#linear-algebra
2 messages · Page 130 of 1
It could work in either channel
So we would get a1T(u1)+a2T(u2)+a3T(u3)=0, and it would have a nontrival solution correct?
Yes
But that could definitely lean more into abstract algebra since this series of channels is more for early university courses whereas you probably wouldn't hit tensors in a first linear algebra course
or maybe you would, but I don't think it's super common
Because there exist non zero a1,a2,a3 such that a1u1+a2u2+a3u3=0
@jagged gulch i'll address my question in abstract algebra, thanks
I'd do it like this https://i.imgur.com/CR1Vlu1.png
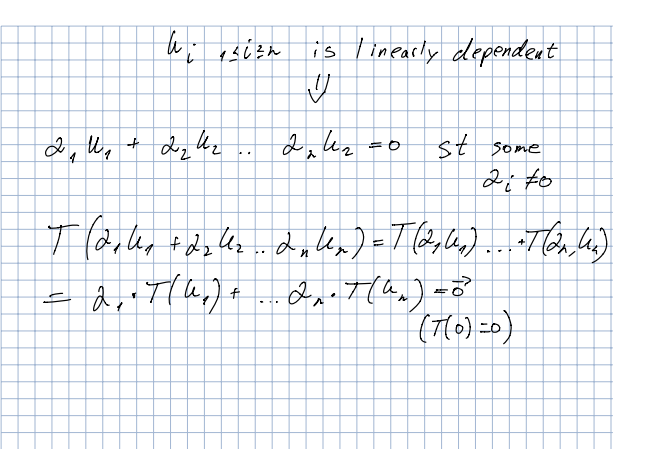
looks okay, @limber sierra ?
basically we have some a_i that has a non-zero solution, equal to 0
that's by definition dependent
https://i.imgur.com/D3p4zsA.pngd
I have a transformation via the matrix A, I need to find the kernel and image of the transformation
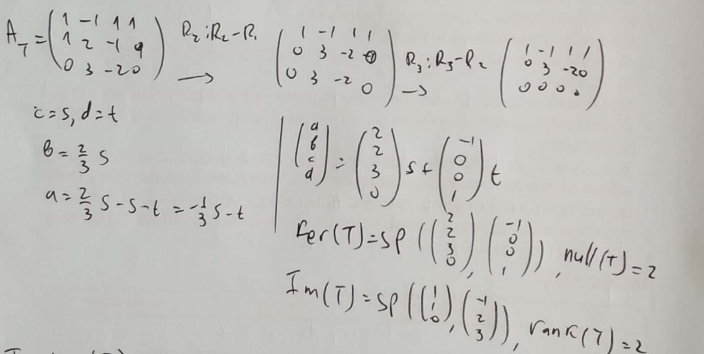
can someone explain what he did to get (a, b, c, d) = (2, 2, 3, 0)... on the right side after the line?
I solved this identically and got stuck after finding a & b (like on the left)
<@&286206848099549185>
a general form of vector in ker(A) is (a,b,c,d). after you write em in terms of free vars s,t you plug in & rewrite (a,b,c,d)=sv_1+tv_2, v_1 & v_2 being vectors
i'm having trouble setting up the equation
Well you need to set up two equations and solve them simultaneously
Let x be the amount of water from the 155°F source and y the amount of water from the 100°F source
Then you need x + y = 75
And what would the weighted average be for the temperature? Set that equal to 110
so $\frac{x+y}{2}=110$?
maddog:
(just an aside: note that, due to 0 in fahrenheit not actually representing "no heat", youll need to adjust for this in some way)
(the most common way to do this, and the way chemists do it, is to work in Kelvin instead of Fahrenheit.)
(there are other approaches though, e.g. adding a suitable constant)
okey dokey @gilded solstice
So as a matrix:
1 2 -1 5
3 -1 2 3
5 3 (a^2 - 9) (a + 10)
There is "no solution", when the matrix is "inconsistant". or in other words there is no place where all the equations "cross" each other.
lol im not sure how to do the no solutions
but for infinitely, we jsut gotto make a few vectors equal i think
so i think:
p(1 3 5) + q(2 -1 3) = (-1 2 (a^2 - 9))
p1 + q2 = -1
p3 + q-1 = 2
p5 + q3 = (a ^ 2 - 9)
hmm maybe im messing this up, anyone with a better grasp on linalg wanna help?
oooh
I've got a feeling, making the column vectors dependant should make it have "no solutions"
of what
you claim C to be the span of what
you seem to have a very weird idea of "span" or "the same thing"
- C is not a span, because it is the linear combinations of every two points in C so it's not just 2 specific points.
- It's not the span, because there are constraints on what the coefficients can be
Np
a span is the linear combination of two vectors
bruh no
the span of a collection of vectors is a set consisting of all the linear combinations of said vectors
bad
It's not two specific points, but every pair of distinct points. And there is only one line passing through each pair.
you can define affine sets as being closed under affine combinations of any arbitrary number of terms, not just 2
Oh, okay, thanks
a set A is affine if x_1, x_2, ..., x_n in A and c_1 + c_2 + ... + c_n = 1 implies sum c_i x_i in A
that is in fact exactly what i just said
can someone help me out with grokking tensor products? im just staring at this, and am a little confused: Z (tensor_Z/4Z) Z/2Z. i havent really looked too deeply into tensor products before this, and was wondering how i'd go about understanding what this structure actually is
um, just an introductory homological algebra class, but i think tensor products generally get introduced in undergrad.. i guess i should have paid attention /:
Its okay wait for the seniors about that
Im engineering student I don't know about that
haha cheers
i feel like i have a dumb question
if you take the RREF of a 3x4 matrix, under what conditions would you not get identity on the left hand side
i ask, because i have a big ass system of equations im trying to slove for mechanics, but when i type it into matlab, it doesnt show me a solution but rather just identity with a 1 in the top left.
If you ignore the last column of your matrix, and the resulting matrix is not invertible, then you won't get the identity
Not invertible, as in the inverse doesn't exist and the determinant is zero, yeah
oh ie i have a free variable
It does not necessarily mean there are no solutions
how are you expecting a 3 by 4 matrix to have an inverse
Anyway, is your question answered? Because I'm not sure what exactly you are looking for?
