#linear-algebra
2 messages · Page 71 of 1
What’s the best linear algebra textbook
I just need to quickly make sure I'm not being dumb here
If V and W are vector spaces and V \neq W and V \subset W, does V neccisarily have fewer basis vectors than W?
I believe so
@leaden wyvern linear algebra done right?
Wdym
so first I found a vector normal to the normal of H
then did the point normal eq with a point on L
by normal to the normal I mean, I found the normal vector of H, which is parallel to R, then found a vector normal to that, which is normal to R
can someone help me verify part b of this problem
I think I'm right
but I'm less confident than I was 2 minutes ago
@leaden wyvern that's the name of the book
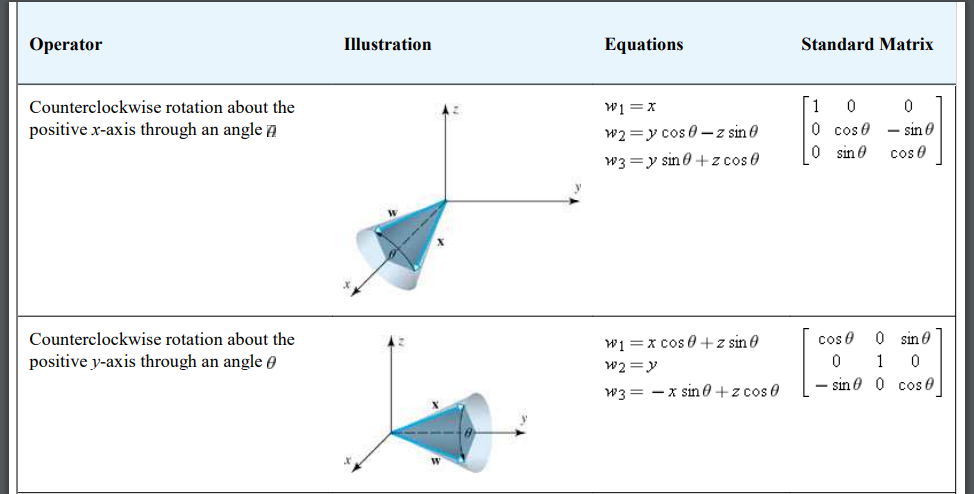
How do they get a negative in front of xsin(theta)
for w_3 for the counter clockwise rotation about the y-axis through angle theta
I tried doing it but my signs are messed up
maybe the XZ plane
cause that looks like the angle they have listed
errr
I think it is xz

Am I just supposed to memorize this lmao
@wild pagoda Try proving that. You’re saying that if V and W are both vector spaces over the same field such that $W \subset V$, then $\dim(W) < \dim(V)$. Try proving the truth of that assertion.
Abhijeet Vats:
Am I just supposed to memorize this lmao
if you look at it for like five seconds you’ll notice that it’s just a 2x2 rotation matrix (which you should definitely memorize) embedded into a 3x3 matrix with the remaining bits filling it up to an identity matrix). the only tricky bit is the signs, which you can derive e.g. by setting the angle to 90 degress and checking where the basis vectors should be taken @radiant meteor
e.g. Ry(π/2) should take
(1,0,0) ↦ (0,0,1)
(0,1,0) ↦ (0,1,0)
(0,0,1) ↦ (-1,0,0)
so the three vectors on the right here should be the columns of the rotation matrix Ry for θ=π/2
which tells me that they messed up either the signs in the formula, or the direction of the arrow in the image
JY1853:
"f vanishes at a given point in S" seems to indicate that there exists an element s in S such that f(s) = 0.
Also, why introduce L? Is there more context behind the question? L seems to have come out of nowhere, as far as I can see.
S has just been stated to be some set. You can't assume it's a linear space.
$F(S) = {f: f: S \to K }$
Abhijeet Vats:
Uhhhh memey notation
But it's the set of functions that map some element of S to some element of K, where K is known to be a field.
I would assume that you could turn it into a vector space over the field K. I mean, it hasn't been stated in the question so maybe it's from previous context.
JY1853:
I suppose but not really, because linear transformations are usually spoken of when you're talking about functions between vector spaces over some field. Here, S is arbitrary.
Uh what text is this?
Okay yea, so going by what kostrikin previously said, you can do it if you assume that S is a linear space, as opposed to just an arbitrary set. In that case, yea, you can just do what he asks you to do in order to check linearity.
There'd be few other ways to interpret 'which of the following conditions are linear'. Unless there has been anything said in particular about this beforehand, it's safe to assume that he's asking you to consider the linearity of a subset of F(S) that is defined by the given conditions.
the way i'd interpet it is: if f,g are functions that satisfy the condition and c is a scalar, do cf and f+g also satisfy it
Can someone explain how do I find h?
Never mind thanks!!! I figured it out I guess
Do I use Cos (angle) times the area of the base which equals to the Volume?
I isolate for Cos and get the angle...
h=w-(vector projection of w onto the plane spanned by u & v)
ik that a b c are column vectors with 3 elements in each
but what does the det tell me about them
@hollow ridge that question doesnt make sense, what do you mean?
row/column space
Doing e.r.os on a matrix changes its r/c space
e.r.os?
