#linear-algebra
2 messages · Page 99 of 1
It's the number of vectors in the basis of the vector space spanned by M
How's one way you can find the number of basis vectors
solve the matrix
What do you mean by solve
If it's a vector space of all m by n matrices then the dimension of such space is m times n
I don't think sm means that
ah yeah, vague wording
let's have @cold topaz clarify what they meant
Yeah
because as stated it's impossible to understand
i don't hate you
i'm pointing out that what you wrote is impossible to understand the way it is written
you are not expressing yourself clearly
since when does me saying that qualify as a sign that i hate you?
I mean it's a reasonable guess to assume sm was given a matrix with real entries
ok.
this is the problem. How do i figure out its dimension?
Lmao
slader says 4.
dimension of WHAT
It's still not a subspace
@cold topaz dimension of what
dimension of WHAT
@dusky epoch M
there's no M here
M_22
For each entry, you will need a matrix vector
$M_{2,2}$ presumably refers to the \textbf{space of 2 by 2 matrices}, and that has dimension 4.
Ann:
Since there are 4 such entries in a 2x2 matrix, the dimension is 4
$M_{2,2}$ isn't a matrix, it's a vector space.
Ann:
Yep

To illustrate, you will need
1 0 0 1
0 0 0 0
0 0 0 0
1 0 0 1
I'm too lazy to use latex
that's one of the many possible bases of M_2,2
so four rows and 12 entries in each?
each entry has 48 element???!~~?!!!!!
There are 48 entries
48 entires is not equal to dim 48
How many vectors will you need to form the full basis of 4x12 matrices
4
Not quite
column vector
Ann let's not complicate it
@cold topaz I'd like to clarify a few things. Vectors aren't just column vectors or arrows in space. Rather, they are elements of a special type of set called a vector space
A vector space follows some special rules, which you should look up in your textbook or on Wikipedia. Any element of a vector space is called a vector.
a vector space is not a 'special type of set'
This set of 4x12 matrices forms a vector space because it follows the rules of a vector space
it's a set with additional structure
Of course, but I'm using special in the sense that it's distinguishable from other sets due to the fact that it follows certain axioms
the underlying set itself doesn't satisfy the vector space axioms
I'm going off the standard and intuitive way of adding matrices and scalar multiplying, there really is no reason to overcomplicate this
Most of the vector spaces encountered in an early linalg class use familiar definitions of addition and scalar multiplication
Extra detail is counterproductive imo
if you've decided to introduce vector spaces, you should do it in a way that doesn't form conceptual clutches which don't generalise
I don't think the approach is to explain the concept in the fullest generality either. Some familiarity needs to be gained in order to generalize
Then what's the point of talking about the axioms of a vector space
You bring up a fair point, which I failed to address earlier. By axioms, I really only meant the closure under addition and scalar multiplication, since the regular definitions of addition and scalar multiplication for various sets cover the rest of the other axioms
Edited for clarity
tbn vector spaces should be introduced as objects of Vect_K
Ummm....it’s the next vector?
what next vector?
So like,
v_1 == <1, 0,0,0,........,0_n........ >
v_2 ==<0,1,0,0,0,.......,0_n,.......>
.
.
.
v_n == <0,0,0,.......1_n,......>
Okay, well for one, you should be more explicit in what the v_i are
Are those even elements of F^{infty}?
Nope, but they can be if you extend on infinitely many zeroes afterwards
oh.....
anyways, the problem is that
You're assuming that F^{\infty} is finite dimensional, so you know it has some finite basis
but you don't know that this is the basis
It oculd be some other finite set of vectors that's the basis
i.e., maybe there's a basis that contains the vector v = <1,1,1,1,1,1,1,....>
All you know is that there exists a finite basis, not what it looks like
I’m not at basis yet. Axler hasn’t covered basis, not until 2.B
nevertheless, I’m only assuming these span the space, not that they are line. indept.
The header says 2.A, lol.
All you know is that there exists a finite basis, not what it looks like
@sonic osprey
oh, okay. Yeah. This is true.
Um...is this approach salvageable?
what does v_{n+1} even mean?
You haven't defined it at all
hint: ||in a finite-dimensional vector space no linearly independent set can have more members than the dimension||
oh lol he hasn't doesn't done basis yet 
hint: ||in a finite-dimensional vector space no linearly independent set can have more members than the dimension||
@wintry steppe
he has done this.....
dimension of a space is formally covered in 2.C
your approach is "imma pull a vector out of my ass that somehow isnt in the span of my v_i and then parrot off that its not in the span and therefore the v_i don't span F^infty but they do span F^infty contradiction bluh bluh"
problem is
Yes. That’s the gist of it
you have not shown you can find a vector not in the span of your v_i
I guess that’s true, cuz i cant seem to find a vector in F^∞
well
if this approach is a deadend, I’d like to know to try and not salvage it.
(I did the type-up in half an hour. It did feel too easy.)
Yo this questions actually pretty cool
I mean, contradiction is the right idea
suppose F^\infty has finite dimension, say n, so no linearly independent set L can have |L|>n
wait.
so take the v_i that span your space like you do, and try to find a vector outside of the span of the v_i for a contradiction
like you tried to do
@dreamy iron you have this lemma already right?
Yes. I have alrdy.
