#linear-algebra
2 messages · Page 209 of 1
oh wow I think I understand yes
then one could probably make a statement about the dimensions based on the rank
that the solutions are unique means that the matrix is full column rank, so rank(A) = n, and m >= n
let's see
how'd you know that m >= n? and is it important to say that?
oh I think I see it now
lemme think for a bit. this part should be easy, but i'm sleepy and i suck at math
right, the idea would be that for unique solutions, the null space should have only the 0 vector
that's because
after you said A spans R^m
means C(A)=R^M
so dimC(A) = dimR^M = m
and we also know that dimC(A) = rank(a) = n
so n=m
nice
you're very good no worries (:
that seems ok to me, i'm sure someone else will pop up with a correction if we made a mistake somewhere
thank you for your help! 🙂 appreciate it
Is "vector in terms of basis" different from "alpha of the linear combination of basis to find vector"?
@misty storm not sure what an alpha of a linear combination is, could you give more context or an example?
not really sure how i'm supposed to approach this problem, I just got introduced to vector spaces and subspaces. My best guess is C right now. Do I write it as a matrix? How do I test for additive closure and all that from its current form

i think a 'vector in terms of a basis' means: for a vector x in your vector space, say R^n, choose a basis v1,...,vn. then your x can be written uniquely as a linear combination of v1,...,vn.
say x = c1v1 + ... + cnvn for some scalars c1,...,cn.
writing x as the vector (c1 ... cn) is expressing x in terms of the basis v1 , ... , vn.
you believe it's C. is that because you are able to write a matrix that has its nullspace defined by the set specified in the question?
or, have you tried doing that, but failed?
no its literally just a hunch, but I did try to write a matrix
have you computed the nullspace of a matrix before, by RREF?
I'm not sure if I understand whhat I'm even supposed to do I just started making a matrix and I moved 4(x3) to one side to set it equal to 0
I think so but I don't really get what nullspace is
my recommendation would be to study some examples of how you compute the nullspace of a matrix. this, you probably did before. then, from understanding how nullspaces are computed, you can tackle your problem of creating a matrix with a specific nullspace.
so is a nullspace just the set of all the vectors that multiply by the matrix and equal zero?
yes, in fact, the nullspace of the matrix A is an example of a subspace
it would be a good exercise to try and prove that, if you haven't already
"W is a subspace because it has a zero element." what does this mean for it to have a zero element
does that mean an entry in the matrix is zero? or a row? or neither
or does that mean if every xn = 0 Ax = 0
$0\in W$
they mean that the zero vector is in W
Mosh

W is a set of vectors, not a matrix
okay so W has a zero element because
0-2(0) = 4(0) etc?
yes, x1=...=x4=0 satisfy the constraint on R4 to make W
i have to take my leave, good luck with your problem, hope i was of help to you
thank you
one of the practice exercises my teacher issued mentions "spaces generated by vectors"
but vectors would only generate a subspace, technically, right?
or is it the same thing basically?
subspaces are spaces
dont think so
how would I go about figuring out wether or not that was the case?
see how many linearly independent vectors there are that generate it ig
0
that still counts as having 1 linearly independent one
sensible
and if I have, say 2 or 3?
that would generate a subspace of dimensions 2 or 3, accordingly?
ah
any clue anyone?
Let A be a real matrix non-square of order m x n, while m ≠ n.
Show that at least one of these matrices is non-invertible: A * transpose(A) , transpose(A) * A.
what does constrain mean in matrices
I have a matrix in non-RREF, and it is asking "Write down all the constrains on the variables xi
, i = 1, . . . , 6 from the system"
Is it correct to do rank(A* transpose(A)) = rank(A)² ?
no
what is it equal to?
it is equal to rank(A)
why's that?
we know that rank(transpose(A)) = rank(A)
then rank(A* transpose(A)) = rank(A) too?
as a quick reason for why it's not rank A squared, if A=I and the dimension was n, the dimension on the left is n and the dimension on the right in your equation is n^2
yeah
you can show that they have the same null spaces
hmm I'm trying to see it
It's easier to see if you replace the right part with rank (transpose(A))
if x is in your nullspace and transpose(A)x=0, then multiplying both sides by A gives one part
if x is in the nullspace of A * transpose(A), then A*transpose(A)x=0 (vector) and so transpose(x)A * transpose(A)x = 0 (number)
but the lefthand side of that equation can be written as a dot product
oo I think I understand now
thanks for the detailed explanation 🙂 I see it now @novel jetty
np. If you're interested in applications of this, it comes up a lot in doing least squares estimates
good to know)
guys
real quick
this is a change o' coordination matrix

is it from a->b
or b->a?
that notation isn't standard, so it depends on what book or notes you're using
hey could anyone help with this?

im assuming part a is just 4x5 matrix, but for the rest i have no clue @solid hedge
That's incorrect dimensions, I'm pretty sure
what did u learn about linear systems?
how come?
i thought so too
u know gauss elimination?
i do but im not too confident with it
having no solutions is equivalent to the right column being independent of the others
but u know the theory behind it?
not really
im having a hard time visualizing possible matrices for each scenario and its connection in terms of ranks
we would assume the matrix would be in RREF right?
you can assume that if you want
they dont give specific numbers right, so it could be anything, but i know rank has to do with leading 1s within a matrix no?
I find it easier to think of things in terms of linearly independent columns, but you could also look at 1's in RREF
ah i see

This video is provided by the Learning Assistance Center of Howard Community College. For more math videos and exercises, go to HCCMathHelp.com.
Do you know the term full rank?
did your class cover span, basis, and linear independence?
going over span rn
ln independance is something im still learning
so im a bit confused about this question
no i dont recall hearing that term
for the purposes of this problem, the right column being in the span of the left columns means that there is a way to write it as a linear combination of the left columns
the left columns being linearly independent means that there is at most one way to get any possible answer
being a basis can be important to parts of this problem, but knowledge of that isn't needed
that would be too much of a hint
finding variables to solve the system of equations is equivalent to finding a linear combination of the left columns that is equal to the right one
using what I said here, you could consider whether it is possible for this to occur at any number of linearly independent left columns
I think it will be hard for you to do things this way if you're struggling with spans and linear independence, but I can't think of a simpler way to do this
ah okay
i was having trouble understanding this passage in lax's linear algebra book , about the transpose of a matrix:
namely the sentence '...we see the matrix T acting from the right on row vectors is the same as the transpose of the matrix T acting from the left on column vectors'. isnt the transpose of the matrix T acting from the left on the row vector l?