Elementary row operations
well row operations change the column space
book examples of doing what, can you take a picture?
ah okay for the row space, row operations don't change the space
but the row space is much less important than the column space
Hmm ok
so you can use either ref or rref to find a basis for the row space
now, for the column space, the more important one
e.r.o.s can show you how the columns are linearly dependent, if they are
if in row echelon form you see that col1 = 2 col2 - 5col3
then in the original matrix col1 = 2lo2-5col 3
so you can use that information to go back to the original matrix and delete the extraneous columns and get a basis for the column space
Lemme work on the last problem of the row space and I’ll let you know what happens when I get to column.
#23
Am I doing this right?
It’s different than the back book answer
@vast torrent
I don't know what that set is supposed to be
if that's a correct ref then that's a correct choice of basis
what's the book's answer?
,w is span {(1,0,5/9,2/9),(0,1,-4/9,2/9)} = span {(2,7,02,2),(-3,-6,1,-2)}?
no I meant sideways
,w is span {(1,0,5/9,2/9)^t,(0,1,-4/9,2/9)^t} = span {(2,7,02,2)^t,(-3,-6,1,-2)^t}?
D:
{transpose(1,0,5/9,2/9),transpose(0,1,-4/9,2/9)^t} = span {transpose(2,7,02,2),transpose(-3,-6,1,-2)}?
,w span {transpose(1,0,5/9,2/9),transpose(0,1,-4/9,2/9)^t} = span {transpose(2,7,02,2),transpose(-3,-6,1,-2)}?
Wolfram Alpha doesn't understand your query!
Perhaps try rephrasing your question?
Display results online and refine query
whatever
What is the easiest way to determine if a linear system is triangular?
Can someone help explain the proof for this
Do you understand why this is true intuitively? (think about matrices)
So every matrix can be considered as a linear transformation and since matrix spaces have m*n bases, the space L(V,W) has dimension mn?
this is my intuition so far
@sonic osprey
yes
oh
ok then
the proof was kinda hard to follow, but i guess they were trying to be rigorous
yeah, depends what the proof is I guess
So every matrix can be considered as a linear transformation and since matrix spaces have m*n bases, the space L(V,W) has dimension mn?
@wintry steppe its true that every matrix M has a linear transformation $v \mapsto Mv$. What's more interesting than that is that every map in $L(V,W)$ can be represented as a matrix
gfauxpas:
wait even for transformations like derivatives and integrals
well yes if you're in a finite dimensional case
so for example
let's take the space of polynomials with the basis ${1,t,t^2,t^3}$
gfauxpas:
and another space with the basis ${1,t,t^2}$
ok
gfauxpas:
then the operator $v \mapsto \int_0^x v , \dd t$ is a linear operator from $\text{span}(1,t,t^2) \to \text{span}(1,t,t^2,t^3)$
gfauxpas:
ohhhh
however if you consider the space of "all integrable functions"
that's infinite dimensional
and the matrix would be 4 by 3
yeah so
you can actually figure out what it would look like if you use the bases I chose
so like
I should have said $v \mapsto \int_0^t v , \dd x$ to keep it t but it doesnt matter
gfauxpas:
$1 \mapsto t$ obviously
gfauxpas:
$t \mapsto \frac 12 t^2 = 0 + 0t + \frac 12 t^2 + 0t^3$
gfauxpas:
so you see now the coefficients
1/2 t^2 is like a vector (0,0,1/2,0)
neat, right?
what about the C?
I chose a definite integral $\int_0^t$
gfauxpas:
oh ok
to avoid that problem
ok so the matrix would look like this : {0,0,0}, {1,0,0}, {0,1/2,0}, {0,0,1/3}?
if you mean those rows stacked on top of each other then yes
yeah thats what i mean
ok so in this case what is the basis of the transformations from space 1 to space 2
there should be 12 basises
oh wait
what do you mean
nm i get it
you can have {4,t^2+t^3, t-t^2,t} and that's probably a basis for the same space
unless I accidentally chose a linearly dependent set by me picking random numbers that is
the set of all transformations for the first space to the second space would have 12 basis's because every transformation can be represented by a 4 by 3 matrix
but there are infinitely many bases
im talking about transformations from {1,t,t^2} to {1,t,t^2,t^3}
the integral is one of them
oh you want a basis for L(span(1,t,t^2),span(1,t,t^2,t^3))?
yeah
no idea
well since i can represent all of those tranformations with a matrix
it would just be the basis of the matrix space
well in matrix form you can make a basis for the matrices
but to say in function form what elements of a basis are for L(span(1,t,t^2),span(1,t,t^2,t^3)) I have no idea
oh ok
this integral transformation is not invertible right?
wait it has to be
because the derivative is the inverse of the integral
i thought only square matrices had inverses
the domain and codomain aren't the same dimension
a derivative will kill the highest power of t
that's the problem with limiting ourselves to a finite dimensional case with polynomials, you cant have a square matrix here
of integrals
of derivatives you can but it wouldnt be invertible
but for infinite dimensions, this isn't a problem?
lots of cool stuff happens in infinite dimensions but not with matrices
there are infinite dimensional things similar to matrices that I don't know how they work
at least for countably infinite bases
so having the domain be one more than the codomain doesnt matter if the bases have infinite cardinality
ok
anyway good night
ty
yeah, you should focus on finite dimensional stuff for now
it becomes harder in infinite dimensional cases, because some things don't transfer over
Functional analysis is kind of the study of infinite dimensional linear alg
maybe I missed it somewhere but the integral operator isn’t surjective; span(1,t,t²) doesn’t hit all of span(1,t,t²,t³) but only span(t,t²,t³); seems kinda relevant to mention here
Wait the integral operator on a vector (function) $f$ is defined by $\int_0^xf$ right?
