#linear-algebra
2 messages · Page 29 of 1
which one
fuck no this is wrong https://cdn.discordapp.com/attachments/540211747613704221/622868945421991936/179701226995318785.png

ye
hegel:

yes
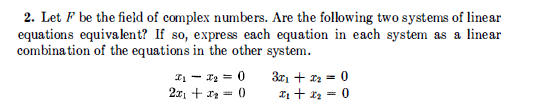

{kind=link}
{kind=link}
{kind=link}
hey do u guys have any idea with this?
FUCK
ll
Spes:
you need to multiply (2x_1 + x_2) by 1/3 too
$\frac{1}{3} (x_1 - x_2) + \frac{1}{3} (2x_1 + x_2) = x_1$
Spes:
okay yes.
NOW we add
whats the difference between an n x 1 vector and m x 1 vector
They're different sizes?
are u asking me?
I'm answering your question
with a question mark
But confusedly
wut
Because your question really makes no sense
It's not that I don't understand it
I've taught college courses in lin alg, it's that your question really makes no sense
"Because your question really makes no sense"
u couldve asked for clarification
i dont see the difficulty in that
Then clarify
as my book defines it, n x 1 vector is a column vector
and when my book goes through an example which results in what they call an m x 1 vector it to me, also looks like a column vector
so i dont understand the difference
Yeah I really didn't need more clarification, my answer was correct
They're different sizes
I'm not sure why you think there's a difference here
you have a weird attitude to solving questions
u might need to reconsidering 'helping people'
telling me they're different sizes helps
i dont need u to be condesending
I've won teaching awards thank you
I'm not sure where you see any condcendingness?
<@&268886789983436800>
"ive won teaching awards"
Please do not use homophobic slurs.
Don't ban him yet let me talk to him
And verbal abuse of the Helpers is unlikely to get you help.
I answered your question, I'm confused why you thought I was being condenscending
How?
if u cant see how ur responses are condensencing, then noone can
its a stylistic approach to how u respond
with question marks
What I see is a miscommunication
teaching is too hard over text
I told you they were different sizes
The question marks were more that I was confused at what you were confused at
u told me they're different sizes, which is helpful but then u question my intelligence by saying "how cant u see that hur durr"
clearly im unaware if im asking
I don't see where I did that?
Did you take the question marks to mean that?
Because I meant them more as my confusion about what you were confused about
And not sure if I was answering what you were confused about
Let's move past the accusations and return to the question.
What is it that you're not following with the n x 1 vs. m x 1 vectors?
i see now, thanks to zopherus that m x 1 is simply a different column vector
of different size
Yes.
In this example, specifically, the result vector is m x 1 because the matrix A is m x n
i dont understand the notation n x 1 and m x 1 to represent column vectors though
In the matrix, m x n is m rows and n columns.
But after multiplication with the n x 1 vector, the result is an m x 1 vector.
okay thank you
@clever cedar when you write a m x 1 matrix it looks like 1 single column with m "shelves"
I see how that seems backwards
thank you @quartz compass
you're welcome
say we have a linear transformation T from a vector space V to W , which is surjective
If V is finite dimensional, then does that imply that the T(v_i's) form a basis of W if v_i are a basis for V
Not necessarily
But if the transformation is surjective, that implies that W is the same dimension by rank nullity theorem right?
And since a linear transformation is defined by the action on the basis, the only way it would be surjective would be for the basis to map to another set of basis
oh wait

nvm
W can be of smaller dimension then V
Yeah
but it would map to a spanning set of W basically
Yep it will
Just think about what that last sentence is really saying
i'm unsure how that last sentence at the bottom follows
oh are you still helping
mb
It's describing how to write v_i in terms of the basis
yes
Which is a pretty trivial equation to write down, but you write it in that form so you can apply the transformation T
Assume we're talking about the same surjective linear transformation T: V->W where V is finite dimensional,
Then im trying to show that a inverse exists, such that S composed with T is the identity map
but what if we have two basis elements in V that map to the same element in W?
I was gonna define S(W_1) = v | T(v) = W_1
I have a few questions if anyone is not busy
never ask to ask, just ask

https://sol.gfxile.net/dontask.html @wintry steppe
can someone help me solve 0.25(t + 64) = 6.4 + t
apples:
can I assume
$$\left(u+v\right)x_1+\left(a\cdot u\right)x_2=0\Leftrightarrow x_1=x_2=0,:a\in \mathbb{R}$$
apples:
can someone help me out pls :S
apples:
yes
@anyone who can help me with my problem
I already did
oh
begins with "if I know that..."
it's about assuming linear independence of two vectors
id assume a = 2
i assume u = v
so u + v = 2u
hence they linearly dependent?
wait
nope u and v are any vectors
if x1 and x2 are = 0
I know they are linearly independent
o
but if I add them and I multiply u by a scaler, are they still linearly independent
$$\left(u+v\right)x_1+\left(a\cdot u\right)x_2=0\Leftrightarrow x_1=x_2=0,:a\in \mathbb{R}$$
apples:
like is this true?