is something like
[1 0 0;
0 0 0;
0 1 0;
0 0 1 ]
considered not in echelon form because of the row of zeros not being on the bottom?
correct, it is not in row echelon form.
but its very close
just need a couple swaps
What does an object mean here?

nothing
a thing
they're introducing a new notation here
it says "you run into this thing, and it looks like this, and you go 'oh, that's a tuple' "
Long story short tuples are equal if all components are equal
tuples are ordered pairs/triples/quadrutuple/quintuple/n-tuple(see the reason why they are called tuples now?), so (0,1) and (1,0) are not the same
Hi #linear-algebra I’m kinda stuck on this problem.
This is what I have so far, just some rando thought that I’ve not managed to string together cohesively.
-
Since $\mathbb{U}_i $ is finite for all i, then each one has a finite basis. Call each basis $\mathcal{B}_i$ respectively.
-
If I take the Union of the bases, I will also get a finite set, (which I can’t prove, but MSE say this is covered in elementary set theory classes.)
$\bigcup^{m}_{i=1}\mathcal{B}_i \text{ is finite. }$
- It would be convenient at this point to take the span of the Union because that equals the subspace sum somehow?? I can prove this...
$span\bigg(\bigcup^{m}_{i=1}\mathcal{B}i \bigg)\stackrel{?}{=} \sum^{m}{i=1}\mathbb{U}_i $
And I’m stuck. I don’t know if this is the right plan of attack.....

Hi #linear-algebra I’m kinda stuck on this problem.
This is what I have so far, just some rando thought that I’ve not managed to string together cohesively.
-
Since $\mathbb{U}_i $ is finite for all i, then each one has a finite basis. Call each basis $\mathcal{B}_i$ respectively.
-
If I take the Union of the bases, I will also get a finite set, (which I can’t prove, but MSE say this is covered in elementary set theory classes.)
$\bigcup^{m}_{i=1}\mathcal{B}_i \text{ is finite. }$
- It would be convenient at this point to take the span of the Union because that equals the subspace sum somehow?? I can prove this...
$span\bigg(\bigcup^{m}_{i=1}\mathcal{B}i \bigg)\stackrel{?}{=} \sum^{m}{i=1}\mathbb{U}_i $
And I’m stuck. I don’t know if this is the right plan of attack.....
Finite union of finite things is finite
Videlicet
Compile Error! Click the  reaction for more information.
reaction for more information.
(You may edit your message to recompile.)

Yes, That's the right angle of attack
I believe it, but I can’t prove it. There’s a proof in Halmos Elementary set theory
The maximum number of elements in a finite union is when the sets are distinct
In that case,you just add the cardinalities
And finite sum of finite numbers is finite
How do I prove point 3?
$span\bigg(\bigcup^{m}_{i=1}\mathcal{B}i \bigg)\stackrel{?}{=} \sum^{m}{i=1}\mathbb{U}_i $
$$span\bigg(\bigcup^{m}_{i=1}\mathcal{B}i \bigg)\stackrel{?}{=} \sum^{m}{i=1}\mathbb{U}_i $$
Videlicet

You know span(UB_i) is a subset of \sum U_i?
i was trying to do double inclusion....
So this was first step....

Span(U B_i) is just the set all linear combos of all the basis vectors....
Now each a_i b_i is in \sum U_i
Yeah. Yeah. Okay. I see that
So,Any Element in that set is in \sum U_i

I mean not exactly U_1,U_2 and so on
Won't representing a set of n-tuples from a field F make sense to be showed as $F_{n}$ instead of $F^n$?
Researcher in Pre-algebra

No
The superscript notation is inspired from how the tuples are constructed from some product
Ohh
And well, any notation works but ^n is common notation
Okay
Also,You can see them as functions from {1,2,3...n} to F
b_i \in B_i, means that b_i is just a vector in U_i.....i see it.
b_i could be in U_j where i!=j
Yes.....of course cuz these subspace could be equal for all we know.....but for sure b_i is in U_i cuz b_i is a vector whose can be decompose as a linear combo of B_i elements, which basis vectors
Wait, I’m confused, youre right. Each B_i can be of some any finite length.
Take U_1=span{b_1,b_2,b_3}
U_2=span{b_3,b_4}
yeah.
b_1 is in U_1,b_2 is in U_1,not U_2
Yeah. I see it.
Okay, so that’s one directional inclusion. How do I do the other inclusion?
For the other direction note that if v=u_1+u_2...u_m, where each u_i is in U_i,then each u_i can be decomposed individually into basis vectors of that space
Suppose u_1=b_1+b_2 and u_2=b_3
Then u_1+u_2 can be written as (b_1+b_2)+(b_3)
so v= b_1 + b_2 + b_3
Okay. Okay. Cool. So the two subspace are equal.
how come you mentioned being unable to prove that the finite union of finite sets is finite 
cuz I don’t know how to do it. But i believe it

Mathematics Stack Exchange
The union of two finite sets is a finite set.
Let $X,Y$ be finite sets.
That means that there are $n, m\in \omega$ such that $X \sim n$ and $Y \sim m$, i.e. there are functions $f: X \overset{\text{
Now,do you know |U A_i|<=\sum{|A_i|}?
yes
so “lengths” of sets...
the union of finitely many sets has at most as many elements as the total of the numbers of elements in each set
Cardinality of union is less than sum of cardinalities
if you take the union of five sets with 1, 10, 100, 420 and 69 elements, the union has cardinality at most 600
sure. I believe it. Ive seen a lot of finite sets in my life.
Well,You can show that fact inductively from |A U B| <= |A|+|B|
So this is some kind of elementary set theory proof?
Suppose A and B have a common element,then |A|+|B| will have atleast one more element compared to |A U B| because you will be counting that one element twice in |A|+|B|
Yes
yes, this is basic set theory
by Induction?
it's mostly bookkeeping
yeap.
|AUBUC|<=|AUB|+|C|<=|A|+|B|+|C|
Repeat similarly
There is also a thing called principle of Inclusion and Exclusion
$|A \cup B|+|A \cap B|=|A|+|B|$
uh
if its basic set theory at this point and it involves induction, i will try it solo. Lol, wish me luck.
Buncho Dragons

