#linear-algebra
2 messages · Page 133 of 1
this is encapsulated by theorems on RREFs and elementary matrices and invertibility
do you know how one typically proves equality of spans?
i can take a quick look.
looks fine so far at a glance, except you never showed that x, y are indeed in span{x+y, x-y}
might be best to quickly justify that
Yeah but do you know how I can do that
write x as a linear combination of (x+y), (x-y)
then do the same for y
as a hint: observe that if we just let the coefficients both be 1
then we have
(x+y) + (x-y) = 2x + 0 = 2x
this is very "close" to what we want
we ended up wtih 2x, not x, but thankfully we can divide both sides by 2
its easy to check that (1/2)(x+y) + (1/2)(x-y) = x
and so x is in span{x+y, x-y}
you can do the same thing for y, it's a similar idea
but rather than subtracting the y, we want to subtract the x
hmm... if only there was something we could multiply (x-y) by to make it look like (y-x)...
yeah, so the combination in that case will be (1/2)(x+y) + (-1/2)(x-y)
and this is indeed equal to y
So i'm confused as to what this question is asking
I multiplied the two and gave the value in row 2 and column 1
what exactly does (AB)_21 mean?
typically the entry in the 2nd row and 1st column of the product AB
so either theyre using a different definition
or your answer was incorrect
hold on lemme check
so why is -25 wrong?
compute AB, then look at the entry in the 2nd row, 1st column
well, somehow you messed up your matrix multiplication
yea that's what i did
isn't it -5 * the first column?
uh
no
we're dealing with AB
not BA
though even if we were
that wouldnt make sense
review your definition of matrix multiplication
wait fr?
it'll be the dot product of the 2nd row of A and the 1st (only) column of B
(5)(-5) + (1)(-3) + (-2)(1) + (-4)(5)
so u times all the terms un column b wow
wait isn't that what I did?
i don't think im doing this right
im not sure what you did
i did -5 * [6, 5, 7] -3 * [-4,1,-4] .... etc
no, you dont take the entire column
the entry in the 2nd row and 1st column of AB is the dot product of the 2nd row of A with the 1st column of B
so each entry in the 2nd row of A gets multipled with the corresponding entry in the 1st (only) column of B
and then we add all those together
done correctly, this is the full product
note that multiplying a 3x4 matrix with a 4x1 matrix gave us a 3x1 matrix
so jsut to verify it's -50?
yes
uh c4t
i dont understand your first step
what did you do to the bottom row?
it seems you simultaneously added and subtracted the top row from it? (though i dont even know where the -7 comes from)
make sure you dont mix up your positives and negatives
I subtracted 3rd from the first
Oh yea I messed my signs up that makes sense
Now I see
I should have subtracted the bottom from the middle
Can I ask for help ?
@sweet sigil yes
why is this problem a big jump in difficulty compared to the other systems i was solving
it wouldnt be so bad if i just had to find one solution
there must be a different strategy i can use for equations like this to find general solution


i don't think i can reduce it as an augmented matrix in echelon form
just have to work with it as a system
and i don't think there is a specific variation for the variables, as any of them can be free variables?
im just going to do this problem without trying to reduce it in echelon form in some way
cause it just doesn't seem to intuitively reduce
i don't think I find gaussian elim to be very useful if you don't have an m x m matrix
maybe im just not thinking about the current problem im doing right
@limber sierra so the integral of that matrix would be xi + xj + xk + c ?

I think I figured out the explanation
@pearl elm
so the answer to b should be that it also spans R^4
Since the column vectors in the RREF span R^4
verifying if a list of vectors spans a space is very boring 😩
Guys
I know that the range of the coefficients matrix is the amount of pivots I am able to generate
But what defines the range of the independent term part ?
not sure why you tagged me. I was derping with my solves earlier
Can someone tell me if this is in row echelon form, not sure because first time encountering no solutions
Also is this in reduced row echelon form (that is if I put it into row echelon form correctly above)
Also is this in reduced row echelon form (that is if I put it into row echelon form correctly above)
@steady cargo yes
Perfect, thank you
The first is not row echleon though
Damn
Is the -15 the problem or do I just make it 0
I feel like I should've kept to -15 but not sure
*sorry confused with row reduced
I tried to reduce the second one as much as I could
that's as far as I could get it
Yea,first is echleon
Are both correct?
Yes
Grand thank you! Is it necessary to make the -15 to 1
No
Since it really doesn't change anything given it is 0=-15, 0=1
Not for row echleon
For reduced it is tho?
Yes
Thank you v much!
Is kernel just another name for nullspace? So many stupid terms I have to keep track of!
Why do they use different names for the same thing if image is just column space and kernel is just null space?
Because kernel is used for other things,too
can someone reference me smth, i dont get how this is "easy to see"
So I have a rref'd matrix [ 1 -1 0, 0 0 1, 0 0 0 ] and they say that the kernel has unit length vector [ 1/sqrt(2) 1/sqrt(2) 0 ] . How on Earth did they get that vector for the kernel?
Oh nevermind, duh. Just solve for the null space and you get [ x x 0 ] for the nullspace, and the unit vector of that is [ 1/sqrt(2) 1/sqrt(2) 0 ]
How do you show this?
Oh I have an idea now
So if $V\neq\brc{0}$ and $\brk{v,v}\geq0$ for all $V$, by definiteness there exists $v\in V$ with $\brk{v,v}>0$. If there exists $\brk{v,v}>0$, suppose for contradiction that there exists $w$ with $\brk{w,w}<0$. Let $a$ be any real number. We cannot have $v+aw=0$ since this would imply $w$ is a multiple of $v$ so $\brk{w,w}$ is a nonnegative multiple of $\brk{v,v}$ and thus $\brk{w,w}\geq0$. Therefore $v+aw\neq0$ for all $a$. Then expanding $\brk{v+aw,v+aw}$ (assuming $V$ is real vector space) we get $\brk{v,v}+2a\brk{v,w}+a^2\brk{w,w}$. Since the discriminant $4\brk{w,w}^2-4\brk{v,v}\brk{w,w}>0$, $\brk{v+aw,v+aw}=\brk{v,v}+2a\brk{v,w}+a^2\brk{w,w}=0$ for some $a$. This contradicts the fact that $\brk{x,x}=0$ iff $x=0$ so no such $w$ can exist
Whoever:
@half forge do you know what linearly dependent means
linear depdent is when we can find solution that doesnt equal 0?