If I have a matrix wrt the standard basis M(T) and I change one of its columns, can I claim that only one of the generalized eigenspaces of T is affected?
If T is a complexified operator
does anyone by any chance have the proof of polarazation identity for complex vectors on hand?
Just expand each term
you could just expand the RHS yeah
using $\nrm{v}^2 = \ang{v,v}$ and then sesquilinearity
Ann:
ahh i see thanks
on part B right now, for part a I got $$2a_1 + a_2 = b$$
What does part B even mean? Not sure what Ax = b means or where to start.
Apollo:
Find x such that Ax=b
aactually nvm
https://i.imgur.com/D3p4zsA.pngd
I have a transformation via the matrix A, I need to find the kernel and image of the transformation
can someone explain what he did to get (a, b, c, d) = (2, 2, 3, 0)... on the right side after the line?
I solved this identically and got stuck after finding a & b (like on the left)
The way I understand it it should be (-1 / 3, 2/3, 0)s
I got the t right...
am I missing something?
because a = -(1/3)s - t
so how did we get to 2 and -1 in the answers?
<@&286206848099549185>
must be a mistake
if it's a = -(1/3)s - t, then you have (-1/3, 2, 2, 0)s + (-1, 0, 0, 1)t
Im not sure what the most efficient way of solving this is
obviously I could plug shit in until it works but that kinda defeats the whole point
anyone can help me out
the intuition behind gram schmidt process of orthogonality
ik the formula but i cant really imagine what's happening
Let us say {b1,b2,b3,b4,b5} is the basis which undergoes the gram Schmidt process
e1 will be just be b1
for e2,you take b2 and then chop off its components along e1
so e1 is always (1 0 0 0.... 0) ?
You can start with a different basis
Yes
got it
say no more fam
daaaaamn now it all makes sense haha
what about dot product
any intuition behind that ?
i mean ik the formula
but why 2 vectors multiplied give off numbers?
We are defining the multiplication to gives us a number
huh?
Nvm
wait so on gram schmidt process wont b1b2b3 end up the same as e1e2e3?
If {e1,e2,e3} is an orthonormal basis yes
bruh what's the point of doing all that formula on the first place
We are trying to reduce the inner product to a dot product
The good thing with dot product is we can safely ignore things like e1.e2
@devout void it won't always end up being e1e2e3, thats not how gram schmidt works. if b1 and b2 are scalar multiples of e1 and e2, then when doing gram schmidt on b3 you will get a scalar multiple of e3.
@devout void as for geometric intuition of the dot product, i personally like 3blue1brown's video on the topic. essentially it has to do with projections.
however in the context of gram schmidt, the dot product is not multiplying vectors. its the euclidean inner product. and like all inner products spaces, the inner product define distance/length and angles between vectors in that inner product (vector) space. since the dot product is the standard inner product for euclidean space, how it defines distance and angles is relatively intuitive and aligns nicely with euclidean geometry.
@hollow finch no no i didnt mean to relate the dot product with gram schmidt
just wanted to ask that aswell
i checked the vid of 3blue1brown and it was rly interesting
nice thats really great to hear
so basically that can be expressed as a transformation of the vectors into 1D
so the sum is literally a number (1 point) ?
@hollow finch ?
the dot product is sometimes denoted this way:
$$\vec{v}\cdot\vec{w}=\vec{v}^T\vec{w}$$
nix:
so as matrix multiplication
the v and w on the right are nx1 column vectors
so a 1xn multiplied with a nx1 gives you a 1x1 matrix which we often just say is a scalar
but you are pretty close to correct. an inner product in general is a function that associates a real number with two vectors in a vector space.
i personally wouldnt call it a transformation but i cant say that would be entirely incorrect
hello
The question asks: if true, give an explanation. If false, provide a counterexample
I believe that it is true. First, I used the def of singular matrices and wrote Aa=0 and Bb=0 for some a,b != 0
can someone help me with spanning and subsets
and I need to show that (A+B)c=0 for some c != 0
with some substitution, I was able to come up with A(c-a) + B(c-b)=0. Is this enough to show that A+B is singular?
lemme come up with one, give me a sec
hm... I'm having trouble
i tried A=[1 1;0 0] and B=[0 0;1 1] and A+B turned out to be singular
i also tried A=[1 2;1 2] and B=[2 4;1 2] and A+B was also singular
and for the special cases, if either mtx is built only with 0s, then the statement also holds true
give me an easy nonsingular matrix
another one, even easier
[1 0; 0 1] lol
write it as a sum of singular matrices
[1 0; 0 1] lol
use this
hm i tried [1 -1; -1 1] and [0 1; 1 0] but the latter matrix is nonsingular : (
oh shoot
[1 0; 0 0] and [0 0; 0 1]
all done
tysm @gray dust !
you're welcome 
you helper ppl are amazing : 3
ello got a question about finding a linear transformation L:
I got the following vectors
u1 = [1 0 1]
u2 = [1 1 1]
u3 = [-1 1 0]
u4 = [2 1 3]
And I need to find L such that L(u1) = u2 and L(u3) = u4.
And the question is whether there is such a L that satisfies the above equations, and if there is find the standardmatrix for it.
I have tried to do it the naive way which is just to solve the equation L(x) = Ax. This yields:
A*[1 0 1] = [1 1 1]
A*[-1 1 0] = [2 1 3]
And then i just solve the linear equation for the 9 different entries in matrix A with gauss-jordan, but this leads to a cumbersome augmented matrix and I'm not sure if this is the right way to do it. Would appreciate if someone could point me to an easier way of solving this. Thanks in advance!
@wintry steppe Let e1, e2, ...., en denote the standard basis vectors. Then you can (much more easily) find linear transformations A, B such that A(e1) = u1 and B(e1) = u2 and A(e2) = u3 and B(e2) = u4. Now, if you make these invertible, there is an easy way to combine A and B to get the linear transformation you want.
Also, looks fine @half forge
@half forge are you familiar with isomorphisms?
