#linear-algebra
2 messages · Page 137 of 1
Read about Gaussian Ellimination first
may i recommend that you read up about gaussian elimination & row operations in your book / lecture notes / whatever
how do you know
T(x,y,z)=t(x)+t(y)+t(z)
this doesn't make sense, unless you say what lowercase t means
I didn't this is one yet
huh?
What's the "constant test", I honestly never heard that term before
But that's not what you've written above in 2?
that was gonna be the 3rd test which I haven't done yet
You could just do it in one step
You can combine the 2nd and 3rd test if you want to save some space:
T(cv+w) = cT(v) + T(w) if the function is indeed linear
Yea, that
"constant test"
jeez louise
does EVERYTHING have to be called a "test" now? are students unable to comprehend the slightly abstract defn otherwise
We didn't!
We introduced homomorphic functions over groups by their defining property and expanded that later on to other algebraic structures :(
I got that
in terms of shittiness it's on par with shit like FOIL
Foil?
It's just a step to learning, it'll be replaced when concepts are fully grasped
Distribution
No, it hinders learning
Any book recommendations for linear algebra? I am sophomore and studying CS.
for non-math majors I always recommend Jim Hefferon's https://hefferon.net/linearalgebra/
as a math major I got a kick out of Hoffman & Kunze, it mentions some stuff about infinite-dimensional spaces which is really useful to get a broader picture and for later courses, e.g. functional analysis
does EVERYTHING have to be called a "test" now?
nothing in maths should ever be called a "test" or "rule", everything comes from something, but honestly what bothers me the most is when people come here expecting us to know the specific terminology of their course lol
Hmm isn't there are book more specific towards CS in linear algebra
Depends on what your CS linear algebra course is. We had the exact same course as the math student
Any book recommendations for linear algebra? I am sophomore and studying CS.
@rare spade linear algebra done right by sheldon axler
I will have numerical linear algebra in 1 year
the exercise problems are great in sheldon axler. u can also get a soln book to it online
QR factorization, LU factorization, Schur factorization, vector spaces etc...
It depends. Do you want to actually do CS or do you want to be a better programmer.
Like do you want to study computer science further along the line is what I mean.
Maybe grad school or something.
Yeah, if you wanna know elementary Linear Algebra, Gilbert Strang's book will suffice.
Otherwise, Sheldon Axler is great!
Or are interested in it overall as a subject. If that's the case Axler is probably p good but you still want more problems. If you just want to have programming applications then there's probably better books for you.
Gilbert Strange or David C. Lay's book.
I was thinking for the purpose of compuiter graphics
Yea try Lay then.
It has problems just for that.
and maybe a book called "Numerical Linear Algebra"
That's the name of the book but I forget who it's by
Thanks!
Np.
If u contains W, shouldn't dim (u) be atleast dim(w) ,so this isn't possible when r>(n-r)?
r will never be greater by n-r because in the beginning it states that r is less than or equal to n.
I have a feeling that it's probably got to do with quotient groups of subspaces.
Which of the following lines are parallel. Select all answers that apply.
x=1+t, y=t, z=2+5t
x+1=y−2=1−z
x=1+t, y=4+t, z=1−t
x=2+2t, y=1+2t, z=−3−10t
in an A=QR factorisation, does Q * Q.T have any significant meaning or connection to A? i only know Q.T * Q should give the indentity matrix. if A is square then Q.T * Q and Q * Q.T are the same, but what if A is non-square?
What do they mean by "in a natural way"? How do I do this?
@elfin mist
Could someone help/share thoughts, please?
Have you thought about how the basis of F^n could look and how you could get a subspace with the dimension (n-r), given another subspace with dimension r?
@elfin mist
Hmm isn't there are book more specific towards CS in linear algebra
Hefferon has tons of examples of applications in its exercises, also it's free and open source.
Have you thought about how the basis of F^n could look and how you could get a subspace with the dimension (n-r), given another subspace with dimension r?
@hard coral
My first line of thought is: The basis of F^n would consist of n elements, and given a subspace of dimension r, I could probably look for another subspace such that the direct sum of the two is F^n. However, finding such a subspace doesn't seem trivial.
If A,B, and C are three distinct points in R3, then AB+BC+CA=2AC
Is it true or false?
Reading that question again, I really think I'm misunderstanding something or that statement is false lol
If we pick r=n, then F^n is in U_r, so let w = F^n, then we have to find a space of dimension 0 which contains F^n of dimension n?
Yeah, wait, this is absurd
Maybe things blow up when r = n. How about we just consider 1 ≤ r < n?
I wonder why they don't give a simple definition for Matrices like saying they are just functions which transform the bases of a vector space to other bases
[2, 0
0, 2]
matrix just transform (1, 0) to (2, 0) etc.
a change of bases
and that is it
Because matrices can be used for other things
Like describing a system of linear equations
well you can think solving linear equation systems as un-doing a linear transformation
because usually in linear algebra courses you start by defining linear operators as functions on vectors spaces such that $\forall v_1,v_2 \in V, \forall \alpha,\beta \in \bR: f(\alpha v_1+\beta v_2) = \alpha f(v_1) + \beta f(v_2)$, and then prove that a linear operator is completely defined by how it acts on the basis
ConfusedReptile:
also, linear operators don't have to be defined on finite-dimensional vector spaces, and in infinite-dimensional ones it may be hard to define a basis for operators to act on
I see
then it is due to axiomatic method
we first define these linear functions
which are nothing but homomorphisms
then we show all they do is transforming bases (AKA generators)
as any homomorphism does
Having another moment, let ${e_1, e_2, e_3}$ be the standard basis and let $f:\mathbb R^3 \to \mathbb R^3$ be a linear map with $f(e_1) = e_2$, $f(e_2) = e_3$ and $f(e_3) = e_1$. Have to show $f$ is a rotation and find the axis/angle of rotation. Axis of rotation is the straight line $L = {(x,x,x) \mid x \in \mathbb R}$ but can't find the angle. Hint is to associate the plane orthogonal to $L$ ie. $V = {x + y + z \mid (x,y,z) \in \mathbb R^3}$ with a subset of $\mathbb R^2$ and check that $f$ gives a rotation on it. which I did via $(\lambda, \mu) = (\lambda, \mu, -\lambda - \mu)$. But now $f(1, 0, -1) = (-1, 1, 0) = (-1, 1)$ and $f(0,1,-1) = (-1, 0, 1) = (-1, 0)$, and the matrix $\begin{pmatrix}-1 & -1 \ 1 & 0\end{pmatrix}$ doesn't correspond to a rotation. Am I going the right way about this?
