#linear-algebra
2 messages · Page 57 of 1
so this matrix which i've dubbed A here
this kind of matrix has a special name in linear algebra
it's called the companion matrix of the polynomial P (whose coefficients, albeit multiplied by -1, are present in its last row)
and the reason for that is that the characteristic polynomial of A is P
Ah right
you have no linear algebra background.
rip
i mean ok it's only true up to a factor of (-1)^n
See... I do everything in a rote manner, primarily we are taught that way
you... what
😐
So please bare with me... If I ask basic questions
😦
" it's only true up to a factor of (-1)^n"
I don't understand what you mean
$\det(A - λI)$ is actually $(-1)^n P(λ)$, not $P(λ)$ itself
Ann:
is (-1)^n ever equal to zero?
no it's not.
it's never equal to zero. it's -1 for odd n and 1 for even n.
last i checked, -1, 0 and 1 were three distinct real numbers.
Alright ... continue
uh
yeah
the charpoly of your original ODE is the same(ish) as the charpoly of the coefficient matrix of the corresponding system
so to answer your original question
Why do we say that the roots of the characteristic polynomial of an ODE, are the eigenvalues?
we say that because it's true in the most literal of ways
Is the process of assuming that e^ct a solution to the ODE and forming this system to find the companion matrix the same in anyway?
no
So it is coincidence?
no, it's not a coincidence
i mean... ok let's put it this way
let's say we start with a system $X' = AX$
Ann:
where A is some arbitrary matrix, not necessarily the companion of some polynomial
and we want to guess solutions like we did for the ODE case
one natural place to start would be to guess solutions of the form $X = Ce^{\lambda t}$ where $C$ is a constant vector
Ann:
substituting that into the system you get $\lambda Ce^{\lambda t} = AC e^{\lambda t}$
Ann:
One sec
dividing out by $e^{\lambda t}$, you get that $AC = \lambda C$, which is literally the definition of $C$ being an eigenvector of $A$
Ann:
e^{\lambda t} this is a diagonal matrix?
A is an n×n matrix here yes
One small clarification
X'=AX is a way to represent several dependent(or independent) equations in matrix form right?
If all the equations are independent, A is a diagonal matrix
it... is an equation in matrix form. you're overthinking it.
Aren't matrices always used to represent systems
Man... thank you very much for your patience and time. Please bare with me a little longer 🙂
Aren't matrices always used to represent systems
no, matrices are used for many things
systems of ODEs are not the only thing matrices are used for
Alright
"one natural place to start would be to guess solutions of the form $X = Ce^{\lambda t}$ where $C$ is a constant vector"
Aravindh_Vasu:
Here, is X a vector?
the right-hand side is C multiplied by a scalar
what do you think the left-hand side could be if the equation i wrote is to make any sense
Alright, sorry, continue
i'm done for now, and am waiting for confirmation from you that you've understood everything i said
I understand.
k
so clearly, if $X = Ce^{\lambda t}$ is to be a solution, and a nontrivial one at that (i.e. $C \neq 0$), we need $C$ to be an eigenvector of $A$, with eigenvalue $\lambda$.
Ann:
so we need $\lambda$ to be an eigenvalue of $A$.
Ann:
so clearly, the eigenvalues of A are of interest to just about exactly the same extent that the roots of the characteristic equation were in the ODE case.
Alright
the first answer on the SE post kinda overcomplicates things a bit
How can the solution have a common $e^{\lambda t}$?
Aravindh_Vasu:
what?
One sec please
Suppose I have two equations; $x_1' = c_1x_1 \ x_2' = c_2x_2$ if I write this in matrix form X'=AX, there can't be a common $e^{\lambda t}$
Aravindh_Vasu:
If we intend to write a solution
Ce^{\lambda t} wouldn't be a valid solution would it?
C is a constant VECTOR.
you would have $\begin{bmatrix} 1 \ 0 \end{bmatrix} e^{c_1t}$ and $\begin{bmatrix} 0 \ 1 \end{bmatrix} e^{c_2t}$ as solutions.
Ann:
seems so.
Okay, so I mistook what you told and hence I asked that question
To be honest... now I can see why eigen values affect the result
But I still can't see why that is the characteristic equation
Let me read the entire thing thrice and come back, in 5 minutes
i'm not sure how much that'd help
if you are as inexperienced with linear algebra as you claim to be
"It is in general true and the aim of the construction that, given some polynomial $p$, the characteristic polynomial of its companion matrix is again the original polynomial $p$."
Someone commented
Aravindh_Vasu:
What does he mean ?
Does he mean, that we kinda reverse engineered the companion matrix, from the polynomial?
Anyways... Thank you very much... seriously... no one's been this patient to me. Thank you.
Does he mean, that we kinda reverse engineered the companion matrix, from the polynomial?
uh
yeah
the whole point of the companion matrix construction is to show that you can have a matrix with a pre-specified polynomial as its charpoly
i... might not be available
i can't guarantee that i'll be avaialble to clear up your doubt
but i guess sure you can ping me
Thank you for your time
"There are more organic interpretations, for instance that the companion matrix is the matrix for the multiplication operator $x$ modulo $p(x)$ in the monomial basis, which corresponds here to the construction of the first order system via the derivatives array."
Another comment
Aravindh_Vasu:
https://math.stackexchange.com/a/3491598/525644
@dusky epoch
Consider taking a look if possible.

Mathematics Stack Exchange
I wrote an answer on Laplace Transform, following a series of lectures by Prof.Ali Hajimiri (kindly take a look at the answer, my question is entirely based on that answer). In this answer, though ...
