#linear-algebra
2 messages · Page 75 of 1
haha it's fine
the idea is pretty straight forward, it's just an algorithm for making an orthonormal basis
although you just need it to be orthogonal
can you define all the vocab just used?
yeah I can but
like orthonormal base and orthogonal
ok
orthogonal just means perpendicular really, but
in this context that boils down to <v,w> = 0
ok I see
so if your basis is orthogonal, all pairs of vectors have that condition
I'm slowly learning the vocab used in the class
so is that equivalent of like a unit vector?
yep
Oh I see
do you know what a projection is or how to compute that
well ok suppose you have two vectors
going from R^3 to R^2
they will generically not be orthogonal to each other, <v,w> != 0
it doesn't matter they could be though
the point is, if we want two vectors to be orthogonalc
it kind of depends, generically speaking
so if you have two vectors that aren't orthogonal, <v,w> != 0
you can simply subtract off the component that's in the direction of the other vector
so that you do have a vector that's orthogonal
that's what the projection is about
yep
so the first step
they are subtracting off the parts that are in the other direction
correct?
the first line is just taking the equation 0 = <v,w>
and plugging in specific values for the components
it's not really solving anything
it's giving an equation in terms of scalars that has to be satisfied for v,w to be orthogonal
so you could consider it to be like, they're trying to simplify it by turning an equation with vectors and matrix into one with just variables
the scalars being w_1 and w_2?
and v_1 and v_2
ok
so the next step
Like honestly I'm so confused
but getting better
much better
any help appreciated
@icy osprey double angle identities?
can you elaborate
$\cos(2 \theta) = 2\cos^{2} (\theta) - 1$
Sup?:
Yeah that's correct although you could've just done it in the last 3 lines
jazzy_fresh:
no $\cos(4 \theta) = 2\cos^{2} (2 \theta) - 1$
Sup?:
only the angles change, not the coefficients of cos
thanks let me write that down
wait so now i am confused
what do i do with that now?
Now isolate cos(2x) and then replace it with what you have
no, you have [cos(2x) + 1]/2 from your previous part
From this new equation, we have sqrt{[cos(4x) + 1]/2} = cos(2x).
Putting that in the first one, we get ( sqrt{[cos(4x) + 1]/2} + 1 )/ 2 = cos^2(x)
anyways, this isn't the place to do this. come to any questions channel
youre gonna have to use the fact that their intersection is just {0}
@limber sierra thanks! got it now
@dusky epoch thx as well
What does 'Maximum Row' mean here https://martin-thoma.com/solving-linear-equations-with-gaussian-elimination/
Martin Thoma
Please note that you should use LU-decomposition to solve linear equations. The following code produces valid solutions, but when your vector $b$ changes you have to do all the work again. LU-decomposition is faster in those cases and not slower in case you don't have to solve...
over here I managed to find a bit more infomation but don't understand the concept till
Gaussian elimination, also known as row reduction, is an algorithm in linear algebra for solving a system of linear equations. It is usually understood as a sequence of operations performed on the corresponding matrix of coefficients. This method can also be used to find the r...
This algorithm differs slightly from the one discussed earlier, by choosing a pivot with largest absolute value. Such a partial pivoting may be required if, at the pivot place, the entry of the matrix is zero. In any case, choosing the largest possible absolute value of the pivot improves the numerical stability of the algorithm, when floating point is used for representing numbers.
'improves the numerical stability of the algorithm'
What does that mean?
Computers only calculate to a finite precision
It turns out that sometimes these errors accumulate to make the results completely wrong
That is called numerical instability
When you improve the numeric stability, you're not allowing small errors to balloon out of control
iirc gaussian elimination is weird wrt numeric stability
it’s like, technically really unstable, but for all practical applications it works just fine
like worst-case it’s completely unusable but the worst case happens so rarely you can just ignore its existence in practice
It's really weird with floating point errors
Which get compounded insanely hard sometimes
But it's actually quite easy to not make a completely naive application of it
To deal with that possibility
Also, in the case where it's all integers or rational numbers in the matrix, you can technically do Gaussian elimination with no floating point errors but instead you get absolutely massive integers you have to work with and a slower algorithm