Linear dependence is a statement about vectors. A collection of vectors is linearly dependent if there is some non trivial linear combination of vectors giving the zero vector. What you mean to ask is why the columns of that matrix are linearly dependent.
The columns of a matrix are linearly dependent (independent) if and only if the columns of the reduced row echelon form are linearly dependent (independent). Look at the rref at the end. How do you know that those columns are linearly dependent?
Columns are linearly dependent if there is a non trivial solution to Ax=0
Or they are inpendent if the only solution to Ax = 0 is the zero vector
probalby the last one
@zealous vine
also question
can a system with no free variables have a basic solution
Guys, is it the variance that usually tells the statistical significance of a data set?
@pastel flame wdym with that (and i think it should be in #probability-statistics )
Oh didnt see that chanel
and i should state that variance (in probability/statistics) is the rate of error
I looked around and I think its called p value
usually in physics i see it as sigma (non caps)
i am not sure i am right but this looks similar to finding is a subset of vectors is a subspace of a vector space
and the this is the scalar multiplication closure axiom which is one way to check if the above thing is true
but idk if that is similar to linear dependence and linear independence
it's the theorem relating to vector space dimension
if you come upon the dimension (3 here) # of independent vectors, that's a valid basis
Could anyone give me an example of how to answer this. Errr maybe this sounds weird but I understand what this is asking I just don't know how I'd put an answer down on paper
hint: for a and b you need to make sure the domain and codomain of your linear transformation don't have the same dimension / have infinite dimensions
injectivity and surjectivity are equivalent for any linear transformation between two spaces of the same finite dimension (easy consequence of rank nullity) - this may also help answer c
so maybe you can start looking there
e.g. start looking at things like R^2 -> R and R -> R^2
So for example would it suffice to say that T : R3 -> R2 is onto but not one to one
well you should probably specify what T is
Yea that's more of what I was asking how I could go about going from the theoretical part to an actual equation T(x) = Ax to write down
but you have the right idea: any linear transformation from R^3 to R^2 cannot be injective, since 3 = rank T + nullity T, and since rank T is at most 2, nullity T has to be at least 1
as for writing down a matrix equation
the columns of A will just be what T does to the standard basis
So I could just say T((x1, x2, x3) ) = [ -1 0, 0 1, 0 0] x is an example of a transformation that's onto but not one to one because it maps R3 to R2
And then similar solution for the other two options
$$T(x_1,x_2,x_3) = \begin{pmatrix} -1 & 0 \ 0 & 1 \ 0 & 0 \end{pmatrix}\begin{pmatrix} x_1 \ x_2 \ x_3 \end{pmatrix}$$
TTerra:
that?
I mean for C I could be as simple as T(x) = I*x I mean that is a linear transformation that is one to one and onto
And this:
yea i forget the shorthand notation
so i might have typed it in wrong when i said it
I really don't understand how to solve this problem and problems like it.
solve the one you're given and see which other ones have the same solution
@desert robin find x and look at the equations that if you insert this x it will be true
the first one is one of those
5(15x - 12 = 12)
ohh

I have achieved big brain status
Could someone look over my solution for 2b?
I have the official solution to compare to if needed
A 3 x 3 matrix A is reduced to i3 by performing the following three elementary row operations (in the given order):
- Add 2(row2) to (row3);
- Swap (row 2) and (row 1);
- Scale (row 2) by 0.5
Write A-1 as a product of appropriate elementary matrices and use this to find A-1. Clearly show your work for better practice.
Could someone help me do this question? I was practicing linear algebra.
what'd you try
that's not what T does
oo
the book writes it weird. T is defined by, for all p in P_2(R), (Tp)(x)=xp(x)+p'(x) for all x
you don't see what
that definition
line 2. i rewrote it to make more sense
stuck how
how to proceed on the steps
$T(1) = x \cdot 1 + (1)' = x$
Ann:
$T(x) = x \cdot x + (x)' = x^2 + 1$
Ann:
you already wrote the gist of what to do
it's just understanding how T actually maps polynomials in P_2
What does the I here mean? A is a defined matrix.
If AD=I, what is matrix D?
identity matrix
Thanks Ann
@half forge so basically, you’re going from β to Ɣ change of coordinates matrix right
That means you plug your vectors in β into the linear transformation definition.
And express it as a 3rd degree polynomial of your Ɣ vectors
whatever you get as your constant values for each one is going to get you your columns for your matrix, ordered from a₀ to a₃
You should get a 4x3 matrix
Also, don’t plug in your basis vectors into x from xf(x). For example, T(1) = x(1) + 0
You view your vectors as polynomials, so that 1 should be a constant polynomial
Similar to what @gray dust wrote, they wrote it wierd. It should really be written T: P₂(ℝ) → P₃(ℝ) defined by T(p(x)) = x•p(x) + p’(x) instead of using f(x). I hope that helps @half forge !!! Also, this is for part (a). Using this format, you should be well in your way for part (b). Good luck!!
What is the order of operations here?:
ABᵀ
Transpose B before multiplication or transpose (AB)?
Great, thanks again!
So when are eigenvectors orthogonal?
your question is kinda vague and i'm compelled to give the smartass answer of "when their inner product is zero"
if you give me some more detail to work with then i can maybe address your issue more directly
hi all, is my answer:
U = {(0, s, s) | s ∈ R}
V = {(-2s, -0.5s, s) | s ∈ R}
correct for (i)?
@flat sedge denoting an arbitrary element of P_2 with f or p doesn't matter. what matters is Tp vs (Tp)(x)
@warped garden may i recommend abbreviating ∈ as "in" rather than "E"?
my bad, changed!
looks correct to me
@dim venture uh i guess nobody else has responded to this yet, so here are my two cents on your proof. you claim that the algebraic multiplicity of 0 is equal to the geometric but you didnt justify that. would be nice if you can clarify why the algebraic mul. cant be n. otherwise it looks okay i guess
@gray dust for sure. I just wanted to see if I could make it more understandable for sunshine thas all.