😄 whenever possible
Is the zero vector(all entries are equal to 0) the same in $\mathbb{R}^{n} $ and $\mathbb{R}^{m}$ if $
m\neq n $
boilhats:
Ann:
Doesn't it have the same meaning in any dimension ?
the zero vector of R^n and the zero vector of R^m are distinct objects
Adding two vector of different dimensions is intuitive in $\bR^n$ so why addition is only possible between vector of the same size?
boilhats:
no
if you think adding two vectors from different spaces is even an operation that could make sense in the first place, let alone be "intuitive", then your intuition has gone way astray
For example if I add (1 2 3) with (1 2) it should give (2 4 3)
It satisfies the triangle law of vector addition
no
(1, 2, 3) + (1, 2) is not a sensible operation
(1, 2, 3) + (1, 2, 0) would make sense and it would give you (2, 4, 3)
theres no difference between (1 2) and (1 2 0) or (1 2 0 0) and so on
but (1, 2) and (1, 2, 0) are not the same object
YES THERE IS
YES THERE IS A DIFFERENCE
THAT'S WHAT I'VE BEEN TRYING TO SAY
if it has 0 as dimension it says that it doesn't go in that direction
so it is the same thing
for example the vector (1,2) says that it goes 1 unit in the x direction and 2 units in the y direction
R^2 is not a subset of R^3!
Doesn't matter
YES IT DOES!!!!!!!!!!!!!!!!!!!!
It doesn't make sense that you can only add vectors if they are in the same dimension
$\bR^2 \neq { (x,y,0) | x, y \in \bR }$ !!!!
Ann:
But (1,2) doesn't define how far you go in the z direction. We don't assume there's a 0 there bc it could also be referring to a vector in R^2
who knows, i could totally define [1 2 3] + [1 2] to be [1 3 5]
bUt OnIoN tHaTs UnNaTuRaL
there's no sensible way of choosing wtf you're doing with that
Notationally, you need 3 numbers to define you vector
If you graph (1,2) it is the same as (1,2,0)
no
no it's not
one lives in R^2, the other lives in R^3
just because geogebra identifies two-dimensional vectors with vectors in R^3 with z coordinate 0
doesn't mean that's actually the case mathematically
You could define it like that boil but nobody does. It's as valid a definition as onion's, which is to say not valid. The notation you need to use always has 3 numbers to refer to a 3-dimensional vector. You will not regret it if you start adopting this notation bc it's very natural and when you get more general you're gonna wish you did
But it may be useful to extend vector and matrices for matrix multiplication and matrix addition
It is, and when you do then stuff like (1,2,0) is gonna be valuable
what does the sign * mean in this context?
let A be a matrice 3x3, let det(A) = 2
what is the meaning of det(A*)
Complex conjugate?
I've seen that mean transpose before as well
conjugate transpose maybe?
thanks
Let A be a square complex matrix
define a supernormal matrix to be a matrix that satisfies
$A^* A A^* A = A A^* A A^*$
gfauxpas:
prove that if A is a supernormal matrix, then A is a normal matrix, AA* = A*A
they give a hint:
"You may wish to use induction to prove there exists a unitary matrix U such that U* AU is diagonal"
I uh
I know that if a matrix M is hermitian, it's jordan decomposition is of the form M = B D B^* where D is diagonal and BB* = I
but we're not given that A = A* so that fact doesn't seem helpful
I do see that A* A A* A and A A* A A* are both Hermitian
but after that I'm stuck
AAAAAAAAAAAAAAA
I don't know if it's helpful to rewrite the supernormal condition as the normal condition squared, (AA*)^2 = (A*A)^2
but that hints towards something to do with diagonalization probably
AA^* is positive definite so it has a square root matrix
if that's relevant
or is it
semi-definite
<@&286206848099549185>
I could interpret the following, after watching the vid, please check if I'm right,
The Jacobian matrix assumes, a basis of [dx 0] and [0 dy], and the matrix tells us where both these vectors land.

An introduction to how the jacobian matrix represents what a multivariable function looks like locally, as a linear transformation.
not really no
that's... honestly not a very good way to say it
the jacobian tells you what linear transformation your function "looks like" the most around a certain point
How does it do that
How do the derivatives accomplish that
Wait... My point was also that
We fix a point as ORIGIN and approximate the non linear transform with a linear transform given by the Jacobian
Right ?
We look how a point, a bit right(dx) to our local origin, is transformed
And similarly we look how a point, a bit up(dy) to our local origin, is transformed
i mean...
ok sure i guess?
i don't really have the energy to critique your wording rn
but it's. approximately like that ig
Cool, thanks.
Well... I made the video.
Anyways, can you please take a look at the conversation above @quartz compass
I've tried to explain my POV
what is your question?
Is my interpretation right(i.e.) https://youtu.be/bohL918kXQk
The Jacobian matrix assumes, a basis of [dx 0] and [0 dy], and the matrix tells us where both these vectors land.
An introduction to how the jacobian matrix represents what a multivariable function looks like locally, as a linear transformation.
But now... I've got another doubt
I can't tell you if you understand something
you have to have confidence yourself, and see that your model of it in your head matches to give the correct results independently
if you can't apply this to compute something concrete to check, then I say you haven't studied it enough
good luck
I'm not helping you past that, sorry
Alrighty, thank you for you time.
you don't have to delete your messages
Ouch that was by mistake

reddit
https://youtu.be/bohL918kXQk In this video Grant explains what the Jacobian matrix represents ( Jacobian matrix...
@dusky epoch Consider taking a look at that video if possible
locally linear = differentiable pretty much
Is this interpretation right or wrong?
Is this what we are doing when we form a Jacobian?
If yes, I've got this another question. While taking a linear transform, we assume that the origin is fixed right ?
@dusky epoch
god. your wording is making me a bit uncomfortable.