To find a equation for the plane which a parallelogram belongs to is it just the cross product of the vectors describing the 2 perpendicular sides?
it gives the normal vector to the plane
there's infinitely many planes that normal vector describes
Oh then I choose one of the points on the parallellogram to find the plane right
Yeah cool
If I'm given two conditions to find the line l1 which is parallell to the plane 2x-y+z=1 and intersects the line l2=(x,y,z)=(2-t,3t-4+2t) perpendicuarly in the same point that l2 intersects the plane x-y-z=0 perpendicuarly, does this mean that
my lines direction vector is given by s(2,-1,1) right? And I want the dot product of (2,-1,1) and (-1,3,2) to be 0 and the dot product of l2s and the other planes normal to be 0 as well?
you are given 2 lines that are perpendicular to the line you want
cross product gives the direction of your line
solving the intersection point gives the whole line
Alright thanks
hey guys i was just looking through this lin-alg book i found and I dont really understand how to go from 1) to 2) as theres no real explanation. any help understanding this would be great
1) 3x+2y=7
2x+5y=12
2) (5.3-2.2)x=5.7-2.12
(2.2-3.5)y=2.7-3.12
and then they say that 2) simplifies to x=1 and y=2
nevermind i got it. their notation is just dumb
Hi guys, I was looking for a bit of help on how to read this https://i.imgur.com/mkwDg6X.png
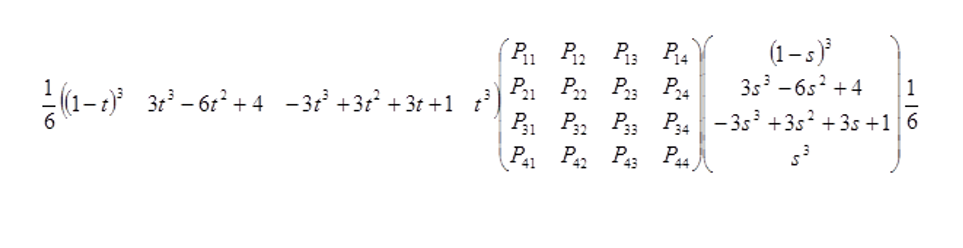
I have no idea how to work it out
Am I allowed to mix elementary row operations like this? (Guassian Elimination)
actual solution ended up being
while I tried and got it wrong
check whether it meets the definition of a subspace
I did. There are 3 conditions it must follow, but all the examples I found are with vectors, and here I have a matrix(a1..a6)
do you know how to add and scale matrices
$\bR^{2 \times 3}$ is a vector space like any other. you should abstract away from the idea that vectors need to look like anything in particular.
Ann:
so now I have to give 2 sets of values to the vector space so that the 2 conditions are satisfied, and then add the 2 new vectors?
??
that's
what
that doesn't make any sense as written
IF you want to show that P is a subspace of R^2×3, THEN you will need to:
- take two arbitrary matrices A, B ∈ P, and an arbitrary scalar c, and show that A+B ∈ P and cA ∈ P.
IF you want to show that P is not a subspace of R^2×3, THEN you will need to:
- EITHER provide an example of two matrices A, B ∈ P such that A+B ∉ P
- OR provide an example of a matrix A ∈ P and a scalar c such that cA ∉ P
what i'm saying here is simply the definition of a subspace, and the negation thereof
i noticed
nothing complicated if you aren't stuck in the view that vectors have to be vertical lists of numbers
the only reason i am using the word "matrix" here is because R^2×3 is a vector space whose elements are matrices. but looking at it purely as a vector space, it's irrelevant what its elements actually are, beyond their behavior when they are added and scaled - and this behavior is precisely what the structure of a vector space describes
thanks
do you require further assistance here
no
ok
Given a Banach space(Actually $$C^n$$ in this case) how do I show that the set of generalized eigenvectors $$E(\lambda )$$ is closed?
AoiKunie:
C^n as in the set of all n times differentiable functions on an interval? also, generalized eigenvectors of what operator?
would you guys reccomend Linear Algebra and its Applications by David Lay as an intro level book?
im trying to find a book to go alongside my course
can't vouch either way for that book bc i've never heard of it until now, but if you want a good linalg course supplement, consider 3blue1brown's Essence of Linear Algebra
it's a video series rather than a book but it's still good
alright and for books if you had to choose from the ones you know
i personally didn't really study out of a book at any point, but i've heard mostly good things about Linear Algebra Done Wrong
Alright thanks
Differentiate
I can differentiate any vector even if it's not continuous?
??
How are they not continuous?
You asked how to solve 4c, so I gave you a hint that works for 4c
It obviously doesn't work if you are given |x| as a function, as it's not differentiable
but e^{2x}, x^2, x are all differentiable
Since all row equivalent matrices correspond to linear systems with the same solution set, and all elementary matrices of size n are row equivalent, does this mean that all elementary matrices of size n have the same solution set?
if you're considering them as augmented matrices then yeah
the empty solution set
Alright, thank you
hey with regards to the SVD why are we putting those on the diagonal in order from greatest to least
im be honest im hecka confused
also how do we know what those represent