thanks bro lol
it should be true
i think
if a is nonzero
since two linearly independent vectors u,v
then (u + v) and u
or (u + v) and v are also linearly independent
interesting
I mean like is there a way to prove it though? I was just going to assume that since I was focusing on proving something else
well yea u could definitely prove that
im sure u dont have to tho
but for intuitive purposes it gives us some insight
I see
thank you for your helo
help*
$$\span \left(u,:v\right)=\span \left(u+v,:a\cdot u\right)$$
apples:
Compile Error! Click the  reaction for details. (You may edit your message)
reaction for details. (You may edit your message)
is this also true
wait
$$\text{span}\left(u,:v\right)=\text{span}\left(u+v,:a\cdot u\right)$$
apples:
yep
same idea
here its easier, try to make u and v from linear combinations of (u+v) and (au)
Wanted to get thoughts on this. What do you suppose the "natural n^2 x n^2" matrix flattening of an order-4 tensor would be? I haven't found any references to a "natural" flattening
i think it is just the flattening onto a matrix of size n^2 by n^2 but i havent seen a reference to a flattening being natural before
as of now im just assuming its just a plain old flattening
for context i am working on this relation at the moment
mostly because i could be a fool but i don't think a matrix of size n x n can be multiplied with a matrix of size n^2 x n^2
nvm i just cant read
nice
nice
this is part of a section of a paper to give an efficiently computable upper bound on the injective tensor norm
its a bizarre topic but quite interesting
so, the matrix they give in the second part has eigenvalues 4, 4, and 8
which means xT A x never equals 1 by the first part
am i getting pranked or am i missing something
oh, i assumed that xT x was 1
Mm, so is it 1/8 <= x^T x <= 1/4 in the end?
$\begin{vmatrix}
1+x_1y_1&1+x_1y_2&1+x_1y_3\
1+x_2y_1&1+x_2y_2&1+x_2y_3\
1+x_3y_1&1+x_3y_2&1+x_3y_3
\end{vmatrix}$
Nguyễn Thành Trung:
Nguyễn Thành Trung:
Nguyễn Thành Trung:
Nguyễn Thành Trung:
Nguyễn Thành Trung:
does any check this prob for me please
i don't know but I find it = 0
but it's not = 0 😐
still don't know why
woops
I check the case n = 2 and it's not zero
but for n >= 3, it = 0
this is J + xy^T, where J is the 3 by 3 matrix of all ones, x = [x1;x2;x3] and y = [y1;y2;y3]
rank(J) = 1
rank(xy^T) <= 1
rank(J + xy^T) <= rank(J) + rank(xy^T) <= 2 < 3
any idea for this problem?
angle sum formulae i guess
||letting a = [α_1; α_2; ...; α_n], your matrix is sin(a)*cos(a)' + cos(a)*sin(a)', in matlab notation||
||so its rank is at most 2||
||so for n above 2 this is guaranteed zero||
let me try
rank(A+B) ≤ rank(A)+rank(B)
$\mathrm{rank}(uv^T)$ is 1 iff $u$ and $v$ are both nonzero, otherwise 0
Ann:
does anyone know how to prove
$\text{rank}(AB) \le \min{\text{rank}(A), \text{rank}(B)}$
Nguyễn Thành Trung:
this my proof
let x in ker(B) => Bx = 0 => ABx = 0 => ker(B) is subset ker(AB) then rank(AB) <= rank(B)
rank(AB) = rank(AB)^T = rank(B^TA^T) <= rank(A^T) = rank(A)
so rank(AB) <= min{rank(A), rank(B)}
I've read some solution in some math forums
but this one made me confused
how "if A is singular, then clearly, nomatter what B is, rank(B) <= rank(A)"
I don't understand
Hi guys, could you tell me about some good resources, books or whatever to learn linear algebra in my own?
I used a book called “linear algebra done wrong” @visual kraken
Apart from trasnposition and inversion, are there some other interesting maps such that
f(x*y) = f(y) * f(x)
?
Do they have a name?
Multiplication endomorphisms?
order flips
Oh.
@fringe vessel I think I found it: anti involution https://en.m.wikipedia.org/wiki/Involution_(mathematics)

In mathematics, an involution, or an involutory function, is a function f that is its own inverse,
f(f(x)) = xfor all x in the domain of f.The term anti-involution refers to involutions based on antihomomorphisms (see § Quaternion algebra, groups, semigroups below)
f(xy) =...
Anti homomorphism would be the more general term for f(xy)=f(y)f(x)
xd it’s a good question
Thanks @slow scroll
@fringe vessel Looks like you're asking about multiplicative and completely multiplicative functions
you can define a completely multiplicative function with a completely additive function, A(x*y) = A(x)+A(y), by f(x) = C^{A(x)} as this gives you f(x * y) = f(x) * f(y) if that interests you
erm, A=log being an example?
yep
I'm not sure if that's what I'm after
I'm looking for functions with f(x*y) = f(y) * f(x) but x and y aren't generally commutative here
transposition and inverstion of matrices being an example
I couldn't find another example yet
complex conjugation usually goes well with transposition
that's where stuff like hermitian and unitary matrices pop up
there's also conjugation like f(x) = a^{-1} x a
not really tho 🤔
f(x*y) = a^{-1} x y a = a^{-1} x a a^{-1}y a = f(x) f(y)
not
f(x*y) = f(y) f(x)
Yo how do i figure this out?