For finite sets
that is the most unintuitive form lmao
Thanks for the help folks! Y’all gave me a lot to work with.... this is all I had before:

It double counts the intersection....it seems intuitive....
eh i guess
i always see it presented as |A U B| = |A| + |B| - |A cap B|
which feels more intuitive to me personally
Oh, lol. That one I have seen. Yes. That’s the form Axler shows in the text.
how would i obtain the basis for the column spaces of A and AB then
it's now known that the column vectors of A span Ax,
but are they necessarily LI?
bases*
no, they are a spanning set
as of now i have found out that C(AB) <= C(A)
but to relate it to the rank, i am not sure
show me the task again, i forget what we're doing
i used linear transformations to prove that im of composition is a subspace of im of the other

by im i mean range of the corresponding linear transformations
that i used
so that i could prove C(AB) <= C(A)
obviously these are both finite dimensional, but
and B is size n x p
but idk if that directly implies rank AB <= rank A
together with C(AB) <= C(A)
wait no, lemme rephrase that
idk if C(AB) <= C(A) and C(AB),C(A) being finite dimensional directly imply rank AB <= rank A
it's the column space
i see
the col space has dim = rank
yes indeed
without thinking too hard about it, consider what happens when the column space of B matches the row space of A
i mean idk what u mean by "matches"
is equal to
somehow i can imagine that in my head, but i don't directly know it
so i have to do casework?
that's the easiest way imo. lots of grunt work without thinking much about it
for sure that would imply rank A = rank B
but in my proof i assume WLOG that rank A <= rank B
so that i need to prove rank AB <= min(rank A, rank B) = rank A
you can split it into a handful of cases
i.e. rank AB < rank A and rank AB = rank A?
i was more thinking about the null and row space of A
or that R(A) = C(B) and otherwise
yeah, like so
what about the null space
like, is there anything other than the zero vector in the null space?
if there is, then the column space of B may or may not have components in the null space of A
im not sure what u mean
i'm not sure i can help you with this proof cuz i would do it based on what the dimensions and rank imply about the null space of A
maybe someone else has a different idea
N(A) contains all the nx1 vectors that produce 0 when mulitplied to A
so the question is
interesting
since rank(A) <= rank(B)
in which ways can B have a higher rank than A? how about the same rank?
i.e. which shapes of A and B, and are they full column/row rank? rank defficient?
- if A is not full rank, then sure
- if they are both full rank, perhaps
there aren't that many options, since the inner shapes must match (cols in A, rows in B)
i was considering that from the start but i guess i thought it was too many to handle
you could also think of what A is doing to B
it's taking vectors from B and using them as coordinates for the vectors in A
the result is a set of vectors in the span of the columns of A
so it cannot be higher dim than col A
i guess that's faster
show that AB is a set of vectors, each of which is a linear comb. of the columns of A
then if A has a nontrivial null space, the rank of AB can be smaller than the rank of A, or of B has very few cols too
as in the cols of AB are l.c.'s of the cols of A
mhm
yeah i just said what u said lmao
interesting!
as in the rows of B that when multiplied to A produces 0?
wait wut
no that sounds wrong lmao
perhaps the transposes of those rows?
if or iff?
can you share the question exactly how it was originally written?
and S is an operator, a matrix, or what?
are we allowed to view it as a matrix
okay
do you know what it means for an operator to be diagonalizable?
you meant eigenvectors
in any case
i'd rather you would have said that S can be written as PDP^-1 where P is invertible and D is diagonal
and now,
$S^2 = PDP^{-1}PDP^{-1}$
Ann

you good from there?

for 21, can i just do W = {(0, 0, a, b, c)}, and for 22 can i just do: W1 = {(0, 0, a, 0, 0)}, W2 = {(0, 0, 0, b, 0)}, W3 = {(0, 0, 0, 0, c)}
Yea
ez
are we assuming char(F) ≠ 2
ah
wait, how is this necessary for columns of A to span C(AB)?
do you know of a way to, for example, span a subspace of dim 5 using 4 linearly independent vectors?
i think you are not ready for this proof, you should go review the basics once more
nope
because there isn't
bases are minimal spanning sets
C(A) is spanned by the cols of A corresponding to cols in the RREF with a leading 1
my problem lies in how exactly i can determine those columns in the RREF with a leading 1
especially in AB
so is this where determining the nullspace of A, whether trivial or nontrivial, comes in?
if T(u) =0 does it means T(t*u)=0? (t= IR)
if T is a linear transformation, yeah
since you can take the scalar t outside
and yes, that's where the nullspace comes in
oh that's what u meant
ty eppa
then if the kth column of B is in N(A), then the kth column of AB is 0_{m,1}
so no leading 1 in the kth column of the RREF of AB and therefore wouldn't be included in the basis of C(AB)
a quick google fu shows that the easiest way is as i said earlier, to write AB as a set of vectors, each of which is a column of B multiplied by A
and then use these rank arguments
google fu?

i'll just send you that, you can go from there using the definition of rank and C(A)
how to solve such a question?

Your conditions will be T(2,2,1)=(0,3,1), T(1,4,0)=(0,0,0),T(1,1,1)=(0,0,0)
Try to think how you get these conditions
yes i got to here but not sure how to continue
right
A linear transform is uniquely defined by how it acts on some basis
what do you mean
Suppose you have some basis {e_1,e_2,e_3}
Given any x,T(x) can be expressed in terms of T(e_1),T(e_2) and T(e_3)(T(c_1e_1+c_2e_2+c_3e_3)=c_1 T(e_1)+ c_2 T(e_2) +c_3 T(e_3))
So,Your transform is uniquely determined by those values
are they asking you to build the transformation or is it just true/false?
is this theorem?
what buncho wrote always applies
how does it called?
i don't think it has a name. buncho just expressed the vector x in terms of the canonical basis, and then used the linearity of T
If you want a name,you can call it the canonical theorem of linear algebra
i cant understand this, it should be seperated ?