I did an rough translate
solve without external "assisting stuff" from parabel y=x^2+1 places(dots) where its distance is 2 from line y=(3/4)x+1
bruh
xd
just because you have y = mx + b doesn't mean you're doing linear algebra
bruh
im only on 5th course, we have 13
Thanks dad
bruh
Awesome
for any n you can find a LI list of n+1 elements
Is that the hint, @dusky epoch ? Leverage the lemma 2.23?
yes do that
Okay, TyTy
yes make use of that
@storm python pubes, I dont understand this discord
why did you call me pubes?
@warm sparrow are you doing an exam

@wintry steppe No


@wintry steppe Because its the final return date and I am leaving to my cottage soon, and if I can't do them until then then I gotta wait
@warm sparrow you didn't answer my question
Lmfao
@storm python Because your name reminds me of the words pube
Holy shit lmao
i see
pubilus

Don't know why you are doing this, but allow me to analyze the situation for you right now
If you want help, you probably shouldn't trigger a lot of other people
And listen to what you've been told
But of course these are all based on the assumption that you want help
that's too much to ask whoever
wtf happened here lmao
$\bigcup_{i=1}^{\infty} A_i = \lim_{i\to \infty} A_i$
Godel:
what do you even mean by the limit of a sequence of sets
well thats what I was not sure about, how you define that and if you need aoc
Was thinking about something like ideals
How would the sets be linearly independent is what I don’t get when they are subsets
yeah thats what I was confused about as well
I mean there has to be like a 'limit set' since they are all nested subsets of V, but I think you need aoc for that
no
the union of the A_i is the union of the A_i
it is by definition the set of all objects that are elements of at least one of the A_i
bruh you're overthinking it
if you wanna get into set theory stuff this is just axiom of union
I think Im just right and you jsut say no without thinking about my thing
you don't need fucking AOC for this
$\bigcup_{i=1}^{\infty} A_i = {v \in V \mid (\exists i \in \bN)(v \in A_i) }$
Ann:
or are you also gonna object to my use of the axiom schema of comprehension?
yeah I dont quite believe it
or my use of, dare i say, an existential quantifier?
so you don't believe in even restricted comprehension?
what are you, a fucking ultrafinitist?
Language please, no need to get mad I found a very nice way and you didn't.
very nice way to do what
you're trying to refute the obvious here
we didn't even get started on the linear algebra
it looks to me like you're just denying that $\bigcup_{i=1}^{\infty} A_i$ exists or denying that what i sent up there (which is literally its definition) is true
Ann:
no, you're denying existence of the maximal element of such union
doesnt matter, continue, I jsut wanted to ask about that.
maximal element? excuse me?
yeah ann you know the maximal element of N
N is not bounded
are you trying to claim that there exists a natural number $N$ such that $$\bigcup_{i=1}^{\infty} A_i = A_N?$$
Ann:
i love this server so much
because that need not be the case at all, except if the ambient vector space is findim. but nothing was said about it being findim.
exactly
what are you "exactly"ing to
yeah, i never argued that there would be such an N.
So guys what’s the answer 😂
btw what does A_i's being linearly independent mean
it still means the same thing as if they weren't
anyway the answer is to check your infinite union against the definition of linear independence
and remembering exactly what the defn of linear independence is for an arbitrary, not necessarily finite set of vectors
Can you dumb it down for me lol
Is it A,B,C or D
ann is telling you what to do
check your definition of linear independence
probably something like *the only linear combinations equal to zero are the trivial ones"
so take a linear combination equal to zero in the union and see if that is true or not
hey, can someone explain to me what dots and lines are in matrices? like what do they mean here?
the columns of the matrix are the vectors a_i
@wintry steppe what are the dots then? does this mean the entire first column is a1, and second is a2, etc....
wb
whats a good place to start learning linear algebra from
any book recommendations?
@uneven crater that's basically it. it's the same as writing a vector like (v_1, ..., v_n); you can't actually write all n entries, so the ellipsis denotes that they're going from 1 to n
👍
@jagged nymph im using https://www.math.brown.edu/~treil/papers/LADW/LADW-2014-09.pdf
the book by friedberg insel and spence is pretty good, i used it in my first year and liked it
axler's LADR is good but if it's your first time learning linalg you probably don't want the "determinant free" approach
ive heard good things about hoffman and kunze
ultimately you want something with a lot of examples
can someone tell me why i have to find the minimum polynomial in Jordan decomposition instead of just finding the algebric and geometric multiplicites of the eigenvalues?
I assume because your teacher told you so?
so it's the same? because he said that you can't be sure about the eigenvectors without the minumum polynomial
Given matrix $A = \begin{bmatrix}
1 & 0 \
1 & \epsilon
\end{bmatrix}$ I want to find $\norm{A}$ and $\norm{A}_{\infty}$
Godel:
Whats the strategy to transform a matrix into an identity matrix
If its possible to make it into an identity matrix, you can use gaussian elimination
it's easier to use the map f(x) = 1 for all x
@wintry steppe did you define matrix norms via the vector norm?
yeah
A_infty is jsut the max length of a row which would be 1 +eps^2)^1/2, not sure about the other one
then if you don't know more about how those matrix norms behave, the general strategy is to (a) find a tight upper bound and (b) find a vector where that value is attained
I tried to find the max of Ax on x=[x1,x2] such that x1^2 + x2^2 = 1
why would the infinity norm be the max length of a row
why not?