Hint :- h(h^-1(x)) = h^-1(h(x)) = x
Well you've shown it exists I'm sure
What happens if two polynomials of degree n-1 agree at n points?
Someone told me their difference would have n roots
but how would a polynomial of degree n-1 have n roots
Thats actually what im kinda confused about rn
The difference has degree <=n-1
So if it has n roots, it's the 0 polynomial
But why does the difference have n roots
d(x)=p(x)-q(x)
And p(x_i)=q(x_i)=y_i for all i=1,...,n
how to prove rank(A) = 1 then A has only one eigenvalue != 0 and it's value = trace(A)??
assuming A is square?
dim ker(A) = n-1
where n is the size of A
so its charpoly has 0 as a root of multiplicity n-1
well if rank(A) = 1 then we have that A = xy^T for some nx1 matrices x and y. Thus the columns of A are all scalar multiples of x. Then it follows from the definition of matrix multiplication that A maps any vector to some scalar multiple of x. Therefore, x would be an eigenvector whose eigenvalue is exactly the sum of the diagonal entries of A. This is exactly trace(A).
Suppose that there is some other eigenvalue of A such that trace(A) = (the previously found eigenvalue). We know that trace(A) is the sum of the eigenvalues of A. If lambda is the eigenvalue we found previously, and lambda2 is another eigenvalue, then we must have that trace(A) = lambda = lambda + lambda2. This implies lambda2 = 0.
lambda2 = 0
so lambda 2 can be -1 + 1
I mean
sum of the rest of eigenvalues = 0 but it's not equivalent to all of them = 0
oh yea rip :/
I mean, you could just say for all v!=0, Av = ax. Therefore 0 and x are the only possible eigenvectors of A. We found the eigenvalue for x, and the eigenvalue for 0 is 0 🤷
@undone garnet mm that's not always true. Two cases are possible, the characteristic polynomial of A is
(x^(n-1))(x-λ) or it could also be x^n (omitting eventual leading signs)
In either case -tr(A) is the coefficient of the order n-1 term
well
because I'm trying to prove
det(A+E) = trace(A) + 1
and I've read some solutions
it guides me to prove eigenvalue of (A+I) = trace(A) + 1
and the others is 1
=> det(A+E) = (trace(A) + 1).1.1.1.1 = trace(A) + 1
the spectrum of A is known in its entirety
0 with multiplicity n-1, some other value λ with multiplicity 1
you're really overthinking it
Uhm wait no, 0 could have also multiplicity n
A+I has eigenvalues 1 and trace(A)+1 if we agree to mean with it that when trace(A)=0 the only eigenvalue is 1
yeah if λ=0
Yes, indeed to prove that det(A+E)=trace(A)+1 we can argue that A is similar to an upper triangular matrix with only 0 on the diagonal except for one entry being trace(A)
So A+E is similar to an upper triangular matrix with only 1 on the diagonal except for the one trace(A)+1 entry
@undone garnet
Was reading through my linalg textbook and found that the zero vector is not a basis of the space it spans. Why is this true?
if it was true then the space that it spans would have dimension 1 even though it isnt a line
geometrically that makes sense, but the dimension itself is defined by the number of basis vectors
@pine hearth the dimension is 0 for that space
According to the textbook I'm using the definition for the dimension is the number of basis vectors fo a space so I was wondering why it had 0 basis vectors
never done exact sequences before, does it just by definition tell us Ker(T_1) = 0?
Yea
can somebody explain the difference of these two funcetions of variance to me? i realize they are the same but for some reason i get different results
@cosmic coral well they have different denominators, so they compute different things
when the mean is known, the first one is an unbiased estimate of the variance. when the mean is not known, the second one is the unbiased estimate
m here is the sample mean
https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms#Level_3 does that mean that it's either transposing A and B or none at all?
Basic Linear Algebra Subprograms (BLAS) is a specification that prescribes a set of low-level routines for performing common linear algebra operations such as vector addition, scalar multiplication, dot products, linear combinations, and matrix multiplication. They are the de...
Do I understand this terminology correctly? Any spanning list of a vector space V needs to be linearly independent? I know that we can have a linearly dependent list of vectors have the same span as if we removed 'excess' vectors. But my book says that the length of any linearly independent list in V needs to be less than or equal than the length of any spanning list. That's where I assume from, that the term spanning list relates to any linearly independent spanning list. Is that correct?
Everything is clear to me, including the stated theorem, but that leads me confused about the term spanning list
Appreciate any answers
No, the answer is that a spanning list/set does not need to be independent
can anybody help me in geometry
when did you tell me this
Ohhh I get it now. The key word in the theorem is that any independent list needs to be shorter or equal in length to every spanning list
Ok that clears it up
Correct
@sonic osprey lie
could someone help me graph the equation y=-1/2x+9/2
This isn't really the right channel for this. #prealg-and-algebra would be more appropriate
Hey all, can someone please help show me why taking the trace of an n x n matrix would be considered a linear transformation?
What would be the geometric intuition of determinants in higher dimensions?
I don't think there would be something equivalent to a volume or area in higher dimensions maybe.
Or there is?
Like a generalization of the notion of ''amount of space'' we get when talking about area or volume.
sure there is
Is there like a name for it?