in that video he mentions what they represent
Does anyone know if closure under scalar multiplication only includes nonzero scalars? Like can your scalar be 0?
<@&286206848099549185>
Thanks
but like, the 0 vector should be in your space anyway
so for "common" spaces this isnt a problem
In order for something to be in the span does my c1u1 + c2u2 ... cnun, does my c's have to be independent of one another?
wdym "independent of one another"
like, distinct? no
0 is in the span of any set of vectors for example
and you get that by setting c1 = c2 = ... = cn = 0
Lets say I end up getting c1 = 4-2c3, c2=8-c3, c3 = c3
Like parametric solutions for my c's
that's still in the span
but uh in that case
note that {u1, u2, ... un} is not linearly independent
So its not linearly independent but it can still span?
The result of a linear combination of eigenvectors is still an eigenvector right
Ye
now multiply the matrix A(u+v)
what's the eigenvalue of the vector (u+v)?
should be able to work that out by linearity in terms of the original eigenvalues
show me
don't spoil it if you know the trick please lol
There's a trick?
Wait
yeah I'm tricking him
how can i relearn linear algebra
What do you mean by relearn?
"Several people are typing"
Go through 3b1b's video series on it, imo
^
Currently one of the best ways to solidify applied LA
I don't believe in relearning
i just wnat to get technical
Well, start with pure LA
you just have your present state of ability at any moment
Actually, learn abstract algebra. Come back to a second course of LA after
so you don't believe in revising notes
"relearning" means nothing other than some illusory baggage of having gone through something without actually retaining anything
what is abstract algebra
I actually feel embarrassed for people who say stuff like that tbh
taking no responsibility for their own learning so blatantly, it's like blaming teachers
btw merosity I've been studying LA recently, eigenvalues etc. If we apply the vector (u+v) to the transformation matrix A, is the eigenvalue u + v
i love that mentality
What I meant was
Au = ru and Av=sv
what's the eigenvalue of A(u+v) = k (u+v)
if you can do it, you should be able to expand the left side by linearity
to solve for k
show me your steps or as far as you can get
can you rederive it?
i think you are trying to say is if you never got the concept in the first place, relearning is stupid
but if you understand the concept, you shouldn't have to actually relearn it
it's not against the law to look stuff up if you're too lazy to rederive something either but
A(u+v) = Au + Av = ru + sv? Do we compare this with ku + kv?
"relearning" an entire subject is more than just forgetting a formula you're too lazy to play around for an hour to rederive
got it bro
Learn abstract algebra anyway it's the best
@quasi vale yeah
@quartz compass i dont understand, we're not getting k = r + s. or are we..?
you tell me, what does the algebra say?
F is any field here...
How and why can I think of these as functions from themselves to some other field?
uh, ku+kv = ru + sv. So what we're getting is that r=k and s=k. So the eigenvalue of u+v is r or s?
@quartz compass
r,s are assumed to be distinct eigenvalues, but having k=r & k=s gives r=s which is a contradiction
So we can't distribute A over (u+v)? That's the problem here?
you can... A(u+v)=Au+Av but pay attention here
original q:
The result of a linear combination of eigenvectors is still an eigenvector right
mero's response:
suppose u and v are different eigenvectors (of a matrix A with eigenvalues r,s respectively)
with different eigenvalues (r,s are distinct)
mero said not to spoil anything but it seems you're stuck, so to spell it out for you, this whole exercise was to show that assuming that a linear combo of u,v is an eigenvector of A leads to a contradiction
Ah.
anyone know a place with good linear algebra problems
khan academy seems to have a limited amount of content
find a textbook
anyone know what they mean by "sharp"
im assuming they mean like the most strict
also idk how this is wrong
Yes most strict
ok
the rank is the number of leading 1's, and since there's 160 rows, the max number of leading 1's is 160
So for example, if you write 0≤rank(A)≤160, you mean that there is no matrix A with given conditions such that rank(A)>160 or rank(A)<0, and there is a matrix A with rank(A)=0 and rank(A)=160
ok, it doesn't tell me which one I got wrong
so maybe it's one of the other ones
col's = rank + nullity = leading 1's + free variables
170 col's = rank 62 + 108 free variables
so I think that's right
and nullity = free variables
Lol
The second one is wrong
Like you said
col's = rank + nullity
so nullity = # cols - rank
minimum rank is 0, so maximum nullity is # cols - 0 = # cols
maximum rank is 160, so minimum nullity is # cols - 160 = 10
@dry spear
imagine the columns as column vectors
okay
and look at what happens when you compute U^T U
all the entries are just dot products of the vectors
well if i imagine the columns as vector
then how do i take transpose
all the columns become rows
how do i use texbot
just put $ before and after
$U^T \cdot U = I$
KS42:
only holds when
like I said
U is an nxn orthonormal matrix
right, so it has to be false right
no
look at the columns as vectors
every entry of U^T U is now every possible dot product, look through that and see which vectors lie on the diagonal and which don't and what that means
ohh
even if it was an nxn matrix the statement of this is just saying diagonal, not identity matrix
that would be orthonormal
but how do i know they lie on the diagonal
the diagonal entries is a vector dotted with itself
write it out, like suppose I give you a 3x2 matrix
ya i got it
the diagonal entries are the vectors dotted with themselves
but
what about the other entries
you don't know that they're 0
right?
erm
the way you get the entry of a matrix AB is to take the dot product of a row vector of A with a column vector of B
where they basically form a crosshair on the entry
we could also just describe all this in terms of summations if that's more explicit but most people don't like that in my experience
im doing summations LOL
alright then I guess show me the summation you get for the entries of U^T U
lemme take a pic
$D_{ij} = \sum_{k=1}^m U_{ik}U_{kj}$
Merosity:
this is what I'm looking at
this is fine
so now try to write the original matrix in terms of vectors and dot products
like let me one sec
hm?
so I'd rewrite the matrix on the right U as
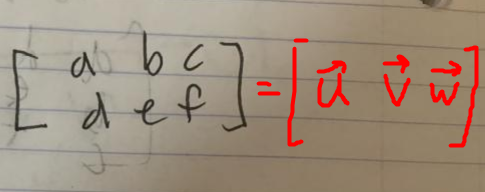
and something similar for the transpose
and start writing the entries of your product matrix in terms of these
the first entry of your matrix product is u dot u
what's the second entry in terms of these vectors? this make sense?
yeah there you go
then u dot w
now you can fill out the whole box just with the vectors like this
so now you can look, when are those off diagonal terms 0?
see where this is headed now? 😛
haha
yeah and the diagonal terms aren't necessarily 1 either
so you're good, glad to help
bet bet thanks
also
this one is false
because the negative doubles
and becoems positives right
becomes**
@quartz compass
hmm what does orthogonal projection look like
like geometrically though