George!:
I assume you mean $V = {x + y + z=0 \mid (x,y,z) \in \mathbb R^3}$ ? Yeah, that's orthogonal to the axis.
ConfusedReptile:
oh yeah sorry
$$
f(a,b,-a-b) = (-a-b,a,b) \rightarrow (-a-b,a)
$$
So rotation matrix is
$$
$\begin{pmatrix}-1 & -1 \ 1 & 0\end{pmatrix}$
$$
hmm, weird indeed
ConfusedReptile:
Compile Error! Click the  reaction for details. (You may edit your message)
reaction for details. (You may edit your message)
yeah got that bit but that isn't a rotation which throws me off
well, strictly speaking we'll probably get 120 degrees just because $f^3 = Id$, but we probably want a better proof than that
ConfusedReptile:
yeah it looks like it should be, but I thought all rotation matrices had the form $\begin{pmatrix}\cos \theta & -\sin \theta \ \sin \theta & \cos \theta\end{pmatrix}$ or am I missing something
George!:
earlier it had you characterise a rotation as a (complex) map R_z(w) = z * w with |z| = 1 and then the angle is arg(z) but substituting R_z(1) = -1 + i you'd get R_z(w) = (-1 + i)*w which doesn't then line up with R_z(i) = -i
two of these "rotations" would be:
$$
\begin{pmatrix}-1 & -1 \ 1 & 0\end{pmatrix} * \begin{pmatrix}-1 & -1 \ 1 & 0\end{pmatrix} = \begin{pmatrix}0 & 1 \ -1 & -1\end{pmatrix}
$$
ConfusedReptile:
I mean it must be the case that matrix is somehow wrong but I can't see how
and three:
$$
\begin{pmatrix}1 & 0 \ 0 & 1\end{pmatrix}
$$
ConfusedReptile:
yeah this is my confusion idk why it doesn't work
wikipedia gives $\begin{pmatrix}0 & 0 & 1 \ 1 & 0 & 0 \ 0 & 1 & 0\end{pmatrix}$ as an example of a rotation matrix about 120 degrees with axis $x = y = z$ as I have, so it definitely is a rotation
George!:
the only place I could be going wrong is finding the associated map on the plane but I don't see where I've made the mistake
hmm, I think the mapping from the plane to $\bR^2$ isn't right.
Because the reason this is not a rotation is because it doesn't conserve distances in the $\bR^2$:
$$
|(-a-b,a)|^2 = 2a^2 +b^2 + 2 a b \neq a^2 + b^2
$$
ConfusedReptile:
yeah thought the issue would be there abouts
let's try one which transforms (0,0) into (1/3,1/3,1/3)
nah, yours already preserves (0,0). Hmm.
yeah I thought it was just me being stupid lol, shouldn't be that hard but it just doesn't seem to work out
that was also a non-starter lol (tried something else too)
@dawn remnant any ideas what's going on?
not due for a week but it's got me at my wits end lol
does anyone know of a good linear algebra textbook that has good explantions on linear transformation
used that one for my linear algebra class and liked it
this one is also popular
if you're looking for something a bit more advanced, then just maybe this (i don't know how good it is)
asking for "explanations on linear transformations" is basically asking for an explanation of linear algebra as a whole. are you looking for something that covers a specific topic?
super easy quick question, if I do:
R3 - R1
Does R3 change or does R1 change?
r1 right
yee ok nvm
@dawn remnant issue turned out to be I wasn't using an orthonormal basis for the plane and that fucked things up, got the right answer now
if you're looking for something a bit more advanced, then just maybe this (i don't know how good it is)
@wintry steppe
Is it legal here to do that?
as if laws would stop me
Hahahahaa
well
if a mod wants me to remove them i will
but
then i'll just link libgen lmao
I'm relieved that someone uses libgen here
e) encodes 2 different operations
for one it swaps lines 1 and 2,
and it adds line 1 to line 3
oh wait, are these all supposed to come from a
100
010
001
matrix
just with some rows swapped, scaled, etc
Yes
The important stuff is: JUST ONE OPERATION
Whe wikipedia article is a good one here
so e would require
r1 swap with r2
r1 + r3
and we are only allowed one operation each row right?
no one operation in general. The matrix is called elementary because it encodes an elementary row operation
In mathematics, an elementary matrix is a matrix which differs from the identity matrix by one single elementary row operation. The elementary matrices generate the general linear group GLn(R) when R is a field. Left multiplication (pre-multiplication) by an elementary matrix ...
basically if you multiply that matrix to another from the left, it just does one thing to it
okay question
if I know what two linear maps do to a basis
i should be able to tell whether one if the conjugate transpose of the other
(these are square matricies)
is there an obvious way to do this
@sleek helm
If you know where the basis goes, you have their matricies. Then just take one's conjugate transpose. Am I misunderstanding the question? Haha
Ah of course I'm thinking finite dimensional
Does conjugate transpose make sense in infinite dimensions? I can't say I know much of that part oop
itd be the hermitian adjoint
Well conjugate transpose corresponds to the adjoint over a orthonormal basis
And adjoint always makes sense
As long as you have an inner product
Oh wait Max even said these have a matrix representation.
yeah the issue is that
my matrix is completely generic
but i did the computation regardless
Hi, is the basis of the row space and column space of a matrix the same thing? Both methods of finding the basis for the row space and col space gives me the basis for the subspace correct?