@dusky epoch thanks! how about:
basis of U: {(0, 1, 1)}
basis of V: {-2, -0.5, 1)}
for (ii)?
yeah
OK I know that is the formal definition of orthogonal. Just didn't know if I could just look at a matrix real quick and see if they're orthogonal.
rref(A) will always equal rref(-A) right? And rref(A) = rref(c * A) for c != 0?
ok so it may happen that A will have two different eigenvectors (for different eigenvalues) and it may so happen that they happen to be orthogonal without it being explicitly visible
however, for a symmetric matrix, eigenvectors corresponding to different eigenvalues are always orthogonal
as for your other question: yes, RREF is invariant under scaling of the original matrix by nonzero factors
One more question.
What is the trace of the matrix 𝐹ᵀ⋅𝐺ᵀ?
F and G are both 3x3 matrices with variables in play so I calculated it all out and got a pretty wild answer that doesn't happen to be correct. Now coming back I noticed the Hint: "no/very little additional calculation is necessary!
Is there something I'm overlooking here?
F = [[1, 2, a ],
[3, 2, 1+b],
[2, 2, 2+c]]
G = [[0, 2+c, -a],
[3, b+c, -1],
[a, 3 , -b]]
``` If this helpsBUT rref changes eigenvalues.
Dang, just wasted a bunch of work because I forgot I can't rref to find the same eigenvalues
Because I'm new to this?
https://i.imgur.com/X7xOrMP.png
can someone give me a hint how to do this

Is it true that a linear transformation T : R^n -> R^m can only be one to one and onto if n = m?
In order to be onto, m must be less than or equal to n (pretty sure about this) and in order to be one-to-one m must be greater than or equal to n (less sure about this part) so I am assuming to satisfy both onto and one-to-one n must be equal to m
Yes
Cool
These transformations are making a lot more sense now once I stopped trying to avoid the abstract stuff
can someone help me with my question 😓
https://i.imgur.com/X7xOrMP.png
can someone give me a hint how to do this
that is my attempt at the problem
i came to that answer after reading this from an sample problem online:
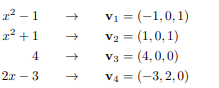
So a singular matrix is a transformation that you can't reverse
@keen patrol which singular matrix?
that's not the right analogy. the transformation might still be reversible.
well i guess for square matrices you are right
because for those injective and surjective fall together
and i guess singular only applies to square, so that would make it right i suppose
but its much better to think differently about the meaning of reversible
endomorphisms are a special case of transformations
just like any function you can undo the transformation if its injective
wait is this regarding my question? im so lost in the topic i cant tell
unrelated i think
flow can you help me out with my question?
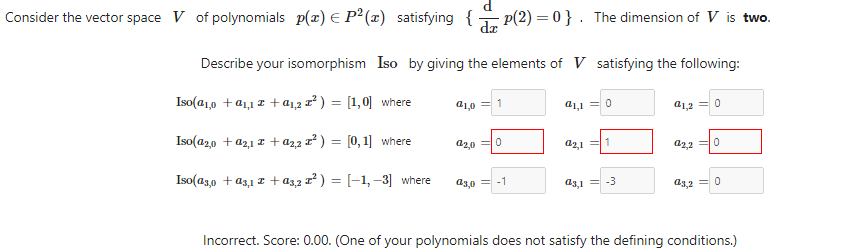
im lost as to what to do with the derivative in it

it feels like i understood every part of the question but i dont know how to apply it
what should I do after that?
then you are done
no, thats not a spanning set of V
because x' = 1
you need linearly independent vectors in V that span V
where do you get x'=1 from?
from your suggestion for a basis
oh i see, sorry i thought you were saying i was wrong because x'=1. so what is x' supposed to be here?
(1,x,x²) cannot be a basis because x is not even in V
and you know the space is two dimensional and you gave me a set of 3 vectors
just take an arbitrary polynomial and look at what you get when you enforce the constraints
let's say we have
p(x) = ax² + bx + c
then we require p'(2) = 0
(ax² + bx + c)'(2) = (2ax + b)(2) = 4a + b = 0
Sorry to interrupt, but here's a quick attempt. For question 5, the eigenvectors are of the form $(w,w)$ where $w \in F^{2}$ and eigenvalue is 1. While for question 6, the eigenvectors are of the form $(0,0,w)$, where $w \in F^{3}$ and the eigenvalue is 5 ?
Otoro:
@smoky lily your space is spanned by vectors of form ax² + bx + c where 4a + b = 0
reading off a basis from this is easy now
you can choose two independent vectors for the basis and the last one will be a linear combination
i think i understand the latter part but im not sure since i dont know basis well. is the basis in that case, (4,1) ?
ill search up basis quick
@old flame your answer for 5) is incomplete. there is another eigenspace
is the basis (4a,b)?
no
a basis is a linearly independent set of vectors that spans the space
your vectors are polynomials
so the basis is 2 polynomials that are linearly independent
well check it
answer is no because they are not even in the space
@old flame you are also missing an eigenspace in 6
how do I check if they're in the same space?
@spiral star I redo question 5 and got eigenvalues of 1 and -1, which results in eigenvectors of $(w,w)$ and $(w,-w)$ for $w \in F^{2}$ ? Am I missing anything else ?
or check if its a basis?