why i need that then?
i can just say the form basis and that all (?)
Yes
You also have to add that condition tells you what the images of the basis elements are
what if i told to find the linear transformtion?
This is your linear transform
I have a linear transform T, which satisfies T(2,2,1)=(0,3,1), T(1,4,0)=(0,0,0), T(1,1,1)=(0,0,0) and any value of T(x) can be computed knowing this
i mean how to find the build of T
you can take the expressions buncho wrote and notice that it's basically a system of 9 variables, 9 equations

would it be rank 1 and nullity 0

what page in Axler is this?
it's exercise 1C
oh. i had not done 21 and 22.
are you asking how to do it or how to make sense of it
put backslashes before *'s or _'s
that prevents discord from making them vanish
det(A*) = det(A)*
Is this true?
Thxx
yes it's true
one way to see it is to just write out the huge formula for the determinant in terms of the entries and see what happens to the complex conjugates
Hmm i see
It didnt seemed to be intuitive to me
ττερρα

Hello sirs, could you suggest me some video on Legendre polynomials? They are given as an example of an orthonormal basis... but I don't really get their sense and meaning
this is for 2x2 matrices. you can do a similar computation for matrices of arbitrary dimension
maybe with some induction if you want to be 1000% careful and rigorous
What is this question exactly asking for? I thought its asking for whether the eigenvalues for this matrix belongs to one of those sets.

Like what are the steps i need to do to get the answer here. Idc about the answer just wanna know what the question is asking for and what to do.
yes, it's asking for the eigenvalues
compute the roots of the polynomial det(matrix - tI) in Z_5
Thx so much
Its actually from a physics problem, so i wouldnt have to be 1000% rigorous luckily
if T is linear, then yes

and U and V are from the input space obviously
is this obvious and I cant see it ? because every where I see has only the +
$T(au+bv)=aT(u)+bT(v)$
Mosh

I have some questions on this problem
My attempt:
Part 1) by using the property of unitary and determinant, I can show that det(U)=1 and
|det(U)| =1
With that, i can then link to the euler’s formula and for some θ, e^iθ = 1 ?
How would this help part 2 tho

but det(U) is not always 1
Even for unitary ones??
they explicitly say it's what you are to prove
it can be written as e^{i theta}
which isn't always 1
it's not even true for orthogonal matrices, a reflection can have determinant -1
(all orthogonal matrices are unitary matrices)
I see where my logic is wrong.
Btw does anyone have any recommendations on materials that can help brush up on some linalg concepts such as inner products, eigenvalues, hermitian etc
Im currently taking a quantum mechanics course and the theory is closely tied to linear algebra and yet, linalg2 course was not a prerequisite
Im struggling quite a bit
what i did here wrong ?

looks right
but 2x3 matix make no sence
how so?
it should be R3->R2
$T[v]=\begin{bmatrix}0&0&0\ -1&0&1\end{bmatrix}v$
Mosh

where v is (a,b,c)
needs to be 2x3 to be able to multiply by a R3 vector and get a R2 vector out
it should be 3x2 (?)
how do you multiply a 3x2 by a 3x1?
If $L: V\to W$ and dim(V)=n and dim(W)=m, then $(L)_\alpha ^\beta \in \mathbb{K}^{m\times n}$
Mosh

yes, it's always T[v]=Av
@nocturne jewelwait a second its still make no sence to muliply 2x3 by 1x3
yeah, cause it's a column vector not a row vector
can someone help with this problem
If a matrix A is not invertible, then A has an eigenvector.
would it be false?
A is not invertible if and only if there is a non-zero vector v such that Av = 0.
so it would be false based on that right
why?
because there is at least 1 matrix
0 = 0 * v
where there is no non zero vector that can make the matrix 0
so if A is not invertible, then its null space is non-trivial, right?
so you can find a non-zero vector v such that Av = 0
right
but that can be written as Av = 0v
and since v is non zero, that says that v is an eigenvector of A
oh i see
i got it now
thanks
i have 1 more
All 2x2 real matrices have eigenvectors.
i think it is true
do all second degree polynomials have roots?
since the roots of the characteristic polynomial of your matrix are the eigenvalues, it's basically the same question
yes
right, that's what i mean
if you can find a matrix whose characteristic polynomial has no real roots then you're done
ok i got it
right
thanks man
this thing rotates vectors by 90 degrees, so it's impossible for any vector to be on the same line as its image
oh i see
which is a nice geometric way to think about it having no eigenvectors
also, by the same logic, you can prove that any real matrix of odd dimension has an eigenvector
which is nice to know
hey guys, i have a troubling friend. he's trying to tell me Axler's convention to use 0 to represent every 0 scalar, vector and matrix is bad but this is sacrilegious because clearly axler is a deity
how do i send him to hell
do not worry, in the afterlife, axler personally sends everyone of those sinners to hell
bet him $10 that he cant find a situation where it creates a meaningful ambiguity in axlers text
sometimes it creates an ambiguity that doesnt matter
(like 0 scalar or 0 matrix would both work)
or its clear from context that only the 0 vector makes sense in a given use
or whatever
(like if youre adding a matrix to it, it must be a matrix)
unless you go out of your way to make it a problem (eg use one-element matrices interchangably with scalars or something dumb), it isnt one
and you win $10
Having a hard time with this problem
Isn't this -4? I'm arguing with my friend since he thinks its -14

Unless the 0 vector is represented by 1 I don't see an issue with using just the symbol '0' and overloading it
,w det {{2, -1, -2}, {0, -3, 0}, {6, 0, -6}}