they're not the same thing; consider for instance the matrix $\begin{pmatrix}1&1\end{pmatrix}$
Namington:
then the vector (1 1) is a basis for its row space
while the vector (1) is a basis for its column space
[or should i say, the set containing only that vector]
Ah i see! Then when do i know to use the row space or col space method to find the basis of a subspace?
uh, what subspace are you looking for?
both row space and column space are subspaces
Oh, let me find an example
In question 2, they used the row space method, and in question 3 they used the column space method
Would it be because W is a subspace of R^5, so we have to ensure that there are 5 variables per vector in the basis? (therefore deciding to use row space method)
And we want to find a subset of S so we use the col space method to ensure the number of variables per vector is 4 or less?
ah; it literally doesnt matter what you use
my guess is that the solution set used both methods just to demonstrate a variety of solutions
though do note that you'll set up the matrices differently
But as you said, the basis would be different
like if you wanted to use the row space method on 3.a
you'd have to set up this matrix:
$\begin{pmatrix}1&0&1&3\2&-1&0&1\-1&3&5&12\0&1&2&5\3&-1&1&4\end{pmatrix}$
Namington:
note that it's just the matrix they set up, but with rows and columns swapped
Mm!
So in actual fact, both methods would give me the same basis for the subspace, as long as i form the matrix correctly for each method
Is that correct?
oh hold on
i misread the question slightly
okay so the row space method WOULD find a basis for these subspaces
the problem is
the row space method "changes" the vectors
because you're row reducing them
whereas when you're taking column spaces, because you refer back to the "original" columns
the vectors are "unchanged"
in question 3, they wanted the basis to be a subset of S
i.e. they didnt want the vectors to change
thats why they used the column space method
Oh so thats what they meant..
Okay but otherwise without that condition
Would both methods give me the same result?
Even though they are written differently
well, they'd give you different bases, but both bases would work
I see!
ie they'd both be a basis of span(S)
you can kind of see this in action in question 2
these are the vectors they find
but 2 of them arent in the original set
the column space method doesnt have this "problem"
hence why they used it when they wanted the vectors to be from the original set
(i.e. in question 3)
I see!! Thank you so much for the clarification
again, both methods will find a valid basis
So in your first example regarding the matrix (1 1), i can use both methods
its just the column space "guarantees" the basis vectors will be from S
where the row space does not
basically yeah
anyway, this may leave you asking "why would someone use the row space method?" the answer is that it often gives "simpler" representations
like in the answer to question 2, the vector (0 0 0 -2 0) is much "simpler" than any of the original vectors
indeed, if you wanted to simplify further, you could continue row reducing into RREF
this is what computers typically do
since these representations are much easier to work with
For $n \in \mathbb{N}$ and $W \leq \mathbb{F}^n$, prove that there exists a system of linear equations whose solution space is $W$.
Note: $A \leq B$ stands for - A is a subspace of B.
does \leq here mean subspace?
Yes, W is a subspace of F^n
the-last-knight:
I've tried to begin with a basis of W, and constructing a matrix with the basis vectors as rows - but I'm not sure how to take it from here.
are you allowed to use that every linear function corresponds to multiplication by a matrix (and vice versa)?
if so, you shouldnt need to explicitly construct a matrix per se
take a basis for $W$, say ${e_1, e_2, \dots, e_k}$ and ``extend" it to a basis for all of $\mathbb{F}^n$: [
{e_1, e_2, \dots, e_k, e_{k+1}, \dots e_{n-1}, e_n}]
Namington:
since matrices correspond to linear functions, we can consider the matrix equation Ax = 0
this is the same as T(x) = 0 for some linear T
but how would we define such a T so that the ONLY solutions come from W?
[hint: linear functions are determined by how they act on the basis]
but how would we define such a T so that the ONLY solutions come from W?
@limber sierra
Hmm, so we want ker(T) = W, of dimension k. So the dimension of the range of T would be n-k, but I'm unsure how to find T still?
as mentioned, the behaviour of a linear function is determined by how it acts on a basis
so if we want T(x) = 0 for x in W
we want T(e_i) = 0 for all e_i in the basis of W
Yes, I understand this
but we want to make sure these are the ONLY solutions
Well we could say that T(e_i) ≠ 0 for e_i not in basis of W
to do this, we know we'll need T(e_i) to not = 0 for k < i <= n
yes
exactly
except theres a slight problem
theres a risk of "cancelling out"
like say we define T(e_i) to be (1, 0, 0, ...) for all e_i not in the basis of W
then T(e_i - e_j) = 0
the solution is to make sure they cant possibly "interfere" by making them affect different entries of the resultant vector
the easiest way to do this is to set T(e_i) = e_i
That can't happen, right? e_i and e_j are linearly independent, so T(e_i) and T(e_j) are too (I hope?)
for e_i not in the basis of W
not necessarily
the 0 function is linear
but its images are never linearly independent
since theyre all 0
Oh, right, but we want our construction to satisfy this. So just to sum it all up, if {w_1, ... w_k} is a basis of W, and we extend this to a basis of F^n, say {w_1, ..., w_n}. Now, we define a linear map from F^n to itself (correct?), such that T(w_i) = 0 for all 1 ≤ i ≤ k, and T(w_j) = w_j for all n≥ j ≥ k+1
Oh yes I'm sorry that was a typographical error
yeah, i figured.
anyway, you just have to check that this construction actually works
i.e. that it's a linear function (which means it corresponds to a matrix, i.e. a system)
Lastly, if the matrix of the linear map T = A, then Ax = 0 is the required homogeneous system?
and that solutions to T(x) = Ax = 0 are precisely x in W [so you must show, if x is in W, then T(x) = 0, and if x is not in W, then T(x) is not 0; hint is to write x as a linear combination of basis vectors.]
yeah
there are other constructions but
this is probably the simplest
Yes it is, indeed. Thank you so much!
it feels kind of "cheaty" to just define a function that satisfies all the criteria we want but
that's the power of linearity

How did you split it? I can't figure it out
Check your notez
hm does this have to do with multilinearity?