its the same line
like this right
yeah
I'm just bored wasting time for fun
even moreso now cause I can't really leave the house that much
oh this one's actually pretty easy to show
$(Ux)^T (Uy)$
Merosity:
can you compute this
woah woah huh
like try to simplify this by algebra, this is like the dot product
since was that a thing
Merosity:
you can use the dot product to compute the angle between a and b right?
yea
$a^Tb$
Merosity:
so now we plug in the matrices
cause if they're the same, then they have the same angle
yeah
there's a rule for when you transpose a product
$(Ux)^T Uy$
Merosity:
Merosity:
ya
do that
oh
what do you get
KS42:
keep simplifying more if you can
KS42:
yup
KS42:
we know that $x \cdot y = 0$
KS42:
nooo
oof
$x \cdot y = |x| |y| \cos 45$
Merosity:
yeah, the main thing is orthogonal matrices correspond to things like rotations and reflections
so if you take two vectors, rotate them the same amount, then the angle between them stays the same
but rotations and reflections are always square matrices
yeah that's true
we have a 3x2
well ok to put it another way, let's just forget all that intuition type stuff and look at what we can compute directly
$x \cdot y = |x| |y| \cos 45$
Merosity:
now right now we would like to do something similar with a dot b
to determine the angle
ya
$a \cdot b = |a||b| \cos \theta$
Merosity:
we just showed a dot b = x dot y
now if we show |a|=|x| and |b|=|y| we have shown everything to be the same so the cos(theta) = cos(45)
we showed a^T dot b = x^T dot y
$a \cdot b = a^T b$
Merosity:
just do the same kind of argument
but instead of a and b do a with itself
since a dot a = |a|^2
but how does that help
basically practice the trick I showed you earlier on your own now, it's really the same thing
yw
Thank u for the response from yesterday @wintry steppe
Pinging just to say thanks idk if its appreciated or annoying so let me know
was really helpful for me to understand the concept of numerical instability
hey can anyone help me with a computer graphics programming assignment. i need help with camera matrix projection and transformation. we are using webgl and javascript in my class. my hw is due friday at 11:59pm. dm if you can help
for this matrix, is it ok to do R1-R3=R3, Or it must be R3-R1=R3?
doesn't matter
there are many possible sequences of row operations that will allow you to row-reduce a matrix
So to follow up, is there ever a wrong way to row reduce a matrix? Not sure how to properly phrase my question but is there a systematic way you should always use? Implying that, if using legal row operations, can you fuck it up? Thinking about it typing this, any row operation results in the same equivalent matrix so you cant fuck it up but just get further from a row reduced one. Someone correct me if I'm wrong or maybe someone will find my epiphany useful aha.
Implying that, if using legal row operations, can you fuck it up?
if by legal you mean free of fuckups
then no
you can only fuck up a row reduction by fucking up the execution of one or more row ops
Hi. I'm stuck at this problem from Evan Chen's Napkin, probably having trouble digesting the material.
well, do you understand the definition of T \otimes S?
as the vector space of the sums of t \otimes s for vectors t and s @sonic osprey sorry for taking long
If you have a cycle of generalized eigenvectors ending in the eigenvector v
Is it possible to have more than one linearly independent eigenvector of rank/height p > 1?
@dusky epoch and @open pivot well... When I do R1-R3=R3,
I get 0 2 -5, which enables me to go all the way to get a diagonal matrix/reduced row echelon form.
But when I do R3-R1=R3, then I get 0 -2 5, which wont let me to get RREF.
Slader has R3-R1=R3.
That's why I'm confused.
er, those are negatives of each other
so it shouldnt impact your ability to get an RREF form
since you can just multiply a row by -1
right. But Slader doesnt do it. It goes like this:
https://www.slader.com/textbook/9781118879160-elementary-linear-algebra-applications-version-11th-edition/201/exercises/15b/