what does that mean then
the sum is the sum of the i-th row
sum of absolute values of entries is not the length
true yeah I just noticed
you sum up the absolute values of each entry and take the max of that
ye
1 +eps
anyways, had trouble with the other one
I tried some things and got me into some weird calculus stuff and not sure if thats the approach
what norm are you using
the regular euclidean norm I guess
|(a,b)| = sqrt(a^2+b^2) is how you measure lengths of vectors or not
the casual way would just be parametrize the unit vectors by (cos t, sin t) and differentiate the result of multiplying by the matrix and maximize the square, assuming epsilon is small replace with (1-t^2/2, t) to approximate by hand
eh, this is probably the 1-norm
I can not understand the determinant definition
Do you have any good source that provides a good explanation ?
the wikipedia page is actually pretty comprehensive
if its just about the intuition behind it then https://www.youtube.com/watch?v=Ip3X9LOh2dk&vl=en
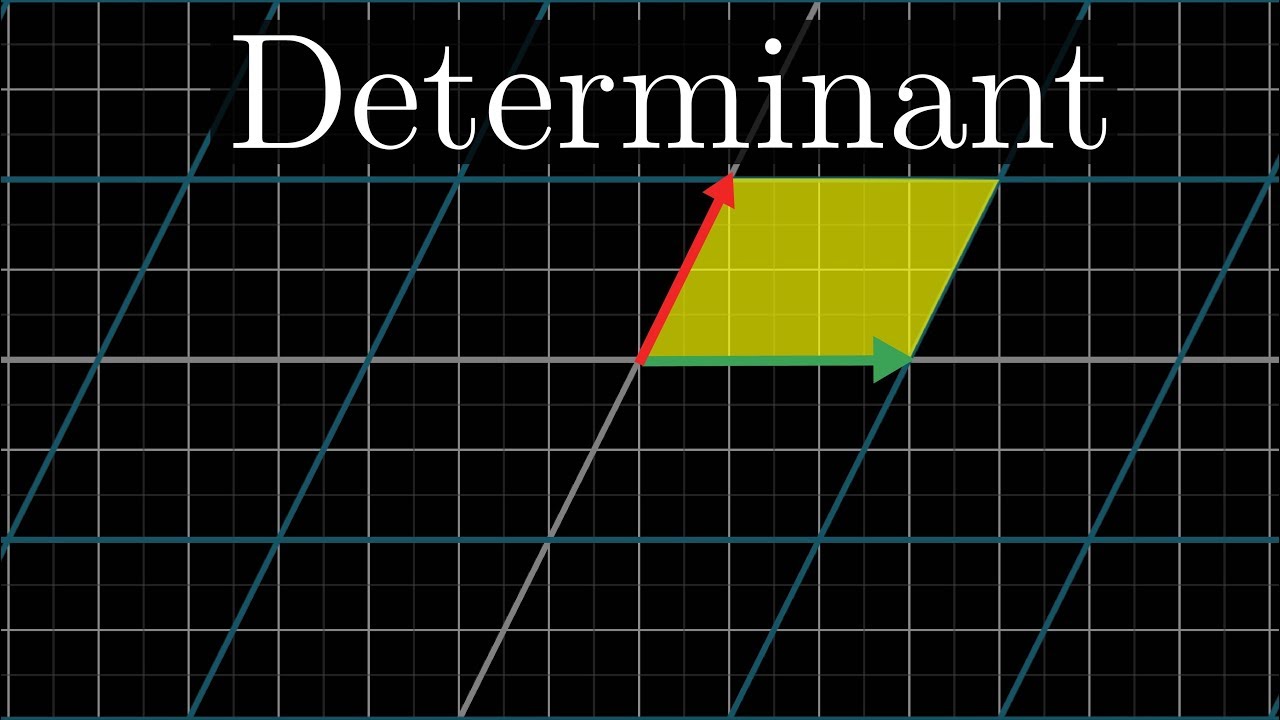
Home page: https://www.3blue1brown.com/
The determinant of a linear transformation measures how much areas/volumes change during the transformation.
Full series: http://3b1b.co/eola
Future series like this are funded by the community, through Patreon, where supporters get ea...
the dude is pretty solid for that if you're willing to invest the time
the definition of the determinant is extremely technical
tbh the best you can do is the intuition of scaling and remember the important properties
it's probably a good idea to draw a parallelogram in the plane with one vertex on the origin and two points at (x_1, y_1) and (x_2, y_2) and find the area of the parallelogram in terms of these numbers just to get a glimpse of the connection first hand
If I have a matrix Af = b such that the k-th column of A is not independent of the rest of the columns of A, how do I prove that the k-th entry of f is non-zero?
My idea was to try to see what happens if the k-th eentry of f is 0
But I'm not getting anywhere
Oh and A is mxn
tehn in this case we know that the rank of A is at most m - 1
I don't think that what you're trying to prove is true.
If I understand correctly, then A = {{1, 1}, {0, 0}}, f = {{1}, {0}}, and b = {{1}, {0}} are such that Af = b, the second column is in the span of the first, but the second coordinate of f is 0.
Err sorry
That there is a solution that has f_k non-zero
Not necessarily that f_k is 0
Oh, I see.
i.e, for some fixed b
And some fixed A, whereby the k-th column of A is not LI of the rest of the columns of A
Well, I think I'd try the same thing you did. Set the k-th entry of f to 0.
It'd probably be easier if you write Af as a linear combination of the columns of A.