Whoever:
So you're saying if we go from span(1,t,t²) to span(t,t²,t³) it would be invertible @broken hawk ?
I suppose that's true but the matrix representation would lose the connotation that the domain and codomain are different
@wintry steppe do you see @Sascha's point
(1,0,0) in the domain would represent a different object from (1,0,0) in the codomain
But if you were willing to live with that loss of information you would indeed have an invertible square matrix
well, I’m not explicitly saying that; it’s true though :P
I’m just saying that there are no constant functions in the image of this operator
(except 0 ofc)
I don't think it's worth it
I didn't mean to imply it was surjective,it just felt right to have the domain be a subspace of the codomain here
Yeah still
@sonic osprey you'll need a bound, or else you have a family of functions instead of a single function
Sure
How do you work out paralel and perpendicular lines
Eg
Find the equation of the straight line passing through the point (,) which is perpendicular to the line y=3x+2
Wont say the coordinates for no ban
it's probably easier to look up the definitions of span & subspace rather than have someone regurgitate them
Wait wtf someone deleted my message?
What's the difference between ||Proj A u || and Proj A u?
Does ||Proj A u even make sense?
is Prof A u the orthogonal projection of u onto A?
sm crossposted to another server, it's already answered
So I have this problem:
A used car salesperson is paid a commission of $25 plus 40% of the selling price in excess of owners cost. The owner claims that used cars typically sell for at least owners cost plus $200 and at most owners cost plus $3000. For each sale made, over what range can the salesperson expect the commission to vary?
And according to a website this is how it's done: 25+1.4(200) <= commission <= 25+1.4(3000)
But I don't get why its multiplied by 1.4 and not .4 considering .4=40%
Im assuming both the 200 and 3000 are equal to the min and max "excess" meaning: (selling price)-(owners cost),
unit vectors mean the length is 1, but the length of a column in A is sqrt(1^2+1^2+1^2+1^2)=2, so you gotta divide by 2
ye
set of all x such that Tx = 0
the transformation
T transforms vectors.
The Kernel of T is the set of vectors that become 0 after T transforms them.
the way you phrase it sounds much more easier
the projv(x) is parallel to the subspace V
if that transformation is 0
x is perpendicular since the dot product of just x with T(x) = 0?
so the question its asking is when is proj_V(x) = 0?
That's exactly it, when x is perpendicular to V
the question wants me to describe the kernel and image
That's a perfect description of the Kernel. Understand the image?
What I've read about the image is that its the set of linearly independent vectors that can be used as building blocks to make other vectors in the vector space
although, I have a hard time wrapping my head around that definition
It reminds me of the span]
No, that's a basis
oh yeah
The image of T is the vectors that T can possibly make.
The possible outputs of T, if you will
the set of all possible outputs of T
is that why its called the image?
the set of all those vectors of a transformation is literally an image on a coordinate plane?
I couldn't tell you lol. It's a very common name for the possible outputs of a function, you'll get very used to the term "image"
okay
i'll take my time with it
I think I'm going to have to retake the course, but I've made my peace of mind with that possibility
and i'll definitely be spending more time in here to make up for it.
not a bad thing.
You're doing fine! These terms do take some time
a lesson learned

Yes. In fact that's a pivot.

You can reduce that 5 and 3 out

what if this happens to be an augmented matrix
that 1 would count as the constant term right ?
yet its still a pivot ?
thonk thonk
hello ? 
fine ok its a pivot
It's a pivot of the matrix. That may not be useful to your system though
Which?
the solution
where did they pull out the inequality from
for projL(x) <= magnitude(x)
They did kinda pull it out of nowhere
With the way the question is set up, the vector x will end up being a hypotenuse, which is always longer than the base.
and the only time a hypotenuse will ever be the length of one of the legs is if we project the hypothenuse to any of the legs
no
no
span is applied to a set of vectors
column space is a concept related to matrices
and the span of sth is a (sub)vectorspace
But isn't column space the pivot columns of the original matrix after rref. So then isn't it the set of linear indepedent vectors such that it's basis is the span
it honestly feels like you're just throwing a ton of linear algebra words together
"it's basis is the span"
doesn't really make any sense
the span of a set of vectors is always going to be linearly dependent, and so cannot be a basis
? If they're linearly dependent how do can they span?
Don't they have to be linearly independent
no
you can consider the span of any set of vectors, not just linearly independent ones
So
Basis - the set of vectors that generate the set of all vectors of some subspace
Span - a set of vectors that generate a subspace
?
no
You should think of span as a function that takes in a set of vectors and outputs all the vectors that can be formed as linear combinations of the vectors you inputted
like you said, but a basis also has to be independent
Oh
So basically
The difference between the set of vectors in a span and a basis is that a basis must be linearly independent but the spans set doesn't
no
it honestly feels like you're just throwing a ton of linear algebra words together
?
okay for one, you meant to say independent
and no, there's are a lot more differences
the span of a set of vector is a vector subspace
and you should know all the properties that brings
that adding any two vectors is still in the subspace, and scaling any vector is still in the subspace
a basis is just any set of vectors, with none of these properties that I just described
But they're linearly Independent right
yes
Does anyone know how the simplex method works?