Solved: Free step-by-step solutions to exercise 15b on page 201 in Elementary Linear Algebra: Applications Version (9781118879160) - Slader
i mean, it could
the user just doesnt go all the way
no clue why they call it "reduced row echelon form"
but i mean, it's slader
i have no clue what the question is, though
did you just need to solve the system? if so you dont need to row reduce all the way
this is the question
is a line through the origin, a plane through the origin, or the origin only. If it is a plane, find an equation for it. If it is a line, find parametric equations for it.```so yeah, you just need to solve the system
and clearly solving this system gets that x_1 = x_2 = x_3 = 0
you dont NEED to fully row reduce to get this result
although you could
take this matrix
multiply the last row by -1
add 3 times the third row to the second row
subtract 3 times the second row from the first row
done
still, the point is that you just need to solve the system
do so in whatever way works for you
hello, i understand determining how a vector can be written given a linear combination of vectors, but i don't understand how a matrix can be written given a linear combination of matrices
This an example
matrices are just vectors in a vector space of matrices
anyway, if you want
note that you're only adding these matrices
and multiplying them by scalars
so they're "indistinguishable" from standard column vectors
for the purposes of this question
you could write, say, $M_1 = \begin{pmatrix}2&2\-1&3\end{pmatrix}$ as $\begin{pmatrix}2\2\-1\3\end{pmatrix}$
Namington:
and similar for the other matrices
just make sure you keep the "rule" consistent, and remember to justify why you can do this
and then you can solve this exactly as you would solve a linear combination of vectors.
ah ok, got it, thank you