Just like polytopes are a general term for polygons and etc...
hypervolumes I think?
it's called "don't complain if you can't visualize spaces higher than R^3, just shut up and do the algebra"
Just consider the integral of some function over a 3d region. That can easily be interpreted as 4d volume
It feels way more intuitive, for sure.
Damn
Living in a 3D space sucks.
Yeah, that seems reasonable.
im having trouble understanding what the last line is saying. L_k b_k are both linear functionals, right? 
er um would L_k be elements of the field that make up the coordinates of L?
Not sure if this is the right channel, so please just redirect me if possible.
(I am also an amateur, so please pardon any incorrect and/or inaccurate terminology.)
Is there a theorem or whatever that states that for every exponential multiple (dunno the proper term) of 4 (4, 16, 64, 256, 1024, and so on), there exists a positive integer (x) such that f(x) = 3x + 1 for that number, where (x) is the sum of all preceding exponential multiples?
For example, for 4^4 = 256, there would be a value (x) such that f(x) = 3x + 1, and (x) would be the sum of (4^0)+(4^1)+(4^2)+(4^3) = 85.
Is there a theorem for that?
so you're asking if 4^n is always of the form 3m + 1
the answer is yes
because 4^n mod 3 = (4 mod 3)^n = 1^n = 1
Does that apply to all integers used as base or just 4?
4 = 1 (mod 3)
4^2 = 1 (mod 3)
suppose 4^n = 1 (mod 3)
4*4^n = 4^(n+1) = 1 (mod 3)
I mean, not exactly always 3x + 1. But for other base integers, will there be something like that too?
if you don't like the mod thing, it is easy enough to rephrase this in plain terms
like @slow scroll suggested we can use induction
you know 4^1 = 3*1 + 1
and if 4^n = 3a + 1 then 4^{n+1} = 4 * (3a+1) = 12a + 4 = 3(4a+ 1) + 1
@slow scroll yes L_k are scalars
Hi all, if A is an n x m matrix, how could I show that the Image of A and the kernel of A are subspaces of R^n and R^m respectively?
f(x) = nx + 1
n+1 = 1 (mod n)
(n+1)^2 = 1 (mod n)
yea so you could proceed by induction for the general case as well. Basically the fact Im using about modular arithmetic is that for
k = n (mod a)
bk = bn (mod a)
so if we know n+1 = 1 mod n
then (n+1)(n+1) = 1*1 = 1 mod n
@leaden ermine show that they are subsets of the spaces, and then show that they contain the 0 vector, are closed under addition and scalar multiplication. Use the fact that a matrix is a linear transformation.
Hi ok, I understand. Do I prove them separately or together? So for one, would I simply say the Image is a subspace of R^n because of those 3 criteria?
yea, but you have to show that each of those criteria hold
and prove them separately for the image and kernel
So for instance, for the zero vector and showing the image is within R^n. Since A0n=0n, the zero vector is an element of R^n and in the image space. For closed under addition we want to show that x+y is an element of the image space, so we just need to show A(x+y)=0 through A(x+y)=Ax+Ay = 0 + 0 = 0
I guess im not sure how to show it without using an example matrix, so Im just using definitions
Ax + Ay is not necessarily 0. I'm not sure where you were going with that.
For any x, y in the image of A, we have that x = Au and y = Aw for some u, w in the domain of A. Try from here
So going off that, we have to show the image contains the zero vector, meaning if we set all variables in the image matrix to zero, our output should be zero right?
at least for the first criteria
Oh so what you had for that was basically valid. It might not hurt to consider A(x-x).
Does this link do a good job of proving these properties? It seems very simple so not sure if its actually proving or just stating...

We prove that for a given matrix, the kernel is a subspace. To prove it, we check the three criteria for a subset of a vector space to be a subspace.
seems like it used the zero vector to prove all 3 criteria?
Well that’s because the kernel has a lot to do with the zero vector lol!
The proof for the image is very similar as well
Hm not really. It really is almost the same
let x, y be in the image of A. Why should x+y also be in the image of A?
For any x in the image, there exists some u such that A(u)=x. I’ll leave it at that
Got it, fair enough thank you for your help! One last question, why would taking the trace of an n x n matrix would be considered a linear transformation?
Yeah it would.
As an exercise, you could try to find the matrix $\operatorname{tr} : M_n(\bbR) \to \bbR$ that takes every matrix in $M_n(\bbR)$ to its trace in $\bbR$.
kxrider:
actually i don't think that is that simple
wouldnt you need 2 matrices to get to a 1x1 matrix
one on left and right
still not that hard tho
[condense columns matrix] [projection onto I_n] [input] [condense rows]
if you plan on writing the trace as a matrix it's going to be a 1 by n^2 matrix
and n of the n^2 entries will be 1, the rest 0
with respect to the obvious basis of M_{n x n}
but for @leaden ermine original question, it is much more straightforward to just verify directly that the trace is linear i.e. tr(aX + bY) = a tr X + b tr Y
Oh well yea, finding a matrix representation for trace is obviously super impractical, but u could do it xd
prove that if A has sum of each row (or column) = 1, A has 1 as an eigenvalue
there is a nonzero vector which is pretty obviously in the kernel of A-E
consider how you might obtain the sum of all the entries of a row vector by multiplying it by a cleverly chosen column vector
well
x = (1, 1, ..., 1)
right?
sorry for misreading
I thought you said no vector
(A-E)x=0 <=> Ax = x => A has 1 as an eigenvalue
yeah
niceeee
thank you 😄
Thx Kxrider and Seoin, was able to verify Trace as a linear transformation
$A, B, C \in M_2$ prove that $(AB-BA)^{2004}C=C(AB-BA)^{2004}$
Nguyễn Thành Trung:
any idea?
is there a ^ missing on the left
Can you think of a counterexample?