For linear programming problems how do we decide which variables to switch when making a new basis
ok so
what is your linear program stated as
i'm going to assume it's "minimize <c,x> subject to Ax = b and x ≥ 0"
Our question primarily asks
if it's not stated like that, we might have some difficulty communicating
and I can provide the matrix if you'd like
why don't you show me the entire problem exactly as stated.
it is stated like that
superb
ok so
you have your basic feasible solution x and your dual vector u
and your optimality condition is uA - c ≤ 0
so among the positive components of uA - c, you select the greatest
that's your entering variable
...if i didn't fuck this up somehow
hold on
yeah
uh. hm
maybe i can't explain this all that well because of all the fucking terminology that i keep having to translate on the fly.
It's okay
If I have any other questions that can maybe specify it further I will let you know
Why is an invertible matrix plus the identity matrix not invertible?
you mean why it sometimes isn't invertible?
Oh
So if A is negative identity matrix
Then it wouldn't be invertible
For example
right you wouldn't check the box
hi all - im working through a problem where the author talks about projecting a vector onto the null-space of the Jacobian matrix corresponding to some multivariate function. im wondering if anyone can help provide some sort of intuition as to what this means, geometrically or otherwise?
@polar imp I believe it’s the component of the vector which is “level” with the function. By level, I mean the derivative of the function in that component is 0.
Why does this give a 2x1 0 vector instead of a 3x1? Is it because the last row is a scaler multiple or because there are only two column vectors?

how do you imagine this?
what if the lines are not necessarily parallel, but skewed
this one too
It’s not asking about skew lines, it’s asking about parallel lines @charred stirrup
Err hmm, what is your definition of parallel?
@real wedge do you know how vectors in a T-cyclic subspace are generated?
Yeah
If W is a T-cyclic subspace of V generated by x then W=span(x,Tx,T^2x...)
T: V -> V
Quick question
If vector v is in null(A) and if BA is defined, then v isn't necessarily in null(BA) right
nope, if v is in null(A) then v is in null(BA)
Why though?
one sec, kiantheboss needs help
Ok
since W=span(x,Tx, ..)
by def, if w is in W, w is a linear combination of vectors in {x, Tx, T^2x, ....}
i.e. w = ax + bTx + cT^2x + ....
basically its just applying definition of span
@restive hound lets say v is in Null(A), then Av = 0
It follows that BA(v) = B(Av) = B(0) = 0 so v is in Null(BA).
Wait what is B(0)?
any linear transformation evaluated at 0 is 0
remember: 0 is always in the null space
matrices too. take A(0) where 0 is any matrix whatsoever
Oh
Also
One more question
Take two matrices A and B, does 0A + a constant times B = some other matrix count as a linear combination
yep
Ok
95% not bad
Just finished my test
Think that's the only question I got wrong
@real wedge did you get 47?
@slow scroll that explanation was for 47 right?
yea
Yeah I think I got that one, its pretty trivial right?
I got it but I was like ehhh this seems too simple
48 has really stumped me tho
48 im not even sure how to use the hint or why the hint helps us
I gtg but i appreciate the help i will be back later
alright
feel free to ping if you need help later
hi nvsdkjnsdjn wtf is normal form
i think its this: https://en.wikipedia.org/wiki/Hesse_normal_form @somber quest
yup it's the 2nd equation on that page
the first blank is some vector orthogonal to the line and the second blank is a vector that lies on the line
ohhhh thank you
u can think about how it works: if you take a position vector $\mathbf x$ on the line and subtract it from any other arbitrary vector $\mathbf a$, the vector $\mathbf x - \mathbf a$ lies on the line and is therefore orthogonal to the same vector that is normal to the line $l$. If $\mathbf n$ is that normal vector, then it follows that $\mathbf n \cdot (\mathbf x - \mathbf a) = 0$ for any $x \in l$.
kxrider:
npnp
@slow scroll im back
hi
hmm i thought I saw the => direction but now im not so sure.
Well, starting with the <= direction, do Let U = g(T). You need to show that UT = TU
yeah
any vector in V is a linear combination of vectors in {Tv, T^2v, .....}
But why doesnt it specify the "generated by ___" part
I guess because the particular vector doesn't really matter, as long as its nonzero
hmm ok
since g(T) = aT + bT^2 + cT^3 + ...
Tg(T) = T(aT + bT^2 + cT^3 + ...)
so why should Tg(T) be equal to g(T)T?
one thing is g(T)(T) = g(T^2)?
well no not exactly
g(T^2) = aT^2 + bT^4 + cT^6 + ...
while
g(T)T = aT^2 + bT^3 + cT^4 + ...
Right
Im a bit confused by the notation
from what u wrote it makes sense that Tg(T) = g(T)T
yea, but why? What are you using to conclude that
err close..... basically.... || T commutes with itself ||
T(aT+bT^2+...) = aT^2+bT^3... = g(T)T works fine as an argument imo.
ok cool, yeah cuz we have not discussed much about commutativity
Ok thats cool, now I guess the => direction utilizes the hint in some way
but I mean if you had some arbitrary operator D, obviously
D(aT+bT^2+...) = aDT+bDT^2... = g(T)D
doesn't follow
unless ur given DT = TD, a hint for the other direction
Like I just dont really know what to do with UT=TU, like what does this give me to work with?