Okay, but I don't understand why we are looking at 2 matrices? My understanding was because we got the equations L(u1) = u2 and L(u3) = u4 this would equate to A *u1 = u2, A*u3 = u4, where * denotes matrixmultiplication, so the standard matrix we are looking for is just A. Also I'm confused as to why you presented them in the order that you did, i.e A(e1) = u1 and B(e1) = u2 and A(e2) = u3 and B(e2) = u4?
My understanding was because we got the equations L(u1) = u2 and L(u3) = u4 this would equate to A u1 = u2, Au3 = u4, where * denotes matrixmultiplication, so the standard matrix we are looking for is just A
you're not wrong. I'm just suggesting an easier way. To say that A(e1) = u1 just means that the first column of A is u1. Similarly for the others. Suppose A is invertible. What happens when you take BA^{-1}?
okay so if I go by your suggestion then I get:
A =
1 -1
0 1
1 0
B =
1 2
1 1
1 3
As the matrices, but A can't be invertible right? because it's not a square matrix?
right, but you can just do something like A(e3) = e3 and B(e3) = e3.
Okay, I got a question about why it's valid to seemingly arbitrarily choose values for the a and b matrices in this fashion? I think theres something I don't seem to understand
like if i chose A(e1) = u4, would that also be valid choice?
oh no okay the input is u1 and u3 so those are the only valid ones for A?
and B is the "output matrix"
You just need A to be invertible, so you clearly can't have A(e1) = u1 and A(e3) = u1 or something like that.
you'll have issues if e3 happens to be in the span of u1 and u3, but ehh im not too worried about it
okay hm so i following your suggestion again i then get:
A =
1 -1 0
0 1 0
1 0 1
B =
1 2 0
1 1 0
1 3 1
yeah. do you understand why you're doing this?
let me think
there are some things I don't understand but I want to express that more clearly.
It's the justification for choosing the values for the matrix A and B.
So the method you presented by choosing the column vectors for the A (idk if this corresponds to the standard matrix yet, maybe thats what u meant by BA^(-1)) is just choosing them as u1 and u3, because I guess we had A*u1 = u2 and A*u3 = u4 and the column vectors of the matrix B corresponds to u2 and u4 since i guess it's the image of L.
Then you somehow want to find the standard matrix by doing BA^(-1)?
ah ye by taking the inverse of the image you reverse it back to the standard matrix? or is it just the input x of the function L(x)?
Well, if A(e1) = u1 and A(e2) = u3 then A^-1(u1) = e1 and A^-1(u3)=e2.
So what happen when you compose this with B?
u get the standard matrix i would assume?
SA = B => S = BA^(-1)
okay, so thats a neat way of doing it if its right
im not quite sure how you define standard matrix, but to be explicit, i just mean
BA^{-1}(u1) = B(A^{-1}(u1)) = B(e1) = u2 and
BA^{-1}(u3) = B(A^{-1}(u3)) = B(e2) = u4
oh okay
but wouldnt BA^(-1) be equal to the standard matrix for the linear function L that satisfies L(u1) = u2 and L(u3) = u4
Because SA = B? I see A as consisting of the input elements u1 and u3 to L and B as the elements of the image of L(u1) and L(u3), and where S denotes the standard matrix
Basically solving the function L(x) = Sx, where S denotes the standard matrix
i may be using terminologies incorrectly here, i apologize
I think you have the right idea. Basically, you were asked to find a matrix that maps u1 to u2 and u3 and u4. We used the fact that it is easy to find a matrix that maps e1 to u1, e2 to e3 and another matrix that maps e1 to u2 and e2 to u4. Taking inverses allows you to combine them to get the matrix of the linear transformation you want
okay it's a neat method that you presented
really appreciate it
I didn't think of it this way
i.e prior to asking
np. the method is sort of inspired by change of basis, if you've heard of that
ah okay
but ye again ty 😄
and sorry to have bothered you with so many questions
and my vague descriptions
hehe
npnp, and nah ur good
ok whenever someone has free time can they dm me or help me with this
from what I've seen on chegg / slader, still confused
like why is x1 assigned 1, x2 assigned 1, and x3 assigned a 0
are a1, a2, a3 supposed to be the columns of A?
yea
are you familiar with the fact that A(1,0,0) = a1, A(0,1,0) = a2 and A(0,0,1) = a3 when A = [a1 a2 a3]?
I am not, not sure what that means
So, A = [a1 a2 a3] is the matrix whose columns are a1, a2, a3. Multiplying A by the vector (1,0,0) just gives you the first column. Similarly for the second and third columns.
And more generally, A(x1, x2, x3) = (x1)a1 + (x2)a2 + (x3)a3.
I guess a few questions, so first, we multiply
a1 1
a2 * 0
a3 0
?
im not sure why you wrote things vertically like that since a1, a2 and a3 are already columns. But the idea is this:
you have A(x1, x2, x3) = b = (1)a1 + (1)a2 + (0)a3 = (0)a1 + (1)a2 + (1)a3. by the definition of matrix multiplication. So what can x1, x3, and x3 be?
why multiply it 1,1,0?
does the matrix multiplication definition say to do that or...
recall this
So, A = [a1 a2 a3] is the matrix whose columns are a1, a2, a3. Multiplying A by the vector (1,0,0) just gives you the first column. Similarly for the second and third columns.
And more generally, A(x1, x2, x3) = (x1)a1 + (x2)a2 + (x3)a3.
A(x1, x2, x3) = (x1)a1 + (x2)a2 + (x3)a3 might not be the definition of matrix multiplication for you, but it follows directly from whatever definition you use, and its the more straightforward characterization for this question.
so why do we multiply the matrix by that specific vector?