that's what I fucking thought
You could have typed that yourself 
Sorry I don't know wolfram Alpha that well. I appreciate the help man
Uhh you don't need wolfram specifically, but do try to learn a few computational things
For example numpy
https://numpy.org/doc/stable/reference/generated/numpy.linalg.det.html
Or matlab
https://www.mathworks.com/help/matlab/ref/det.html
These will help you verify computational things
This MATLAB function returns the determinant of square matrix A.
How much Axiom of Choice is needed to prove the following:
given linearly independent vectors v_ 0, (v_i : i in I) in a vector space V, there is a linear map f : V -> basefield such that f(v_i) = 0 but f(v_0) is non-zero?
this is probably a better fit for the computing software channel
i can possibly answer your question there
yes, it's mainly for linalg, but computationally. this channel is more for theory stuff
humm..
I have a feeling no choice is needed here but this is a bit of an infirmal argument, you probably have to look closer to see if i’m using choice somehow. defining S=span(v0){0}={v| there is a in k st v=ak}{0} we can define a relation on Sxk by vRa iff v=av0. Now this relation is a function as if vRa and vRb then av0=bv0 which implies (a-b)v0=0 and if a-b is nonzero we multiply by the inverse to get v0=0 a contradiction. Now we call this function f and extend it to all of V by saying g(v)=0 if v is not in S and g(v) =f(v) otherwise. Do you think this works @viral flint ?
There is a weird thing discord is doing with the backslashes. Wherever you see {0} nest to some set you should remove it from that set
It's treating them as escapes.
Whenever \ is typed in front of a letter: \a, it doesn't get hidden. But \ in front of certain characters (mostly everything except letters and numbers and space) escapes it and disappears. It's to remove the formatting effects of *,_ (italics/bold/underline) and `.
I see
do \\ to get \
Yes
Also
The relation -> function part is indeed, not a big deal
You're basically defining f(kv_0) = k, right?
The challenge is to extend that to the whole space so that it is linear.
Yes, i just did it that way to be safe
Your extension is not linear, as can be seen if we consider
k = g(kv) = g((kv + v_1) + (-v_1)) =/= 0 + 0 = g(kv + v_1) + g(-v_1)
where v_1 is a non-zero vector not in S.
Ah shit you’re right

There is a pretty "standard" way to prove this, but it requires constructing a basis for V, which relies on the Axiom of Choice.
Which is why I asked whether you need the full strength of AoC.
Yes i know the standard proof, i was hoping that i could circumvent it aomehow
Hey guys, why is it that if
B is the set of vectors
dim(B) = dim (V) (the vector space)
If it's linearly independent then B spans V
and vice versa?

B is a set of vectors in V?


if you have a set of linearly independent vectors taken from V, then you can do elementary transformations to get back to the canonical basis, i.e. rref a matrix with those vectors as its columns into an identity matrix
so you could express the canonical basis as a linear combination of the vectors in B (which were taken from V), and then use those canonical basis vectors to generate any vector in V
(this is just an example, not a proof)
What is the basis of vector space R(R)
what is R(R)?
Maybe they meant Rn?
if im asked to prove/dis that in the euclidean space : does it refers to standard multiplication as the inner product?

Well im waiting for them to respond, not someone with a wild guess
My guess is you can still just use a general IP
does it matters?
which vector space are u and v from?
any*
any complex inner product space?
( any u and v )
...
that's not what Edd asked
i mean from any vector space
Ok so if it's any complex IP space, then just a general IP
is it usually like that when the question doesn't refer to a specific IP?
Mosh

yeah, can't say anything about it, other than presumably they mean this $\Vert u \Vert^2$ norm is induced by the inner product $\langle u,u \rangle$
Edd

which is precisely what mosh just said
got it
The one thing is that the proof should be done in a complex IP space, so taking a real component makes sense
yea question asked for both
but yeah what I tex'd is the start, then it's just use linearity / conjugate linearity
something like $\langle u, v \rangle = \overline{ \langle v, u \rangle }$ is gonna be needed
Edd

what to do after that?
.
expand the IP using linearity and conjugate linearity
by which space of R?
?
in order to exapnd the IP I need to know U and V dimension
no??
$\langle u-v,u-v\rangle = \langle u,u-v\rangle - \langle v,u-v\rangle$ by linearity
Mosh


yea its just what i got by now
<u-v,u-v>=<u,u-v>-<v,u-v>=<u,u>-<u,v>-<v,u>+<v,v>
i think i got something wrong

yeah
why not
why would it
those are scalars
what two things are equal and have opposite signs
what are wrong with the cancels?
i got this now and it seems fine


the RHS of this is not the RHS of the original problem
-2Re<u,v> =? -<u,v>-<u,v>
but that is the euclidean space
what?
u and v are in general complex, and so is <u,v>
you can't just remove the Re
you're gonna need this
we're in a general (complex) inner product space V
such an inner product is a map $V\times V\to\bC$
RoκερραJαnpu

do it for unitary spaces 1st
if you do it right for the complex one, it applies ot the real one too
the result simplifies in real inner product spaces
what should be assumed in complex ?
and is it wrong for euclidiean space?
use the properties of inner products on unitary spaces
and use this
Which topics in linear algebra is important if I am going to learn tensors
bases, the 4 fundamental subspaces, svds, diagonalization
you can always reshape tensors into matrices, and the idea is to use tensors as mappings between vector spaces
though to represent stuff directly as multidimensional arrays, multilinear maps and forms are handy
What is a-8(6+)m=

Is it considered bad practice to use round brackets for vectors and square brackets for matrices?

$m\cdot n =0$
Mosh

do you know how to find the value of inner product? @opaque heath you should've learnt that
if you already solved it just let us know by saying all g ok?
i already solved it but i won't give you answer otherwise ann will hate me
ok so where are you stuck at?
for handing in assignments, i think its fine.. just be consistent
Would anybody mind helping me out with this
I've been looking at it for a while now and I'm not sure where to start. The question should be self explanatory enough to not need much background clarification.
start by writing ABv=lambda v
now it'd be nice if we had BA there instead of AB
we can nearly get it if we multiply on the left by B
BABv = lambda Bv
so we should just define the new vector u=Bv
BAu = lambda u
oh hey, u is apparently the eigenvector of BA with eigenvalue lambda now
byotiful
thank you i feel stupid now
kinda just 50% writing down the eigenvalue/eigenvector thing and 50% just trying random stuff and hoping something sticks
to make an omelette you gotta break some eggs etc etc haha
you're welcome
thank
did you get 1,2,3,4,5,6,7 as possible values?

What is abstract algebra? since I can't post in that channel.
the study of algebraic structures and their morphisms
groups, rings and ideals, fields, modules, algebras, etc
not a perfect definition but
good enough for a rough idea
i think youre allowed to post, you can give yourself the role if you look at the #get-advanced-access channel
how do i solve this?