L(5u)
= 5L(u)
= 5[2,1]
= [10,5]
so is the second just 6 and -18?
It's [6,-18] yeah
Remember a linear function lets scalar multiples out, and splits over addition
honestly im absolutely blocked with this one, any hint will help
@half ice
-, but yeah
wouldnt it be plus?
5L(u)+ (-6L(v))
yea got it
@half ice last question if u dont mind

Say you multiply A by some vector x. What is the size of x?
4
I like to keep that diagram in mind when multiplying two matrices. That's multiplying AB. @digital garnet
x would need to be size 2
so k = 2
Now, Null(A) is a subspace of the input vectors
right
wouldnt it be r^2 as well
Nop. R4 in that case. The outputs are size 4 vectors
Col(b) is 1, you're correct there
Transpose the matrix first, then Row(B) switches to Col(B)
right
and then
the
null(b) would be 5
cuz it outputs in r^5
i got 5/6
one of them is wrong but im not sure which one


hmm

do you know what the definition of linear is
it means it can be expressed in a straight line right
thats not a formal definition
a map $f$ is linear if, for all vectors $x, y$ in its domain and scalars $r$, it satisfies:
[ f(x+y) = f(x) + f(y)]
[rf(x) = f(rx)]
Namington:
so you need to check whether those hold.
to use part C as an example, we want to check whether $L(x_1 + y_1, x_2 + y_2, x_3 + y_3) = L(x_1, x_2, x_3) + L(y_1, y_2, y_3)$, and whether $rL(x_1, x_2, x_3) = L(xr_1, rx_2, rx_3)$
Namington:
so lets do that
$L(x_1 + y_1, x_2 + y_2, x_3 + y_3) = (x_1 + y_1, x_2 + y_2, -x_3 - y_3) = (x_1, x_2, -x_3) + (y_1, y_2, -y_3) = L(x_1, x_2, x_3) + L(y_1, y_2, y_3)$
Namington:
so indeed, it satisfies the additivity condition
do you follow the reasoning there?
and then:
$rL(x_1, x_2, x_3) = r(x_1, x_2, -x_3) = (rx_1, rx_2, -rx_3) = L(rx_1, rx_2, rx_3)$
Namington:
so it also satisfies the multiplicative condition
hence, the map L in part C is linear
but if we look at, say, the map from part A
$rL(x_1, x_2, x_3) = L(1, x_2, x_3) = (r, rx_2, rx_3)$ while $L(r, rx_2, rx_3) = (1, rx_2, rx_3)$
Namington:
so the map from part A does not satisfy the multiplication condition
since $(r, rx_2, rx_3) \neq (1, rx_2, rx_3)$ for some values of $r$ (in fact, every $r$ except $r = 1$)
Namington:
[it also doesn't satisfy the additivity condition]
so the map from part A is not linear
correct
$(1, 5)$ and $(-2, -3)$
Namington:
then $L(x + y) = L(1 - 2, 5 - 3) = L(-1, 2) = (-8, 6)$
Namington:
but $L(x) + L(y) = L(1, 5) + L(-2, -3) = (-6, 15) + (-2, 9) = (-8, 24)$
Namington:
and $(-8, 6) \neq (-8, 24)$ so $L(x+y) \neq L(x) + L(y)$
Namington:
i think e is
it is, but let's verify
just for the sake of example
we want to show $L(x + y) = L(x) + L(y)$, and also $rL(x) = L(rx)$
Namington:
so write
so C,E are the only ones that show linear mapping right
yeah lets ee

oh shoot
did i miss one?
hold on
i misread E
i just realized
i thought the second term was x_1 + 4x_2
my bad
E actually isnt linear
thats entirely my mistake, apologies
oh also
so that means we missed one more
wait holy shit
but i cant seem to figure out which
ok so hold on
i just glanced over B
but its actually linear
idk what im thinking, sorry
i just had major brain farts
gimme a sec
for part E, we can see it isnt linear with an example
consider two vectors $(0, 0)$, then $L(0 + 0, 0+0) = (0, 4, 0)$ while $L(0) + L(0) = (0,4,0) + (0,4,0) = (0,8,0)$
Namington:
meanwhile, for part B
note that the 0 doesnt actually ever
affect anything
the difference between A and B is
in A, the 1 is interplaying with summation/products
i.e. it changes with sums and scalar multiples
but the 0 in part B never will
since 0 + 0 = 0 always
(obviously)
and 0 * r = 0
sorry, im really not sure what i was thinking earlier
christ
so jus b n c
yeah, that seems good now; B and C
yes tysm!!!!!!
yeah i just got lazy mentally
now gotta find standard matrixes
the general heuristic trick is that
if you just have multiplication by a constant, it's probably linear
but if you add in higher-degree terms (like 4x^2 or whatever)
or addition of constants
it's probably not linear (unless the constant is 0)
and if you have "weird" functions like absolute value and whatnot
it's also probably not linear, but worth checking
since sometimes things simplify nicely
or sometimes, a function that you didnt expect to be linear actually is
finding the matrices should be pretty simple, since the columns of a matrix are just where the basis vectors get mapped to, which are easy to look at

Well, you know how your standard basis vectors are affected under this transformation
@nimble egret
🤔
well
there's an easy way to check
multiply the matrix by the vector
and see if you get the result
oh are we saying A what i just stated
i get [1,6,9]
multiplying by column vector [1, 0, 0] right?
yes
but what should you get?