Yes
So we see tht
$Af = f_1A_1 + f_2A_2 + \cdots + f_kA_k + \cdots + f_nA_n = b$
Liria ^(;,;)^:
Oh
Oh wait because it's LI
We can wirte $A_k$ as a linear combination of $A_1 + cdots A_n$
Liria ^(;,;)^:
But I don't think that that helps us?
Like if we let $A_k = c_1A_1 + \cdots + c_nA_n$
Liria ^(;,;)^:
Sure.
Then we can rewrite $Af = f_1A_1 + \cdots + f_kA_k + \cdots + f_nA_n = (f_1 + c_1f_k)A_1 + \cdots + (f_n + c_nf_k)A_n$ right?
Liria ^(;,;)^:
Like the value of $f_k$ doesnt' really matter because you can make somethingg equivalent to $f_k$ by increasing each element of $f$ by $c_i$ right?
Liria ^(;,;)^:
What you're showing right now is that, whatever f_k is, there is a solution f such that f_k = 0.
Not saying it's wrong, but you're not proving what you want to prove.
Yea
Oooh wait
Ok we can go the other way around
We can decrease each element $f_i$ by $c_i$
Liria ^(;,;)^:
To go and recreate $f_k$?
Liria ^(;,;)^:
Yeah, pretty much.
Wait can I just sum them all up and say that $f_k = \sum c_i$ lol
Liria ^(;,;)^:
To reiterate, you'd start with $Af = f_1 A_1 + \dots + f_{k - 1} A_{k - 1} + f_{k + 1} A_{k + 1} + \dots + f_n A_n$ and end up with $Af = (f_1 - c_1) A_1 + \dots + (f_{k - 1} - c_{k - 1}) A_{k - 1} + A_k + (f_{k + 1} - c_{k + 1}) A_{k + 1} + \dots + (f_n - c_n) A_n$.
Red Herring:
Liria ^(;,;)^:
$A_k = c_1A_1 + \cdots + c_nA_n$.
Red Herring:
Okie.
Thank you!
Wait one more question
"Consider a fixed b in R^m and Ax = b which is consistent. Prove that there is a feasible solution g such that at most m coordinates of g are non-zero"
Yes
If it's consistent then we require rank(A) = m
So I'm all but certain that that plays into it
Yes, it does play into it.
And that if we have more than m coordinates of g non-zero then it would stop being o solution because then we'd have too many 0s in out output?
?
There's nothing stopping a feasible solution from having more than m coordinates.
Err wait sorry
If we have fewer than m non-zero coordinates, such as m - 1 coordinates being non-zero then our solution would... I think we'd still get a solution though?
But I mean it just says prove that there is a feasible solution with this constraint
So I'm not really sure besides the rank(A) = m part
Ok, so you want to show that there is a feasible solution g with at most m coordinates non-zero.
So, let's try proving by contradiction.
Suppose that there isn't a feasible solution with at most m coordinates non-zero.
Let x be an arbitrary feasible solution.
What can you say about Ax?
Actually, let's start with the lead you have before considering what Ax looks like.
What is the definition of rank?
Hm, this definition is not very suggestive. So, in the previous problem, we wrote Af as a linear combination of the columns of A.
Could you interpret rank in this context?
rank is equivalent to the number of LI columns
Yes
And column space, yeah?
yes
The columnpsace is the range of the matrix; any coordinate in g that goes to 0 is basically just throwing out that column of the matrix from its output
Right.
rank is equivalent to the number of LI columns
So, this is good.
I'm going to give another equivalent statement that's more helpful.
The rank is the dimension of the column space.
This will tell you something about expressing Ax as a linear combination of the columns of A. Namely, if you have Ax as a linear combination of more than rank(A) columns of A, then you can do better.
Precisely.
But we can't reduce $g$ to have fewer than m coordinates?
Liria ^(;,;)^:
So, we let x be an arbitrary feasible solution such that Ax = b and x has more than m nonzero coordinates.
That means that we can write Ax = A_1 x_1 + ... + A_n x_n.
You say that we can reduce that number of coordinates to exactly m.
What you should say at this point is that you can rewrite A_1 x_1 + ... + A_n x_n as a linear combination of m columns of A.
That is, Ax = A_1 c_1 + ... + A_m c_m.
Yes
This shows there is a vector g such that Ag = b and g has at most m nonzero coordinates.
Do you see why?
Because if you had less then you would not gget b
There might be a vector v with less than m nonzero coordinates such that Av = b. We don't know.
We have insufficient information to determine ttat
Consider this. If you have A is a matrix and x is a vector, then you can write Ax as a linear combination of the columns of A if the product Ax makes sense.
What if you start with a linear combination of columns of A?
What do you mean?
What I mean is Ax = A_1 x_1 + ... + A_n x_n.
Then, A_1 x_1 + ... + A_n x_n = Ax, right?
Yes
The rank is the dimension of the column space.
This will tell you something about expressing Ax as a linear combination of the columns of A. Namely, if you have Ax as a linear combination of more than rank(A) columns of A, then you can do better.
Liria ^(;,;)^Today at 3:38 PM
Yes
we can reduce the number of non-zero coordinates down to exactly m
Red HerringToday at 3:38 PM
Precisely.
Liria ^(;,;)^Today at 3:39 PM
But we can't reduce g to have fewer than m coordinates?
Red HerringToday at 3:41 PM
So, we let x be an arbitrary feasible solution such that Ax = b and x has more than m nonzero coordinates.