(x1, x2, x3) is a generic vector. It can be anything
just like the x in Ax = b can be anything
oh I meant the (1,0,0), am i multiplying the entire A matrix by that? Or am i multiplying column 1 by that and column 2 by something different and so on?
the entire matrix. When you apply whatever definition of matrix multiplication you use to compute A(1,0,0), the last two zeros of (1,0,0) will kill the last two columns leaving you with a1. Similarly for the other columns. Its just a general fact.
ohh and we are trying to get this in RREF?
no, don't think of it that way. Since
A(x1, 0, 0) = (x1)A(1,0,0) = (x1)a1
A(0, x2, 0) = (x2)A(1,0,0) = (x2)a2
A(0, 0, x3) = (x3)A(1,0,0) = (x1)a3
we have by linearity,
A(x1,x2,x3) = A((x1, 0, 0) + (0, x2, 0) + (0, 0, x3)) = A(x1, 0, 0) + A(0, x2, 0) + A(0, 0, x3) = (x1)a1 + (x2)a2 + (x3)a3
The important thing is that A(x1, x2, x3) = (x1)a1 + (x2)a2 + (x3)a3
So if b = a1 + a2, and x = (x1,x2,x3) and
Ax = A(x1,x2,x3) = (x1)a1 + (x2)a2 + (x3)a3 = a1 + a2 = b
So what must the x1,x2,x3 be here?
1,1,0? so its a1 + a2 = a1 + a2?
exactly. And we also have b = a2 + a3 = a1 + a2. So what other value of (x1,x2,x3) gives us b?
hmm not sure, just has to be a zeroed out a1 right? and assume a2 + a3 = a1 + a2?
so 0,1,1?
yep!, so A(1,1,0) = A(0,1,1) = b.
We have found two solutions to Ax = b. So how many solutions exist?
couldn't we just keep incrementing it? Like
2,2,0 and 0,2,2
3,3,0 and 0,3,3
?
by linearity, we have A(2,2,0) = 2A(1,1,0) = 2b
so not quite, but ur on the right track. for any system Ax = b, we can say exactly one of the following about the solutions:
- there are infinitely many
- there is exactly one
- there are no solutions.
ohhh ok so it's infinite then
yep.
npnp
does anyone know any good resources to make my own exams
I want to practice matrix maths but idk where to find good study material
and whenever i study for tests, i write and solve my own questions for further prep
but idk what the questions on IB further math look like 😦
^
schaums?
oh wait
is that schaum's outlines?
and also what's the ib database
(i'm not taking IB, but I want to practice just in case I apply to foreign colleges and need to compete with Irish or Welsh or other English peoples)
they're kind of an old series aren't they
I happen to own a linalg one but in Spanish
it's from the early 70s
ok, what's giving you trouble here?
so the actual number is the same but concept is different
range is the whole solutions of T(v)
without null
and rank is the dimension of this T(v)?
no
rank is dim(range), and range includes 0 always
the range of T is the set of all T(v) for v in the domain
So if i have a T that makes Rcubed to Rsquared basically range is a span of 2 vectors and rank is equal 2?
ye
that's never pronounced as R cubed
anyway no just because T: R^3 -> R^2 doesn't mean range(T) will be all of R^2
T can have rank 1 or 0 if you pick the numbers just right
well lets say i picked a matrice that it's vectors are independant
than my statement is correct ?
vague af lmao
wait
let me type it detailed
if i use a matrice 2x3 i will get this T: R^3 -> R^2
1- if my matrice has 3 vectors whom 2 are linear independant then my range will be these 2 vectors and rank = 2
2- if my matrice has 1 vector independant then range is 1 vector and rank is 1
my range will be these 2 vectors
will be spanned by these two vectors
yes sorry
but otherwise yes
Rang(T)= Span {(v1),(v2)}
and if i pick a matrix 2x3 where all nums are 0
then rang(T) = Span {(0)} dim(rang(T)) = 0
okay i guess i got it
thanks Ann
What about A^-1 M Av
this is how to apply a T on another T1 starting from orthonormal base ?
... wat
ehm
Well if i have my normal i j k base
every vector is expressed as xi +yj + zk
wher x y z scalars
if i have another base with different i j k
i would express this base as a matrix transformation of 3x3
where each column has each vector base
now if i want to apply a transformation into this 3x3 base
i need to do the formula A^-1 M Av
@half forge when is it due? I’m gonna sleep first then I’ll prolly be able to help.
if det(A) = 4 and det(B) = 5
find the value of det(2A^-1 B)
When do I multiply by 2?
wait actually... nvm
It's just 2 * 1/4 * 5 right?
if I'm reading your notation right, yes.
if i have 2 random bases B and C how can i find a vector in C be expressed in B coordinates?
"Vector in c" doesn't make sense
B and C describe the same vector space( Assuming both are basis)
alright shall i post an exercise ?
Go ahead
exercise number 2
we have 2 bases B and B' in R^2 and Matrix A which expressed the T of base B
find matrix P from B' to B
ik how to do this
if i have 2 random bases B and C how can i find a vector in C be expressed in B coordinates?
@devout void Notice how each vector in C can be expressed as a linear combination of vectors information B and express according.
Eg: let {(1,0),(0,1)} be B and {(1,1),(1,2)} be C. take (x1,x2) expressed in basis C. That would be the vector x1(1,1)+x2(1,2) in our basis B
Which is (x1+x2,x1+ 2x2)
ik when 1 base is the classic base
my problem is when both bases are weird
like this exercise
Let A be the matrix whose columns are basis of B and A' be the matrix whose columns are basis of B'
x and y be the representations of some vector in B and B' respectively
Then Ax=A'y
DrunkenDrake:
So matrix you need is $A^{-1} A'$
DrunkenDrake:
Can you take derivatives and integrals of a matrix
yes entrywise
that feels kinda cheating
i'd honestly be more tempted to interpret "derivative of a matrix" as the derivative of the linear transformation the matrix represents
in which case yeah, derivatives and integrals are certainly allowed
(though derivatives wont be super interesting)

Is Gilbert Strang's book on Linear Algebra good to teach myself liner algebra?
im just gonna come in here
My teacher in class told us that the first column of your L matrix will always be the first column of your A matrix
before doing any reduction
but this is implying that you need 1's along the diagonal
is this only during LDU factorization that the requirement comes up?
and then during simple LU factorization you can just take the first column of A for L?
or is my teacher full of shit
I believe is
0 -8
0 0
incorrect
im sorry that answer is incorrect for both lower and upper
if anyone is able to walk me through this problem id appreciate it
Row reduce the first matrix on the left
jan Niku:
great. Now D= will be equal to
-8 0
0 6
that's incorrect
oh wait its an error with this site  one moment
one moment
i figured it out, sorry
Nice
despite the teacher telling us we could get partial credit, the site uses the inputs to verify it's correct rather than using a bank
so you cant actually get partial credit

damn that sucks.
thanks 🙇♂️
I hate only homework. I wished they would just let us do it in paper then submit it
so we can get partial credit
im just frustrated because there was no indication that it was using my inputs, so i thought i was performing it incorrectly
is there a good reason why i should expect each of the right hand column equations to be true
it doesnt look like you could further split down A into vectors then do the multiplication at least if a^-1 is already split
oh wait
nvm i figured it out, it just doesnt seem reasonable it should work that way when you split it up
since x4 is a column of 0's
when describing the solution in parametric form
should i include a vector multiplied by x4?