:(
Okay... What I intended to ask is, when we do a 2D linear transform, the (0,0) vector remains the same. Am I right ?
a linear transformation always sends the zero vector to the zero vector regardless of dimension
this is one of the most basic facts of linalg
I never figured out the answer to me AAAAAA problem, posting it again
Let A be a square complex matrix that satisfies what we will define as the supernormal property
$(A^\dagger A)^2 = (A A^\dagger)^2$
gfauxpas:
prove that if A satisfies the above supernormal property then A is normal:
$A^\dagger A = A A^\dagger$
gfauxpas:
in terms of screaming notation, prove A^* A A^* A = A A^* A A^* implies A A^* = A^* A
<@&286206848099549185>
where do learn this kind of linear algebra?
thanks everyone for the help on linear algebra last semester!! it helped A LOT!! @half ice @dusky epoch @vast torrent @gray dust @quartz compass @slow scroll
@north sierra
Did you pass?
yeah with a good mark 🙂 @half ice
"a linear transformation always sends the zero vector to the zero vector regardless of dimension
this is one of the most basic facts of linalg
"(How to tag messages like you do?)
@dusky epoch
Okay now my doubt is:
When we look at (1, 1), in the unzoomed version, IT IS NOT FIXED. I actually had to move the camera frame to be centered around (1,1) in the zoomed in version. Now a linear transform has its origin ("local";(x0,y0)) fixed right ?
So even if were to approximate the non-linear transform with a linear transform around a point. That point has to be fixed shouldn't it?
so apparently my question becomes much easier if you write A using its singular value decomposition but Idk what that is so I'll look it up this weekend
@alpine echo i mean yeah ofc it's not fixed, it's sent to f(1,1). the point is that f(1+Δx,1+Δy) is approximately a linear function of (Δx, Δy). so if you insist on that physical wording, your frame of reference gets shifted like that, and gets transformed and moved along with the point you're zooming in on
wait woah
hol up
this is true???
so the dual has the exact same cardinality in the finite case, but always has a larger cardinality if the basis of V is countable?
actually wait, any uncountable set will have larger cardinality than any countable set
right?
actually wait, any uncountable set will have larger cardinality than any countable set
right?
yes that's what uncountable means
that's what I figured, I just wasn't sure if it like somehow depends on how you define cardinality in the infinite case
also, that isn't the definition right? My understanding is that countable is defined as "there exists a bijection between the set and the natural numbers" and uncountable is defined as not countable
oh actually I guess "same cardinality" is defined as just "there exists a bijection between the sets"
so yeah
that theorem is still super weird though
and I guess less cardinality would be "there exists an injection but not a bijection"
let V is s real vector space and a linear trans f: V -> V, find maximum dimension of subspace W that W not equal V and f(W) is subset of W
@pallid rampart
can we assume findim?
@mighty marten Think about the definitions of span and basis. If you have a countable basis {e1,e2,...} of a vector space V, then V is precisely the set of FINITE linear combinations of these basis vectors. This means you can identify V with sequence of real numbers, where only finitely many elements are nonzero.
On the other hand, for ANY sequence of real numbers (a1,a2,...), you get an element of the dual that sends ek to ak. It is not too hard to show that this space has larger dimension.
are you counting in row or column major order?
to get the row i'd do smth like ceiling(n/9)
to get the col, do n%9. if the result is 0, change it to 9 
yup np 
Wait span is only finite linear combinations?
Interesting
Is there a name for like an analogue for a basis but it allows infinite linear combinations?
Like for example 1, x, x^2 ... for the set of all continuous infinitely differentiable functions?
yes, because "infinite" linear combinations of an arbitrary basis set would require discussion of convergence and topology.
so that is no longer a purely algebraic thing.
but you do have bases involving infinite linear combinations where there is topology, like Schauder bases.
(As opposed to Hamel bases, which are the purely algebraic object, where you talk about finite linear combinations).
Say more about how it would involve topology. I get the general idea of why infinite sums are weird to work with, but what would exactly would break if you tried to use them
And why is an infinite "basis" allowed for the dual space
Or uncountable
I guess because that's not really it's basis
@mighty marten
Worth checking is a book on functional analysis. Some things in standard lin alg don't hold in infinite dimensional spaces
That might be a bit too advanced for me now (I haven't had a proper algebra or analysis course), but it seems like a fun topic
Is there a tl:dr you could give?
For what breaks in infinite dimensional vector spaces
Like a few examples
Like Gomez said, the second you're talking about a sum of infinite things, you need to start talking convergence and that requires topology
Convergence in what sense?
So, functional analysis can be thought of as vector spaces equipped with a topological structure
Right because an inner product or norm can induce one
(Well an inner product gives rise to a norm)
So a lot of the course is focused on bringing linear transformations into the topology world
Like a transformation can be continuous, or bounded, ect
Topology is the study of spaces from the point of view of "connection between points"
But isn't there also algebraic topology that takes a completely different approach?
Like I was talking to a prof in my school about topology and he said that there are approaches that don't really use the point set definitions
Alg top is fun. Take a space, like a torus.
Draw a line on it with the same start point and end point, so a closed loop
If you can deform one line into another without breaking the line, then we consider these to be the same line.
It turns out that this forms a group on the shape, we call this the fundamental group. It tells us things about the shape
Point set is important to know, but alg top is by far more powerful
I imagine alg top requires point set
Or does it?
Like familiarity with it is required to learn alg top
It uses the languages of point set
Not that it uses it
But point set bites the dust at even the basics of alg top
You need point set and group theory so let's say it's two layers deep. It's one of the easier courses at this level though
So like a semester of group theory and a semester of point set?
It also helps that Hatcher is one of the most well written books that currently exist
Yeah that's the pre-reqs
Would it be worth getting at this stage?
So I can like occasionally take a glance at it
As I learn more group theory
a well written algebra book? i don't believe it
Or would it be completely incomprehensible to me
No Hatcher is alg top. There is still no well written algebra book sadly
Jacobson?
oh
The great Sloth King seems to like it
I'm not sure I've taken a look at jacobson so maybe I don't know!