Yes
cofactor expansion?
i dont get how multilinearlity is used tho cuz how is the first row a linear combination of the second and third rows
well, I was able to find the property that you were referring to to split it, something like this right
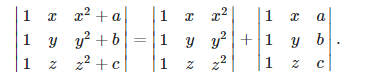
So isn't it 10 + 1/2*5?
Why 1/2?
hey guys, i need some help. is this true or false?
it sounds like itd be true to me
but im in this class at the moment myself
trying to think what a proof would look like here 
@warped garden it looks to me like any vector in the nullspace will work
ill have to screw around more to figure out why exactly
so just take any non 0 x where Ax=0, then the system Ax=b will be inconsistent
i may have used some wrong words there
im wondering now if this is just asking if its impossible to find an inverse mapping from the nullspace to the original vectors which is obviously impossible for a singular A
if it's non-trivial, the solns will not be all non-zeros, which means there won't be a case where the row is all zeros and b = non-zero?
not sure if i'm approaching it the right way
The rows of the matrix will be linearly dependent
So,you have atmost n-1 degrees of freedom
So, yes
Hello
I am having exam on linear Algebra, inner product spaces to be precise
Could you guys help in preparation
I study in second year rn
Sure
Thankyou
to check if something is closed under vector addition, if I add two arbitrary vectors in the set, do I have to be able to rewrite them is some form that looks like my original vector?
Yes
so then this would not work here because the ab right, its not possible
alright thanks, im trying to visualize this but I just cant
Hey everyone. I have the same task as mentioned here:
https://math.stackexchange.com/questions/3096931/prove-or-disprove-that-if-a-b-and-c-are-nonempty-sets-and-a-times-b-a-tim
I guess the answer by William Elliot is right but don't understand line 4. Why would (x) elem AxC => x elem C? (x) could be element of A and thus in AxC, can't it?
Are you sure you did not just misread that? It states (a,x) \in A x C => x in C
I let the (a,x) slide because I thought the a wouldn't be important but I guess that was wrong.
I think I found my error. I thought axc = a \cap c
This is the task we should solve
I'm not familiar with that notation, unless (X) denotes a light bulb :')
This is our notation for this symbol
clearly it means a tensor product
Oh that's strange
Well A x B usually notates the carthesian product so
$ A \times B = { (a,b) | a\in A \wedge b \in B}$
Tobii:
yeah we also noted that one but we use the symbol <>
I think my question has been solved. As I mixed the terms. With the carthesian product it makes sense. I'll try to figure out the task with the new understanding xD
why are the three subtracted terms all zero
-(0x1x2) -(0x1x2) -(0x1x1)
oh
wait
I did this method
oh wait
what columns do you pick
to be the outer 2
the first 2 columns get picked?
oops
that's why
ok so it's zero
Give a vector ~u whose orthogonal projection on the vector (1, 1, 1) has norm equal to 1/3 and forms an angle of π/3 with (1, 1, 1).
Any tips for this?
This is what I've tried:
Just curious, you can take a dot product of two matrices right?
sure
pick your favorite identification of an m x n matrix with an element of R^(mn) or C^(mn) or whatever
then just use the dot product there
which is a convoluted way of saying multiply all the corresponding entries and add it up
it's not the only inner product on matrices, but if you want the closest thing to the dot product of vectors that you're used to, it's pretty much the only choice
Ooh I see, thanks
Hi, this is true correct? My reasoning is that if its a subspace of dim 3, it means it lies in R^3 and is therefore spanning a space of at max R^3. any subset of it would have 3 vectors or less
hi! I want to find the intersection of these 2 non parallel lines: y=1/2x+2 y=2x+4 Do i use linear equations to solve it?
let's go to #prealg-and-algebra @thick condor
ok
Yes that’s right @cerulean quest
thank you!
How to prove that the cofactor matrix of an orthogonal matrix Q is ±Q?
@gaunt field the cofactor matrix is the transpose of the adjugate matrix, which is the inverse, scaled by the determinant of Q.
I didn't learn what the adjugate matrix is
is this correct?
i know how to find coefficients but i am confused for this
should it be x^2 y or 1/x^2y ?
oh ok
can someone please explain to me how this is a sufficient proof that $\bR^\infty$ is an infinite dimensional vector space?
nix:

are you asking why a space is infinite dimensional if it has an infinite linearly independent set?
well if it were finite dimensional, then you'd have a finite basis. but then you can find a bigger one. and a bigger one. and so on
but all bases of finite dimensional spaces should have the same cardinality, contradiction
might be an overkill way of looking at it, but that's one way to see it
does that make sense?
hm yeah my textbook only says that something is infinite dimensional if there is no finite spanning set
proving "it has an infinite linearly independent set" is definitely a lot easier
sorry could you elaborate on which finite spanning set?
do you mean that if the supposed spanning set was e1,...,en then we couldnt write e(n+1) in terms of that set because they are linearly independent or am i missing it
i see that the vectors e1,...,en are linearly independent, but im not seeing how we can then say that en is linearly independent with any finite spanning set...
i dont think im fully understanding what you mean
okay i see that. it makes sense
im not 100% how i would write that as a formal proof, but im going to mull it over and sleep on it.
thank you very much for the help ❤️ ❤️ ❤️
@warm briar @wintry steppe

How do I show that e^x and e^-x are linearly independent in C[0, 1]
Show if ae^x+be^(-x)=0 for all x in [0,1] implies a=b=0
So.. if I multiplied by e^-x, then that becomes a + be^x = 0. since e^x can't be 0, then they are linearly independent
Yea,That works ig
how else would i prove it?
looks like it's clear to ask...
what is the (2,3) entry?
don't even know where to begin lol
Probably ( I gotta guess here as we had another notation for such things) the entry in the 2nd row at the 3rd column?
guess I was just curious how finding that entry correlates to this solution
idk how A32 is -1
Well A_{32} seems to A developed by the 3rd row, 2nd column (Leibniz formula?)