You can definitely brute force this
Maybe there is something clever with diagonalization or something
Wait actually
It has to be a diagonal matrix
In order for this to be true
oh I see
(AB-BA)^{2004} that is
Nguyễn Thành Trung:
$(AB-BA)^2 = (a^2+bc)I$
Nguyễn Thành Trung:
So that's it then
2004 is even
So you're done
It's a well known result that the matrices that commute with every other matrices are the ones of the form aI
For some a
(I meant to say that, not diagonal)
is this an acceptable proof?
can I call that induction
first line is given as a theorem
If this is a class on proof writing, then you need to be a bit more rigourous with your induction
@split grove
If you are just trying to show your result, then, this should do.
What matrix could I multiply a 2x10 matrix by, to get the same matrix, but every other column is 1/3 its size?
Do you multiply on the left or right?
@mint surge
as such, what would be the dimensions of such a matrix?
I'm new to linear algebra, not quite sure if it was possible or nt
I might not understand the question I was given
It is possible.
@mint surge So, do you multiply the new matrix on the left or right, and what are the dimensions of such a matrix?
Think elementary matrices
My initial guess would be to put it on the left, because if I were doing a scalar thats where i'd put it
So, what would the size be?
And can that make every other column 1/3 its size?
@mint surge
That's the part I've lost myself on. Column size would have to be nx2 to multiply with a 2x10
2x10
so, that means the matrix you multiply needs to have size?
hmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmmm
10x10?
n x k by k x m = n x m
but it might not be possible multiplying on the left
did you manage to do it for multiplying on the left?
Try expressing your product in terms of row/column vectors
I did some experiments with 2x2's but I couldnt get it to correctly go to every other row.
(Im using matlab)
If I were to do a 10x10, how would I represent "every other column"
So would I just make the diagonal
1 1/3 1 1/3 1 1/3?
going all the way down
Got it, thanks!
yeah, that's the idea
j^j should be t^j, right?
yes
okay that would make more sense.
i don't think im quite clear on why this is dual. The trivial example make sense where the every basis vector e'_k in the dual of Rn maps every basis vector e_j in Rn to 1 if j=k, and 0 otherwise.
I'm not sure if I am seeing the connection
Question.. let T(V) denote the tensor algebra or a vector space V and I the ideal generated by elements of the form x tensor x.. then the exterior algebra Wedge(V) is defined as T(V)/I. There is a natural surjection pi: T(V) -> Wedge(V).
There is also a isomorphism between T(V’) and multilinear maps out of V, and an isomorphism between Wedge(V’) and alternating multilinear maps out of V. Here V’ denotes the dual of V.
We can define the Wedge product on the level of the exterior algebra as follows..
a Wedge b = pi(a0 tensor b0), where a0 and b0 are any two representatives of a and b in T(V’).
Now say we want to define the Wedge product on the level of multilinear maps as is usually done In textbooks. Say a corresponds to the alternating multilinear map A and b to the alternating multilinear map B by the isomorphism mentioned earlier.
We can define the Wedge product of these two maps as Alt(A tensor B) or (some term with factorials) Alt(A tensor B)
Which of these corresponds to a Wedge b as defined earlier? And which of these is the one used in differential geometry when taking Wedge products of forms? If they differ, why the difference?
So your question is if we use the one with factorials or not?
@hollow phoenix
That choice depends on your definition of the alt map
Err my question is which one corresponds to the Wedge product as defined earlier
Oh .
Wait.
So the two maps are actually the same then?
So some people define the alt map with dividing by n!
Ah..
But both of these ways lead to the same map which corresponds to
Dividing
I checked stackexcuange
Ok yeah
Anyway they’re both the same map that corresponds to the former Wedge product?
Yeah, so if you include that in your definition of the alt map
Ah wonderful
You need to cancel the factorials from Alt(A \tensor B)
Confusion resolved I guess
And stuff like that
Any reason why people define it this way (on the level of maps) and not in the exterior algebra which feels much more natural
Well it's the same
They define the exterior Algebra using this map
👌
@hollow phoenix Wikipedia defines it without the n!
While lee defines it with the n!
Okay so .. let i1 denote the isomorphism between T(V) ~ multilinear maps and i2 the isomorphism between Wedge(V) ~ alternating multilinear maps. And let Alt denote the alternating operator. Then given a in T(V) is it true that
pi a = i2^-1 Alt i1 a? For which definition of Alt is this true?
I guess it’s the one with the n! ?
@quaint heart
Hmm, I need to think about that for a bit
Wait sorry, what is i2?
@hollow phoenix
Do you mean between Wedge(V) and alternating multilinear maps or something?