And honestly if you don't know whether or not you want to buy to, just do the illegal thing
I like owning physical copies
i just know lang is horrid
I read Fraleigh and liked it but I know many who didn't
and everyone tells me every other book is worse
I'll wait on Hatcher for now
Probably couldn't understand it anyways
At this point
I'm so excited to learn algebra and analysis
Seems like it'll open the door to a lot of really interesting fields groups topics
analysis good algebra abstract nonsense
I mean it will open the door to interesting groups and fields
mfw there's a a fields medal but no groups medal

There should be a rings medal
Have you seen no group theory yet? You're in for a good time
And it's just a ring
I've seen group theory
I actually think I know quite a bit of it for someone who doesn't know group theory
That's the really interesting one. The rest of math is about turning things that aren't group theory into group theory.
Like I was exposed to the concept of groups rings a fields a while ago, and I've done some group theory though number theory
Unless we can turn them into linear algebra, but group theory is a good second
With Euler's theorem Lagrange's theorem
Actually it should really be the other way around
Lagrange's theorem Euler's theorem
They're both the same in a way
Lagrange:
The order of a group is divisible by the order of any of its subgroups
Which implies that:
a^|G| = e
This gives Euler's theorem if applied onto a mod n group
Yeah
That was the point I was making
Euler's theorem is a special case of Lagrange's theorem
Good, glad you know this connection. Seems like you know some good group theory
Yeah I do
And I think about it a lot. That is, whenever I see a new mathematical object I try to categorize it as a group ring or field if possible
Like my first thought when learning the definition of a vector space was "oh this is kinda like a group on top of a field"
And one of my first questions is "can the scalars be any field or just the reals"
I've know the concepts and motivation for a while, just not the theorems and proofs
Like really the only major theorem I know is Lagrange's theorem and I don't know a proof
I'd equate it to knowing what a derivative is, but not the chain rule
That's exactly what a vector space is. Group of vectors, field of scalars, and a scalar-vector multiplication that links them both
Scalars can be any field. You can pick wacky ones like F5, the field of 5 elements
Or C. Lots is done in C
That's pretty much true
Although I'm pretty sure I don't know the math for why that's the case
Something about it being the algebraic closure of the reals?
It's just very nice, and it's also topologically nice
And yeah, any polynomial you make that has coefficients in C also has roots in C
working with C spoils you for when you have to deal with R again
I love complex numbers
They were my second "favorite" topic in math
Like learning the connections between trig functions and exponentials
And how they're kinda about rotation
Have you done a complex analysis course?
Assuming you've done some calculus, do it. It's a very fun and easy course
For some reason my college doesn't have real as a prereq
I'm looking forward to it
Though honestly I'm more hyped to learn algebra
complex analysis is mostly disjoint from real analysis
For a long time I complex analysis was the course I was looking forward to taking
Real analysis is difficult and is largely about topological properties of R.
Complex analysis is easy and is largely about taking line integrals over well behaved complex functions
Like starting in 10th grade I believe
Because I kept seeing a general pattern of "complex numbers make everything cooler"
And I wanted to learn more
My first love in math was combinatorics though
Like permutations and combinations
I love those problems where you need to figure out the right approach to count something
Grats, a lot of people can't handle those lol
I've gotten much better through practice here, but every once in a while I still get stumped
Those are consistantly the problems I do best on when it comes to competition style problems
and the Putnam this year had like none of then
putnam this year was hella wack
(I kinda feel like we should move to #math-discussion but idk)
difficulty ordering was like non existence
I wasted so much time on B1
Nobody is here lol we're good
3 hours to be exact
i would've got B2 and B4
:((
i took like 2
then spent 15 on B3 and was like oh this is trivial
But no proof
where'd you get stuck, was it proving those 4 points were the only one's you were adding?
Yeah someone on reddit said B3 was trivial
B3 is trivial
they're both orthogonal matrices so determinants are +-1 so like
it followed trivially
ooh lmao that's what took me a while, i ended up just saying it was obvious
(Though it took me an embarrassingly long time considering I had seen a extremely elegant proof on 3b1b)
That I just couldn't quite remember
The hardest part was finding the squares
Well I looked at it and was pretty sure I saw what all of them were
But I couldn't figure out how to prove it
once you have the points you have angle restrictions
that make the 5 you can make show up quickly
I ended up just saying "the squares are of these 4 forms" with no proof
But I'm pretty sure I get that right because I had 5n+1
I'm expecting a 1 or a 2
For B1
Got all of A1 though
Didn't know how to attempt any of the others
On A side
No one in my group could do A2 because we all forgot what a centeroid was
Well all except 1
properties of I are like useless
(There were only 4 of us total though)
I'm expecting somewhere from a 10-12
i'm hoping 30+
Which I don't think is that bad for my first time taking it with little to no prior experience in competition math
Nice
if i get full points on A2 B1 B3 and some points on A1 and A4
10+ as a freshman 20+ as a sophomore 30+ as a junior 40+ as a senior
Idk if I'll manage it though
if they're like this year it's feasible tho because like if i knew algebra A5 would've been trivial, B3 was trivial, and B2 was trivial by dominating convergence if i had known that
so that's like 30 points once you've taken classes you'll probably have taken by senior year
B4 was also apparently really easy
i guess it's really just time tho
Yeah I need to take classes
Because I didn't know how to approach most of them this year
I'm not even sure if I'd have gotten B3. My linear was a little rusty