If you have some polynomial g(T), then you can conclude that Ug(T) = g(T)U.
Another hint: you want to show that there is some polynomial $g(T)$ such that $Uw = g(T)w$ for all $w \in V$, i.e. the \emph{actions} of $g(T)$ and $U$ are the same
kxrider:
right
starting from Uw, you can bring T into the mix by representing w as some linear combo h(T)(v) = w.
and that fact is from 47 right?
yes
nope, not true. Just take T to be some linear operator from R to R (i.e. a constant). f(x)a = x^2a != f(xa) = x^2a^2
f(x)a is f(x) times a???
so g(T)(v) is multiplication? hat
what
Sorry idk why this notation is confusing me
well, by choosing some a in R to be my operator, im assuming a basis for R and a would act like a matrix.
Fine, take T to be an arbitrary linear operator on a space V and let g(T) = T^2.
Then g(T)(v) = T^2(v) = T(T(v)) but
g(T(v)) = well uh, actually means nothing here.
just think of g(T) as a linear operator itself
g(T(v)) means nothing. T(v) is not a linear operator, so T(v) is not even in the domain of g
u put v into g(T) and that goes to w
ok
yeah
So
Uw=U(g(T)(v))
g(T)(v)= aTv+bT^2v+...
U(aTv+bT^2v+...) = aUT+bUT^2+...
= aTU+bT^2U+...
lol is this something?
Yay
then I guess you can say that equals g(T)(w) but im still trying to figure out why
its the notation im trying to wrap my head around again
what equals g(T)(w)?
= aTU+bT^2U+...?
yeah ur going to have to be more clear what you are writing here.
aTU+bT^2U+... = g(T)U is an operator, not a vector. g(T)(w) is a vector
but im trying to show Uw = g(T)(w) right? for all w in V
yes. have we confused letters? You just need to show that there exists some polynomial that equals U when evaluated at T. Its not necessarily the same g that gives us w = g(T)(v)
kxrider:
its a vector, and no, you are not done.
Dang it
You need Uw = p(T)w for any w in V where p is some polynomial
hint: || you should apply the result from 47 again ||
apply it to U(v)?
yep
yep
Wait thats what we trying to prove
no not yet
polynomial is commutative
yesyes
👏
np
Really appreciate it
I need some help with this question, do I correct this quote by changing the part where it says "A won’t be an invertible matrix.” into "a is only invertible if there is no solution or infinitely many"?
@river jasper Its true that A would not be invertible in general, but that doesn't mean there isn't an exact solution (i.e. exact model) for the data. Like you said, there could be none or there could be infinitely many whenever A is not invertible.
Which case do we care about for linear regression?
@slow scroll it would be infinitely many right? since we're trying to find the line of best fit
if I have a bunch of random points that look roughly like a line, are there going to be infinitely many lines that exactly hit every point?
thats what infinitely many solutions would mean
oh then given that circumstance there would be no solution
yep. linear regression is non-trivial only when Ax = b has no solution (i.e. when there is no exact model)
so if our best possible fit model (i.e. x) deviates from b, then it follows that Ax = b had no solution to begin with
by deviates, i mean Ax is not exactly b
oh so would the corrected quote be “Here’s an easy way to remember how this works: Doing linear regression is just trying to solve Ax = b. But if any of the observed points in b deviate from the model, A won’t have a solution"
to eliminate the thought that the line of best fit could have infinite many solution
yep, exactly
@river jasper err Ax = b won't have a solution
"A won't have a solution" wouldn't make sense
oh yeah I need to specify, thank you!!
npnp
hi, when we say a vector space is a subspace of R^3, does that mean it has to span R^3?
no, and any proper subspace will in fact not span its parent space
the span of a subspace would just be itself
so, what makes something a subspace of R^3
read up the definition of a subspace
apart from, the space containing (0, 0, 0) and it's closed under addition and scalar multiplication
that's the answer to your question
is that the only requirement
that's the definition
something is a subspace of R^3 if and only if it satisfies the definition of a subspace of R^3
it has to be a subset of the parent space, obviously
in addition to the closure properties
tautological as that may sound
oh i get it now. subspace of R^3 means it's a vector space which is a subset of R^3 and it follows the definition of a subspace
so, is there such thing as a "subspace of V" where V is just a subset of R^3
any vector space has subspaces
when you have a subset of a vector space, you are assuming that properties like associativity, commutativity, scalar multiplication, etc already exist on the set. All that remains are the usual properties that you have to check.
Not that I know of, but the span of any subset of R3 is a subspace of R3
so you can take any subset and "use" it to make a subspace containing those vectors
i see
for these two vector spaces, is it true that V1 is not a subspace of R^3 because (2, 4, 6) is not inside?
and V2 is a subspace of R^3
yes, V2 is a subspace while V1 is not
for V4, it is not a subspace of R^3 because it doesn't contain the zero vector. but how would i go about showing V5 is a subspace?