Otoro:
@spiral star gotcha, working on it now then
sorry i know im really lost on this topic
@old flame yea that's better now. for 5 you cannot have more than 2 eigenspaces because you are in F²
and the two eigenvalues 1 and -1 are correct :)
@spiral star oh yeah, whoops, I forgot theres a theorem stating that haha, thank you 🙂
so p(x) = ax² + bx + c
so for example (4x^2+x, 8x^2+2x+100)
also before you said x is not in the vector space
is that another reason why this is wrong?
your vector space is polynomials of at most degree 2 whose derivative evaluated at 2 is zero
if you take the derivative of 4x^2+x you get 8x +1, evaluate this at x = 2 and you get 17 which is certainly not 0
so this polynomial is not even in your vector space
would (100,104) work?
no, those are linearly dependent
all constant polynomials are in the same span
look, you can just read it off
i did the whole thing for you already
let's take a generic polynomial ax² + bx + c and enforce the constraints, (ax² + bx + c)'(2) = 0
this holds exactly if 4a = b 4a + b = 0
wait that's a typo
gotta scroll up
there we go
can you not find a basis of Ker [4, 1, 0]?
what is Ker?
kernel
nullspace
you just solve the linear system 4a + b + 0c = 0 for a,b,c
it has rank 1 so you have 2 degrees of freedom
hence, your space has dimension 2
i havent reached the topic of null spaces yet
weird
i need to give everything a reread theres so much information for me here
you do polynomial spaces but you dont know what a basis or kernel of a linear map is
yet you talk about isomorphisms
very weird
i went straight from doing matrixes to this and im very confused
are you sure you didnt miss anything in the lecture
i did miss one lecture so thats why
but you can solve 4a + b + 0c = 0 for a,b,c right?
trivial solution always works
i am asking you for all solutions
there are infinitely many
ok so 4a=-b, a=-b/4 ?
yes,
and b and c would be free variables
so, choose two linearly independent solutions
what if i choose b=1, then a= -1/4
can i directly plug it into ax² + bx + c and say thats one basis
i found the derivative of it and it wasnt zero
what part of the "choose two linearly independent solutions" was unclear
yes, your choice of a and b works, but you need to choose c as well
you can choose (-1, 4, 0) and (0,0,1) for (a,b,c) for example
so one polynomial would be -x² + 4x and the other would be 1
they are independent
and they would be a basis
b=1, then a= -1/4 and c=0 would be linearly independent arent they? ( they dont rely on the other variable )
also why is 1 independent but before when i mentioned 100,104 that is dependent?
since they're both constants?
@spiral star is the other subspace for question 6, $(0,0,0)$ for $\lambda \neq 5$ ?
Otoro:
that doesnt make much sense. what kind of eigenvalue is "lambda \neq 5"
wait, then what about $\lambda=0$ for $(w_1,w_2,w_3)$ where $w_1,w_2,w_3 \in F^{3}$
@smoky lily you have the wrong idea. a b c are scalars, linear independence is about vectors
Otoro:
lol
look at the def of eigenvalue and eigenvector
im going to first reread everything to see if everything starts clicking
you really wont get very far in linear algebra if you dont understand linear independence and basis
you need this for almost everything
@spiral star basically theres 3 equations to solve right ? thus by solving I got my answer above, Im guessing Im missing a case am I right ?
ah, sorry let me see then
note, the eigenspace of 0 is just the kernel
also note that a linear map is fully described by the images of a basis
so if you map a basis you get a matrix for the linear map
and then you can almost read off the answer
for F^n you can choose the obvious standard basis (1,0,..., 0), (0,1,...,0), ...
and then your matrix for the linear map in 6 would look like this i think $\mqty[0 & 2 & 0 \ 0 & 0 & 0 \ 0 & 0 & 5]$
Flow:
first column is 0, you immediately see that (1,0,0) is in Ker(T)
and (0,1,0) and (0,0,1) are not in Ker(T)
so Ker(T) = span(1,0,0)
which is the eigenspace that belongs to eigenvalue 0
im sorry, but what does linear map in 6 mean
exercise 6
the given linear map
T(z1, z2, z3) = ...
if i choose the standard basis of F³ then i get that matrix from above
which represents T
oh let me try to summarise what you have said
im going to watch videos on basis and linear independence then reread everything. thanks for everything flow !!
ill be back later if i need help maybe
so we can represent $F^{3}$ in terms of the standard basis $(1,0,0),(0,1,0),(0,0,1)$. From the transformation matrix, we see that $(1,0,0)$ gets mapped to 0, so it is the only basis vector in null of eigenvalue 0. Since the set of eigenvectors correspond to the set in null of eigenvalue, $(1,0,0)$ is the set of eigenvectors ?
Otoro:
(1,0,0) spans the nullspace
you can conclude this from the rank nullity theorem immediately
is that because $dim F^{3} = 1 + 2$, where 2 is the dimension of range ?
Otoro:
yes
oh ok thank you
you can learn all of this by just applying T to a basis of F³
in particular, the standard basis
i forgot about the standard basis lol, my bad
if e1, e2, e3 are the standard basis vectors, then {T(e1), T(e2), T(e3)} spans range(T)
T(e2) and T(e3) are linearly independent and T(e1) = 0
so rank(T) = 2
and dim null(T) = 1
and of course since e1 is in null(T) it must span it
i guess since you are reading axler you havent done anything with determinants?
nope
alright
you're correct
ok, then im not gonna argue with characterstic polynomials 😄
but if you had determinants, then finding eigenvalues would be a bit easier
to compute at least
ahhh, I guess I will learn the easier method later then
but for now I guess its only solving equations and looking at the coefficient matrix then
thank you very much
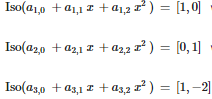
from here, what do i do with whats on the left hand side?
[1,0]
[0,1]
[1,-2]
also what is that called? resultant of the transformation?
same topic btw
iso is just a linear map
so if p and q are your chosen basis vectors then the third line states iso(p - 2q)
i see, thank you
Once again, here's my attempt. For question 7, for $\lambda= n$, the eigenvectors are the $F^{n}$ standard basis. Then for $\lambda=-n$, the eigenvectors are ${(-1,0,0,...),(0,-1,0,...),...,(0,...,0,-1)}$ consisting of n vectors. For question 8, using the previous logic, since from the standard basis, the basis vector $(1,0,...) \in null(T-(1)I)$, it is the eigenvector for $\lambda=1$. Similarly, $(-1,0,...) \in null(T-(-1)I)$ is the eigenvector for $\lambda=-1$
Otoro:
<@&286206848099549185>
For 7) there is only one eigenvalue and that is n
@native rampart why isnt $-n$ an eigenvalue ? by the way what about q8 ?