L([1, 0, 0]) = [8, 2, 7] correct?
yes
so if you multiply A by [1, 0, 0], you should get [8, 2, 7] correct?
yes
so clearly something went wrong right?

it should become pretty intuitive
that if [8, 2, 7] was the first column of A
then multiplying by the column vector [1, 0, 0]
would give [8, 2, 7] regardless of what the other entries are
similarly, if [1, 6, 9] was the middle column of A
then multiplying by [0, 1, 0] would give [1, 6, 9] regardless of what the other entires are
i'm sure you can figure this out for the last column as well

umm how?
you should be able to do the matrix multiplication
and verify whether your answers are correct or not

yes


Hint: The statement is wrong
Example:
$v_1=\begin{bmatrix}1\0\end{bmatrix},v_2=\begin{bmatrix}0\1\end{bmatrix},v_3=\begin{bmatrix}1\1\end{bmatrix}$ spans $\bR^2$, but is it isomorphic to $\bR^3$?
Whoever:
lol sure you're not stupid
yo im not being dumb again right, this is never true @pallid rampart
a subspace always has to be a subset of its parent vector space right...
Yes
Yes
But the theorem is, a subspace H of V always has smaller or equal dimension than V
so "a subspace always has to be a subset of its parent vector space right..." is true, but it's not that relevant here
You can have 2 dimensional sub space of R^3
wait what since when
I.e. take the basis (1,0,0) and (0,1,0)
These are linearly independent
2 elements
R^2 is isomorphic to a subspace of R^3
Yes
when I say it's not that relevant, I kind of meant that it's obvious that it's true
By definition it's a subset of the parent vector space
gotcha
@steady fiber nah why
are you trying to just milk answers without reading a book jesus christ
bruh
like if you truly understand what a change of basis matrix does
you can see right away it cannot be one
assuming that is a change of basis matrix, think about what matrix would give you the inverse change of basis
change of basis matrix from C to B
oohhhhh shit
@steady fiber so i remembered the property that change of basis matrices have to be invertible, but it said change of coordinates, so i didn't rly pay attention
but its a change of basis LOL
Suppose we use the Gram-Schmidt process on an ordered set of vectors S to get another set S'.
Is there any special relationship between a S and S'? For example, suppose I find some vector u that is orthogonal to every vector in S. Is any information lost by using u as the first element in S' as opposed to the first element in S? Would it mess up QR decomposition?
ik that's a a lot of questions. Sorry about that.
@hollow finch
S should be a basis. Then, S' is an orthonormal basis on the same space. That's what Gram-Schmidt do.
If S is a basis to your space, there exists no vector orthogonal to all vectors S in your space.
is anyone familiar with hamming code
looking at hamming code, and I guess if you don't get ooo as the messace vector then there was an error
but if there is an error, how do you know what to change in your original message
It matches the second column of your matrix
So change the second element of your message
@finite kraken
ohh
I always get lost with finding the ker(T)
I get you write out a polynomial
and then row reduce accordingly
then you find your free variables etc.
but once you do that, how do you know what the span should be?
Like i'm assuming you use the form of your original polynomial at^2+bt+c
@finite kraken
With the line:
a = -c
b = 0
c = c
You've proven that the polynomials that map to zero are exactly:
-ct² + c
= -c(t² - 1)
But that's the set spanned by t² - 1, so you can express it as the span instead
yeah I see
Oop
okay but
could a ker(t) have multiple parts for the set
like
ker(t)=span (t^2-1, t)
something like that
the kernel can be specified as the span of multiple polynomials
generally though, you'll want as few as possible
hmmm
also, ker(T) not ker(t)
It ends up being the case that the number of columns without a pivot is equal to the number of vectors in the basis of ker(T)
I think subspaces for me were the hardest topic i've ever encountered
You have one column without a pivot, and so you have one free variable, and so the kernel can be spanned with one polynomial
ohh
so if I had
2 free variables
then i'd probably have a span of 2 polynomials
ohhh
its probably a rule, i'll check my book
Thank you so much for the help! I appreciate it
It's a consequence of rank-nullity theorem, as far as I know?
definitions are super important no matter what
yeah True
@half ice right of course. What I was thinking about was an example a professor went over in his class for finding bases for the orthogonal complement of a subspace.
Say we want to find a basis for the orthogonal complement to a line in R^4. And I find 5 different vectors u1, u2,...,u5 that are orthogonal by inspection. If we did the Gram Schmidt process on a specific combination (say S={u2, u4, u5}) to get S', would there be any special relationship between S and S'? Or is it no different than using Gram Schmidt on u1, u2, and u3?