That means that we can write Ax = A_1 x_1 + ... + A_n x_n.
You say that we can reduce that number of coordinates to exactly m.
What you should say at this point is that you can rewrite A_1 x_1 + ... + A_n x_n as a linear combination of m columns of A.
That is, Ax = A_1 c_1 + ... + A_m c_m.
Try to rereading this if you don't get it yet.
I will in a few, I'm goisg to eat now 
Hi
[6, -5, -2/3] + t[1,3,2]
Is this a vectorial equation or a symmetric equation ?
Or a vectorial equation in symmetric form? lol
it's not an equation at all on account of there not being an equals sign
haha sorry
that's the equation of a line
imagine the first vector as being a point on the line, then the choice of t tells you by how much in the direction of the other vector you 'slide'
Ok I gotcha
hmm
Would the left side be parametric equation and the right side symmetric equation ?
left side yeah, right side I'm unfamiliar with that terminology
maybe it goes by a different name in the US, maybe someone else knows
I used Stewart, and they used that terminology.
Can anyone help with this Gaussian elimination question, part bii? I have an answer but it's different to my friend's and I'm not exactly sure why
My working for bi and bii
if i want to find the values of x, y, z so that the given matrix is orthogonally diagonalizable, where do i begin?
Bruh
I'm assuming orthogonally diagonalizable means it's a symmetric matrix
true @quartz compass
that's what im focusing
and got the transpose
and then it's a mess
don't think so hard
look at what entries have to be the same to make it symmetric
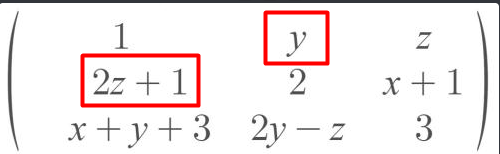
make 2 more equations
you should have a system of linear equations, surely you know a way to solve that
we get three equations with three unknowns
I'll post my question again since you buried it
Just looking for a check really, I think I've done the right thing in part ii but the fact I got a different answer to a mate worries me slightly
,w {{0, 0, 1}, {0, 1, 0}, {1, 0, 0}} * {{1, 2, 2}, {5, 4, 4}, {2, 4, 8}} * {{0, 1, 0}, {0, 0, 1}, {1, 0, 0}} = {{1, 0, 0}, {1/2, 1, 0}, {1/4, 1/8, 1}} * {{8, 2, 4}, {0, 4, 2}, {0, 0, 3/4}}
Iirc, LU decompositions aren't unique.
@autumn basin
Unsure if pivoting strategy would make the factorization unique, tho.
oh my dumb brain never thought to use WA to check smh
seems like I had the right idea then
Get your friend to check, too. They could be right as well.
good point
my lecture notes are so strange on this topic, he prefers using a "D L U" decomposition and writing A=D-L-U so that L and U's elements are negative
While you're here mate, I wonder if you'd be able to look at another small part
Sure.
In this question, seems like I get complex eigenvalues - I'm not entirely sure how to interpret that
Yeah
I have lambda=+-root(2)*i which doesn't sound fantastic
That's normal
o
That means your eigenvectors are being rotated
could you explain what you mean by that? Sorry, I'm not exactly the best at linear algebra 😦
That's chill, basically all linear transformations can be represented as a composite transformation, and what diagonalization does is that it decomposes a transformation into a change of basis, then a scaling, and then a change of basis back
But for complex eigenvalues things change
If we take
0 -1
1 0
Then the eigenvalues are +-i
That's one example
See where it takes i hat and j hat
Ok, I think I see what you mean
Here there's pure rotation
But you can have scaling and rotation
With complex eigenvalues
I honestly forgot how to do the computations for complex eigenvalues
This is my working for the problem so far
although I can't really compare 1 and root(2)i
Note that it's the max of the absolute value of lambda you're looking for.
oh hang on
right
well that's just root(2) then
man, I'm really good at missing small stuff which is kinda worrying
Same.
Word
tbh it's linear algebra I have the most trouble with since I'm better at misreading matrices than I am at actually using them
I saw this problem yesterday, where you prove that this is infinite dimensional, but I can't seem to crack it myself
Definitely seems like the way to go is to prove the existence of a set of independent vectors which has a cardinality larger than the dimension
But I've no way of proving it
Do you have a rough idea of what to try?
I proceeded by contradiction, stated that a basis for F infty is B={v1, v2, ..., vk}
So dim F inf = k
And I stated that all sets of independent vectors have a cardinality leq |B|
Could you show that this has a greater dimension than R^n for any n?
I think that's basically his argument.
What's missing is what v_1, ..., v_k actually are.
Yeah
Did you try a particular basis?
No
I mean standard basis is what I had in the back of my head
But standard basis is infinite
But I haven't proved that
So, I'm thinking, each of these vectors eventually ends.
Er, as in the tail is 0's.
I don't think that's a fair assumption
Standard bases are easy to work with
Oh, ok.
I was thinking of using pivots and matrix representations
Making this more or less a direct proof ig
You can do simpler than that.
A basis is a list of linearly independent vectors with the right length.
Yeah
You assumed that the dimension of the space is k.
Yep
This means any list of k linearly independent vectors is a basis.
Yep
I was thinking of using another basis
But I didn't really know what to do with it
Well, you said you had the standard basis in mind, so let's use the standard basis of F^k.
So, that list is supposedly a basis of F^infty.
Except?