@half forge apply the sub space test. Assign p(x), q(x) ∈ W as arbitrary polynomials of third degree. Take the sum of those polynomials expanded. And you’ll see the first two terms that satisfy the condition provided are the only ones that matter. From there, you can deduce whether or not vector addition is satisfied.
Then assign c ∈ ℝ and see if scalar multiplication works out under the conditions provided. And lastly, for the zero vector existence in W, you should be able to see it is similar to the previous two justifications.
Otherwise, recall the dimension of P_n(F) is usually n + 1. But for subspaces note dim(W) ≤ dim(V). Depending on how your basis for W looks like, then you can determine W’s dimension.
Good luck!
Hint: if dim(W) = dim(V), then V = W. Is this the case? Or nah? Just something to think about on your problem.
it's very similar to what you did in a)
you can just smush those three 2-vectors together to make the 2x3 matrix you want
is it worth practicing and getting fast at reducing matrices to reduced row echelon form by hand or do we learn a better tool to do it later
or is it not that useful of a skill in general
entirely useless
useless. If your class is online just use a online calcaulator
You could just write a program,if calculator is not sufficient
There is a program my friend gave me
ok, cause i was thinking about cranking out a few worksheets a day but if people usually just do it with a calculator and thats allowed on exams then whatever
I don't think that would be allowed on exams
:/ nvm then
@lavish drift is your class online?
yeah but theres a webcam during exams
It isn't too bad for 3x3 matrices
and a browser lockdown thing
You could always write your own code
and honesty my biggest problem with exams is time anyway so ig its time to learn another useless skill
yeah it doesn't sound too hard, im like ok at python
But anyways, if your professor does not allow a calc the problems given will be easy
@native rampart and a browser lockdown thing. So he can't leave and go to his desktop
ill send an email to my prof anyway just to make sure
Sounds good. But if you want practice do some 3 x 3
kk thanks
Don't worry about it. you'll do great @lavish drift
With time, you could essentially skip steps in row reduction and draw an arrow to what you interpreted in your head. Every step is just super tedious
try a matrix with more cols than rows
no but does my reason prove this statement correct?
no it doesn't
that's like trying to prove "all people in this room are over 18" by pointing at one specific person and saying they are 20
oh
so isn't that how you say true or false by considering special cases?
idk, i am confused. how should i even approach this
@dusky epoch I still don't get it though, can u explain me how it's true or false
try a matrix with more cols than rows
This
@short tide
Im here
I attempted doing
a11+b11
for the first entry box
No dice.
This
@native rampart lol idk what you mean by try
a matrix with more columns could have any kind of numbers? how would it help with this question
the question is saying that for every single augmented matrix with a pivot position in every row, the equation Ax=b is inconsistent
you've shown one example where it's inconsistent
does that make the statement true?
👍
The first should indeed be a11+b11. I'm having some issues with my computer, I'll get back at you once everything works @ned
sure
This doesn't work @stark acorn?
@short tide I figured it out my man.
I already knew how to do it, i was just trying to check my work by parrtially puting the answer in, and it was giving me wrong answer, but when i put full answer in. I got full marks
$||A||_{max}\le||A||_2$
Tomás Sentagne:
not sure if this is the right channel but this seems like itd be easy but i dont know what im doing wrong to get the answer im getting for y
pic didnt save 😔
,rotate 50
;_; im confused
Very first step
You are adding the two equations so that the y's cancel out
But you subtracted the x's instead of adding them
Np
Hello guys, I'm looking for three subspace $U$, $V$ and $W$ of $\mathbb{R}^3$ such that $U \cap V = {0}, V \cap W = {0}, W \cap U = {0}$ yet the sum is not direct. I don't really know what i'm really looking for. Any quick help please ? :)
Gas:
Isn't that the definition of a direct sum?
No the direct sum is $U_1\oplus\cdots\oplus U_n$ if $(U_1+\cdots+U_{i-1}+U_{i+1}+\cdots+U_n)\cap U_i=0$ for $i=0,1,2,\dots,n$
Whoever:
Ok,I meant U+V+W with those conditions
U+V+W meet what condition?
Such that no two out of U,V and W intersect non trivially
Oh then i need to have $(U \cap W) \neq 0$ or $(U \cap V) \neq 0$ or $(V \cap W) \neq 0$ ?
Gas:
Well yeah that's not direct sum
Gas:
You need to have $(U+V)\cap W\neq0$
Whoever:
oh ?
So you may choose two subspaces with $U\cap V=0$ and $U+V=$ the whole space, then choose $W$ that is disjoint from $U,V$
Why not $U \cap (V + W) \neq 0$ or $ (U + W) \cap V \neq 0$ ?
well
they are the same
just by changing the roles of U,V,W you get the same thing
sure
But like
if i want to go trivial
i could get $U = \span{(1,0,0),(0,1,0)}, V = \span{(0,0,1)}$
Gas:
Compile Error! Click the  reaction for details. (You may edit your message)
reaction for details. (You may edit your message)
(my span doesn't work :( )
\text{span}
$U = \text{span}{(1,0,0),(0,1,0)}, V = \text{span}{(0,0,1)}$
Gas:
Then U+V would be $\mathbb{R}^3$
Gas:
Oh
I might have understood haha
If i take $W = \text{span}{(1,1,1)}$ then it should work right ?