Ok, got confused for a sec
So the funny thing is, I'm thinking of Wedge(V) as the subspace of alternating tensors of T(V)
Hmm
I mean they’re the same in some sense..
But like the defintion I’m using is like
Wedge V and T(V) are different spaces
They are both quotient maps
hmmm....
Hold up
Can we agree that pi is
At least
Canonical?
Theres like no ambiguity
Hmm
Send an element of T(V) to its equivalence class in Wedge(V)
And i1 and i2 are canonical as well..
So there seems only one choice of Alt that makes that identity work ..
I mean I’m seeing Alt as a operator sending multilinear maps to multilinear maps
And pi is the natiral surjection
Yeah
So a priori they’re different things ..
I guess write everything out
Yeah
Yes
Thanks 4 help
👌
@quaint heart ehh wtf
Wikipedia uses the k! In the alternation shit but still uses the factors in front of the Wedge product
So a wedge b as defined here is actually different than a wedge b as I defined it ..
If you use k! you need the factors
Otherwise you don't
Cause you want to cancel out the 1/(k+m)! From alt
And replace it with (1/k!)(1/m!)
If you don't use k! You don't need factors
@hollow phoenix
You do this for homomorphism reasons
Oh rite
Ugh that means that the map I mentioned and the map given here are not the same..
I guess I’ll live with it
I have a question assigned in my homework and I'd like to verify if my answer is correct
Is this statement true or false, if a system has more equations than variables, it's rref must have a row of 0's
I think the answer is true but my answer divides the solution into 3 cases, one solution, infinite and none
With one solution, you only need one equation for each variable, as such any more equations would be redundant and be reduced down to 0's
With infinitely many, you'd need to intersect two planes which only required two equations out of the 3 variables, any more would be redundant and reduced down to 0's
With none, there would be redundant parallel planes which would be reduced to 0's
are you talking about the rref of the augmented matrix?
Yes
Consider the case where the first n-1 equations are linearly independent and the nth equation is a linear combination of the others, but inconsistent. Then every row will have a pivot in the augmented matrix. In the last row, you will have zeros everywhere except in the last column. @toxic pendant
i.e. the pivot for the last row is in the last column of the augmented matrix
That is very simple and upsetting that I didn't think of it
You're saying that for example, with 4 equations the last one could be (0,0,0|5)?
well in rref it would be a 1, but yea
Thank you for the assistance
np
Another thing, why do we use rref instead of systems?
if you make a matrix into REF, there could be multiple answers right?
its not always useful to think of transformations as systems, you can deduce a lot of things about a transformation by examining its rref
@north sierra Sure
er wait, answers to what? You mean solutions to Ax=b?
oh yea ref is not unique, but rref is
yea
when a matrix is not augmented
it doens't matter if all the row positions are 0 except for the last one right
so like
[0 0 0 4]
matter for what?
cause if its a augmented matrix having all 0s in a row except for the last one means its inconsistent
ok, but a non augmented matrix is not an equation
yea if its just a regular ol matrix and the last column doesn't correspond to anything in particular then its fine
oh just dot product everything
u•v=||u|| ||v|| cos θ where θ is angle between u and v
So jus need to show
u•w=||u|| ||w|| cos θ/2 and similarly for v
that seems like the simplest way?
you can put a slash in front of the || to stop it from making spoilers: \||v\|| gives ||v||
If I had a set of vectors {[1,0],[0,1], [1,0]} would this be Linerly dependent? I heard that sets cant have the two elements that are the same so would the set collapse to {[1,0],[0,1]}?
do you know the definition of linear dependence
If the solution to the homogeneous linear combo has a at least one nonzero solution
The constants of course of the linear combo
so if i take the linear combination n[1, 0] + 0[0, 1] - n[1, 0], i can get zero even tho the coefficients are not all zero
Yes but in my next question I asked if the set is equivalent to {[1,0],[0,1} which is linearly independent
depends on what you mean by equivalent; the sets span the same space
I mean like in set theory the sets {1,2,3} is equivalent to {1,2,3,3}
So for a set of vectors can we say the same?
you dont usually deal with sets of vectors, theyre typically lists
So they're not sets?
if my matrix is inconsistent
plugging in the values into the original equation wont be True right?
what values?
the last value of each row in an aguemented matrix
augmented
is there a name for that btw?
Question that's killing me: is it possible nullspace of a 4x3 vector to contain only the zero vector?
"the solution"
If the matrix is inconsistent, then there is no solution of course. I'm not quite sure what the other coordinates of the solution would represent if the system is inconsistent.
James, if you mean 4x3 matrix, then no
np. I or someone may ping you if they can think of a better answer lol
okie dokie
4x3 matrix, yes what I meant... im tired and struggling 😦
Why is that the case?
I am so confused...
consider the column space of that matrix. You can't have more than 3 vectors in a basis for R^3, so one of the vectors must be "redundant." Therefore the representation of any solution to Ax = b is not unique
so it must contain at least 2 vectors, and by definition the nullspace contains the zero vector
specifically, the solutions to Ax = 0 wouldn't be unique. If it was, then it would exactly line up with the definition of linear independence.
Does that make sense?
More or less...