Slightly better now after doing a brief review
B3 was kinda a dumb problem tbh
you kinda just had to know that P was the reflection matrix and that orthogonal matrices had determinants ±1
My proudest Putnam achievement was solving A5 2017 just by thinking about it during orientation
Yeah
There was a dumb presentation that they had us watch and I was able to just figure it out
i didn't get that one when i did a mock practice exam for that one
Then I later realized that it was a fakesolve but I was quickly able to fix it
To be fair, I had reasoning not a formal proof
i only know a meme measure theory proof that one of the people in my program did
Like I was certain I was correct I just had no idea how to formally write it up
I ended up talking to a math prof and he helped me turn it into a formal proof
ah
Lemme go to my desk so I can type at a computer
ok
I'm pretty sure I remember it
an outline should be mostly sufficient
so it starts by defining 3 functions a(n) b(n) and c(n)
that count the number of ways players a b and c can draw the nth card
so let's say there are m cards
a(m) = 1, b(m) = c(m) = 0
because only the first player can draw the highest numbered card
then it uses the relations
$$a(k) = \sum_{i=k+1}^{m} c(i) + 1$$
$$b(k) = \sum_{i=k+1}^{m} a(i) $$
$$c(k) = \sum_{i=k+1}^{m} b(i)$$
0.5772156649:
for example, for player A to draw card 5, she must draw it after c draws 6, 7, 8, 9 ... k
plus 1 for it being the first draw of the game
the formulas for b and c are the same just without the +1
from there you can compute
$$a(m-1) = 1 : b(m-1) = 1 : c(m-1) = 0$$
$$a(m-2) = 1 : b(m-2) = 2 : c(m-2) = 1$$
0.5772156649:
but we can subtract 1 from a(m-2) b(m-2) and c(m-2) since you only care about the highest value
since we're ultimately after the highest of a(1) b(1) and c(1)
this gives us, in a sense, $$a(m-2) \approx c(m)$$ $$b(m-2) \approx a(m)$$ $$c(m-2) \approx b(m)$$
0.5772156649:
approx meaning preserving order
that is, which is greatest
so then you just look at m/2 mod(3)
(if m is odd, no single player has the greatest chance of winning)
if it's 0, a is most likely, if it's 1, b is most likely, if it's 2, c is most likely
and that's the proof (or at least a sketch)
the proof i know defines sequences rather than functions and then messes around with them
I mean it's kinda a sequence
and you end with some high powered facts about the measure of those sequences
i mean yeah
like it's a function on the naturals
isn't that literally a sequence
it just counts backwards from m
i guess that's true
I originally thought of it as a sequence of vectors
where the vectors are (a(k),b(k),c(k))
and then you can think of the step rule as a matrix
hm yeah that feels more intuitive
it was to me
the prof didn't like it
or possibly he just thought it was harder to make rigorous
but turning things into linear algebra usually makes proofs easier
and then you get a nice reason that you can subtract 1 from all of the terms
which is that (1,1,1) is an eigenvector
with eigenvalue 2
so (1,2,1) = (0,1,0) + (1,1,1)
ok but also i feel like that requires sufficient motivation as to why you're adding that eigenvector
and the (1,1,1) can't contribute anything to what's largest because it's an eigenvector
well anyways, I'm gonna go. I should probably be going to bed
gn
I'm struggling on how to start with this one, could someone give me a push?
Let v1 = (1,1,0),v2 = (2,0,1), v3 = (0,1,0) and let f exist End(R^3) such that f(v1)=f(v2)=u and f(v3) = w, being u and w linearly independent:
Find the kernel, image and determine f(2,2,1)```@compact light first of all, do those three vectors span R3?
yes @vast torrent
so the image is (u,u,v) but you cannot reduce it to (u,v) because theyre vertical can you?
I read the question wrong, let me read it again
np
what is (u,u,v)
f is a transformation, didnt write it well
the image is a set
how is it called in english
ker(f) and im(f)?
im(f) is called image in my country
right but im(f) is a set, what do yuou mean by parentheses?
yes same in America
image or range, theyre the same thing
but yoiu need something like
span{x,y,z} for the image
cool so i was guessing the range would be (u u w) in columns
but the range is a set
it has to be using the notation {s,t in R: sv+tw} or something
im saying that is the matrix
cant it be displayed as a matrix?
i mean
sorry
matrix of the transformation
which, when reduced, gives the basis of the image and therefore the dimension
that is my aproach but i dont think its right for this problem
how would you solve it?
the image is span(u,w)
can you reduce the matrix by colums?
both row & col reduction are a thing
thats why u,w are the base of the image
thx, how would you aproach the kernel then?
same as usual but with constants? (u(a,b,c),w(d,e,f))
Av = 0
A being (0,u,w)
and v= (x,y,z)
I don't see how you can give an answer with actual numbers since youre not given u and w
but you can factor the space as the direct sum of the image and the kernel
meaning you just need any vector that's not in span(u,w)
that single vector will span the kernel
by rank nullity, you know the kernel has dimension 1
Okay, so i shouldnt be able to give number answers on those two questions
I was only wondering that because they gave v1 v2 and v3
Thanks!
here's my lin alg i've been working on for three days https://math.stackexchange.com/questions/3497813/showing-a-condition-is-sufficient-to-normalcy
Mathematics Stack Exchange
This is from a practice exam for my quals.
Let $A$ be an $n \times n$ complex matrix.
Suppose A satisfies the following property:
$(AA^\dagger)^2 = (A^\dagger A)^2$
Prove that $A$ is normal, th...
if anyone wants to jump in
I found a question that asked to prove: $|a \times b|^2=|a|^2|b|^2-(a\cdot b)^2$
Brandonhotdog:
So I initially attempted:
$|a \times b|_i^2 = |\epsilon _{ijk} a_j b_k|^2$
Then I could either write:
There's an easier way
yeah there might be but I want to try and getting a better understanding of index notation
$|\epsilon _{ijk} a_j b_k|^2=(\epsilon _{ijk})^2 a_j a_j b_k b_k , or , \epsilon _{ijk} a_j b_k \epsilon _{imn} a_m b_n$
and yep, I messed the first one up lol
Brandonhotdog:
Better
Brandonhotdog:
So with the above equation
The right expression is correct
the one on the left side of the RHS is wrong
But I don't really understand why I have to make new indexes when I square it, why can't I just repeat i and j?