Otoro:
Write n equations $(\sum x_i)=\lambda x_j$(as j varies over n) and solve for $x_i$
x_1+x_2=k x_1
x_1+x_2=k x_2 if we are taking n=2 and k to be the eigenvalue
DrunkenDrake:
well thats how I got n
Sorry,I am wrong
There is more than one eigen value
If you solve the system of equations,you get lambda=n or (x_1+x_2+....x_n=0,lambda =0)
For the first,your eigen vector will be (1,1,1...1) for your kernel, it will be
{(1,0,0,0....,-1),(0,1,0,0...,-1).....(0,0,...1,-1)}
@native rampart may I ask is $\lambda=0$ always an eigenvalue for all operators
Otoro:
sorry typo
Otoro:
x_1+x_2=k x_1
x_1+x_2=k x_2 if we are taking n=2 and k to be the eigenvalue
Have you tried solving this system of equations?
ohhh so you subtract all the equations after the transformation
that will yield, $\lambda(x_1-x_2-...-x_n)=0$ ?
Well, Everything in linear algebra is indirectly linear equations
Otoro:
I believe this transformation is not one-to-one. Because even though T : R^2 -> R^4 and 4 >= 2, when I row reduce this to RREF there is a free variable and there's not a pivot in every column
I mean it would be better if you dealt with 2 equations at a time
Is that an appropriate way to prove a transformation isn't one-to-one?
Like $\lambda(x_1-x_2)=0 ,\lambda(x_1-x_3)=0...$
DrunkenDrake:
so that means that $x_1=x_2=...=x_n$ or $\lambda=0$
Otoro:
Yes
which concludes that the other eigenvalue is 0 ?
what about the case of $x_1=...=x_n$, is this the other set of eigenvector ? (the set where all vectors are the same)
Otoro:
Yes
so it would be of the form $(a,a,...,a) \in F^{n}$ n a's
Otoro:
Yes
and a just being an element in F right ?
Yes
nope,its infinite dimensional, so every elements shifts to the right by 1
My bad
no worries
You get$ \lambda z_1=z_2, \lambda z_2=z_3.... and so on$
DrunkenDrake:
Which is to say $z_2=\lambda z_1, z_3=\lambda^{2} z_1....$
DrunkenDrake:
You get The eigenvalues to be everything in F
oh....
Which is to say $z_2=\lambda z_1, z_3=\lambda^{2} z_1....$
@native rampart Because this is the only equation we have
DrunkenDrake:
as in $z_n=\lambda^{n-1}z_1$ ?
Otoro:
how do you even solve that though
That is the solution
The eigenvector is $(z_1,\lambda z_1,\lambda^{2} z_1...)=z_1(1,\lambda ,\lambda^{2}...) $
DrunkenDrake:
z_1 is a free variable and lambda is the eigen value
Yes
alright, thank you
The following is written in an exercise I'm doing:
Sub–intensity matrices have non–negative
off diagonal elements, negative diagonal elements and non–positive row sums. More pre-
cisely, a square matrix $A=(a_{ij})_{i,j=0,\ldots,n}$ for which
$$
a_{i j} \geq 0, i \neq j \text { and } a_{i i} \leq-\sum_{j=1 \atop j \neq i}^{n} a_{i j}, i=1, \ldots, n
$$
Schuams:
So it is basically the definition of sub-intensity matrices. The problem is that the text says that the diagonal elements are negative but what is written here: $$
a_{i i} \leq-\sum_{j=1 \atop j \neq i}^{n} a_{i j}, i=1, \ldots, n
$$
Does not necessarily mean that $a_{ii}$ is negative. It could also be 0, right?
Schuams:
Is the sum non negative?
??
I'm saying that what is written in text is not in accordance with the mathematical formulation. This is my question.
Read it again
ok
Okay, step by step
This $$
\sum_{j=1 \atop j \neq i}^{n} a_{i j}, \quad i=1, \ldots, n
$$ is 0 or negative, right?
Schuams:
If that is true, then it means that $$
-\sum_{j=1 \atop j \neq i}^{n} a_{i j}, i=1, \ldots, n
$$ is 0 or positive, right?
Schuams:
This $$
\sum_{j=1 \atop j \neq i}^{n} a_{i j}, \quad i=1, \ldots, n
$$ is 0 or negative, right?
@chilly solstice 0 or positive
DrunkenDrake:
Each a_ij(i != j) is positive or zero
What dimension does $\exp{(Ax)}$ has in $$
\exp (\boldsymbol{A} x)=\sum_{n=0}^{\infty} \frac{x^{n}}{n !} \boldsymbol{A}^{n}
$$
$A$ is a $n\times n$-matrix
Schuams:
Same as dimension of A
okay, thx
Usually when you want to exponentiate a matrix, you want to diagonalize it first?
Here is my attempt, By rank-nullity, $\dim V=\dim null T+k$. Hence we know that $\dim V \geq k$, which by theorem, implies that V contains at least k distinct eigenvectors. Let the k eigenvectors be $v_1,..,v_k$. Since $Tv_i=\lambda_iv_i, \forall i \in {1,...,k}$, $(T-\lambda_iI)v_i=0$, this implies that $null(T-\lambda_iI) \neq {0}$. I am stuck here, not sure how to progress, any hints would be appreciated or an alternate approach would be nice too
Probably,but you can't always diagonalise a matrix
Otoro:
ok. hmmm
There need not be k distinct eigenvectors
Take the rotation matrix for instance
[cos x -sin x]
[sin x cos x]
im sorry but I havent learnt matrix with eigenvctors yet
Take T(1,0)=(cos x,-sin x)
T(0,1)=(-sin x,cos x)
but the theorem is that each operator on V has at least dim V amount of distinct eigenvectors
Don't think that's true
what's the definition of a substochastic matrix? what is eta? what is an intensity matrix? what is otherwise known about A?