I honestly haven't understood what tf was going on for a while so I think that'll have to do for now
if v1, v2, v3, v4 are the columns of A and if the kernel is nontrivial, then that means there is an x = (a,b,c,d) not equal to the zero vector such that
av1 + bv2 + cv3 + dv4 = 0
sorry for interrupting, but if i have a a*b coefficient matrix where a are the row and b are columns, how do I know if it's consistent or inconsistent
without knowing the matrix values
I'm not sure I understand what you mean by the a*b thing xd
axb matrix?
where 4 is the row
so you have a axb matrix
and 6 is column
oh wow lag
yeah i said where a is the row
and b is the column
i said are but i meant is lol
but yeah
Anyway, it could be inconsistent whenever a>b.
so if you have a matrix A, and an equation Ax = b. There are some values of b that yield solutions (the column space of A)
what if a<b?
then the solutions are not unique
that means its rref form has free variable(s)
and to be clear, the conditions a<b and a>b guarantee non-uniqueness and inconsistency respectively, but any transformation can be both (or neither for square matrices)
a>b guarantees inconsistency
most of the time, sure. but it could have solutions if a row is a linear combo of the others @slow scroll
ok well i have this similar question in my textbook
how would i even solve this if i it's not guaranteed
to be inconsistent
or the opposite
to say its consistent just means that you choose b such that Ax = b has solution(s)
the "b" is the vector form of the RHS of the system. so take a random system;
.... = 1
..... = 3
... = -1
b = (1, 3, -1)
The variables of the system are just x = (x1, x2, x3)
and the coefficients of each variable correspond to a coordinate of the matrix A.
@north sierra i feel like you would REALLY benefit from watching a linalg video series that emphasizes viewing matrices as transformations on spaces
yea +1 to that.
that's a nice start
and then get some practice with khanacademy's linalg pset, the usual stuff
mk... stuck again... if matrix A has a column space that is 2x2 and a nullspace that is 2x2 then does A need to be 4x4?
yes
sorry, interpreted it wrong
the column space and nullspace are both 2 dimensional
yep
digging through my notes for it but can't find it 😐
rank(a) + nullity(a) someting somethin
yea rank nullity. basically
rank(a) + nullity(A) = columns of A
so A must have 4 columns, does it need to have 4 rows?
hmm it should have a minimum of 2 rows just because rank(A) = rank(A^T)
there is no similar equality relating the dimension of the null space and the dimension of the left null space tho
okay i get what you explained now @slow scroll
i still haven't learnt vectors
so these videos are not working out for me
im still in he process of learning vectors tho
(started today)
keep on learning that stuff, but let me ask you this: how many variables does a 4x7 matrix have?
7
right, and the pivots correspond to the "basic variables." So if there are 4 pivots, then how many free variables does there have to be?
3
so no row will be a zero row (example: 0 0 0 = b where b is a non zero)
so it's consistent
plus having 3 free variables means it has infinite number of solutions
so thats also another reason?
nope that is not necessarily true. Because there are free variables tho, how many solutions does a consistent system have with this matrix?
infinite?
yep.
so what's not necessarily true?
its not necessarily inconsistent. It is entirely dependent on the choice of RHS for the system of equations. And as a disclaimer, for a 4x7 matrix it could very well be the case that it is never inconsistent i.e. there are always solutions to Ax = b for any choice of b
oh ok lol. well yea you have the right idea about the free variables and everything
oh ok lol
linear algebra is hard to imagine
but its fun
so like when you find the general solution (RREF), you have found lines where they all intersect one another at the same point?
well they are not necessarily lines. they can be higher order spaces. This is a decent visualization tho. lets say you have
x+y+z=1
x+y+z=2
These planes never intersect (they are parallel to each other) and naturally there is no solution (x,y,z) to this system (i.e. its matrix representation is inconsistent).
when you start to think of matrices more as transformations, you'll think of them more frequently as collections of column vectors. so a 2x3 matrix for example would have 3 vectors from R2 (2d vectors) A = [v1 v2 v3].
I have some 3x3 matrix A, I calculated the basis for the column space and nullspace of A and A^t. If I wanted to check if the vectors of the basis of the column space of A and the vectors of the basis of the nullspace of A^t give a basis of R^3 I just need to see if the 3 basis vectors are linearly independent, right?
Im struggling to understand the problem...
If nullity(A^T) + rank(A) = 3, then yea, all that remains is to check is if they are linearly independent
perfect, I really should just have some more confidence :p
Thanks for the huge help tonight kxrider, your efforts are greatly appreciated
is span the plane containing the three points? how do I check if vectors lie in a span :o
(ping me ty <3)
@leaden fiber turn the three vectors in the parentheses into a matrix A. let one of the vectors you're testing be b. see if Ax = b has solutions
Well can you find the rank of the corresponding matrix or note that two are linearly dependent
Matrix is not invertible so you need a little bit of work
what is the rank of a matrix :o
the span of a set of vectors is the smallest subspace that contains them all
so, a plane in this case?
yeah their span looks like a plane in R^3
are these LD
ya
linearly dependent
ok yeah they are
the maximum number of linearly independent column/row (depending on matrix size) vectors of a matrix
I don't understand >.> wdym by maximum number tho, isn't it just three if all three vectors are linearly independent?