N_A = N_{rref A}, and finding dim(N_{rref A}) is just a matter of counting the number of free columns (columns that don't have pivots).
A is just the coefficient matrix corresponding to this system btw
Can someone look over this proof? My approach was to first prove that a certain list is a basis with a contradiction argument. Then use this basis to show the properties of a direct sum. "F" in linear algebra done right is the real or complex numbers. For the proof, I wanted in either case for the dimension of F to be 1.
The part where I consider the F to be dimension 1 is where I'm a concerned about.
I think that assuming that null(T) has a basis is not a correct step (at least in the context of Axler's book)
I believe we proved null(T) to be a subspace in all cases, so shouldn't that mean it has a basis?
Yes, that is correct, null(T) is always a subspace, but I'm pretty sure, that doesn't necessarily means that it will be finite dimensional
You may consider the linear function that takes any polynomial (so that the domain is a infinite dimensional space) to the 0 scalar, the null space is the same as the space of all the polynomials
Ah, darn.
I see
Ya, the problem doesn't say anything about V being finite-dimensional. Thanks for that. Does the proof work if it is finite-dimensional?
mmm
in the last part, where you justify that the intersection is {0}, you should show that a*u doesnt belong to the null space (although this a pretty direct)
the part where you show that R spans range(T) seems kinda weird to me, but this doesn't really mean that it's wrong too lol,
I don't think that saying that dim F = 1 is wrong (at least when we talk about real and complex fields)
Im pretty sure that Axler says that it is of dimension 1
(maybe in the chapter of duality ?)
I would inspect the proof a bit more but I have some things to do 😦 sorry
it was proved earlier in Axler's book that if U is a subspace of V, then there is another subspace W so that V is the direct sum of U and W. I believe that in the finite dimensional case, having U = null T can simplify your proof. i dont see right away how you might use this fact for the general case though.
edit: after some thought i think this fact can be used nicely in the general (not finite dimensional) case. please message if you would like to talk more about it
no, these are not possible values
so please reread the question completely
you missed one statement
sorry i just fell asleep

this is my work i dont see anythign wrong with it though
i saw it
can you guess which statement you missed?

let's read this again
missing what i mean is not to satisfy 1 statement
@opaque heath

all g?
yesyes
よかたああ。。
@blissful vault You don't need to reference bases for this proof. I can walk u through it if you'd like. Just ping me. EDIT: actually you kind of do need bases, but in an almost trivial way i guess.
Hi I have a question about SVD / PCA
are there any caveats when you cannot use it?
not when you should not use it
but you numerically / algebraically cannot use it?
(from #help-7|zen1thxyz )
i don't see a reason why one couldn't calculate it
other than issues with numerical stability and how long it takes for huge matrices
i.e. the singular values might be very small but nonzero, and the computer does not have enough precision to get nonzero values. or backwards, small errors make singular values that should be 0 turn into small values
the latter can anyways be handled by using low rank approx
thanks for the reply!
sorry I missed this
hmm?
I'm already using the low_rank packages, but it still give an error
what error are you getting
RuntimeError: svd_cuda: For batch 0: U(65,65) is zero, singular U.
i've never used pytorch, i couldn't say what the problem is
you'll have to trace the error back to see what exactly is the issue. all matrices have an svd
File "/usr/local/lib/python3.7/dist-packages/torch/_lowrank.py", line 170, in _svd_lowrank
U, S, V = torch.svd(B_t)
RuntimeError: svd_cuda: For batch 0: U(65,65) is zero, singular U.
I think it is somewhere deep inside their package
okay so, theoretically, all matrix have an SVD
that's good to know
thanks!

Yes
But what are you confused about
Do you not understand the question or not understand how to do it?
What I've got here is a matrix in some set of coordinates (s_1,s_2,s_3) and we're making a change of coordinates s -> t such that the matrix becomes constant. Does anyone know how they found that exact change of coordinates to make it work?

actually I'm not even sure I understand how to get the new matrix given that change of coordinates
Hey 🙂 I've got a question concerning vectors. (It's been quite some time since I learned about them in uni)
For context: I'm implementing a 3D visualization application.
I've got a camera object in a 3D coordinate system. It's position would be my vector A.
I've got a point where my camera is looking at. This would be my vector B.
Now I want to calculate the straight line that is in a 90 degree angle from the line AB (Red Line in the picture).
Or to be more precise: Let's say I want to move the camera on the red line 1 unit to the left (which would move vector B also 1 unit to the left). What is my camera position now?
(Keep in mind: It has to be in 3D)

do you have the red line segment?
except for the degenerate case where a and b lie on the same ray with source at the origin, a and b should span a plane
you could then do gram schmidt on b-a and a by keeping b-a as is
the second vector that gram schmidt yields will be in the direction of the red line segment
you would then want to move along the ray a + (second vector from g.s.)
if a and b are linearly dependent though, you will need more information
otherwise what you drew here as a red line segment would be a plane
okay. thank you very much for the help. there is still some stuff which I don't understand (yet). but now i know what I have to google and look into (gram-schmidt etc.)
maths 🤯 .
Where could I find a proof or explanation of equivalence of definitions of a bilinear non degenerate form: the first one is this crazy abstract thing

The second one is that the associated Gram matrix is inversible?
only proves equivalence between the second sentence of your image and the matrix property
(because the first sentence is actually more general)
(applies to the infinite dim case as well)
actually https://www.mat.uniroma2.it/~sorrenti/MAT204Fall06_files/Lecture5.pdf is a better source
proof of prop 4
Strange that they even consider** ii and iii** as different things. The roles are interchangeable

these are general bilinear forms
the form need not be symmetric
b(u,v) =/= b(v,u)
if you wanna write this as a matrix (since they said n-dimensional), this means that the col and row spaces might be different
and so the null and left null spaces might also be different
but still, we just change the order of input; we prove just ii for example and then we say that to prove iii we just consider a function defined by the Gram matrix transposed and then that there is a bijection...
i'm not sure i follow
where'd the gram matrix come from?
gram matrices are (hermitian) symmetric and define inner products
those are only a special case of bilinear forms
and also, if you just transpose, it's still the same vector u_0, for example, just now on the other side of the transposed matrix
the way this is written makes it clear that the left and right null spaces might be different
i.e. in general, u_0 =/= v_0
Haha I think that they decided to call every associated matrix Gram matrix in my course 🤪 ... This is how they illustrate Sylvester's theorem

doesn't it just say the Gram matrix is a bilinear form?
not that all bilinear forms are gram matrices
They say "the Gram matrix of the associated bilinear form looks like this ☝️ "
But yes indeed, probably all that in the context od symmetric bilinear applications... the Sylvester's theorem makes no sense otherwise?
wouldn't that just mean they took the bilinear form B and did B^T B?
idk which of all the sylvester theorems you mean
Yes like they gave two definitions of this theorem, the first one like this