Ups, sorry,
The problem:
Definition of sub-stochastic matrix and stochastic:
Definition of sub-intensity matrix and intensity matrix:
Is R2 in the span of R3. Short and sweet question lol
its impossible to add vectors from R^3 to get vectors from R^2
you can ``cheat" and consider the space $\left{\begin{pmatrix}a\b\0\end{pmatrix}\mid a, b\in \bR\right}$
Namington:
or whatever
but this doesnt really count
this is still a subset of R^3; its elements are not in R^2.
depends on the definition of "is" 😎
you could define an isomorphism between that space and R^2
at least i think
also im pretty sure this is a stupid question to ask, but would (det(A)I)*A^-1=adj(A)?
you could define an isomorphism between that space and R^2
indeed, and one isomorphism that works is "exactly what you'd expect"
i.e. $\begin{pmatrix}a\b\0\end{pmatrix} \mapsto \begin{pmatrix}a\b\end{pmatrix}$
Namington:
How can I prove that $(x \mapsto sin(x^k))_{k\in \mathbb{N}}, x\in \mathbb{R}$ is linearly independent other than using limited developments? I find it kinda ugly
Svet L'octogone:
Anyone have experience solving Dudeney's cryptarithmetic problem, or know how to use linear algebra in solving a cryptarithmetic problem
Suppose $a_1\sin(x^{k_1})+\cdots+a_n\sin(x^{k_n})$ with integers $0<k_1<k_2<\cdots<k_n$. Restrict this function on the positive reals then substitute $x\mapsto \sqrt[k_1]{x}$, then we get $a_1\sin(x)+a_2\sin(x^{k_2/k_1})+\cdots+a_n\sin(x^{k_n/k_1})=0$. Differentiate the left side gives $a_1\cos(x)+a_2(k_2/k_1)x^{k_2/k_1-1}\cos(x^{k_2/k_1})+\cdots+a_n(k_n/k_1)x^{k_n/k_1-1}\cos(x^{k_n/k_1})=0$. Substitute $x=0$ gives $a_1=0$. Then the equation becomes $a_2\sin(x^{k_2})+\cdots+a_n\sin(x^{k_n})$ and applying the same procedure gives $a_1=a_2=\cdots=a_n=0$
Whoever:
@calm hamlet also not sure what you meant by limited development
I meant $sin(x)=\sum_{k=0}^n \frac{(-1)^{n+1}x^{2n+1}}{(2n+1)!}+\underset{x\to 0}{o}(x^{2n+1})$
Svet L'octogone:
But ty
ok sorry man
ah yes, absolute value inequalities. classic linear algebra...
It isn't possible for a linear transformation where T : R3 > R3 to be one-to-one but not onto, correct?
But not what?
One-to-one means bijective?
One to one is inyective
One to one and onto is biyective
I think with linear transformations is equivalent
yikes, I've never seen "onto" before
It is equivalent if you make sure the image of the basis of R3 by the function is still a basis of R3
well
The only way to make it one to one, is that, given a base of R³ goes to a base from R³ I think
If so, is biyective too
Because you could have a function where the Ker is a vectorial plane or whatever, so it would not take values from all R3
and hmm, this question is basically the theorem about (trivial kernel <=> injectivity).
Because you could have a function where the Ker is a vectorial plane or whatever, so it would not take values from all R3
@calm hamlet
If is one to one, the Ker = {0}
True
and since the dimensionalities of the domain and codomain are the same (they are the same space), it's also a bijection. So yeah.
Imagine that f(e_1), f(e_2) and f(e_3) are linear dependent then.
af(e_1) + bf(e_2) = cf(e_3)
f(ae_1 + be_2) = f(ce_3).
f(ae_1 + be_2 - ce_3) = 0.
The function is inyective, then
ae_1 + be_2 = ce_3, but that's a contradiction, then, f(e_1), f(e_2), f(e_3) are linear independent, then, form a basis, hence, surjective
I think is the idea of the proof
To show that with linear maps One to One => Onto
But I think they're equivalent
hi, question regarding large matrices and inversion
for most cases, in order to figure out whether it's invertible, we would typically calculate the determinant and make sure it doesn't equate 0 (as 1/0 would be undefined)
however, how would we calculate if it is invertible for large matrices?
typically gaussian elimination is the fastest method
a square matrix is invertible iff its RREF form has a 0 row
this is still inconvenient to do by hand for large matrices
but its what computers do
(With slight optimizations)
i'm not that familiar with using gaussian elimination for calculating matrices, will it be able to determine the determinant if i use that method?
basically the question i'm attempting to do is a 3 by 3 matrix with one variable a, i'm supposed to return which values of a would make the matrix not invertible
well, one can compute the determinant via gaussian elimination, but the process is a bit specific + requires some bookkeeping
and it probably wouldnt be suited for that specific use case
yikes
im not sure theres a good way to get out of just calculating the determinant
Since it's just 3x3 you can take a determinant pretty easily, then set it to 0
well yea, but i worry we'll be given similar problems with 4x4 etc, sounds very tedious and i'm not great at too many operations
tysm tho !
@random shoal 1 look tells me det=0
@gray dust thanks I figured out why it was wrong
@random shoal beside explicitly computing you can see the rows/cols are linearly dependent
This is not linear algebra
#prealg-and-algebra would be a better fit, or any questions channel.
KK
$dim range T = k, T \in L(V)$. Prove T has at most k+1 eigenvalues. After some thoughts, here goes again. By theorem, range T contains at most k eigenvalues. In null T, for $v \neq 0$, $Tv=0=\lambda \cdot v$ this implies $\lambda=0$ is an eigvenvalue in null T. There is no other eigenvalues in null T since it would not yield 0 with a non zero vector. Therefore, T has at most k+1 eigenvalues. Is this ok ?
Otoro:
Yes
$dim range T = k, T \in L(V)$. Prove T has at most k+1 eigenvalues. After some thoughts, here goes again. By theorem, range T contains at most k eigenvalues. In null T, for $v \neq 0$, $Tv=0=\lambda \cdot v$ this implies $\lambda=0$ is an eigvenvalue in null T. There is no other eigenvalues in null T since it would not yield 0 with a non zero vector. Therefore, T has at most k+1 eigenvalues. Is this ok ?
@old flame yes.(Assuming you know eigenvectors of different eigenvalues are linear independent )
thanks, just wanted to make sure i wasn't missing some hidden math
@native rampart thank very much, yes I know that theorem, but are you implying that it's useful for this question ?