The length is infinite
So the proof should rely on proving the standard basis is a basis
The length of the standard basis of F^infty is infinite, yes, but what I stated was
k linearly independent vectors is basis + standard basis of F^k is k linearly independent vectors => standard basis of F^k is a basis of F^infty
noob question but wouldn't F^inf include some finite sequences? and if so how would that work with an inf basis
F^infty is defined above (see pic) as all infinite sequences.
No finite sequences.
There are no finite sequences
oh whew
I think that answers it
k linearly independent vectors is basis + standard basis of F^k is k linearly independent vectors => standard basis of F^k is a basis of F^infty
@eternal finch Small mistake here vectors in F^k are lists of len k but in F^infty should be len infinity
Ah, right.
Yes, my bad.
Standard basis of F^k with zero tails appended to themeach vector would be linearly independent.
I don't really think I can zero in onto any list of k independent vectors, because they don't form a basis
Er, what I mean was, for example, if I have k = 2, then the standard basis of F^2 is {(1, 0), (0, 1)}.
So, I could propose {(1, 0, 0, ...), (0, 1, 0, ...)} as my basis of F^infty.
So, I guess by "them" I meant the vectors.
But I would assume you would have to do things differently with a finite dimensional vector space vs an infinite dimensional vector space
Or is it enough to prove dim F^k = k
And just take the limit
I'm not sure "limit" is defined, but isn't
Or is it enough to prove dim F^k = k
And just take the limit
the spirit of this captured by your argument
I proceeded by contradiction, stated that a basis for F infty is B={v1, v2, ..., vk}
So dim F inf = k
And I stated that all sets of independent vectors have a cardinality leq |B|
already?
But I would assume you would have to do things differently with a finite dimensional vector space vs an infinite dimensional vector space
Also, unsure what the thing being done is.
Well, yes, that's certainly true.
Nothing done so far hinges on things particular to a finite-dimensional vector space.
Luckily.
To recap the work so far.
Let B be a basis of F^infty.
Let |B| = k.
Hence, dim F^infty = k.
Any list of k linearly independent vectors in F^infty is a basis.
Yep
Inspired by the standard basis, choose the standard basis of F^k but with each vector given an infinite number of zeros at the end.
That's a list of k linearly independent vectors in F^infty.
Yeah.
Np, was fun.
can u please enlighten me what's going on?
Huh. What's the codomain of T?
before that, it says Suppose that T: P2 -> P3
and this is the rest
so I plug in xp(x+1) for x of x^2?
this looks like linalg but is really just #prealg-and-algebra
example. a function on R, f(x)=sin(x)+x^2. f(x^2)=?
I m going to ask a pretty stupid question
If I have a matrix with the aumented part
Just the coeficient matrix
Can I do row operations ?
If I have a matrix with the aumented part
Just the coeficient matrix
Do you mean if you have a matrix without the augmented part?
But yes, you can do row operations on a nonaugmented matrix.
Can iswitch columns ?
Yeah
Sure, you can switch columns.
You can do anything to a matrix
Augmented matrices are just notation to make life easier
When solving a linear equation
Why this is so? (Can't understand from the reason given in parentheses)
if a_2 through a_m were zero it'd force a_1 to be zero too
Oh understood. Thank you
Officially taking Linear Algebra I starting on June 9th c::
Any tips before I start?
if you're taking a theory-focused course get comfortable with fields, complex numbers, and polynomials
that was basically the first week or so of mine
and if you are not taking a theory-focused LA course
drop and take a theory focused LA course
^
the computations are made a lot easier if you know what's happening behind the scenes
e.g. multiplying matrices is just composing linear transformations with some basis choices
well, not "easier", but less mindless
maybe thats not a good example
i dont think any la class is purely computational tbh
yeah perhaps
like one example is probably determinants
finding the right cofactor expansion and all
maybe thats not a good example
@wintry steppe I think it's a good example
"measuring how n-dimensional volume scales with the linear map" is a pretty good explanation for the determinant that i think you can motivate in 2-d without too much theory
I still don't quite understand determinant but most of the computation problems are pretty easy to solve
its literally just how volume scales, geometrically at least
geometric intuition is honestly not very important
john is wrong
i like geometric intuition
the only important thing about the determinant is whether its zero or not so
Same. I love it geometric intuition.
yeah
I wish I could explain more stuff geometrically...
algebraist's view of the determinant vs geometer's view of the determinant lmao
im not saying geo intuition isnt important, im saying it isnt important for determinents
I guess if you never plan on changing coordinates the value doesn't matter
changing coordinates
Oh yeah. Good application.
I watched 3b1b and know the geometric intuition but I don't see the connection between the geometry and permutation and stuff
everyone arguing about the determinant
y'all this is how axler made his book
lol
that's why they had to make a book to do linear algebra wrong
my linear algebra prof said on the first day "axler's book is linear algebra done wrong"
Hey, I quite like Axler.
lol
"unique basis element of alternating n tensors on R^n sending the usual basis to 1"
I like Axler's book. I feel it's very readable for me
theres your defn
I like Axler's book. I feel it's very readable for me
Yes, I was quite surprised at the clarity.
im not saying axler is a bad book at all, i actually like it
But I don't have much experience in rigorous math
im not saying axler is a bad book at all, i actually like it
Yeah, got it, up with determinants. :^)
I'm writing a book called "Calculus Done Right" and we don't ever use limits, we just define derivatives as linear maps
bruh
Wowie.
yes im in
damn
i really like axler's proof that every complex operator has an eigenvalue (i think thats the one)
its a well written book
b-ok
my uni used friedberg for first year la until just last year, when they used axler
Yep.
||>buying books||
I actually still go on ||gen.lib.rus.ec||, but almost always end up using the ||b-ok|| mirror.