Well i don't know a better explanation than "try it with numbers and you'll see your way doesn't work" 🤷♂️
You're squaring across sums
yeah I suppose if I drop the Einstein summation convention and write it explicitly it may help me understand it
prove what, the original proof or that I need to use different indexes?
I found a question that asked to prove: $|a \times b|^2=|a|^2|b|^2-(a\cdot b)^2$
gfauxpas:
This one
Yeah, dw I've seen the geometric proof and yeah I agree it's very neat
It's just that I'm really trying to hammer down my understanding of index notation
cause it seems really useful in many cases
It is often useful but not worth a lack of clarity at other times
Okay I think I got a nice idea what my mistake is
$\epsilon _{ijk} a_j b_k = \sum^3 _j \sum ^3 _k \epsilon _{ijk} a_j b_k$ via Einstein summation notation
Brandonhotdog:
Brandonhotdog:
It's clear that $(\sum ^3 _i a_i)^2 = (\sum ^3 _i a_i)(\sum ^3 _i a_i) =(a_1+a_2+a_3) (a_1+a_2+a_3)$
Brandonhotdog:
This is clearly not equal to $\sum ^3 _i a_i a_i$
Brandonhotdog:
So I'm going to conclude that you can't repeat the index used by a summation for another summation, all summations must use a different index
that might be wrong lol
I personally only use Einstein summation to avoid tediousness, if there's any chance of confusion consider being verbose
i despise einstein convention always
Physicists suck at notation
Its just a fact
Physicists suck at notation
Physicists suck at notation
Whoops
Internet was going out there
It's handy for inner product proofs on tuples
yeah I was going through mathematical methods by p hobson, and they gloss over the use of Kronecker delta and levi-cevita real quick and more or less just don't use it at all
Or on differential forms
Also I found this on some linear algebra notes, if anyone can make sense of it that'd be grand lol
oh snap actually
As long as you accept $a^2=\sum _i \sum _j a_i a_j$ it makes sense
Brandonhotdog:
wait never mind I still don't get it
so they used i and j with the omega squared part but also used i and j for omega dot r, I don't see why they're allowed to re use i and j
nothing particularly mystical about it if you imagine the sum signs written in
$\sum_i (a_i+b_i) = \sum_i a_i + \sum_i b_i$
Merosity:
it's kind of like this, if I understand your confusion
it's not like we're "reusing i" for the sums on the right side of that equation because i is in both
ah okay
Yeah actually that helps a lot
So in general it seems like every mistake I've had in index notation is when I used Einstein summation convention lol
it can be nice
it can fool you into believing matrix multiplication is commutative even
handful of the gross vector cal identities can be proved more simply
yeah but tbf isn't that just index notation
and all Einstein summation does is drop the sums from being written
it also forces certain indexing conventions so you have each thing showing up twice
sure, I was talking about index notation in general, not specifically einstein summation notation I guess
yeah I agree it's been really useful when I managed to do it right
imo I don't think it really deserves to be called anything, but I guess it's kind of the main notational hurdle you're facing right now so understandable
yeah I can see it become second nature with time
definitely going to be encountering a lot of new notation in this area if you keep going that's for sure haha
tbh my uni really should have just not told us about Einstein's convention right after introducing index notation
and yeah it seems like that lol
eh
well I say that, pretty much all resources online I've seen use the convention so I'd have to at least know it existed
I mean true, it is pretty speedy
one of einstein's greatest contributions
yeah I was being facetious.
well that's a new word for my vocabulary
What implies what with operators on a Hilbert space: semi-definiteness and self-adjointness.? I read on a complex space theyre equivalent,is that right? What about a real space?
Actually i can see self adjointness implies positive semidefiniteness bc
<x,A²x>=<A'x,Ax>=<Ax,Ax> >=0
So the question is the other way around
set all k_i = 0; now it's zero
what
sorry but your determinant fails to always be nonzero for all values of a_i and k_i and i just demonstrated that
there should be a coulumn (1, a0^k1, a0^k2, ..., a0^kn)
and
a0, a1, ..., an is distinct natural numbers
k1, k2, ..., kn are in N* and distinct
set all k_i = 0; your determinant is STILL zero.
ok, set all k_i = 1; your determinant is still zero.
you should've mentioned all that before i forced it out of you with an intentionally trivial counterexample!
A matrix is pos semidefinite if x'Mx>=0 for all x
<Mx, x> ≥ 0 yeah
But apparently under some hypotheses semi positive definite implies self adjoint or vice versa
https://en.m.wikipedia.org/wiki/Positive_element second paragraph
In mathematics, especially functional analysis, a self-adjoint (or Hermitian) element
A
{\displaystyle A}
of a C*-algebra
A
{\displaystyle {\mathcal ...
e is an orthonormal base. I have to find k such that 2e1 + 2e2 + e3 is an eigenvector in F: R3 --> R3
i know how to find an eigenvector belonging to given eigenvalues
but how do i find the eigenvalues in this case?
This is what i get when i solve the determinant of (A-xI)
(x is an eigenvalue and I is the identity matrix)
what do you mean?
What are e1,e2,e3?
Orthonormal base of what?
R3? That's all.you know about them.i mean?
My gut feeling is that you shouldnt start by looking at roots of the char polynomial. I personally would try solving
A[2e¹+2e²+e³]=λ[2e¹+2e²+e³]
For starters
But I'm not 100% certain
They're not the standard unit basis vectors? Theyre arbitrary orthonormal unit vectors?