Yes
Could you explain
Suppose there are (k+1) eigenvalues,there will be atleast (k+1) independent vectors in range T(because say e1,e2,...e(k+1) are the corresponding eigenvectors for each eigenvalue. Te1,Te2,...Te(k+1) are also linear independent and lie in range of T)
But ,range of T has dimension k
So there cant be k+1 eigenvalues ?
Yes
But then doesn't that allows more or less than k+1
Except when domain and codomain are finite-dimensional and have the same dimension
@wintry steppe
Yes, my bad, but, my prove was for R³ to R³, and they have the same dimension, then, it works there
Anyways, I forget the fundamental Theorem of linear maps hahaha
Dim Ker T + Dim Im T = Dim V
For T: V -> W
If Ker T = {0} then, Dim Ker T = 0, and get Dim Im T = Dim V = Dim W (If you suppose they have the same dimension) then, Im T = W, one to one => onto, if Onto, then
Dim Ker T + Dim Im T = Dim V => Dim Ker T = 0.
Then, if Dim V = Dim W, T is one to one if and only if T is onto, right? And suppose that Din V is finite
Does row operation change determinant ?
what do your notes say
did you at least look this up
Yes
It says if you interchange rows it will be negative. But my actual question is why it doesnt affect it. I think I should have made my question more clear.
It says if you interchange rows it will be negative
*negated
Does row operation change determinant ?
@viscid kernel scaling definitely does in most cases
Swapping rows may change the sign of determinant
@native rampart what if the determinant before row reduction was 0 ?
Scaling scales the determinant by the constant by which the row is scaled
So no, doesn't change
Aight thanks. Also if for example you are trying to diagonalise a 3x3 matrix A. After some calculations you found 3 eigenvectors. You use the formula M^-1 A M. Do you have to put these eigenvectors in the columns of M or the rows ?
Columns
Reason ? And is it always like that, also if you have like 3 vectors if you are trying to find if they are linearly independent ?
Do you know change of basis?
Yes I do,
Same thing as that
I have solved many many problems. So you just say that thats how matrix multiplication works ?
Yea, Because of the way matrix multiplication works ,the basis vectors should be along columns
Hmm
So its kind of a convention in linear algebra that you put the vectors in the columns of a matrix.
instead of D=M^-1 AM, D=diag containing A's eigenvalues, it may help to write AM=MD. with M's cols being A's eigenvectors this is just the eigenvalue eqn in matrix form
Hmm aight I got. Its just that you always work with the columns of your matrix. It that also the reason why the rowspace is called the column space kf A transpose ?
col(A) is span of A's cols. in A^T you just look at A sideways, look at A's rows as cols of A^T
I cant thank yall enough. so Im retaking linear algebra this year, the reason why I ask this is cuz during class we were trying to find if the given three vectors were linearly independent or not. My professors put those three vectors in the rows of the matrix and did row reduction afterwards.
So according to yall you actually have to put it in the columns. But in this, it doesnt matter cuz the rank of A and A transpose is the same, am I right ?
row rank=col rank
Oh so Im totally right, right ? 😄 I have to be sure
you can put the vectors as cols, row reduce & count off pivots. doesn't matter, you can put em as rows and row reduce the same
Also, If you feel wrong about row reduction,you can always do column reduction
@native rampart does column reduction even exist, if so is it even allowed ?
Never heard of that before
Just replace rows with columns,wherever there is a mention of row in row reduction
i actually find it makes sense to put as rows then do row ops, since all you're really doing is taking linear combos of the rows. and by defn of linear dependence, if you can take linear combos of vectors to produce the 0 vector then those vectors are linearly dependent
Thank yall. These type of things always confuses me when I take linear algebra. Ima write that down on my notes.
Rokabe, I know that makes it a lot easier, but also confusing for other people 😄
i'm not talking about what's easier, just why using row ops to test linear dependence makes sense
Oh my bad xD
putting the vectors as the rows of a matrix then doing row ops is identical to taking linear combos of the vectors
DAMNN, rokabe why have I never thought of that, that way.
same thing if i replace row with col
Aight
I have another question
Is there a reason why ( A*M )^T = M^T * A^T ???
Why do they both switch ?
Do you know what a linear functional is?
Nope
Is there a reason why ( A*M )^T = M^T * A^T ???
Why do they both switch ?
write out the matrix product
and the defn of transpose, like in terms of the entries
A linear functional is a function f:V to F such that f(ca1+a2)=cf(a1)+f(a2)
drake, what's that have to do with baklava's question
also a linear functional is just a linear map whose codomain is R lol thats it
Well, There's a nice motivation of transpose ,you can get from linear functionals
Drake, I know what that is but. Ur confusing me even more I think.
Ok, nvm then
Still thanks tho
drake, baklava asked why the transpose is anti-multiplicative
Ann, exactly
i dont see the point in trying to motivate anything when its literally just a purely formal property of the transpose
like for real
Just gotta accept it ?
no you can prove it lol
by some symbol pushing
or alternatively i can try to give you a visual that explains it using the visual for matrix multiplication
Isnt there an intuition behind, Without those complicated proofs?
@dusky epoch Id like to
Rarther visual than proof based
these need not be mutually exclusive
Aight
Yup
now transpose this entire picture
so that A ends up on top and transposed, and B ends up on the left and transposed
Oh I see
Love you
Does $\exp (\boldsymbol{A} x)=\sum_{n=0}^{\infty} \frac{x^{n}}{n !} \boldsymbol{A}^{n}$ always converge for $x \ge 0$? $A$ is a squared $m\times m$ matrix.
Schuams:
How do one calculate the convergence?
The reason why I'm asking this, is because I want to write a function in python, so I need to know how one calculates the convergence. 🙂
Maybe I do not even need to know this. I do not know.
A is a sub-intensity matrix or it can also be an intensity matrix
@chilly solstice i guess that's more an analysis question but... this should always converge, for all x and all A.
if you consider the space of all m x m matrices over either R or C, then as usual for such finite dimensional spaces, all norms are equivalent and induce the same topology. so you can take any norm you like, for example the operator norm. then you can use the fact that this norm is submultiplicative, i.e.
|x^n A^n| <= (|x| |A|)^n
and then note that exp(|x| |A|) converges as it would for any real valued argument.