Gas:
Yes
Okay thanks a lot for the tip :)
You may find a simpler one though
span{(1,0)}, span{(0,1)}, and span{(1,1)}
But yeah you got the idea
lmao you're welcome
You might know "take half and square it"?
anyone know how to do b
are we supposed to get a matrix when we multiply the vector with its transpose
one gives a 1x1 and the other gives a 3x3
yea
and the rank is the # of pivots right
how do we find rank of the matrix if they're variables
its all comes from the same column itll be rank 1
because the entries will be linear combinations of v1,v2,v3
does that makes sense?
how does the linear combinations make the rank 1
because for a v * vt transpose matrix its all a linear combination of v
and v has a rank of one
ohhh i see now
the rank wouldnt change
because it's a linear combination so ye the rank wouldnt change then

v^T also has a rank of one right
What does |v> mean?
commonly denotes a state vector in quantum mechanics
i think this is lin alg not sure tho
what is meant by proper and lower semi-cont function?
Why are all 1 dimensional invariant subspaces the eigenspaces?
Isn't it possible to have a 1 dimensional invariant subspace that is not an eigenspace?
@vast thicket give me an example. if you can't then prove such spaces are eigenspaces
if W is 1 dimensional and T invariant and {v} is a basis for W then forall w in W, T(w) in span{v}
so T(w) = c_w v for some scalar c_w
but this does not imply that it is an eigenspace because the scalars may be different
@gray dust
is linear algerba same thing as algerba?
No, it is far more complicated.
algebra < linear algebra < algebra < linear algebra
@vast thicket you didn't do enough to conclude anything
v in W & W is T invariant, so Tv in W, ie exists c where Tv=cv, hence v is an eigenvector of T
by linearity, forall kv in W, Tkv=kTv=kcv=ckv
@gray dust the eigenspace is E_k = {v in V: T(v) = kv}
k is fixed here
but in W you got for each v there exists c
this c may be different for each v in W
v is fixed
if W is 1 dimensional and T invariant and {v} is a basis for W
v in W & W is T invariant, so Tv in W, ie exists c where Tv=cv
i agree that every v in W is an eigenvector of T
but does this mean W is an eigenspace?
v is fixed
okay W = span{v}
and W is T invariant so T(v) = cv for some c
so v is an eigenvector of T
that's my argument broken up
does W = {w in V: T(w) = cw}?
@gray dust if T(v) = cv is v unique?
nvm
we can also take multiples of v
does W = {w in V: T(w) = cw}?
not always
span{i} is id_{R^2} invariant & 1-dim. its vectors get scaled by 1 but E_1=R^2
oh i see
so every 1 dimensional T invariant subspace is a subspace of an eigenspace?
or its an eigenspace in W
i think we can say that if V has 1 dimensional non trivial T invariant subspace then T has an eigenvalue
so if T does not have an eigenvalue then there are no 1 dimensional non trivial T invariant subspace
span{v} is T invariant iff v is an eigenvector of T
idk if it clarified the wording in the ans key but np
can someone explain too me , whats linear indpeendent?
Found the trace easily but could someone please help me with what the A^T(2, 3) means?
likely the (2,3) entry of A^T
Transposes means switch columns and rows
Oh its just the entry 2,3?
seems so
no prob
is this implying that only 4 pivots are needed, instead of the usual 6, one per each column?
just a bit confused on the question
if i have a system that looks like this, can i take the determinant to determine Linear indepence?
yep, it's non-zero iff the columns are L.I. iff the rows are L.I.
iff the only solution to that system is the trivial vector (0,0,0,0)
it might help to reduce to [upper|lower] triangular form through gaussian elimination and then the determinant is the product of the diagonal entries
so basically yes
i'll do that right now
do i have to do row echelon form?
@half forge yes to this I mean
Can someone give me some clarification on c for this question?

The term "weights"
well
not
weights
yeah the scalars
But how exactly am i providing those scalars
to complete the equation
well 0
uh.
not sure
so
im assuming the scalars have to be in terms of a and b
right
because i'
trying to show that [a b] is in the span of those two vectors
so rref gives me those totals in terms of a and b
oh
i understand it now actually
actually
dumb question from me
now that i look at it
hmm.
the first matrix is the same as the one in the question description but with the third column multiplied by 2
similar thing happens in the second matrix
Thats all i need to know
the third one is obtained by swapping the first and third columns
Thank you 🙂
np
@jagged gulch How do these effect the determinant
I forgot the property regarding these
ah yeah, so in both cases it's adding a multiple of a column to another column
as it turns out, it doesn't effect the determinant
ooh the second one is not the same thing actually
the second matrix first multiplied the second column by 6, then adding the first column to the second column
you should know what multiplying a column (or row) by a scalar does to the determinant, and row reductions (replacing a column with the sum of it and the scalar multiple of another row) don't effect the determinant
@jagged gulch Thanks, I kind've get it now.
yeah, unfortunately I can't give you any intuition as to why the determinant isn't changed by adding a scalar multiple of a column to another column, but depending on how your prof introduced it that might just be a property you have to memorize
or at least get a feel for
I think so, this is for calc 3
Oh so then you definitely have to memorize it lol
was linear algebra a prereq for calc 3 for you?
Nope
yeah they kind of just spring a lot of linear algebra on you early on in calc 3
Haha for sure
good luck in your course
The last half year has been dense
in about 7 months, Ive done calc I, Calc II, and Calc III
that's the general consensus lol
It was hard getting acustomed to a completely online course
what book did your prof use for calc 2?
There was no lectures
Just homework assignments, quizz, and tests
Everything self-taught
I remember tutoring someone using that book, I remember not being a big fan but it looks like they've revamped it in the past year
no lectures!
did you at least have office hours?
Gas:
nvm :)
Idk if anyone is around, but i have a kind of simple question. Can a mapping T(v) from V -> W exist if v does not include every vector in V
axler kind of beats around this point imo and does not directly say if this is the case or not. and its a focal point of my homework and class work
Can a mapping from a subspace of V be a linear map if that subspace is defined
gotcha so the entire domain must be defined
Yes
that was my understadning and was how i went about my homework. glad to hear i can go to bed
thanks!