That has kind of a checkerboard pattern which is encoded in the (-1)^(row+column)
I dont see how they made that connection to the entry b_23 on the fly though
Find a vector u whose orthogonal projection on the vector (1, 1, 1) has a norm equal to 1/3 and forms an angle of π / 3 with (1, 1, 1)
Any help with this?
@bleak ginkgo You know the magnitude of v so you can simplify both of those expressions right away
And I would be very careful not to put a dot between the magnitudes on the last line, since we use that for the dot product not scalar products
looking for some help ive been stuck on this problem for almost an hour a^x− (b⋅ c) ÷ d for a = 7 , b = 3, c = 2, d = 6 , and x = 6 i keep getting the same answer which isnt one of the 4 multiple choice answers
@bleak ginkgo You know the magnitude of v so you can simplify both of those expressions right away
@hollow finch I know the magnitute of v is sqrt(3), but I can't find a way to use the first formula with the second
With that first expression (the 1/3 one) you can solve for u dot v
You can factor scalars outside of the magnitude
Then you can solve for the magnitude of u
well yeah i guess if you meant u1+u2+u3 but i dont think thats the way you want to do this
I mean let's see, how many solutions are we going to have for u. Is u unique or are there infinitely many?
There can be infinitely vectors with those conditions prob
I probably need the parametric vector
Or I could just find a vector and prove those expression.
I tried making a system of ecuations with both formulas but something went wrong
$ \lVert \frac{\vec{u} \cdot \vec{v}}{\lVert \vec{v} \rVert^2} \cdot \vec{v} \rVert = \frac{1}{3} = \lVert \frac{u_{1} + u_{1} + u_{1}}{3} \cdot (1, 1, 1) \rVert $
Zombie:
$ \lVert u_{1} + u_{2} + u_{3} \rVert = \frac{1}{3} $
Zombie:
$ \sqrt{u_{1}^2 + u_{2}^2 + u_{3}^2} = \frac{1}{3} $
Zombie:
@hollow finch Am I way too lost?
Cuz of that I get |u| = 1/3
So I now know the magnitute of u and v
@bleak ginkgo I wonder if you could choose a convenient component of u (say u3=0) and then find a u1 and u2 with the desired magnitude and direction
Maybe it could be in the form $|\vec{u}| (\cos(\theta),\sin(\theta),0)$
nix:
Not sure if that would work but it's an idea
Hello.
if I want to normalize a vector, I need to divide it by its norm right?
if it's nonzero, yes
so the norm of v=(-4, 0, 4) is <v, v>, which is -4 * -4 + 0 * 0 + 4 * 4 = 16 + 16 = 32
so v = ( -0.125, 0, 0.125) right?
how do I confirm this length is equal to 1?
oh
You forgot the sqrt
the norm is thje square root of <v, v>
And I'm too tired to get this right first try lol
You got sooo much opportunity to miscalculate something
just a question since the book doesn't specify
u1 = v1
u2 = v2 - ... * u1 and so on
uh
basically I'm confused how u4 looks like
Tobii:
hope i didnt mistype
thanks
So basically you subtract the parts of u_1 to u_3 from v_4 to get u_4
Then you still have to get their length to 1
If I have a plane that is perpendicular to the xy plane and goes through two points. ¿How can I calculate it?
why are we allowed to commute the Qs?
oh it does?
honestly maybe this is something i just forgot tbh
ok thanks
yea i will
gross but ill read it
it will be good to know
appreciate the help
the way you should prove (AB)^T = B^T A^T is by using the fact that the transpose of a matrix is the matrix of the pullback of a linear map wrt the dual bases
even though it probably ends up being the exact same calculation
Use the fact that transpose is an anti-isomorphism and an involution

Question: if someone said P3 i guess polynomial degree 3? how many dimensions does that have
an nth-degree polynomial is generally defined by n+1 coefficients
So 4?
just polynomial degree +1?
ie how many dimensions does p4 have it would be 5?
yes
Awesome, thanks for clearing that up
why is this the case?
I know the standard matrix multiplied the vector is the effect of the transformation on that vector
what's a matrix times the ith column of the identity matrix
meaning every linear transformation that can be done on a vector is a product of the matrix and that vector
ith column?
yes
it's whatever the ith column is in the original
correct
the span of the identity matrix would be every possible matrix with some dimension n right?
so wouldn't the images of the columns be any possible column with dimension n
let me ask a possibly more helpful question
how did you define the standard matrix of a linear transformation
the matrix which multiplied by any vector gives you the transformation of that vector
okay, so if $x = (x_1,\dots,x_n)\in\bR^n$, then $$Tx = T(\sum x_i e_i) = \sum x_i Te_i.$$ by writing things out like this, you should be able to prove, just using the definitions, that the matrix of $T$ is the $m \times n$ matrix with columns $Te_1, \dots, Te_n$, which is precisely what you should show. this doesn't require any fancy tricks, just definition pushing
TTerra:
Can you make the set of functions $\bR\to\bR$ into an inner product space?
Whoever:
i know you can if you restrict to bounded functions, but that's not what you're looking for
Preferably a more explicit inner product rather than one that depends on axiom of choice
Oh
How?
wait nvm
im dumb
that gives a norm which is definitely not induced by an ip (i had the sup norm in mind lmao)

Hmm I think if you consider the set of bounded functions [0,1]->R then you can do the Lebesgue integral
of product
how do i do this
subtract eq. 2 from eq. 1
get -3x + 3z = 0 so x = z
add 2 times eq. 1 to eq. 2
get 3w + 3y so w = -y
so the solution pairs can be parametrized as (-p, q, p, q) or rather, p* (-1, 0, 1, 0) + q * (0, 1, 0, 1)
thanks
Are there any good resources to check out that show all the theorems and proofs that we should know from each chapter?