I'm waiting for Lartomato to write his answer 🙂
oh no
Another argument would be: If you have $A = U J U^{-1}$, then $\exp(A) = U \exp(D) U^{-1}$, which is really easy to see from its formula (and it also holds true on partial sums of that formula). Thus it suffices to show that $\exp(J)$ converges for all Jordan-Normal forms $J$. Then you can write $J = D + N$ with a diagonal matrix $D$ and a nilpotent matrix $N$ (and $DN = ND$). From this with some more algebraic manipulations, you'll find that the only thing you need is that $\exp(D)$ converges for all diagonal matrices $D$, and that follows because for diagonal matrices, you can just take the exponential on the diagonal entries
Lartomato:
I first thought this was another nice and quick way to do things, but as I started writing things out I didn't like it anymore because it got very long, lol
But if you want to avoid analytical arguments about norms as long as possible, and just do linear-algebra-things, that's how you can proceed. And it's also a good philosophy to keep in mind, because very often you will calculate exponentials of matrices by using their jordan normal form
is it desirable to talk about convergence while trying to ignore analytical arguments?
seems kinda strange to me at least 🤔
If you don't like analysis, but life forces you to talk about convergence of things anyway, you can try to minimize the impact of analysis on your life at least 😄
lmao i can relate to the "if you dont like analysis" part very much
And it's just my sledgehammer neanderthal method for matrices: "huh??? MATRIX THING? i must JORDAN NORMAL FORM"
i think the analytical argument was short and easy tho in this case :)
Ye I don't disagree, like I said, I first thought "oh jordan will save me" but then it got a bit out of hand
i just wanted to know about convergence. thanks. regarding the coding part found somehting on stack
👍
damn my dude doing his calc and linear homework at the same time
Do you know what an eigen value is?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Ok,you don't?
Yea
Read your textbook
Or you can help me this time
nah fam this is a really easy exercise once you've looked up the definitions of the things
This is my solution
This is showing: If A is a sub-intensity matrix then P is a sub-stochastic matrix.
As you see, I'm very close.
I'm not sure how to argue for that the left hand side of the last inequalty is P?
no wait
got it, i think
If $a_{ii} < 0$, then $\sum_{i=1}^n a_{ii} \le a_{ii}$, right?
oh, never mind
Anyone that can explain this to me? Appreciated
do you know what "one-to-one" means? and how to check whether a transformation is one-to-one?
If the column vectors of the matrix are linearly indep. then the transformation should be one-to-one
If Im not mistaken
that's one way to check, sure
Yeah but I dont rly get the notation. It's the transformation part that confuses me
Idk how I should construct the matrices
a transformation is just a function
they happen to have matrix representations, but you shoudlnt rely on matrix representations for everything about transformations
(although they can be helpful, particularly for part 3 of that question)
Yeah Im still starting out on these
try some examples; see if you can make up a one-to-one linear transformation that satisfies part 1
and then see if you can make one up that isn't one-to-one
do the same for part 2
for part 2, you can view it as solving a system of equations
I rly dont get how u want me to approach it :"D. Isnt part 1 the example itself?
what do you mean by that?
Well, for part 1, isn't what is displayed all the info I can use?
How can I take examples
if i said "all numbers greater than 10 are even"
T(a)=u will always be u, how do I "take an example" with it
you can come up with examples
for example, 12 is an example where this is true, but 13 is an example where this is false
Oh ur talking in general
so the statement in general is false
Thought u wanted me to work with what was given lol
(or perhaps in the context of this question, its better to say that there's not enough information)
well im saying
let a be a specific vector
let b be another vector
just to play around with it
it might help you be more comfortable with the concepts
sure, and make T a one-to-one linear transformation
for simplicity, we can make it the identity transformation
which is clearly 1-to-1
so T(a) = T(1, 2, 3) = (1, 2, 3) = u
and similarly T(b) = (3, 5, 7) = v
so whats u + v?
(4, 7, 10)?
right, and we can come up with a c value that makes T(c) = (4, 7, 10)
indeed, that c value is just (4, 7, 10) itself
so we know that there are one-to-one functions that satisfy part 1
so at the very least, we know the asnwer to part 1 isnt A
now we can check for a non-one-to-one transformation for part 1
There isnt right? x^3 is always one-to-one
uh
Or is it not tied to just one function
R^3 doesnt mean a cube is involved
Ye sorry
it means theres three entries in the vectors
"not one-to-one" means it'll map multiple vectors to the same thing
so why not try mapping all vectors to the same thing?
say, let's take something super simple
T(x) = (0, 0, 0)
this definitely isnt one-to-one
Yeah
but it's a valid linear transformation
then T(a) = (0, 0, 0) for any choice of a
and T(b) = (0, 0, 0) also
and T(c) = (0, 0, 0) too
but (0, 0, 0) = (0, 0, 0) + (0, 0, 0)
so we've found a not one-to-one function that satisfies part 1
in other words: it's possible for a function that satisfies part 1 to be one-to-one, but it's also possible for it not to be
(so we don't have enough information.)
Okay so T can take any operation I want; in other words it can be any function I want
So to speak
well i was just trying to come up with examples
and yeah, T can be any linear transformation from R^3 to R^3 for part 1
Yeah but T confuses me. Is T the "function" part? That is to say, it can take any rule I want so long as it's either scalars or summations?
T is the "function" symbol, yes
it's convention to use a capital T in linear algebra
but you may be familiar with f for more general functions
"linear transformation" is just a specific type of function
So long as it satisfies the linear transformation rules
indeed
Okay
for part 2 though
we're given more specific information
we're no longer allowed to pick the value of a, b, c freely
sure, but that's not helpful if we don't know what rule to pick
that said, note that $T\begin{pmatrix}6\-4\3\end{pmatrix} = T\begin{pmatrix}4\-4\3\end{pmatrix} + T\begin{pmatrix}2\-1\0\end{pmatrix}$
Namington:
i cant type sorry
Yeah I noticed that
fixed
anyway, this gives us hints about what our mapping rule should be