Check if it satisfies the 3 conditions required for it to be a subspace.
do i make 2 arbitrary vectors and use them to see if it satisfies the conditions
So:
-
$0 \in V_5$
-
$x,y \in V_5 \implies x+y \in V_5$
-
$\lambda \in F, x \in V_5 \implies \lambda \cdot x \in V_5$
Abhijeet Vats:
i think i got it, thank you
I mean, clearly, you need to just check conditions 2 & 3. Condition 1 is self-evident. For condition 2, you need to pick two arbitrary vectors. For condition 3, consider an arbitrary vector and a scalar
You're welcome.
I know that to get the orthonormal basis I need to get u1,u2,u3,u4
but how do I find the kernel?
its the set of vectors that go to 0 after a transformation correct?
Yes that’s the kernel of a linear map.
So, for this, the linear map takes a vector in F^4 (w,x,y,z) and maps it to a vector in F^2 (w+x+y+z, w -x-y+z).
hold on..
when I'm looking for the null space or kernel
I need to augment the matrix with variables w,x,y,z
?
and set it equal to 0?
No, I just found the linear map associated with the matrix
But basically, the way I'd get the kernel is to turn information about the matrix into information about the linear map. Then, you can focus on getting the kernel
Because this matrix $A$ is associated with a linear map $f:F^4 \to F^2$. So, $f(w,x,y,z) = (w+x+y+z,w-x-y+z)$
Abhijeet Vats:
@ionic dust
can I show you work I did
Sure
I did it differently
rewrote x2 in terms of x3 and x4
then set x3 and x4 to x and y
not sure if I was on the right track with this approach
oh i messed up
the last one i thought was -1 instead of 1
hold on
Ya that looks more reasonable. That's what you would've gotten if you had set the vector that I wrote above to (0,0)
I mean
There is a precise definition for what a kernel is
Suppose we have a linear map between two vector spaces $f:V \to W$. Then:
$Ker(f) = {x \in V: f(x) = 0 }$
Abhijeet Vats:
I think I will practice basis, kernel, and span
I tend to get confused between a basis and span
There are formal definitions for all of those terms. Refer to them whenever you're confused.
Like, it takes time to get the definitions in and really wrap your head around them. So, take as much time as you need.
okay
The image is the set of vectors that are linearly independent
so if I have redundant column vectors I exclude them from the image?
I'm not really familiar with image but the set of vectors that come from the image of a matrix
they will always be linearly independent?
it feels as if you're throwing linear algebra words together without much of an understanding for what any of them mean 
Let $f:V \to W$ be a linear map. Then:
$f(V) = {w \in W: \exists x \in V: f(x) = w }$
That's your image set. Linear independence is another thing entirely.
Abhijeet Vats:
There are formal definitions for all of those terms. Refer to them whenever you're confused.
^^^
Fuck
@ionic dust
abhi
okay
just a stylistic note
you might wanna replace x with v
bc then you get v denoting an element of V
just like w denotes one of W
The image is the set of vectors that are linearly independent
@ionic dust
I suppose you might be talking about a transformation matrix?
N/𝔄:
No u
A complex 4x4 matrix A satisfies A^4 = 0
What are all its possible Jordan normal forms?
To help answer that, can I say that A^4 must be A's characteristic polynomial?
It seems I can infer 0 is an eigenvalue
you mean the polynomial p(t) = t^4, and 0 is the only eigenvalue.
The question just states A^4=0. It doesn't say anything else about it
If I can show that 0 is indeed the only eigenvalue of A then I know right away there is only 8 possible Jordan normal forms
By Cayley-Hamilton theorem, a matrix satisfies its own characteristic equation. But can I say that since A^4=0, p(t) = t^4 must be its characteristic polynomial?
suppose A has a nonzero EV λ
with eigenvector v
then v must be an eigenvector of A^4 with eigenvalue λ^4
contradiction
hm
I need to review the properties of how eigenvalues change under matrix operations
Thanks for that
Oh yea that is trivial
just from definition of eigenvalues/vectors
Oh yea that is trivial

I forgot what the trick was here. Which row/column should I go through
the one with most zeros
Because if I go down the second column I get all 0s
The determinant is 0 anyways
Or is the determinant just 0 then
I see I thought that was kind of weird but that makes sense
Because if you use the transpose and then gauss you can bring the 0 to the outside
I just wasnt expecting our professor to make it easy
Thank you though
Oh the determinant of the transpose is the same as the determinant of the orignal right?
Yes
the matrix isn't invertible, since there is a linearly dependent column, so determinant is zero
Surjective?
In this case its neither but if there wasnt that colum of zero it could be both normally
Because of invertible matrices
Do you mean as a transformation matrix for a function? 
As a transformation yes
Oh lol
same thing...
yea, square matrices are either bijective or neither injective nor surjective
np
Last question for now. Because this is neither the determinant has to be 0 because there isnt a pivot in every column
yea
Alright perfect. Thank you very much
npnp
…to be fair, the question “if M is a 7x7 matrix with {property}, what is its determinant” is like almost guaranteed to have 0 as the answer. maybe ±1, if they get creative
Let $S=\begin{bmatrix}0&I_2\I_2&0\end{bmatrix}$, a 4-by-4 nonsingular matrix and define the linear transformation $\sigma:\mathds{F}^{n\times n}\to\mathds{F}^{n\times n}$ by $\sigma(A)=S^{-1}A^TS.$
Determine if $\sigma$ is an epimorphism.
fields!:
ofc n=4
I'm not really sure how to go about this. For any B in the vector space, I found the image of A = B - S^{-1} A^T S using 2-by-2 block matrices
iirc the definition of block matrices, but you get the gist
i.e. B = [B1 B2 B3 B4], A = [A1 A2 A3 A4]
you just need to show that for any 4x4 matrix B there is a matrix A such that sigma(A) = B. Try working backwards
are we talking about sigma being a RING epimorphism?
bc it fails to even be a ring homomorphism
epimorphism means "surjective linear transformation" here
it is still a linear transformation
start with the second pic
i used block matrices here
where each A_i and B_j are 2by2
so am i doing it right?