Suppose I have some basis for R^m which is not orthonormal
say for example R^2 and basis is {(2,1), (-1,3}}
ok
when want to find inner product in this basis i then will have dot product of these basis vectors
do i take it in cartesian system or what?
i mean how do i find then say
Commander Vimes:
you need the gram matrix of your basis
and how do i construct it?
$G_{ij} = \ang{v_i, v_j}$ where your basis is ${v_1, v_2, \dots, v_n}$ and $\ang{\cdot, \cdot}$ is the standard inner product
Ann:
then for two vectors $x$ and $y$ (expressed as coordinate vectors in your basis) their inner product is $x^TGy$
i-jth entry of gram matrix
Ann:
can someone help a sistah out with linear transformations
I am confused where it says ordered basis
im not quite sure what it means by "relative to the appropriate ordered basis"
I guess they just want you to use the standard basis for M2x2(R)? @half forge
stuck where? Finding the matrix representation in the standard basis?
yes
so typically, you would identify matrices with columns vectors. So [[a,b],[c,d]] goes to the column (a,b,c,d). i.e. we identify the basis vectors [[1,0],[0,0]], [[0,1],[0,0]], [[0,0],[1,0]], [[0,0],[0,1]] with the columns (1,0,0,0), (0,1,0,0) (0,0,1,0) and (0,0,0,1) respectively.
So from here you can build up the matrix. For example,
UT maps [[a,0],[0,0]] to 6a so using our identification, (1,0,0,0) maps to 6. Similarly with the others
how do I check if every vector in a matrix is also in another matrix?
so typically, you would identify matrices with columns vectors. So [[a,b],[c,d]] goes to the column (a,b,c,d). i.e. we identify the basis vectors [[1,0],[0,0]], [[0,1],[0,0]], [[0,0],[1,0]], [[0,0],[0,1]] with the columns (1,0,0,0), (0,1,0,0) (0,0,1,0) and (0,0,0,1) respectively.
So from here you can build up the matrix. For example,
UT maps [[a,0],[0,0]] to 6a so using our identification, (1,0,0,0) maps to 6. Simil
If I have two matrices A and B, where the column of B > Column of A, then all the vectors in B cannot be in A, but all the vectors in A can be in B. To check this I need to check if the column of B is linearly independent? Do I have to check for matrix A as well?
you can't determine if a non-square matrix has one unique solution or infinty or no solution through finding out wether determinant is 0 or not?
You mean (column vectors of A) form a subset of (column vectors of B) ? Or col rank of A<col rank B?
@native rampart 😄 can I ?
Its asking specifically to check if all the vectors in A are contained in B
Can you share the specific question?
yes
hold on
So W is a square matrix, but V is a mxn matrix with more columns than rows
W is a 6x6 while V is 7x6
Clearly the columns in V are linearly independent since given a mxn matrix if m>n then it is linearly independent
You could have all columns to be (1,0,0,0,0,0)
Np
So V is linearly independent, but do I need to check if W is also linearly independent?
Columns of V cannot be linearly independent
Because a basis of R^6 can have only 6 vectors
And there are 7 column vectors of V
oh, i got told that if there are more columns then rows it is linearly independent
maybe its if there are more rows than columns
Anyway,first calculate the column rank of V
If it's 6,all vectors in W will be part of V
If it's 6,We are showing V=R^6 and W being a subspace of R^6 will be a subspace of V
Which means all vectors in W will be in V
If it's not 6,it will be a lot more work
so if the column rank of w = column rank v then all of W is in V?
@bold python If that rank is the number of rows,yes. Generally no
What is it then?
Find a basis of col W and col V and check if the basis vectors of col W can be written in terms of basis vectors of col V
Idk if you could simplify that process
If a basis vector of col W cannot be written in that form,then it's not in V
(dim col W and dim col V is useful, because you can stop as soon as you find 4 linearly independent vectors in col V)
shouldnt i stop as soon as i find 3 linearly independent vectors in col V?
yeah yeah, but I was thinking since W is 3
okey ill try what you said now
thanks drunken
Well, You might end up needing only 3 with the right basis, but well 4 to be safe
So I know that if a given mtx. A is symmetric positive definite then $det(A) > 0$. Namely I am assuming the opposite does not hold? Im sure one can find matrices whose determinant is positive, but the matrix itself not positive definite right?
Fredrikpiano:
ok, thanks)
so for the negative identity mtx (2x2) the determinant equals 1, but both eigenvalues will be -1. Easy to see
how would I go about solving this
You can write z=(8/5)x+(6/5)y
Now note x and y can be anything in R
But z will be unique for a given x and y
So, general solution will be x(1,0,8/5)+y(0,1,6/5)
wait how did you know the the first two in each vector were 10 and 01?
Have you understood why general solution is (x,y,(8/5)x+(6/5)y)?
no
Have you understood you can arbitarily choose x,y but not z?
because no matter what you pick for xy z is the only thing that matters to make the equation true?
Yes
So,you can say general solution is x=s,y=t and z=thing that makes the thing true
And the thing makes the thing true is 8/5 s + 6/5 t
I think I understand
01 is used to make the equation simple
so its obvious that 8/5 and 6/5 are the solution?
ahhh I get it
if I have a linear system of equations in R3 and one equation is a scalar of another then I have parallel planes or the same plane?
is this linear? @plush idol
what class are you taking that assigned it
APES
I think it literally just wants you to graph that data using google sheets
When it comes to row operations, when you interchange 2 rows when do you need to cahnge the sign on that row
What sign? Are you talking about determinants?
That's 2 row operations
oh ok
Can anyone explain what a trivial vs non trivial linear combination means
I looked it up and google says that trivial basically means it has a 0 in it
Though my professor just contradicted that so I’m confused
I think the trivial combination is that one that has all scalars 0
yep
Why do you even make up a namr for that?
So if I have 3 vectors for a set then all 3 have to be 0 then it’s “trivial”
so you could say e.g. a set of vectors is linearly independent if the only linear combination that makes the zero vector is the trivial one
Why do you even make up a namr for that?