Seems messy
they are the standard unit basis vectors, sorry for being unclear
aaah well that's a lot easier
so it's just
$A \begin{bmatrix} 2 \ 2 \ 1 \end{bmatrix} = \lambda \begin{bmatrix} 2 \ 2 \ 1 \end{bmatrix}$
gfauxpas:
shouldn't be so bad

should [0, 2, 0] x [0, 0, 2] be [-4, 0, 0] or [4, 0, 0]?
and what exactly determines what it should be?
is that matrix multiplication
vector cross product
there are at least 2 ways to computer the cross product, following the formula exactly will get you one answer
cross product is anticommutative though, axb = -bxa
I was interpreting the question slightly differently. Nothing determines what it should be, the sign of the cross product is a choice of convention, just like choosing a left or right handed coordinate system
I dunno, but your answer is valid too
i guess my question is more about what makes a coordinate system left or right handed
or what makes the result of the cross product left or right handed
just choice of how you pick your basis vectors
are you familiar with the geometric interpretation of the determinant nox?
if you pick positive x to be right, positive y to be forwards and positive z to be up that'd be right handed

the way they've drawn it, they flipped the direction of positive z
that right hand looks like the guy is in pain
it really does lol
nox, are you familiar with the geometric interpretation of determinants?
I remembered the right hand rule in college probably by how most people do, thumb is x, index finger is y, and middle finger is z
idk if the right thumb is meant to bend like that
I do middle x, index y, thumb z
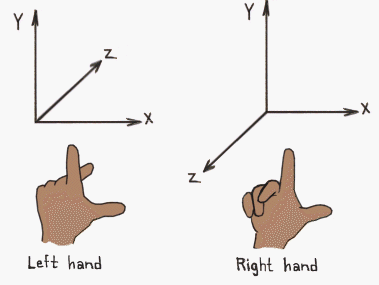

funny I actually kind of use that rule too
for the magnetic force only though on a charged particle and I only keep the thumb pointing up with x and y being my fingers curling
curl all your fingers from x to y
Right so the definition of the inner product over a complex vector space is some good comedy
According to wiki and wolfram it has linearity in the first argument
According to mathematical methods by P. Hobson it has linearity in the second argument
Imma go with the wiki and wolfram version for now till the I get 0% in a test cause they implicitly used the other definition after which I'll quit physics and resort to a life of fishing on the Galapagos islands
I'd say use whatever your class uses
I don't go to lectures so I don't know what my classes use lmao
and I'm aware it's a poor life choice but so is my existence so oh well
On another note, this book I'm reading mentioned Bessel's inequality
I don't really understand the point of it, is it even worth learning at the start or is it low key kinda important?
I don't know how to find a basis for span(S), can someone give me some instructions ?
what does a basis need to satisfy
The set of vectors is called a basis if it span a space and these vectors are linearly independent ?
can you find a set of vectors that satisfy one but not the other?
The other ? What do you mean ? I don't get it
There are two conditions there
can you find a set of vectors that satisfy one of the conditions?
I can't, i have tried but none of mine solutions work.
you can't find any set of vectors that satisfy just one of the conditions?
No i can't
you can't find a set of vectors that span the space?
Yes i have tried many solutions but none of them works.
I’m supposed to prove that these vectors are linear independent, however I get that they are linear dependent.
If they are linear independent, only the trivial solution of the coefficients is possible in below equation:
$c_1 \vec{v_1} + c_2 \vec{v_2} + c_3 \vec{v_3} = \vec{0}$
Green Plant:
I get the solution to be parametric
Can you show all your work
Why did you put the vectors in rows?
It creates a system of linear equations
Right?
Since the x1 variable should equal 0
Same with x2, x3, x4
Is that the system you want?
For example, think about how many variables this system has, compared to how many variables your original system with c's and v's has
I know I don’t have enough variables but using gauss on a system of linear equations to prove that vectors are linear independent is the only way we’ve been taught
Are you sure this is exactly how you were taught to do it
Or maybe think about why this method even works
It’s at least what my notes tell me
This method is supposed to prove whether any linear combinations are possible to form other vectors
Ugh
This is why you should actually understand what you're doing and why you're doing it
Rather than just rote following some rules
You should put the vectors in columns
And gauss that one?
Because the same variabel coefficient adds with the other when doing matrix mult?
I have no clue what you're trying to say
Yes
With your choice of v's, this is
Oki
$c_1 \begin{pmatrix} 1 \1\0\0 \end{pmatrix} + c_2 \begin{pmatrix} 2\0\1\0 \end{pmatrix} + c_3 \begin{pmatrix} 3 \0\0\1 \end{pmatrix} = \begin{pmatrix} 0\0\0\0 \end{pmatrix}$
Zopherus:
indeed
Ye I got them as linear independent once my matrix was correctly constructed
been like
11 hours since, but you could've seen those are clearly linearly independent because of the placement of the 1s
Let B = {(1,0,0,...), (0,1,0,...), ...} be the standard basis for Z^w and suppose f:Z^w->Z is a linear functional zero on each basis element. Does it follow that f is always zero?
what is Z^w exactly
are you doing stuff on modules instead vector spaces?
@pliant harbor
Z^w is the set of infinite integer sequences. w is the first infinite ordinal.
@grave island Only finite combinations of the basis vectors are guaranteed to be in the kernel.
I suppose you can't call it a basis because you need infinitely many basis vectors to express almost all sequences. However, the meaning of B is clear.
I thought so too, but I couldn't figure out how to assign the rest of the sequences values without contradiction.