Sup gamers
In this book
I'm a bit confused about the first two parts of chapter one
Are n-tuples the same as vectors?
Vectors can be described as n tuples
(Thanks to the axiom of choice)
Also,Does lang never formally define what a span of a set of vectors is?
is it a sufficient proof that 0 is an eigenvalue if it satisfies Av - Lv = 0
where L is the eigenvalue
Yea, You can safely treat vectors as n tuples
(For an example of vector space, which we don't usually describe through n tuples,take the vector space of polynomials whose degree is less than some n)
for a nxn matrix A, does A^2 =/= 0 imply it is not invertible?
no
a matrix can satisfy A^2 ≠ 0 and be invertible, or satisfy A^2 ≠ 0 and be not invertible
referring to Drake's response, what does it mean for a nullspace to be non-trivial?
Sorry I thought that meant =
no worries, I am just curious to understand what you meant
A non trivial null space means the space of vectors v such that Av=0 has non zero elements in it
so if I have dim(Ker(A)) = n-1, where A is a nxn matrix with n>1, then the nullspace is said to be non-trivial
that's a stronger condition than just saying the nullspace is nontrivial
nontrivial just means dim(ker(A)) > 0
Okay, thank you
This is very helpful, thank you both
so if I have dim(Ker(A)) = n-1, where A is a nxn matrix with n>1, then the nullspace is said to be non-trivial
As Ann was saying, since I have dim(Ker(A)) = n-1, does this suggest I have n-1 linearly independent eigenvectors corresponding to 0?
yes
what other ways are there to show diagonalizibility other than algebraic multiplicity = geometric multiplicity
If the minimal polynomial is a product of linear factors,That would imply the operator is diagonalizable
(Like (x-1)(x-2) and not (x-1)^2(x-2) )
thank you, but I don't have the matrix so I cannot determine the minimal polynomial
here is more context for my question:
A is a nxn matrix
rank(A) = 1
A^2 =/= 0 (not equal to 0)
0 is an eigenvalue
there are n-1 linearly independent eigenvectors corresponding to 0
the goal is to show A is diagonalizable
I am able to determine geometric multiplicity based on the dimension of the nullspace, but am stuck at the algebraic multiplicity
(and I'm also not sure if I need to prove geo m = alg m for the non-zero eigenvalue)
There is only one non zero eigenvalue
that should imply that geo m = alg m for that non zero eigenvalue but I'm not sure how to show it, or be sure of it
both multiplicities are 1 lol
just that simple? ffs
You have an eigen basis of nullspace,now just add a last vector which is not in null space. Let x be that vector not in null space A(Ax)!=0,so Ax has to be cx for some c.(Since the space of vectors not in null space is spanned by 1 vector)
yeah it is just that simple
You have an eigen basis of nullspace,now just add a last vector which is not in null space. Let x be that vector not in null space A(Ax)!=0,so Ax has to be cx for some c.(Since the space of vectors not in null space is spanned by 1 vector)
I don't know what this shows or implies
nvm,ignore
so I'm still stuck on showing the alg m of the 0 eigenvalue is n-1
Are you ok with showing it's diagonalizable?
I was thinking of determining the number of repeated roots for the characteristic polynomial
Now,write the matrix in that basis
If you write the characterstic equation,you get the algebraic multilplicity of 0 is n-1
Det(A- lambdai)=0^k and show k = n-1?
Det(A- lambdai)=0^k and show k = n-1?
@dim venture *x
@dim venture *x
U lost me here
det(A-xI)=x^(n-1) (x-c)
(Write A in a basis in which (n-1) basis vectors are mapped to zero and the last is not )
You have an eigen basis of nullspace,now just add a last vector which is not in null space. Let x be that vector not in null space A(Ax)!=0,so Ax has to be cx for some c.(Since the space of vectors not in null space is spanned by 1 vector)
I think I don't know what you are saying because I don't even understand what is going on here
Did you show any vector not in null space of A is an eigenvector?(in this case, where dim(ker(A))=n-1)
That is What I tried to show
No, I thought the definition of an eigenvector v was Av = Cv, where C is the eigenvalue
I still don't understand how to calculate inner products
I don't get the operation
<u, v > = ?
< {1, 1}, {2, 2} > = ?
inner product of (a,b,c) and (p,q,r) is ap + bq + cr
ok
so if I take two vectors {1, 1} and {-2, 2} I should get -2 + 2 = 0 right
ah
ok it makes sense now
Inner product could be something other than a dot product
mm
Sorry
OK
I don't understand this
Let V be a vector space over R
and let these:
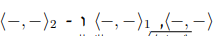
be inner products
what the hell does that mean?
also ignore the symbol between them, it just means "and" in Hebrew
i'm guessing you're considering three different inner products
one is denoted by simple brackets, another by brackets with a _1 and the third by brackets with a _2
what does that mean with a_2
i'm just talking about the subscript symbols lol
these subscripts just let you distinguish between the three products
yeah so 3 different inner products but
how do I know what the operation is
it's just a minus sign
like if you took two vectors $v, w$ then their 3 inner products would be $\ang{v,w}, \ang{v,w}_1$ and $\ang{v,w}_2$
Ann:
You define the operation
OK, the question continues :
We defined the norm to be
https://i.imgur.com/fMbNnsG.png
and with (1) and (2) as well
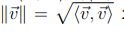
the first question is "show that if u, v in V then
https://i.imgur.com/DZELHSn.png
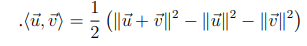
Just expand
yeah just expand
expand what... ?
use $\nrm{x}^2 = \ang{x,x}$
Ann:
the operation is undefined I thought
on the right hand side
three times
then linearity
it's just algebra
the fact that you don't have a formula for <v,w> should not stop you from being able to do manipulations
OK, so I just use the characteristics of inner products then
yeah, properties - translation
ll u + v ll ^ 2 = <u, v>
ll u ll ^2 = <u, u>
ll v ll^2 = <v, v>
so we have <u, v > = 1/2 * ( <u, v> - <u, u> - <v, v>) = 1/2 * ( <u, u - v> + <v, v> )...?
or ehm
-u
ll u + v ll ^ 2 = <u, v>
ll u ll ^2 = <u, u>
ll v ll^2 = <v, v>
@magic light | | u+v | |^2 is not that
Yes
( u + v, u + v ) = (u + v, u) + (u + v, v) = (u, u) + (v, u) + (u, v) + (v, u)?
since its over R
then (v, u) = (u, v)
that should be product not parenthesis
sorry
< u + v, u + v > = <u + v, u> + <u + v, v> = <u, u> + <v, u> + <u, v> + <v, u>
man this requires concentration
if I'm given a base (e1, e2) are these special vectors?