Habit.
b-ok is too damn good
that day will never come
this is the proof
not for me

what the fuckj
Lol, I will stop sh*tposting.
Wow, math is so elegant
oh fu*k
There is the elegant math that everyone likes, and there is combinatorics
Ew the font
elegent math
prime numbers
yes marcus had cursed font in 1st edition
this is somehow worse than comic sans

no
@wintry steppe are you a geometer
ok good
why's that good
geometers suck >: (
he can compute christoffel symbols all day to make himself feel better
honestly makes it better
Oh TTerra, the class im taking is an intro to linear algebra lol
that still doesnt really distinguish between computation-based or theory-based
but
i dont know what a computational class entails, but i guess you could get comfortable with basic geometry in R^2 and R^3 concerning vectors, lines, planes
you'll probably learn it all in the class anyways but those things aren't too hard to learn
tbf my class had a standard amount of theory
nothing too in depth but it wasnt all just "find the determinant of this matrix"
i should be using my uni's "computational" class as an example
as you can see, its not too computational
if your course has an emphasis on stuff like matrix operations, computing things, the determinant, etc it's "computational"
Literally all they say
yeah thats a good way to put it
Matrices, systems of linear equations, vector spaces, linear transformations, determinants, inner products and norms, eigenvalues and eigenvectors, diagonalization
if it has an emphasis on stuff like arbitrary vector spaces, proving theorems, etc
then thats "theory"-based
yeah that sounds more computational but it depends how each topic is "approached"
my undergrad LA course started as a ring theory course for like 2 weeks
wat
and only introduced matrices after about 2 months of vector space theory
i think any theory focused course on LA starts with fields and/or rings
defined some basic ones, ways to "make new structures" out of rings
so quotienting and stuff
defined fields
we never actually defined an ideal so like
suuuper basic
but this served as an intro to proofs
proving basic theorems about rings, getting an intuition for what Q[x]/(x^2-5) would mean or whatever
wow that sounds a lot more advanced than what my class did
i would have loved something like that
maybe its just cause i havent taken algebra yet but i dont really see where rings would come up in LA
other than "by the way this is a ring" for a few things
were there any advantages to working with them?
i mean im assuming some module stuff was introduces
as they are more general structures than vector space(altho nowhere near as nice)
well this class was weird in general
to be fair
like we did 2 lectures of category theory definitions randomly???
purely so we could state the first isomorphism theorem using commutative diagrams
???????
tf
wtf
im still not sure the motivation behind that
we actually didnt do MUCH module stuff
we did prove first iso for arbitrary modules but
"accidentally"
lol
like our proof didnt rely on vector space properties at all
so the lecturer was like
"btw if you repalce the word 'vector space' with 'module' the proof still works"
what year is this
first year "honors" course
lol
good lord
"whats some good lab rats to experiment wierd cirriculum"
"ah yes the freshmen ofc"
nah it was
basically a big state school
but canadian
the university of alberta, ranked roughly #100
this linear algebra class didnt actually cover that much content? like
what the hell
we never used the word "jordan" i dont think for example
we got to a little bit of spectral stuff at the end of the course but thats about it
change of basis stuff was given a whole 1 lecture, and i still dont really know gram-schmidt [besides "it's iwasawa decomp"]
its
not very good
also the lecturer changes every year so
its probably very different nowadays
this was half a decade ago and it was taught by an analyst for some reason?
and our intro analysis was taught by an algebraist which had some
...interesting... consequences
hold on one sec
this is how we initially discussed the derivative
we gave it a proper definition later
but yeahhh
now this is comedy
imagine proving linearity by observing that the derivative function forms a subalgebra of the real functions on an interval of R
truly the optimal approach
anyway, this was "interesting" but most of the course was very slow
like we only defined a derivative in the second semester lmao
well okay
we got the definition in like
the last lecture of the first semester
[and it showed up on the final]
is there anything to be gained at all by defining the derivative that way
other than tormenting first years with the words algebra and subalgebra
well its not a definition its just an algebraic contextualization
anyway uhhhh i guess the motivation was that
and this is just conjecture
but maybe its that
we were introducing derivatives really late, as i said
second semester
so the prof figured "students have already developed a lot of linear algebra intuition"
"so i might as well discuss the derivative using algebraic notions of linearity"
"before getting into the boring technical stuff"
maybe?