"If Q is a quadratic form over a real vector space V of dimension "n" and if Q(x)= Σai*xi for a basis {v1,...vn} then the numbers p, q do not depend from the basis {v1,...vn}"
mhm. quadratic forms are symmetric
then they say that "in terms of matrices"...

but obviously they mean symmetric forms indeed
so if I understand correctly this one can be generalised for all symmetric forms in some way?
I think they would call it Sylvester's law of inertia https://en.wikipedia.org/wiki/Sylvester's_law_of_inertia
yep that's what i was looking at
and you can see that they immediately require the matrix to be symmetric

Seems that a symmetric matrix always defines a quadratic form and in the other sense

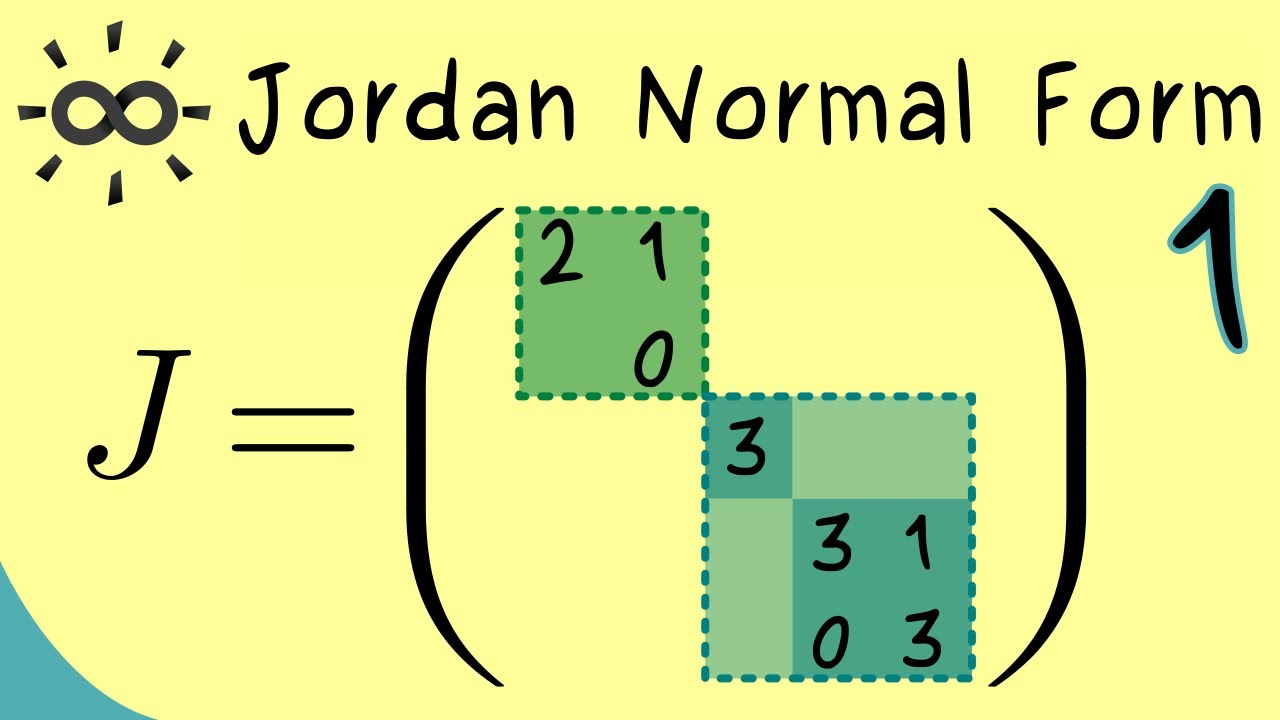
Does anyone know what a minimal polynomial of a square matrix can tell about it's Jordan form? (for example here m_A is the minimal, and xhi_A is the char poly)
the largest multiplicity of the minimal polynomial is the largest jordan block
(for each eigenvalue)
can this largest block appear multiple times?
yes, take for example the identity matrix

In linear algebra, a Jordan normal form, also known as a Jordan canonical form
or JCF,
is an upper triangular matrix of a particular form called a Jordan matrix representing a linear operator on a finite-dimensional vector space with respect to some basis. Such a matrix has each non-zero off-diagonal entry equal to 1, immediately above the main ...
go to the "Minimal polynomial" paragraph
I understand it intuitively like this
There are several "Jordan chains" and each Jordan block corresponds to an separate "chain"
That's why it's logical that the sum of the geometrical multiplicities is the number of blocks
well i'm quite confused about this jordan thing
couldn't find much resources on youtube
The sum of algebraic multiplicities is the sum of "sizes" of blocks
There is one
yeah that's like diagonalizable matrices
as a particular case
Support the channel on Steady: https://steadyhq.com/en/brightsideofmaths
Or support me via PayPal: https://paypal.me/brightmaths
Watch all parts: https://youtube.com/playlist?list=PLBh2i93oe2qtoBYrEIrVaLfEhZTnf7jml
PDF versions: https://steadyhq.com/en/brightsideofmaths/posts/1f1b4813-516a-48a8-9666-354c92b45ce7
Linear algebra series: https:...
there are 5 parts
i saw all parts of this, it didn't give me intuitions
he gives the "chains" thing as a given
it follows from the primary decomposition theorem
In linear algebra, a Jordan normal form, also known as a Jordan canonical form
or JCF,
is an upper triangular matrix of a particular form called a Jordan matrix representing a linear operator on a finite-dimensional vector space with respect to some basis. Such a matrix has each non-zero off-diagonal entry equal to 1, immediately above the main ...
see paragraph
Invariant subspace decompositions
so if you have a split characteristic polynomial (for example in complex numbers) then you can split your vector space in invariant subspaces in such a way that they will be generalized eigenspaces
but don't worry we were learning this stuff 3 months though our section is "physics"
true, but the thing is, we also can define a generalized eigenspace like this