Why can't you just do:
Let $B \in \mathbb F^{n \times n}$. Since $S$ is symmetric and $S^{-1} = S$, we have $$\sigma(S^{-1}B^T S) = S^{-1}(S^{-1}B^T S)^T S$$ $$ = S^{-1}S^T B (S^{-1})^T S = S^{-1}SBS^{-1}S = B $$
oh, so you're only considering $F^{n \times n}$ as a vector space? not as a ring?
yeah you can do that, and honestly you should
@slow scroll we have to add S^{-1} B^T S
what?
right. my bad
this is what i meant by work backwards earlier
,,\sigma(A)=A+S^{-1}A^TS
I just took B = S^-1 A^T S
and deduced that S B S^{-1} = A^T
$\sigma(A)=A+S^{-1}A^TS$
fields!:
ok well that's. an entirely different transformation lol
im much confoosed
fields misspecified the transformation in question
hmm well same concept should apply
nope, dim im σ < 16
assuming i didn't screw anything up
yeah so
nope. this ain't surjective
bc it's not injective and it's a map between findim spaces
i can explain how i arrived at this but it might be a little tricky
check norm axioms
idk maybe dnsvjsnv
do u have a name for them? xd
| does exist
if you dont know what these objects are, you should probably get that cleared up first
before trying to answer questions about them
No, it's not true. Even in R² you can create triangles that aren't right triangles
take: every triangle is right
geometry has left the chat
Since fields hasn't said anything, I'm curious how you showed that sigma isn't surjective, if ur still down to share, Ann.
okay great so
aight
i'll need to lay out some notation
i'll denote by e_ij the 4 by 4 matrix with a 1 in its (i, j) entry and zeroes elsewhere
yes, i'm familiar > i'll denote by e_ij the 4 by 4 matrix with a 1 in its (i, j) entry and zeroes elsewhere
Ann:
and also, $e_{ij} e_{kl} = \delta_{jk} e_{il}$
Ann:
do these statements make sense to you
it's the kronecker delta
nope, doesn't ring a bell
but ive learned about bases of ker sigma and of im sigma
about dimensions, and the rank nullity theorem
delta_{jk} is 1 when j=k, 0 otherwise, thats all
but rnt isn't useful here since the space is infinite-dimensional...
oh ok
so it talks about the entries along the diagonal
this space is not infinite dimensional btw its 16
right sorry lol, was thinking of the number of elts the space has
rank-nullity theorem
if you let $e_i$ denote the i'th col of the identity matrix, you can write $e_{ij} = e_ie_j^T$
Ann:
so you get $e_{ij} e_{kl} = e_i(e_j^Te_k)e_l^T = e_i(\delta_{jk})e_l^T$
Ann:
bc the e_i form an orthonormal basis
haven't learnt orthonormality yet, but ok
Ann:
yes
Ann:
transpose
or rather e_i^T e_j ?
e_i^T e_j would be delta_{ij}
damn, i confused e_ij with the entry e_ij
rewriting things the way Ann laid out i get:
σ(e11) = e11 + e13 e11 e13 + e24 e11 e24 + e31 e11 e31 + e42 e11 e42
= e11 + e13 e13 + 0 + e31 e31 + 0
= e11 + 0 + 0 + 0 + 0
= e11 != e11 + e33
did i make a mistake somewhere?
"slr"?
sorry late reply
@slow scroll also that's wrong
it's (e13+e24+e31+e42)e11(e13+e24+e31+e42)
not e13e11e13 + e24e11e24 + e31e11e31 + e42e11e42
yea, distributed incorrectly 🤦♂️
e11 - e33 in ker(sigma)
so dim im(sigma) < 16
this follows directly from
dim ker(sigma) > 0
because it's a finite-dimensional space?
^
yea, rank nullity holds on finite dimensional spaces
ah yes, it follows from the rank nullity theorem
Also, tanks for explaining ann
thanks guys!
i have another question
is this also a correct way of justifying that dim ker sigma > 0?
since the choice of E is "not dependent" on B, C, and D
and I chose B instead to be equal to -E^T
sigma here is the same linear transformation in the previous question i asked
well this is a characterization of the entire kernel
so unless you're explicitly asked for it i'd say this is a bit above and beyond
oh so i should just look at the basis of ker sigma
since its dimension is the cardinality of ker
lol i confused dim ker sigma with |ker sigma|
in this case dim ker sigma = 12 > 0
steinitz replacement theorem?
oh
god
suppose F spans R^2
and what if it doesn't?
your contradiction gives you that F either is LD or fails to span R^2
as written that's all you can conclude
pft. knew it
how do i use the steinitz replacement theorem then?