So you have to be very careful in proving or disproving this.
i smell choice
Kraft Macaroni:
Compile Error! Click the  reaction for details. (You may edit your message)
reaction for details. (You may edit your message)
hiya I have a quick question about Jordan bases and root spaces/eigenspaces. Basically I have a function with matrix $A = \begin{pmatrix} 0 & 3 & 3 // -1 & 8 & 6 // 2 & -14 & -10\end{pmatrix}$ and I need to find a jordan basis. I compute its eigenvalues and they are -1 and 0 with -1 being of multiplicity 2 so I find the vector in the eigenspace of -1 to be (3,3,-4). After computing the rootspace of -1 though I get that the remaining basis vector that spans the root space is (3,-1,4) which is different from that of my textbook of (1,0,2/3) even though i havent made any mistakes in gaussian elimination. It just seems that my choice of setting free variable to 4 is different to theirs of setting the free variable to 2/3 instead, yet the two vectors are linearly independent. Should i be worried or is this fine
Kraft Macaroni:
\\
Kraft Macaroni:
?
<@&286206848099549185>
Can you show us your computations
If I'm given these 2 lines https://gyazo.com/51062d6d235ef2b86791888940809ce7 and want to construct a line that's orthogonal to both these lines and intersects them first I take the cross product of the direction vectors for l1 and l2 to get the direction vector for the new line l3 but how do I decide the point for which it passes through?
I have the line l3 as (x,y,z)=(x0,y0,z0)+u(1,5,1), but unsure how to continue to get x0,y0,z0?

{kind=link}
{kind=link}
{kind=link}
Let a~0 if a is eventually zero and let a~b if a-b~0. Then ~ partitions Z^w into equivalence classes and f is constant on each class. However, we can't just define f to be zero on the class containing 0 and 1 on a different class. This might cause a contradiction once we define f on the other classes.
Well, (1, 1, 1, 1,....) isn't a sum of a finite combination of the basis elements
So you're def gonna need something a tad bit more refined than just linearity
Gonna have to throw stuff specific to Z^w at it
like your equivalence of sequences
This is Gauss Jordan Elimination method
but I don't get why he subtracted the first row from the second row.
you can subtract whatever row you want
yes, you can do any elementary row operation
ohh ok
but What I am curious about is
why did he do that way?
And Is there a reason that It's okay to subtract whatever row I want?
the goal is to get to an identity matrix on the left side, in that case, it gives you most of the the identity matrix with one step
the reason is that you could just think of it as adding and subtracting equations to get the value of a single variable
which is what it is, with the actual x, y, z and so on abstracted out
I've tried all sorts of stuff. For example, I know that the kernel is infinite dimensional since it contains the set of eventually zero sequences. However, Z^w has uncountably infinite dimension when represented with a true basis, so that doesn't help much.
@pliant harbor Saying it vanishes on the vectors e_j is just saying it vanishes on a subspace U with countable dimension. If you complete the set {e1,e2,...,} into a Hamel basis (which as you observe is uncountable), then just consider the dual functional of a basis element b which is not one of the ek.
dual functional meaning that for something in the span of your Hamel basis, it spits out the coefficient of b in the linear combination.
I'm not sure where you're going with "saying it..." I know exactly how much my observation implies: not much.
Applying f to anything in the image of f*, the dual functional, would yield zero. So we can say f o f* = 0. Unfortunately, this does not imply f = 0.
Actually, forget that. f* is not even well defined. You're returning an uncountably long sequence, so f* will have codomain Z^k where k is an uncountable ordinal. Z^k and Z^w cannot be reconciled.
I suppose you mean that the functional returns b expressed in terms of e_1, e_2, ... In that case, f* and f o f* are well-defined and I see what you're talking about, but I don't see how to obtain any information on f.
Actually, in that case f* is just the identity. You have to clarify your definition of the dual functional.
@pliant harbor Sorry, I did not expect such a quick reply and was away from the computer.
Also, I was perhaps a little unclear. I am simply defining for each element $e_\alpha\in X$ of a Hamel basis $\mathcal{B}={e_\alpha}$ a functional $f_\alpha$ whose action is given by $f_\alpha(\sum_\beta \lambda_\beta e_\beta)=\lambda_\alpha$.
gomez:
In particular, I am NOT taking duals of functionals. I am simply constructing elements of the dual space X' (functionals) corresponding to each basis vector of X. This construction is basis dependent.
For finite dimensional spaces this process gives you an isomorphism between X and X', but for infinite dimensional spaces, these $f_\alpha$ won't span $X'$.
gomez:
To summarise:
-
We take your countable set of linearly independent vectors ${e_n}$
-
We complete it to a Hamel basis of the full space of sequences (which as you correctly observed must be uncountable)
-
We choose one of the elements $e$ of the Hamel basis that was not in your original countable collection and take the corresponding $f_e\in X'$ as outlined above. This functional has the desired properties.
gomez:
would this definition of vector product make sense geometrically, if u and v are sides in a parallellogram the length of |u x v| = the area of the parallellogram
😦
You're attempting to change the definition of the cross product
u x v cannot be the diagonal of that parallelogram, since its diagonal is u + v
u x v produces a vector that is perpendicular to both u and v
true lmao
so what i edited to now should be fine then
the whole thing about diagonal is not relaly needed in my sentence
so i left it out instead of changing it to u+v
Okay, here's the other thing: your definition doesn't really provide a way for us to determine the direction of the vector product. In other words, I could determine its magnitude by calculating the area of the parallelogram but I could not determine its direction.
so in simple terms what would be the geometric def
it's the vector with the length you specified which is perpendicular to both its inputs such that u, v and u x v obey the right hand rule
that sounds way better and makes way more sense indeed
what exactly is giving you trouble?
I've set up the equation in the form Ax=B
not sure how to continue
and i dont know how to find the determinent for a 2x2 matrix
i knwo how to do it for a 3x3
the det of a 2×2 matrix is INCREDIBLY easy
$\det \begin{bmatrix} a & b \ c & d \end{bmatrix} = ad - bc$
Ann:
oh
it's just that