(a simple eigenspace would be a particular case for m=1)

why do we take m to be the multiplicity in the min poly?
a larger m will give a larger kernel i believe
so normally eigenspaces don't sum to the vectorspace, but generalized ones do?
yes, if the characteristic polynomial is split
wdym split?
for example x^2+1 is not split, but (x+1)^2 is
(But in complex numbers all of them are split)
This is the fundamental theorem of algebra
For some time, but since a certain "m" the increasing stops 😄
I didn't remember using Jordan forms (yet)
But diagonalisation for example in mechanics you diagonalise the inertia tensor to find an axis such that the moment of inertia L would be colinear to the rotation vector ω
But I am in the first year so it will come soon I guess
I don't like Jordan form, too much calculations involved :/
but it's cool to have a general form of diagonalization
However that's one of the major subjects
jordan form is nice

{kind=link}
is it true that $\tr_{V^}\left( \rho \left( g^{-1} \right)^ \right)=\tr_{V} \rho \left( g^{-1} \right)$?
ProphetX

can someone help find the jordan form of this?

it's alphas on the main diagonal, and ones on a diagonal which is 2 above the main
the characteristic polynomial of this is (x - a)^n
i'm not sure what the process is now
do we know if the order of this matrix is even or odd
no, but we can separate into these cases
this is a simple permutation away from being in jnf
it'll have 2 blocks and both blocks will have alphas down the diagonal
and their sizes are half the size of the whole matrix
why though
with the obvious interpretation for odd orders (ie order 2k+1 gives a block of size k and a block of size k+1)
the jordan basis is {e_1, e_3, e_5, ..., e_2, e_4, e_6, ...}
like. if you reorder your basis vectors so that all the odd ones come first and then all the even ones
how do you know all this?
by looking ig
umm how would i derive all this
lol
this just happened to jump out at me
maybe if you were wearing pants you would know
Given a vector v, is there a name for the space of linear operators such that v is an eigenvector?
And more generally for a set of vectors, the space of operators for which each vector is an eigenvector, so the intersection of these spaces over the elements in the set
Saw this late. I appreciate it. I found a solution for this exercise.
This is how I would do it:
Let $u \in V \setminus \ker f$ and suppose WLOG that $f(u) = 1$. Now, let $v \in V$. Then there is $c \in F$ such that $$f(v) = c = cf(u) = f(cu).$$ Therefore, $v - cu \in \ker f$
kxrider

What's the "V\ ker f"? I haven't seen the slash notation before.
"V - ker f." Just the set of V not in ker f
so $v-cu = x$ for some $x \in \ker f$, and $v = x + cu$. Hmm, yesterday I thought it was obvious that this is a unique way to write $v$ as sum of an element of the kernel and an element of $span{u}$, but now im not so sure actually.
kxrider

yea yea it is. If x' + c'u = v = x + cu then x'-x = (c-c')u and therefore 0 = f(x'-x) = (c-c')f(u) = c-c' so c = c'.
and since c is uniquely determined, x is also uniquely determined.
yea, i guess to make the idea slightly more intuitive, v uniquely determines the "cu" as cu = f(v)u.
@blissful vault does that make sense? I'm using the characterization of the direct sum that goes like V = U \oplus W if each vector in V can be written uniquely as a sum of an element of U and an element of W
Yes! That looks vastly simplified from what I was doing with basis.
ye, and this way you sidestep all of the dimensionality issues.
sanity check: most two-element lists are linearly independent in C as a vector space over R, but linearly dependent in C as a vector space over C?
yeah, all two element sets of vectors in C are linearly dependent over C.
"Given an orthogonal transformation, prove that the complement of an invariant subspace is also invariant"
sounds easy but I can't figure it out, help?
Let T be orthogonal (thus <Tv, Tw> = <v, w> for all v, w) and V be an invariant subspace. Let W be its complement.
Then you want to show that for any w ∈ W, Tw ∈ W. Being ∈ W is equivalent to being orthogonal to every element of V, i.e. x ∈ W iff <x, v> = 0 for every v ∈ V.
So assuming w ∈ W, can you show that Tw ∈ W?
@viral flint assume Tw is not in W, that is Tw in V. Then if v is in V we should have 0 = <w, v> = <Tw, Tv> forcing Tw to be in W, contradiction
You are talking about the orthogonal complement of a subspace and not the complement of a subset, right?
this would be false still
given set X and Y in X
you take Y^c
for each x either x is in Y or in Y^c
the same for orthogonal complement
well technically you should treat also zero vector but it is easy
It doesn't seem like you did, which is why I asked in the first place.
This part is wrong.
Tw is not in W, that is Tw in V. Then if v is in V we should have 0 = <w, v> = <Tw, Tv> forcing
Consider a plane and its normal line in R^3. There are plenty of points which are neither in the plane nor in the line.
yes but man
not only one line is in orthogonal complement for plane
oh
i got your point
uh
i would have cleared up my proof then
but gtg
sorry
Let $A\in\C^{n\times n}$ be normal. Show that $A$ is Hermitian if and only if all eigenvalues of $A$ are real. Formulate and prove similar statements for skew Hermitian and unitary matrices.
!superficialsicko

what does "similar statements" mean?
as in $A$ is skew Hermitian and unitary iff all eigenvalues of $A$ are real?
!superficialsicko

no
simiar does not mean copy-pasted
A is skew-Hermitian iff all eigenvalues of A are _____. A is unitary iff all eigenvalues of A are _____.
they ask you to fill in the blanks here
figured
!superficialsicko

!superficialsicko

!superficialsicko

!superficialsicko

!superficialsicko

nvm i got it lmaoo
any hint as to how i prove that A is unitary only if all eigenvalues of A have modulus 1?
given that A is normal in C^{nxn}
if you already know that a unitary matrix is diagonalizable, you can use that
not really
but i do know that A is normal iff it's unitary diagonalizable
and any A, whether or not it's normal, is unitary similar to an upper triangular matrix
unitary matrices are also normal, hence unitarily diagonalisable
i see
that's what they meant
ty
ill think about it
since A is unitary diagonalizable
U^*AU = D for some unitary U, diagonal D
then
\begin{align*}
D^* &= ((U^A)U)^\
&= U^(U^A)^\
&= U^A^(U^)^*\
&= U^*A^U
\end{align}
!superficialsicko

but $U^*AU = D$
!superficialsicko

so is D* always equal to D?
oh right
i was so confused when i thought D* = D
it seems like D*D needs to be equal to 1
i mean I
Yes
and from there im lost