What does this mean
I think it's linear algebra
I'm guessing something about a matrix of 2nx2n size judging by the context in the litterature
But that still doesnt explain R
2n-by-2n matrices with entries in R yes
$\bR^{2n \times 2n}$ is the set of all $2n$ by $2n$ matrices with real entries
Ann:
If I have a system of however many equations with variables x1,x2,x3,x4 and one of those variables say x2 all had zero coefficients leaving the augmented matrix with a column of zeroes, what is significant about that? You can't ignore it can you?
You can't ignore it. If the entire x2 column is made of zeros.
e.g
1 0 2 3
3 0 2 1
1 0 2 3
It means x2 is free.
Which means x2 can be anything.
If x2 has all zero coefficients, than there's no x2.
Does a column of zeroes making x2 free, differ from any other scenario where x2 might be free?
If you relabel x3 as x2 and x4 as x3, than you won't have that nonexistent column in the matrix. Why do you think there should be x2 in the first place?
Does a column of zeroes making x2 free, differ from any other scenario where x2 might be free?
@open pivot it's different in the way that non of other variables depend on x2 in that case. Therefor, it doesn't exist in the first place. You can add a ton more empty columns like those, but they won't affect other solutions or the dimensionality of fundamental system of solutions.
In all practical situations x2 shouldn't exist so it should be meaningless.
But in some questions they do matter.
So it would generally make the matrix unsolvable.
Can you give an example? I've never seen a question about a variable that doesn't exist.
If a question asked to solve the matrix:
1 0 2 3
3 0 2 1
1 0 2 3
You can't just remove the column.
You can, or you can just use Gauss method. The result would still be same, except of meaningless $x_2 \in R$.
Dmytr:
I'm working through a problem with a system of 3 equations in 4 variables but supposedly x2 "does not appear in these equations". My thinking was with no x2 why should it exist to begin with?
It wouldn't be meaningless.
With Gauss-Jordan, it would become inconsistant.
Because you won't be able to put it in REF.
Because your missing an entire pivot.
Right, I'm asked to put the system into an augmented matrix and use G-J to analyse the solutions
So would you have to ignore x2 in order to row reduce the matrix?
I wouldn't but @long tendon disagrees. So maybe I'm wrong.
I'll post the question if it helps
If they particularly ask about that very matrix then, while it's a dumb impractical question, they're indeed forcing you to write something like $x_2 \in R$
Dmytr:
Here is the problem, they note 'x2' doesn't appear, and I don't know if that means its significant to the question
Feels like a trick question.
Since I would initially interpret it as:
2 0 1 3 2
1 0 1 1 c```
But algebraically I would agree with @long tendon and ignore x2.You must show what?
My best answer is what @shadow drift mentioned about x2 being free to choose implying inf. many sol. But the latter part of the question asks for what values of c are there solutions. But if there are already infinitely many why does c matter?
Yep, for some values of c there would be no solutions at all. x2 can be chosen freely if (x1, x3, x4) is a valid solution. In other words, x2 doesn't change anything about the solution at all.
Yep, for some values of c there would be no solutions at all. x2 can be chosen freely if (x1, x3, x4) is a valid solution. In other words, x2 doesn't change anything about the solution at all.
If you interpret it as:
1 0 0 2 1
2 0 1 3 2
1 0 1 1 c
And try to do gauss-jordan, it won't work.
Because the entire matrix is inconsistent.
So it has no solutions.
Yep, for some values of c there would be no solutions at all. x2 can be chosen freely if (x1, x3, x4) is a valid solution. In other words, x2 doesn't change anything about the solution at all.
But yeah, if you interpret it as:
1 0 2 1
2 1 3 2
1 1 1 c
You should be able to do gauss jordan. And depending on what c is the number of solutions will change.
e.g c = 0, there won't be solutions.
Cheers for the help guys
Hi guys! Can anyone help me solve this linear equation.
https://gyazo.com/34559fc21d44d06b04b0288084f3982f
Gyazo
Gyazo
I need to solve for h and there can also be more than 1 H
B is a linear combo of v1 and v2

{kind=link}
{kind=link}
@tardy eagle $c_1 \cdot <9, (18 + 3h), (9 + h)]> + c_2 \cdot <9, 12, (11 - h)> = <-3,-3,-2>$
Sup?:
idk the coding so I couldn't write the vector in column form
but there's 3 equations with 3 unknowns
so you can solve for h
Like, equation 1 will be 9c1 + 9c2 = -3 and then so on
Hmm I have it on paper but basically I tried to get it to row reduced echolean form with v1, v2 and b as the 2 columns but I cant find a way to solve for H
That method works when it is b that contains the h but I cant solve it when the 2 vectors contain h instead (the other way around)