What have you tried?
Prove that Col(AB) is contained in Col(A)
Let vector b ∈ Col(AB)
So this means there is a vector c so that (AB)c = b
Col(AB) is contained in Col(A) if Col(AB) is a subset of Col(A)
Ax = b
so Ax = (AB)c
You found an x such that Ax=b
I first had what you just said... but for that to be true A has to be invertible, so you can multiply both sides by A^-1 right?
and you don't know if A is invertible or not
That is to show that an x exists
But,we have already found an x without invoking that,so it's fine
Yeah and if it exists, the proof is done, but if it doesn't then how does it prove the statement 🤔
yes but
can you just insert that
for that you'd have to multiply both sides by A^-1 right
So when I get to Ax = A(Bc) I've proven that Col(AB) is a subset of Col(A)
Yes
Actually it's more like A(Bc)=b therefore atleast one x such that Ax=b must exist
yes,by saying we have shown atleast one such x exists
when I write there is c so (AB)c = b
or A(Bc) = b
so there is an x such that Ax = b
so b is in Col A
Yea,You are done
and so Col(AB) is a subset of Col(A)
Wow alright thanks :)
So for this one I got:
b ∈ Col(AB)
So there is a c such that (AB)c = b
So Bx = b does not always have a solution
So Col(AB) is not a subset of Col(B)
Is that correct?
Yes
alr ty
If you want to be more rigorous, take some matrices A and B and give a case where there is a element in col(AB) but not in Col(B)
For C its basically the other way around right?
Let b be in Row(AB)
So there is a c such that ((AB)^T) c = b
or (B^T A^T)c = b
or B^T (A^T c) = b
So A^T x = b does not always have a solution
so Row(AB) is not a subset of Row(A)
B^T x = b does have a solution
so Row(AB) ⊆ Row(B)
(can i ask a question or should I wait)
@dim venture no go ahead
okay thank you
:)
(its computation it'll be quick)
I got
[ 0 6 -12
6 3 -3
12 -3 12]
but apparently its wrong
the formula I used was ePB * [T]E = [T]B
Does ePb*[a]b=[a]e?
Does it not? I thought it did
Idk the notation
From Course Notes
Idk the notation
ah then this might help clarify
this should have been a very simple direct multiplication, but it said I was wrong. I am confident in my computation, but please feel free to check me
[T]b = P^-1* [T]e* P
(P here is ePb)
oh
I guess you should read the text
You are right. The immediate examples only showed how to find the change of basis matrix ePb
(I got it right now, thanks Drake)
@native rampart
About the examples you asked for:
A = [1 1]
[1 1]
B = [0 1]
[0 0]
AB = [0 1]
[0 1]
Yea,When you are submitting(assuming this is an assignment), write these examples as to why your wrong claims doesn't work
[1]
[1] this is in Col(AB), but not in Col(B).
And [0 1] is in Row(AB), but not in Row(A)
You mean when submitting answers
Yes
If wrong, yes
I'll keep that in mind 🤔
I got 1 more proof
Gonna try it now
One sec 😅
If AB = 0, then Col(B) is a subspace of Nul(A)
Let vector b ∈ Col(B)
So there is a c such that Bc = b
Ab = A(Bc) = (AB)c = o c = o
Ab = o
so b is in Null(A)
So Col(B) ⊆ Null(A)
Yes
Nice
I'm getting the answers on monday so that's why I'm asking lol
For this question
A and B are nxn matrices with Rank n. So they have a pivot in every column and row. So they are invertible so AB = A = B. So AB also has Rank n
is that correct 🤔
Aren't you supposed to write that AB = IB = B
But equivalent
Yes
A and B are invertible matrices. The product is again invertible. So AB can be reduced to I. So it has Rank n
Yea,That works too
quick question on norms
what approach would you guys take to 1 and 2?
for 1 i used the holder inequality after multiplying through by |v|_1
but that doesnt work for 2 and now im stuck
i feel like i should have seen something
Let b be an element of Col(A)
There is a c such that Ac = b
So (AB)x = b
or A(Bx) = b has a solution.
So Col(A) ⊆ Col(AB)
Also works if B is surjective
🤨
https://i.imgur.com/T8osaqH.png
How do I find the base of the image and kernel here?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
usually I would have a Transformation matrix
so I would eliminate columns to find the base
nvm
and I would make it equal to 0 to find the kernel
but how would I find the image and kernel here?
do I just go with the regular base -
T(1, 0, 0) T(0, 1, 0) T(0, 0, 1) and then put these in a matrix and eliminate?
for the image at least
Yes
OK
Remember that a basis for the image of a linear transformation (or any vector space) is not unique.
So for example T(1, 0, 0) I get the matrix:
3 -1
4 0
what do I do with this matrix though?
T(0, 1, 0 ) =
-2 5
1 3
T(0, 0, 1) =
0 1
-1 0
yeah
The only thing that you know is that set spans the image.
usually I put these in a matrix so I can rule out any linear dependency
Now you've got to show that it is a basis - i.e. all the matrices are linearly independet.
Wait...
Let b be an element of Col(A)
There is a c such that Ac = b
So (AB)x = b
or A(Bx) = b has a solution.
So Col(A) ⊆ Col(AB)
Is this proof not correct @native rampart ? 🤨
but these are matrices themselves whcih confuses me
You actually do the same thing in a sense.
It is correct. Just wanted to generalise(Didn't work)
oh alr
You make a linear combination of the matrices that you've come up with right?
You end up with a system of equations
4 actually.
You make a linear combination of the matrices that you've come up with right?
that's what I don't get
It's like you would with vectors right?
with vectors you just put them side by side I guess