@native rampart
A set is linear independent if the only linear combination of set that get 0 is the trivial one
everything is trivial when you don't know how to prove it 😉
Math is trivial, anyways
Is there a trivial map?
Ok
"trivial map" is probably not a standard name, "trivial linear combination" on the other hand I've heard of it at least once
there's also https://en.wikipedia.org/wiki/Function_(mathematics)#empty_function lol
I have read trivial map, I think
(though the empty set is not a vector space so that's out of this context)
It isn't a convention
Can't you have an "empty vector space"?
yep, a vector space needs additive and multiplicative identities
Yea,You can't have an empty group either
You can have the vector space that only contains 0
can anyone help me understand how to do 2b? from google and my book, I see that it has to add up all the vectors, then scalar multiply them, then using the solution, subtract it by the original vectors to get 0 is what im reading
what would happen if R^3 had a linearly independent set of 4 vectors?
you don't need to do anything with linear combinations for 2b
i think it would just depend on if two vectors equals the next, like x1 + x2 = x3 then it would be safe to assume that the x4 (4th vector) would be dependent too
if a subset of the vectors is linearly dependent, then the whole set is as well
you are right
so i would do this? v1 + v2 = v3 then Av1 + Bv2 = ABv3? where A = alpha and B = beta
and v = verticies from left to right
Hi I’m studying for a midterm, can anyone help me with any of these problems? #4 and #5 is multiple choice but she requires a sentence of explanation
I know the answer for 4 is B and for 5 it’s C but idk how to word why
what is there to solve

Great way to start
Im trying to answer this questions. My hunch was to reduce the statement to reduced row echelon which turns out to be The 3x3 identity matrix. My instinct is to say that what ever a, b, and c are transformed to in that process is the answer
but i dont have much a theoretical basis as to why i think that
I was looking for a row of 0's because that would tell me that the associated variable (a,b,c) combination must equal 0
@lucid cedar you may want to double-check your work
The REF is not equal to the identity matrix
{kind=link}
{kind=link}
{kind=link}
{kind=link}
is row(A) equivalent to range(A)?
yes, there are different naming conventions in different classrooms
i was wondering if row was just another name for range
what does your textbook define row as

In linear algebra, the column space (also called the range or image) of a matrix A is the span (set of all possible linear combinations) of its column vectors. The column space of a matrix is the image or range of the corresponding matrix transformation.
Let
...
i think its just the same as this one
ok so the row space is not equivalent to range
sry I can't help you on this one then, I'm only familiar with ranges
yea i messed up a row operation
its supposed to be
1 0 15
0 1 -9
0 0 0
so does this mean that the c row must equal 0?
like i had originally thought
yea
then yes, it must be 0 for the system to be consistent
what can i say about the other rows? do i need to make any further inference on those rows?
nope, the other rows are not 0 rows so you'll never obtain a case where 0 = some nonzero real number
gotcha
This is the final matrix. If the bottom row is set to 0 like we said then we get c = 3a + b. Im not sure how to begin making a statement about what a and b are
@lucid cedar Yes, that's enough. To get a consistent system(at least one solution), we need the rank of the augmented matrix to be equal to the rank of the coefficient matrix, and that can only happen when -3a -b + c = 0 or c = 3a + b, no need to say anything about a or b
np
can someone tell me whats the standard basis for p3?
if you get the rref of a homogenous system, you still get a homogenous system right?
and vice versa? you can only get a homogenous system in the rref only if the original was also a homogenous system
So the thing is if you are doing row reduction appropriately you are at every single step still in the same linear system
You never leave that "world" so to speak you are only uncovering new or different things about the same system
Homogenous systems by their nature will keep a column of 0s in their augmented part throughout all of the row reduction
thank you! just wanted to make sure that a zero column will always stay as a zero column
I have this matrix and i need to find all 2x2 matrices B such that AB = BA
i set B as
w x
y z
then plugged them in AB = BA, solved for w,x,y,z
is this the right move?
Yes, what did you find for B?
if a square matrix can be expressed as a product of elementary matrices, it's possible to have different elementary matrix combinations that give the same product, right?
yes
I have consistently scored a 95 on every assignment thus far in linear algebra 🤣
Cool
Now if I can just get through the latter half of the semester with 90 or above ill be happy
This course is pretty relentless though but I feel like its helping me understand the content more thoroughly
We only get graded on exams and everything is open response so you have to be very detailed in your response. But that's probably starting to get off topic so ill digress
hey guys, what's the intuitive meaning behind linear independent vectors having only trivial solns?
i understand a set of vectors are linearly independent if they only have the trivial soln, but i can't seem to understand why
Because that's the definiton.
If A is 3x3 does det(-A) = -det(A)?
Since all row operations correspond to an elementary matrix, what would be the matrix that represents a row +/- another row?
you get the elementary matrixes corresponding to an operation by applying the respective operation to the identity matrix
that makes a lot of sense
what is lambda in eigen value? Im so confused
lambda is just the symbol used for eigenvalues
like x is used as a symbol for a variable
the values of $\lambda$ that satisfy $\det(M - \lambda I) = 0$ are called eigenvalues, they're just variables
bacono:
okay, i have a question, and i think its quite a dumb one
but i am having trouble understanding the meaning of a matrix
e.g, we can represent a linear operator as a matrix
but we can also make a matrix out of a set of column vectors
i get that they are different
but like using the latter as a LO on identity, i just don't know what to think now
the representation of a linear operator as a matrix means to literally take the basis vectors, map them under the linear operator, and then use the resulting vectors as the columns of the representation
if i say the term "a linear transformation is determined by what it does to a basis"
do you understand what i mean?
i think so
if so, make a system of linear equations out of basis vectors, and you should be able to see the correspondence between matrices and linear transformations
(since matrices are "condensed" ways to write a system of linear equations)
the representation of a linear operator as a matrix means to literally take the basis vectors, map them under the linear operator, and then use the resulting vectors as the columns of the representation
@brisk fractal yeah, but the problem is
say i use a matrix(square) on to identity, depending on whether I is in front or behind, i will be working with either rows or columns of the matrix
so say the matrix is composed by a set of column vectors, but i used it as a LO on identity
so what the hell does the rows of said matrix mean? since it was originally formed by column vectors
if so, make a system of linear equations out of basis vectors, and you should be able to see the correspondence between matrices and linear transformations
@limber sierra yeah, i get that.
i am just confused when thinking of matrices made from position(column) vectors and matrices that we know are representing a system of linear equations
when matrix multiplied with identity, sure, everything works out perfectly.