im not sure this really explains it
and i cant say it provided any advantages
yeah that seems like a pretty reasonable take on it
it still would be a lot more straightforward to define it with limits and then show linearity though, i think
but i guess if you want to instill the "linear approximations" intuition early, that's one way to try it
well we defined it with limits right after
this particular definition was always phrased as "optional"
and was never necessary for anything, the rest of the course was a fairly standard analysis course
hell, it didnt even do any topology
besides defining open/closed sets on R^n
and that kinda thing - limit points and whatnot
we never defined a metric space or whatever
or a topology
or etcetc
so if anything it was fairly "light"
maybe the instructor just wanted to include something to his personal taste
yeah, that's what i'd guess
he also defined power series using R[x] and then someone in the class told him
"not everyone here is actually taking the linear algebra class also"
and i just remember him having like
a mortified look on his face
remembering that there were like 2 engineering students in this course for some reason
[iirc though the engineering students did fairly well, so good on them]
Let V be a $\mathbb{F} $-vector space, and $ U \subset V$ it's linear subspace. Then $ U $ is Abelian group, and we can look at factor group $ V \backslash U = {x + U | x \in V }$
milos:
Oh it got lost by copy pasting I guess
Let V be a $\mathbb{F} $-vector space, and $ U \subset V$ it's linear subspace. Then $ U $ is Abelian group, and we can look at factor group $ V \backslash U = {x + U | x \in V }$
milos:
whats the problem
@elfin ingot chess 5+0
im in game now
In linear algebra, the quotient of a vector space V by a subspace N is a vector space obtained by "collapsing" N to zero. The space obtained is called a quotient space and is denoted V/N (read V mod N or V by N).
okay 1 sec
Like, we defined factor group in this case as G/~_1
@wintry steppe @elfin ingot smh take it into #chess-go-shogi
And ~_1 is a class of equivalence
It is called quotient space
No, I mean back when we did groups
We didn't mention the definition I sent above
What definition did you use?
We defined a relation of equivalence
~_r and ~_l
r is for right cosests, and l is for left cosets
Nah nvm, looks like I forgot the definition of a coset lol
And that was my problem
Hey, could someone help me with a problem I have? i need to calculate the Gradient of this function
[||P(UV - M)||_F^2] with respect to U and V.
where P is a sort of indicator function that I think shouldn't affect the gradient.
How should I start on this? Any advice or things to look at?
RamJam413:
I am asked to draw k = 2v - w + u I just don't see it. Is it like something outside of the triangle?
,rccw
@fickle tree Idea: Consider 2v - w + u = (v-w) + (v+u)
Something like this? @brittle fog
Why the yellow is v-w? I don't see where you came up with this sorry
I would just go through this step by step
Start from B
Then go along v
Add another v to it
Imagine the tip of w coming to where you are, and going to its tail
And then add u
And then you join B with that point
Which would end up being the tip of a rectangular base pyramid identical to this one on the top right if you were to tile it
can someone help he bring (6;5)(-3;-2) matrix to 20th degree
@rocky skiff Compute its SVD and then raise it to the 20th power
Or find a pattern from one or two powers and extrapolate
I don't think you need SVD; the matrix is diagonalizable, so you can use eigendecomposition instead.
oh right
what does SVD stand for? I'm assuming D is diagonalization or something?
Singular value decomposition.
its a whole thing
is that like a more general Jordan Canonical Form?
(you don't have to answer that, I have wikipedia)
I honestly think I have never seen this before.
Im not sure if its any more or less general but its probbaly more computationally efficient and perhaps intuitively helpful
It sort of breaks the matrix up into its actions on space
In my mind its similar to separating a vector into its direction and magnitude
it also works on m by n matrices, I see!
Man, numerical analysis gets all the cool stuff.
I would say SVD is also very analytically important for algebraic reasons
What do you mean by separate values?
So if x is an eigenvector of A, what does that imply
compute $A\vec{x}$
Namington:
yeah
and reason what $\lambda$ must be to make $A\vec{x} = \lambda x$
Namington:
it's important to keep in mind that this definition, fundamentally, is what an eigenvector is
so fi you dont know how to approach a question
think of this definition first
and see if it's useful
@brittle fog that some eigen*vector=Ax
Do you happen to know how to compute a complicated matrix gradient @limber sierra
i'd rather not.
ok
alright i messed up my matrix multriplication is the problem
🤦
is there a matrix multiplication calculator htat works
??????????
that's the correct multiplication
but you asked it the wrong question
your original vector is (1, 1/2)
that vector is (1, 3/2)
[and you really shouldn't be relying on calculators to multiply small matrices anyway]
goddammit
i read 3/2 for some reason 😄
what's the connection here with determinant?
if the rhs=0 for this, does that mean the determinant is zero?
im not sure what you mean by "rhs" here
right-hand-side
(a-lambdaI)x
yes
anyway, as that image says
A - lambda I is singular
which means "has determinant 0"
It also equals 0 when x is an eigenvector
It also equals 0 when x is an eigenvector
oh yeah, shit, sorry
an eigenvector of that eigenvalue
Question regarding the definition of linear-independence.
Abhijeet Vats:
@stoic python
https://discordapp.com/channels/268882317391429632/359052604149465088/683880845077118997
Namington:
@stoic python
https://discordapp.com/channels/268882317391429632/540211747613704221/700913275843510293
Given P : the sum of the several scaled-vectors equal the zero-vector
Given Q: all the various scalars are zero.
These definitions are in the form P implies Q.
If I take their negation I should get the definition of linear dependence, right??
not(P implies Q) == not( P or not(Q) ) == not(P) and Q
I can't mangle the above into a form that says
_there exists a NON-zero scalars in our set of scalar and the sum of the several scaled-vectors is still equal to the zero-vector. _
Videlicet:
Yes I think I misunderstood your question and didn't answer
A dependent set of vectors is a set of vectors that are not independent
yup, i agree.
I don't think this takes the form P → Q. Instead, I think you're looking at:
P: The sum equals zero
Q: The scalars are all non-zero
S: The set is independent
Then:
P and Q → S
That is actually an if and only if, cause that's how definitions do.