in your example the three vectors in the parentheses are linearly dependent. do the math and you see that one vector can be expressed as a linear combo of the others. the rank is 2
if they WERE linearly independent, then rank = 3. we call that "full rank"
no problem 
did you spot the linear dependent thing by eye though, and is there a way of finding out without doing the math?
still gonna do the math ofc, just wondering if there's an intuitive way of making guesses
call the vectors v1 v2 v3. it doesn't take long to see that v1 + 2*v2 = v3
yw 🙂
does the linear dependency in the span affect the steps I need to take in checking whether the two vectors lie in the span?
if the set of vectors were LI, you'd have a nice basis for R^3
(does R^3 mean a 3D space)
you can think of it like that
and having a basis for R^3 means EVERY vector in R^3 can be expressed as a linear combo of v1/v2/v3
so you wouldn't have to bother checking to see if the other two vectors lie in the span of v1/v2/v3
ah right :o
oh no I lost my notes for class, forgot how to check if A(x)=B
do I just do:
-1x+1x+1x=1
1y+2y+5y=1
0z+3z+6z=-1? but there'd always be a value for x,y, and z
(in class we used x1, x2 and x3 instead of x,y, and z so me using xyz is probably inaccurate but less confusing typing it out here)
turn v1/v2/v3 into a 3x3 matrix and call it A
call one of the vectors you're testing b
when you solve Ax=b, make an augmented matrix from A and b, then get it into reduced form to solve for x
This is augmented matrix, right?
yes
if the matrix has at least one solution, then b lies in the span of the set of v1/v2/v3
this is inconsistent
Uh @leaden fiber in general, you can take the determinant of the 3 by 3 matrix
It completely classifies invertibility/linear independency
Invertibility essentially means that the vectors span R^n, meaning that any element of R^n can be expressed as a linear combination of the vectors.
everything could all be zero?
no
oh right
:o
me bad me bad
yeah so that means the vector doesn't lie in span right?
you get a row of 0s except with a nonzero constant at the end
this implies 0x_1 + 0x_2 + 0x_3 = 1 which isn't true. no solution for x
thus b lies outside the span
np
what if there are infinite solutions?
for the second one both of the lines give 0 3 6 -1 so one goes 0 0 0 0
so infinite solutions
that counts as having solutions right?
if the matrix has at least one solution, then b lies in the span of the set of v1/v2/v3 @leaden fiber
use the definition of linear dependence
don't ping me personally. >:|
what the fuck im just trying to get some help u tell me to move out of that channel and then now u tell me not to ping u
i don’t understand
just trying to get help man
ok let me spell this out for you
- the reason there are 10 questions channels is so that many people can get help at once without having to shout over one another in 1 channel, and i expected you to move to one of those.
- i am not the only one who provides help. you should've waited 15 minutes and then, if nobody came, pinged @ Helpers.
my bad
and also this is the wrong channel
then why don’t u just help me and i’ll just get out of ur hair
guys
when doing system of equations with gauss elimination sometimes multiply and add method can be done in head and you straight up write the equivilent system of quations but sometimes the method is to hard to do in head and requires to write it down and calculcate. is those "side calculations" supposed to be on a side paper which can be thrown away before handing in only the solutions?
basically if i cant do it in head do i have to present my calculation in the answer?
because watching others they are either gods at head calulations or they have a side paper which they do the in between calculations on then dont include in their answers
@floral prairie i seriously doubt your teacher will take away points for including side calculations necessary for row operations on your paper, but perhaps ask them anyway if that's ok
if it were ME i'd rather find space on the original paper to do calculations instead of getting another sheet of paper, but like i said, ask your teacher if that's ok
$A^{2017} = 0, AB=BA$ prove that $r(AB)\le r(B)-1$
Nguyễn Thành Trung:
uhhuh
but no solution here yet
$r(AB) + r(BA^{2016}) \le r(B) + r(ABA^{2016})$
Nguyễn Thành Trung:
$\Leftrightarrow r(AB) \le r(B) - r(BA^{2016})$
Nguyễn Thành Trung:
Nguyễn Thành Trung:
hm...
well
so for an augmented matrix
[1 3 | 2 ]
[0 3 | 0 ]
does this have one solution?
since there are two pivots
Well, you can think about it
Try actually solving the system
the second variable = 0, and back substituting, the first variable is 2
what does back substituting mean
oh does back substiuting just mean doing operations
okay i see what you mean
thx
@pallid swallow wait im confused again
i can solve that matrix in two ways
one way that can make it inconsistent
and another way that can make it not inconsistent
so does that mean it has more than one solution
How did you show it’s inconsistent?
wait acutally
i dont think i can now
i thought i did
so how do i know
if it has one solution
or more than one
well it has two pivots
so i think it has 1
but i need someone to confirm lol
i have doubts
Usually you can tell by how many free variables there are
oh i remember how i showed it was inconsistent
At least one free var means infinitely many solutions
so i did r2 - r1
which gave
1 3 | 2
0 0 | -2
oh nvm
i forgot the -1 in the bottom left
but i have 0 free variables
so would that mean one solution?
What’s your rref or ref?
1 0 | 2
0 1 | 0
Yeah one solution