{v}+\vec{w}:\vec{v}\in V$ and $\vec{w}\in W}$?
Trenton

Sorry I can’t follow, where does the $V+W$ comes from?
Trenton

i am saying that the second set you wrote is the sum of the subspaces V and W
and since W is a subspace of V, this set is all of V
Ok got it thanks
what you're probably thinking of here is the union of all elements (cosets) in V/W, which is V+W or V, and not the separate elements themselves.
hint || you only need the image of the basis ||
no my question is more like
would the plane's normal be mapped to the image plane's normal
you can visualize a skew transformation in 3d
or in 2D, take A= [1 1; 0 1]
and take the line y=0 and x=0. You should get analogous case for planes also
Any relations between even and odd functions and symmetric and skew symmetric matrices?
New to linear algebra.
use linearity to calculate T(-x) = T(-1 * x)
is this odd or even?
Odd
Well consider the function
T(X)=X^t
On the set of symmetric matrices this is even
On the set of skew symmetric matrices this is odd



font is so small
pretty cool
Yeah so, I think the best analogy that can be done between even functions and symmetric matrices is that both of them are the eigenspace associated to the eigenvalue 1 of a certain involution on a given vector space.
And similarly
Odd functions and skew-symmetric functions are the eigenspace associated to the eigenvalue -1 of a certain linear involution.
And this gives you a decomposition of your space
as a direct sum of these eigenspaces
In one case you can write any function as a unique sum of even and odd functions.
And in the case of real square matrices, you can write any matrix as a unique sum of symmetric and skew-symmetric matrices.
By playing around with different vector spaces and different linear involutions, you can get similar decompositions.

Let $(V, <\cdot , \cdot>)$ be an inner product space and $W \subseteq V$ a linear subspace. Then, $$(W^{\perp})^\perp = \overline{W}$$
Siupa

Some hints?
I'm working with Hilbert spaces but I wrote inner product spaces because I don't think completeness is necessary for the proof
I believe you can show $(W^{\perp})^{\perp} \subseteq \overline{W}$

for the other way around, take $w\in \overline{W}$ and so you get a sequence $(w_n) \subseteq W$ with $w_n \to w$

maybe you can do something with <w_n, x>
completeness is necessary
you need W to be closed subspace at least
I mean if W is closed then this is just telling $(W^{\perp})^{\perp} = W$
Siupa

true
I'm interested in the case where W need not be closed, so that the closure is non-trivial
ig you don't need it then
can you take over from here?
Don't know let me see, I'll try
use continuity of inner products

What is an endomorphism and how do you check whether a certain transformation is an endomorphism? The term endomorphism has been used freely by professors and assistant-helpers alike and I just took it as a given but i never really understood what it actually meant. My current understanding of the term is that an endomorphism is a transformation in which the domain and the image are in the same set. (sorry if i used any incorrect terms as my course isnt taught in English nor is English my first language)
in the linear algebra context, an endomorphism is just a linear map from a vector space to itself
checking that something is an endomorphism boils down to checking that it is linear
So T: V->V: (something somthing) would always be an endomorphism as long as it is linear
yes
if you ever see the word "automorphism" that just means an endomorphism with an inverse that's also an endomorphism
(the inverse being an endomorphism part is usually automatic, like in linear algebra)
so in general there's no need to worry about it as exam question for linear algebra will most probably involve endomorphisms, correct?
i'd worry if i didn't know what an endomorphism was
fortunately, it's simple
i dunno about exam questions 
I had an inkling of what it was, just wanted confirmation, thanks for answering ❤️
whats a circulant matrix?
A matrix where each row is the same, but shifted one step with respect to the previous row
In linear algebra, a circulant matrix is a square matrix in which all row vectors are composed of the same elements and each row vector is rotated one element to the right relative to the preceding row vector. It is a particular kind of Toeplitz matrix.
In numerical analysis, circulant matrices are important because they are diagonalized by a di...
ah thank you
They are all diagonalized by the Fourier matrix (on that page too)
hi! sorry for messaging here but i just have a problem with these two matrices. the second matrix was a result of adding the row of the first matrix to the negative of the second row


so i thought the determinants would be the negative of each other
but they're equal for all values of t
why is that?
adding a multiple of a row to another row doesnt change det
what ur thinking of instead is that scaling a row by k scales det by k
ohhhh okay okay
my problem now is
i have a different set of matrices now


and i arrived at the second matrix by adding the first row to the negative of the second row
and the determinants are the negative of each other there
so i'm really confused i'm sorry
ohhh i get it!
then added 1st to 2nd, doesnt change det
and then i added it to the second row
thank you so much and i'm so sorry for my questions
have a great day
np 
@tropic kernel hang on
those matrices dont match what u did
following what u did, row 1 should be 0, 1-t, 0
this is the effect of adding -1*row 2 to row 1, which doesnt change det
but 0, t-1, 0 (maybe from an algebra mistake) is -1 times the actual result, which is why the det is mistakenly scaled by -1

No assignment
What is your definition of a reflection matrix?
@sly dock Q takes a vector $x$ and negates it's $u$ component because $Qx = x - 2(x, u)$. So it is reflection across the plane with normal vector $u$.
IlIIllIIIlllIIIIllll

“Every entry off the main diagonal of N is 0.” is this not the same thing as saying N is a diagonal matrix
then what is it?
wdym
you tell us anamono
oh
i was just asking what’s the difference between “Every entry off the main diagonal of N is 0” and “N is a diagonal matrix”
Hey all, How is everyone? 🙂
I need to get matrix J=P^-1AP where J is Jordan matrix, A is then given matrix and P is an invertible matrix