i tried using the contrapositive
the theorem states that if a finite set spans a vector space, then any linearly independent set is finite
*where the elements of the linearly independent sets are vectors in the space
you can prove that F actually does span R^2.
ah yes, for any vector (r1,r2) in R^2,
(r1,r2) = a(2,1) + b(1,2) + c(1,1)
and all i have to do is solve for a, b, c
how do i do #4 ? it doesn't seem linearly dependent
there's just no way to 'cancel out' the x^2 term without setting the coefficient of x^2+x+1 to 0
nvm, i know what to do. damn it
If a and b are vectors, then (a x b)^2 = 2(a x b), right?
cause if that's a cross product it doesn't make sense
what do you even mean by like. squaring a vector
x is cross product
what do you even mean by like. squaring a vector
^
|(axb)|^2 = 2|axb|?
ah
it's true iff a×b = 0
So we can do (a • b)^2 = a•a + 2a•b + b•b but not with x
uh
no, (a · b)^2 ≠ a·a + 2a·b + b·b in general
if you take a = b = (1, 0, 0) you get the left hand side as 1 and the right hand side as 4
oh sorry I meant (a+b)^2
what do you mean by squaring a vector
^
(a+b)•(a+b)?
oh
okay, (a+b)·(a+b) DOES equal a·a + 2a·b + b·b yes
So (a+b) x (a+b) = ?
you don't even need to expand
(a+b)×(a+b) is the cross product of a vector with itself
your assumption holds if and only if a×b = 0
My linear algebra prof is just going to be posting lecture notes for the remainder of term due to virus
So we are basically just gonna have to self study 😦
Are any two lines in 3-d space coplanar?
I am pretty sure the answer is no, but can't we always find a vector perpendicular to both of the lines and so if we let a plane have the direction ratios of the perpendicular vector?
Sorry out of context but nice name you have there
@timber blaze Wouldn't you get a vector perpendicular to both lines if you take the cross product of their direction vectors?
can someone help me understand this passage from this paper: "since R is an orthogonal matrix, only 3 of its 9 components are independent". Furthermore, how would one determine which 3 of the 9 components they are referring to ?
in this case, R is a composition of 3x3 rotation matrices, if that helps

What do you get when you actually multiply LDU together?
They gave you L, D, and U. So, multiply them. What's LDU?
Multiply the matrices with the variables
Hi
I need help with some problems
Can someone help me please?

idk how to upload images here

well ,there are 2 images only
I have also another problem, if A is a nxn matrix. Is this true: if rank A=n, then A can be diagonalized?
@slow scroll Could u give me a hand?
for the first one, there is a formula you plug the points into
which one?
You have every point on y = ax + b + μ, where μ is the error. You want to minimize Σ |μ|
I have no idea how to do that
well, you have a system of equations:
-a + b = c
a + b = 2
2a + b = 7
you can create a matrix equation out of this.
and plug it into the least squares formula
I don't know the formula
I don't think the question is asking for the least squares regression
"least linear" which is ez to calculate by hand
you mean linear least squares?
I don't mean to bother you, but i need to send this assigment in less than 20 minutes 😬
im talking about the one where you solve A*Ax = A*b
For example, let's say the line is y = 2x + 1
It passes through the point (1,3)
This misses the point (1,2) by one unit. So, that adds 1 error
You're looking to minimize the total error
That (-1, c) is throwing me off pretty bad though. It must be possible to get a and b with only two points
Or no, clearly they depend on c
@desert portal yea so it is least squares. can confirm
umm so do you know how to get this in Ax = b form?
-a + b = c
a + b = 2
2a + b = 7
you get $\begin{pmatrix} -1&1\1&1\2&1 \end{pmatrix} \begin{pmatrix} a\b \end{pmatrix} = \begin{pmatrix} c\2\7\end{pmatrix}$ right
kxrider:
yeah
let A be the matrix part, and b be the right hand side, and let x be the (a,b)^T solution we're looking for.
To find the least squares solution, you just have to solve this:
A^T Ax = A^T b
That is, you compute A^T A = G and compute A^T b = b' which give you a new matrix and vector respectively. the solution to Gx = b' is (a,b)^T
Then you can just take the components of (a,b)^T and add them together to get your answer
for the next question: in short, rank A = n only gives you invertibility of A. This is not enough to conclude diagonalizability.
in fact, its not even necessary for diagonalizability since there are plenty of non-invertible matrices which are not diagonalizable.

@desert portal you know what T(6x, 4y) is
since T is linear, its 2T(3x, 2y)
What is T(6x, 4y) + T(5x, 7y)?
(apply properties of linear transformations)
Yea, this is T(11x,11y), do you see why?
Apply linearity one more time to get 11T(x,y) = (1,11,11)
but it's not an option
maybe it's d?
Holy shit, I forgot this
I promise it's the last one

{kind=link}
{kind=link}
Find A(2,3)^T and find values of a and b that make 2 and eigenvalue. Then umm, plug and chug the answer choices to see which one is an eigenvector. im sry i can't reply quickly
is the answer to this question unique?
There's a nice solution here. An equation for the plane is:
4x + 0y - 5z = 0
This makes it easy to generate two vectors
what I did is: I found two vectors that are orthogonal to my v. Then I did p+tv1+tv2.
Typo? You mean
p + tv1 + sv2
And p can be (0,0,0) cuz origin