But when matrix multiplying with something else, the answer can be very different, naturally(if LO, then its on lhs, if as a matrix of column vectors, then its on rhs)
so i am just wondering if there is any special meaning in the rows of vector matrices? hope it makes sense
and columns of LO
removed
@thorny kraken #real-complex-analysis
oh sry im learning this in my linear algebra class lul
i did, ty ^^
if you don't mind, can delete here, since my question wil;l be buried
oh right, I completely forgot that rule
@frigid otter Think about it as taking a factor of c from each column, that is why it is c^n where n is the order of the square matrix
@twilit terrace AI = IA = A for a square matrix
rows are generally insignificant as far as I know other than interpreting as the coefficients of a system, but of note is that dim(Col(A)) = dim(Row(A)) = RankA
namington explained how to interpret the rows better than I could
how the fuck do I prove these
I'm thinking doing something with (AA)_k = AA_k for the kth column, and then messing with some linear combination stuff but I can't seem to get anywhere
Using similarity probably
Hello
Can someone please explain to me where (-1 -4) came from?
Thats the question
@brisk fractal
I believe for thr first one you can show that the columns of A*A are linear combinations of the column vectors of A
you're right
Hello
@wintry steppe use the first equation in the system
the jacobian times S = -f(X_i)
Yeah i have no idea what that means
you're right, but you have f, and f(1,2) = (-1,-4)
I know where (-3 1 2 4) came from
but i have no idea where (-1 -4) came from
clearly theres calculation
@brisk fractal
I believe for thr first one you can show that the columns of A*A are linear combinations of the column vectors of A
@cloud bloom I wrote that $A_n \neq \sum_{i \neq n} \alpha_i A_i$, so that implies $AA_n \neq \sum_{i\neq n} \alpha_i AA_i$, and so the product rows are linearly independent, if that works
bacono:
*product columns
What should i calculate to find (-1 -4) ?
sorry, it's (1,4), and -f(1,2) = (-1,-4)
So its the 2nd row times the value from the given Xo (1,2)
?
How did we get negative then
?
It doesnt make sense
its value is not equal to (-1 -4)
Sounds like im going to have to ask this question on Chegg
yes
where the heck did we get -1 -4
the relation between these
I dont understand words
i understand with examples
where did we get -1 -4
calculation?
applying -f since these are the same thing
WHAT IS -F
I am not getting you
Should the 2nd row in the matrix turn it into negative?
you are showing me a formula that i have no grasp of if i have no idea what its about
sorry
those is should be 0s
and thats -f(X_0)
so compute f(X_0) and take the negative
what's f(1, 2)?
I don't understand dude, are you just not understanding any part of the solution or just that matrix calculation?
so we know that the product here is -f(X_0)
so the question becomes
what is f(X_0)?
we know thajt X_0 is (1, 2)
and f(x, y) = (y-x^3, x^2 + y^2 - 1)
so we compute
f(1, 2) = (2 - 1^3, 1^2 + 2^2 - 1) = (1, 4)
but since it was -f(X_0)
instead of f(X_0)
we take the negative
(-1, -4)
and that is equal to J_f(X_0) * S_i
because of the equations given above
I will have to try it on the paper one sec
the point is that we're not computing this via matrix multiplication
rather we're applying this formula
with i = 0
using how f was defined at the start of the solution
and the provided initial value for X_0 (1, 2)
Now i Understood it
Why didnt u tell me that I have to replace values 1 , and 2 in this equation then shift the signs? You made this x10 confusing
Thats all there is to it
Just replacement and shifting sign LOL
This formula, FUCK IT TO HELL
It made everything confusing
i dont even consider this a formula
i was trying to say that
and if you dont understand that formula, i'm concerned about your ability to actually understand the process
I dont even know what a matrix is, its empty language. I may know how to compute, calculate , fidn the inverse, and with some logic
but its literally empty language/math
Its useless
i just have to pass the course =P
If i understand how something is done then I know how to replicate it
it doesnt matter about the origin
whats a cool linear algebra related topic i should do a project on
Can some one help me solve this Markov question? Find a transition matrix T where T^6 equals the identity matrix. The closest I've got is the T matrix in the image above, but T^5 = I, which make this answer incorrect.
You're pretty close
As a hint, the following would work
0 0 1
i 0 0
0 i 0
@spring tide
the problem with transition matrices is that their rows have to sum to 1
it's not hard to come up with matrices such that A^6 = I; you can simply make the characteristic polynomial have a few of the sixth roots of 1
I figured it out. The order of a permutation can be expressed by the least common multiple of its disjoint cycle lengths. For example (1 2)(3 4 5) would be 6.
lol, trust me. it took me two days to figure that out
so im the dumb one if anything
Can someone give me a hint for this question? We just started RREF 🤯 and my prof isn't available until tomorrow but I want to finish this tonight 😭
@strange dove
6 columns means there are 6 variables in the system
But if you look at the values in the columns the equations in that system only involve 3 of those 6 variables
So the remaining 3 variables are free to take on any value
Well up to 3 variables are unsused column 3 has an unspecified value
And column 5 too sorry
But still at least 1 unused
Rouche Capelli theorem is used to determine the number of solutions
the solution x is not unique, and it's infinite
You can look into that and see how it applies to your matrices
Right there are infinitely many solutions because the first column in particular is all zeroes
there aren't pivots in each column, and although there aren't pivots in each row, the specific x doesn't lead to an inconsistency in the system
so there are infinitely man non-unique solutions
hey!